The web is constantly changing. Whether it’s news or updates to your social feed, it’s a constant flow of information. As a user, that’s great. But have you ever stopped to think how search engines deal with all the change?
It turns out, they “index” the web on a regular basis — sending bots out, to constantly crawl webpages, looking for changes. Today, bot traffic accounts for about 30% of total traffic on the Internet, and given how foundational search is to using the Internet, it should come as no surprise that search engine bots make up a large proportion of that what might come as a surprise is how inefficient the model is, though: we estimate that over 50% of crawler traffic is wasted effort.
This has a huge impact. There’s all the additional capacity that owners of websites need to bake into their site to absorb the bots crawling all over it. There’s the transmission of the data. There’s the CPU cost of running the bots. And when you’re running at the scale of the Internet, all of this has a pretty big environmental footprint.
Part of the problem, though, is nobody had really stopped to ask: maybe there’s a better way?
Right now, the model for indexing websites is the same as it has been since the 1990s: a “pull” model, where the search engine sends a crawler out to a website after a predetermined amount of time. During Impact Week last year, we asked: what about flipping the model on its head? What about moving to a push model, where a website could simply ping a search engine to let it know an update had been made?
There are a heap of advantages to such a model. The website wins: it’s not dealing with unnecessary crawls. It also makes sure that as soon as there’s an update to its content, it’s reflected in the search engine — it doesn’t need to wait for the next crawl. The website owner wins because they don’t need to manage distinct search engine crawl submissions. The search engine wins, too: it saves money on crawl costs, and it can make sure it gets the latest content.
Of course, this needs work to be done on both sides of the equation. The websites need a mechanism to alert the search engines; and the search engines need a mechanism to receive the alert, so they know when to do the crawl.
Crawler Hints — Cloudflare’s Solution for Websites
Solving this problem is why we launched Crawler Hints. Cloudflare sits in a unique position on the Internet — we’re serving on average 36 million HTTP requests per second. That represents a lot of websites. It also means we’re uniquely positioned to help solve this problem: to help give crawlers hints about when they should recrawl if new content has been added or if content on a site has recently changed.
With Crawler Hints, we send signals to web indexers based on cache data and origin status codes to help them understand when content has likely changed or been added to a site. The aim is to increase the number of relevant crawls as well as drastically reduce the number of crawls that don’t find fresh content, saving bandwidth and compute for both indexers and sites alike, and improving the experience of using the search engines.
But, of course, that’s just half the equation.
IndexNow Protocol — the Search Engine Moves from Pull to Push
Websites alerting the search engine about changes is useless if the search engines aren’t listening — and they simply continue to crawl the way they always have. Of course, search engines are incredibly complicated, and changing the way they operate is no easy task.
The IndexNow Protocol is a standard developed by Microsoft, Seznam.cz and Yandex, and it represents a major shift in the way search engines operate. Using IndexNow, search engines have a mechanism by which they can receive signals from Crawler Hints. Once they have that signal, they can shift their crawlers from a pull model to a push model.
In a recent update, Microsoft has announced that millions of websites are now using IndexNow to signal to search engine crawlers when their content needs to be crawled and IndexNow was used to index/crawl about 7% of all new URLsclicked when someone is selecting from web search results.
On the Cloudflare side, since the release of Crawler Hints in October 2021, Crawler Hints has processed about six-hundred-billion signals to IndexNow.
That’s a lot of saved crawls.
How to enable Crawler Hints
By enabling Crawler Hints on your website, with the simple click of a button, Cloudflare will take care of signaling to these search engines when your content has changed via the IndexNow API. You don’t need to do anything else!
Crawler Hints is free to use and available to all Cloudflare customers. If you’d like to see how Crawler Hints can benefit how your website is indexed by the world’s biggest search engines, please feel free to opt-into the service by:
Sign in to your Cloudflare Account.
In the dashboard, navigate to the Cache tab.
Click on the Configuration section.
Locate the Crawler Hints and enable.
Upon enabling Crawler Hints, Cloudflare will share when content on your site has changed and needs to be re-crawled with search engines using the IndexNow protocol (this blog can help if you’re interested in finding out more about how the mechanism works).
What’s Next?
Going forward, because the benefits are so substantial for site owners, search operators, and the environment, we plan to start defaulting Crawler Hints on for all our customers. We’re also hopeful that Google, the world’s largest search engine and most wasteful user of Internet resources, will adopt IndexNow or a similar standard and lower the burden of search crawling on the planet.
When we think of helping to build a better Internet, this is exactly what comes to mind: creating and supporting standards that make it operate better, greener, faster. We’re really excited about the work to date, and will continue to work to improve the signaling to ensure the most valuable information is being sent to the search engines in a timely manner. This includes incorporating additional signals such as etags, last-modified headers, and content hash differences. Adding these signals will help further inform crawlers when they should reindex sites, and how often they need to return to a particular site to check if it’s been changed. This is only the beginning. We will continue testing more signals and working with industry partners so that we can help crawlers run efficiently with these hints.
And finally: if you’re on Cloudflare, and you’d like to be part of this revolution in how search engines operate on the web (it’s free!), simply follow the instructions in the section above.
In July 2021, as part of Impact Innovation Week, we announced our intention to launch Crawler Hints as a means to reduce the environmental impact of web searches. We spent the weeks following the announcement hard at work, and in October 2021, we announced General Availability for the first iteration of the product. This post explains how we built it, some of the interesting engineering problems we had to solve, and shares some metrics on how it’s going so far.
Before We Begin…
Search indexers crawl sites periodically to check for new content. Algorithms vary by search provider, but are often based on either a regular interval or cadence of past updates, and these crawls are often not aligned with real world content changes. This naive crawling approach may harm customer page rank and also works to the detriment of search engines with respect to their operational costs and environmental impact. To make the Internet greener and more energy efficient, the goal of Crawler Hints is to help search indexers make more informed decisions on when content has changed, saving valuable compute cycles/bandwidth and having a net positive environmental impact.
Cloudflare is in an advantageous position to help inform crawlers of content changes, as we are often the “front line” of the interface between site visitors and the origin server where the content updates take place. This grants us knowledge of some key data points like headers, content hashes, and site purges among others. For customers who have opted in to Crawler Hints, we leverage this data to generate a “content freshness score” using an ensemble of active and passive signals from our customer base and request flow. To help with efficiency, Crawler Hints helps to improve SEO for websites behind Cloudflare, improves relevance for search engine users, and improves origin responsiveness by reducing bot traffic to our customers’ origin servers.
