Post Syndicated from Sascha Moellering original https://aws.amazon.com/blogs/architecture/field-notes-optimize-your-java-application-for-amazon-ecs-with-quarkus/
In this blog post, I show you an interesting approach to implement a Java-based application and compile it to a native image using Quarkus. This native image is the main application, which is containerized, and runs in an Amazon Elastic Container Service and Amazon Elastic Kubernetes Service cluster on AWS Fargate.
Amazon ECS is a fully managed container orchestration service, Amazon EKS is a fully managed Kubernetes service, both services support Fargate to provide serverless compute for containers. Fargate removes the need to provision and manage servers, lets you specify and pay for resources per application, and improves security through application isolation by design. AWS Lambda is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you.
Quarkus is a Supersonic Subatomic Java framework that uses OpenJDK HotSpot as well as GraalVM and over fifty different libraries like RESTEasy, Vertx, Hibernate, and Netty. In a previous blog post, I demonstrated how GraalVM can be used to optimize the size of Docker images. GraalVM is an open source, high-performance polyglot virtual machine from Oracle. I use it to compile native images ahead of time to improve startup performance, and reduce the memory consumption and file size of Java Virtual Machine (JVM)-based applications. The framework that allows ahead-of-time-compilation (AOT) is called Substrate.
Application Architecture
First, review the GitHub repository containing the demo application.
Our application is a simple REST-based Create Read Update Delete (CRUD) service that implements basic user management functionalities. All data is persisted in an Amazon DynamoDB table. Quarkus offers an extension for Amazon DynamoDB that is based on AWS SDK for Java V2. This Quarkus extension supports two different programming models: blocking access and asynchronous programming. For local development, DynamoDB Local is also supported. DynamoDB Local is the downloadable version of DynamoDB that lets you write and test applications without accessing the DynamoDB service. Instead, the database is self-contained on your computer. When you are ready to deploy your application in production, you can make a few minor changes to the code so that it uses the DynamoDB service.
The REST-functionality is located in the class UserResource which uses the JAX-RS implementation RESTEasy. This class invokes the UserService that implements the functionalities to access a DynamoDB table with the AWS SDK for Java. All user-related information is stored in a Plain Old Java Object (POJO) called User.
Building the application
To create a Docker container image that can be used in the task definition of my ECS cluster, follow these three steps: build the application, create the Docker Container Image, and push the created image to my Docker image registry.
To build the application, I used Maven with different profiles. The first profile (default profile) uses a standard build to create an uber JAR – a self-contained application with all dependencies. This is very useful if you want to run local tests with your application, because the build time is much shorter compared to the native-image build. When you run the package command, it also execute all tests, which means you need DynamoDB Local running on your workstation.
$ docker run -p 8000:8000 amazon/dynamodb-local -jar DynamoDBLocal.jar -inMemory -sharedDb
$ mvn package
The second profile uses GraalVM to compile the application into a native image. In this case, you use the native image as base for a Docker container. The Dockerfile can be found under src/main/docker/Dockerfile.native and uses a build-pattern called multi-stage build.
$ mvn package -Pnative -Dquarkus.native.container-build=true
An interesting aspect of multi-stage builds is that you can use multiple FROM statements in your Dockerfile. Each FROM instruction can use a different base image, and begins a new stage of the build. You can pick the necessary files and copy them from one stage to another, thereby limiting the number of files you have to copy. Use this feature to build your application in one stage and copy your compiled artifact and additional files to your target image. In this case, you use ubi-quarkus-native-image:20.1.0-java11 as base image and copy the necessary TLS-files (SunEC library and the certificates) and point your application to the necessary files with JVM properties.
FROM quay.io/quarkus/ubi-quarkus-native-image:20.1.0-java11 as nativebuilder
RUN mkdir -p /tmp/ssl-libs/lib \
&& cp /opt/graalvm/lib/security/cacerts /tmp/ssl-libs \
&& cp /opt/graalvm/lib/libsunec.so /tmp/ssl-libs/lib/
FROM registry.access.redhat.com/ubi8/ubi-minimal
WORKDIR /work/
COPY target/*-runner /work/application
COPY --from=nativebuilder /tmp/ssl-libs/ /work/
RUN chmod 775 /work
EXPOSE 8080
CMD ["./application", "-Dquarkus.http.host=0.0.0.0", "-Djava.library.path=/work/lib", "-Djavax.net.ssl.trustStore=/work/cacerts"]
In the second and third steps, I have to build and push the Docker image to a Docker registry of my choice which is straight forward:
$ docker build -f src/main/docker/Dockerfile.native -t
$ docker push <repo/image:tag>Setting up the infrastructure
You’ve compiled the application to a native-image and have built a Docker image. Now, you set up the basic infrastructure consisting of an Amazon Virtual Private Cloud (VPC), an Amazon ECS or Amazon EKS cluster with on AWS Fargate launch type, an Amazon DynamoDB table, and an Application Load Balancer.
