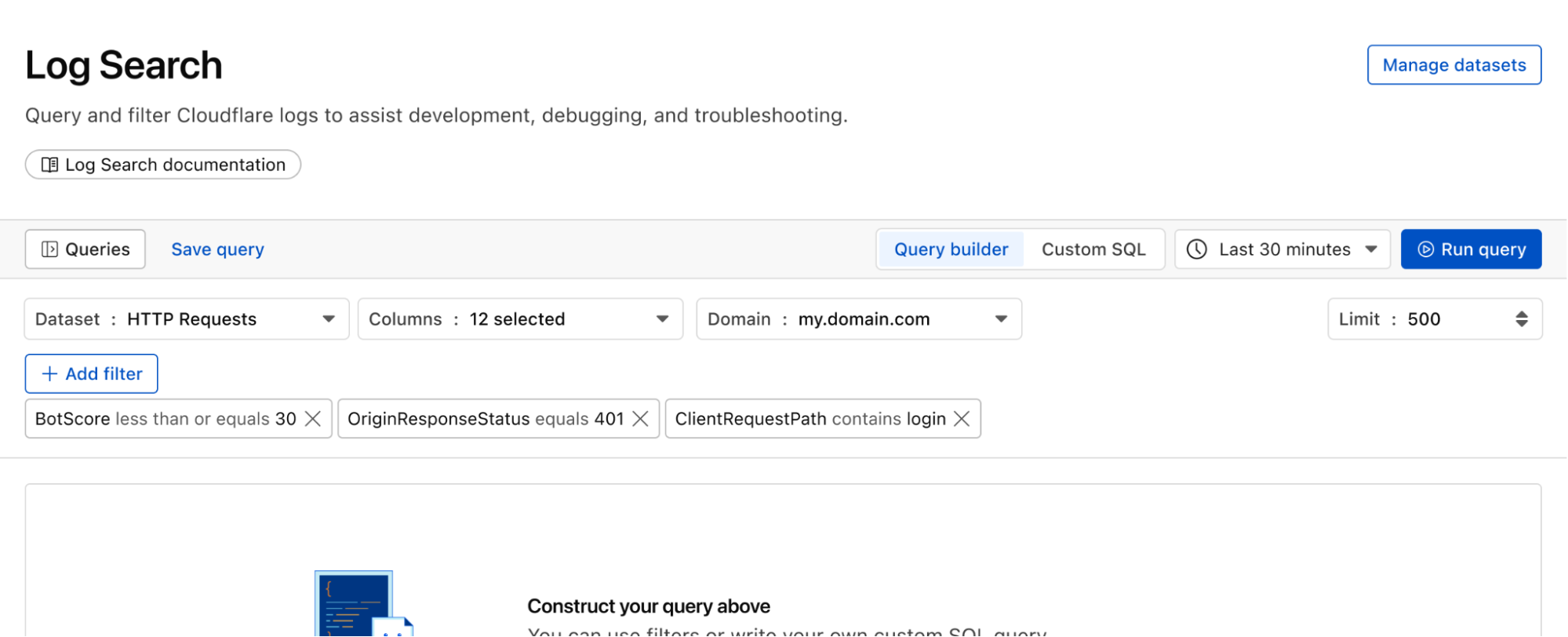
We have some big news to share today: Replicate, the leading platform for running AI models, is joining Cloudflare.
We first started talking to Replicate because we shared a lot in common beyond just a passion for bright color palettes. Our mission for Cloudflare’s Workers developer platform has been to make building and deploying full-stack applications as easy as possible. Meanwhile, Replicate has been on a similar mission to make deploying AI models as easy as writing a single line of code. And we realized we could build something even better together by integrating the Replicate platform into Cloudflare directly.
We are excited to share this news and even more excited for what it will mean for customers. Bringing Replicate’s tools into Cloudflare will continue to make our Developer Platform the best place on the Internet to build and deploy any AI or agentic workflow.
What does this mean for you?
Before we spend more time talking about the future of AI, we want to answer the questions that are top of mind for Replicate and Cloudflare users. In short:
For existing Replicate users: Your APIs and workflows will continue to work without interruption. You will soon benefit from the added performance and reliability of Cloudflare’s global network.
For existing Workers AI users: Get ready for a massive expansion of the model catalog and the new ability to run fine-tunes and custom models directly on Workers AI.
Now – let’s get back into why we’re so excited about our joint future.
The AI Revolution was not televised, but it started with open source
Before AI was AI, and the subject of every conversation, it was known for decades as “machine learning”. It was a specialized, almost academic field. Progress was steady but siloed, with breakthroughs happening inside a few large, well-funded research labs. The models were monolithic, the data was proprietary, and the tools were inaccessible to most developers. Everything changed when the culture of open-source collaboration — the same force that built the modern Internet — collided with machine learning, as researchers and companies began publishing not just their papers, but their model weights and code.
This ignited an incredible explosion of innovation. The pace of change in just the past few years has been staggering; what was state-of-the-art 18 months ago (or sometimes it feels like just days ago) is now the baseline. This acceleration is most visible in generative AI.
We went from uncanny, blurry curiosities to photorealistic image generation in what felt like the blink of an eye. Open source models like Stable Diffusion unlocked immediate creativity for developers, and that was just the beginning. If you take a look at Replicate’s model catalog today, you’ll see thousands of image models of almost every flavor, each iterating on the previous.
This happened not just with image models, but video, audio, language models and more….
But this incredible, community-driven progress creates a massive practical challenge: How do you actually run these models? Every new model has different dependencies, requires specific GPU hardware (and enough of it), and needs a complex serving infrastructure to scale. Developers found themselves spending more time fighting with CUDA drivers and requirements.txt files than actually building their applications.
This is exactly the problem Replicate solved. They built a platform that abstracts away all that complexity (using their open-source tool Cog to package models into standard, reproducible containers), letting any developer or data scientist run even the most complex open-source models with a simple API call.
Today, Replicate’s catalog spans more than 50,000 open-source models and fine-tuned models. While open source unlocked so many possibilities, Replicate’s toolset goes beyond that to make it possible for developers to access any models they need in one place. Period. With their marketplace, they also offer seamless access to leading proprietary models like GPT-5 and Claude Sonnet, all through the same unified API.
What’s worth noting is that Replicate didn’t just build an inference service; they built a community. So much innovation happens through being inspired by what others are doing, iterating on it, and making it better. Replicate has become the definitive hub for developers to discover, share, fine-tune, and experiment with the latest models in a public playground.
Stronger together: the AI catalog meets the AI cloud
Coming back to the Workers Platform mission: Our goal all along has been to enable developers to build full-stack applications without having to burden themselves with infrastructure. And while that hasn’t changed, AI has changed the requirements of applications.
The types of applications developers are building are changing — three years ago, no one was building agents or creating AI-generated launch videos. Today they are. As a result, what they need and expect from the cloud, or the AI cloud, has changed too.
To meet the needs of developers, Cloudflare has been building the foundational pillars of the AI Cloud, designed to run inference at the edge, close to users. This isn’t just one product, but an entire stack:
Workers AI: Serverless GPU inference on our global network.
AI Gateway: A control plane for caching, rate-limiting, and observing any AI API.
Data Stack: Including Vectorize (our vector database) and R2 (for model and data storage).
Orchestration: Tools like AI Search (formerly Autorag), Agents, and Workflows to build complex, multi-step applications.
Foundation: All built on our core developer platform of Workers, Durable Objects, and the rest of our stack.
As we’ve been helping developers scale up their applications, Replicate has been on a similar mission — to make deploying AI models as easy as deploying code. This is where it all comes together. Replicate brings one of the industry’s largest and most vibrant model catalog and developer community. Cloudflare brings an incredibly performant global network and serverless inference platform. Together, we can deliver the best of both worlds: the most comprehensive selection of models, runnable on a fast, reliable, and affordable inference platform.
Our shared vision
For the community: the hub for AI exploration
The ability to share models, publish fine-tunes, collect stars, and experiment in the playground is the heart of the Replicate community. We will continue to invest in and grow this as the premier destination for AI discovery and experimentation, now supercharged by Cloudflare’s global network for an even faster, more responsive experience for everyone.
The future of inference: one platform, all models
Our vision is to bring the best of both platforms together. We will bring the entire Replicate catalog — all 50,000+ models and fine-tunes — to Workers AI. This gives you the ultimate choice: run models in Replicate’s flexible environment or on Cloudflare’s serverless platform, all from one place.
But we’re not just expanding the catalog. We are thrilled to announce that we will be bringing fine-tuning capabilities to Workers AI, powered by Replicate’s deep expertise. We are also making Workers AI more flexible than ever. Soon, you’ll be able to bring your own custom models to our network. We’ll leverage Replicate’s expertise with Cog to make this process seamless, reproducible, and easy.
The AI Cloud: more than just inference
Running a model is just one piece of the puzzle. The real magic happens when you connect AI to your entire application. Imagine what you can build when Replicate’s massive catalog is deeply integrated with the entire Cloudflare developer platform: run a model and store the results directly in R2 or Vectorize; trigger inference from a Worker or Queue; use Durable Objects to manage state for an AI agent; or build real-time generative UI with WebRTC and WebSockets.
To manage all this, we will integrate our unified inference platform deeply with the AI Gateway, giving you a single control plane for observability, prompt management, A/B testing, and cost analytics across all your models, whether they’re running on Cloudflare, Replicate, or any other provider.
Welcome to the team!
We are incredibly excited to welcome the Replicate team to Cloudflare. Their passion for the developer community and their expertise in the AI ecosystem are unmatched. We can’t wait to build the future of AI together.
Cloudflare Workflows is our take on “Durable Execution.” They provide a serverless engine, powered by the Cloudflare Developer Platform, for building long-running, multi-step applications that persist through failures. When Workflows became generally available earlier this year, they allowed developers to orchestrate complex processes that would be difficult or impossible to manage with traditional stateless functions. Workflows handle state, retries, and long waits, allowing you to focus on your business logic.
However, complex orchestrations require robust testing to be reliable. To date, testing Workflows was a black-box process. Although you could test if a Workflow instance reached completion through an await to its status, there was no visibility into the intermediate steps. This made debugging really difficult. Did the payment processing step succeed? Did the confirmation email step receive the correct data? You couldn’t be sure without inspecting external systems or logs.
Why was this necessary?
As developers ourselves, we understand the need to ensure reliable code, and we heard your feedback loud and clear: the developer experience for testing Workflows needed to be better.
The black box nature of testing was one part of the problem. Beyond that, though, the limited testing offered came at a high cost. If you added a workflow to your project, even if you weren’t testing the workflow directly, you were required to disable isolated storage because we couldn’t guarantee isolation between tests. Isolated storage is a vitest-pool-workers feature to guarantee that each test runs in a clean, predictable environment, free from the side effects of other tests. Being forced to have it disabled meant that state could leak between tests, leading to flaky, unpredictable, and hard-to-debug failures.
This created a difficult choice for developers building complex applications. If your project used Workers, Durable Objects, and R2 alongside Workflows, you had to either abandon isolated testing for your entire project or skip testing. This friction resulted in a poor testing experience, which in turn discouraged the adoption of Workflows. Solving this wasn’t just an improvement, it was a critical step in making Workflows part of any well-tested Cloudflare application.
Introducing isolated testing for Workflows
We’re introducing a new set of APIs that enable comprehensive, granular, and isolated testing for your Workflows, all running locally and offline with vitest-pool-workers, our testing framework that supports running tests in the Workers runtime workerd. This enables fast, reliable, and cheap test runs that don’t depend on a network connection.
They are available through the cloudflare:test module, with @cloudflare/vitest-pool-workers version 0.9.0 and above. The new test module provides two primary functions to introspect your Workflows:
introspectWorkflowInstance: useful for unit tests with known instance IDs
introspectWorkflow: useful for integration tests where IDs are typically generated dynamically.
Let’s walk through a practical example.
A practical example: testing a blog moderation workflow
Imagine a simple Workflow for moderating a blog. When a user submits a comment, the Workflow requests a review from workers-ai. Based on the violation score returned, it then waits for a moderator to approve or deny the comment. If approved, it calls a step.do to publish the comment via an external API.
Testing this without our new APIs would be impossible. You’d have no direct way to simulate the step’s outcomes and simulate the moderator’s approval. Now, you can mock everything.
Here’s the test code using introspectWorkflowInstance with a known instance ID:
This test mocks the outcomes of steps that require external API calls, such as the ‘AI content scan’, which calls Workers AI, and the ‘publish comment’ step, which calls an external blog API.
If the instance ID is not known, because you are either making a worker request that starts one/multiple Workflow instances with random generated ids, you can call introspectWorkflow(env.MY_WORKFLOW). Here’s the test code for that scenario, where only one Workflow instance is created:
Notice how in both examples we’re calling the introspectors with await using – this is the Explicit Resource Management syntax from modern JavaScript. It is crucial here because when the introspector objects go out of scope at the end of the test, its disposal method is automatically called. This is how we ensure each test works with its own isolated storage.
The modify and modifyAll functions are the gateway to controlling instances. Inside its callback, you get access to a modifier object with methods to inject behavior such as mocking step outcomes, events and disabling sleeps.
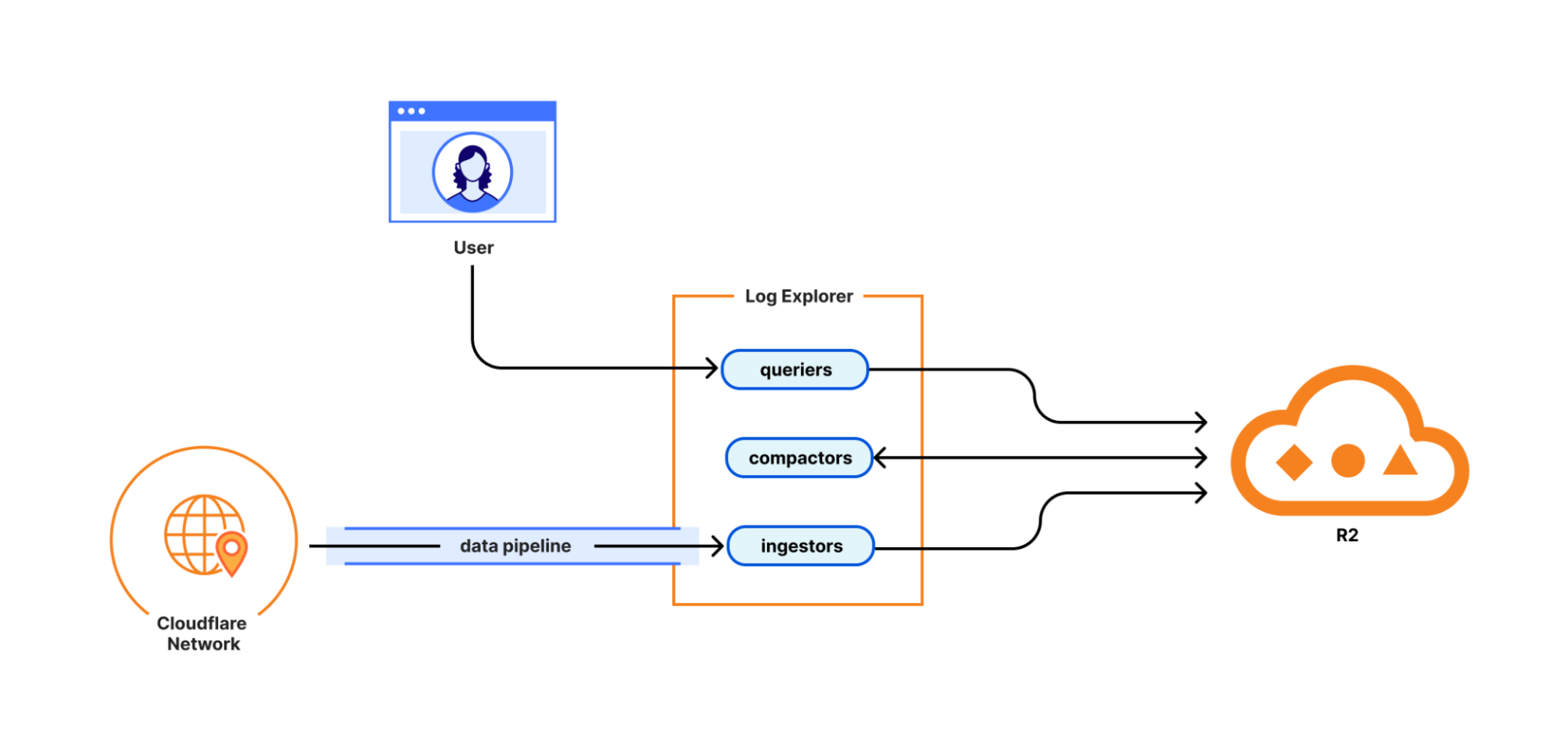
To understand the solution, you first need to understand the local architecture. When you run wrangler dev, your Workflows are powered by Miniflare, a simulator for testing Cloudflare Workers, and workerd. Each running workflow instance is backed by its own SQLite Durable Object, which we call the “Engine DO”. This Engine DO is responsible for executing steps, persisting state, and managing the instance’s lifecycle. It lives inside the local isolated Workers runtime.
Meanwhile, the Vitest test runner is a separate Node.js process living outside of workerd. This is why we have a Vitest custom pool that allows tests to run inside workerd called vitest-pool-workers. Vitest-pool-workers has a Runner Worker, which is a worker to run the tests with bindings to everything specified in the user wrangler.json file. This worker has access to the APIs under the “cloudflare:test” module. It communicates with Node.js through a special DO called Runner Object via WebSocket/RPC.
The first approach we considered was to use the test runner worker. In its current state, Runner worker has access to Workflow bindings from Workflows defined on the wrangler file. We considered also binding each Workflow’s Engine DO namespace to this runner worker. This would give vitest-pool-workers direct access to the Engine DOs where it would be possible to directly call Engine methods.
While promising, this approach would have required undesirable changes to the core of Miniflare and vitest-pool-workers, making it too invasive for this single feature.
Firstly, we would have needed to add a new unsafe field to Miniflare’s Durable Objects. Its sole purpose would be to specify the service name of our Engines, preventing Miniflare from applying its default user prefix which would otherwise prevent the Durable Objects from being found.
Secondly, vitest-pool-workers would have been forced to bind every Engine DO from the Workflows in the project to its runner, even those not being tested. This would introduce unwanted bindings into the test environment, requiring an additional cleanup to ensure they were not exposed to the user’s tests env.
The breakthrough
The solution is a combination of privileged local-only APIs and Remote Procedure Calls (RPC).
First, we added a set of unsafe functions to the local implementation of the Workflows binding, functions that are not available in the production environment. They act as a controlled access point, accessible from the test environment, allowing the test runner to get a stub to a specific Engine DO by providing its instance ID.
Once the test runner has this stub, it uses RPC to call specific, trusted methods on the Engine DO via a special RpcTarget called WorkflowInstanceModifier. Any class that extends RpcTarget has its objects replaced by a stub. Calling a method on this stub, in turn, makes an RPC back to the original object.
This simpler approach is far less invasive because it’s confined to the Workflows environment, which also ensures any future feature changes are safely isolated.
Introspecting Workflows with unknown IDs
When creating Workflows instances (either by create() or createBatch()) developers can provide a specific ID or have it automatically generated for them. This ID identifies the Workflow instance and is then used to create the associated Engine DO ID.
The logical starting point for implementation was introspectWorkflowInstance(binding, instanceID), as the instance ID is known in advance. This allows us to generate the Engine DO ID required to identify the engine associated with that Workflow instance.
But often, one part of your application (like an HTTP endpoint) will create a Workflow instance with a randomly generated ID. How can we introspect an instance when we don’t know its ID until after it’s created?
The answer was to use a powerful feature of JavaScript: Proxy objects.
When you use introspectWorkflow(binding), we wrap the Workflow binding in a Proxy. This proxy non-destructively intercepts all calls to the binding, specifically looking for .create() and .createBatch(). When your test triggers a workflow creation, the proxy inspects the call. It captures the instance ID — either one you provided or the random one generated — and immediately sets up the introspection on that ID, applying all the modifications you defined in the modifyAll call. The original creation call then proceeds as normal.
env[workflow] = new Proxy(env[workflow], {
get(target, prop) {
if (prop === "create") {
return new Proxy(target.create, {
async apply(_fn, _this, [opts = {}]) {
// 1. Ensure an ID exists
const optsWithId = "id" in opts ? opts : { id: crypto.randomUUID(), ...opts };
// 2. Apply test modifications before creation
await introspectAndModifyInstance(optsWithId.id);
// 3. Call the original 'create' method
return target.create(optsWithId);
},
});
}
// Same logic for createBatch()
}
}
When the await using block from introspectWorkflow() finishes, or the dispose() method is called at the end of the test, the introspector is disposed of, and the proxy is removed, leaving the binding in its original state. It’s a low-impact approach that prioritizes developer experience and long-term maintainability.
Get started with testing Workflows
Ready to add tests to your Workflows? Here’s how to get started:
Update your dependencies: Make sure you are using @cloudflare/vitest-pool-workers version 0.9.0 or newer. Run the following command in your project: npm install @cloudflare/vitest-pool-workers@latest
Start writing tests: Import introspectWorkflowInstance or introspectWorkflow from cloudflare:test in your test files and use the patterns shown in this post to mock, control, and assert on your Workflow’s behavior. Also check out the official API reference.
