Post Syndicated from Matt Boyle original https://blog.cloudflare.com/using-apache-kafka-to-process-1-trillion-messages/
Cloudflare has been using Kafka in production since 2014. We have come a long way since then, and currently run 14 distinct Kafka clusters, across multiple data centers, with roughly 330 nodes. Between them, over a trillion messages have been processed over the last eight years.
Cloudflare uses Kafka to decouple microservices and communicate the creation, change or deletion of various resources via a common data format in a fault-tolerant manner. This decoupling is one of many factors that enables Cloudflare engineering teams to work on multiple features and products concurrently.
We learnt a lot about Kafka on the way to one trillion messages, and built some interesting internal tools to ease adoption that will be explored in this blog post. The focus in this blog post is on inter-application communication use cases alone and not logging (we have other Kafka clusters that power the dashboards where customers view statistics that handle more than one trillion messages each day). I am an engineer on the Application Services team and our team has a charter to provide tools/services to product teams, so they can focus on their core competency which is delivering value to our customers.
In this blog I’d like to recount some of our experiences in the hope that it helps other engineering teams who are on a similar journey of adopting Kafka widely.
Tooling
One of our Kafka clusters is creatively named Messagebus. It is the most general purpose cluster we run, and was created to:
- Prevent data silos;
- Enable services to communicate more clearly with basically zero integration cost (more on how we achieved this below);
- Encourage the use of a self-documenting communication format and therefore removing the problem of out of date documentation.
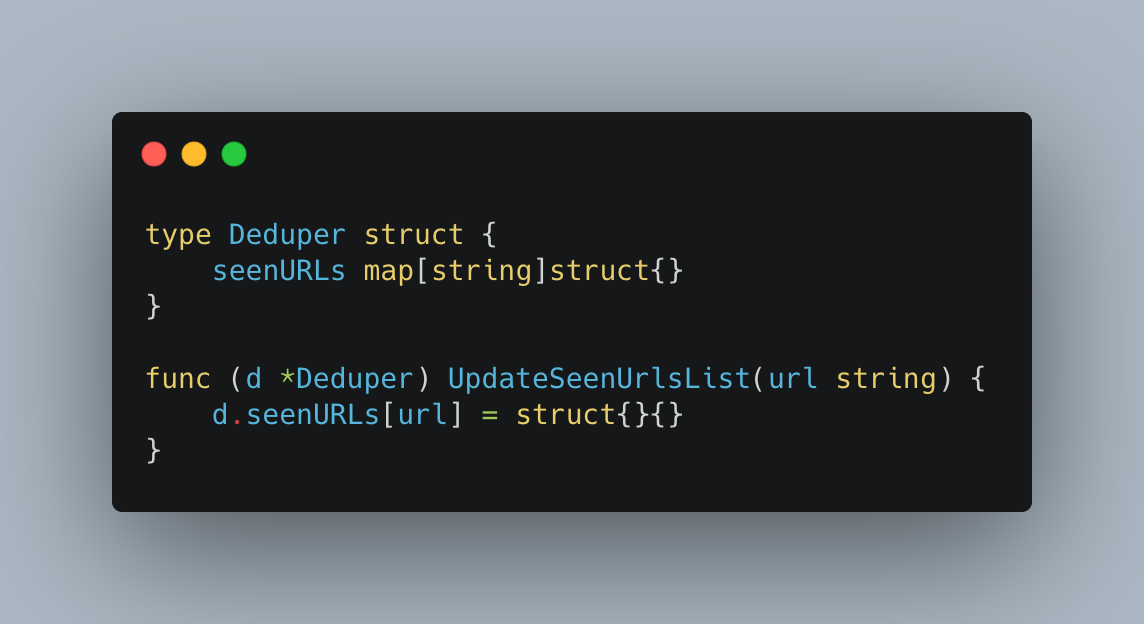
To make it as easy to use as possible and to encourage adoption, the Application Services team created two internal projects. The first is unimaginatively named Messagebus-Client. Messagebus-Client is a Go library that wraps the fantastic Shopify Sarama library with an opinionated set of configuration options and the ability to manage the rotation of mTLS certificates.
The success of this project is also somewhat its downfall. By providing a ready-to-go Kafka client, we ensured teams got up and running quickly, but we also abstracted some core concepts of Kafka a little too much, meaning that small unassuming configuration changes could have a big impact.
