As we conclude Developer Week 2025, we’re proud to reflect upon the capabilities we’ve added to our developer platform. It’s so rewarding to deliver products, features and tools that help developers build smarter and ship faster, and even more so hearing your responses throughout the week!
Our VP of Product, Rita Kozlov, kicked off Developer Week 2025 discussing the ever-evolving landscape of development, particularly in the age of AI. AI is no longer just a buzzword or a trope for a science-fiction future — in the realm of modern development, it’s a core tenet (and utility) of how we build, innovate, and solve problems. It’s influencing how and how frequently we ship code, as well as enabling anyone to write it.
It’s exciting to not only witness this technical revolution, but also to be building a platform that enables developers to be part of it. We want to hear your feedback and see what you build with the new capabilities — reach out to us on Discord or X.
Here’s a recap of our Developer Week 2025 announcements:
Toolkit for AI agents includes new Agents SDK support for MCP (Model Context Protocol) clients, authentication/authorization/hibernation for MCP servers, and Durable Objects free tier.
Fully managed Retrieval-Augmented Generation (RAG) pipelines powered by Cloudflare’s global network and developer platform simplifies how you build and scale RAG pipelines to power your context-aware AI and search applications.
Workflows — a durable execution engine built directly on top of Workers — is Generally Available and production-ready with new human-in-the-loop capabilities, more scale, and more metrics.
Workers connect to your MySQL databases with Hyperdrive to deliver optimal performance for regional databases, with support for your favorite drivers and ORMs.
The Cloudflare Vite plugin integrates Vite, one of the most popular build tools for web development, with the Workers runtime. We announced the 1.0 release and official support for React Router v7.
You can now deploy static sites, full-stack, and stateful applications on Cloudflare Workers — the primitives are all here. Framework support for React Router v7, Astro, Vue, and more are generally available today, as is the Cloudflare Vite plugin.
We announced Cloudflare Realtime and RealtimeKit, a complete toolkit for shipping real-time audio and video apps in days with SDKs for Kotlin, React Native, Swift, JavaScript, and Flutter.
Securely store, manage, and deploy account level secrets to Cloudflare Workers through Cloudflare Secrets Store, available in beta — with role-based access control, audit logging, and Wrangler support.
Workers Observability powers up with General Availability of Workers Logs and new Query Builder to help you investigate log events across all of your Workers.
Cloudflare has been tracking and comparing our speed with other top networks since 2021. We take a look at how things have changed since our last update.
We’ve just shipped our new streaming ingestion service, Pipelines. And, we’ve acquired Arroyo, enabling us to bring new SQL-based, stateful transformations to Pipelines and R2.
We re-architected Super Slurper from the ground up using our Developer Platform — leveraging Cloudflare Workers, Durable Objects, and Queues — and improved transfer speeds to R2 by up to 5x.
We’re announcing Workers VPC: a global private network that allows applications deployed on Cloudflare Workers to connect to your legacy cloud infrastructure. Now, you can unlock access to your existing APIs and data in external clouds and build global, modern, cross-cloud apps on Workers.
Cloudflare’s Startup Program offers up to \$250,000 in credits for companies building on our Developer Platform across 4 tiers: \$5,000, \$25,000, \$100,000, and \$250,000.
Cloudflare Containers are coming this June. Run new types of workloads on our network with an experience that is simple, scalable, global and deeply integrated with Workers.
Workers AI inference is faster with speculative decoding & prefix caching. Use our new batch inference for handling large request volumes seamlessly. Build tailored AI apps with more LoRA options. Lastly, new models and a refreshed dashboard round out this Developer Week update for Workers AI.
Cloudflare replaced a queues-based architecture in our National Center for Missing & Exploited Children (NCMEC) reporting system with Cloudflare Workflows for a structured, retryable workflow that’s easier to debug and maintain.
With recent developments in Certificate Transparency (CT), Cloudflare built a next-generation CT log on top of Cloudflare’s Developer Platform.
Even though 2025 Developer Week has come to a close, we can’t wait to hear what you’re building and hope you’ll share it with us on X or Discord. If you’re looking to get started, check out our developer documentation.
Worker 앱을 구축하는 개발자는 필요한 인프라에 대해 걱정하지 않고 구축 중인 앱에만 집중하고 Cloudflare 네트워크의 이점을 활용할 수 있습니다. 개인 프로젝트부터 비즈니스 크리티컬 워크로드에 이르기까지 많은 앱에는 영구적인 데이터가 필요합니다. Workers는 키-값 및 개체 스토리지와 같이 개발자의 필요에 맞는 다양한 데이터베이스 및 스토리지 옵션을 제공합니다.
오늘날 많은 앱은 관계형 데이터베이스를 기반으로 구축됩니다. 이제 모든 사용자는 Cloudflare의 관계형 데이터베이스를 보완하는 D1을 이용할 수 있습니다. 2022년 말 알파 버전에서 2024년 4월 정식 출시(GA) 버전에 이르는 여정은 개발자가 관계형 데이터와 SQL에 익숙한 상태에서 프로덕션 워크로드를 구축할 수 있도록 하는 데 중점을 두었습니다.