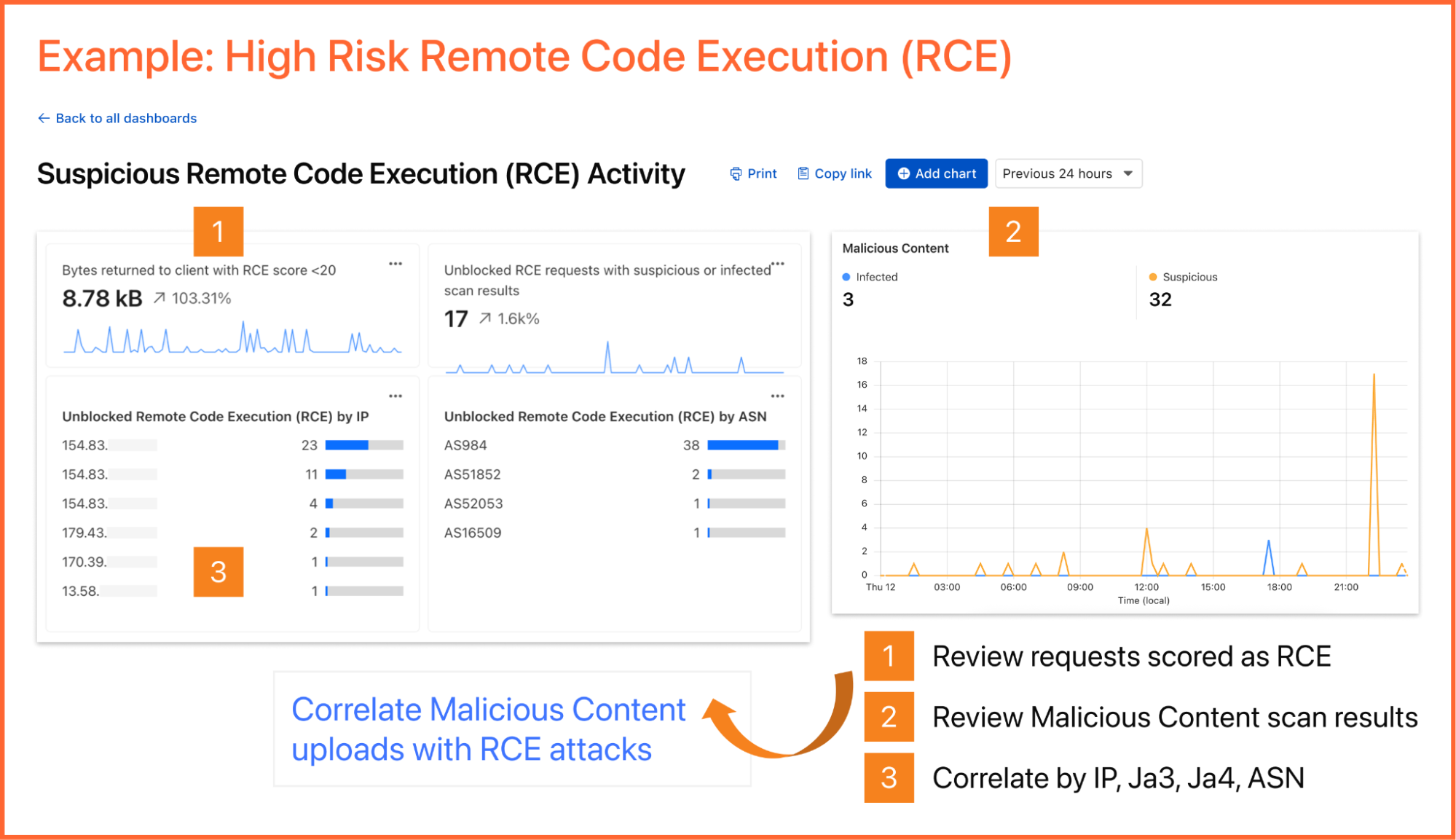
In early September 2025, attackers used a phishing email to compromise one or more trusted maintainer accounts on npm. They used this to publish malicious releases of 18 widely used npm packages (for example chalk, debug, ansi-styles) that account for more than 2 billion downloads per week. Websites and applications that used these compromised packages were vulnerable to hackers stealing crypto assets (“crypto stealing” or “wallet draining”) from end users. In addition, compromised packages could also modify other packages owned by the same maintainers (using stolen npm tokens) and included code to steal developer tokens for CI/CD pipelines and cloud accounts.
As it relates to end users of your applications, the good news is that Cloudflare Page Shield, our client-side security offering will detect compromised JavaScript libraries and prevent crypto-stealing. More importantly, given the AI powering Cloudflare’s detection solutions, customers are protected from similar attacks in the future, as we explain below.
Excerpt from the injected malicious payload, along with the rest of the innocuous normal code.Among other things, the payload replaces legitimate crypto addresses with attacker’s addresses (for multiple currencies, including bitcoin, ethereum, solana).
Finding needles in a 3.5 billion script haystack
Everyday, Cloudflare Page Shield assesses 3.5 billion scripts per day or 40,000 scripts per second. Of these, less than 0.3% are malicious, based on our machine learning (ML)-based malicious script detection. As explained in a prior blog post, we preprocess JavaScript code into an Abstract Syntax Tree to train a message-passing graph convolutional network (MPGCN) that classifies a given JavaScript file as either malicious or benign.
The intuition behind using a graph-based model is to use both the structure (e.g. function calling, assertions) and code text to learn hacker patterns. For example, in the npm compromise, the malicious code injected in compromised packages uses code obfuscation and also modifies code entry points for crypto wallet interfaces, such as Ethereum’s window.ethereum, to swap payment destinations to accounts in the attacker’s control. Crucially, rather than engineering such behaviors as features, the model learns to distinguish between good and bad code purely from structure and syntax. As a result, it is resilient to techniques used not just in the npm compromise but also future compromise techniques.
Our ML model outputs the probability that a script is malicious which is then transformed into a score ranging from 1 to 99, with low scores indicating likely malicious and high scores indicating benign scripts. Importantly, like many Cloudflare ML models, inferencing happens in under 0.3 seconds.
Model Evaluation
Since the initial launch, our JavaScript classifiers are constantly being evolved to optimize model evaluation metrics, in this case, F1 measure. Our current metrics are
Metric
Latest: Version 2.7
Improvement over prior version
Precision
98%
5%
Recall
90%
233%
F1
94%
123%
Some of the improvements were accomplished through:
More training examples, curated from a combination of open source datasets, security partners, and labeling of Cloudflare traffic
Better training examples, for instance, by removing samples with pure comments in them or scripts with nearly equal structure
Better training set stratification, so that training, validation and test sets all have similar distribution of classes of interest
Tweaking the evaluation criteria to maximize recall with 99% precision
Given the confusion matrix, we should expect about 2 false positives per second, if we assume ~0.3% of the 40,000 scripts per second are flagged as malicious. We employ multiple LLMs alongside expert human security analysts to review such scripts around the clock. Most False Positives we encounter in this way are rather challenging. For example, scripts that read all form inputs except credit card numbers (e.g. reject input values that test true using the Luhn algorithm), injecting dynamic scripts, heavy user tracking, heavy deobfuscation, etc. User tracking scripts often exhibit a combination of these behaviors, and the only reliable way to distinguish truly malicious payloads is by assessing the trustworthiness of their connected domains. We feed all newly labeled scripts back into our ML training (& testing) pipeline.
Most importantly, we verified that Cloudflare Page Shield would have successfully detected all 18 compromised npm packages as malicious (a novel attack, thus, not in the training data)..
Planned improvements
Static script analysis has proven effective and is sometimes the only viable approach (e.g., for npm packages). To address more challenging cases, we are enhancing our ML signals with contextual data including script URLs, page hosts, and connected domains. Modern Agentic AI approaches can wrap JavaScript runtimes as tools in an overall AI workflow. Then, they can enable a hybrid approach that combines static and dynamic analysis techniques to tackle challenging false positive scenarios, such as user tracking scripts.
In the npm attack, we did not see any activity in the Cloudflare network related to this compromise among Page Shield users, though for other exploits, we catch its traffic within minutes. In this case, patches of the compromised npm packages were released in 2 hours or less, and given that the infected payloads had to be built into end user facing applications for end user impact, we suspect that our customers dodged the proverbial bullet. That said, had traffic gotten through, Page Shield was already equipped to detect and block this threat.
Also make sure to consult our Page Shield Script detection to find malicious packages. Consult the Connections tab within Page Shield to view suspicious connections made by your applications.
Several scripts are marked as malicious.
Several connections are marked as malicious.
And be sure to complete the following steps:
Audit your dependency tree for recently published versions (check package-lock.json / npm ls) and look for versions published around early–mid September 2025 of widely used packages.
Rotate any credentials that may have been exposed to your build environment.
Revoke and reissue CI/CD tokens and service keys that might have been used in build pipelines (GitHub Actions, npm tokens, cloud credentials).
Pin dependencies to known-good versions (or use lockfiles), and consider using a package allowlist / verified publisher features from your registry provider.
Scan build logs and repos for suspicious commits/GitHub Actions changes and remove any unknown webhooks or workflows.
While vigilance is key, automated defenses provide a crucial layer of protection against fast-moving supply chain attacks. Interested in better understanding your client-side supply chain? Sign up for our free, custom Client-Side Risk Assessment.
The era of agentic commerce is coming, and it brings with it significant new challenges for security. That’s why Cloudflare is partnering with Visa and Mastercard to help secure automated commerce as AI agents search, compare, and purchase on behalf of consumers.
Through our collaboration, Visa developed the Trusted Agent Protocol and Mastercard developed Agent Pay to help merchants distinguish legitimate, approved agents from malicious bots. Both Trusted Agent Protocol and Agent Pay leverage Web Bot Auth as the agent authentication layer to allow networks like Cloudflare to verify traffic from AI shopping agents that register with a payment network.
The challenges with agentic commerce
Agentic commerce is commerce driven by AI agents. As AI agents execute more transactions, merchants need to protect themselves and maintain trust with their customers. Merchants are beginning to see the promise of agentic commerce but face significant challenges:
How can they distinguish a helpful, approved AI shopping agent from a malicious bot or web crawler?
Is the agent representing a known, repeat customer or someone entirely new?
Are there particular instructions the consumer gave to their agent that the merchant should respect?
We are working with Visa and Mastercard, two of the most trusted consumer brands in payments, to address each of these challenges.
Web Bot Auth is the foundation to securing agentic commerce
In May, we shared a new proposal called Web Bot Auth to cryptographically authenticate agent traffic. Historically, agent traffic has been classified using the user agent and IP address. However, these fields can be spoofed, leading to inaccurate classifications and bot mitigations can be applied inaccurately. Web Bot Auth allows an agent to provide a stable identifier by using HTTP Message Signatures with public key cryptography.
As we spent time collaborating with the teams at Visa and Mastercard, we found that we could leverage Web Bot Auth as the foundation to ensure that each commerce agent request was verifiable, time-based, and non-replayable.
Visa’s Trusted Agent Protocol and Mastercard’s Agent Pay present three key solutions for merchants to manage agentic commerce transactions. First, merchants can identify a registered agent and distinguish whether a particular interaction is intended to browse or to pay. Last, merchants can indicate to agents how a payment is expected, whether that is through a network token, browser-use guest checkout, or a micropayment.
This allows merchants that integrate with these protocols to instantly recognize a trusted agent during two key interactions: the initial browsing phase to determine product details and final costs, and the final payment interaction to complete a purchase. Ultimately, this provides merchants with the tools to verify these signatures, identify trusted interactions, and securely manage how these agents can interact with their site.
How it works: leveraging HTTP message signatures
To make this work, an ecosystem of participants need to be on the same page. It all starts with agentdevelopers, who build the agents to shop on behalf of consumers. These agents then interact with merchants, who need a reliable way to assess the request is made on behalf of consumers. Merchants rely on networks like Cloudflare to verify the agent’s cryptographic signatures and ensure the interaction is legitimate. Finally, there are payment networks like Visa and Mastercard, who can link cardholder identity to agentic commerce transactions, helping ensure that transactions are verifiable and accountable.
When developing their protocols, Visa and Mastercard needed a secure way to authenticate each agent developer and securely transmit information from the agent to the merchant’s website. That’s where we came in and worked with their teams to build upon Web Bot Auth. Web Bot Auth proposals specify how developers of bots and agents can attach their cryptographic signatures in HTTP requests by using HTTP Message Signatures.
Both Visa and Mastercard protocols require agents to register and have their public keys (referenced as the keyid in the Signature-Input header) in a well-known directory, allowing merchants and networks to fetch the keys to validate these HTTP message signatures. To start, Visa and Mastercard will be hosting their own directories for Visa-registered and Mastercard-registered agents, respectively
The newly created agents then communicate their registration, identity, and payment details with the merchant using these HTTP Message Signatures. Both protocols build on Web Bot Auth by introducing a new tag that agents must supply in the Signature-Input header, which indicates whether the agent is browsing or purchasing. Merchants can use the tag to determine whether to interact with the agent. Agents must also include the nonce field, a unique sequence included in the signature, to provide protection against replay attacks.
An agent visiting a merchant’s website to browse a catalog would include an HTTP Message Signature in their request to verify their agent is authorized to browse the merchant’s storefront on behalf of a specific Visa cardholder:
Trusted Agent Protocol and Agent Pay are designed for merchants to benefit from its validation mechanisms without changing their infrastructure. Instead, merchants can set the rules for agent interactions on their site and rely upon Cloudflare as the validator. For these requests, Cloudflare will run the following checks:
Confirm the presence of the Signature-Input and Signature headers.
Pull the keyid from the Signature-Input. If Cloudflare has not previously retrieved and cached the key, fetch it from the public key directory.
Confirm the current time falls between the created and expires timestamps.
Check nonce uniqueness in the cache. By checking if a nonce has been recently used, Cloudflare can reject reused or expired signatures, ensuring the request is not a malicious copy of a prior, legitimate interaction.
Check the validity of the tag, as defined by the protocol. If the agent is browsing, the tag should be agent-browser-auth. If the agent is paying, the tag should be agent-payer-auth.
We recently introduced support for x402 transactions into Cloudflare’s Agent SDK, allowing anyone building an agent to easily transact using the new x402 protocol. We will similarly be working with Visa and Mastercard over the coming months to bring support for their protocols directly to the Agents SDK. This will allow developers to manage their registered agent’s private keys and to easily create the correct HTTP message signatures to authorize their agent to browse and transact on a merchant website.
Conceptually, the requests in a Cloudflare Worker would look something like this:
/**
* Pseudocode example of a Cloudflare Worker acting as a trusted agent.
* This version explicitly illustrates the signing logic to show the core flow.
*/
// Helper function to encapsulate the signing protocol logic.
async function createSignatureHeaders(targetUrl, credentials) {
// Internally, this function would perform the detailed cryptographic steps:
// 1. Generate timestamps and a unique nonce.
// 2. Construct the 'Signature-Input' header string with all required parameters.
// 3. Build the canonical 'Signature Base' string according to the spec.
// 4. Use the private key to sign the base string.
// 5. Return the fully formed 'Signature-Input' and 'Signature' headers.
const signedHeaders = new Headers();
signedHeaders.set('Signature-Input', 'sig2=(...); keyid="..."; ...');
signedHeaders.set('Signature', 'sig2=:...');
return signedHeaders;
}
export default {
async fetch(request, env) {
// 1. Load the final API endpoint and private signing credentials.
const targetUrl = new URL(request.url).searchParams.get('target');
const credentials = {
privateKey: env.PAYMENT_NETWORK_PRIVATE_KEY,
keyId: env.PAYMENT_NETWORK_KEY_ID
};
// 2. Generate the required signature headers using the helper.
const signatureHeaders = await createSignatureHeaders(targetUrl, credentials);
// 3. Attach the newly created signature headers to the request for authentication.
const signedRequestHeaders = new Headers(request.headers);
signedRequestHeaders.set('Host', new URL(targetUrl).hostname);
signedRequestHeaders.set('Signature-Input', signatureHeaders.get('Signature-Input'));
signedRequestHeaders.set('Signature', signatureHeaders.get('Signature'));
// 4. Forward the fully signed request to the protected API.
return fetch(targetUrl, { headers: signedRequestHeaders });
},
};
We’ll also be creating new managed rulesets for our customers that make it easy to allow agents that are using the Trusted Agent Protocol or Agent Pay. You might want to disallow most automated traffic to your storefront but not miss out on revenue opportunities from agents authorized to make a purchase on behalf of a cardholder. A managed rule would make this straightforward to implement. As the website owner, you could enable a managed rule that automatically allows all trusted agents registered with Visa or Mastercard to come to your site, passing your other bot protection & WAF rules.
These will continue to evolve, and we will incorporate feedback to ensure that agent registration and validation works seamlessly across all networks and aligns with the Web Bot Auth proposal. American Express will also be leveraging Web Bot Auth as the foundation to their agentic commerce offering.
On October 4, independent developer Theo Browne published a series of benchmarks designed to compare server-side JavaScript execution speed between Cloudflare Workers and Vercel, a competing compute platform built on AWS Lambda. The initial results showed Cloudflare Workers performing worse than Node.js on Vercel at a variety of CPU-intensive tasks, by a factor of as much as 3.5x.
We were surprised by the results. The benchmarks were designed to compare JavaScript execution speed in a CPU-intensive workload that never waits on external services. But, Cloudflare Workers and Node.js both use the same underlying JavaScript engine: V8, the open source engine from Google Chrome. Hence, one would expect the benchmarks to be executing essentially identical code in each environment. Physical CPUs can vary in performance, but modern server CPUs do not vary by anywhere near 3.5x.
On investigation, we discovered a wide range of small problems that contributed to the disparity, ranging from some bad tuning in our infrastructure, to differences between the JavaScript libraries used on each platform, to some issues with the test itself. We spent the week working on many of these problems, which means over the past week Workers got better and faster for all of our customers. We even fixed some problems that affect other compute providers but not us, such as an issue that made trigonometry functions much slower on Vercel. This post will dig into all the gory details.
It’s important to note that the original benchmark was not representative of billable CPU usage on Cloudflare, nor did the issues involved impact most typical workloads. Most of the disparity was an artifact of the specific benchmark methodology. Read on to understand why.
With our fixes, the results now look much more like we’d expect:
There is still work to do, but we’re happy to say that after these changes, Cloudflare now performs on par with Vercel in every benchmark case except the one based on Next.js. On that benchmark, the gap has closed considerably, and we expect to be able to eliminate it with further improvements detailed later in this post.
We are grateful to Theo for highlighting areas where we could make improvements, which will now benefit all our customers, and even many who aren’t our customers.
Our benchmark methodology
We wanted to run Theo’s test with no major design changes, in order to keep numbers comparable. Benchmark cases are nearly identical to Theo’s original test but we made a couple changes in how we ran the test, in the hopes of making the results more accurate:
Theo ran the test client on a laptop connected by a Webpass internet connection in San Francisco, against Vercel instances running in its sfo1 region. In order to make our results easier to reproduce, we chose instead to run our test client directly in AWS’s us-east-1 datacenter, invoking Vercel instances running in its iad1 region (which we understand to be in the same building). We felt this would minimize any impact from network latency. Because of this, Vercel’s numbers are slightly better in our results than they were in Theo’s.
We chose to use Vercel instances with 1 vCPU instead of 2. All of the benchmarks are single-threaded workloads, meaning they cannot take advantage of a second CPU anyway. Vercel’s CTO, Malte Ubl, had stated publicly on X that using single-CPU instances would make no difference in this test, and indeed, we found this to be correct. Using 1 vCPU makes it easier to reason about pricing, since both Vercel and Cloudflare charge for CPU time ($0.128/hr for Vercel in iad1, and $0.072/hr for Cloudflare globally).
Theo’s benchmarks covered a variety of frameworks, making it clear that no single JavaScript library could be at fault for the general problem. Clearly, we needed to look first at the Workers Runtime itself. And so we did, and we found two problems – not bugs, but tuning and heuristic choices which interacted poorly with the benchmarks as written.
Sharding and warm isolate routing: A problem of scheduling, not CPU speed
Over the last year we shipped smarter routing that sends traffic to warm isolates more often. That cuts cold starts for large apps, which matters for frameworks with heavy initialization requirements like Next.js. The original policy optimized for latency and throughput across billions of requests, but was less optimal for heavily CPU-bound workloads for the same reason that such workloads cause performance issues in other platforms like Node.js: When the CPU is busy computing an expensive operation for one request, other requests sent to the same isolate must wait for it to finish before they can proceed.
The system uses heuristics to detect when requests are getting blocked behind each other, and automatically spin up more isolates to compensate. However, these heuristics are not precise, and the particular workload generated by Theo’s tests – in which a burst of expensive traffic would come from a single client – played poorly with our existing algorithm. As a result, the benchmarks showed much higher latency (and variability in latency) than would normally be expected.
