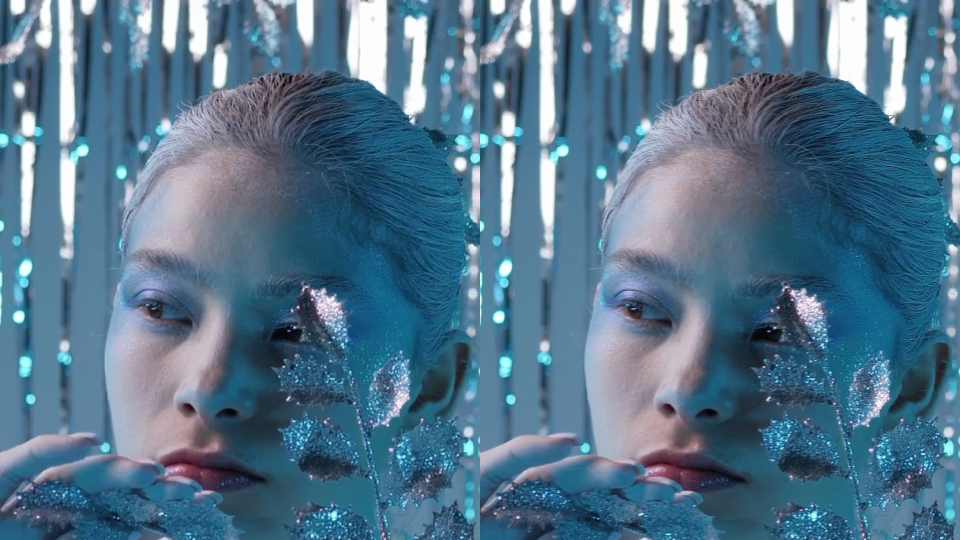Kendra Albert gave an excellent talk at USENIX Security this year, pointing out that the legal agreements surrounding vulnerability disclosure muzzle researchers while allowing companies to not fix the vulnerabilities—exactly the opposite of what the responsible disclosure movement of the early 2000s was supposed to prevent. This is the talk.
Thirty years ago, a debate raged over whether vulnerability disclosure was good for computer security. On one side, full disclosure advocates argued that software bugs weren’t getting fixed and wouldn’t get fixed if companies that made insecure software wasn’t called out publicly. On the other side, companies argued that full disclosure led to exploitation of unpatched vulnerabilities, especially if they were hard to fix. After blog posts, public debates, and countless mailing list flame wars, there emerged a compromise solution: coordinated vulnerability disclosure, where vulnerabilities were disclosed after a period of confidentiality where vendors can attempt to fix things. Although full disclosure fell out of fashion, disclosure won and security through obscurity lost. We’ve lived happily ever after since.
Or have we? The move towards paid bug bounties and the rise of platforms that manage bug bounty programs for security teams has changed the reality of disclosure significantly. In certain cases, these programs require agreement to contractual restrictions. Under the status quo, that means that software companies sometimes funnel vulnerabilities into bug bounty management platforms and then condition submission on confidentiality agreements that can prohibit researchers from ever sharing their findings.
In this talk, I’ll explain how confidentiality requirements for managed bug bounty programs restrict the ability of those who attempt to report vulnerabilities to share their findings publicly, compromising the bargain at the center of the CVD process. I’ll discuss what contract law can tell us about how and when these restrictions are enforceable, and more importantly, when they aren’t, providing advice to hackers around how to understand their legal rights when submitting. Finally, I’ll call upon platforms and companies to adapt their practices to be more in line with the original bargain of coordinated vulnerability disclosure, including by banning agreements that require non-disclosure.
And this is me from 2007, talking about “responsible disclosure”:
This was a good idea—and these days it’s normal procedure—but one that was possible only because full disclosure was the norm. And it remains a good idea only as long as full disclosure is the threat.
For over two decades, we’ve built real-time communication on the Internet using a patchwork of specialized tools. RTMP gave us ingest. HLS and DASH gave us scale. WebRTC gave us interactivity. Each solved a specific problem for its time, and together they power the global streaming ecosystem we rely on today.
But using them together in 2025 feels like building a modern application with tools from different eras. The seams are starting to show—in complexity, in latency, and in the flexibility needed for the next generation of applications, from sub-second live auctions to massive interactive events. We’re often forced to make painful trade-offs between latency, scale, and operational complexity.
Today Cloudflare is launching the first Media over QUIC (MoQ) relay network, running on every Cloudflare server in datacenters in 330+ cities. MoQ is an open protocol being developed at the IETF by engineers from across the industry—not a proprietary Cloudflare technology. MoQ combines the low-latency interactivity of WebRTC, the scalability of HLS/DASH, and the simplicity of a single architecture, all built on a modern transport layer. We’re joining Meta, Google, Cisco, and others in building implementations that work seamlessly together, creating a shared foundation for the next generation of real-time applications on the Internet.
An evolutionary ladder of compromise
To understand the promise of MoQ, we first have to appreciate the history that led us here—a journey defined by a series of architectural compromises where solving one problem inevitably created another.
The RTMP era: Conquering latency, compromising on scale
In the early 2000s, RTMP (Real-Time Messaging Protocol) was a breakthrough. It solved the frustrating “download and wait” experience of early video playback on the web by creating a persistent, stateful TCP connection between a Flash client and a server. This enabled low-latency streaming (2-5 seconds), powering the first wave of live platforms like Justin.tv (which later became Twitch).
But its strength was its weakness. That stateful connection, which had to be maintained for every viewer, was architecturally hostile to scale. It required expensive, specialized media servers and couldn’t use the commodity HTTP-based Content Delivery Networks (CDNs) that were beginning to power the rest of the web. Its reliance on TCP also meant that a single lost packet could freeze the entire stream—a phenomenon known as head-of-line blocking—creating jarring latency spikes. The industry retained RTMP for the “first mile” from the camera to servers (ingest), but a new solution was needed for the “last mile” from servers to your screen (delivery).
The HLS & DASH era: Solving for scale, compromising on latency
The catalyst for the next era was the iPhone’s rejection of Flash. In response, Apple created HLS (HTTP Live Streaming). HLS, and its open-standard counterpart MPEG-DASH abandoned stateful connections and treated video as a sequence of small, static files delivered over standard HTTP.
This enabled much greater scalability. By moving to the interoperable open standard of HTTP for the underlying transport, video could now be distributed by any web server and cached by global CDNs, allowing platforms to reach millions of viewers reliably and relatively inexpensively. The compromise? A significant trade-off in latency. To ensure smooth playback, players needed to buffer at least three video segments before starting. With segment durations of 6-10 seconds, this baked 15-30 seconds of latency directly into the architecture.
While extensions like Low-Latency HLS (LL-HLS) have more recently emerged to achieve latencies in the 3-second range, they remain complex patches fighting against the protocol’s fundamental design. These extensions introduce a layer of stateful, real-time communication—using clever workarounds like holding playlist requests open—that ultimately strain the stateless request-response model central to HTTP’s scalability and composability.
The WebRTC Era: Conquering conversational latency, compromising on architecture
In parallel, WebRTC (Web Real-Time Communication) emerged to solve a different problem: plugin-free, two-way conversational video with sub-500ms latency within a browser. It worked by creating direct peer-to-peer (P2P) media paths, removing central servers from the equation.
But this P2P model is fundamentally at odds with broadcast scale. In a mesh network, the number of connections grows quadratically with each new participant (the “N-squared problem”). For more than a handful of users, the model collapses under the weight of its own complexity. To work around this, the industry developed server-based topologies like the Selective Forwarding Unit (SFU) and Multipoint Control Unit (MCU). These are effective but require building what is essentially a private, stateful, real-time CDN—a complex and expensive undertaking that is not standardized across infrastructure providers.
This journey has left us with a fragmented landscape of specialized, non-interoperable silos, forcing developers to stitch together multiple protocols and accept a painful three-way tension between latency, scale, and complexity.
Introducing MoQ
This is the context into which Media over QUIC (MoQ) emerges. It’s not just another protocol; it’s a new design philosophy built from the ground up to resolve this historical trilemma. Born out of an open, community-driven effort at the IETF, MoQ aims to be a foundational Internet technology, not a proprietary product.
Its promise is to unify the disparate worlds of streaming by delivering:
Sub-second latency at broadcast scale: Combining the latency of WebRTC with the scale of HLS/DASH and the simplicity of RTMP.
Architectural simplicity: Creating a single, flexible protocol for ingest, distribution, and interactive use cases, eliminating the need to transcode between different technologies.
Transport efficiency: Building on QUIC, a UDP based protocol to eliminate bottlenecks like TCP head-of-line blocking.
The initial focus was “Media” over QUIC, but the core concepts—named tracks of timed, ordered, but independent data—are so flexible that the working group is now simply calling the protocol “MoQ.” The name reflects the power of the abstraction: it’s a generic transport for any real-time data that needs to be delivered efficiently and at scale.
MoQ is now generic enough that it’s a data fanout or pub/sub system, for everything from audio/video (high bandwidth data) to sports score updates (low bandwidth data).
A deep dive into the MoQ protocol stack
MoQ’s elegance comes from solving the right problem at the right layer. Let’s build up from the foundation to see how it achieves sub-second latency at scale.
The choice of QUIC as MoQ’s foundation isn’t arbitrary—it addresses issues that have plagued streaming protocols for decades.
By building on QUIC (the transport protocol that also powers HTTP/3), MoQ solves some key streaming problems:
No head-of-line blocking: Unlike TCP where one lost packet blocks everything behind it, QUIC streams are independent. A lost packet on one stream (e.g., an audio track) doesn’t block another (e.g., the main video track). This alone eliminates the stuttering that plagued RTMP.
Connection migration: When your device switches from Wi-Fi to cellular mid-stream, the connection seamlessly migrates without interruption—no rebuffering, no reconnection.
Fast connection establishment: QUIC’s 0-RTT resumption means returning viewers can start playing instantly.
Baked-in, mandatory encryption: All QUIC connections are encrypted by default with TLS 1.3.
The core innovation: Publish/subscribe for media
With QUIC solving transport issues, MoQ introduces its key innovation: treating media as subscribable tracks in a publish/subscribe system. But unlike traditional pub/sub, this is designed specifically for real-time media at CDN scale.
Instead of complex session management (WebRTC) or file-based chunking (HLS), MoQ lets publishers announce named tracks of media that subscribers can request. A relay network handles the distribution without needing to understand the media itself.
How MoQ organizes media: The data model
Before we see how media flows through the network, let’s understand how MoQ structures it. MoQ organizes data in a hierarchy:
Tracks: Named streams of media, like “video-1080p” or “audio-english”. Subscribers request specific tracks by name.