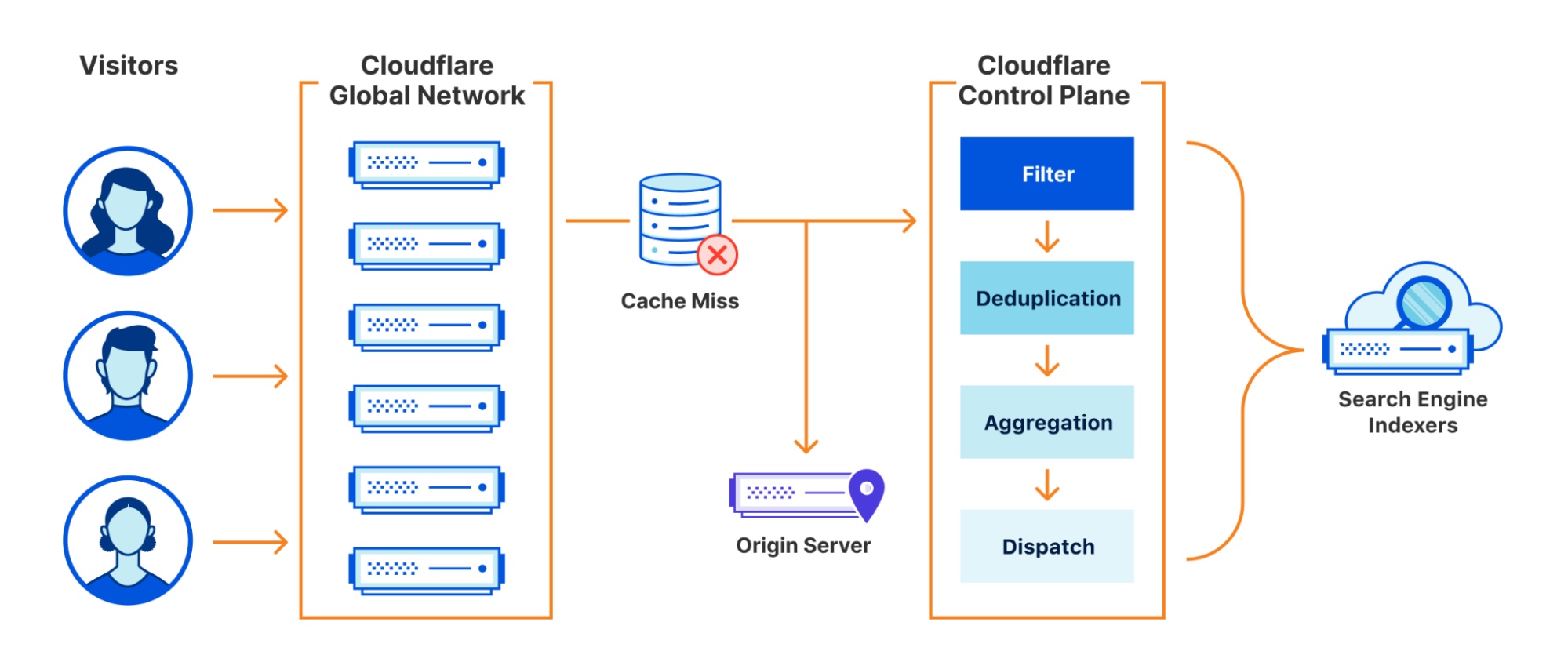
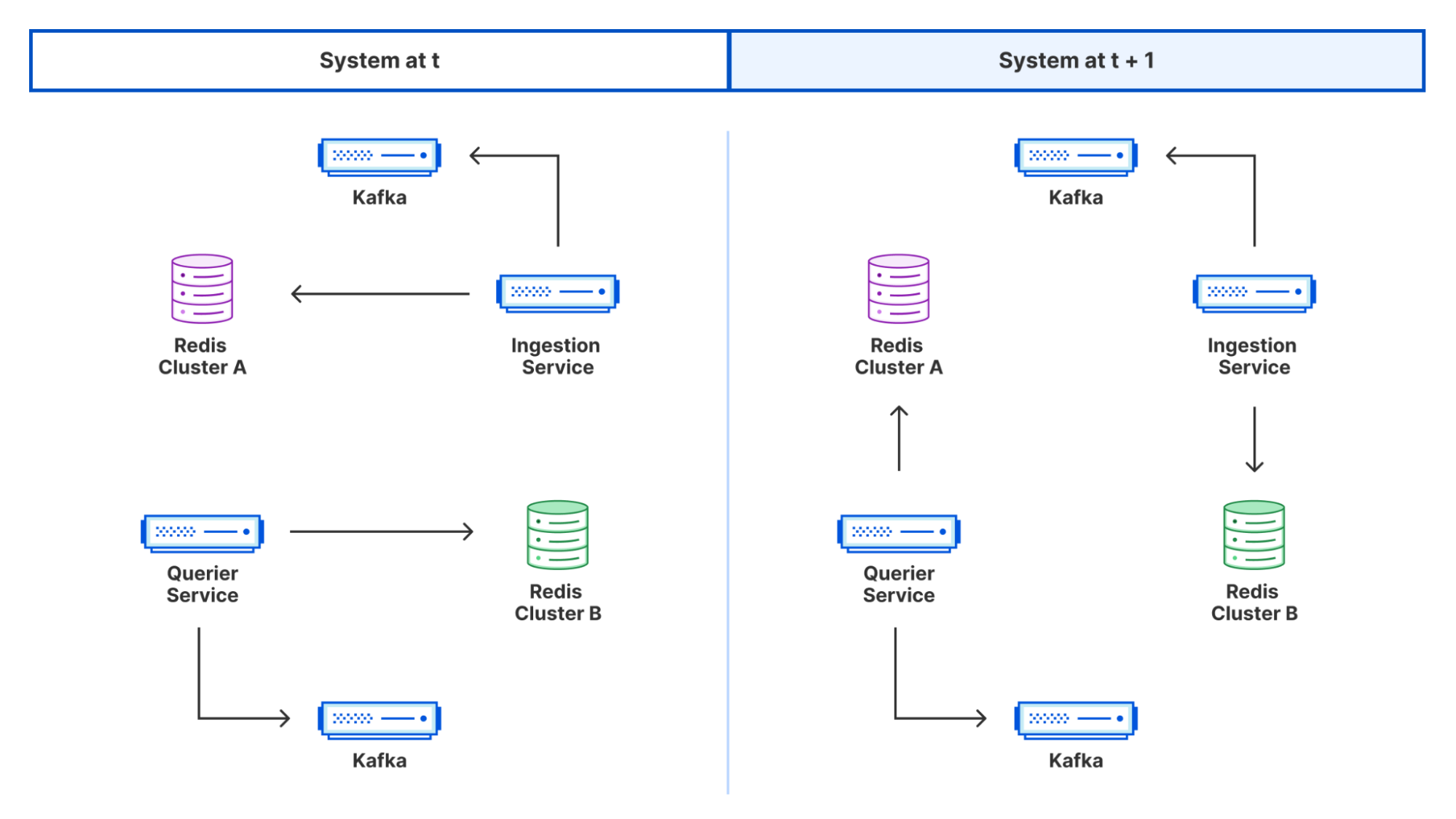
A high level design of the system we built looks as follows:
In this blog we will dig into each aspect of it in more detail.