It’s important to understand that, as a result of this problem, the benchmark was not really measuring CPU time. Pricing on the Workers platform is based on CPU time – that is, time spent actually executing JavaScript code, as opposed to time waiting for things. Time spent waiting for the isolate to become available makes the request take longer, but is not billed as CPU time against the waiting request. So, this problem would not have affected your bill.
After analyzing the benchmarks, we updated the algorithm to detect sustained CPU-heavy work earlier, then bias traffic so that new isolates spin up faster. The result is that Workers can more effectively and efficiently autoscale when different workloads are applied. I/O-bound workloads coalesce into individual already warm isolates while CPU-bound are directed so that they do not block each other. This change has already been rolled out globally and is enabled automatically for everyone. It should be pretty clear from the graph when the change was rolled out:
V8 garbage collector tuning
While this scheduling issue accounted for the majority of the disparity in the benchmark, we did find a minor issue affecting code execution performance during our testing.
The range of issues that we uncovered in the framework code in these benchmarks repeatedly pointed at garbage collection and memory management issues as being key contributors to the results. But, we would expect these to be an issue with the same frameworks running in Node.js as well. To see exactly what was going on differently with Workers and why it was causing such a significant degradation in performance, we had to look inwards at our own memory management configuration.
The V8 garbage collector has a huge number of knobs that can be tuned that directly impact performance. One of these is the size of the “young generation”. This is where newly created objects go initially. It’s a memory area that’s less compact, but optimized for short-lived objects. When objects have bounced around the “young space” for a few generations they get moved to the old space, which is more compact, but requires more CPU to reclaim.
V8 allows the embedding runtime to tune the size of the young generation. And it turns out, we had done so. Way back in June of 2017, just two months after the Workers project kicked off, we – or specifically, I, Kenton, as I was the only engineer on the project at the time – had configured this value according to V8’s recommendations at the time for environments with 512MB of memory or less. Since Workers defaults to a limit of 128MB per isolate, this seemed appropriate.
V8’s entire garbage collector has changed dramatically since 2017. When analyzing the benchmarks, it became apparent that the setting which made sense in 2017 no longer made sense in 2025, and we were now limiting V8’s young space too rigidly. Our configuration was causing V8’s garbage collection to work harder and more frequently than it otherwise needed to. As a result, we have backed off on the manual tuning and now allow V8 to pick its young space size more freely, based on its internal heuristics. This is already live on Cloudflare Workers, and it has given an approximately 25% boost to the benchmarks with only a small increase in memory usage. Of course, the benchmarks are not the only Workers that benefit: all Workers should now be faster. That said, for most Workers the difference has been much smaller.
Tuning OpenNext for performance
The platform changes solved most of the problem. Following the changes, our testing showed we were now even on all of the benchmarks save one: Next.js.
Next.js is a popular web application framework which, historically, has not had built-in support for hosting on a wide range of platforms. Recently, a project called OpenNext has arisen to fill the gap, making Next.js work well on many platforms, including Cloudflare. On investigation, we found several missing optimizations and other opportunities to improve performance, explaining much of why the benchmark performed poorly on Workers.
Unnecessary allocations and copies
When profiling the benchmark code, we noticed that garbage collection was dominating the timeline. From 10-25% of the request processing time was being spent reclaiming memory.
So we dug in and discovered that OpenNext, and in some cases Next.js and React itself, will often create unnecessary copies of internal data buffers at some of the worst times during the handling of the process. For instance, there’s one pipeThrough() operation in the rendering pipeline that we saw creating no less than 50 2048-byte Buffer instances, whether they are actually used or not.
We further discovered that on every request, the Cloudflare OpenNext adapter has been needlessly copying every chunk of streamed output data as it’s passed out of the renderer and into the Workers runtime to return to users. Given this benchmark returns a 5 MB result on every request, that’s a lot of data being copied!
In other places, we found that arrays of internal Buffer instances were being copied and concatenated using Buffer.concat for no other reason than to get the total number of bytes in the collection. That is, we spotted code of the form getBody().length. The function getBody() would concatenate a large number of buffers into a single buffer and return it, without storing the buffer anywhere. So, all that work was being done just to read the overall length. Obviously this was not intended, and fixing it was an easy win.
We’ve started opening a series of pull requests in OpenNext to fix these issues, and others in hot paths, removing some unnecessary allocations and copies:
We’re not done. We intend to keep iterating through OpenNext code, making improvements wherever they’re needed – not only in the parts that run on Workers. Many of these improvements apply to other OpenNext platforms. The shared goal of OpenNext is to make NextJS as fast as possible regardless of where you choose to run your code.
Inefficient Streams Adapters
Much of the Next.js code was written to use Node.js’s APIs for byte streams. Workers, however, prefers the web-standard Streams API, and uses it to represent HTTP request and response bodies. This necessitates using adapters to convert between the two APIs. When investigating the performance bottlenecks, we found a number of examples where inefficient streams adapters are being needlessly applied. For example:
res.getBody() was performing a Buffer.concat(chunks) to copy accumulated chunks of data into a new Buffer, which was then passed as an iterable into a Node.js stream.Readable that was then wrapped by an adapter that returns a ReadableStream. While these utilities do serve a useful purpose, this becomes a data buffering nightmare since both Node.js streams and Web streams each apply their own internal buffers! Instead we can simply do:
const stream = ReadableStream.from(chunks);
This returns a ReadableStream directly from the accumulated chunks without additional copies, extraneous buffering, or passing everything through inefficient adaptation layers.
In other places we see that Next.js and React make extensive use of ReadableStream to pass bytes through, but the streams being created are value-oriented rather than byte-oriented! For example,
const readable = new ReadableStream({
pull(controller) {
controller.enqueue(chunks.shift());
if (chunks.length === 0) {
controller.close();
}
}); // Default highWaterMark is 1!
Seems perfectly reasonable. However, there’s an issue here. If the chunks are Buffer or Uint8Array instances, every instance ends up being a separate read by default. So if the chunk is only a single byte, or 1000 bytes, that’s still always two reads. By converting this to a byte stream with a reasonable high water mark, we can make it possible to read this stream much more efficiently:
Now, the stream can be read as a stream of bytes rather than a stream of distinct JavaScript values, and the individual chunks can be coalesced internally into 4096 byte chunks, making it possible to optimize the reads much more efficiently. Rather than reading each individual enqueued chunk one at a time, the ReadableStream will proactively call pull() repeatedly until the highWaterMark is reached. Reads then do not have to ask the stream for one chunk of data at a time.
While it would be best for the rendering pipeline to be using byte streams and paying attention to back pressure signals more, our implementation can still be tuned to better handle cases like this.
The bottom line? We’ve got some work to do! There are a number of improvements to make in the implementation of OpenNext and the adapters that allow it to work on Cloudflare that we will continue to investigate and iterate on. We’ve made a handful of these fixes already and we’re already seeing improvements. Soon we also plan to start submitting patches to Next.js and React to make further improvements upstream that will ideally benefit the entire ecosystem.
JSON parsing
Aside from buffer allocations and streams, one additional item stood out like a sore thumb in the profiles: JSON.parse() with a reviver function. This is used in both React and Next.js and in our profiling this was significantly slower than it should be. We built a microbenchmark and found that JSON.parse with a reviver argument recently got even slower when the standard added a third argument to the reviver callback to provide access to the JSON source context.
For those unfamiliar with the reviver function, it allows an application to effectively customize how JSON is parsed. But it has drawbacks. The function gets called on every key-value pair included in the JSON structure, including every individual element of an Array that gets serialized. In Theo’s NextJS benchmark, in any single request, it ends up being called well over 100,000 times!
Even though this problem affects all platforms, not just ours, we decided that we weren’t just going to accept it. After all, we have contributors to V8 on the Workers runtime team! We’ve upstreamed a V8 patch that can speed up JSON.parse() with revivers by roughly 33 percent. That should be in V8 starting with version 14.3 (Chrome 143) and can help everyone using V8, not just Cloudflare: Node.js, Chrome, Deno, the entire ecosystem. If you are not using Cloudflare Workers or didn’t change the syntax of your reviver you are currently suffering under the red performance bar.
We will continue to work with framework authors to reduce overhead in hot paths. Some changes belong in the frameworks, some belong in the engine, some in our platform.
Node.js’s trigonometry problem
We are engineers, and we like to solve engineering problems — whether our own, or for the broader community.
Theo’s benchmarks were actually posted in response to a different benchmark by another author which compared Cloudflare Workers against Vercel. The original benchmark focused on calling trigonometry functions (e.g. sine and cosine) in a tight loop. In this benchmark, Cloudflare Workers performed 3x faster than Node.js running on Vercel.
The author of the original benchmark offered this as evidence that Cloudflare Workers are just faster. Theo disagreed, and so did we. We expect to be faster, but not by 3x! We don’t implement math functions ourselves; these come with V8. We weren’t happy to just accept the win, so we dug in.
It turns out that Node.js is not using the latest, fastest path for these functions. Node.js can be built with either the clang or gcc compilers, and is written to support a broader range of operating systems and architectures than Workers. This means that Node.js’ compilation often ends up using a lowest-common denominator for some things in order to provide support for the broadest range of platforms. V8 includes a compile-time flag that, in some configurations, allows it to use a faster implementation of the trig functions. In Workers, mostly by coincidence, that flag is enabled by default. In Node.js, it is not. We’ve opened a pull request to enable the flag in Node.js so that everyone benefits, at least on platforms where it can be supported.
Assuming that lands, and once AWS Lambda and Vercel are able to pick it up, we expect this specific gap to go away, making these operations faster for everyone. This change won’t benefit our customers, since Cloudflare Workers already uses the faster trig functions, but a bug is a bug and we like making everything faster.
Benchmarks are hard
Even the best benchmarks have bias and tradeoffs. It’s difficult to create a benchmark that is truly representative of real-world performance, and all too easy to misinterpret the results of benchmarks that are not. We particularly liked Planetscale’s take on this subject.
These specific CPU-bound tests are not an ideal choice to represent web applications. Theo even notes this in his video. Most real-world applications on Workers and Vercel are bound by databases, downstream services, network, and page size. End user experience is what matters. CPU is one piece of that picture. That said, if a benchmark shows us slower, we take it seriously.
While the benchmarks helped us find and fix many real problems, we also found a few problems with the benchmarks themselves, which contributed to the apparent disparity in speed:
Running locally
The benchmark is designed to be run on your laptop, from which it hits Cloudflare’s and Vercel’s servers over the Internet. It makes the assumption that latency observed from the client is a close enough approximation of server-side CPU time. The reasons are fair: As Theo notes, Cloudflare does not permit an application to measure its own CPU time, in order to prevent timing side channel attacks. Actual CPU time can be seen in logs after the fact, but gathering those may be a lot of work. It’s just easier to measure time from the client.
However, as Cloudflare and Vercel are hosted from different data centers, the network latency to each can be a factor in the benchmark, and this can skew the results. Typically, this effect will favor Cloudflare, because Cloudflare can run your Worker in locations spread across 330+ cities worldwide, and will tend to choose the closest one to you. Vercel, on the other hand, usually places compute in a central location, so latency will vary depending on your distance from that location.
For our own testing, to minimize this effect, we ran the benchmark client from a VM on AWS located in the same data center as our Vercel instances. Since Cloudflare is well-connected to every AWS location, we think this should have eliminated network latency from the picture. We chose AWS’s us-east-1 / Vercel’s iad1 for our test as it is widely seen as the default choice; any other choice could draw questions about cherry-picking.
Not all CPUs are equal
Cloudflare’s servers aren’t all identical. Although we refresh them aggressively, there will always be multiple generations of hardware in production at any particular time. Currently, this includes generations 10, 11, and 12 of our server hardware.
Other cloud providers are no different. No cloud provider simply throws away all their old servers every time a new version becomes available.
Of course, newer CPUs run faster, even for single-threaded workloads. The differences are not as large as they used to be 20-30 years ago, but they are not nothing. As such, an application may get (a little bit) lucky or unlucky depending on what machine it is assigned to.
In cloud environments, even identical CPUs can yield different performance depending on circumstances, due to multitenancy. The server your application is assigned to is running many others as well. In AWS Lambda, a server may be running hundreds of applications; in Cloudflare, with our ultra-efficient runtime, a server may be running thousands. These “noisy neighbors” won’t share the same CPU core as your app, but they may share other resources, such as memory bandwidth. As a result, performance can vary.
It’s important to note that these problems create correlated noise. That is, if you run the test again, the application is likely to remain assigned to the same machines as before – this is true of both Cloudflare and Vercel. So, this noise cannot be corrected by simply running more iterations. To correct for this type of noise on Cloudflare, one would need to initiate requests from a variety of geographic locations, in order to hit different Cloudflare data centers and therefore different machines. But, that is admittedly a lot of work. (We are not familiar with how best to get an application to switch machines on Vercel.)
A Next.js config bug
The Cloudflare version of the NextJS benchmark was not configured to use force-dynamic while the Vercel version was. This triggered curious behavior. Our understanding is that pages which are not “dynamic” should normally be rendered statically at build time. With OpenNext, however, it appears the pages are still rendered dynamically, but if multiple requests for the same page are received at the same time, OpenNext will only invoke the rendering once. Before we made the changes to fix our scheduling algorithm to avoid sending too many requests to the same isolate, this behavior may have somewhat counteracted that problem. Theo reports that he had disabled force-dynamic in the Cloudflare version specifically for this reason: with it on, our results were so bad as to appear outright broken, so he intentionally turned it off.
Ironically, though, once we fixed the scheduling issue, using “static” rendering (i.e. not enabling force-dynamic) hurt Cloudflare’s performance for other reasons. It seems that when OpenNext renders a “cacheable” page, streaming of the response body is inhibited. This interacted poorly with a property of the benchmark client: it measured time-to-first-byte (TTFB), rather than total request/response time. When running in dynamic mode – as the test did on Vercel – the first byte would be returned to the client before the full page had been rendered. The rest of the rendering would happen as bytes streamed out. But with OpenNext in non-dynamic mode, the entire payload was rendered into a giant buffer upfront, before any bytes were returned to the client.
Due to the TTFB behavior of the benchmark client, in dynamic mode, the benchmark actually does not measure the time needed to fully render the page. We became suspicious when we noticed that Vercel’s observability tools indicated more CPU time had been spent than the benchmark itself had reported.
One option would have been to change the benchmarks to use TTLB instead – that is, wait until the last byte is received before stopping the timer. However, this would make the benchmark even more affected by network differences: The responses are quite large, ranging from 2MB to 15MB, and so the results could vary depending on the bandwidth to the provider. Indeed, this would tend to favor Cloudflare, but as the point of the test is to measure CPU speed, not bandwidth, it would be an unfair advantage.
Once we changed the Cloudflare version of the test to use force-dynamic as well, matching the Vercel version, the streaming behavior then matched, making the request fair. This means that neither version is actually measuring the cost of rendering the full page to HTML, but at least they are now measuring the same thing.
As a side note, the original behavior allowed us to spot that OpenNext has a couple of performance bottlenecks in its implementation of the composable cache it uses to deduplicate rendering requests. While fixes to these aren’t going to impact the numbers for this particular set of benchmarks, we’re working on improving those pieces also.
A React SSR config bug
The React SSR benchmark contained a more basic configuration error. React inspects the environment variable NODE_ENV to decide whether the environment is “production” or a development environment. Many Node.js-based environments, including Vercel, set this variable automatically in production. Many frameworks, such as OpenNext, automatically set this variable for Workers in production as well. However, the React SSR benchmark was written against lower-level React APIs, not using any framework. In this case, the NODE_ENV variable wasn’t being set at all.
And, unfortunately, when NODE_ENV is not set, React defaults to “dev mode”, a mode that contains extra debugging checks and is therefore much slower than production mode. As a result, the numbers for Workers were much worse than they should have been.
Arguably, it may make sense for Workers to set this variable automatically for all deployed workers, particularly when Node.js compatibility is enabled. We are looking into doing this in the future, but for now we’ve updated the test to set it directly.
What we’re going to do next
Our improvements to the Workers Runtime are already live for all workers, so you do not need to change anything. Many apps will already see faster, steadier tail latency on compute heavy routes with less jitter during bursts. In places where garbage collection improved, some workloads will also use fewer billed CPU seconds.
We also sent Theo a pull request to update OpenNext with our improvements there, and with other test fixes.
But we’re far from done. We still have work to do to close the gap between OpenNext and Next.js on Vercel – but given the other benchmark results, it’s clear we can get there. We also have plans for further improvements to our scheduling algorithm, so that requests almost never block each other. We will continue to improve V8, and even Node.js – the Workers team employs multiple core contributors to each project. Our approach is simple: improve open source infrastructure so that everyone gets faster, then make sure our platform makes the most of those improvements.
And, obviously, we’ll be writing more benchmarks, to make sure we’re catching these kinds of issues ourselves in the future. If you have a benchmark that shows Workers being slower, send it to us with a repro. We will profile it, fix what we can upstream, and share back what we learn!
Cloudflare launched fifteen years ago with a mission to help build a better Internet. Over that time the Internet has changed and so has what it needs from teams like ours. In this year’s Founder’s Letter, Matthew and Michelle discussed the role we have played in the evolution of the Internet, from helping encryption grow from 10% to 95% of Internet traffic to more recent challenges like how people consume content.
This year’s themes focused on helping prepare the Internet for a new model of monetization that encourages great content to be published, fostering more opportunities to build community both inside and outside of Cloudflare, and evergreen missions like making more features available to everyone and constantly improving the speed and security of what we offer.
We shipped a lot of new things this year. In case you missed the dozens of blog posts, here is a breakdown of everything we announced during Birthday Week 2025.
To support a diverse and open Internet, we are now sponsoring Ladybird (an independent browser) and Omarchy (an open-source Linux distribution and developer environment).
We are opening our office doors in four major cities (San Francisco, Austin, London, and Lisbon) as free hubs for startups to collaborate and connect with the builder community.
We are removing cost as a barrier for the next generation by giving students with .edu emails 12 months of free access to our paid developer platform features.
We are partnering with Coinbase to create the x402 Foundation, encouraging the adoption of the x402 protocol to allow clients and services to exchange value on the web using a common language
Our Automatic SSL/TLS system has upgraded over 6 million domains to more secure encryption modes by default and will soon automatically enable post-quantum connections.
We made our CSAM Scanning Tool easier to adopt by removing the need to create and provide unique credentials, helping more site owners protect their platforms.
Updates across Workers and beyond for a more powerful developer platform – such as support for larger and more concurrent Container images, support for external models from OpenAI and Anthropic in AI Search (previously AutoRAG), and more.
A deep-dive into how we’ve hardened the Workers runtime with new defense-in-depth security measures, including V8 sandboxes and hardware-assisted memory protection keys.
We announced the Cloudflare Email Service private beta, allowing developers to reliably send and receive transactional emails directly from Cloudflare Workers.
The TCP Connection Time (Trimean) graph shows that we are the fastest TCP connection time in 40% of measured ISPs – and the fastest across the top networks.
We are using our network’s vast performance data to tune congestion control algorithms, improving speeds by an average of 10% for QUIC traffic.
Come build with us!
Helping build a better Internet has always been about more than just technology. Like the announcements about interns or working together in our offices, the community of people behind helping build a better Internet matters to its future. This week, we rolled out our most ambitious set of initiatives ever to support the builders, founders, and students who are creating the future.
For founders and startups, we are thrilled to welcome Cohort #6 to the Workers Launchpad, our accelerator program that gives early-stage companies the resources they need to scale. But we’re not stopping there. We’re opening our doors, literally, by launching new physical hubs for startups in our San Francisco, Austin, London, and Lisbon offices. These spaces will provide access to mentorship, resources, and a community of fellow builders.
We’re also investing in the next generation of talent. We announced free access to the Cloudflare developer platform for all students, giving them the tools to learn and experiment without limits. To provide a path from the classroom to the industry, we also announced our goal to hire 1,111 interns in 2026 — our biggest commitment yet to fostering future tech leaders.
And because a better Internet is for everyone, we’re extending our support to non-profits and public-interest organizations, offering them free access to our production-grade developer tools, so they can focus on their missions.
Whether you’re a founder with a big idea, a student just getting started, or a team working for a cause you believe in, we want to help you succeed.
Until next year
Thank you to our customers, our community, and the millions of developers who trust us to help them build, secure, and accelerate the Internet. Your curiosity and feedback drive our innovation.
It’s been an incredible 15 years. And as always, we’re just getting started!
When you build on Cloudflare, we consider it our job to do the heavy lifting for you. That’s been true since we introduced Cloudflare Workers in 2017, when we first provided a runtime for you where you could just focus on building.
That commitment is still true today, and many of today’s announcements are focused on just that — removing friction where possible to free you up to build something great.
There are only so many blog posts we can write (and that you can read)! We have been busy on a much longer list of new improvements, and many of them we’ve been rolling out consistently over the course of the year. Today’s announcement breaks down all the new capabilities in detail, in one single post. The features being released today include:
Resize, clip and reformat video files on-demand with Media Transformations — now GA
Alongside that, we’re constantly adding new building blocks, to make sure you have all the tools you need to build what you set out to. Those launches (that also went out today, but require a bit more explanation) include:
Deploy your own AI vibe coding platform to Cloudflare with VibeSDK
AI Search (formerly AutoRAG) — now with More Models To Choose From
AutoRAG is now AI Search! The new name marks a new and bigger mission: to make world-class search infrastructure available to every developer and business. AI Search is no longer just about retrieval for LLM apps: it’s about giving you a fast, flexible index for your content that is ready to power any AI experience. With recent additions like NLWeb support, we are expanding beyond simple retrieval to provide a foundation for top quality search experiences that are open and built for the future of the web.
