Post Syndicated from Ramesh H Singh original https://aws.amazon.com/blogs/big-data/introducing-genai-powered-business-description-recommendations-for-custom-assets-in-amazon-sagemaker-catalog/
An organization’s data can come from various sources, including cloud-based pipelines, partner ecosystems, open table formats like Apache Iceberg, software as a service (SaaS) platforms, and internal applications. Although much of this data is business-critical, the ability to make it documented and discoverable at scale continues to challenge teams—especially when assets don’t originate from pre-integrated AWS based sources.
To help bridge this gap, Amazon SageMaker Catalog—part of the next generation of Amazon SageMaker—now supports generative AI-powered recommendations for business descriptions, including table summaries, use cases, and column-level descriptions for custom structured assets registered programmatically. This new capability, powered by large language models (LLMs) in Amazon Bedrock, extends automated metadata generation to the broader spectrum of enterprise data, including Iceberg tables in Amazon Simple Storage Service (Amazon S3) or datasets from third-party and internal applications.
With just a few clicks, you can create AI-generated suggestions, review and refine descriptions, and publish enriched asset metadata directly to the catalog. This helps reduce manual documentation effort, improves metadata consistency, and accelerates asset discoverability across organizations.
This launch is part of our broader investment in generative AI-powered cataloging and metadata intelligence across SageMaker Catalog. By combining machine learning (ML) with human oversight and governance controls, we’re making it straightforward for organizations to scale trusted, usable data across business units.
In this post, we demonstrate how to generate AI recommendations for business descriptions for custom structured assets in SageMaker Catalog.
Challenges when using incomplete metadata for custom and external data
SageMaker Catalog supports automated documentation for assets harvested from AWS-centered services like AWS Glue and Amazon Redshift. These built-in integrations automatically pull schema and generate contextual metadata, making it straightforward for data consumers to discover and understand what’s available.
However, many critical datasets originate outside of these services, such as:
- Iceberg tables stored in Amazon S3
- Structured datasets from third-party platforms like Snowflake or Databricks
- Relational assets manually registered using APIs
As a result, customers had to manually enter business descriptions and column-level context—a process that delays publishing, introduces inconsistency, and undermines the discoverability of important assets.
With this launch, SageMaker Catalog adds support for generative AI-powered metadata generation for custom schema-based data assets registered programmatically through APIs. We use large language models (LLMs) in Amazon Bedrock to automatically generate key elements for custom structured assets. This includes providing a comprehensive table summary, detailed column-level descriptions, and suggesting potential analytical use cases. These automated capabilities help streamline the documentation process, ensuring consistency and efficiency across data assets.
Customer Spotlight
Across industries, customers are managing thousands of structured datasets that don’t originate from AWS-native pipelines. These datasets often lack documentation—not because they’re unimportant, but because documenting them is time-consuming, repetitive, and often deprioritized.
How Amazon’s Finance is revolutionizing data management with AI-powered metadata generation
As a large-scale organization with diverse data needs, Amazon’s Finance team manages thousands of data assets. Within the Finance organization, numerous datasets often lack proper documentation, creating bottlenecks that hinder critical financial analysis and decision-making.
Balaji Kumar Gopalakrishnan, Principal Engineer at Amazon Finance, shares how the AI-powered metadata generation capability is transforming their data management approach:
“As a finance organization, we manage numerous datasets that lack proper documentation, creating bottlenecks for critical financial analysis. The AI-powered auto-documentation capability would be transformative for our team—alleviating the manual documentation effort that delays asset discovery and usability. This would dramatically reduce our time-to-insight for reporting while enforcing consistent metadata standards across all our manually registered assets.”
This empowers teams like Amazon Finance to streamline metadata generation and documentation, making critical financial data easier to access and work with. By automating metadata creation, teams can focus on high-impact analysis, accelerating their decision-making process and improving the overall efficiency of the organization.
Key Benefits
This new feature directly addresses key challenges faced by cataloging teams by enabling them to:
- Accelerate time to publish: Minimize the delay between data availability and catalog readiness.
- Improve metadata quality: Ensure consistent, LLM-generated context, regardless of schema authors.
- Enhance discoverability: Enable quick and easy access to data through rich, searchable descriptions.
- Build trust: Provide transparent, editable AI suggestions to ensure metadata aligns with organizational needs and domain accuracy.
For data producers, this capability eliminates the need for repetitive, manual documentation, saving valuable time. By automating metadata generation, it also standardizes how metadata is written and structured across assets, resulting in faster publishing and quicker data access for consumers.
On the consumer side, the enhanced metadata offers greater clarity, allowing users to understand the data and its usage at a glance. With complete and curated metadata, they can trust the source, while working more independently and reducing reliance on subject matter experts (SMEs) and data stewards for interpretation.
Solution overview
In this post, we demonstrate how to manually create a structured asset and use the new AI-powered capability to generate business metadata to improve asset usability. The asset we add is a product inventory table with the following columns:
Table : ProductInventory
Columns :
productID : string
name: string
price: double
stock_quantity : integer
shipped_from : integer
Prerequisites
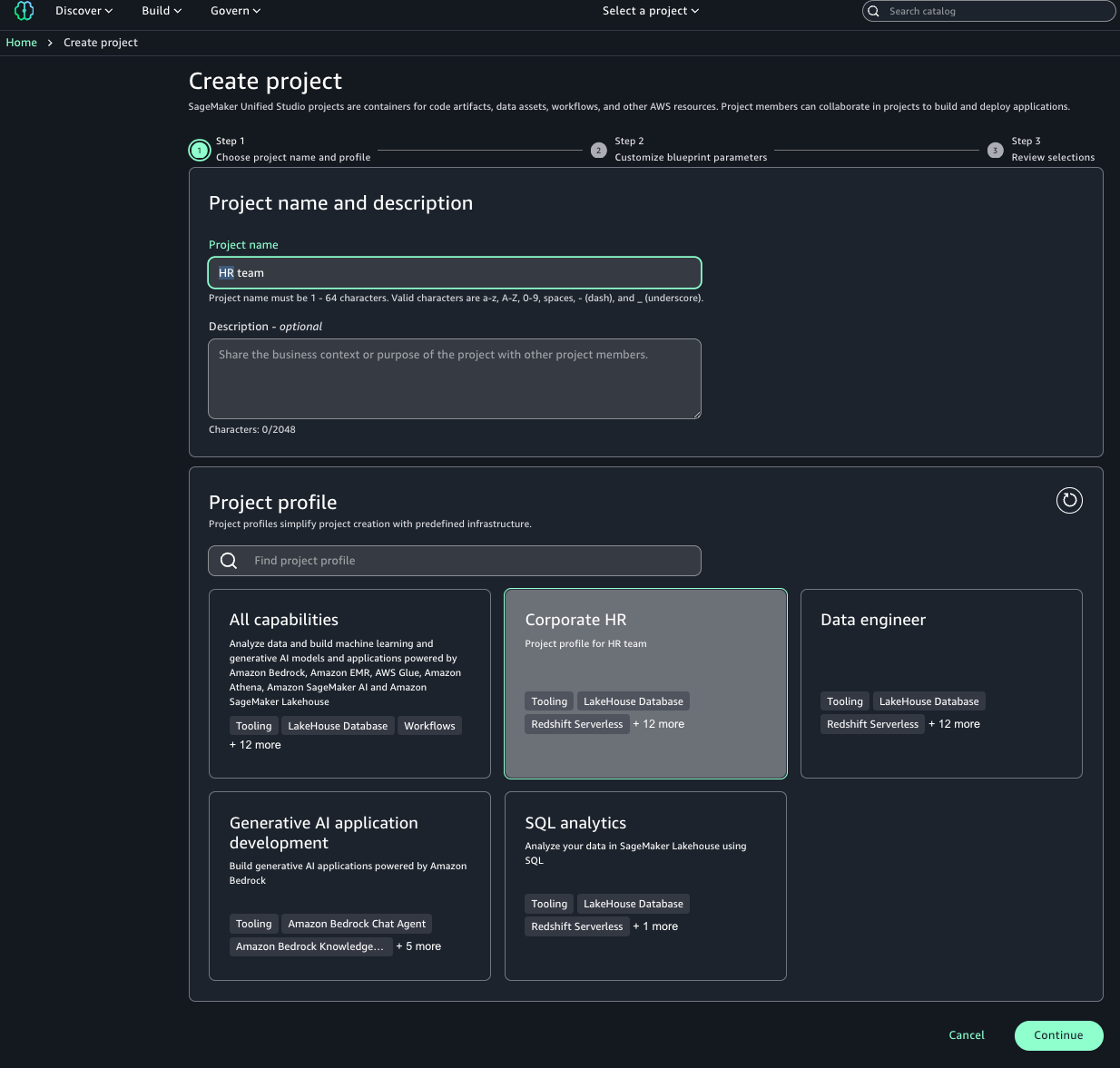
To follow this post, you must have an Amazon SageMaker Unified Studio domain set up with a domain owner or domain unit owner privileges. You must have a project that we will use to publish assets. For instructions, refer to the SageMaker Unified Studio Getting started guide.