D1이란 무엇인가요?
D1은 Cloudflare의 기본 제공 서버리스 관계형 데이터베이스입니다. Worker 앱의 경우, D1은 SQLite의 SQL 방언을 사용하는 SQL의 표현성과 Drizzle ORM과 같은 객체-관계 매퍼(ORM)를 비롯한 개발자 도구 통합을 제공합니다. D1은 Workers 또는 HTTP API를 통해 액세스할 수 있습니다.
서버리스는 프로비저닝이 필요 없고 Time Travel을 통한 기본적인 재해 복구와 사용량 기반 요금제를 의미합니다. D1에는 개발자가 프로덕션으로 전환하기 전에 D1을 실험해 볼 수 있는 넉넉한 무료 티어가 포함되어 있습니다.
데이터를 글로벌화하는 방법은 무엇일까요?
D1 GA는 안정성과 개발자 경험의 만족도를 높이는 데 주력해 왔습니다. 이제 Cloudflare는 전 세계에 분산되어 있는 앱에 더 나은 지원을 제공하기 위해 D1을 확장할 계획입니다.
Workers 모델에서 요청이 수신되면 가장 가까운 데이터 센터에서 서버리스 실행을 호출합니다. Worker 앱은 사용자 요청에 따라 전 세계적으로 확장할 수 있습니다. 그러나 앱 데이터는 중앙 집중식 데이터베이스에 저장되며, 글로벌 사용자 트래픽은 데이터 위치에 액세스하기 위해 왕복해야 합니다. 예를 들어, 오늘날 D1 데이터베이스는 단일 위치에 있습니다.
Workers는 자주 액세스하는 데이터 위치를 고려하기 위해 Smart Placement를 지원합니다. Smart Placement는 데이터베이스와 같은 중앙 집중식 백엔드 서비스에 더 가까운 곳에 있는 Worker를 호출하여 대기 시간을 줄이고 앱 성능을 개선합니다. Cloudflare는 글로벌 앱에서 Worker 배치를 다뤘지만, 데이터 배치 문제도 처리해야 합니다.
그렇다면 Cloudflare의 기본 제공 데이터베이스 솔루션인 D1이 어떻게 글로벌 앱의 데이터 배치를 더욱 효과적으로 지원할 수 있을까요? 해답은 비동기 읽기 복제에 있습니다.
비동기 읽기 복제란 무엇인가요?
Postgres, MySQL, SQL Server 또는 Oracle과 같은 데이터베이스에는 읽기복제본이라는 서버 유형이 있습니다. 이 서버는 거의 최신 상태의 읽기 전용 사본 역할을 하는 별도의 기본 데이터베이스 서버입니다. 관리자는 주 서버의 스냅샷에서 새 서버를 시작하고 주 서버가 복제본 서버에 업데이트를 비동기적으로 전송하도록 구성하여 읽기 복제본을 만듭니다. 업데이트가 비동기적으로 이루어지기 때문에 읽기 복제본은 주 서버의 현재 상태보다 늦어질 수 있습니다. 기본 서버와 복제본 서버 사이의 이러한 지연을 복제본지연이라고 하며, 읽기 복제본을 두 개 이상 보유할 수 있습니다.
비동기 읽기 복제는 데이터베이스 성능을 개선하기 위해 긴 시간 동안 검증된 솔루션입니다.
여러 복제본에 부하를 분산하여 처리량을 늘릴 수 있습니다.
복제본이 쿼리를 수행하는 사용자와 가까운 곳에 있으면 쿼리 대기 시간을 줄일 수 있습니다.
일부 데이터베이스 시스템은 동기 복제 기능도 제공합니다. 동기 복제 시스템에서는 모든 복제본이 쓰기를 확인할 때까지 기다려야 합니다. 동기 복제 시스템은 가장 느린 복제본과 같은 속도로 실행될 수 있으며 복제본에 장애가 발생하면 작업이 중단될 수 있습니다. 따라서 글로벌 규모로 성능을 개선하고 싶다면 동기 복제 사용을 최소화하는 것이 좋습니다!
읽기 복제본은 독립적으로 업데이트되기 때문에 각 복제본의 내용은 언제든지 달라질 수 있습니다. 주 복제본이든 읽기 복제본이든 모든 쿼리가 동일한 서버로 전송되는 경우 기본 데이터베이스가 지원하는 일관성 모델에 따라 결과가 일관성 있게 유지되어야 합니다. 읽기 복제본을 사용하는 경우 결과는 다소 오래된 것일 수도 있습니다.
읽기 복제본이 있는 서버 기반 데이터베이스를 사용할 때는 세션 내의 모든 쿼리에 동일한 서버를 일관되게 사용하는 것이 중요합니다. 동일한 세션 내에서 서로 다른 읽기 복제본으로 전환하게 되면 앱에서 설정된 일관성 모델이 손상될 수 있습니다. 이로 인해 데이터베이스 작동 방식에 대한 가정을 위반하여 앱에서 잘못된 결과가 반환될 수도 있습니다!
