Post Syndicated from Taylor Smith original https://blog.cloudflare.com/media-transformations-for-video-open-beta/
Today, we are thrilled to announce Media Transformations, a new service that brings the magic of Image Transformations to short-form video files wherever they are stored.
Since 2018, Cloudflare Stream has offered a managed video pipeline that empowers customers to serve rich video experiences at global scale easily, in multiple formats and quality levels. Sometimes, the greatest friction to getting started isn’t even about video, but rather the thought of migrating all those files. Customers want a simpler solution that retains their current storage strategy to deliver small, optimized MP4 files. Now you can do that with Media Transformations.
For customers with a huge volume of short video, such as generative AI output, e-commerce product videos, social media clips, or short marketing content, uploading those assets to Stream is not always practical. Furthermore, Stream’s key features like adaptive bitrate encoding and HLS packaging offer diminishing returns on short content or small files.
Instead, content like this should be fetched from our customers’ existing storage like R2 or S3 directly, optimized by Cloudflare quickly, and delivered efficiently as small MP4 files. Cloudflare Images customers reading this will note that this sounds just like their existing Image Transformation workflows. Starting today, the same workflow can be applied to your short-form videos.
The distinction between video and images online can sometimes be blurry — consider an animated GIF: is that an image or a video? (They’re usually smaller as MP4s anyway!) As a practical example, consider a selection of product images for a new jacket on an e-commerce site. You want a consumer to know how it looks, but also how it flows. So perhaps the first “image” in that carousel is actually a video of a model simply putting the jacket on. Media Transformations empowers customers to optimize the product video and images with similar tools and identical infrastructure.
Any website that is already enabled for Image Transformations is now enabled for Media Transformations. To enable a new zone, navigate to “Transformations” under Stream (or Images), locate your zone in the list, and click Enable. Enabling and disabling a zone for transformations affects both Images and Media transformations.
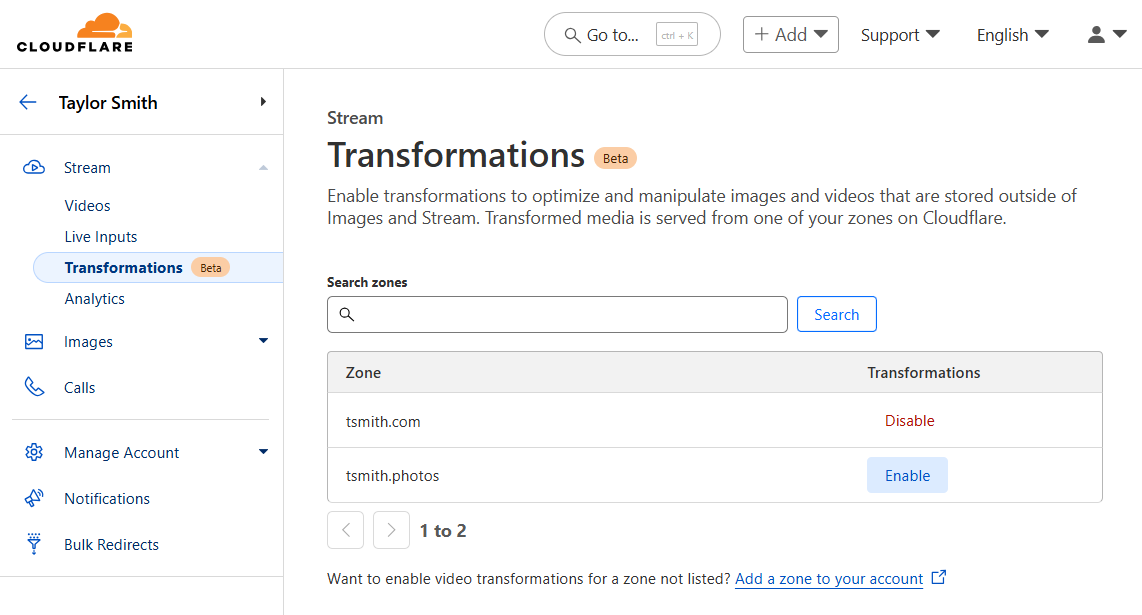
After enabling Media Transformations on a website, it is simple to construct a URL that transforms a video. The pattern is similar to Image Transformations, but uses the media endpoint instead of the image endpoint:
https://example.com/cdn-cgi/media/<OPTIONS>/<SOURCE-VIDEO>The <OPTIONS> portion of the URL is a comma-separated list of flags written as key=value. A few noteworthy flags:
-
modecan bevideo(the default) to output a video,frameto pull a still image of a single frame, or even spritesheet to generate an image with multiple frames, which is useful for seek previews or storyboarding. -
timespecifies the exact start time from the input video to extract a frame or start making a clip -
durationspecifies the length of an output video to make a clip shorter than the original -
fit, together withheightandwidthallow resizing and cropping the output video or frame. -
Setting
audioto false removes the sound in the output video.
