Post Syndicated from Luis Morales original https://aws.amazon.com/blogs/big-data/implement-apache-flink-near-online-data-enrichment-patterns/
Stream data processing allows you to act on data in real time. Real-time data analytics can help you have on-time and optimized responses while improving the overall customer experience.
Data streaming workloads often require data in the stream to be enriched via external sources (such as databases or other data streams). Pre-loading of reference data provides low latency and high throughput. However, this pattern may not be suitable for certain types of workloads:
- Reference data updates with high frequency
- The streaming application needs to make an external call to compute the business logic
- Accuracy of the output is important and the application shouldn’t use stale data
- Cardinality of reference data is very high, and the reference dataset is too big to be held in the state of the streaming application
For example, if you’re receiving temperature data from a sensor network and need to get additional metadata of the sensors to analyze how these sensors map to physical geographic locations, you need to enrich it with sensor metadata data.
Apache Flink is a distributed computation framework that allows for stateful real-time data processing. It provides a single set of APIs for building batch and streaming jobs, making it easy for developers to work with bounded and unbounded data. Amazon Managed Service for Apache Flink (successor to Amazon Kinesis Data Analytics) is an AWS service that provides a serverless, fully managed infrastructure for running Apache Flink applications. Developers can build highly available, fault tolerant, and scalable Apache Flink applications with ease and without needing to become an expert in building, configuring, and maintaining Apache Flink clusters on AWS.
You can use several approaches to enrich your real-time data in Amazon Managed Service for Apache Flink depending on your use case and Apache Flink abstraction level. Each method has different effects on the throughput, network traffic, and CPU (or memory) utilization. For a general overview of data enrichment patterns, refer to Common streaming data enrichment patterns in Amazon Managed Service for Apache Flink.
This post covers how you can implement data enrichment for near-online streaming events with Apache Flink and how you can optimize performance. To compare the performance of the enrichment patterns, we ran performance testing based on synthetic data. The result of this test is useful as a general reference. It’s important to note that the actual performance for your Flink workload will depend on various and different factors, such as API latency, throughput, size of the event, and cache hit ratio.