예시 A와 B라는 두 개의 복제본이 있다고 가정해 보겠습니다. 복제본 A는 기본 데이터베이스보다 100밀리초가, 복제본 B는 2초 지연됩니다. 사용자가 다음과 같은 상황을 원한다고 가정해 보겠습니다.
쿼리 1 실행
1a. 쿼리 1 결과를 기반으로 일부 계산
(1a)의 계산 결과를 기반으로 쿼리 2 실행
시간 t=10초가 되면 쿼리 1이 복제본 A로 이동하여 반환됩니다. 쿼리 1은 t=9.9초에서 기본 데이터베이스의 상태를 반영합니다. 계산을 처리하는 데 500밀리초가 걸린다고 가정하면, t=10.5초에서 쿼리 2가 복제본 B로 전송됩니다. 복제본 B는 기본 데이터베이스보다 2초 지연되므로, t=10.5초가 되면 쿼리 2는 t=8.5초의 데이터베이스 상태를 반영합니다. 앱의 관점에서 보면 쿼리 2의 결과는 마치 데이터베이스가 시간을 거슬러 올라간 것처럼 보입니다!
공식적으로 쿼리는 커밋된 데이터만 확인하기 때문에 이를 읽기 커밋된 일관성(read committed consistency)이라고 합니다. 그러나 다른 보장은 없으며, 심지어 사용자가 직접 작성한 데이터를 읽을 수도 없습니다. 읽기 커밋은 유효한 일관성 모델이지만, 읽기 커밋 모델이 허용하는 모든 잠재적 경쟁 조건을 추론하기는 어렵기 때문에 앱을 올바르게 작성하기 어렵습니다.
스냅샷 격리는 대부분의 개발자가 잘 알고 있으면서 쉽게 사용할 수 있는 일관성 모델입니다. Cloudflare는 D1 데이터베이스의 활성 복제본을 최대 하나로 유지하고 모든 HTTP 요청을 해당 단일 데이터베이스로 라우팅하는 방식으로 이 모델을 D1에 구현했습니다. D1 데이터베이스의 활성 복제본이 하나만 있도록 하는 것은 분산 시스템에서 복잡한 문제를 야기하지만, Cloudflare는 Durable Objects를 사용하여 D1을 구축함으로써 이 문제를 성공적으로 해결했습니다. Durable Objects는 전 세계적인 유일성을 보장하기 때문에 Cloudflare가 Durable Objects를 사용하게 되면, HTTP 요청을 D1 Durable Objects로 전송함으로써 쉽게 라우팅할 수 있습니다.
이 방법은 데이터베이스의 활성 복제본이 여러 개 있는 경우에는 효과가 없습니다. 이러한 경우, 수신되는 일반 HTTP 요청을 매번 동일한 복제본으로 일관되게 라우팅하는 100% 신뢰할 수 있는 방법이 없기 때문입니다. 이전 섹션의 예시에서 살펴본 것처럼, 관련 요청을 100% 동일한 복제본으로 라우팅하지 못하면 Cloudflare가 제공할 수 있는 최상의 일관성 모델은 읽기 커밋이 되는 결과를 초래합니다.
특정 복제본으로 일관되게 라우팅할 수 없는 경우, 또 다른 접근 방식은 요청을 임의의 복제본으로 라우팅하고 선택한 복제본이 프로그래머에게 ‘논리적인’ 일관성 모델에 따라 요청에 응답하도록 하는 것입니다. Cloudflare가 요청에 램포트 타임스탬프를 포함하면 어떤 복제본을 사용하든 ‘순차적 일관성’을 구현할 수 있습니다. 순차적 일관성 모델에는 ‘내가 쓴 것 읽기’, ‘읽기 작업 이후에 쓰기’와 같은 중요한 속성과 전체 쓰기 순서라는 속성이 있습니다. 전체 쓰기 순서는 모든 복제본이 동일한 순서로 트랜잭션이 커밋되는 것을 목격한다는 의미이며, 이는 Cloudflare가 트랜잭션 시스템에서 원하는 것과 정확히 일치합니다. 순차적 일관성에는 시스템의 개별 엔터티가 임의로 최신 상태가 아닐 수 있기에 주의해야 하지만, Cloudflare가 API를 설계할 때 복제본 지연을 고려할 수 있다는 점에서 이점이 되기도 합니다.
D1이 모든 데이터베이스 쿼리마다 앱에 램포트 타임스탬프를 제공하고 해당 앱이 마지막으로 확인한 램포트 타임스탬프를 D1에 알리면, Cloudflare는 각 복제본이 순차적 일관성 모델에 따라 쿼리의 작동 방식을 결정하도록 할 수 있다는 아이디어입니다.
복제본의 순차적 일관성을 달성하는 간단하면서도 효과적인 방법은 다음과 같습니다.
데이터베이스에 대한 모든 단일 요청에 램포트 타임스탬프를 할당합니다. 이 경우 값이 감소하기보다는 항상 단조적으로 증가하는(monotonically) 커밋 토큰이 원활하게 작동합니다.
