Post Syndicated from Vishal Naik original https://aws.amazon.com/blogs/architecture/deploy-llms-on-amazon-eks-using-vllm-deep-learning-containers/
Organizations face significant challenges when deploying large language models (LLMs) efficiently at scale. Key challenges include optimizing GPU resource utilization, managing network infrastructure, and providing efficient access to model weights.When running distributed inference workloads, organizations often encounter complexity in orchestrating model operations across multiple nodes. Common challenges include effectively distributing model components across available GPUs, coordinating seamless communication between processing units, and maintaining consistent performance with low latency and high throughput.
vLLM is an open source library for fast LLM inference and serving. The vLLM AWS Deep Learning Containers (DLCs) are optimized for customers deploying vLLMs on Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), and Amazon Elastic Kubernetes Service (Amazon EKS), and are provided at no additional charge. These containers package a preconfigured, pre-tested environment that functions seamlessly out of the box, includes the necessary dependencies such as drivers and libraries for running vLLMs efficiently, and offers built-in support for Elastic Fabric Adapter (EFA) for high-performance multi-node inference workloads. You don’t have to build the inference environment from scratch anymore. Instead, you can install the vLLM DLC and it will automatically set up and configure the environment, and you can start deploying the inference workloads at scale.
In this post, we demonstrate how to deploy the DeepSeek-R1-Distill-Qwen-32B model using AWS DLCs for vLLMs on Amazon EKS, showcasing how these purpose-built containers simplify deployment of this powerful open source inference engine. This solution can help you solve the complex infrastructure challenges of deploying LLMs while maintaining performance and cost-efficiency.
AWS DLCs
AWS DLCs provide generative AI practitioners with optimized Docker environments to train and deploy generative AI models in their pipelines and workflows across Amazon EC2, Amazon EKS, and Amazon ECS. AWS DLCs are targeted for self-managed machine learning (ML) customers who prefer to build and maintain their AI/ML environments on their own, want instance-level control over their infrastructure, and manage their own training and inference workloads. DLCs are available as Docker images for training and inference, and also with PyTorch and TensorFlow.DLCs are kept current with the latest version of frameworks and drivers, are tested for compatibility and security, and are offered at