Groups: Independently decodable chunks of a track. For video, this typically means a GOP (Group of Pictures) starting with a keyframe. New subscribers can join at any Group boundary.
Objects: The actual packets sent on the wire. Each Object belongs to a Track and has a position within a Group.
This simple hierarchy enables two capabilities:
Subscribers can start playback at Group boundaries without waiting for the next keyframe
Relays can forward Objects without parsing or understanding the media format
The network architecture: From publisher to subscriber
MoQ’s network components are also simple:
Publishers: Announce track namespaces and send Objects
Subscribers: Request specific tracks by name
Relays: Connect publishers to subscribers by forwarding immutable Objects without parsing or transcoding the media
A Relay acts as a subscriber to receive tracks from upstream (like the original publisher) and simultaneously acts as a publisher to forward those same tracks downstream. This model is the key to MoQ’s scalability: one upstream subscription can fan out to serve thousands of downstream viewers.
The MoQ Stack
MoQ’s architecture can be understood as three distinct layers, each with a clear job:
The Transport Foundation (QUIC or WebTransport): This is the modern foundation upon which everything is built. MoQT can run directly over raw QUIC, which is ideal for native applications, or over WebTransport, which is required for use in a web browser. Crucially, theWebTransport protocol and its correspondingW3C browser API make QUIC’s multiplexed reliable streams and unreliable datagrams directly accessible to browser applications. This is a game-changer. Protocols like SRT may be efficient, but their lack of native browser support relegates them to ingest-only roles. WebTransport gives MoQ first-class citizenship on the web, making it suitable for both ingest and massive-scale distribution directly to clients.
The MoQT Layer: Sitting on top of QUIC (or WebTransport), the MoQT layer provides the signaling and structure for a publish-subscribe system. This is the primary focus of the IETF working group. It defines the core control messages—like ANNOUNCE, and SUBSCRIBE—and the basic data model we just covered. MoQT itself is intentionally spartan; it doesn’t know or care if the data it’s moving is H.264 video, Opus audio, or game state updates.
The Streaming Format Layer: This is where media-specific logic lives. A streaming format defines things like manifests, codec metadata, and packaging rules. WARP is one such format being developed alongside MoQT at the IETF, but it isn’t the only one. Another standards body, like DASH-IF, could define a CMAF-based streaming format over MoQT. A company that controls both original publisher and end subscriber can develop its own proprietary streaming format to experiment with new codecs or delivery mechanisms without being constrained by the transport protocol.
This separation of layers is why different organizations can build interoperable implementations while still innovating at the streaming format layer.
End-to-End Data Flow
Now that we understand the architecture and the data model, let’s walk through how these pieces come together to deliver a stream. The protocol is flexible, but a typical broadcast flow relies on the ANNOUNCE and SUBSCRIBE messages to establish a data path from a publisher to a subscriber through the relay network.
Here is a step-by-step breakdown of what happens in this flow:
Initiating Connections: The process begins when the endpoints, acting as clients, connect to the relay network. The Original Publisher initiates a connection with its nearest relay (we’ll call it Relay A). Separately, an End Subscriber initiates a connection with its own local relay (Relay B). These endpoints perform a SETUP handshake with their respective relays to establish a MoQ session and declare supported parameters.
Announcing a Namespace: To make its content discoverable, the Publisher sends an ANNOUNCE message to Relay A. This message declares that the publisher is the authoritative source for a given track namespace. Relay A receives this and registers in a shared control plane (a conceptual database) that it is now a source for this namespace within the network.
Subscribing to a Track: When the End Subscriber wants to receive media, it sends a SUBSCRIBE message to its relay, Relay B. This message is a request for a specific track name within a specific track namespace.
Connecting the Relays: Relay B receives the SUBSCRIBE request and queries the control plane. It looks up the requested namespace and discovers that Relay A is the source. Relay B then initiates a session with Relay A (if it doesn’t already have one) and forwards the SUBSCRIBE request upstream.
Completing the Path and Forwarding Objects: Relay A, having received the subscription request from Relay B, forwards it to the Original Publisher. With the full path now established, the Publisher begins sending the Objects for the requested track. The Objects flow from the Publisher to Relay A, which forwards them to Relay B, which in turn forwards them to the End Subscriber. If another subscriber connects to Relay B and requests the same track, Relay B can immediately start sending them the Objects without needing to create a new upstream subscription.
An Alternative Flow: The PUBLISH Model
More recent drafts of the MoQ specification have introduced an alternative, push-based model using a PUBLISH message. In this flow, a publisher can effectively ask for permission to send a track’s objects to a relay without waiting for a SUBSCRIBE request. The publisher sends a PUBLISH message, and the relay’s PUBLISH_OK response indicates whether it will accept the objects. This is particularly useful for ingest scenarios, where a publisher wants to send its stream to an entry point in the network immediately, ensuring the media is available the instant the first subscriber connects.
Advanced capabilities: Prioritization and congestion control
MoQ’s benefits really shine when networks get congested. MoQ includes mechanisms for handling the reality of network traffic. One such mechanism is Subgroups.
Subgroups are subdivisions within a Group that effectively map directly to the underlying QUIC streams. All Objects within the same Subgroup are generally sent on the same QUIC stream, guaranteeing their delivery order. Subgroup numbering also presents an opportunity to encode prioritization: within a Group, lower-numbered Subgroups are considered higher priority.
This enables intelligent quality degradation, especially with layered codecs (e.g. SVC):
Subgroup 0: Base video layer (360p) – must deliver
Subgroup 1: Enhancement to 720p – deliver if bandwidth allows
Subgroup 2: Enhancement to 1080p – first to drop under congestion
When a relay detects congestion, it can drop Objects from higher-numbered Subgroups, preserving the base layer. Viewers see reduced quality instead of buffering.
The MoQ specification defines a scheduling algorithm that determines the order for all objects that are “ready to send.” When a relay has multiple objects ready, it prioritizes them first by group order (ascending or descending) and then, within a group, by subgroup id. Our implementation supports the group order preference, which can be useful for low-latency broadcasts. If a viewer falls behind and its subscription uses descending group order, the relay prioritizes sending Objects from the newest “live” Group, potentially canceling unsent Objects from older Groups. This can help viewers catch up to the live edge quickly, a highly desirable feature for many interactive streaming use cases. The optimal strategies for using these features to improve QoE for specific use cases are still an open research question. We invite developers and researchers to use our network to experiment and help find the answers.
Implementation: building the Cloudflare MoQ relay
Theory is one thing; implementation is another. To validate the protocol and understand its real-world challenges, we’ve been building one of the first global MoQ relay networks. Cloudflare’s network, which places compute and logic at the edge, is very well suited for this.
Our architecture connects the abstract concepts of MoQ to the Cloudflare stack. In our deep dive, we mentioned that when a publisher ANNOUNCEs a namespace, relays need to register this availability in a “shared control plane” so that SUBSCRIBE requests can be routed correctly. For this critical piece of state management, we use Durable Objects.
When a publisher announces a new namespace to a relay in, say, London, that relay uses a Durable Object—our strongly consistent, single-threaded storage solution—to record that this namespace is now available at that specific location. When a subscriber in Paris wants a track from that namespace, the network can query this distributed state to find the nearest source and route the SUBSCRIBE request accordingly. This architecture builds upon the technology we developed for Cloudflare’s real-time services and provides a solution to the challenge of state management at a global scale.
An Evolving Specification
Building on a new protocol in the open means implementing against a moving target. To get MoQ into the hands of the community, we made a deliberate trade-off: our current relay implementation is based on a subset of the features defined in draft-ietf-moq-transport-07. This version became a de facto target for interoperability among several open-source projects and pausing there allowed us to put effort towards other aspects of deploying our relay network.
This draft of the protocol makes a distinction between accessing “past” and “future” content. SUBSCRIBE is used to receive future objects for a track as they arrive—like tuning into a live broadcast to get everything from that moment forward. In contrast, FETCH provides a mechanism for accessing past content that a relay may already have in its cache—like asking for a recording of a song that just played.
Both are part of the same specification, but for the most pressing low-latency use cases, a performant implementation of SUBSCRIBE is what matters most. For that reason, we have focused our initial efforts there and have not yet implemented FETCH.
This is where our roadmap is flexible and where the community can have a direct impact. Do you need FETCH to build on-demand or catch-up functionality? Or is more complete support for the prioritization features within SUBSCRIBE more critical for your use case? The feedback we receive from early developers will help us decide what to build next.
As always, we will announce our updates and changes to our implementation as we continue with development on our developer docs pages.
Kick the tires on the future
We believe in building in the open and interoperability in the community. MoQ is not a Cloudflare technology but a foundational Internet technology. To that end, the first demo client we’re presenting is an open source, community example.
Even though this is a preview release, we are running MoQ relays at Cloudflare’s full scale, like we do every production service. This means every server that is part of the Cloudflare network in more than 330 cities is now a MoQ relay.
We invite you to experience the “wow” moment of near-instant, sub-second streaming latency that MoQ enables. How would you use a protocol that offers the speed of a video call with the scale of a global broadcast?
Interoperability
We’ve been working with others in the IETF WG community and beyond on interoperability of publishers, players and other parts of the MoQ ecosystem. So far, we’ve tested with:
The Internet’s media stack is being refactored. For two decades, we’ve been forced to choose between latency, scale, and complexity. The compromises we made solved some problems, but also led to a fragmented ecosystem.
MoQ represents a promising new foundation—a chance to unify the silos and build the next generation of real-time applications on a scalable protocol. We’re committed to helping build this foundation in the open, and we’re just getting started.
MoQ is a realistic way forward, built on QUIC for future proofing, easier to understand than WebRTC, compatible with browsers unlike RTMP.
The protocol is evolving, the implementations are maturing, and the community is growing. Whether you’re building the next generation of live streaming, exploring real-time collaboration, or pushing the boundaries of interactive media, consider whether MoQ may provide the foundation you need.
Availability and pricing
We want developers to start building with MoQ today. To make that possible MoQ at Cloudflare is in tech preview – this means it’s available free of charge for testing (at any scale). Visit our developer homepage for updates and potential breaking changes.
Indie developers and large enterprises alike ask about pricing early in their adoption of new technologies. We will be transparent and clear about MoQ pricing. In general availability, self-serve customers should expect to pay 5 cents/GB outbound with no cost for traffic sent towards Cloudflare.
Enterprise customers can expect usual pricing in line with regular media delivery pricing, competitive with incumbent protocols. This means if you’re already using Cloudflare for media delivery, you should not be wary of adopting new technologies because of cost. We will support you.
