Post Syndicated from Ajay Vohra original https://aws.amazon.com/blogs/big-data/automate-secure-access-to-amazon-mwaa-environments-using-existing-openid-connect-single-sign-on-authentication-and-authorization/
Customers use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) to run Apache Airflow at scale in the cloud. They want to use their existing login solutions developed using OpenID Connect (OIDC) providers with Amazon MWAA; this allows them to provide a uniform authentication and single sign-on (SSO) experience using their adopted identity providers (IdP) across AWS services. For ease of use for end-users of Amazon MWAA, organizations configure a custom domain endpoint to their Apache Airflow UI endpoint. For teams operating and managing multiple Amazon MWAA environments, securing and customizing each environment is a repetitive but necessary task. Automation through infrastructure as code (IaC) can alleviate this heavy lifting to achieve consistency at scale.
This post describes how you can integrate your organization’s existing OIDC-based IdPs with Amazon MWAA to grant secure access to your existing Amazon MWAA environments. Furthermore, you can use the solution to provision new Amazon MWAA environments with the built-in OIDC-based IdP integrations. This approach allows you to securely provide access to your new or existing Amazon MWAA environments without requiring AWS credentials for end-users.
Overview of Amazon MWAA environments
Managing multiple user names and passwords can be difficult—this is where SSO authentication and authorization comes in. OIDC is a widely used standard for SSO, and it’s possible to use OIDC SSO authentication and authorization to access Apache Airflow UI across multiple Amazon MWAA environments.
When you provision an Amazon MWAA environment, you can choose public or private Apache Airflow UI access mode. Private access mode is typically used by customers that require restricting access from only within their virtual private cloud (VPC). When you use public access mode, the access to the Apache Airflow UI is available from the internet, in the same way as an AWS Management Console page. Internet access is needed when access is required outside of a corporate network.
Regardless of the access mode, authorization to the Apache Airflow UI in Amazon MWAA is integrated with AWS Identity and Access Management (IAM). All requests made to the Apache Airflow UI need to have valid AWS session credentials with an assumed IAM role that has permissions to access the corresponding Apache Airflow environment. For more details on the permissions policies needed to access the Apache Airflow UI, refer to Apache Airflow UI access policy: AmazonMWAAWebServerAccess.
Different user personas such as developers, data scientists, system operators, or architects in your organization may need access to the Apache Airflow UI. In some organizations, not all employees have access to the AWS console. It’s fairly common that employees who don’t have AWS credentials may also need access to the Apache Airflow UI that Amazon MWAA exposes.
In addition, many organizations have multiple Amazon MWAA environments. It’s common to have an Amazon MWAA environment setup per application or team. Each of these Amazon MWAA environments can be run in different deployment environments like development, staging, and production. For large organizations, you can easily envision a scenario where there is a need to manage multiple Amazon MWAA environments. Organizations need to provide secure access to all of their Amazon MWAA environments using their existing OIDC provider.
Solution Overview
The solution architecture integrates an existing OIDC provider to provide authentication for accessing the Amazon MWAA Apache Airflow UI. This allows users to log in to the Apache Airflow UI using their OIDC credentials. From a system perspective, this means that Amazon MWAA can integrate with an existing OIDC provider rather than having to create and manage an isolated user authentication and authorization through IAM internally.
