No matter what business you’re in, there is one universal truth – your success or failure depends on customer satisfaction and trust. And when your IT systems fail, it’s your customers who pay the price. Being unable to place an order due to unexpected downtime (which can cost a large organization as much as $9,000 per minute) or having their credit card data compromised in a preventable security breach (which costs the average organization nearly $5 million) will force even your most loyal customers to go somewhere else.
Monitoring with Zabbix doesn’t just keep your infrastructure safe, it keeps your reputation safe and makes sure that your customers continue to be your customers. It does this by guaranteeing the performance, reliability, and security of your digital services – while also supporting better customer service and continuous improvement. Keep reading to see how it’s possible.
Table of Contents
Say goodbye to downtime
Your customers are looking to meet their needs quickly and effectively. Unexpected service disruptions cause them to feel neglected and force them to look elsewhere for solutions.
Monitoring your infrastructure with Zabbix can effectively eliminate downtime through proactive issue detection, which locates anomalies and performance issues like high CPU usage, packet loss, and latency in real time – before they have a chance to make life harder for customers.
If an issue does occur, Zabbix’s predictive alerting capabilities let your tech teams know about anything that could potentially impact an application or service, which lets them meet SLAs and provide a better, more reliable customer experience with fewer service disruptions, which in turns leads to higher levels of trust and satisfaction.
Outperform your competitors
No matter how good your products or services happen to be, you still need to provide smooth and fast online user experience if you want repeat use and positive reviews. Monitoring with Zabbix optimizes network traffic by helping you to identify bandwidth bottlenecks or misconfigured devices with a single glance at a dashboard, allowing better traffic management and a better online experience for customers.
It also improves response times, which allows you to be confident that your applications and services remain responsive. This is especially important for real-time services like video conferencing, e-commerce, or customer support.
Turn good customer service into outstanding customer service
What turns a casual, one-time user into a repeat customer? In most cases, it all comes down to making that user feel seen, informed, and supported. Zabbix helps you maintain consistent system performance, and nothing builds trust like stability.
With a bit of configuration and the help of IT service management tools like ServiceNow, Zabbix can provide clear, easy-to-access logs and metrics that help your customer service reps better understand your customers and the process of serving them, including:
• Customer satisfaction (CSAT)
• Preferred communication channel
• Average ticket count
• Average response time
• Average ticket resolution time
• Ticket resolution rate
• Ticket backlog
• Interactions per ticket
With this information, your team will be able to communicate proactively when issues happen, giving customers accurate information about the issue and the expected resolution time.
Keep your customers safe from cyber threats
The consequences of a data breach are deep and far-reaching, and they include financial losses, reputational damage, legal troubles, regulatory fines, and a loss of customer trust. Despite a greater emphasis on data security, hackers are constantly finding new ways to gain access to valuable corporate data and credentials by combining next-generation AI technologies with long-established tools.
Monitoring with Zabbix gives IT and security teams the visibility and early warning systems they need to spot and react to potential threats. Zabbix continuously monitors systems, networks, and applications for predefined thresholds and anomalies, identifying possible network intrusions or misconfigurations and notifying the relevant security stakeholders.
On top of that, Zabbix can monitor any existing security tools your team runs, tracking antivirus software, firewalls, IDS/IPS tools, and endpoint protection solutions to make sure they are functioning properly and running the latest versions. It can also integrate with SIEM systems (like Splunk, ELK, or Wazuh) as well as custom scripts in order to provide extended security analytics.
Meet (and exceed) your SLAs
Service Level Agreements (SLAs) are a framework for managing the expectations of both customers and businesses. They define agreed-on standards of service, but tracking them is more than just a way to measure compliance – it’s a tool that you can use to improve your overall service delivery and operations.
With Zabbix, you can monitor any quantifiable metric that’s relevant to your SLAs, such as system uptime/downtime, response time, the availability of web services, databases, or network devices, transaction success and failure rates, and much more. In addition, Zabbix can use real-time data and built-in SLA calculation to automatically calculate current SLA compliance and send an alert if an SLA is at risk of being breached, by using triggers based on thresholds.
If you’d rather track the metrics on your own, no problem – by using Zabbix dashboards, you can visualize SLA compliance in real-time, with the dashboards showing availability percentages, event timelines, and breach summaries, while giving you easy-to-understand views of service health. The result is better products and services that are aligned with customer expectations.
Build a continuous improvement culture
When it’s time to roll out a new feature or upgrade, you naturally want to have ALL the necessary data at your fingertips. Monitoring usage patterns and performance metrics with Zabbix not only gives you advanced visualizations (forecasting, capacity planning insights, etc.) but can also highlight cases where data analysis led to tangible improvements.
Want more input from customers and users? Zabbix can make sure that the improvements to your product are community-driven by giving you the data you need to run regular user surveys and forums to gather product feedback. It can even help you publish a public roadmap with transparent prioritization based on community input.
Conclusion
Customer satisfaction is about a lot more than just good service – it’s also about consistency, reliability, and transparency. Zabbix empowers businesses to deliver all three by providing a comprehensive, proactive, and scalable monitoring solution.
That’s why customers in verticals as diverse as aerospace and education turn to Zabbix to keep them informed about what’s working – and what isn’t. By integrating Zabbix into your IT operations, you’re not just improving system performance – you’re actively investing in customer satisfaction and loyalty.
Find out more about what Zabbix can do for you and your customers by taking a look at real-world case studies from companies like yours.
At the recent Zabbix Summit community meeting, participants gathered to discuss an exciting initiative – the creation of the first-ever community-driven Zabbix book. While several books about Zabbix have been published in the past (often written by individual authors over a decade ago), this project marks a new milestone. For the first time, Zabbix community members from around the world are coming together to co-author a book, share their expertise, and tell the Zabbix story from many perspectives.
What is the Zabbix Book?
The project, hosted at thezabbixbook.com, is an open, collaborative effort led by Nathan Liefting and Patrik Uytterhoeven from Opensource ICT Solutions B.V. The goal is to create a community-built guide to Zabbix, written by users, for users. As Zabbix trainers, Patrik and Nathan have both been long-time (don’t want to say old) contributors to the Zabbix community, authoring multiple books and blog posts.
The Zabbix Book will cover topics ranging from cloud templates and infrastructure monitoring to host triggers, Zabbix internals, SNMP, low-level discovery, multi-factor authentication, and much more. Each contributor can choose a specific chapter or topic that matches their expertise, making it a truly collective and flexible effort.
The content is managed on GitHub, written in Markdown, and follows open contribution principles. The aim is to complete the main foundation of the book alongside the release of Zabbix 8.0 LTS (expected in 2026, Q1/Q2), with an update to include new 8.0 features approximately a month later.
Why write a Zabbix Book when documentation exists?
While the official Zabbix documentation remains the primary source for technical accuracy, the Zabbix Book serves as an alternative and more narrative approach to learning, created by everyday Zabbix users. It’s designed to introduce new users to Zabbix through practical examples, real-world use cases, and community wisdom – making it easier for newcomers to connect the dots.
How the community works together
During the Summit breakout session, the group discussed:
• The current project status and foundational setup
• How contributions are managed — commits, rules, and legal aspects
• Missing topics and a call for more writers, editors, and translators
• Ideas for practical information and real-world examples (like JMX, SNMP, etc.)
• Donations and funding goals, including ideas for supporting open-source projects, good causes, or new Zabbix community features
The project embraces an open, democratic spirit – anyone can contribute, vote, or help improve the book’s structure, content, and readability. The Zabbix Book is created by the Monitoring Penmasters Foundation, which was created in order to make it a real community project – all the intellectual rights belong to the foundation itself, and when revenue is created there will be a vote on where to donate the money.
Currently, the Monitoring Penmasters foundation consists of Patrik, Nathan, and Zabbix CEO and Founder Alexei Vladishev, who is involved in the book’s review and has agreed to contribute to some parts of the book while allocating design resources from Zabbix itself.
The project has also gotten a big assist from Brian van Baekel of Opensource ICT Solutions, a dedicated community member and certified Zabbix trainer who has given his fair share of presentations and written extensively about Zabbix and its capabilities.