If you’re interested in partnering with Cloudflare in adopting the protocol early or contributing to its development, please reach out to us at [email protected]! Engineers excited about the future of the Internet are standing by.
A few years ago, scammers invented a new phishing email. They would claim to have hacked your computer, turned your webcam on, and videoed you watching porn or having sex. BuzzFeed has an article talking about a “shockingly realistic” variant, which includes photos of you and your house—more specific information.
The article contains “steps you can take to figure out if it’s a scam,” but omits the first and most fundamental piece of advice: If the hacker had incriminating video about you, they would show you a clip. Just a taste, not the worst bits so you had to worry about how bad it could be, but something. If the hacker doesn’t show you any video, they don’t have any video. Everything else is window dressing.
I remember when this scam was first invented. I calmed several people who were legitimately worried with that one fact.
Developing a new video conferencing application often begins with a peer-to-peer setup using WebRTC, facilitating direct data exchange between clients. While effective for small demonstrations, this method encounters scalability hurdles with increased participants. The data transmission load for each client escalates significantly in proportion to the number of users, as each client is required to send data to every other client except themselves (n-1).
In the scaling of video conferencing applications, Selective Forwarding Units (SFUs) are essential. Essentially a media stream routing hub, an SFU receives media and data flows from participants and intelligently determines which streams to forward. By strategically distributing media based on network conditions and participant needs, this mechanism minimizes bandwidth usage and greatly enhances scalability. Nearly every video conferencing application today uses SFUs.
In 2024, we announced Cloudflare Realtime (then called Cloudflare Calls), our suite of WebRTC products, and we also released Orange Meets, an open source video chat application built on top of our SFU.
We also realized that use of an SFU often comes with a privacy cost, as there is now a centralized hub that could see and listen to all the media contents, even though its sole job is to forward media bytes between clients as a data plane.
We believe end-to-end encryption should be the industry standard for secure communication and that’s why today we’re excited to share that we’ve implemented and open sourced end-to-end encryption in Orange Meets. Our generic implementation is client-only, so it can be used with any WebRTC infrastructure. Finally, our new designated committer distributed algorithm is verified in a bounded model checker to verify this algorithm handles edge cases gracefully.
End-to-end encryption for video conferencing is different than for text messaging
End-to-end encryption describes a secure communication channel whereby only the intended participants can read, see, or listen to the contents of the conversation, not anybody else. WhatsApp and iMessage, for example, are end-to-end-encrypted, which means that the companies that operate those apps or any other infrastructure can’t see the contents of your messages.
Whereas encrypted group chats are usually long-lived, highly asynchronous, and low bandwidth sessions, video and audio calls are short-lived, highly synchronous, and require high bandwidth. This difference comes with plenty of interesting tradeoffs, which influenced the design of our system.
We had to consider how factors like the ephemeral nature of calls, compared to the persistent nature of group text messages, also influenced the way we designed E2EE for Orange Meets. In chat messages, users must be able to decrypt messages sent to them while they were offline (e.g. while taking a flight). This is not a problem for real-time communication.
The bandwidth limitations around audio/video communication and the use of an SFU prevented us from using some of the E2EE technologies already available for text messages. Apple’s iMessage, for example, encrypts a message N-1 times for an N-user group chat. We can’t encrypt the video for each recipient, as that could saturate the upload capacity of Internet connections as well as slow down the client. Media has to be encrypted once and decrypted by each client while preserving secrecy around only the current participants of the call.
Messaging Layer Security (MLS)
Around the same time we were working on Orange Meets, we saw a lot of excitement around new apps being built with Messaging Layer Security (MLS), an IETF-standardized protocol that describes how you can do a group key exchange in order to establish end-to-end-encryption for group communication.
Previously, the only way to achieve these properties was to essentially run your own fork of the Signal protocol, which itself is more of a living protocol than a solidified standard. Since MLS is standardized, we’ve now seen multiple high-quality implementations appear, and we’re able to use them to achieve Signal-level security with far less effort.
Implementing MLS here wasn’t easy: it required a moderate amount of client modification, and the development and verification of an encrypted room-joining protocol. Nonetheless, we’re excited to be pioneering a standards-based approach that any customer can run on our network, and to share more details about how our implementation works.
We did not have to make any changes to the SFU to get end-to-end encryption working. Cloudflare’s SFU doesn’t care about the contents of the data forwarded on our data plane and whether it’s encrypted or not.
Orange Meets: the basics
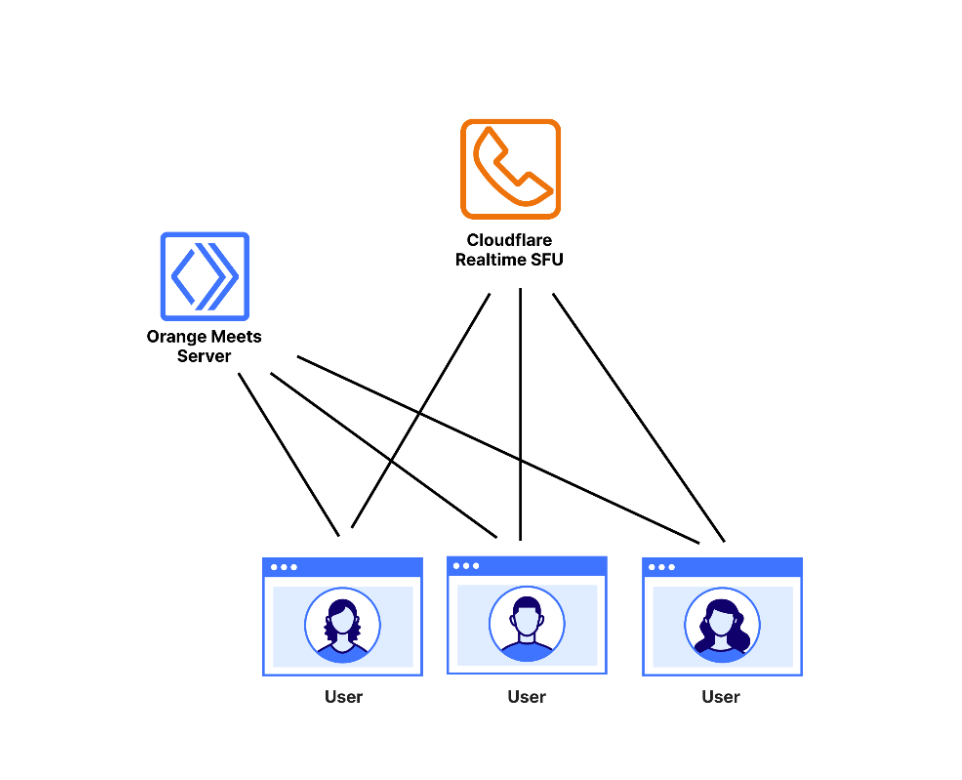
Orange Meets is a video calling application built on Cloudflare Workers that uses the Cloudflare Realtime SFU service as the data plane. The roles played by the three main entities in the application are as follows:
The user is a participant in the video call. They connect to the Orange Meets server and SFU, described below.
The Orange Meets Server is a simple service run on a Cloudflare Worker that runs the small-scale coordination logic of Orange Meets, which is concerned with which user is in which video call — called a room — and what the state of the room is. Whenever something in the room changes, like a participant joining or leaving, or someone muting themselves, the app server broadcasts the change to all room participants. You can use any backend server for this component, we just chose Cloudflare Workers for its convenience.
Cloudflare Realtime Selective Forwarding Unit (SFU) is a service that Cloudflare runs, which takes everyone’s audio and video and broadcasts it to everyone else. These connections are potentially lossy, using UDP for transmission. This is done because a dropped video frame from five seconds ago is not very important in the context of a video call, and so should not be re-sent, as it would be in a TCP connection.
The network topology of Orange Meets
Next, we have to define what we mean by end-to-end encryption in the context of video chat.
End-to-end encrypting Orange Meets
The most immediate way to end-to-end encrypt Orange Meets is to simply have the initial users agree on a symmetric encryption/decryption key at the beginning of a call, and just encrypt every video frame using that key. This is sufficient to hide calls from Cloudflare’s SFU. Some source-encrypted video conferencing implementations, such as Jitsi Meet, work this way.
The issue, however, is that kicking a malicious user from a call does not invalidate their key, since the keys are negotiated just once. A joining user learns the key that was used to encrypt video from before they joined. These failures are more formally referred to as failures of post-compromise security and perfect forward secrecy. When a protocol successfully implements these in a group setting, we call the protocol a continuous group key agreement protocol.
Fortunately for us, MLS is a continuous group key agreement protocol that works out of the box, and the nice folks at Phoenix R&D and Cryspen have a well-documented open-source Rust implementation of most of the MLS protocol.
All we needed to do was write an MLS client and compile it to WASM, so we could decrypt video streams in-browser. We’re using WASM since that’s one way of running Rust code in the browser. If you’re running a video conferencing application on a desktop or mobile native environment, there are other MLS implementations in your preferred programming language.
Our setup for encryption is as follows:
Make a web worker for encryption. We wrote a web worker in Rust that accepts a WebRTC video stream, broken into individual frames, and encrypts each frame. This code is quite simple, as it’s just an MLS encryption:
Postprocess outgoing audio/video. We take our normal stream and, using some newer features of the WebRTC API, add a transform step to it. This transform step simply sends the stream to the worker:
Once we do this for both audio and video streams, we’re done.
Handling different codec behaviors
The streams are now encrypted before sending and decrypted before rendering, but the browser doesn’t know this. To the browser, the stream is still an ordinary video or audio stream. This can cause errors to occur in the browser’s depacketizing logic, which expects to see certain bytes in certain places, depending on the codec. This results in some extremely cypherpunk artifacts every dozen seconds or so:
Fortunately, this exact issue was discovered by engineers at Discord, who handily documented it in their DAVE E2EE videocalling protocol. For the VP8 codec, which we use by default, the solution is simple: split off the first 1–10 bytes of each packet, and send them unencrypted:
fn split_vp8_header(frame: &[u8]) -> Option<(&[u8], &[u8])> {
// If this is a keyframe, keep 10 bytes unencrypted. Otherwise, 1 is enough
let is_keyframe = frame[0] >> 7 == 0;
let unencrypted_prefix_size = if is_keyframe { 10 } else { 1 };
frame.split_at_checked(unencrypted_prefix_size)
}
These bytes are not particularly important to encrypt, since they only contain versioning info, whether or not this frame is a keyframe, some constants, and the width and height of the video.
And that’s truly it for the stream encryption part! The only thing remaining is to figure out how we will let new users join a room.
“Join my Orange Meet”
Usually, the only way to join the call is to click a link. And since the protocol is encrypted, a joining user needs to have some cryptographic information in order to decrypt any messages. How do they receive this information, though? There are a few options.
