Post Syndicated from Natasha Wissmann original https://blog.cloudflare.com/whats-new-with-notifications/


Back in 2019, we blogged about our brand new Notification center as a centralized hub for configuring notifications on your account. Since then, we’ve talked a lot about new types of notifications you can set up, but not as much about updates to the notification platform itself. So what’s new with Notifications?
Why we care about notifications
We know that notifications are incredibly important to our customers. Cloudflare sits in between your Internet property and the rest of the world. When something goes wrong, you want to know right away because it could have a huge impact on your end users. However, you don’t want to have to sit on the Cloudflare Dashboard all day, pressing refresh on analytics pages over and over just to make sure that you don’t miss anything important. This is where Notifications come in. Instead of requiring you to actively monitor your Internet properties, you want Cloudflare to be able to directly inform you when something might be going wrong.
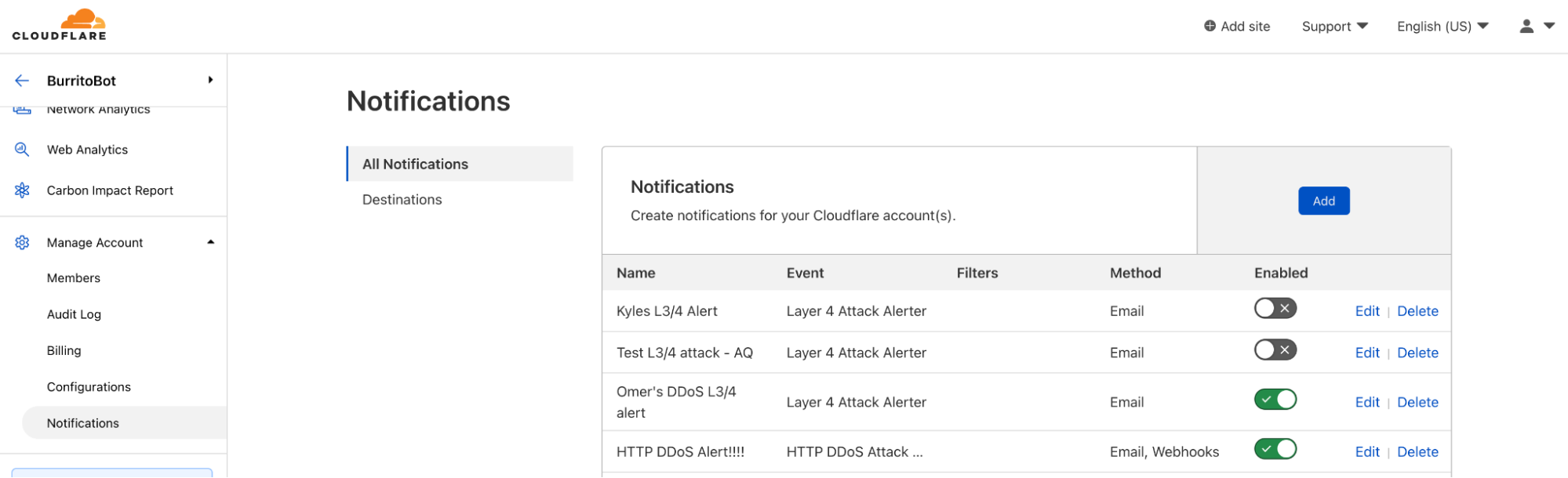
Cloudflare has many different notification types to ensure that you don’t miss anything important. We have notifications to inform you that you’ve been DDoS’d, or that the Firewall is blocking more requests than normal, or that your origin is seeing high levels of 5xx errors, or even that your Workers script’s CPU usage is above average. We’re constantly adding new notifications, so make sure to check our Cloudflare Development Docs to see what’s new!
Emails are out, webhooks are in
So we have all of these super great notifications, but how do we actually inform you of an event? The classic answer is “we email you.” All of our customers have the ability to configure notifications to send to the email addresses of their choosing.