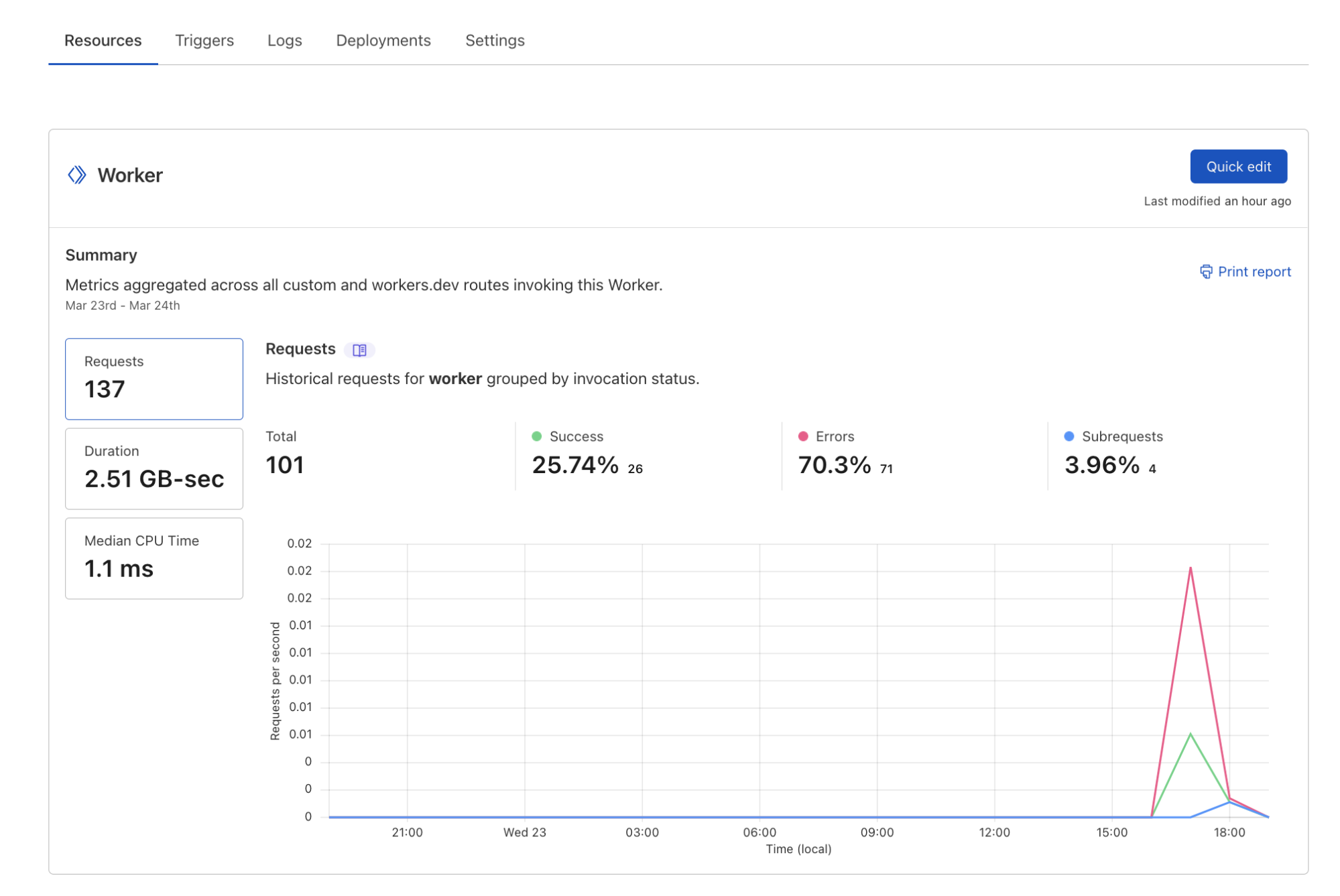
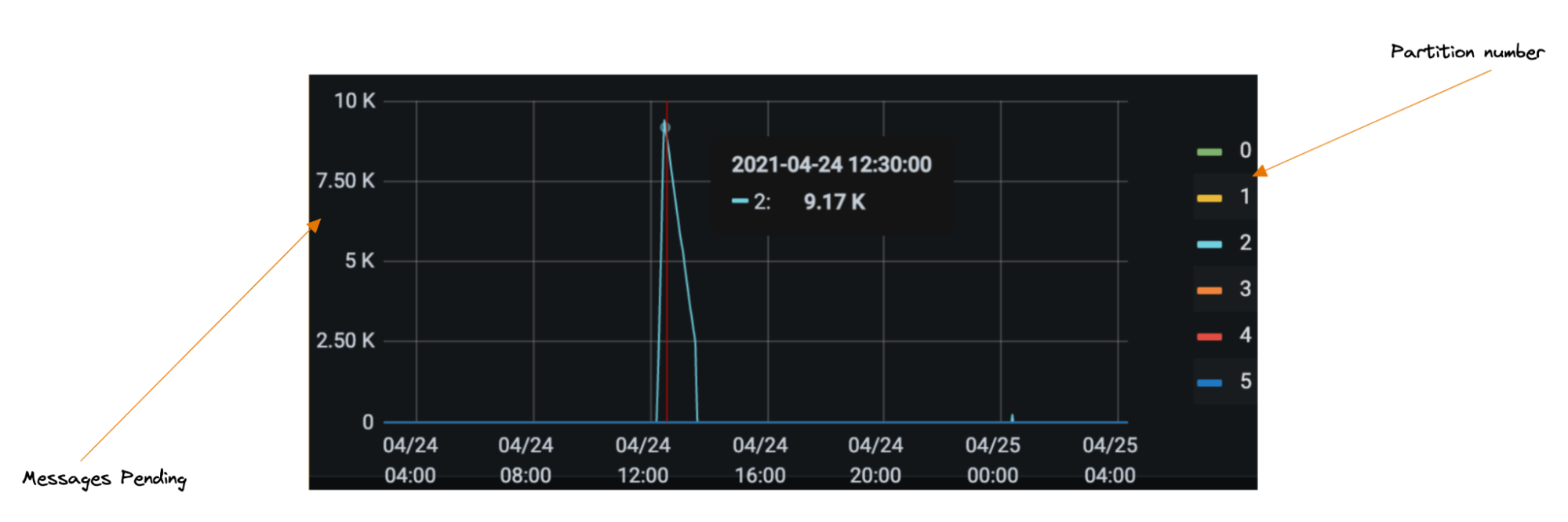
One such example led to partition skew (a large portion of messages being directed towards a single partition, meaning we were not processing messages in real time; see the chart below). One drawback of Kafka is you can only have one consumer per partition, so when incidents do occur, you can’t trivially scale your way to faster throughput.
That also means before your service hits production it is wise to do some back of the napkin math to figure out what throughput might look like, otherwise you will need to add partitions later. We have since amended our library to make events like the below less likely.