Create an asset
Complete the following steps to manually create the asset:
- The manually registered asset types need to use the
amazon.datazone.RelationalTableFormType form type. Get the latest revision in your domain. Run the following command, replacing the domain-identifier with your domain:
aws datazone get-form-type --domain-identifier dzd_xxxxf --form-type-identifier amazon.datazone.RelationalTableFormType
The latest revision returned is 7, which we use in the next steps:
{
"createdAt": "2024-12-23T21:12:50.484000+00:00",
"createdBy": "SYSTEM",
"domainId": "dzd_xxxxf",
"imports": [
{
"name": "amazon.datazone.RelationalColumnMixin",
"revision": "5"
},
{
"name": "amazon.datazone.RelationalTableMixin",
"revision": "5"
}
],
"model": {
"smithy": "$version: \"2.0\"\n\nnamespace amazon.datazone\n\nstructure RelationalColumn with [ RelationalColumnMixin ] {\n\n}\n\nlist RelationalColumns {\n member: RelationalColumn\n}\n\n@documentation(\"A generic form-type to capture relational table details\")\nstructure RelationalTableFormType with [ RelationalTableMixin ] {\n\n columns: RelationalColumns\n}"
},
"name": "amazon.datazone.RelationalTableFormType",
"originDomainId": "dzd_amazon_datazone_domain",
"originProjectId": "dzd_amazon_datazone_domain_project",
"owningProjectId": "dzd_amazon_datazone_domain_project",
