Post Syndicated from Anubhav Rao original https://aws.amazon.com/blogs/devops/your-devops-and-developer-productivity-guide-to-reinvent-2023/
Your DevOps and Developer Productivity guide to re:Invent 2023
ICYMI – AWS re:Invent is less than a week away! We can’t wait to join thousands of builders in person and virtually for another exciting event. Still need to save your spot? You can register here.
With so much planned for the DevOps and Developer Productivity (DOP) track at re:Invent, we’re highlighting the most exciting sessions for technology leaders and developers in this post. Sessions span intermediate (200) through expert (400) levels of content in a mix of interactive chalk talks, hands-on workshops, and lecture-style breakout sessions.
You will experience the future of efficient development at the DevOps and Developer Productivity track and get a chance to talk to AWS experts about exciting services, tools, and new AI capabilities that optimize and automate your software development lifecycle. Attendees will leave re:Invent with the latest strategies to accelerate development, use generative AI to improve developer productivity, and focus on high-value work and innovation.
How to reserve a seat in the sessions
Reserved seating is available for registered attendees to secure seats in the sessions of their choice. Reserve a seat by signing in to the attendee portal and navigating to Event, then Sessions.
Do not miss the Innovation Talk led by Vice President of AWS Generative Builders, Adam Seligman. In DOP225-INT Build without limits: The next-generation developer experience at AWS, Adam will provide updates on the latest developer tools and services, including generative AI-powered capabilities, low-code abstractions, cloud development, and operations. He’ll also welcome special guests to lead demos of key developer services and showcase how they integrate to increase productivity and innovation.
DevOps and Developer Productivity breakout sessions
What are breakout sessions?
AWS re:Invent breakout sessions are lecture-style and 60 minutes long. These sessions are delivered by AWS experts and typically reserve 10–15 minutes for Q&A at the end. Breakout sessions are recorded and made available on-demand after the event.
Level 200 — Intermediate
DOP201 | Best practices for Amazon CodeWhisperer Generative AI can create new content and ideas, including conversations, stories, images, videos, and music. Learning how to interact with generative AI effectively and proficiently is a skill worth developing. Join this session to learn about best practices for engaging with Amazon CodeWhisperer, which uses an underlying foundation model to radically improve developer productivity by generating code suggestions in real time.
DOP202 | Realizing the developer productivity benefits of Amazon CodeWhisperer Developers spend a significant amount of their time writing undifferentiated code. Amazon CodeWhisperer radically improves productivity by generating code suggestions in real time to alleviate this burden. In this session, learn how CodeWhisperer can “write” much of this undifferentiated code, allowing developers to focus on business logic and accelerate the pace of their innovation.
DOP205 | Accelerate development with Amazon CodeCatalyst In this session, explore the newest features in Amazon CodeCatalyst. Learn firsthand how these practical additions to CodeCatalyst can simplify application delivery, improve team collaboration, and speed up the software development lifecycle from concept to deployment.
