Post Syndicated from Noritaka Sekiyama original https://aws.amazon.com/blogs/big-data/migrate-workloads-from-aws-data-pipeline/
AWS Data Pipeline helps customers automate the movement and transformation of data. With Data Pipeline, customers can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks. Launched in 2012, Data Pipeline predates several popular Amazon Web Services (AWS) offerings for orchestrating data pipelines such as AWS Glue, AWS Step Functions, and Amazon Managed Workflows for Apache Airflow (Amazon MWAA).
Data Pipeline has been a foundational service for getting customer off the ground for their extract, transform, load (ETL) and infra provisioning use cases. Some customers want a deeper level of control and specificity than possible using Data Pipeline. With the recent advancements in the data industry, customers are looking for a more feature-rich platform to modernize their data pipelines to get them ready for data and machine learning (ML) innovation. This post explains how to migrate from Data Pipeline to alternate AWS services to serve the growing needs of data practitioners. The option you choose depends on your current workload on Data Pipeline. You can migrate typical use cases of Data Pipeline to AWS Glue, Step Functions, or Amazon MWAA.
Note that you will need to modify the configurations and code in the examples provided in this post based on your requirements. Before starting any production workloads after migration, you need to test your new workflows to ensure no disruption to production systems.
Migrating workloads to AWS Glue
AWS Glue is a serverless data integration service that helps analytics users to discover, prepare, move, and integrate data from multiple sources. It includes tooling for authoring, running jobs, and orchestrating workflows. With AWS Glue, you can discover and connect to hundreds of different data sources and manage your data in a centralized data catalog. You can visually create, run, and monitor ETL pipelines to load data into your data lakes. Also, you can immediately search and query cataloged data using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
We recommend migrating your Data Pipeline workload to AWS Glue when:
- You’re looking for a serverless data integration service that supports various data sources, authoring interfaces including visual editors and notebooks, and advanced data management capabilities such as data quality and sensitive data detection.
- Your workload can be migrated to AWS Glue workflows, jobs (in Python or Apache Spark) and crawlers (for example, your existing pipeline is built on top of Apache Spark).
- You need a single platform that can handle all aspects of your data pipeline, including ingestion, processing, transfer, integrity testing, and quality checks.
- Your existing pipeline was created from a pre-defined template on the AWS Management Console for Data Pipeline, such as exporting a DynamoDB table to Amazon S3, or importing DynamoDB backup data from S3, and you’re looking for the same template.
- Your workload doesn’t depend on a specific Hadoop ecosystem application such as Apache Hive.
- Your workload doesn’t require orchestrating on-premises servers, user-managed Amazon Elastic Compute Cloude (Amazon EC2) instances, or a user-managed Amazon EMR cluster.
Example: Migrate EmrActivity on EmrCluster to export DynamoDB tables to S3
One of the most common workloads on Data Pipeline is to backup Amazon DynamoDB tables to Amazon Simple Storage Service (Amazon S3). Data Pipeline has a pre-defined template named Export DynamoDB table to S3 to export DynamoDB table data to a given S3 bucket.

The template uses EmrActivity (named TableBackupActivity) which runs on EmrCluster (named EmrClusterForBackup) and backs up data on DynamoDBDataNode to S3DataNode.
You can migrate these pipelines to AWS Glue because it natively supports reading from DynamoDB.
To define an AWS Glue job for the preceding use case:
- Open the AWS Glue console.
- Choose ETL jobs.
- Choose Visual ETL.
- For Sources, select Amazon DynamoDB.
- On the node
Data source - DynamoDB, for DynamoDB source, select Choose the DynamoDB table directly, then select your source DynamoDB table from the menu. - For Connection options, enter
s3.bucketanddynamodb.s3.prefix. - Choose
+(plus) to add a new node. - For Targets, select Amazon S3.
- On the node
Data target - S3 bucket, for Format, select your preferred format, for example, Parquet. - For S3 Target location, enter your destination S3 path.
- On Job details tab, select IAM role. In case you do not have the IAM role, follow Configuring IAM permissions for AWS Glue.
- Choose Save and Run.

Your AWS Glue job has been successfully created and started.
You might notice that there is no property to manage read I/O rate. It’s because the default DynamoDB reader used in Glue Studio does not scan the source DynamoDB table. Instead it uses DynamoDB export.
Example: Migrate EmrActivity on EmrCluster to import DynamoDB from S3
Another common workload on Data Pipeline is to restore DynamoDB tables using backup data on Amazon S3. Data Pipeline has a pre-defined template named Import DynamoDB backup data from S3 to import DynamoDB table data from a given S3 bucket.