"status": "ENABLED"
}
- Create a new asset type that uses the
amazon.datazone.RelationalTableFormType revision returned in the previous step:
aws datazone create-asset-type \
> --domain-identifier dzd_xxxxf \
> --name MyAssetType \
> --description "Manually registered custom asset type" \
> --owning-project-identifier 4zxxxx3r \
> --forms-input '{"MyCustomForm": {"required": true, "typeIdentifier": "amazon.datazone.RelationalTableFormType","typeRevision":"7"}}'
You will receive a success response similar to the following:
{
"description": "Manually registered custom asset type",
"domainId": "dzd_xxxxf",
"formsOutput": {
"AssetCommonDetailsForm": {
"required": false,
"typeName": "amazon.datazone.AssetCommonDetailsFormType",
"typeRevision": "6"
},
"MyCustomForm": {
"required": true,
"typeName": "amazon.datazone.RelationalTableFormType",
"typeRevision": "7"
}
},
"name": "MyAssetType",
"revision": "1"
}
- Create the asset for the table using the asset type and replacing the domain and project identifiers in your domain. For this example, we also enable
businessNameGeneration:
aws datazone create-asset --domain-identifier dzd_xxxxf \
--name ProductInventory \
--owning-project-identifier 4zxxxx3r \
--type-identifier MyAssetType \
--forms-input '[{