The <SOURCE-VIDEO> is a full URL to a source file or a root-relative path if the origin is on the same zone as the transformation request.
A full list of supported options, examples, and troubleshooting information is available in DevDocs.
I used my phone to take this video of the randomness mobile in Cloudflare’s Austin Office and put it in an R2 bucket. Of course, it is possible to embed the original video file from R2 directly:
That video file is almost 30 MB. Let’s optimize it together — a more efficient choice would be to resize the video to the width of this blog post template. Let’s apply a width adjustment in the options portion of the URL:
https://example.com/cdn-cgi/media/width=760/https://pub-d9fcbc1abcd244c1821f38b99017347f.r2.dev/aus-mobile.mp4That will deliver the same video, resized and optimized:
Not only is this video the right size for its container, now it’s less than 4 MB. That’s a big bandwidth savings for visitors.
As I recorded the video, the lobby was pretty quiet, but there was someone talking in the distance. If we wanted to use this video as a background, we should remove the audio, shorten it, and perhaps crop it vertically. All of these options can be combined, comma-separated, in the options portion of the URL:
https://example.com/cdn-cgi/media/mode=video,duration=10s,width=480,height=720,fit=cover,audio=false/https://pub-d9fcbc1abcd244c1821f38b99017347f.r2.dev/aus-mobile.mp4The result:
If this were a product video, we might want a small thumbnail to add to the carousel of images so shoppers can click to zoom in and see it move. Use the “frame” mode and a “time” to generate a static image from a single point in the video. The same size and fit options apply:
https://example.com/cdn-cgi/media/mode=frame,time=3s,width=120,height=120,fit=cover/https://pub-d9fcbc1abcd244c1821f38b99017347f.r2.dev/aus-mobile.mp4Which generates this optimized image:

Try it out yourself using our video or one of your own:
-
Enable transformations on your website/zone and use the endpoint:
https://[your-site]/cdn-cgi/media/ -
Mobile video: https://pub-d9fcbc1abcd244c1821f38b99017347f.r2.dev/aus-mobile.mp4
-
Check out the Media Transformation URL Generator from Kristian Freeman on our Developer Relations team, which he built using the Streamlit Python framework on Workers.
We are eager to start supporting real customer content, and we will right-size our input limitations with our early adopters. To start:
-
Video files must be smaller than 40 megabytes.
-
Files must be MP4s and should be h.264 encoded.
-
Videos and images generated with Media Transformations will be cached. However, in our initial beta, the original content will not be cached which means regenerating a variant will result in a request to the origin.
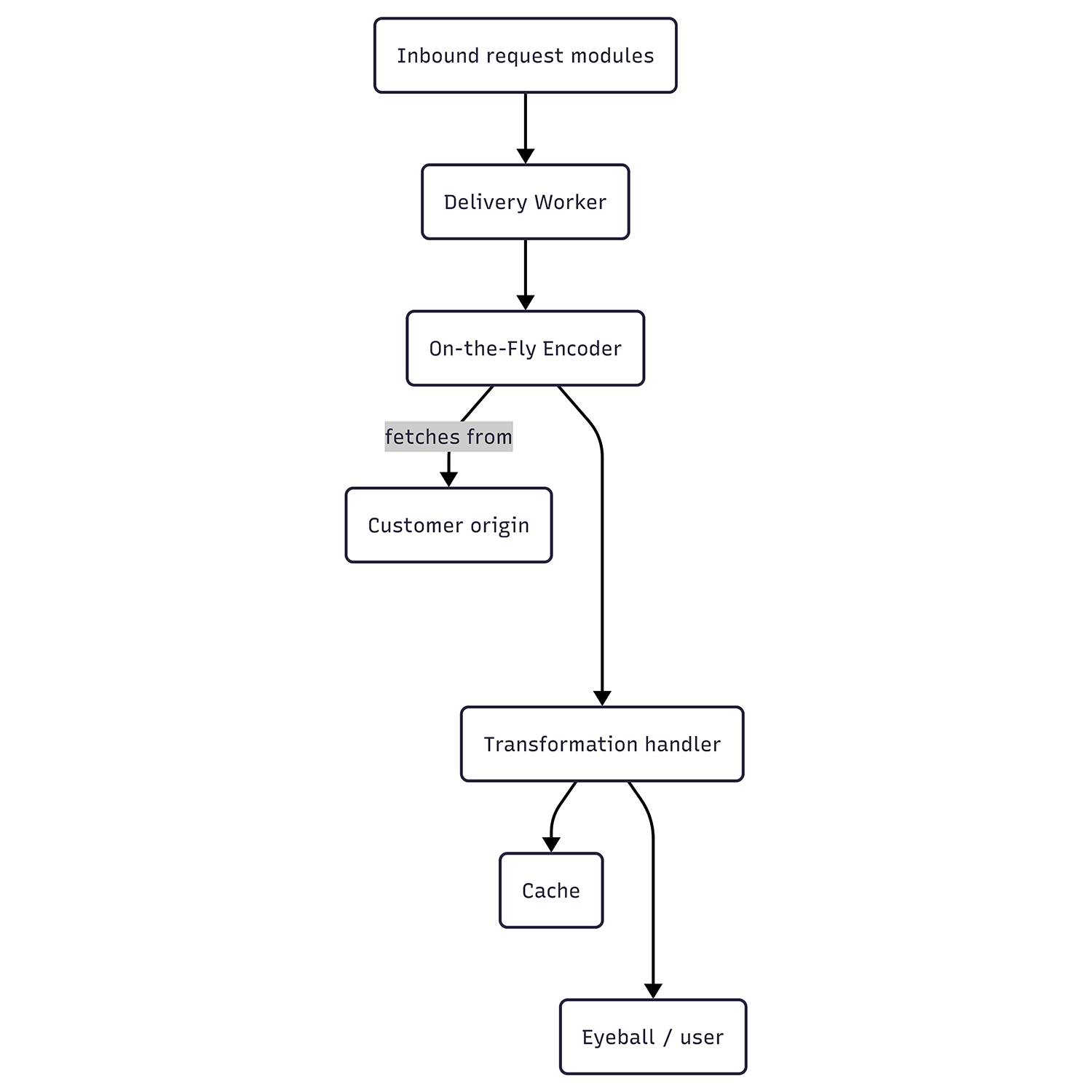