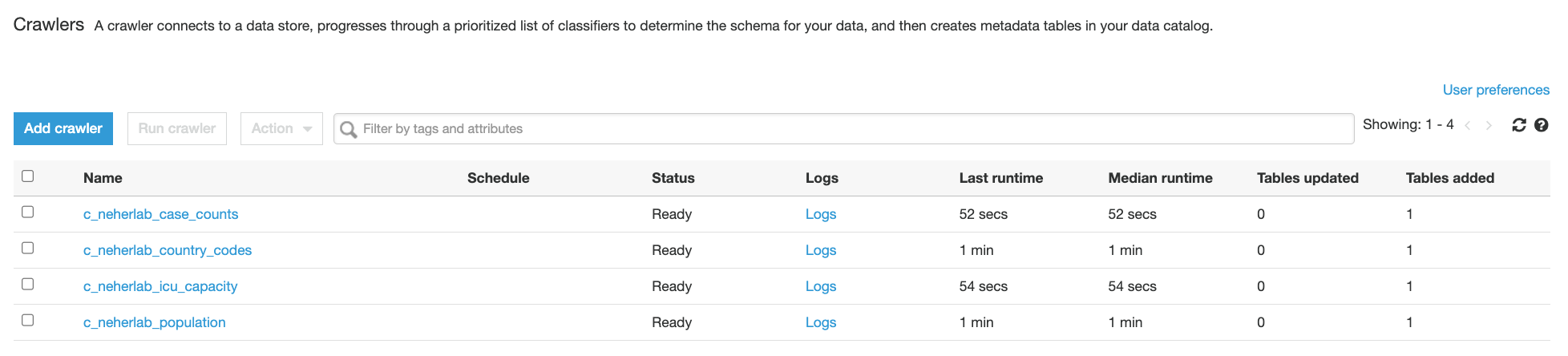
DOP206 | AWS infrastructure as code: A year in review AWS provides services that help with the creation, deployment, and maintenance of application infrastructure in a programmatic, descriptive, and declarative way. These services help provide rigor, clarity, and reliability to application development. Join this session to learn about the new features and improvements for AWS infrastructure as code with AWS CloudFormation and AWS Cloud Development Kit (AWS CDK) and how they can benefit your team.
DOP207 | Build and run it: Streamline DevOps with machine learning on AWS While organizations have improved how they deliver and operate software, development teams still run into issues when performing manual code reviews, looking for hard-to-find defects, and uncovering security-related problems. Developers have to keep up with multiple programming languages and frameworks, and their productivity can be impaired when they have to search online for code snippets. Additionally, they require expertise in observability to successfully operate the applications they build. In this session, learn how companies like Fidelity Investments use machine learning–powered tools like Amazon CodeWhisperer and Amazon DevOps Guru to boost application availability and write software faster and more reliably.
DOP208 | Continuous integration and delivery for AWS AWS provides one place where you can plan work, collaborate on code, build, test, and deploy applications with continuous integration/continuous delivery (CI/CD) tools. In this session, learn about how to create end-to-end CI/CD pipelines using infrastructure as code on AWS.
DOP209 | Governance and security with infrastructure as code In this session, learn how to use AWS CloudFormation and the AWS CDK to deploy cloud applications in regulated environments while enforcing security controls. Find out how to catch issues early with cdk-nag, validate your pipelines with cfn-guard, and protect your accounts from unintended changes with CloudFormation hooks.
DOP210 | Scale your application development with Amazon CodeCatalyst Amazon CodeCatalyst brings together everything you need to build, deploy, and collaborate on software into one integrated software development service. In this session, discover the ways that CodeCatalyst helps developers and teams build and ship code faster while spending more time doing the work they love.
DOP211 | Boost developer productivity with Amazon CodeWhisperer Generative AI is transforming the way that developers work. Writing code is already getting disrupted by tools like Amazon CodeWhisperer, which enhances developer productivity by providing real-time code completions based on natural language prompts. In this session, get insights into how to evaluate and measure productivity with the adoption of generative AI–powered tools. Learn from the AWS Disaster Recovery team who uses CodeWhisperer to solve complex engineering problems by gaining efficiency through longer productivity cycles and increasing velocity to market for ongoing fixes. Hear how integrating tools like CodeWhisperer into your workflows can boost productivity.
DOP212 | New AWS generative AI features and tools for developers Explore how generative AI coding tools are changing the way developers and companies build software. Generative AI–powered tools are boosting developer and business productivity by automating tasks, improving communication and collaboration, and providing insights that can inform better decision-making. In this session, see the newest AWS tools and features that make it easier for builders to solve problems with minimal technical expertise and that help technical teams boost productivity. Walk through how organizations like FINRA are exploring generative AI and beginning their journey using these tools to accelerate their pace of innovation.