"content": "{\r\n \"tableName\": \"ProductInventory\",\r\n \"columns\": [\r\n {\r\n \"columnName\": \"productID\",\r\n \"dataType\": \"string\"\r\n },\r\n {\r\n \"columnName\": \"name\",\r\n \"dataType\": \"string\"\r\n },\r\n {\r\n \"columnName\": \"price\",\r\n \"dataType\": \"double\"\r\n },\r\n {\r\n \"columnName\": \"stock_quantity\",\r\n \"dataType\": \"integer\"\r\n },\r\n {\r\n \"columnName\": \"shipped_from\",\r\n \"dataType\": \"string\"\r\n }\r\n ]\r\n}",
"formName": "MyCustomForm",
"typeIdentifier": "amazon.datazone.RelationalTableFormType"}]'
The following is an example success response after the asset is created:
{
"createdAt": "2025-06-24T23:47:51.734000+00:00",
"createdBy": "9665be38-c692-4474-a41f-5d9793040f08",
"domainId": "dzd_xxxxf",
"firstRevisionCreatedAt": "2025-06-24T23:47:51.734000+00:00",
"firstRevisionCreatedBy": "9665be38-c692-4474-a41f-5d9793040f08",
"formsOutput": [
{
"content": "{\"tableName\":\"ProductInventory\",\"columns\":[{\"columnName\":\"productID\",\"dataType\":\"string\"},{\"columnName\":\"name\",\"dataType\":\"string\"},{\"columnName\":\"price\",\"dataType\":\"double\"},{\"columnName\":\"stock_quantity\",\"dataType\":\"integer\"},{\"columnName\":\"shipped_from\",\"dataType\":\"string\"}]}",
"formName": "MyCustomForm",
"typeName": "amazon.datazone.RelationalTableFormType"
}
],
"id": "4e4w5chq6lf3tz",
"name": "ProductInventory",
"owningProjectId": "4zxxxx3r",