Keeping Things Fresh
Cloudflare has a large global network spanning 250 cities. A popular use case for Cloudflare is to use our CDN product to cache your website’s assets so that users accessing your site can benefit from lightning fast response times. You can read more about how Cloudflare manages our cache here. The important thing to call out for the purpose of this post is that the cache is Data Center local. A cache hit in London might be a cache miss in San Francisco unless you have opted-in to tiered-caching, but that is beyond the scope of this post.
For Crawler Hints to work, we make use of a number of signals available at request time to make an informed decision on the “freshness” of content. For our first iteration of Crawler Hints, we used a cache miss from Cloudflare’s cache as a starting basis. Although a naive signal on its own, getting the data pipelines in place to forward cache miss data from our global network to our control plane meant we would have everything in place to iterate on and improve the signal processing quickly going forward. To do this, we leveraged some existing services from our data team that takes request data , marshalls it into Cap’n Proto format, and forwards it to a message bus (we use apache Kafka). These messages include the URLs of the resources that have met the signal criteria, along with some additional metadata for analytics/future improvement.
The amount of traffic our global network receives is substantial. We serve over 28 million HTTP requests per second on average, with more than 35 million HTTP requests per second at peak. Typically, Cloudflare teams sample this data to enable products such as being alerted when you are under attack. For Crawler Hints, every cache miss is important. Therefore, 100% of all cache misses for opted-in sites were sent for further processing, and we’ll discuss more on opt-in later.
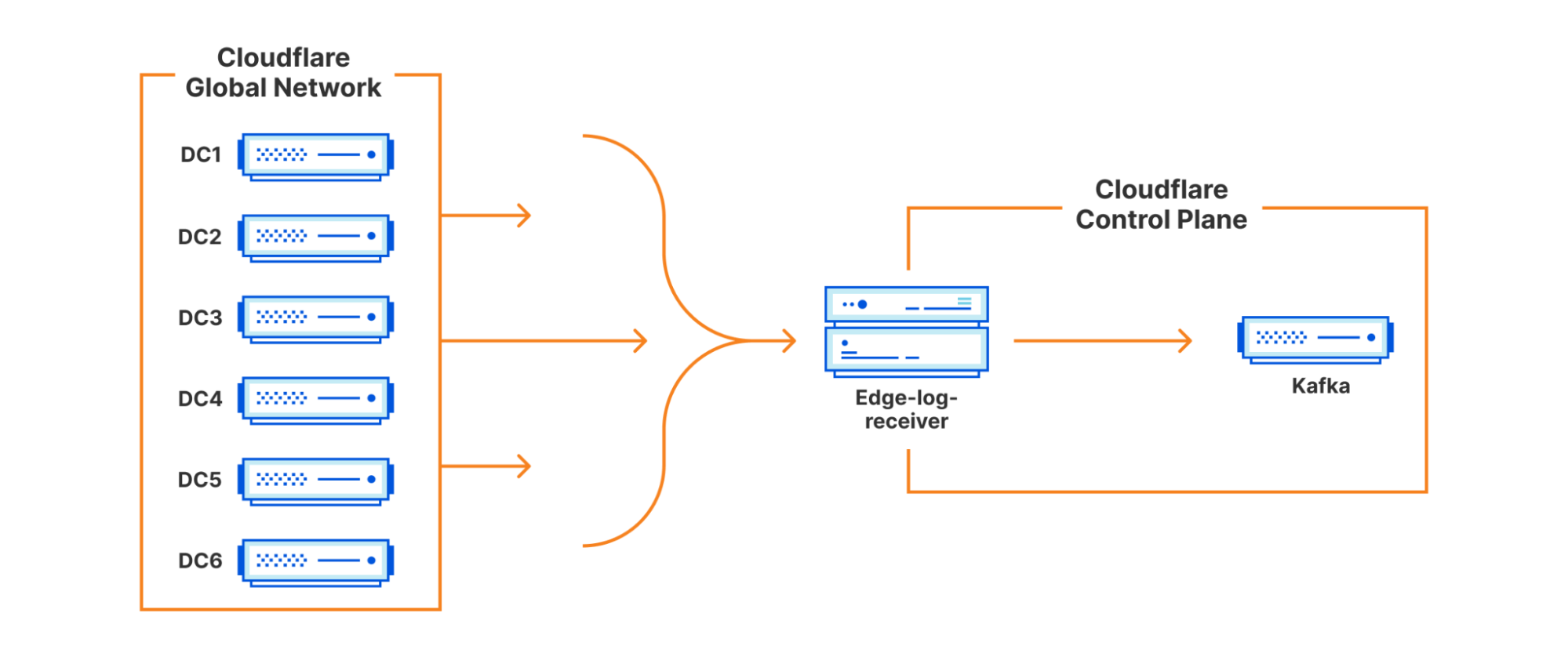
Redis as a Distributed Buffer
With messages buffered in Kafka, we can now begin the work of aggregation and deduplication. We wrote a consumer service that we call an ingestor. The ingestor reads the data from Kafka. The ingestor performs validation to ensure proper sanitization and data integrity and passes this data onto the next stage of the system. We run the ingestor as part of a Kafka consumer group, allowing us to scale our consumer count up to the partition size as throughput increases.
We ultimately want to deliver a set of “fresh” content to our search partners on a dynamic interval. For example, we might want to send a batch of 10,000 URLs every two minutes. There are, however, a couple of important things to call out though:
There should be no duplicate resources in each batch.
We should strike a balance in our size and frequency such that overall request size isn’t too large, but big enough to remove some pressure on the receiving API by not sending too many requests at once.