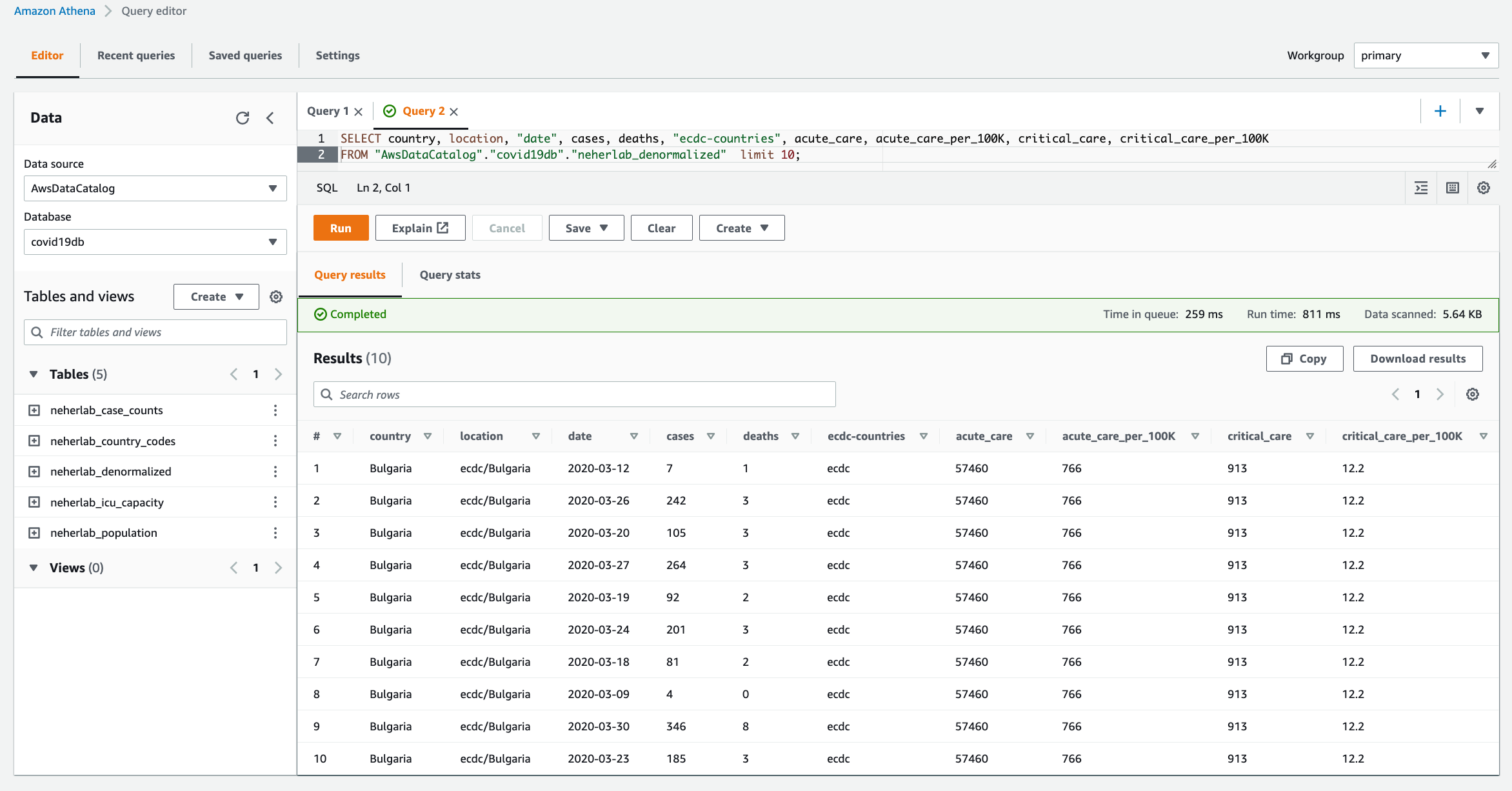
DOP220 | Simplify building applications with AWS SDKs AWS SDKs play a vital role in using AWS services in your organization’s applications and services. In this session, learn about the current state and the future of AWS SDKs. Explore how they can simplify your developer experience and unlock new capabilities. Discover how SDKs are evolving, providing a consistent experience in multiple languages and empowering you to do more with high-level abstractions to make it easier to build on AWS. Learn how AWS SDKs are built using open source tools like Smithy, and how you can use these tools to build your own SDKs to serve your customers’ needs.