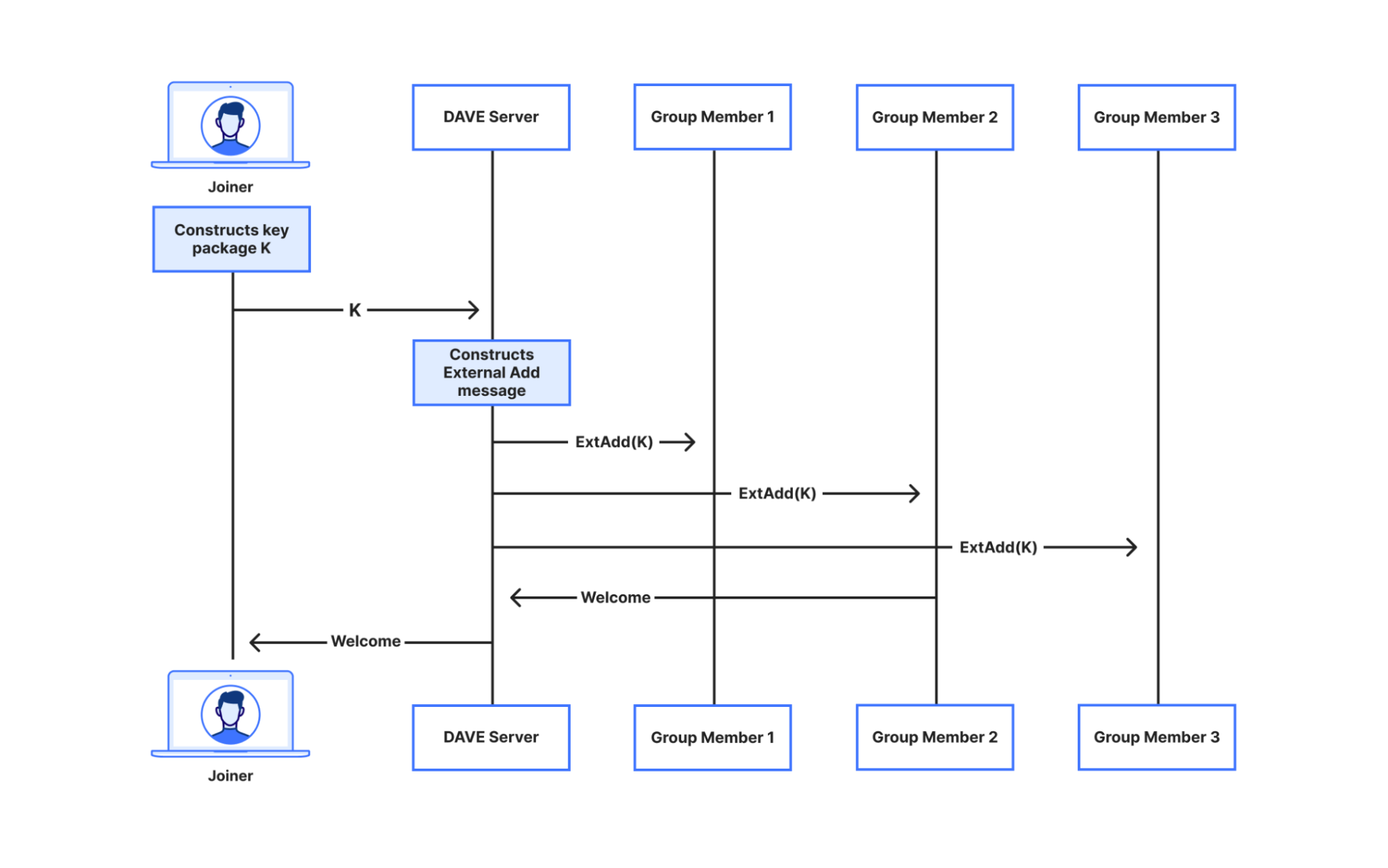
DAVE does it by using an MLS feature called external proposals. In short, the Discord server registers itself as an external sender, i.e., a party that can send administrative messages to the group, but cannot receive any. When a user wants to join a room, they provide their own cryptographic material, called a key package, and the server constructs and sends an MLS External Add message to the group to let them know about the new user joining. Eventually, a group member will commit this External Add, sending the joiner a Welcome message containing all information necessary to send and receive video.
A user joining a group via MLS external proposals. Recall the Orange Meets app server functions as a broadcast channel for the whole group. We consider a group of 3 members. We write member #2 as the one committing to the proposal, but this can be done by any member. Member #2 also sends a Commit message to the other members, but we omit this for space.
This is a perfectly viable way to implement room joining, but implementing it would require us to extend the Orange Meets server logic to have some concept of MLS. Since part of our goal is to keep things as simple as possible, we would like to do all our cryptography client-side.
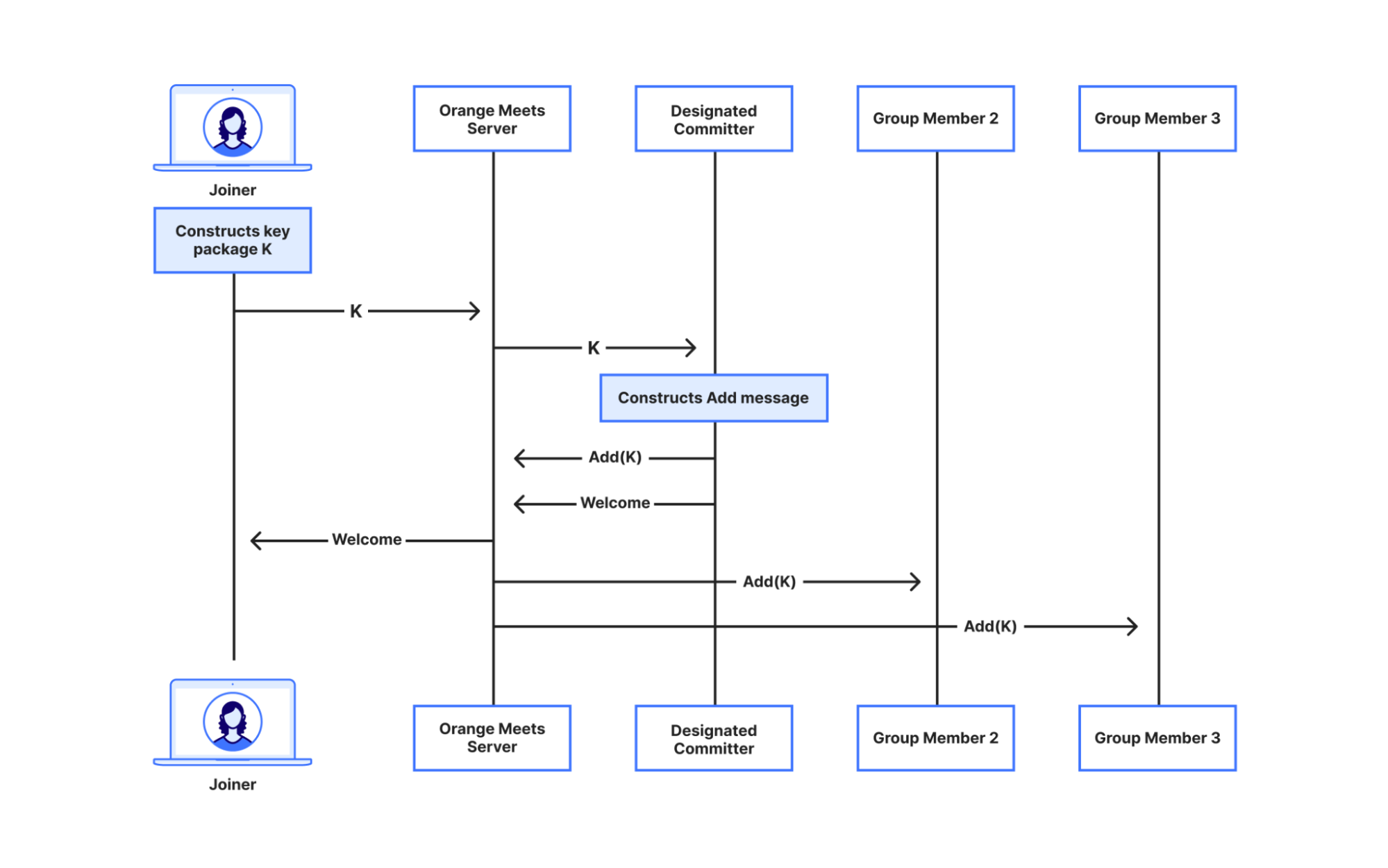
So instead we do what we call the designated committer algorithm. When a user joins a group, they send their cryptographic material to one group member, the designated committer, who then constructs and sends the Add message to the rest of the group. Similarly, when notified of a user’s exit, the designated committer constructs and sends a Remove message to the rest of the group. With this setup, the server’s job remains nothing more than broadcasting messages! It’s quite simple too—the full implementation of the designated committer state machine comes out to 300 lines of Rust, including the MLS boilerplate, and it’s about as efficient.
A user joining a group via the designated committer algorithm.
One cool property of the designated committer algorithm is that something like this isn’t possible in a text group chat setting, since any given user (in particular, the designated committer) may be offline for an arbitrary period of time. Our method works because it leverages the fact that video calls are an inherently synchronous medium.
Verifying the Designated Committer Algorithm with TLA+
The designated committer algorithm is a pretty neat simplification, but it comes with some non-trivial edge cases that we need to make sure we handle, such as:
How do we make sure there is only one designated committer at a time? The designated committer is the alive user with the smallest index in the MLS group state, which all users share.
What happens if the designated committer exits? Then the next user will take its place. Every user keeps track of pending Adds and Removes, so it can continue where the previous designated committer left off.
If a user has not caught up to all messages, could they think they’re the designated committer? No, they have to believe first that all prior eligible designated committers are disconnected.
To make extra sure that this algorithm was correct, we formally modeled it and put it through the TLA+ model checker. To our surprise, it caught some low-level bugs! In particular, it found that, if the designated committer dies while adding a user, the protocol does not recover. We fixed these by breaking up MLS operations and enforcing a strict ordering on messages locally (e.g., a Welcome is always sent before its corresponding Add).
You can find an explainer, lessons learned, and the full PlusCal program (a high-level language that compiles to TLA+) here. The caveat, as with any use of a bounded model checker, is that the checking is, well, bounded. We verified that no invalid protocol states are possible in a group of up to five users. We think this is good evidence that the protocol is correct for an arbitrary number of users. Because there are only two distinct roles in the protocol (designated committer and other group member), any weird behavior ought to be reproducible with two or three users, max.