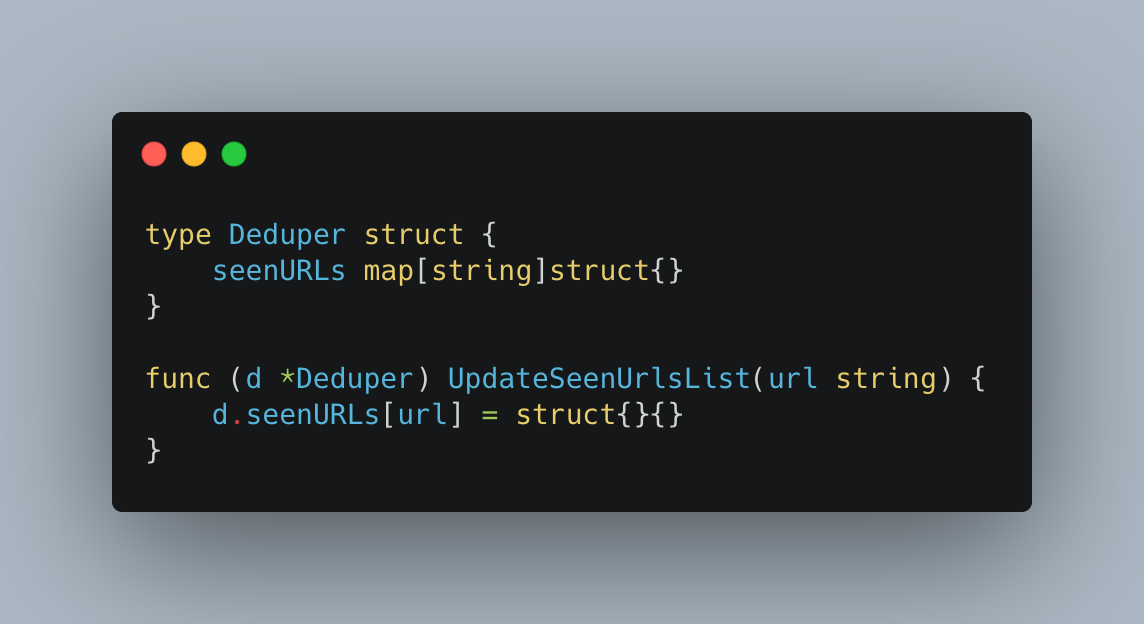
For the deduplication, the simplest thing to do would be to have an in-memory map in our service to track resources between a pre-specified interval. A naive implementation in Go might look something like this.
The problem with this approach is we have little resilience. If the service was to crash, we would lose all the data for our current batch. Furthermore, if we were to run multiple instances of our services, they would all have a different “view” of which resources they had seen before and therefore we would not be deduplicating.To mitigate this issue, we decided to use a specialist caching service. There are a number of distributed caches that would fit the bill, but we chose Redis given our team’s familiarity with operating it at scale.
Redis is well known as a Key Value(KV) store often used for caching things,optionally with a specified Time To Live(TTL). Perhaps slightly less obvious is its value as a distributed buffer, housing ephemeral data with periodic flush/tear-downs. For Crawler Hints, we leveraged both these traits via a multi-generational, multi-cluster setup to achieve a highly available rolling aggregation service.
Two standalone Redis clusters were spun up. For each generation of request data, one cluster would be designated as the active primary. The validated records would be inserted as keys on the primary, serving the dual purpose of buffering while also deduplicating since Redis keys are unique. Separately, a downstream service (more on this later!) would periodically issue the command for these inserters to switch from the active primary (cluster A) to the inactive cluster (cluster B). Cluster A could then be flushed with records being batch read in a size of our choosing.
Buffering for Dispatch
At this point, we have clean, batched data. Things are looking good! However, there’s one small hiccup in the plan: we’re reading these batches from Redis at some set interval. What if it takes longer to dispatch than the interval itself? What if the search partner API is having issues?
We need a way to ensure the durability of the batch URLs and reduce the impact of any dispatch issues. To do this, we revisit an old friend from earlier: Kafka. The batches that get read from Redis are then fed into a Kafka topic. We wrote a Kafka consumer that we call the “dispatcher service” which runs within a consumer group to enable us to scale it if necessary just like the ingestor. The dispatcher reads from the Kafka topic and sends a batch of resources to each of our API partners.
Launching in tandem with Cloudflare, Crawler Hints was a joint venture between a few early adopters in the search engine space to provide a means for sites to inform indexers of content changes called IndexNow. You can read more about this launch here. IndexNow is a large part of what makes Crawler Hints possible. As part of its manifest, it provides a common API spec to publish resources that should be re-indexed. The standardized API makes abstracting the communication layer quite simple for the partners that support it. “Pushing” these signals to our search engine partners is a big step away from the inefficient “Pull” based model that is used today (you can read more about that here). We launched with Yandex and Bing as Search Engine Partners.
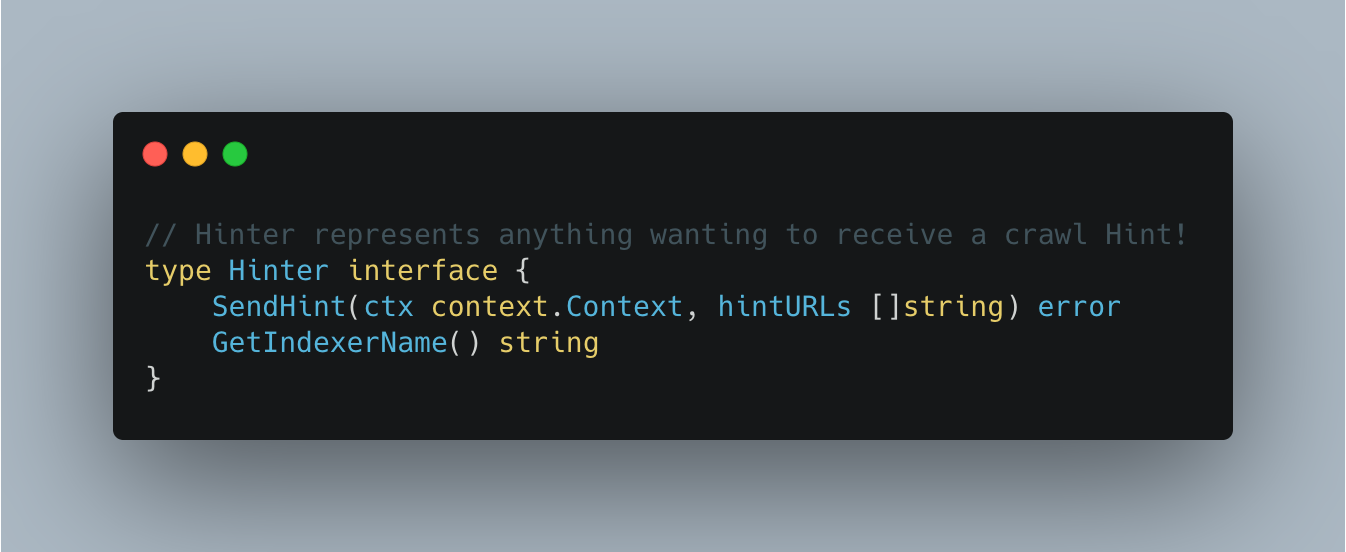
To ensure we can add more partners in the future, we defined an interface which we call a “Hinter”.