We discuss three enrichment patterns, detailed in the following table.
| . | Synchronous Enrichment | Asynchronous Enrichment | Synchronous Cached Enrichment |
| Enrichment approach | Synchronous, blocking per-record requests to the external endpoint | Non-blocking parallel requests to the external endpoint, using asynchronous I/O | Frequently accessed information is cached in the Flink application state, with a fixed TTL |
| Data freshness | Always up-to-date enrichment data | Always up-to-date enrichment data | Enrichment data may be stale, up to the TTL |
| Development complexity | Simple model | Harder to debug, due to multi-threading | Harder to debug, due to relying on Flink state |
| Error handling | Straightforward | More complex, using callbacks | Straightforward |
| Impact on enrichment API | Max: one request per message | Max: one request per message | Reduce I/O to enrichment API (depends on cache TTL) |
| Application latency | Sensitive to enrichment API latency | Less sensitive to enrichment API latency | Reduce application latency (depends on cache hit ratio) |
| Other considerations | none | none |
Customizable TTL. Only synchronous implementation as of Flink 1.17 |
| Result of the comparative test (Throughput) | ~350 events per second | ~2,000 events per second | ~28,000 events per second |
Solution overview
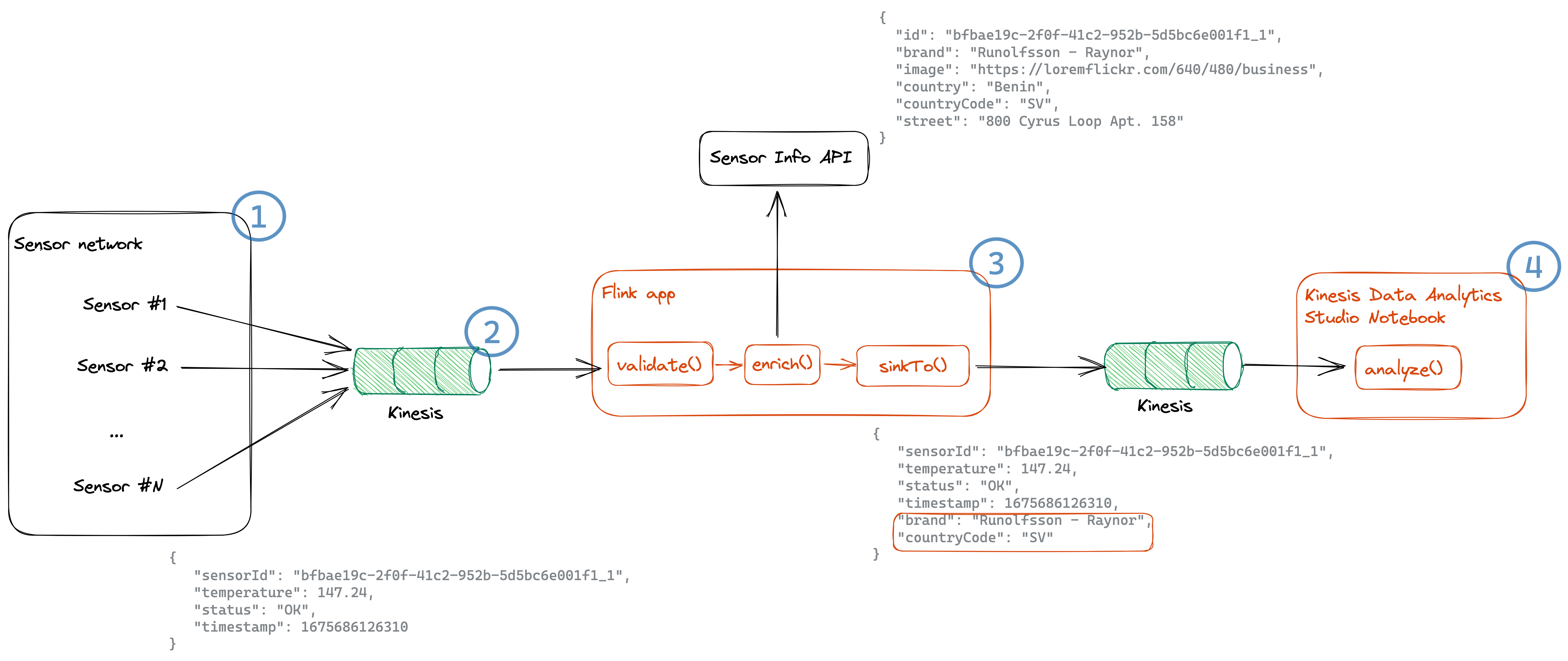
For this post, we use an example of a temperature sensor network (component 1 in the following architecture diagram) that emits sensor information, such as temperature, sensor ID, status, and the timestamp this event was produced. These temperature events get ingested into Amazon Kinesis Data Streams (2). Downstream systems also require the brand and country code information of the sensors, in order to analyze, for example, the reliability per brand and temperature per plant side.
Based on the sensor ID, we enrich this sensor information from the Sensor Info API (3), which provide us with information of the brand, location, and an image. The resulting enriched stream is sent to another Kinesis data stream and can then be analyzed in an Amazon Managed Service for Apache Flink Studio notebook (4).
Prerequisites
To get started with implementing near-online data enrichment patterns, you can clone or download the code from the GitHub repository. This repository implements the Flink streaming application we described. You can find the instructions on how to set up Flink in either Amazon Managed Service for Apache Flink or other available Flink deployment options in the README.md file.
If you want to learn how these patterns are implemented and how to optimize performance for your Flink application, you can simply follow along with this post without deploying the samples.
