Post Syndicated from Jonas Otten original https://blog.cloudflare.com/building-rakelimit/


Cloudflare’s globally distributed network is not just designed to protect HTTP services but any kind of TCP or UDP traffic that passes through our edge. To this end, we’ve built a number of sophisticated DDoS mitigation systems, such as Gatebot, which analyze world-wide traffic patterns. However, we’ve always employed defense-in-depth: in addition to global protection systems we also use off-the shelf mechanisms such as TCP SYN-cookies, which protect individual servers locally from the very common SYN-flood. But there’s a catch: such a mechanism does not exist for UDP. UDP is a connectionless protocol and does not have similar context around packets, especially considering that Cloudflare powers services such as Spectrum which are agnostic to the upper layer protocol (DNS, NTP, …), so my 2020 intern class project was to come up with a different approach.
Protecting UDP services
First of all, let’s discuss what it actually means to provide protection to UDP services. We want to ensure that an attacker cannot drown out legitimate traffic. To achieve this we want to identify floods and limit them while leaving legitimate traffic untouched.
The idea to mitigate such attacks is straight forward: first identify a group of packets that is related to an attack, and then apply a rate limit on this group. Such groups are determined based on the attributes available to us in the packet, such as addresses and ports.
We do not want to completely drop the flood of traffic, as legitimate traffic may still be part of it. We only want to drop as much traffic as necessary to comply with our set rate limit. Completely ignoring a set of packets just because it is slightly above the rate limit is not an option, as it may contain legitimate traffic.
This ensures both that our service stays responsive but also that legitimate packets experience as little impact as possible.
While rate limiting is a somewhat straightforward procedure, determining groups is a bit harder, for a number of reasons.
Finding needles in the haystack
The problem in determining groups in packets is that we have barely any context. We consider four things as useful attributes as attack signatures: the source address and port as well as the destination address and port. While that already is not a lot, it gets worse: the source address and port may not even be accurate. Packets can be spoofed, in which case an attacker hides their own address. That means only keeping a rate per source address may not provide much value, as it could simply be spoofed.
But there is another problem: keeping one rate per address does not scale. When bringing IPv6 into the equation and its whopping address space it becomes clear it’s not going to work.
To solve these issues we turned to the academic world and found what we were looking for, the problem of Heavy Hitters. Heavy Hitters are elements of a datastream that appear frequently, and can be expressed relative to the overall elements of the stream. We can define for example that an element is considered to be a Heavy Hitter if its frequency exceeds, say, 10% of the overall count. To do so we naively could suggest to simply maintain a counter per element, but due to the space limitations this will not scale. Instead probabilistic algorithms such as a CountMin sketch or the SpaceSaving algorithm can be used. These provide an estimated count instead of a precise one, but are capable of doing this with constant memory requirements, and in our case we will just save rates into the CountMin sketch instead of counts. So no matter how many unique elements we have to track, the memory consumption is the same.
We now have a way of finding the needle in the haystack, and it does have constant memory requirements, solving our problem. However, reality isn’t that simple. What if an attack is not just originating from a single port but many? Or what if a reflection attack is hitting our service, resulting in random source addresses but a single source port? Maybe a full /24 subnet is sending us a flood? We can not just keep a rate per combination we see, as it would ignore all these patterns.
Grouping the groups: How to organize packets
Luckily the academic world has us covered again, with the concept of Hierarchical Heavy Hitters. It extends the Heavy Hitter concept by using the underlying hierarchy in the elements of the stream. For example, an IP address can be naturally grouped into several subnets:

In this case we defined that we consider the fully-specified address, the /24 subnet and the /0 wildcard. We start at the left with the fully specified address, and each step walking towards the top we consider less information from it. We call these less-specific addresses generalisations, and measure how specific a generalisation is by assigning a level. In our example, the address 192.0.2.123 is at level 0, while 192.0.2.0/24 is at level 1, etc.
If we want to create a structure which can hold this information for every packet, it could look like this:
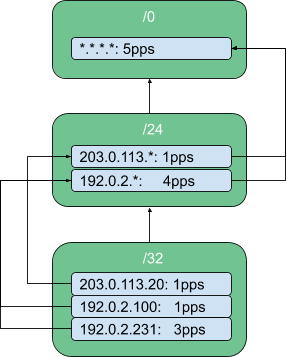
We maintain a CountMin-sketch per subnet and then apply Heavy Hitters. When a new packet arrives and we need to determine if it is allowed to pass we simply check the rates of the corresponding elements in every node. If no rate exceeds the rate limit that we set, e.g. 25 packets per second (pps), it is allowed to pass.
The structure could now keep track of a single attribute, but we would waste a lot of context around packets! So instead of letting it go to waste, we use the two-dimensional approach for addresses proposed in the paper Hierarchical Heavy Hitters with SpaceSaving algorithm, and extend it further to also incorporate ports into our structure. Ports do not have a natural hierarchy such as addresses, so they can only be in two states: either specified (e.g. 8080) or wildcard.
