Post Syndicated from Anand Krishna original https://aws.amazon.com/blogs/devops/cicd-on-serverless-applications-using-aws-codeartifact/
Developing and deploying applications rapidly to users requires a working pipeline that accepts the user code (usually via a Git repository). AWS CodeArtifact was announced in 2020. It’s a secure and scalable artifact management product that easily integrates with other AWS products and services. CodeArtifact allows you to publish, store, and view packages, list package dependencies, and share your application’s packages.
In this post, I will show how we can build a simple DevOps pipeline for a sample JAVA application (JAR file) to be built with Maven.
Solution Overview
We utilize the following AWS services/Tools/Frameworks to set up our continuous integration, continuous deployment (CI/CD) pipeline:
- AWS Cloud Development Kit (AWS CDK)
- AWS CodeArtifact
- AWS CloudFormation
- Amazon CloudWatch
- AWS CodeBuild
- AWS CodeCommit
- AWS CodePipeline
- AWS Command Line Interface (AWS CLI)
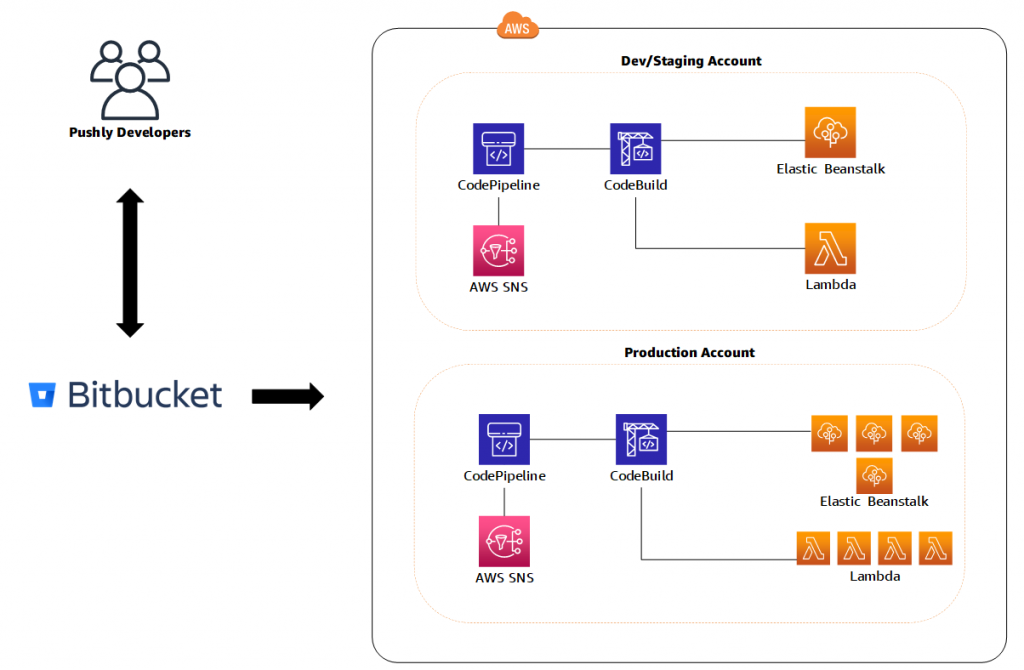
The following diagram illustrates the pipeline architecture and flow:

Our pipeline is built on CodePipeline with CodeCommit as the source (CodePipeline Source Stage). This triggers the pipeline via a CloudWatch Events rule. Then the code is fetched from the CodeCommit repository branch (main) and sent to the next pipeline phase. This CodeBuild phase is specifically for compiling, packaging, and publishing the code to CodeArtifact by utilizing a package manager—in this case Maven.
After Maven publishes the code to CodeArtifact, the pipeline asks for a manual approval to be directly approved in the pipeline. It can also optionally trigger an email alert via Amazon Simple Notification Service (Amazon SNS). After approval, the pipeline moves to another CodeBuild phase. This downloads the latest packaged JAR file from a CodeArtifact repository and deploys to the AWS Lambda function.
Clone the Repository
Clone the GitHub repository as follows:
git clone https://github.com/aws-samples/aws-cdk-codeartifact-pipeline-sample.git
Code Deep Dive
After the Git repository is cloned, the directory structure is shown as in the following screenshot :

Let’s study the files and code to understand how the pipeline is built.
The directory java-events is a sample Java Maven project. Find numerous sample applications on GitHub. For this post, we use the sample application java-events.
To add your own application code, place the pom.xml and settings.xml files in the root directory for the AWS CDK project.
Let’s study the code in the file lib/cdk-pipeline-codeartifact-new-stack.ts of the stack CdkPipelineCodeartifactStack. This is the heart of the AWS CDK code that builds the whole pipeline. The stack does the following:
- Creates a CodeCommit repository called ca-pipeline-repository.
- References a CloudFormation template (lib/ca-template.yaml) in the AWS CDK code via the module @aws-cdk/cloudformation-include.
- Creates a CodeArtifact domain called cdkpipelines-codeartifact.
- Creates a CodeArtifact repository called cdkpipelines-codeartifact-repository.
- Creates a CodeBuild project called JarBuild_CodeArtifact. This CodeBuild phase does all of the code compiling, packaging, and publishing to CodeArtifact into a repository called cdkpipelines-codeartifact-repository.
- Creates a CodeBuild project called JarDeploy_Lambda_Function. This phase fetches the latest artifact from CodeArtifact created in the previous step (cdkpipelines-codeartifact-repository) and deploys to the Lambda function.
- Finally, creates a pipeline with four phases:
- Source as CodeCommit (ca-pipeline-repository).
- CodeBuild project JarBuild_CodeArtifact.
- A Manual approval Stage.
- CodeBuild project JarDeploy_Lambda_Function.
CodeArtifact shows the domain-specific and repository-specific connection settings to mention/add in the application’s pom.xml and settings.xml files as below:

Deploy the Pipeline
The AWS CDK code requires the following packages in order to build the CI/CD pipeline:
- @aws-cdk/core
- @aws-cdk/aws-codepipeline
- @aws-cdk/aws-codepipeline-actions
- @aws-cdk/aws-codecommit
- @aws-cdk/aws-codebuild
- @aws-cdk/aws-iam
- @aws-cdk/cloudformation-include
Install the required AWS CDK packages as below:
npm i @aws-cdk/core @aws-cdk/aws-codepipeline @aws-cdk/aws-codepipeline-actions @aws-cdk/aws-codecommit @aws-cdk/aws-codebuild @aws-cdk/pipelines @aws-cdk/aws-iam @ @aws-cdk/cloudformation-include
Compile the AWS CDK code:
npm run build
Deploy the AWS CDK code:
cdk synth
cdk deploy
After the AWS CDK code is deployed, view the final output on the stack’s detail page on the AWS CloudFormation :

How the pipeline works with artifact versions (using SNAPSHOTS)
In this demo, I publish SNAPSHOT to the repository. As per the documentation here and here, a SNAPSHOT refers to the most recent code along a branch. It’s a development version preceding the final release version. Identify a snapshot version of a Maven package by the suffix SNAPSHOT appended to the package version.
The application settings are defined in the pom.xml file. For this post, we define the following:
- The version to be used, called 1.0-SNAPSHOT.
- The specific packaging, called jar.
- The specific project display name, called JavaEvents.
- The specific group ID, called JavaEvents.
The screenshot below shows the pom.xml settings we utilised in the application:

You can’t republish a package asset that already exists with different content, as per the documentation here.
When a Maven snapshot is published, its previous version is preserved in a new version called a build. Each time a Maven snapshot is published, a new build version is created.
When a Maven snapshot is published, its status is set to Published, and the status of the build containing the previous version is set to Unlisted. If you request a snapshot, the version with status Published is returned. This is always the most recent Maven snapshot version.
For example, the image below shows the state when the pipeline is run for the FIRST RUN. The latest version has the status Published and previous builds are marked Unlisted.

For all subsequent pipeline runs, multiple Unlisted versions will occur every time the pipeline is run, as all previous versions of a snapshot are maintained in its build versions.

Fetching the Latest Code
Retrieve the snapshot from the repository in order to deploy the code to an AWS Lambda Function. I have used AWS CLI to list and fetch the latest asset of package version 1.0-SNAPSHOT.
Listing the latest snapshot
export ListLatestArtifact = `aws codeartifact list-package-version-assets —domain cdkpipelines-codeartifact --domain-owner $Account_Id --repository cdkpipelines-codeartifact-repository --namespace JavaEvents --format maven --package JavaEvents --package-version "1.0-SNAPSHOT"| jq ".assets[].name"|grep jar|sed ’s/“//g’`
NOTE : Please note the dynamic CDK variable $Account_Id which represents AWS Account ID.
Fetching the latest code using Package Version
aws codeartifact get-package-version-asset --domain cdkpipelines-codeartifact --repository cdkpipelines-codeartifact-repository --format maven --package JavaEvents --package-version 1.0-SNAPSHOT --namespace JavaEvents --asset $ListLatestArtifact demooutput
Notice that I’m referring the last code by using variable $ListLatestArtifact. This always fetches the latest code, and demooutput is the outfile of the AWS CLI command where the content (code) is saved.
Testing the Pipeline
Now clone the CodeCommit repository that we created with the following code:
git clone https://git-codecommit.<region>.amazonaws.com/v1/repos/codeartifact-pipeline-repository
Enter the following code to push the code to the CodeCommit repository:
cp -rp cdk-pipeline-codeartifact-new /* ca-pipeline-repository
cd ca-pipeline-repository
git checkout -b main
git add .
git commit -m “testing the pipeline”
git push origin main
Once the code is pushed to Git repository, the pipeline is automatically triggered by Amazon CloudWatch events.
The following screenshots shows the second phase (AWS CodeBuild Phase – JarBuild_CodeArtifact) of the pipeline, wherein the asset is successfully compiled and published to the CodeArtifact repository by Maven:



The following screenshots show the last phase (AWS CodeBuild Phase – Deploy-to-Lambda) of the pipeline, wherein the latest asset is successfully pulled and deployed to AWS Lambda Function.
Asset JavaEvents-1.0-20210618.131629-5.jar is the latest snapshot code for the package version 1.0-SNAPSHOT. This is the same asset version code that will be deployed to AWS Lambda Function, as seen in the screenshots below:


The following screenshot of the pipeline shows a successful run. The code was fetched and deployed to the existing Lambda function (codeartifact-test-function).

Cleanup
To clean up, You can either delete the entire stack through the AWS CloudFormation console or use AWS CDK command like below –
cdk destroy
For more information on the AWS CDK commands, please check the here or sample here.
Summary
In this post, I demonstrated how to build a CI/CD pipeline for your serverless application with AWS CodePipeline by utilizing AWS CDK with AWS CodeArtifact. Please check the documentation here for an in-depth explanation regarding other package managers and the getting started guide.







































 Ease of development
Ease of development