Get involved
If you’d like to contribute, share your expertise, or simply follow the book’s progress, visit thezabbixbook.com to explore the current chapters and learn how to join the project. The project’s digital chapters are available to everyone, and while the writing and printing are still in progress, we hope to see finalized online and printed versions in spring 2026.
It’s also worth remembering that even though the book is free to download and use, the creators do have costs and financial contributions are welcome – you can chip in here.
Together, we’re not just writing a book — we’re writing a piece of Zabbix community history!
Lab9 Pro is the B2B division of Lab9, Belgium’s leading Apple Premium Partner. With over 30 years of experience, Lab9 Pro specializes in integrating and supporting Apple systems within businesses, educational institutions, and public organizations. Beyond Apple expertise, Lab9 Pro also designs, implements, and maintains complete IT infrastructures, including networks, servers, storage, and security solutions.
The challenge
It’s impossible to manage devices at organizations without the use of a good MDM (Mobile Device Management) system such as Jamf. As the leading provider of Apple device management solutions, Jamf empowers organizations to deploy, manage, and secure Apple devices at scale.
Even in smaller organizations Jamf is the right solution, as small and medium-sized enterprises (SMEs) often lack the resources to manage their MDM systems. Offering an MSP model solves a lot of problems for these customers.
For Apple device management, the typical customer has a few certificates issued by Apple, which require approval of the user agreement by the Apple business or school manager. Without getting too technical about Apple Device management, depending on the customer the certificates need to be renewed on different dates. If the user agreement is not approved, automated device enrollment will stop working.
Lab9 Pro found themselves needing to check all certificates and user agreements for MSP customers manually, which involved an unacceptably high error rate that often caused discontinuity of the MDM system.
The solution
Lab9 Pro were already using Zabbix to monitor customer environments and their own infrastructure, including storage, firewalls, switches, and more. Because Zabbix offers a wide variety of options that make it possible to monitor almost anything, it was only logical to explore whether Zabbix could also be used to monitor the MDM certificates.
The research phase
Step one was to check the availability of certificate information. Unfortunately, Apple Business Manager’s API did not help much, as it does not provide certificate details. Instead, the team at Lab9 Pro investigated the Jamf API.
Although it doesn’t directly return certificate information either, they found something even more useful – Jamf’s API provides customer instance notifications. These include alerts when certificates (VPP, PUSH, DEP, etc.) are about to expire (typically 10 days in advance) as well as when the Device Enrollment Program (user agreement) is not approved.
Zabbix implementation
Since Lab9 Pro manages multiple MSP tenants, they created a dedicated Zabbix template. This template includes both pre-filled and empty macros:
Pre-filled macros:
• {$JAMF.AUTH.INTERVAL}: Interval for retrieving the bearer token
• {$JAMF.NOTIF.INTERVAL}: Interval for retrieving Jamf notifications
• {$JAMF.PATH.AUTH}: API path for retrieving the bearer token
• {$JAMF.PATH.NOTIFICATIONS}: API path for retrieving Jamf notifications
Empty macros:
• {$JAMF.URL}: Jamf URL
• {$JAMF.API.USER}: Jamf user account for authentication
• {$JAMF.API.PASSWORD}: Jamf password (stored as a secret value)
The team configured an item to perform an API call to retrieve the bearer token. A preprocessing rule in JavaScript stores this token in a variable. Discovery rules proved very useful for executing API calls to retrieve Jamf notifications using the bearer token. This was achieved by configuring preprocessing steps and Low-Level Discovery (LLD) macros to pass the Jamf URL and bearer token. Trigger prototypes for each certificate were also added within the same discovery rule.
The results
Whenever a certificate is nearing expiration, a problem is automatically displayed on Lab9 Pro’s Zabbix dashboard, which is visible on TV screens placed throughout their office in order to make sure the entire team is aware of upcoming certificate renewals.
Since Lab9 Pro began monitoring MDM certificates through the Jamf API, they have experienced zero expired certificates, which in turn has allowed them to avoid situations where devices become unmanaged and require a full setup again.
Zabbix makes it possible for Lab9 Pro to keep their clients’ MDM systems operational, while allowing them to either proactively inform them when certificates need to be renewed or handle the renewal process on their behalf.
Zabbix Summit 2025 is officially in the history books, so now is the perfect time for a casual, behind‑the‑scenes run‑through of what went down. If you were there, this should ring a few bells (or spark some “oh hey, I forgot about that” moments). If you couldn’t make it, consider this your own personal highlight reel!
Featuring approximately 550 attendees from 42 countries, the Summit took place from October 8-10 at the Radisson Blu Hotel Latvija in the heart of downtown Riga. The 13th in-person version of our premier yearly event was in many ways our biggest and boldest yet, and it included keynote sessions, two parallel tracks (including a developer track), workshops, hands-on sessions, training and certification exams, and a variety of evening social and networking events.
Open source, open house
On October 8, we welcomed nearly 100 guests to our brand-new headquarters for Zabbix Summit 2025’s Open House Day. The new facility gave us plenty of space to host everyone, and visitors got to explore our new HQ, take part in a fun quiz with Zabbix facts, and catch up with longtime colleagues while meeting new ones from the community and the Zabbix team.
Day 1: Looking ahead
The Summit officially kicked off with Zabbix Founder and CEO Alexei Vladishev’s keynote address, entitled “Zabbix 8.0: A New Chapter in Monitoring.” The address laid out in detail what’s around the corner for Zabbix, including:
Zabbix Academy – a new learning hub with self-paced, expert-built courses to boost Zabbix skills anytime and from anywhere.
Zabbix France – Zabbix is acquiring IZI-IT and opening a new office in France to provide localized support and closer collaboration with French clients and partners.
Zabbix Cloud – a host of new features, including automatic upgrades and backups, plus predictable pricing and simplified user management.
Zabbix 8.0 LTS (coming in 2026) – a major leap forward with APM and OpenTelemetry for end-to-end visibility, Complex Event Processing (CEP) and AI-based correlation, plus new UI & visualizations for a smoother experience.
Zabbix Mobile App – coming with 8.0 LTS for iOS & Android, the app will offer instant push notifications, issue management, collaboration, seamless connection with Zabbix Cloud, and multi-server views in your pocket.
Zabbix Marketplace (2026) – A new global space to connect Zabbix users with vendor and partner solutions, Zabbix Marketplace will extend the power of Zabbix beyond our core product.
Next up was initMAX Founder and CEO Tomáš Heřmánek, who showed how to turn physical sensor data from analog inputs into Zabbix metrics with budget hardware and integrations, complete with templates and triggers.
Another crowd-pleasing session reached the audience thanks to Richard Germanus of CANCOM, who shared the story of how CANCOM consolidated six monitoring systems into one, managing approximately 30,000 hosts, deploying 162 Zabbix proxies, standardizing templates, integrating Power BI for dashboards, automating with APIs, and offering monitoring-as-a-service.
Shortly thereafter, a lightning talk by SEB Bank’s Giedrius Stasiulionis explored “Monitoring Sounds with Zabbix” – in other words, converting audio and sound waves into meaningful metrics, a fresh and inventive notion.
The day’s other lightning talk, “Monitor Your Nearby Areas and Events with Zabbix” by longtime Summit fixture and Zabbix superfan Janne Pikkarainen, showed how anyone can use Zabbix to centralize event data like train timetables, traffic patterns, or cinema showtimes.
Developer track: Something for everyone
Meanwhile, the Summit Developer track was full of special sessions for builders and extension authors, such as “Extend Zabbix Agent 2 with Your Plugin”, which saw Senior Golang Developer Eriks Sneiders show an appreciative audience how Zabbix agent 2’s plugin architecture works, how to use existing plugins, and how to build brand-new custom ones.
Other topics in the Developer track included template design, advanced scripting, API tips, and internal tooling, giving Zabbix techies some food for thought and hopefully sparking a batch of fresh ideas!
Day 2: Showing the big picture
After a long first day and night, Zabbix Summit 2025’s special guest Dylan Beattie made some noise and woke everyone up with a talk entitled “Open Source, Open Mind: The Cost of Free Software.”
Dylan took the Summit audience on a journey through the history and philosophy of free and open source software, touching on questions about licensing issues, looking at the motivations of developers, discussing edge cases and challenges, and asking whether truly sustainable open-source ecosystems can exist.