Preventing Man-in-the-Middle attacks
One important concern to address in any end-to-end encryption setup is how to prevent the service provider from replacing users’ key packages with their own. If the Orange Meets app server did this, and colluded with a malicious SFU to decrypt and re-encrypt video frames on the fly, then the SFU could see all the video sent through the network, and nobody would know.
To resolve this, like DAVE, we include a safety number in the corner of the screen for all calls. This number uniquely represents the cryptographic state of the group. If you check out-of-band (e.g., in a Signal group chat) that everyone agrees on the safety number, then you can be sure nobody’s key material has been secretly replaced.
In fact, you could also read the safety number aloud in the video call itself, but doing this is not provably secure. Reading a safety number aloud is an in-band verification mechanism, i.e., one where a party authenticates a channel within that channel. If a malicious app server colluding with a malicious SFU were able to construct believable video and audio of the user reading the safety number aloud, it could bypass this safety mechanism. So if your threat model includes adversaries that are able to break into a Worker and Cloudflare’s SFU, and simultaneously generate real-time deep-fakes, you should use out-of-band verification 😄.
Future work
There are some areas we could improve on:
There is another attack vector for a malicious app server: it is possible to simply serve users malicious Javascript. This problem, more generally called the Javascript Cryptography Problem, affects any in-browser application where the client wants to hide data from the server. Fortunately, we are working on a standard to address this, called Web Application Manifest Consistency, Integrity, and Transparency. In short, like our Code Verify solution for WhatsApp, this would allow every website to commit to the Javascript it serves, and have a third party create an auditable log of the code. With transparency, malicious Javascript can still be distributed, but at least now there is a log that records the code.
We can make out-of-band authentication easier by placing trust in an identity provider. Using OpenPubkey, it would be possible for a user to get the identity provider to sign their cryptographic material, and then present that. Then all the users would check the signature before using the material. Transparency would also help here to ensure no signatures were made in secret.
Conclusion
We built end-to-end encryption into the Orange Meets video chat app without a lot of engineering time, and by modifying just the client code. To do so, we built a WASM (compiled from Rust) service worker that sets up an MLS group and does stream encryption and decryption, and designed a new joining protocol for groups, called the designated committer algorithm, and formally modeled it in TLA+. We made comments for all kinds of optimizations that are left to do, so please send us a PR if you’re so inclined!
The other speakers mostly talked about how cool AI was—and sometimes about how cool their own company was—but I was asked by the Democrats to specifically talk about DOGE and the risks of exfiltrating our data from government agencies and feeding it into AIs.
My written testimony is here. Video of the hearing is here.
Today, we are thrilled to announce Media Transformations, a new service that brings the magic of Image Transformations to short-form video files wherever they are stored.
Since 2018, Cloudflare Stream has offered a managed video pipeline that empowers customers to serve rich video experiences at global scale easily, in multiple formats and quality levels. Sometimes, the greatest friction to getting started isn’t even about video, but rather the thought of migrating all those files. Customers want a simpler solution that retains their current storage strategy to deliver small, optimized MP4 files. Now you can do that with Media Transformations.
Short videos, big volume
For customers with a huge volume of short video, such as generative AI output, e-commerce product videos, social media clips, or short marketing content, uploading those assets to Stream is not always practical. Furthermore, Stream’s key features like adaptive bitrate encoding and HLS packaging offer diminishing returns on short content or small files.
Instead, content like this should be fetched from our customers’ existing storage like R2 or S3 directly, optimized by Cloudflare quickly, and delivered efficiently as small MP4 files. Cloudflare Images customers reading this will note that this sounds just like their existing Image Transformation workflows. Starting today, the same workflow can be applied to your short-form videos.
What’s in a video?
The distinction between video and images online can sometimes be blurry — consider an animated GIF: is that an image or a video? (They’re usually smaller as MP4s anyway!) As a practical example, consider a selection of product images for a new jacket on an e-commerce site. You want a consumer to know how it looks, but also how it flows. So perhaps the first “image” in that carousel is actually a video of a model simply putting the jacket on. Media Transformations empowers customers to optimize the product video and images with similar tools and identical infrastructure.
How to get started
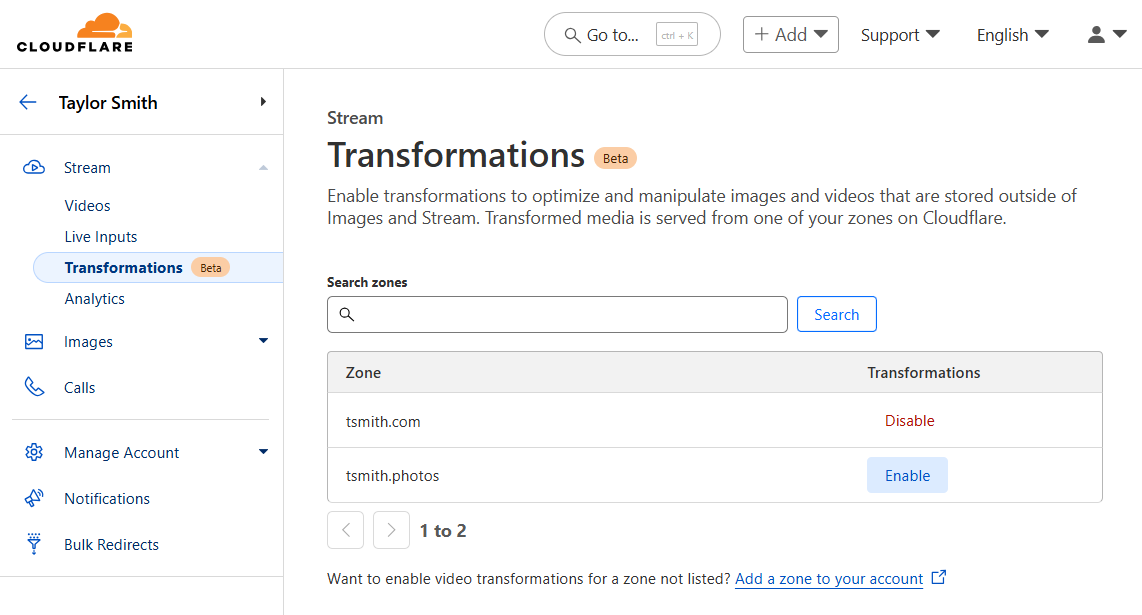
Any website that is already enabled for Image Transformations is now enabled for Media Transformations. To enable a new zone, navigate to “Transformations” under Stream (or Images), locate your zone in the list, and click Enable. Enabling and disabling a zone for transformations affects both Images and Media transformations.
After enabling Media Transformations on a website, it is simple to construct a URL that transforms a video. The pattern is similar to Image Transformations, but uses the media endpoint instead of the image endpoint:
The <OPTIONS> portion of the URL is a comma-separated list of flags written as key=value. A few noteworthy flags:
mode can be video (the default) to output a video, frame to pull a still image of a single frame, or even spritesheet to generate an image with multiple frames, which is useful for seek previews or storyboarding.
time specifies the exact start time from the input video to extract a frame or start making a clip
duration specifies the length of an output video to make a clip shorter than the original
fit, together with height and width allow resizing and cropping the output video or frame.
Setting audio to false removes the sound in the output video.
The <SOURCE-VIDEO> is a full URL to a source file or a root-relative path if the origin is on the same zone as the transformation request.
A full list of supported options, examples, and troubleshooting information is available in DevDocs.
A few examples
I used my phone to take this video of the randomness mobile in Cloudflare’s Austin Office and put it in an R2 bucket. Of course, it is possible to embed the original video file from R2 directly:
That video file is almost 30 MB. Let’s optimize it together — a more efficient choice would be to resize the video to the width of this blog post template. Let’s apply a width adjustment in the options portion of the URL:
That will deliver the same video, resized and optimized:
Not only is this video the right size for its container, now it’s less than 4 MB. That’s a big bandwidth savings for visitors.
As I recorded the video, the lobby was pretty quiet, but there was someone talking in the distance. If we wanted to use this video as a background, we should remove the audio, shorten it, and perhaps crop it vertically. All of these options can be combined, comma-separated, in the options portion of the URL:
If this were a product video, we might want a small thumbnail to add to the carousel of images so shoppers can click to zoom in and see it move. Use the “frame” mode and a “time” to generate a static image from a single point in the video. The same size and fit options apply:
We are eager to start supporting real customer content, and we will right-size our input limitations with our early adopters. To start:
Video files must be smaller than 40 megabytes.
Files must be MP4s and should be h.264 encoded.
Videos and images generated with Media Transformations will be cached. However, in our initial beta, the original content will not be cached which means regenerating a variant will result in a request to the origin.