However, email isn’t always the optimal choice. What happens when an email gets sent to spam, or filtered out into another folder that you rarely check? What if you’re a person who never cleans out their inbox and has four thousand unread emails that can drown out new important emails that come in? You want a way for notifications to go directly to the messaging platform that you check the most, whether that’s Slack or Microsoft Teams or Discord or something else entirely. For customers on our Professional, Business, and Enterprise plans, this is where webhooks come in.
Webhooks are incredibly powerful! They’re a type of API with a simple, standardized behavior. They allow one service (Cloudflare) to send events directly to another service. This destination service can be nearly anything: messaging platforms, data management systems, workflow automation systems, or even your own internal APIs.
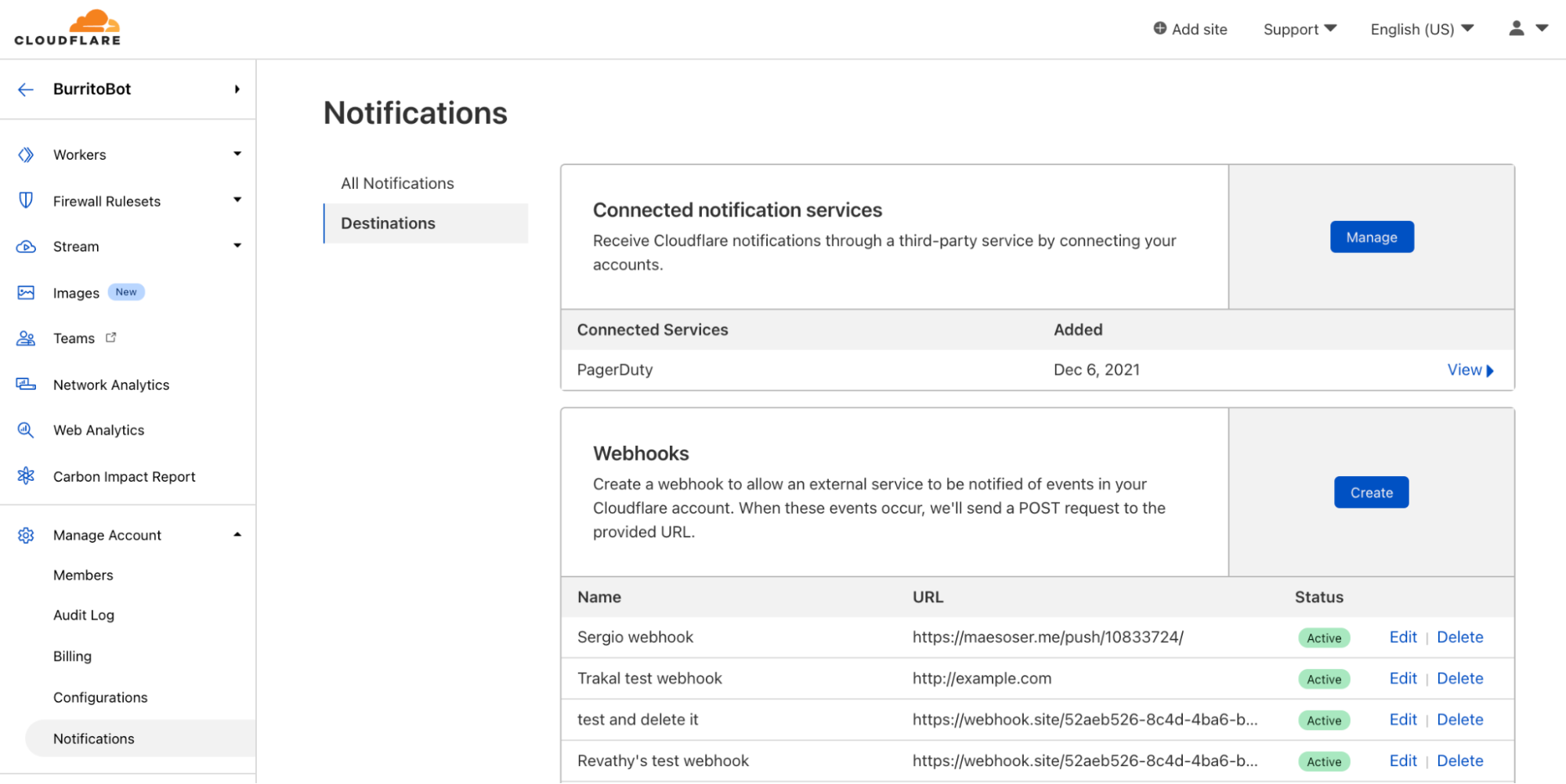
While Cloudflare has had first class support for webhooking into Slack, Microsoft Teams, Google Chat, and customer’s own APIs for a while, we’ve recently added support for DataDog, Discord, OpsGenie, and Splunk as well. You can read about how to set up each of those types of webhooks in our Cloudflare Development Docs.