With AI Search you can now use models from different providers like OpenAI and Anthropic. Last month during AI Week we announced BYO Provider Keys for AI Gateway. That capability now extends to AI Search. By attaching your keys to the AI Gateway linked to your AI Search instance, you can use many more models for both embedding and inference.
Once configured, your AI Search instance will be able to reference models available through your AI Gateway when making a /ai-search request:
export default {
async fetch(request, env) {
// Query your AI Search instance with a natural language question to an OpenAI model
const result = await env.AI.autorag("my-ai-search").aiSearch({
query: "What's new for Cloudflare Birthday Week?",
model: "openai/gpt-5"
});
// Return only the generated answer as plain text
return new Response(result.response, {
headers: { "Content-Type": "text/plain" },
});
},
};
In the coming weeks we will also roll out updates to align the APIs with the new name. The existing APIs will continue to be supported for the time being. Stay tuned to the AI Search Changelog and Discord for more updates!
Connect to production services and resources from local development with Remote Bindings — now GA
Remote bindings for local development are generally available, supported in Wrangler v4.37.0, the Cloudflare Vite plugin, and the @cloudflare/vitest-pool-workers package. Remote bindings are bindings that are configured to connect to a deployed resource on your Cloudflare account instead of the locally simulated resource.
For example, here’s how you can instruct Wrangler or Vite to send all requests to env.MY_BUCKET to hit the real, deployed R2 bucket instead of a locally simulated one:
With the above configuration, all requests to env.MY_BUCKET will be proxied to the remote resource, but the Worker code will still execute locally. This means you get all the benefits of local development like faster execution times – without having to seed local databases with data.
You can pair remote bindings with environments, so that you can use staging data during local development and leave production data untouched.
For example, here’s how you could point Wrangler or Vite to send all requests to env.MY_BUCKET to staging-storage-bucket when you run wrangler dev --env staging (CLOUDFLARE_ENV=staging vite dev if using Vite).
With these changes, Workers become even more powerful and easier to adopt, regardless of where you’re coming from. The APIs that you are familiar with are there, and more packages you need will just work.
Larger Container instances, more concurrent instances
Cloudflare Containers now has higher limits on concurrent instances and an upcoming new, larger instance type.
Previously you could run 50 instances of the dev instance type or 25 instances of the basic instance type concurrently. Now you can run concurrent containers with up to 400 GiB of memory, 100 vCPUs, and 2 TB of disk. This allows you to run up to 1000 dev instances or 400 basic instances concurrently. Enterprise customers can push far beyond these limits — contact us if you need more. If you are using Containers to power your app and it goes viral, you’ll have the ability to scale on Cloudflare.
Cloudflare Containers also now has a new instance type coming soon — standard-2 which includes 8 GiB of memory, 1 vCPU, and 12 GB of disk. This new instance type is an ideal default for workloads that need more resources, from AI Sandboxes to data processing jobs.
Workers Builds provides more disk and CPU — and is now GA
This year, we are excited to announce that Workers Builds is now Generally Available. Here’s what’s new:
Increased disk space for all plans: We’ve increased the disk size from 8 GB to 20 GB for both free and paid plans, giving you more space for your projects and dependencies
More compute for paid plans: We’ve doubled the CPU power for paid plans from 2 vCPU to 4 vCPU, making your builds significantly faster
Faster single-core and multi-core performance: To ensure consistent, high performance builds, we now run your builds on the fastest available CPUs at the time your build runs
A more consistent look and feel for the Cloudflare dashboard
Durable Objects, R2, and Workers now all have a more consistent look with the rest of our developer platform. As you explore these pages you’ll find that things should load faster, feel smoother and are easier to use.
Across storage products, you can now customize the table that lists the resources on your account, choose which data you want to see, sort by any column, and hide columns you don’t need. In the Workers and Pages dashboard, we’ve reduced clutter and have modernized the design to make it faster for you to get the data you need.
And when you create a new Pipeline or a Hyperdrive configuration, you’ll find a new interface that helps you get started and guides you through each step.
This work is ongoing, and we’re excited to continue improving with the help of your feedback, so keep it coming!
Resize, clip and reformat video files on-demand with Media Transformations — now GA
In March 2025 we announced Media Transformations in open beta, which brings the magic of Image transformations to short-form video files — including video files stored outside of Cloudflare. Since then, we have increased input and output limits, and added support for audio-only extraction. Media Transformations is now generally available.
Media Transformations is ideal if you have a large existing volume of short videos, such as generative AI output, e-commerce product videos, social media clips, or short marketing content. Content like this should be fetched from your existing storage like R2 or S3 directly, optimized by Cloudflare quickly, and delivered efficiently as small MP4 files or used to extract still images and audio.
https://example.com/cdn-cgi/media/<OPTIONS>/<SOURCE-VIDEO>
EXAMPLE, RESIZE:
EXAMPLE, STILL THUMBNAIL:
https://example.com/cdn-cgi/media/mode=frame,time=3s,width=120,height=120,fit=cover/https://pub-d9fcbc1abcd244c1821f38b99017347f.r2.dev/aus-mobile.mp4
Media Transformations includes a free tier available to all customers and is included with Media Platform subscriptions. Check out the transform videos documentation for all the latest, then enable transformations for your zone today!
Infrequent Access in R2 is now GA
R2 Infrequent Access is now generally available. Last year, we introduced the Infrequent Access storage class designed for data that doesn’t need to be accessed frequently. It’s a great fit for use cases including long-tail user content, logs, or data backups.
Since launch, Infrequent Access has been proven in production by our customers running these types of workloads at scale. The results confirmed our goal: a storage class that reduces storage costs while maintaining performance and durability.
Pricing is simple. You pay less on data storage, while data retrievals are billed per GB to reflect the additional compute required to serve data from underlying storage optimized for less frequent access. And as with all of R2, there are no egress fees, so you don’t pay for the bandwidth to move data out.
Here’s how you can upload an object to R2 infrequent access class via Workers:
export default {
async fetch(request, env) {
// Upload the incoming request body to R2 in Infrequent Access class
await env.MY_BUCKET.put("my-object", request.body, {
storageClass: "InfrequentAccess",
});
return new Response("Object uploaded to Infrequent Access!", {
headers: { "Content-Type": "text/plain" },
});
},
};
You can also monitor your Infrequent Access vs. Standard storage usage directly in your R2 dashboard for each bucket. Get started with R2 today!
Playwright in Browser Rendering is now GA
We’re excited to announce three updates to Browser Rendering:
Our support for Playwright is now Generally Available, giving developers the stability and confidence to run critical browser tasks.
We’re introducing support for Stagehand, enabling developers to build AI agents using natural language, powered by Cloudflare Workers AI.
Finally, to help developers scale, we are tripling limits for paid plans, with more increases to come.
The browser is no longer only used by humans. AI agents need to be able to reliably navigate browsers in the same way a human would, whether that’s booking flights, filling in customer info, or scraping structured data. Playwright gives AI agents the ability to interact with web pages and perform complex tasks on behalf of humans. However, running browsers at scale is a significant infrastructure challenge. Cloudflare Browser Rendering solves this by providing headless browsers on-demand. By moving Playwright support to Generally Available, and now synced with the latest version v1.55, customers have a production-ready foundation to build reliable, scalable applications on.
To help AI agents better navigate the web, we’re introducing support for Stagehand, an open source browser automation framework. Rather than dictating exact steps or specifying selectors, Stagehand enables developers to build more reliably and flexibly by combining code with natural-language instructions powered by AI. This makes it possible for AI agents to navigate and adapt if a website changes – just like a human would.
To get started with Playwright and Stagehand, check our changelog with code examples and more.
Imagine you have an idea for an AI application that you’re really excited about — but the cost of GPU time and complex infrastructure stops you in your tracks before you even write a line of code. This is the problem founders everywhere face: balancing high infrastructure costs with the need to innovate and scale quickly.
Our startup programs remove those barriers, so founders can focus on what matters the most: building products, finding customers, and growing a business. Cloudflare for Startups launched in 2018 to provide enterprise-level application security and performance services to growing startups. As we built out our Developer Platform, we pivoted last year to offer founders up to $250,000 in cloud credits to build on our Developer Platform for up to one year.
During Birthday Week 2022, we announced our Cloudflare Workers Launchpad Program with an initial $1.25 billion in potential funding for startups building on Cloudflare Workers, made possible through partnerships with 26 leading venture capital (VC) firms. Within months, we expanded VC-backed funding to $2 billion.
Since 2022, we’ve welcomed 145 startups from 23 countries. These startups are solving problems across verticals such as AI and machine learning, developer tools, 3D design, cloud infrastructure, data tools, ad tech, media, logistics, finance, and other industries. We’re especially proud of the female founder representation in recent cohorts — with nearly a third of companies in Cohort #5 run by a female founder.
Participants engaged in bootcamp sessions with Cloudflare leadership and product teams, covering key topics like product pricing and scaling sales. Startups received hands-on design support from our Solutions Architecture team, empowering these builders to build and scale their full-stack applications on the Cloudflare network. We facilitate countless introductions across the VC network, and are happy to see funding and M&A activity as these startups scale. Cloudflare also identified direct opportunities and acquired Nefeli Networks (Cohort #2) and Outerbase (Cohort #4).
Check out what Launchpad alumni have to say about their experience in the program:
Langbase (Cohort #3) Ship hyper-personalized AI apps to any LLM, any data, any developer in seconds
“For Langbase, the best part about Workers Launchpad was the incredible support from Cloudflare’s internal teams. It wasn’t just about access to infrastructure; it was the hands-on migration help, rapid feedback loops, and genuine partnership from engineers, product folks, and the broader Cloudflare community. That human support empowered us to iterate faster, solve hard problems, and truly feel like we were building something impactful together.
Langbase has quickly become one of the most powerful serverless AI clouds for building and deploying AI agents. We process 700 TB of agent memory and 1.2 billion AI agent runs a month. Langbase is an agent lab, and we’ve also launched a coding agent called Command.new, an “agent of agents” that can take your prompts and turn them into production-ready agents by provisioning infrastructure and writing the agent’s code in TypeScript.
My advice for anyone joining future Workers Launchpad cohorts is to use every resource offered. Engage deeply with the Cloudflare teams, ask for feedback early and often, and be open to sharing your challenges and wins, especially in the Discord community, which is super helpful. Cloudflare listens closely to participant feedback and genuinely wants to help startups succeed. Treat it as a two-way conversation and a collaborative growth opportunity. This mindset is what unlocks the real power of the program.”
-Ahmad Awais, Founder & CEO of Langbase
Sherpo.io (Cohort #4) AI-first no-code platform to build and sell digital content
“Since joining Cohort #4, we’ve exited closed beta and expanded our product suite for content creators. Today, more than 3,000 creators worldwide power their digital product stores with Sherpo, while we continue building and scaling.
We learned as much from fellow startups as from Cloudflare during office hours and sessions, and we got to meet incredible people along the way, including Cloudflare’s CSO, Stephanie Cohen.
For anyone joining, attend every session, listen closely, and ask questions—they’re incredibly valuable. Building on Workers has given us a real advantage, and the team’s pace of innovation only compounds it.”
Tightknit AI (Cohort #4) Embedded community engagement platform built for SaaS
“Beyond the cloud credits that Launchpad provided us to play with every Cloudflare product, the most important aspect of the program we found was our ability to access (and even contribute) to the product roadmap. We were able to connect with product managers and solutions architects that have helped us take our work to the next level.
We’ve recently passed half a million users on the platform and have started to close not just the top Saas businesses in the world, but the top AI companies in the world, including Clay, Gamma, Lindy, beehiiv, Amplitude, Mixpanel, and so many more. The best part is that 100% of application logic is still powered by Cloudflare!
The biggest piece of advice for anyone starting the cohort is attend office hours as much as you can. I can’t tell you how many times we were able to unblock ourselves or even provide real product feedback/bug reports. It was amazing to meet the rest of the cohort and solve problems together that ordinary Cloudflare developers just do not face. So my advice is don’t miss the office hours. They were by far the most valuable part of our experience.”
Render Better (Cohort #4) Increase e-commerce revenue by automatically optimizing your site speed
“My favorite part of the Launchpad was the community and the leaders who brought us together. The startup and product teams provided expert advice on both business and technical questions through meetings, 1-on-1s, and Discord. Many of them were former founders, so they understood what we were going through and helped us get what we needed. They were crucial in helping us get unstuck, whether we were using obscure Cloudflare features or needed connections to the right people.
I met a lot of great founders who are on the same journey and face the same struggles. Watching them grow was motivating and gave us a morale boost to keep up the fast pace a startup needs.
Since Launchpad, Render Better has scaled to 60 automated site speed optimizations, helping e-commerce sites convert 20% higher powered by Cloudflare Workers. Our growth accelerated after the program, and we’re now optimizing traffic for some of the biggest e-commerce brands like PSD, Polywood, and Self-Portrait. Render Better now processes 5 billion requests each month, made possible by Cloudflare’s global edge network and Workers platform.
Launchpad is truly just that: Cloudflare gives you the resources and attention to help you grow from an idea into something big. Build fast and take as much advantage of the fuel they give you to fly your startup rocket!”
-James Koshigoe, Founder & CEO of Render Better
Launchpad is growing into more than just a program. It is a community of builders and innovators showing what is possible with Cloudflare’s network behind them. With that foundation, we are excited to introduce the next group of entrepreneurs taking the stage in Cohort #6.
Introducing Cohort #6
Before introducing Cohort #6, we want to give one last shout out to Cohort #5. As Launchpad alumni, we cannot wait to see what you achieve. If you didn’t get a chance to check out Cohort #5’s demo day, watch the recording here.
With that, help us give a warm welcome to the participants of Workers Launchpad Cohort #6:
We’re excited to see what Cohort #6 accomplishes. Follow @CloudflareDev on X and join our Developer Discord to stay updated on their progress. If you’re a startup interested in joining Workers Launchpad, applications for Cohort #7 are now open.
Allow us to introduce Cap’n Web, an RPC protocol and implementation in pure TypeScript.
Cap’n Web is a spiritual sibling to Cap’n Proto, an RPC protocol I (Kenton) created a decade ago, but designed to play nice in the web stack. That means:
Like Cap’n Proto, it is an object-capability protocol. (“Cap’n” is short for “capabilities and”.) We’ll get into this more below, but it’s incredibly powerful.
Cap’n Web is more expressive than almost every other RPC system, because it implements an object-capability RPC model. That means it:
Supports bidirectional calling. The client can call the server, and the server can also call the client.
Supports passing functions by reference: If you pass a function over RPC, the recipient receives a “stub”. When they call the stub, they actually make an RPC back to you, invoking the function where it was created. This is how bidirectional calling happens: the client passes a callback to the server, and then the server can call it later.
Similarly, supports passing objects by reference: If a class extends the special marker type RpcTarget, then instances of that class are passed by reference, with method calls calling back to the location where the object was created.
Supports promise pipelining. When you start an RPC, you get back a promise. Instead of awaiting it, you can immediately use the promise in dependent RPCs, thus performing a chain of calls in a single network round trip.
Supports capability-based security patterns.
In short, Cap’n Web lets you design RPC interfaces the way you’d design regular JavaScript APIs – while still acknowledging and compensating for network latency.
The best part is, Cap’n Web is absolutely trivial to set up.
A client looks like this:
import { newWebSocketRpcSession } from "capnweb";
// One-line setup.
let api = newWebSocketRpcSession("wss://example.com/api");
// Call a method on the server!
let result = await api.hello("World");
console.log(result);
And here’s a complete Cloudflare Worker implementing an RPC server:
import { RpcTarget, newWorkersRpcResponse } from "capnweb";
// This is the server implementation.
class MyApiServer extends RpcTarget {
hello(name) {
return `Hello, ${name}!`
}
}
// Standard Workers HTTP handler.
export default {
fetch(request, env, ctx) {
// Parse URL for routing.
let url = new URL(request.url);
// Serve API at `/api`.
if (url.pathname === "/api") {
return newWorkersRpcResponse(request, new MyApiServer());
}
// You could serve other endpoints here...
return new Response("Not found", {status: 404});
}
}
That’s it. That’s the app.
You can add more methods to MyApiServer, and call them from the client.
You can have the client pass a callback function to the server, and then the server can just call it.
You can define a TypeScript interface for your API, and easily apply it to the client and server.
It just works.
Why RPC? (And what is RPC anyway?)
Remote Procedure Calls (RPC) are a way of expressing communications between two programs over a network. Without RPC, you might communicate using a protocol like HTTP. With HTTP, though, you must format and parse your communications as an HTTP request and response, perhaps designed in REST style. RPC systems try to make communications look like a regular function call instead, as if you were calling a library rather than a remote service. The RPC system provides a “stub” object on the client side which stands in for the real server-side object. When a method is called on the stub, the RPC system figures out how to serialize and transmit the parameters to the server, invoke the method on the server, and then transmit the return value back.
The merits of RPC have been subject to a great deal of debate. RPC is often accused of committing many of the fallacies of distributed computing.
But this reputation is outdated. When RPC was first invented some 40 years ago, async programming barely existed. We did not have Promises, much less async and await. Early RPC was synchronous: calls would block the calling thread waiting for a reply. At best, latency made the program slow. At worst, network failures would hang or crash the program. No wonder it was deemed “broken”.
Things are different today. We have Promise and async and await, and we can throw exceptions on network failures. We even understand how RPCs can be pipelined so that a chain of calls takes only one network round trip. Many large distributed systems you likely use every day are built on RPC. It works.
The fact is, RPC fits the programming model we’re used to. Every programmer is trained to think in terms of APIs composed of function calls, not in terms of byte stream protocols nor even REST. Using RPC frees you from the need to constantly translate between mental models, allowing you to move faster.
When should you use Cap’n Web?
Cap’n Web is useful anywhere where you have two JavaScript applications speaking to each other over a network, including client-to-server and microservice-to-microservice scenarios. However, it is particularly well-suited to interactive web applications with real-time collaborative features, as well as modeling interactions over complex security boundaries.
Cap’n Web is still new and experimental, so for now, a willingness to live on the cutting edge may also be required!
Features, features, features…
Here’s some more things you can do with Cap’n Web.
HTTP batch mode
Sometimes a WebSocket connection is a bit too heavyweight. What if you just want to make a quick one-time batch of calls, but don’t need an ongoing connection?
For that, Cap’n Web supports HTTP batch mode:
import { newHttpBatchRpcSession } from "capnweb";
let batch = newHttpBatchRpcSession("https://example.com/api");
let result = await batch.hello("World");
console.log(result);
(The server is exactly the same as before.)
Note that once you’ve awaited an RPC in the batch, the batch is done, and all the remote references received through it become broken. To make more calls, you need to start over with a new batch. However, you can make multiple calls in a single batch:
let batch = newHttpBatchRpcSession("https://example.com/api");
// We can call make multiple calls, as long as we await them all at once.
let promise1 = batch.hello("Alice");
let promise2 = batch.hello("Bob");
let [result1, result2] = await Promise.all([promise1, promise2]);
console.log(result1);
console.log(result2);
And that brings us to another feature…
Chained calls (Promise Pipelining)
Here’s where things get magical.
In both batch mode and WebSocket mode, you can make a call that depends on the result of another call, without waiting for the first call to finish. In batch mode, that means you can, in a single batch, call a method, then use its result in another call. The entire batch still requires only one network round trip.
let namePromise = batch.getMyName();
let result = await batch.hello(namePromise);
console.log(result);
Notice the initial call to getMyName() returned a promise, but we used the promise itself as the input to hello(), without awaiting it first. With Cap’n Web, this just works: The client sends a message to the server saying: “Please insert the result of the first call into the parameters of the second.”
Or perhaps the first call returns an object with methods. You can call the methods immediately, without awaiting the first promise, like:
let batch = newHttpBatchRpcSession("https://example.com/api");
// Authencitate the API key, returning a Session object.
let sessionPromise = batch.authenticate(apiKey);
// Get the user's name.
let name = await sessionPromise.whoami();
console.log(name);
This works because the promise returned by a Cap’n Web call is not a regular promise. Instead, it’s a JavaScript Proxy object. Any methods you call on it are interpreted as speculative method calls on the eventual result. These calls are sent to the server immediately, telling the server: “When you finish the call I sent earlier, call this method on what it returns.”
Did you spot the security?
This last example shows an important security pattern enabled by Cap’n Web’s object-capability model.
When we call the authenticate() method, after it has verified the provided API key, it returns an authenticated session object. The client can then make further RPCs on the session object to perform operations that require authorization as that user. The server code might look like this:
class MyApiServer extends RpcTarget {
authenticate(apiKey) {
let username = await checkApiKey(apiKey);
return new AuthenticatedSession(username);
}
}
class AuthenticatedSession extends RpcTarget {
constructor(username) {
super();
this.username = username;
}
whoami() {
return this.username;
}
// ...other methods requiring auth...