How it works
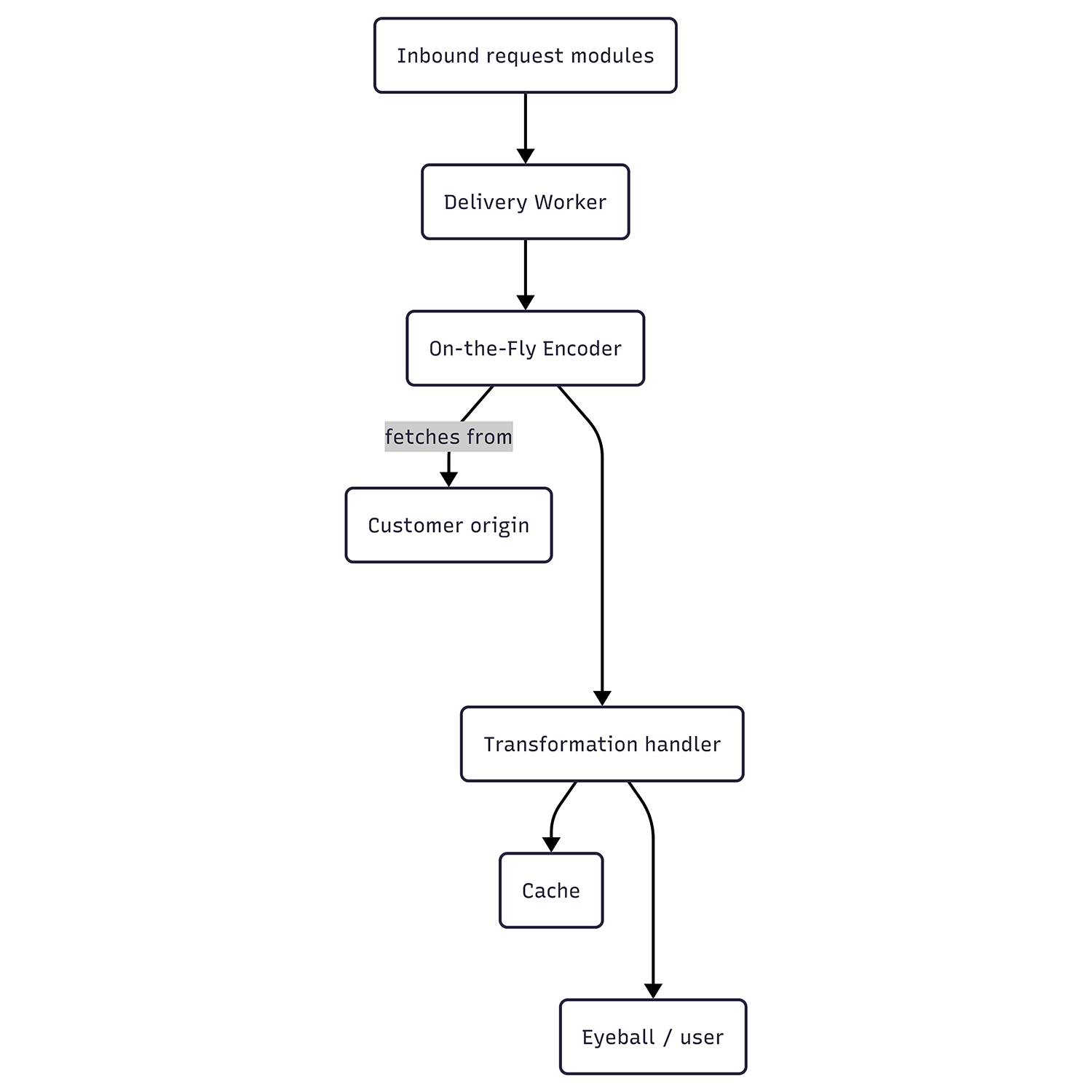
Unlike Stream, Media Transformations receives requests on a customer’s own website. Internally, however, these requests are passed to the same On-the-Fly Encoder (“OTFE”) platform that Stream Live uses. To achieve this, the Stream team built modules that run on our servers to act as entry points for these requests.
These entry points perform some initial validation on the URL formatting and flags before building a request to Stream’s own Delivery Worker, which in turn calls OTFE’s set of transformation handlers. The original asset is fetched from the customer’s origin, validated for size and type, and passed to the same OTFE methods responsible for manipulating and optimizing video or still frame thumbnails for videos uploaded to Stream. These tools do a final inspection of the media type and encoding for compatibility, then generate the requested variant. If any errors were raised along the way, an HTTP error response will be generated using similar error codes to Image Transformations. When successful, the result is cached for future use and delivered to the requestor as a single file. Even for new or uncached requests, all of this operates much faster than the video’s play time.
What it costs
Media Transformations will be free for all customers while in beta. We expect the beta period to extend into Q3 2025, and after that, Media Transformations will use the same subscriptions and billing mechanics as Image Transformations — including a free allocation for all websites/zones. Generating a still frame (single image) from a video counts as 1 transformation. Generating an optimized video is billed as 1 transformation per second of the output video. Each unique transformation is only billed once per month. All Media and Image Transformations cost $0.50 per 1,000 monthly unique transformation operations, with a free monthly allocation of 5,000.
Using this post as an example, recall the two transformed videos and one transformed image above — the big original doesn’t count because it wasn’t transformed. The first video (showing blog post width) was 15 seconds of output. The second video (silent vertical clip) was 10 seconds of output. The preview square is a still frame. These three operations would count as 26 transformations — and they would only bill once per month, regardless of how many visitors this page receives.
Looking ahead
Our short-term focus will be on right-sizing input limits based on real customer usage as well as adding a caching layer for origin fetches to reduce any egress fees our customers may be facing from other storage providers. Looking further, we intend to streamline Images and Media Transformations to further simplify the developer experience, unify the features, and streamline enablement: Cloudflare’s Media Transformations will optimize your images and video, quickly and easily, wherever you need them.
Try it for yourself today using our sample asset above, or get started by enabling Transformations on a zone in your account and uploading a short file to R2, both of which offer a free tier to get you going.
Cloudflare Stream is an end-to-end solution for video encoding, storage, delivery, and playback. Our focus has always been on simplifying all aspects of video for developers. This goal continues to motivate us as we introduce first-class portrait (vertical) video support today. Newly uploaded or ingested portrait videos will now automatically be processed in full HD quality.
Why portrait video
In the past few years, the popularity of portrait video has exploded, motivated by short-form video content applications such as TikTok or YouTube Shorts. However, Cloudflare customers have been confused as to why their portrait videos appear to be lower quality when viewed on portrait-first devices such as smartphones. This is because our video encoding pipeline previously did not support high-quality portrait videos, leading them to be grainy and lower quality. This pain point has now been addressed with the introduction of high-definition portrait video.
The current stream pipeline
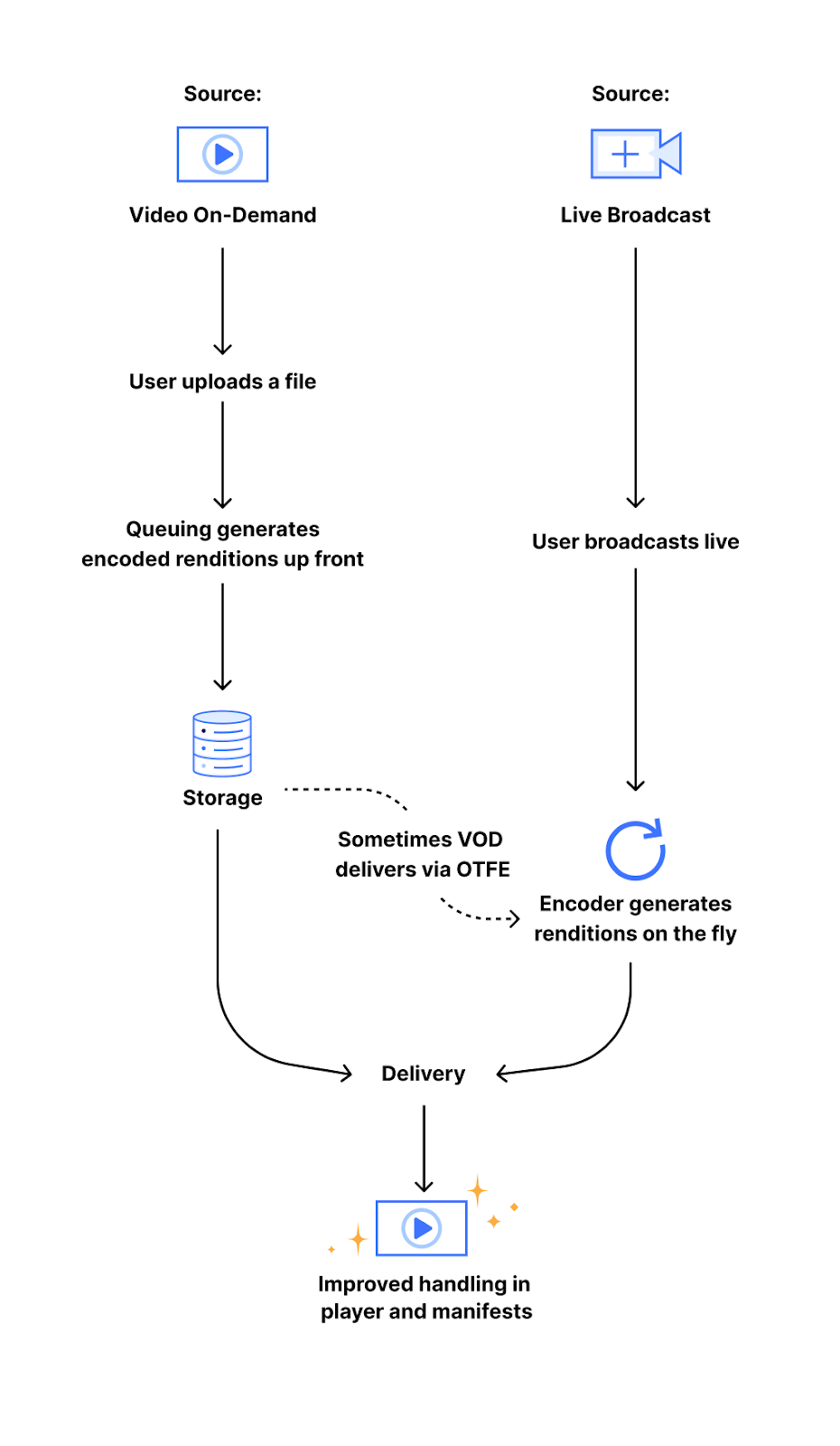
When you upload a video to Stream, it is first encoded into several different “renditions” (sizes or resolutions) before delivery. This is done in order to enable playback in a wide variety of network conditions, as well as to standardize the way a video is experienced. By using these adaptive bitrate renditions, we are able to offer viewers the highest quality streaming experience which fits their network bandwidth, meaning someone watching a video with a slow mobile connection would be served a 240p video (a resolution of 320×240 pixels) and receive the 1080p (a resolution of 1920×1080 pixels) version when they are watching at home on their fiber Internet connection. This encoding pipeline follows one of two different paths:
The first path is our video on-demand (VOD) encoding pipeline, which generates and stores a set of encoded video segments at each of our standard video resolutions. The other path is our on-the-fly encoding (OTFE) pipeline, which uses the same process as Stream Live to generate resolutions upon user request. Both pipelines work with the set of standard resolutions, which are identified through a constrained target (output) height. This means that we encode every rendition to heights of 240 pixels, 360 pixels, etc. up to 1080 pixels.
When originally conceived, this encoding pipeline was not designed with portrait video in mind because portrait video was less common. As a result, portrait videos were encoded with lower quality dimensions that were consistent with landscape video encoding. For example, a portrait HD video would have the dimensions 1920×1080 — scaling that down to the height of a landscape HD video would result in the much smaller output of 1080×606. However, current smartphones all have HD displays, making the discrepancy clear when a portrait video is viewed in portrait mode on a phone. With this new change to our encoding pipeline, all newly uploaded portrait videos will now be automatically encoded with constrained target width, using a new set of standard resolutions for portrait video. These resolutions are the same as the current set of landscape resolutions, but with the dimensions reversed: 240×426 up to 1080×1920.
Technical details
As the Stream intern this summer, I was tasked with this project, as well as the expectation of shipping a long-requested change, by the end of my internship. The first step in implementing this change was to familiarize myself with the complex architecture of Stream’s internal systems. After this, I began brainstorming a few different implementation decisions, like how to consistently track orientation through various stages of the pipeline. Following a group discussion to decide which choices would be the most scalable, least complex, and best for users, it was time to write the technical specification.