The reception for the Messagebus-Client has been largely positive. We spent time as a team to understand what the predominant use cases were, and took the concept one step further to build out what we call the connector framework.
Connectors
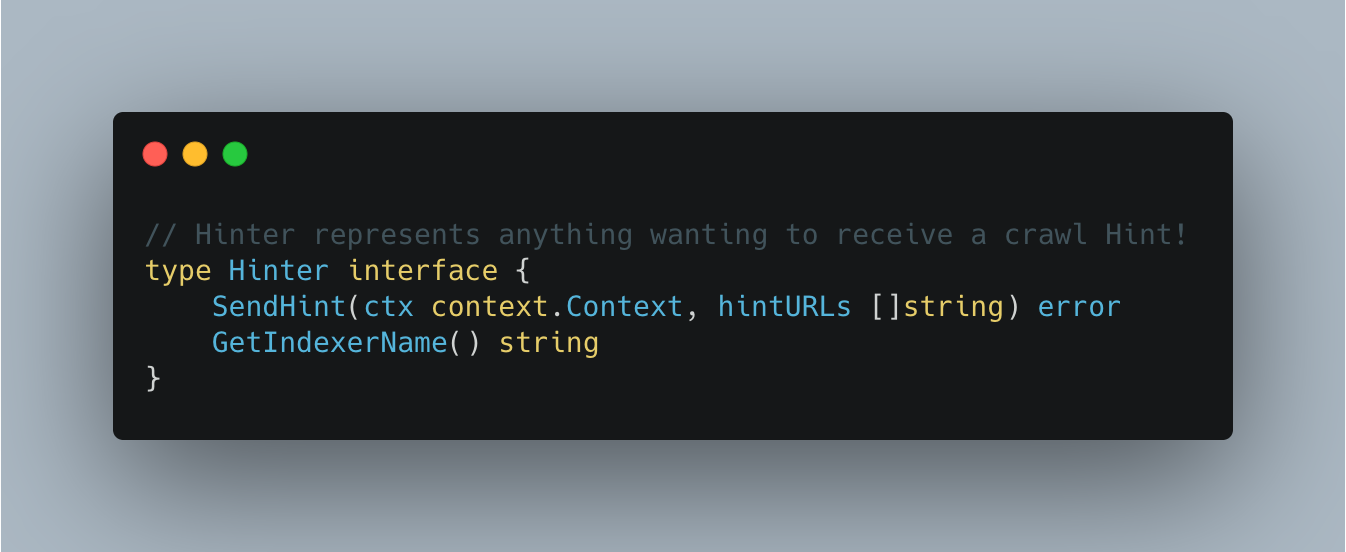
The connector framework is based on Kafka-connectors and allows our engineers to easily spin up a service that can read from a system of record and push it somewhere else (such as Kafka, or even Cloudflare’s own Quicksilver). To make this as easy as possible, we use Cookiecutter templating to allow engineers to enter a few parameters into a CLI and in return receive a ready to deploy service.
