Post Syndicated from Ramkumar Nottath original https://aws.amazon.com/blogs/big-data/accelerating-sql-analytics-with-amazon-redshift-mcp-server/
As data analysts and engineers, we often find ourselves switching between multiple tools to explore database schemas, understand table structures, and execute queries across different Amazon Redshift data warehouses. Using natural language to explore metadata and data can simplify this process, but an AI agent often needs the additional context of your Redshift cluster configurations and schemas to successfully discover and build the best execution path.
This is where the Model Context Protocol (MCP) can act as a bridge between the AI agent and your Redshift clusters to provide the necessary information to better support natural language interfaces to your data. MCP is an open standard that enables AI applications to securely connect to external data sources and tools, providing them with rich, real-time context about your specific environment. Unlike static tools, MCP allows AI agents to dynamically discover database structures, understand table relationships, and execute queries with full awareness of your Amazon Redshift setup.
To address these challenges and unlock the full potential of conversational data analysis, Amazon Web Services (AWS) released the Amazon Redshift MCP server, an open source solution that innovates how you interact with Amazon Redshift data warehouses. The Amazon Redshift MCP server integrates seamlessly with Amazon Q Developer command line interface (CLI), Claude Desktop, Kiro, and other MCP-compatible tools. It can enable discover, explore, and analyze your Amazon Redshift metadata and data through natural language conversations with an AI assistant that truly understands your database environment.
In this post, we walk through setting up the Amazon Redshift MCP server and demonstrate how a data analyst can efficiently explore Redshift data warehouses and perform data analysis using natural language queries.
What is the Amazon Redshift MCP Server?
The Amazon Redshift MCP server is a MCP implementation that provides AI agents with safe, structured access to Amazon Redshift resources. It enables:
- Cluster discovery – Automatically discover both provisioned Redshift clusters and serverless workgroups
- Metadata exploration – Browse databases, schemas, tables, and columns through natural language
- Safe query execution – Execute SQL queries in READ ONLY mode with built-in safety protections
- Multi-cluster support – Work with multiple clusters and workgroups simultaneously for data reconciliation tasks
The MCP server acts as a bridge between Amazon Q CLI and your Amazon Redshift infrastructure, translating natural language requests into appropriate API calls and SQL queries. The following diagram illustrates the high-level architecture.
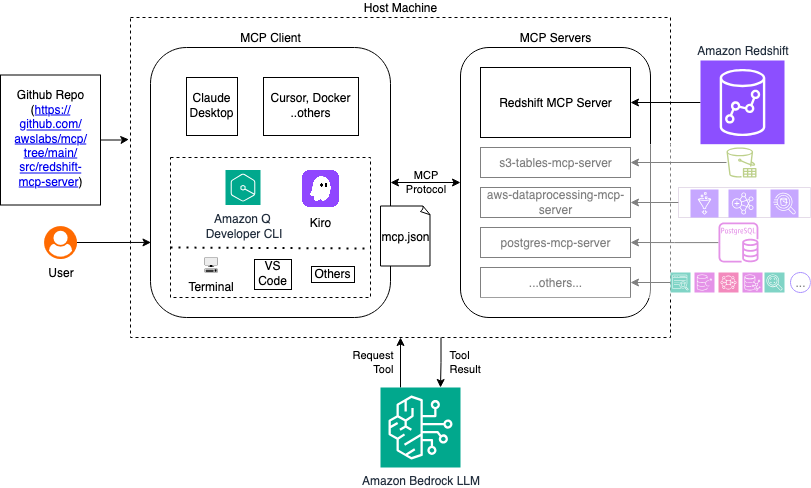
The following video demonstrates the solution outlined in this post.
Prerequisites
Before you begin, ensure you have the following:
System requirements
- Python 3.10 or newer
uvpackage manager (installation guide)- Amazon Q CLI or other tools such as Claude Desktop installed and configured
AWS requirements
- AWS credentials configured using AWS Command Line Interface (AWS CLI), environment variables, or AWS Identity and Access Management (IAM) roles
- Appropriate IAM permissions for Amazon Redshift access
- At least one Redshift cluster or serverless workgroup
Required IAM permissions
The user identity needs the following IAM permissions in your access policies:
Installation and configuration
The following section covers the steps required to install and configure Amazon Redshift MCP server.
Install required dependencies
Complete the following steps to install required dependencies:
- Install the
uvpackage manager if you haven’t already:
- Install Python 3.10 or newer:
uv python install 3.10
Configure the MCP server
The MCP server can be configured using several MCP supported clients. In this post we discuss the steps using Amazon Q Developer CLI and Claude Desktop.Complete the following instructions to set up Amazon Q Developer CLI on your host machine and access the Amazon Redshift MCP Server:
- Install the Amazon Q Developer CLI.
- Configure the Amazon Redshift MCP server in your Amazon Q CLI configuration. Edit the MCP configuration file at
~/.aws/amazonq/mcp.json:
For further details on installation, refer to the Installation section in the Amazon Redshift MCP server README.md.