no additional cost. They are also quickly customizable by following our recipe guides. Using AWS DLCs as a building block for generative AI environments reduces the burden on operations and infrastructure teams, lowers TCO for AI/ML infrastructure, accelerates the development of generative AI products, and helps the generative AI teams focus on the value-added work of deriving generative AI-powered insights from the organization’s data.
Solution overview
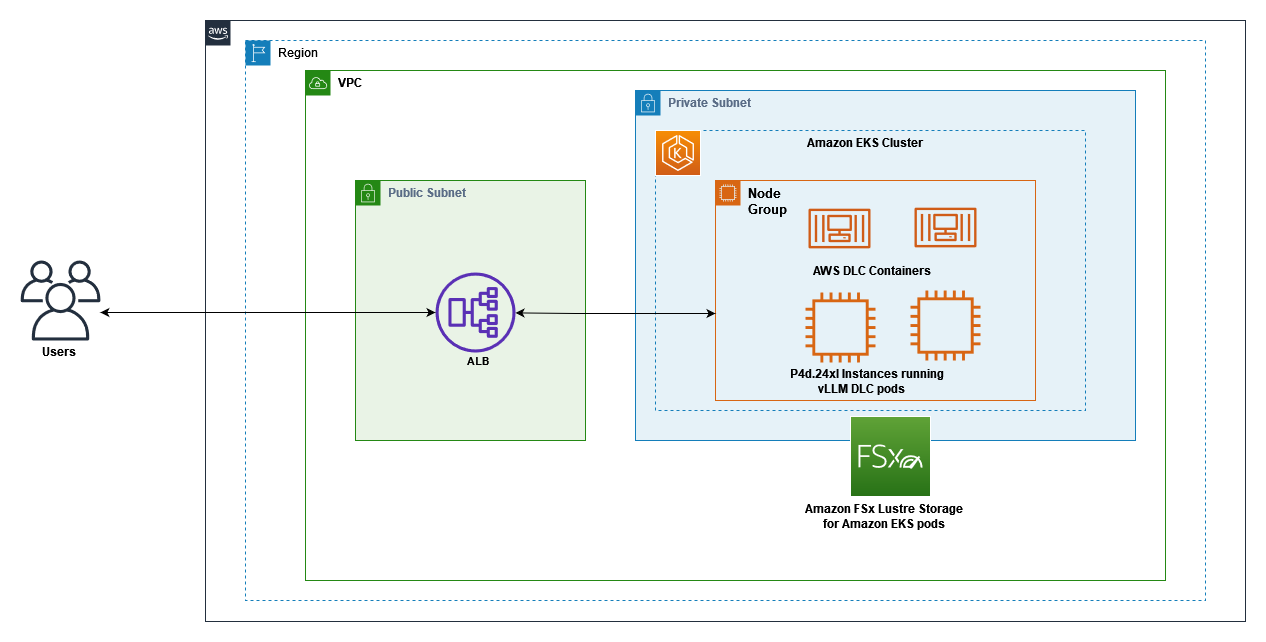
The following diagram shows the interaction between Amazon EKS, GPU-enabled EC2 instances with EFA networking, and Amazon FSx for Lustre storage. Client requests flow through the Application Load Balancer (ALB) to the vLLM server pods running on EKS nodes, which access model weights stored on FSx for Lustre. This architecture provides a scalable, high-performance solution for serving LLM inference workloads with optimal cost-efficiency.
The following diagram illustrates the DLC stack on AWS. The stack demonstrates a comprehensive architecture from EC2 instance foundation through container runtime, essential GPU drivers, and ML frameworks like PyTorch. The layered diagram shows how CUDA, NCCL, and other critical components integrate to support high-performance deep learning workloads.
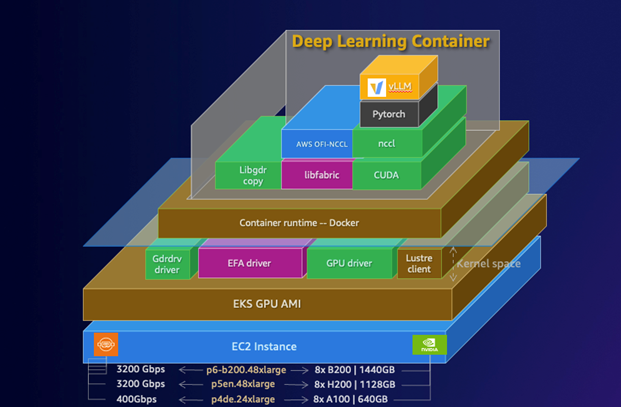
The vLLM DLCs are specifically optimized for high-performance inference, with built-in support for tensor parallelism and pipeline parallelism across multiple GPUs and nodes. This optimization enables efficient scaling of large models like DeepSeek-R1-Distill-Qwen-32B, which would otherwise be challenging to deploy and manage. The containers also include optimized CUDA configurations and EFA drivers, facilitating maximum throughput for distributed inference workloads. This solution uses the following AWS services and components:
- AWS DLCs for vLLMs – Pre-configured, optimized Docker images that simplify deployment and maximize performance
- EKS cluster – Provides the Kubernetes control plane for orchestrating containers
- P4d.24xlarge instances – EC2 P4d instances with 8 NVIDIA A100 GPUs each, configured in a managed node group
- Elastic Fabric Adapter – Network interface that enables high-performance computing applications to scale efficiently
- FSx for Lustre – High-performance file system for storing model weights
- LeaderWorkerSet pattern – Custom Kubernetes resource for deploying vLLM in a distributed configuration
- AWS Load Balancer Controller – Manages the ALB for external access
By combining these components, we create an inference system that delivers low-latency, high-throughput LLM serving capabilities with minimal operational overhead.