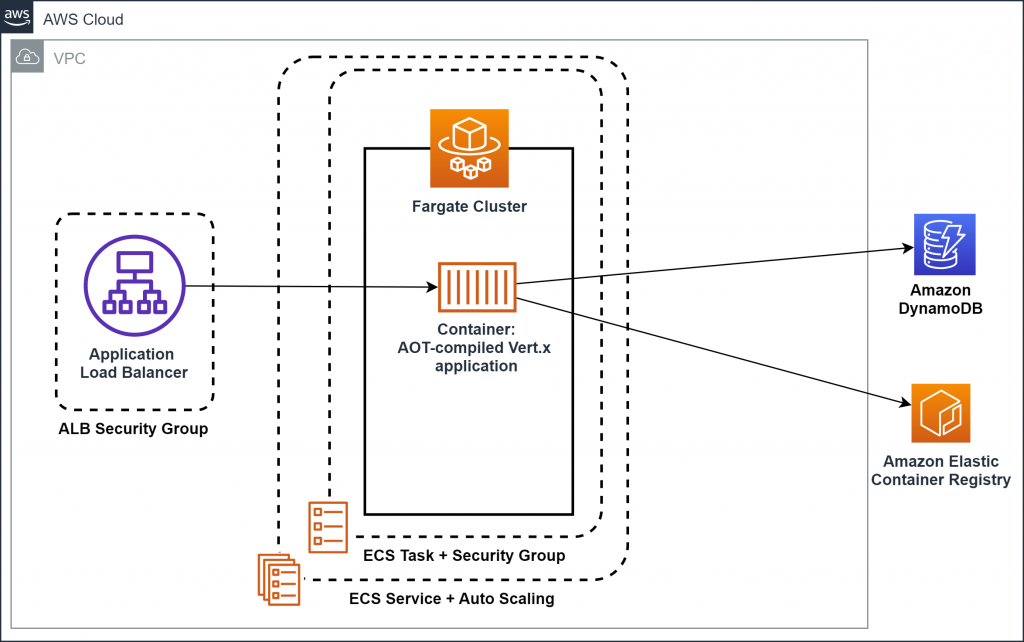
Figure 1: Architecture of the infrastructure (for Amazon ECS)
Codifying your infrastructure allows you to treat your infrastructure just as code. In this case, you use the AWS Cloud Development Kit (AWS CDK), an open source software development framework, to model and provision your cloud application resources using familiar programming languages. The code for the CDK application can be found in the demo application’s code repository under eks_cdk/lib/ecs_cdk-stack.ts or ecs_cdk/lib/ecs_cdk-stack.ts. Set up the infrastructure in the AWS Region us-east-1:
$ npm install -g aws-cdk // Install the CDK
$ cd ecs_cdk
$ npm install // retrieves dependencies for the CDK stack
$ npm run build // compiles the TypeScript files to JavaScript
$ cdk deploy // Deploys the CloudFormation stack
The output of the AWS CloudFormation stack is the load balancer’s DNS record. The heart of our infrastructure is an Amazon ECS or Amazon EKS cluster with AWS Fargate launch type. The Amazon ECS cluster is set up as follows:
const cluster = new ecs.Cluster(this, "quarkus-demo-cluster", {
vpc: vpc
});
const logging = new ecs.AwsLogDriver({
streamPrefix: "quarkus-demo"
})
const taskRole = new iam.Role(this, 'quarkus-demo-taskRole', {
roleName: 'quarkus-demo-taskRole',
assumedBy: new iam.ServicePrincipal('ecs-tasks.amazonaws.com')
});
const taskDef = new ecs.FargateTaskDefinition(this, "quarkus-demo-taskdef", {
taskRole: taskRole
});
const container = taskDef.addContainer('quarkus-demo-web', {
image: ecs.ContainerImage.fromRegistry("<repo/image:tag>"),
memoryLimitMiB: 256,
cpu: 256,
logging
});
container.addPortMappings({
containerPort: 8080,
hostPort: 8080,
protocol: ecs.Protocol.TCP
});
const fargateService = new ecs_patterns.ApplicationLoadBalancedFargateService(this, "quarkus-demo-service", {
cluster: cluster,
taskDefinition: taskDef,
publicLoadBalancer: true,
desiredCount: 3,
listenerPort: 8080
});
Cleaning up
After you are finished, you can easily destroy all of these resources with a single command to save costs.
$ cdk destroy
Conclusion
In this post, I described how Java applications can be implemented using Quarkus, compiled to a native-image, and ran using Amazon ECS or Amazon EKS on AWS Fargate. I also showed how AWS CDK can be used to set up the basic infrastructure. I hope I’ve given you some ideas on how you can optimize your existing Java application to reduce startup time and memory consumption. Feel free to submit enhancements to the sample template in the source repository or provide feedback in the comments.
We also encourage you to explore how you to optimize your Java application for AWS Lambda with Quarkus.