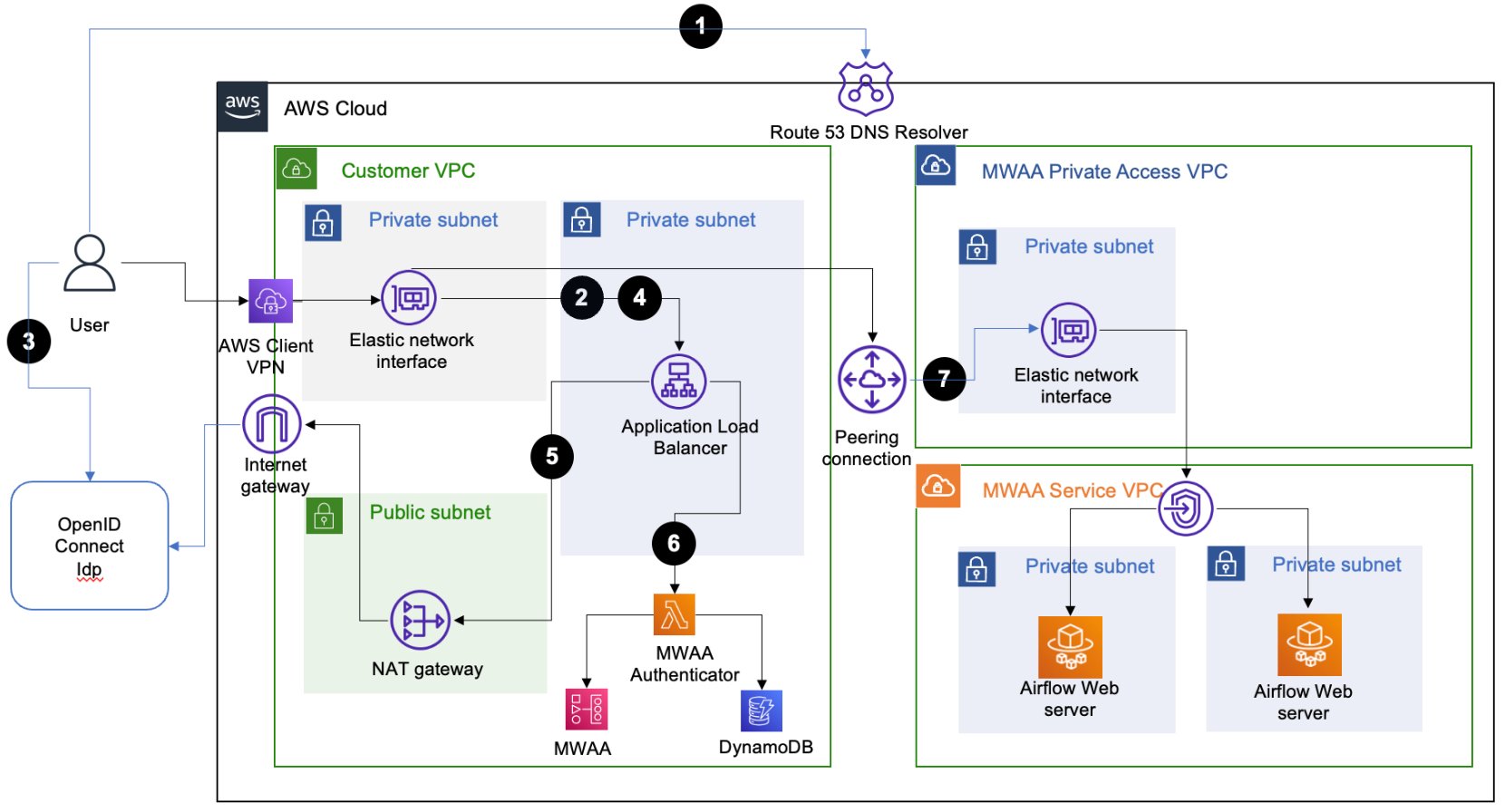
The solution architecture relies on an Application Load Balancer (ALB) setup with a fully qualified domain name (FQDN) with public (internet) or private access. This ALB provides SSO access to multiple Amazon MWAA environments. The user-agent (web browser) call flow for accessing an Apache Airflow UI console to the target Amazon MWAA environment includes the following steps:
- The user-agent resolves the ALB domain name from the Domain Name System (DNS) resolver.
- The user-agent sends a login request to the ALB path
/aws_mwaa/aws-console-ssowith a set of query parameters populated. The request uses the required parametersmwaa_envandrbac_roleas placeholders for the target Amazon MWAA environment and the Apache Airflow role-based access control (RBAC) role, respectively. - Once it receives the request, the ALB redirects the user-agent to the OIDC IdP authentication endpoint. The user-agent authenticates with the OIDC IdP with the existing user name and password.