Later, Inqbeo Founder Christian Anton shared a system in which a central Zabbix instance serves multiple tenants, with the architecture leveraging Kafka to stream metric data partitioned per tenant, storing results in S3 (in Prometheus format), and visualizing via Grafana. This enables isolation and the creation of custom dashboards.
Other main-stage sessions tackled topics like scaling Zabbix, managing large datasets, tag and template strategies, and AI/automation in monitoring.
Connecting people with the Community track
Zabbix Summit 2025 also introduced a Community track, a dedicated space at Zabbix where users, enthusiasts, and contributors could share ideas and shape the future of Zabbix. Instead of deeply technical or development-level presentations, this track focused on community-driven topics like integrations, templates, connectors, media types, and open resources.
A key highlight was the “Zabbix Book Breakout Room”, led by Alexei Vladishev himself along with longtime community members Patrik Uytterhoeven, Brian van Baekel, and Nathan Liefting. Zabbix users were able to brainstorm ideas for new chapters, missing topics, translations, and community contributions to the online Zabbix Book.
Turning ideas into action
Day 2 was also full of hands-on workshops, including a fascinating one from the team at initMAX that was based on their day 1 presentation. Participants got kits with an ESP32 board, a camera, a 3D-printed counter mount, and a few other odds and ends. They were then guided step-by-step as they integrated the device into Zabbix, built monitoring scenarios, and used AI models to interpret camera images.
One of the things that makes the Zabbix Summit experience so special is the depth of the networking experience – there’s no awkward small talk or simple business card exchanges here, but rather a series of real connections made, deals closed, and new partnerships cemented.
Accordingly, a lot of the magic at Zabbix Summit 2025 happened after hours, with everyone gathering at Riga’s famed Monkey Club for the Summit Welcome Event on October 8 to enjoy a lively atmosphere, a wide selection of cocktails, and plenty of opportunities to connect with fellow monitoring and observability enthusiasts.
October 9’s Main Event took place in the Tallinn Quarter Angārs, which blended concert hall energy with an open-plan street food kitchen and bar that gave everyone plenty of room to mingle.
A special treat was provided in the form of an original Zabbix-related song by Zabbix PHP Developer and part-time rock star Vladimirs Maksimovs, which got the entire crowd on its feet and set the tone for an unforgettable evening.
In what has become a bit of a tradition within a tradition, the Summit officially wrapped up on October 10 at Riga’s Burzma Food Hall, with its relaxed atmosphere, multiple cuisines, and communal tables. It’s proven to be the perfect place for reflecting on Summit highlights, swapping contact info, or plotting collaborations.
Thank you to our sponsors!
We want to extend our heartfelt thanks to all the sponsors of Zabbix Summit 2025, whose commitment not only helped us bring everyone together under one roof but also contributed to the growth of both Zabbix and the entire global monitoring ecosystem. We value your partnership and look forward to working with you for many years to come!
Thanks again to our sponsors and everyone else who helped make Zabbix Summit 2025 possible!
In case you couldn’t make it…
If you didn’t manage to make the trip, you can still enjoy the Summit atmosphere in the privacy of your own home! Recordings of both days are available on Zabbix’s YouTube channel:
The slides and texts of the presentations are also available here.
And that’s a wrap on Zabbix Summit 2025! From mind-blowing tech talks to caffeinated hallway chats and everything in between, this year’s Summit experience delivered. Whether you came for the deep dives or just the cool merch (no shame in that), we hope you went away inspired, connected, and maybe just a little more obsessed with monitoring and observability than before. See you in 2026!
The Global Clubs Partner network brings together 52 partners from 45 countries, all working together to positively impact their local communities and open up opportunities for the next generation.
Last month, our Global Clubs Partners came together in Sri Lanka for our annual meetup, celebrating collaboration and community. Hosted alongside the second-ever Coolest Projects Sri Lanka, the gathering brought partners from across the world to share ideas, learn together, and build connections that will carry into the year ahead.
Building connections across the network
The in-person meetups are all about strengthening the sense of community among Global Clubs Partners. Ellie Proffitt from the RPF Global Partners team shared why coming together is so important:
“It was wonderful to hear everyone’s experiences and connect over our shared mission. Everyone was so keen to learn from each other, and being able to do that face to face made it even more valuable.”
The Sri Lanka meetup gave partners the space to get to know one another, learn from each other’s experiences, and think together about future goals for their clubs.
Exploring together
The agenda combined presentations, workshops, and plenty of time for discussion. It began with the Raspberry Pi Foundation team giving a presentation on our mission and strategy for partner work and beyond. Afterwards, each organisation introduced themselves and partners showcased their activities and successes. Together we explored how to build and sustain Code Club communities, experimented with creative ways to use AI in clubs, and got hands-on with unplugged activities that make computing accessible in low-tech settings. Partners also shared approaches to adapting content for their local contexts, and finished by developing their own vision and strategy for the next 12 months.
The variety of sessions meant there was something for everyone, whether partners were looking for new teaching ideas, strategic guidance, or inspiration from peers.
“There were so many interesting topics, I wish we had more time to go more in depth. I love being able to speak with other organisations doing similar work. Having the Raspberry Pi Foundation facilitate the connections is an asset.” – Global Partner
Inspiring moments at Coolest Projects Sri Lanka
As part of the meetup, partners had the chance to attend Coolest Projects Sri Lanka 2025, where young people showcased their incredible tech creations. Seeing children proudly present projects ranging from apps to hardware builds was a highlight for many.
“We have picked the top 100 [Coolest Projects] entries and they are here today exhibiting that to all our visitors joining from various parts of the world and we are happy to have representatives from the global Raspberry Pi Foundation family also.” – Prabhath, Code Club mentor and founder of STEMUp Educational Foundation
Looking ahead
The team left Sri Lanka with deeper connections, renewed energy, and a shared commitment to making computing education accessible to all.
“I feel part of something bigger — a worldwide movement where kids everywhere are learning to create with technology, not just consume it. Being a Global Partner means we can learn from what’s working in other countries, adapt those ideas for us, and also contribute our own innovations back to the network.” – Global Partner
Could your organisation become a Global Clubs Partner?
You can find out how your organisation could join our Global Clubs Partner network on the Code Club website, or contact us directly with your questions or ideas about a partnership.