Project overview
The project is structured as follows:
The main method in the ProcessTemperatureStream class sets up the run environment and either takes the parameters from the command line, if it’s is a local environment, or uses the application properties from Amazon Managed Service for Apache Flink. Based on the parameter EnrichmentStrategy, it decides which implementation to pick: synchronous enrichment (default), asynchronous enrichment, or cached enrichment based on the Flink concept of KeyedState.
We go over the three approaches in the following sections.
Synchronous data enrichment
When you want to enrich your data from an external provider, you can use synchronous per-record lookup. When your Flink application processes an incoming event, it makes an external HTTP call and after sending every request, it has to wait until it receives the response.
As Flink processes events synchronously, the thread that is running the enrichment is blocked until it receives the HTTP response. This results in the processor staying idle for a significant period of processing time. On the other hand, the synchronous model is easier to design, debug, and trace. It also allows you to always have the latest data.
It can be integrated into your streaming application as such:
The implementation of the enrichment function looks like the following code:
To optimize the performance for synchronous enrichment, you can use the KeepAlive flag because the HTTP client will be reused for multiple events.
For applications with I/O-bound operators (such as external data enrichment), it can also make sense to increase the application parallelism without increasing the resources dedicated to the application. You can do this by increasing the ParallelismPerKPU setting of the Amazon Managed Service for Apache Flink application. This configuration describes the number of parallel subtasks an application can perform per Kinesis Processing Unit (KPU), and a higher value of ParallelismPerKPU can lead to full utilization of KPU resources. But keep in mind that increasing the parallelism doesn’t work in all cases, such as when you are consuming from sources with few shards or partitions.
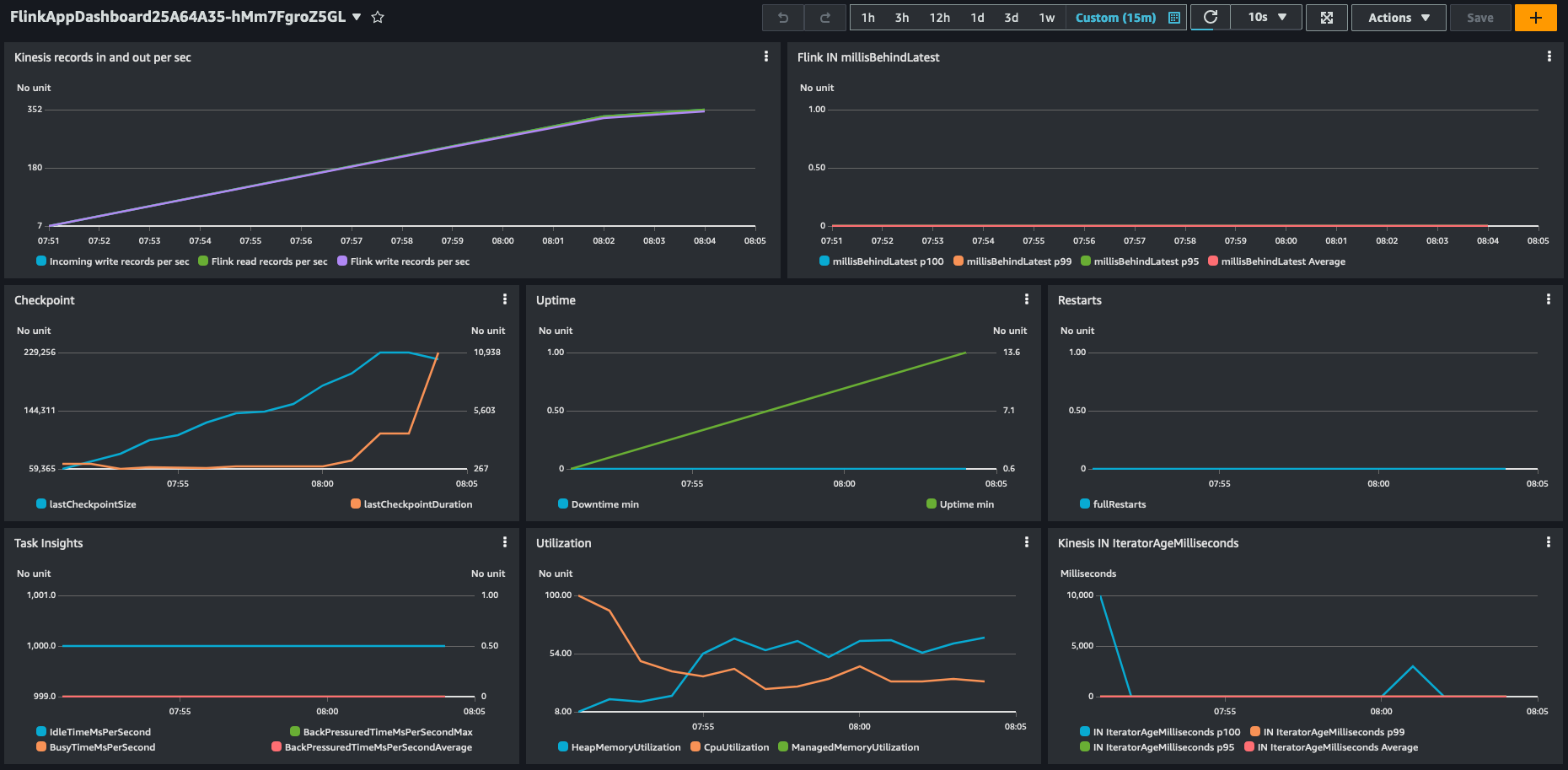
In our synthetic testing with Amazon Managed Service for Apache Flink, we saw a throughput of approximately 350 events per second on a single KPU with 4 parallelism per KPU and the default settings.
Asynchronous data enrichment
Synchronous enrichment doesn’t take full advantage of computing resources. That’s because Fink waits for HTTP responses. But Flink offers asynchronous I/O for external data access. This allows you to enrich the stream events asynchronously, so it can send a request for other elements in the stream while it waits for the response for the first element and requests can be batched for greater efficiency.
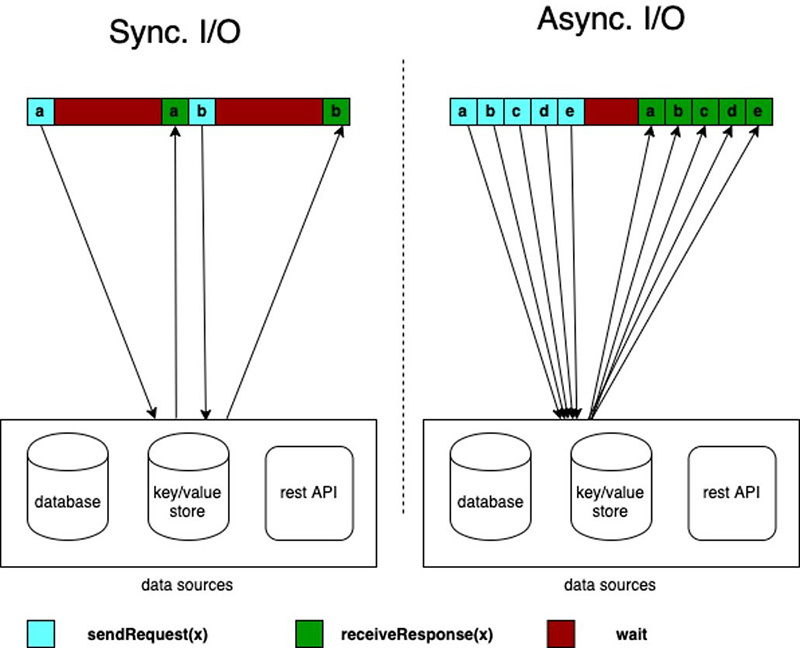
While using this pattern, you have to decide between unorderedWait (where it emits the result to the next operator as soon as the response is received, disregarding the order of the elements on the stream) and orderedWait (where it waits until all inflight I/O operations complete, then sends the results to the next operator in the same order as the original elements were placed on the stream). When your use case doesn’t require event ordering, unorderedWait provides better throughput and less idle time. Refer to Enrich your data stream asynchronously using Amazon Managed Service for Apache Flink to learn more about this pattern.
