Post Syndicated from Di Hei original https://github.blog/2024-02-13-bringing-npm-registry-services-to-github-codespaces/
The npm engineering team recently transitioned to using GitHub Codespaces for local development for npm registry services. This shift to Codespaces has substantially reduced the friction of our inner development loop and boosted developer productivity. In this post, we would like to share our experiences and learnings from this transition, hoping this information may be useful to you.
What are npm registry services
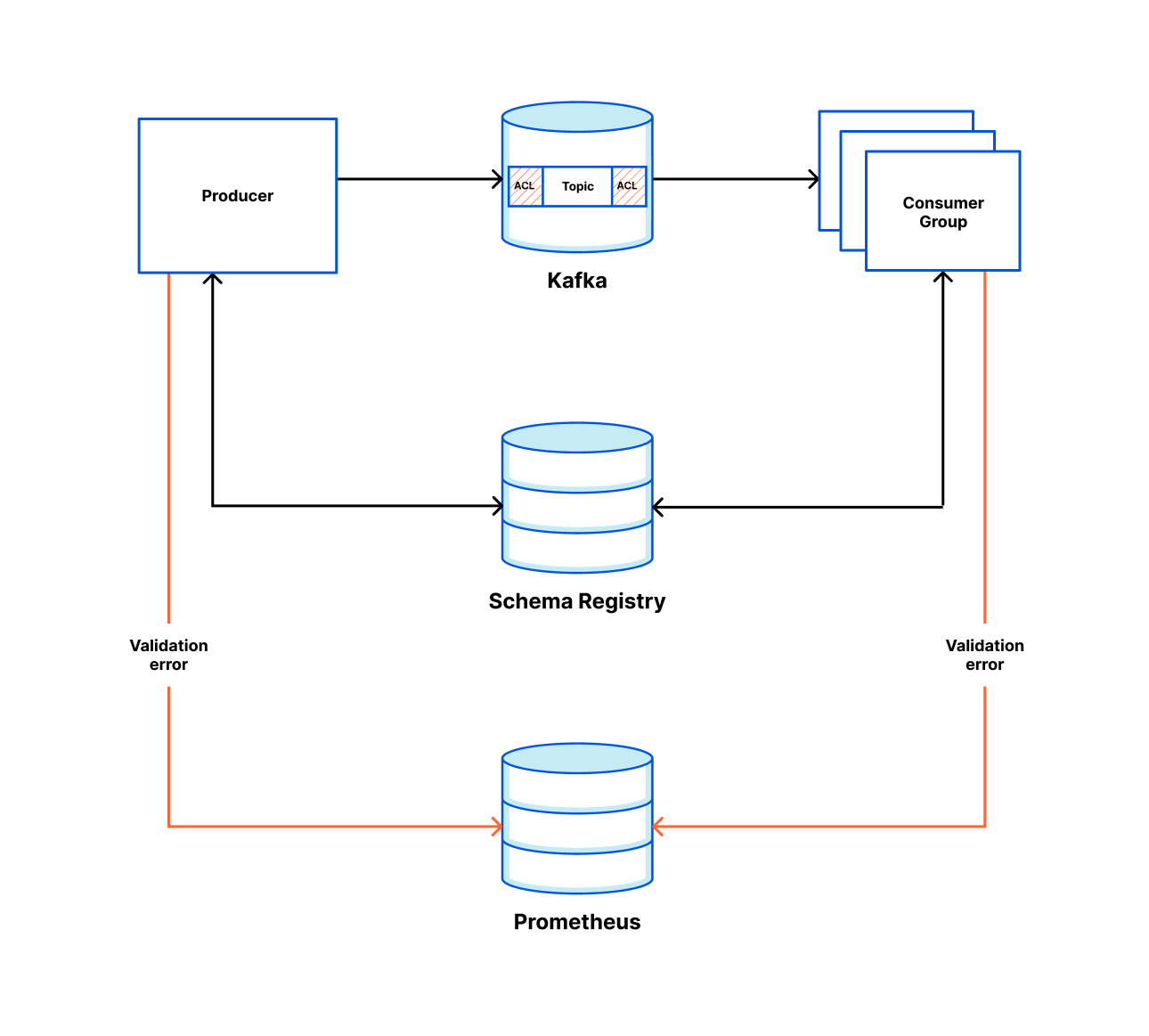
npm registry services, the Node.js microservices that power the npm registry, are distributed across 30+ different repositories. Each microservice has its own repository and is containerized using Docker. With Codespaces, we develop npm registry services using Docker on Codespaces with Visual Studio Code.