"predictionConfiguration": {
"businessNameGeneration": {
"enabled": true
}
},
"readOnlyFormsOutput": [],
"revision": "1",
"typeIdentifier": "MyAssetType",
"typeRevision": "1"
}
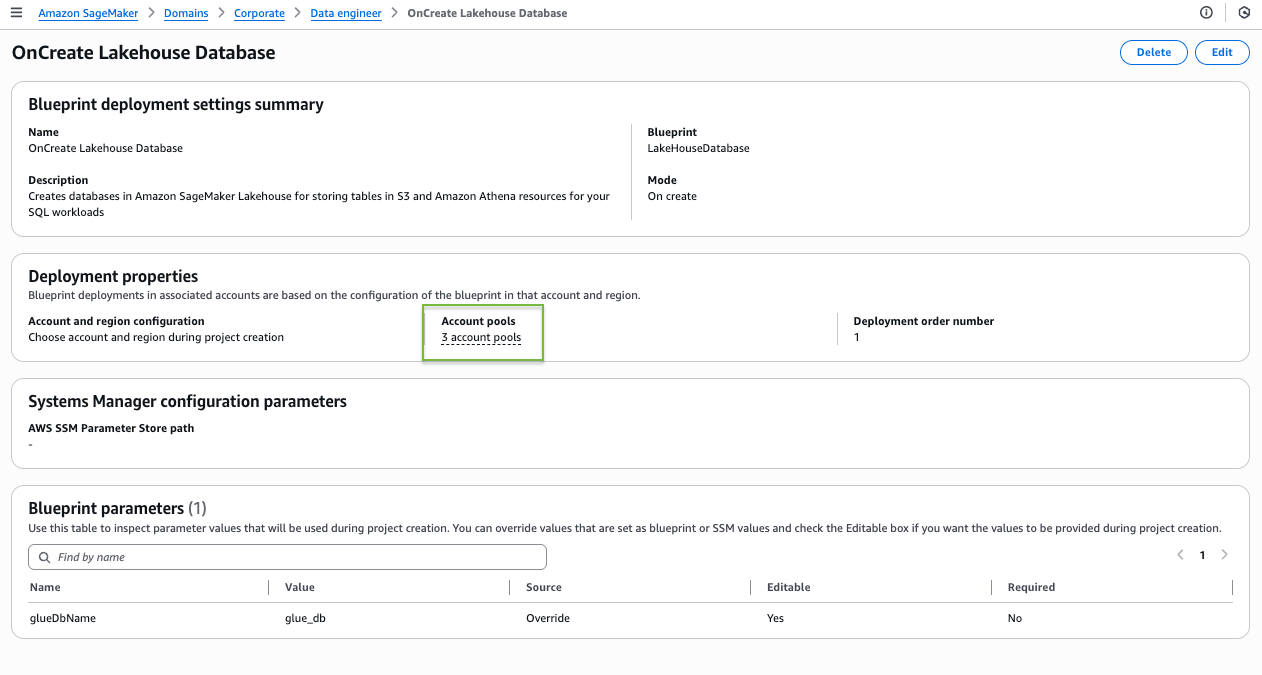
When an asset is created with businessNameGeneration enabled, it generates the business name predictions asynchronously. After they are generated, they are returned as suggestions under the asset’s readOnlyForms.
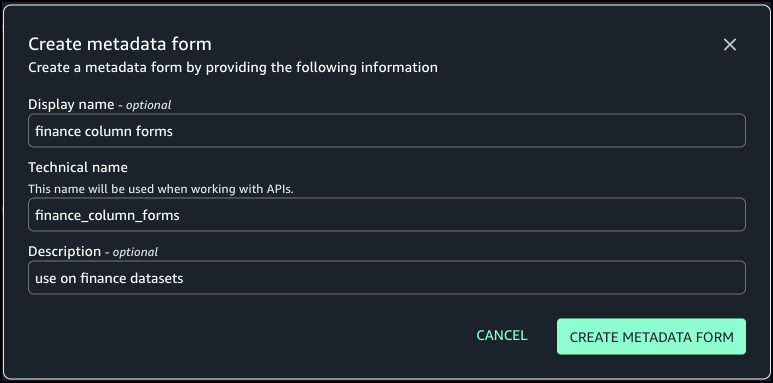
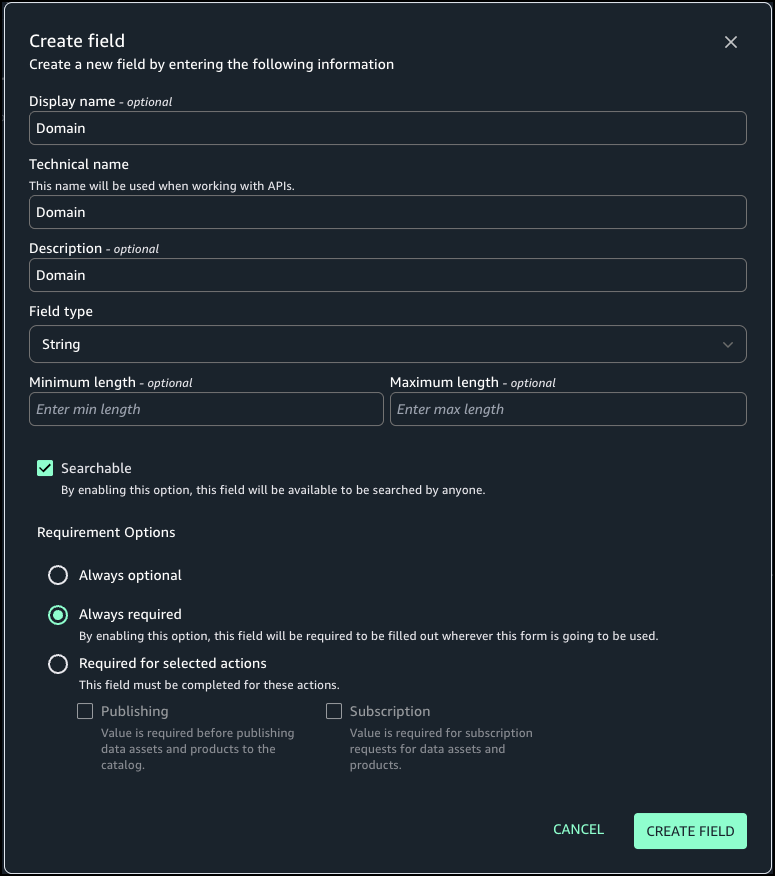
Generate business metadata
Complete the following steps to generate metadata:
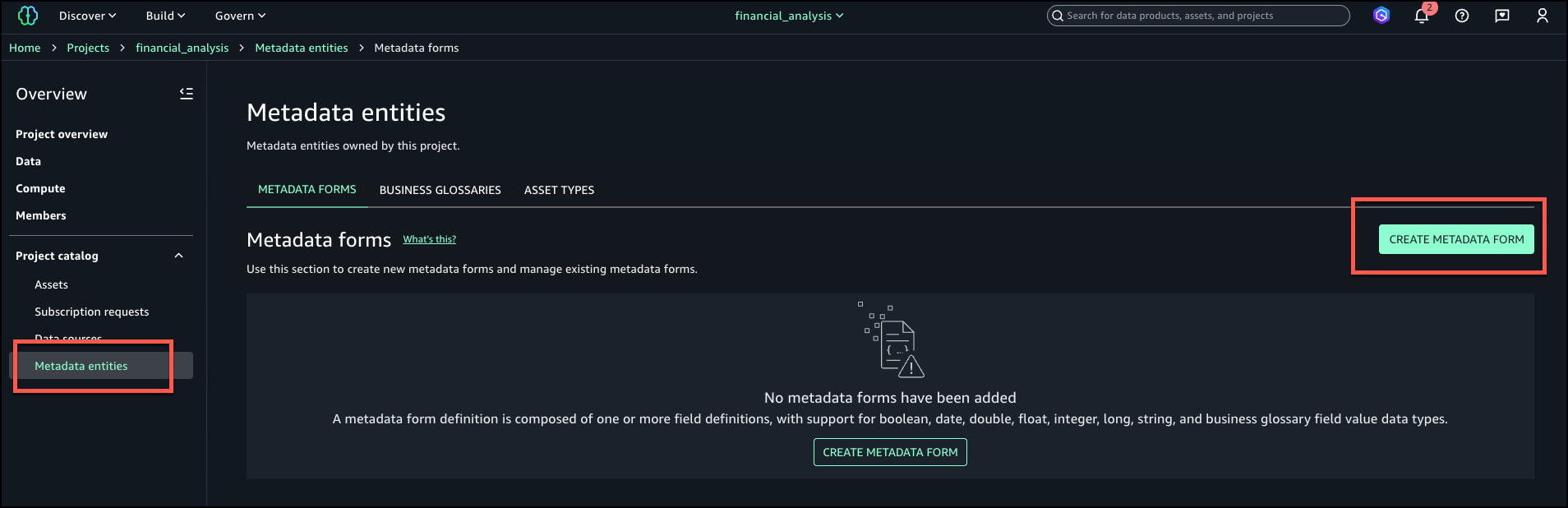
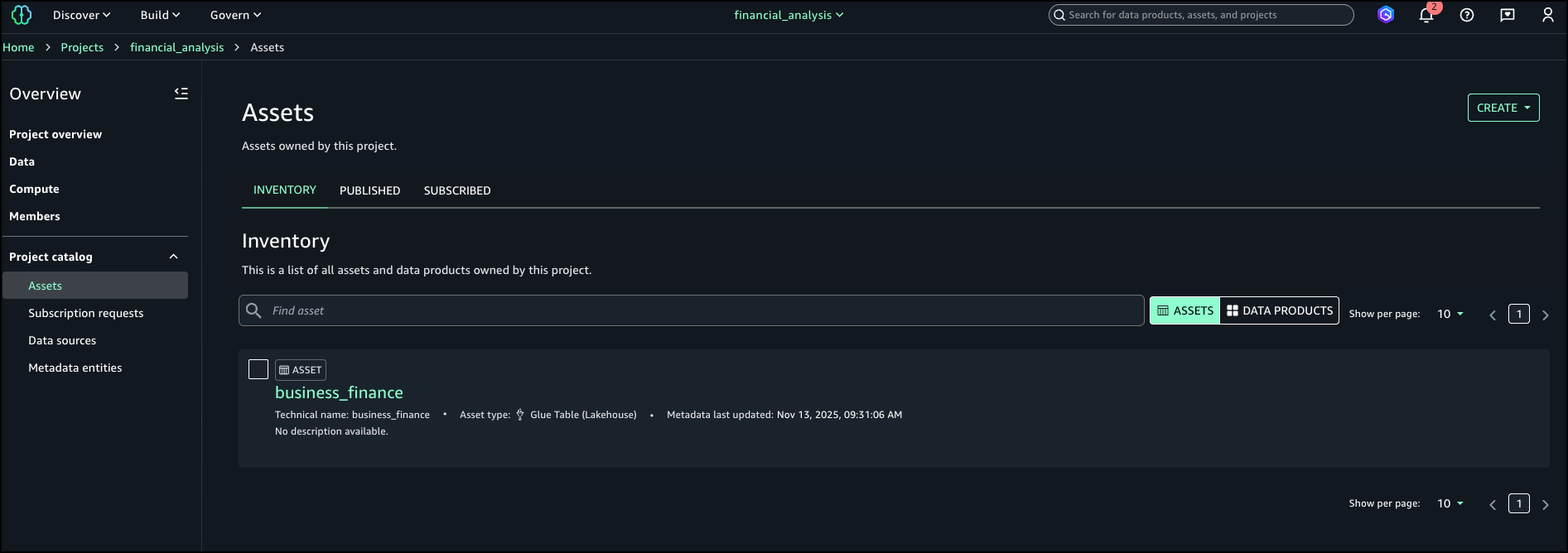
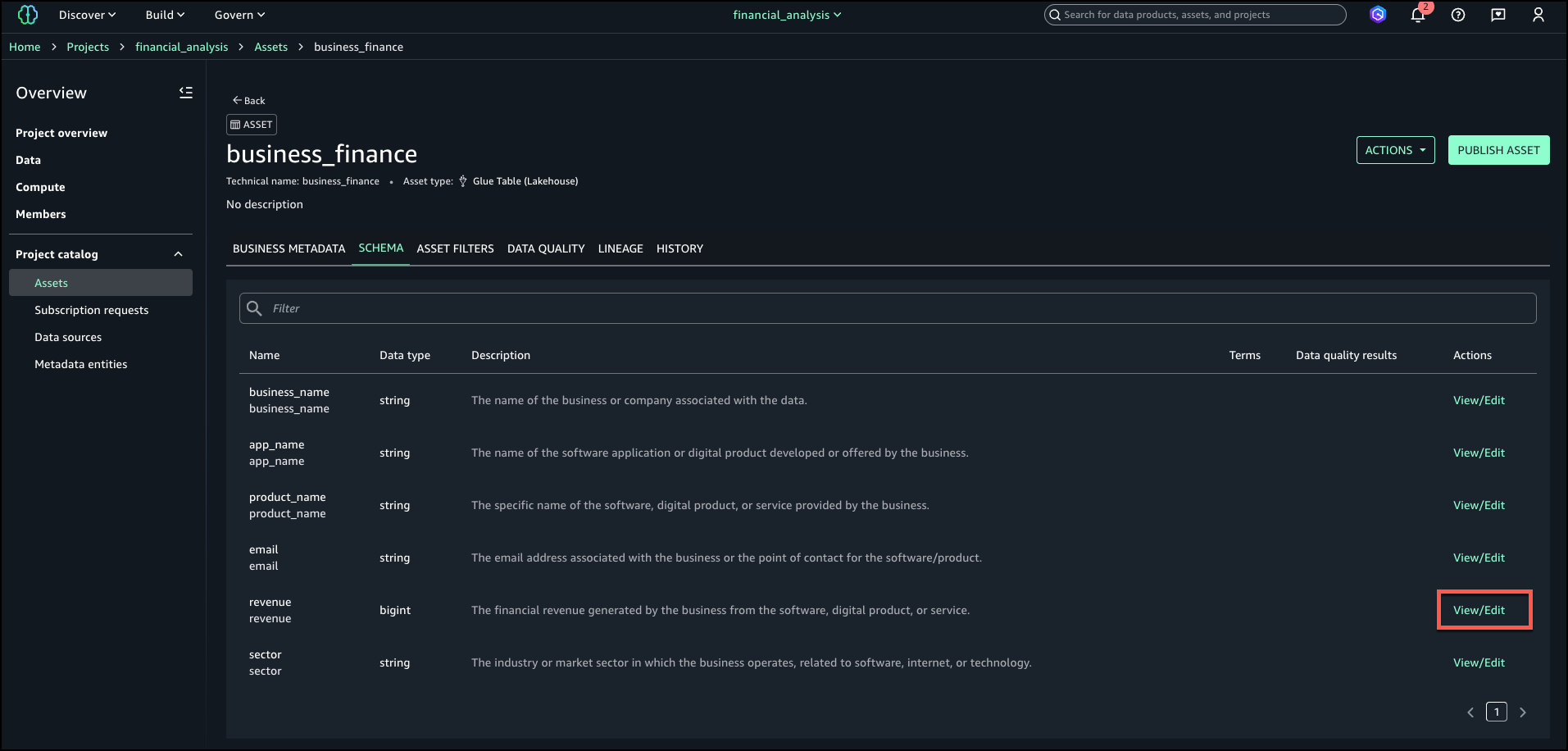
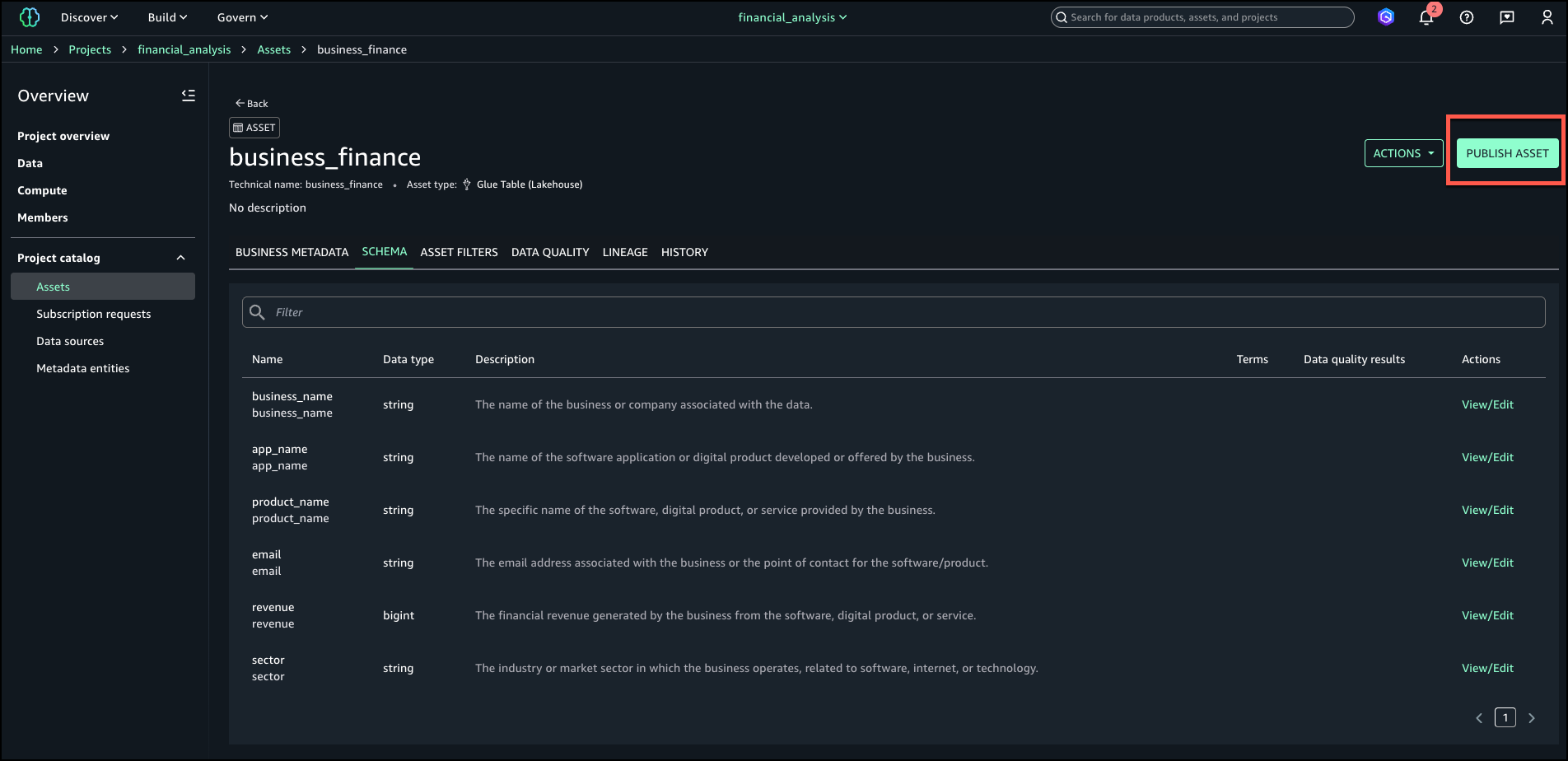
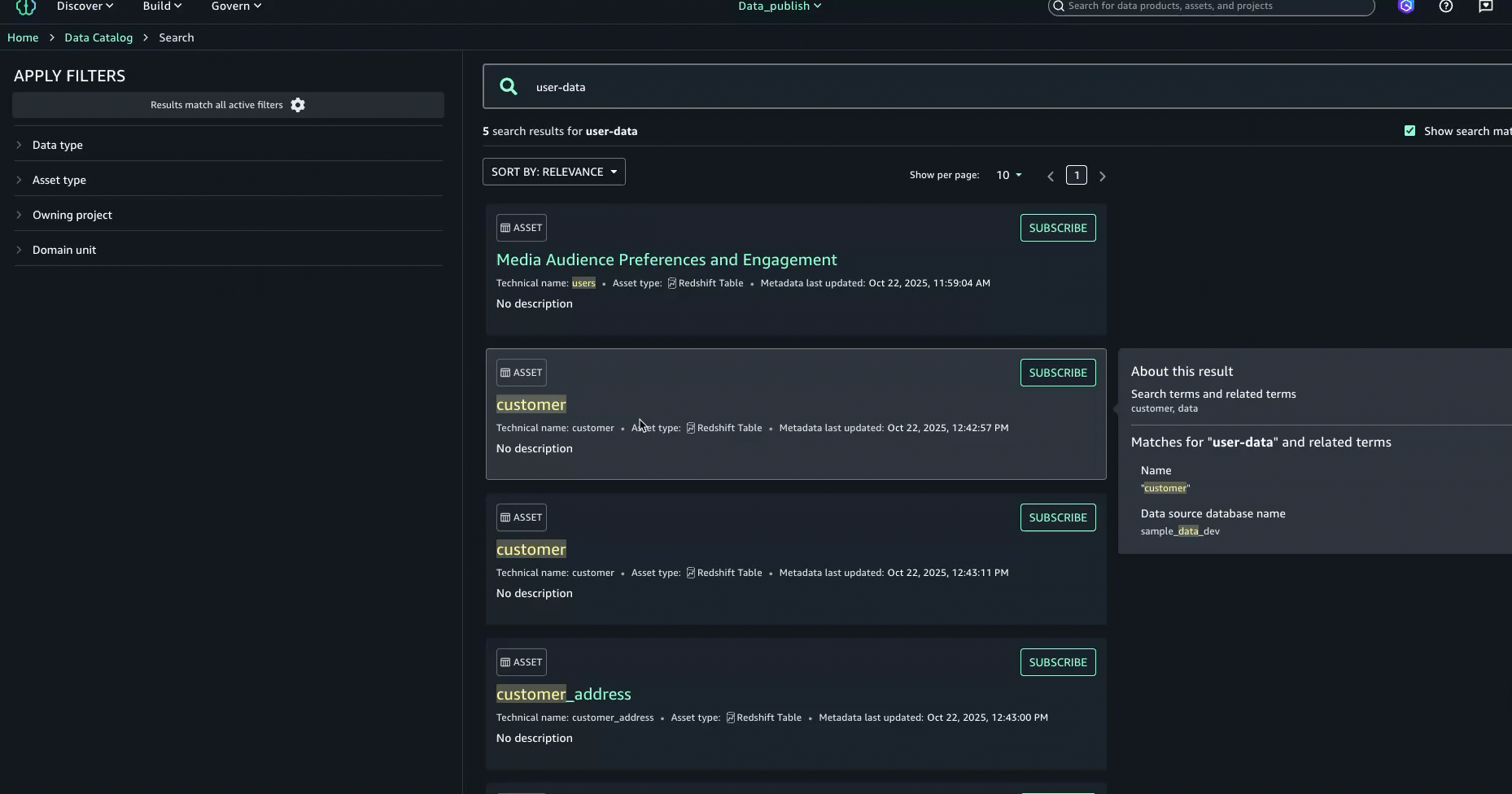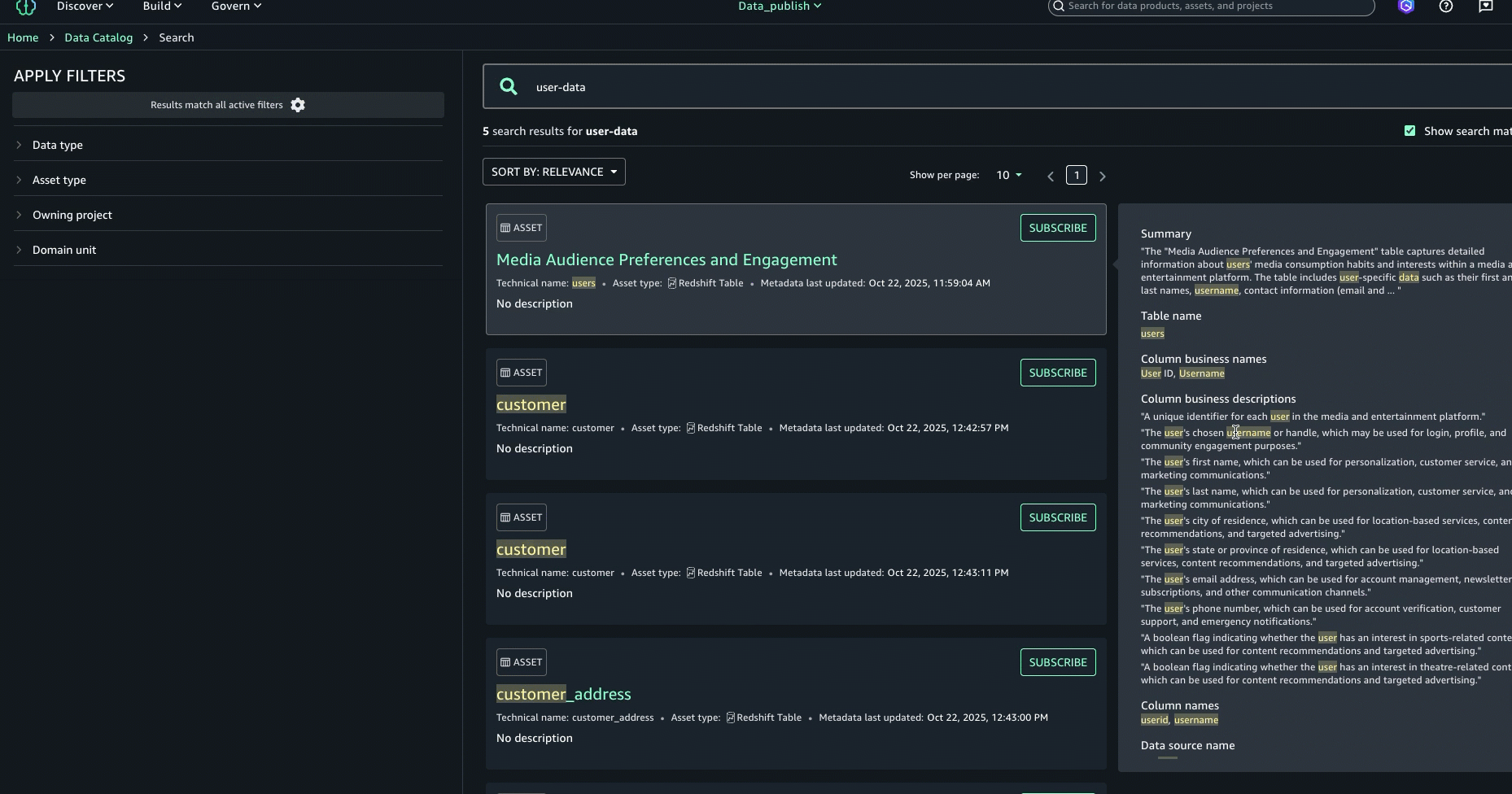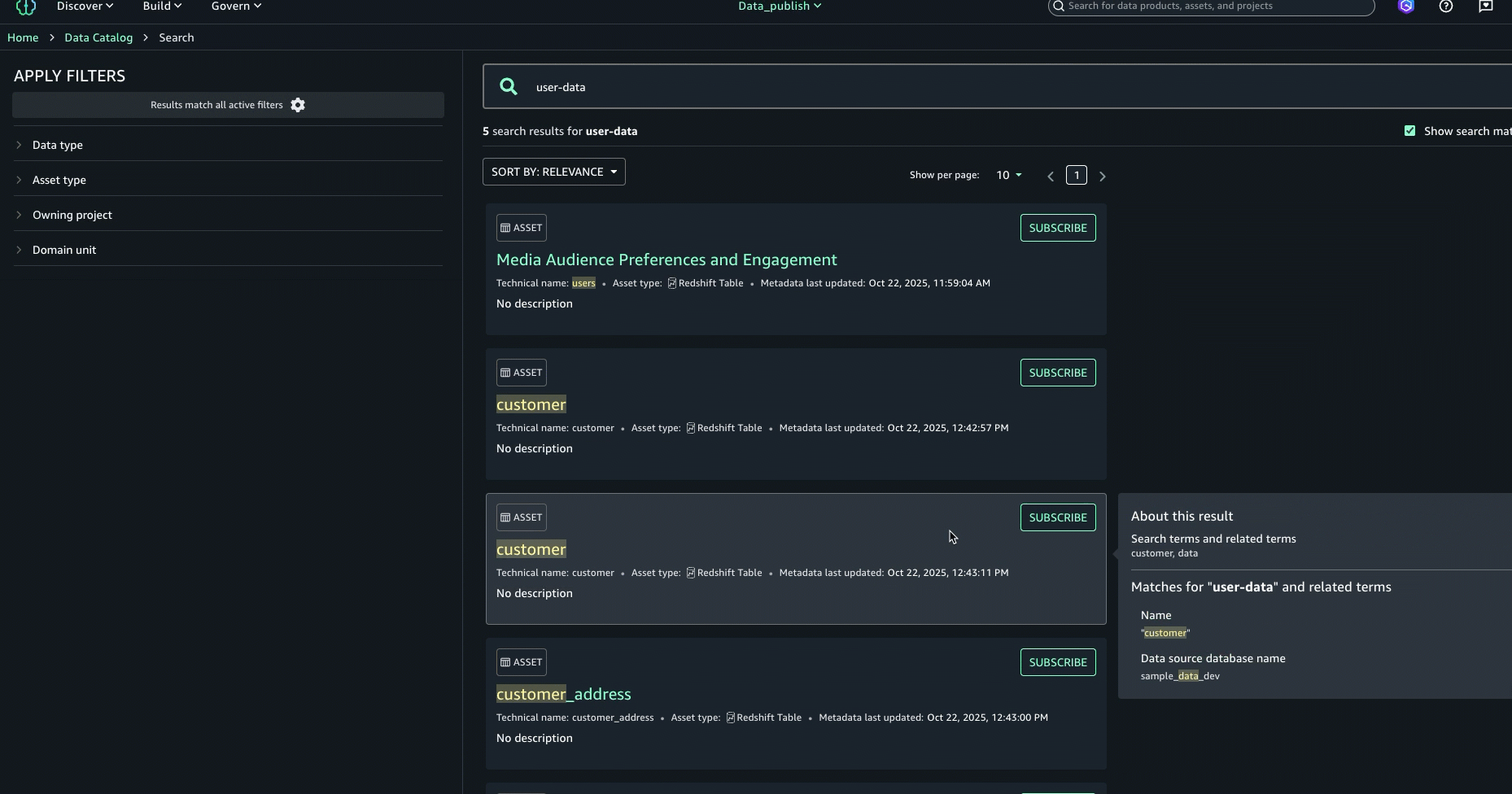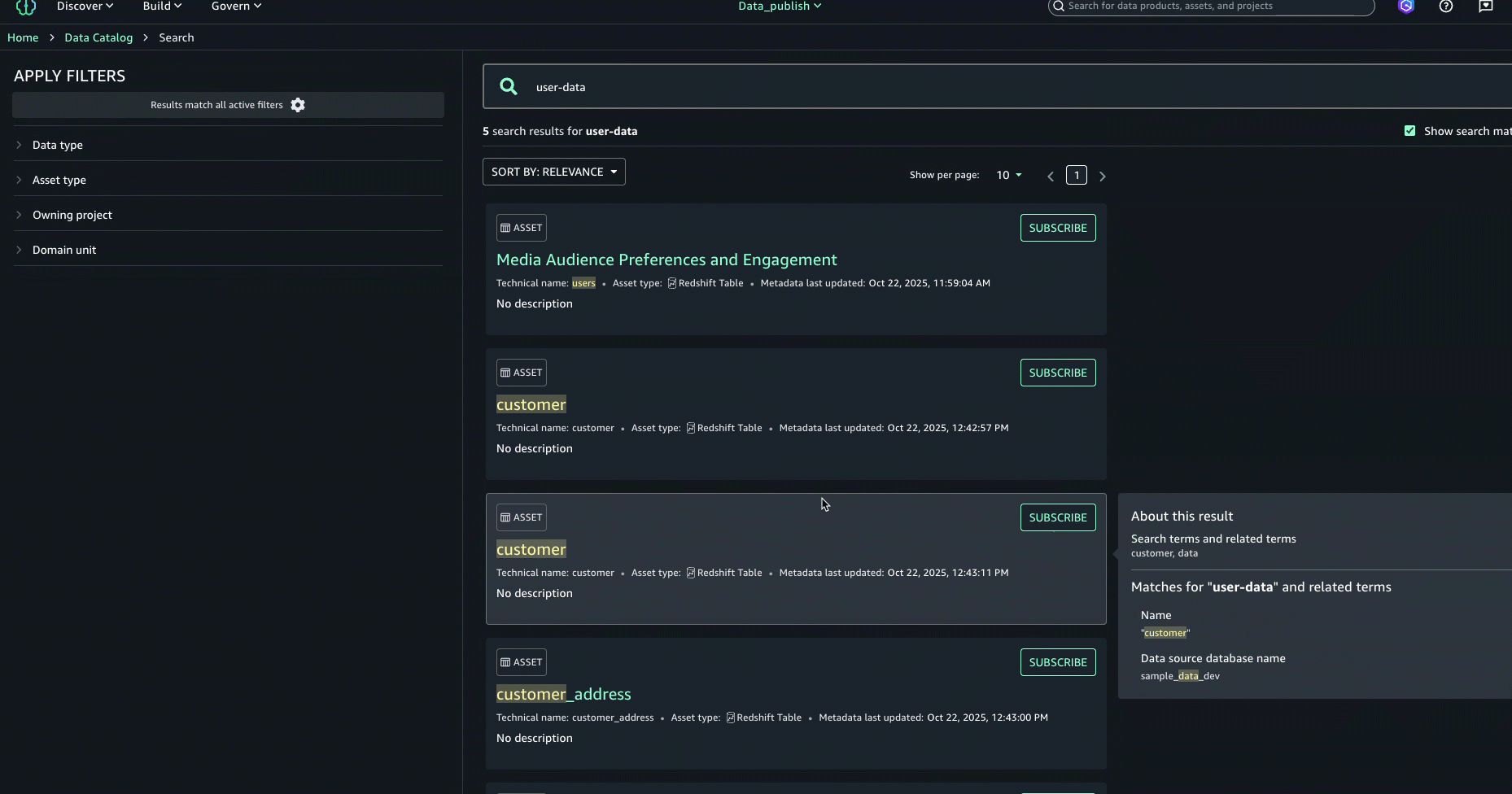
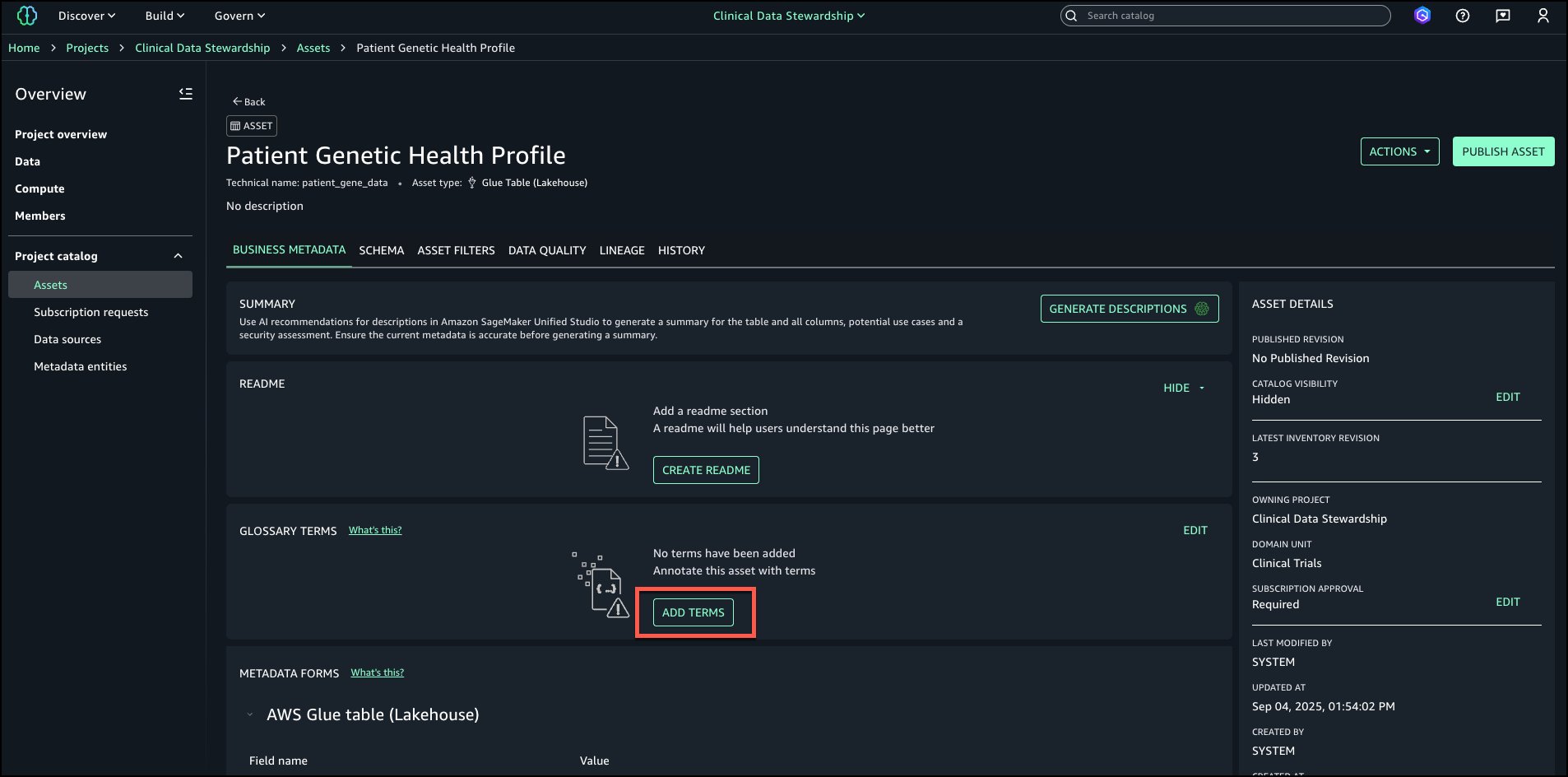
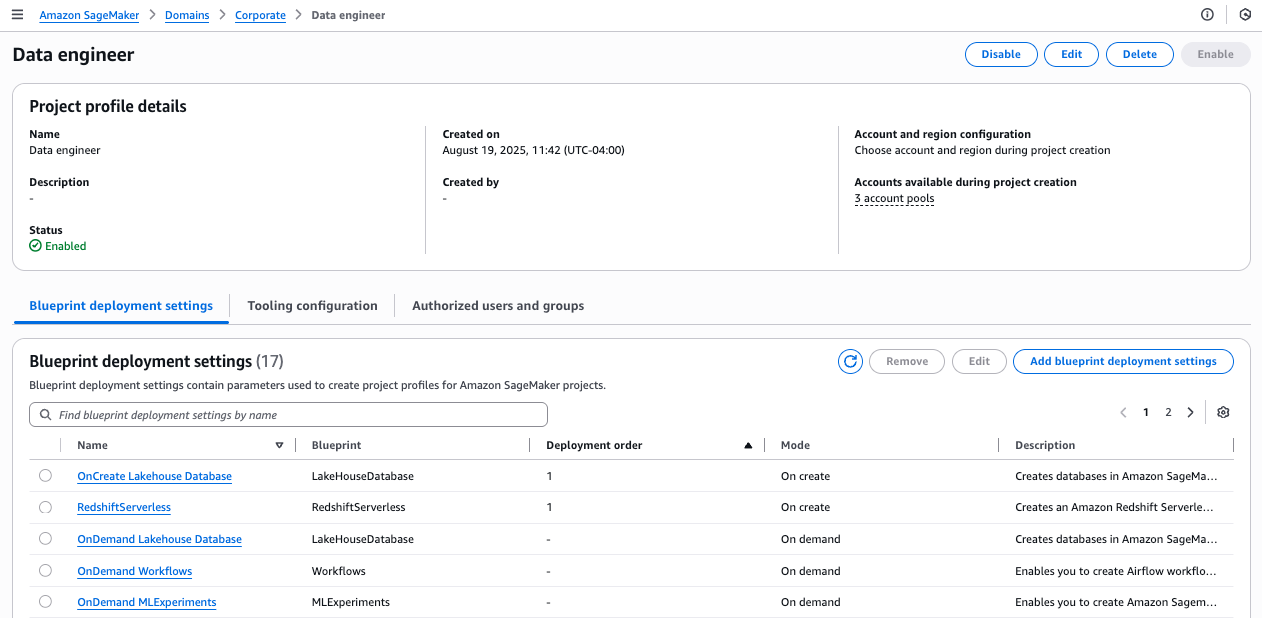
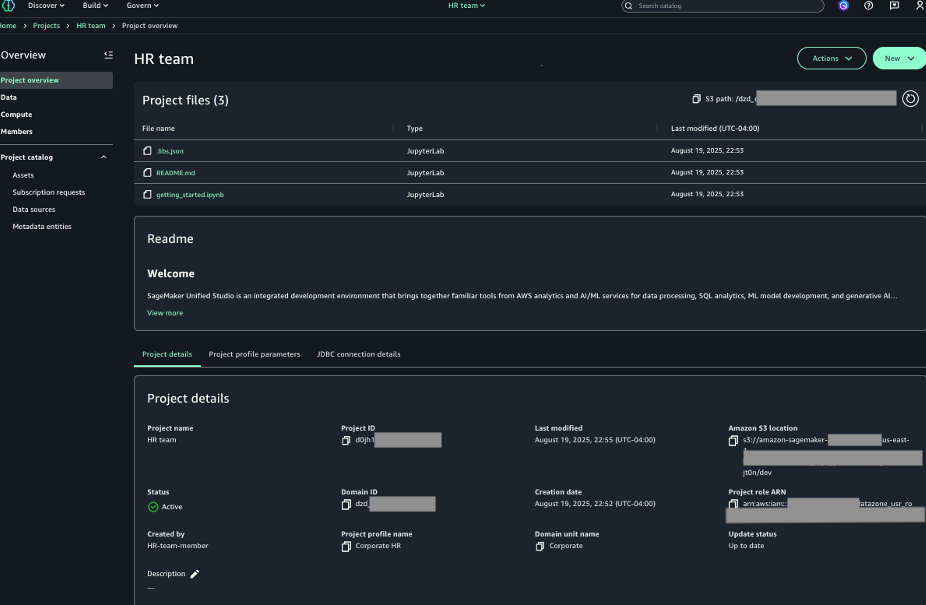
- Log in to the SageMaker Unified Studio portal, open the project that you used, and choose Assets in the navigation pane.

The business name is already generated for the asset and columns.
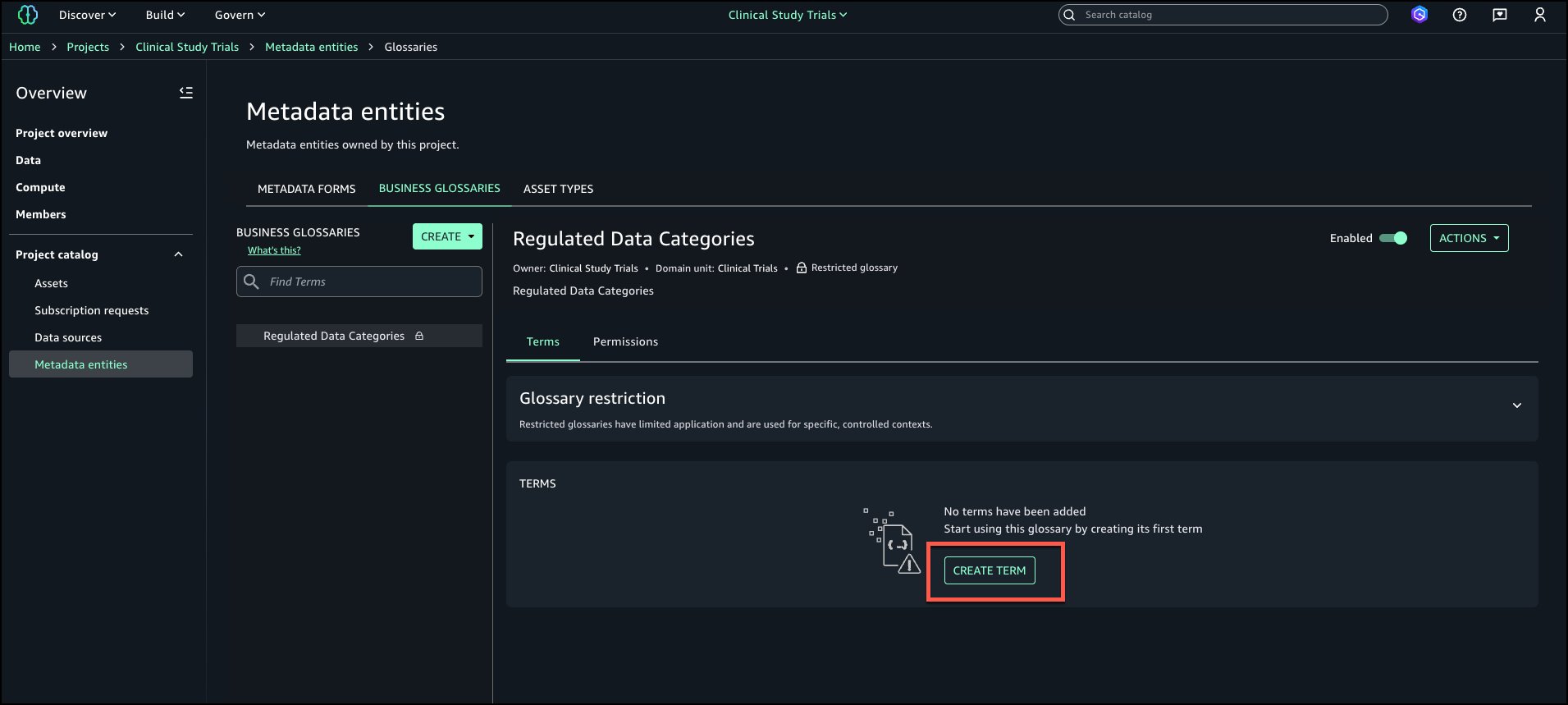
- To generate descriptions, choose Generate descriptions.