The asynchronous enrichment can be added as follows:
The enrichment function works similar as the synchronous implementation. It first retrieves the sensor info as a Java Future, which represents the result of an asynchronous computation. As soon as it’s available, it parses the information and then merges both objects into an EnrichedTemperature:
In our testing with Amazon Managed Service for Apache Flink, we saw a throughput of 2,000 events per second on a single KPU with 2 parallelism per KPU and the default settings.
Synchronous cached data enrichment
Although numerous operations in a data flow focus on individual events independently, such as event parsing, there are certain operations that retain information across multiple events. These operations, such as window operators, are referred to as stateful due to their ability to maintain state.
The keyed state is stored within an embedded key-value store, conceptualized as a part of Flink’s architecture. This state is partitioned and distributed in conjunction with the streams that are consumed by the stateful operators. As a result, access to the key-value state is limited to keyed streams, meaning it can only be accessed after a keyed or partitioned data exchange, and is restricted to the values associated with the current event’s key. For more information about the concepts, refer to Stateful Stream Processing.
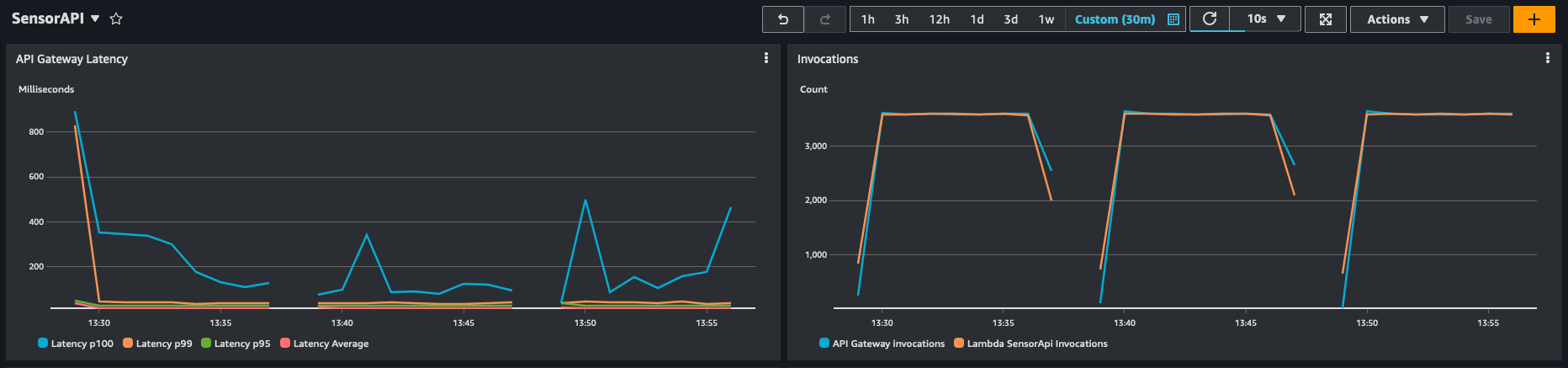
You can use the keyed state for frequently accessed information that doesn’t change often, such as the sensor information. This will not only allow you to reduce the load on downstream resources, but also increase the efficiency of your data enrichment because no round-trip to an external resource for already fetched keys is necessary and there’s also no need to recompute the information. But keep in mind that Amazon Managed Service for Apache Flink stores transient data in a RocksDB backend, which adds a latency to retrieving the information. But because RocksDB is local to the node processing the data, this is faster than reaching out to external resources, as you can see in the following example.