전체 쓰기 작업 순서를 유지하려면 모든 쓰기 쿼리를 메인 데이터베이스로 전송합니다.
모든 복제본에 읽기 쿼리를 전송하되, 복제본이 쿼리의 램포트 타임스탬프 이후에 발생한 기본 데이터베이스의 업데이트를 받을 때까지 쿼리 서비스를 지연해야 합니다.
이 구현의 장점은 특히 읽기 중심 워크로드를 동일한 복제본으로 일관되게 전송하는 일반적인 경우에 속도가 빠르며, 다른 복제본으로 라우팅하는 요청도 처리할 수 있다는 점입니다.
미리 보기: 세션을 통해 D1에 읽기 복제 지원하기
D1에 읽기 복제를 도입하기 위해 세션이라는 새로운 개념을 통해 D1 API를 확장할 예정입니다. 세션은 앱의 단일 논리적 세션에 속하는 모든 쿼리를 캡슐화하는 역할을 합니다. 예를 들어, 세션은 특정 웹 브라우저나 모바일 앱에서 발생하는 모든 요청을 나타낼 수 있습니다. 세션을 사용하는 경우 쿼리에서는 기본 데이터베이스나 가까운 복제본 중 요청에 가장 적합한 D1 데이터베이스 복제본이 사용됩니다. D1의 세션 구현은 세션 내의 모든 쿼리에 대해 순차적 일관성을 보장합니다.
세션 API는 D1의 일관성 모델을 변경하므로 개발자는 새로운 API를 사용하도록 옵트인해야 합니다. 기존 D1 API 메서드는 동일하게 유지되며 이전과 동일한 스냅샷 격리 일관성 모델을 계속 사용할 수 있습니다. 그러나 신규 세션 API를 사용하여 만든 쿼리만 복제본을 사용합니다.
다음은 D1 세션 API의 예시입니다.
export default {
async fetch(request: Request, env: Env) {
// When we create a D1 Session, we can continue where we left off
// from a previous Session if we have that Session's last commit
// token. This Worker will return the commit token back to the
// browser, so that it can send it back on the next request to
// continue the Session.
//
// If we don't have a commit token, make the first query in this
// session an "unconditional" query that will use the state of the
// database at whatever replica we land on.
const token = request.headers.get('x-d1-token') ?? 'first-unconditional'
const session = env.DB.withSession(token)
// Use this Session for all our Workers' routes.
const response = await handleRequest(request, session)
if (response.status === 200) {
// Set the token so we can continue the Session in another request.
response.headers.set('x-d1-token', session.latestCommitToken)
}
return response
}
}
async function handleRequest(request: Request, session: D1DatabaseSession) {
const { pathname } = new URL(request.url)
if (pathname === '/api/orders/list') {
// This statement is a read query, so it will execute on any
// replica that has a commit equal or later than `token` we used
// to create the Session.
const { results } = await session.prepare('SELECT * FROM Orders').all()
return Response.json(results)
} else if (pathname === '/api/orders/add') {
const order = await request.json<Order>()
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session
.prepare('INSERT INTO Orders VALUES (?, ?, ?)')
.bind(order.orderName, order.customer, order.value)
.run()
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
// The Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session
.prepare('SELECT COUNT(*) FROM Orders')
.all()
return Response.json(results)
}
return new Response('Not found', { status: 404 })
}
D1은 세션 구현 시 커밋 토큰을 사용합니다. 커밋 토큰은 데이터베이스에 커밋된 특정 쿼리를 식별합니다. 세션 내에서 D1은 커밋 토큰을 사용하여 쿼리가 올바른 순서로 정렬되도록 보장합니다. 위 예시에서, Cloudflare가 대기 기간 동안 복제본을 전환하더라도 D1 세션은 신규 순서의 “INSERT” 이후에 “SELECT COUNT(*)” 쿼리가 실행되도록 합니다.
Workers 가져오기 핸들러에서 세션을 시작하는 방법에는 몇 가지 옵션이 있습니다. db.withSession(<condition>) 을 사용하면 다음과 같은 인수를 사용할 수 있습니다.
condition 인수
동작
<commit_token>
(1) 주어진 커밋 토큰으로 세션 시작
(2) 후속 쿼리가 순차적으로 일관성이 있는 경우
first-unconditional
(1) 첫 번째 쿼리가 읽기인 경우, 현재 복제본이 무엇이든 해당 쿼리를 읽고 해당 읽기의 커밋 토큰을 후속 쿼리의 기준으로 사용합니다. 첫 번째 쿼리가 쓰기인 경우, 쿼리를 기본으로 전달하고 쓰기의 커밋 토큰을 후속 쿼리의 기준으로 사용합니다.