The following screenshot shows the generated names on the Schema tab.

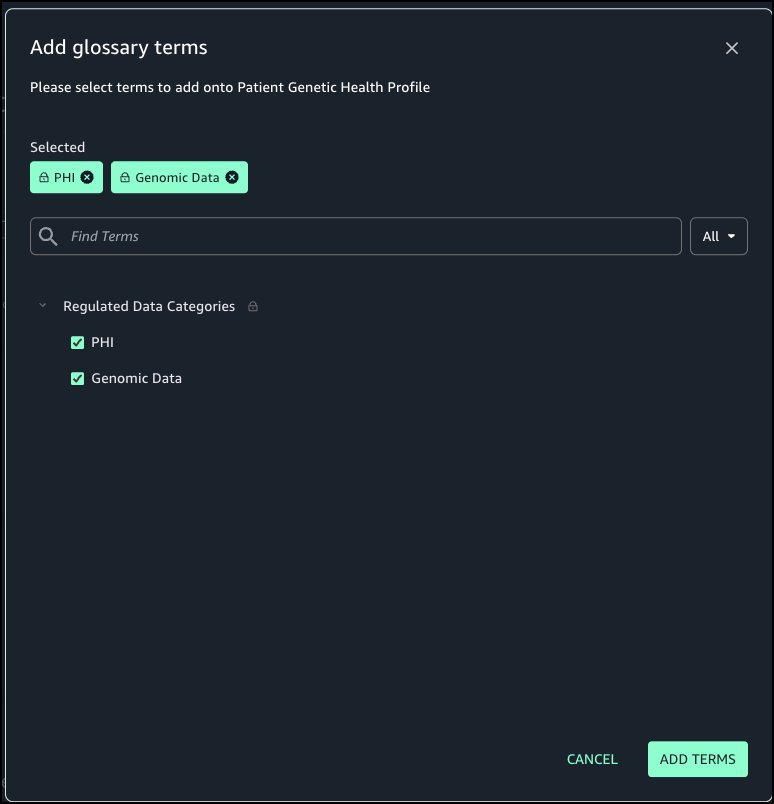
- If you approve of the generated names, choose Accept all.

- Choose Accept all again to confirm.

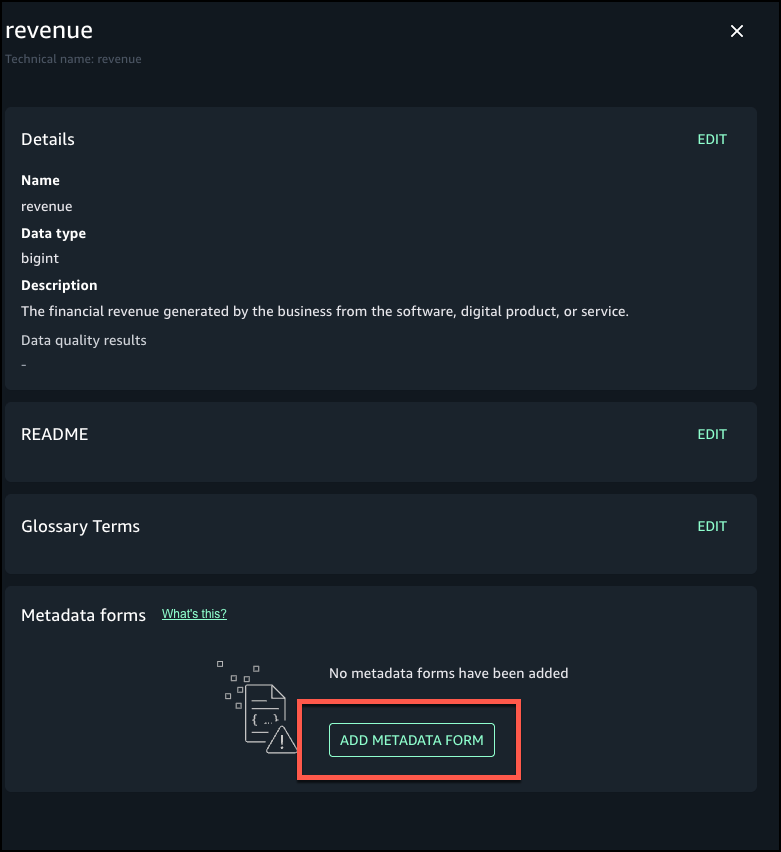
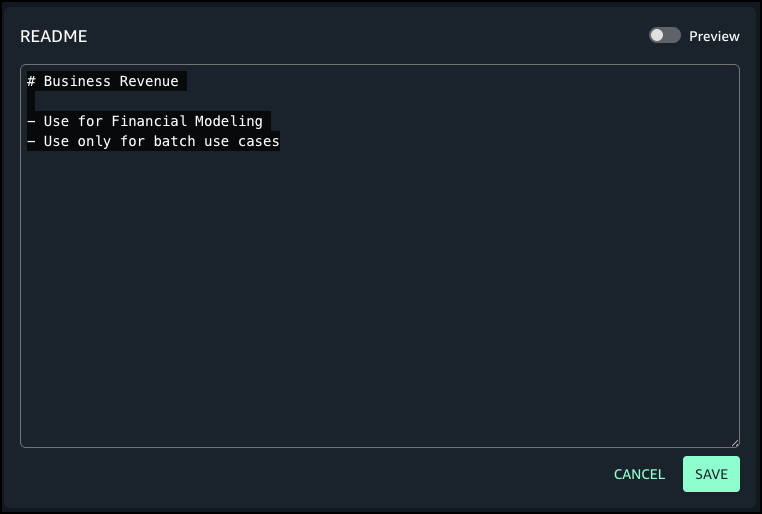
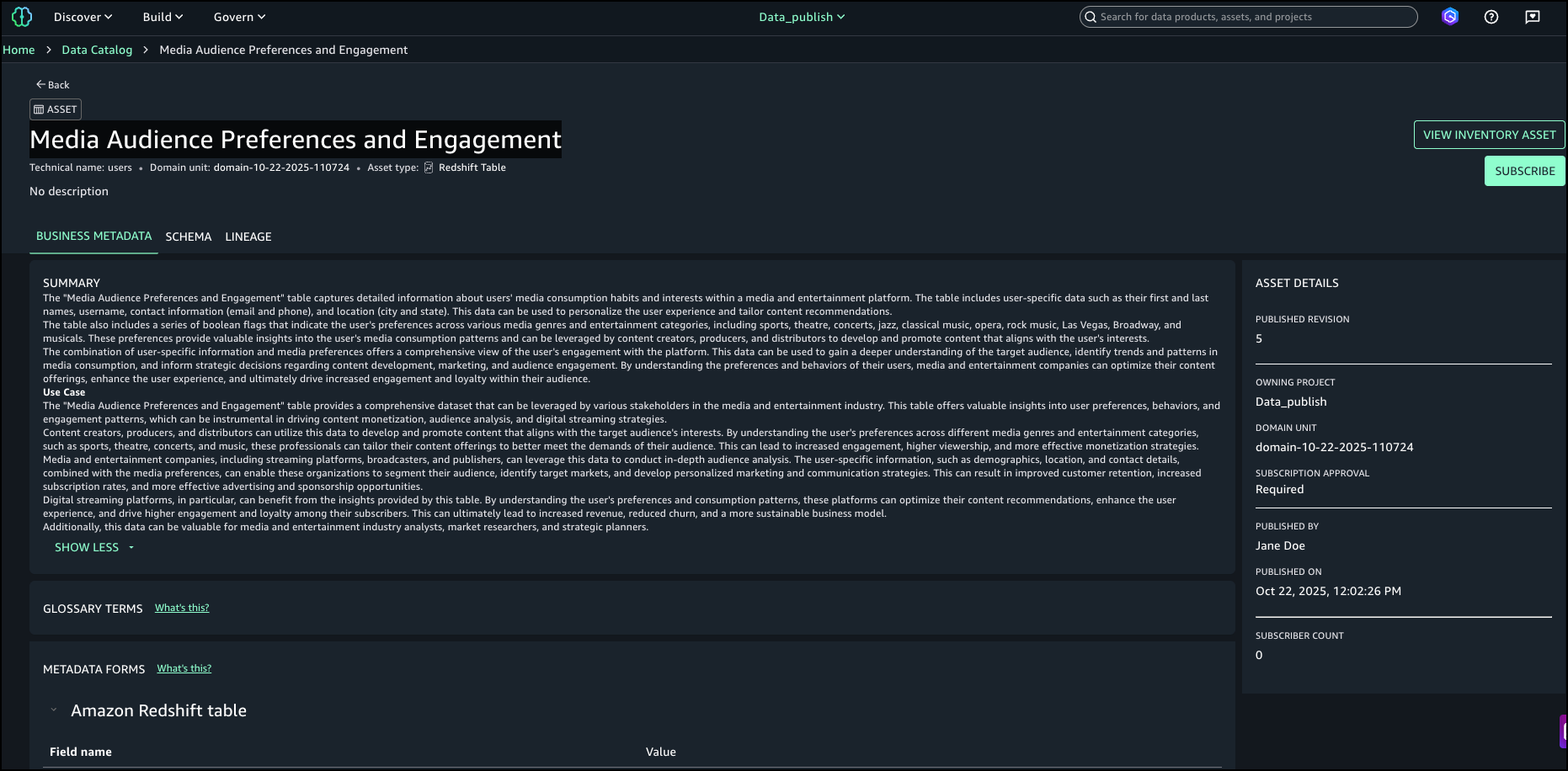
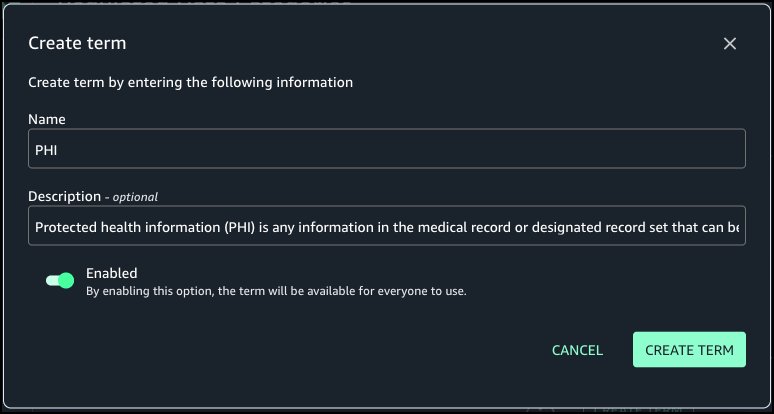
- Choose Generate descriptions to create suggested table and column descriptions.


- Review the generated recommendations and choose Accept all if it looks accurate.

