Post Syndicated from Eddie Moser original https://aws.amazon.com/blogs/devops/how-pushly-media-used-aws-to-pivot-and-quickly-spin-up-a-startup/
This is a guest post from Pushly. In their own words, “Pushly provides a scalable, easy-to-use platform designed to deliver targeted and timely content via web push notifications across all modern desktop browsers and Android devices.”
Introduction
As a software engineer at Pushly, I’m part of a team of developers responsible for building our SaaS platform.
Our customers are content publishers spanning the news, ecommerce, and food industries, with the primary goal of increasing page views and paid subscriptions, ultimately resulting in increased revenue.
Pushly’s platform is designed to integrate seamlessly into a publisher’s workflow and enables advanced features such as customizable opt-in flow management, behavioral targeting, and real-time reporting and campaign delivery analytics.
As developers, we face various challenges to make all this work seamlessly. That’s why we turned to Amazon Web Services (AWS). In this post, I explain why and how we use AWS to enable the Pushly user experience.
At Pushly, my primary focus areas are developer and platform user experience. On the developer side, I’m responsible for building and maintaining easy-to-use APIs and a web SDK. On the UX side, I’m responsible for building a user-friendly and stable platform interface.
The CI/CD process
We’re a cloud native company and have gone all in with AWS.
AWS CodePipeline lets us automate the software release process and release new features to our users faster. Rapid delivery is key here, and CodePipeline lets us automate our build, test, and release process so we can quickly and easily test each code change and fail fast if needed. CodePipeline is vital to ensuring the quality of our code by running each change through a staging and release process.
One of our use cases is continuous reiteration deployment. We foster an environment where developers can fully function in their own mindset while adhering to our company’s standards and the architecture within AWS.
We deploy code multiple times per day and rely on AWS services to run through all checks and make sure everything is packaged uniformly. We want to fully test in a staging environment before moving to a customer-facing production environment.
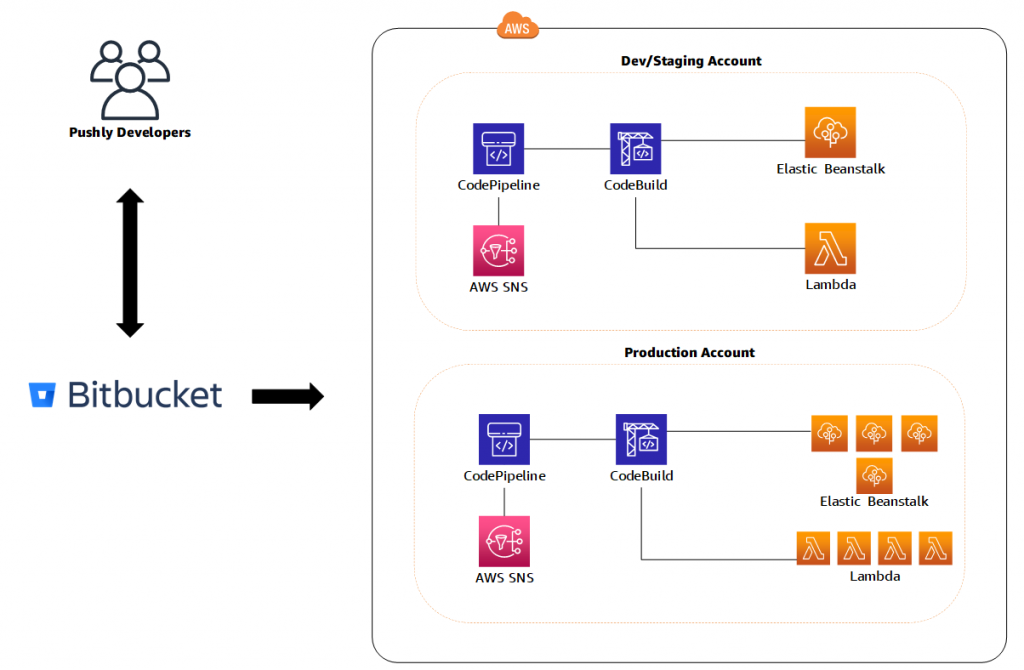
The development and staging environments
Our development environment allows developers to securely pull down applications as needed and access the required services in a development AWS account. After an application is tested and is ready for staging, the application is deployed to our staging environment—a smaller reproduction of our production environment—so we can test how the changes work together. This flow allows us to see how the changes run within the entire Pushly ecosystem in a secure environment without pushing to production.
When testing is complete, a pull request is created for stakeholder review and to merge the changes to production branches. We use AWS CodeBuild, CodePipeline, and a suite of in-house tools to ensure that the application has been thoroughly tested to our standards before being deployed to our production AWS account.
Here is a high level diagram of the environment described above:
 Ease of development
Ease of development
 Ease of development
Ease of developmentEase of development was—and is—key. AWS provides the tools that allow us to quickly iterate and adapt to ever-changing customer needs. The infrastructure as code (IaC) approach of AWS CloudFormation allows us to quickly and simply define our infrastructure in an easily reproducible manner and rapidly create and modify environments at scale. This has given us the confidence to take on new challenges without concern over infrastructure builds impacting the final product or causing delays in development.
The Pushly team
Although Pushly’s developers all have the skill-set to work on both front-end-facing and back-end-facing projects, primary responsibilities are split between front-end and back-end developers. Developers that primarily focus on front-end projects concentrate on public-facing projects and internal management systems. The back-end team focuses on the underlying architecture, delivery systems, and the ecosystem as a whole. Together, we create and maintain a product that allows you to segment and target your audiences, which ensures relevant delivery of your content via web push notifications.