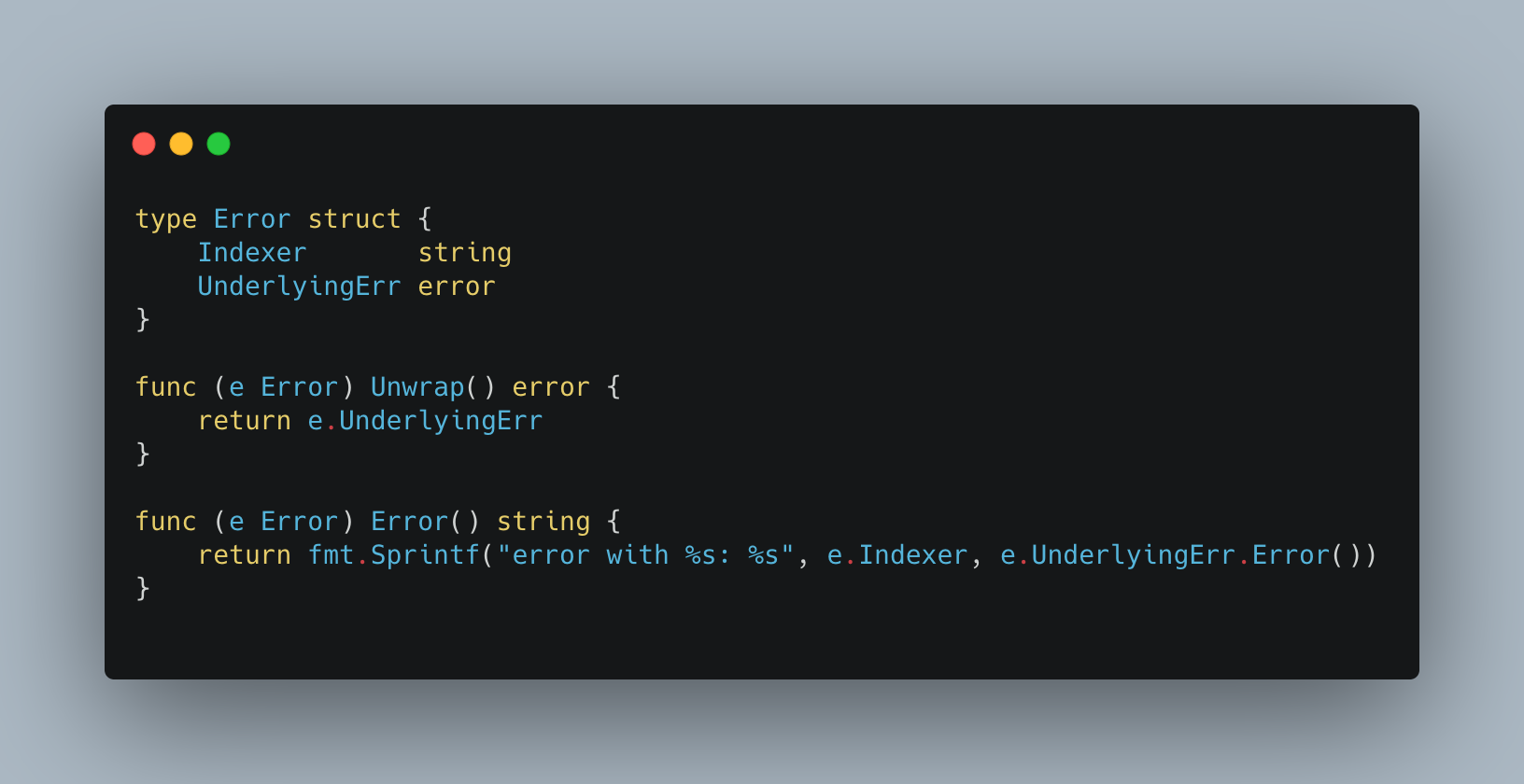
We then satisfy this interface for each partner that we work with. We return a custom error from the Hinter service that is of type *indexers.Error. The definition of which is:
This allows us to “bubble up” information about which indexer has failed and increment metrics and retry only those calls to indexers which have failed.
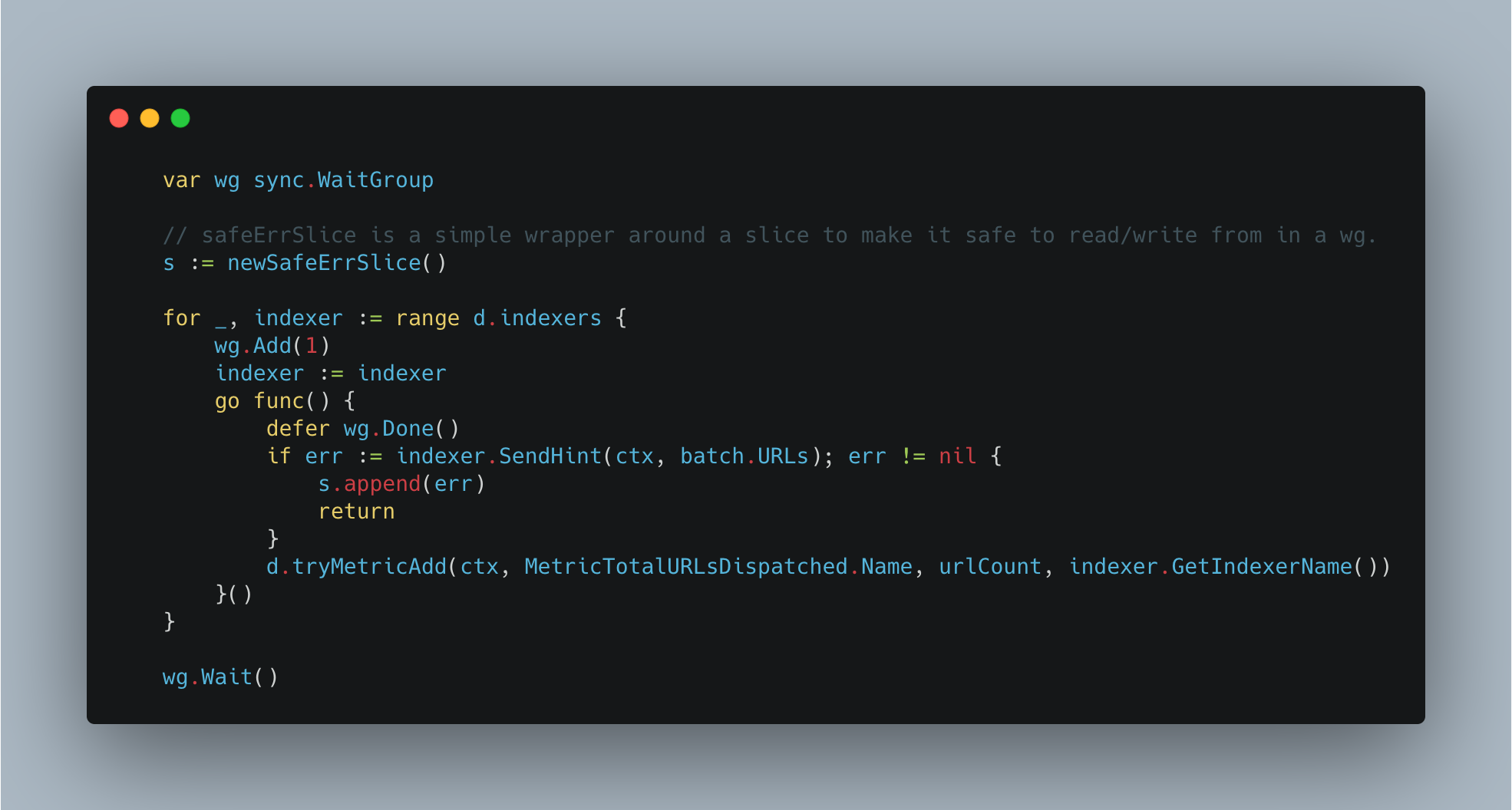
This all culminates together with the following in our service layer:
Simple, performant, maintainable, AND easy to add more partners in the future.
