Post Syndicated from Umang Aggarwal original https://aws.amazon.com/blogs/architecture/modernizing-financial-analytics-with-amazon-sagemaker-unified-studio/
Avanse Financial Services is one of India’s leading education loan providers. Their Data Engineering Team had built a data lake on AWS using Amazon Simple Storage Service (Amazon S3), Amazon Athena, and AWS Glue for data ingestion and processing. However, their analytics and reporting layer ran on an external analytics application that wasn’t integrated with AWS. Data had to be copied from Amazon S3 into this external application before analysts could run any report, its license consumed a significant portion of their budget despite low utilization, and every integration with AWS services required custom-built pipelines.
After evaluating their options, Avanse migrated to a cloud-native lakehouse architecture using Amazon SageMaker Unified Studio, which unified their data engineering, analytics, and artificial intelligence (AI) workflows in a single governed environment on AWS. In this post, we walk through their migration journey so you can adapt their approach to your own environment.
Why Avanse chose to modernize
The separation between their AWS data lake and their external analytics application created five problems:
- Daily data synchronization bottleneck. Every report required a 4-hour batch copy from Amazon S3 into the external analytics application before analysts could query it. Business decisions were based on data that was at least a day old.
- Fixed licensing costs disconnected from usage. The external analytics application charged an annual fee regardless of how many queries analysts ran. Avanse needed usage-based pricing that matched what they actually consumed, not a fixed fee for capacity they weren’t using.
- Limited auditability. The external analytics application ran on a shared server where different business units (risk, collections, portfolio management) shared the same resources. It lacked granular audit trails, making it difficult to trace who accessed what data and when, or to allocate costs per team.
- No centralized data discovery. Although AWS Glue Data Catalog managed schema metadata for the data lake, the external analytics application couldn’t access it. Analysts working in that application relied on folder structures and manual documentation to find the right datasets, slowing onboarding and increasing the risk of using outdated data.
- Disconnected from AWS services. The external analytics application couldn’t query data in Amazon S3 or use AWS Glue catalogs natively. Every data flow required connectors and custom-built pipelines, adding maintenance overhead.
Additionally, some datasets were stored on Network File System (NFS) storage outside of Amazon S3, creating another data silo that needed to be consolidated.
Avanse chose Amazon SageMaker Unified Studio because it addressed all five challenges: direct querying of data in Amazon S3 avoiding synchronization, usage-based compute through Amazon Athena and Amazon EMR Serverless, project-based isolation with per-project billing, lineage tracking with AWS IAM Identity Center, and native integration with their existing AWS services.
Solution overview
The core architectural change was moving from a two-application model to a single integrated stack:
- Previous architecture
- Avanse’s data ingestion and processing ran on AWS (Amazon S3, AWS Glue, Athena), but analytics and reporting ran on an external analytics application. Data had to be batch-copied from Amazon S3 into this external application daily before analysts could query it. Each system had its own access controls, and there was no shared catalog or lineage tracking between them.
- New architecture