(2) 후속 쿼리가 순차적으로 일관성이 있는 경우
first-primary
(1) 기본 쿼리(읽기 또는 쓰기)에 대해 첫 번째 쿼리 실행
(2) 후속 쿼리가 순차적으로 일관성이 있는 경우
null 또는 누락된 인수
first-unconditional 처럼 취급
세션의 마지막 쿼리에서 커밋 토큰을 ‘왕복(round-tripping)’하고 이를 사용하여 신규 세션을 시작하면 한 세션이 여러 요청에 걸쳐 있도록 할 수 있습니다. 이렇게 하면 웹 앱이나 모바일 앱과 같은 개별 사용자 에이전트가 사용자에게 일관된 순서로 쿼리를 표시할 수 있습니다.
D1의 읽기 복제는 추가 사용량이나 스토리지에 따른 비용 없이 기본으로 제공되며 복제본 구성이 필요하지 않습니다. Cloudflare는 앱의 D1 트래픽을 모니터링하고 데이터베이스 복제본을 자동으로 생성하여 사용자 트래픽을 사용자와 가까운 여러 서버로 분산합니다. Cloudflare의 서버리스 모델에 따라, D1 개발자는 복제본 프로비저닝 및 관리에 대해 걱정할 필요가 없습니다. 대신 개발자는 복제 및 데이터 일관성 절충안을 위한 앱 설계에 집중해야 합니다.
Cloudflare는 글로벌 읽기 복제 및 앞서 언급한 제안을 실현하기 위해 적극적으로 노력하고 있습니다(Cloudflare Developer Discord의 #d1 채널에서 피드백을 공유해 주세요). 그동안 D1 GA에는 몇 가지 흥미로운 새 기능이 추가될 예정입니다.
D1 GA 확인하기
2023년 10월 D1의 오픈 베타 이후, Cloudflare는 핵심 서비스에 필요한 안정성, 확장성, 개발자 경험에 집중해 왔습니다. 당사는 개발자가 D1으로 앱을 더 빠르게 빌드하고 디버깅할 수 있도록 몇 가지 새로운 기능에 투자했습니다.
더 큰 규모의 데이터베이스로 더 크게 구축하기 Cloudflare는 더 큰 데이터베이스가 필요하다는 개발자들의 의견에 귀를 기울였습니다. 그 결과, D1은 이제 최대 10GB 크기의 데이터베이스를 지원하며, Workers 유료 요금제에서는 사용자가 최대 50,000개의 데이터베이스를 보유할 수 있습니다. D1의 수평적 확장을 통해 앱은 각 비즈니스 엔터티의 데이터베이스 사용 사례를 모델링할 수 있습니다. 특히, 새로운 D1 데이터베이스는 베타 출시 이후 특정 기간 내에 D1 알파 데이터베이스에 비해 40배 더 많은 요청을 처리하는 것으로 나타났습니다.
가져오기 및 대용량 데이터 내보내기 개발자는 다음과 같은 여러 가지 이유로 데이터를 가져오거나 내보냅니다.
서로 다른 데이터베이스 시스템 간 데이터베이스 마이그레이션 테스트
로컬 개발 또는 테스트를 위한 데이터 복사
규정 준수와 같은 사용자 지정 요구 사항을 위한 수동 백업
이전에는 D1에 대해 SQL 파일을 실행할 수 있었습니다. 그러나 Cloudflare는 wrangler d1 execute –file=<filename> 을 개선하여 데이터베이스가 불완전한 상태로 남지 않도록 보장하고 있습니다. 또한 원격 프로덕션 데이터베이스를 보호하기 위해 이제 wrangler d1 execute 가 로컬 우선으로 기본 설정됩니다.
npx wrangler d1 create northwind-traders
# omit --remote to run on a local database for development
npx wrangler d1 execute northwind-traders --remote --file=./schema.sql
npx wrangler d1 execute northwind-traders --remote --file=./data.sql
다음 방법을 통해 D1 데이터베이스 데이터 및 스키마, 스키마 전용 또는 데이터 전용을 SQL 파일로 내보낼 수 있습니다.
# database schema & data
npx wrangler d1 export northwind-traders --remote --output=./database.sql
# single table schema & data
npx wrangler d1 export northwind-traders --remote --table='Employee' --output=./table.sql
# database schema only
npx wrangler d1 export <database_name> --remote --output=./database-schema.sql --no-data=true
쿼리 성능 디버깅 SQL 쿼리 성능을 이해하고 느린 쿼리를 디버깅하는 것은 프로덕션 워크로드에서 매우 중요한 단계입니다. Cloudflare는 개발자가 GraphQL API를 통해서도 쿼리 성능 메트릭을 분석할 수 있도록 실험적인 `wrangler d1 insights`를 추가했습니다.
# To find top 10 queries by average execution time:
npx wrangler d1 insights <database_name> --sort-type=avg --sort-by=time --count=10
개발자 도구 D1은 다양한 커뮤니티 개발자 프로젝트의 지원을 받고 있습니다. 이제 버전 5.12.0에서는 Prisma ORM을 비롯한 새로운 기능이 추가되어 Workers와 D1을 지원합니다.