}
Here’s what makes this work: It is impossible for the client to “forge” a session object. The only way to get one is to call authenticate(), and have it return successfully.
In most RPC systems, it is not possible for one RPC to return a stub pointing at a new RPC object in this way. Instead, all functions are top-level, and can be called by anyone. In such a traditional RPC system, it would be necessary to pass the API key again to every function call, and check it again on the server each time. Or, you’d need to do authorization outside of the RPC system entirely.
This is a common pain point for WebSockets in particular. Due to the design of the web APIs for WebSocket, you generally cannot use headers nor cookies to authorize them. Instead, authorization must happen in-band, by sending a message over the WebSocket itself. But this can be annoying for RPC protocols, as it means the authentication message is “special” and changes the state of the connection itself, affecting later calls. This breaks the abstraction.
The authenticate() pattern shown above neatly makes authentication fit naturally into the RPC abstraction. It’s even type-safe: you can’t possibly forget to authenticate before calling a method requiring auth, because you wouldn’t have an object on which to make the call. Speaking of type-safety…
TypeScript
If you use TypeScript, Cap’n Web plays nicely with it. You can declare your RPC API once as a TypeScript interface, implement in on the server, and call it on the client:
// Shared interface declaration:
interface MyApi {
hello(name: string): Promise<string>;
}
// On the client:
let api: RpcStub<MyApi> = newWebSocketRpcSession("wss://example.com/api");
// On the server:
class MyApiServer extends RpcTarget implements MyApi {
hello(name) {
return `Hello, ${name}!`
}
}
Now you get end-to-end type checking, auto-completed method names, and so on.
Note that, as always with TypeScript, no type checks occur at runtime. The RPC system itself does not prevent a malicious client from calling an RPC with parameters of the wrong type. This is, of course, not a problem unique to Cap’n Web – JSON-based APIs have always had this problem. You may wish to use a runtime type-checking system like Zod to solve this. (Meanwhile, we hope to add type checking based directly on TypeScript types in the future.)
An alternative to GraphQL?
If you’ve used GraphQL before, you might notice some similarities. One benefit of GraphQL was to solve the “waterfall” problem of traditional REST APIs by allowing clients to ask for multiple pieces of data in one query. For example, instead of making three sequential HTTP calls:
GET /user
GET /user/friends
GET /user/friends/photos
…you can write one GraphQL query to fetch it all at once.
That’s a big improvement over REST, but GraphQL comes with its own tradeoffs:
New language and tooling. You have to adopt GraphQL’s schema language, servers, and client libraries. If your team is all-in on JavaScript, that’s a lot of extra machinery.
Limited composability. GraphQL queries are declarative, which makes them great for fetching data, but awkward for chaining operations or mutations. For example, you can’t easily say: “create a user, then immediately use that new user object to make a friend request, all-in-one round trip.”
Different abstraction model. GraphQL doesn’t look or feel like the JavaScript APIs you already know. You’re learning a new mental model rather than extending the one you use every day.
How Cap’n Web goes further
Cap’n Web solves the waterfall problem without introducing a new language or ecosystem. It’s just JavaScript. Because Cap’n Web supports promise pipelining and object references, you can write code that looks like this:
let user = api.createUser({ name: "Alice" });
let friendRequest = await user.sendFriendRequest("Bob");
What happens under the hood? Both calls are pipelined into a single network round trip:
Create the user.
Take the result of that call (a new User object).
Immediately invoke sendFriendRequest() on that object.
All of this is expressed naturally in JavaScript, with no schemas, query languages, or special tooling required. You just call methods and pass objects around, like you would in any other JavaScript code.
In other words, GraphQL gave us a way to flatten REST’s waterfalls. Cap’n Web lets us go even further: it gives you the power to model complex interactions exactly the way you would in a normal program, with no impedance mismatch.
But how do we solve arrays?
With everything we’ve presented so far, there’s a critical missing piece to seriously consider Cap’n Web as an alternative to GraphQL: handling lists. Often, GraphQL is used to say: “Perform this query, and then, for every result, perform this other query.” For example: “List the user’s friends, and then for each one, fetch their profile photo.”
In short, we need an array.map() operation that can be performed without adding a round trip.
Cap’n Proto, historically, has never supported such a thing.
But with Cap’n Web, we’ve solved it. You can do:
let user = api.authenticate(token);
// Get the user's list of friends (an array).
let friendsPromise = user.listFriends();
// Do a .map() to annotate each friend record with their photo.
// This operates on the *promise* for the friends list, so does not
// add a round trip.
// (wait WHAT!?!?)
let friendsWithPhotos = friendsPromise.map(friend => {
return {friend, photo: api.getUserPhoto(friend.id))};
}
// Await the friends list with attached photos -- one round trip!
let results = await friendsWithPhotos;
Wait… How!?
.map() takes a callback function, which needs to be applied to each element in the array. As we described earlier, normally when you pass a function to an RPC, the function is passed “by reference”, meaning that the remote side receives a stub, where calling that stub makes an RPC back to the client where the function was created.
But that is NOT what is happening here. That would defeat the purpose: we don’t want the server to have to round-trip to the client to process every member of the array. We want the server to just apply the transformation server-side.
To that end, .map() is special. It does not send JavaScript code to the server, but it does send something like “code”, restricted to a domain-specific, non-Turing-complete language. The “code” is a list of instructions that the server should carry out for each member of the array. In this case, the instructions are:
Invoke api.getUserPhoto(friend.id).
Return an object {friend, photo}, where friend is the original array element and photo is the result of step 1.
But the application code just specified a JavaScript method. How on Earth could we convert this into the narrow DSL?
The answer is record-replay: On the client side, we execute the callback once, passing in a special placeholder value. The parameter behaves like an RPC promise. However, the callback is required to be synchronous, so it cannot actually await this promise. The only thing it can do is use promise pipelining to make pipelined calls. These calls are intercepted by the implementation and recorded as instructions, which can then be sent to the server, where they can be replayed as needed.
And because the recording is based on promise pipelining, which is what the RPC protocol itself is designed to represent, it turns out that the “DSL” used to represent “instructions” for the map function is just the RPC protocol itself. 🤯
Implementation details
JSON-based serialization
Cap’n Web’s underlying protocol is based on JSON – but with a preprocessing step to handle special types. Arrays are treated as “escape sequences” that let us encode other values. For example, JSON does not have an encoding for Date objects, but Cap’n Web does. You might see a message that looks like this:
To encode a literal array, we simply double-wrap it in []:
{
names: [["Alice", "Bob", "Carol"]]
}
In other words, an array with just one element which is itself an array, evaluates to the inner array literally. An array whose first element is a type name, evaluates to an instance of that type, where the remaining elements are parameters to the type.
Note that only a fixed set of types are supported: essentially, “structured clonable” types, and RPC stub types.
On top of this basic encoding, we define an RPC protocol inspired by Cap’n Proto – but greatly simplified.
RPC protocol
Since Cap’n Web is a symmetric protocol, there is no well-defined “client” or “server” at the protocol level. There are just two parties exchanging messages across a connection. Every kind of interaction can happen in either direction.
In order to make it easier to describe these interactions, I will refer to the two parties as “Alice” and “Bob”.
Alice and Bob start the connection by establishing some sort of bidirectional message stream. This may be a WebSocket, but Cap’n Web also allows applications to define their own transports. Each message in the stream is JSON-encoded, as described earlier.
Alice and Bob each maintain some state about the connection. In particular, each maintains an “export table”, describing all the pass-by-reference objects they have exposed to the other side, and an “import table”, describing the references they have received. Alice’s exports correspond to Bob’s imports, and vice versa. Each entry in the export table has a signed integer ID, which is used to reference it. You can think of these IDs like file descriptors in a POSIX system. Unlike file descriptors, though, IDs can be negative, and an ID is never reused over the lifetime of a connection.
At the start of the connection, Alice and Bob each populate their export tables with a single entry, numbered zero, representing their “main” interfaces. Typically, when one side is acting as the “server”, they will export their main public RPC interface as ID zero, whereas the “client” will export an empty interface. However, this is up to the application: either side can export whatever they want.
From there, new exports are added in two ways:
When Alice sends a message to Bob that contains within it an object or function reference, Alice adds the target object to her export table. IDs assigned in this case are always negative, starting from -1 and counting downwards.
Alice can send a “push” message to Bob to request that Bob add a value to his export table. The “push” message contains an expression which Bob evaluates, exporting the result. Usually, the expression describes a method call on one of Bob’s existing exports – this is how an RPC is made. Each “push” is assigned a positive ID on the export table, starting from 1 and counting upwards. Since positive IDs are only assigned as a result of pushes, Alice can predict the ID of each push she makes, and can immediately use that ID in subsequent messages. This is how promise pipelining is achieved.
After sending a push message, Alice can subsequently send a “pull” message, which tells Bob that once he is done evaluating the “push”, he should proactively serialize the result and send it back to Alice, as a “resolve” (or “reject”) message. However, this is optional: Alice may not actually care to receive the return value of an RPC, if Alice only wants to use it in promise pipelining. In fact, the Cap’n Web implementation will only send a “pull” message if the application has actually awaited the returned promise.
Putting it together, a code sequence like this:
{
names: [["Alice", "Bob", "Carol"]]
}
Might produce a message exchange like this:
// Call api.getByName(). `api` is the server's main export, so has export ID 0.
-> ["push", ["pipeline", 0, "getMyName", []]
// Call api.hello(namePromise). `namePromise` refers to the result of the first push,
// so has ID 1.
-> ["push", ["pipeline", 0, "hello", [["pipeline", 1]]]]
// Ask that the result of the second push be proactively serialized and returned.
-> ["pull", 2]
// Server responds.
<- ["resolve", 2, "Hello, Alice!"]
Cap’n Web is new and still highly experimental. There may be bugs to shake out. But, we’re already using it today. Cap’n Web is the basis of the recently-launched “remote bindings” feature in Wrangler, allowing a local test instance of workerd to speak RPC to services in production. We’ve also begun to experiment with it in various frontend applications – expect more blog posts on this in the future.
In any case, Cap’n Web is open source, and you can start using it in your own projects now.
I can recall countless late nights as a student spent building out ideas that felt like breakthroughs. My own thesis had significant costs associated with the tools and computational resources I needed. The reality for students is that turning ideas into working applications often requires production-grade tools, and having to pay for them can stop a great project before it even starts. We don’t think that cost should stand in the way of building out your ideas.
Cloudflare’s Developer Platform already makes it easy for anyone to go from idea to launch. It gives you all the tools you need in one place to work on that class project, build out your portfolio, and create full-stack applications. We want students to be able to use these tools without worrying about the cost, so starting today, students at least 18 years old in the United States with a verified .edu email can receive 12 months of free access to Cloudflare’s developer features. This is the first step for Cloudflare for Students, and we plan to continue expanding our support for the next generation of builders.
What’s included
12 months of our paid developer features plan at no upfront cost
Eligible student accounts will receive increased usage allotments for our developer features compared to our free plan. That includes Workers, Pages Functions, KV, Containers, Vectorize, Hyperdrive, Durable Objects, Workers Logpush, and Queues. With these, you can build everything from APIs and full-stack apps to data pipelines and websites.
After 12 months, you can easily renew your subscription by upgrading to our Workers Paid plan. If you choose not to, your account will automatically revert to the free plan, and you won’t be charged.
Here’s a look at the increased usage allotments students can receive today. Above those free allotments, our standard usage rates will apply.
You’ll also have access to a dedicated Discord channel just for students. We want to see what you’re building! This is a place to connect with peers, get support, and share ideas in a community of student developers.
What others have built with Cloudflare’s Developer Platform
Curious about what’s possible with Cloudflare’s developer features? Here are some projects from our community:
Adventure is a text-based adventure game running on Cloudflare Workers that uses Workers AI to generate the stories with the @cf/google/gemma-3-12b-it model.
The project’s developer chose Workers AI with the OpenNext adapter because it made deployment simple and handled scaling automatically. It uses the Workers Paid plan mainly to enable Workers Logpush and get access to detailed logs for better monitoring and analysis.
When a new game starts, the server gives the AI a custom prompt to set the scene and explain how the adventure should work. From there, each time the player makes a choice, their story history is sent back to the server, which asks the AI to continue the narrative, allowing the story to evolve dynamically based on the player’s choices.
The code below shows how this logic is implemented:
"use server";
import { getCloudflareContext } from "@opennextjs/cloudflare";
async function prime(env: CloudflareEnv) {
const id = Math.floor(Math.random() * 1000000);//unique ID for each game run
const messages = [
{
role: "user",
content:
`The user is playing a text-based adventure game. Each game is different, this is game ${id}. Your first job is to create a short background story in 3-4 sentences. Scenarios may include interesting locations such as jungles, deserts, caves.
After the first message, each of your messages will be responses to the user interaction. State three short options (A, B, C). The user responses will be the chosen action. Your responses should end by asking the user about their choice.
Your message will be shown to the user directly, so avoid "Certainly", "Great", "Let's get started", and other filler content, and avoid bringing up technical details such as "this is game #id".
The games should have a win condition that is actually feasible given the story, and if the player loses, the message should end with "Try again.".
`,
},
];
//Call Workers AI to generate the first response (story intro)
const { response } = await env.AI.run("@cf/google/gemma-3-12b-it", { messages });
return [
...messages,
{ role: "assistant", content: response }
];
}
/**
* Main server action for the adventure game.
* If no input yet, it primes the game with the opening story
* If there is input, it continues the story based on the full history
* Uses getCloudflareContext from @opennextjs/cloudflare to access env.
*/
export async function adventureAction(input: any[]) {
let { env } = await getCloudflareContext({ async: true });
return input.length === 0
? await prime(env)
: [...input,
{ role: "assistant", content: (await env.AI.run("@cf/google/gemma-3-12b-it", { messages: input })).response }
];
}
DNS over Discord is a bot that lets you run DNS lookups right inside Discord. Instead of switching to a terminal or online tool, you can use simple slash commands to check records like A, AAAA, MX, TXT, and more.
The developer behind the project chose Cloudflare Workers because it’s a great platform for running small JavaScript apps that handle requests, which made it a good fit for Discord’s slash commands. Since every command translates into a request and the bot sees a lot of traffic, the free tier wasn’t enough, so it now runs on Workers Paid to keep up reliably without hitting request limits.
In this project, the Worker checks if the request is a Discord interaction, and if so, it sends it to the right command (e.g., /dig, /multi-dig, etc.), using a handler that calls out to a custom framework for Discord slash commands. If it’s not from Discord, it can also serve routes like the privacy page or terms of service.
Here’s what that looks like in code:
export default {
// Process all requests to the Worker
fetch: async (request, env, ctx) => {
try {
// Include the env in the context we pass to the handler
ctx.env = env;
// Check if it's a Discord interaction (or a health check)
const resp = await handler(request, ctx);
if (resp) return resp;
// Otherwise, process the request
const url = new URL(request.url);
if (request.method === 'GET' && url.pathname === '/privacy')
return new textResponse(Privacy);
if (request.method === 'GET' && url.pathname === '/terms')
return new textResponse(Terms);
// Fallback if nothing matches
return new textResponse(null, { status: 404 });
} catch (err) {
// Log any errors
captureException(err);
// Re-throw the error
throw err;
}
},
};
placeholders.dev is a service that generates placeholder images, making it easy for developers to prototype and scaffold websites without dealing with hosting or asset management. Users can generate placeholders instantly with a simple URL, such as: https://images.placeholders.dev/350x150
Since placeholders are typically used in early development, speed and consistency matter, and images need to load instantly so the workflow isn’t interrupted. Running on Cloudflare Workers makes the service fast and consistent no matter where developers are.
This project uses the Workers Paid plan because it regularly exceeds the free-tier limits on requests and compute time. The Worker below shows the core of how the service works. When a request comes in, it looks at the URL path (like /300x150) to determine the size of the placeholder, applies some defaults for style, and then returns an SVG image on the fly.
Check out Built With Workers to see what other developers are building with our developer platform.
How do I get started?
This offering is available to United States students at least 18 years old with a verified .edu billing email address.
Based on when your account was created, you can redeem this offer either by signing up for a free Cloudflare account with your .edu email or by filling out a form to request access for your existing .edu account. Just make sure your verified .edu email address is your billing email address.
Fill out our form and a member of our team will help you get access
Note: in order to receive the credit, your verified .edu email address needs to be your billing email address
Expanding Cloudflare for Students coverage
While our first offering is primarily for institutions in the US, we’re working on expanding support for our students in other countries and plan to add additional higher education domain names after launch. If you’re at an educational institution outside of the United States, please reach out to us and apply for your educational/academic domain to be added. We’ll let you know as soon as it becomes available in your region. Check our Cloudflare for Students page for updates and keep an eye out for emails if you have an account with a newly supported domain.
Whether you’re gearing up for your first hackathon, launching a side project, or looking to build the next big thing, you can get started today with free access and join a global developer community already building on Cloudflare.
Cloudflare’s offices bring together builders in some of the world’s most popular technology hubs. We have a long history of using those spaces for one-off events and meet ups over the last fifteen years, but we want to do more. Starting in 2026, we plan to open the doors of our offices routinely to startups and builders from outside of our team who need the space to collaborate, meet new people, or just type away at a keyboard in a new (and beautiful) location.
What are our offices meant to be?
Prior to 2020, we expected essentially every team member of Cloudflare to be present in one of our offices five days a week. That worked well for us and helped facilitate the launch of dozens of technologies as well as a community and culture that defined who we are.
Like every other team on the planet, the COVID pandemic forced us to revisit that approach. We used the time to think about what our offices could be, in a world where not every team member showed up every day of the week. While we decided we would be open to remote and hybrid work, we still felt like some of our best work was done in person together. The goal became building spaces that encouraged team members to be present.
Several hard hats and a few leases later, we’ve created a network of offices around the world designed to evolve with the way people work. These spaces aren’t just places to sit — they’re environments that empower people to do their best work — whether that means quiet focus, creative problem-solving, or lively collaboration. From a library tucked into a quiet zone in our waterfront Lisbon office, to the high-ceilinged collaboration areas in the heart of Austin, each office reflects our belief that great spaces support diverse working styles and help teams thrive together.
Our offices are meant to connect our teams, and we believe that by opening our doors to the wider community, we can foster even more innovation and help new companies collaborate better. Cloudflare has always been a hub for builders, and now we’re making that commitment official by welcoming startups into our physical spaces.
Why make them even more open to the community?
Our spaces have served as hosts to community events since the earliest days of Cloudflare. We have brought together just about every group from hackathons to language meet-ups to university orientation sessions. Cloudflare exists to help build a better Internet and in many cases a better digital environment starts with relationships built in a real life environment.
One of the most common pieces of feedback we have received in the last few years after hosting these events is “I really miss connecting with people like this.” And we hear that most often from small teams in the earliest stages of their journey. In the last few years as the start-ups we support with our platform increasingly begin remote-first and only open dedicated spaces in later stages of their growth.
We know that building a company can be a lonely path. We have helped over the last several years by providing a robust free plan and a comprehensive start-up program, but we think we can do more.
Cloudflare’s network supports a significant percentage of the Internet and, as you would expect, the Internet follows the sun. More people use it during the daytime than at night, meaning our data center utilization peaks in specific times of the day. We take advantage of that pattern to run services that are less latency-sensitive in regions overnight.
Our physical locations follow a similar pattern. Utilization resembles a bell curve with Tuesdays, Wednesdays, and Thursdays seeing a lot of traffic while Mondays and Fridays tend to be quieter. Like our CPUs at night, we think we can use that excess capacity to help build a better Internet by giving builders a space to congregate and helping our team connect with more of our users.
How will this work?
Beginning in January of 2026, we plan to make our office locations available to a capped number of external visitors as all-day coworking spaces on select days of each week. We will provide a registration process (more on that below) and set some ground rules. To start, we plan to expand this offering to San Francisco, Austin, London, and Lisbon.
When external visitors arrive, they’ll have access to our common spaces to bring together their teams or just get some work done by themselves. No mandatory talks or obligations. Just fantastic working spaces available to use at no cost.
How can you participate?
We will provide more details in the next few weeks, but the general structure will be based on the following steps.
Enroll in the Cloudflare for Startups Program. Bonus if you are a Workers Launchpad participant or alumni.
Sit tight for now. We will email participating Startup Program customers first to participate with a form requesting office access.
Once the form is filled out, a member of our team will reach out after. If you want to get a head start, fill out the form here.
We plan to roll this out on a cohort basis. Once approved and all requirements are met, register your visit (and that of any additional team members) at least three business days prior to the date requested.
Respect our working spaces as you would your own.
What’s next?
We hope to expand to other locations in the future. Want to get to the front of the line? Sign up for our Startup program here today and we will reach out to Startup Program participants before we roll out the program.
At Cloudflare, we believe that helping build a better Internet means encouraging a healthy ecosystem of options for how people can connect safely and quickly to the resources they need. Sometimes that means we tackle immense, Internet-scale problems with established partners. And sometimes that means we support and partner with fantastic open teams taking big bets on the next generation of tools.