- Analytics now run directly against data in Amazon S3 through Amazon SageMaker Unified Studio. There’s no data copy step. Analysts query the same data that the ingestion pipelines produce, using Athena for SQL and EMR Serverless for large-scale processing. Governance, access control, and lineage are centralized through IAM Identity Center and SageMaker Catalog.
The following diagram illustrates the target architecture. It follows a lakehouse pattern, storing data in open formats on Amazon S3 while maintaining ACID transaction support for the consistency financial regulators expect.
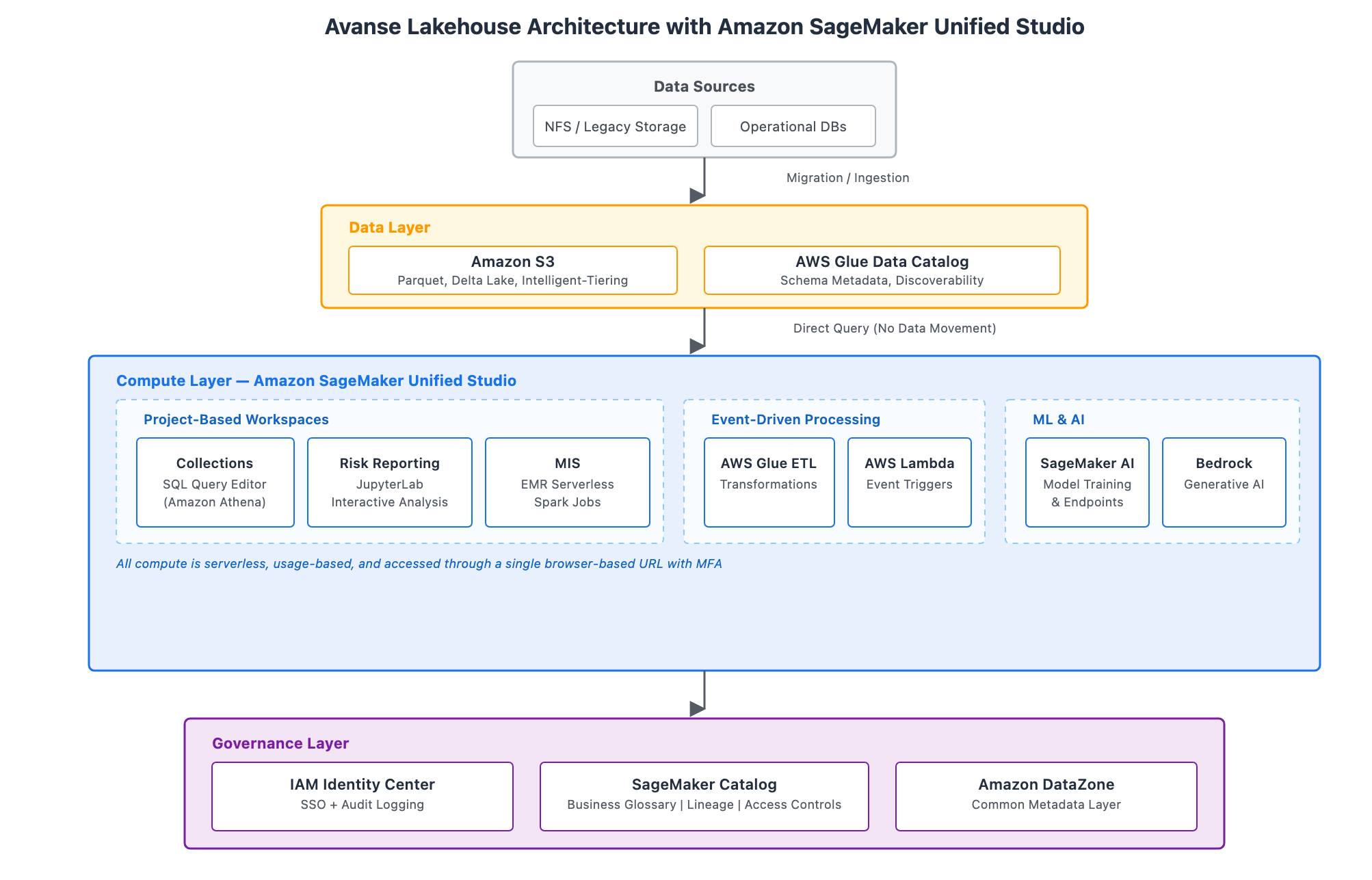
The architecture has three layers:
- Data layer – Amazon S3 stores data in open formats (Parquet, Delta Lake) with S3 Intelligent-Tiering for automatic cost optimization. AWS Glue Data Catalog maintains schema metadata, making data discoverable across tools.
- Compute layer – Amazon SageMaker Unified Studio provides project-based workspaces organized by business function. Collections uses the built-in SQL Query Editor powered by Athena, Risk Reporting uses JupyterLab for interactive analysis, and MIS runs large-scale Spark jobs through Amazon EMR Serverless. AWS Glue ETL handles data transformations and AWS Lambda provides event-driven triggers for report generation. For machine learning (ML) workloads, Amazon SageMaker AI supports model training and deployment, with Amazon Bedrock available for generative AI capabilities such as enhancing risk narratives.
- Governance layer – IAM Identity Center provides SSO and audit logging across workspaces. SageMaker Catalog serves as the business glossary with data lineage tracking and access controls. Amazon DataZone connects components through a common metadata layer.
Migration journey
Avanse followed a five-phase approach. The timelines can be adapted to your environment, but the systematic progression from validation through production deployment is key.
Phase 1: Technical validation (72-hour workshop)
Avanse started with a focused 72-hour workshop using isolated SageMaker environments where developers could experiment without impacting production. Their team tested SQL analytics against existing Athena tables and validated that Python and PySpark could replicate their existing analytics workflows.
The team confirmed that querying data directly in Amazon S3 addressed their synchronization bottleneck entirely. The 4-hour daily data copy was no longer necessary, which validated the migration approach.
Phase 2: Data migration and storage optimization
Avanse migrated datasets from NFS storage and legacy analytics formats into Amazon S3, consolidating the data into a single location. They implemented S3 Intelligent-Tiering, which automatically moves data between access tiers based on usage patterns, optimizing costs without impacting retrieval performance.
They replaced legacy analytics connectors with native Athena workgroups within SageMaker Unified Studio, avoiding data synchronization entirely. Source data remained in Amazon S3, queryable by both Athena SQL and SageMaker notebooks, establishing a single source of truth.
Phase 3: Compute modernization
Avanse moved from a shared analytics server to project-based isolation in SageMaker Unified Studio. Each business function (Risk Reporting, Collections, MIS) received its own project with dedicated compute spaces running JupyterLab. Project-specific IAM execution roles provided access controls and cost allocation per business unit.
A single browser-based URL with multi-factor authentication (MFA) now provides access to SQL analytics using the built-in query editor, ML development in JupyterLab notebooks, and big data processing through Amazon EMR Serverless. This replaced the need for local analytics client installations.
