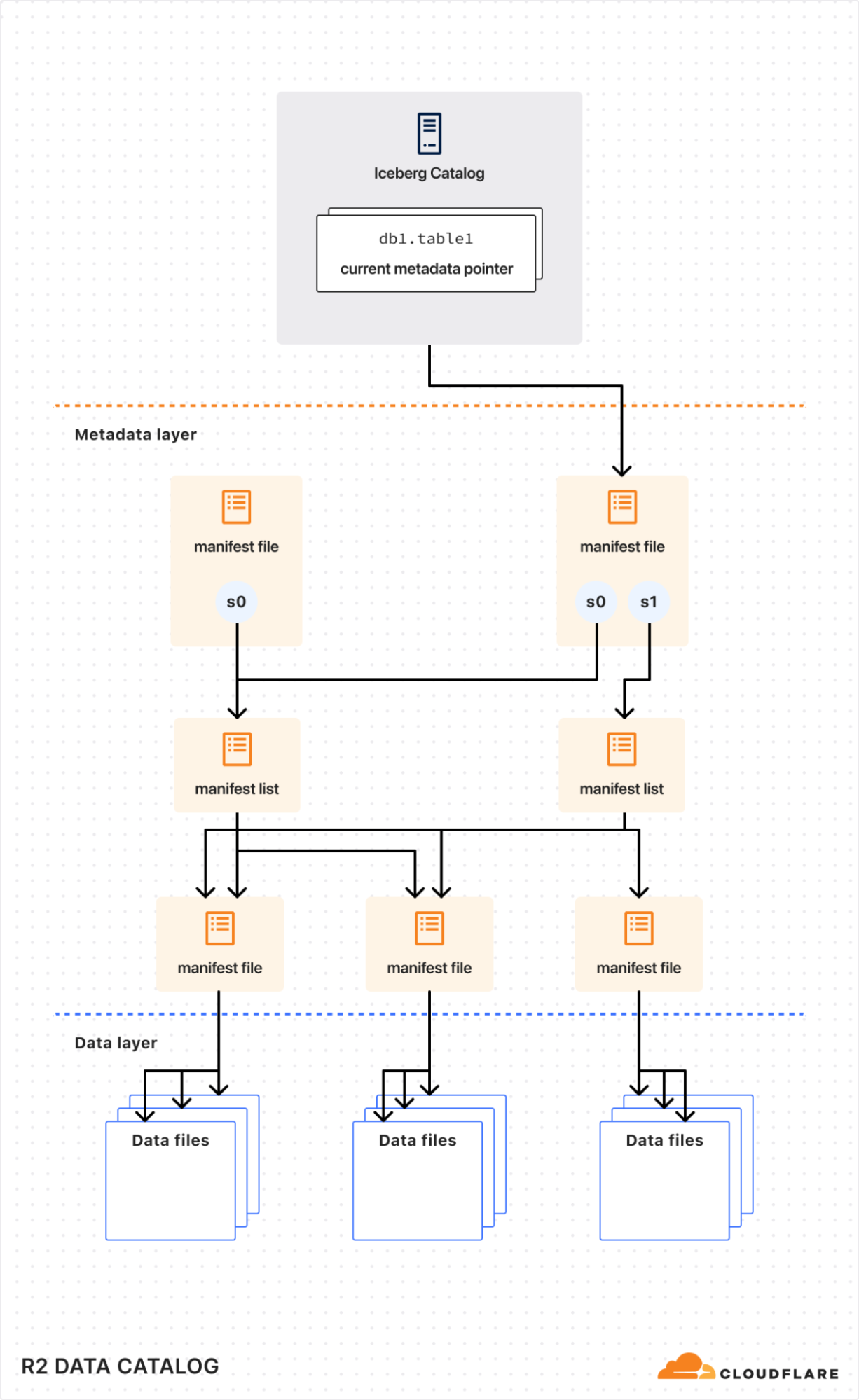
As we conclude Developer Week 2025, we’re proud to reflect upon the capabilities we’ve added to our developer platform. It’s so rewarding to deliver products, features and tools that help developers build smarter and ship faster, and even more so hearing your responses throughout the week!
Our VP of Product, Rita Kozlov, kicked off Developer Week 2025 discussing the ever-evolving landscape of development, particularly in the age of AI. AI is no longer just a buzzword or a trope for a science-fiction future — in the realm of modern development, it’s a core tenet (and utility) of how we build, innovate, and solve problems. It’s influencing how and how frequently we ship code, as well as enabling anyone to write it.
It’s exciting to not only witness this technical revolution, but also to be building a platform that enables developers to be part of it. We want to hear your feedback and see what you build with the new capabilities — reach out to us on Discord or X.
Here’s a recap of our Developer Week 2025 announcements:
Toolkit for AI agents includes new Agents SDK support for MCP (Model Context Protocol) clients, authentication/authorization/hibernation for MCP servers, and Durable Objects free tier.
Fully managed Retrieval-Augmented Generation (RAG) pipelines powered by Cloudflare’s global network and developer platform simplifies how you build and scale RAG pipelines to power your context-aware AI and search applications.
Workflows — a durable execution engine built directly on top of Workers — is Generally Available and production-ready with new human-in-the-loop capabilities, more scale, and more metrics.
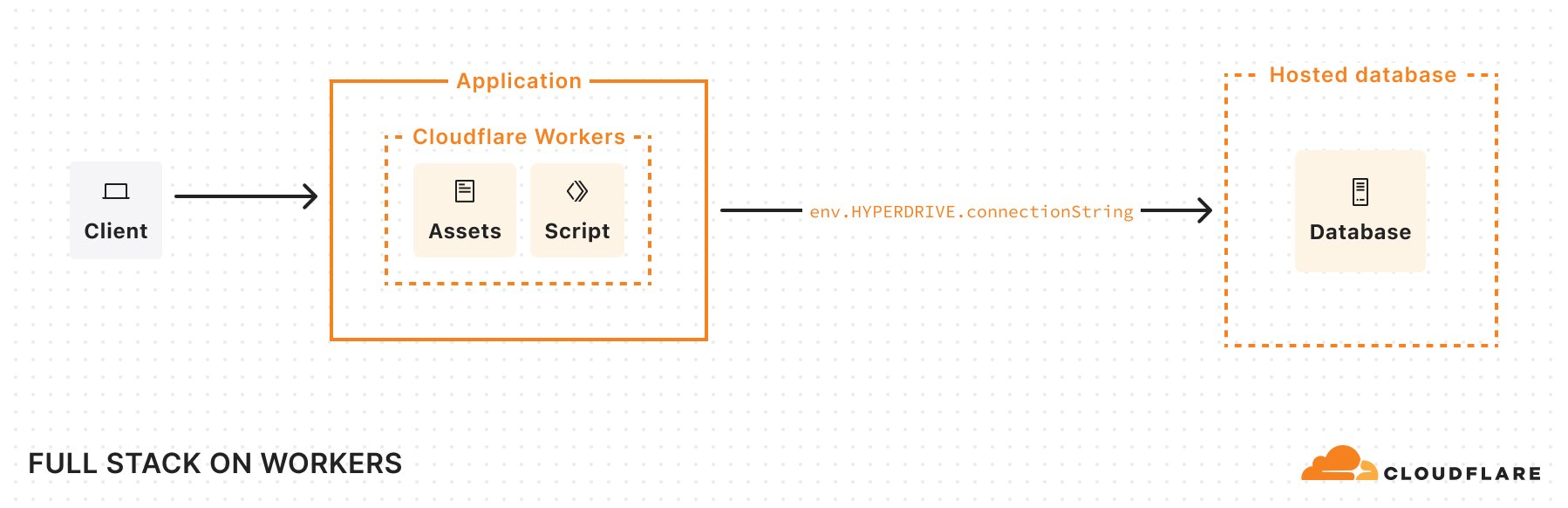
Workers connect to your MySQL databases with Hyperdrive to deliver optimal performance for regional databases, with support for your favorite drivers and ORMs.
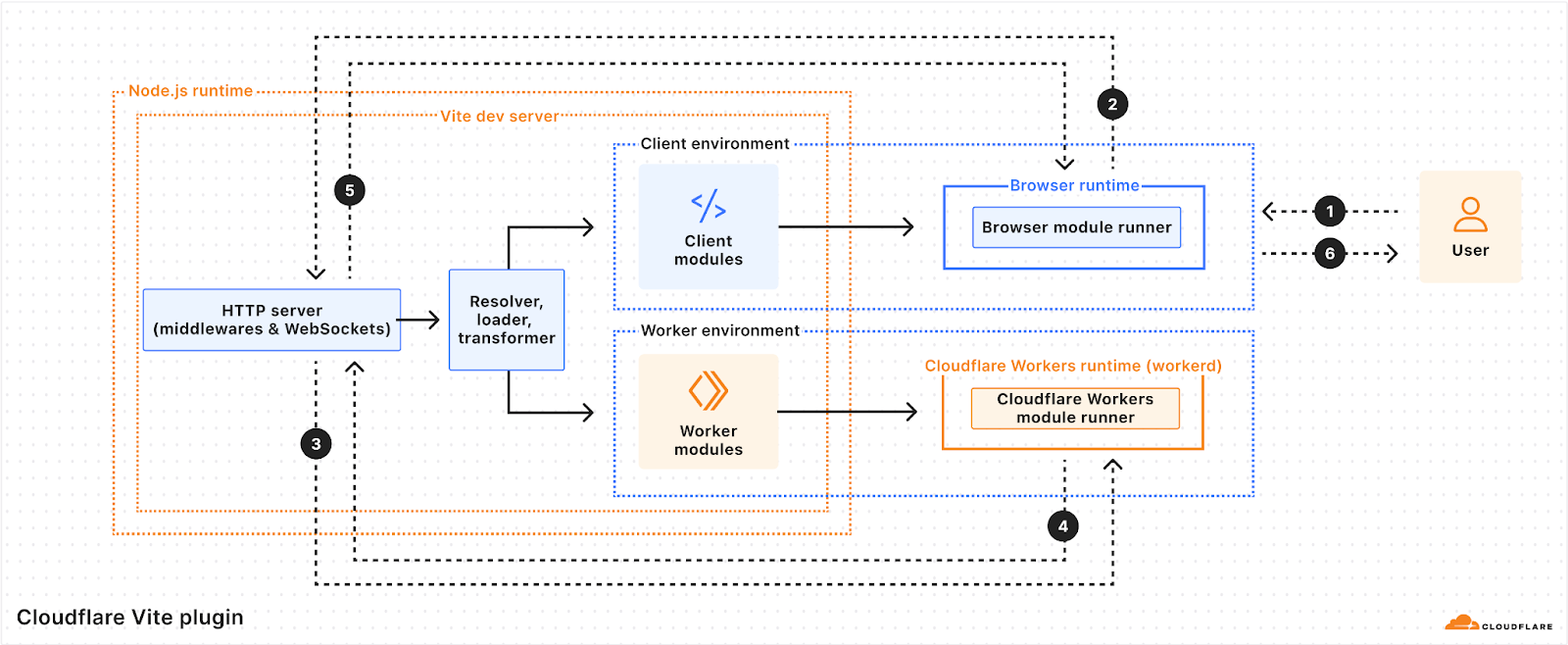
The Cloudflare Vite plugin integrates Vite, one of the most popular build tools for web development, with the Workers runtime. We announced the 1.0 release and official support for React Router v7.
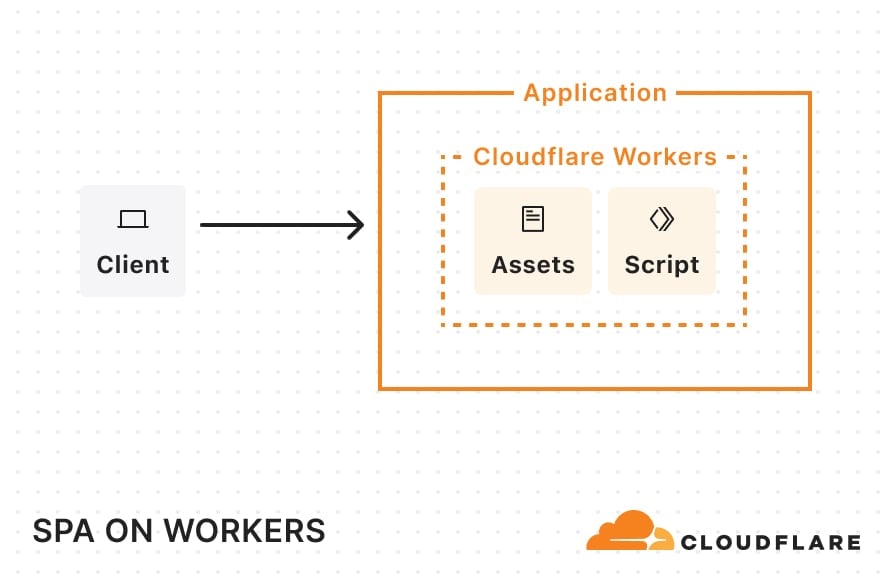
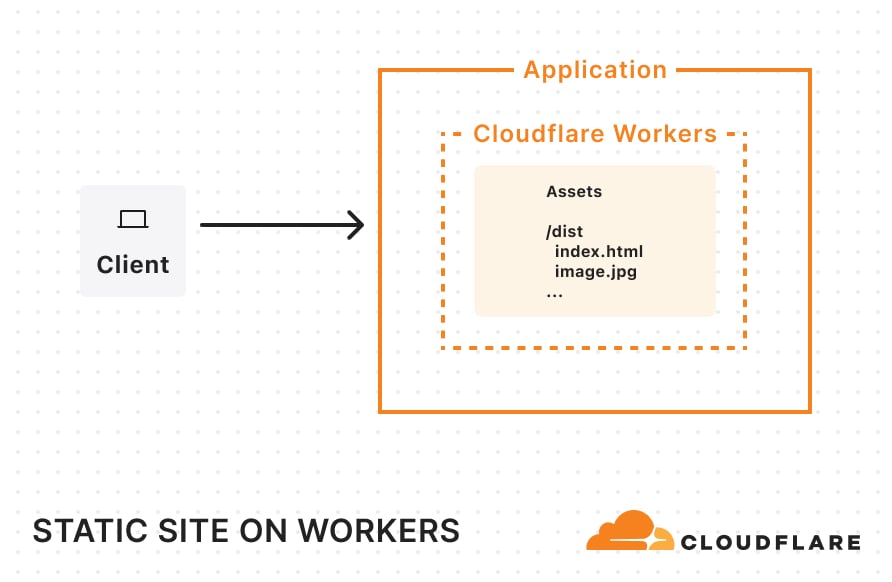
You can now deploy static sites, full-stack, and stateful applications on Cloudflare Workers — the primitives are all here. Framework support for React Router v7, Astro, Vue, and more are generally available today, as is the Cloudflare Vite plugin.
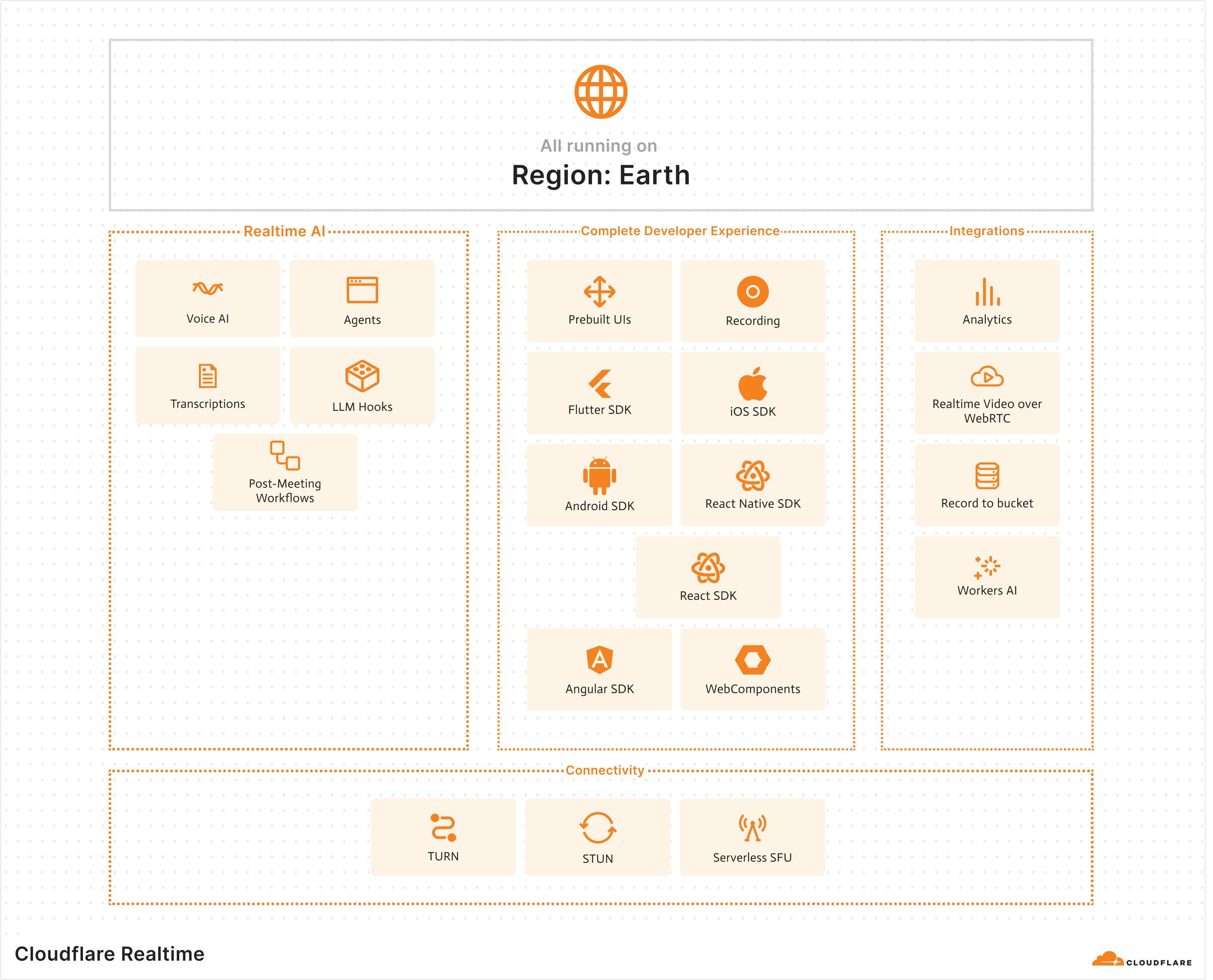
We announced Cloudflare Realtime and RealtimeKit, a complete toolkit for shipping real-time audio and video apps in days with SDKs for Kotlin, React Native, Swift, JavaScript, and Flutter.
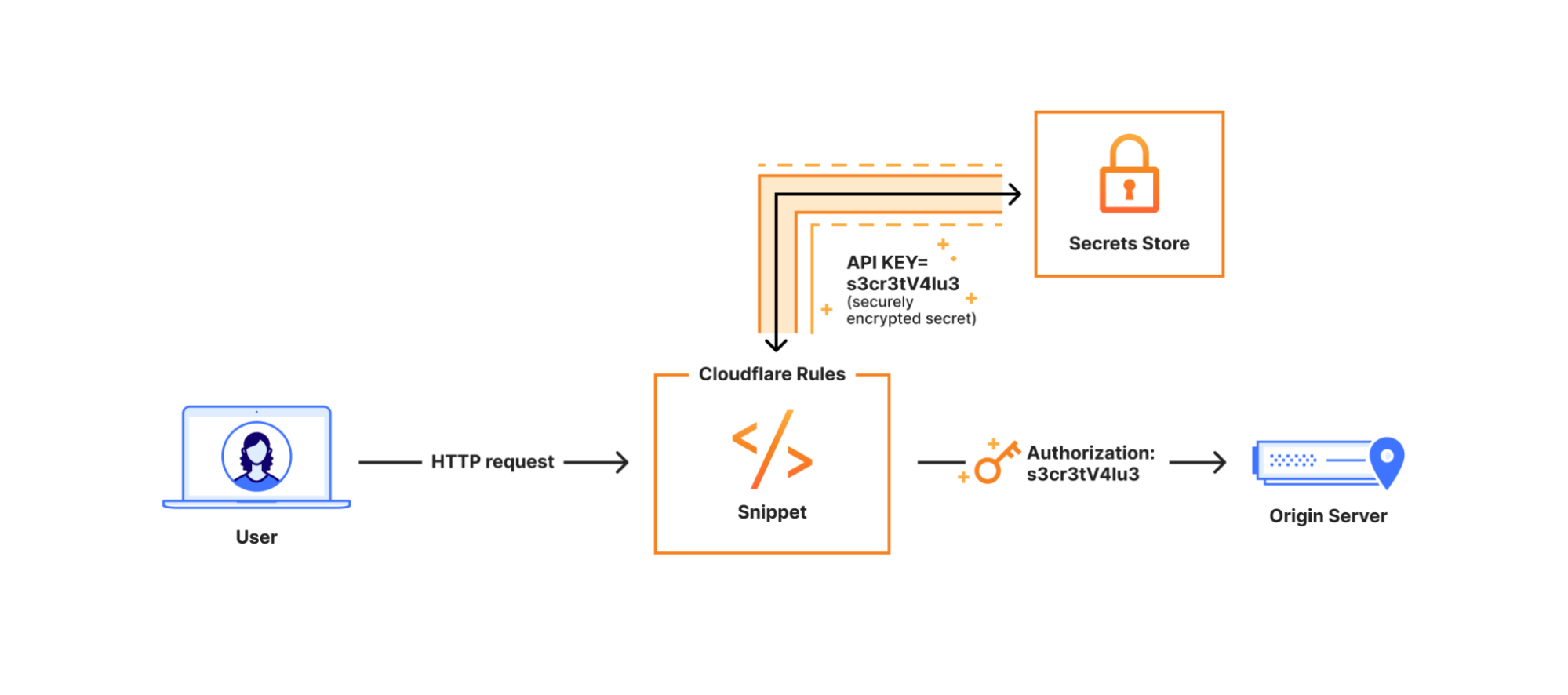
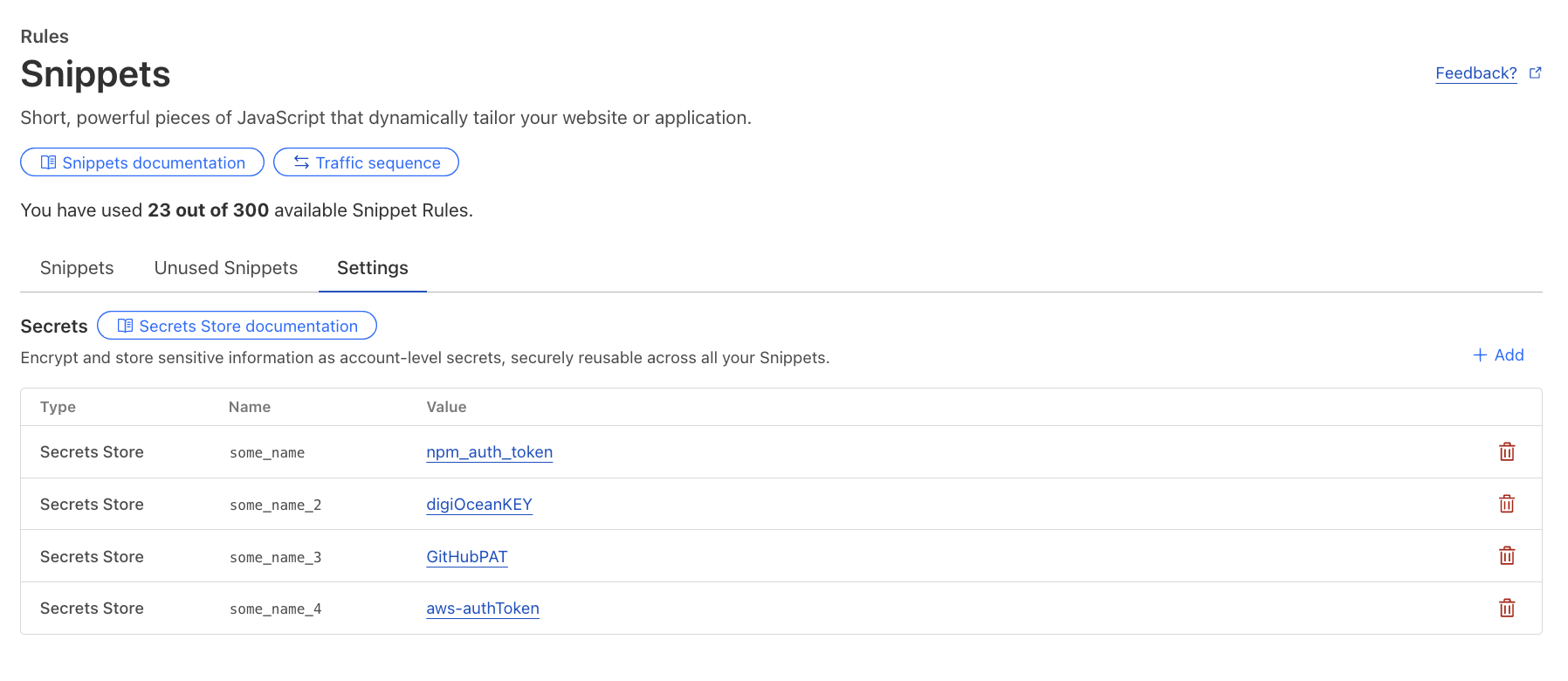
Securely store, manage, and deploy account level secrets to Cloudflare Workers through Cloudflare Secrets Store, available in beta — with role-based access control, audit logging, and Wrangler support.
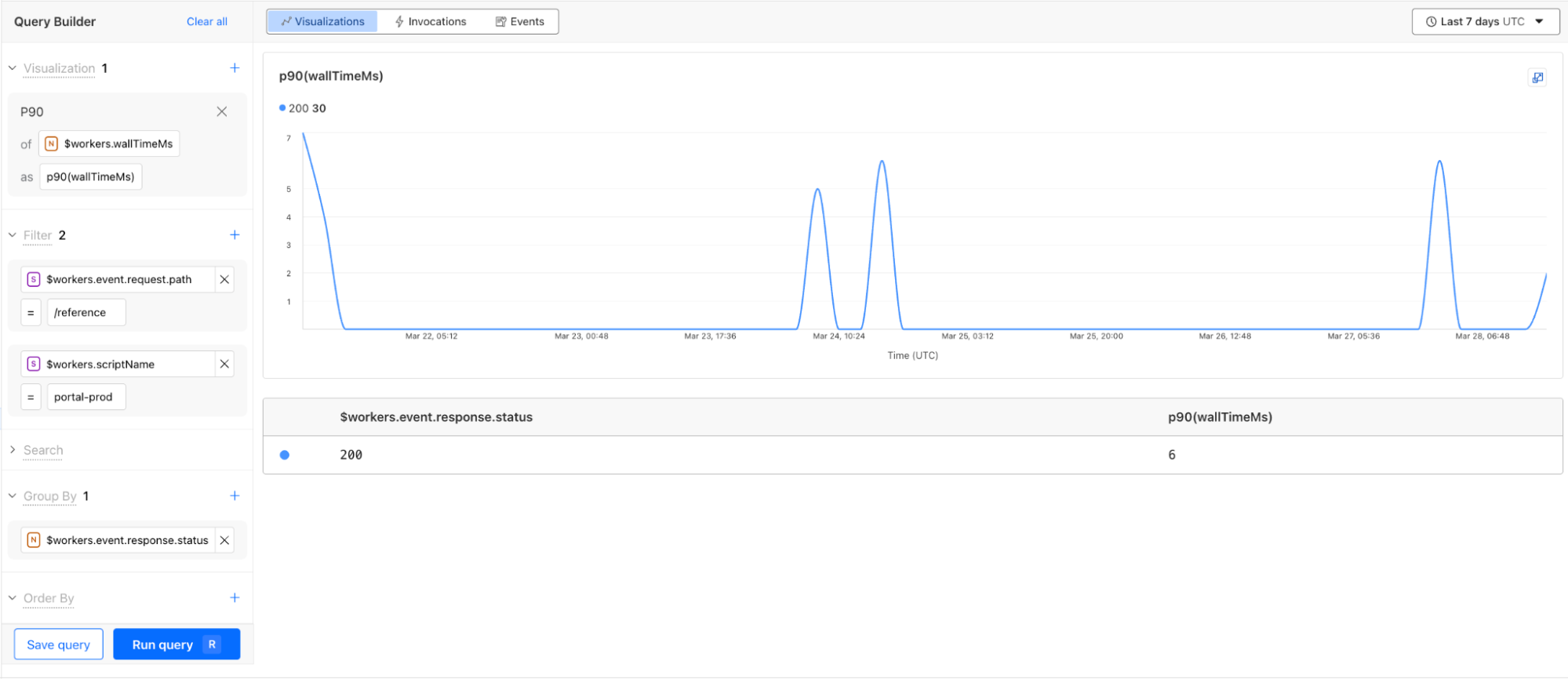
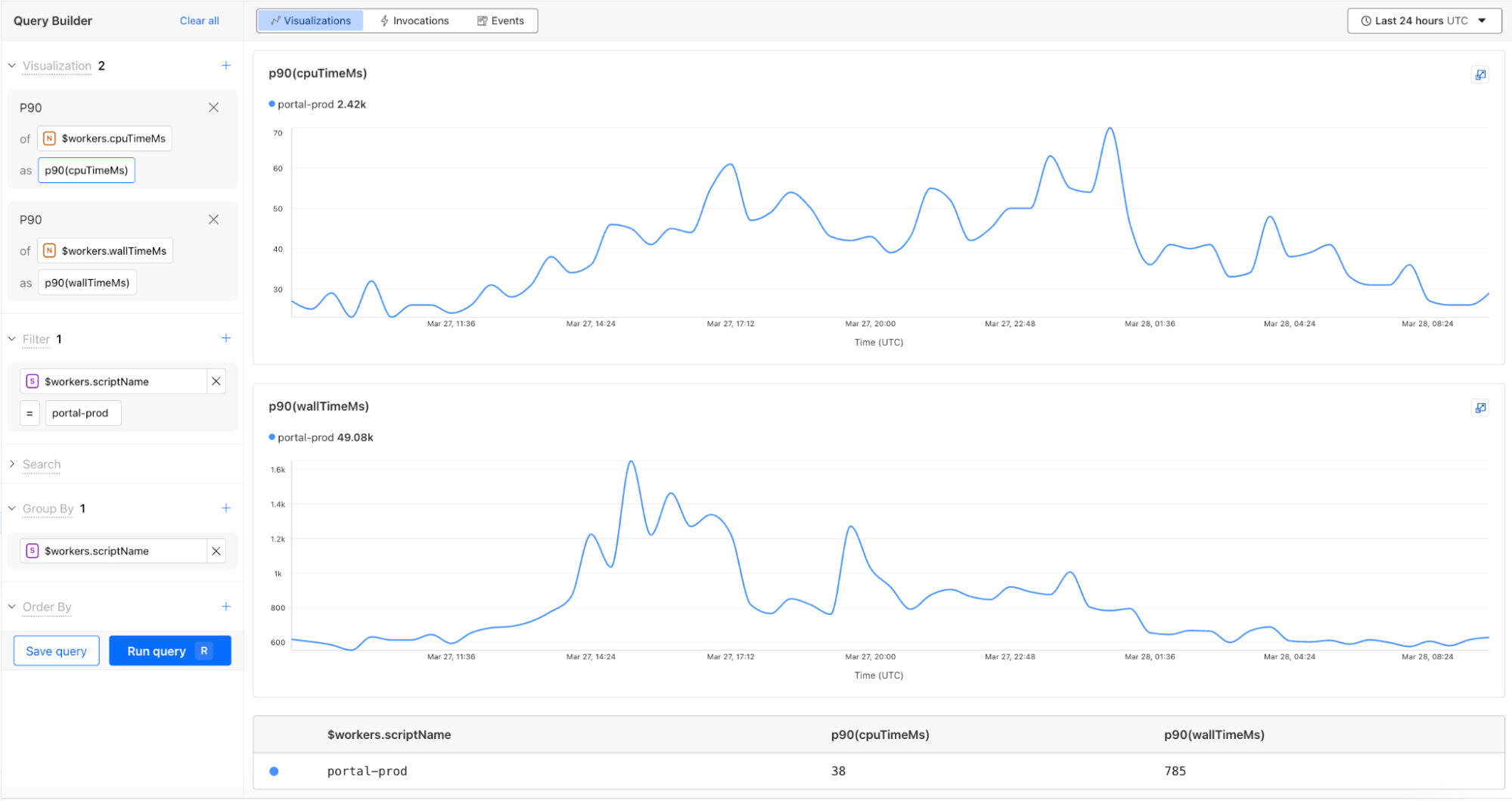
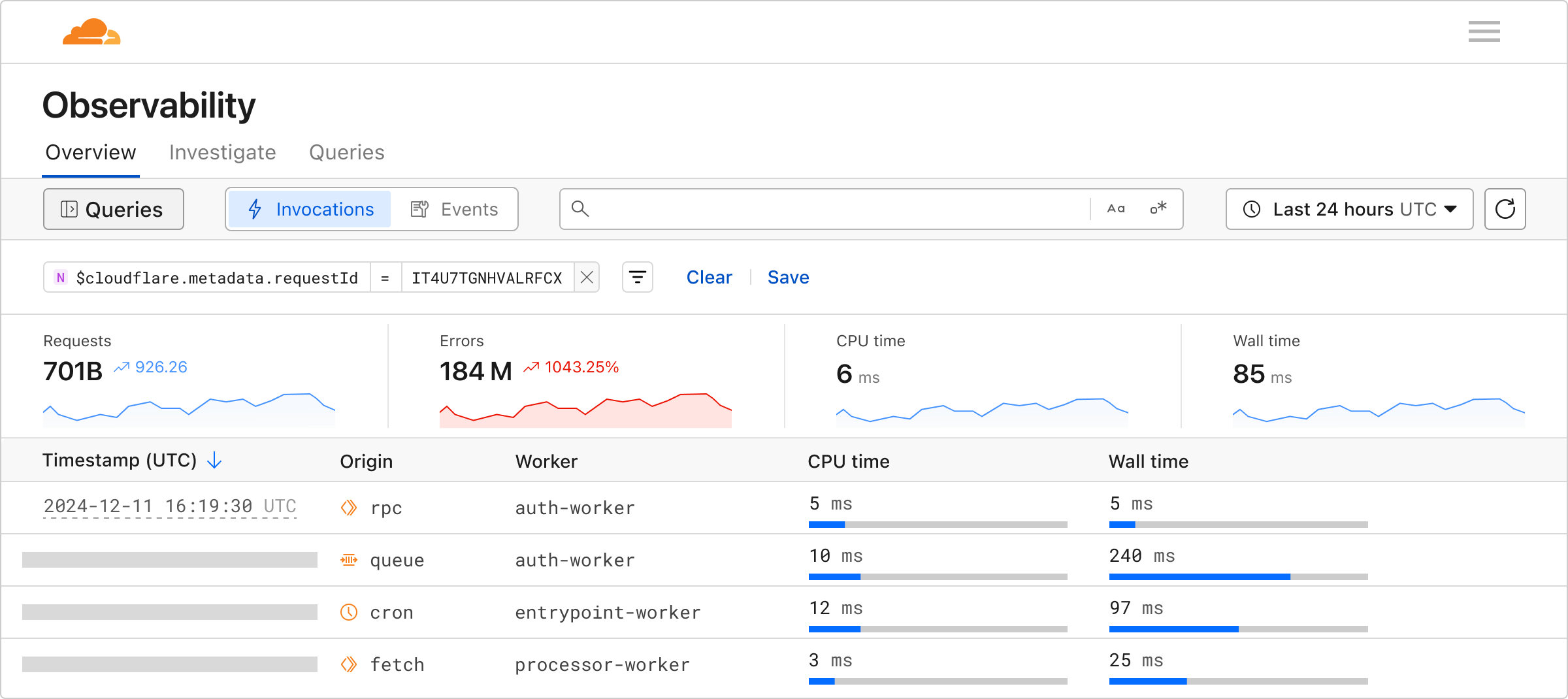
Workers Observability powers up with General Availability of Workers Logs and new Query Builder to help you investigate log events across all of your Workers.
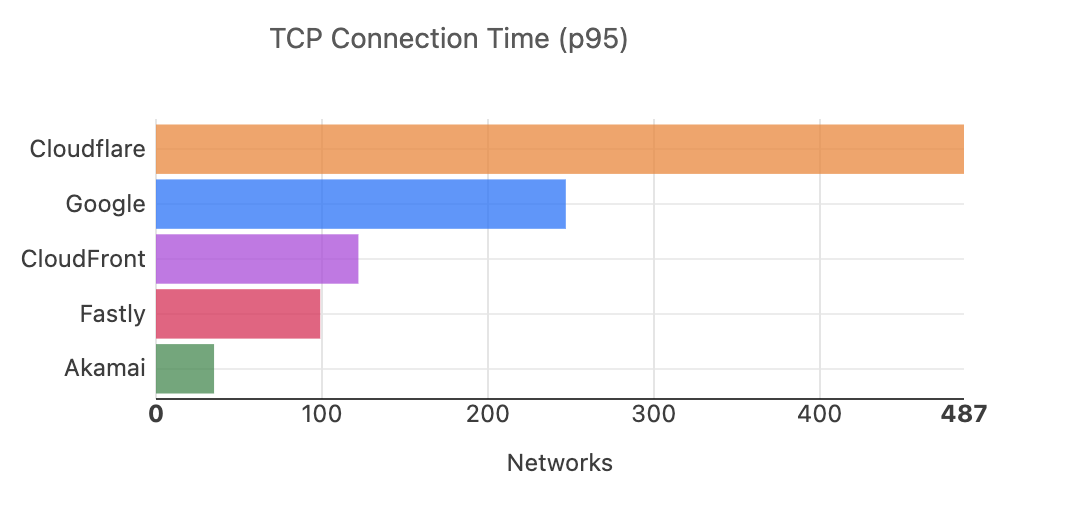
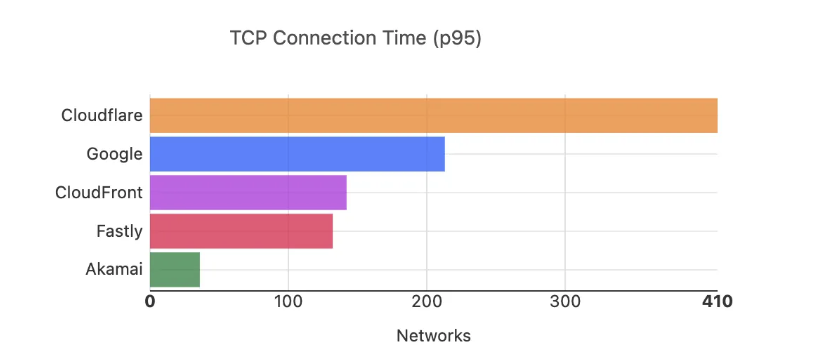
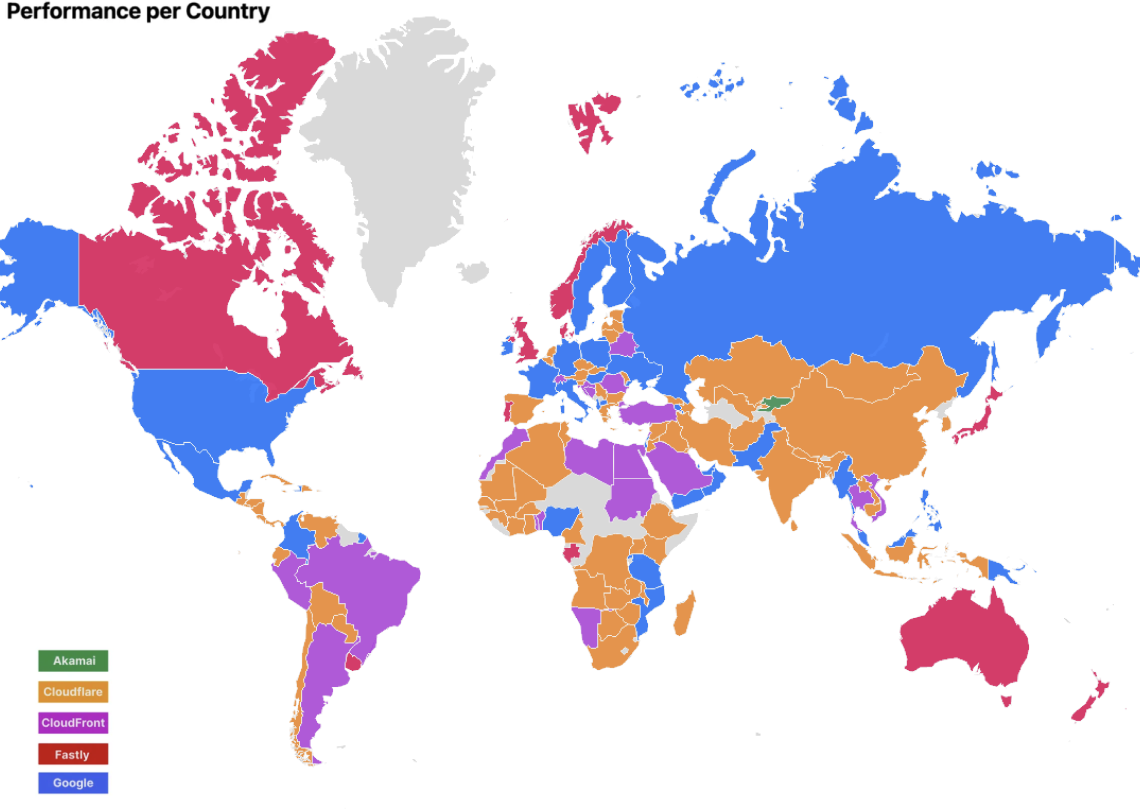
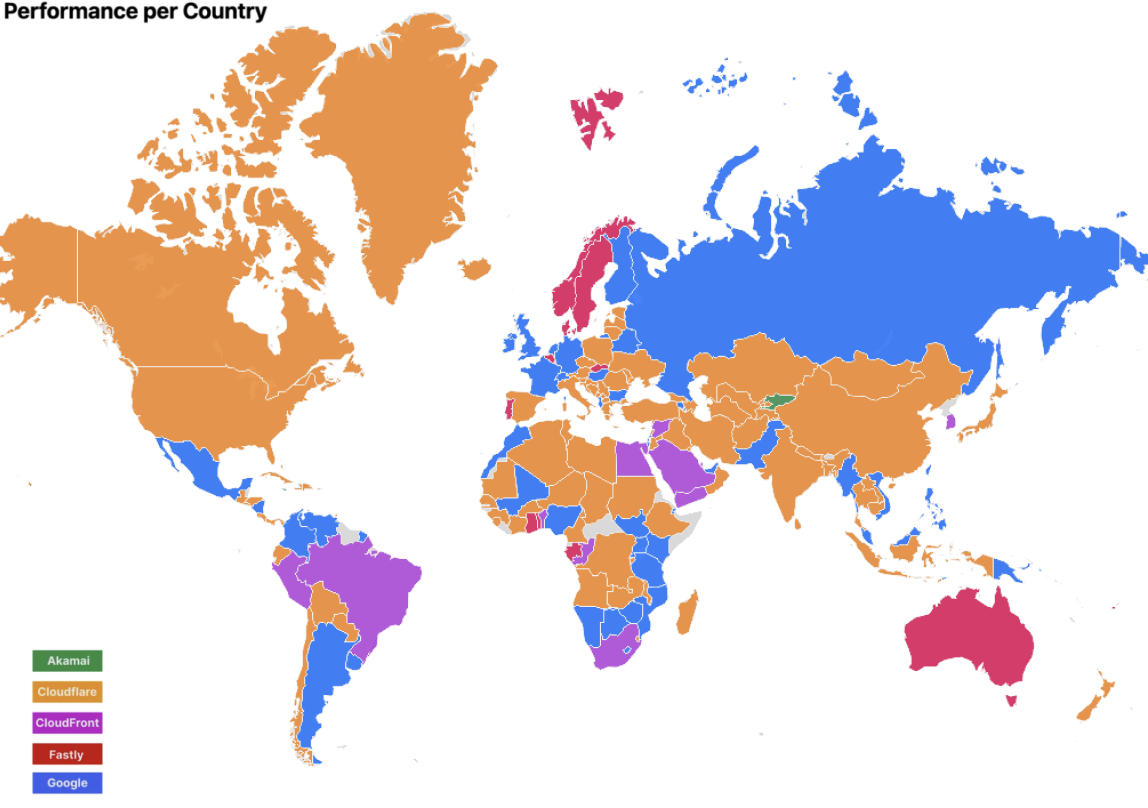
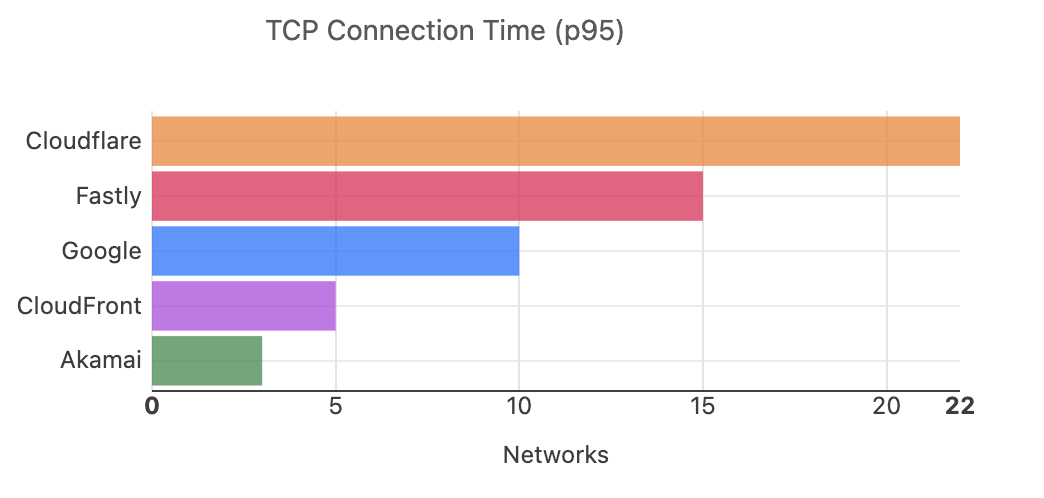
Cloudflare has been tracking and comparing our speed with other top networks since 2021. We take a look at how things have changed since our last update.
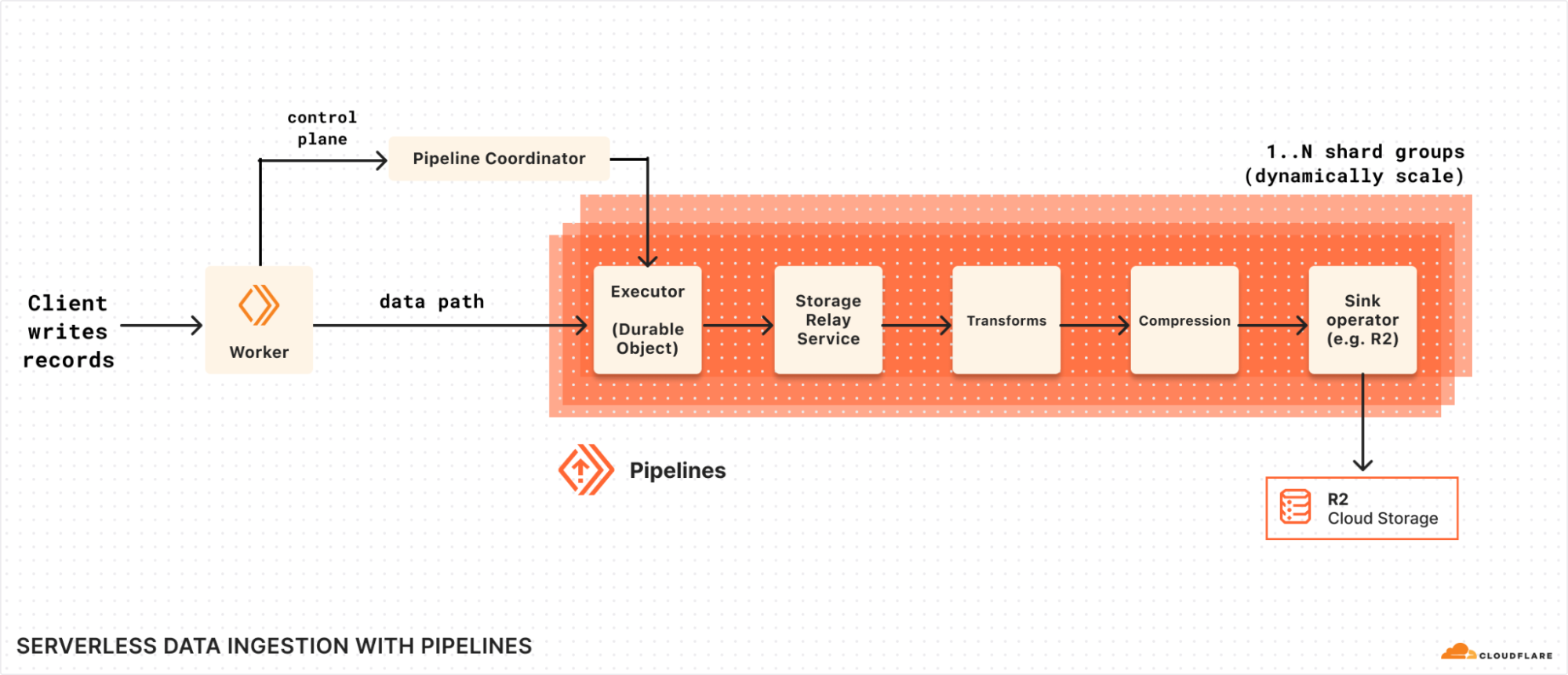
We’ve just shipped our new streaming ingestion service, Pipelines. And, we’ve acquired Arroyo, enabling us to bring new SQL-based, stateful transformations to Pipelines and R2.
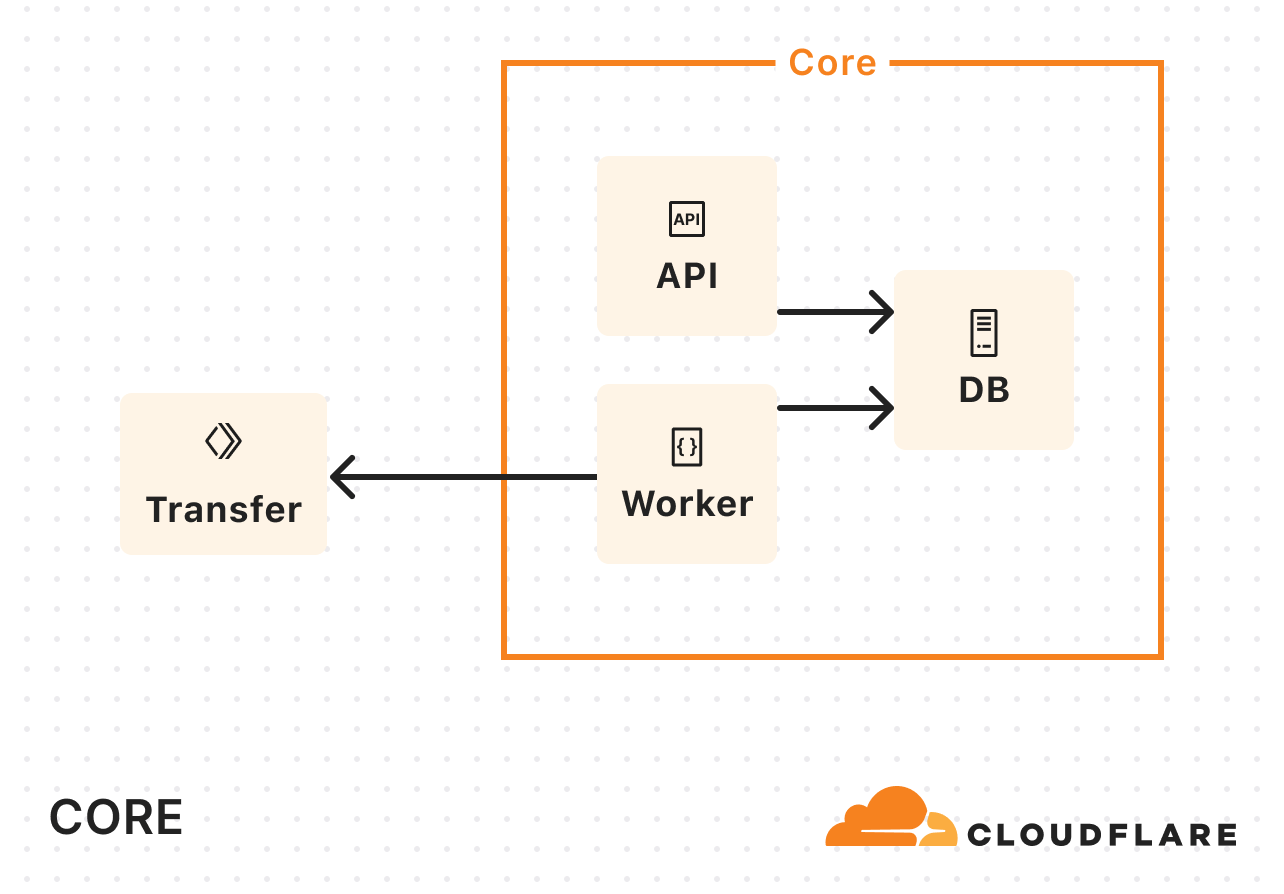
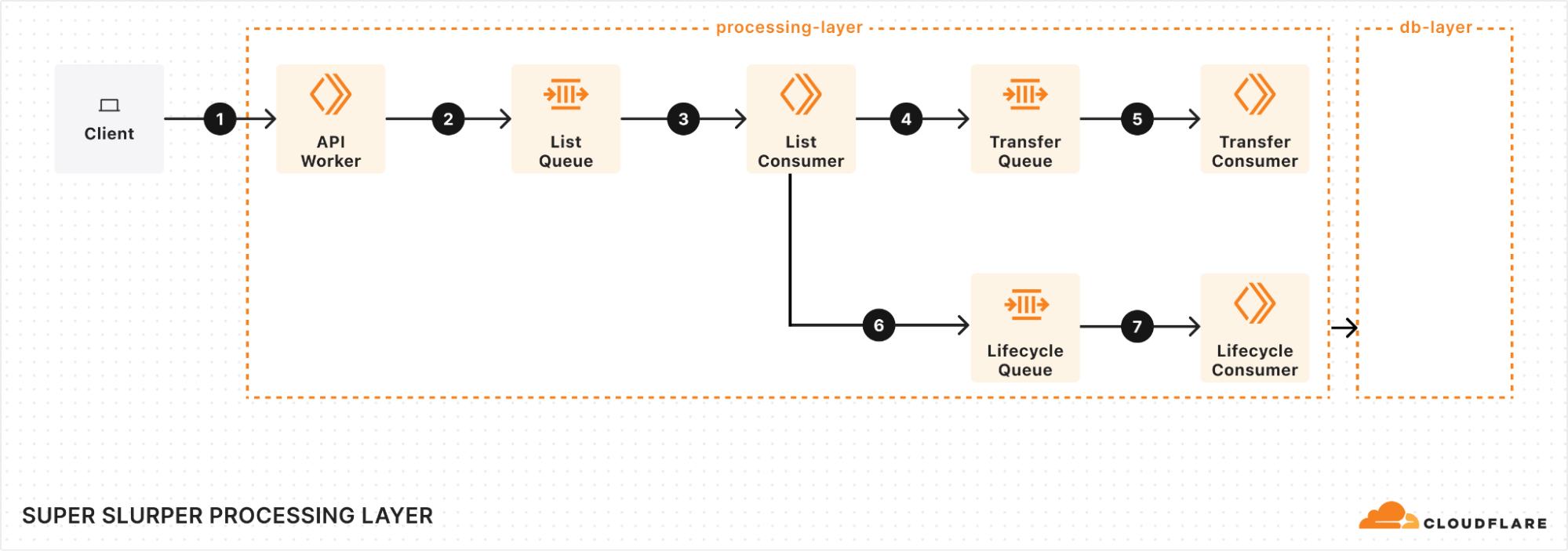
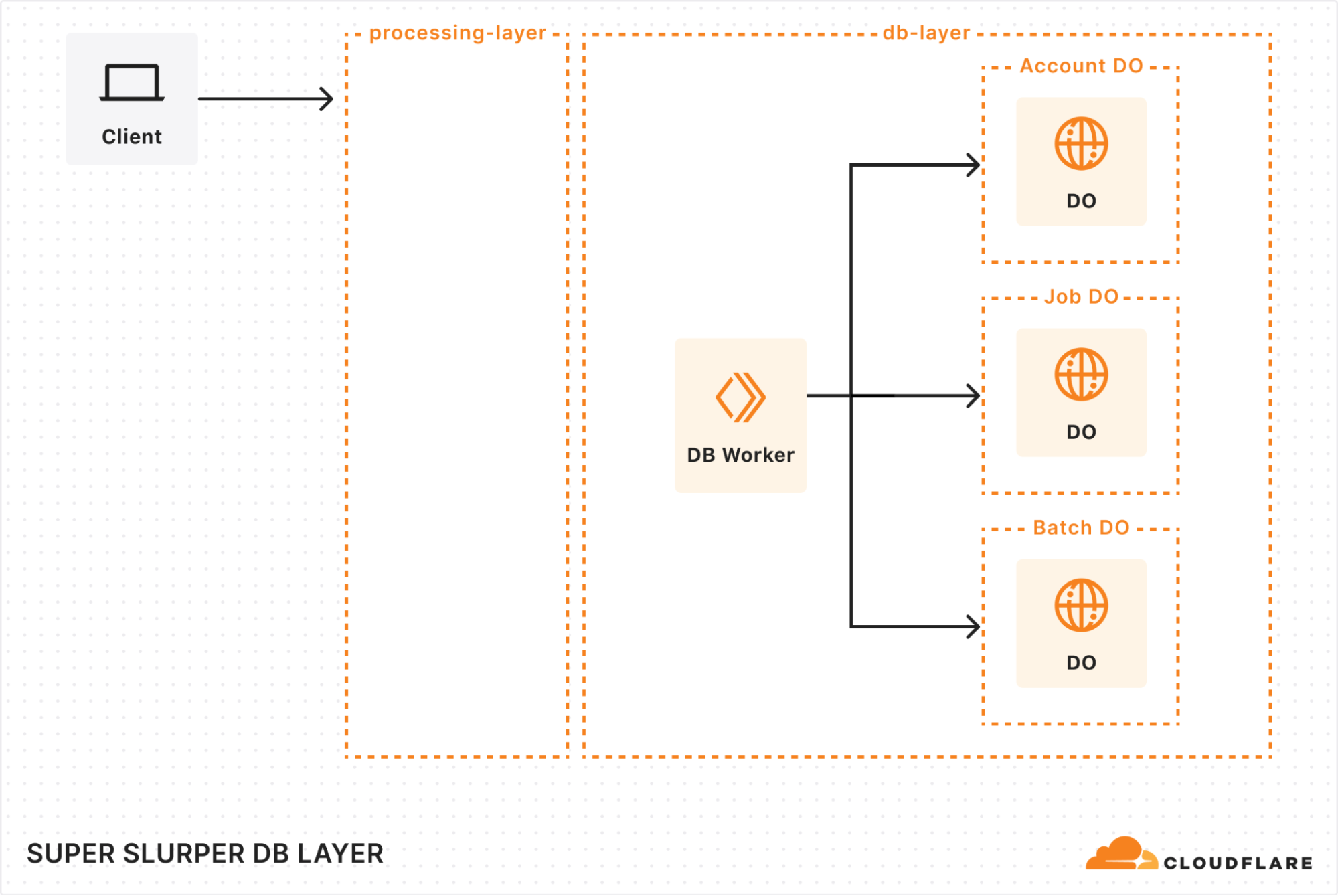
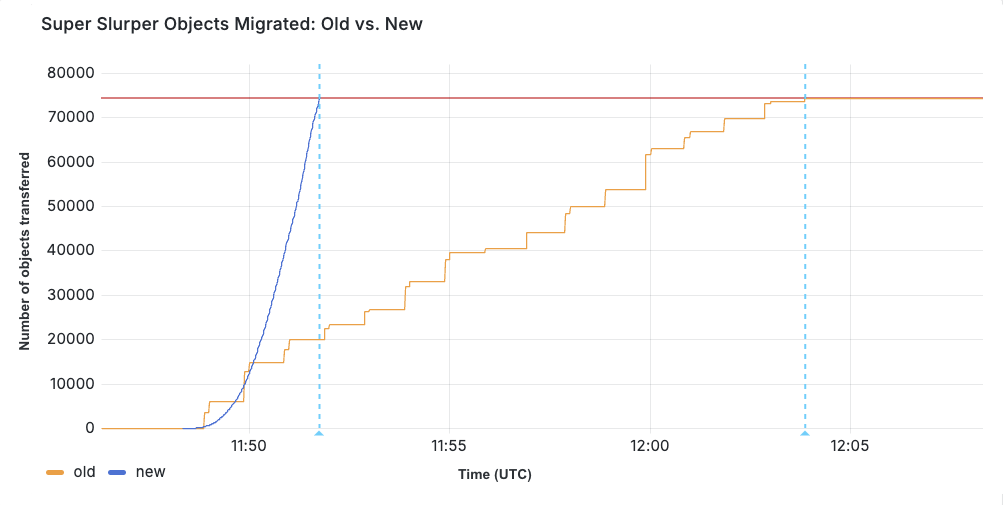
We re-architected Super Slurper from the ground up using our Developer Platform — leveraging Cloudflare Workers, Durable Objects, and Queues — and improved transfer speeds to R2 by up to 5x.
We’re announcing Workers VPC: a global private network that allows applications deployed on Cloudflare Workers to connect to your legacy cloud infrastructure. Now, you can unlock access to your existing APIs and data in external clouds and build global, modern, cross-cloud apps on Workers.
Cloudflare’s Startup Program offers up to \$250,000 in credits for companies building on our Developer Platform across 4 tiers: \$5,000, \$25,000, \$100,000, and \$250,000.
Cloudflare Containers are coming this June. Run new types of workloads on our network with an experience that is simple, scalable, global and deeply integrated with Workers.
Workers AI inference is faster with speculative decoding & prefix caching. Use our new batch inference for handling large request volumes seamlessly. Build tailored AI apps with more LoRA options. Lastly, new models and a refreshed dashboard round out this Developer Week update for Workers AI.
Cloudflare replaced a queues-based architecture in our National Center for Missing & Exploited Children (NCMEC) reporting system with Cloudflare Workflows for a structured, retryable workflow that’s easier to debug and maintain.
With recent developments in Certificate Transparency (CT), Cloudflare built a next-generation CT log on top of Cloudflare’s Developer Platform.
Even though 2025 Developer Week has come to a close, we can’t wait to hear what you’re building and hope you’ll share it with us on X or Discord. If you’re looking to get started, check out our developer documentation.
During Cloudflare’s Birthday Week in September 2024, we introduced a revamped Startup Program designed to make it easier for startups to adopt Cloudflare through a new credits system. This update focused on better aligning the program with how startups and developers actually consume Cloudflare, by providing them with clearer insight into their projected usage, especially as they approach graduation from the program.
Today, we’re excited to announce an expansion to that program: new credit tiers that better match startups at every stage of their journey. But before we dive into what’s new, let’s take a quick look at what the Startup Program is and why it exists.
A refresher: what is the Startup Program?
Cloudflare for Startups provides credits to help early-stage companies build the next big idea on our platform. Startups accepted into the program receive credits valid for one year or until they’re fully used, whichever comes first.
Beyond credits, the program includes access to up to three domains with enterprise-level services, giving startups the same advanced tools we provide to large companies to protect and accelerate their most critical applications.
We know that building a startup is expensive, and Cloudflare is uniquely positioned to support the full-stack needs of modern applications. Our goal is simple: ensure that you have access to the best of Cloudflare’s global network, without the barriers of cost or availability.
Since launching the revamped credits system in September, we’ve learned a lot from the startups in our program, including what they’re building, what they need, and where they need more flexibility. One of the most common requests was more credit tier options.
That’s why we’re introducing new tiers that provide even more options to startups as they scale.
Introducing additional credit tiers
The Cloudflare for Startups Program now offers four credit tiers:
Credit Amount
$5,000
$25,000
$100,000
$250,000
Stage
Bootstrapped, stealth startups
Up-and-coming startups
Seed-funded startups
Tier 1 startups
Description
For startups who are just getting started. This tier is great for building, testing, and iterating your product.
For startups with early adopters and proving product market fit.
For startups that have raised capital, and are experiencing high growth.
For scaling startups that belong to our Tier 1 VC and accelerator network, are building a mission-critical AI application, or are participating in our Workers Launchpad Program.
Criteria
Building a software-based product or service
Founded in the last 5 years
Valid and matching email address
$5,000 criteria plus:
Active LinkedIn
Funded up to $1M
$25,000 criteria plus:
Funded between $1M and $5M
Belong to any of our 250+ approved VC or Accelerator partners
$100,000 criteria plus:
High growth / AI companies, OR
Tier 1 VC & Accelerators
These tiers are designed to offer simplicity and clarity by aligning with where you are in your growth journey. (You can check out eligibility criteria and apply to the Startup Program here). These tiers are still subject to the same Cloudflare for Startups Terms of Service. Credits are valid for up to one year or when all credits are consumed (whichever comes first).
Why are we adding additional credit tiers?
We understand that each startup may have different needs depending on where they’re at in their journey. Some are just getting off the ground, others are scaling rapidly, and each has unique infrastructure needs. With this expansion, we’re reaffirming Cloudflare’s commitment to startups of all sizes, making it easier for you to access the right level of support and resources, exactly when you need them.
Whether you’re launching your MVP or preparing for your next funding round, Cloudflare is here to help you grow.
What can I use the credit tiers for?
The vast majority of Cloudflare products (including all products found on the pay-as-you-go plans) can be used on the Startup Program. Beyond going to the website to see what products are included, below are a few examples of what you can use your credits for:
Build AI applications
Store your training data in R2, build AI-powered agents (via Agents SDK) that autonomously perform tasks with Durable Objects and Workers, or use one of over 50 models to run inference tasks on Cloudflare’s global network.
Create immersive realtime experiences
Deliver live audio and video via our Realtime Kit, enhance the experience with an AI-powered chatbot running on Workers AI to transcribe the call, broadcast to large audiences with Stream.
Build durable multi-step applications
Design and run long-lived, multi-step processes like onboarding flows, document processing, or order fulfillment. Use Workflows to coordinate logic across Workers, Durable Objects, Queues, and AI tasks. Easily handle retries, timeouts, and state management without complex orchestration infrastructure.
What are startups saying about Cloudflare?
Webstudio’s no-code platform is powered by Cloudflare’s Developer Platform
“From a modern design tool, you’d expect real-time collaborative features and would like to have resources as close to users as possible. Since betting on the Developer Platform architecture, Cloudflare has done more for us than any other vendor out there!” – Oleg Isonen (Founder & CEO)
GrackerAI’s cybersecurity research engine runs on Cloudflare’s AI and serverless architecture
“Cloudflare’s fusion of edge computing and AI empowers developers to deploy and utilize AI models with unprecedented efficiency and scale, marking a significant leap forward in how we build and interact with intelligent systems.” – Deepak Gupta (Co-founder & CEO)
Render Better powers faster ecommerce experiences with Cloudflare Workers
“Each month Render Better optimizes billions of monthly requests for ecommerce visitors, delivering faster loading sites that make top brands millions more in revenue. We’re able to scale up with Cloudflare’s serverless workers, handling every request at the network edge within milliseconds, thanks to the rock solid, DX-friendly scope of the Developer Platform.” – James Koshigoe (Co-founder & CEO)
What will you build on Cloudflare?
We can’t wait to see what you will build on Cloudflare. Apply here to take advantage of the Cloudflare for Startups Program.
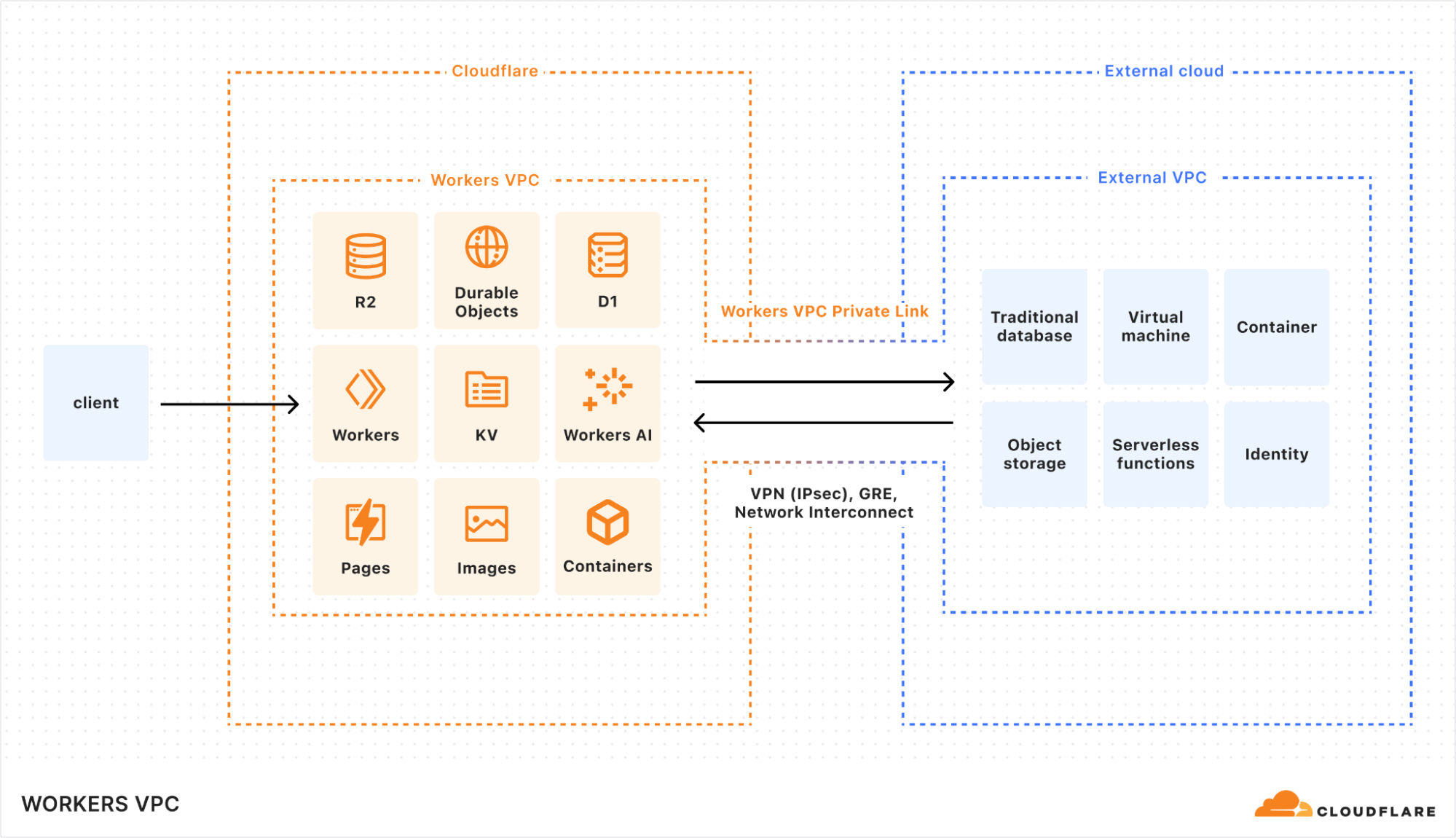
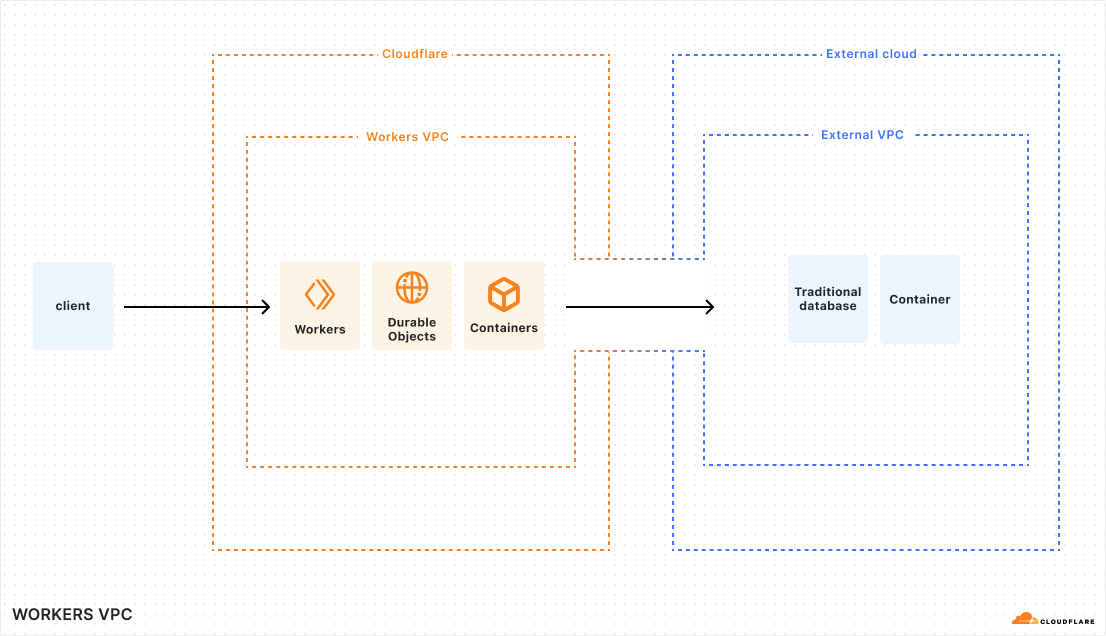
Today, we’re sharing a preview of a new feature that makes it easier to build cross-cloud apps: Workers VPC.
Workers VPC is our take on the traditional virtual private cloud (VPC), modernized for a network and compute that isn’t tied to a single cloud region. And we’re complementing it with Workers VPC Private Links to make building across clouds easier. Together, they introduce two new capabilities to Workers:
A way to group your apps’ resources on Cloudflare into isolated environments, where only resources within a Workers VPC can access one another, allowing you to secure and segment app-to-app traffic (a “Workers VPC”).
A way to connect a Workers VPC to a legacy VPC in a public or private cloud, enabling your Cloudflare resources to access your resources in private networks and vice versa, as if they were in a single VPC (the “Workers VPC Private Link”).
Workers VPC and Workers VPC Private Link enable bidirectional connectivity between Cloudflare and external clouds
When linked to an external VPC, Workers VPC makes the underlying resources directly addressable, so that application developers can think at the application layer, without dropping down to the network layer. Think of this like a unified VPC across clouds, with built-in service discovery.
We’re actively building Workers VPC on the foundation of our existing private networking products and expect to roll it out later in 2025. We wanted to share a preview of it early to get feedback and learn more about what you need.
Building private cross-cloud apps is hard
Developers are increasingly choosing Workers as their platform of choice, building rich, stateful applications on it. We’re way past Workers’ original edge use-cases: you’re modernizing more of your stack and moving more business logic on to Workers. You’re choosing Workers to build real-time collaboration applications that access your external databases, large scale applications that use your secured APIs, and Model Context Protocol (MCP) servers that expose your business logic to agents as close to your end users as possible.
Now, you’re running into the final barrier holding you back in external clouds: the VPC. Virtual private clouds provide you with peace of mind and security, but they’ve been cleverly designed to deliberately add mile-high barriers to building your apps on Workers. That’s the unspoken, vested interest behind getting you to use more legacy VPCs:it’s yet another way that captivity cloudshold your data and apps hostage and lock you in.
In conversation after conversation, you’ve told us “VPCs are a blocker”. We get it: your company policies mandate the VPC, and with good reason! So, to access private resources from Workers, you have to either 1) create new public APIs that perform authentication to provide secure access, or 2) set up and scale Cloudflare Tunnels and Zero Trust for each resource that you want to access. That’s a lot of hoops to jump through before you can even start building.
While we have the storage and compute options for you to build fully on Workers, we also understand that you won’t be moving your applications or your data overnight! But we think you should at least be free to choose Workers today to build modern applications, AI agents, and real-time global applications with your existing private APIs and databases. That’s why we’re building Workers VPC.
We’ve witnessed the pain of building around VPCs first hand. In 2024, we shipped support for private databases for Hyperdrive. This made it possible for you to connect to databases in an external VPC from Cloudflare Workers, using Cloudflare Tunnels as the underlying network solution. As a point-to-point solution, it’s been working great! But this solution has its limitations: managing and scaling a Cloudflare Tunnel for each resource in your external cloud isn’t sustainable for large, complex architectures.
We want to provide a dead-simple solution for you to unlock access to external cloud resources, in a manner that scales as you modernize more of your workloads with Workers. And we’re leveraging the experience we have in building Magic WAN and Magic Cloud Networking to make that possible.
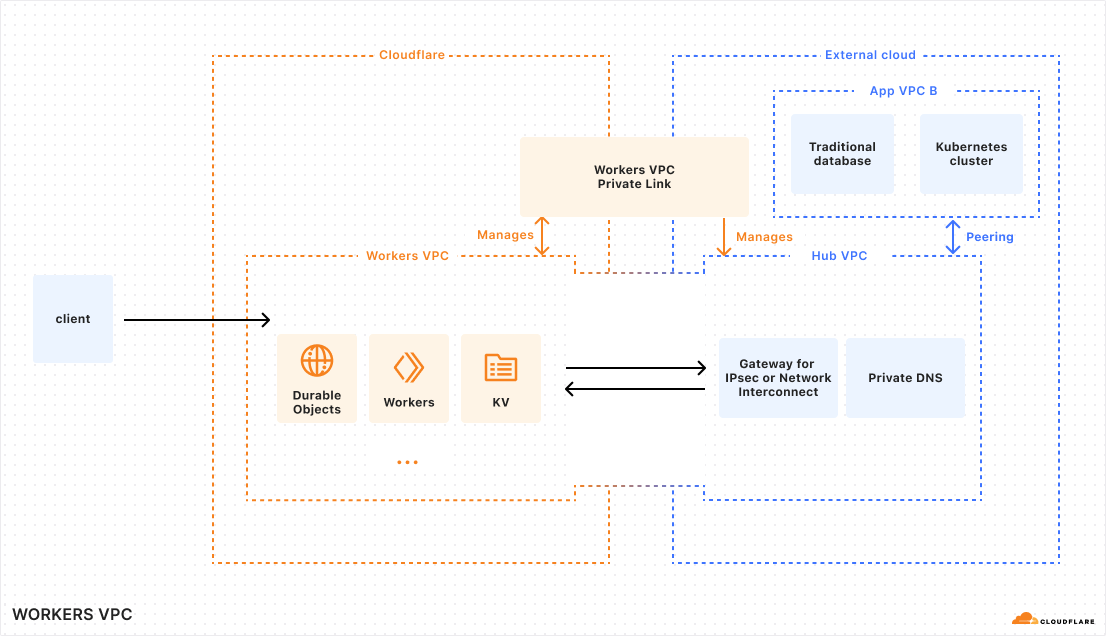
So, we’re taking VPCs global with Workers VPC. And we’re letting you connect them to your legacy private networks with Workers VPC Private Links. Because we think you should be free to build secure, global, cross-cloud apps on Workers.
Global cross-cloud apps need a global VPC
Private networks are complex to set up, they span across many layers of abstraction, and entire teams are needed to manage them. There are few things as complex as managing architectures that have outgrown their original point-to-point network! So we knew we needed to provide a simple solution for isolated environments on our platform.
Workers VPCs are, by definition, virtual private clouds. That means that they allow you to define isolated environments of Workers and Developer Platform resources like R2, Workers KV, and D1 that have secure access to one another. Other resources in your Cloudflare account won’t have access to these — VPCs allow you to specify certain sets of resources that are associated with certain apps and ensure no cross-application access of resources happens.
Workers VPCs are the equivalent of the legacy VPC, re-envisioned for the Cloudflare Developer Platform. The main difference is how Workers VPCs are implemented under the hood: instead of being built on top of regional, IP-based networking, Workers VPCs are built for global scale with the Cloudflare network performing isolation of resources across all of its datacenters.
And as you would expect from traditional VPCs, Workers VPCs have networking capabilities that allow them to seamlessly integrate with traditional networks, enabling you to build cross-cloud apps that never leave the networks you trust. That’s where Workers VPC Private Links comes in.
Like AWS PrivateLink and other VPC-to-VPC approaches, Workers VPC Private Links connect your Workers VPC to your external cloud using either standard tunnels over IPsec or Cloudflare Network Interconnect. When a Private Link is established, resources from either side can access one another directly, with nothing exposed over the public Internet, as if they were a single, connected VPC.
Workers VPC Private Link automatically provisions a gateway for IPsec tunnels or Cloudflare Network Interconnect and configures DNS for routing to Cloudflare resources
To make this possible, Workers VPC and Private Links work together to automatically provision and manage the resources in your external cloud. This establishes the connection between both networks and configures the resources required to make bidirectional routing possible. And, because we know some teams will want to maintain full responsibility over resource provisioning, Workers VPC Private Link can automatically provide you with Terraform scripts to provision external cloud resources that you can run yourself.
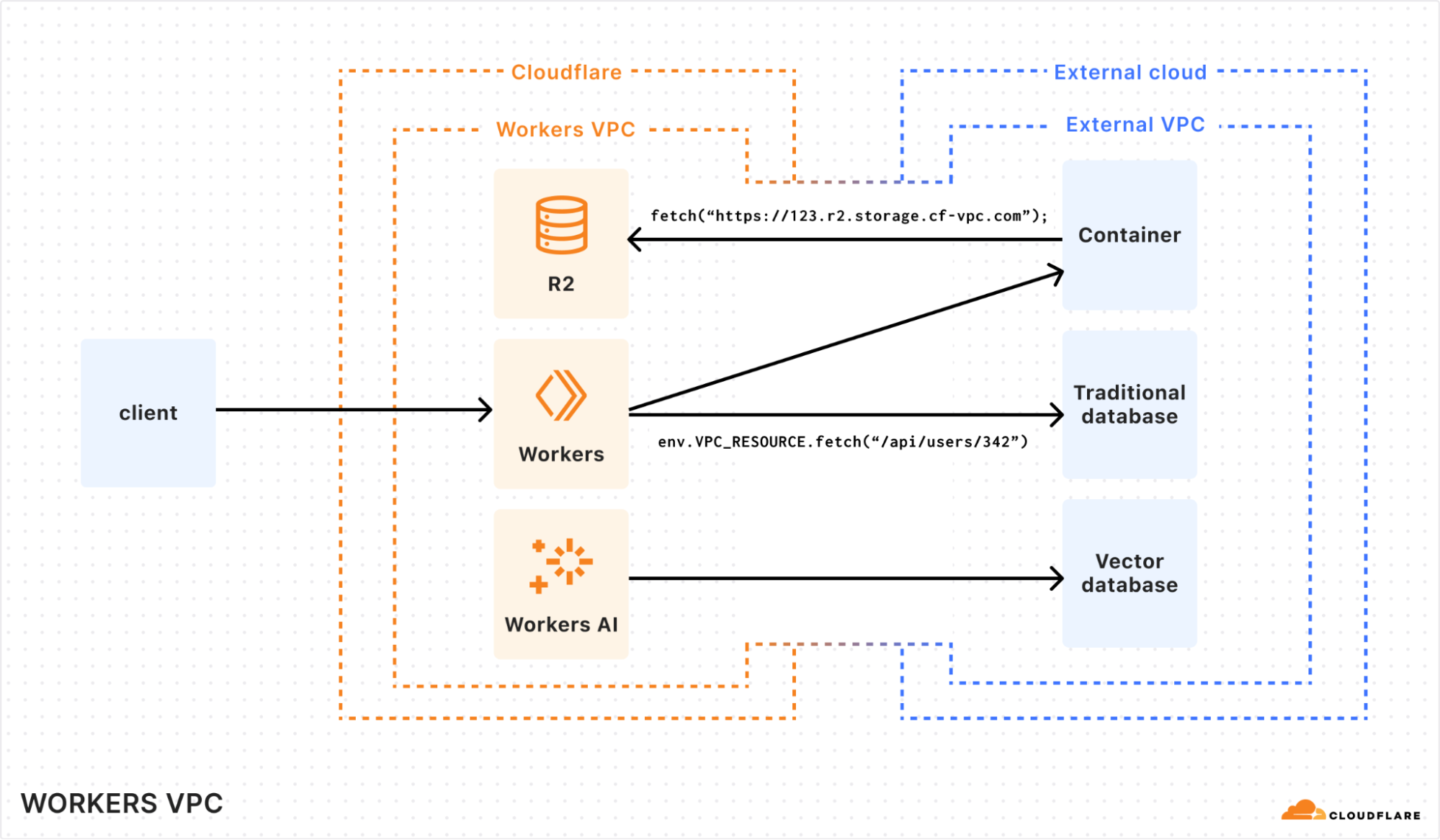
After the connection is made, Workers VPC will automatically detect the resources in your external VPC and make them available as bindings with unique IDs. Requests made through the Workers VPC resource binding will automatically be routed to your external VPC, where DNS resolution will occur (if you’re using hostname-accessed resources) and will be routed to the expected resource.
For example, connecting from Cloudflare Workers to a private API in an external VPC is just a matter of calling fetch() on a binding to a named Workers VPC resource:
Similarly, Cloudflare resources are accessible via a standardized URL that has been configured within a private DNS resource in your external cloud by Workers VPC Private Link. If you were attempting to access R2 objects from an API in your VPC, you would be able to make the request to the expected URL:
Best of all, since Workers VPC is built on our existing platform, it takes full advantage of our networking and routing capabilities to reduce egress fees and let you build global apps.
First, by supporting Cloudflare Network Interconnect as the underlying connection method, Workers VPC Private Links can help you lower your bandwidth costs by taking advantage of discounted external cloud egress pricing. Second, since Workers VPC is global by nature, your Workers and resources can be placed wherever needed to ensure optimal performance. For instance, with Workers’ Smart Placement, you can ensure that your Workers are automatically placed in a region closest to your external, regional VPC to maximize app performance.
An end-to-end connectivity cloud
Workers VPC unlocks huge swaths of your workloads that are currently locked into external clouds, without requiring you to expose those private resources to the public Internet to build on Workers. Here are real examples of applications that you’ve told us you’re looking forward to build on Workers with Workers VPC:
Sample architecture of real-time canvas application built on Workers and Durable Objects accessing a private database and container in an external VPC
Let’s say you’re trying to build a new feature for your application on Workers. You also want to add real-time collaboration to your app using Durable Objects. And you’re using Containers as well because you need to access FFmpeg for live video processing. In each scenario, you need a way to persist the state updates in your existing traditional database and access your existing APIs.
While in the past, you might have had to create a separate API just to handle update operations from Workers and Durable Objects, you can now directly access the traditional database and update the value directly with Workers VPC.
Same thing goes for Model Context Protocol (MCP) servers! If you’re building an MCP server on Workers, you may want to expose certain functionality that isn’t immediately available as a public API, especially if time to market is important. With Workers VPC, you can create new functionality directly in your MCP server that builds upon your private APIs or databases, enabling you to ship quickly and securely.
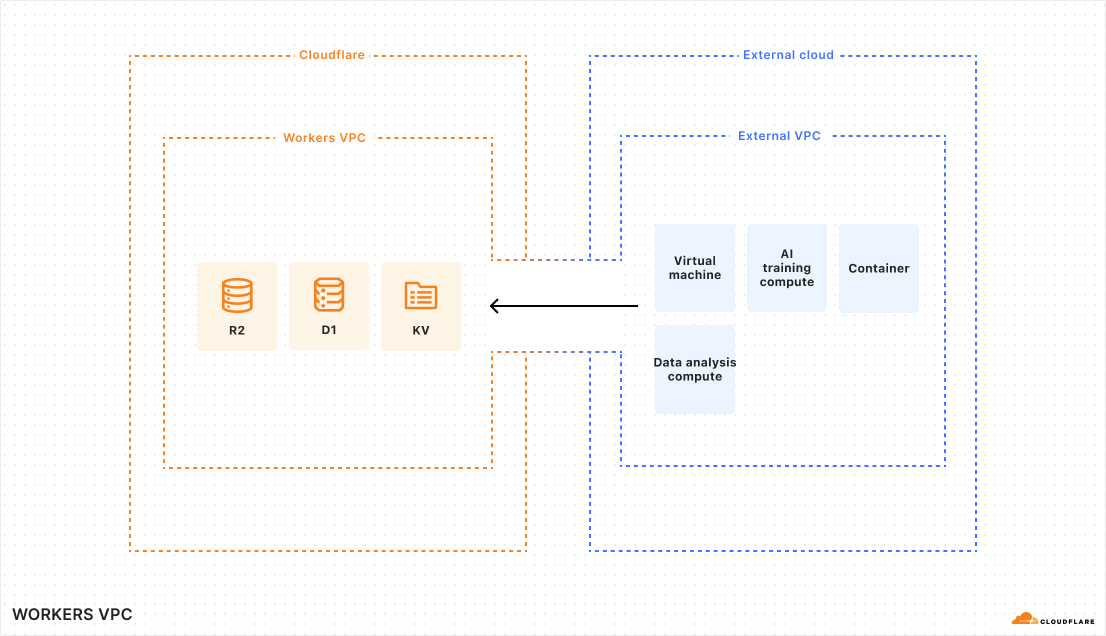
Sample architecture of external cloud resources accessing data from R2, D1, KV
Lots of development teams are landing more and more data on the Cloudflare Developer Platform, whether it is storing AI training data on R2 due to its zero-egress cost efficiency, application data in D1 with its horizontal sharding model, or configuration data in KV for its global single-digit millisecond read latencies.
Now, you need to provide a way to use the training data in R2 from your compute in your external cloud to train or fine-tune LLM models. Since you’re accessing user data, you need to use a private network because it’s mandated by your security teams. Likewise, you need to access user data and configuration data in D1 and KV for certain administrative or analytical tasks and you want to do so while avoiding the public Internet. Workers VPC enables direct, private routing from your external VPC to Cloudflare resources, with easily accessible hostnames from the automatically configured private DNS.
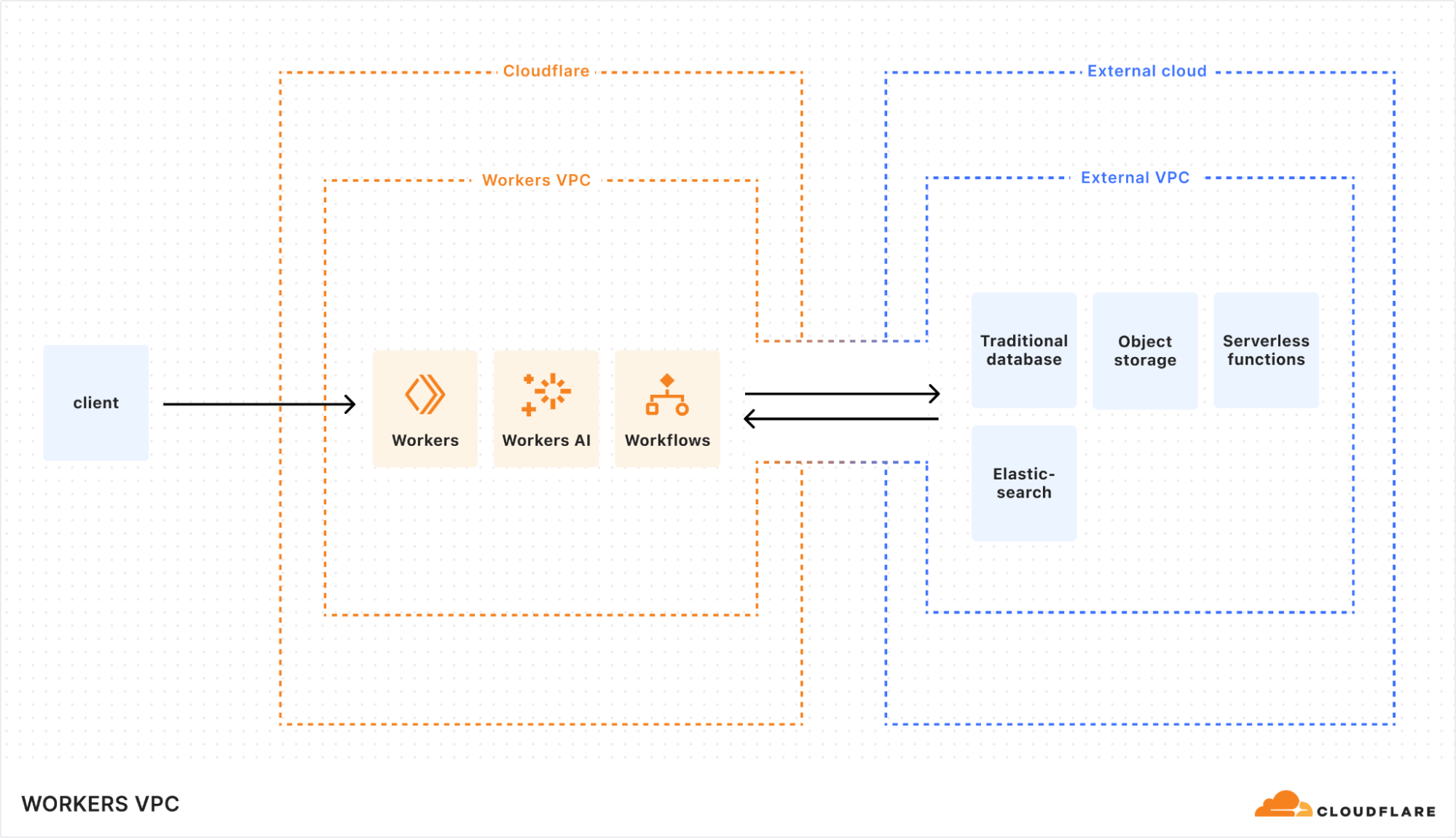
Finally, let’s use an AI agents example — it’s Developer Week 2025 after all! This AI agent is built on Workers, and uses retrieval augmented generation (RAG) to improve the results of its generated text while minimizing the context window.
You’re using PostgreSQL and Elasticsearch in your external cloud because that’s where your data currently resides and you’re a fan of pgvector. You’ve decided to use Workers because you want to get to market quickly, and now you need to access your database. Your database is, once again, placed in a private network and is inaccessible from the public Internet.
While you could provision a new Hyperdrive and Cloudflare Tunnel in a container, since your Workers VPC is already set up and linked, you can access the database directly using either Workers or Hyperdrive.
And what if new documents get added to your object storage in your external cloud? You might want to kick off a workflow to process the new document, chunk it, get embeddings for it, and update the state of your application in consequence, all while providing real-time updates to your end users about the status of the workflow?
Well, in that case, you can use Workflows, triggered by a serverless function in the external cloud. The Workflow will then fetch the new document in object storage, process it as needed, use your preferred embedding provider (whether Workers AI or another provider) in order to process and update the vector stores in Postgres, and then update the state of your application.
These are just some of the workloads that we know will benefit from Workers VPC on day 1. We’re excited to see what you build and are looking forward to working with you to make global VPCs real.
A new era for virtual private clouds
We’re incredibly excited for you to be able to build more on Workers with Workers VPC. We believe that private access to your APIs and databases in your private networks will redefine what you can build on Workers. Workers VPCs unlock access to your private resources to let your ship faster, more performant apps on Workers. And we’re obviously going to ensure that Containers integrate natively with Workers VPC.
We’re actively building Workers VPC on the networking primitives and on-ramps we’ve been using to connect customer networks at scale, and our goal is to ship an early preview later in 2025.
We’re planning to tackle connectivity from Workers to external clouds first, enabling you to modernize more apps that need access to private APIs and databases with Workers, before expanding to support full-directional traffic flows and multiple Workers VPC networks. If you want to shape the vision of Workers VPC and have workloads trapped in a legacy cloud, express interest here.
With quick access to flexible infrastructure and innovative AI tools, startups are able to deploy production-ready applications with speed and efficiency. Cloudflare plays a pivotal role for countless applications, empowering founders and engineering teams to build, scale, and accelerate their innovations with ease — and without the burden of technical overhead. And when applicable, initiatives like our Startup Program and Workers Launchpad offer the tooling and resources that further fuel these ambitious projects.
Cloudflare recently announcedAI agents, allowing developers to leverage Cloudflare to deploy agents to complete autonomous tasks. We’re already seeing some great examples of startups leveraging Cloudflare as their platform of choice to invest in building their agent infrastructure. Read on to see how a few up-and-coming startups are building their AI agent platforms, powered by Cloudflare.
Lamatic AI built a scalable AI agent platform using Workers for Platform
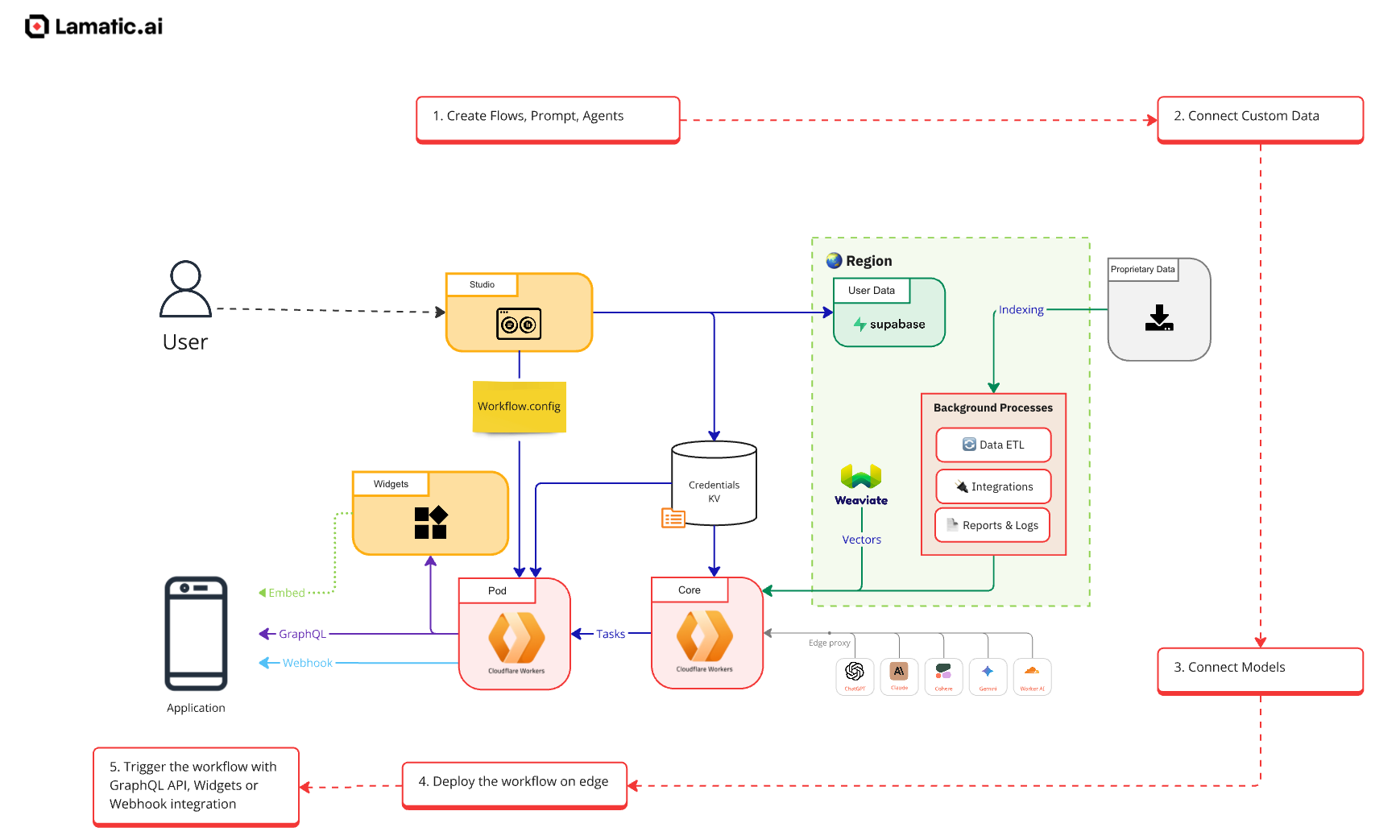
Founded in 2023, Lamatic.ai empowers SaaS startups to seamlessly integrate intelligent AI agents into their products. Lamatic.ai simplifies the deployment of AI agents by offering a fully managed lifecycle with scalability and security in mind. SaaS providers have been leveraging Lamatic to replatform their AI workflows via a no-code visual builder to reduce technical debt and ship products faster. Designed for high availability, scalability, and low latency, Lamatic’s architecture enables developers to build AI-driven applications that remain performant under heavy load. After acquiring a high amount of users in a short amount of time on Product Hunt, Lamatic identified there was real interest to solve complex problems with AI Agents, and the team knew they needed to build a solution with scalability and performance in mind.
Cloudflare plays a key role in supporting Lamatic’s growth. Powered by Cloudflare Workers, Lamatic ensures requests process closer to end users, minimizing latency while offloading computational strain from centralized servers. In just a few months, Lamatic.ai has efficiently scaled to over three million serverless requests per month, supporting over 1,000 customers — all managed by a lean three-person team.
Customers design their Agent Flows through a no-code visual builder, which generates an interoperable YAML configuration. Sensitive credentials such as API keys and model access tokens are securely encrypted and stored in Workers KV, ensuring they are only decrypted at runtime for enhanced security. All YAML configurations are then compiled into a Workers-compatible JavaScript bundle. When a project is deployed, Lamatic orchestrates critical components like sync jobs for scheduled data ETL operations and incoming webhooks to handle event-driven workflows via Cloudflare Queues. Once deployed, the project is fully operational as a Cloudflare Worker with an exposed API endpoint, allowing customers to integrate AI-powered automation directly into their applications with minimal friction.
To scale out their platform, Lamatic.ai built their architecture isolating serverless and AI logic on a per-customer basis. Rather than batching requests into a centralized cluster, Lamatic.ai distributes workloads across Cloudflare’s global network, ensuring each customer and endpoint is served by its own Worker executing dedicated logic. This per-customer deployment model — enabled by Workers for Platforms— allows Lamatic.ai to deliver customer-specific serverless functions at scale, and reduces technical overhead as they onboard additional customers. Each customer gets a dedicated Worker whose request and rate limits are enabled based on their level of subscription.
Beyond request processing, Lamatic uses Cloudflare Workers KV as a distributed config store to ensure high availability and security. All values are encrypted at rest with AES-256-GCM and decrypted only at runtime, keeping operations both secure and low-latency. Tokens and user credentials are encrypted and stored in the database and KV.
To further enhance performance, Cloudflare Queues plays a key role in orchestrating task completion. Lamatic uses Queues to offload work from Workers requests, and handle tasks such as webhooks and coordinating distributed processes, both essential for maintaining system consistency and reliability at scale. While Workers handle sync requests at point of execution, longer running jobs process via Queues. For example, during a scheduled ETL sync, new data records generated are stored as a message queue on Cloudflare Pub/Sub. A consumer Worker collects these messages and makes an API request to the pod using the Workers Queue. The consumer Worker consumes more messages as each queue is finished processing.
Another example of where this has been optimal is for managing AI workflows. Many AI workflows involve concurrent requests to multiple data sources, Queues streamlines data processing and efficiently feeds information into customers’ Retrieval Augmented Generation (RAG) workflows. This approach smooths out workload spikes, reduces bottlenecks, and ensures that AI agents can reliably aggregate and process data without delays.
Beyond this, Lamatic.ai offers Workers AI as one of the support inference providers that customers can use across their platform. Customers can choose to run one of the many open source models hosted on Workers AI, depending on their use case (chatbot, image generation, voice, etc.). Together, these layers solve the challenges of scaling AI agents by handling high volumes of data, maintaining low-latency responses, and ensuring robust security. With Cloudflare’s infrastructure as its backbone, Lamatic.ai has built a resilient and high-performing platform that meets the rigorous demands of modern AI applications, making it an ideal choice for startups embedding AI-driven features into their products.
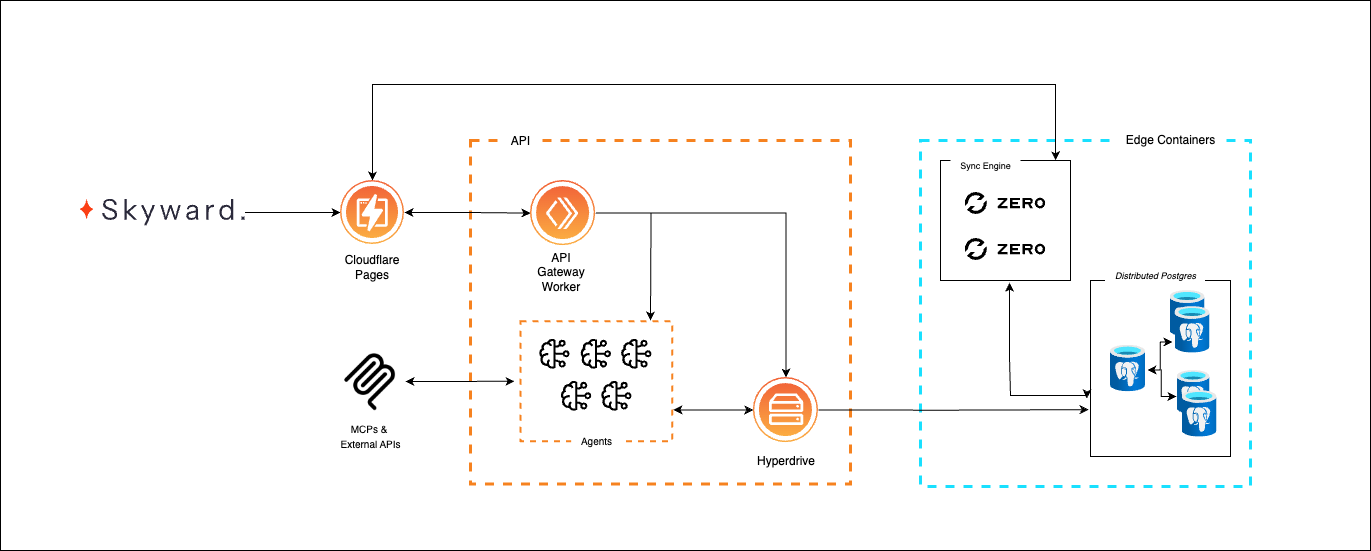
Skyward AI automates compliance using AI agents with Durable Objects and agents
Skyward AI is transforming compliance operations by leveraging Cloudflare’s serverless computing capabilities to build AI-driven compliance agents that streamline critical tasks like evidence collection, real-time risk analysis, and policy updates. Compliance teams in fintech, supply chain, and other highly regulated industries use these AI Agents to extract and organize evidence, provide real-time recommendations, and orchestrate policy and procedural updates automatically. By handling document parsing, risk monitoring, and policy enforcement, these AI Agents reduce the risk of human error while allowing compliance professionals to focus on high-value tasks.
Skyward has built an AI agents platform designed with a serverless-first approach, avoiding the constraints of centralized cloud computing. To achieve this, the company leverages Cloudflare’s Developer Platform to create and maintain a highly responsive and scalable infrastructure. Workers handle incoming requests like chat inputs, compliance checks, or authentication, and route them efficiently across multiple geographies. Skyward initially built their AI agents infrastructure using Durable Objects,Workflows and JavaScript-native RPC for AI coordination, but has recently transitioned to Cloudflare’s new AI agents framework. Given that agents provides a framework for building and orchestrating AI agents, the migration has helped Skyward abstract the need to manage Durable Objects manually, significantly reducing time spent on managing these tools. While this release is fairly recent, the transition has helped simplify the way that agents communicate, but it also preserved the benefits of their original design like data privacy, isolation, and concurrency management. This has also made it easier to provide real-time feedback and responses to their end users.
Skyward optimizes real-time compliance automation by achieving sub-100 ms response times for AI agent queries. Workloads are structured to minimize unnecessary network round-trips, and a sync-engine approach proactively preloads and pushes data to clients, delivering a highly responsive user experience. To proxy AI inference, Skyward uses AI Gateway to provide observability into usage, performance, and costs across multiple vendors, improving their AI operational efficiency. Leveraging Cloudflare’s serverless Developer Platform has allowed Skyward to simplify their architecture while supporting global availability, avoiding the need for Kubernetes clusters or complex locking mechanisms. The team also avoids the burden of managing regional deployments, as Cloudflare’s multi-region support ensures consistent performance worldwide without added operational complexity.
State management is a critical component to execute agentic workflows. Each compliance session runs within a dedicated Durable Object, which keeps relevant data close to the execution layer. This setup minimizes database round-trips and ensures that tasks like Anti-Money Laundering (AML) checks, Know Your Business (KYB) validation, and document processing remain efficient. Once a compliance session is complete, the system summarizes and stores the relevant information in Postgres and R2, optimizing memory usage without requiring persistent cloud infrastructure.
To balance low-latency operations with long-term storage, Skyward employs a multi-layered data management strategy. The Skyward team, using Hyperdrive, has been able to reduce query latency by nearly 50%, allowing compliance teams to receive immediate feedback. At the company’s core, Skyward’s goal is to offer a platform that is “streamlined for compliance teams”. The team maintains that a speedy feedback loop ensures end customers get the data and responses needed to act. Whether there’s one agent or hundreds of agents processing tasks in parallel, Hyperdrive ensures that database requests to assets like extensive company documentation (i.e. regulations, policies, procedures, internal documents), complex regulatory knowledge graphs, and on-demand context information for conversational workflows are all as performant as possible.
Durable Objects facilitate real-time session state, ensuring AI agents function smoothly without complex locking mechanisms. For larger compliance-related documents, such as legal PDFs and archived data, Cloudflare R2 provides long-term storage, ensuring only frequently accessed information remains readily available. This approach enhances performance while keeping storage management efficient and cost-effective.
Security and scalability remain priorities for compliance-focused AI applications. Skyward enforces strict access controls, ensuring that only authorized users can access development and production environments. Each AI session maintains an auditable log of key events, user actions, and approvals, supporting the ability to export these insights for compliance and legal requirements. Because each agent is deployed in its own instance and has its own database, Skyward ensures that there is a detailed record of every required user, agent interaction, and auditing requirements. On top of this, the ability to deploy and scale globally with Cloudflare’s network has allowed Skyward to maintain consistent, high-performance operations across multiple regions without extensive infrastructure overhead.
Looking ahead, Skyward plans to further enhance AI agent responsiveness by running select models directly on Cloudflare Workers AI, reducing reliance on external inference providers. The team plans to further integrate Workers for Platforms in an effort to better isolate customer data and workflows, giving end users greater control over their compliance automation. As Cloudflare continues to evolve its AI capabilities, Skyward aims to push the boundaries of distributed AI compliance solutions, making regulatory adherence more automated, scalable, and secure.
Building on Cloudflare
We’re inspired by how startups like Lamatic AI and Skyward AI are building their AI agent platforms on Cloudflare. This kind of innovation is why we’re proud to see so many startups trust Cloudflare for a scalable, reliable, and efficient foundation.
We’re also thrilled to share that both Lamatic AI and Skyward AI have been invited to join Cloudflare’s upcoming Workers Launchpad Cohort #5. Speaking of Workers Launchpad, it’s been a few months since our last update — let’s take a look at what’s new.
Thank you to Workers Launchpad Cohort #4, and a warm welcome to Cohort #5
The Workers Launchpad team is blown away by what customers are demonstrating on the Developer Platform. Members of Cohort #4 presented at our bi-annual Demo Day. We had customers demonstrate what they’re building across a multitude of industries, including (of course) AI / ML, developer tools, 3D design, cloud infrastructure, adtech, media, and beyond. It’s incredibly encouraging to see what all these amazing companies are building on the Cloudflare network, and we look forward to continuing to partner with them throughout their startup journey.
Following the Demo Day for Workers Launchpad Cohort #4, we’ve seen the largest influx of applications from startups across the globe eager to join Cohort #5. This next wave of founders is pushing the boundaries of what’s possible, building in areas like AI agents, developer tooling, MCP, media, and beyond. With each new cohort, we’re continually inspired by the caliber of founding teams, the bold ideas they bring to life, and the real-world problems they’re tackling with technology.
Help us give some love and a warm welcome to the participants of Cohort #5:
We can’t wait to share more about what Cohort #5 achieves. Be sure to follow @CloudflareDev on X and join our Developer Discord server to hear updates on the cohorts.
If you’re developing your application on our Developer Platform, we’d love to learn how Cloudflare is powering your journey. Please share more about what you’re building, and our team will be sure to review your submission. And if you’re a startup and interested in joining Workers Launchpad, feel free to apply for Cohort 6 — applications are now open!
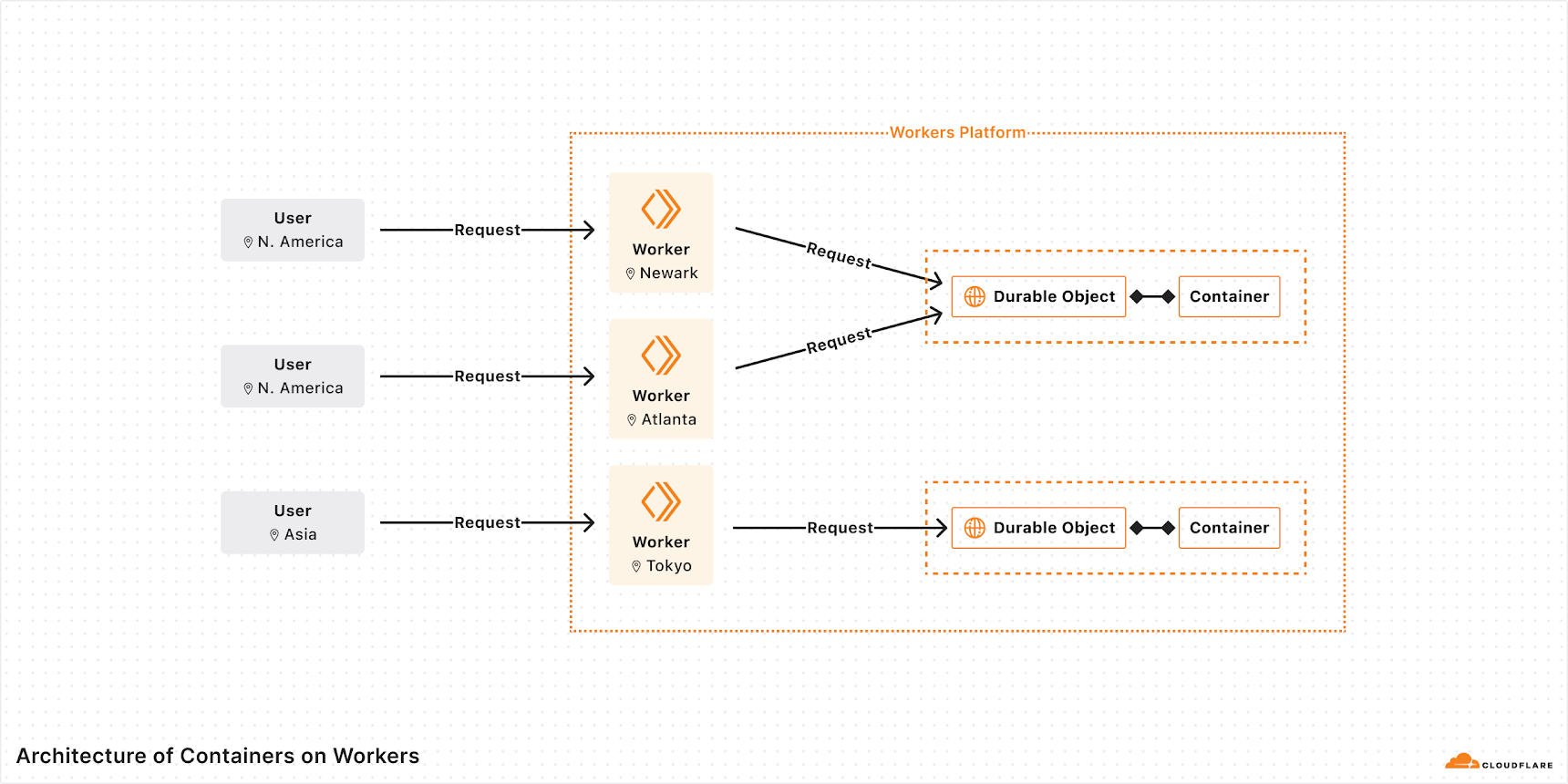
It is almost the end of Developer Week and we haven’t talked about containers: until now. As some of you may know, we’ve been working on a container platform behind the scenes for some time.
In late June, we plan to release Containers in open beta, and today we’ll give you a sneak peek at what makes it unique.
Workers are the simplest way to ship software around the world with little overhead. But sometimes you need to do more. You might want to:
Run user-generated code in any language
Execute a CLI tool that needs a full Linux environment
Use several gigabytes of memory or multiple CPU cores
Port an existing application from AWS, GCP, or Azure without a major rewrite
Cloudflare Containers let you do all of that while being simple, scalable, and global.
Through a deep integration with Workers and an architecture built on Durable Objects, Workers can be your:
API Gateway: Letting you control routing, authentication, caching, and rate-limiting before requests reach a container
Service Mesh: Creating private connections between containers with a programmable routing layer
Orchestrator: Allowing you to write custom scheduling, scaling, and health checking logic for your containers
Instead of having to deploy new services, write custom Kubernetes operators, or wade through control plane configuration to extend the platform, you just write code.
Let’s see what it looks like.
Deploying different application types
A stateful workload: executing AI-generated code
First, let’s take a look at a stateful example.
Imagine you are building a platform where end-users can run code generated by an LLM. This code is untrusted, so each user needs their own secure sandbox. Additionally, you want users to be able to run multiple requests in sequence, potentially writing to local files or saving in-memory state.
To do this, you need to create a container on-demand for each user session, then route subsequent requests to that container. Here’s how you can accomplish this:
First, you write some basic Wrangler config, then you route requests to containers via your Worker:
import { Container } from "cloudflare:workers";
export default {
async fetch(request, env) {
const url = new URL(request.url);
if (url.pathname.startsWith("/execute-code")) {
const { sessionId, messages } = await request.json();
// pass in prompt to get the code from Llama 4
const codeToExecute = await env.AI.run("@cf/meta/llama-4-scout-17b-16e-instruct", { messages });
// get a different container for each user session
const id = env.CODE_EXECUTOR.idFromName(sessionId);
const sandbox = env.CODE_EXECUTOR.get(id);
// execute a request on the container
return sandbox.fetch("/execute-code", { method: "POST", body: codeToExecute });
}
// ... rest of Worker ...
},
};
// define your container using the Container class from cloudflare:workers
export class CodeExecutor extends Container {
defaultPort = 8080;
sleepAfter = "1m";
}
Then, deploy your code with a single command: wrangler deploy. This builds your container image, pushes it to Cloudflare’s registry, readies containers to boot quickly across the globe, and deploys your Worker.
$ wrangler deploy
That’s it.
How does it work?
Your Worker creates and starts up containers on-demand. Each time you call env.CODE_EXECUTOR.get(id) with a unique ID, it sends requests to a unique container instance. The container will automatically boot on the first fetch, then put itself to sleep after a configurable timeout, in this case 1 minute. You only pay for the time that the container is actively running.
When you request a new container, we boot one in a Cloudflare location near the incoming request. This means that low-latency workloads are well-served no matter the region. Cloudflare takes care of all the pre-warming and caching so you don’t have to think about it.
This allows each user to run code in their own secure environment.
Stateless and global: FFmpeg everywhere
Stateless and autoscaling applications work equally well on Cloudflare Containers.
Imagine you want to run a container that takes a video file and turns it into an animated GIF using FFmpeg. Unlike the previous example, any container can serve any request, but you still don’t want to send bytes across an ocean and back unnecessarily. So, ideally the app can be deployed everywhere.
To do this, you declare a container in Wrangler config and turn on autoscaling. This specific configuration ensures that one instance is always running and if CPU usage increases beyond 75% of capacity, additional instances are added:
To route requests, you just call env.GIF_MAKER.fetch and requests are automatically sent to the closest container:
import { Container } from "cloudflare:workers";
export class GifMaker extends Container {
defaultPort: 1337,
}
export default {
async fetch(request, env) {
const url = new URL(request.url);
if (url.pathname === "/make-gif") {
return env.GIF_MAKER.fetch(request)
}
// ... rest of Worker ...
},
};
Going beyond the basics
From the examples above, you can see that getting a basic container service running on Workers just takes a few lines of config and a little Workers code. There’s no need to worry about capacity, artifact registries, regions, or scaling.
For more advanced use, we’ve designed Cloudflare Containers to run on top of Durable Objects and work in tandem with Workers. Let’s take a look at the underlying architecture and see some of the advanced use cases it enables.
Durable Objects as programmable sidecars
Routing to containers is enabled using Durable Objects under the hood. In the examples above, the Container class from cloudflare:workers just wraps a container-enabled Durable Object and provides helper methods for common patterns. In the rest of this post, we’ll look at examples using Durable Objects directly, as this should shed light on the platform’s underlying design.
Each Durable Object acts as a programmable sidecar that can proxy requests to the container and manages its lifecycle. This allows you to control and extend your containers in ways that are hard on other platforms.
You can manually start, stop, and execute commands on a specific container by calling RPC methods on its Durable Object, which now has a new object at this.ctx.container:
class MyContainer extends DurableObject {
// these RPC methods are callable from a Worker
async customBoot(entrypoint, envVars) {
this.ctx.container.start({ entrypoint, env: envVars });
}
async stopContainer() {
const SIGTERM = 15;
this.ctx.container.signal(SIGTERM);
}
async startBackupScript() {
await this.ctx.container.exec(["./backup"]);
}
}
You can also monitor your container and run hooks in response to Container status changes.
For instance, say you have a CI job that runs builds in a Container. You want to post a message to a Queue based on the exit status. You can easily program this behavior:
And lastly, if you have state that needs to be loaded into a container each time it runs, you can use status hooks to persist state from the container before it sleeps and to reload state into the container after it starts:
import { startAndWaitForPort } from "./helpers"
class MyContainer extends DurableObject {
constructor(ctx, env) {
super(ctx, env)
this.ctx.blockConcurrencyWhile(async () => {
this.ctx.storage.sql.exec('CREATE TABLE IF NOT EXISTS state (value TEXT)');
this.ctx.storage.sql.exec('INSERT INTO state (value) SELECT '' WHERE NOT EXISTS (SELECT * FROM state)');
await startAndWaitForPort(this.ctx.container, 8080);
await this.setupContainer();
this.ctx.container.monitor().then(this.onContainerExit);
});
}
async setupContainer() {
const initialState = this.ctx.storage.sql.exec('SELECT * FROM state LIMIT 1').one().value;
return this.ctx.container
.getTcpPort(8080)
.fetch("http://container/state", { body: initialState, method: 'POST' });
}
async onContainerExit() {
const response = await this.ctx.container
.getTcpPort(8080)
.fetch('http://container/state');
const newState = await response.text();
this.ctx.storage.sql.exec('UPDATE state SET value = ?', newState);
}
}
Building around your Containers with Workers
Not only do Durable Objects allow you to have fine-grained control over the Container lifecycle, the whole Workers platform allows you to extend routing and scheduling behavior as you see fit.
Using Workers as an API gateway
Workers provide programmable ingress logic from over 300 locations around the world. In this sense, they provide similar functionality to an API gateway.
For instance, let’s say you want to route requests to a different version of a container based on information in a header. This is accomplished in a few lines of code:
Or you want to rate limit and authenticate requests to the container:
async fetch(request, env) {
const url = new URL(request.url);
if (url.pathname.startsWith('/api/')) {
const token = request.headers.get("token");
const isAuthenticated = await authenticateRequest(token);
if (!isAuthenticated) {
return new Response("Not authenticated", { status: 401 });
}
const { withinRateLimit } = await env.MY_RATE_LIMITER.limit({ key: token });
if (!withinRateLimit) {
return new Response("Rate limit exceeded for token", { status: 429 });
}
return env.MY_APP.fetch(request);
}
// ...
}
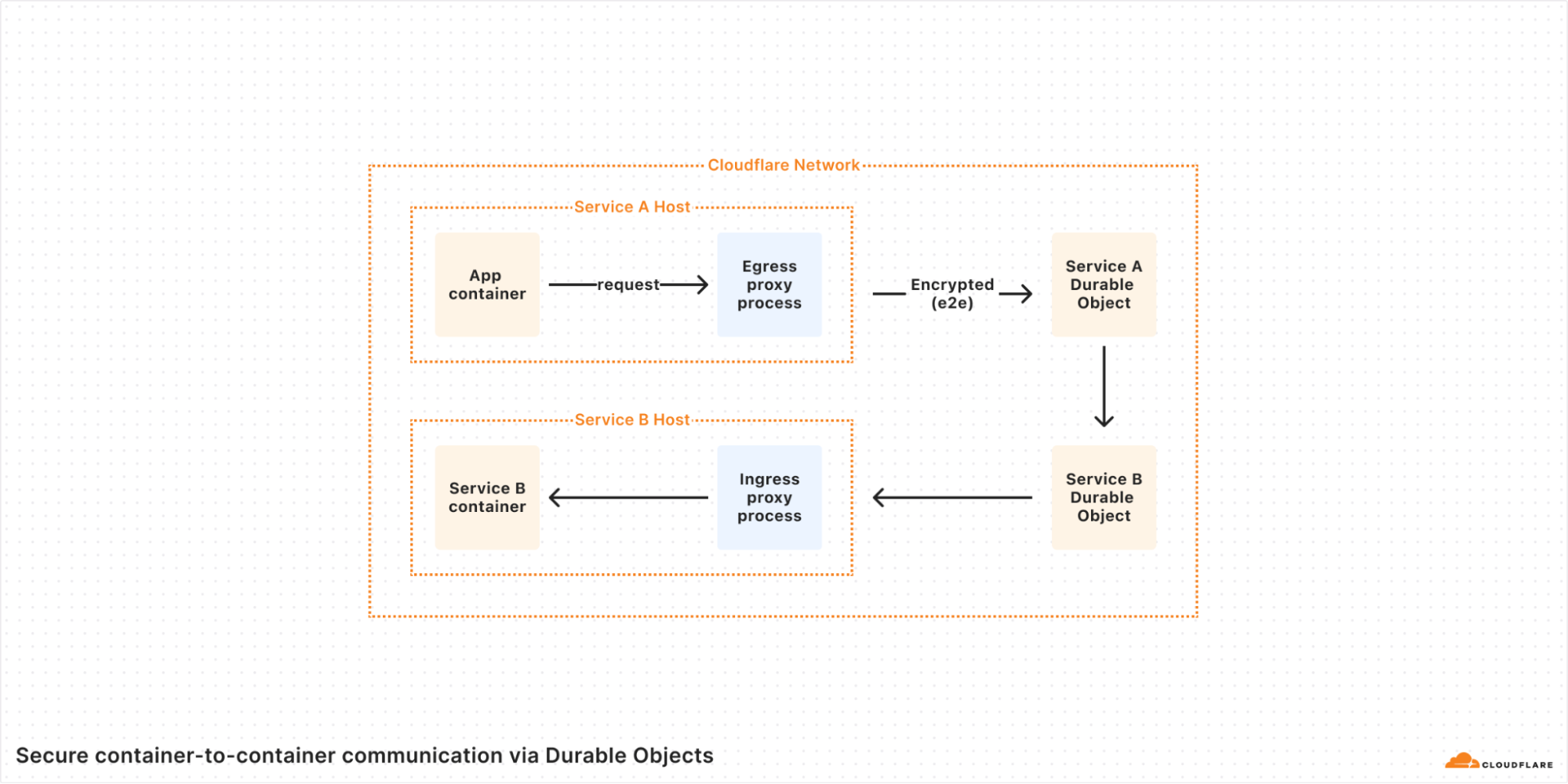
Using Workers as a service mesh
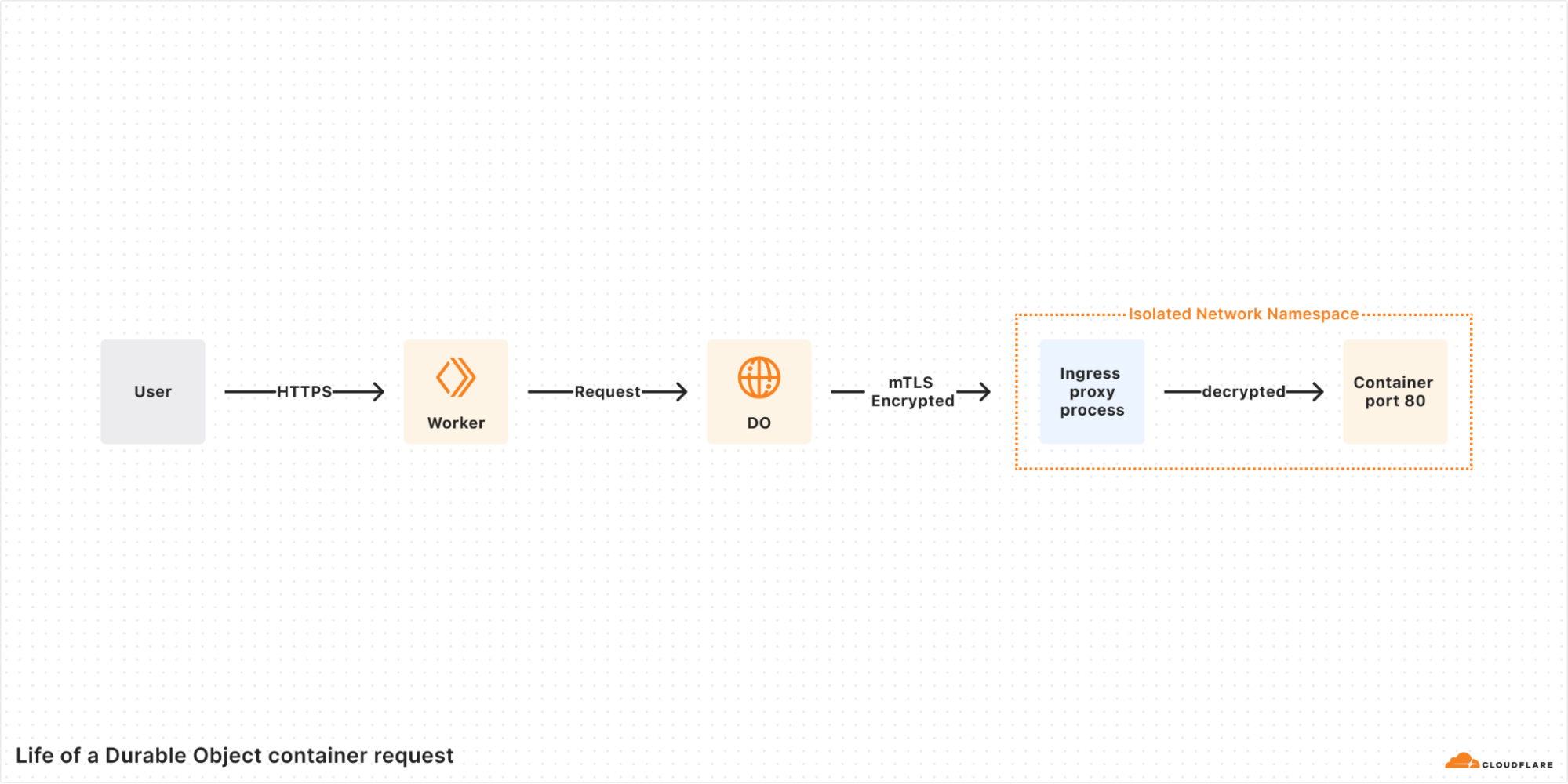
By default, Containers are private and can only be accessed via Workers, which can connect to one of many container ports. From within the container, you can expose a plain HTTP port, but requests will still be encrypted from the end user to the moment we send the data to the container’s TCP port in the host. Due to the communication being relayed through the Cloudflare network, the container does not need to set up TLS certificates to have secure connections in its open ports.
You can connect to the container through a WebSocket from the client too. See this repository for a full example of using Websockets.
Just as the Durable Object can act as proxy to the container, it can act as a proxy from the container as well. When setting up a container, you can toggle Internet access off and ensure that outgoing requests pass through Workers.
// ... when starting the container...
this.ctx.container.start({
workersAddress: '10.0.0.2:8080',
enableInternet: false, // 'enableInternet' is false by default
});
// ... container requests to '10.0.0.2:8080' securely route to a different service...
override async onContainerRequest(request: Request) {
const containerId = this.env.SUB_SERVICE.idFromName(request.headers['X-Account-Id']);
return this.env.SUB_SERVICE.get(containerId).fetch(request);
}
You can ensure all traffic in and out of your container is secured and encrypted end to end without having to deal with networking yourself.
This allows you to protect and connect containers within Cloudflare’s network… or even when connecting to external private networks.
Using Workers as an orchestrator
You might require custom scheduling and scaling logic that goes beyond what Cloudflare provides out of the box.
We don’t want you having to manage complex chains of API calls or writing an operator to get the logic you need. Just write some Worker code.
For instance, imagine your containers have a long startup period that involves loading data from an external source. You need to pre-warm containers manually, and need control over the specific region to prewarm. Additionally, you need to set up manual health checks that are accessible via Workers. You’re able to achieve this fairly simply with Workers and Durable Objects.
import { Container, DurableObject } from "cloudflare:workers";
// A singleton Durable Object to manage and scale containers
class ContainerManager extends DurableObject {
scale(region, instanceCount) {
for (let i = 0; i < instanceCount; i++) {
const containerId = env.CONTAINER.idFromName(`instance-${region}-${i}`);
// spawns a new container with a location hint
await env.CONTAINER.get(containerId, { locationHint: region }).start();
}
}
async setHealthy(containerId, isHealthy) {
await this.ctx.storage.put(containerId, isHealthy);
}
}
// A Container class for the underlying compute
class MyContainer extends Container {
defaultPort = 8080;
async onContainerStart() {
// run healthcheck every 500ms
await this.scheduleEvery(0.5, 'healthcheck');
}
async healthcheck() {
const manager = this.env.MANAGER.get(
this.env.MANAGER.idFromName("manager")
);
const id = this.ctx.id.toString();
await this.container.fetch("/_health")
.then(() => manager.setHealthy(id, true))
.catch(() => manager.setHealthy(id, false));
}
}
The ContainerManager Durable Object exposes the scale RPC call, which you can call as needed with a region and instanceCount which scales up the number of active Container instances in a given region using a location hint. The this.schedule code executes a manually defined healthcheck method on the Container and tracks its state in the Manager for use by other logic in your system.
These building blocks let users handle complex scheduling logic themselves. For a more detailed example using standard Durable Objects, see this repository.
We are excited to see the patterns you come up with when orchestrating complex applications built with containers, and trust that between Workers and Durable Objects, you’ll have the tools you need.
Integrating with more of Cloudflare’s Developer Platform
Let’s finish up by taking a quick look at how you can integrate Containers with these two tools.
Running a short-lived job with Workflows & R2
You need to download a large file from R2, compress it, and upload it. You want to ensure that this succeeds, but don’t want to write retry logic and error handling yourself. Additionally, you don’t want to deal with rotating R2 API tokens or worry about network connections — it should be secure by default.
This is a perfect opportunity for a Workflow using Containers. The container can do the heavy lifting of compressing files, Workers can stream the data to and from R2, and the Workflow can ensure durable execution.
Lastly, imagine you have an AI agent that needs to spin up cloud infrastructure (you like to live dangerously). To do this, you want to use Terraform, but since it’s run from the command line, you can’t run it on Workers.
By defining a tool, you can enable your Agent to run the shell commands from a container:
// Make tools that call to a container from an agent
const createExternalResources = tool({
description: "runs Terraform in a container to create resources",
parameters: z.object({ sessionId: z.number(), config: z.string() }),
execute: async ({ sessionId, config }) => {
return this.env.TERRAFORM_RUNNER.get(sessionId).applyConfig(config);
},
});
// Expose RPC Methods that call to the container
class TerraformRunner extends DurableObject {
async applyConfig(config) {
await this.ctx.container.getTcpPort(8080).fetch(APPLY_URL, {
method: 'POST',
body: JSON.stringify({ config }),
});
}
// ...rest of DO...
}
Containers are so much more powerful when combined with other tools. Workers make it easy to do so in a secure and simple way.
Pay for what you use and use the right tool
The deep integration between Workers and Containers also makes it easy to pick the right tool for the job with regards to cost.
With Cloudflare Containers, you only pay for what you use. Charges start when a request is sent to the container or it is manually started. Charges stop after the container goes to sleep, which can happen automatically after a configurable timeout. This makes it easy to scale to zero, and allows you to get high utilization even with highly-variable traffic.
Containers are billed for every 10ms that they are actively running at the following rates:
Memory: $0.0000025 per GB-second
CPU: $0.000020 per vCPU-second
Disk $0.00000007 per GB-second
After 1 TB of free data transfer per month, egress from a Container will be priced per-region. We’ll be working out the details between now and the beta, and will be launching with clear, transparent pricing across all dimensions so you know where you stand.
Workers are lighter weight than containers and save you money by not charging when waiting on I/O. This means that if you can, running on a Worker helps you save on cost. Luckily, on Cloudflare it is easy to route requests to the right tool.
Cost comparison
Comparing containers and functions services on paper is always going to be an apples to oranges exercise, and results can vary so much depending on use case. But to share a real example of our own, a year ago when Cloudflare acquired Baselime, Baselime was a heavy user of AWS Lambda. By moving to Cloudflare, they lowered their cloud compute bill by 80%.
Below we wanted to share one representative example that compares costs for an application that uses both containers and serverless functions together. It’d be easy for us to come up with a contrived example that uses containers sub-optimally on another platform, for the wrong types of workloads. We won’t do that here. We know that navigating cloud costs can be challenging, and that cost is a critical part of deciding what type of compute to use for which pieces of your application.
In the example below, we’ll compare Cloudflare Containers + Workers against Google Cloud Run, a very well-regarded container platform that we’ve been impressed by.
Example application
Imagine that you run an application that serves 50 million requests per month, and each request consumes an average 500 ms of wall-time. Requests to this application are not all the same though — half the requests require a container, and the other half can be served just using serverless functions.
Requests per month
Wall-time (duration)
Compute required
Cloudflare
Google Cloud
25 million
500ms
Container + serverless functions
Containers + Workers
Google Cloud Run + Google Cloud Run Functions
25 million
500ms
Serverless functions
Workers
Google Cloud Run Functions
Container pricing
On both Cloud Run and Cloudflare Containers, a container can serve multiple requests. On some platforms, such as AWS Lambda, each container instance is limited to a single request, pushing cost up significantly as request count grows. In this scenario, 50 requests can run simultaneously on a container with 4 GB memory and half of a vCPU. This means that to serve 25 million requests of 500ms each, we need 625,000 seconds worth of compute
In this example, traffic is bursty and we want to avoid paying for idle-time, so we’ll use Cloud Run’s request-based pricing.
Price per vCPU second
Price per GB-second of memory
Price per 1m requests
Monthly Price for Compute + Requests
Cloudflare Containers
$0.000020
$0.0000025
$0.30
$20.00
Google Cloud Run
$0.000024
$0.0000025
$0.40
$23.75
* Comparison does not include free tiers for either provider and uses a single Tier 1 GCP region
Compute pricing for both platforms are comparable. But as we showed earlier in this post, Containers on Cloudflare run anywhere, on-demand, without configuring and managing regions. Each container has a programmable sidecar with its own database, backed by Durable Objects. It’s the depth of integration with the rest of the platform that makes containers on Cloudflare uniquely programmable.
Function pricing
The other requests can be served with less compute, and code written in JavaScript, TypeScript, Python or Rust, so we’ll use Workers and Cloud Run Functions.
These 25 million requests also run for 500 ms each, and each request spends 480 ms waiting on I/O. This means that Workers will only charge for 20 ms of “CPU-time”, the time that the Worker actually spends using compute. This ratio of low CPU time to high wall time is extremely common when building AI apps that make inference requests, or even when just building REST APIs and other business logic. Most time is spent waiting on I/O. Based on our data, we typically see Workers use less than 5 ms of CPU time per request vs seconds of wall time (waiting on APIs or I/O).
The Cloud Run Function will use an instance with 0.083 vCPU and 128 MB memory and charge on both CPU-s and GiB-s for the full 500 ms of wall-time.
Total Price for “wall-time”
Total Price for “CPU-time”
Total Price for Compute + Requests
Cloudflare Workers
N/A
$0.83
$8.33
Google Cloud Run Functions
$1.44
N/A
$11.44
* Comparison does not include free tiers and uses a single Tier 1 GCP region.
This comparison assumes you have configured Google Cloud Run Functions with a max of 20 concurrent requests per instance. On Google Cloud Run Functions, the maximum number of concurrent requests an instance can handle varies based on the efficiency of your function, and your own tolerance for tail latency that can be introduced by traffic spikes.
Workers automatically scale horizontally, don’t require you to configure concurrency settings (and hope to get it right), and can run in over 300 locations.
A holistic view of costs
The most important cost metric is the total cost of developing and running an application. And the only way to get the best results is to use the right compute for the job. So the question boils down to friction and integration. How easily can you integrate the ideal building blocks together?
As more and more software makes use of generative AI, and makes inference requests to LLMs, modern applications must communicate and integrate with a myriad of services. Most systems are increasingly real-time and chatty, often holding open long-lived connections, performing tasks in parallel. Running an instance of an application in a VM or container and calling it a day might have worked 10 years ago, but when we talk to developers in 2025, they are most often bringing many forms of compute to the table for particular use cases.
This shows the importance of picking a platform where you can seamlessly shift traffic from one source of compute to another. If you want to rate-limit, serve server-side rendered pages, API responses and static assets, handle authentication and authorization, make inference requests to AI models, run core business logic via Workflows, or ingest streaming data, just handle the request in Workers. Save the heavier compute only for where it is actually the only option. With Cloudflare Workers and Containers, this is as simple as an if-else statement in your Worker. This makes it easy to pick the right tool for the job.
Coming June 2025
We are collecting feedback and putting the finishing touches on our APIs now, and will release the open beta to the public in late June 2025.
From day one of building Cloudflare Workers, it’s been our goal to build an integrated platform, where Cloudflare products work together as a system, rather than just as a collection of separate products. We’ve taken this same approach with Containers, and aim to make Cloudflare not only the best place to deploy containers across the globe, but the best place to deploy the types of complete applications that developers are building, that use containers in tandem with serverless functions, Workflows, Agents, and much more.
We’re excited to get this into your hands soon. Stay on the lookout this summer.
Cloudflare plays a significant role in supporting the Internet’s infrastructure. As a reverse proxy by approximately 20% of all websites, we sit directly in the request path between users and the origin, helping to improve performance, security, and reliability at scale. Beyond that, our global network powers services like delivery, Workers, and R2 — making Cloudflare not just a passive intermediary, but an active platform for delivering and hosting content across the Internet.
Since Cloudflare’s launch in 2010, we have collaborated with the National Center for Missing and Exploited Children (NCMEC), a US-based clearinghouse for reporting child sexual abuse material (CSAM), and are committed to doing what we can to support identification and removal of CSAM content.
Members of the public, customers, and trusted organizations can submit reports of abuse observed on Cloudflare’s network. A minority of these reports relate to CSAM, which are triaged with the highest priority by Cloudflare’s Trust & Safety team. We will also forward details of the report, along with relevant files (where applicable) and supplemental information to NCMEC.
The process to generate and submit reports to NCMEC involves multiple steps, dependencies, and error handling, which quickly became complex under our original queue-based architecture. In this blog post, we discuss how Cloudflare Workflows helped streamline this process and simplify the code behind it.
Life before Cloudflare Workflows
When we designed our latest NCMEC reporting system in early 2024, Cloudflare Workflows did not exist yet. We used the Workers platform Queues as a solution for managing asynchronous tasks, and structured our system around them.
Our goal was to ensure reliability, fault tolerance, and automatic retries. However, without an orchestrator, we had to manually handle state, retries, and inter-queue messaging. While Queues worked, we needed something more explicit to help debug and observe the more complex asynchronous workflows we were building on top of the messaging system that Queues gave us.
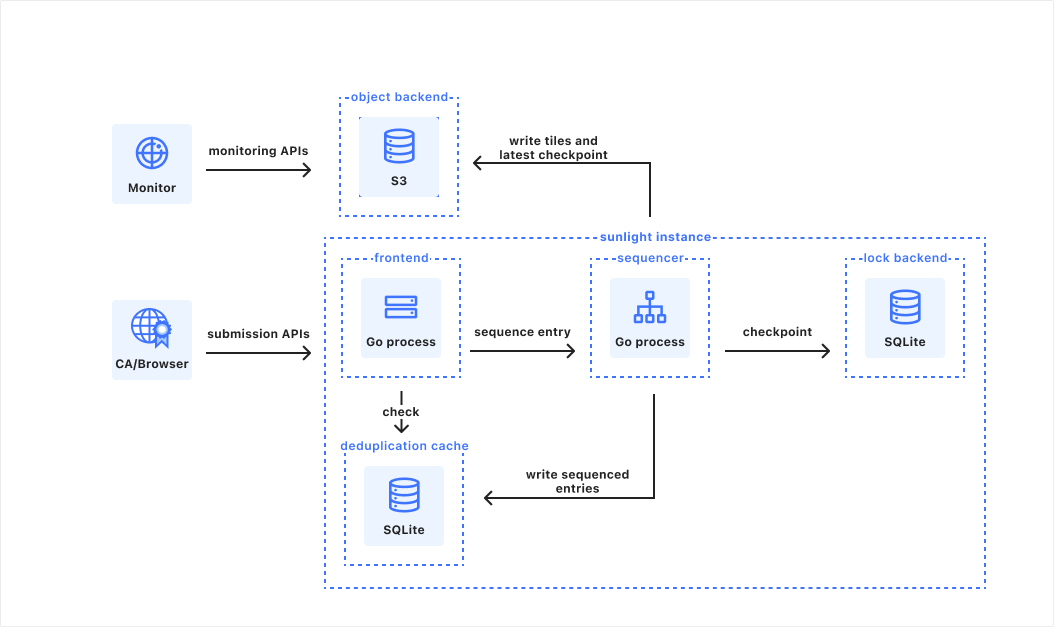
In our queue-based architecture each report would go through multiple steps:
Validate input: Ensure the report has all necessary details.
Initiate report: Call the NCMEC API to create a report.
Fetch impounded files (if applicable): Retrieve files stored in R2.
Upload files: Send files to NCMEC via API.
Finalize report: Mark the report as completed.
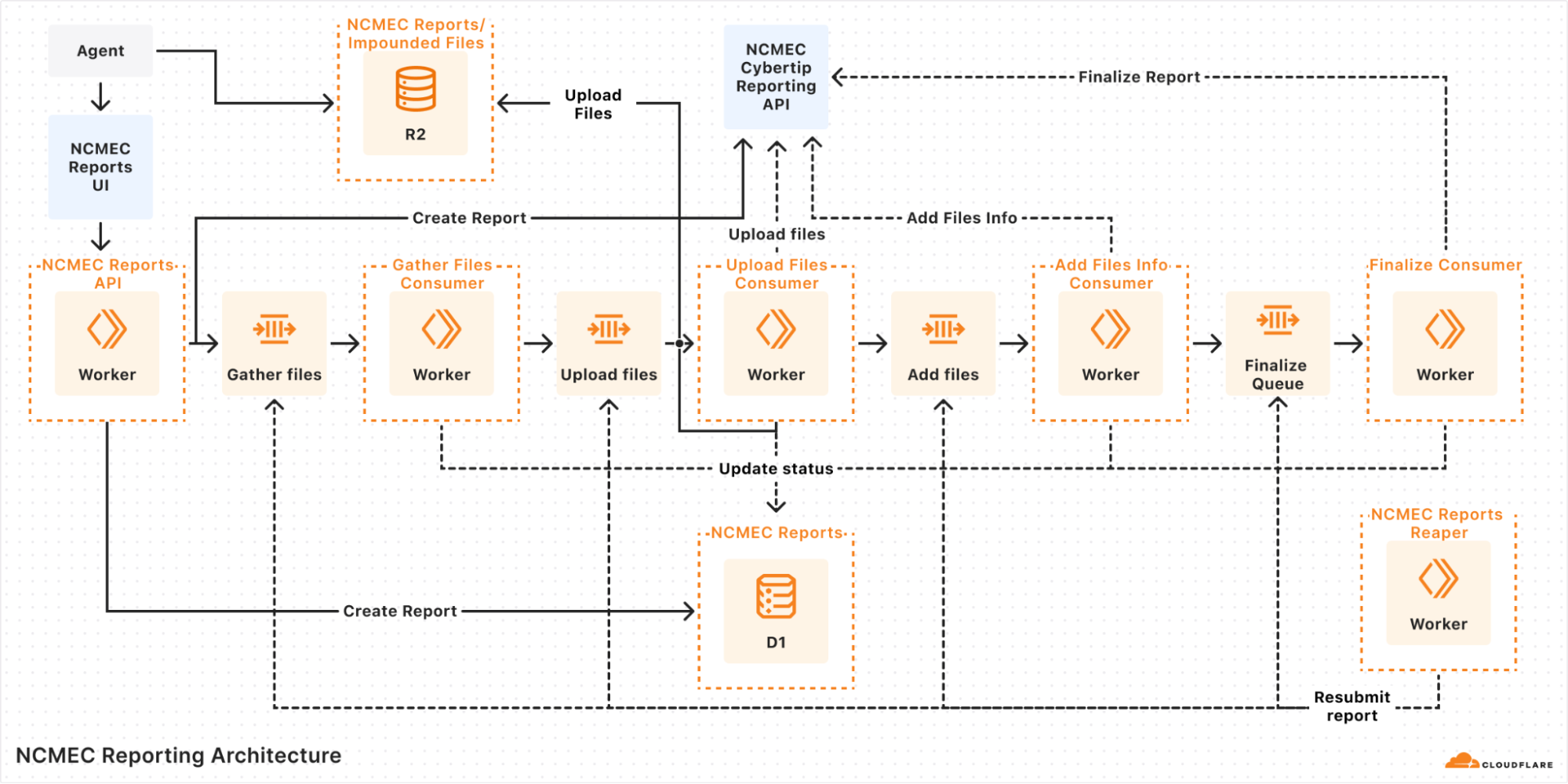
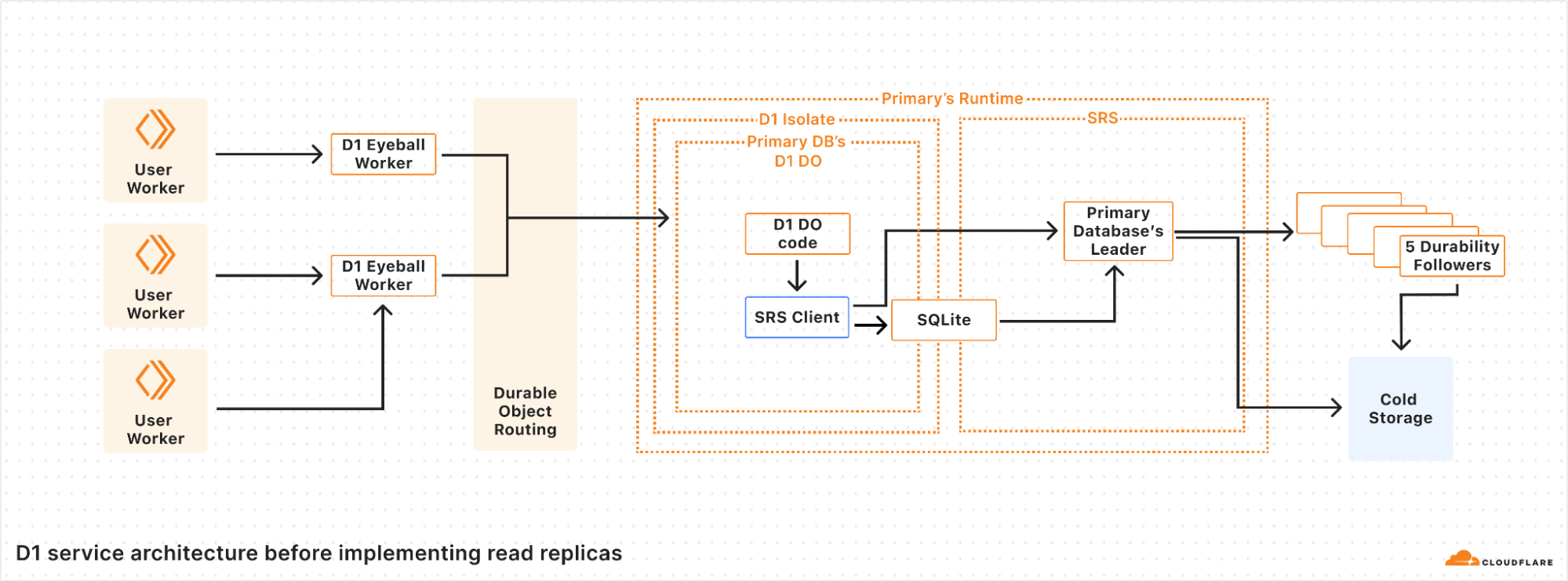
A diagram of our queue-based architecture
Each of these steps was handled by a separate queue, and if an error occurred, the system would retry the message several times before marking the report as failed. But errors weren’t always straightforward — for instance, if an external API call consistently failed due to bad input or returned an unexpected response shape, retries wouldn’t help. In those cases, the report could get stuck in an intermediate state, and we’d often have to manually dig through logs across different queues to figure out what went wrong.
Even more frustrating, when handling failed reports, we relied on a “Reaper” — a cron job that ran every hour to resubmit failed reports. Since a report could fail at any step, the Reaper had to deduce which queue failed and send a message to begin reprocessing. This meant:
Debugging was a nightmare: Tracing the journey of a single report meant jumping between logs for multiple queues.
Retries were unreliable: Some queues had retry logic, while others relied on the Reaper, leading to inconsistencies.
State management was painful: We had no clear way to track whether a report was halfway through the pipeline or completely lost, except by looking through the logs.
Operational overhead was high: Developers frequently had to manually inspect failed reports and resubmit them.
Queues gave us a solid foundation for moving messages around, but it wasn’t meant to handle orchestration. What we’d really done was build a bunch of loosely connected steps on top of a message bus and hoped it would all hold together. It worked, for the most part, but it was clunky, hard to reason about, and easy to break. Just understanding how a single report moved through the system meant tracing messages across multiple queues and digging through logs.
We knew we needed something better: a way to define workflows explicitly, with clear visibility into where things were and what had failed. But back then, we didn’t have a good way to do that without bringing in heavyweight tools or writing a bunch of glue code ourselves. When Cloudflare Workflows came along, it felt like the missing piece, finally giving us a simple, reliable way to orchestrate everything without duct tape.
The solution: Cloudflare Workflows
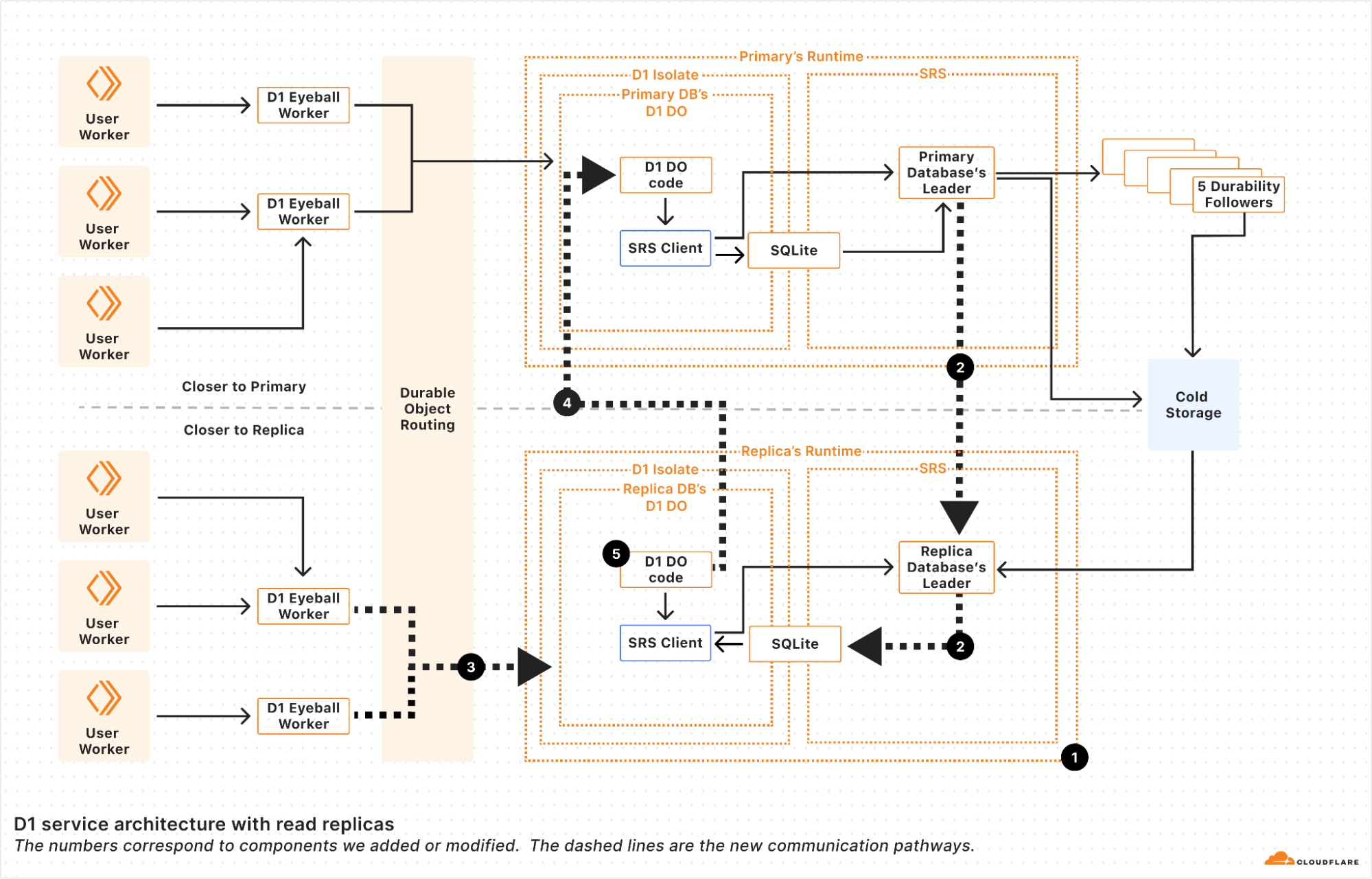
Once Cloudflare Workflows was announced, we saw an immediate opportunity to replace our queue-based architecture with a more structured, observable, and retryable system. Instead of relying on a web of multiple queues passing messages to each other, we now have a single workflow that orchestrates the entire process from start to finish. Critically, if any step failed, the Workflow could pick back up from where it left off, without having to repeat earlier processing steps, re-parsing files, or duplicating uploads.
With Cloudflare Workflows, each report follows a clear sequence of steps:
Creating the report: The system validates the incoming report and initiates it with NCMEC.
Checking for impounded files: If there are impounded files associated with the report, the workflow proceeds to file collection.
Gathering files: The system retrieves impounded files stored in R2 and prepares them for upload.
Uploading files to NCMEC: Each file is uploaded to NCMEC using their API, ensuring all relevant evidence is submitted.
Adding file metadata: Metadata about the uploaded files (hashes, timestamps, etc.) is attached to the report.
Finalizing the report: Once all files are processed, the report is finalized and marked as complete.
Here’s a simplified version of the orchestrator:
import { WorkflowEntrypoint, WorkflowEvent, WorkflowStep } from 'cloudflare:workers';
export class ReportWorkflow extends WorkflowEntrypoint<Env, ReportType> {
async run(event: WorkflowEvent<ReportType>, step: WorkflowStep) {
const reportToCreate: ReportType = event.payload;
let reportId: number | undefined;
try {
await step.do('Create Report', async () => {
const createdReport = await createReportStep(reportToCreate, this.env);
reportId = createdReport?.id;
});
if (reportToCreate.hasImpoundedFiles) {
await step.do('Gather Files', async () => {
if (!reportId) throw new Error('Report ID is undefined.');
await gatherFilesStep(reportId, this.env);
});
await step.do('Upload Files', async () => {
if (!reportId) throw new Error('Report ID is undefined.');
await uploadFilesStep(reportId, this.env);
});
await step.do('Add File Metadata', async () => {
if (!reportId) throw new Error('Report ID is undefined.');
await addFilesInfoStep(reportId, this.env);
});
}
await step.do('Finalize Report', async () => {
if (!reportId) throw new Error('Report ID is undefined.');
await finalizeReportStep(reportId, this.env);
});
} catch (error) {
console.error(error);
throw error;
}
}
}
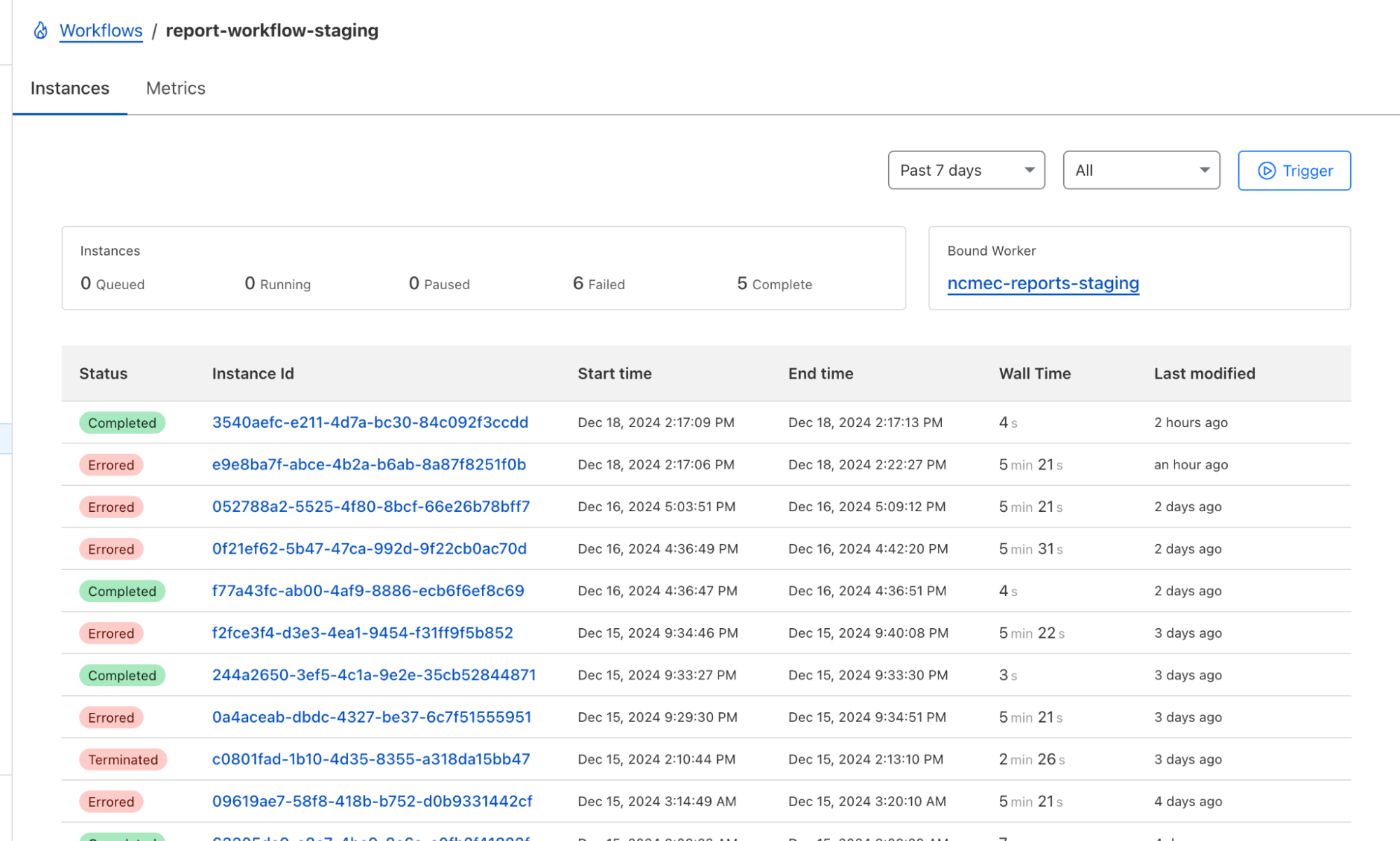
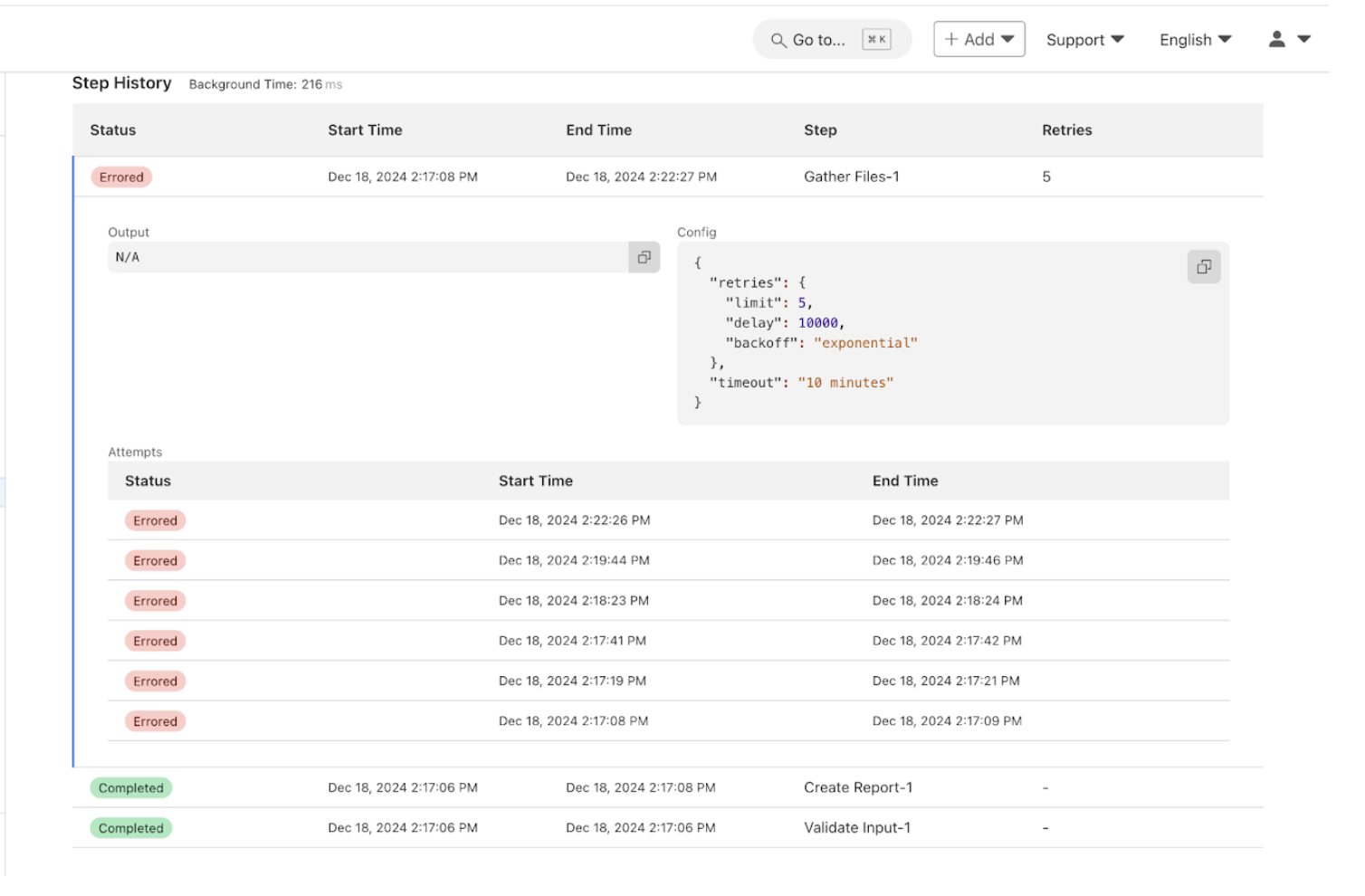
Not only can tasks be broken into discrete steps, but the Workflows dashboard gives us real-time visibility into each report processed and the status of each step in the workflow!
This allows us to easily see active and completed workflows, identify which steps failed and where, and retry failed steps or terminate workflows. These features revolutionize how we troubleshoot issues, providing us with a tool to deep dive into any issues that arise and retry steps with a click of a button.
Below are two dashboard screenshots, one of our running workflows and the second of an inspection of the success and failures of each step in the workflow. Some workflows look slower or “stuck” — that’s because failed steps are retried with exponential backoff. This helps smooth over transient issues like flaky APIs without manual intervention.
Cloudflare Workflows Dashboard for our NCMEC Workflow
Cloudflare Workflows Dashboard containing a breakout of the NCMEC Workflow Steps
Cloudflare Workflows transformed how we handle NCMEC incident reports. What was once a complex, queue-based architecture is now a structured, retryable, and observable process. Debugging is easier, error handling is more robust, and monitoring is seamless.
Deploy your own Workflows
If you’re also building larger, multi-step applications, or have an existing Workers application that has started to approach what we ended up with for our incident reporting process, then you can typically wrap that code within a Workflow with minimal changes. Workflows can read from R2, write to KV, query D1 and call other APIs just like any other Worker, but are designed to help orchestrate asynchronous, long-running tasks.
To get started with Workflows, you can head to the Workflows developer documentation and/or pull down the starter project and dive into the code immediately:
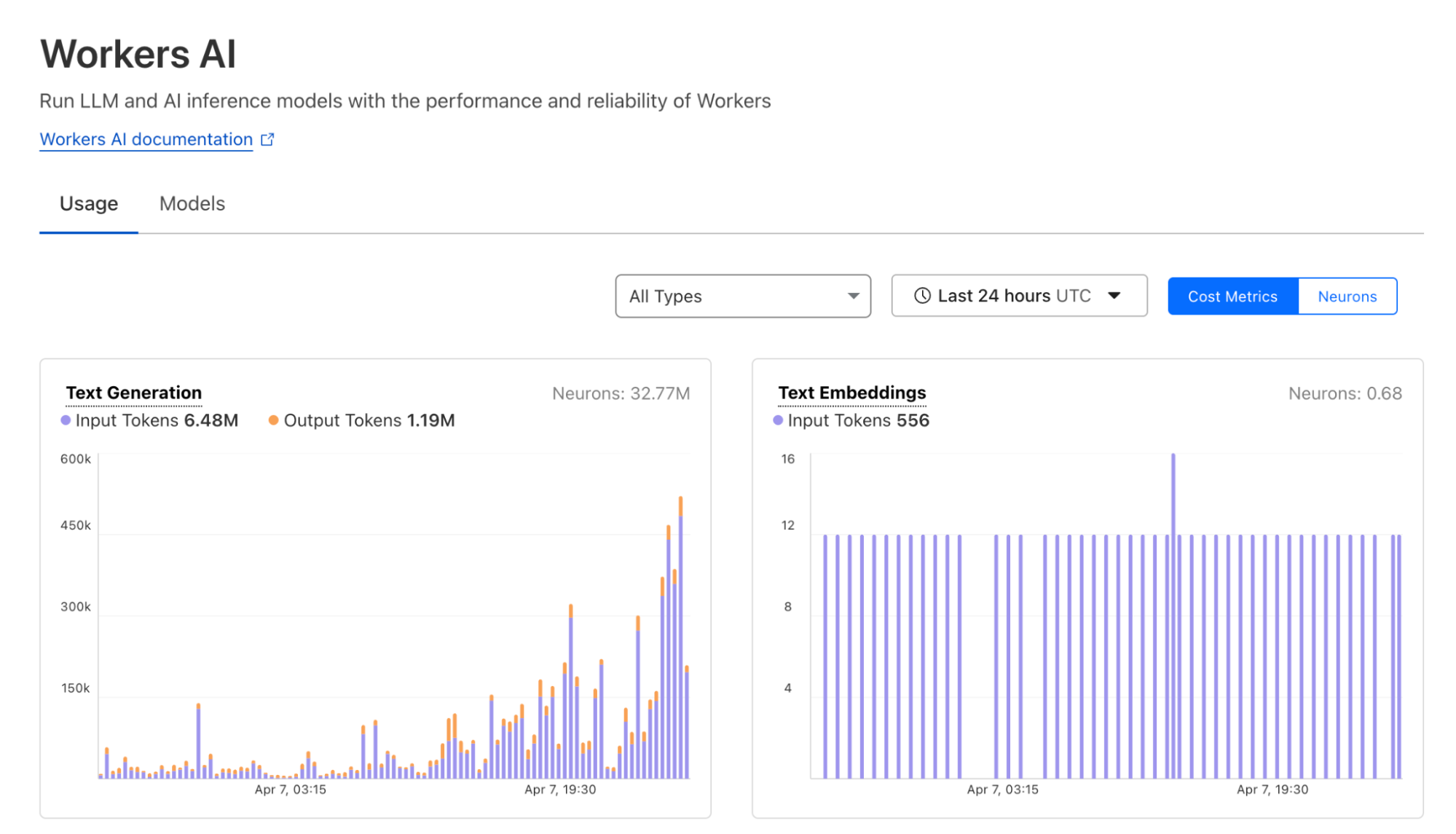
Since the launch of Workers AI in September 2023, our mission has been to make inference accessible to everyone.
Over the last few quarters, our Workers AI team has been heads down on improving the quality of our platform, working on various routing improvements, GPU optimizations, and capacity management improvements. Managing a distributed inference platform is not a simple task, but distributed systems are also what we do best. You’ll notice a recurring theme from all these announcements that has always been part of the core Cloudflare ethos — we try to solve problems through clever engineering so that we are able to do more with less.
Today, we’re excited to introduce speculative decoding to bring you faster inference, an asynchronous batch API for large workloads, and expanded LoRA support for more customized responses. Lastly, we’ll be recapping some of our newly added models, updated pricing, and unveiling a new dashboard to round out the usability of the platform.
Speeding up inference by 2-4x with speculative decoding and more
We’re excited to roll out speed improvements to models in our catalog, starting with the Llama 3.3 70b model. These improvements include speculative decoding, prefix caching, an updated inference backend, and more. We’ve previously done a technical deep dive on speculative decoding and how we’re making Workers AI faster, which you can read about here. With these changes, we’ve been able to improve inference times by 2-4x, without any significant change to the quality of answers generated. We’re planning to incorporate these improvements into more models in the future as we release them. Today, we’re starting to roll out these changes so all Workers AI users of @cf/meta/llama-3.3-70b-instruct-fp8-fast will enjoy this automatic speed boost.
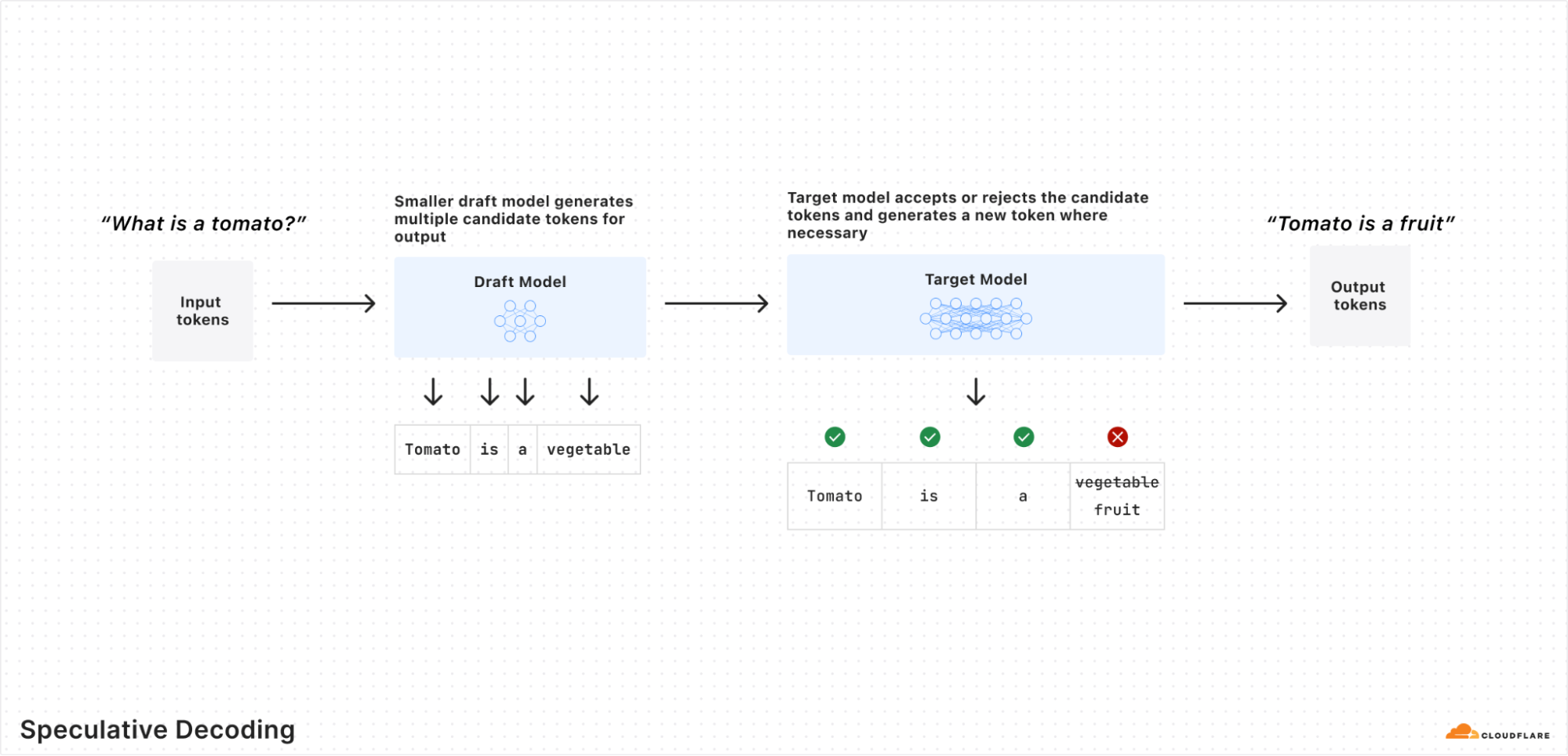
What is speculative decoding?
The way LLMs work is by generating text by predicting the next token in a sentence given the previous tokens. Typically, an LLM is able to predict a single future token (n+1) with one forward pass through the model. These forward passes can be computationally expensive, since they need to work through all the parameters of a model to generate one token (e.g., 70 billion parameters for Llama 3.3 70b).
With speculative decoding, we put a small model (known as the draft model) in front of the original model that helps predict n+x future tokens. The draft model generates a subset of candidate tokens, and the original model just has to evaluate and confirm if they should be incorporated into the generation. Evaluating tokens is less computationally expensive, as the model can evaluate multiple tokens concurrently in a forward pass. As such, inference times can be sped up by 2-4x — meaning that users can get responses much faster.
What makes speculative decoding particularly efficient is that it’s able to use unused GPU compute left behind due to the GPU memory bottleneck LLMs create. Speculative decoding takes advantage of the unused compute by squeezing in a draft model to generate tokens faster. This means we’re able to improve the utilization of our GPUs by using them to their full extent without having parts of the GPU sit idle.
What is prefix caching?
With LLMs, there are usually two stages of generation – the first is known as “pre-fill”, which processes the user’s input tokens such as the prompt and context. Prefix caching is aimed at reducing the pre-fill time of a request. As an example, if you were asking a model to generate code based on a given file, you might insert the whole file into the context window of a request. Then, if you want to make a second request to generate the next line of code, you might send us the whole file again in the second request. Prefix caching allows us to cache the pre-fill tokens so we don’t have to process the context twice. With the same example, we would only do the pre-fill stage once for both requests, rather than doing it per request. This method is especially useful for requests that reuse the same context, such as Retrieval Augmented Generation (RAG), code generation, chatbots with memory, and more. Skipping the pre-fill stage for similar requests means faster responses for our users and more efficient usage of resources.
How did you validate that quality is preserved through these optimizations?
Since this is an in-place update to an existing model, we were particularly cautious in ensuring that we would not break any existing applications with this update. We did extensive A/B testing through a blind arena with internal employees to validate the model quality, and we asked internal and external customers to test the new version of the model to ensure that response formats were compatible and model quality was acceptable. Our testing concluded that the model performed up to standards, with people being extremely excited about the speed of the model. Most LLMs are not perfectly deterministic even with the same set of inputs, but if you do notice something off, please let us know through Discord or X.
Asynchronous batch API
Next up, we’re announcing an asynchronous (async) batch API which is helpful for users of large workloads. This feature allows customers to receive their inference responses asynchronously, with the promise that the inference will be completed at a later time rather than immediately erroring out due to capacity.
An example use case of batch workloads is people generating summaries of a large number of documents. You probably don’t need to use those summaries immediately, as you’ll likely use them once the whole document is complete versus one paragraph at a time. For these use cases, we’ve made it super simple for you to start sending us these requests in batches.
Why batch requests?
From talking to our customers, the most common use case we hear about is people creating embeddings or summarizing a large number of documents. Unfortunately, this is also one of the hardest use cases to manage capacity for as a serverless platform.
To illustrate this, imagine that you want to summarize a 70 page PDF. You typically chunk the document and then send an inference request for each chunk. If each chunk is a few paragraphs on a page, that means that we receive around 4 requests per page multiplied by 70 pages, which is about 280 requests. Multiply that by tens or hundreds of documents, and multiply that by a handful of concurrent users — this means that we get a sudden massive influx of thousands of requests when users start these large workloads.
The way we originally built Workers AI was to handle incoming requests as quickly as possible, assuming there’s a human on the other side that needed an immediate response. The unique thing about batch workloads is that while they’re not latency sensitive, they do require completeness guarantees — you don’t want to come back the next day to realize none of your inference requests actually executed.
With the async API, you send us a batch of requests, and we promise to fulfill them as fast as possible and return them to you as a batch. This guarantees that your inference request will be fulfilled, rather than immediately (or eventually) erroring out. The async API also benefits users who have real-time use cases, as the model instances won’t be immediately consumed by these batch requests that can wait for a response. Inference times will be faster since there won’t be a bunch of competing requests in a queue waiting to reach the inference servers.
We have select models that support batch inference today, which include:
Users can send a batch request to supported models by passing a flag:
let res = await env.AI.run("@cf/meta/llama-3.3-70b-instruct-batch", {
"requests": [{
"prompt": "Explain mechanics of wormholes"
}, {
"prompt": "List different plant species found in America"
}]
}, {
queueRequest: true
});
Check out our developer docs to learn more about the batch API, or use our template to deploy a worker that implements the batch API.
Today, our batch API can be used by sending us an array of requests, and we’ll return your responses in an array. This is helpful for use cases like summarizing large amounts of data that you know beforehand. This means you can send us a single HTTP request with all of your requests, and receive a single HTTP request back with your responses. You can check on the status of the batch by polling it with the request ID we return when your batch is submitted. For the next iteration of our async API, we plan to allow queue-based inputs and outputs, where you push requests and pull responses from a queue. This will integrate tightly with Event Notifications and Workflows, so you can execute subsequent actions upon receiving a response.
iterated on this and now support 8 models as well as larger ranks of up to 32 and LoRA files up to 500 MB. Models that support LoRA inference now include:
In essence, a Low Rank Adaptation (LoRA) adapter allows people to take a trained adapter file and use it in conjunction with a model to alter the response of a model. We did a deep dive on LoRAs in our Birthday Week blog post, which goes into further technical detail. LoRA adapters are great alternatives to fine-tuning a model, as it isn’t as expensive to train and adapters are much smaller and more portable. They are also effective enough to tweak the output of a model to fit a certain style of response.
How do I get started?
To get started, you first need to train your own LoRA adapter or find a public one on HuggingFace. Then, you’ll upload the adapter_model.safetensors and adapter_config.json to your account with the documented wrangler commands or through the REST API. LoRA files are private and scoped to your own account. After that, you can start running fine-tuned inference — check out our LoRA developer docs to get started.
const response = await env.AI.run(
"@cf/qwen/qwen2.5-coder-32b-instruct", //the model supporting LoRAs
{
messages: [{"role": "user", "content": "Hello world"}],
raw: true, //skip applying the default chat template
lora: "00000000-0000-0000-0000-000000000", //the finetune id OR finetune name
}
);
Quality of life improvements: updated pricing and a new dashboard for Workers AI
While the team has been focused on large engineering milestones, we’ve also landed some quality of life improvements over the last few months. In case you missed it, we’ve announced an updated pricing model where usage will be shown in units such as tokens, audio seconds, image size/steps, etc. but still billed in neurons in the backend.
Today, we’re unveiling a new dashboard that allows users to see their usage in both units as well as neurons (built on new Workers Observability components!). Model pricing is also available via dashboard and developer docs on the models page. And if you use AI Gateway, Workers AI usage will also be displayed as metrics now.
New models available in Workers AI
Lastly, we’ve steadily been adding new models on Workers AI, with over 10 new models and a few updates on existing models. Pricing is also now listed directly on the model page in the developer docs. To summarize, here are the new models we’ve added on Workers AI, including four new ones we’re releasing today:
@cf/baai/bge-m3: a multi-lingual embeddings model that supports over 100 languages. It can also simultaneously perform dense retrieval, multi-vector retrieval, and sparse retrieval, with the ability to process inputs of different granularities.
@cf/baai/bge-reranker-base: our first reranker model! Rerankers are a type of text classification model that takes a query and context, and outputs a similarity score between the two. When used in RAG systems, you can use a reranker after the initial vector search to find the most relevant documents to return to a user by reranking the outputs.
@cf/openai/whisper-large-v3-turbo: a faster, more accurate speech-to-text model. This model was added earlier but is graduating out of beta with pricing included today.
@cf/myshell-ai/melotts: our first text-to-speech model that allows users to generate an MP3 with voice audio from text input.
@cf/meta/llama-4-scout-17b-16e-instruct: 17 billion parameter MoE model with 16 experts that is natively multimodal. Offers industry-leading performance in text and image understanding.
[NEW] @cf/mistralai/mistral-small-3.1-24b-instruct: a 24B parameter model achieving state-of-the-art capabilities comparable to larger models, with support for vision and tool calling.
[NEW] @cf/google/gemma-3-12b-it: well-suited for a variety of text generation and image understanding tasks, including question answering, summarization and reasoning, with a 128K context window, and multilingual support in over 140 languages.
[NEW] @cf/qwen/qwq-32b: a medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini.
[NEW] @cf/qwen/qwen2.5-coder-32b-instruct: the current state-of-the-art open-source code LLM, with its coding abilities matching those of GPT-4o.
In addition, we are rolling out some in-place updates to existing models in our catalog:
As we release these new models, we’ll be deprecating old models to encourage use of the state-of-the-art models and make room in our catalog. We will send out an email notice on this shortly. Stay up to date with our model releases and deprecation announcements by subscribing to our Developer Docs changelog.
We’re (still) just getting started
Workers AI is one of Cloudflare’s newer products in a nascent industry, but we still operate with very traditional Cloudflare principles – learning how we can do more with less. Our engineering team is focused on solving the difficult problems that come with growing a distributed inference platform at a global scale, and we’re excited to release these new features today that we think will improve the platform as a whole for all our users. With faster inference times, better reliability, more customization possibilities, and better usability, we’re excited to see what you can do with more Workers AI — let us know what you think!
Any public certification authority (CA) can issue a certificate for any website on the Internet to allow a webserver to authenticate itself to connecting clients. Take a moment to scroll through the list of trusted CAs for your web browser (e.g., Chrome). You may recognize (and even trust) some of the names on that list, but it should make you uncomfortable that any CA on that list could issue a certificate for any website, and your browser would trust it. It’s a castle with 150 doors.
Certificate Transparency (CT) plays a vital role in the Web Public Key Infrastructure (WebPKI), the set of systems, policies, and procedures that help to establish trust on the Internet. CT ensures that all website certificates are publicly visible and auditable, helping to protect website operators from certificate mis-issuance by dishonest CAs, and helping honest CAs to detect key compromise and other failures.
In this post, we’ll discuss the history, evolution, and future of the CT ecosystem. We’ll cover some of the challenges we and others have faced in operating CT logs, and how the new static CT API log design lowers the bar for operators, helping to ensure that this critical infrastructure keeps up with the fast growth and changing landscape of the Internet and WebPKI. We’re excited to open source our Rust implementation of the new log design, built for deployment on Cloudflare’s Developer Platform, and to announce test logs deployed using this infrastructure.
What is Certificate Transparency?
In 2011, the Dutch CA DigiNotar was hacked, allowing attackers to forge a certificate for *.google.com and use it to impersonate Gmail to targeted Iranian users in an attempt to compromise personal information. Google caught this because they used certificate pinning, but that technique doesn’t scale well for the web. This, among other similar attacks, led a team at Google in 2013 to develop Certificate Transparency (CT) as a mechanism to catch mis-issued certificates. CT creates a public audit trail of all certificates issued by public CAs, helping to protect users and website owners by holding CAs accountable for the certificates they issue (even unwittingly, in the event of key compromise or software bugs). CT has been a great success: since 2013, over 17 billion certificates have been logged, and CT was awarded the prestigious Levchin Prize in 2024 for its role as a critical safety mechanism for the Internet.
Let’s take a brief look at the entities involved in the CT ecosystem. Cloudflare itself operates the Nimbus CT logs and the CT monitor powering the Merkle Towndashboard.
Certification Authorities (CAs) are organizations entrusted to issue certificates on behalf of website operators, which in turn can use those certificates to authenticate themselves to connecting clients.
CT-enforcing clients like the Chrome, Safari, and Firefox browsers are web clients that only accept certificates compliant with their CT policies. For example, a policy might require that a certificate includes proof that it has been submitted to at least two independently-operated public CT logs.
Log operators run CT logs, which are public, append-only lists of certificates. CAs and other clients can submit a certificate to a CT log to obtain a “promise” from the CT log that it will incorporate the entry into the append-only log within some grace period. CT logs periodically (every few seconds, typically) update their log state to incorporate batches of new entries, and publish a signed checkpoint that attests to the new state.
Monitors are third parties that continuously crawl CT logs and check that their behavior is correct. For instance, they verify that a log is self-consistent and append-only by ensuring that when new entries are added to the log, no previous entries are deleted or modified. Monitors may also examine logged certificates to help website operators detect mis-issuance.
Challenges in operating a CT log
Despite the success of CT, it is a less than perfect system. Eric Rescorla has an excellent writeup on the many compromises made to make CT deployable on the Internet of 2013. We’ll focus on the operational complexities of running a CT log.
Let’s look at the requirements for running a CT log from Chrome’s CT log policy (which are more or less mirrored by those of Safari and Firefox), and what can go wrong. The requirements center around integrity and availability.
To be considered a trusted auditing source, CT logs necessarily have stringent integrity requirements. Anything the log produces must be correct and self-consistent, meaning that a CT log cannot present two different views of the log to different clients, and must present a consistent history for its entire lifetime. Similarly, when a CT log accepts a certificate and promises to incorporate it by returning a Signed Certificate Timestamp (SCT) to the client, it must eventually incorporate that certificate into its append-only log.
The integrity requirements are unforgiving. A single bit-flip due to a hardware failure or cosmic ray can (andhas) caused logs to produce incorrect results and thus be disqualified by CT programs. Even software updates to running logs can be fatal, as a change that causes a correctness violation cannot simply be rolled back. Perhaps the greatest risk to individual log integrity is failing to incorporate certificates for which they issued SCTs, for example if they fail to commit those pending certificates to durable storage. See Andrew Ayer’s great synopsis for more examples of CT log failures (up to 2021).
A CT log must also meet certain availability requirements to effectively provide its core functionality as a publicly auditable log. Clients must be able to reliably retrieve log data — Chrome’s policy requires a minimum of 99% average uptime over a 90-day rolling period for each API endpoint — and any entries for which an SCT has been issued must be incorporated into the log within the grace period, called the Maximum Merge Delay (MMD), 24 hours in Chrome’s policy.
The design of the current CT log read APIs puts strain on the ability of log operators to meet uptime requirements. The API endpoints are dynamic and not easily cacheable without bespoke caching rules that are aware of the CT API. For instance, the get-entries endpoint allows a client to request arbitrary ranges of entries from a log, and the get-proof-by-hash requires the server to construct inclusion proofs for any certificate requested by the client. To serve these requests, CT log servers need to be backed by databases easily 5-10TB in size capable of serving tens of millions of requests per day. This increases operator complexity and expense, not to mention the high cost of bandwidth of serving these requests.
MMD violations are unfortunately not uncommon. Cloudflare’s own Nimbus logs have experienced prolonged outages in the past, most recently in November 2023 due to complete power loss in the datacenter running the logs. During normal log operation, if the log accepts entries more quickly than it incorporates them, the backlog can grow to exceed the MMD. Log operators can remedy this by rate-limiting or temporarily disabling the write APIs, but this can in turn contribute to violations of the uptime requirements.
The high bar for log operation has limited the organizations operating CT logs to only Cloudflare and five others! Losing one or two logs is enough to compromise the stability of the CT ecosystem. Clearly, a change is needed.
A next-generation CT log design
In May 2024, Let’s Encrypt announcedSunlight, an implementation of a next-generation CT log designed for the modern WebPKI, incorporating a decade of lessons learned from running CT and similar transparency systems. The new CT log design, called the static CT API, is partially based on the Go checksum database, and organizes log data as a series of tiles that are easy to cache and serve. The new design provides efficiency improvements that cut operation costs, help logs to meet availability requirements, and reduce the risk of integrity violations.
The static CT API is split into two parts, the monitoring APIs (so named because CT monitors are the primary clients), and the submission APIs for adding new certificates to the log.
The monitoring APIs replace the dynamic read APIs of RFC 6962, and organize log data into static, cacheable tiles. (See Russ Cox’s blog post for an in-depth explanation of tiled logs.) CT log operators can efficiently serve static tiles from S3-compatible object storage buckets and cache them using CDN infrastructure, without needing dedicated API servers. Clients can then download the necessary tiles to retrieve specific log entries or reconstruct arbitrary proofs.
The static CT API introduces another efficiency by deduplicating intermediate and root “issuer” certificates in a log entry’s certificate chain. The number of publicly-trusted issuer certificates is small (in the low thousands), so instead of storing them repeatedly for each log entry, only the issuer hash is stored. Clients can look up issuer certificates by hash from a separate endpoint.
The submission APIs remain backwards-compatible with RFC 6962, meaning that TLS clients and CAs can submit to them without any changes. However, there is one notable addition: the static CT specification requires logs to hold on to requests as it batches and sequences them, and responds with an SCT only after entries have been incorporated into the log. The specification defines a required SCT extension indicating the entry’s index in the log. At the cost of slightly delayed SCT issuance (on the order of seconds), this change eliminates one of the major pain points of operating a CT log (the Merge Delay).
Having the log index of a certificate available in an SCT enables further efficiencies. SCT auditing refers to the process by which TLS clients or monitors can check if a log has fulfilled its promise to incorporate a certificate for which it has issued an SCT. In the RFC 6962 API, checking if a certificate is present in a log when you don’t already know the index requires using the get-proof-by-hash endpoint to look up the entry by the certificate hash (and the server needs to maintain a mapping from hash to index to efficiently serve these requests). Instead, with the index immediately available in the SCT, clients can directly retrieve the specific log data tile covering that index, even with efficient privacy-preserving techniques.
Since it was announced, the static CT API has taken the CT ecosystem by storm. Aside from Sunlight and our brand new Azul (discussed below), there are at least two other independent implementations, Itko and Trillian Tessera. Several CT monitors (including crt.sh, certspotter, Censys, and our own Merkle Town) have added support for the new log format, and as of April 1, 2025, Chrome has begun accepting submissions for static CT API logs into their CT log program.
A static CT API implementation on Workers
This section discusses how we designed and built our static CT log implementation, Azul (short for azulejos, the colorful Portuguese and Spanish ceramic tiles). For curious readers and prospective CT log operators, we encourage you to follow the instructions in the repo to quickly set up your own static CT log. Questions and feedback in the form of GitHub issues are welcome!
The advent of the static CT API gave us the perfect opportunity to rethink how we run our CT logs. There were a few design decisions we made early on to shape the project.
First and foremost, we wanted to run our CT logs on our distributed global network. Especially after the painful November 2023 control plane outage, there’s been a push to deploy services on our highly available and resilient network instead of running in centralized datacenters.
Second, with Cloudflare’s deeply engrained culture of dogfooding (building Cloudflare on top of Cloudflare), we decided to implement the CT log on top of Cloudflare’s Developer Platform and Workers.
Dogfooding gives us an opportunity to find pain points in our product offerings, and to provide feedback to our development teams to improve the developer experience for everyone. We restricted ourselves to only features and default limits generally available to customers, so that we could have the same experience as an external Cloudflare developer, and would produce an implementation that anyone could deploy.
Another major design decision was to implement the CT log in Rust, a modern systems programming language with static typing and built-in memory safety that is heavily used across Cloudflare, and which already has mature (if sometimes lacking full feature parity) Workers bindings that we have used to build several production services. This also provided us with an opportunity to produce Rust crates porting Go implementations of various C2SP specifications that can be reused across other projects.
For the new logs to be deployable, they needed to be at least as performant as existing CT logs. As a point of reference, the Nimbus2025 log currently handles just over 33 million requests per day (~380/s) across the read APIs, and about 6 million per day (~70/s) across the write APIs.
Implementation
We based Azul heavily on Sunlight, a Go application built for deployment as a standalone server. As such, this section serves as a reference for translating a traditional server to Cloudflare’s serverless platform.
To start, let’s briefly review the Sunlight architecture (described in more detail in the README and original design doc). A Sunlight instance is a single Go process, serving one or multiple CT logs. It is backed by three different storage locations with different properties:
A “lock backend” which stores the current checkpoint for each log. This datastore needs to be strongly consistent, but only stores trivial amounts of data.
A per-log object storage bucket from which to serve tiles, checkpoints, and issuers to CT clients. This datastore needs to be strongly consistent, and to handle multiple terabytes of data.
A per-log deduplication cache, to return SCTs for previously-submitted (pre-)certificates. This datastore is best-effort (as duplicate entries are not fatal to log operation), and stores tens to hundreds of gigabytes of data.
Two major components handle the bulk of the CT log application logic:
A frontend HTTP server handles incoming requests to the submission APIs to add new certificates to the log, validates them, checks the deduplication cache, adds the certificate to a pool of entries to be sequenced, and waits for sequencing to complete before responding to the client.
The sequencer periodically (every 1s, by default) sequences the pool of pending entries, writes new tiles to the object backend, persists the latest checkpoint covering the new log state to the lock and object backends, and signals to waiting requests that the pool has been sequenced.
A static CT API log running on a traditional server using the Sunlight implementation.
Next, let’s look at how we can translate these components into ones suitable for deployment on Workers.
Making it work
Let’s start with the easy choices. The static CT monitoring APIs are designed to serve static, cacheable, compressible assets from object storage. The API should be highly available and have the capacity to serve any number of CT clients. The natural choice is Cloudflare R2, which provides globally consistent storage with capacity for large data volumes, customizability to configure caching and compression, and unbounded read operations.
A static CT API log running on Workers using a preliminary version of the Azul implementation which ran into performance limitations.
The static CT submission APIs are where the real challenge lies. In particular, they allow CT clients to submit certificate chains to be incorporated into the append-only log. We used Workers as the frontend for the CT log application. Workers run in data centers close to the client, scaling on demand to handle request load, making them the ideal place to run the majority of the heavyweight request handling logic, including validating requests, checking the deduplication cache (discussed below), and submitting the entry to be sequenced.
The next question was where and how we’d run the backend to handle the CT log sequencing logic, which needs to be stateful and tightly coordinated. We chose Durable Objects (DOs), a special type of stateful Cloudflare Worker where each instance has persistent storage and a unique name which can be used to route requests to it from anywhere in the world. DOs are designed to scale effortlessly for applications that can be easily broken up into self-contained units that do not need a lot of coordination across units. For example, a chat application can use one DO to control each chat room. In our model, then, each CT log is controlled by a single DO. This architecture allows us to easily run multiple CT logs within a single Workers application, but as we’ll see, the limitations of individual single-threaded DOs can easily become a bottleneck. More on this later.
With the CT log backend as a Durable Object, several other components fell into place: Durable Objects’ strongly-consistent transactional storage neatly fit the requirements for the “lock backend” to persist the log’s latest checkpoint, and we can use an alarm to trigger the log sequencing every second. We can also use location hints to place CT logs in locations geographically close to clients for reduced latency, similar to Google’s Argon and Xenon logs.
The choice of datastore for the deduplication cache proved to be non-obvious. The cache is best-effort, and intended to avoid re-sequencing entries that are already present in the log. The cache key is computed by hashing certain fields of the add-[pre-]chain request, and the cache value consists of the entry’s index in the log and the timestamp at which it was sequenced. At current log submission rates, the deduplication cache could grow in excess of 50 GB for 6 months of log data. In the Sunlight implementation, the deduplication cache is implemented as a local SQLite database, where checks against it are tightly coupled with sequencing, which ensures that duplicates from in-flight requests are correctly accounted for. However, this architecture did not translate well to Cloudflare’s architecture. The data size doesn’t comfortably fit within Durable Object Storage or single-database D1 limits, and it was too slow to directly read and write to remote storage from within the sequencing loop. Ultimately, we split the deduplication cache into two components: a local fixed-size in-memory cache for fast deduplication over short periods of time (on the order of minutes), and the other a long-term deduplication cache built on Cloudflare Workers KV a global, low-latency, eventually-consistent key-value store without storage limitations.
With this architecture, it was relatively straightforward to port the Go code to Rust, and to bring up a functional static CT log up on Workers. We’re done then, right? Not quite. Performance tests showed that the log was only capable of sequencing 20-30 new entries per second, well under the 70 per second target of existing logs. We could work around this by simply running more logs, but that puts strain on other parts of the CT ecosystem — namely on TLS clients and monitors, which need to keep state for each log. Additionally, the alarm used to trigger sequencing would often be delayed by multiple seconds, meaning that the log was failing to produce new tree heads at consistent intervals. Time to go back to the drawing board.
Making it fast
In the design thus far, we’re asking a single-threaded Durable Object instance to do a lot of multi-tasking. The DO processes incoming requests from the Frontend Worker to add entries to the sequencing pool, and must periodically sequence the pool and write state to the various storage backends. A log handling 100 requests per second needs to switch between 101 running tasks (the extra one for the sequencing), plus any async tasks like writing to remote storage — usually 10+ writes to object storage and one write to the long-term deduplication cache per sequenced entry. No wonder the sequencing task was getting delayed!
A static CT API log running on Workers using the Azul implementation with batching to improve performance.
We were able to work around these issues by adding an additional layer of DOs between the Frontend Worker and the Sequencer, which we call Batchers. The Frontend Worker uses consistent hashing on the cache key to determine which of several Batchers to submit the entry to, and the Batcher helps to reduce the number of requests to the Sequencer by buffering requests and sending them together in batches. When the batch is sequenced, the Batcher distributes the responses back to the Frontend Workers that submitted the request. The Batcher also handles writing updates to the deduplication cache, further freeing up resources for the Sequencer.
By limiting the scope of the critical block of code that needed to be run synchronously in a single DO, and leaning on the strengths of DOs by scaling horizontally where the workload allows it, we were able to drastically improve application performance. With this new architecture, the CT log application can handle upwards of 500 requests per second to the submission APIs to add new log entries, while maintaining a consistent sequencing tempo to keep per-request latency low (typically 1-2 seconds).
Developing a Workers application in Rust
One of the reasons I was excited to work on this project is that it gave me an opportunity to implement a Workers application in Rust, which I’d never done from scratch before. Not everything was smooth, but overall I would recommend the experience.
To be clear, these rough edges are expected! The Workers platform is continuously gaining new features, and it’s natural that the Rust bindings would fall behind. As more developers rely on (and contribute to, hint hint) the Rust bindings, the developer experience will continue to improve.
What is next for Certificate Transparency
The WebPKI is constantly evolving and growing, and upcoming changes, in particular shorter certificate lifetimes and larger post-quantum certificates, are going to place significantly more load on the CT ecosystem.
The CA/Browser Forum defines a set of Baseline Requirements for publicly-trusted TLS server certificates. As of 2020, the maximum certificate lifetime for publicly-trusted certificates is 398 days. However, there is a ballot measure to reduce that period to as low as 47 days by March 2029. Let’s Encrypt is going even further, and at the end of 2024 announced that they will be offering short-lived certificates with a lifetime of only six days by the end of 2025. Based on some back-of-the-envelope calculations using statistics from Merkle Town, these changes could increase the number of logged entries in the CT ecosystem by 16-20x.
If you’ve been keeping up with this blog, you’ll also know that post-quantum certificates are on the horizon, bringing with them larger signature and public key sizes. Today, a certificate with an P-256 ECDSA public key and issuer signature can be less than 1kB. Dropping in a ML-DSA44 public key and signature brings the same certificate size to 4.6 kB, assuming the SCTs use 96-byte UOVls-pkc signatures. With these choices, post-quantum certificates could require CT logs to store 4x the amount of data per log entry.
The static CT API design helps to ensure that CT logs are much better equipped to handle this increased load, especially if the load is distributed across multiple logs per operator. Our new implementation makes it easy for log operators to run CT logs on top of Cloudflare’s infrastructure, adding more operational diversity and robustness to the CT ecosystem. We welcome feedback on the design and implementation as GitHub issues, and encourage CAs and other interested parties to start submitting to and consuming from our test logs.
Today, we’re launching the open beta of Pipelines, our streaming ingestion product. Pipelines allows you to ingest high volumes of structured, real-time data, and load it into our object storage service, R2. You don’t have to manage any of the underlying infrastructure, worry about scaling shards or metadata services, and you pay for the data processed (and not by the hour). Anyone on a Workers paid plan can start using it to ingest and batch data — at tens of thousands of requests per second (RPS) — directly into R2.
But this is just the tip of the iceberg: you often want to transform the data you’re ingesting, hydrate it on-the-fly from other sources, and write it to an open table format (such as Apache Iceberg), so that you can efficiently query that data once you’ve landed it in object storage.
The good news is that we’ve thought about that too, and we’re excited to announce that we’ve acquired Arroyo, a cloud-native, distributed stream processing engine, to make that happen.
With Arroyo and our just announced R2 Data Catalog, we’re getting increasingly serious about building a data platform that allows you to ingest data across the planet, store it at scale, and run compute over it.
However, the true power comes from the processing of data streams between ingestion and when they’re written to sinks like R2. Being able to write SQL that acts on windows of data as it’s being ingested, that can transform & aggregate it, and even extract insights from the data in real-time, turns out to be extremely powerful.
This is where Arroyo comes in, and we’re going to be bringing the best parts of Arroyo into Pipelines and deeply integrate it with Workers, R2, and the rest of our Developer Platform.
The Arroyo origin story
(By Micah Wylde, founder of Arroyo)
We started Arroyo in 2023 to bring real-time (stream) processing to everyone who works with data. Modern companies rely on data pipelines to power their applications and businesses — from user customization, recommendations, and anti-fraud, to the emerging world of AI agents.
But today, most of these pipelines operate in batch, running once per hour, day, or even month. After spending many years working on stream processing at companies like Lyft and Splunk, it was no mystery why: it was just too hard for developers and data scientists to build correct, performant, and reliable pipelines. Large tech companies hire streaming experts to build and operate these systems, but everyone else is stuck waiting for batches to arrive.
When we started, the dominant solution for streaming pipelines — and what we ran at Lyft and Splunk — was Apache Flink. Flink was the first system that successfully combined a fault-tolerant (able to recover consistently from failures), distributed (across multiple machines), stateful (and remember data about past events) dataflow with a graph-construction API. This combination of features meant that we could finally build powerful real-time data applications, with capabilities like windows, aggregations, and joins. But while Flink had the necessary power, in practice the API proved too hard and low-level for non-expert users, and the stateful nature of the resulting services required endless operations.
We realized we would need to build a new streaming engine — one with the power of Flink, but designed for product engineers and data scientists and to run on modern cloud infrastructure. We started with SQL as our API because it’s easy to use, widely known, and declarative. We built it in Rust for speed and operational simplicity (no JVM tuning required!). We constructed an object-storage-native state backend, simplifying the challenge of running stateful pipelines — which each are like a weird, specialized database. And then in the summer of 2023, we open-sourced it. Today, dozens of companies are running Arroyo pipelines with use cases including data ingestion, anti-fraud, IoT observability, and financial trading.
But we always knew that the engine was just one piece of the puzzle. To make streaming as easy as batch, users need to be able to develop and test query logic, backfill on historical data, and deploy serverlessly without having to worry about cluster sizing or ongoing operations. Democratizing streaming ultimately meant building a complete data platform. And when we started talking with Cloudflare, we realized they already had all of the pieces in place: R2 provides object storage for state and data at rest, Cloudflare Queues for data in transit, and Workers to safely and efficiently run user code. And Cloudflare, uniquely, allows us to push these systems all the way to the edge, enabling a new paradigm of local stream processing that will be key for a future of data sovereignty and AI.
That’s why we’re incredibly excited to join with the Cloudflare team to make this vision a reality.
Ingestion at scale
While transformations and a streaming SQL API are on the way for Pipelines, it already solves two critical parts of the data journey: globally distributed, high-throughput ingestion and efficient loading into object storage.
Creating a pipeline is as simple as running one command:
$ npx wrangler@latest pipelines create my-clickstream-pipeline --r2-bucket my-bucket
🌀 Creating pipeline named "my-clickstream-pipeline"
✅ Successfully created pipeline my-clickstream-pipeline with ID
0e00c5ff09b34d018152af98d06f5a1xvc
Id: 0e00c5ff09b34d018152af98d06f5a1xvc
Name: my-clickstream-pipeline
Sources:
HTTP:
Endpoint: https://0e00c5ff09b34d018152af98d06f5a1xvc.pipelines.cloudflare.com/
Authentication: off
Format: JSON
Worker:
Format: JSON
Destination:
Type: R2
Bucket: my-bucket
Format: newline-delimited JSON
Compression: GZIP
Batch hints:
Max bytes: 100 MB
Max duration: 300 seconds
Max records: 100,000
🎉 You can now send data to your pipeline!
Send data to your pipeline's HTTP endpoint:
curl "https://0e00c5ff09b34d018152af98d06f5a1xvc.pipelines.cloudflare.com/" -d '[{ ...JSON_DATA... }]'
By default, a pipeline can ingest data from two sources – Workers and an HTTP endpoint – and load batched events into an R2 bucket. This gives you an out-of-the-box solution for streaming raw event data into object storage. If the defaults don’t work, you can configure pipelines during creation or anytime after. Options include: adding authentication to the HTTP endpoint, configuring CORS to allow browsers to make cross-origin requests, and specifying output file compression and batch settings.
We’ve built Pipelines for high ingestion volumes from day 1. Each pipeline can scale to ~100,000 records per second (and we’re just getting started here). Once records are written to a Pipeline, they are then durably stored, batched, and written out as files in an R2 bucket. Batching is critical here: if you’re going to act on and query that data, you don’t want your query engine querying millions (or tens of millions) of tiny files. It’s slow (per-file & request overheads), inefficient (more files to read), and costly (more operations). Instead, you want to find the right balance between batch size for your query engine and latency (not waiting too long for a batch): Pipelines allows you to configure this.
To further optimize queries, output files are partitioned by date and time, using the standard Hive partitioning scheme. This can optimize queries even further, because your query engine can just skip data that is irrelevant to the query you’re running. The output in your R2 bucket might look like this:
Hive-partioned files from Pipelines in an R2 bucket
Output files are stored as new-line delimited JSON (NDJSON) — which makes it easy to materialize a stream from these files (hint: in the future you’ll be able to use R2 as a pipeline source too). Finally, the file names are ULIDs – so they’re sorted by time by default.
First you shard, then you shard some more
What makes Pipelines so horizontally scalable and able to acknowledge writes quickly is how we built it: we use Durable Objects and the embedded, zero-latency SQLite storage within each Durable Object to immediately persist data as it’s written, before then processing it and writing it to R2.
For example: imagine you’re an e-commerce or SaaS site and need to ingest website usage data (known as clickstream data), and make it available to your data science team to query. The infrastructure which handles this workload has to be resilient to several failure scenarios. The ingestion service needs to maintain high availability in the face of bursts in traffic. Once ingested, the data needs to be buffered, to minimize downstream invocations and thus downstream cost. Finally, the buffered data needs to be delivered to a sink, with appropriate retry & failure handling if the sink is unavailable. Each step of this process needs to signal backpressure upstream when overloaded. It also needs to scale: up during major sales or events, and down during the quieter periods of the day.
Data engineers reading this post might be familiar with the status quo of using Kafka and the associated ecosystem to handle this. But if you’re an application engineer: you use Pipelines to build an ingestion service without learning about Kafka, Zookeeper, and Kafka streams.
Pipelines horizontal sharding
The diagram above shows how Pipelines splits the control plane, which is responsible for accounting, tracking shards, and Pipelines lifecycle events, and the data path, which is a scalable group of Durable Objects shards.
When a record (or batch of records) is written to Pipelines:
The Pipelines Worker receives the records either through the fetch handler or worker binding.
Contacts the Coordinator, based upon the pipeline_id to get the execution plan: subsequent reads are cached to reduce pressure on the coordinator.
Executes the plan, which first shards to a set of Executors, while are primarily serving to scale read request handling
These then re-shard to another set of executors that are actually handling the writes, beginning with persisting to Durable Object storage, which will be replicated for durability and availability by the Storage Relay Service (SRS).
After SRS, we pass to any configured Transform Workers to customize the data.
The data is batched, written to output files, and compressed (if applicable).
The files are compressed, data is packaged into the final batches, and written to the configured R2 bucket.
Each step of this pipeline can signal backpressure upstream. We do this by leveraging ReadableStreams and responding with 429s when the total number of bytes awaiting write exceeds a threshold. Each ReadableStream is able to cross Durable Object boundaries by using JSRPC calls between Durable Objects. To improve performance, we use RPC stubs for connection reuse between Durable Objects. Each step is also able to retry operations, to handle any temporary unavailability in the Durable Objects or R2.
We also guarantee delivery even while updating an existing pipeline. When you update an existing pipeline, we create a new deployment, including all the shards and Durable Objects described above. Requests are gracefully re-routed to the new pipeline. The old pipeline continues to write data into R2, until all the Durable Object storage is drained. We spin down the old pipeline only after all the data has been written out. This way, you won’t lose data even while updating a pipeline.
You’ll notice there’s one interesting part in here — the Transform Workers — which we haven’t yet exposed. As we work to integrate Arroyo’s streaming engine with Pipelines, this will be a key part of how we hand over data for Arroyo to process.
So, what’s it cost?
During the first phase of the open beta, there will be no additional charges beyond standard R2 storage and operation costs incurred when loading and accessing data. And as always, egress directly from R2 buckets is free, so you can process and query your data from any cloud or region without worrying about data transfer costs adding up.
In the future, we plan to introduce pricing based on volume of data ingested into Pipelines and delivered from Pipelines:
Workers Paid ($5 / month)
Ingestion
First 50 GB per month included
\$0.02 per additional GB
Delivery to R2
First 50 GB per month included
\$0.02 per additional GB
We’re also planning to make Pipelines available on the Workers Free plan as the beta progresses.
We’ll be sharing more as we bring transformations and additional sinks to Pipelines. We’ll provide at least 30 days notice before we make any changes or start charging for usage, which we expect to do by September 15, 2025.
What’s next?
There’s a lot to build here, and we’re keen to build on a lot of the powerful components that Arroyo has built: integrating Workers as UDFs (User-Defined Functions), adding new sources like Kafka clients, and extending Pipelines with new sinks (beyond R2).
We’ll also be integrating Pipelines with our just-launched R2 Data Catalog: enabling you ingest streams of data directly into Iceberg tables and immediately query them, without needing to rely on other systems.
Read replication of D1 databases is in public beta!
D1 read replication makes read-only copies of your database available in multiple regions across Cloudflare’s network. For busy, read-heavy applications like e-commerce websites, content management tools, and mobile apps:
D1 read replication lowers average latency by routing user requests to read replicas in nearby regions.
D1 read replication increases overall throughput by offloading read queries to read replicas, allowing the primary database to handle more write queries.
The main copy of your database is called the primary database and the read-only copies are called read replicas. When you enable replication for a D1 database, the D1 service automatically creates and maintains read replicas of your primary database. As your users make requests, D1 routes those requests to an appropriate copy of the database (either the primary or a replica) based on performance heuristics, the type of queries made in those requests, and the query consistency needs as expressed by your application.
All of this global replica creation and request routing is handled by Cloudflare at no additional cost.
To take advantage of read replication, your Worker needs to use the new D1 Sessions API. Click the button below to run a Worker using D1 read replication with this code example to see for yourself!
D1 Sessions API
D1’s read replication feature is built around the concept of database sessions. A session encapsulates all the queries representing one logical session for your application. For example, a session might represent all requests coming from a particular web browser or all requests coming from a mobile app used by one of your users. If you use sessions, your queries will use the appropriate copy of the D1 database that makes the most sense for your request, be that the primary database or a nearby replica.
The sessions implementation ensures sequential consistency for all queries in the session, no matter what copy of the database each query is routed to. The sequential consistency model has important properties like “read my own writes” and “writes follow reads,” as well as a total ordering of writes. The total ordering of writes means that every replica will see transactions committed in the same order, which is exactly the behavior we want in a transactional system. Said another way, sequential consistency guarantees that the reads and writes are executed in the order in which you write them in your code.
Some examples of consistency implications in real-world applications:
You are using an online store and just placed an order (write query), followed by a visit to the account page to list all your orders (read query handled by a replica). You want the newly placed order to be listed there as well.
You are using your bank’s web application and make a transfer to your electricity provider (write query), and then immediately navigate to the account balance page (read query handled by a replica) to check the latest balance of your account, including that last payment.
Why do we need the Sessions API? Why can we not just query replicas directly?
Applications using D1 read replication need the Sessions API because D1 runs on Cloudflare’s global network and there’s no way to ensure that requests from the same client get routed to the same replica for every request. For example, the client may switch from WiFi to a mobile network in a way that changes how their requests are routed to Cloudflare. Or the data center that handled previous requests could be down because of an outage or maintenance.
D1’s read replication is asynchronous, so it’s possible that when you switch between replicas, the replica you switch to lags behind the replica you were using. This could mean that, for example, the new replica hasn’t learned of the writes you just completed. We could no longer guarantee useful properties like “read your own writes”. In fact, in the presence of shifty routing, the only consistency property we could guarantee is that what you read had been committed at some point in the past (read committed consistency), which isn’t very useful at all!
Since we can’t guarantee routing to the same replica, we flip the script and use the information we get from the Sessions API to make sure whatever replica we land on can handle the request in a sequentially-consistent manner.
Here’s what the Sessions API looks like in a Worker:
export default {
async fetch(request: Request, env: Env) {
// A. Create the session.
// When we create a D1 session, we can continue where we left off from a previous
// session if we have that session's last bookmark or use a constraint.
const bookmark = request.headers.get('x-d1-bookmark') ?? 'first-unconstrained'
const session = env.DB.withSession(bookmark)
// Use this session for all our Workers' routes.
const response = await handleRequest(request, session)
// B. Return the bookmark so we can continue the session in another request.
response.headers.set('x-d1-bookmark', session.getBookmark())
return response
}
}
async function handleRequest(request: Request, session: D1DatabaseSession) {
const { pathname } = new URL(request.url)
if (request.method === "GET" && pathname === '/api/orders') {
// C. Session read query.
const { results } = await session.prepare('SELECT * FROM Orders').all()
return Response.json(results)
} else if (request.method === "POST" && pathname === '/api/orders') {
const order = await request.json<Order>()
// D. Session write query.
// Since this is a write query, D1 will transparently forward it to the primary.
await session
.prepare('INSERT INTO Orders VALUES (?, ?, ?)')
.bind(order.orderId, order.customerId, order.quantity)
.run()
// E. Session read-after-write query.
// In order for the application to be correct, this SELECT statement must see
// the results of the INSERT statement above.
const { results } = await session
.prepare('SELECT * FROM Orders')
.all()
return Response.json(results)
}
return new Response('Not found', { status: 404 })
}
To use the Session API, you first need to create a session using the withSession method (step A). The withSession method takes a bookmark as a parameter, or a constraint. The provided constraint instructs D1 where to forward the first query of the session. Using first-unconstrained allows the first query to be processed by any replica without any restriction on how up-to-date it is. Using first-primary ensures that the first query of the session will be forwarded to the primary.
// A. Create the session.
const bookmark = request.headers.get('x-d1-bookmark') ?? 'first-unconstrained'
const session = env.DB.withSession(bookmark)
Providing an explicit bookmark instructs D1 that whichever database instance processes the query has to be at least as up-to-date as the provided bookmark (in case of a replica; the primary database is always up-to-date by definition). Explicit bookmarks are how we can continue from previously-created sessions and maintain sequential consistency across user requests.
Once you’ve created the session, make queries like you normally would with D1. The session object ensures that the queries you make are sequentially consistent with regards to each other.
// C. Session read query.
const { results } = await session.prepare('SELECT * FROM Orders').all()
For example, in the code example above, the session read query for listing the orders (step C) will return results that are at least as up-to-date as the bookmark used to create the session (step A).
More interesting is the write query to add a new order (step D) followed by the read query to list all orders (step E). Because both queries are executed on the same session, it is guaranteed that the read query will observe a database copy that includes the write query, thus maintaining sequential consistency.
// D. Session write query.
await session
.prepare('INSERT INTO Orders VALUES (?, ?, ?)')
.bind(order.orderId, order.customerId, order.quantity)
.run()
// E. Session read-after-write query.
const { results } = await session
.prepare('SELECT * FROM Orders')
.all()
Note that we could make a single batch query to the primary including both the write and the list, but the benefit of using the new Sessions API is that you can use the extra read replica databases for your read queries and allow the primary database to handle more write queries.
The session object does the necessary bookkeeping to maintain the latest bookmark observed across all queries executed using that specific session, and always includes that latest bookmark in requests to D1. Note that any query executed without using the session object is not guaranteed to be sequentially consistent with the queries executed in the session.
When possible, we suggest continuing sessions across requests by including bookmarks in your responses to clients (step B), and having clients passing previously received bookmarks in their future requests.
// B. Return the bookmark so we can continue the session in another request.
response.headers.set('x-d1-bookmark', session.getBookmark())
This allows all of a client’s requests to be in the same session. You can do this by grabbing the session’s current bookmark at the end of the request (session.getBookmark()) and sending the bookmark in the response back to the client in HTTP headers, in HTTP cookies, or in the response body itself.
Consistency with and without Sessions API
In this section, we will explore the classic scenario of a read-after-write query to showcase how using the new D1 Sessions API ensures that we get sequential consistency and avoid any issues with inconsistent results in our application.
The Client, a user Worker, sends a D1 write query that gets processed by the database primary and gets the results back. However, the subsequent read query ends up being processed by a database replica. If the database replica is lagging far enough behind the database primary, such that it does not yet include the first write query, then the returned results will be inconsistent, and probably incorrect for your application business logic.
Using the Sessions API fixes the inconsistency issue. The first write query is again processed by the database primary, and this time the response includes “Bookmark 100”. The session object will store this bookmark for you transparently.
The subsequent read query is processed by database replica as before, but now since the query includes the previously received “Bookmark 100”, the database replica will wait until its database copy is at least up-to-date as “Bookmark 100”. Only once it’s up-to-date, the read query will be processed and the results returned, including the replica’s latest bookmark “Bookmark 104”.
Notice that the returned bookmark for the read query is “Bookmark 104”, which is different from the one passed in the query request. This can happen if there were other writes from other client requests that also got replicated to the database replica in-between the two queries our own client executed.
Enabling read replication
To start using D1 read replication:
Update your Worker to use the D1 Sessions API to tell D1 what queries are part of the same database session. The Sessions API works with databases that do not have read replication enabled as well, so it’s safe to ship this code even before you enable replicas. Here’s an example.
D1 read replication is built into D1, and you don’t pay extra storage or compute costs for replicas. You incur the exact same D1 usage with or without replicas, based on rows_read and rows_written by your queries. Unlike other traditional database systems with replication, you don’t have to manually create replicas, including where they run, or decide how to route requests between the primary database and read replicas. Cloudflare handles this when using the Sessions API while ensuring sequential consistency.
Since D1 read replication is in beta, we recommend trying D1 read replication on a non-production database first, and migrate to your production workloads after validating read replication works for your use case.
If you don’t have a D1 database and want to try out D1 read replication, create a test database in the Cloudflare dashboard.
Observing your replicas
Once you’ve enabled D1 read replication, read queries will start to be processed by replica database instances. The response of each query includes information in the nested meta object relevant to read replication, like served_by_region and served_by_primary. The first denotes the region of the database instance that processed the query, and the latter will be true if-and-only-if your query was processed by the primary database instance.
In addition, the D1 dashboard overview for a database now includes information about the database instances handling your queries. You can see how many queries are handled by the primary instance or by a replica, and a breakdown of the queries processed by region. The example screenshots below show graphs displaying the number of queries executed and number of rows read by each region.
Under the hood: how D1 read replication is implemented
D1 is implemented on top of SQLite-backed Durable Objects running on top of Cloudflare’s Storage Relay Service.
D1 is structured with a 3-layer architecture. First is the binding API layer that runs in the customer’s Worker. Next is a stateless Worker layer that routes requests based on database ID to a layer of Durable Objects that handle the actual SQL operations behind D1. This is similar to how most applications using Cloudflare Workers and Durable Objects are structured.
For a non-replicated database, there is exactly one Durable Object per database. When a user’s Worker makes a request with the D1 binding for the database, that request is first routed to a D1 Worker running in the same location as the user’s Worker. The D1 Worker figures out which D1 Durable Object backs the user’s D1 database and fetches an RPC stub to that Durable Object. The Durable Objects routing layer figures out where the Durable Object is located, and opens an RPC connection to it. Finally, the D1 Durable Object then handles the query on behalf of the user’s Worker using the Durable Objects SQL API.
In the Durable Objects SQL API, all queries go to a SQLite database on the local disk of the server where the Durable Object is running. Durable Objects run SQLite in WAL mode. In WAL mode, every write query appends to a write-ahead log (the WAL). As SQLite appends entries to the end of the WAL file, a database-specific component called the Storage Relay Service leader synchronously replicates the entries to 5 durability followers on servers in different datacenters. When a quorum (at least 3 out of 5) of the durability followers acknowledge that they have safely stored the data, the leader allows SQLite’s write queries to commit and opens the Durable Object’s output gate, so that the Durable Object can respond to requests.
Our implementation of WAL mode allows us to have a complete log of all of the committed changes to the database. This enables a couple of important features in SQLite-backed Durable Objects and D1:
We construct databases anywhere in the world by downloading all of the WAL entries from cold storage and replaying each WAL entry in order.
We implement Point-in-time recovery (PITR) by replaying WAL entries up to a specific bookmark rather than to the end of the log.
Unfortunately, having the main data structure of the database be a log is not ideal. WAL entries are in write order, which is often neither convenient nor fast. In order to cut down on the overheads of the log, SQLite checkpoints the log by copying the WAL entries back into the main database file. Read queries are serviced directly by SQLite using files on disk — either the main database file for checkpointed queries, or the WAL file for writes more recent than the last checkpoint. Similarly, the Storage Relay Service snapshots the database to cold storage so that we can replay a database by downloading the most recent snapshot and replaying the WAL from there, rather than having to download an enormous number of individual WAL entries.
WAL mode is the foundation for implementing read replication, since we can stream writes to locations other than cold storage in real time.
We implemented read replication in 5 major steps.
First, we made it possible to make replica Durable Objects with a read-only copy of the database. These replica objects boot by fetching the latest snapshot and replaying the log from cold storage to whatever bookmark primary database’s leader last committed. This basically gave us point-in-time replicas, since without continuous updates, the replicas never updated until the Durable Object restarted.
Second, we registered the replica leader with the primary’s leader so that the primary leader sends the replicas every entry written to the WAL at the same time that it sends the WAL entries to the durability followers. Each of the WAL entries is marked with a bookmark that uniquely identifies the WAL entry in the sequence of WAL entries. We’ll use the bookmark later.
Note that since these writes are sent to the replicas before a quorum of durability followers have confirmed them, the writes are actually unconfirmed writes, and the replica leader must be careful to keep the writes hidden from the replica Durable Object until they are confirmed. The replica leader in the Storage Relay Service does this by implementing enough of SQLite’s WAL-index protocol, so that the unconfirmed writes coming from the primary leader look to SQLite as though it’s just another SQLite client doing unconfirmed writes. SQLite knows to ignore the writes until they are confirmed in the log. The upshot of this is that the replica leader can write WAL entries to the SQLite WAL immediately, and then “commit” them when the primary leader tells the replica that the entries have been confirmed by durability followers.
One neat thing about this approach is that writes are sent from the primary to the replica as quickly as they are generated by the primary, helping to minimize lag between replicas. In theory, if the write query was proxied through a replica to the primary, the response back to the replica will arrive at almost the same time as the message that updates the replica. In such a case, it looks like there’s no replica lag at all!
In practice, we find that replication is really fast. Internally, we measure confirm lag, defined as the time from when a primary confirms a change to when the replica confirms a change. The table below shows the confirm lag for two D1 databases whose primaries are in different regions.
Replica Region
Database A
(Primary region: ENAM)
Database B (Primary region: WNAM)
ENAM
N/A
30 ms
WNAM
45 ms
N/A
WEUR
55 ms
75 ms
EEUR
67 ms
75 ms
Confirm lag for 2 replicated databases. N/A means that we have no data for this combination. The region abbreviations are the same ones used for Durable Object location hints.
The table shows that confirm lag is correlated with the network round-trip time between the data centers hosting the primary databases and their replicas. This is clearly visible in the difference between the confirm lag for the European replicas of the two databases. As airline route planners know, EEUR is appreciably further away from ENAM than WNAM, but from WNAM, both European regions (WEUR and EEUR) are about equally as far away. We see that in our replication numbers.
The exact placement of the D1 database in the region matters too. Regions like ENAM and WNAM are quite large in themselves. Database A’s placement in ENAM happens to be further away from most data centers in WNAM compared to database B’s placement in WNAM relative to the ENAM data centers. As such, database B sees slightly lower confirm lag.
Try as we might, we can’t beat the speed of light!
Third, we updated the Durable Object routing system to be aware of Durable Object replicas. When read replication is enabled on a Durable Object, two things happen. First, we create a set of replicas according to a replication policy. The current replication policy that D1 uses is simple: a static set of replicas in every region that D1 supports. Second, we turn on a routing policy for the Durable Object. The current policy that D1 uses is also simple: route to the Durable Object replica in the region close to where the user request is. With this step, we have updateable read-only replicas, and can route requests to them!
Fourth, we updated D1’s Durable Object code to handle write queries on replicas. D1 uses SQLite to figure out whether a request is a write query or a read query. This means that the determination of whether something is a read or write query happens after the request is routed. Read replicas will have to handle write requests! We solve this by instantiating each replica D1 Durable Object with a reference to its primary. If the D1 Durable Object determines that the query is a write query, it forwards the request to the primary for the primary to handle. This happens transparently, keeping the user code simple.
As of this fourth step, we can handle read and write queries at every copy of the D1 Durable Object, whether it’s a primary or not. Unfortunately, as outlined above, if a user’s requests get routed to different read replicas, they may see different views of the database, leading to a very weak consistency model. So the last step is to implement the Sessions API across the D1 Worker and D1 Durable Object. Recall that every WAL entry is marked with a bookmark. These bookmarks uniquely identify a point in (logical) time in the database. Our bookmarks are strictly monotonically increasing; every write to a database makes a new bookmark with a value greater than any other bookmark for that database.
Using bookmarks, we implement the Sessions API with the following algorithm split across the D1 binding implementation, the D1 Worker, and D1 Durable Object.
First up in the D1 binding, we have code that creates the D1DatabaseSession object and code within the D1DatabaseSession object to keep track of the latest bookmark.
// D1Binding is the binding code running within the user's Worker
// that provides the existing D1 Workers API and the new withSession method.
class D1Binding {
// Injected by the runtime to the D1 Binding.
d1Service: D1ServiceBinding
function withSession(initialBookmark) {
return D1DatabaseSession(this.d1Service, this.databaseId, initialBookmark);
}
}
// D1DatabaseSession holds metadata about the session, most importantly the
// latest bookmark we know about for this session.
class D1DatabaseSession {
constructor(d1Service, databaseId, initialBookmark) {
this.d1Service = d1Service;
this.databaseId = databaseId;
this.bookmark = initialBookmark;
}
async exec(query) {
// The exec method in the binding sends the query to the D1 Worker
// and waits for the the response, updating the bookmark as
// necessary so that future calls to exec use the updated bookmark.
var resp = await this.d1Service.handleUserQuery(databaseId, query, bookmark);
if (isNewerBookmark(this.bookmark, resp.bookmark)) {
this.bookmark = resp.bookmark;
}
return resp;
}
// batch and other SQL APIs are implemented similarly.
}
The binding code calls into the D1 stateless Worker (d1Service in the snippet above), which figures out which Durable Object to use, and proxies the request to the Durable Object.
class D1Worker {
async handleUserQuery(databaseId, query) {
var doId = /* look up Durable Object for databaseId */;
return await this.D1_DO.get(doId).handleWorkerQuery(query, bookmark)
}
}
Finally, we reach the Durable Objects layer, which figures out how to actually handle the request.
class D1DurableObject {
async handleWorkerQuery(queries, bookmark) {
var bookmark = bookmark ?? "first-primary";
var results = {};
if (this.isPrimaryDatabase()) {
// The primary always has the latest data so we can run the
// query without checking the bookmark.
var result = /* execute query directly */;
bookmark = getCurrentBookmark();
results = result;
} else {
// This is running on a replica.
if (bookmark === "first-primary" || isWriteQuery(query)) {
// The primary must handle this request, so we'll proxy the
// request to the primary.
var resp = await this.primary.handleWorkerQuery(query, bookmark);
bookmark = resp.bookmark;
results = resp.results;
} else {
// The replica can handle this request, but only after the
// database is up-to-date with the bookmark.
if (bookmark !== "first-unconstrained") {
await waitForBookmark(bookmark);
}
var result = /* execute query locally */;
bookmark = getCurrentBookmark();
results = result;
}
}
return { results: results, bookmark: bookmark };
}
}
The D1 Durable Object first figures out if this instance can handle the query, or if the query needs to be sent to the primary. If the Durable Object can execute the query, it ensures that we execute the query with a bookmark at least as up-to-date as the bookmark requested by the binding.
The upshot is that the three pieces of code work together to ensure that all of the queries in the session see the database in a sequentially consistent order, because each new query will be blocked until it has seen the results of previous queries within the same session.
Conclusion
D1’s new read replication feature is a significant step towards making globally distributed databases easier to use without sacrificing consistency. With automatically provisioned replicas in every region, your applications can now serve read queries faster while maintaining strong sequential consistency across requests, and keeping your application Worker code simple.
We’re excited for developers to explore this feature and see how it improves the performance of your applications. The public beta is just the beginning—we’re actively refining and expanding D1’s capabilities, including evolving replica placement policies, and your feedback will help shape what’s next.
Note that the Sessions API is only available through the D1 Worker Binding for now, and support for the HTTP REST API will follow soon.
Try out D1 read replication today by clicking the “Deploy to Cloudflare” button, check out documentation and examples, and let us know what you build in the D1 Discord channel!
Super Slurper is Cloudflare’s data migration tool that is designed to make large-scale data transfers between cloud object storage providers and Cloudflare R2 easy. Since its launch, thousands of developers have used Super Slurper to move petabytes of data from AWS S3, Google Cloud Storage, and other S3-compatible services to R2.
But we saw an opportunity to make it even faster. We rearchitected Super Slurper from the ground up using our Developer Platform — building on Cloudflare Workers, Durable Objects, and Queues — and improved transfer speeds by up to 5x. In this post, we’ll dive into the original architecture, the performance bottlenecks we identified, how we solved them, and the real-world impact of these improvements.
Initial architecture and performance bottlenecks
Super Slurper originally shared its architecture with SourcingKit, a tool built to bulk import images from AWS S3 into Cloudflare Images. SourcingKit was deployed on Kubernetes and ran alongside the Images service. When we started building Super Slurper, we split it into its own Kubernetes namespace and introduced a few new APIs to make it easier to use for the object storage use case. This setup worked well and helped thousands of developers move data to R2.
However, it wasn’t without its challenges. SourcingKit wasn’t designed to handle the scale required for large, petabytes-scale transfers. SourcingKit, and by extension Super Slurper, operated on Kubernetes clusters located in one of our core data centers, meaning it had to share compute resources and bandwidth with Cloudflare’s control plane, analytics, and other services. As the number of migrations grew, these resource constraints became a clear bottleneck.
For a service transferring data between object storage providers, the job is simple: list objects from the source, copy them to the destination, and repeat. This is exactly how the original Super Slurper worked. We listed objects from the source bucket, pushed that list to a Postgres-based queue (pg_queue), and then pulled from this queue at a steady pace to copy objects over. Given the scale of object storage migrations, bandwidth usage was inevitably going to be high. This made it challenging to scale.
To address the bandwidth constraints operating solely in our core data center, we introduced Cloudflare Workers into the mix. Instead of handling the copying of data in our core data center, we started calling out to a Worker to do the actual copying:
As Super Slurper’s usage grew, so did our Kubernetes resource consumption. A significant amount of time during data transfers was spent waiting on network I/O or storage, and not actually doing compute-intensive tasks. So we didn’t need more memory or more CPU, we needed more concurrency.
To keep up with demand, we kept increasing the replica count. But eventually, we hit a wall. We were dealing with scalability challenges when running on the order of tens of pods when we wanted multiple orders of magnitude more.
We decided to rethink the entire approach from first principles, instead of leaning on the architecture we had inherited. In about a week, we built a rough proof of concept using Cloudflare Workers, Durable Objects, and Queues. We listed objects from the source bucket, pushed them into a queue, and then consumed messages from the queue to initiate transfers. Although this sounds very similar to what we did in the original implementation, building on our Developer Platform allowed us to automatically scale an order of magnitude higher than before.
Cloudflare Queues: Enables asynchronous object transfers and auto-scales to meet the number of objects being migrated.
Cloudflare Workers: Runs lightweight compute tasks without the overhead of Kubernetes and optimizes where in the world each part of the process runsfor lower latency and better performance.
SQLite-backed Durable Objects (DOs): Acts as a fully distributed database, eliminating the limitations of a single PostgreSQL instance.
Hyperdrive: Provides fast access to historical job data from the original PostgreSQL database, keeping it as an archive store.
We ran a few tests and found that our proof of concept was slower than the original implementation for small transfers (a few hundred objects), but it matched and eventually exceeded the performance of the original as transfers scaled into the millions of objects. That was the signal we needed to invest the time to take our proof of concept to production.
We removed our proof of concept hacks, worked on stability, and found new ways to make transfers scale to even higher concurrency. After a few iterations, we landed on something we were happy with.
New architecture: Workers, Queues, and Durable Objects
Processing layer: managing the flow of migration
At the heart of our processing layer are queues, consumers, and workers. Here’s what the process looks like:
Kicking off a migration
When a client triggers a migration, it starts with a request sent to our API Worker. This worker takes the details of the migration, stores them in the database, and adds a message to the List Queue to start the process.
Listing source bucket objects
The List Queue Consumer is where things start to pick up. It pulls messages from the queue, retrieves object listings from the source bucket, applies any necessary filters, and stores important metadata in the database. Then, it creates new tasks by enqueuing object transfer messages into the Transfer Queue.
We immediately queue new batches of work, maximizing concurrency. A built-in throttling mechanism prevents us from adding more messages to our queues when unexpected failures occur, such as dependent systems going down. This helps maintain stability and prevents overload during disruptions.
Efficient object transfers
The Transfer Queue Consumer Workers pull object transfer messages from the queue, ensuring that each object is processed only once by locking the object key in the database. When the transfer finishes, the object is unlocked. For larger objects, we break them into manageable chunks and transfer them as multipart uploads.
Handling failures gracefully
Failures are inevitable in any distributed system, and we had to make sure we accounted for that. We implemented automatic retries for transient failures, so issues don’t interrupt the flow of the migration. But if something can’t be resolved with retries, the message goes into the Dead Letter Queue (DLQ), where it is logged for later review and resolution.
Job completion & lifecycle management
Once all the objects are listed and the transfers are in progress, the Lifecycle Queue Consumer keeps an eye on everything. It monitors the ongoing transfers, ensuring that no object is left behind. When all the transfers are complete, the job is marked as finished and the migration process wraps up.
Database layer: durable storage & legacy data retrieval
When building our new architecture, we knew we needed a robust solution to handle massive datasets while ensuring retrieval of historical job data. That’s where our combination of Durable Objects (DOs) and Hyperdrive came in.
Durable Objects
We gave each account a dedicated Durable Object to track migration jobs. Each job’s DO stores vital details, such as bucket names, user options, and job state. This ensured everything stayed organized and easy to manage. To support large migrations, we also added a Batch DO that manages all the objects queued for transfer, storing their transfer state, object keys, and any extra metadata.
As migrations scaled up to billions of objects, we had to get creative with storage. We implemented a sharding strategy to distribute request loads, preventing bottlenecks and working around SQLite DO’s 10 GB storage limit. As objects are transferred, we clean up their details, optimizing storage space along the way. It’s surprising how much storage a billion object keys can require!
Hyperdrive
Since we were rebuilding a system with years of migration history, we needed a way to preserve and access every past migration detail. Hyperdrive serves as a bridge to our legacy systems, enabling seamless retrieval of historical job data from our core PostgreSQL database. It’s not just a data retrieval mechanism, but an archive for complex migration scenarios.
Results: Super Slurper now transfers data to R2 up to 5x faster
So, after all of that, did we actually achieve our goal of making transfers faster?
We ran a test migration of 75,000 objects from AWS S3 to R2. With the original implementation, the transfer took 15 minutes and 30 seconds. After our performance improvements, the same migration completed in just 3 minutes and 25 seconds.
When production migrations started using the new service in February, we saw even greater improvements in some cases, especially depending on the distribution of object sizes. Super Slurper has been around for about two years. But the improved performance has led to it being able to move much more data — 35% of all objects copied by Super Slurper happened just in the last two months.
Challenges
One of the biggest challenges we faced with the new architecture was handling duplicate messages. There were a couple of ways duplicates could occur:
Queues provides at-least-once delivery, which means consumers may receive the same message more than once to guarantee delivery.
Failures and retries could also create apparent duplicates. For example, if a request to a Durable Object fails after the object has already been transferred, the retry could reprocess the same object.
If not handled correctly, this could result in the same object being transferred multiple times. To solve this, we implemented several strategies to ensure each object was accurately accounted for and only transferred once:
Since listing is sequential (e.g., to get object 2, you need the continuation token from listing object 1), we assign a sequence ID to each listing operation. This allows us to detect duplicate listings and prevent multiple processes from starting simultaneously. This is particularly useful because we don’t wait for database and queue operations to complete before listing the next batch. If listing 2 fails, we can retry it, and if listing 3 has already started, we can short-circuit unnecessary retries.
Each object is locked when its transfer begins, preventing parallel transfers of the same object. Once successfully transferred, the object is unlocked by deleting its key from the database. If a message for that object reappears later, we can safely assume it has already been transferred if the key no longer exists.
We rely on database transactions to keep our counts accurate. If an object fails to unlock, its count remains unchanged. Similarly, if an object key fails to be added to the database, the count isn’t updated, and the operation will be retried later.
As a last failsafe, we check whether the object already exists in the target bucket and was published after the start of our migration. If so, we assume it was transferred by our process (or another) and safely skip it.
What’s next for Super Slurper?
We’re always exploring ways to make Super Slurper faster, more scalable, and even easier to use — this is just the beginning.
Data migrations are still currently limited to 3 concurrent migrations per account, but we want to increase that limit. This will allow object prefixes to be split up into separate migrations and run in parallel, drastically increasing the speed at which a bucket can be migrated. For more information on Super Slurper and how to migrate data from existing object storage to R2, refer to our documentation.
P.S. As part of this update, we made the API much simpler to interact with, so migrations can now be managed programmatically!
Apache Iceberg is quickly becoming the standard table format for querying large analytic datasets in object storage. We’re seeing this trend firsthand as more and more developers and data teams adopt Iceberg on Cloudflare R2. But until now, using Iceberg with R2 meant managing additional infrastructure or relying on external data catalogs.
So we’re fixing this. Today, we’re launching the R2 Data Catalog in open beta, a managed Apache Iceberg catalog built directly into your Cloudflare R2 bucket.
If you’re not already familiar with it, Iceberg is an open table format built for large-scale analytics on datasets stored in object storage. With R2 Data Catalog, you get the database-like capabilities Iceberg is known for – ACID transactions, schema evolution, and efficient querying – without the overhead of managing your own external catalog.
R2 Data Catalog exposes a standard Iceberg REST catalog interface, so you can connect the engines you already use, like PyIceberg, Snowflake, and Spark. And, as always with R2, there are no egress fees, meaning that no matter which cloud or region your data is consumed from, you won’t have to worry about growing data transfer costs.
Ready to query data in R2 right now? Jump into the developer docs and enable a data catalog on your R2 bucket in just a few clicks. Or keep reading to learn more about Iceberg, data catalogs, how metadata files work under the hood, and how to create your first Iceberg table.
What is Apache Iceberg?
Apache Iceberg is an open table format for analyzing large datasets in object storage. It brings database-like features – ACID transactions, time travel, and schema evolution – to files stored in formats like Parquet or ORC.
Historically, data lakes were just collections of raw files in object storage. However, without a unified metadata layer, datasets could easily become corrupted, were difficult to evolve, and queries often required expensive full-table scans.
Iceberg solves these problems by:
Providing ACID transactions for reliable, concurrent reads and writes.
Maintaining optimized metadata, so engines can skip irrelevant files and avoid unnecessary full-table scans.
Supporting schema evolution, allowing columns to be added, renamed, or dropped without rewriting existing data.
Iceberg is already widely supported by engines like Apache Spark, Trino, Snowflake, DuckDB, and ClickHouse, with a fast-growing community behind it.
How Iceberg tables are stored
Internally, an Iceberg table is a collection of data files (typically stored in columnar formats like Parquet or ORC) and metadata files (typically stored in JSON or Avro) that describe table snapshots, schemas, and partition layouts.
To understand how query engines interact efficiently with Iceberg tables, it helps to look at an Iceberg metadata file (simplified):
schemas: Iceberg tracks schema changes over time. Engines use schema information to safely read and write data without needing to rewrite underlying files.
snapshots: Each snapshot references a specific set of data files that represent the state of the table at a point in time. This enables features like time travel.
partition-specs: These define how the table is logically partitioned. Query engines leverage this information during planning to skip unnecessary partitions, greatly improving query performance.
By reading Iceberg metadata, query engines can efficiently prune partitions, load only the relevant snapshots, and fetch only the data files it needs, resulting in faster queries.
Why do you need a data catalog?
Although the Iceberg data and metadata files themselves live directly in object storage (like R2), the list of tables and pointers to the current metadata need to be tracked centrally by a data catalog.
Think of a data catalog as a library’s index system. While books (your data) are physically distributed across shelves (object storage), the index provides a single source of truth about what books exist, their locations, and their latest editions. Without this index, readers (query engines) would waste time searching for books, might access outdated versions, or could accidentally shelve new books in ways that make them unfindable.
Similarly, data catalogs ensure consistent, coordinated access, allowing multiple query engines to safely read from and write to the same tables without conflicts or data corruption.
Create your first Iceberg table on R2
Ready to try it out? Here’s a quick example using PyIceberg and Python to get you started. For a detailed step-by-step guide, check out our developer docs.
1. Enable R2 Data Catalog on your bucket:
npx wrangler r2 bucket catalog enable my-bucket
Or use the Cloudflare dashboard: Navigate to R2 Object Storage > Settings > R2 Data Catalog and click Enable.
2. Create a Cloudflare API token with permissions for both R2 storage and the data catalog.
3. Install PyIceberg and PyArrow, then open a Python shell or notebook:
You can now append more data or run queries, just as you would with any Apache Iceberg table.
Pricing
While R2 Data Catalog is in open beta, there will be no additional charges beyond standard R2 storage and operations costs incurred by query engines accessing data. Storage pricing for buckets with R2 Data Catalog enabled remains the same as standard R2 buckets – \$0.015 per GB-month. As always, egress directly from R2 buckets remains \$0.
In the future, we plan to introduce pricing for catalog operations (e.g., creating tables, retrieving table metadata, etc.) and data compaction.
Below is our current thinking on future pricing. We’ll communicate more details around timing well before billing begins, so you can confidently plan your workloads.
Pricing
R2 storage
For standard storage class
$0.015 per GB-month (no change)
R2 Class A operations
$4.50 per million operations (no change)
R2 Class B operations
$0.36 per million operations (no change)
Data Catalog operations
e.g., create table, get table metadata, update table properties
$9.00 per million catalog operations
Data Catalog compaction data processed
$0.05 per GB processed
$4.00 per million objects processed
Data egress
$0 (no change, always free)
What’s next?
We’re excited to see how you use R2 Data Catalog! If you’ve never worked with Iceberg – or even analytics data – before, we think this is the easiest way to get started.
Next on our roadmap is tackling compaction and table optimization. Query engines typically perform better when dealing with fewer, but larger data files. We will automatically re-write collections of small data files into larger files to deliver even faster query performance.
We’re also collaborating with the broad Apache Iceberg community to expand query-engine compatibility with the Iceberg REST Catalog spec.
We’re excited to announce Workers Observability – a new section in the Cloudflare Dashboard that allows you to query detailed log events across all Workers in your account to extract deeper insights.
In 2024, we set out to build the best first-party observability for any cloud platform. Since then, we’ve improved metrics reporting for all resources, launched Workers Logs to automatically ingest and store logs for Workers, and rebuilt real-time logs with improved filtering. However, observability insights have been limited to a single Worker.
Starting today, you can use Workers Observability to understand what is happening across all of your Workers:
Workers Metrics Dashboard (Beta): A single dashboard to view metrics and logs from all of your Workers
Query Builder (Beta): Construct structured queries to explore your logs, extract metrics from logs, create graphical and tabular visualizations, and save queries for faster future investigations.
Workers Logs: Now Generally Available, with a public API and improved invocation-based grouping.
Building queries
The Query Builder allows you to interact with your logs, and answer the “why” to any question you have. You can find it by navigating to Workers & Pages > Observability in the dashboard.
Using the Query Builder, you can now answer more questions than ever. For example, this query shows the p90 wall time for 200 OK responses from the /reference endpoint is 6 milliseconds.
The key components to structuring a query in the Query Builder are:
Visualizations: An aggregate function like average, count, percentile, or unique that performs a calculation on a group of values to return a single value. Each aggregate function returns a graph visualization and a summary table.
Filters: A condition that allows you to exclude data not matching the criteria.
Search: A condition that only returns the data matching the specified string.
Group by: A function to collapse a field into only its distinct values, allowing you to more granularly apply aggregate functions.
Order by: A sorting function to order the returned rows.
Limits: A cap on the number of returned rows, allowing you to focus on what is important.
The Query Builder relies on structured logs for efficient indexed queries and extracting metrics from logs. Workers Observability natively supports and encourages structured logs. Structured logs store context-rich metadata as key-value pairs in the form of distinct fields (high dimensionality), each with many potential unique values (high cardinality). Invocation Logs, which can be enabled in your Worker, contain deep insights from Cloudflare’s network, and are a great example of a structured log. By logging important metadata as a structured log, you empower yourself to answer questions about your system that you couldn’t predict when writing the code.
Internally at Cloudflare, we’ve already found tremendous value from this new product. During development, the Workers Observability team was able to use the Query Builder to discover a bug in the Workers Observability team’s staging environment. A query on the number of the events per script returned the following response:
After mapping this drop in recorded events against recent staging deployments, the team was able to isolate and root cause the introduction of the bug. Along with fixing the bug, the team also introduced new staging alerts to prevent errors like this from going unnoticed.
Queries built with the Query Builder or Workers Logs can be saved with a custom name and description. You can star your favorite queries, and also share them with your teammates using a shareable link, making it easier than ever to debug together and invest in developing visualizations from your telemetry data.
CPU time and wall time
You can now monitor CPU time and wall time for every Workers invocation across all of our observability offerings, including Tail Workers, Workers Logpush, and Workers Logs. These metrics help show how much time is spent executing code compared to the total elapsed time for the invocation, including I/O time.
For example, using the CPU time and wall time surfaced in the Invocation Log, you can use the Query Builder to show the p90 CPU time and wall time traffic for a single Worker script.
Revamped Workers metrics
In February, we released a new view into your Workers’ metrics to help you monitor your gradual deployments with improved visualizations. Today, we are also launching a new Workers Metrics overview page in the Observability tab. Now you can easily compare metrics across Workers and understand the current state of your deployments, all from a single view.
Invocations view
Invocations are mechanisms to trigger the execution of a Worker or Durable Object in response to an event, such as an alarm, cron job, or a fetch.
When the Worker or Durable Object executes, log events are emitted. To date, we have surfaced logs in an events view where each log is ordered by the time it was published.
We’re now introducing an Invocations View, so you can group and view all logs from each invocation. These views are available in each Worker’s view and the Workers Observability tab.
Workers Observability API
You can now use the Workers Observability API to programmatically retrieve your telemetry data and populate the tool of your choice.
The API allows you to automate, integrate, and customize in ways that our dashboard may not. For example, you may want to analyze your logs in a notebook or correlate your Workers logs with logs from a different source. Leveraging the Workers Observability API can help you optimize your monitoring strategy, automate repetitive tasks, and improve flexibility in how you interact with your telemetry data.
Enable Workers Logs today
To use Workers Logs, enable it in your Workers’ settings in the dashboard or add the following configuration to your Workers’ wrangler file:
We’re just getting started. We have lots in store to help make Cloudflare’s developer observability best-in-class. Join us in Discord in the #workers-observability channel for feedback and feature requests.
As the Internet has become enmeshed in our everyday lives, so has our need for speed. No one wants to wait when adding shoes to our shopping carts, or accessing corporate assets from across the globe. And as the Internet supports more and more of our critical infrastructure, speed becomes more than just a measure of how quickly we can place a takeout order. It becomes the connective tissue between the systems that keep us safe, healthy, and organized. Governments, financial institutions, healthcare ecosystems, transit — they increasingly rely on the Internet. This is why at Cloudflare, building the fastest network is our north star.
We’re happy to announce that we are the fastest network in 48% of the top 1000 networks by 95th percentile TCP connection time between November 2024, and March 2025, up from 44% in September 2024.
In this post, we’re going to share with you how our network performance has changed since our last post in September 2024, and talk about what makes us faster than other networks. But first, let’s talk a little bit about how we get this data.
How does Cloudflare get this data?
It’s happened to all of us — you casually click on a site, and suddenly you’ve reached a Cloudflare-branded error page. While you are shaking your fist at the sky, something interesting is happening on the back end. Cloudflare is using Real User Monitoring (RUM) to collect the data used to compare our performance against other networks. The monitoring we do is slightly different than the RUM Cloudflare offers to customers. When the error page loads, a 100 KB file is fetched and loaded. This file is hosted on networks like Cloudflare, Akamai, Amazon CloudFront, Fastly, and Google Cloud CDN. Your browser processes the performance data, and sends it to Cloudflare, where we use it to get a clear view of how these different networks stack up in terms of speed.
We’ve been collecting and refining this data since June 2021. You can read more about how we collect that data here, and we regularly track our performance during Innovation Weeks to hold ourselves accountable to you that we are always in pursuit of being the fastest network in the world.
How are we doing?
In order to evaluate Cloudflare’s speed relative to others, we measure performance across the top 1000 “eyeball” networks using the list provided by the Asia Pacific Network Information Centre (APNIC). So-called “eyeball” networks are those with a large concentration of subscribers/end users. This information is important, because it gives us signals for where we can expand our presence or peering, or optimize our traffic engineering. When benchmarking, we assess the 95th percentile TCP connection time. This is the time it takes a user to establish a TCP connection to the server they are trying to reach. This metric helps us illustrate how Cloudflare’s network makes your traffic faster by serving your customers as locally as possible.
When we look at Cloudflare’s performance across the top 1000 networks, we can see that we’re fastest in 487, or over 48%, of these networks, between November 2024 and March 2025:
In September 2024, we ranked #1 in 44% of these networks:
So why did we jump? To get a better understanding of why, let’s take a look at the countries where we improved, which will give us a better sense of where to dive in. This is what our network map looked like in September 2024 (grey countries mean we do not have enough data or users to derive insights):
(September 2024)
Today, using those same 95th percentile TCP connect times, we rank #1 in 48% of networks and the network map looks like this:
(March 2025)
We made most of our gains in Africa, where countries that previously didn’t have enough samples saw an increase in samples, and Cloudflare pulled ahead. This could mean that there was either an increase in Cloudflare users, or an increase in error pages shown. These countries got faster almost exclusively due to the presence of our Edge Partner deployments, which are Cloudflare locations embedded in last mile networks. In next-generation markets like many African countries, these locations are crucial towards being faster as connectivity to end users tends to fall back to places like South Africa or London if in-country peering does not exist.
But let’s take a look at a couple of other places and see why we got faster.
In Canada, we were not the fastest in September 2024, but we are the fastest today. Today, we are the fastest in 40% of networks, which is the most out of all of our competitors:
But when you look at the overall country numbers, we see that the race for the fastest network is quite close:
Canada 95th Percentile TCP Connect Time by Provider
Rank
Entity
Connect Time (P95)
#1 Diff
1
Cloudflare
179 ms
–
2
Fastly
180 ms
+0.48% (+0.87 ms)
3
Google
180 ms
+0.74% (+1.32 ms)
4
CloudFront
182 ms
+1.74% (+3.11 ms)
5
Akamai
215 ms
+20% (+36 ms)
The difference between Cloudflare and the third-fastest network is a little over a millisecond! As we’ve pointed out previously, such fluctuations are quite common, especially at higher percentiles. But there is still a significant difference between us and the slowest network; we’re around 20% faster.
However, looking at a place like Japan where were not the fastest in September 2024 but are now the fastest, there is a significant difference between Cloudflare and the number two network:
Japan 95th Percentile TCP Connect Time by Provider
Rank
Entity
Connect Time (P95)
#1 Diff
1
Cloudflare
116 ms
–
2
Fastly
122 ms
+5.23% (+6.08 ms)
3
Google
124 ms
+6.21% (+7.22 ms)
4
CloudFront
127 ms
+8.91% (+10 ms)
5
Akamai
153 ms
+32% (+37 ms)
Why is this? We are in more locations in Japan than our competitors and added more Edge Partner deployments in these locations, bringing us even closer to end-users. Edge Partner deployments are collaborations with ISPs, where we take space in their data centers, and peer with them directly.
Why?
Why do we track our network performance like this? The answer is simple: to improve user experience. This data allows us to track a key performance metric for Cloudflare and the other networks. When we see that we’re lagging in a region, it serves as a signal to dig deeper into our network.
This data is a gold mine for the teams tasked with improving Cloudflare’s network. When there are countries where Cloudflare is behind, it gives us signals for where we should expand or investigate. If we’re slow, we may need to invest in additional peering. If a region we have invested in heavily is slower, we may need to investigate our hardware. The example from Japan shows exactly how this can benefit: we took a location where we were previously on par with our competitors, added peering in new locations, and we pulled ahead.
On top of this map, we have autonomous system (ASN) level granularity on how we are performing on each one of the top 1000 eyeball networks, and we continuously optimize our traffic flow with each of them. This allows us to track individual networks that may lag and improve the customer experience in those networks through turning up peering, or even adding new deployments in those regions.
What’s next?
We’re sharing our updates on our journey to become #1 everywhere so that you can see what goes into running the fastest network in the world. From here, our plan is the same as always: identify where we’re slower, fix it, and then tell you how we’ve gotten faster.
Program your traffic at the edge — fast, flexible, and free
Cloudflare Snippets are now generally available (GA) for all paid plans, giving you a fast, flexible way to control HTTP traffic using lightweight JavaScript “code rules” — at no extra cost.
Need to transform headers dynamically, fine-tune caching, rewrite URLs, retry failed requests, replace expired links, throttle suspicious traffic, or validate authentication tokens? Snippets provide a production-ready solution built for performance, security, and control.
With GA, we’re introducing a new code editor to streamline writing and testing logic. This summer, we’re also rolling out an integration with Secrets Store — enabling you to bind and manage sensitive values like API keys directly in Snippets, securely and at scale.
What are Snippets?
Snippets bring the power of JavaScript to Cloudflare Rules, letting you write logic that runs before a request reaches your origin or after a response returns from upstream. They’re ideal when built-in rule actions aren’t quite enough. While Cloudflare Rules let you define traffic logic without code, Snippets extend that model with greater flexibility for advanced scenarios.
Automated deployment and versioning via Terraform.
Best of all? Snippets are included at no extra cost for Pro, Business, and Enterprise plans — with no usage-based fees.
The journey to GA: How Snippets became production-grade
Cloudflare Snippets started as a bold idea: bring the power of JavaScript-based logic to Cloudflare Rules, without the complexity of a full-stack developer platform.
Over the past two years, Snippets have evolved into a production-ready “code rules” solution, shaping the future of HTTP traffic control.
2022: Cloudflare Snippets were announced during Developer Week as a solution for users needing flexible HTTP traffic modifications without a full Worker.
2023:Alpha launch — hundreds of users tested Snippets for high-performance traffic logic.
2024:7x traffic growth, processing 17,000 requests per second. Terraform support and production-grade backend were released.
2025:General Availability — Snippets introduces a new code editor, increased limits alongside other Cloudflare Rules products, integration with Trace, and a production-grade experience built for scale, handling over 2 million requests per second at peak. Integration with the Secrets Store is rolling out this summer.
New: Snippets + Trace
Cloudflare Trace now shows exactly which Snippets were triggered on a request. This makes it easier to debug traffic behavior, verify logic execution, and understand how your Snippets interact with other products in the request pipeline.
Whether you’re fine-tuning header logic or troubleshooting a routing issue, Trace gives you real-time insight into how your edge logic behaves in production.
Coming soon: Snippets + Secrets Store
In the third quarter, you’ll be able to securely access API keys, authentication tokens, and other sensitive values from Secrets Store directly in your Snippets. No more plaintext secrets in your code, no more workarounds.
Once rolled out, secrets can be configured for Snippets via the dashboard or API under the new “Settings” button.
When to use Snippets vs. Cloudflare Workers
Snippets are fast, flexible, and free, but how do they compare to Cloudflare Workers? Both allow you to programmatically control traffic. However, they solve different problems:
Feature
Snippets
Workers
Execute scripts based on request attributes (headers, geolocation, cookies, etc.)
✅
❌
Modify HTTP requests/responses or serve a different response
✅
✅
Add, remove, or rewrite headers dynamically
✅
✅
Cache assets at the edge
✅
✅
Route traffic dynamically between origins
✅
✅
Authenticate requests, pre-sign URLs, run A/B testing
✅
✅
Perform compute-intensive tasks (e.g., AI inference, image processing)
❌
✅
Store persistent data (e.g., KV, Durable Objects, D1)
❌
✅
Deploy via CLI (Wrangler)
❌
✅
Use TypeScript, Python, Rust or other programming languages
❌
✅
Use Snippets when:
You need ultra-fast conditional traffic modifications directly on Cloudflare’s network.
You want to extend Cloudflare Rules beyond built-in actions.
You need free, unlimited invocations within the execution limits.
You are migrating from VCL, Akamai’s EdgeWorkers, or on-premise logic.
Use Workers when:
Your application requires state management, Developer Platform product integrations, or high compute limits.
You are building APIs, full-stack applications, or complex workflows.
You need logging, debugging tools, CLI support, and gradual rollouts.
Still unsure? Check out our detailed guide for best practices.
Snippets in action: real-world use cases
Below are practical use cases demonstrating Snippets. Each script can be dynamically triggered using our powerful Rules language, so you can granularly control which requests your Snippets will be applied to.
1. Dynamically modify headers
Inject custom headers, remove unnecessary ones, and tweak values on the fly:
export default {
async fetch(request) {
const timestamp = Date.now().toString(16); // convert timestamp to HEX
const modifiedRequest = new Request(request, { headers: new Headers(request.headers) });
modifiedRequest.headers.set("X-Hex-Timestamp", timestamp); // send HEX timestamp to upstream
const response = await fetch(modifiedRequest);
const newResponse = new Response(response.body, response); // make response from upstream immutable
newResponse.headers.append("x-snippets-hello", "Hello from Cloudflare Snippets"); // add new response header
newResponse.headers.delete("x-header-to-delete"); // delete response header
newResponse.headers.set("x-header-to-change", "NewValue"); // replace the value of existing response header
return newResponse;
},
};
2. Serve a custom maintenance page
Route traffic to a maintenance page when your origin is undergoing planned maintenance:
export default {
async fetch(request) { // for all matching requests, return predefined HTML response with 503 status code
return new Response(`
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>We'll Be Right Back!</title>
<style> body { font-family: Arial, sans-serif; text-align: center; padding: 20px; } </style>
</head>
<body>
<h1>We'll Be Right Back!</h1>
<p>Our site is undergoing maintenance. Check back soon!</p>
</body>
</html>
`, { status: 503, headers: { "Content-Type": "text/html" } });
}
};
3. Retry failed requests to a backup origin
Ensure reliability by automatically rerouting requests when your primary origin returns an unexpected response:
export default {
async fetch(request) {
const response = await fetch(request); // send original request to the origin
if (!response.ok && !response.redirected) { // if response is not 200 OK or a redirect, send to another origin
const newRequest = new Request(request); // clone the original request to construct a new request
newRequest.headers.set("X-Rerouted", "1"); // add a header to identify a re-routed request at the new origin
const url = new URL(request.url); // clone the original URL
url.hostname = "backup.example.com"; // send request to a different origin / hostname
return await fetch(url, newRequest); // serve response from the backup origin
}
return response; // otherwise, serve response from the primary origin
},
};
4. Redirect users based on their location
Send visitors to region-specific sites for better localization:
export default {
async fetch(request) {
const country = request.cf.country; // identify visitor's country using request.cf property
const redirectMap = { US: "https://example.com/us", EU: "https://example.com/eu" }; // define redirects for each country
if (redirectMap[country]) return Response.redirect(redirectMap[country], 301); // redirect on match
return fetch(request); // otherwise, proceed to upstream normally
}
};
Getting started with Snippets
Snippets are available right now in the Cloudflare dashboard under Rules > Snippets:
Go to Rules → Snippets.
Use prebuilt templates or write your own JavaScript code.
Configure a flexible rule to trigger your Snippet.
Cloudflare Snippets are now generally available, bringing fast, cost-free, and intelligent HTTP traffic control to all paid plans.
With native integration into Cloudflare Rules and Terraform — and Secrets Store integration coming this summer — Snippets provide the most efficient way to manage advanced traffic logic at scale.
Explore Snippets in the Cloudflare Dashboard and start optimizing your traffic with lightweight, flexible rules that enhance performance and reduce complexity.
Every cloud platform needs a secure way to store API tokens, keys, and credentials — welcome, Cloudflare Secrets Store! Today, we are very excited to announce and launch Secrets Store in beta. We built Cloudflare Secrets Store to help our customers centralize management, improve security, and restrict access to sensitive values on the Cloudflare platform.
Wherever secrets exist at Cloudflare – from our developer platform, to AI products, to Cloudflare One – we’ve built a centralized platform that allows you to manage them in one place.
We are excited to integrate Cloudflare Secrets Store with the whole portfolio of Cloudflare products, starting today with Cloudflare Workers.
Securing your secrets across Workers
If you have a secret you want to use across multiple Workers, you can now use the Cloudflare Secrets Store to do so. You can spin up your store from the dashboard or by using Wrangler CLI:
wrangler secrets-store store create <name>
Then, create a secret:
wrangler secrets-store secret create <store-id>
Once the secret is created, you can specify the binding to deploy in a Worker immediately.
Last step – you can now reference the secret in code!
const openAIkey = await env.open_AI_key.get();
Environment variables and secrets were first launched in Cloudflare Workers back in 2020. Now, there are millions of local secrets deployed on Workers scripts. However, these are not all unique. Many of these secrets have duplicate values within a customer’s account. For example, a customer may reuse the same API token in ten different scripts, but since each secret is accessible only on the per-Worker level, that value would be stored in ten different local secrets. Plus, if you need to roll that secret, there is no seamless way to do so that preserves a single source of truth.
With thousands of secrets duplicated across scripts — each requiring manual creation and updates — scoping secrets to individual Workers has created significant friction for developers. Additionally, because Workers secrets are created and deployed locally, any secret is accessible – in terms of creation, editing, and deletion – to anyone who has access to that script.
Now, you can create account-level secrets and variables that can be shared across all Workers scripts, centrally managed and protected within the Secrets Store.
Building a secure secrets manager
The most important feature of a Secret Store, of course, is to make sure that your secrets are stored securely.
Once the secret is created, its value will not be readable by anyone, be it developers, admins, or Cloudflare employees. Only the permitted service will be able to use the value at runtime.
This is why the first thing that happens when you deploy a new secret to Cloudflare is encrypting the secret prior to storing it in our database. We make sure your tokens are safe and protected using a two-level key hierarchy, where the root key never leaves a secure system. This is done by making use of DEKs (Data Encryption Keys) to encrypt your secrets and a separate KEK (Key Encryption Key) to encrypt the DEKs themselves. The data encryption keys are refreshed frequently, making the possibility and impact scope of a single DEK exposure very small. In the future, we will introduce periodic key rotations for our KEK and also provide a way for customers to have their own account-specific DEKs.
After the secrets are encrypted, there are two permissions checks when deploying a secret from the Secrets Store to a Worker. First, the user must have sufficient permissions to create the binding. Second, when the Worker makes a fetch call to retrieve the secret value, we verify that the Worker has an appropriate binding to access that secret.
The secrets are automatically propagated across our network using Quicksilver – so that every secret is on every server– to ensure they’re immediately accessible and ready for the Worker to use. Wherever your Worker is deployed, your secrets will be, too.
If you’d like to use a secret to secure your AI model keys before passing on to AI Gateway:
export default {
async fetch(request, env, ctx) {
const prompt = "Write me a pun about Cloudflare";
const openAIkey = await env.open_AI_key.get();
const response = await fetch("https://gateway.ai.cloudflare.com/v1/YOUR_ACCOUNT_TAG/openai/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${openAIkey}`,
},
body: JSON.stringify({
model: "gpt-3.5-turbo",
messages: [
{ role: "user", content: prompt }
],
temperature: 0.8,
max_tokens: 100,
}),
});
const data = await response.json();
const answer = data.choices?.[0]?.message?.content || "No pun found 😢";
return new Response(answer, {
headers: { "Content-Type": "text/plain" },
});
}
};
Cloudflare Secrets Store, with built-in RBAC
Now, a secret’s value can be updated once and applied everywhere — but not by everyone. Cloudflare Secrets Store uses role-based access control (RBAC) to ensure that only those with permission can view, create, edit, or delete secrets. Additionally, any changes to the Secrets Store are recorded in the audit logs, allowing you to track changes.
Whereas per-Worker secrets are tied to the Workers account role, meaning that anyone who can modify the Worker can modify the secret, access to account-level secrets is restricted with more granular controls. This allows for differentiation between security admins who manage secrets and developers who use them in the code.
Secrets Store Admin
Secrets Store Reporter
Secrets Store Deployer
Create secrets
✓
Update secrets
✓
Delete secrets
✓
View secrets metadata
✓
✓
✓
Deploy secrets (i.e. bind to a Worker)
✓
Each secret can also be scoped to a particular Cloudflare product to ensure the value is only used where it is meant to be. Today, the secrets are restricted to Workers by default, but once the Secrets Store supports multiple products, you’ll be able to specify where the secret can be used (e.g. “I only want this secret to be accessible through Firewall Rules”).
What’s next for Secrets Store
Secrets Store will support all secrets across Cloudflare, including:
Cloudflare Access has service tokens to authenticate against your Zero Trust policies.
Transform Rules require sensitive values in the request headers to grant access or pass onto to something else.
AI Gateway relies upon secret keys from each provider to position Cloudflare between the end user and the AI model.
…and more!
Right now, to use a secret within a Worker, you have to create a binding for that specific secret. In the future, we’ll allow you to create a binding to the store itself so that the Worker can access any secret within that store. We’ll also allow customers to create multiple secret stores within their account so that they can manage secrets by group when creating access policies.
Every Cloudflare account can create up to twenty secrets for free. We’re currently finalizing our pricing and will publish more details for each tier soon.
We’re thrilled to get Secrets Store into our customers’ hands and are excited to continue building it out to support more products and features as we work towards making Secrets Store GA.
Over the past few years, we’ve seen developers push the boundaries of what’s possible with real-time communication — tools for collaborative work, massive online watch parties, and interactive live classrooms are all exploding in popularity.
We use AI more and more in our daily lives. Text-based interactions are evolving into something more natural: voice and video. When users interact with the applications and tools that AI developers create, we have high expectations for response time and connection quality. Complex applications of AI are built on not just one tool, but a combination of tools, often from different providers which requires a well connected cloud to sit in the middle for the coordination of different AI tools.
Developers already use Workers, Workers AI, and our WebRTC SFU and TURN services to build powerful apps without needing to think about coordinating compute or media services to be closest to their user. It’s only natural for there to be a singular “Region: Earth” for real-time applications.
We’re excited to introduce Cloudflare Realtime — a suite of products to help you make your apps truly interactive with real-time audio and video experiences. Cloudflare Realtime now brings together our SFU, STUN, and TURN services, along with the new RealtimeKit.
Say hello to RealtimeKit
RealtimeKit is a collection of mobile SDKs (iOS, Android, React Native, Flutter), SDKs for the Web (React, Angular, vanilla JS, WebComponents), and server side services (recording, coordination, transcription) that make it easier than ever to build real-time voice, video, and AI applications. RealtimeKit also includes user interface components to build interfaces quickly.
The amazing team behind Dyte, a leading company in the real-time ecosystem, joined Cloudflare to accelerate the development of RealtimeKit. The Dyte team spent years focused on making real-time experiences accessible to developers of all skill levels, and had a deep understanding of the developer journey — they built abstractions that hid WebRTC’s complexity without removing its power.
Already a user of Cloudflare’s products, Dyte was a perfect complement to Cloudflare’s existing real-time infrastructure spanning 300+ cities worldwide. They built a developer experience layer that made complex media capabilities accessible. We’re incredibly excited for their team to join Cloudflare as we help developers define the future of user interaction for real-time applications as one team.
For many developers, what starts as “let’s add video chat” can quickly escalate into weeks of technical deep dives into WebSockets and WebRTC. While we are big believers in the potential of WebRTC, we also know that it comes with real challenges when building for the first time. Debugging WebRTC sessions can require developers to learn about esoteric new concepts such as navigating ICE candidate failures, TURN server configurations, and SDP negotiation issues.
The challenges of building a WebRTC app for the first time don’t stop there. Device management adds another layer of complexity. Inconsistent camera and microphone APIs across browsers and mobile platforms introduce unexpected behaviors in production. Chrome handles resolution switching one way, Safari another, and Android WebViews break in uniquely frustrating ways. We regularly see applications that function perfectly in testing environments fail mysteriously when deployed to certain devices or browsers.
Systems that work flawlessly with 5 test users collapse under the load of 50 real-world participants. Bandwidth adaptation falters, connection management becomes unwieldy, and maintaining consistent quality across diverse network conditions proves nearly impossible without specialized expertise.
What starts as a straightforward feature becomes a multi-month project requiring low-level engineering to solve problems that aren’t core to your business.
We realized that we needed to extend our products to client devices to help solve these problems.
RealtimeKit SDKs for Kotlin, React Native, Swift, JavaScript, Flutter
RealtimeKit is our toolkit for building real-time applications without common WebRTC headaches. The core of RealtimeKit is a set of cross-platform SDKs that handle all the low-level complexities, from session establishment and media permissions to NAT traversal and connection management. Instead of spending weeks implementing and debugging these foundations, you can focus entirely on creating unique experiences for your users.
Recording capabilities come built-in, eliminating one of the most commonly requested yet difficult-to-implement features in real-time applications. Whether you need to capture meetings for compliance, save virtual classroom sessions for students who couldn’t attend live, or enable content creators to archive their streams, RealtimeKit handles the entire media pipeline. No more wrestling with MediaRecorder APIs or building custom recording infrastructure — it just works, scaling alongside your user base.
We’ve also integrated voice AI capabilities from providers like ElevenLabs directly into the platform. Adding AI participants to conversations becomes as simple as a function call, opening up entirely new interaction models. These AI voices operate with the same low latency as human participants — tens of milliseconds across our global network — creating truly synchronous experiences where AI and humans converse naturally. Combined with RealtimeKit’s ability to scale to millions of concurrent participants, this enables entirely new categories of applications that weren’t feasible before.
The Developer Experience
RealtimeKit focuses on what developers want to accomplish, rather than how the underlying protocols work. Adding participants or turning on recording are just an API call away. SDKs handle device enumeration, permission requests, and UI rendering across platforms. Behind the scenes, we’re solving the thorny problems of media orchestration and state management that can be challenging to debug.
We’ve been quietly working towards launching the Cloudflare RealtimeKit for years. From the very beginning, our global network has been optimized for minimizing latency between our network and end users, which is where the majority of network disruptions are introduced.
We developed a Selective Forwarding Unit (SFU) that intelligently routes media streams between participants, dynamically adjusting quality based on network conditions. Our TURN infrastructure solves the complex problem of NAT traversal, allowing connections to be established reliably behind firewalls. With Workers AI, we brought inference capabilities to the edge, minimizing latency for AI-powered interactions. Workers and Durable Objects provided the WebSockets coordination layer necessary for maintaining consistent state across participants.
SFU and TURN services are now Generally Available
We’re also announcing the General Availability of our SFU and TURN services for WebRTC developers that need more control and a low-level integration with the Cloudflare network.
SFU now supports simulcast, a very common feature request. Simulcast allows developers to select media streams from multiple options, similar to selecting the quality level of an online video, but for WebRTC. Users with different network qualities are now able to receive different levels of quality, either automatically defined by the SFU or manually selected.
Our TURN service now offers advanced analytics with insight into regional, country, and city level usage metrics. Together with Custom Identifiers, and revocable tokens, Cloudflare’s TURN service offers an in-depth view into usage and helps avoid abuse.
Our SFU and TURN products continue to be one of the most affordable ways to build WebRTC apps at scale, at 5 cents per GB after 1,000 GB of free usage each month.
Partnering with Hugging Face to make realtime AI communication seamless
FastRTC is a lightweight Python library from Hugging Face that makes it easy to stream real-time audio and video into and out of AI models using WebRTC. TURN servers are a critical part of WebRTC infrastructure and ensure that media streams can reliably connect across firewalls and NATs. For users of FastRTC, setting up a globally distributed TURN server can be complex and expensive.
Through our new partnership with Hugging Face, FastRTC users now have free access to Cloudflare’s TURN Server product, giving them reliable connectivity out of the box. Developers get 10 GB of TURN bandwidth each month using just a Hugging Face access token — no setup, no credit card, no servers to manage. As projects grow, they can easily switch to a Cloudflare account for more capacity and a larger free tier.
This integration allows AI developers to focus on building voice interfaces, video pipelines, and multimodal apps without worrying about NAT traversal or network reliability. FastRTC simplifies the code, and Cloudflare ensures it works everywhere. See these demos to get started.
Ship AI-powered realtime apps in days, not weeks
With RealtimeKit, developers can now implement complex real-time experiences in hours. The SDKs abstract away the most time-consuming aspects of WebRTC development while providing APIs tailored to common implementation patterns. Here are a few of the possibilities:
Video conferencing: Add multi-participant video calls to your application with just a few lines of code. RealtimeKit handles the connection management, bandwidth adaptation, and device permissions that typically consume weeks of development time.
Live streaming: Build interactive broadcasts where hosts can stream to thousands of viewers while selectively bringing participants on-screen. The SFU automatically optimizes media routing based on participant roles and network conditions.
Real-time synchronization: Implement watch parties or collaborative viewing experiences where content playback stays synchronized across all participants. The timing API handles the complex delay calculations and adjustments traditionally required.
Voice AI integrations: Add transcription and AI voice participants without building custom media pipelines. RealtimeKit’s media processing APIs integrate with your existing authentication and storage systems rather than requiring separate infrastructure.
When we’ve seen our early testers use the RealtimeKit, it doesn’t just accelerate their existing projects, it fundamentally changes which projects become viable.
RealtimeKit is currently in a closed beta ready for select customers to start kicking the tires. There is currently no cost to test it out during the beta. Request early access here or via the link in your Cloudflare dashboard. We can’t wait to see what you build.
Today, we are announcing the 1.0 release of the Cloudflare Vite plugin, as well as official support for React Router v7!
Over the past few years, Vite’s meteoric rise has seen it become one of the most popular build tools for web development, with a large ecosystem and vibrant community. The Cloudflare Vite plugin brings the Workers runtime right into its beating heart! Previously, the Vite dev server would always run your server code in Node.js, even if you were deploying to Cloudflare Workers. By using the new Environment API, released experimentally in Vite 6, your Worker code can now run inside the native Cloudflare Workers runtime (workerd). This means that the dev server matches the production behavior as closely as possible, and provides confidence as you develop and deploy your applications.
Vite 6 includes the most significant changes to Vite’s architecture since its inception and unlocks many new possibilities for the ecosystem. Fundamental to this is the Environment API, which enables the Vite dev server to interact with any number of custom runtime environments. This means that it is now possible to run server code in alternative JavaScript runtimes, such as our own workerd.
We are grateful to have collaborated closely with the Vite team on its design and implementation. When you see first-hand the thoughtful and generous way in which they go about their work, it’s no wonder that Vite and its ecosystem are in such great shape!
Vite 6 with a Cloudflare Worker environment
Here you can see how it all fits together. The user views a page in the browser (1), which triggers a request to the Vite Dev Server (2). Vite processes the request, resolving, loading, and transforming source files into modules that are added to the client and Worker environments. The client modules are downloaded to the browser to be run as client-side JavaScript, and the Worker modules are sent to the Cloudflare Workers runtime to handle server-side requests. The request is handled by the Worker (3 and 4) and the Vite Dev Server returns the response to the browser (5), which displays the result to the user (6).
Single-page applications
Vite has become the go-to choice for developing single-page applications (SPAs), whether your preferred frontend framework is React, Vue, Svelte, or one of many others.
Create a new app
Let’s try out the new Cloudflare Vite plugin by creating a new React SPA using the create-cloudflare CLI.
This command runs create-vite and then makes the necessary changes to incorporate the Cloudflare Vite plugin.
Using the button below, you can also create a React SPA project on Cloudflare Workers, connected to a git repository of your choice, configured with Cloudflare Workers Builds to automatically deploy, and set up to use the new Vite plugin for local development.
Update an existing app
If you would instead like to update an existing Vite SPA project in the same way, you can follow these two steps:
Add the @cloudflare/vite-plugin dependency to the list of plugins:
import { defineConfig } from "vite";
import react from "@vitejs/plugin-react";
import { cloudflare } from "@cloudflare/vite-plugin";
// https://vite.dev/config/
export default defineConfig({
plugins: [react(), cloudflare()],
});
Add a wrangler.jsonc configuration file alongside your Vite config:
For a purely front-end application, the Cloudflare plugin integrates the Vite dev server with Workers Assets to ensure that settings such as html_handling and not_found_handling behave the same way as they do in production. This is just the beginning, however. The real magic happens when you add a Worker backend that is seamlessly integrated into your development and deployment workflow.
Develop the app
To see this in action, start the Vite development server, which will run your Worker in the Cloudflare Workers runtime:
npm run dev
In your browser, click the first displayed button a few times to increment the counter. This is a classic SPA running JavaScript in your browser. Next, click the second button to fetch the response from the API. Notice that it displays Name from API is: Cloudflare. This is making an API request to a Cloudflare Worker running inside Vite.
Have a look at api/index.ts. This file contains a Worker that is invoked for any request not matching a static asset. It returns a JSON response if the pathname starts with /api/.
Edit api/index.ts by changing the name it returns to ’Cloudflare Workers’ and save your changes. If you click the second button in the browser again, it will now display the new name while preserving the previously set counter value. Vite tracked your changes and updated the Worker environment without affecting the client environment. With Vite and the Cloudflare plugin, you can iterate on the client and server parts of your app together, without losing UI state between edits.
The Cloudflare Vite integration doesn’t end with the dev server. vite build outputs the client and server parts of your application with a single command. vite preview allows you to preview your build output in the Workers runtime prior to deployment. Finally, wrangler deploy recognises that you have generated a Vite build and deploys your application directly without any additional bundling.
React Router v7
While Vite began its life primarily as a build tool for single-page applications, it has since become the foundation for the current generation of full-stack frameworks. Astro, Qwik, React Router, SvelteKit and others have all adopted Vite, drawing on its development server, build pipeline, and phenomenal developer experience. In addition to working with the Vite team on the Environment API, we have also partnered closely with the Remix team on their adoption of Vite Environments. Today, we are announcing first-class support for React Router v7 (the successor to Remix) in the Cloudflare Vite plugin.
You can use the create-cloudflare CLI to create a new React Router application configured with the Cloudflare Vite plugin.
Run npm run dev to start the dev server. You can also try building (npm run build), previewing (npm run preview), and deploying (npm run deploy) your application.
Have a look at the code below, taken from workers/app.ts. This is the file referenced in the main field in wrangler.jsonc:
This single file defines your Worker at both dev and build time and puts you in full control. No more build-time adapters! Notice how the env and ctx are passed down directly in the request handler. These are then accessible in your loaders and actions, which are running inside the Workers runtime along with the rest of your server code. You can add other exports to this file to suit your needs and then reference them in your Worker config. Want to add a Durable Object or a Workflow? Go for it!
This will be the first in a series of full-stack frameworks to be supported and we look forward to continuing discussion and collaboration with a range of teams over the coming months. If you are a framework contributor looking to improve integration with Cloudflare and/or the Vite Environment API, then please feel free to explore the code and reach out on GitHub or Discord.
Workers
While this post has focused thus far on using Vite to build web applications, the Cloudflare plugin enables you to use Vite to build anything you can build with Workers. The full Cloudflare Developer Platform is supported, including KV, D1, Service Bindings, RPC, Durable Objects, Workflows, Workers AI, etc. In fact, in most cases, taking an existing Worker and developing it with Vite is as simple as following these two steps:
Install the dependencies:
npm install –save-dev vite @cloudflare/vite-plugin
And add a Vite config:
// vite.config.ts
import { defineConfig } from "vite";
import { cloudflare } from "@cloudflare/vite-plugin";
export default defineConfig({
plugins: [cloudflare()],
});
That’s it! By default, the plugin will look for a wrangler.json, wrangler.jsonc, or wrangler.toml config file in the root of your Vite project. By using Vite, you can draw on its rich ecosystem of plugins and integrations and easily customize your build output.
Wrapping up
In 2024, we announcedgetPlatformProxy() as a way to access Cloudflare bindings from development servers running in Node. At the end of that post, we imagined a future where it would instead be possible to develop directly in the Workers runtime. This would eliminate the many subtle ways that development and production behavior could differ. Today, that future is a reality, and we can’t wait for you to try it out!
Start a new project with our React Router, React, or Vue templates using the create-cloudflare CLI, use the “Deploy to Cloudflare” button below, or try adding @cloudflare/vite-plugin to your existing Vite applications. We’re excited to see what you build!
Today, we’re announcing support for MySQL in Cloudflare Workers and Hyperdrive. You can now build applications on Workers that connect to your MySQL databases directly, no matter where they’re hosted, with native MySQL drivers, and with optimal performance.
Connecting to MySQL databases from Workers has been an area we’ve been focusing on for quite some time. We want you to build your apps on Workers with your existing data, even if that data exists in a SQL database in us-east-1. But connecting to traditional SQL databases from Workers has been challenging: it requires making stateful connections to regional databases with drivers that haven’t been designed for the Workers runtime.
After multiple attempts at solving this problem for Postgres, Hyperdrive emerged as our solution that provides the best of both worlds: it supports existing database drivers and libraries while also providing best-in-class performance. And it’s such a critical part of connecting to databases from Workers that we’re making it free (check out the Hyperdrive free tier announcement).
With new Node.js compatibility improvements and Hyperdrive support for the MySQL wire protocol, we’re happy to say MySQL support for Cloudflare Workers has been achieved. If you want to jump into the code and have a MySQL database on hand, this “Deploy to Cloudflare” button will get you setup with a deployed project and will create a repository so you can dig into the code.
Read on to learn more about how we got MySQL to work on Workers, and why Hyperdrive is critical to making connectivity to MySQL databases fast.
Getting MySQL to work on Workers
Until recently, connecting to MySQL databases from Workers was not straightforward. While it’s been possible to make TCP connections from Workers for some time, MySQL drivers had many dependencies on Node.js that weren’t available on the Workers runtime, and that prevented their use.
This led to workarounds being developed. PlanetScale provided a serverless driver for JavaScript, which communicates with PlanetScale servers using HTTP instead of TCP to relay database messages. In a separate effort, a fork of the mysql package was created to polyfill the missing Node.js dependencies and modify the mysql package to work on Workers.
These solutions weren’t perfect. They required using new libraries that either did not provide the level of support expected for production applications, or provided solutions that were limited to certain MySQL hosting providers. They also did not integrate with existing codebases and tooling that depended on the popular MySQL drivers (mysql and mysql2). In our effort to enable all JavaScript developers to build on Workers, we knew that we had to support these drivers.
Improving our Node.js compatibility story was critical to get these MySQL drivers working on our platform. We first identified net and stream as APIs that were needed by both drivers. This, complemented by Workers’ nodejs_compat to resolve unused Node.js dependencies with unenv, enabled the mysql package to work on Workers:
Further work was required to get mysql2 working: dependencies on Node.js timers and the JavaScript eval API remained. While we were able to land support for timers in the Workers runtime, eval was not an API that we could securely enable in the Workers runtime at this time.
mysql2 uses eval to optimize the parsing of MySQL results containing large rows with more than 100 columns (see benchmarks). This blocked the driver from working on Workers, since the Workers runtime does not support this module. Luckily, prior effort existed to get mysql2 working on Workers using static parsers for handling text and binary MySQL data types without using eval(), which provides similar performance for a majority of scenarios.
In mysql2 version 3.13.0, a new option to disable the use of eval() was released to make it possible to use the driver in Cloudflare Workers:
import { createConnection } from 'mysql2/promise';
export default {
async fetch(request, env, ctx): Promise<Response> {
const connection = await createConnection({
host: env.DB_HOST,
user: env.DB_USER,
password: env.DB_PASSWORD,
database: env.DB_NAME,
port: env.DB_PORT
// The following line is needed for mysql2 to work on Workers (as explained above)
// mysql2 uses eval() to optimize result parsing for rows with > 100 columns
// eval() is not available in Workers due to runtime limitations
// Configure mysql2 to use static parsing with disableEval
disableEval: true
});
const [results, fields] = await connection.query(
'SHOW tables;'
);
return new Response(JSON.stringify({ results, fields }), {
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
},
});
},
} satisfies ExportedHandler<Env>;
So, with these efforts, it is now possible to connect to MySQL from Workers. But, getting the MySQL drivers working on Workers was only half of the battle. To make MySQL on Workers performant for production uses, we needed to make it possible to connect to MySQL databases with Hyperdrive.
Supporting MySQL in Hyperdrive
If you’re a MySQL developer, Hyperdrive may be new to you. Hyperdrive solves a core problem: connecting from Workers to regional SQL databases is slow. Database drivers require many roundtrips to establish a connection to a database. Without the ability to reuse these connections between Worker invocations, a lot of unnecessary latency is added to your application.
Hyperdrive solves this problem by pooling connections to your database globally and eliminating unnecessary roundtrips for connection setup. As a plus, Hyperdrive also provides integrated caching to offload popular queries from your database. We wrote an entire deep dive on how Hyperdrive does this, which you should definitely check out.
Getting Hyperdrive to support MySQL was critical for us to be able to say “Connect from Workers to MySQL databases”. That’s easier said than done. To support a new database type, Hyperdrive needs to be able to parse the wire protocol of the database in question, in this case, the MySQL protocol. Once this is accomplished, Hyperdrive can extract queries from protocol messages, cache results across Cloudflare locations, relay messages to a datacenter close to your database, and pool connections reliably close to your origin database.
Adapting Hyperdrive to parse a new language, MySQL protocol, is a challenge in its own right. But it also presented some notable differences with Postgres. While the intricacies are beyond the scope of this post, the differences in MySQL’s authentication plugins across providers and how MySQL’s connection handshake uses capability flags required some adaptation of Hyperdrive. In the end, we leveraged the experience we gained in building Hyperdrive for Postgres to iterate on our support for MySQL. And we’re happy to announce MySQL support is available for Hyperdrive, with all of the performanceimprovements we’ve made to Hyperdrive available from the get-go!
Now, you can create new Hyperdrive configurations for MySQL databases hosted anywhere (we’ve tested MySQL and MariaDB databases from AWS (including AWS Aurora), GCP, Azure, PlanetScale, and self-hosted databases). You can create Hyperdrive configurations for your MySQL databases from the dashboard or the Wrangler CLI:
In your Wrangler configuration file, you’ll need to set your Hyperdrive binding to the ID of the newly created Hyperdrive configuration as well as set Node.js compatibility flags:
From your Cloudflare Worker, the Hyperdrive binding provides you with custom connection credentials that connect to your Hyperdrive configuration. From there onward, all of your queries and database messages will be routed to your origin database by Hyperdrive, leveraging Cloudflare’s network to speed up routing.
import { createConnection } from 'mysql2/promise';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request, env, ctx): Promise<Response> {
// Hyperdrive provides new connection credentials to use with your existing drivers
const connection = await createConnection({
host: env.HYPERDRIVE.host,
user: env.HYPERDRIVE.user,
password: env.HYPERDRIVE.password,
database: env.HYPERDRIVE.database,
port: env.HYPERDRIVE.port,
// Configure mysql2 to use static parsing (as explained above in Part 1)
disableEval: true
});
const [results, fields] = await connection.query(
'SHOW tables;'
);
return new Response(JSON.stringify({ results, fields }), {
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
},
});
},
} satisfies ExportedHandler<Env>;
As you can see from this code snippet, you only need to swap the credentials in your JavaScript code for those provided by Hyperdrive to migrate your existing code to Workers. No need to change the ORMs or drivers you’re using!
Get started building with MySQL and Hyperdrive
MySQL support for Workers and Hyperdrive has been long overdue and we’re excited to see what you build. We published a template for you to get started building your MySQL applications on Workers with Hyperdrive:
As for what’s next, we’re going to continue iterating on our support for MySQL during the beta to support more of the MySQL protocol and MySQL-compatible databases. We’re also going to continue to expand the feature set of Hyperdrive to make it more flexible for your full-stack workloads and more performant for building full-stack global apps on Workers.
Finally, whether you’re using MySQL, PostgreSQL, or any of the other compatible databases, we think you should be using Hyperdrive to get the best performance. And because we want to enable you to build on Workers regardless of your preferred database, we’re making Hyperdrive available to the Workers free plan.
We want to hear your feedback on MySQL, Hyperdrive, and building global applications with Workers. Join the #hyperdrive channel in our Developer Discord to ask questions, share what you’re building, and talk to our Product & Engineering teams directly.
In September 2024, we introduced beta support for hosting, storing, and serving static assets for free on Cloudflare Workers — something that was previously only possible on Cloudflare Pages. Being able to host these assets — your client-side JavaScript, HTML, CSS, fonts, and images — was a critical missing piece for developers looking to build a full-stack application within a single Worker.
Today we’re announcing ten big improvements to building apps on Cloudflare. All together, these new additions allow you to build and host projects ranging from simple static sites to full-stack applications, all on Cloudflare Workers:
You can build complete full-stack apps on Workers without a framework: you can “just use Vite” and React together, and build a backend API in the same Worker. See our Vite + React template for an example.
The Cloudflare Vite plugin is now v1.0 and generally available. The Vite plugin allows you to run Vite’s development server in the Workers runtime (workerd), meaning you get all the benefits of Vite, including Hot Module Replacement, while still being able to use features that are exclusive to Workers (like Durable Objects).
You can now use static _headers and _redirects configuration files for your applications on Workers, something that was previously only available on Pages. These files allow you to add simple headers and configure redirects without executing any Worker code.
In addition to PostgreSQL, you can now connect to MySQL databases in addition from Cloudflare Workers, via Hyperdrive. Bring your existing Planetscale, AWS, GCP, Azure, or other MySQL database, and Hyperdrive will take care of pooling connections to your database and eliminating unnecessary roundtrips by caching queries.
More Node.js APIs are available in the Workers Runtime — including APIs from the crypto, tls, net, and dns modules. We’ve also increased the maximum CPU time for a Workers request from 30 seconds to 5 minutes.
The Images binding in Workers is generally available, allowing you to build more flexible, programmatic workflows.
These improvements allow you to build both simple static sites and more complex server-side rendered applications. Like Pages, you only get charged when your Worker code runs, meaning you can host and serve static sites for free. When you want to do any rendering on the server or need to build an API, simply add a Worker to handle your backend. And when you need to read or write data in your app, you can connect to an existing database with Hyperdrive, or use any of our storage solutions: Workers KV, R2, Durable Objects, or D1.
If you’d like to dive straight into code, you can deploy a single-page application built with Vite and React, with the option to connect to a hosted database with Hyperdrive, by clicking this “Deploy to Cloudflare” button:
Start with Workers
Previously, you needed to choose between building on Cloudflare Pages or Workers (or use Pages for one part of your app, and Workers for another) just to get started. This meant figuring out what your app needed from the start, and hoping that if your project evolved, you wouldn’t be stuck with the wrong platform and architecture. Workers was designed to be a flexible platform, allowing developers to evolve projects as needed — and so, we’ve worked to bring pieces of Pages into Workers over the years.
Now that Workers supports both serving static assets and server-side rendering, you should start with Workers. Cloudflare Pages will continue to be supported, but, going forward, all of our investment, optimizations, and feature work will be dedicated to improving Workers. We aim to make Workers the best platform for building full-stack apps, building upon your feedback of what went well with Pages and what we could improve.
Before, building an app on Pages meant you got a really easy, opinionated on-ramp, but you’d eventually hit a wall if your application got more complex. If you wanted to use Durable Objects to manage state, you would need to set up an entirely separate Worker to do so, ending up with a complicated deployment and more overhead. You also were limited to real-time logs, and could only roll out changes all in one go.
When you build on Workers, you can immediately bind to any other Developer Platform service (including Durable Objects, Email Workers, and more), and manage both your front end and back end in a single project — all with a single deployment. You also get the whole suite of Workers observability tooling built into the platform, such as Workers Logs. And if you want to rollout changes to only a certain percentage of traffic, you can do so with Gradual Deployments.
These latest improvements are part of our goal to bring the best parts of Pages into Workers. For example, we now support static _headers and _redirects config files, so that you can easily take an existing project from Pages (or another platform) and move it over to Workers, without needing to change your project. We also directly integrate with GitHub and GitLab with Workers Builds, providing automatic builds and deployments. And starting today, Preview URLs are posted back to your repository as a comment, with feature branch aliases and environments coming soon.
To learn how to migrate an existing project from Pages to Workers, read our migration guide.
Next, let’s talk about how you can build applications with different rendering modes on Workers.
Building static sites, SPAs, and SSR on Workers
As a quick primer, here are all the architectures and rendering modes we’ll be discussing that are supported on Workers:
Static sites: When you visit a static site, the server immediately returns pre-built static assets — HTML, CSS, JavaScript, images, and fonts. There’s no dynamic rendering happening on the server at request-time. Static assets are typically generated at build-time and served directly from a CDN, making static sites fast and easily cacheable. This approach works well for sites with content that rarely changes.
Single-Page Applications (SPAs): When you load an SPA, the server initially sends a minimal HTML shell and a JavaScript bundle (served as static assets). Your browser downloads this JavaScript, which then takes over to render the entire user interface client-side. After the initial load, all navigation occurs without full-page refreshes, typically via client-side routing. This creates a fast, app-like experience.
Server-Side Rendered (SSR) applications: When you first visit a site that uses SSR, the server generates a fully-rendered HTML page on-demand for that request. Your browser immediately displays this complete HTML, resulting in a fast first page load. Once loaded, JavaScript “hydrates” the page, adding interactivity. Subsequent navigations can either trigger new server-rendered pages or, in many modern frameworks, transition into client-side rendering similar to an SPA.
Next, we’ll dive into how you can build these kinds of applications on Workers, starting with setting up your development environment.
Setup: build and dev
Before uploading your application, you need to bundle all of your client-side code into a directory of static assets. Wrangler bundles and builds your code when you run wrangler dev, but we also now support Vite with our new Vite plugin. This is a great option for those already using Vite’s build tooling and development server — you can continue developing (and testing with Vitest) using Vite’s development server, all using the Workers runtime.
To get started using the Cloudflare Vite plugin, you can scaffold a React application using Vite and our plugin, by running:
The Vite plugin informs Wrangler that this /dist directory contains the project’s built static assets — which, in this case, includes client-side code, some CSS files, and images.
Once deployed, this single-page application (SPA) architecture will look something like this:
When a request comes in, Cloudflare looks at the pathname and automatically serves any static assets that match that pathname. For example, if your static assets directory includes a blog.html file, requests for example.com/blog get that file.
Static sites
If you have a static site created by a static site generator (SSG) like Astro, all you need to do is create a wrangler.jsonc file (or wrangler.toml) and tell Cloudflare where to find your built assets:
Once you’ve added this configuration, you can simply build your project and run wrangler deploy. Your entire site will then be uploaded and ready for traffic on Workers. Once deployed and requests start flowing in, your static site will be cached across Cloudflare’s network.
You can try starting a fresh Astro project on Workers today by running:
By enabling this, the platform assumes that any navigation request (requests which include a Sec-Fetch-Mode: navigate header) are intended for static assets and will serve up index.html whenever a matching static asset match cannot be found. For non-navigation requests (such as requests for data) that don’t match a static asset, Cloudflare will invoke the Worker script. With this setup, you can render the frontend with React, use a Worker to handle back-end operations, and use Vite to help stitch the two together. This is a great option for porting over older SPAs built with create-react-app, which was recently sunset.
Another thing to note in this Wrangler configuration file: we’ve defined a Hyperdrive binding and enabled Smart Placement. Hyperdrive lets us use an existing database and handles connection pooling. This solves a long-standing challenge of connecting Workers (which run in a highly distributed, serverless environment) directly to traditional databases. By design, Workers operate in lightweight V8 isolates with no persistent TCP sockets and a strict CPU/memory limit. This isolation is great for security and speed, but it makes it difficult to hold open database connections. Hyperdrive addresses these constraints by acting as a “bridge” between Cloudflare’s network and your database, taking care of the heavy lifting of maintaining stable connections or pools so that Workers can reuse them. By turning on Smart Placement, we also ensure that if requests to our Worker originate far from the database (causing latency), Cloudflare can choose to relocate both the Worker—which handles the database connection—and the Hyperdrive “bridge” to a location closer to the database, reducing round-trip times.
SPA example: Worker code
Let’s look at the “Deploy to Cloudflare” example at the top of this blog. In api/index.js, we’ve defined an API (using Hono) which connects to a hosted database through Hyperdrive.
import { Hono } from "hono";
import postgres from "postgres";
import booksRouter from "./routes/books";
import bookRelatedRouter from "./routes/book-related";
const app = new Hono();
// Setup SQL client middleware
app.use("*", async (c, next) => {
// Create SQL client
const sql = postgres(c.env.HYPERDRIVE.connectionString, {
max: 5,
fetch_types: false,
});
c.env.SQL = sql;
// Process the request
await next();
// Close the SQL connection after the response is sent
c.executionCtx.waitUntil(sql.end());
});
app.route("/api/books", booksRouter);
app.route("/api/books/:id/related", bookRelatedRouter);
export default {
fetch: app.fetch,
};
When deployed, our app’s architecture looks something like this:
If Smart Placement moves the placement of my Worker to run closer to my database, it could look like this:
Server-Side Rendering (SSR)
If you want to handle rendering on the server, we support a number of popular full-stack frameworks.
Here’s a version of our previous example, now using React Router v7’s server-side rendering:
Deploy to Workers, with as few changes as possible
Node.js compatibility
We’ve also continued to make progress supporting Node.js APIs, recently adding support for the crypto, tls, net, and dns modules. This allows existing applications and libraries that rely on these Node.js modules to run on Workers. Let’s take a look at an example:
Previously, if you tried to use the mongodb package, you encountered the following error:
Error: [unenv] dns.resolveTxt is not implemented yet!
This occurred when mongodb used the node:dns module to do a DNS lookup of a hostname. Even if you avoided that issue, you would have encountered another error when mongodb tried to use node:tls to securely connect to a database.
Now, you can use mongodb as expected because node:dns and node:tls are supported. The same can be said for libraries relying on node:crypto and node:net.
Additionally, Workers now expose environment variables and secrets on the process.env object when the nodejs_compat compatibility flag is on and the compatibility date is set to 2025-04-01 or beyond. Some libraries (and developers) assume that this object will be populated with variables, and rely on it for top-level configuration. Without the tweak, libraries may have previously broken unexpectedly and developers had to write additional logic to handle variables on Cloudflare Workers.
Now, you can just access your variables as you would in Node.js.
We have also raised the maximum CPU time per Worker request from 30 seconds to 5 minutes. This allows for compute-intensive operations to run for longer without timing out. Say you want to use the newly supported node:crypto module to hash a very large file, you can now do this on Workers without having to rely on external compute for CPU-intensive operations.
Workers Builds
We’ve also made improvements to Workers Builds, which allows you to connect a Git repository to your Worker, so that you can have automatic builds and deployments on every pushed change. Workers Builds was introduced during Builder Day 2024, and initially only allowed you to connect a repository to an existing Worker. Now, you can bring a repository and immediately deploy it as a new Worker, reducing the amount of setup and button clicking needed to bring a project over. We’ve improved the performance of Workers Builds by reducing the latency of build starts by 6 seconds — they now start within 10 seconds on average. We also boosted API responsiveness, achieving a 7x latency improvement thanks to Smart Placement.
Note: On April 2, 2025, Workers Builds transitioned to a new pricing model, as announced during Builder Day 2024. Free plan users are now capped at 3,000 minutes of build time, and Workers Paid subscription users will have a new usage-based model with 6,000 free minutes included and $0.005 per build minute pricing after. To better support concurrent builds, Paid plans will also now get six (6) concurrent builds, making it easier to work across multiple projects and monorepos. For more information on pricing, see the documentation.
Last week, we wrote a blog post that covers how the Images binding enables more flexible, programmatic workflows for image optimization.
Previously, you could access image optimization features by calling fetch() in your Worker. This method requires the original image to be retrievable by URL. However, you may have cases where images aren’t accessible from a URL, like when you want to compress user-uploaded images before they are uploaded to your storage. With the Images binding, you can directly optimize an image by operating on its body as a stream of bytes.
We’re excited to see what you’ll build, and are focused on new features and improvements to make it easier to create any application on Workers. Much of this work was made even better by community feedback, and we encourage everyone to join our Discord to participate in the discussion.