The template uses EmrActivity (named TableLoadActivity) which runs on EmrCluster (named EmrClusterForLoad) and loads data from S3DataNode to DynamoDBDataNode.
You can migrate these pipelines to AWS Glue because it natively supports writing to DynamoDB.
Prerequisites are to create a destination DynamoDB table and catalog it on Glue Data Catalog using Glue crawler, Glue console, or the API.
- Open the AWS Glue console.
- Choose ETL jobs.
- Choose Visual ETL.
- For Sources, select Amazon S3.
- On the node
Data source - S3 bucket, for S3 URL, enter your S3 path. - Choose
+(plus) to add a new node. - For Targets, select AWS Glue Data Catalog.
- On the node
Data target - Data Catalog, for Database, select your destination database on Data Catalog. - For Table, select your destination table on Data Catalog.
- On Job details tab, select IAM role. In case you do not have the IAM role, follow Configuring IAM permissions for AWS Glue.
- Choose Save and Run.

Your AWS Glue job has been successfully created and started.
Migrating workloads to Step Functions
AWS Step Functions is a serverless orchestration service that lets you build workflows for your business-critical applications. With Step Functions, you use a visual editor to build workflows and integrate directly with over 11,000 actions for over 250 AWS services, including AWS Lambda, Amazon EMR, DynamoDB, and more. You can use Step Functions for orchestrating data processing pipelines, handling errors, and working with the throttling limits on the underlying AWS services. You can create workflows that process and publish machine learning models, orchestrate micro-services, as well as control AWS services, such as AWS Glue, to create ETL workflows. You also can create long-running, automated workflows for applications that require human interaction.
We recommend migrating your Data Pipeline workload to Step Functions when:
- You’re looking for a serverless, highly available workflow orchestration service.
- You’re looking for a cost-effective solution that charges at single-task granularity.