Codespaces reduces the friction of inner dev loop
Prior to Codespaces, a significant hurdle in npm local development was the difficulty in testing code across multiple services. We lacked a straightforward way to run multiple registry services locally, instead relying on our staging environment for testing. For example, to verify a code change in one service that affected a user workflow involving five other services, we could only run that service locally and connect to the remaining five in the staging environment. Due to security reasons, access to our staging environment is only possible via a VPN, adding another layer of complexity to the code testing process.
Codespaces addressed this issue by simplifying the process of running multiple registry services locally. When working in a codespace we no longer need a VPN connection for the inner dev loop. This change spares the team from potential issues related to VPN connectivity, and significantly simplifies the process of getting started.
As developers, we often rely on breakpoints for debugging. Now, with all registry services running within a single workspace, we can debug code and hit breakpoints across multiple services in Visual Studio Code as if they were one service. This is a significant improvement over previous developer experience, where hitting breakpoints in the services within the staging environment was not possible.
Codespaces boosts developer productivity
Codespaces has made it easier for outside contributors to participate. For example, if a GitHub engineer outside of the npm team wishes to contribute, they can get started within minutes with Codespaces, as the development environment is pre-configured and ready to go. Previously, setting up the development environment and granting permissions to access the staging resources would take days and often resulted in partners from other teams like design simply not contributing.
Port forwarding gives us access to TCP ports running within a codespace. Automatic port forwarding in Codespaces allows us to access services from a browser on our local machine for testing and debugging.
The in browser Codespaces experience, powered by Visual Studio Code for the Web, offers the flexibility to work from any computer. This is particularly helpful when you are away from your primary work computer, but need to test a quick change. The Web-based Codespaces experience provides a zero-install experience running entirely in your browser.
Remember those times when you were bogged down with a local environment issue that was not only time-consuming to troubleshoot but also difficult to reproduce on other machines? With Codespaces, you can quickly spin up a new Codespaces instance within minutes for a fresh start. The best part? There’s no need to fix the issue; you can simply discard the old codespace.
Things we learned from our use of Codespaces
Codespaces has tons of features to save you time and automate processes. Here are a few tips we learned from our use of Codespaces.
The prebuild feature of Codespaces is an excellent way to speed up the creation of a new codespace by creating a snapshot of your devcontainer and caching all the cloned repositories that can be used at startup time for the codespace. Codespaces prebuilds enable you to select branches and leverage GitHub Actions for automatic updates of these prebuilds.
You can store account-specific development secrets, such as access tokens, in Codespaces on a per-repository basis, ensuring secure usage within Codespaces. Those secrets are available as environment variables in your environment.
Another tip is specific to the Visual Studio Code Dev Container. Consider utilizing the Dev Container’s lifecycle events (such as postCreateCommand in devcontainer.json) to automate the Codespaces setup as much as possible. Ultimately, it’s a balance between time saved through automation and time invested in building and maintaining it. However, automation typically results in greater time savings because everyone who uses the configuration benefits.
Another trick is to use GitHub dotfiles to personalize your Codespaces. Dotfiles are files and folders on Unix-like systems starting with . that control the configuration of applications and shells on your system. You can use GitHub dotfiles to set up your personalized settings in Codespaces.
Conclusion
The adoption of GitHub Codespaces has substantially improved the developer experience of working on npm registry services. It has not only reduced the development environment setup time from hours to minutes but also facilitated better debugging experiences. Furthermore, it provides time-saving features like prebuilds. We hope this blog post offers valuable insights into our use of Codespaces. For more information, please refer to Codespaces documentation.
Harness the power of Codespaces. Learn more or get started now.
The post Bringing npm registry services to GitHub Codespaces appeared first on The GitHub Blog.