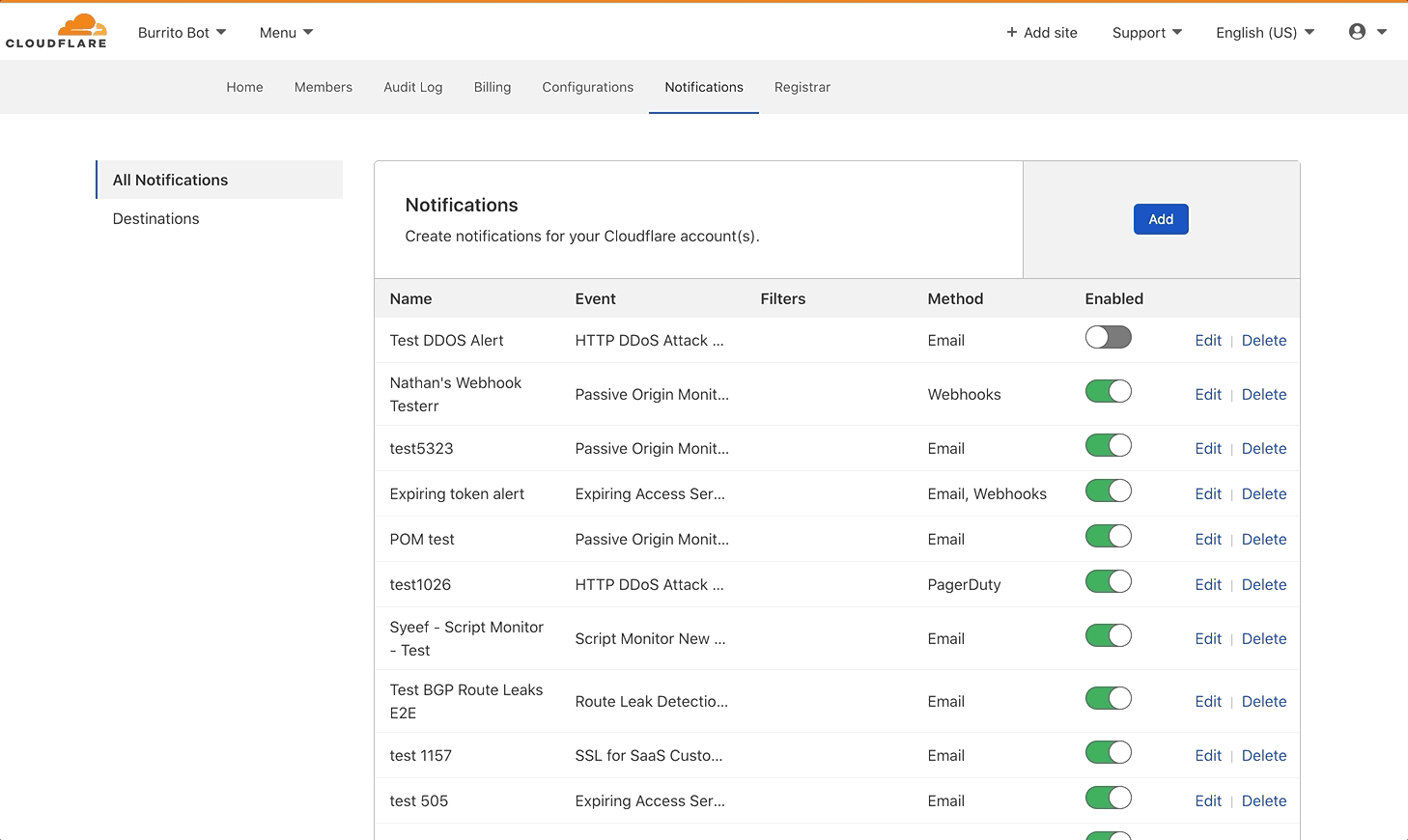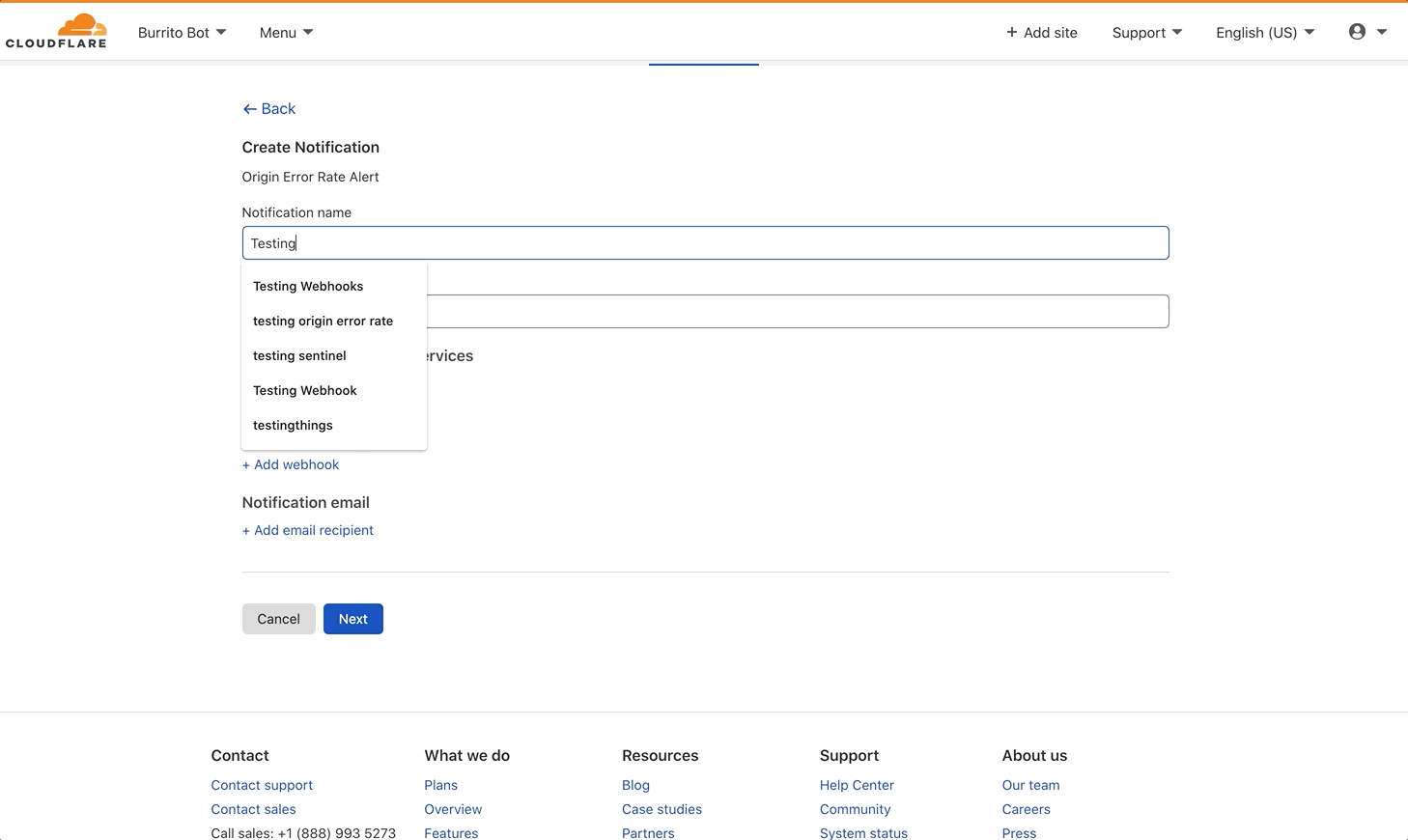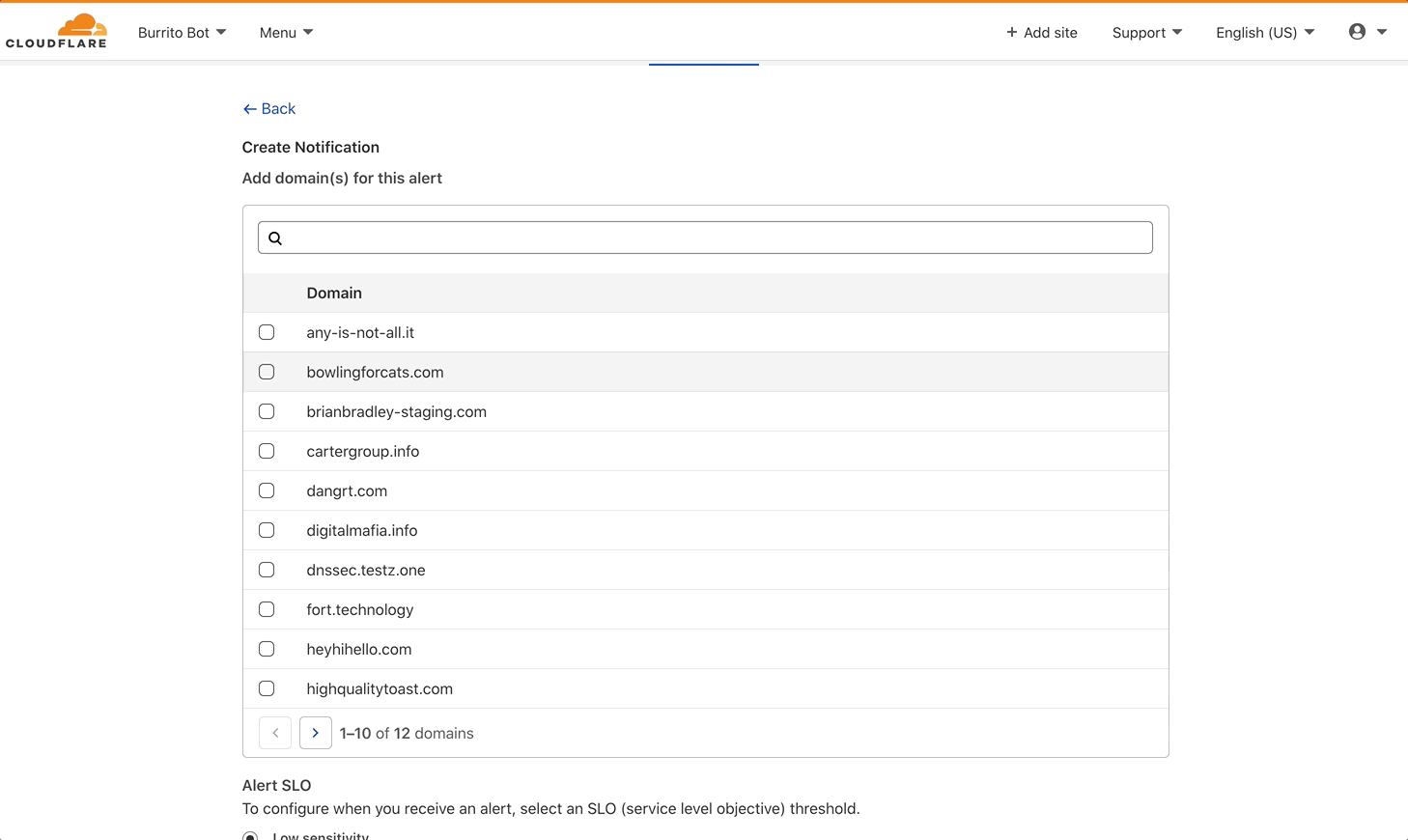