To use keyed streams, you have to partition your stream using the .keyBy(...) method, which assures that events for the same key, in this case sensor ID, will be routed to the same worker. You can implement it as follows:
We are using the sensor ID as the key to partition the stream and later enrich it. This way, we can then cache the sensor information as part of the keyed state. When picking a partition key for your use case, choose one that has a high cardinality. This leads to an even distribution of events across different workers.
To store the sensor information, we use the ValueState. To configure the state management, we have to describe the state type by using the TypeHint. Additionally, we can configure how long a certain state will be cached by specifying the time-to-live (TTL) before the state will be cleaned up and has to retrieved or recomputed again.
As of Flink 1.17, access to the state is not possible in asynchronous functions, so the implementation must be synchronous.
It first checks if the sensor information for this particular key exists; if so, it gets enriched. Otherwise, it retrieves the sensor information, parses it, and then merges both objects into an EnrichedTemperature:
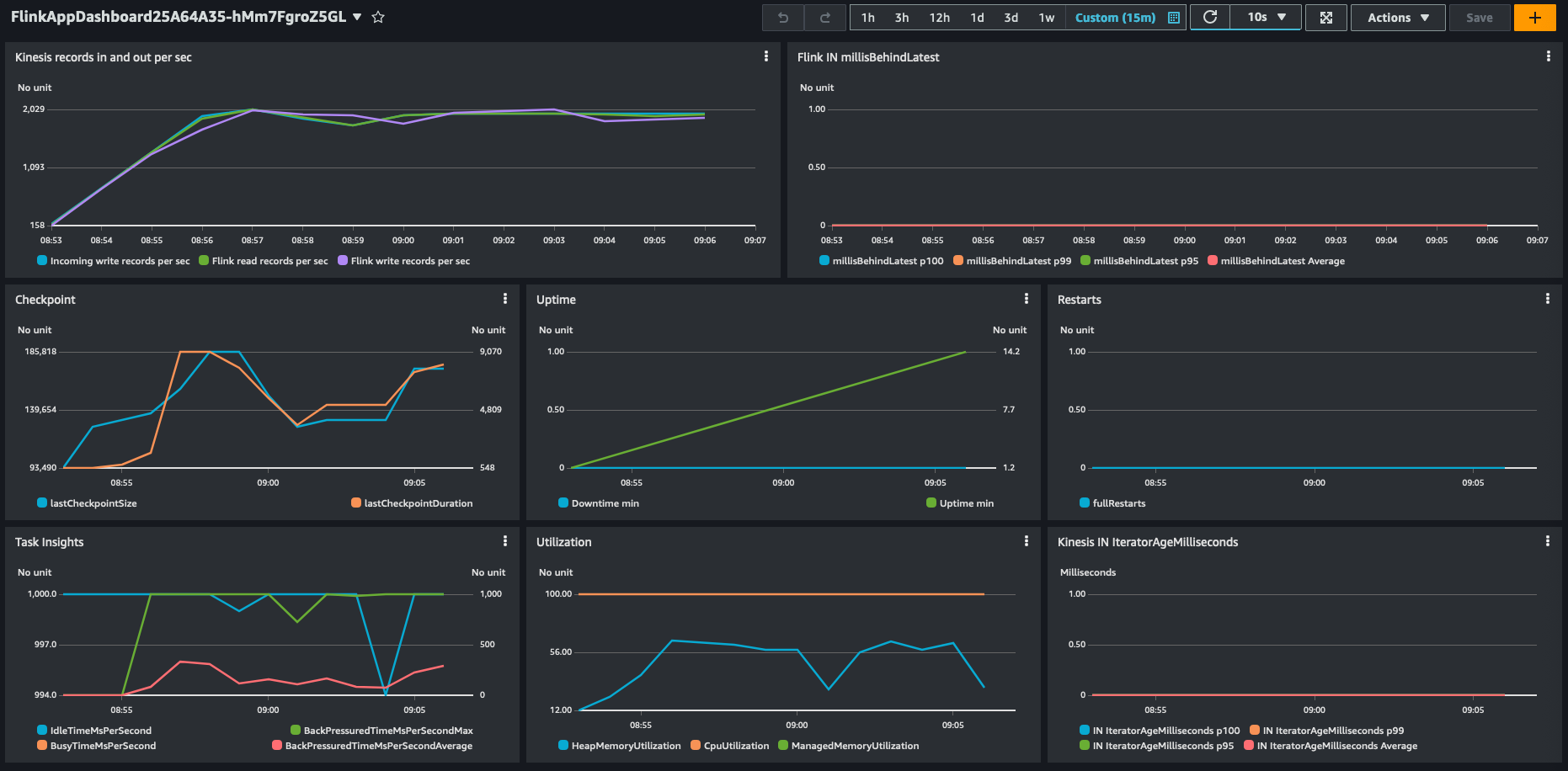
In our synthetic testing with Amazon Managed Service for Apache Flink, we saw a throughput of 28,000 events per second on a single KPU with 4 parallelism per KPU and the default settings.