Rolling out Crawler Hints
At Cloudflare, we often release things that haven’t been done before at scale. This project is a great example of that. Trying to gauge how many users would be interested in this product and what the uptake might be like on day one, day ten, and day one thousand is close to impossible. As engineers responsible for running this system, it is essential we build in checks and balances so that the system does not become overwhelmed and responds appropriately. For this particular project, there are three different types of “protection” we put in place. These are:
Customer opt-in
Monitoring & Alerts
System resilience via “self-healing”
Customer opt-in
Cloudflare takes any changes that can impact customer traffic flow seriously. Considering Crawler Hints has the potential to change how sites are seen externally (even if in this instance the site’s viewers are robots!) and can impact things like SEO and bandwidth usage, asking customers to opt-in is a sensible default. By asking customers to opt-in to the service, we can start to get an understanding of our system’s capacity and look for bottle necks and how to remove them. To do this, we make extensive use of Prometheus, Grafana, and Kibana.
Monitoring & Alerting
We do our best to make our systems as “self-healing” and easy to run as possible, but as they say, “By failing to prepare, you are preparing to fail.” We therefore invest a lot of time creating ways to track the health and performance of our system and creating automated alerts when things fall outside of expected bounds.
Below is a small sample of the Grafana dashboard we created for this project. As you can see, we can track customer enablement and the rate of hint dispatch in real time. The bottom two panels show the throughput of our Kafka clusters by partition. Even just these four metrics give us a lot of insight into how things are going, but we also track (as well as other things):
Lag on Kafka by partition (how far behind real time we are)
Bad messages received from Kafka
Amount of URLs processed per “run”
Response code per index partner over time
Response time of partner API over time
Health of the Redis clusters (how much memory is used, frequency of commands we are using received by the cluster)
Memory, CPU usage, and pods available against configured limits/requests
It seems a lot to track, but this information is invaluable to us, and we use it to generate alerts that notify the on-call engineer if a threshold is breached. For example, we have an alert that would escalate to an engineer if our Redis cluster approached 80% capacity. For some thresholds we specify, we may want the system to “self-heal.” In this instance, we would want an engineer to investigate as this is outside the bounds of “normal,” and it might be that something is not working as expected. An alternative reason that we might receive alerts is that our product has increased in popularity beyond our expectations, and we simply need to increase the memory limit. This requires context and is therefore best left to a human to make this decision.
System Resilience via “self-healing”
We do everything we can to not disturb on-call engineers, and therefore, we try to make the system as “self-healing” as possible. We also don’t want to have too much extra resource running as it can be expensive and use limited capacity that another Cloudflare service might need more – it’s a trade off. To do this, we make use of a few patterns and tools common in every distributed engineer’s toolbelt. Firstly, we deploy on Kubernetes. This enables us to make use of great features like Horizontal Pod Autoscaling. When any of our pods reach ~80% memory usage, a new pod is created which will pick up some of the slack up to a predefined limit.
Secondly, by using a message bus, we get a lot of control over the amount of “work” our services have to do in a given time frame. In general, a message bus is “pull” based. If we want more work, we ask for it. If we want less work, we pull less. This holds for the most part, but with a system where being close to real time is important, it is essential that we monitor the “lag” of the topic, or how far we are behind real time. If we are too far behind, we may want to introduce more partitions or consumers.
Finally, networks fail. We therefore add retry policies to all HTTP calls we make before reporting them a failure. For example, if we were to receive a 500 (Internal Server Error) from one of our partner APIs, we would retry up to five times using an exponential backoff strategy before reporting a failure.
Data from the first couple of months
Since the release of Crawler Hints on October 18, 2021 until December 15, 2021, Crawler Hints has processed over twenty five billion crawl signals, has been opted-in to by more than 81,000 customers, and has handled roughly 18,000 requests per second. It’s been an exciting project to be a part of, and we are just getting started.
What’s Next?
We will continue to work with our partners to improve the standard even further and continue to improve the signaling on our side to ensure the most valuable information is being pushed on behalf of our customers in a timely manner.
If you’re interested in building scalable services and solving interesting technical problems, we are hiring engineers on our team in Austin, Lisbon, and London.
In the midst of the hottest summer on record, Cloudflare held its first ever Impact Week. We announced a variety of products and initiatives that aim to make the Internet and our planet a better place, with a focus on environmental, social, and governance projects. Today, we’re excited to share an update on Crawler Hints, an initiative announced during Impact Week. Crawler Hints is a service that improves the operating efficiency of the approximately 45% of Internet traffic that comes from web crawlers and bots.
Crawler Hints achieves this efficiency improvement by ensuring that crawlers get information about what they’ve crawled previously and if it makes sense to crawl a website again.
Today we are excited to announce two updates for Crawler Hints:
The first: Crawler Hints now supports IndexNow, a new protocol that allows websites to notify search engines whenever content on their website content is created, updated, or deleted. By collaborating with Microsoft and Yandex, Cloudflare can help improve the efficiency of their search engine infrastructure, customer origin servers, and the Internet at large.
The second: Crawler Hints is now generally available to all Cloudflare customers for free. Customers can benefit from these more efficient crawls with a single button click. If you want to enable Crawler Hints, you can do so in the Cache Tab of the Dashboard.
What problem does Crawler Hints solve?
Crawlers help make the Internet work. Crawlers are automated services that travel the Internet looking for… well, whatever they are programmed to look for. To power experiences that rely on indexing content from across the web, search engines and similar services operate massive networks of bots that crawl the Internet to identify the content most relevant to a user query. But because content on the web is always changing, and there is no central clearinghouse for when these changes happen on websites, search engine crawlers have a Sisyphean task. They must continuously wander the Internet, making guesses on how frequently they should check a given site for updates to its content.
Companies that run search engines have worked hard to make the process as efficient as possible, pushing the state-of-the-art for crawl cadence and infrastructure efficiency. But there remains one clear area of waste: excessive crawl.
At Cloudflare, we see traffic from all the major search crawlers, and have spent the last year studying how often these bots revisit a page that hasn’t changed since they last saw it. Every one of these visits is a waste. And, unfortunately, our observation suggests that 53% of this crawler traffic is wasted.