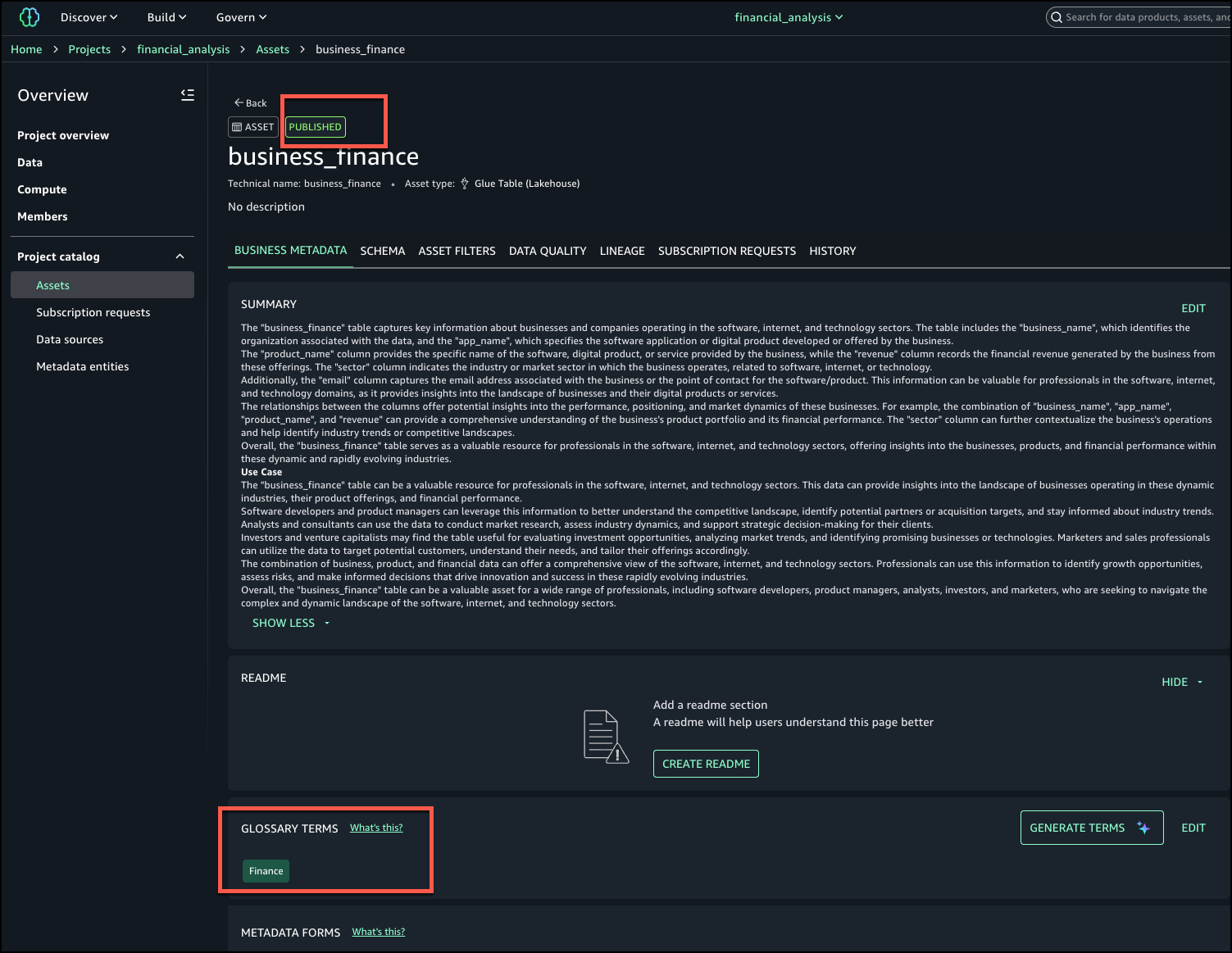
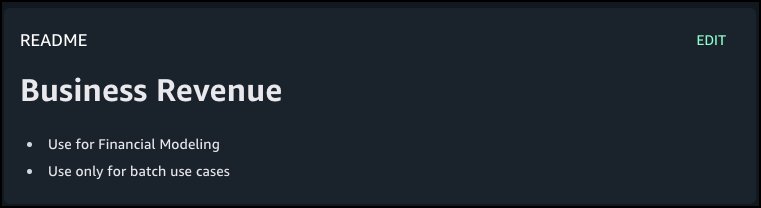
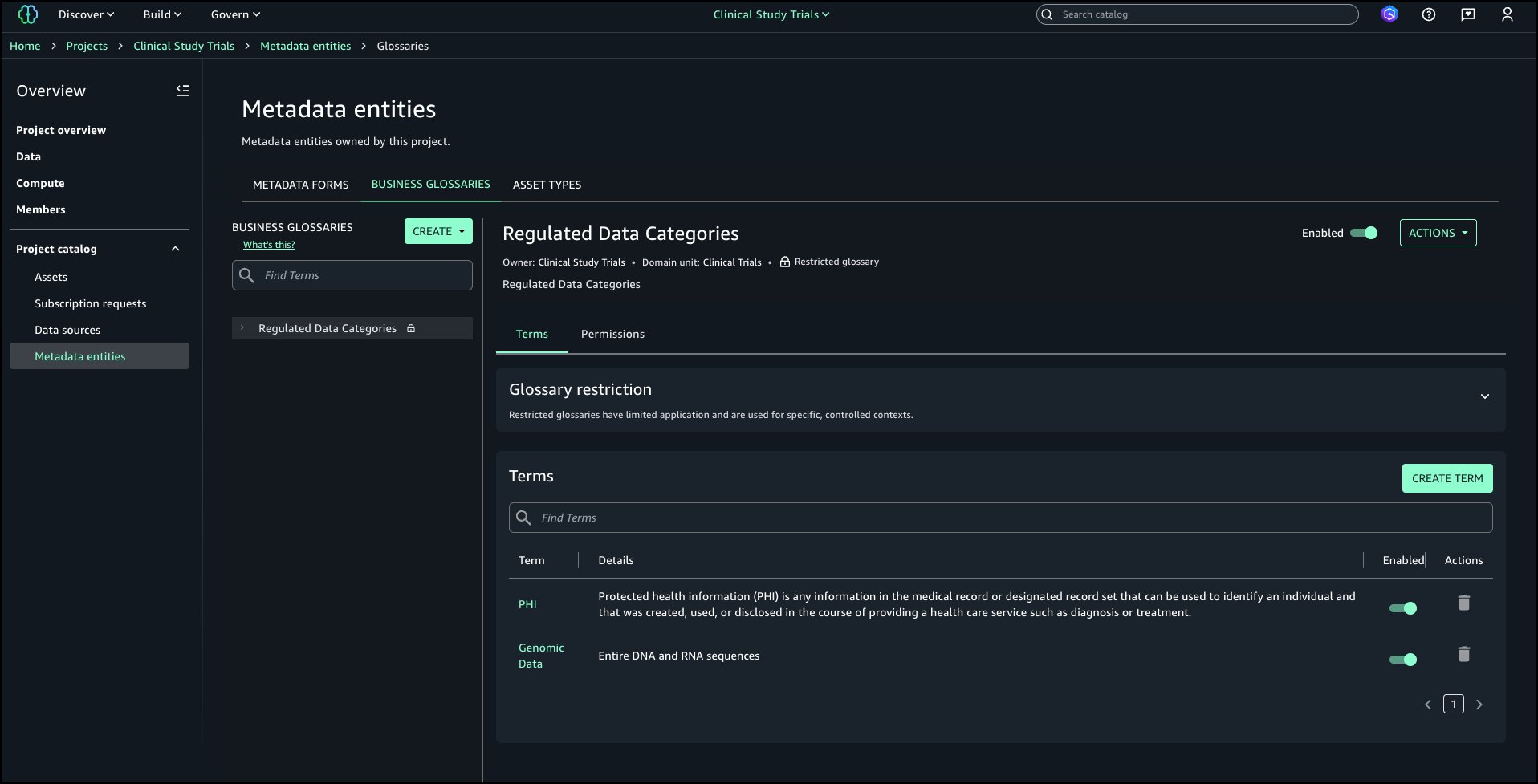
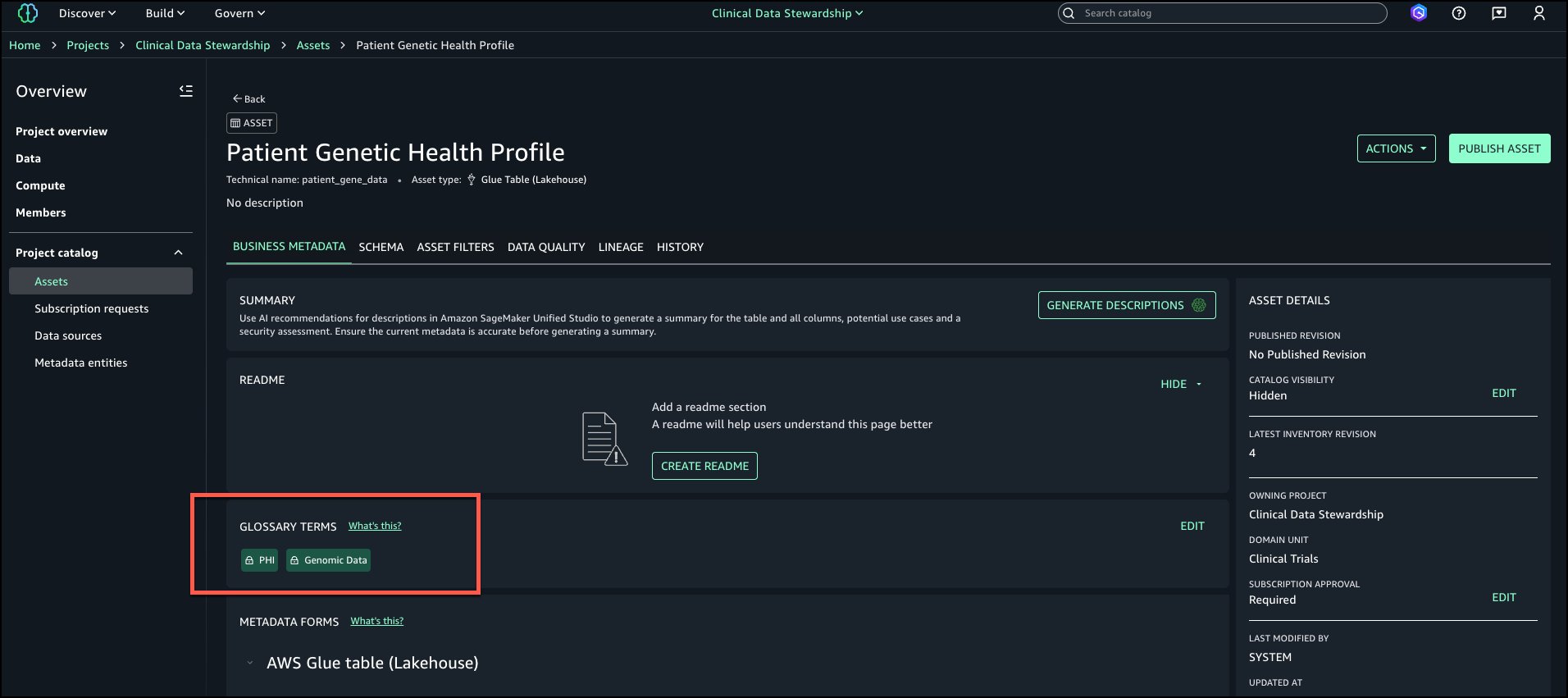
The following screenshot shows the generated descriptions.