- If user authentication is successful, the OIDC IdP redirects the user-agent back to the configured ALB with a
redirect_urlwith the authorization code included in the URL. - The ALB uses the authorization code received to obtain the
access_tokenand OpenID JWT token withopenid emailscope from the OIDC IdP. It then forwards the login request to the Amazon MWAA authenticator AWS Lambda function with the JWT token included in the request header in thex-amzn-oidc-dataparameter. - The Lambda function verifies the JWT token found in the request header using ALB public keys. The function subsequently authorizes the authenticated user for the requested
mwaa_envandrbac_rolestored in an Amazon DynamoDB table. The use of DynamoDB for authorization here is optional; the Lambda code functionis_allowedcan be customized to use other authorization mechanisms. - The Amazon MWAA authenticator Lambda function redirects the user-agent to the Apache Airflow UI console in the requested Amazon MWAA environment with the login token in the redirect URL. Additionally, the function provides the logout functionality.
Amazon MWAA public network access mode
For the Amazon MWAA environments configured with public access mode, the user agent uses public routing over the internet to connect to the ALB hosted in a public subnet.
The following diagram illustrates the solution architecture with a numbered call flow sequence for internet network reachability.

Amazon MWAA private network access mode
For Amazon MWAA environments configured with private access mode, the user agent uses private routing over a dedicated AWS Direct Connect or AWS Client VPN to connect to the ALB hosted in a private subnet.
The following diagram shows the solution architecture for Client VPN network reachability.
Automation through infrastructure as code
To make setting up this solution easier, we have released a pre-built solution that automates the tasks involved. The solution has been built using the AWS Cloud Development Kit (AWS CDK) using the Python programming language. The solution is available in our GitHub repository and helps you achieve the following:
- Set up a secure ALB to provide OIDC-based SSO to your existing Amazon MWAA environment with default Apache Airflow Admin role-based access.
- Create new Amazon MWAA environments along with an ALB and an authenticator Lambda function that provides OIDC-based SSO support. With the customization provided, you can define the number of Amazon MWAA environments to create. Additionally, you can customize the type of Amazon MWAA environments created, including defining the hosting VPC configuration, environment name, Apache Airflow UI access mode, environment class, auto scaling, and logging configurations.
The solution offers a number of customization options, which can be specified in the cdk.context.json file. Follow the setup instructions to complete the integration to your existing Amazon MWAA environments or create new Amazon MWAA environments with SSO enabled. The setup process creates an ALB with an HTTPS listener that provides the user access endpoint. You have the option to define the type of ALB that you need. You can define whether your ALB will be public facing (internet accessible) or private facing (only accessible within the VPC). It is recommended to use a private ALB with your new or existing Amazon MWAA environments configured using private UI access mode.
The following sections describe the specific implementation steps and customization options for each use case.
Prerequisites
Before you continue with the installation steps, make sure you have completed all prerequisites and run the setup-venv script as outlined within the README.md file of the GitHub repository.
Integrate to a single existing Amazon MWAA environment
If you’re integrating with a single existing Amazon MWAA environment, follow the guides in the Quick start section. You must specify the same ALB VPC as that of your existing Amazon MWAA VPC. You can specify the default Apache Airflow RBAC role that all users will assume. The ALB with an HTTPS listener is configured within your existing Amazon MWAA VPC.
Integrate to multiple existing Amazon MWAA environments
To connect to multiple existing Amazon MWAA environments, specify only the Amazon MWAA environment name in the JSON file. The setup process will create a new VPC with subnets hosting the ALB and the listener. You must define the CIDR range for this ALB VPC such that it doesn’t overlap with the VPC CIDR range of your existing Amazon MWAA VPCs.
When the setup steps are complete, implement the post-deployment configuration steps. This includes adding the ALB CNAME record to the Amazon Route 53 DNS domain.
For integrating with Amazon MWAA environments configured using private access mode, there are additional steps that need to be configured. These include configuring VPC peering and subnet routes between the new ALB VPC and the existing Amazon MWAA VPC. Additionally, you need to configure network connectivity from your user-agent to the private ALB endpoint resolved by your DNS domain.