Now our structure looks like this:
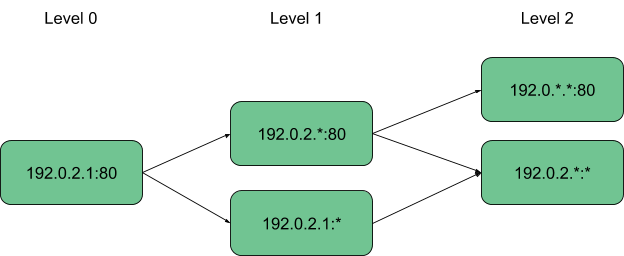
Now let’s talk about the algorithm we use to traverse the structure and determine if a packet should be allowed to pass. The paper Hierarchical Heavy Hitters with SpaceSaving algorithm provides two methods that can be used on the data structure: one that updates elements and increases their counters, and one that provides all elements that currently are Heavy Hitters. This is actually not necessary for our use-case, as we are only interested if the element, or packet, we are looking at right now would be a Heavy Hitter to decide if it can pass or not.
Secondly, our goal is to prevent any Heavy Hitters from passing, thus leaving the structure with no Heavy Hitters whatsoever. This is a great property, as it allows us to simplify the algorithm substantially, and it looks like this:
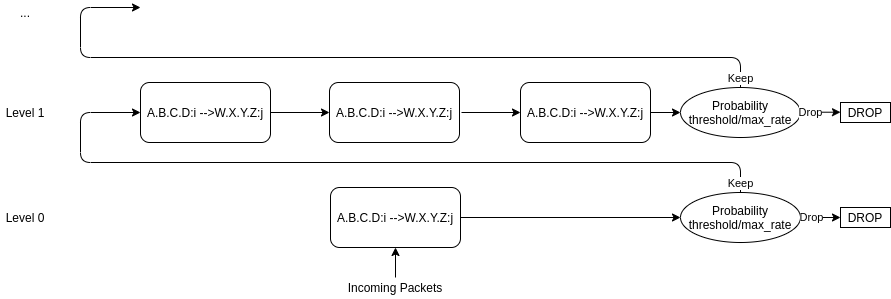
As you may notice, we update every node of a level and maintain the maximum rate we see. After each level we calculate a probability that determines if a packet should be passed to the next level, based on the maximum rate we saw on that level and a set rate limit. Each node essentially filters the traffic for the following, less specific level.
I actually left out a small detail: a packet is not dropped if any rate exceeds the limit, but instead is kept with the probability rate limit/maximum rate seen. The reason is that if we just drop all packets if the rates exceed the limit, we would drop the whole traffic, not just a subset to make it comply with our set rate limit.
Since we now still update more specific nodes even if a node reaches a rate limit, the rate limit will converge towards the underlying pattern of the attack as much as possible. That means other traffic will be impacted as minimally as possible, and that with no manual intervention whatsoever!
BPF to the rescue: building a Go library
As we want to use this algorithm to mitigate floods, we need to spend as little computation and overhead as possible before we decide if a packet should be dropped or not. As so often, we looked into the BPF toolbox and found what we need: Socketfilters. As our colleague Marek put it: “It seems, no matter the question – BPF is the answer.”.
Socketfilters are pieces of code that can be attached to a single socket and get executed before a packet will be passed from kernel to userspace. This is ideal for a number of reasons. First, when the kernel runs the socket filter code, it gives it all the information from the packet we need, and other mitigations such as firewalls have been executed. Second the code is executed per socket, so every application can activate it as needed, and also set appropriate rate limits. It may even use different rate limits for different sockets. The third reason is privileges: we do not need to be root to attach the code to a socket. We can execute code in the kernel as a normal user!
BPF also has a number of limitations which have been already covered on this blog in the past, so we will focus on one that’s specific to our project: floating-point numbers.
To calculate rates we need floating-point numbers to provide an accurate estimate. BPF, and the whole kernel for that matter, does not support these. Instead we implemented a fixed-point representation, which uses a part of the available bits for the fractional part of a rational number and the remaining bits for the integer part. This allows us to represent floats within a certain range, but there is a catch when doing arithmetic: while subtraction and addition of two fixed-points work well, multiplication and division requires double the number of bits to ensure there will not be any loss in precision. As we use 64 bits for our fixed-point values, there is no larger data type available to ensure this does not happen. Instead of calculating the result with exact precision, we convert one of the arguments into an integer. That results in the loss of the fractional part, but as we deal with large rates that does not pose any issue, and helps us to work around the bit limitation as intermediate results fit into the available 64 bits. Whenever fixed-point arithmetic is necessary the precision of intermediate results has to be carefully considered.
There are many more details to the implementation, but instead of covering every single detail in this blog post lets just look at the code.
We open sourced rakelimit over on Github at cloudflare/rakelimit! It is a full-blown Go library that can be enabled on any UDP socket, and is easy to configure.
The development is still in early stages and this is a first prototype, but we are excited to continue and push the development with the community! And if you still can’t get enough, look at our talk from this year’s Linux Plumbers Conference.