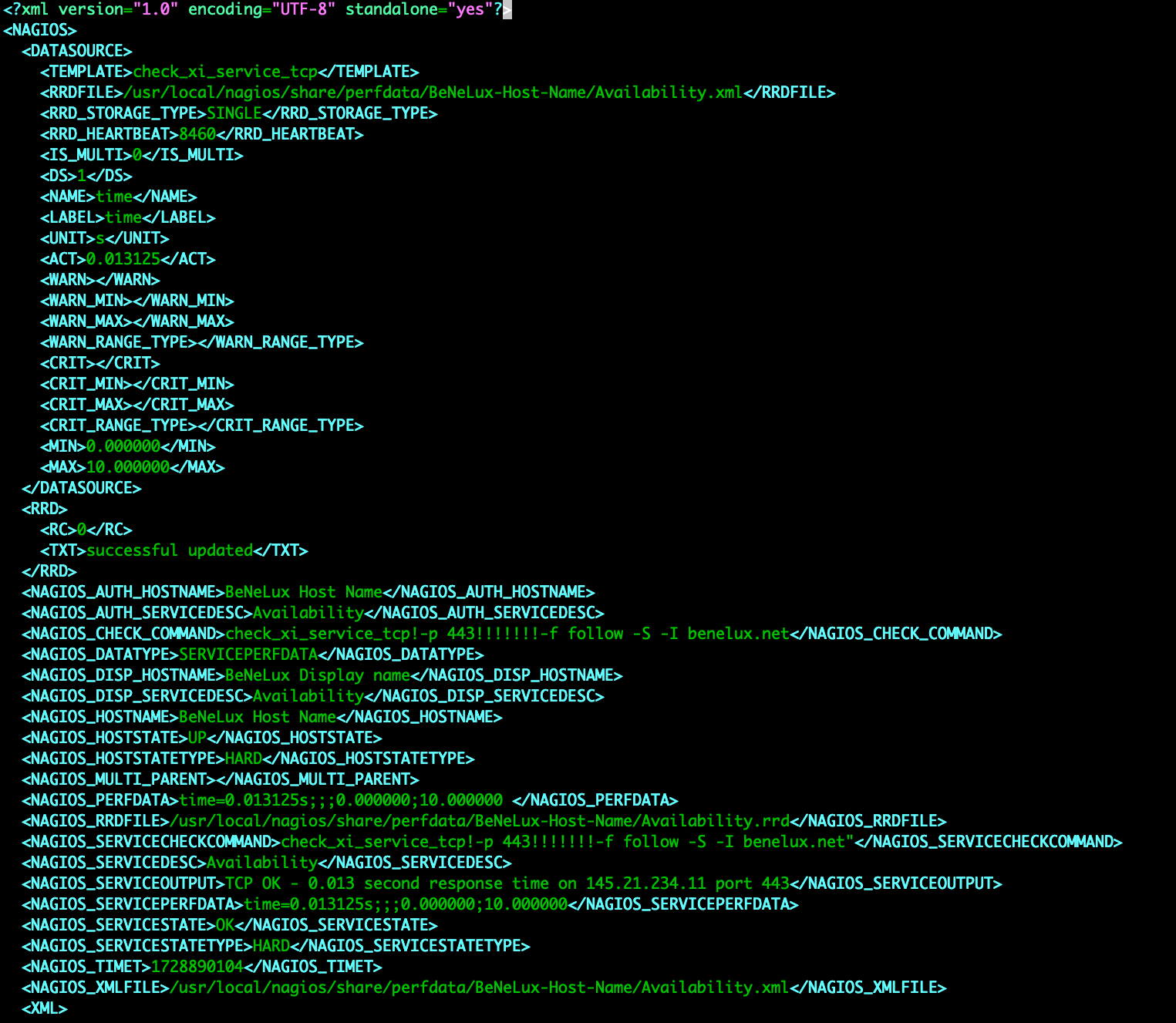
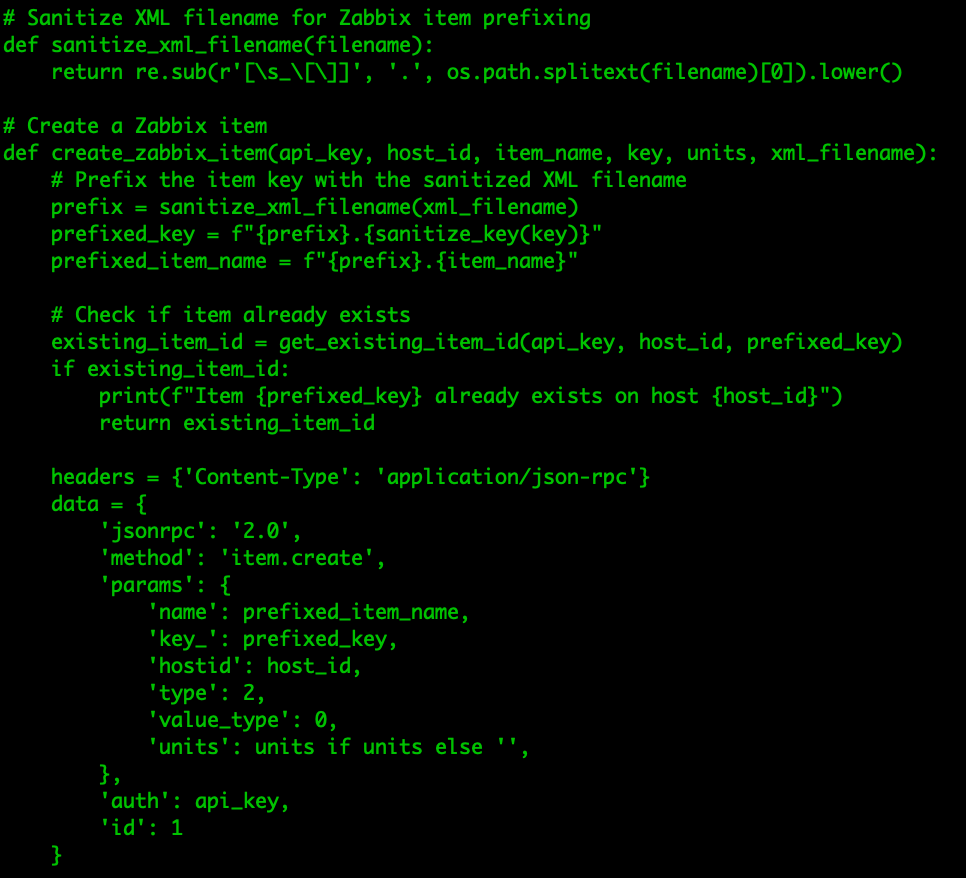
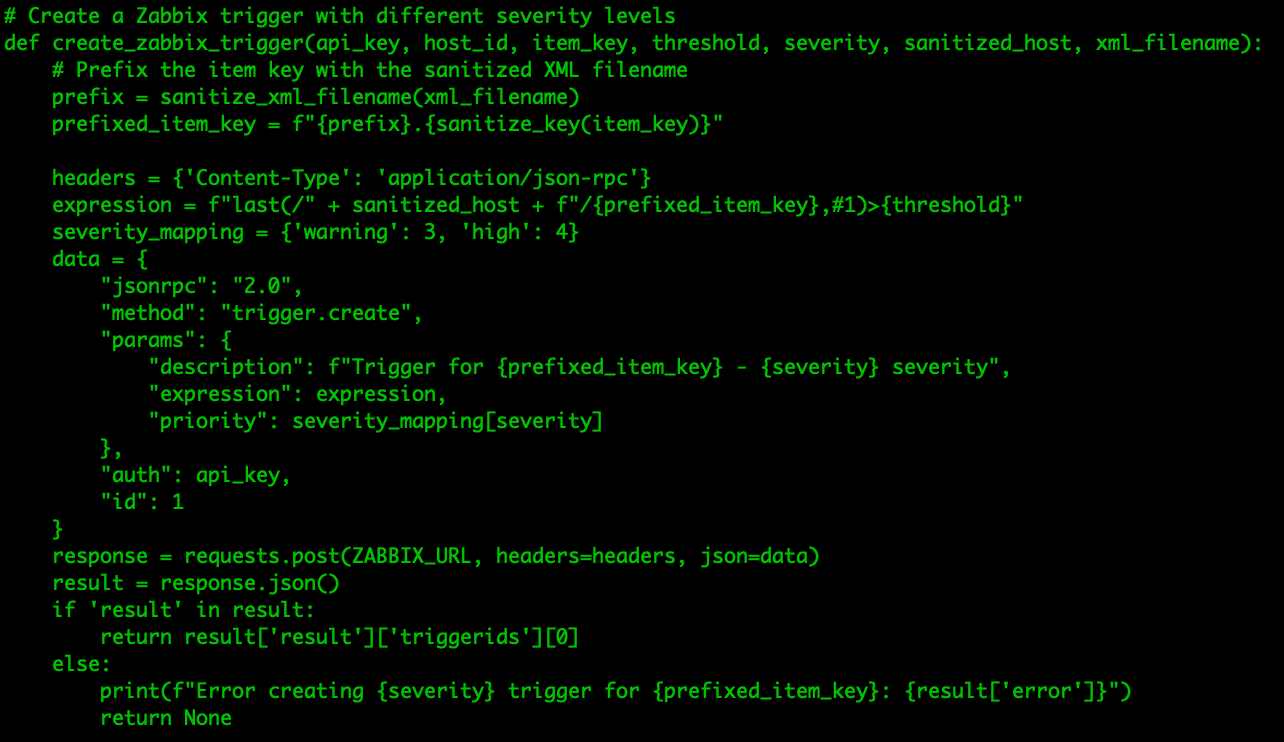
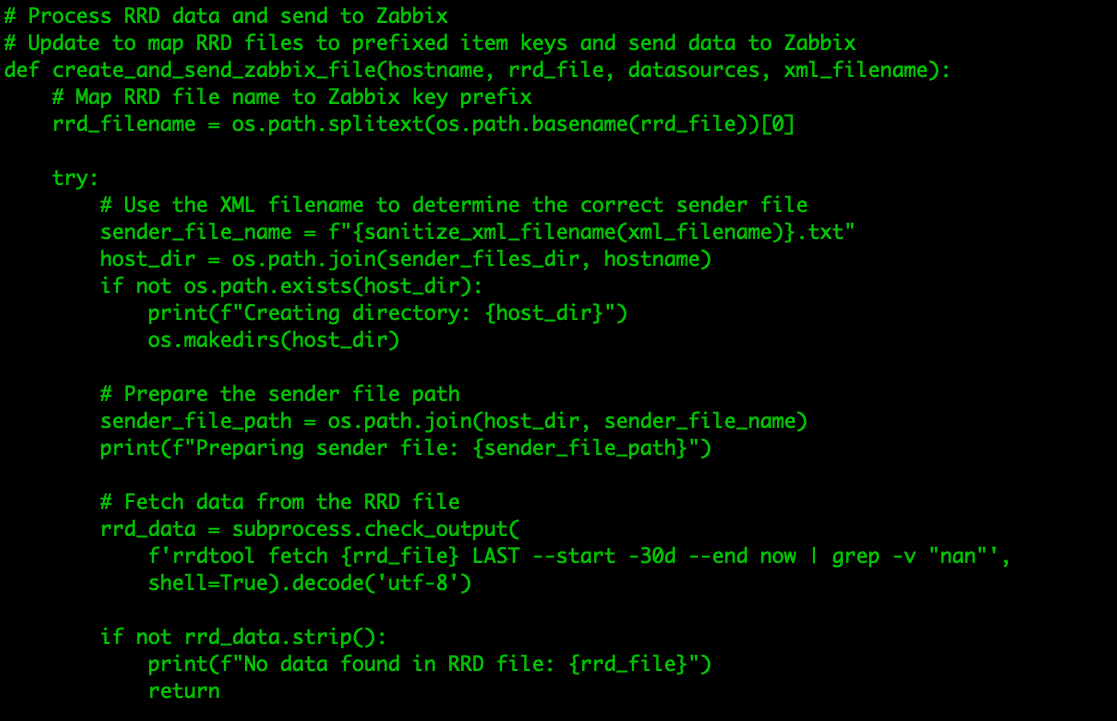
If you are running Zabbix, you know that it can be a tedious job to add hosts, link templates, and (even harder) make sure it is consistent with your CMDB. What if you already have a CMDB? In that case, it means you need to synchronize the CMDB with Zabbix…manually? Of course not!