다음 단계
현재 글로벌 읽기 복제 설계와 함께 정식 출시(GA)를 통해 제공되는 기능은 개발자 앱의 SQL 데이터베이스 요구 사항을 충족하기 위한 시작에 불과합니다. 아직 D1을 사용해 보지 않으셨다면 지금 바로 시작하시거나, D1의 개발자 문서를 방문하여 아이디어를 얻거나, Cloudflare Developer Discord의 #d1 채널에 참여하여 다른 D1 개발자 및 당사의 제품 엔지니어링 팀과 이야기를 나눌 수 있습니다.
Developers who build Worker applications focus on what they’re creating, not the infrastructure required, and benefit from the global reach of Cloudflare’s network. Many applications require persistent data, from personal projects to business-critical workloads. Workers offer various database and storage options tailored to developer needs, such as key-value and object storage.
Relational databases are the backbone of many applications today. D1, Cloudflare’s relational database complement, is now generally available. Our journey from alpha in late 2022 to GA in April 2024 focused on enabling developers to build production workloads with the familiarity of relational data and SQL.
What’s D1?
D1 is Cloudflare’s built-in, serverless relational database. For Worker applications, D1 offers SQL’s expressiveness, leveraging SQLite’s SQL dialect, and developer tooling integrations, including object-relational mappers (ORMs) like Drizzle ORM. D1 is accessible via Workers or an HTTP API.
Serverless means no provisioning, default disaster recovery with Time Travel, and usage-based pricing. D1 includes a generous free tier that allows developers to experiment with D1 and then graduate those trials to production.
How to make data global?
D1 GA has focused on reliability and developer experience. Now, we plan on extending D1 to better support globally-distributed applications.
In the Workers model, an incoming request invokes serverless execution in the closest data center. A Worker application can scale globally with user requests. Application data, however, remains stored in centralized databases, and global user traffic must account for access round trips to data locations. For example, a D1 database today resides in a single location.
Workers support Smart Placement to account for frequently accessed data locality. Smart Placement invokes a Worker closer to centralized backend services like databases to lower latency and improve application performance. We’ve addressed Workers placement in global applications, but need to solve data placement.
The question, then, is how can D1, as Cloudflare’s built-in database solution, better support data placement for global applications? The answer is asynchronous read replication.
What is asynchronous read replication?
In a server-based database management system, like Postgres, MySQL, SQL Server, or Oracle, a read replica is a separate database server that serves as a read-only, almost up-to-date copy of the primary database server. An administrator creates a read replica by starting a new server from a snapshot of the primary server and configuring the primary server to send updates asynchronously to the replica server. Since the updates are asynchronous, the read replica may be behind the current state of the primary server. The difference between the primary server and a replica is called replica lag. It’s possible to have more than one read replica.
Asynchronous read replication is a time-proven solution for improving the performance of databases:
It’s possible to increase throughput by distributing load across multiple replicas.
It’s possible to lower query latency when the replicas are close to the users making queries.
Note that some database systems also offer synchronous replication. In a synchronous replicated system, writes must wait until all replicas have confirmed the write. Synchronous replicated systems can run only as fast as the slowest replica and come to a halt when a replica fails. If we’re trying to improve performance on a global scale, we want to avoid synchronous replication as much as possible!
Consistency models & read replicas
Most database systems provide read committed, snapshot isolation, or serializable consistency models, depending on their configuration. For example, Postgres defaults to read committed but can be configured to use stronger modes. SQLite provides snapshot isolation in WAL mode. Stronger modes like snapshot isolation or serializable are easier to program against because they limit the permitted system concurrency scenarios and the kind of concurrency race conditions the programmer has to worry about.
Read replicas are updated independently, so each replica’s contents may differ at any moment. If all of your queries go to the same server, whether the primary or a read replica, your results should be consistent according to whatever consistency model your underlying database provides. If you’re using a read replica, the results may just be a little old.
In a server-based database with read replicas, it’s important to stick with the same server for all of the queries in a session. If you switch among different read replicas in the same session, you compromise the consistency model provided by your application, which may violate your assumptions about how the database acts and cause your application to return incorrect results!