Create new Amazon MWAA environments
You can configure the new Amazon MWAA environments you want to provision through this solution. The cdk.context.json file defines a dictionary entry in the MwaaEnvironments array. Configure the details that you need for each of the Amazon MWAA environments. The setup process creates an ALB VPC, ALB with an HTTPS listener, Lambda authorizer function, DynamoDB table, and respective Amazon MWAA VPCs and Amazon MWAA environments in them. Furthermore, it creates the VPC peering connection between the ALB VPC and the Amazon MWAA VPC.
If you want to create Amazon MWAA environments with private access mode, the ALB VPC CIDR range specified must not overlap with the Amazon MWAA VPC CIDR range. This is required for the automatic peering connection to succeed. It can take between 20–30 minutes for each Amazon MWAA environment to finish creating.
When the environment creation processes are complete, run the post-deployment configuration steps. One of the steps here is to add authorization records to the created DynamoDB table for your users. You need to define the Apache Airflow rbac_role for each of your end-users, which the Lambda authorizer function matches to provide the requisite access.
Verify access
Once you’ve completed with the post-deployment steps, you can log in to the URL using your ALB FQDN. For example, If your ALB FQDN is alb-sso-mwaa.example.com, you can log in to your target Amazon MWAA environment, named Env1, assuming a specific Apache Airflow RBAC role (such as Admin), using the following URL: https://alb-sso-mwaa.example.com/aws_mwaa/aws-console-sso?mwaa_env=Env1&rbac_role=Admin. For the Amazon MWAA environments that this solution created, you need to have appropriate Apache Airflow rbac_role entries in your DynamoDB table.
The solution also provides a logout feature. To log out from an Apache Airflow console, use the normal Apache Airflow console logout. To log out from the ALB, you can, for example, use the URL https://alb-sso-mwaa.example.com/logout.
Clean up
Follow the readme documented steps in the section Destroy CDK stacks in the GitHub repo, which shows how to clean up the artifacts created via the AWS CDK deployments. Remember to revert any manual configurations, like VPC peering connections, that you might have made after the deployments.
Conclusion
This post provided a solution to integrate your organization’s OIDC-based IdPs with Amazon MWAA to grant secure access to multiple Amazon MWAA environments. We walked through the solution that solves this problem using infrastructure as code. This solution allows different end-user personas in your organization to access the Amazon MWAA Apache Airflow UI using OIDC SSO.
To use the solution for your own environments, refer to Application load balancer single-sign-on for Amazon MWAA. For additional code examples on Amazon MWAA, refer to Amazon MWAA code examples.
About the Authors
 Ajay Vohra is a Principal Prototyping Architect specializing in perception machine learning for autonomous vehicle development. Prior to Amazon, Ajay worked in the area of massively parallel grid-computing for financial risk modeling.
Ajay Vohra is a Principal Prototyping Architect specializing in perception machine learning for autonomous vehicle development. Prior to Amazon, Ajay worked in the area of massively parallel grid-computing for financial risk modeling.
 Jaswanth Kumar is a customer-obsessed Cloud Application Architect at AWS in NY. Jaswanth excels in application refactoring and migration, with expertise in containers and serverless solutions, coupled with a Masters Degree in Applied Computer Science.
Jaswanth Kumar is a customer-obsessed Cloud Application Architect at AWS in NY. Jaswanth excels in application refactoring and migration, with expertise in containers and serverless solutions, coupled with a Masters Degree in Applied Computer Science.
 Aneel Murari is a Sr. Serverless Specialist Solution Architect at AWS based in the Washington, D.C. area. He has over 18 years of software development and architecture experience and holds a graduate degree in Computer Science. Aneel helps AWS customers orchestrate their workflows on Amazon Managed Apache Airflow (MWAA) in a secure, cost effective and performance optimized manner.
Aneel Murari is a Sr. Serverless Specialist Solution Architect at AWS based in the Washington, D.C. area. He has over 18 years of software development and architecture experience and holds a graduate degree in Computer Science. Aneel helps AWS customers orchestrate their workflows on Amazon Managed Apache Airflow (MWAA) in a secure, cost effective and performance optimized manner.
 Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.
Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.