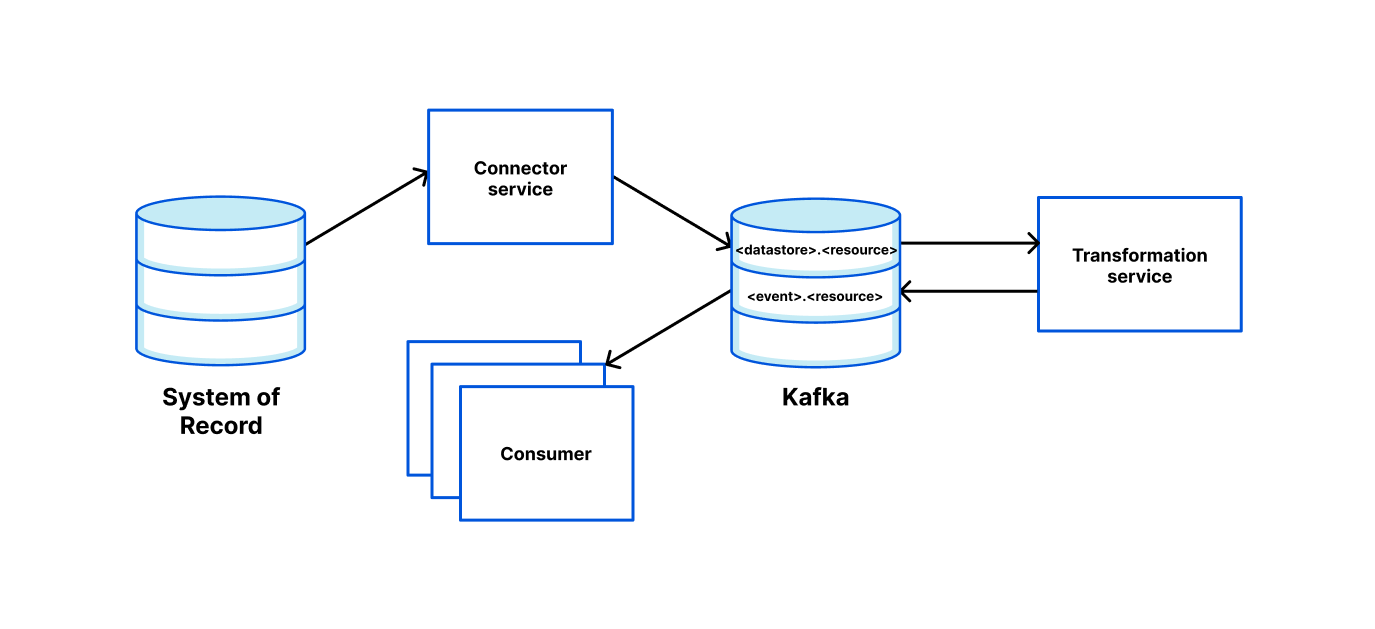
We provide the ability to configure data pipelines via environment variables. For simple use cases, we provide the functionality out of the box. However, extending the readers, writers and transformations is as simple as satisfying an interface and “registering” the new entry.
For example, adding the environment variables:
READER=kafka
TRANSFORMATIONS=topic_router:topic1,topic2|pf_edge
WRITER=quicksilver
will:
- Read messages from Kafka topic “topic1” and “topic2”;
- Transform the message using a transformation function called “pf_edge” which maps the request from a Kafka protobuf to a Quicksilver request;
- Write the result to Quicksilver.
Connectors come readily baked with basic metrics and alerts, so teams know they can move to production quickly but with confidence.