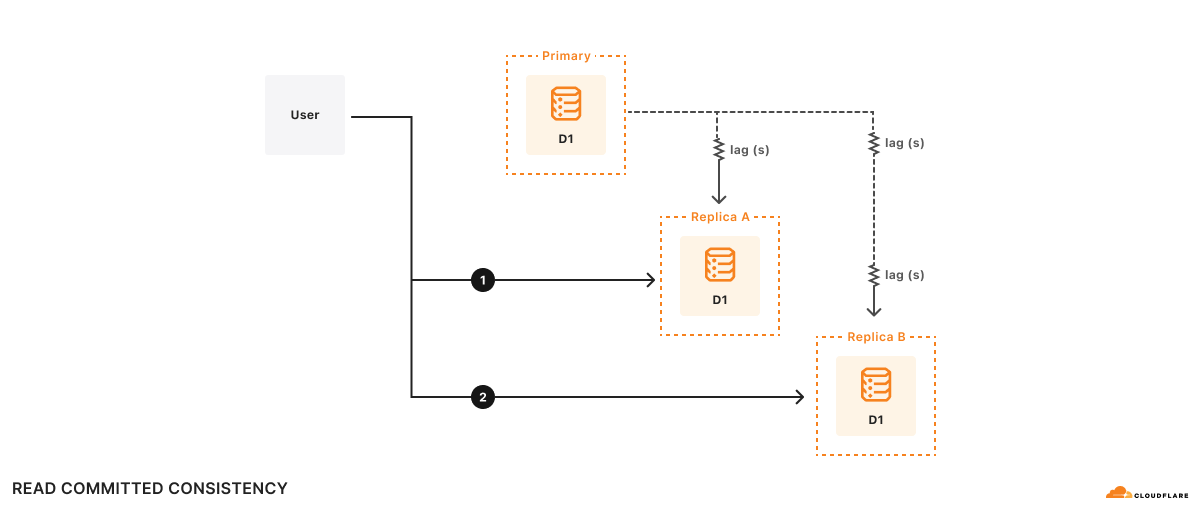
Example For example, there are two replicas, A and B. Replica A lags the primary database by 100ms, and replica B lags the primary database by 2s. Suppose a user wishes to:
Execute query 1
1a. Do some computation based on query 1 results
Execute query 2 based on the results of the computation in (1a)
At time t=10s, query 1 goes to replica A and returns. Query 1 sees what the primary database looked like at t=9.9s. Suppose it takes 500ms to do the computation, so at t=10.5s, query 2 goes to replica B. Remember, replica B lags the primary database by 2s, so at t=10.5s, query 2 sees what the database looks like at t=8.5s. As far as the application is concerned, the results of query 2 look like the database has gone backwards in time!
Formally, this is read committed consistency since your queries will only see committed data, but there’s no other guarantee – not even that you can read your own writes. While read committed is a valid consistency model, it’s hard to reason about all of the possible race conditions the read committed model allows, making it difficult to write applications correctly.
Snapshot isolation is a familiar consistency model that most developers find easy to use. We implement this consistency model in D1 by ensuring at most one active copy of the D1 database and routing all HTTP requests to that single database. While ensuring that there’s at most one active copy of the D1 database is a gnarly distributed systems problem, it’s one that we’ve solved by building D1 using Durable Objects. Durable Objects guarantee global uniqueness, so once we depend on Durable Objects, routing HTTP requests is easy: just send them to the D1 Durable Object.
This trick doesn’t work if you have multiple active copies of the database since there’s no 100% reliable way to look at a generic incoming HTTP request and route it to the same replica 100% of the time. Unfortunately, as we saw in the previous section’s example, if we don’t route related requests to the same replica 100% of the time, the best consistency model we can provide is read committed.
Given that it’s impossible to route to a particular replica consistently, another approach is to route requests to any replica and ensure that the chosen replica responds to requests according to a consistency model that “makes sense” to the programmer. If we’re willing to include a Lamport timestamp in our requests, we can implement sequential consistency using any replica. The sequential consistency model has important properties like “read my own writes” and “writes follow reads,” as well as a total ordering of writes. The total ordering of writes means that every replica will see transactions commit in the same order, which is exactly the behavior we want in a transactional system. Sequential consistency comes with the caveat that any individual entity in the system may be arbitrarily out of date, but that caveat is a feature for us because it allows us to consider replica lag when designing our APIs.
The idea is that if D1 gives applications a Lamport timestamp for every database query and those applications tell D1 the last Lamport timestamp they’ve seen, we can have each replica determine how to make queries work according to the sequential consistency model.
A robust, yet simple, way to implement sequential consistency with replicas is to:
Associate a Lamport timestamp with every single request to the database. A monotonically increasing commit token works well for this.
Send all write queries to the primary database to ensure the total ordering of writes.
Send read queries to any replica, but have the replica delay servicing the query until the replica receives updates from the primary database that are later than the Lamport timestamp in the query.
What’s nice about this implementation is that it’s fast in the common case where a read-heavy workload always goes to the same replica and will work even if requests get routed to different replicas.
Sneak Preview: bringing read replication to D1 with Sessions
To bring read replication to D1, we will expand the D1 API with a new concept: Sessions. A Session encapsulates all the queries representing one logical session for your application. For example, a Session might represent all requests coming from a particular web browser or all requests coming from a mobile app. If you use Sessions, your queries will use whatever copy of the D1 database makes the most sense for your request, be that the primary database or a nearby replica. D1’s Sessions implementation will ensure sequential consistency for all queries in the Session.
Since the Sessions API changes D1’s consistency model, developers must opt-in to the new API. Existing D1 API methods are unchanged and will still have the same snapshot isolation consistency model as before. However, only queries made using the new Sessions API will use replicas.
Here’s an example of the D1 Sessions API:
export default {
async fetch(request: Request, env: Env) {
// When we create a D1 Session, we can continue where we left off
// from a previous Session if we have that Session's last commit
// token. This Worker will return the commit token back to the
// browser, so that it can send it back on the next request to
// continue the Session.