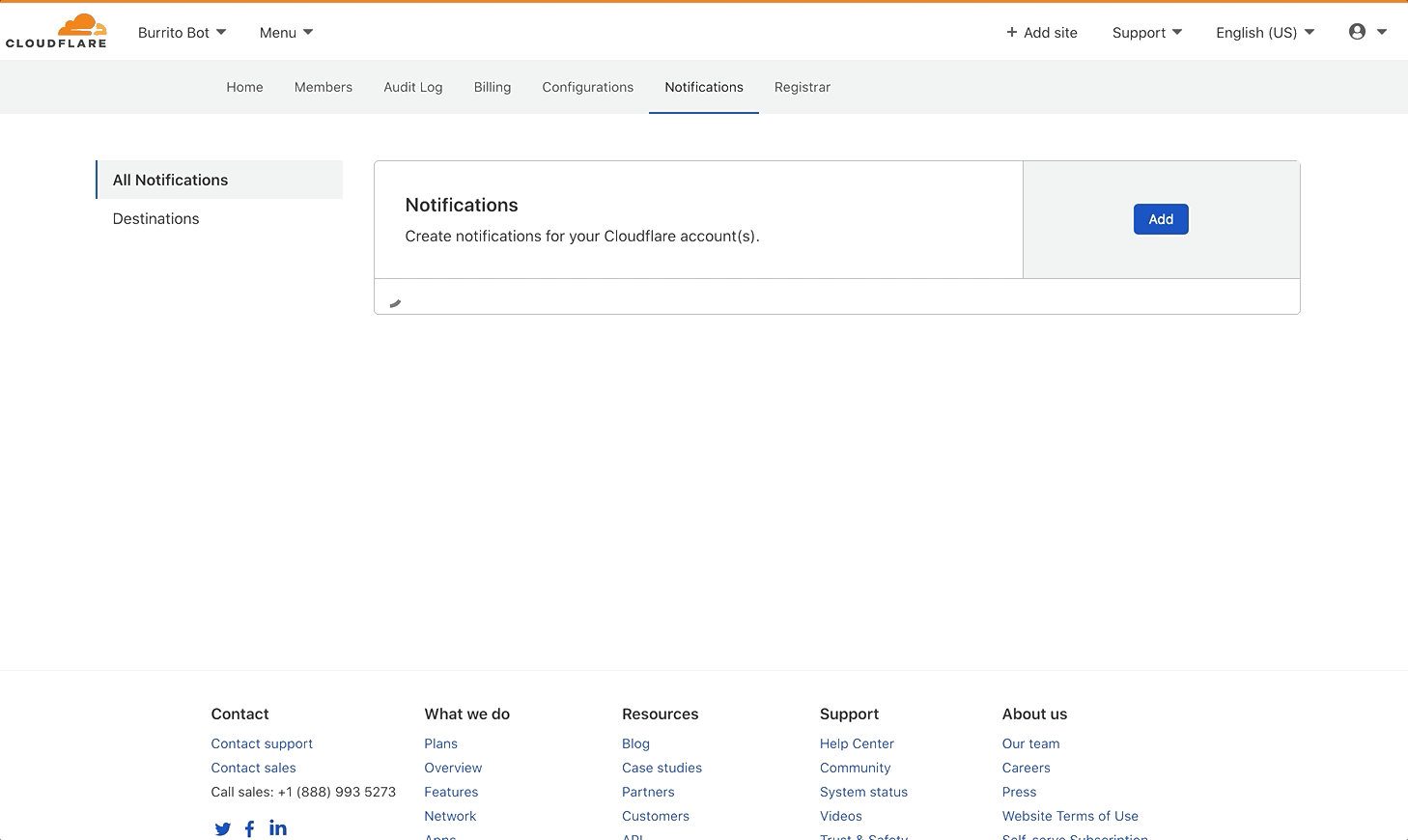
Because webhooks are so versatile, more and more customers are using them! The number of webhooks configured within Cloudflare’s notification system doubles, on average, every three months. Customers can configure webhooks in the Notifications tab in the dashboard.