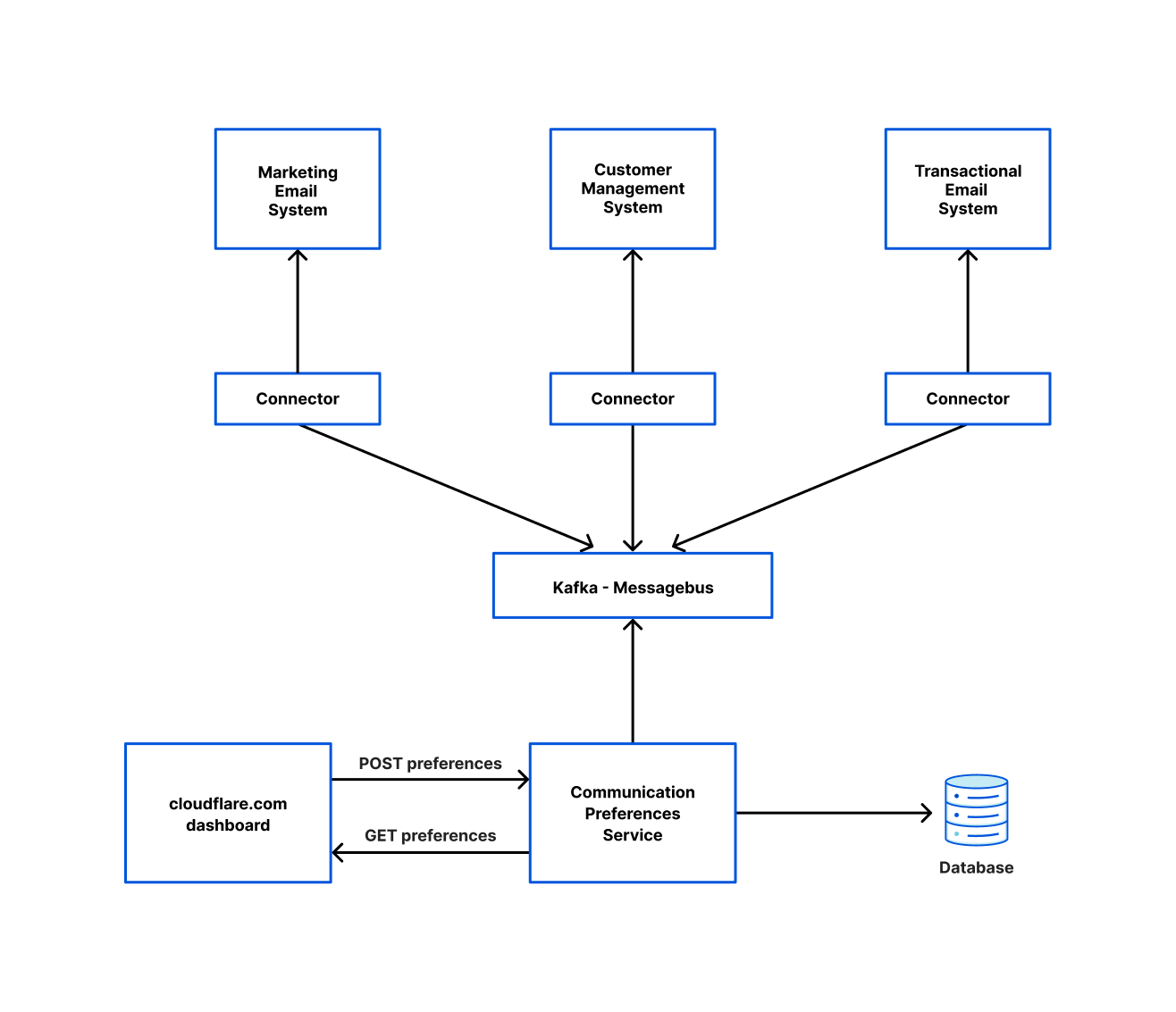
Below is a diagram of how one team used our connector framework to read from the Messagebus cluster and write to various other systems. This is orchestrated by a system the Application Service team runs called Communication Preferences Service (CPS). Whenever a user opts in/out of marketing emails or changes their language preferences on cloudflare.com, they are calling CPS which ensures those settings are reflected in all the relevant systems.