Prerequisites
Before getting started, make sure you have the following prerequisites:
- An AWS account with access to EC2 P4 instances (you might need to request a quota increase)
- Access to a terminal that has the following tools installed:
- An AWS CLI profile (vllm-profile) configured with an AWS Identity and Access Management (IAM) role or user that has the following permissions:
- Create, manage, and delete EKS clusters and node groups (see Create a Kubernetes cluster on the AWS Cloud for more details)
- Create, manage, and delete EC2 resources, including virtual private clouds (VPCs), subnets, security groups, and internet gateways (see Identity-based policies for Amazon EC2 for more details)
- Create and manage IAM roles (see Identity-based policies and resource-based policies for more details)
- Create, update, and delete AWS CloudFormation stacks
- Create, delete, and describe FSx file systems (see Identity and access management for Amazon FSx for Lustre for more details)
- Create and manage Elastic Load Balancers
This solution can be deployed in AWS Regions where Amazon EKS, P4d instances, and FSx for Lustre are available. This guide uses the us-west-2 Region. The complete deployment process takes approximately 60–90 minutes.
Clone our GitHub repository containing the necessary configuration files:
Create an EKS cluster
First, we create an EKS cluster in the us-west-2 Region using the provided configuration file. This sets up the Kubernetes control plane that will orchestrate our containers. The cluster is configured with a VPC, subnets, and security groups optimized for running GPU workloads.
This will take approximately 15–20 minutes to complete. During this time, eksctl creates a CloudFormation stack that provisions the necessary resources for your EKS cluster, as shown in the following screenshot.
You can validate the cluster creation with the following code:
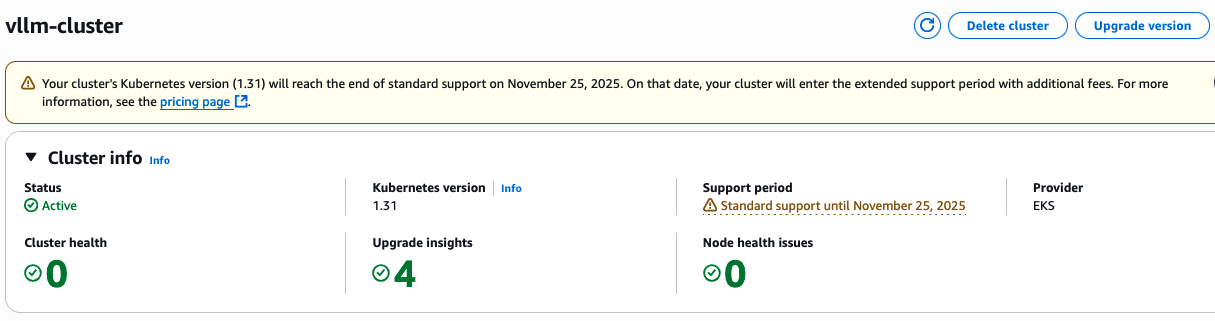
You can also see the cluster created on the Amazon EKS console.
Create a node group with EFA support
Next, we create a managed node group with P4d.24xlarge instances that have EFA enabled. These instances are equipped with 8 NVIDIA A100 GPUs each, providing substantial computational power for LLM inference. When deploying EFA-enabled instances like p4d.24xlarge for high-performance ML workloads, you must place them in private subnets to facilitate secure, optimized networking. By dynamically identifying and using a private subnet’s Availability Zone in your node group configuration, you can maintain proper network isolation while supporting the high-throughput, low-latency communication essential for distributed training and inference with LLMs. We identify the Availability Zone using the following code:
This will take approximately 10–15 minutes to complete. The EFA configuration is particularly important for multi-node deployments, because it enables high-throughput, low-latency networking between nodes. This is crucial for distributed inference workloads where communication between GPUs on different nodes can become a bottleneck. After the node group is created, configure kubectl to connect to the cluster:
Verify that the nodes are ready:
The following is an example of the expected output:
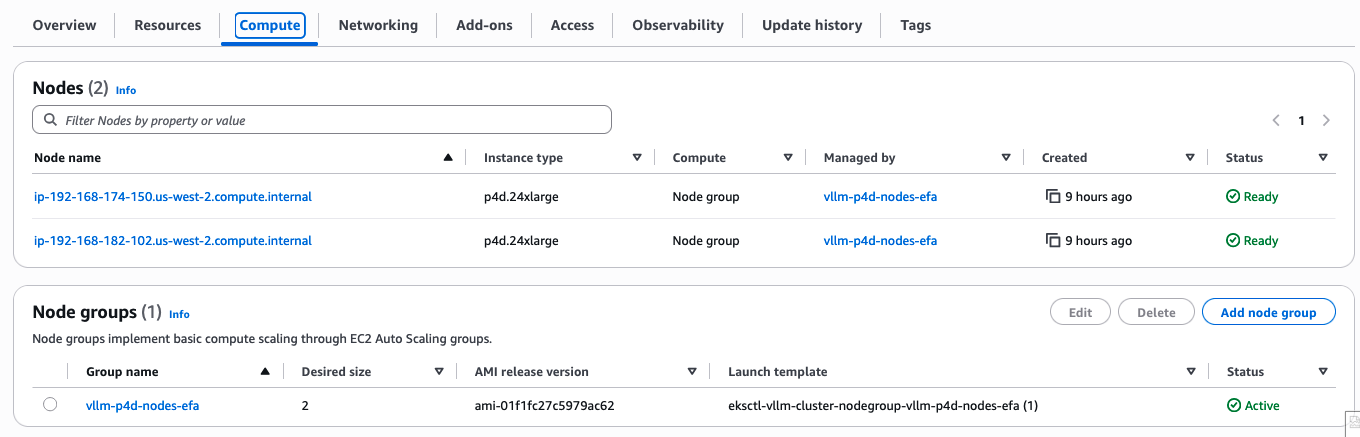
You can also see the node group created on the Amazon EKS console.
Check NVIDIA device pods
Because we’re using an Amazon EKS optimized AMI with GPU support (ami-0ad09867389dc17a1), the NVIDIA device plugin is already included in the cluster, so there’s no need to install it separately. Verify that the NVIDIA device plugin is running:
The following is an example of the expected output:
Verify that GPUs are available in the cluster:
The following is our expected output:
Create an FSx for Lustre file system
For optimal performance, we create an FSx for Lustre file system to store our model weights. FSx for Lustre provides high-throughput, low-latency access to data, which is essential for loading large model weights efficiently. We use the following code:
The file system is configured with 1.2 TB of storage capacity, SCRATCH_2 deployment type for high performance, and security groups that allow access from our EKS nodes. You can also check the FSx for Lustre file system on the FSx for Lustre console.

Install the AWS FSx CSI Driver
To mount the FSx for Lustre file system in our Kubernetes pods, we install the AWS FSx CSI Driver. This driver enables Kubernetes to dynamically provision and mount FSx for Lustre volumes.
Verify that the AWS FSx CSI Driver is running:
The following is an example of the expected output:
Create Kubernetes resources for FSx for Lustre
We create the necessary Kubernetes resources to use our FSx for Lustre file system:
Verify that the resources were created successfully:
The following is an example of the expected output:
These resources include:
- A StorageClass that defines how to provision FSx for Lustre volumes
- A PersistentVolume that represents our existing FSx for Lustre file system
- A PersistentVolumeClaim that our pods will use to mount the file system
Install the AWS Load Balancer Controller
To expose our vLLM service to the outside world, we install the AWS Load Balancer Controller. This controller manages ALBs for our Kubernetes services and ingresses. Refer to Install AWS Load Balancer Controller with Helm for addition details.
Verify that the AWS Load Balancer Controller is running:
Configure security groups for the ALB
We create a dedicated security group for the ALB and configure it to allow inbound traffic on port 80 from our client IP addresses. We also configure the node security group to allow traffic from the ALB security group to the vLLM service port.