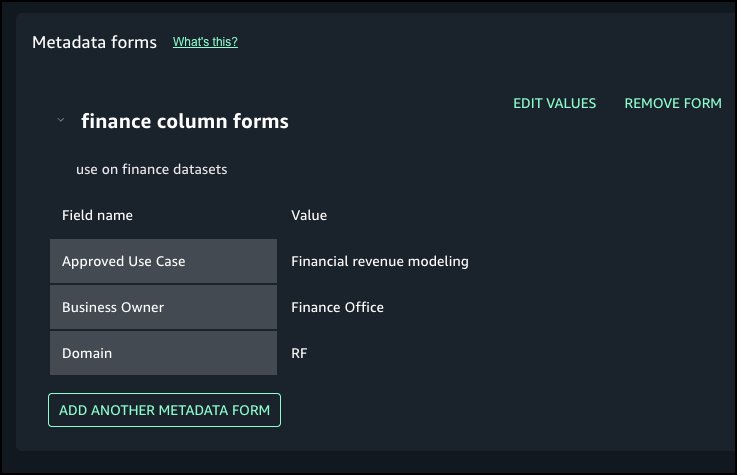
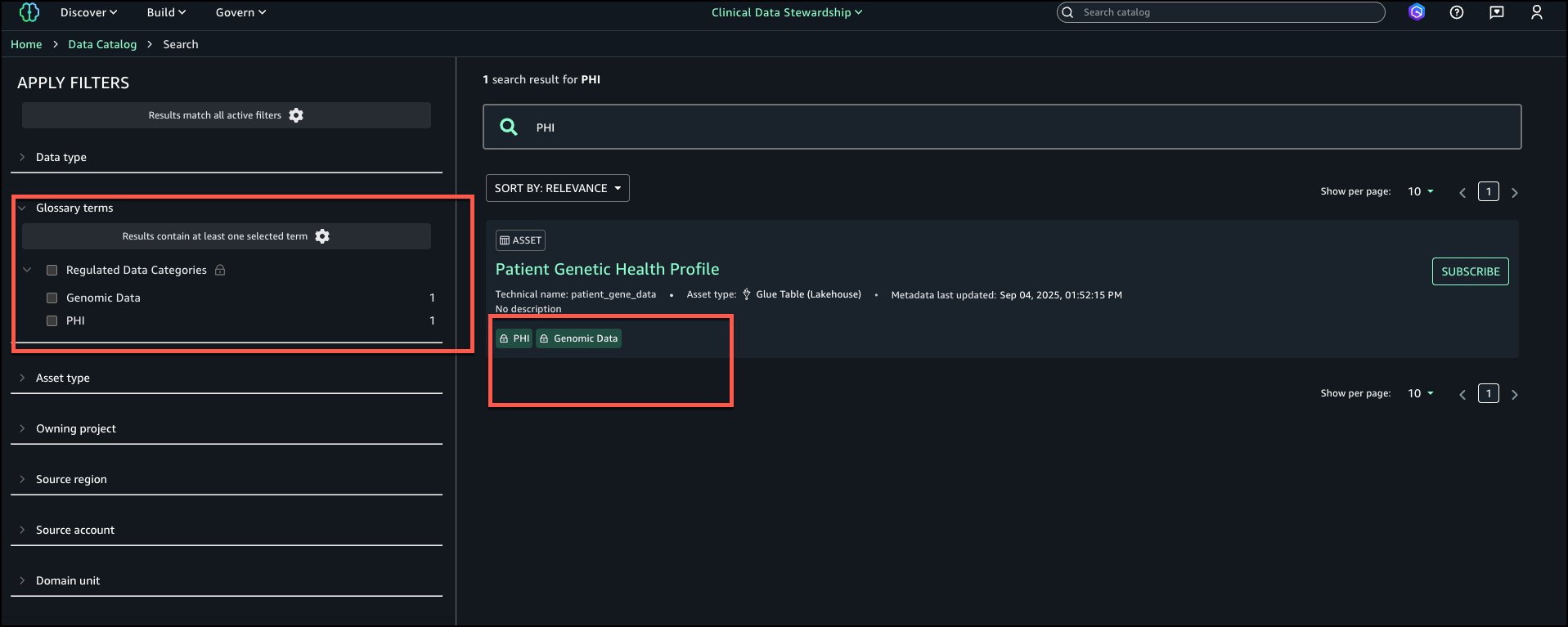
Even when assets are registered as custom, you can use this feature to generate business context and seamlessly publish it to SageMaker catalog.
Conclusion
As enterprise data environments become increasingly distributed and sourced from diverse platforms, maintaining metadata quality at scale presents a challenge. This feature uses generative AI to automate the creation of business descriptions, including table summaries, use cases, and column-level metadata, reducing manual effort while preserving alignment with governance requirements.
The feature is available in the next generation of SageMaker through SageMaker Catalog for custom structured assets (with schema) registered programmatically using an API. For implementation details, refer to the product documentation.
About the authors
 Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on LinkedIn.
Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on LinkedIn.
 Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters.
Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters.
 Balaji Kumar Gopalakrishnan is a Principal Engineer at Amazon Finance Technology. He has been with Amazon since 2013, solving real-world challenges through technology that directly impact the lives of Amazon customers. Outside of work, Balaji enjoys hiking, painting, and spending time with his family. He is also a movie buff!
Balaji Kumar Gopalakrishnan is a Principal Engineer at Amazon Finance Technology. He has been with Amazon since 2013, solving real-world challenges through technology that directly impact the lives of Amazon customers. Outside of work, Balaji enjoys hiking, painting, and spending time with his family. He is also a movie buff!
Mohit Dawar is a Senior Software Engineer at AWS working on DataZone and SageMaker Unified Studio. Over the past three years, he has led efforts around the core metadata catalog, generative AI-powered metadata curation, and lineage visualization. He enjoys working on large-scale distributed systems, experimenting with AI to improve user experience, and building tools that make data governance feel effortless. Connect with him on LinkedIn.
Mark Horta is a Software Development Manager at AWS working on DataZone and SageMaker Unified Studio. He is responsible for leading the engineering efforts for SageMaker Catalog focusing on generative-AI metadata generation and curation and data lineage.



















 Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on
Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on  Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters.
Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters. Balaji Kumar Gopalakrishnan is a Principal Engineer at Amazon Finance Technology. He has been with Amazon since 2013, solving real-world challenges through technology that directly impact the lives of Amazon customers. Outside of work, Balaji enjoys hiking, painting, and spending time with his family. He is also a movie buff!
Balaji Kumar Gopalakrishnan is a Principal Engineer at Amazon Finance Technology. He has been with Amazon since 2013, solving real-world challenges through technology that directly impact the lives of Amazon customers. Outside of work, Balaji enjoys hiking, painting, and spending time with his family. He is also a movie buff! Mohit Dawar is a Senior Software Engineer at AWS working on DataZone and SageMaker Unified Studio. Over the past three years, he has led efforts around the core metadata catalog, generative AI-powered metadata curation, and lineage visualization. He enjoys working on large-scale distributed systems, experimenting with AI to improve user experience, and building tools that make data governance feel effortless. Connect with him on
Mohit Dawar is a Senior Software Engineer at AWS working on DataZone and SageMaker Unified Studio. Over the past three years, he has led efforts around the core metadata catalog, generative AI-powered metadata curation, and lineage visualization. He enjoys working on large-scale distributed systems, experimenting with AI to improve user experience, and building tools that make data governance feel effortless. Connect with him on  Mark Horta is a Software Development Manager at AWS working on DataZone and SageMaker Unified Studio. He is responsible for leading the engineering efforts for SageMaker Catalog focusing on generative-AI metadata generation and curation and data lineage.
Mark Horta is a Software Development Manager at AWS working on DataZone and SageMaker Unified Studio. He is responsible for leading the engineering efforts for SageMaker Catalog focusing on generative-AI metadata generation and curation and data lineage.



 Rajat Mathur is a Software Development Manager at AWS, leading the Amazon DataZone and SageMaker Unified Studio engineering teams. His team designs, builds, and operates services which make it faster and easier for customers to catalog, discover, share, and govern data. With deep expertise in building distributed data systems at scale, Rajat plays a key role in advancing AWS’s data analytics and AI/ML capabilities.
Rajat Mathur is a Software Development Manager at AWS, leading the Amazon DataZone and SageMaker Unified Studio engineering teams. His team designs, builds, and operates services which make it faster and easier for customers to catalog, discover, share, and govern data. With deep expertise in building distributed data systems at scale, Rajat plays a key role in advancing AWS’s data analytics and AI/ML capabilities. Jie Lan is a Software Engineer at AWS based in New York, where he works on the Amazon SageMaker team. He is passionate about developing cutting-edge solutions in the big data and AI space, helping customers leverage cloud technology to solve complex problems.
Jie Lan is a Software Engineer at AWS based in New York, where he works on the Amazon SageMaker team. He is passionate about developing cutting-edge solutions in the big data and AI space, helping customers leverage cloud technology to solve complex problems.





























 Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance.
Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance. Santhosh Padmanabhan is a Software Development Manager at AWS, leading the Amazon DataZone engineering team. His team designs, builds, and operates services specializing in data, machine learning, and AI governance. With deep expertise in building distributed data systems at scale, Santhosh plays a key role in advancing AWS’s data governance capabilities.
Santhosh Padmanabhan is a Software Development Manager at AWS, leading the Amazon DataZone engineering team. His team designs, builds, and operates services specializing in data, machine learning, and AI governance. With deep expertise in building distributed data systems at scale, Santhosh plays a key role in advancing AWS’s data governance capabilities.









 Adiascar Cisneros is a Tableau Senior Product Manager based in Atlanta, GA. He focuses on the integration of the Tableau Platform with AWS services to amplify the value users get from our products and accelerate their journey to valuable, actionable insights. His background includes analytics, infrastructure, network security, and migrations. Follow him on
Adiascar Cisneros is a Tableau Senior Product Manager based in Atlanta, GA. He focuses on the integration of the Tableau Platform with AWS services to amplify the value users get from our products and accelerate their journey to valuable, actionable insights. His background includes analytics, infrastructure, network security, and migrations. Follow him on  Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data governance and analytics, mainly in the financial services industry. Joel has led data transformation projects on fraud analytics, claims automation, and Master Data Management. He leverages his experience to advise customers on their data strategy and technology foundations.
Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data governance and analytics, mainly in the financial services industry. Joel has led data transformation projects on fraud analytics, claims automation, and Master Data Management. He leverages his experience to advise customers on their data strategy and technology foundations. Yogesh Dhimate is a Sr. Partner Solutions Architect at AWS, leading technology partnership with Tableau. Prior to joining AWS, Yogesh worked with leading companies including Salesforce driving their industry solution initiatives. With over 20 years of experience in product management and solutions architecture Yogesh brings unique perspective in cloud computing and artificial intelligence.
Yogesh Dhimate is a Sr. Partner Solutions Architect at AWS, leading technology partnership with Tableau. Prior to joining AWS, Yogesh worked with leading companies including Salesforce driving their industry solution initiatives. With over 20 years of experience in product management and solutions architecture Yogesh brings unique perspective in cloud computing and artificial intelligence. Ariana Rahgozar is a Sr. Senior Solutions Architect at AWS, leading customers design and implement technical solutions as part of their cloud journey.
Ariana Rahgozar is a Sr. Senior Solutions Architect at AWS, leading customers design and implement technical solutions as part of their cloud journey.




















 Eric Fleishman is a software engineer at AWS in Seattle. He loves diving into cloud technology and solving complex problems to build impactful solutions. Outside of work, he is all about staying active—whether its snowboarding down the slopes or working out. He enjoys pushing his limits and embracing new challenges.
Eric Fleishman is a software engineer at AWS in Seattle. He loves diving into cloud technology and solving complex problems to build impactful solutions. Outside of work, he is all about staying active—whether its snowboarding down the slopes or working out. He enjoys pushing his limits and embracing new challenges. Theo Tolv is a Senior Analytics Architect based in Stockholm, Sweden. He’s worked with small and big data for most of his career, and has built applications running on AWS since 2008. In his spare time he likes to tinker with electronics and read space opera.
Theo Tolv is a Senior Analytics Architect based in Stockholm, Sweden. He’s worked with small and big data for most of his career, and has built applications running on AWS since 2008. In his spare time he likes to tinker with electronics and read space opera. Fabricio Hamada is a Senior Data Strategy Solutions Architect at AWS.
Fabricio Hamada is a Senior Data Strategy Solutions Architect at AWS. Lionel Pulickal is Sr. Solutions Architect at AWS
Lionel Pulickal is Sr. Solutions Architect at AWS