Strict Schemas
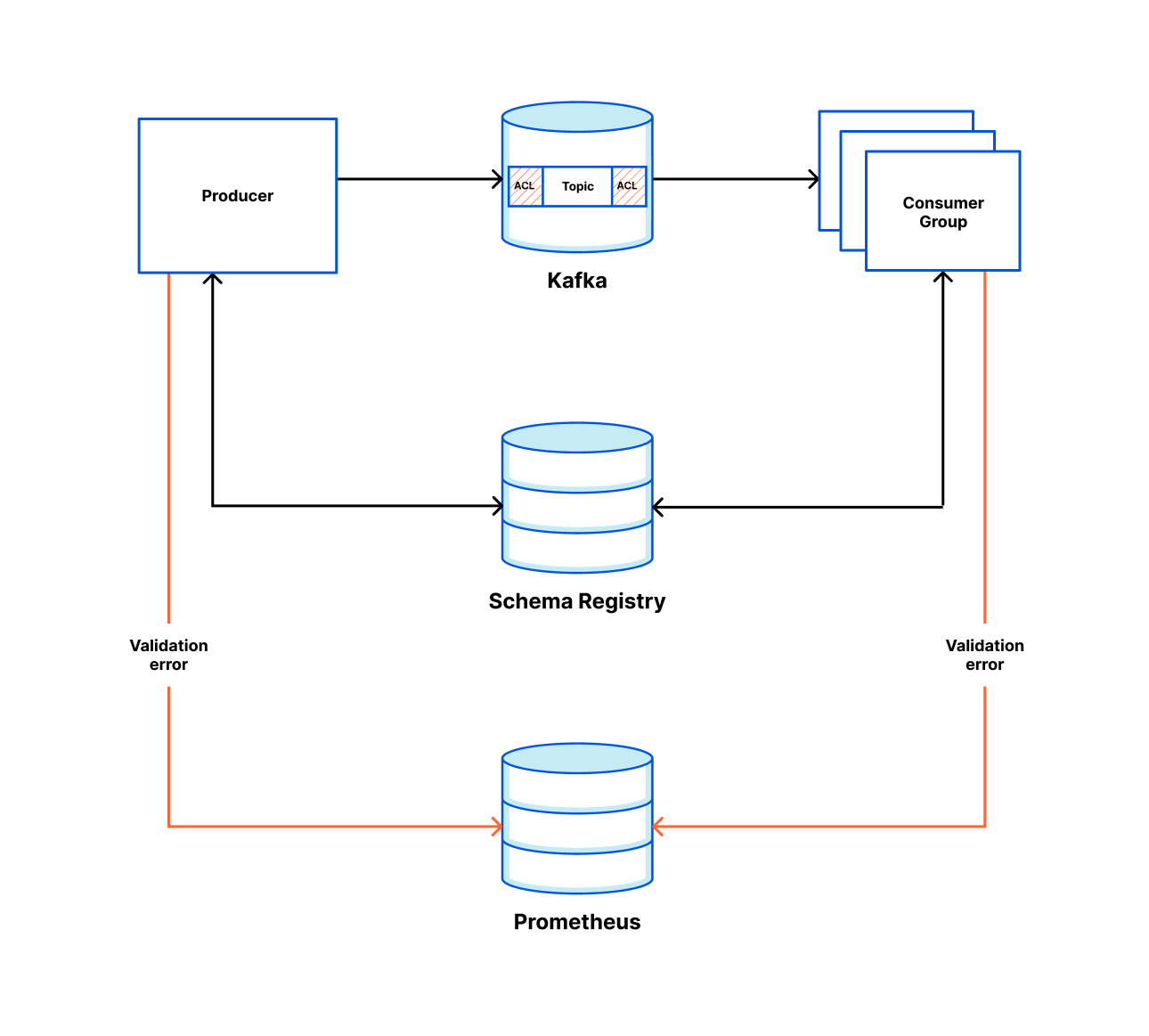
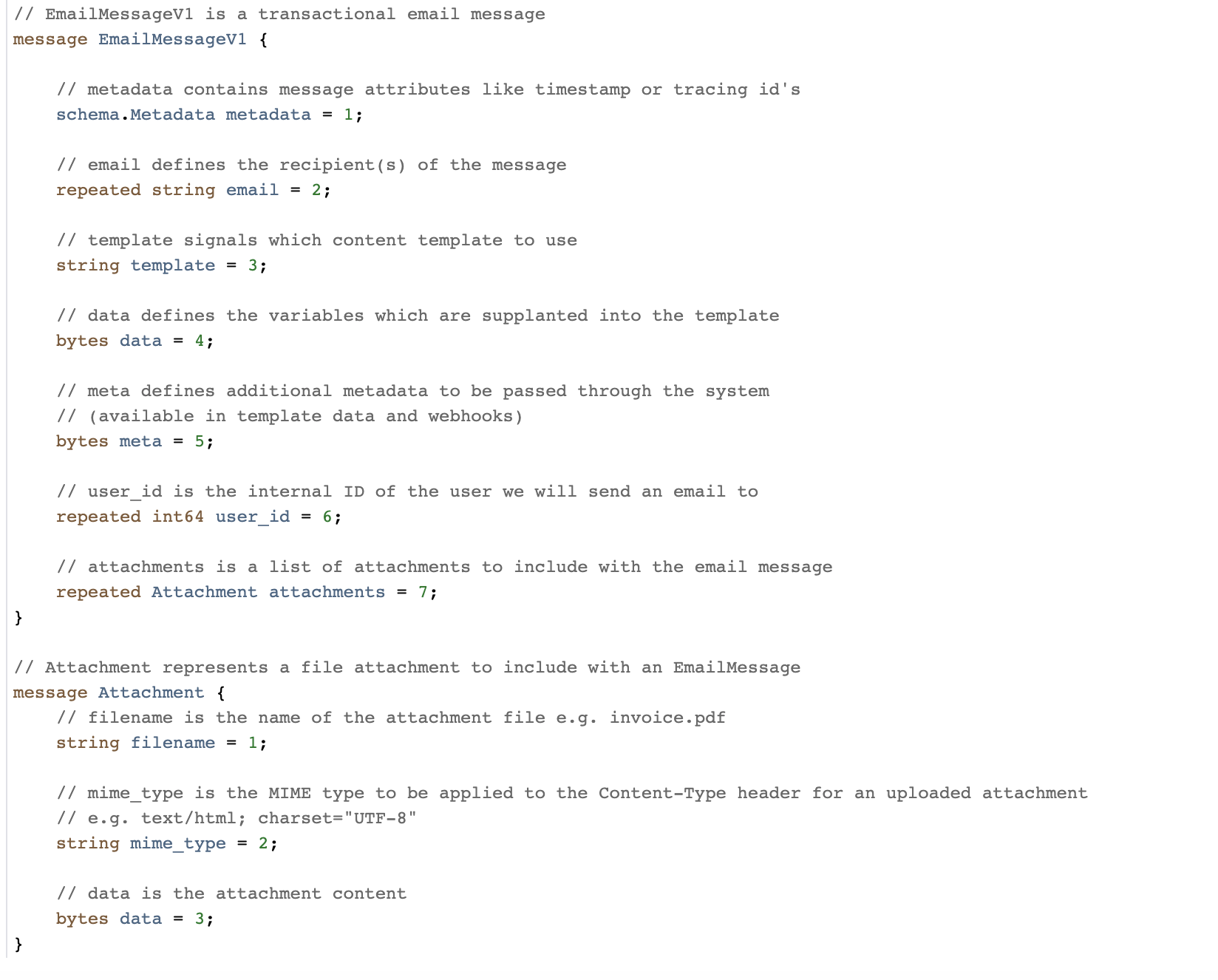
Alongside the Messagebus-Client library, we also provide a repo called Messagebus Schema. This is a schema registry for all message types that will be sent over our Messagebus cluster. For message format, we use protobuf and have been very happy with that decision. Previously, our team had used JSON for some of our kafka schemas, but we found it much harder to enforce forward and backwards compatibility, as well as message sizes being substantially larger than the protobuf equivalent. Protobuf provides strict message schemas (including type safety), the forward and backwards compatibility we desired, the ability to generate code in multiple languages as well as the files being very human-readable.
We encourage heavy commentary before approving a merge. Once merged, we use prototool to do breaking change detection, enforce some stylistic rules and to generate code for various languages (at time of writing it’s just Go and Rust, but it is trivial to add more).
Furthermore, in Messagebus Schema we store a mapping of proto messages to a team, alongside that team’s chat room in our internal communication tool. This allows us to escalate issues to the correct team easily when necessary.
One important decision we made for the Messagebus cluster is to only allow one proto message per topic. This is configured in Messagebus Schema and enforced by the Messagebus-Client. This was a good decision to enable easy adoption, but it has led to numerous topics existing. When you consider that for each topic we create, we add numerous partitions and replicate them with a replication factor of at least three for resilience, there is a lot of potential to optimize compute for our lower throughput topics.
Observability