Before we continue – this blog post and plugin both belong to Opensource ICT Solutions. We specialize in Zabbix (it’s our core business!) and as such try to make a living out of this open-source product. The plugin we will discuss is open source, and as such we do not have a commercial benefit from it – it’s brought to you by us, as a way to give back to the community (and maybe score some consultancy opportunities).
If you are familiar with NetBox already, it’s time to get excited. If you are not familiar with it, NetBox provides a powerful “single source of truth” for managing everything in your network: IP address management (IPAM), data center infrastructure management (DCIM), device inventory, rack layouts, cabling, virtual assets, and more. It’s built under the Apache 2.0 license, so the core software is fully open source, with an active community contributing plugins, integrations, and custom extensions. The platform is highly flexible – you can add custom fields, enforce custom validation and protection rules, integrate via REST and GraphQL APIs, and run multiple automations.
How cool would it be if you could use that in combination with Zabbix, so that if you create a new entity in your CMDB (your single source of truth) and sync that with Zabbix, you could just focus on one product and always can be assured your monitoring is complete?
What are we solving?
Many of our customers use NetBox as their CMDB and Zabbix as their monitoring solution. The challenge they run into is keeping NetBox and Zabbix in sync — a task engineers don’t usually enjoy.
For customers who don’t use a CMDB (or at least not NetBox), there’s always the uncertainty of whether a host in Zabbix has the right templates and macros applied. While Zabbix does allow bulk updates, you still need detailed knowledge of each device’s role to keep things consistent.
NetBox, on the other hand, already stores much richer context about configuration items. A device or virtual machine can have a role, device type, tenant, and even its site or location defined. All that’s missing is a way to leverage this information to make sure those devices are monitored correctly in Zabbix.
On top of that, this approach makes it simple – if a device is registered in the CMDB (and therefore something you’re responsible for), it’s also monitored in the right way. From a project delivery perspective, documentation only needs to be done once, and it ensures that it’s actually done. In short: if it’s not in the CMDB, it’s not monitored — and therefore not our responsibility.
It also means the project delivery engineer(s) don’t necessarily need to know in depth how Zabbix works: as long as they can populate the CMDB – the monitoring will be taken care of automatically.
What did we develop?
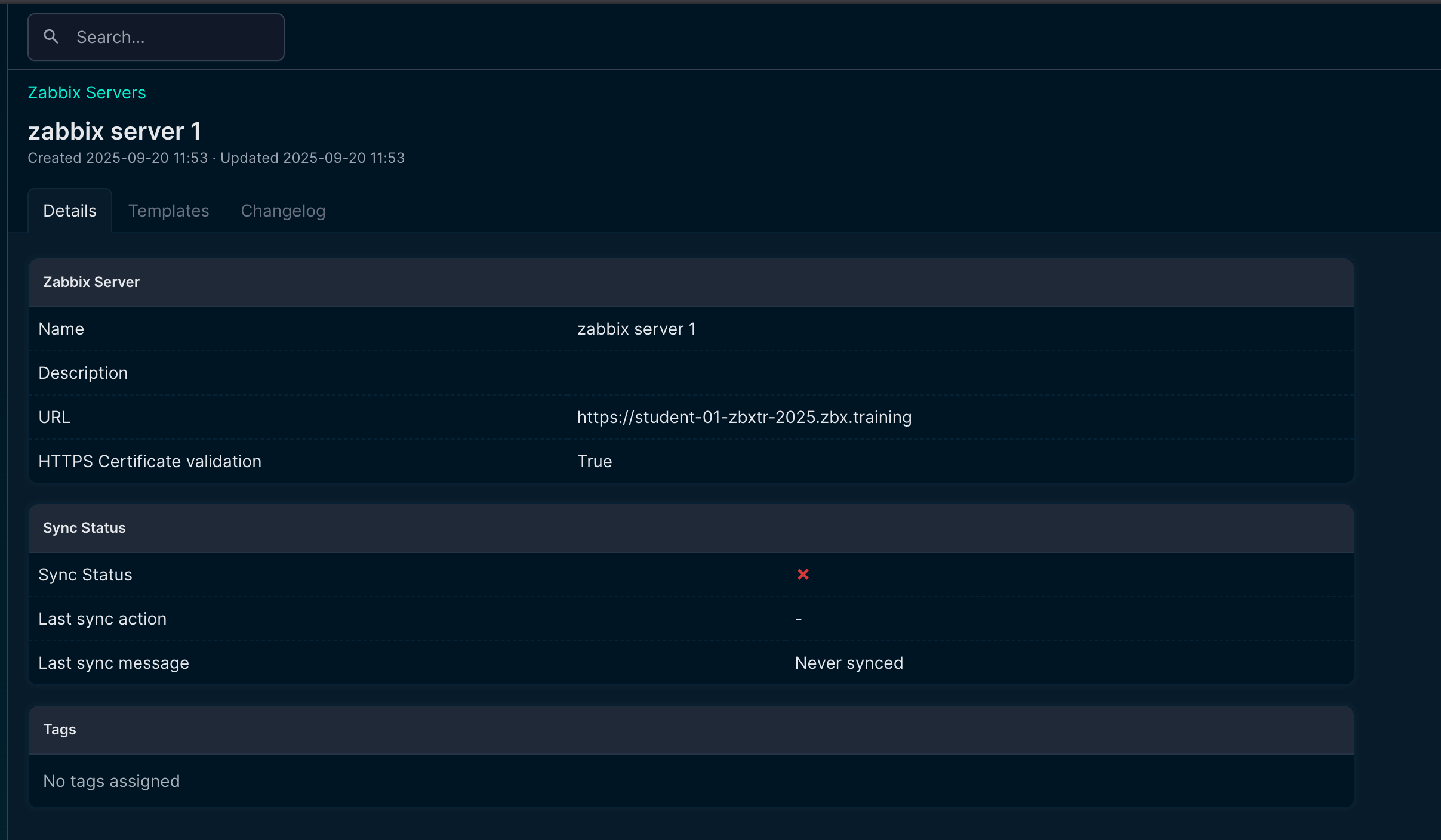
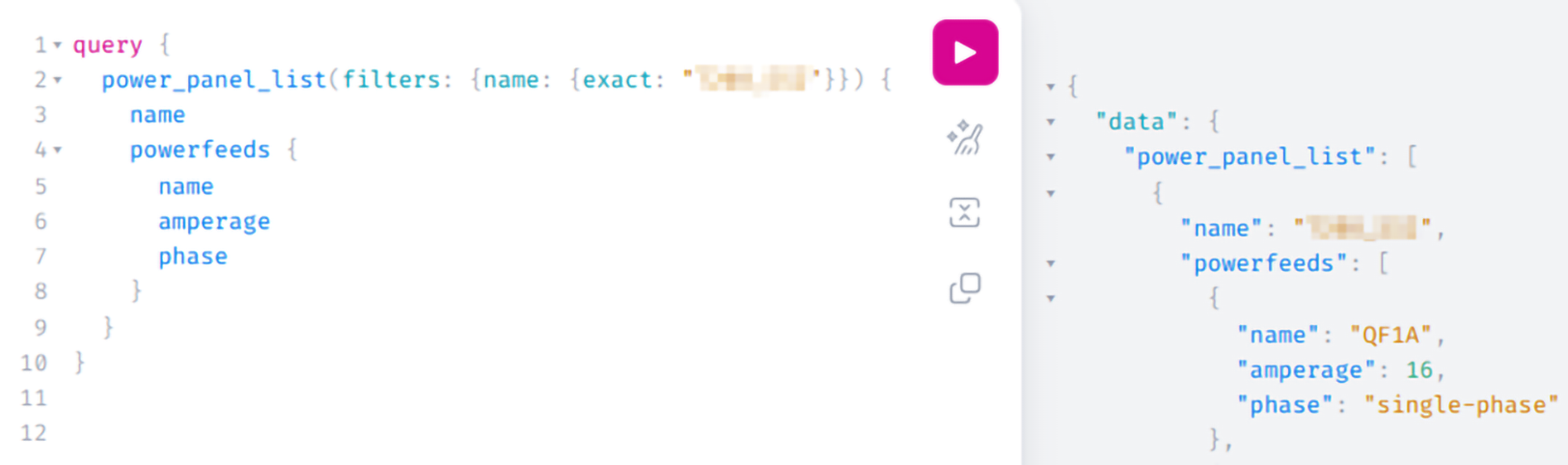
In short, a native plugin for NetBox that communicates with the Zabbix API. From there, it will gather information like templates and macros that exist in your Zabbix environment. This is completely API based, so in NetBox you just add an new Zabbix Server and let it synchronize:
Screenshot about a new Zabbix server in NetBox
At this point, nothing fancy happens. It is just establishing the connection and synchronizing templates, macros, etc. The rest of the configuration is done in your NetBox instance.
How does it look?
We’ve got the normal/native menu list items from NetBox, and for those familiar with it already the list below shows nothing new except for the “Zabbix” option:
Organization – Define sites, locations, and tenants to structure your infrastructure