DevOps and Developer Productivity chalk talks
What are chalk talks?
Chalk Talks are highly interactive sessions with a small audience. Experts lead you through problems and solutions on a digital whiteboard as the discussion unfolds. Each begins with a short lecture (10–15 minutes) delivered by an AWS expert, followed by a 45- or 50-minute Q&A session with the audience.
Level 300 — Advanced
DOP306 | Streamline DevSecOps with a complete software development service Security is not just for application code—the automated software supply chains that build modern software can also be exploited by attackers. In this chalk talk, learn how you can use Amazon CodeCatalyst to incorporate security tests into every aspect of your software development lifecycle while maintaining a great developer experience. Discover how CodeCatalyst’s flexible actions-based CI/CD workflows streamline the process of adapting to security threats.
DOP309-R | AI for DevOps: Modernizing your DevOps operations with AWS As more organizations move to microservices architectures to scale their businesses, applications increasingly have become distributed, requiring the need for even greater visibility. IT operations professionals and developers need more automated practices to maintain application availability and reduce the time and effort required to detect, debug, and resolve operational issues. In this chalk talk, discover how you can use AWS services, including Amazon CodeWhisperer, Amazon CodeGuru and Amazon DevOps Guru, to start using AI for DevOps solutions to detect, diagnose, and remedy anomalous application behavior.
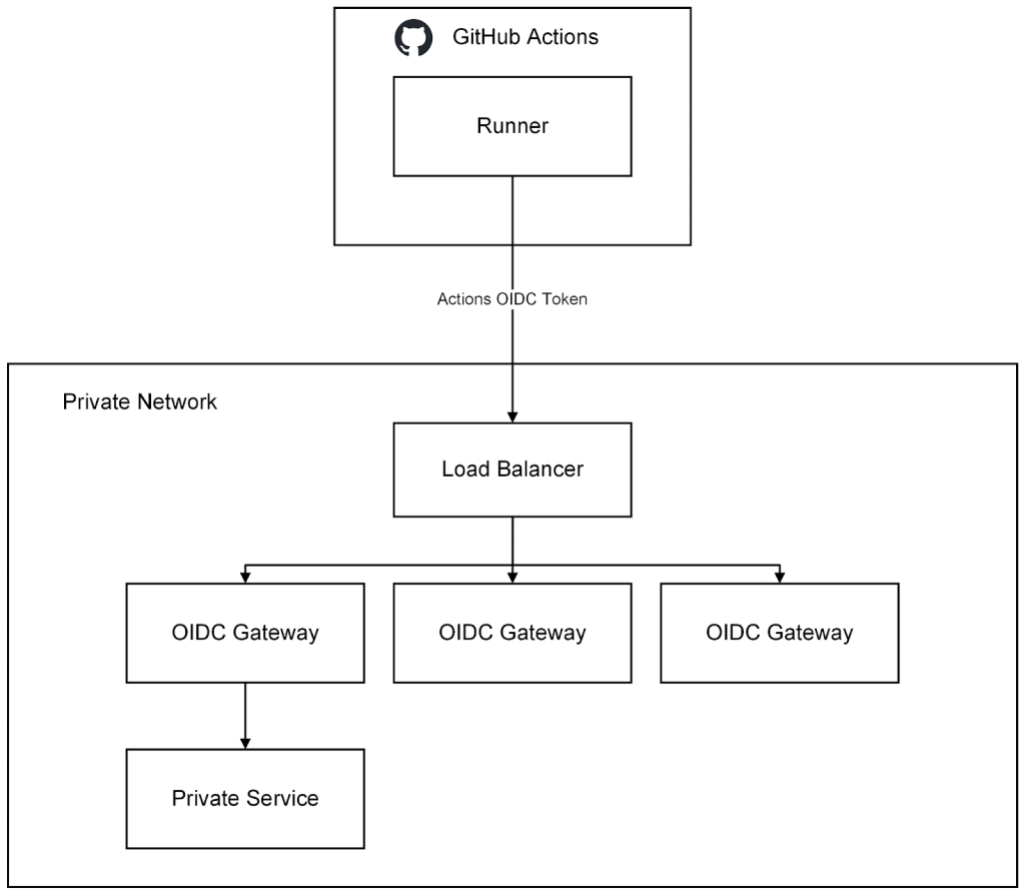
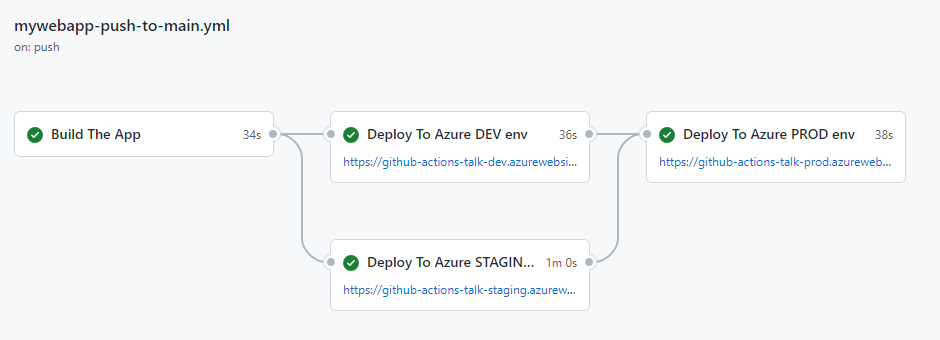
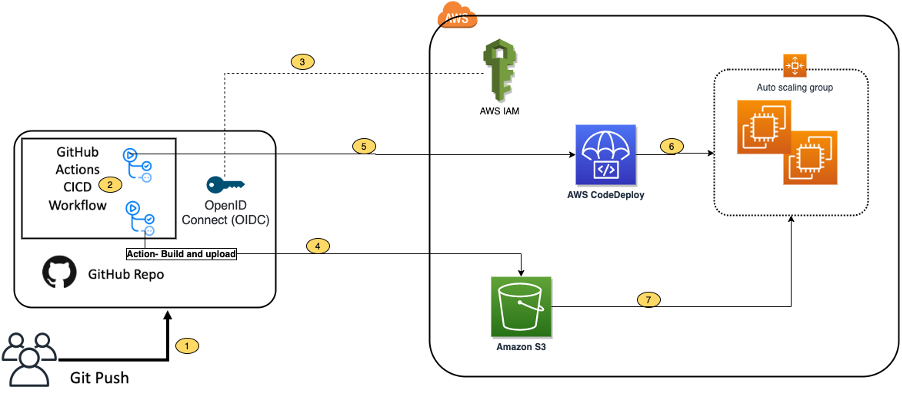
DOP310-R | Better together: GitHub Actions, Amazon CodeCatalyst, or AWS CodeBuild Learn how combining GitHub Actions with Amazon CodeCatalyst or AWS CodeBuild can maximize development efficiency. In this chalk talk, learn about the tradeoffs of using GitHub Actions runners hosted on Amazon EC2 or Amazon ECS with GitHub Actions hosted on CodeCatalyst or CodeBuild. Explore integration with other AWS services to enhance workflow automation. Join this talk to learn how GitHub Actions on AWS can take your development processes to the next level.