Making it easy for teams to observe Kafka is essential for our decoupled engineering model to be successful. We therefore have automated metrics and alert creation wherever we can to ensure that all the engineering teams have a wealth of information available to them to respond to any issues that arise in a timely manner.
We use Salt to manage our infrastructure configuration and follow a Gitops style model, where our repo holds the source of truth for the state of our infrastructure. To add a new Kafka topic, our engineers make a pull request into this repo and add a couple of lines of YAML. Upon merge, the topic and an alert for high lag (where lag is defined as the difference in time between the last committed offset being read and the last produced offset being produced) will be created. Other alerts can (and should) be created, but this is left to the discretion of application teams. The reason we automatically generate alerts for high lag is that this simple alert is a great proxy for catching a high amount of issues including:
- Your consumer isn’t running.
- Your consumer cannot keep up with the amount of throughput or there is an anomalous amount of messages being produced to your topic at this time.
- Your consumer is misbehaving and not acknowledging messages.
For metrics, we use Prometheus and display them with Grafana. For each new topic created, we automatically provide a view into production rate, consumption rate and partition skew by producer/consumer. If an engineering team is called out, within the alert message is a link to this Grafana view.

In our Messagebus-Client, we expose some metrics automatically and users get the ability to extend them further. The metrics we expose by default are:
For producers:
- Messages successfully delivered.
- Message failed to deliver.