To that end, today we are excited to announce our support of two independent, open source projects: Ladybird, an ambitious project to build a completely independent browser from the ground up, and Omarchy, an opinionated Arch Linux setup for developers.
Two open source projects strengthening the open Internet
Cloudflare has a long history of supporting open-source software – both through our own projects shared with the community and external projects that we support. We see our sponsorship of Ladybird and Omarchy as a natural extension of these efforts in a moment where energy for a diverse ecosystem is needed more than ever.
Ladybird, a new and independent browser
Most of us spend a significant amount of time using a web browser – in fact, you’re probably using one to read this blog! The beauty of browsers is that they help users experience the open Internet, giving you access to everything from the largest news publications in the world to a tiny website hosted on a Raspberry Pi.
Unlike dedicated apps, browsers reduce the barriers to building an audience for new services and communities on the Internet. If you are launching something new, you can offer it through a browser in a world where most people have absolutely zero desire to install an app just to try something out. Browsers help encourage competition and new ideas on the open web.
While the openness of how browsers work has led to an explosive growth of services on the Internet, browsers themselves have consolidated to a tiny handful of viable options. There’s a high probability you’re reading this on a Chromium-based browser, like Google’s Chrome, along with about 65% of users on the Internet. However, that consolidation has also scared off new entrants in the space. If all browsers ship on the same operating systems, powered by the same underlying technology, we lose out on potential privacy, security and performance innovations that could benefit developers and everyday Internet users.
A screenshot of Cloudflare Workers developer docs in Ladybird
This is where Ladybird comes in: it’s not Chromium based – everything is built from scratch. The Ladybird project has two main components: LibWeb, a brand-new rendering engine, and LibJS, a brand-new JavaScript engine with its own parser, interpreter, and bytecode execution engine.
Building an engine that can correctly and securely render the modern web is a monumental task that requires deep technical expertise and navigating decades of specifications governed by standards bodies like the W3C and WHATWG. And because Ladybird implements these standards directly, it also stress-tests them in practice. Along the way, the project has found, reported, and sometimes fixed countless issues in the specifications themselves, contributions that strengthen the entire web platform for developers, browser vendors, and anyone who may attempt to build a browser in the future.
Whether to build something from scratch or not is a perennial source of debate between software engineers, but absent the pressures of revenue or special interests, we’re excited about the ways Ladybird will prioritize privacy, performance, and security, potentially in novel ways that will influence the entire ecosystem.
A screenshot of the Omarchy development environment
Omarchy, an independent development environment
Developers deserve choice, too. Beyond the browser, a developer’s operating system and environment is where they spend a ton of time – and where a few big players have become the dominant choice. Omarchy challenges this by providing a complete, opinionated Arch Linux distribution that transforms a bare installation into a modern development workstation that developers are excited about.
Perfecting one’s development environment can be a career-long art, but learning how to do so shouldn’t be a barrier to beginning to code. The beauty of Omarchy is that it makes Linux approachable to more developers by doing most of the setup for them, making it look good, and then making it configurable. Omarchy provides most of the tools developers need – like Neovim, Docker, and Git – out of the box, and tons of other features.
At its core, Omarchy embraces Linux for all of its complexity and configurability, and makes a version of it that is accessible and fun to use for developers that don’t have a deep background in operating systems. Projects like this ensure that a powerful, independent Linux desktop remains a compelling choice for people building the next generation of applications and Internet infrastructure.
Our support comes with no strings attached
We want to be very clear here: we are supporting these projects because we believe the Internet can be better if these projects, and more like them, succeed. No requirement to use our technology stack or any arrangement like that. We are happy to partner with great teams like Ladybird and Omarchy simply because we believe that our missions have real overlap.
Notes from the teams
Ladybird is still in its early days, with an alpha release planned for 2026, but we encourage anyone who is interested to consider contributing to the open source codebase as they prepare for launch.
“Cloudflare knows what it means to build critical web infrastructure on the server side. With Ladybird, we’re tackling the near-monoculture on the client side, because we believe it needs multiple implementations to stay healthy, and we’re extremely thankful for their support in that mission.”
– Andreas Kling, Founder, Ladybird
Omarchy 3.0 was released just last week with faster installation and increased Macbook compatibility, so if you’ve been Linux-curious for a while now, we encourage you to try it out!
“Cloudflare’s support of Omarchy has ensured we have the fastest ISO and package delivery from wherever you are in the world. Without a need to manually configure mirrors or deal with torrents. The combo of a super CDN, great R2 storage, and the best DDoS shield in the business has been a huge help for the project.”
– David Heinemeier Hansson, Creator of Omarchy and Ruby on Rails
A better Internet is one where people have more choice in how they browse and develop new software. We’re incredibly excited about the potential of Ladybird, Omarchy, and other audacious projects that support a free and open Internet.
When we first launched Workers AI, we made a bet that AI models would get faster and smaller. We built our infrastructure around this hypothesis, adding specialized GPUs to our datacenters around the world that can serve inference to users as fast as possible. We created our platform to be as general as possible, but we also identified niche use cases that fit our infrastructure well, such as low-latency image generation or real-time audio voice agents. To lean in on those use cases, we’re bringing on some new models that will help make it easier to develop for these applications.
Today, we’re excited to announce that we are expanding our model catalog to include closed-source partner models that fit this use case. We’ve partnered with Leonardo.Ai and Deepgram to bring their latest and greatest models to Workers AI, hosted on Cloudflare’s infrastructure. Leonardo and Deepgram both have models with a great speed-to-performance ratio that suit the infrastructure of Workers AI. We’re starting off with these great partners — but expect to expand our catalog to other partner models as well.
The benefits of using these models on Workers AI is that we don’t only have a standalone inference service, we also have an entire suite of Developer products that allow you to build whole applications around AI. If you’re building an image generation platform, you could use Workers to host the application logic, Workers AI to generate the images, R2 for storage, and Images for serving and transforming media. If you’re building Realtime voice agents, we offer WebRTC and WebSocket support via Workers, speech-to-text, text-to-speech, and turn detection models via Workers AI, and an orchestration layer via Cloudflare Realtime. All in all, we want to lean into use cases that we think Cloudflare has a unique advantage in, with developer tools to back it up, and make it all available so that you can build the best AI applications on top of our holistic Developer Platform.
Leonardo Models
Leonardo.Ai is a generative AI media lab that trains their own models and hosts a platform for customers to create generative media. The Workers AI team has been working with Leonardo for a while now and have experienced the magic of their image generation models firsthand. We’re excited to bring on two image generation models from Leonardo: @cf/leonardo/phoenix-1.0 and @cf/leonardo/lucid-origin.
“We’re excited to enable Cloudflare customers a new avenue to extend and use our image generation technology in creative ways such as creating character images for gaming, generating personalized images for websites, and a host of other uses… all through the Workers AI and the Cloudflare Developer Platform.” – Peter Runham, CTO, Leonardo.Ai
The Phoenix model is trained from the ground up by Leonardo, excelling at things like text rendering and prompt coherence. The full image generation request took 4.89s end-to-end for a 25 step, 1024×1024 image.
curl --request POST \
--url https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/run/@cf/leonardo/draco-1.0 \
--header 'Authorization: Bearer {TOKEN}' \
--header 'Content-Type: application/json' \
--data '{
"prompt": "A 1950s-style neon diner sign glowing at night that reads '\''OPEN 24 HOURS'\'' with chrome details and vintage typography.",
"width":1024,
"height":1024,
"steps": 25,
"seed":1,
"guidance": 4,
"negative_prompt": "bad image, low quality, signature, overexposed, jpeg artifacts, undefined, unclear, Noisy, grainy, oversaturated, overcontrasted"
}'
The Lucid Origin model is a recent addition to Leonardo’s family of models and is great at generating photorealistic images. The image took 4.38s to generate end-to-end at 25 steps and a 1024×1024 image size.
curl --request POST \
--url https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/run/@cf/leonardo/lucid-origin \
--header 'Authorization: Bearer {TOKEN}' \
--header 'Content-Type: application/json' \
--data '{
"prompt": "A 1950s-style neon diner sign glowing at night that reads '\''OPEN 24 HOURS'\'' with chrome details and vintage typography.",
"width":1024,
"height":1024,
"steps": 25,
"seed":1,
"guidance": 4,
"negative_prompt": "bad image, low quality, signature, overexposed, jpeg artifacts, undefined, unclear, Noisy, grainy, oversaturated, overcontrasted"
}'
Deepgram Models
Deepgram is a voice AI company that develops their own audio models, allowing users to interact with AI through a natural interface for humans: voice. Voice is an exciting interface because it carries higher bandwidth than text, because it has other speech signals like pacing, intonation, and more. The Deepgram models that we’re bringing on our platform are audio models which perform extremely fast speech-to-text and text-to-speech inference. Combined with the Workers AI infrastructure, the models showcase our unique infrastructure so customers can build low-latency voice agents and more.
“By hosting our voice models on Cloudflare’s Workers AI, we’re enabling developers to create real-time, expressive voice agents with ultra-low latency. Cloudflare’s global network brings AI compute closer to users everywhere, so customers can now deliver lightning-fast conversational AI experiences without worrying about complex infrastructure.” – Adam Sypniewski, CTO, Deepgram
@cf/deepgram/nova-3 is a speech-to-text model that can quickly transcribe audio with high accuracy. @cf/deepgram/aura-1 is a text-to-speech model that is context aware and can apply natural pacing and expressiveness based on the input text. The newer Aura 2 model will be available on Workers AI soon. We’ve also improved the experience of sending binary mp3 files to Workers AI, so you don’t have to convert it into an Uint8 array like you had to previously. Along with our Realtime announcements (coming soon!), these audio models are the key to enabling customers to build voice agents directly on Cloudflare.
With the AI binding, a call to the Nova 3 speech-to-text model would look like this:
As well, we’ve added WebSocket support to the Deepgram models, which you can use to keep a connection to the inference server live and use it for bi-directional input and output. To use the Nova model with WebSocket support, it would look like this:
As well, we’ve added WebSocket support to the Deepgram models, which you can use to keep a connection to the inference server live and use it for bi-directional input and output. To use the Nova model with WebSocket support, check out our Developer Docs.
All the pieces work together so that you can:
Capture audio with Cloudflare Realtime from any WebRTC source
Pipe it via WebSocket to your processing pipeline
Transcribe with audio ML models Deepgram running on Workers AI
Process with your LLM of choice through a model hosted on Workers AI or proxied via AI Gateway
Orchestrate everything with Realtime Agents
Try these models out today
Check out our developer docs for more details, pricing and how to get started with the newest partner models available on Workers AI.
If you’re here on the Cloudflare blog, chances are you already understand AI pretty well. But step outside our circle, and you’ll find a surprising number of people who still don’t know what it really is — or why it matters.
We wanted to come up with a way to make AI intuitive, something you can actually see and touch to get what’s going on. Hands on, not just hand-wavy.
The idea we landed on is simple: nothing comes into the world fully formed. Like us, and like the Internet, AI didn’t show up fully formed. So we asked ourselves: what if we told the story of AI as it learns and grows?
Episode by episode, we’d give it new capabilities, explain how those capabilities work, and explore how they change the way AI interacts with the world. Giving it a voice. Letting it see. Helping it learn. And maybe even letting it imagine the future.
So we made AI Avenue, a show where I (Craig) explore the fun, human, and sometimes surprising sides of AI… with a little help from my co-host Yorick, a robot hand with a knack for comic timing and the occasional eye-roll. Together, we travel, talk to incredible people, and get hands-on with AI to show it’s not just something to read about. It’s something you can touch, try, and enjoy.
The idea behind AI Avenue
We wanted to make something that would strip away the jargon and make AI approachable, friendly, and most importantly, fun.
In AI Avenue, we address people’s fears, show them the art of the possible, and highlight the positive human stories where AI is augmenting — not replacing — what people can do. And yes, we even let people touch AI themselves. Also yes, the previous paragraphs “intentionally included” a few em-dashes.
The result? A fast-paced, playful series that mixes demos, interviews, and real-world examples, all showing AI as something you can explore, question, and use in ways that matter to you.
You can sign up now to be notified when each episode drops and learn more about the journey ataiavenue.show.
Who we worked with
We had an absolute blast partnering with some of the most exciting players in the space:
Anthropic — on building safe, aligned AI models.
Engineered Arts — creators of the humanoid robot Ameca, who makes several appearances throughout the series.
ElevenLabs — powering lifelike voice synthesis.
HeyGen — creating realistic AI-generated video avatars and translations.
Roboflow — enabling computer vision projects with powerful image datasets and tools.
Be My Eyes — using AI and volunteers to make the world more accessible for people who are blind or have low vision.
Writer — bringing enterprise-grade generative AI into real-world workflows.
Episodes: One Ability at a Time
Across six episodes, we follow Yorick’s upgrades and occasional misadventures as he learns to talk, see, think, and even imagine the future.
Episode 1: Voice — We start in London where Yorick gets his voice and immediately starts chiming in on everything.
Episode 2: Vision — In San Francisco, Yorick tries computer vision for the first time. We watch someone go shopping for the first time.
Episode 3: Thinking — Hosting a live trivia stream online, Yorick begins confidently spouting answers that aren’t quite true. We head to New York City to meet someone whose life was saved by ChatGPT.
Episode 4: Learning — Yorick discovers generative AI and decides he can make the show himself, spawning multiple Craig clones and raising questions about ethics and creativity.
Episode 5: Doing — It turns out everyone we talk to just wants a robot to do their dishes. We dig into what “doing” means in AI and robotics and whether Yorick is on board.
Episode 6: Smell — In our finale, we explore the agentic AI future, quantum computing, and big sci-fi dreams, then hang out with a 9-year-old vibe coder because, well, the children are the future.
Get hands-on
Every episode is paired with developer tutorials so you can experiment with the same AI tools that we feature. No matter your skill level, you can tinker, build, and see for yourself what AI can do. We strongly believe the most important thing you can do right now is to touch AI, play with it. Now is the time.
Follow along the avenue
Yorick and I will be releasing each episode of AI Avenue as it’s ready, and we’d love to have you along for the ride.
Sign up to be notified when new episodes launch and explore more about the show at aiavenue.show.
We are witnessing in real time as AI fundamentally changes how people work across every industry. Customer support agents can respond to ten times the tickets. Software engineers are reviewers of AI generated code instead of spending hours pounding out boiler plate code. Salespeople can get back to focusing on building relationships instead of tedious follow up and administration.
This technology feels magical, and Cloudflare is committed to helping companies build world class AI-driven experiences for their employees and customers.
There is a but, however. Any time a brand new technology with such widespread appeal emerges, the technology often outpaces the tools in place to govern, secure and control the technology. We’re already starting to see stories of vibe coded apps leaking all their users’ details. LLM chats that were intended to only be shared between colleagues, are actually out on the web, being indexed by search engines for all the world to see. AI Agents are being given the keys to the application kingdom, enabling them to work autonomously across an organization — but without proper tracking and control. And then there’s the risk of a well-meaning employee uploading confidential company or customer data into an LLM, which then uses it to train future models.
Beyond internal data used for LLM training, content creators and media companies are also faced with a decision about how they want LLM scrapers and information retrieval bots to interact with their content. Cloudflare has found that it can be hundreds, or even thousands, of times harder to generate site traffic (and therefore ad revenue) from an AI response versus a search engine result.
We’re hearing more and more of these stories from CISOs, CIOs, Creators, and even CEOs. These leaders are faced with a difficult choice: clamping down on all AI usage and bots — or letting them run wild. There needs to be something in between. And for that to be a real option, the tools to manage and secure AI need to catch up to AI itself.
This week, that’s what Cloudflare is focused on. Welcome to AI Week! Over the coming week, we will focus on four core areas to help companies secure and deliver AI experiences safely and securely:
Securing AI environments and workflows: AI is incredibly powerful. The problem is, innovation is outpacing control — we want to change that. And as one of the few zero trust providers also building out AI infrastructure for the web, we’re uniquely positioned to be able to do so.
Protecting original content from misuse by AI: AI Companies are devouring organic content as quickly as it’s created… and creators aren’t seeing any benefit. We want to give content creators control over the content that they have worked so hard to develop.
Helping developers build world-class, secure, AI experiences: the possibilities for developers to create new applications on top of (or even building with) AI are endless. We want to allow developers to create AI driven applications that are as close to users as possible, with security controls built-in from day one.
Making Cloudflare better for you with AI: AI is changing the nature of interfaces. For example, finding and mitigating issues buried in thousands and millions of logs and events across website, employee, and email usage is something that used to be tedious — but now with AI, it can be made easy. We’re working day and night to integrate AI into Cloudflare itself to make things more efficient for ourselves and our customers.
Securing AI environments and workflows
As Artificial Intelligence innovation continues to accelerate at an unprecedented pace, the speed of its development is increasingly outpacing the implementation of robust security controls. This rapid advancement, while promising immense benefits, simultaneously introduces novel and complex security challenges that traditional measures are often ill-equipped to address. Organizations are finding themselves grappling with the inherent risks of adopting powerful AI tools without adequate safeguards, leading to vulnerabilities such as Shadow AI and the uncontrolled proliferation of AI models, making the development of specialized AI security paramount.
As we look around the zero trust space, none of the other providers are moving fast enough to keep up with AI’s pace of innovation. This is something we know a thing or two about — and after this week, if you’re worried about governing AI usage inside your organization, we will have you covered.
We will be announcing new and powerful controls to detect Shadow AI and control unauthorized AI usage. Additionally, we’ve built options for teams to establish the “paved path” of AI tooling in an organization to supercharge employee productivity without sacrificing security. Finally, we’ll be announcing new ways of protecting your own models from poisoning or attacks.
Protecting original content from AI
The explosion of Large Language Models (LLMs) has also created a new challenge for content creators: the unauthorized scraping and training of their valuable content. Cloudflare recognizes the critical need for creators to maintain control over their intellectual property. That’s why we’ve introduced Crawl Control, a groundbreaking initiative designed to empower content owners to manage how their content is accessed and used by AI models.
In the past two months, we’ve seen incredible progress with Crawl Control. We’ve significantly expanded the number of participating content providers, allowing more creators to leverage this innovative protection. We’ve also refined our detection mechanisms to more accurately identify AI crawlers and ensure that only authorized access occurs. Furthermore, we’ve streamlined the integration process, making it easier for new publishers to onboard and begin protecting their content within minutes. Our goal remains to provide content creators with the tools they need to thrive in the age of AI, ensuring they are compensated and acknowledged for the content they produce.
Helping you build world-class, secure, AI experiences
We believe that AI experiences should have security controls by default. This is why we are heavily investing in both our developer platform’s AI Gateway and the associated security controls for those products. This two pronged approach allows developers to iterate and test new ideas without the fear of painful or embarrassing security issues.
The Cloudflare AI Gateway allows developers to deploy AI-driven applications with unparalleled speed and efficiency, ensuring that these applications are as close to end-users as possible. This proximity minimizes latency and maximizes performance, delivering a seamless and responsive user experience that is critical in today’s fast-paced digital landscape.
This week, we’re announcing significant enhancements to the AI Gateway, further solidifying its position as the premier platform for AI application deployment. These improvements include advanced caching mechanisms that reduce redundant model calls, leading to faster response times and lower operational costs. We are also introducing expanded observability features, providing developers with deeper insights into their AI model’s performance and usage patterns, which will enable more effective debugging and optimization. Furthermore, new integrations with popular AI frameworks and services will simplify the development workflow, allowing developers to leverage the AI Gateway’s benefits with even greater ease. Our commitment is to provide developers with the tools to innovate and deliver cutting-edge AI experiences to their users.
Making Cloudflare better with AI
We’re integrating AI across our entire product suite to enhance the Cloudflare experience itself. From intelligent threat detection that adapts to emerging attack patterns, to AI-powered optimizations that fine-tune network performance, our goal is to leverage AI to make our platform more intuitive, efficient, and secure. We envision a future where Cloudflare’s products proactively anticipate user needs, automate complex tasks, and deliver unparalleled insights, all powered by seamlessly embedded AI. This commitment to internal AI integration ensures that as the digital landscape evolves, Cloudflare remains at the forefront of innovation, continuously delivering superior value to our users.
We cannot wait to share these updates and announcements with you. Follow our AI Week hub page for all the latest releases from our blog and CloudflareTV.
Today, we are announcing Cloudflare’s Browser Developer Program, a collaborative initiative to strengthen partnership between Cloudflare and browser development teams.
At Cloudflare, we aim to help build a better Internet. One way we achieve this is by providing website owners with the tools to detect and block unwanted traffic from bots through Cloudflare Challenges or Turnstile. As both bots and our detection systems become more sophisticated, the security checks required to validate human traffic become more complicated. While we aim to strike the right balance, we recognize these security measures can sometimes cause issues for legitimate browsers and their users.
Building a better web together
A core objective of the program is to provide a space for intentional collaboration where we can work directly with browser developers to ensure that both accessibility and security can co-exist. We aim to support the evolving browser landscape, while upholding our responsibility to our customers to deliver the best security products. This program provides a dedicated channel for browser teams to share feedback, report issues, and help ensure that Cloudflare’s Challenges and Turnstile work seamlessly with all browsers.