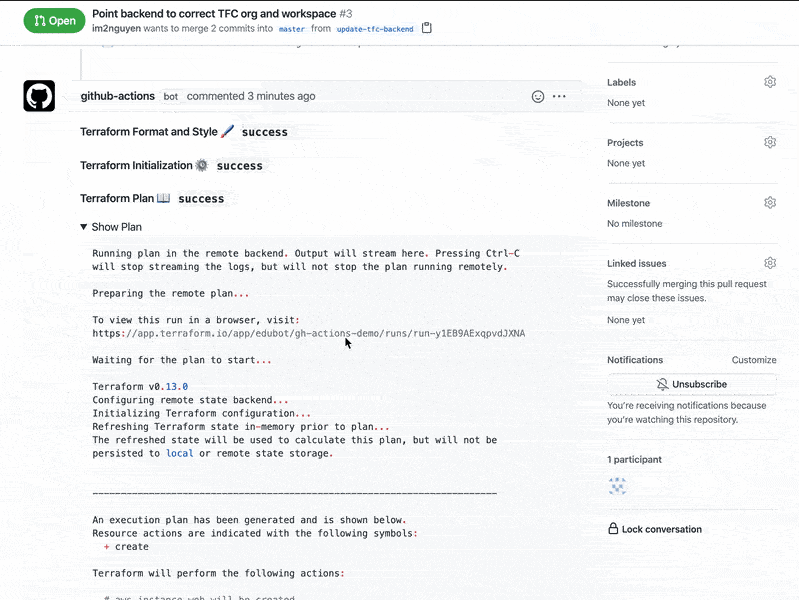
DOP311 | Building infrastructure as code with AWS CloudFormation AWS CloudFormation helps you manage your AWS infrastructure as code, increasing automation and supporting infrastructure-as-code best practices. In this chalk talk, learn the fundamentals of CloudFormation, including templates, stacks, change sets, and stack dependencies. See a demo of how to describe your AWS infrastructure in a template format and provision resources in an automated, repeatable way.
DOP312 | Creating custom constructs with AWS CDK Join this chalk talk to get answers to your questions about creating, publishing, and sharing your AWS CDK constructs publicly and privately. Learn about construct levels, how to test your constructs, how to discover and use constructs in your AWS CDK projects, and explore Construct Hub.
DOP313-R | Multi-account and multi-Region deployments at scale Many AWS customers are implementing multi-account strategies to more easily manage their cloud infrastructure and improve their security and compliance postures. In this chalk talk, learn about various options for deploying resources into multiple accounts and AWS Regions using AWS developer tools, including AWS CodePipeline, AWS CodeDeploy, and Amazon CodeCatalyst.
DOP314 | Simplifying cloud infrastructure creation with the AWS CDK The AWS Cloud Development Kit (AWS CDK) is an open source software development framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation. In this chalk talk, get an introduction to the AWS CDK and see a demo of how it can simplify infrastructure creation. Through code examples and diagrams, see how the AWS CDK lets you use familiar programming languages for declarative infrastructure definition. Also learn how it provides higher-level abstractions and constructs over native CloudFormation.
DOP317 | Applying Amazon’s DevOps culture to your team In this chalk talk, learn how Amazon helps its developers rapidly release and iterate software while maintaining industry-leading standards on security, reliability, and performance. Learn about the culture of two-pizza teams and how to maintain a culture of DevOps in a large enterprise. Also, discover how you can help build such a culture at your own organization.
DOP318 | Testing for resilience with AWS Fault Injection Simulator As cloud-based systems grow in scale and complexity, there is increased need to test distributed systems for resiliency. AWS Fault Injection Simulator (FIS) allows you to stress test your applications to understand failure modes and build more resilient services. Through code examples and diagrams, see how to set up and run fault injection experiments on AWS. By the end of this session, understand how FIS helps identify weaknesses and validate improvements to build more resilient cloud-based systems.
DOP319-R | Zero-downtime deployment strategies AWS services support a wealth of deployment options to meet your needs, ranging from in-place updates to blue/green deployment to continuous configuration with feature flags. In this chalk talk, hear about multiple options for deploying changes to Amazon EC2, Amazon ECS, and AWS Lambda compute platforms using AWS CodeDeploy, AWS AppConfig, AWS CloudFormation, AWS Cloud Development Kit (AWS CDK), and Amazon CodeCatalyst.
DOP320 | Build a path to production with Amazon CodeCatalyst blueprints Amazon CodeCatalyst uses blueprints to configure your software projects in the service. Blueprints instruct CodeCatalyst on how to set up a code repository with working sample code, define cloud infrastructure, and run pre-configured CI/CD workflows for your project. In this session, learn how blueprints in CodeCatalyst can give developers a compliant software service they’ll want to use on AWS.