Racks – Manage physical racks and their layout in data centers
Devices – Inventory of physical and virtual devices like servers, routers, and switches
Connections – Model physical cabling and logical connections between devices
Wireless – Manage wireless LANs, SSIDs, and related equipment
IPAM – IP Address Management: subnets, prefixes, IPs, and VRFs
VPN – Configure tunnels, peers, and VPN terminations
Virtualization – Track clusters, virtual machines, and virtual interfaces
Circuits – Manage provider circuits, WAN links, and related contracts
Power – Define power feeds, panels, and outlet connections.
Provisioning – Support for building and automating device/service onboarding
Customization – Extend NetBox with custom fields, rules, and UI tweaks
Operations – Tools for workflows, jobs, and operational tasks
Admin – Administrative settings for users, groups, and global configuration
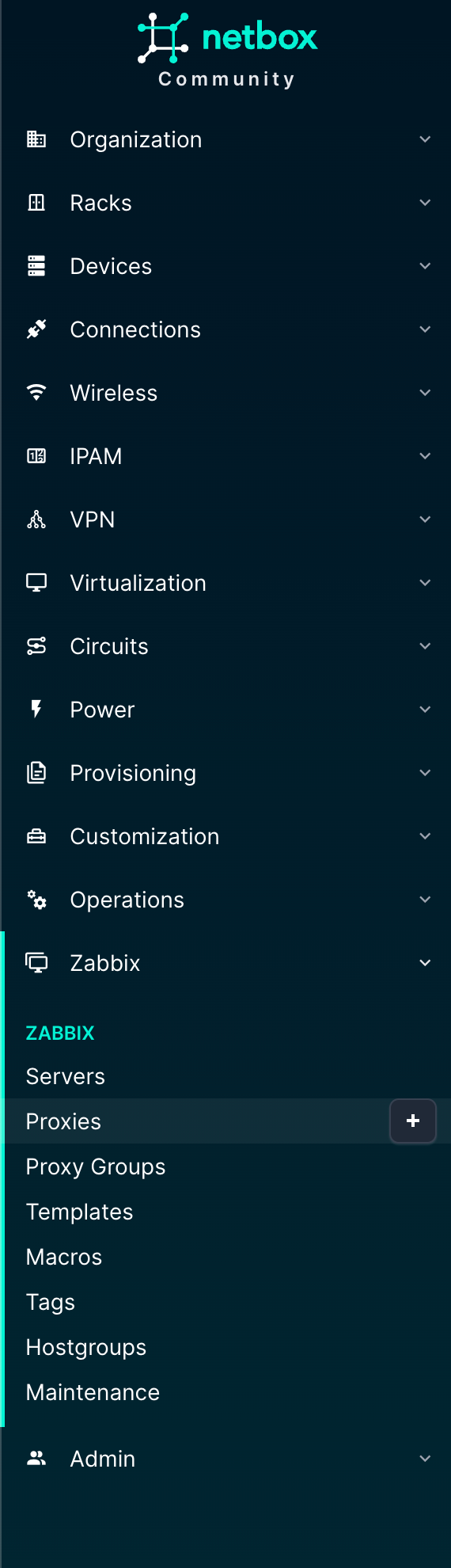
The Zabbix menu is new here and actually gives us control over what is present in Zabbix. The objects here should look familiar if you know Zabbix:
Servers
Proxies
Proxy Groups
Templates
Macros
Tags
Hostgroups
Maintenance
NetBox menu including Zabbix plugin
In the various NetBox native objects, there will be information regarding the Zabbix setup.
Is it available already?
Of course it is, otherwise this blog post would’ve been completely useless! Installation can be done via https://pypi.org/project/nbxsync.
We released our NetBox plugin under the GNU Affero General Public License v3 (AGPL-3.0) because it best protects both our work and the community. Unlike permissive licenses, AGPL ensures that anyone who modifies or extends the plugin must share their changes under the same license, even if the software is only offered as a service. This prevents closed forks, guarantees improvements flow back into the community, and aligns with the collaborative spirit of NetBox and Zabbix.
While AGPL still allows use in commercial environments, it prevents organizations from profiting off private modifications without contributing back. In short, AGPL-3.0 keeps the plugin fair, transparent, and truly open source. This is also the license Zabbix uses, so the community is already familiar with it.
We think documentation is important, as we’ve often been in a situation where we had to discover ourselves how something works due to lack of documentation. We really try to keep you out of that situation and therefor created extensive documentation for this project. Obviously, we can help you when you are lost, but as that costs us time as well it won’t be a free service. The documentation is available here: https://nbxsync.com.
As we think it’s great to work on a project together, we welcome community contributions. However, in order to accept any pull requests, please create an issue on our Github repo first. Please do read our development guidelines and understand that we are more than happy to incorporate suggestions/pull requests if they benefit the wider community.
As it’s a native plugin, the installation is straightforward and well documented by NetBox: https://netboxlabs.com/docs/netbox/plugins/installation/. In our documentation, we provide the plugin-specific configuration. If this feels daunting, we’re more than happy to assist you with it as part of our consultancy offering.
So, with NetBox in place and the plugin installed, let’s actually walk through the NetBox configuration to give you a feeling of how it works. We will have to configure quite a bit in NetBox as a foundation, which hopefully is done already if you’ve got NetBox implemented in your organization.