- Your workloads are orchestrating tasks for multiple AWS services, such as Amazon EMR, AWS Lambda, AWS Glue, or DynamoDB.
- You’re looking for a low-code solution that comes with a drag-and-drop visual designer for workflow creation and doesn’t require learning new programming concepts.
- You’re looking for a service that provides integrations with over 250 AWS services covering over 11,000 actions out-of-the-box, as well as allowing integrations with custom non-AWS services and activities.
- Both Data Pipeline and Step Functions use JSON format to define workflows. This allows you to store your workflows in source control, manage versions, control access, and automate with continuous integration and development (CI/CD). Step Functions use a syntax called Amazon State Language, which is fully based on JSON and allows a seamless transition between the textual and visual representations of the workflow.
- Your workload requires orchestrating on-premises servers, user-managed EC2 instances, or a user-managed EMR cluster.
With Step Functions, you can choose the same version of Amazon EMR that you’re currently using in Data Pipeline.
For migrating activities on Data Pipeline managed resources, you can use AWS SDK service integration on Step Functions to automate resource provisioning and cleaning up. For migrating activities on on-premises servers, user-managed EC2 instances, or a user-managed EMR cluster, you can install an SSM agent to the instance. You can initiate the command through the AWS Systems Manager Run Command from Step Functions. You can also initiate the state machine from the schedule defined in Amazon EventBridge.
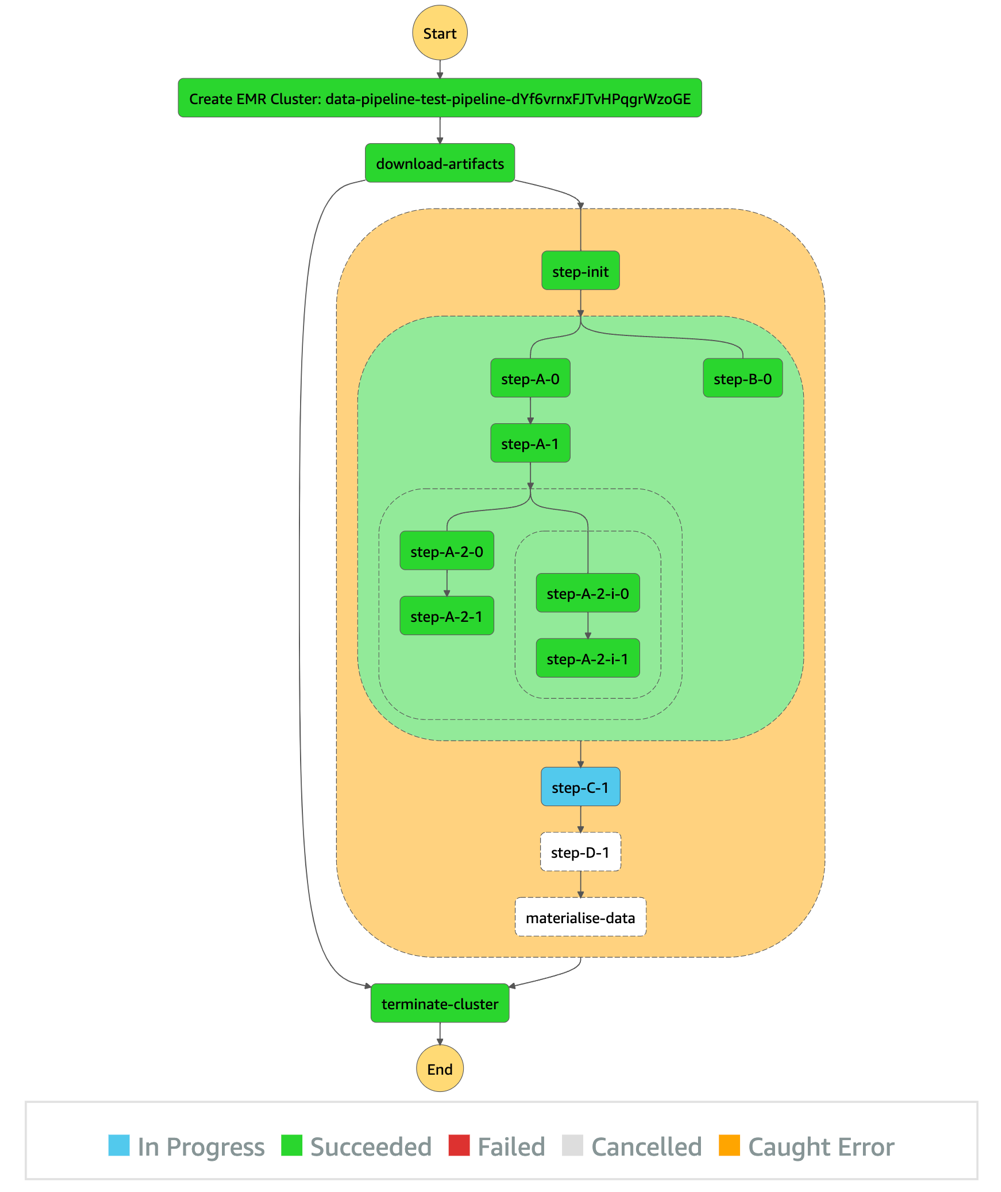
Example: Migrate HadoopActivity on EmrCluster
To migrate HadoopActivity on EmrCluster on Data Pipeline to Step Functions:
- Open the AWS Step Functions console.
- Choose State machines.
- Choose Create state machine.
- In the Choose a template wizard, search for
emr, select Manage an EMR job, and choose Select.