With Crawler Hints, we expect to make this task a bit more tractable by providing an additional heuristic to the people who run these crawlers. This will allow them to know when content has been changed or added to a site instead of relying on preferences or previous changes that might not reflect the true change cadence for a site. Crawler Hints aims to increase the proportion of relevant crawls and limit crawls that don’t find fresh content, improving customer experience and reducing the need for repeated crawls.
Cloudflare sits in a unique position on the Internet to help give crawlers hints about when they should recrawl a site. Don’t knock on a website’s door every 30 seconds to see if anything is new when Cloudflare can proactively tell your crawler when it’s the best time to index new or changed content. That’s Crawler Hints in a nutshell!
If you want to learn more about Crawler Hints, see the original blog.
What is IndexNow?
IndexNow is a standard that was written by Microsoft and Yandex search engines. The standard aims to provide an efficient manner of signaling to search engines and other crawlers for when they should crawl content. Cloudflare’s Crawler Hints now supports IndexNow.
In its simplest form, IndexNow is a simple ping so that search engines know that a URL and its content has been added, updated, or deleted, allowing search engines to quickly reflect this change in their search results. – www.indexnow.org
By enabling Crawler Hints on your website, with the simple click of a button, Cloudflare will take care of signaling to these search engines when your content has changed via the IndexNow protocol. You don’t need to do anything else!
What does this mean for search engine operators? With Crawler Hints you’ll receive a near real-time, pushed feed of change events of Cloudflare websites (that have opted in). This, in turn, will dramatically improve not just the quality of your results, but also the energy efficiency of running your bots.
Collaborating with Industry leaders
Cloudflare is in a unique position to have a sizable portion of the Internet proxied behind us. As a result, we are able to see trends in the way bots access web resources. That visibility allows us to be proactive about signaling which crawls are required vs. not. We are excited to work with partners to make these insights useful to our customers. Search engines are key constituents in this equation. We are happy to collaborate and share this vision of a more efficient Internet with Microsoft Bing, and Yandex. We have been testing our interaction via IndexNow with Bing and Yandex for months with some early successes.
This is just the beginning. Crawler Hints is a continuous process that will require working with more and more partners to improve Internet efficiency more generally. While this may take time and participation from other key parts of the industry, we are open to collaborate with any interested participant who relies on crawling to power user experiences.
“The cache data from CDNs is a really valuable signal for content freshness. Cloudflare, as one of the top CDNs, is key in the adoption of IndexNow to become an industry-wide standard with a large portion of the internet actually using it. Cloudflare has built a really easy 1-click button for their users to start using it right away. Cloudflare’s mission of helping build a better Internet resonates well with why I started IndexNow i.e. to build a more efficient and effective Search.” – Fabrice Canel, Principal Program Manager
“Yandex is excited to join IndexNow as part of our long-term focus on sustainability. We have been working with the Cloudflare team in early testing to incorporate their caching signals in our crawling mechanism via the IndexNow API. The results are great so far.” – Maxim Zagrebin, Head of Yandex Search
“DuckDuckGo is supportive of anything that makes search more environmentally friendly and better for end users without harming privacy. We’re looking forward to working with Cloudflare on this proposal.” – Gabriel Weinberg, CEO and Founder
How do Cloudflare customers benefit?
Crawler Hints doesn’t just benefit search engines. For our customers and origin owners, Crawler Hints will ensure that search engines and other bot-powered experiences will always have the freshest version of your content, translating into happier users and ultimately influencing search rankings. Crawler Hints will also mean less traffic hitting your origin, improving resource consumption. Moreover, your site performance will be improved as well: your human customers will not be competing with bots!
And for Internet users? When you interact with bot-fed experiences — which we all do every day, whether we realize it or not, like search engines or pricing tools — these will now deliver more useful results from crawled data, because Cloudflare has signaled to the owners of the bots the moment they need to update their results.
How can I enable Crawler Hints for my website?
Crawler Hints is free to use for all Cloudflare customers and promises to revolutionize web efficiency. If you’d like to see how Crawler Hints can benefit how your website is indexed by the worlds biggest search engines, please feel free to opt-into the service:
Sign in to your Cloudflare Account.
In the dashboard, navigate to the Cache tab.
Click on the Configuration section.
Locate the Crawler Hints sign up card and enable. It’s that easy.
Once you’ve enabled it, we will begin sending hints to search engines about when they should crawl particular parts of your website. Crawler Hints holds tremendous promise to improve the efficiency of the Internet.
What’s next?
We’re thrilled to collaborate with industry leaders Microsoft Bing, and Yandex to bring IndexNow to Crawler Hints, and to bring Crawler Hints to a wide audience in general availability. We look forward to working with additional companies who run crawlers to help make this process more efficient for the whole Internet.
Cloudflare is known for innovation, for needle-moving projects that help make the Internet better. For Impact Week, we wanted to take this approach to innovation and apply it to the environmental impact of the Internet. When it comes to tech and the environment, it’s often assumed that the only avenue tech has open to it is harm mitigation: for example, climate credits, carbon offsets, and the like. These are undoubtedly important steps, but we wanted to take it further — to get into harm reduction. So we asked — how can the Internet at large use less energy and be more thoughtful about how we expend computing resources in the first place?
Cloudflare has a global view into the traffic of the Internet. More than 1 in 6 websites use our network, and we observe the traffic flowing to and from them continuously. While most people think of surfing the Internet as a very human activity, nearly half of all traffic on the global network is generated by automated systems.
We’ve analyzed this automated traffic, from so-called “bots,” in order to understand the environmental impact. Most of the bot traffic is malicious. Cloudflare protects our clients from this malicious traffic and, in doing so, mitigates their environmental impact. If these bots were not stopped by Cloudflare, they would generate database requests and force dynamic page generation on services far less efficient than Cloudflare’s network.
We even went a step further, committing to plant trees to offset the carbon cost of our bot mitigation services. While we’d love to be able to tell the bad actors to think of the environment and stop running their bots, we don’t think they’d listen. So, instead, we aim to mitigate them as efficiently as possible.
But there’s another type of bot that we don’t want to go away: good bots that index the web for useful reasons. These good bots represent more than 5% of global Internet traffic. The majority of this good bot traffic comes from what are known as search engine crawlers, and they are critical to making the web navigable.
Large-Scale Problems, Large-Scale Opportunities
Online search remains magical. Enter a query into a box on a search engine like Google, Bing, Yandex, or Baidu and, in a fraction of a second, get a list of web resources with information on whatever you’re looking for. To make this magic happen, search engines need to scour the web and, simplistically, make a copy of its contents that are stored and sorted on their own systems to be quickly retrieved whenever needed.
Companies that run search engines have worked hard to make the process as efficient as possible, pushing the state-of-the-art in terms of server and data center efficiency. But there remains one clear area of waste: excessive crawl.
At Cloudflare, we see traffic from all the major search crawlers. We’ve spent the last year studying how often these good bots revisit a page that hasn’t changed since they last saw it. Every one of these visits is a waste. And, unfortunately, our observation suggests that 53% of this good bot traffic is wasted.