Unlike Stream, Media Transformations receives requests on a customer’s own website. Internally, however, these requests are passed to the same On-the-Fly Encoder (“OTFE”) platform that Stream Live uses. To achieve this, the Stream team built modules that run on our servers to act as entry points for these requests.
These entry points perform some initial validation on the URL formatting and flags before building a request to Stream’s own Delivery Worker, which in turn calls OTFE’s set of transformation handlers. The original asset is fetched from the customer’s origin, validated for size and type, and passed to the same OTFE methods responsible for manipulating and optimizing video or still frame thumbnails for videos uploaded to Stream. These tools do a final inspection of the media type and encoding for compatibility, then generate the requested variant. If any errors were raised along the way, an HTTP error response will be generated using similar error codes to Image Transformations. When successful, the result is cached for future use and delivered to the requestor as a single file. Even for new or uncached requests, all of this operates much faster than the video’s play time.
Media Transformations will be free for all customers while in beta. We expect the beta period to extend into Q3 2025, and after that, Media Transformations will use the same subscriptions and billing mechanics as Image Transformations — including a free allocation for all websites/zones. Generating a still frame (single image) from a video counts as 1 transformation. Generating an optimized video is billed as 1 transformation per second of the output video. Each unique transformation is only billed once per month. All Media and Image Transformations cost $0.50 per 1,000 monthly unique transformation operations, with a free monthly allocation of 5,000.
Using this post as an example, recall the two transformed videos and one transformed image above — the big original doesn’t count because it wasn’t transformed. The first video (showing blog post width) was 15 seconds of output. The second video (silent vertical clip) was 10 seconds of output. The preview square is a still frame. These three operations would count as 26 transformations — and they would only bill once per month, regardless of how many visitors this page receives.
Our short-term focus will be on right-sizing input limits based on real customer usage as well as adding a caching layer for origin fetches to reduce any egress fees our customers may be facing from other storage providers. Looking further, we intend to streamline Images and Media Transformations to further simplify the developer experience, unify the features, and streamline enablement: Cloudflare’s Media Transformations will optimize your images and video, quickly and easily, wherever you need them.
Try it for yourself today using our sample asset above, or get started by enabling Transformations on a zone in your account and uploading a short file to R2, both of which offer a free tier to get you going.