//
// If we don't have a commit token, make the first query in this
// session an "unconditional" query that will use the state of the
// database at whatever replica we land on.
const token = request.headers.get('x-d1-token') ?? 'first-unconditional'
const session = env.DB.withSession(token)
// Use this Session for all our Workers' routes.
const response = await handleRequest(request, session)
if (response.status === 200) {
// Set the token so we can continue the Session in another request.
response.headers.set('x-d1-token', session.latestCommitToken)
}
return response
}
}
async function handleRequest(request: Request, session: D1DatabaseSession) {
const { pathname } = new URL(request.url)
if (pathname === '/api/orders/list') {
// This statement is a read query, so it will execute on any
// replica that has a commit equal or later than `token` we used
// to create the Session.
const { results } = await session.prepare('SELECT * FROM Orders').all()
return Response.json(results)
} else if (pathname === '/api/orders/add') {
const order = await request.json<Order>()
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session
.prepare('INSERT INTO Orders VALUES (?, ?, ?)')
.bind(order.orderName, order.customer, order.value)
.run()
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
// The Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session
.prepare('SELECT COUNT(*) FROM Orders')
.all()
return Response.json(results)
}
return new Response('Not found', { status: 404 })
}
D1’s implementation of Sessions makes use of commit tokens. Commit tokens identify a particular committed query to the database. Within a session, D1 will use commit tokens to ensure that queries are sequentially ordered. In the example above, the D1 session ensures that the “SELECT COUNT(*)” query happens after the “INSERT” of the new order, even if we switch replicas between the awaits.
There are several options on how you want to start a session in a Workers fetch handler. db.withSession(<condition>) accepts these arguments:
condition argument
Behavior
<commit_token>
(1) starts Session as of given commit token
(2) subsequent queries have sequential consistency
first-unconditional
(1) if the first query is read, read whatever current replica has and use the commit token of that read as the basis for subsequent queries. If the first query is a write, forward the query to the primary and use the commit token of the write as the basis for subsequent queries.
(2) subsequent queries have sequential consistency
first-primary
(1) runs first query, read or write, against the primary
(2) subsequent queries have sequential consistency
null or missing argument
treated like first-unconditional
It’s possible to have a session span multiple requests by “round-tripping” the commit token from the last query of the session and using it to start a new session. This enables individual user agents, like a web app or a mobile app, to make sure that all of the queries the user sees are sequentially consistent.
D1’s read replication will be built-in, will not incur extra usage or storage costs, and will require no replica configuration. Cloudflare will monitor an application’s D1 traffic and automatically create database replicas to spread user traffic across multiple servers in locations closer to users. Aligned with our serverless model, D1 developers shouldn’t worry about replica provisioning and management. Instead, developers should focus on designing applications for replication and data consistency tradeoffs.
We’re actively working on global read replication and realizing the above proposal (share feedback In the #d1 channel on our Developer Discord). Until then, D1 GA includes several exciting new additions.
Check out D1 GA
Since D1’s open beta in October 2023, we’ve focused on D1’s reliability, scalability, and developer experience demanded of critical services. We’ve invested in several new features that allow developers to build and debug applications faster with D1.
Build bigger with larger databases We’ve listened to developers who requested larger databases. D1 now supports up to 10GB databases, with 50K databases on the Workers Paid plan. With D1’s horizontal scaleout, applications can model database-per-business-entity use cases. Since beta, new D1 databases process 40x more requests than D1 alpha databases in a given period.
Import & export bulk data Developers import and export data for multiple reasons:
Database migration testing to/from different database systems
Data copies for local development or testing
Manual backups for custom requirements like compliance
While you could execute SQL files against D1 before, we’re improving wrangler d1 execute –file=<filename> to ensure large imports are atomic operations, never leaving your database in a halfway state. wrangler d1 execute also now defaults to local-first to protect your remote production database.
To import our Northwind Traders demo database, you can download the schema & data and execute the SQL files.
npx wrangler d1 create northwind-traders
# omit --remote to run on a local database for development
npx wrangler d1 execute northwind-traders --remote --file=./schema.sql
npx wrangler d1 execute northwind-traders --remote --file=./data.sql
D1 database data & schema, schema-only, or data-only can be exported to a SQL file using:
# database schema & data
npx wrangler d1 export northwind-traders --remote --output=./database.sql
# single table schema & data
npx wrangler d1 export northwind-traders --remote --table='Employee' --output=./table.sql
# database schema only
npx wrangler d1 export <database_name> --remote --output=./database-schema.sql --no-data=true
Debug query performance Understanding SQL query performance and debugging slow queries is a crucial step for production workloads. We’ve added the experimental wrangler d1 insights to help developers analyze query performance metrics also available via GraphQL API.
# To find top 10 queries by average execution time:
npx wrangler d1 insights <database_name> --sort-type=avg --sort-by=time --count=10
Developer tooling Various community developer projects support D1. New additions include Prisma ORM, in version 5.12.0, which now supports Workers and D1.
Next steps
The features available now with GA and our global read replication design are just the start of delivering the SQL database needs for developer applications. If you haven’t yet used D1, you can get started right now, visit D1’s developer documentation to spark some ideas, or join the #d1 channel on our Developer Discord to talk to other D1 developers and our product engineering team.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.