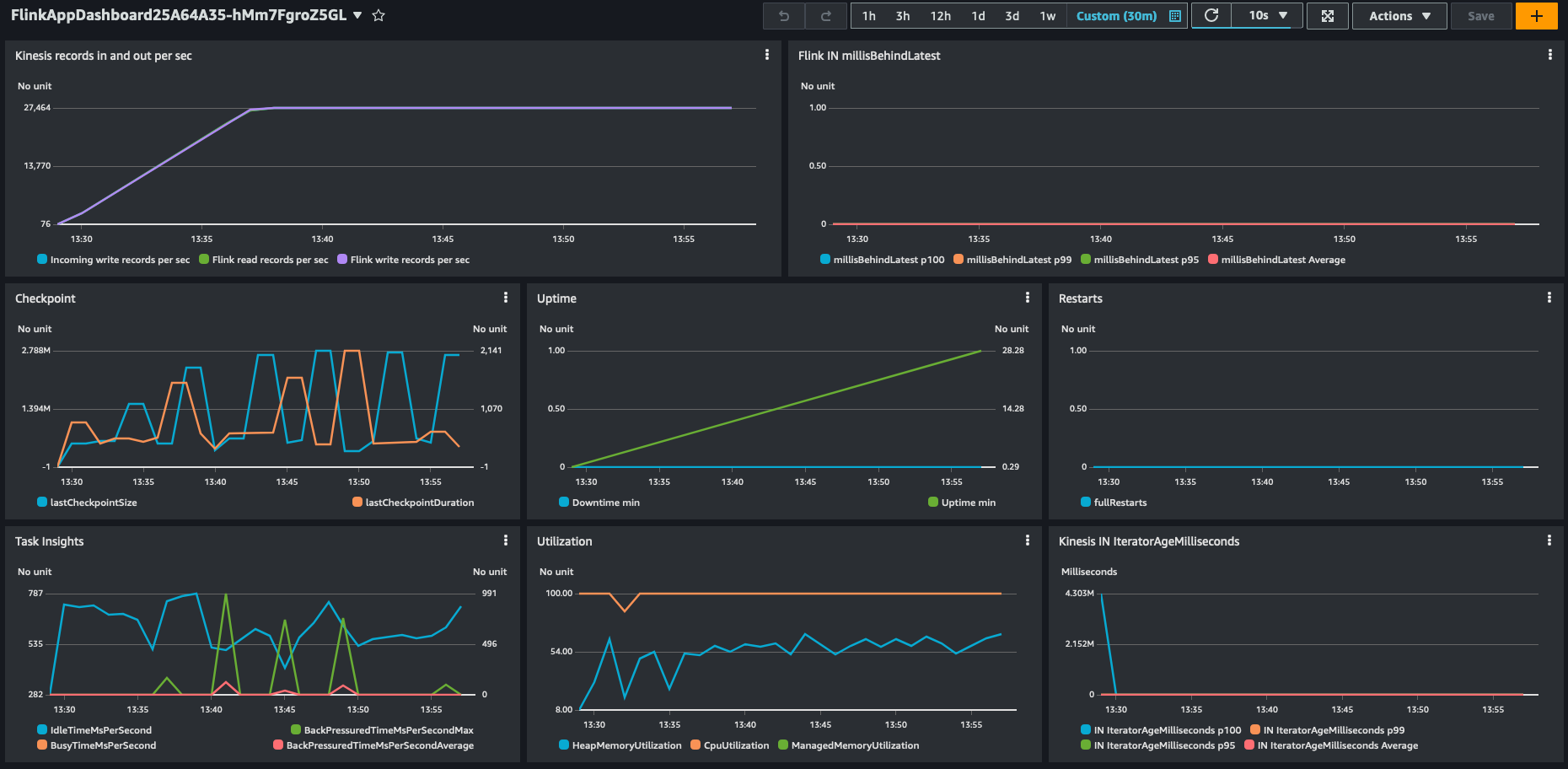
You can also see the impact and reduced load on the downstream sensor API.
Test your workload on Amazon Managed Service for Apache Flink
This post compared different approaches to run an application on Amazon Managed Service for Apache Flink with 1 KPU. Testing with a single KPU gives a good performance baseline that allows you to compare the enrichment patterns without generating a full-scale production workload.
It’s important to understand that the actual performance of the enrichment patterns depends on the actual workload and other external systems the Flink application interacts with. For example, performance of cached enrichment may vary with the cache hit ratio. Synchronous enrichment may behave differently depending on the response latency of the enrichment endpoint.
To evaluate which approach best suits your workload, you should first perform scaled-down tests with 1 KPU and a limited throughput of realistic data, possibly experimenting with different values of Parallelism per KPU. After you identify the best approach, it’s important to test the implementation at full scale, with real data and integrating with real external systems, before moving to production.
Summary
This post explored different approaches to implement near-online data enrichment using Flink, focusing on three communication patterns: synchronous enrichment, asynchronous enrichment, and caching with Flink KeyedState.
We compared the throughput achieved by each approach, with caching using Flink KeyedState being up to 14 times faster than using asynchronous I/O, in this particular experiment with synthetic data. Furthermore, we delved into optimizing the performance of Apache Flink, specifically on Amazon Managed Service for Apache Flink. We discussed strategies and best practices to maximize the performance of Flink applications in a managed environment, enabling you to fully take advantage of the capabilities of Flink for your near-online data enrichment needs.
Overall, this overview offers insights into different data enrichment patterns, their performance characteristics, and optimization techniques when using Apache Flink, particularly in the context of near-online data enrichment scenarios and on Amazon Managed Service for Apache Flink.
We welcome your feedback. Please leave your thoughts and questions in the comments section.
About the authors
 Luis Morales works as Senior Solutions Architect with digital-native businesses to support them in constantly reinventing themselves in the cloud. He is passionate about software engineering, cloud-native distributed systems, test-driven development, and all things code and security.
Luis Morales works as Senior Solutions Architect with digital-native businesses to support them in constantly reinventing themselves in the cloud. He is passionate about software engineering, cloud-native distributed systems, test-driven development, and all things code and security.
 Lorenzo Nicora works as Senior Streaming Solution Architect helping customers across EMEA. He has been building cloud-native, data-intensive systems for several years, working in the finance industry both through consultancies and for fin-tech product companies. He leveraged open source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as Senior Streaming Solution Architect helping customers across EMEA. He has been building cloud-native, data-intensive systems for several years, working in the finance industry both through consultancies and for fin-tech product companies. He leveraged open source technologies extensively and contributed to several projects, including Apache Flink.