The Boston Consulting Group estimates that running the Internet generated 2% of all carbon output, or about 1 billion metric tonnes per year. If 5% of all Internet traffic is good bots, and 53% of that traffic is wasted by excessive crawl, then finding a solution to reduce excessive crawl could help save as much as 26 million tonnes of carbon cost per year. According to the U.S. Environmental Protection Agency, that’s the equivalent of planting 31 million acres of forest, shutting down 6 coal-fired power plants forever, or taking 5.5 million passenger vehicles off the road.
Obviously, it’s not quite that simple. But suffice it to say there’s a big opportunity to make a meaningful impact on the environmental cost of the Internet if we are able to ensure that any search engine only crawls once or whenever it changes.
Recognizing this problem, we’ve been talking with the largest operators of good bots for the last several years to see if, together, we could address the issue.
Crawler Hints
Today, we’re excited to announce Crawler Hints. Crawler Hints provide high quality data to search engine crawlers on when content has been changed on sites using Cloudflare, allowing them to precisely time their crawling, avoid wasteful crawls, and generally reduce resource consumption of customer origins, crawler infrastructure, and Cloudflare infrastructure in the process. The cherry on top: because search engine crawlers now receive signals on when content is fresh, the search experiences powered by these “good bots” will improve, delighting Internet users at large with more relevant and useful content. Crawler Hints is a win for the Internet and a win for the Internet’s energy footprint.
With Crawler Hints, we expect to make crawling a bit more tractable by providing an additional heuristic to bot developers that will allow them to know when content has been changed or added to a site instead of relying on preferences or previous changes that might not reflect the true change cadence for a site.
How will this work?
At its simplest we want a way to proactively tell a search engine when a page has changed, rather than having to wait for the search engine to discover a change has happened. Search engines actually typically have a few ways to tell them about when an individual page or group of pages changes.
If you wanted to efficiently tell Google about changes you’d have to keep track of when Google last crawled the page and tell them to recrawl when a change happens. You wouldn’t want to tell Google every time a page changes as there’s a time delay between requesting a recrawl and the spider coming to visit. You could be telling Google to come back during the gap between the request and the spider coming to call.
And there isn’t just one search engine and new search crawlers get created. Trying to keep search engines up to date as your site changes, efficiently, would be messy and very difficult. This is, in part, because this model does not contain explicit information about when something changed.
This model just doesn’t work well. And that’s partly why search engine crawlers inevitably waste energy recrawling sites over and over again regardless of whether there is something new to find.
However, there is an existing mechanism used by search engines to discover the structure of websites that’s perfect: the sitemap. The sitemap is a well-defined, open protocol for telling a crawler about the pages on a site, when they last changed and how often they are likely to change.
Sitemaps have some limitations (on number of URLs and bytes) but do have a mechanism for large sites with millions of URLs. But building sitemaps can be complex and require special software. Getting a consistent, up to date sitemap for a website (especially one that uses different technologies) can be very hard.
That’s where Cloudflare comes in. We see what pages our customers are serving, we know which ones have changed (either by hash value or timestamp) and so can automatically build a complete record of when and which pages have changed.
And we can keep track of when a search crawler visited a particular page and only serve up exactly what changed since last time. Since we can keep track of this on a per-search engine basis it can be very efficient. Each search engine gets its own automagically updated list of URLs or sitemap of just what’s changed since their last visit.
And it adds absolutely no load to the origin website. Cloudflare can tell a search engine in almost real-time about a page’s modifications and provide a view of what changed since their last visit.
The sitemaps protocol also contains a priority for a page. Since we know how often a page is visited we can also hint to a search engine that a page is seen frequently by visitors and thus may be more important to add to the index than another page.
There are a few details to work out, such as how a search engine should identify itself to get its personalized list of URLs, but the protocol is open and in no way depends on Cloudflare. In fact, we hope that every host and Cloudflare-like service will consider implementing the protocol. We plan to continue to work with the search and hosting communities to refine the protocol in order to make it more efficient. Our goal is to ensure that search engines can have the freshest index, content creators will have their new content optimally indexed, and a big chunk of unnecessary Internet traffic, and the corresponding carbon cost, will disappear.
Conclusion
Crawler Hints doesn’t just benefit search engines. For our customers and origin owners, Crawler Hints will ensure that search engines and other bot-powered experiences will always have the freshest version of your content, translating into happier users and ultimately influencing search rankings. Crawler Hints will also mean less traffic hitting your origin, improving resource consumption and limiting carbon impact. Moreover, your site performance will be improved as well: your human customers will not be competing with bots!
And for Internet users? When you interact with bot-fed experiences — which we all do every day, whether we realize it or not, like search engines or pricing tools — these will now deliver more useful results from crawled data, because Cloudflare has signaled to the owners of the bots the moment they need to update their results.
Finally, and perhaps the one we’re most excited about, for the Internet more generally: it’s going to be greener. Energy usage across the web will be greatly reduced.
Win win win. The types of outcomes that bring us to work every day, and what we think of in helping to build a better Internet.
This is an exciting problem to solve, and we look forward to working with others that want to help the Internet be more efficient and performant while reducing needless energy consumption. We plan on having more news to share on this front soon. If you operate a bot that relies on content freshness and are interested in working with us on this project, please email [email protected].
Yandex prioritizes long-term sustainability over short-lived success, and joins the global community in its pursuit of climate change mitigation. As a part of its commitment to quality service and user experience, Yandex focuses on ensuring relevance and usability of search results. We believe that a Cloudflare’s solution will strengthen search performance by improving the accuracy of returned results, and look forward to partnering with Cloudflare on boosting the efficiency of valuable bots across the Internet.
“DuckDuckGo is supportive of anything that makes search more environmentally friendly and better for end users without harming privacy. We’re looking forward to working with Cloudflare on this proposal.” – Gabriel Weinberg, CEO and Founder, DuckDuckGo.
Nearly a year ago (the Internet Archive’s Wayback Machine partnered with Cloudflare) to help power their “Always Online” service and, in turn, to have the Internet Archive learn about high-quality Web URLs to archive. That win-win partnership has been a huge success for the Wayback Machine and, in turn, our partners, as it has helped ensure we better fulfill our mission to help make the Web more useful and reliable by backing up, and making available for future generations, much of the public Web. Building on that ongoing relationship with Cloudflare, the Internet Archive is thrilled to start using this new “Crawler Hints” service. With it, we expect to be able to do more with less. To be able to focus our server and bandwidth resources on more of the Web pages that have changed, and less on those that have not. We expect this will have a material impact on our work. The fact the service also promises to reduce the carbon impact of the Web overall makes it especially worthwhile and, as such, we are proud to be part of the effort. –– Mark Graham, Director, the Wayback Machine at the Internet Archive
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.