Those who forget history are doomed to repeat it
Webhooks are cool, but they still leave room for error. What happens when you receive a notification but accidentally delete it? Or when someone new starts at your company, but you forget to update the notification settings to send to the new employee?
Before now, Cloudflare notifications were entirely point in time. We sent you a notification via your preferred method, and we no longer had any visibility into that notification. If that notification gets lost on your end, we don’t have any way to help recover the information it contained.
Notification history fixes that exact issue. Users are able to see a log of the notifications that were sent, when they were sent, and who they were sent to. Customers on Free, Professional, or Business plans are able to see notification history for the past 30 days. Customers on Enterprise plans are able to see notification history for the past 90 days.
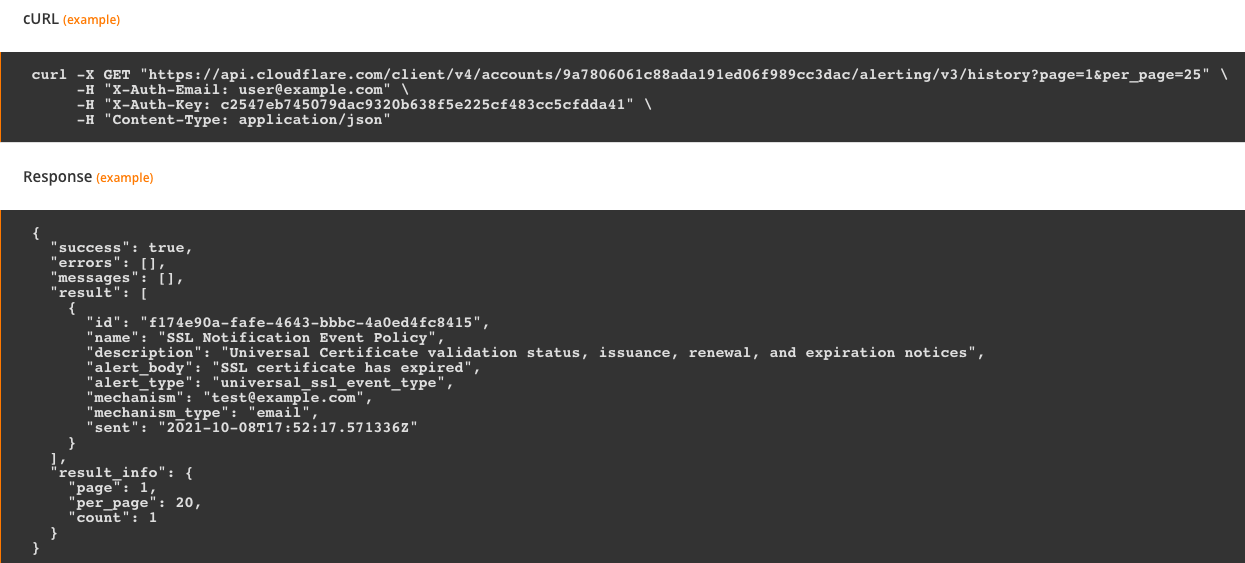
Right now, notification history is only available via API, but stay tuned for updates about viewing directly in the Cloudflare Dashboard!