Post Syndicated from Michael Conterio original https://www.raspberrypi.org/blog/how-to-create-educational-video-content-computing-computer-science/
Over the past five years, we’ve made lots of online educational video content for our online courses, for our Isaac Computer Science platform for GCSE and A level, and for our remote lessons based on our Teach Computing Curriculum hosted on Oak National Academy.
We have learned a lot from experience and from learner feedback, and we want to share this knowledge with others. We’re also aware there’s always more to learn from people across the computing education community. That’s one reason we’re continually working to broaden the range of educators we work with. Another is that we want all learners to see themselves represented in our educational materials, because everyone belongs in computer science.

To make progress with all these goals, we ran a pilot programme for educators called Teach Online at the end of 2021 and the start of 2022. Through Teach Online, we provided twelve educators with training, opportunities, and financial and material support to help them with creating online educational content, particularly videos.
Over five online sessions and a final in-person day, we trained them in not only the production of educational videos, but also some of the pedagogy behind it. The pilot programme has now finished, and we thought we’d share some of the key points from the sessions with you in the wider community.
Learning to create a great online learning experience
When you learn new skills and knowledge, it’s important to think about how you apply these. For this reason, a useful question you can use throughout the learning process is “Why?”. So as you think about how to create the best online learning experience, ask yourself in different contexts throughout the content design and production:
- Why am I using this style of video to illustrate this topic?
- Why am I presenting these ideas in this order?
- Why am I using this choice of words?
For example, it’s easy to default to creating ‘talking head’ videos featuring one person talking directly to the camera. But you should always ask why — what are the reasons for using a ‘talking head’ style. Instead, or in addition, you can make videos more engaging and support the learning experience by:
- Turning the video into an interview
- Adding other camera angles or screencasts to focus on demonstrations
- Cutting away to B-roll footage (additional video that can provide context or related action, while the voiceover continues) or to still images that help connect a concept to concrete examples
Planning is key
By planning your content carefully instead of jumping into production right away, you can:
- Better visualise what your video should look like by creating a storyboard
- Keep learners engaged by deliberately splitting learning up into smaller chunks while still keeping a narrative flow between them
- Develop your learners’ understanding of key computing concepts by using semantic waves to unpack and repack concepts
The Teach Online participants told us that they particularly enjoyed learning more about planning videos:
“I now understand that a little planning can make the difference between a mediocre online learning experience and a professional-looking valuable learning experience.” – Educator who participated in our Teach Online programme
“Planning the session using a storyboard is so helpful to visualise the actual recording.” – Educator who participated in our Teach Online programme
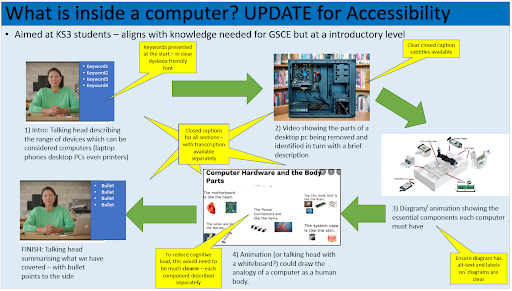
Considering equity, diversity, and inclusion
We are committed to making computing and computer science accessible and engaging, so we embed measures to improve equity, diversity, and inclusion throughout our free learning and teaching resources, including the Teach Online programme. It’s important not to leave this aspect of creating educational content as an afterthought: you can only make sure that your content is truly as equitable and inclusive as you can make it if you address this at every stage of your process. As an added bonus, many ways of making your content more accessible not only benefit learners with specific needs, but support and engage all of your audience so everyone can learn more easily.
Best practices that you can use while creating online content include:
- Reducing the detail on the screen at any one time, to reduce cognitive load
- Creating closed captions and transcripts for videos, and including informative alt text for images
- While modelling coding, explicitly leaving in moments where you make mistakes and need to fix them, to show that this is normal
Connecting with your learner audience
One of video’s key advantages is the ability to immediately connect with the audience. To help with that, you can try to talk directly to a single viewer, using “you” and “I” rather than “we”. You can also show off your personality in the presentation slides you use and the backgrounds of your videos.
“[I will use my learning from the programme] by adapting teaching and learning to actively engage learners.” – Educator who participated in our Teach Online programme
It’s important to find your own personal presenting style. There is not one perfect way to present, and you should experiment to find how you are best able to communicate with your viewers. How formal or informal will you be? Is your delivery calm or energetic? Whatever you decide, you may want to edit your script to better fit your style. A practical tip for doing this is to read your video scripts aloud while you are writing them to spot any language that feels awkward to you when spoken.
“It was really great to try the presenting skills, and I learned a lot about my style.” – Educator who participated in our Teach Online programme

Connecting with each other
Throughout the Teach Online programme, we helped participants create a community with each other. Finding your own community can give you the support that you need to create, and help you continue to develop your knowledge and skills. Working together is great, whether that’s collaborating in-person locally, or online via for example the CAS forums or social media.
“I very much liked the diverse group of educators in this programme, and appreciated everyone sharing their experiences and tips.” – Educator who participated in our Teach Online programme
The Teach Online graduate have told us about the positive impact the programme has had on their teaching in their own contexts. So far we’ve worked with graduates to create Isaac Computer Science videos covering data structures, high- and low-level languages, and string handling.
What do you want to know about creating online educational content?
There is a growing need for online educational content, particularly videos — not only to improve access to education, but also to support in-person teaching. By investing in training educators, we help diversify the pool of people working in this area, improve the confidence of those who would like to start, and provide them with the skills and knowledge to successfully create great content for their learners.
In the future we’d also like to support the wider community of educators with creating online educational content. What resources would you find useful? Share your thoughts in the comments section below.
The post How to create great educational video content for computing and beyond appeared first on Raspberry Pi.