DOP321-R | Code faster with Amazon CodeWhisperer Traditionally, building applications requires developers to spend a lot of time manually writing code and trying to learn and keep up with new frameworks, SDKs, and libraries. In the last three years, AI models have grown exponentially in complexity and sophistication, enabling the creation of tools like Amazon CodeWhisperer that can generate code suggestions in real time based on a natural language description of the task. In this session, learn how CodeWhisperer can accelerate and enhance your software development with code generation, reference tracking, security scans, and more.
DOP324 | Accelerating application development with AWS client-side tools Did you know AWS has more than just services? There are dozens of AWS client-side tools and libraries designed to make developing quality applications easier. In this chalk talk, explore some of the tools available in your development workspace. Learn more about command line tooling (AWS CLI), libraries (AWS SDK), IDE integrations, and application frameworks that can accelerate your AWS application development. The audience helps set the agenda so there’s sure to be something for every builder.
DevOps and Developer Productivity workshops
What are workshops?
Workshops are two-hour interactive learning sessions where you work in small group teams to solve problems using AWS services. Each workshop starts with a short lecture (10–15 minutes) by the main speaker, and the rest of the time is spent working as a group.
Level 300 — Advanced
DOP301 | Boost your application availability with AIOps on AWS As applications become increasingly distributed and complex, developers and IT operations teams can benefit from more automated practices to maintain application availability and reduce the time and effort spent detecting, debugging, and resolving operational issues manually. In this workshop, learn how AWS AIOps solutions can help you make the shift toward more automation and proactive mechanisms so your IT team can innovate faster. The workshop includes use cases spanning multiple AWS services such as AWS Lambda, Amazon DynamoDB, Amazon API Gateway, Amazon RDS, and Amazon EKS. Learn how you can reduce MTTR and quickly identify issues within your AWS infrastructure. You must bring your laptop to participate.
DOP302 | Build software faster with Amazon CodeCatalyst In this workshop, learn about creating continuous integration and continuous delivery (CI/CD) pipelines using Amazon CodeCatalyst. CodeCatalyst is a unified software development service on AWS that brings together everything teams need to plan, code, build, test, and deploy applications with continuous CI/CD tools. You can utilize AWS services and integrate AWS resources into your projects by connecting your AWS accounts. With all of the stages of an application’s lifecycle in one tool, you can deliver quality software quickly and confidently. You must bring your laptop to participate.
DOP303-R | Continuous integration and delivery on AWS In this workshop, learn to create end-to-end continuous integration and continuous delivery (CI/CD) pipelines using AWS Cloud Development Kit (AWS CDK). Review the fundamental concepts of continuous integration, continuous deployment, and continuous delivery. Then, using TypeScript/Python, define an AWS CodePipeline, AWS CodeBuild, and AWS CodeCommit workflow. You must bring your laptop to participate.
DOP304 | Develop AWS CDK resources to deploy your applications on AWS In this workshop, learn how to build and deploy applications using infrastructure as code with AWS Cloud Development Kit (AWS CDK). Create resources using AWS CDK and learn maintenance and operations tips. In addition, get an introduction to building your own constructs. You must bring your laptop to participate.
DOP305 | Develop AWS CloudFormation templates to manage your infrastructure In this workshop, learn how to develop and test AWS CloudFormation templates. Create CloudFormation templates to deploy and manage resources and learn about CloudFormation language features that allow you to reuse and extend templates for many scenarios. Explore testing tools that can help you validate your CloudFormation templates, including cfn-lint and CloudFormation Guard. You must bring your laptop to participate.
DOP307-R | Hands-on with Amazon CodeWhisperer In this workshop, learn how to build applications faster and more securely with Amazon CodeWhisperer. The workshop begins with several examples highlighting how CodeWhisperer incorporates your comments and existing code to produce results. Then dive into a series of challenges designed to improve your productivity using multiple languages and frameworks. You must bring your laptop to participate.