Phase 4: Governance implementation
Avanse deployed SageMaker Catalog as their central business data catalog. Analysts now discover approved datasets through semantic search rather than navigating folder structures or relying on manual documentation. They mapped technical Athena table names to business terms. For example, analysts search for “collection efficiency” and find the relevant tables with descriptions, schemas, and lineage.
Lineage capture traces each metric in risk reports back to source tables, transformations, and intermediate datasets. Every action (notebook execution, SQL query, data access) is tied to IAM Identity Center users, creating the comprehensive audit trail their compliance team needed.
Phase 5: Use case migration
Rather than attempting a big-bang migration, Avanse moved critical workflows one at a time:
- Portfolio MIS (Monthly/Fortnightly)
- Previously required the daily 4-hour data copy from Amazon S3 into the external analytics application before report generation could begin. Avanse avoided the data synchronization step entirely and now generates MIS reports by querying existing Athena tables directly in Amazon S3. Because the source data was already on AWS, there was no need to involve the external application for this activity. Report generation dropped from hours to under 30 minutes.
- Collection Efficiency and Bounce Calculation
- Ported complex legacy analytics procedures for calculating metrics like collection efficiency and bounce rates to event-driven processing using AWS Glue ETL, AWS Lambda, and PySpark jobs for high-volume data aggregation. The serverless execution model charges only for compute time consumed.
- EDW Risk Reporting
- Large-scale regulatory joins of Enterprise Data Warehouse assets previously ran as legacy scheduled procedures. These now run as SQL queries in the SageMaker Unified Studio query editor, where analysts execute them on-demand or schedule them through Athena workgroups. The distributed query engine handles complex multi-table joins spanning millions of rows.
- Scorecard Generation
- Model building shifted from the external analytics application to SageMaker AI workflows. Data scientists use JupyterLab with Python libraries and deploy models directly to SageMaker endpoints, avoiding data movement between separate environments.
Overcoming technical challenges
One technical challenge was code migration. Avanse’s analytics code base contained years of accumulated proprietary scripts and procedures. Direct line-by-line translation was not practical. Instead, they took a pragmatic approach: basic data transformations moved to SQL in Athena, complex business logic was rewritten in PySpark for scalability, and statistical procedures were replaced with Python libraries like pandas and scikit-learn. The approach was to focus on what the code accomplishes, then implement it using cloud-native patterns.
The other technical challenge was performance validation. The team needed to confirm that querying data in Amazon S3 would deliver acceptable performance compared to the external analytics application’s in-memory processing. Queries against Parquet-formatted data in Amazon S3 using Athena delivered comparable performance for standard reporting workloads, while avoiding the 4-hour daily data synchronization step entirely. For large-scale regulatory joins spanning millions of rows, Amazon EMR Serverless provided distributed Spark processing that completed in minutes rather than the hours required in the external application.
Key outcomes
| Area | Result |
| Licensing costs | Avoided external analytics application fees entirely |
| Storage costs | Reduced through S3 Intelligent-Tiering, which automatically moves data between access tiers based on usage patterns |
| Report generation | From over 4 hours (including data synchronization from Amazon S3 to the external analytics application) to under 30 minutes with direct Amazon S3 querying |
| Compliance audits | From weeks of manual investigation to days with automated lineage reports |
| Compute costs | Usage-based serverless model replaced always-on external analytics infrastructure |
| Collaboration | Unified browser-based environment for data scientists, analysts, and engineers |
“By adopting SageMaker Unified Studio, we as the Data Team eliminated legacy licensing costs, reduced storage and compute expenses with a serverless, usage-based model, and accelerated our periodic report generation. At the same time, we transformed compliance and collaboration by cutting audit timelines while unifying our teams in a single, efficient data environment.” – Komal Thakkar, AVP – Lead, Data Engineering, Avanse Financial Services
Best practices
Based on their experience, Avanse recommends:
- Start with a workshop. Validate your specific use cases in a 72-hour technical validation before committing to full migration.
- Migrate use cases, not code. Focus on what your analytics accomplish, then implement using cloud-native patterns rather than translating legacy scripts line by line.
- Invest in governance early. Implement the data catalog and lineage tracking from day one.
- Embrace project-based isolation. Organize around business functions for clear cost allocation and security boundaries.
- Document business logic. Use migration as an opportunity to capture undocumented knowledge in the business glossary and dataset descriptions.
Conclusion
Avanse’s migration from an external analytics application to Amazon SageMaker Unified Studio consolidated their analytics stack into a single integrated environment on AWS. By querying data directly in Amazon S3 instead of copying it into the external application, they alleviated their biggest operational bottleneck. Project-based isolation replaced a shared server model, giving each business unit independent compute and clear cost visibility. And centralized governance through SageMaker Catalog and IAM Identity Center gave their compliance team the audit trails they had been missing.
The serverless, usage-based model means Avanse no longer pays for idle capacity. The lakehouse architecture supports new analytics patterns as they emerge, and native integration with AWS services, including generative AI through Amazon Bedrock, positions them to adopt new capabilities as their needs evolve.
Next steps
Start your analytics modernization journey by scheduling a 72-hour technical validation workshop. Contact your AWS account team to discuss your migration approach.
For more information, see: