Chances are you might have heard of io_uring. It first appeared in Linux 5.1, back in 2019, and was advertised as the new API for asynchronous I/O. Its goal was to be an alternative to the deemed-to-be-broken-beyond-repair AIO, the “old” asynchronous I/O API.
Calling io_uring just an asynchronous I/O API doesn’t do it justice, though. Underneath the API calls, io_uring is a full-blown runtime for processing I/O requests. One that spawns threads, sets up work queues, and dispatches requests for processing. All this happens “in the background” so that the user space process doesn’t have to, but can, block while waiting for its I/O requests to complete.
A runtime that spawns threads and manages the worker pool for the developer makes life easier, but using it in a project begs the questions:
1. How many threads will be created for my workload by default?
2. How can I monitor and control the thread pool size?
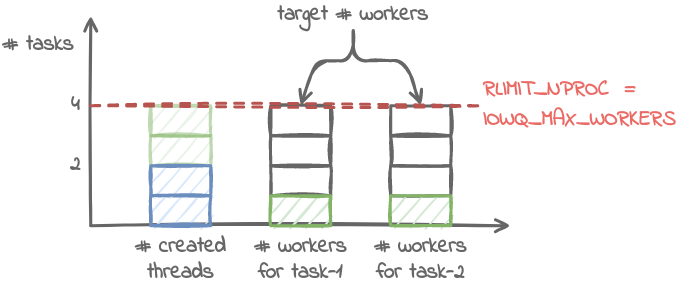
By default, io_uring limits the unbounded workers created to the maximum processor count set by RLIMIT_NPROC and the bounded workers is a function of the SQ ring size and the number of CPUs in the system.
… it also leads to more questions:
3. What is an unbounded worker?
4. How does it differ from a bounded worker?
Things seem a bit under-documented as is, hence this blog post. Hopefully, it will provide the clarity needed to put io_uring to work in your project when the time comes.
Before we dig in, a word of warning. This post is not meant to be an introduction to io_uring. The existing documentation does a much better job at showing you the ropes than I ever could. Please give it a read first, if you are not familiar yet with the io_uring API.
Not all I/O requests are created equal
io_uring can perform I/O on any kind of file descriptor; be it a regular file or a special file, like a socket. However, the kind of file descriptor that it operates on makes a difference when it comes to the size of the worker pool.
io-wq divides work into two categories: 1. Work that completes in a bounded time, like reading from a regular file or a block device. This type of work is limited based on the size of the SQ ring. 2. Work that may never complete, we call this unbounded work. The amount of workers here is limited by RLIMIT_NPROC.
This answers the latter two of our open questions. Unbounded workers handle I/O requests that operate on neither regular files (S_IFREG) nor block devices (S_ISBLK). This is the case for network I/O, where we work with sockets (S_IFSOCK), and other special files like character devices (e.g. /dev/null).
We now also know that there are different limits in place for how many bounded vs unbounded workers there can be running. So we have to pick one before we dig further.
Capping the unbounded worker pool size
Pushing data through sockets is Cloudflare’s bread and butter, so this is what we are going to base our test workload around. To put it in io_uring lingo – we will be submitting unbounded work requests.
While doing that, we will observe how io_uring goes about creating workers.
To observe how io_uring goes about creating workers we will ask it to read from a UDP socket multiple times. No packets will arrive on the socket, so we will have full control over when the requests complete.
$ ./target/debug/udp-read -h
udp-read 0.1.0
read from UDP socket with io_uring
USAGE:
udp-read [FLAGS] [OPTIONS]
FLAGS:
-a, --async Set IOSQE_ASYNC flag on submitted SQEs
-h, --help Prints help information
-V, --version Prints version information
OPTIONS:
-c, --cpu <cpu>... CPU to run on when invoking io_uring_enter for Nth ring (specify multiple
times) [default: 0]
-w, --workers <max-unbound-workers> Maximum number of unbound workers per NUMA node (0 - default, that is
RLIMIT_NPROC) [default: 0]
-r, --rings <num-rings> Number io_ring instances to create per thread [default: 1]
-t, --threads <num-threads> Number of threads creating io_uring instances [default: 1]
-s, --sqes <sqes> Number of read requests to submit per io_uring (0 - fill the whole queue)
[default: 0]
While it is parametrized for easy experimentation, at its core it doesn’t do much. We fill the submission queue with read requests from a UDP socket and then wait for them to complete. But because data doesn’t arrive on the socket out of nowhere, and there are no timeouts set up, nothing happens. As a bonus, we have complete control over when requests complete, which will come in handy later.
Let’s run the test workload to convince ourselves that things are working as expected. strace won’t be very helpful when using io_uring. We won’t be able to tie I/O requests to system calls. Instead, we will have to turn to in-kernel tracing.
Thankfully, io_uring comes with a set of ready to use static tracepoints, which save us the trouble of digging through the source code to decide where to hook up dynamic tracepoints, known as kprobes.
We can discover the tracepoints with perf list or bpftrace -l, or by browsing the events/ directory on the tracefs filesystem, usually mounted under /sys/kernel/tracing.
$ sudo perf list 'io_uring:*'
List of pre-defined events (to be used in -e):
io_uring:io_uring_complete [Tracepoint event]
io_uring:io_uring_cqring_wait [Tracepoint event]
io_uring:io_uring_create [Tracepoint event]
io_uring:io_uring_defer [Tracepoint event]
io_uring:io_uring_fail_link [Tracepoint event]
io_uring:io_uring_file_get [Tracepoint event]
io_uring:io_uring_link [Tracepoint event]
io_uring:io_uring_poll_arm [Tracepoint event]
io_uring:io_uring_poll_wake [Tracepoint event]
io_uring:io_uring_queue_async_work [Tracepoint event]
io_uring:io_uring_register [Tracepoint event]
io_uring:io_uring_submit_sqe [Tracepoint event]
io_uring:io_uring_task_add [Tracepoint event]
io_uring:io_uring_task_run [Tracepoint event]
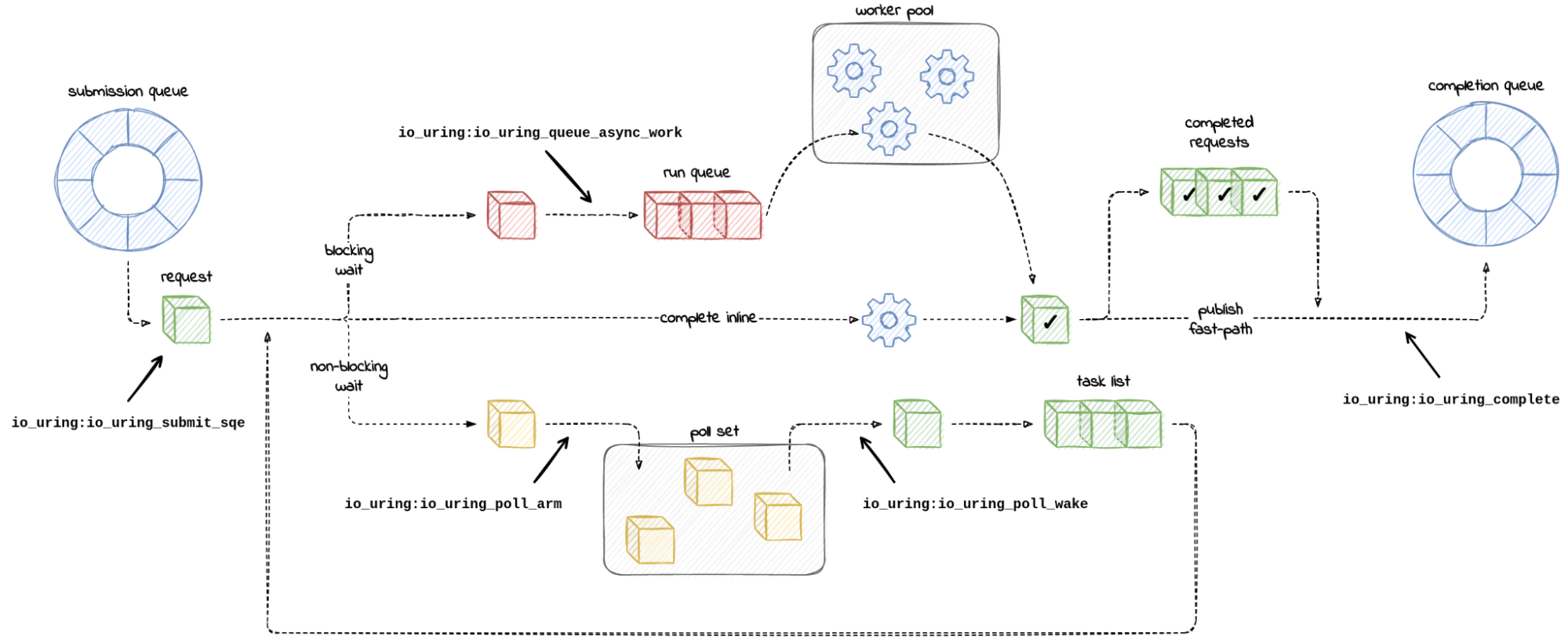
Judging by the number of tracepoints to choose from, io_uring takes visibility seriously. To help us get our bearings, here is a diagram that maps out paths an I/O request can take inside io_uring code annotated with tracepoint names – not all of them, just those which will be useful to us.
Starting on the left, we expect our toy workload to push entries onto the submission queue. When we publish submitted entries by calling io_uring_enter(), the kernel consumes the submission queue and constructs internal request objects. A side effect we can observe is a hit on the io_uring:io_uring_submit_sqe tracepoint.
$ sudo perf stat -e io_uring:io_uring_submit_sqe -- timeout 1 ./udp-read
Performance counter stats for 'timeout 1 ./udp-read':
4096 io_uring:io_uring_submit_sqe
1.049016083 seconds time elapsed
0.003747000 seconds user
0.013720000 seconds sys
But, as it turns out, submitting entries is not enough to make io_uring spawn worker threads. Our process remains single-threaded:
So, by default, io_uring performs a non-blocking read on sockets. This is bound to fail with -EAGAIN in our case. What follows is that io_uring registers a wake-up call (io_async_wake()) for when the socket becomes readable. There is no need to perform a blocking read, when we can wait to be notified.
This resembles polling the socket with select() or [e]poll() from user space. There is no timeout, if we didn’t ask for it explicitly by submitting an IORING_OP_LINK_TIMEOUT request. io_uring will simply wait indefinitely.
We can observe io_uring when it calls vfs_poll, the machinery behind non-blocking I/O, to monitor the sockets. If that happens, we will be hitting the io_uring:io_uring_poll_arm tracepoint. Meanwhile, the wake-ups that follow, if the polled file becomes ready for I/O, can be recorded with the io_uring:io_uring_poll_wake tracepoint embedded in io_async_wake() wake-up call.
This is what we are experiencing. io_uring is polling the socket for read-readiness:
To make io_uring spawn worker threads, we have to force the read requests to be processed concurrently in a blocking fashion. We can do this by marking the I/O requests as asynchronous. As io_uring_enter(2) man-page says:
IOSQE_ASYNC
Normal operation for io_uring is to try and issue an
sqe as non-blocking first, and if that fails, execute
it in an async manner. To support more efficient over‐
lapped operation of requests that the application
knows/assumes will always (or most of the time) block,
the application can ask for an sqe to be issued async
from the start. Available since 5.6.
The thread count went up by the number of submitted I/O requests (4,096). And there is one extra thread – the main thread. io_uring has spawned workers.
If we trace it again, we see that requests are now taking the blocking-read path, and we are hitting the io_uring:io_uring_queue_async_work tracepoint on the way.
$ sudo perf stat -a -e io_uring:io_uring_poll_arm,io_uring:io_uring_queue_async_work -- ./udp-read --async
^C./udp-read: Interrupt
Performance counter stats for 'system wide':
0 io_uring:io_uring_poll_arm
4096 io_uring:io_uring_queue_async_work
1.335559294 seconds time elapsed
$
We got what we wanted. We are now using the worker thread pool.
However, having 4,096 threads just for reading one socket sounds like overkill. If we were to limit the number of worker threads, how would we go about that? There are four ways I know of.
Method 1 – Limit the number of in-flight requests
If we take care to never have more than some number of in-flight blocking I/O requests, then we will have more or less the same number of workers. This is because:
io_uring spawns workers only when there is work to process. We control how many requests we submit and can throttle new submissions based on completion notifications.
io_uring retires workers when there is no more pending work in the queue. Although, there is a grace period before a worker dies.
The downside of this approach is that by throttling submissions, we reduce batching. We will have to drain the completion queue, refill the submission queue, and switch context with io_uring_enter() syscall more often.
We can convince ourselves that this method works by tweaking the number of submitted requests, and observing the thread count as the requests complete. The --sqes <n> option (submission queue entries) controls how many read requests get queued by our workload. If we want a request to complete, we simply need to send a packet toward the UDP socket we are reading from. The workload does not refill the submission queue.
In 5.15 the io_uring_register() syscall gained a new command for setting the maximum number of bound and unbound workers.
IORING_REGISTER_IOWQ_MAX_WORKERS
By default, io_uring limits the unbounded workers cre‐
ated to the maximum processor count set by
RLIMIT_NPROC and the bounded workers is a function of
the SQ ring size and the number of CPUs in the system.
Sometimes this can be excessive (or too little, for
bounded), and this command provides a way to change
the count per ring (per NUMA node) instead.
arg must be set to an unsigned int pointer to an array
of two values, with the values in the array being set
to the maximum count of workers per NUMA node. Index 0
holds the bounded worker count, and index 1 holds the
unbounded worker count. On successful return, the
passed in array will contain the previous maximum va‐
lyes for each type. If the count being passed in is 0,
then this command returns the current maximum values
and doesn't modify the current setting. nr_args must
be set to 2, as the command takes two values.
Available since 5.15.
By the way, if you would like to grep through the io_uring man pages, they live in the liburing repo maintained by Jens Axboe – not the go-to repo for Linux API man-pages maintained by Michael Kerrisk.
Since it is a fresh addition to the io_uring API, the io-uring Rust library we are using has not caught up yet. But with a bit of patching, we can make it work.
We can tell our toy program to set IORING_REGISTER_IOWQ_MAX_WORKERS (= 19 = 0x13) by running it with the --workers <N> option:
This works perfectly. We have spawned just eight io_uring worker threads to handle 4k of submitted read requests.
Question remains – is the set limit per io_uring instance? Per thread? Per process? Per UID? Read on to find out.
Method 3 – Set RLIMIT_NPROC resource limit
A resource limit for the maximum number of new processes is another way to cap the worker pool size. The documentation for the IORING_REGISTER_IOWQ_MAX_WORKERS command mentions this.
This resource limit overrides the IORING_REGISTER_IOWQ_MAX_WORKERS setting, which makes sense because bumping RLIMIT_NPROC above the configured hard maximum requires CAP_SYS_RESOURCE capability.
Setting the new process limit without using a dedicated UID or outside a dedicated user namespace, where other processes are running under the same UID, can have surprising effects.
Why? io_uring will try over and over again to scale up the worker pool, only to generate a bunch of -EAGAIN errors from create_io_worker() if it can’t reach the configured RLIMIT_NPROC limit:
We are hogging one core trying to spawn new workers. This is not the best use of CPU time.
So, if you want to use RLIMIT_NPROC as a safety cap over the IORING_REGISTER_IOWQ_MAX_WORKERS limit, you better use a “fresh” UID or a throw-away user namespace:
Anti-Method 4 – cgroup process limit – pids.max file
There is also one other way to cap the worker pool size – limit the number of tasks (that is, processes and their threads) in a control group.
It is an anti-example and a potential misconfiguration to watch out for, because just like with RLIMIT_NPROC, we can fall into the same trap where io_uring will burn CPU:
Here, we again see io_uring wasting time trying to spawn more workers without success. The kernel does not let the number of tasks within the service’s control group go over the limit.
Okay, so we know what is the best and the worst way to put a limit on the number of io_uring workers. But is the limit per io_uring instance? Per user? Or something else?
One ring, two ring, three ring, four …
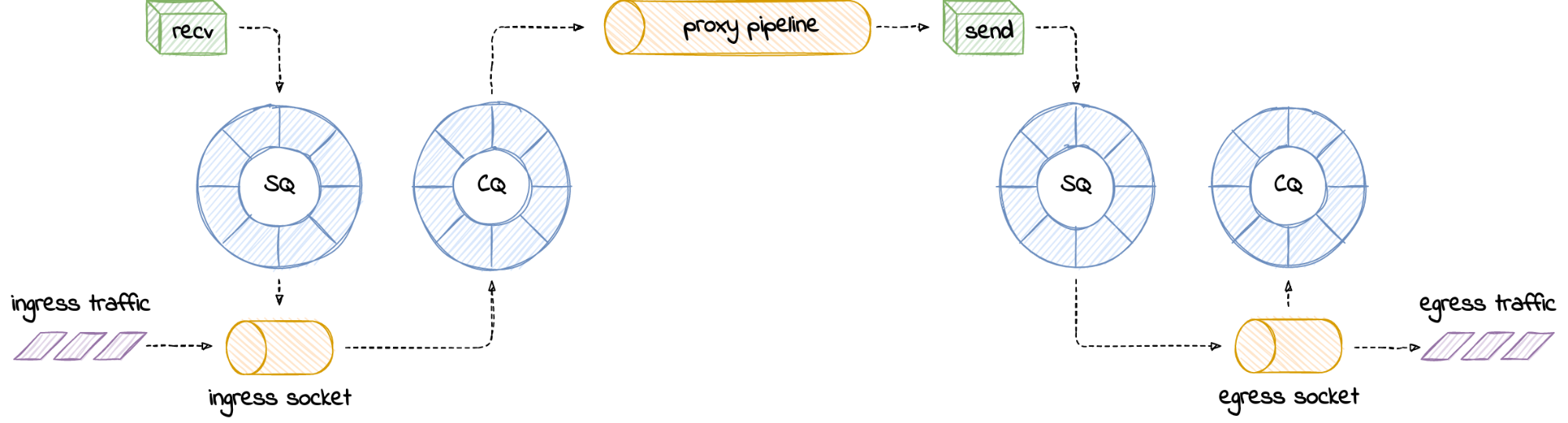
Your process is not limited to one instance of io_uring, naturally. In the case of a network proxy, where we push data from one socket to another, we could have one instance of io_uring servicing each half of the proxy.
How many worker threads will be created in the presence of multiple io_urings? That depends on whether your program is single- or multithreaded.
In the single-threaded case, if the main thread creates two io_urings, and configures each io_uring to have a maximum of two unbound workers, then:
… four workers will be spawned in total – two for each of the program threads. This is reflected by the owner thread ID present in the worker’s name (iou-wrk-<tid>).
So you might think – “It makes sense! Each thread has their own dedicated pool of I/O workers, which service all the io_uring instances operated by that thread.”
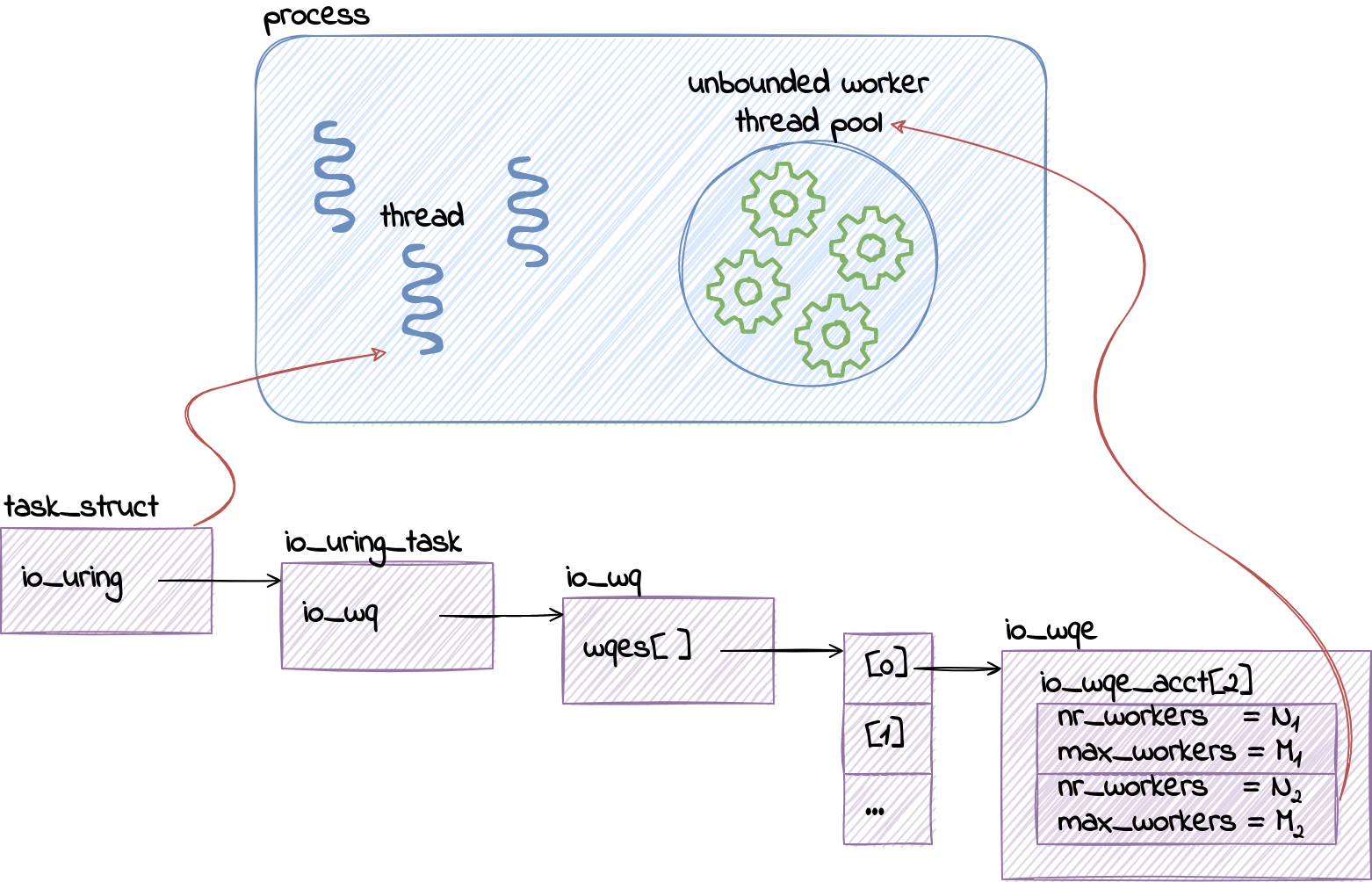
And you would be right1. If we follow the code – task_struct has an instance of io_uring_task, aka io_uring context for the task2. Inside the context, we have a reference to the io_uring work queue (struct io_wq), which is actually an array of work queue entries (struct io_wqe). More on why that is an array soon.
Moving down to the work queue entry, we arrive at the work queue accounting table (struct io_wqe_acct [2]), with one record for each type of work – bounded and unbounded. This is where io_uring keeps track of the worker pool limit (max_workers) the number of existing workers (nr_workers).
The perhaps not-so-obvious consequence of this arrangement is that setting just the RLIMIT_NPROC limit, without touching IORING_REGISTER_IOWQ_MAX_WORKERS, can backfire for multi-threaded programs.
See, when the maximum number of workers for an io_uring instance is not configured, it defaults to RLIMIT_NPROC. This means that io_uring will try to scale the unbounded worker pool to RLIMIT_NPROC for each thread that operates on an io_uring instance.
A multi-threaded process, by definition, creates threads. Now recall that the process management in the kernel tracks the number of tasks per UID within the user namespace. Each spawned thread depletes the quota set by RLIMIT_NPROC. As a consequence, io_uring will never be able to fully scale up the worker pool, and will burn the CPU trying to do so.
Lastly, there’s the case of NUMA systems with more than one memory node. io_uring documentation clearly says that IORING_REGISTER_IOWQ_MAX_WORKERS configures the maximum number of workers per NUMA node.
That is why, as we have seen, io_wq.wqes is an array. It contains one entry, struct io_wqe, for each NUMA node. If your servers are NUMA systems like Cloudflare, that is something to take into account.
Luckily, we don’t need a NUMA machine to experiment. QEMU happily emulates NUMA architectures. If you are hardcore enough, you can configure the NUMA layout with the right combination of -smp and -numa options.
But why bother when the libvirt provider for Vagrant makes it so simple to configure a 2 node / 4 CPU layout:
… we get just two workers on a machine with two NUMA nodes. Not the outcome we were hoping for.
Why are we not reaching the expected pool size of <max workers> × <# NUMA nodes> = 2 × 2 = 4 workers? And is it possible to make it happen?
Reading the code reveals that – yes, it is possible. However, for the per-node worker pool to be scaled up for a given NUMA node, we have to submit requests, that is, call io_uring_enter(), from a CPU that belongs to that node. In other words, the process scheduler and thread CPU affinity have a say in how many I/O workers will be created.
We can demonstrate the effect that jumping between CPUs and NUMA nodes has on the worker pool by operating two instances of io_uring. We already know that having more than one io_uring instance per thread does not impact the worker pool limit.
This time, however, we are going to ask the workload to pin itself to a particular CPU before submitting requests with the --cpu option – first it will run on CPU 0 to enter the first ring, then on CPU 2 to enter the second ring.
Voilà. We have reached the said limit of <max workers> x <# NUMA nodes>.
Outro
That is all for the very first installment of the Missing Manuals. io_uring has more secrets that deserve a write-up, like request ordering or handling of interrupted syscalls, so Missing Manuals might return soon.
In the meantime, please tell us what topic would you nominate to have a Missing Manual written?
Oh, and did I mention that if you enjoy putting cutting edge Linux APIs to use, we are hiring? Now also remotely 🌎.
_____
1And it probably does not make the users of runtimes that implement a hybrid threading model, like Golang, too happy. 2To the Linux kernel, processes and threads are just kinds of tasks, which either share or don’t share some resources.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.