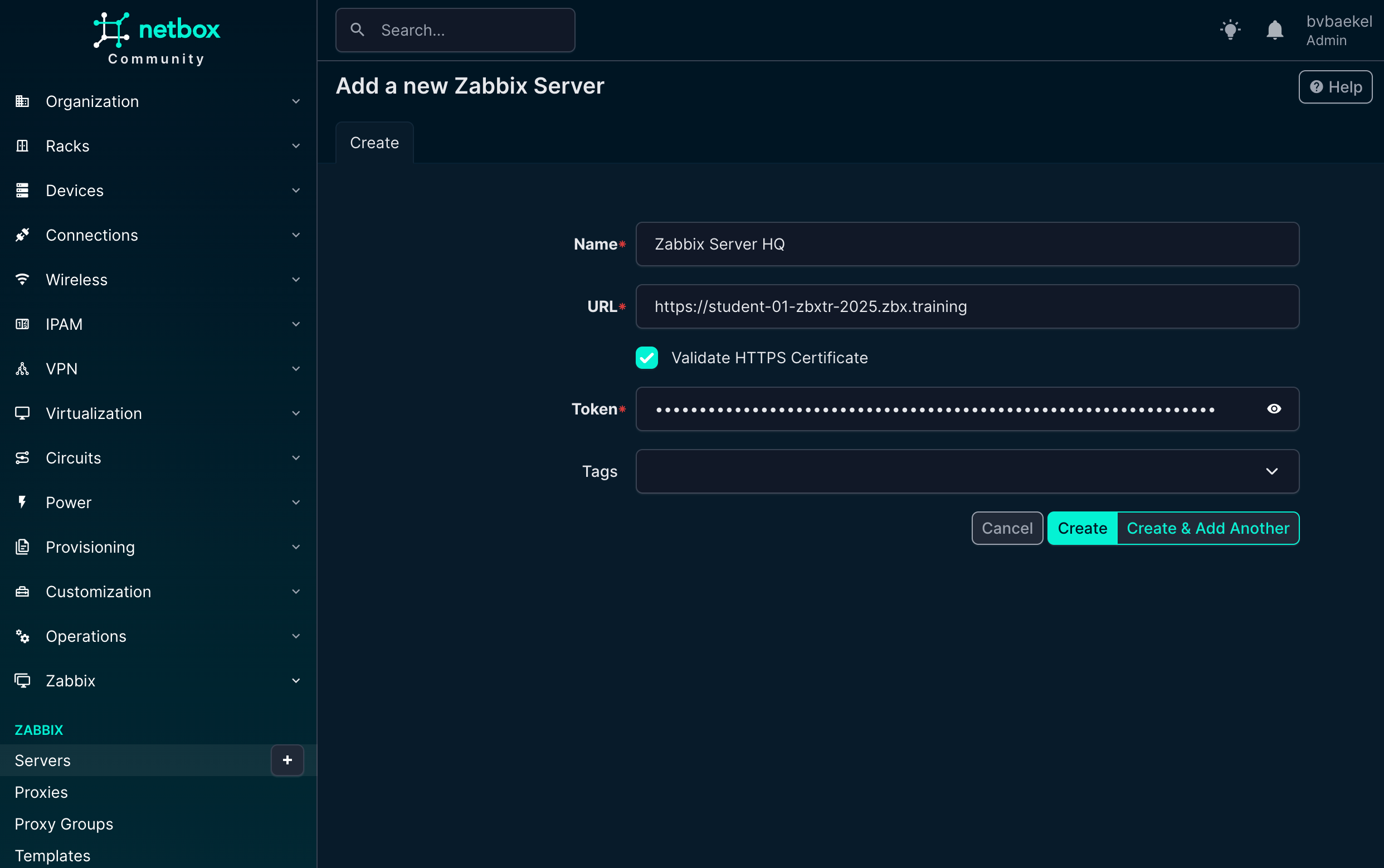
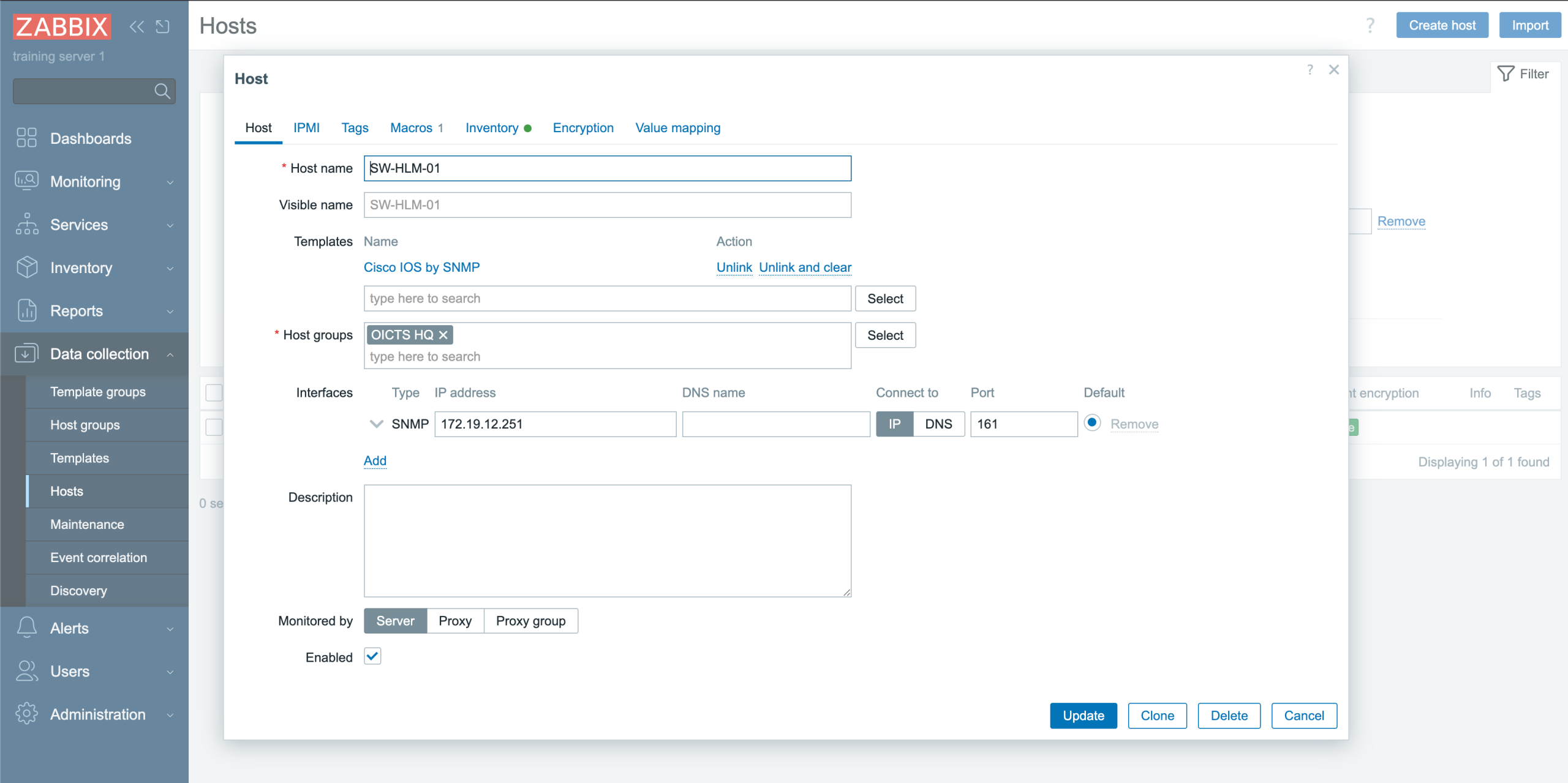
In any case, we need to add one or multiple new Zabbix servers. We open the Zabbix menu and click on “Servers” where we add this server:
NetBox Zabbix Server configuration
Once added, NetBox will automatically synchronize with the Zabbix server and get the templates out of it, ready to be used! The macros will also get synchronized along with the templates,, so they are also available in NetBox.