What the program includes
Browser developers in the program will benefit from:
A two-way communication channel to Cloudflare’s team dedicated to addressing browser-specific concerns, feedback, and issues.
Best practices for building and testing against Cloudflare Challenges and Turnstile.
A private community forum for updates, questions, and discussion between browser developers and Cloudflare engineers.
Early visibility into updates or changes to that may impact how your browser handles Cloudflare Challenges.
(If applicable) Testing integration where we will incorporate your browser into our testing pipeline and monitor its performance with our releases.
This program is designed as a partnership where Cloudflare will, with our best effort, ensure our security products work properly with all browsers, while giving browser developers a voice in how these systems evolve. As an output of this program, we expect to publish clear browser requirements to run Cloudflare Challenges while striking the balance between openness and security.
For end users browsing the web, we continue to support a wide range of browsers. We will continue to update this list based on the insights and collaborations from the Browser Developer Program. We are also committed to ensuring our Challenge interstitial pages and Turnstile provide clear, actionable UI/UX for any error or failed states, making it easier for you to understand and resolve issues you may encounter.
How to apply
If you are working on a browser and want to ensure your users have a seamless experience with Cloudflare-protected websites, we encourage you to apply here.
We’ll ask for basic information about your project and ask you to sign our Browser Developer Program Agreement. In addition, we expect participants to adhere to our Community Code of Conduct and commit to constructive engagement.
Once you’re accepted, you’ll be invited to a private space in the Cloudflare Community where you can engage directly with our team.
Why is this important?
Cloudflare Challenges, a security mechanism to verify whether a visitor is a human or a bot, serve a wide variety of browsers in the world today. Chrome leads with 68.0%, Safari at 8.7%, Firefox at 6.3%, Edge at 4.8%, and Opera at 6.2%. However, the very long tail of browsers that collectively make up the remaining traffic, each representing less than 1% individually but together painting a picture of an incredibly diverse web ecosystem.
Browser traffic distribution, with 100+ browsers comprising the ‘Other’ category
This diversity spans a wide range of environments, each with unique constraints and capabilities:
Emerging and experimental browsers pushing the boundaries of web technology
Privacy-focused browsers such as DuckDuckGo that prioritize user data protection
Embedded browsers inside social media apps like Facebook, Instagram, and TikTok
WebViews used by mobile applications
Gaming and VR browsers such as Oculus for headsets and gaming consoles
Smart device browsers built into classroom displays and home appliances
Supporting this level of diversity poses real engineering challenges. Many of these browsers deviate from standard assumptions. Some lack full support for modern Web APIs, others operate under more stringent data privacy policies, and some are optimized for environments where our script to verify visitors may be hindered or blocked from running properly. These browsers are not bad or malicious. But their behavior may fall outside the typical patterns observed in mainstream browsers, which can lead to problematic or failed Challenge flows which we would like to avoid.
From an engineering perspective, our job is to strike a difficult balance. If our logic is too rigid that it expects only the behaviors of the majority, we risk excluding legitimate users on less conventional platforms. But if we relax our standards too much, we increase the attack surface for abuse. We cannot overfit to the top 5 browsers, nor can we afford to treat all clients as equal in capability or trustworthiness.
The Browser Developer Program is one way to close this gap. By working directly with browser teams, especially those building for niche or emerging environments, we can better understand the constraints they operate under and collaborate to make each of our systems more compatible and resilient.
Join us!
This program is free to join, and is open to any browser developer, no matter the size or the lifecycle stage. Our goal is to listen, learn, and collaborate with browser developers to create a better experience for everyone.
We believe this program will ultimately benefit end users the most. By joining this program, you will help us build solutions that prioritize both the security needs of businesses as well as the diverse ways people access the Internet.
Many developers, data scientists, and researchers do much of their work in Python notebooks: they’ve been the de facto standard for data science and sharing for well over a decade. Notebooks are popular because they make it easy to code, explore data, prototype ideas, and share results. We use them heavily at Cloudflare, and we’re seeing more and more developers use notebooks to work with data – from analyzing trends in HTTP traffic, querying Workers Analytics Engine through to querying their own Iceberg tables stored in R2.
Traditional notebooks are incredibly powerful — but they were not built with collaboration, reproducibility, or deployment as data apps in mind. As usage grows across teams and workflows, these limitations face the reality of work at scale.
marimo reimagines the notebook experience with these challenges in mind. It’s an open-source reactive Python notebook that’s built to be reproducible, easy to track in Git, executable as a standalone script, and deployable. We have partnered with the marimo team to bring this streamlined, production-friendly experience to Cloudflare developers. Spend less time wrestling with tools and more time exploring your data.
Want to start exploring your Cloudflare data with marimo right now? Head over to notebooks.cloudflare.com. Or, keep reading to learn more about marimo, how we’ve made authentication easy from within notebooks, and how you can use marimo to explore and share notebooks and apps on Cloudflare.
Why marimo?
marimo is an open-source reactive Python notebook designed specifically for working with data, built from the ground up to solve many problems with traditional notebooks.
The core feature that sets marimo apart from traditional notebooks is its reactive execution model, powered by a statically inferred dataflow graph on cells. Run a cell or interact with a UI element, and marimo either runs dependent cells or marks them as stale (your choice). This keeps code and outputs consistent, prevents bugs before they happen, and dramatically increases the speed at which you can experiment with data.
Thanks to reactive execution, notebooks are also deployable as data applications, making them easy to share. While you can run marimo notebooks locally, on cloud servers, GPUs — anywhere you can traditionally run software — you can also run them entirely in the browser with WebAssembly, bringing the cost of sharing down to zero.
Because marimo notebooks are stored as Python, they enjoy all the benefits of software: version with Git, execute as a script or pipeline, test with pytest, inline package requirements with uv, and import symbols from your notebook into other Python modules. Though stored as Python, marimo also supports SQL and data sources like DuckDB, Postgres, and Iceberg-based data catalogs (which marimo’s AI assistant can access, in addition to data in RAM).
To get an idea of what a marimo notebook is like, check out the embedded example notebook below:
Want to create your own notebook to run locally instead? Here’s a quick example that shows you how to authenticate with your Cloudflare account and list the zones you have access to:
mkdir cloudflare-zones-notebook
cd cloudflare-zones-notebook
3. Initialize a new uv project (this creates a .venv and a pyproject.toml):
uv init
4. Add marimo and required dependencies:
uv add marimo
5. Create a file called list-zones.py and paste in the following notebook:
import marimo
__generated_with = "0.14.10"
app = marimo.App(width="full", auto_download=["ipynb", "html"])
@app.cell
def _():
from moutils.oauth import PKCEFlow
import requests
# Start OAuth PKCE flow to authenticate with Cloudflare
auth = PKCEFlow(provider="cloudflare")
# Renders login UI in notebook
auth
return (auth,)
@app.cell
def _(auth):
import marimo as mo
from cloudflare import Cloudflare
mo.stop(not auth.access_token, mo.md("Please **sign in** using the button above."))
client = Cloudflare(api_token=auth.access_token)
zones = client.zones.list()
[zone.name for zone in zones.result]
return
if __name__ == "__main__":
app.run()
6. Open the notebook editor:
uv run marimo edit list-zones.py --sandbox
7. Log in via the OAuth prompt in the notebook. Once authenticated, you’ll see a list of your Cloudflare zones in the final cell.
That’s it! From here, you can expand the notebook to call Workers AI models, query Iceberg tables in R2 Data Catalog, or interact with any Cloudflare API.
How OAuth works in notebooks
Think of OAuth like a secure handshake between your notebook and Cloudflare. Instead of copying and pasting API tokens, you just click “Sign in with Cloudflare” and the notebook handles the rest.
We built this experience using PKCE (Proof Key for Code Exchange), a secure OAuth 2.0 flow that avoids client secrets and protects against code interception attacks. PKCE works by generating a one-time code that’s exchanged for a token after login, without ever sharing a client secret. Learn more about how PKCE works.
The login widget lives in moutils.oauth, a collaboration between Cloudflare and marimo to make OAuth authentication simple and secure in notebooks. To use it, just create a cell like this:
auth = PKCEFlow(provider="cloudflare")
# Renders login UI in notebook
auth
When you run the cell, you’ll see a Sign in with Cloudflare button:
Once logged in, you’ll have a read-only access token you can pass when using the Cloudflare API.
Running marimo on Cloudflare: Workers and Containers
If you have a local notebook you want to share, you can publish it to Workers. This works because marimo can export notebooks to WebAssembly, allowing them to run entirely in the browser. You can get started with just two commands:
If your notebook needs authentication, you can layer in Cloudflare Access for secure, authenticated access.
For notebooks that require more compute, persistent sessions, or long-running tasks, you can deploy marimo on our new container platform. To get started, check out our marimo container example on GitHub.
What’s next for Cloudflare + marimo
This blog post marks just the beginning of Cloudflare’s partnership with marimo. While we’re excited to see how you use our joint WebAssembly-based notebook platform to explore your Cloudflare data, we also want to help you bring serious compute to bear on your data — to empower you to run large scale analyses and batch jobs straight from marimo notebooks. Stay tuned!
We are thrilled to announce the General Availability of Cloudflare Log Explorer, a powerful new product designed to bring observability and forensics capabilities directly into your Cloudflare dashboard. Built on the foundation of Cloudflare’s vast global network, Log Explorer leverages the unique position of our platform to provide a comprehensive and contextualized view of your environment.
Security teams and developers use Cloudflare to detect and mitigate threats in real-time and to optimize application performance. Over the years, users have asked for additional telemetry with full context to investigate security incidents or troubleshoot application performance issues without having to forward data to third party log analytics and Security Information and Event Management (SIEM) tools. Besides avoidable costs, forwarding data externally comes with other drawbacks such as: complex setups, delayed access to crucial data, and a frustrating lack of context that complicates quick mitigation.
Log Explorer has been previewed by several hundred customers over the last year, and they attest to its benefits:
“Having WAF logs (firewall events) instantly available in Log Explorer with full context — no waiting, no external tools — has completely changed how we manage our firewall rules. I can spot an issue, adjust the rule with a single click, and immediately see the effect. It’s made tuning for false positives faster, cheaper, and far more effective.”
“While we use Logpush to ingest Cloudflare logs into our SIEM, when our development team needs to analyze logs, it can be more effective to utilize Log Explorer. SIEMs make it difficult for development teams to write their own queries and manipulate the console to see the logs they need. Cloudflare’s Log Explorer, on the other hand, makes it much easier for dev teams to look at logs and directly search for the information they need.”
With Log Explorer, customers have access to Cloudflare logs with all the context available within the Cloudflare platform. Compared to external tools, customers benefit from:
Reduced cost and complexity: Drastically reduce the expense and operational overhead associated with forwarding, storing, and analyzing terabytes of log data in external tools.
Faster detection and triage: Access Cloudflare-native logs directly, eliminating cumbersome data pipelines and the ingest lags that delay critical security insights.
Accelerated investigations with full context: Investigate incidents with Cloudflare’s unparalleled contextual data, accelerating your analysis and understanding of “What exactly happened?” and “How did it happen?”
Minimal recovery time: Seamlessly transition from investigation to action with direct mitigation capabilities via the Cloudflare platform.
Log Explorer is available as an add-on product for customers on our self serve or Enterprise plans. Read on to learn how each of the capabilities of Log Explorer can help you detect and diagnose issues more quickly.
Monitor security and performance issues with custom dashboards
Custom dashboards allow you to define the specific metrics you need in order to monitor unusual or unexpected activity in your environment.
Getting started is easy, with the ability to create a chart using natural language. A natural language interface is integrated into the chart create/edit experience, enabling you to describe in your own words the chart you want to create. Similar to the AI Assistant we announced during Security Week 2024, the prompt translates your language to the appropriate chart configuration, which can then be added to a new or existing custom dashboard.
As an example, you can create a dashboard for monitoring for the presence of Remote Code Execution (RCE) attacks happening in your environment. An RCE attack is where an attacker is able to compromise a machine in your environment and execute commands. The good news is that RCE is a detection available in Cloudflare WAF. In the dashboard example below, you can not only watch for RCE attacks, but also correlate them with other security events such as malicious content uploads, source IP addresses, and JA3/JA4 fingerprints. Such a scenario could mean one or more machines in your environment are compromised and being used to spread malware — surely, a very high risk incident!
A reliability engineer might want to create a dashboard for monitoring errors. They could use the natural language prompt to enter a query like “Compare HTTP status code ranges over time.” The AI model then decides the most appropriate visualization and constructs their chart configuration.
While you can create custom dashboards from scratch, you could also use an expert-curated dashboard template to jumpstart your security and performance monitoring.
Available templates include:
Bot monitoring: Identify automated traffic accessing your website
API Security: Monitor the data transfer and exceptions of API endpoints within your application
API Performance: See timing data for API endpoints in your application, along with error rates
Account Takeover: View login attempts, usage of leaked credentials, and identify account takeover attacks
Performance Monitoring: Identify slow hosts and paths on your origin server, and view time to first byte (TTFB) metrics over time
Security Monitoring: monitor attack distribution across top hosts and paths, correlate DDoS traffic with origin Response time to understand the impact of DDoS attacks.
Investigate and troubleshoot issues with Log Search
Continuing with the example from the prior section, after successfully diagnosing that some machines were compromised through the RCE issue, analysts can pivot over to Log Search in order to investigate whether the attacker was able to access and compromise other internal systems. To do that, the analyst could search logs from Zero Trust services, using context, such as compromised IP addresses from the custom dashboard, shown in the screenshot below:
Log Search is a streamlined experience including data type-aware search filters, or the ability to switch to a custom SQL interface for more powerful queries. Log searches are also available via a public API.
Save time and collaborate with saved queries
Queries built in Log Search can now be saved for repeated use and are accessible to other Log Explorer users in your account. This makes it easier than ever to investigate issues together.
Monitor proactively with Custom Alerting (coming soon)
With custom alerting, you can configure custom alert policies in order to proactively monitor the indicators that are important to your business.
Starting from Log Search, define and test your query. From here you can opt to save and configure a schedule interval and alerting policy. The query will run automatically on the schedule you define.
Tracking error rate for a custom hostname
If you want to monitor the error rate for a particular host, you can use this Log Search query to calculate the error rate per time interval:
SELECT SUBSTRING(EdgeStartTimeStamp, 1, 14) || '00:00' AS time_interval,
COUNT() AS total_requests,
COUNT(CASE WHEN EdgeResponseStatus >= 500 THEN 1 ELSE NULL END) AS error_requests,
COUNT(CASE WHEN EdgeResponseStatus >= 500 THEN 1 ELSE NULL END) * 100.0 / COUNT() AS error_rate_percentage
FROM http_requests
WHERE EdgeStartTimestamp >= '2025-06-09T20:56:58Z'
AND EdgeStartTimestamp <= '2025-06-10T21:26:58Z'
AND ClientRequestHost = 'customhostname.com'
GROUP BY time_interval
ORDER BY time_interval ASC;
Running the above query returns the following results. You can see the overall error rate percentage in the far right column of the query results.
Proactively detect malware
We can identify malware in the environment by monitoring logs from Cloudflare Secure Web Gateway. As an example, Katz Stealer is malware-as-a-service designed for stealing credentials. We can monitor DNS queries and HTTP requests from users within the company in order to identify any machines that may be infected with Katz Stealer malware.
And with custom alerts, you can configure an alert policy so that you can be notified via webhook or PagerDuty.
Maintain audit & compliance with flexible retention (coming soon)
With flexible retention, you can set the precise length of time you want to store your logs, allowing you to meet specific compliance and audit requirements with ease. Other providers require archiving or hot and cold storage, making it difficult to query older logs. Log Explorer is built on top of our R2 storage tier, so historical logs can be queried as easily as current logs.
How we built Log Explorer to run at Cloudflare scale
With Log Explorer, we have built a scalable log storage platform on top of Cloudflare R2 that lets you efficiently search your Cloudflare logs using familiar SQL queries. In this section, we’ll look into how we did this and how we solved some technical challenges along the way.
Log Explorer consists of three components: ingestors, compactors, and queriers. Ingestors are responsible for writing logs from Cloudflare’s data pipeline to R2. Compactors optimize storage files, so they can be queried more efficiently. Queriers execute SQL queries from users by fetching, transforming, and aggregating matching logs from R2.
During ingestion, Log Explorer writes each batch of log records to a Parquet file in R2. Apache Parquet is an open-source columnar storage file format, and it was an obvious choice for us: it’s optimized for efficient data storage and retrieval, such as by embedding metadata like the minimum and maximum values of each column across the file which enables the queriers to quickly locate the data needed to serve the query.
Log Explorer stores logs on a per-customer level, just like Cloudflare D1, so that your data isn’t mixed with that of other customers. In Q3 2025, per-customer logs will allow you the flexibility to create your own retention policies and decide in which regions you want to store your data.
But how does Log Explorer find those Parquet files when you query your logs? Log Explorer leverages the Delta Lake open table format to provide a database table abstraction atop R2 object storage. A table in Delta Lake pairs data files in Parquet format with a transaction log. The transaction log registers every addition, removal, or modification of a data file for the table – it’s stored right next to the data files in R2.
Given a SQL query for a particular log dataset such as HTTP Requests or Gateway DNS, Log Explorer first has to load the transaction log of the corresponding Delta table from R2. Transaction logs are checkpointed periodically to avoid having to read the entire table history every time a user queries their logs.
Besides listing Parquet files for a table, the transaction log also includes per-column min/max statistics for each Parquet file. This has the benefit that Log Explorer only needs to fetch files from R2 that can possibly satisfy a user query. Finally, queriers use the min/max statistics embedded in each Parquet file to decide which row groups to fetch from the file.
Log Explorer processes SQL queries using Apache DataFusion, a fast, extensible query engine written in Rust, and delta-rs, a community-driven Rust implementation of the Delta Lake protocol. While standing on the shoulders of giants, our team had to solve some unique problems to provide log search at Cloudflare scale.
Log Explorer ingests logs from across Cloudflare’s vast global network, spanning more than 330 cities in over 125 countries. If Log Explorer were to write logs from our servers straight to R2, its storage would quickly fragment into a myriad of small files, rendering log queries prohibitively expensive.
Log Explorer’s strategy to avoid this fragmentation is threefold. First, it leverages Cloudflare’s data pipeline, which collects and batches logs from the edge, ultimately buffering each stream of logs in an internal system named Buftee. Second, log batches ingested from Buftee aren’t immediately committed to the transaction log; rather, Log Explorer stages commits for multiple batches in an intermediate area and “squashes” these commits before they’re written to the transaction log. Third, once log batches have been committed, a process called compaction merges them into larger files in the background.
While the open-source implementation of Delta Lake provides compaction out of the box, we soon encountered an issue when using it for our workloads. Stock compaction merges data files to a desired target size S by sorting the files in reverse order of their size and greedily filling bins of size S with them. By merging logs irrespective of their timestamps, this process distributed ingested batches randomly across merged files, destroying data locality. Despite compaction, a user querying for a specific time frame would still end up fetching hundreds or thousands of files from R2.
For this reason, we wrote a custom compaction algorithm that merges ingested batches in order of their minimum log timestamp, leveraging the min/max statistics mentioned previously. This algorithm reduced the number of overlaps between merged files by two orders of magnitude. As a result, we saw a significant improvement in query performance, with some large queries that had previously taken over a minute completing in just a few seconds.
Follow along for more updates
We’re just getting started! We’re actively working on even more powerful features to further enhance your experience with Log Explorer. Subscribe to the blog and keep an eye out for more updates in our Change Log to our observability and forensics offering soon.
Get access to Log Explorer
To get access to Log Explorer, reach out for a consultation or contact your account manager. Additionally, you can read more in our Developer Documentation.
There’s a lot of talk right now about building AI agents, but not a lot out there about what it takes to make those agents truly useful.
An Agent is an autonomous system designed to make decisions and perform actions to achieve a specific goal or set of goals, without human input.
No matter how good your agent is at making decisions, you will need a person to provide guidance or input on the agent’s path towards its goal. After all, an agent that cannot interact or respond to the outside world and the systems that govern it will be limited in the problems it can solve.
That’s where the “human-in-the-loop” interaction pattern comes in. You’re bringing a human into the agent’s loop and requiring an input from that human before the agent can continue on its task.
In this blog post, we’ll useKnock and the CloudflareAgents SDK to build an AI Agent for a virtual card issuing workflow that requires human approval when a new card is requested.
Knock is messaging infrastructure you can use to send multi-channel messages across in-app, email, SMS, push, and Slack, without writing any integration code.
With Knock, you gain complete visibility into the messages being sent to your users while also handling reliable delivery, user notification preferences, and more.
You can use Knock to power human-in-the-loop flows for your agents using Knock’sAgent Toolkit, which is a set of tools that expose Knock’s APIs and messaging capabilities to your AI agents.
Using the Agent SDK as the foundation of our AI Agent
The Agents SDK provides an abstraction for building stateful, real-time agents on top of Durable Objects that are globally addressable and persist state using an embedded, zero-latency SQLite database.
Building an AI agent outside of using the Agents SDK and the Cloudflare platform means we need to consider WebSocket servers, state persistence, and how to scale our service horizontally. Because a Durable Object backs the Agents SDK, we receive these benefits for free, while having a globally addressable piece of compute with built-in storage, that’s completely serverless and scales to zero.