Early on we ran all services entirely off of AWS Lambda. This allowed us to develop new features quickly in an elastic, cost efficient way. As our applications have matured, we’ve identified some services that would benefit from an always on environment and moved them to AWS Elastic Beanstalk. The capability to quickly iterate and move from service to service is a credit to AWS, because it allows us to customize and tailor our services across multiple AWS offerings.
Elastic Beanstalk has been the fastest and simplest way for us to deploy this suite of services on AWS; their blue/green deployments allow us to maintain minimal downtime during deployments. We can easily configure deployment environments with capacity provisioning, load balancing, autoscaling, and application health monitoring.
The business side
We had several business drivers behind choosing AWS: we wanted to make it easier to meet customer demands and continually scale as much as needed without worrying about the impact on development or on our customers.
Using AWS services allowed us to build our platform from inception to our initial beta offering in fewer than 2 months! AWS made it happen with tools for infrastructure deployment on top of the software deployment. Specifically, IaC allowed us to tailor our infrastructure to our specific needs and be confident that it’s always going to work.
On the infrastructure side, we knew that we wanted to have a staging environment that truly mirrored the production environment, rather than managing two entirely disparate systems. We could provide different sets of mappings based on accounts and use the templates across multiple environments. This functionality allows us to use the exact same code we use in our current production environment and easily spin up additional environments in 2 hours.
The need for speed
It took a very short time to get our project up and running, which included rewriting different pieces of the infrastructure in some places and completely starting from scratch in others.
One of the new services that we adopted is AWS CodeArtifact. It lets us have fully customized private artifact stores in the cloud. We can keep our in-house libraries within our current AWS accounts instead of relying on third-party services.
CodeBuild lets us compile source code, run test suites, and produce software packages that are ready to deploy while only having to pay for the runtime we use. With CodeBuild, you don’t need to provision, manage, and scale your own build servers, which saves us time.
The new tools that AWS is releasing are going to even further streamline our processes. We’re interested in the impact that CodeArtifact will have on our ability to share libraries in Pushly and with other business units.
Cost savings is key
What are we saving by choosing AWS? A lot. AWS lets us scale while keeping costs at a minimum. This was, and continues to be, a major determining factor when choosing a cloud provider.
By using Lambda and designing applications with horizontal scale in mind, we have scaled from processing millions of requests per day to hundreds of millions, with very little change to the underlying infrastructure. Due to the nature of our offering, our traffic patterns are unpredictable. Lambda allows us to process these requests elastically and avoid over-provisioning. As a result, we can increase our throughput tenfold at any time, pay for the few minutes of extra compute generated by a sudden burst of traffic, and scale back down in seconds.
In addition to helping us process these requests, AWS has been instrumental in helping us manage an ever-growing data warehouse of clickstream data. With Amazon Kinesis Data Firehose, we automatically convert all incoming events to Parquet and store them in Amazon Simple Storage Service (Amazon S3), which we can query directly using Amazon Athena within minutes of being received. This has once again allowed us to scale our near-real-time data reporting to a degree that would have otherwise required a significant investment of time and resources.
As we look ahead, one thing we’re interested in is Lambda custom stacks, part of AWS’s Lambda-backed custom resources. Amazon supports many languages, so we can run almost every language we need. If we want to switch to a language that AWS doesn’t support by default, they still provide a way for us to customize a solution. All we have to focus on is the code we’re writing!
The importance of speed for us and our customers is one of our highest priorities. Think of a news publisher in the middle of a briefing who wants to get the story out before any of the competition and is relying on Pushly—our confidence in our ability to deliver on this need comes from AWS services enabling our code to perform to its fullest potential.
Another way AWS has met our needs was in the ease of using Amazon ElastiCache, a fully managed in-memory data store and cache service. Although we try to be as horizontal thinking as possible, some services just can’t scale with the immediate elasticity we need to handle a sudden burst of requests. We avoid duplicate lookups for the same resources with ElastiCache. ElastiCache allows us to process requests quicker and protects our infrastructure from being overwhelmed.
In addition to caching, ElastiCache is a great tool for job locking. By locking messages by their ID as soon as they are received, we can use the near-unlimited throughput of Amazon Simple Queue Service (Amazon SQS) in a massively parallel environment without worrying that messages are processed more than once.
The heart of our offering is in the segmentation of subscribers. We allow building complex queries in our dashboard that calculate reach in real time and are available to use immediately after creation. These queries are often never-before-seen and may contain custom properties provided by our clients, operate on complex data types, and include geospatial conditions. No matter the size of the audience, we see consistent sub-second query times when calculating reach. We can provide this to our clients using Amazon Elasticsearch Service (Amazon ES) as the backbone to our subscriber store.
Summary
AWS has countless positives, but one key theme that we continue to see is overall ease of use, which enables us to rapidly iterate. That’s why we rely on so many different AWS services—Amazon API Gateway with Lambda integration, Elastic Beanstalk, Amazon Relational Database Service (Amazon RDS), ElastiCache, and many more.
We feel very secure about our future working with AWS and our continued ability to improve, integrate, and provide a quality service. The AWS team has been extremely supportive. If we run into something that we need to adjust outside of the standard parameters, or that requires help from the AWS specialists, we can reach out and get feedback from subject matter experts quickly. The all-around capabilities of AWS and its teams have helped Pushly get where we are, and we’ll continue to rely on them for the foreseeable future.