Due to the implementation method we chose, making this change involved tracing the life of a video from upload to delivery through both of our encoding pipelines and applying different logic for portrait videos. Previously, all video renditions were identified by their height at each stage of the pipeline, making certain parts of the pipeline completely agnostic to the orientation of a video. With the proposed changes, we would now be using the constraining dimension and orientation to identify a video rendition. Therefore, much of the work involved modifying the different portions of the pipeline to use these new parameters.
The first area of the pipeline to be modified was the Stream API service, which is the process which handles all Stream API calls. The API service enqueues the rendition encoding jobs for a video after it is uploaded, so it was necessary to introduce a new set of renditions designed for portrait videos, and enqueue the corresponding encoding jobs. The queuing system is handled by our in-house queue management system, which handles jobs generically and therefore did not require any changes.
Following this, I tackled the on-the-fly encoding pipeline. The area of interest here was the delivery portion of our pipeline, which generated the set of encoding resolutions to pass on to our on-the-fly encoder. Here I also introduced a new set of portrait renditions and the corresponding logic to encode them for portrait videos. This part of the backend is written and hosted on Cloudflare Workers, which made it very easy and quick to deploy and test changes.
Finally, we wanted to change how we presented these quality levels to users in the Stream built-in player and thought that using the new constrained dimension rather than always showing the height would feel more familiar. For portrait videos, we now display the size of the constraining dimension, which also means quality selection for portrait videos encoded under our old system now more accurately reflects their quality, too. As an example, a 9:16 portrait video would have been encoded to a maximum size of 608×1080 by the previous pipeline. Now, such a rendition will be marked as 608p rather than the full-quality 1080p, which would be a 1080×1920 rendition.
Stream as a whole is built on many of our own Developer Platform products, such as Workers for handling delivery, R2 for rendition storage, Workers AI for automatic captioning, and Durable Objects for bitrate observation, all of which enhance our ability to deploy and ship new updates quickly. Throughout my work on this project, I was able to see all of these pieces in action, as well as gain a new understanding of the powerful tools Cloudflare offers for developers.
Results and findings
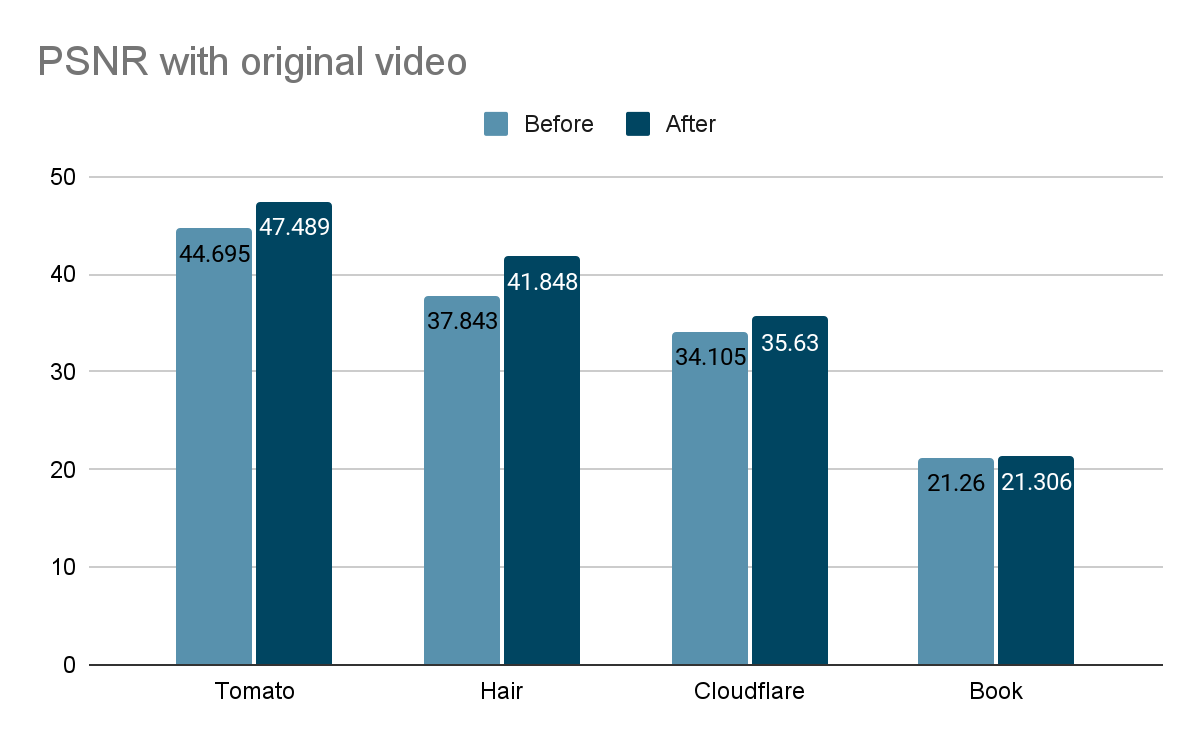
After the change, portrait videos are now encoded to higher resolutions and visibly appear to be higher quality. To confirm these differences, I analyzed the effect of the pipeline change on four different sample videos using the peak-signal-to-noise ratio (PSNR, a mathematical representation of image quality). Since the old pipeline produced lower resolution videos, the comparison here is between an upscaled version of the old pipeline rendition and the current pipeline rendition. In the graph below, higher values reflect higher quality relative to the unencoded original video.
According to this metric, we see an increase in quality from the pipeline changes as high as 8%. However, the quality increase is most noticeable to the human eye in videos that feature fine details or a high amount of movement, which is not always captured in the PSNR. For example, compare a side-by-side of a frame from the book sample video encoded both ways:
The difference between the old and new encodings is most clear when zoomed in:
Maximize the Stream player and look at the quality selector (in the gear menu) to see the new quality level labels – select the highest option to compare. Note the improved sharpness of the text in the book sample as well as the improved detail in the hair and eye shadow of the hair and makeup sample.
Implementation challenges
Due to the complex nature of our encoding pipelines, there were several technical challenges to making a large change like this. Aside from simply uploading videos, many of the features we offer, like downloads or clipping, require tweaking to produce the correct video renditions. This involved modifying many parts of the encoding pipeline to ensure that portrait video logic was handled.
There were also some edge cases which were not caught until after release. One release of this feature contained a bug in the on-the-fly encoding logic which caused a subset of new portrait livestream renditions to have negative bitrates, making them unusable. This was due to an internal representation of video renditions’ constraining dimensions being mistakenly used for bitrate observation. We remedied this by increasing the scope of our end-to-end testing to include more portrait video tests and live recording interaction tests.
Another small bug caused downloading very small videos to sometimes fail. This was because for videos under 240p, our smallest encoding resolution, the non-constraining dimension was not being properly scaled to match the aspect ratio of the video, causing some specific combinations of dimensions to be interpreted as portrait when they should have been landscape, and vice versa. This bug was fixed quickly, but was not initially caught after the release since it required a very specific set of conditions to activate. After this experience, I added a few more unit tests involving small videos.
That’s a wrap
As my internship comes to a close, reflecting on the experience makes me grateful for all the team members who have helped me throughout this time. I am very glad to have shipped this project which addresses a long-standing concern and will have real-world customer impact. Support for high-definition portrait video is now available, and we will continue to make improvements to our video solutions suite. You can see the difference yourself by uploading a portrait video to Stream! Or, perhaps you’d like to help build a better Internet, too — our internship and early talent programs are a great way to jumpstart your own journey.
Sample video acknowledgements: The sample video of the book was created by the Stream Product Manager and shows the opening page of The Strange Wonder of Roots by Evan Griffith (HarperCollins). The hair and makeup fashion video was sourced from Mixkit, a great source of free media for video projects.
The NSA has a video recording of a 1982 lecture by Adm. Grace Hopper titled “Future Possibilities: Data, Hardware, Software, and People.” The agency is (so far) refusing to release it.
Basically, the recording is in an obscure video format. People at the NSA can’t easily watch it, so they can’t redact it. So they won’t do anything.
With digital obsolescence threatening many early technological formats, the dilemma surrounding Admiral Hopper’s lecture underscores the critical need for and challenge of digital preservation. This challenge transcends the confines of NSA’s operational scope. It is our shared obligation to safeguard such pivotal elements of our nation’s history, ensuring they remain within reach of future generations. While the stewardship of these recordings may extend beyond the NSA’s typical purview, they are undeniably a part of America’s national heritage.
Consumer Reports has analyzed a bunch of popular Internet-connected video doorbells. Their security is terrible.
First, these doorbells expose your home IP address and WiFi network name to the internet without encryption, potentially opening your home network to online criminals.
[…]
Anyone who can physically access one of the doorbells can take over the device—no tools or fancy hacking skills needed.
Simon Willison has been playing with the video processing capabilities of the new Gemini Pro 1.5 model from Google, and it’s really impressive.
Which means a lot of scary new video prompt injection attacks. And remember, given the current state of technology, prompt injection attacks are impossible to prevent in general.
Stream Live lets users easily scale their live-streaming apps and websites to millions of creators and concurrent viewers while focusing on the content rather than the infrastructure — Stream manages codecs, protocols, and bit rate automatically.
For Speed Week this year, we introduced a closed beta of Low-Latency HTTP Live Streaming (LL-HLS), which builds upon the high-quality, feature-rich HTTP Live Streaming (HLS) protocol. Lower latency brings creators even closer to their viewers, empowering customers to build more interactive features like chat and enabling the use of live-streaming in more time-sensitive applications like live e-learning, sports, gaming, and events.
Today, in celebration of Birthday Week, we’re opening this beta to all customers with even lower latency. With LL-HLS, you can deliver video to your audience faster, reducing the latency a viewer may experience on their player to as little as three seconds. Low Latency streaming is priced the same way, too: $1 per 1,000 minutes delivered, with zero extra charges for encoding or bandwidth.
Broadcast with latency as low as three seconds.
LL-HLS is an extension of the HLS standard that allows us to reduce glass-to-glass latency — the time between something happening on the broadcast end and a user seeing it on their screen. That includes factors like network conditions and transcoding for HLS and adaptive bitrates. We also include client-side buffering in our understanding of latency because we know the experience is driven by what a user sees, not when a byte is delivered into a buffer. Depending on encoder and player settings, broadcasters' content can be playing on viewers' screens in less than three seconds.
On the left, OBS Studio broadcasting from my personal computer to Cloudflare Stream. On the right, watching this livestream using our own built-in player playing LL-HLS with three second latency!
Same pricing, lower latency. Encoding is always free.