In the example, we’ll use these features to build an agent that users interact with in real-time via chat, and that can be paused and resumed as needed. The Agents SDK is the ideal platform for powering asynchronous agentic workflows, such as those required in human-in-the-loop interactions.
Setting up our Knock messaging workflow
Within Knock, we design our approval workflow using the visual workflow builder to create the cross-channel messaging logic. We then make the notification templates associated with each channel to which we want to send messages.
Knock will automatically apply theuser’s preferences as part of the workflow execution, ensuring that your user’s notification settings are respected.
You can find an example workflow that we’ve already created for this demo in the repository. You can use this workflow template via theKnock CLI to import it into your account.
Building our chat UI
We’ve built the AI Agent as a chat interface on top of the AIChatAgent abstraction from Cloudflare’s Agents SDK (docs). The Agents SDK here takes care of the bulk of the complexity, and we’re left to implement our LLM calling code with our system prompt.
// src/index.ts
import { AIChatAgent } from "agents/ai-chat-agent";
import { openai } from "@ai-sdk/openai";
import { createDataStreamResponse, streamText } from "ai";
export class AIAgent extends AIChatAgent {
async onChatMessage(onFinish) {
return createDataStreamResponse({
execute: async (dataStream) => {
try {
const stream = streamText({
model: openai("gpt-4o-mini"),
system: `You are a helpful assistant for a financial services company. You help customers with credit card issuing.`,
messages: this.messages,
onFinish,
maxSteps: 5,
});
stream.mergeIntoDataStream(dataStream);
} catch (error) {
console.error(error);
}
},
});
}
}
On the client side, we’re using the useAgentChat hook from the agents/ai-react package to power the real-time user-to-agent chat.
We’ve modeled our agent as a chat per user, which we set up using the useAgent hook by specifying the name of the process as the userId.
This means we have an agent process, and therefore a durable object, per-user. For our human-in-the-loop use case, this becomes important later on as we talk about resuming our deferred tool call.
Deferring the tool call to Knock
We give the agent our card issuing capability through exposing an issueCard tool. However, instead of writing the approval flow and cross-channel logic ourselves, we delegate it entirely to Knock by wrapping the issue card tool in our requireHumanInput method.
Now when the user asks to request a new card, we make a call out to Knock to initiate our card request, which will notify the appropriate admins in the organization to request an approval.
To set this up, we need to use Knock’s Agent Toolkit, which exposes methods to work with Knock in our AI agent and power cross-channel messaging.
import { createKnockToolkit } from "@knocklabs/agent-toolkit/ai-sdk";
import { tool } from "ai";
import { z } from "zod";
import { AIAgent } from "./index";
import { issueCard } from "./api";
import { BASE_URL } from "./constants";
async function initializeToolkit(agent: AIAgent) {
const toolkit = await createKnockToolkit({ serviceToken: agent.env.KNOCK_SERVICE_TOKEN });
const issueCardTool = tool({
description: "Issue a new credit card to a customer.",
parameters: z.object({
customerId: z.string(),
}),
execute: async ({ customerId }) => {
return await issueCard(customerId);
},
});
const { issueCard } = toolkit.requireHumanInput(
{ issueCard: issueCardTool },
{
workflow: "approve-issued-card",
actor: agent.name,
recipients: ["admin_user_1"],
metadata: {
approve_url: `${BASE_URL}/card-issued/approve`,
reject_url: `${BASE_URL}/card-issued/reject`,
},
}
);
return { toolkit, tools: { issueCard } };
}
There’s a lot going on here, so let’s walk through the key parts:
We wrap our issueCard tool in the requireHumanInput method, exposed from the Knock Agent Toolkit
We want the messaging workflow to be invoked to be our approve-issued-card workflow
We pass the agent.name as the actor of the request, which translates to the user ID
We set the recipient of this workflow to be the user admin_user_1
We pass the approve and reject URLs so that they can be used in our message templates
The wrapped tool is then returned as issueCard
Under the hood, these options are passed to theKnock workflow trigger API to invoke a workflow per-recipient. The set of the recipients listed here could be dynamic, or go to a group of users throughKnock’s subscriptions API.
We can then pass the wrapped issue card tool to our LLM call in the onChatMessage method on the agent so that the tool call can be called as part of the interaction with the agent.
export class AIAgent extends AIChatAgent {
// ... other methods
async onChatMessage(onFinish) {
const { tools } = await initializeToolkit(this);
return createDataStreamResponse({
execute: async (dataStream) => {
const stream = streamText({
model: openai("gpt-4o-mini"),
system: "You are a helpful assistant for a financial services company. You help customers with credit card issuing.",
messages: this.messages,
onFinish,
tools,
maxSteps: 5,
});
stream.mergeIntoDataStream(dataStream);
},
});
}
}
Now when the agent calls the issueCardTool, we invoke Knock to send our approval notifications, deferring the tool call to issue the card until we receive an approval. Knock’s workflows take care of sending out the message to the set of recipient’s specified, generating and delivering messages according to each user’s preferences.
Using Knockworkflows for our approval message makes it easy to build cross-channel messaging to reach the user according to their communicationpreferences. We can also leveragedelays,throttles,batching, andconditions to orchestrate more complex messaging.
Handling the approval
Once the message has been sent to our approvers, the next step is to handle the approval coming back, bringing the human into the agent’s loop.
The approval request is asynchronous, meaning that the response can come at any point in the future. Fortunately, Knock takes care of the heavy lifting here for you, routing the event to the agent worker via awebhook that tracks the interaction with the underlying message. In our case, that’s a click to the “approve” or “reject” button.
First, we set up a message.interacted webhook handler within the Knock dashboard to forward the interactions to our worker, and ultimately to our agent process.
In our example here, we route the approval click back to the worker to handle, appending a Knock message ID to the end of the approve_url and reject_url to track engagement against the specific message sent. We do this via liquid inside of our message templates in Knock: {{ data.approve_url }}?messageId={{ current_message.id }} . One caveat here is that if this were a production application, we’re likely going to handle our approval click in a different application than this agent is running. We co-located it here for the purposes of this demo only.
Once the link is clicked, we have a handler in our worker to mark the message as interacted using Knock’smessage interaction API, passing through the status as metadata so that it can be used later.
import Knock from '@knocklabs/node';
import { Hono } from "hono";
const app = new Hono();
const client = new Knock();
app.get("/card-issued/approve", async (c) => {
const { messageId } = c.req.query();
if (!messageId) return c.text("No message ID found", { status: 400 });
await client.messages.markAsInteracted(messageId, {
status: "approved",
});
return c.text("Approved");
});
The message interaction will flow from Knock to our worker via the webhook we set up, ensuring that the process is fully asynchronous. The payload of the webhook includes the full message, including metadata about the user that generated the original request, and keeps details about the request itself, which in our case contains the tool call.
import { getAgentByName, routeAgentRequest } from "agents";
import { Hono } from "hono";
const app = new Hono();
app.post("/incoming/knock/webhook", async (c) => {
const body = await c.req.json();
const env = c.env as Env;
// Find the user ID from the tool call for the calling user
const userId = body?.data?.actors[0];
if (!userId) {
return c.text("No user ID found", { status: 400 });
}
// Find the agent DO for the user
const existingAgent = await getAgentByName(env.AIAgent, userId);
if (existingAgent) {
// Route the request to the agent DO to process
const result = await existingAgent.handleIncomingWebhook(body);
return c.json(result);
} else {
return c.text("Not found", { status: 404 });
}
});
We leverage the agent’s ability to be addressed by a named identifier to route the request from the worker to the agent. In our case, that’s the userId. Because the agent is backed by a durable object, this process of going from incoming worker request to finding and resuming the agent is trivial.
Resuming the deferred tool call
We then use the context about the original tool call, passed through to Knock and round tripped back to the agent, to resume the tool execution and issue the card.
export class AIAgent extends AIChatAgent {
// ... other methods
async handleIncomingWebhook(body: any) {
const { toolkit } = await initializeToolkit(this);
const deferredToolCall = toolkit.handleMessageInteraction(body);
if (!deferredToolCall) {
return { error: "No deferred tool call given" };
}
// If we received an "approved" status then we know the call was approved
// so we can resume the deferred tool call execution
if (result.interaction.status === "approved") {
const toolCallResult =
await toolkit.resumeToolExecution(result.toolCall);
const { response } = await generateText({
model: openai("gpt-4o-mini"),
prompt: `You were asked to issue a card for a customer. The card is now approved. The result was: ${JSON.stringify(toolCallResult)}.`,
});
const message = responseToAssistantMessage(
response.messages[0],
result.toolCall,
toolCallResult
);
// Save the message so that it's displayed to the user
this.persistMessages([...this.messages, message]);
}
return { status: "success" };
}
}
Again, there’s a lot going on here, so let’s step through the important parts:
We attempt to transform the body, which is the webhook payload from Knock, into a deferred tool call via the handleMessageInteraction method
If the metadata status we passed through to the interaction call earlier has an “approved” status then we resume the tool call via the resumeToolExecution method
Finally, we generate a message from the LLM and persist it, ensuring that the user is informed of the approved card
With this last piece in place, we can now request a new card be issued, have an approval request be dispatched from the agent, send the approval messages, and route those approvals back to our agent to be processed. The agent will asynchronously process our card issue request and the deferred tool call will be resumed for us, with very little code.
Protecting against duplicate approvals
One issue with the above implementation is that we’re prone to issuing multiple cards if someone clicks on the approve button more than once. To rectify this, we want to keep track of the tool calls being issued, and ensure that the call is processed at most once.
To power this we leverage theagent’s built-in state, which can be used to persist information without reaching for another persistence store like a database or Redis, although we could absolutely do so if we wished. We can track the tool calls by their ID and capture their current status, right inside the agent process.
Here, we create the initial state for the tool calls as an empty object. We also add a quick setter helper method to make interactions easier.
Next up, we need to record the tool call being made. To do so, we can use the onAfterCallKnock option in the requireHumanInput helper to capture that the tool call has been requested for the user.
const { issueCard } = toolkit.requireHumanInput(
{ issueCard: issueCardTool },
{
// Keep track of the tool call state once it's been sent to Knock
onAfterCallKnock: async (toolCall) =>
agent.setToolCallStatus(toolCall.id, "requested"),
// ... as before
}
);
Finally, we then need to check the state when we’re processing the incoming webhook, and mark the tool call as approved (some code omitted for brevity).
export class AIAgent extends AIChatAgent {
async handleIncomingWebhook(body: any) {
const { toolkit } = await initializeToolkit(this);
const deferredToolCall = toolkit.handleMessageInteraction(body);
const toolCallId = result.toolCall.id;
// Make sure this is a tool call that can be processed
if (this.state.toolCalls[toolCallId] !== "requested") {
return { error: "Tool call is not requested" };
}
if (result.interaction.status === "approved") {
const toolCallResult = await toolkit.resumeToolExecution(result.toolCall);
this.setToolCallStatus(toolCallId, "approved");
// ... rest as before
}
}
}
Conclusion
Using the Agents SDK and Knock, it’s easy to build advanced human-in-the-loop experiences that defer tool calls.
Knock’s workflow builder and notification engine gives you building blocks to create sophisticated cross-channel messaging for your agents. You can easily create escalation flows that send messages through SMS, push, email, or Slack that respect the notification preferences of your users. Knock also gives you complete visibility into the messages your users are receiving.
The Durable Object abstraction underneath the Agents SDK means that we get a globally addressable agent process that’s easy to yield and resume back to. The persistent storage in the Durable Object means we can retain the complete chat history per-user, and any other state that’s required in the agent process to resume the agent with (like our tool calls). Finally, the serverless nature of the underlying Durable Object means we’re able to horizontally scale to support a large number of users with no effort.
If you’re looking to build your own AI Agent chat experience with a multiplayer human-in-the-loop experience, you’ll find the complete code from this guideavailable in GitHub.
Quickly identify any security misconfigurations for SaaS applications to safeguard applications, users, and data
… all through a natural language interface!
Today, we also announced our collaboration with Anthropic to bring remote MCP to Claude users, and showcased how other leading companies such as Atlassian, PayPal, Sentry, and Webflow have built remote MCP servers on Cloudflare to extend their service to their users. We’ve also been using the same infrastructure and tooling to build out our own suite of remote servers, and today we’re excited to show customers what’s ready for use and share what we’ve learned along the way.
Cloudflare’s MCP servers available today:
These MCP servers allow your MCP Client to read configurations from your account, process information, make suggestions based on data, and even make those suggested changes for you. All of these actions can happen across Cloudflare’s many services including application development, security, and performance.
Cloudflare Documentation Server: Get up to date reference information on Cloudflare
Our Cloudflare Documentation server enables any MCP Client to access up-to-date documentation in real-time, rather than relying on potentially outdated information from the model’s training data. If you’re new to building with Cloudflare, this server synthesizes information right from our documentation and exposes it to your MCP Client, so you can get reliable, up-to-date responses to any complex question like “Search Cloudflare for the best way to build an AI Agent”.
Workers Bindings server: Build with developer resources
Connecting to the Bindings MCP server lets you leverage application development primitives like D1 databases, R2 object storage and Key Value stores on the fly as you build out a Workers application. If you’re leveraging your MCP Client to generate code, the bindings server provides access to read existing resources from your account or create fresh resources to implement in your application. In combination with our base prompt designed to help you build robust Workers applications, you can add the Bindings MCP server to give your client all it needs to start generating full stack applications from natural language.
Full example output using the Workers Bindings MCP server can be found here.
Workers Observability server: Debug your application
The Workers Observability MCP server integrates with Workers Logs to browse invocation logs and errors, compute statistics across invocations, and find specific invocations matching specific criteria. By querying logs across all of your Workers, this MCP server can help isolate errors and trends quickly. The telemetry data that the MCP server returns can also be used to create new visualizations and improve observability.
Container server: Spin up a development environment
The Container MCP server provides any MCP client with access to a secure, isolated execution environment running on Cloudflare’s network where it can run and test code if your MCP client does not have a built in development environment (e.g. claude.ai). When building and generating application code, this lets the AI run its own commands and validate its assumptions in real time.
Browser Rendering server: Fetch and convert web pages, take screenshots
The Browser Rendering MCP server provides AI friendly tools from our RESTful interface for common browser actions such as capturing screenshots, extracting HTML content, and converting pages to Markdown. These are particularly useful when building agents that require interacting with a web browser.
Radar server: Ask questions about how we see the Internet and Scan URLs
Logpush server: Get quick summaries for Logpush job health
Logpush jobs deliver comprehensive logs to your destination of choice, allowing near real-time information processing. The Logpush MCP server can help you analyze your Logpush job results and understand your job health at a high level, allowing you to filter and narrow down for jobs or scenarios you care about. For example, you can ask “provide me with a list of recently failed jobs.” Now, you can quickly find out which jobs are failing with which error message and when, summarized in a human-readable format.
AI Gateway server: Check out your AI Gateway logs
Use this MCP server to inspect your AI Gateway logs and get details about the data from your prompts and the AI models responses. In this example we ask our agent “What is my average latency for my AI Gateway logs in the Cloudflare Radar account?”
AutoRAG server: List and search documents on your AutoRAGs
Having AutoRAG RAGs available to query as MCP tools greatly expands the typical static one-shot retrieval and opens doors to use cases where the agent can dynamically decide if and when to retrieve information from one or more RAGs, combine them with other tools and APIs, cross-check information and generate a much more rich and complete final answer.
Here we have a RAG that has a few blog posts that talk about retrocomputers. If we ask “tell me about restoring an amiga 1000 using the blog-celso autorag” the agent will go into a sequence of reasoning steps:
“Now that I have some information about Amiga 1000 restoration from blog-celso, let me search for more specific details.”
“Let me get more specific information about hardware upgrades and fixes for the Amiga 1000.”
“Let me get more information about the DiagROM and other tools used in the restoration.”
“Let me search for information about GBA1000 and other expansions mentioned in the blog.”
And finally, “Based on the comprehensive information I’ve gathered from the blog-celso AutoRAG, I can now provide you with a detailed guide on restoring an Amiga 1000.”
And at the end, it generates a very detailed answer based on all of the data from all of the queries:
Audit Logs server: Query audit logs and generate reports for review
Audit Logs record detailed information about actions and events within a system, providing a transparent history of all activity. However, because these logs can be large and complex, it may take effort to query and reconstruct a clear sequence of events. The Audit Logs MCP server helps by allowing you to query audit logs and generate reports. Common queries include if anything notable happened in a Cloudflare account under a user around a particular time of the day, or identifying whether any users used API keys to perform actions on the account. For example, you can ask “Were there any suspicious changes made to my Cloudflare account yesterday around lunch time?” and obtain the following response:
DNS Analytics server: Optimize DNS performance and debug issues based on current set up
Cloudflare’s DNS Analytics provides detailed insights into DNS traffic, which helps you monitor, analyze, and troubleshoot DNS performance and security across your domains. With Cloudflare’s DNS Analytics MCP server, you can review DNS configurations across all domains in your account, access comprehensive DNS performance reports, and receive recommendations for performance improvements. By leveraging documentation, the MCP server can help identify opportunities for improving performance.
Digital Experience Monitoring server: Get quick insight on critical applications for your organization
Cloudflare Digital Experience Monitoring (DEM) was built to help network professionals understand the performance and availability of their critical applications from self-hosted applications like Jira and Bitbucket to SaaS applications like Figma or Salesforce. The Digital Experience Monitoring MCP server fetches DEM test results to surface performance and availability trends within your Cloudflare One deployment, providing quick insights on users, applications, and the networks they are connected to. You can ask questions like: Which users had the worst experience? What times of the day were applications most and least performant? When do I see the most HTTP status errors? When do I see the shortest, longest, or most instability in the network path?
CASB server: Insights from SaaS Integrations
Cloudflare CASB provides the ability to integrate with your organization’s SaaS and cloud applications to discover assets and surface any security misconfigurations that may be present. A core task is helping security teams understand information about users, files, and other assets they care about that transcends any one SaaS application. The CASB MCP server can explore across users, files, and the many other asset categories to help understand relationships from data that can exist across many different integrations. A common query may include “Tell me about “Frank Meszaros” and what SaaS tools they appear to have accessed”.
Get started with our MCP servers
You can start using our Cloudflare MCP servers today! If you’d like to read more about specific tools available in each server, you can find them in our public GitHub repository. Each server is deployed to a server URL, such as
https://observability.mcp.cloudflare.com/sse.
If your MCP client has first class support for remote MCP servers, the client will provide a way to accept the server URL directly within its interface. For example, if you are using claude.ai, you can:
Navigate to your settings and add a new “Integration” by entering the URL of your MCP server
Authenticate with Cloudflare
Select the tools you’d like claude.ai to be able to call
If your client does not yet support remote MCP servers, you will need to set up its respective configuration file (mcp_config.json) using mcp-remote to specify which servers your client can access.
While we’re launching with these initial 13 MCP servers, we are just getting started! We want to hear your feedback as we shape existing and build out more Cloudflare MCP servers that unlock the most value for your teams leveraging AI in their daily workflows. If you’d like to provide feedback, request a new MCP server, or report bugs, please raise an issue on our GitHub repository.
Building your own MCP server?
If you’re interested in building your own servers, we’ve discovered valuable best practices that we’re excited to share with you as we’ve been building ours. While MCP is really starting to gain momentum and many organizations are just beginning to build their own servers, these principals should help guide you as you start building out MCP servers for your customers.
An MCP server is not our entire API schema: Our goal isn’t to build a large wrapper around all of Cloudflare’s API schema, but instead focus on optimizing for specific jobs to be done and reliability of the outcome. This means while one tool from our MCP server may map to one API, another tool may map to many. We’ve found that fewer but more powerful tools may be better for the agent with smaller context windows, less costs, a faster output, and likely more valid answers from LLMs. Our MCP servers were created directly by the product teams who are responsible for each of these areas of Cloudflare – application development, security and performance – and are designed with user stories in mind. This is a pattern you will continue to see us use as we build out more Cloudflare servers.
Specialize permissions with multiple servers: We built out several specialized servers rather than one for a critical reason: security through precise permission scoping. Each MCP server operates with exactly the permissions needed for its specific task – nothing more. By separating capabilities across multiple servers, each with its own authentication scope, we prevent the common security pitfall of over-privileged access.
Add robust server descriptions within parameters: Tool descriptions were core to providing helpful context to the agent. We’ve found that more detailed descriptions help the agent understand not just the expected data type, but also the parameter’s purpose, acceptable value ranges, and impact on server behavior. This context allows agents to make intelligent decisions about parameter values rather than providing arbitrary and potentially problematic inputs, allowing your natural language to go further with the agent.
Using evals at each iteration: For each server, we implemented evaluation tests or “evals” to assess the model’s ability to follow instructions, select appropriate tools, and provide correct arguments to those tools. This gave us a programmatic way to understand if any regressions occurred through each iteration, especially when tweaking tool descriptions.
Ready to start building? Click the button below to deploy your first remote MCP server to production:
Or check out our documentation to learn more! If you have any questions or feedback for us, you can reach us via email at [email protected] or join the chatter in the Cloudflare Developers Discord.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.