- For Choose how to use this template, select Build on it.
- Choose Use template.


- For Create an EMR cluster state, configure API Parameters based on the EMR release label, EMR capacity, IAM role, and so on based on the existing EmrClusternode configuration on Data Pipeline.


- For Run first step state, configure API Parameters based on the JAR file and arguments based on the existing HadoopActivity node configuration on Data Pipeline.
- If you have further activities configured on the existing HadoopActivity, repeat step 8.
- Choose Create.
Your state machine has been successfully configured. Learn more in Manage an Amazon EMR Job.
Migrating workloads to Amazon MWAA
Amazon MWAA is a managed orchestration service for Apache Airflow that lets you use the Apache Airflow platform to set up and operate end-to-end data pipelines in the cloud at scale. Apache Airflow is an open-source tool used to programmatically author, schedule, and monitor sequences of processes and tasks referred to as workflows. Apache Airflow brings in new concepts like executors, pools, and SLAs that provide you with superior data orchestration capabilities. With Amazon MWAA, you can use Airflow and Python programming language to create workflows without having to manage the underlying infrastructure for scalability, availability, and security. Amazon MWAA automatically scales its workflow runtime capacity to meet your needs and is integrated with AWS security services to help provide you with fast and secure access to your data.
We recommend migrating your Data Pipeline workloads to Amazon MWAA when:
- You’re looking for a managed, highly available service to orchestrate workflows written in Python.
- You want to transition to a fully managed, widely adopted open source technology—Apache Airflow—for maximum portability.
- You require a single platform that can handle all aspects of your data pipeline, including ingestion, processing, transfer, integrity testing, and quality checks.
- You’re looking for a service designed for data pipeline orchestration with features such as rich UI for observability, restarts for failed workflows, backfills, retries for tasks, and lineage support with OpenLineage.
- You’re looking for a service that comes with more than 1,000 pre-built operators and sensors, covering AWS as well as non-AWS services.
- Your workload requires orchestrating on-premises servers, user-managed EC2 instances, or a user-managed EMR cluster.
Amazon MWAA workflows are defined as directed acyclic graphs (DAGs) using Python, so you can also treat them as source code. Airflow’s extensible Python framework enables you to build workflows connecting with virtually any technology. It comes with a rich user interface for viewing and monitoring workflows and can be easily integrated with version control systems to automate the CI/CD process. With Amazon MWAA, you can choose the same version of Amazon EMR that you’re currently using in Data Pipeline.
Example: Migrate HadoopActivity on EmrCluster
Complete the following steps in case you do not have existing MWAA environments:
- Create an AWS CloudFormation template on your computer by copying the template from the quick start guide into a local text file.
- On the CloudFormation console, choose Stacks in the navigation pane.
- Choose Create stack with the option With new resources (standard).
- Choose Upload a template file and select the local template file.
- Choose Next.
- Complete the setup steps, entering a name for the environment, and leave the rest of the parameters as default.
- On the last step, acknowledge that resources will be created and choose Submit.
The creation can take 20–30 minutes, until the status of the stack changes to CREATE_COMPLETE. The resource that will take the most time is the Airflow environment. While it’s being created, you can continue with the following steps, until you’re required to open the Airflow UI.
An Airflow workflow is based on a DAG, which is defined by a Python file that programmatically specifies the different tasks involved and its interdependencies. Complete the following scripts to create the DAG:
- Create a local file named
emr_dag.pyusing a text editor with following snippets, and configure the EMR related parameters based on the existing Data Pipeline definition:
Defining the schedule in Amazon MWAA is as simple as updating the schedule_interval parameter for the DAG. For example, to run the DAG daily, set schedule_interval='@daily'.
Now, you create a workflow that invokes the Amazon EMR step you just created:
- On the Amazon S3 console, locate the bucket created by the CloudFormation template, which will have a name starting with the name of the stack followed by
-environmentbucket-(for example,myairflowstack-environmentbucket-ap1qks3nvvr4). - Inside that bucket, create a folder called
dags, and inside that folder, upload the DAG fileemr_dag.pythat you created in the previous section. - On the Amazon MWAA console, navigate to the environment you deployed with the CloudFormation stack.
If the status is not yet Available, wait until it reaches that state. It shouldn’t take longer than 30 minutes after you deployed the CloudFormation stack.
- Choose the environment link on the table to see the environment details.
It’s configured to pick up DAGs from the bucket and folder you used in the previous steps. Airflow will monitor that folder for changes.
- Choose Open Airflow UI to open a new tab accessing the Airflow UI, using the integrated IAM security to sign you in.

If there are issues with the DAG file you created, it will display an error on top of the page indicating the lines affected. In that case, review the steps and upload again. After a few seconds, it will parse it and update or remove the error banner.
Clean up
After you migrate your existing Data Pipeline workload and verify that the migration was successful, delete your pipelines in Data Pipeline to stop further runs and billing.
Conclusion
In this blog post, we outlined a few alternate AWS services for migrating your existing Data Pipeline workloads. You can migrate to AWS Glue to run and orchestrate Apache Spark applications, AWS Step Functions to orchestrate workflows involving various other AWS services, or Amazon MWAA to help manage workflow orchestration using Apache Airflow. By migrating, you will be able to run your workloads with a broader range of data integration functionalities. If you have additional questions, post in the comments or read about migration examples in our documentation.
About the authors
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team and AWS Data Pipeline team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team and AWS Data Pipeline team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
 Vaibhav Porwal is a Senior Software Development Engineer on the AWS Glue and AWS Data Pipeline team. He is working on solving problems in orchestration space by building low cost, repeatable, scalable workflow systems that enables customers to create their ETL pipelines seamlessly.
Vaibhav Porwal is a Senior Software Development Engineer on the AWS Glue and AWS Data Pipeline team. He is working on solving problems in orchestration space by building low cost, repeatable, scalable workflow systems that enables customers to create their ETL pipelines seamlessly.
 Sriram Ramarathnam is a Software Development Manager on the AWS Glue and AWS Data Pipeline team. His team works on solving challenging distributed systems problems for data integration across AWS serverless and serverfull compute offerings.
Sriram Ramarathnam is a Software Development Manager on the AWS Glue and AWS Data Pipeline team. His team works on solving challenging distributed systems problems for data integration across AWS serverless and serverfull compute offerings.
 Matt Su is a Senior Product Manager on the AWS Glue team and AWS Data Pipeline team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytics services. In his spare time, he enjoys skiing and gardening.
Matt Su is a Senior Product Manager on the AWS Glue team and AWS Data Pipeline team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytics services. In his spare time, he enjoys skiing and gardening.