- Start Amazon Q CLI to verify the MCP server is properly configured:

You should notice the Amazon Redshift MCP server initialize successfully in the startup logs.To set up Amazon Q Developer CLI on your host machine and access the Amazon Redshift MCP Server using Claude Desktop, complete the following steps:
- Download and install Claude Desktop for your operating system
- Open Claude Desktop and in the bottom left, choose the gear icon to navigate to Settings
- Choose the Developer tab and configure your MCP server by adding the same configuration as step 3 in the Amazon Q CLI setup
- Restart Claude Desktop to activate the MCP server connection
- Test the integration by starting a new conversation and asking:
Show me all available Redshift clusters
Use case: Customer purchase analysis
Imagine a practical scenario where a data analyst needs to explore customer purchase data across multiple Redshift clusters. The following walkthrough demonstrates how the MCP server simplifies this workflow.As a data analyst at an ecommerce company, you need to:
- Discover available Redshift clusters
- Explore the database structure to find customer and sales data
- Analyze customer purchase patterns
- Generate insights for the business team
To accomplish these tasks, you follow these steps:
- Ask Amazon Q to show you available Amazon Redshift resources:
Amazon Q will use the MCP server to discover your clusters and provide details such as cluster identifiers and types (provisioned or serverless), current status and availability, connection endpoints and configuration, and node types and capacity information.
- Explore the database structure to understand your data organization:
Amazon Q will use the MCP server to systematically explore the objects in the cluster:
- Before analyzing data, understand the table schemas:
Amazon Q will use the MCP server to will examine the table columns and provide detailed schema information.
- Analyze customer purchase patterns using natural language queries:
Amazon Q will use the MCP server to run the appropriate SQL queries and provide insights.
- The MCP server supports analyzing data across multiple clusters:
Amazon Q will use the MCP server to run the appropriate SQL queries compare the data across analytics-cluster and marketing-cluster.
Best Practices
The MCP server comes equipped with several essential safety protections designed to safeguard your data and system performance. The READ ONLY mode serves as a critical safeguard against unintended data modifications, and we recommend enabling this feature when applicable to your use case. To further enhance security, the server implements query validation mechanisms that scrutinize operations for potential harmful impacts, with user-in-loop validation being recommended for optimal safety. For resource management, the server enforces resource limits to prevent performance-impacting runaway queries, again benefiting from user-in-loop validation for best results. In terms of accessibility, the MCP capability maintains broad availability across all AWS Regions where Amazon Redshift Data API is supported, with throttling limits aligned to existing Amazon Redshift Data API service quotas to ensure consistent performance and reliability.For best results, follow these recommendations:
- Start with discovery – Begin by exploring cluster and database structure and tables
- Use natural language – Describe what you want to analyze rather than writing SQL directly
- Iterate gradually – Build complex analyses step by step
- Verify results – Cross-check important findings with business stakeholders
- Document insights – Save important queries and results for future reference
Conclusion
The Amazon Redshift MCP server transforms how data analysts interact with Redshift clusters by enabling natural language data exploration and analysis through agentic tooling like Kiro and Amazon Q CLI. By eliminating the need to manually write SQL queries and navigate complex database structures, analysts can focus on generating insights rather than wrestling with syntax and schema discovery.Whether you’re performing a one-time analysis, generating regular reports, or exploring new datasets, the Amazon Redshift MCP server provides a powerful, intuitive interface for your data analysis workflows.Ready to get started? Here’s what to do next:
- Install the MCP server following the configuration steps in this post
- Explore your Amazon Redshift environment using natural language queries
- Start with simple analyses and gradually build complexity
- Share insights with your team using the natural language summaries
- Provide feedback to help improve the MCP server capabilities
Check out these blog posts to help you navigate using natural language with your use cases:
- Implementing conversational AI for S3 Tables using Model Context Protocol (MCP)
- Accelerating development with the AWS Data Processing MCP Server and Agent
- Introducing MCP Server for Apache Spark History Server for AI-powered debugging and optimization
- Billing and Cost Management MCP Server
- Introducing enhanced AI assistance in Amazon SageMaker Unified Studio: Agentic chat, Amazon Q Developer CLI, and MCP integration



















 Ramkumar Nottath is a Principal Solutions Architect at AWS focusing on Analytics services. He enjoys working with various customers to help them build scalable, reliable big data and analytics solutions. His interests extend to various technologies such as analytics, data warehousing, streaming, data governance, and machine learning. He loves spending time with his family and friends.
Ramkumar Nottath is a Principal Solutions Architect at AWS focusing on Analytics services. He enjoys working with various customers to help them build scalable, reliable big data and analytics solutions. His interests extend to various technologies such as analytics, data warehousing, streaming, data governance, and machine learning. He loves spending time with his family and friends. Mert Hocanin is a Principal Big Data Architect at AWS within the AWS Lake Formation Product team. He has been with Amazon for over 10 years, and enjoys helping customers build their data lakes with a focus on governance on a wide variety of services. When he isn’t helping customers build data lakes, he spends his time with his family and traveling.
Mert Hocanin is a Principal Big Data Architect at AWS within the AWS Lake Formation Product team. He has been with Amazon for over 10 years, and enjoys helping customers build their data lakes with a focus on governance on a wide variety of services. When he isn’t helping customers build data lakes, he spends his time with his family and traveling.