Verify that the security groups were created and configured correctly:
Deploy the vLLM server
Finally, we deploy the vLLM server using the LeaderWorkerSet pattern. The AWS DLCs provide an optimized environment that minimizes the complexity typically associated with deploying LLMs.The vLLM DLCs come preconfigured with the following features:
- Optimized CUDA libraries for maximum GPU utilization
- EFA drivers and configurations for high-speed node-to-node communication
- Ray framework setup for distributed computing
- Performance-tuned vLLM installation with support for tensor and pipeline parallelism
This prepackaged solution dramatically reduces deployment time, the need for complex environment setup, dependency management, and performance tuning that would otherwise require specialized expertise.
The deployment will start immediately, but the pod might remain in ContainerCreating state for several minutes (5–15 minutes) while it pulls the large GPU-enabled container image. After the container starts, it will take additional time (10–15 minutes) to download and load the DeepSeek model.You can monitor the progress with the following code:
The following is the expected output when pods are running:
We also deploy an ingress resource that configures the ALB to route traffic to our vLLM service:
You can check the status of the ingress with the following code:
The following is an example of the expected output:
Test the deployment
When the deployment is complete, we can test our vLLM server. It provides the following API endpoints:
- /v1/completions – For text completions
- /v1/chat/completions – For chat completions
- /v1/embeddings – For generating embeddings
- /v1/models – For listing available models
The following is an example of the expected output:
You can also test the chat completions API:
If you encounter errors, check the logs of the vLLM pods:
Performance considerations
In this section, we discuss different performance considerations.
Elastic Fabric Adapter
EFA provides significant performance benefits for distributed inference workloads:
- Reduced latency – Lower and more consistent latency for communication between GPUs across nodes
- Higher throughput – Higher throughput for data transfer between nodes
- Improved scaling – Better scaling efficiency across multiple nodes
- Better performance – Significantly improved performance for distributed inference workloads
FSx for Lustre integration
Using FSx for Lustre for model storage provides several benefits:
- Persistent storage – Model weights are stored on the FSx for Lustre file system and persist across pod restarts
- Faster loading – After the initial download, model loading is much faster
- Shared storage – Multiple pods can access the same model weights
- High performance – FSx for Lustre provides high-throughput, low-latency access to the model weights
Application Load Balancer
Using the AWS Load Balancer Controller with ALB provides several advantages:
- Path-based routing – ALB supports routing traffic to different services based on the URL path
- SSL/TLS termination – ALB can handle SSL/TLS termination, reducing the load on your pods
- Authentication – ALB supports authentication through Amazon Cognito or OIDC
- AWS WAF – ALB can be integrated with AWS WAF for additional security
- Access logs – ALB can log the requests to an Amazon Simple Storage Service (Amazon S3) bucket for auditing and analysis
Clean up
To avoid incurring additional charges, clean up the resources created in this post. Run the provided ./cleanup.sh script to clean the Kubernetes resources (ingress, LeaderworkerSet, PersistentVolumeClaim, PersistentVolume, AWS Load Balancer Controller, and storage class), IAM resources, the FSX for Lustre file system, and the EKS cluster:
For more detailed cleanup instructions, including troubleshooting CloudFormation stack deletion failures, refer to the README.md file in the GitHub repository.
Conclusion
In this post, we demonstrated how to deploy the DeepSeek-R1-Distill-Qwen-32B model on Amazon EKS using vLLMs, with GPU support, EFA, and FSx for Lustre integration. This architecture provides a scalable, high-performance system for serving LLM inference workloads.AWS Deep Learning Containers for vLLM provide a streamlined, optimized environment that simplifies LLM deployment by minimizing the complexity of environment configuration, dependency management, and performance tuning. By using these preconfigured containers, organizations can reduce deployment timelines and focus on deriving value from their LLM applications.By combining AWS DLCs with Amazon EKS, P4d instances with NVIDIA A100 GPUs, EFA, and FSx for Lustre, you can achieve optimal performance for LLM inference while maintaining the flexibility and scalability of Kubernetes.This solution helps organizations:
- Deploy LLMs efficiently at scale
- Optimize GPU resource utilization with container orchestration
- Improve networking performance between nodes with EFA
- Accelerate model loading with high-performance storage
- Provide a scalable, high performance inference API
The complete code and configuration files for this deployment are available in our GitHub repository. We encourage you to try it out and adapt it to your specific use case.