For consumer:
- Messages successfully consumed.
- Message consumption errors.
Some teams use these for alerting on a significant change in throughput, others use them to alert if no messages are produced/consumed in a given time frame.
A Practical Example
As well as providing the Messagebus framework, the Application Services team looks for common concerns within Engineering and looks to solve them in a scalable, extensible way which means other engineering teams can utilize the system and not have to build their own (thus meaning we are not building lots of disparate systems that are only slightly different).
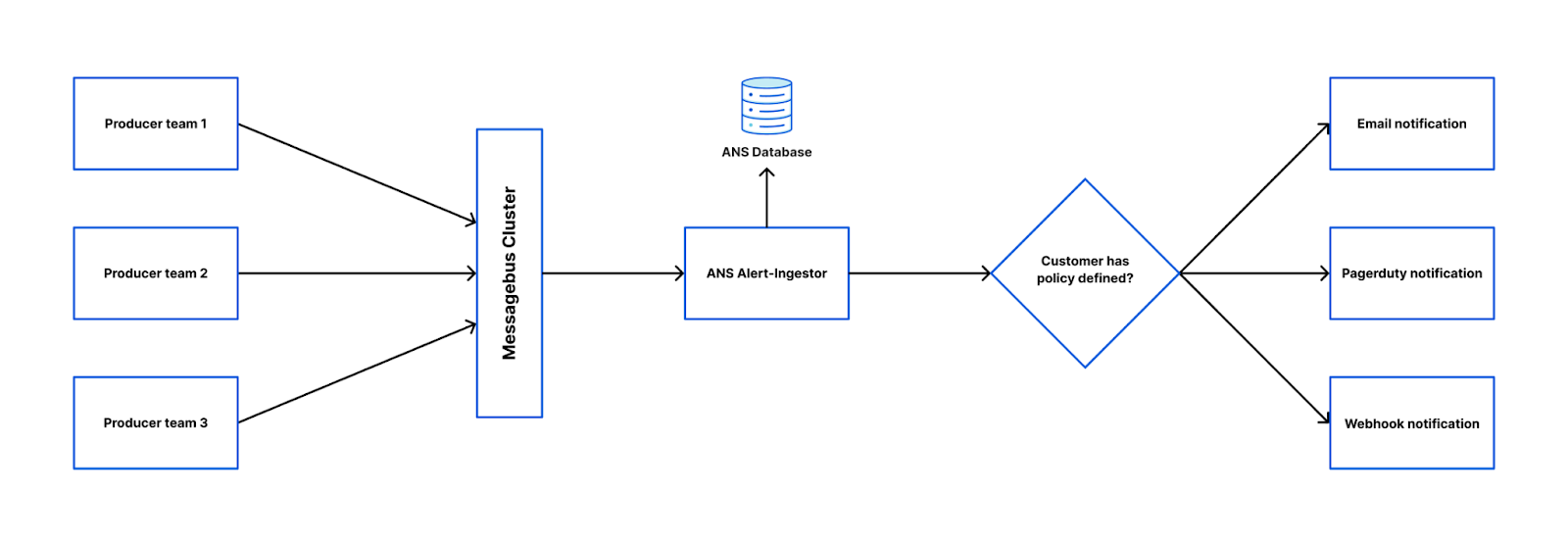
One example is the Alert Notification System (ANS). ANS is the backend service for the “Notifications” tab in the Cloudflare dashboard. You may have noticed over the past 12 months that new alert and policy types have been made available to customers very regularly. This is because we have made it very easy for other teams to do this. The approach is:
- Create a new entry into ANS’s configuration YAML (We use CUE lang to validate the configuration as part of our continuous integration process);
- Import our Messagebus-Client into your code base;
- Emit a message to our alert topic when an event of interest takes place.
That’s it! The producer team now has a means for customers to configure granular alerting policies for their new alert that includes being able to dispatch them via Slack, Google Chat or a custom webhook, PagerDuty or email (by both API and dashboard). Retrying and dead letter messages are managed for them, and a whole host of metrics are made available, all by making some very small changes.
What’s Next?
Usage of Kafka (and our Messagebus tools) is only going to increase at Cloudflare as we continue to grow, and as a team we are committed to making the tooling around Messagebus easy to use, customizable where necessary and (perhaps most importantly) easy to observe. We regularly take feedback from other engineers to help improve the Messagebus-Client (we are on the fifth version now) and are currently experimenting with abstracting the intricacies of Kafka away completely and allowing teams to use gRPC to stream messages to Kafka. Blog post on the success/failure of this to follow!
If you’re interested in building scalable services and solving interesting technical problems, we are hiring engineers on our team in Austin, and Remote US.