DOP308 | Enforcing development standards with Amazon CodeCatalyst In this workshop, learn how Amazon CodeCatalyst can accelerate the application development lifecycle within your organization. Discover how your cloud center of excellence (CCoE) can provide standardized code and workflows to help teams get started quickly and securely. In addition, learn how to update projects as organization standards evolve. You must bring your laptop to participate.
Level 400 — Expert
DOP401 | Get better at building AWS CDK constructs In this workshop, dive deep into how to design AWS CDK constructs, which are reusable and shareable cloud components that help you meet your organization’s security, compliance, and governance requirements. Learn how to build, test, and share constructs representing a single AWS resource, as well as how to create higher-level abstractions that include built-in defaults and allow you to provision multiple AWS resources. You must bring your laptop to participate.
DevOps and Developer Productivity builders’ sessions
What are builders’ sessions?
These 60-minute group sessions are led by an AWS expert and provide an interactive learning experience for building on AWS. Builders’ sessions are designed to create a hands-on experience where questions are encouraged.
Level 300 — Advanced
DOP322-R | Accelerate data science coding with Amazon CodeWhisperer Generative AI removes the heavy lifting that developers experience today by writing much of the undifferentiated code, allowing them to build faster. Helping developers code faster could be one of the most powerful uses of generative AI that we will see in the coming years—and this framework can also be applied to data science projects. In this builders’ session, explore how Amazon CodeWhisperer accelerates the completion of data science coding tasks with extensions for JupyterLab and Amazon SageMaker. Learn how to build data processing pipeline and machine learning models with the help of CodeWhisperer and accelerate data science experiments in Python. You must bring your laptop to participate.
Level 400 — Expert
DOP402-R | Manage dev environments at scale with Amazon CodeCatalyst Amazon CodeCatalyst Dev Environments are cloud-based environments that you can use to quickly work on the code stored in the source repositories of your project. They are automatically created with pre-installed dependencies and language-specific packages so you can work on a new or existing project right away. In this session, learn how to create secure, reproducible, and consistent environments for VS Code, AWS Cloud9, and JetBrains IDEs. You must bring your laptop to participate.
DOP403-R | Hands-on with Amazon CodeCatalyst: Automating security in CI/CD pipelines In this session, learn how to build a CI/CD pipeline with Amazon CodeCatalyst and add the necessary steps to secure your pipeline. Learn how to perform tasks such as secret scanning, software composition analysis (SCA), static application security testing (SAST), and generating a software bill of materials (SBOM). You must bring your laptop to participate.
DevOps and Developer Productivity lightning talks
What are lightning talks?
Lightning talks are short, 20-minute demos led from a stage.
DOP221 | Amazon CodeCatalyst in real time: Deploying to production in minutes In this follow-up demonstration to DOP210, see how you can use an Amazon CodeCatalyst blueprint to build a production-ready application that is set up for long-term success. See in real time how to create a project using a CodeCatalyst Dev Environment and deploy it to production using a CodeCatalyst workflow.
DevOps and Developer Productivity code talks
What are code talks?
Code talks are 60-minute, highly-interactive discussions featuring live coding. Attendees are encouraged to dig in and ask questions about the speaker’s approach.
DOP203 | The future of development on AWS This code talk includes a live demo and an open discussion about how builders can use the latest AWS developer tools and generative AI to build production-ready applications in minutes. Starting at an Amazon CodeCatalyst blueprint and using integrated AWS productivity and security capabilities, see a glimpse of what the future holds for developing on AWS.
DOP204 | Tips and tricks for coding with Amazon CodeWhisperer Generative AI tools that can generate code suggestions, such as Amazon CodeWhisperer, are growing rapidly in popularity. Join this code talk to learn how CodeWhisperer can accelerate and enhance your software development with code generation, reference tracking, security scans, and more. Learn best practices for prompt engineering, and get tips and tricks that can help you be more productive when building applications.
Want to stay connected?
Get the latest updates for DevOps and Developer Productivity by following us on Twitter and visiting the AWS devops blog.