Our addition of LL-HLS support builds on all the best parts of Stream including simple, predictable pricing. You never have to pay for ingress (broadcasting to us), compute (encoding), or egress. This allows you to stream with peace of mind, knowing there are no surprise fees and no need to trade quality for cost. Regardless of bitrate or resolution, Stream costs \$1 per 1,000 minutes of video delivered and \$5 per 1,000 minutes of video stored, billed monthly.
Stream also provides both a built-in web player or HLS/DASH manifests to use in a compatible player of your choosing. This enables you or your users to go live using the same protocols and tools that broadcasters big and small use to go live to YouTube or Twitch, but gives you full control over access and presentation of live streams. We also provide access control with signed URLs and hotlinking prevention measures to protect your content.
Powered by the strength of the network
And of course, Stream is powered by Cloudflare's global network for fast delivery worldwide, with points of presence within 50ms of 95% of the Internet connected population, a key factor in our quest to slash latency. We ingest live video close to broadcasters and move it rapidly through Cloudflare’s network. We run encoders on-demand and generate player manifests as close to viewers as possible.
Getting started with LL-HLS
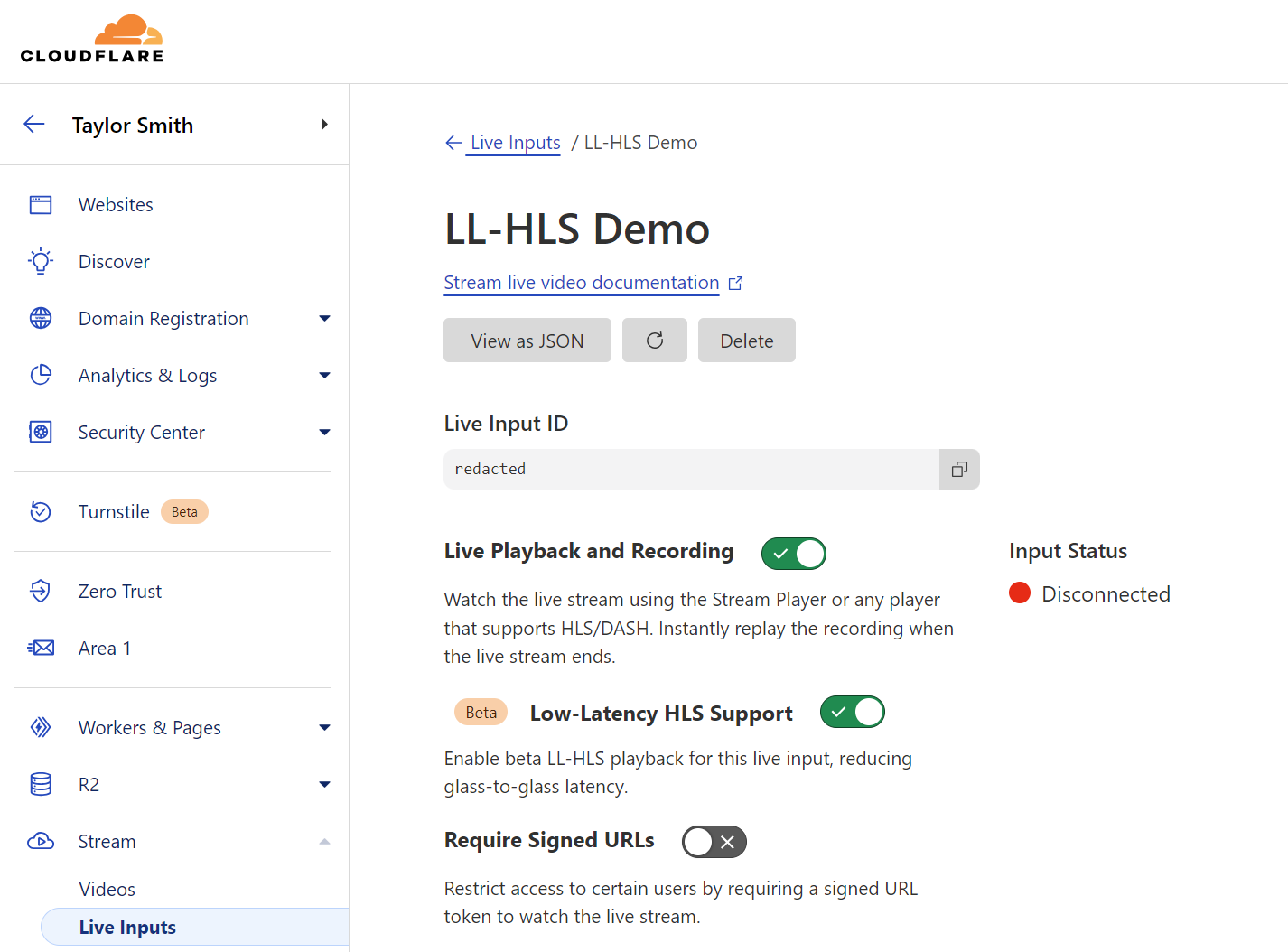
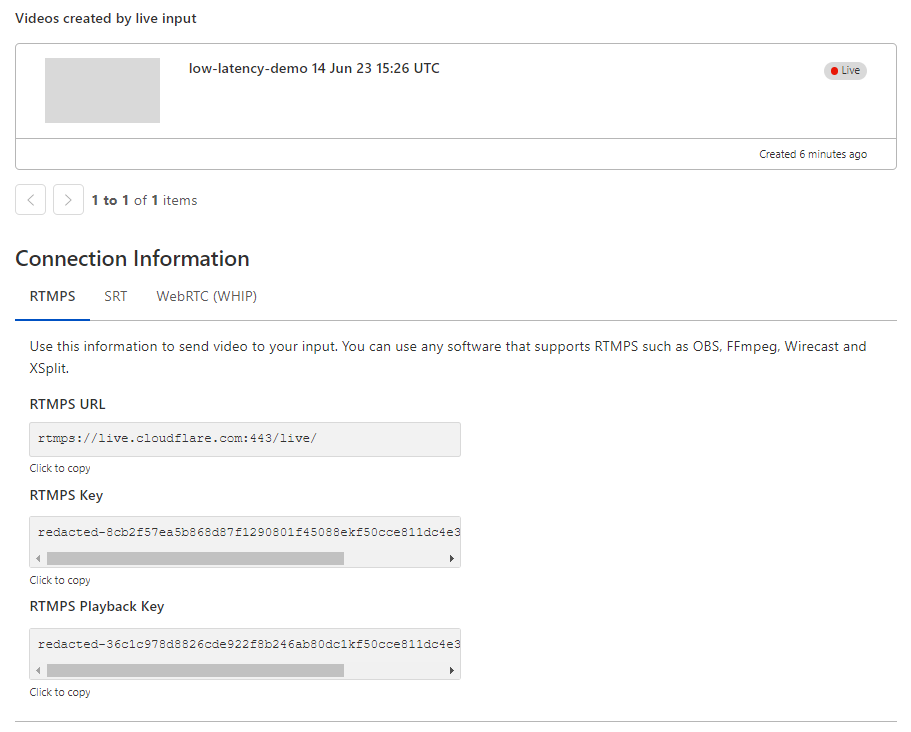
Getting started with Stream Live only takes a few minutes, and by using Live Outputs for restreaming, you can even test it without changing your existing infrastructure. First, create or update a Live Input in the Cloudflare dashboard. While in beta, Live Inputs will have an option to enable LL-HLS called “Low-Latency HLS Support.” Activate this toggle to enable the new pipeline.
Stream will automatically provide the RTMPS and SRT endpoints to broadcast your feed to us, just as before. For the best results, we recommend the following broadcast settings:
Codec: h264
GOP size / keyframe interval: 1 second
Optionally, configure a Live Output to point to your existing video ingest endpoint via RTMPS or SRT to test Stream while rebroadcasting to an existing workflow or infrastructure.
Stream will automatically provide RTMPS and SRT endpoints to broadcast your feed to us as well as an HTML embed for our built-in player.
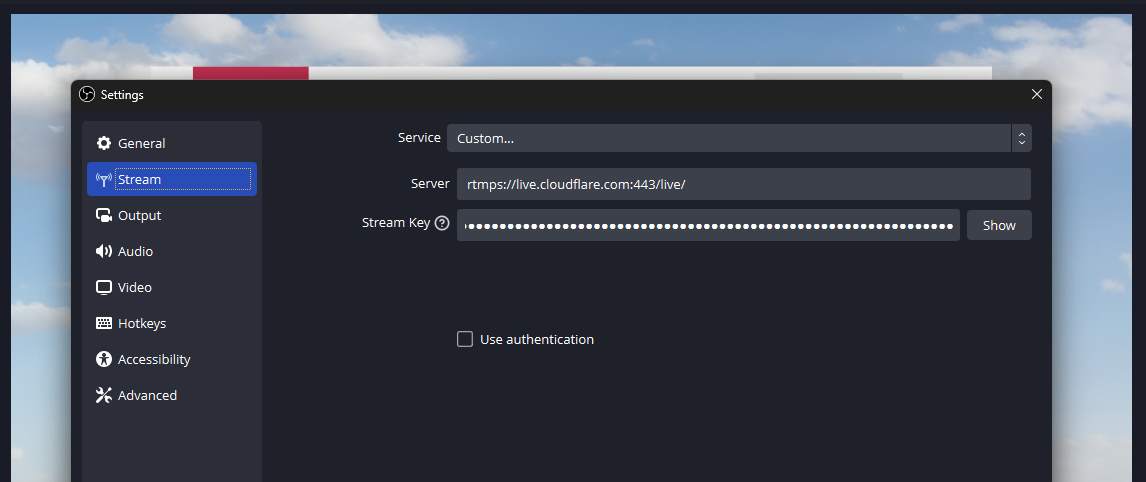
This connection information can be added easily to a broadcast application like OBS to start streaming immediately:
During the beta, our built-in player will automatically attempt to use low-latency for any enabled Live Input, falling back to regular HLS otherwise. If LL-HLS is being used, you’ll see “Low Latency” noted in the player.
During this phase of the beta, we are most closely focused on using OBS to broadcast and Stream’s built-in player to watch — which uses HLS.js under the hood for LL-HLS support. However, you may test the LL-HLS manifest in a player of your own by appending ?protocol=llhls to the end of the HLS manifest URL. This flag may change in the future and is not yet ready for production usage; watch for changes in DevDocs.
Sign up today
Low-Latency HLS is Stream Live’s latest tool to bring your creators and audiences together. All new and existing Stream subscriptions are eligible for the LL-HLS open beta today, with no pricing changes or contract requirements — all part of building the fastest, simplest serverless live-streaming platform. Join our beta to start test-driving Low-Latency HLS!
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.