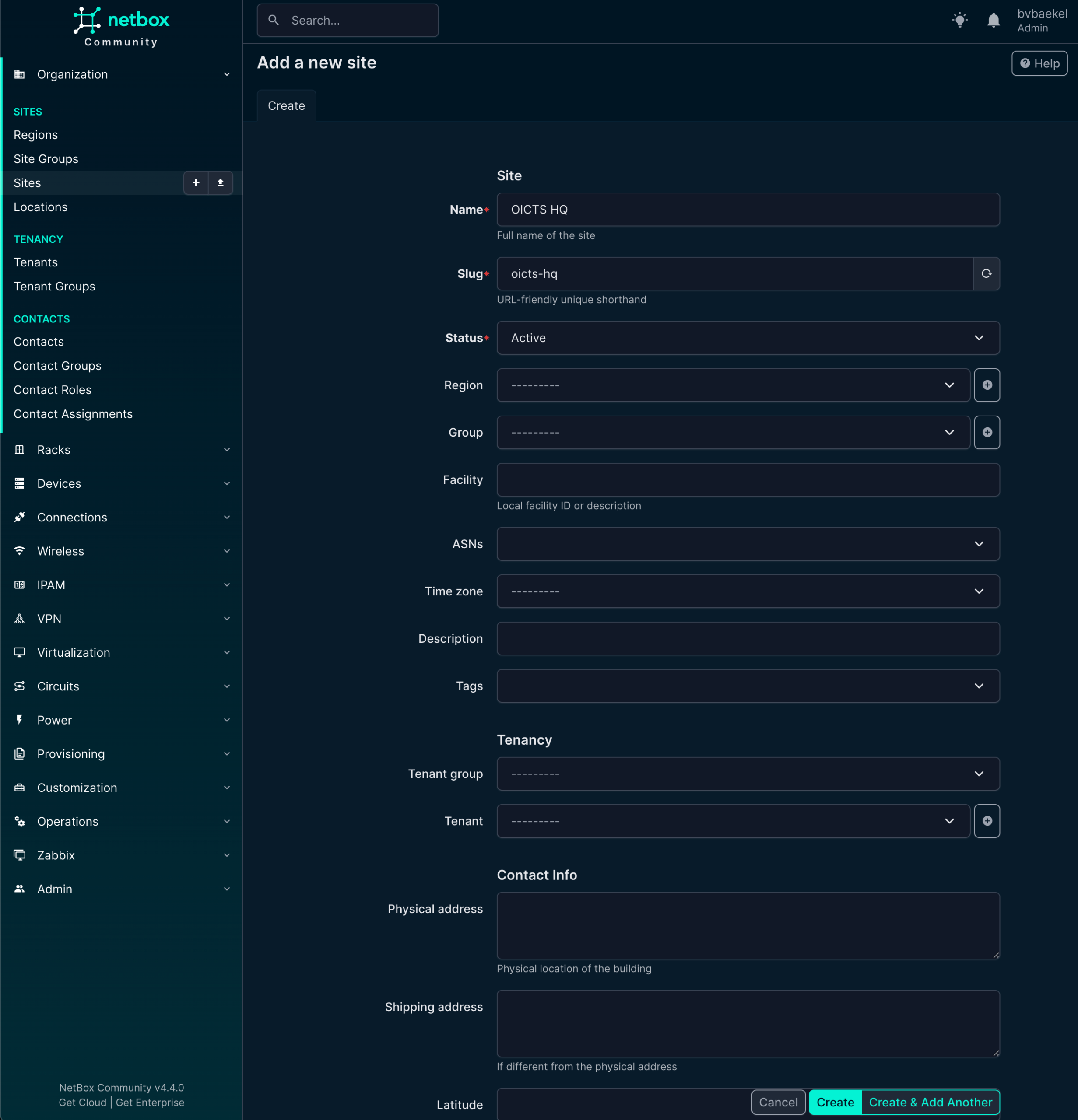
NetBox dictates that devices should be in a site, so we start with that. In Organization → Sites we create a new site. A few fields are mandatory and populated in the screenshot below:
NetBox Sites Configuration
Name, Slug, and Status are mandatory. In a production setup, you probably want to populate some other fields as well, such as Tenant, Region, etc. But we are not writing a NetBox tutorial and as such we will completely ignore that. Once you are done, click on “Create” at the bottom of the configuration.
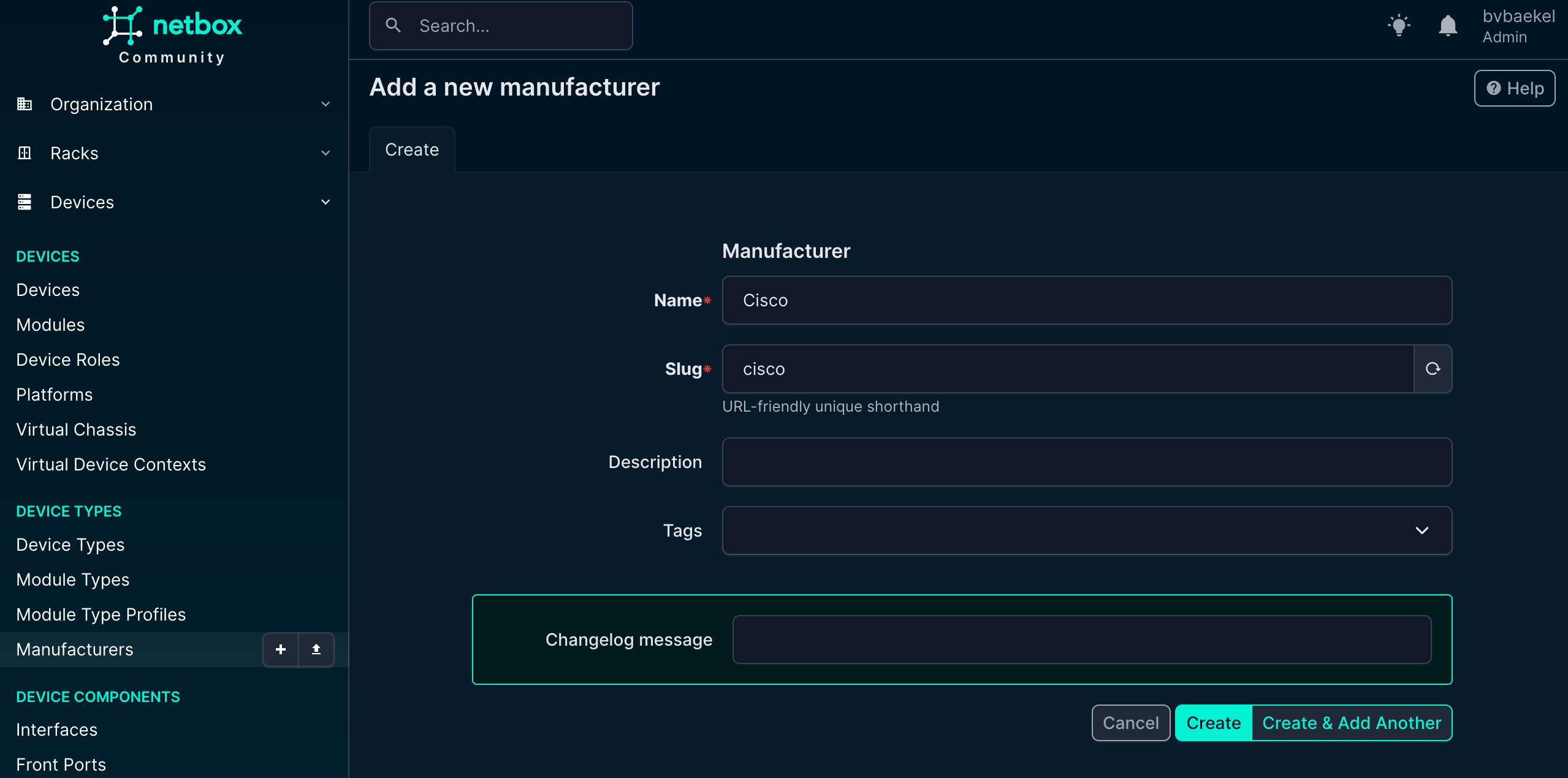
After the site has been created, it is time to add a Manufacturer under the menu “Devices.”
Once done, click on “Create” at the bottom of the configuration. Of course you can (or should) add multiple vendors – all that you actually use!
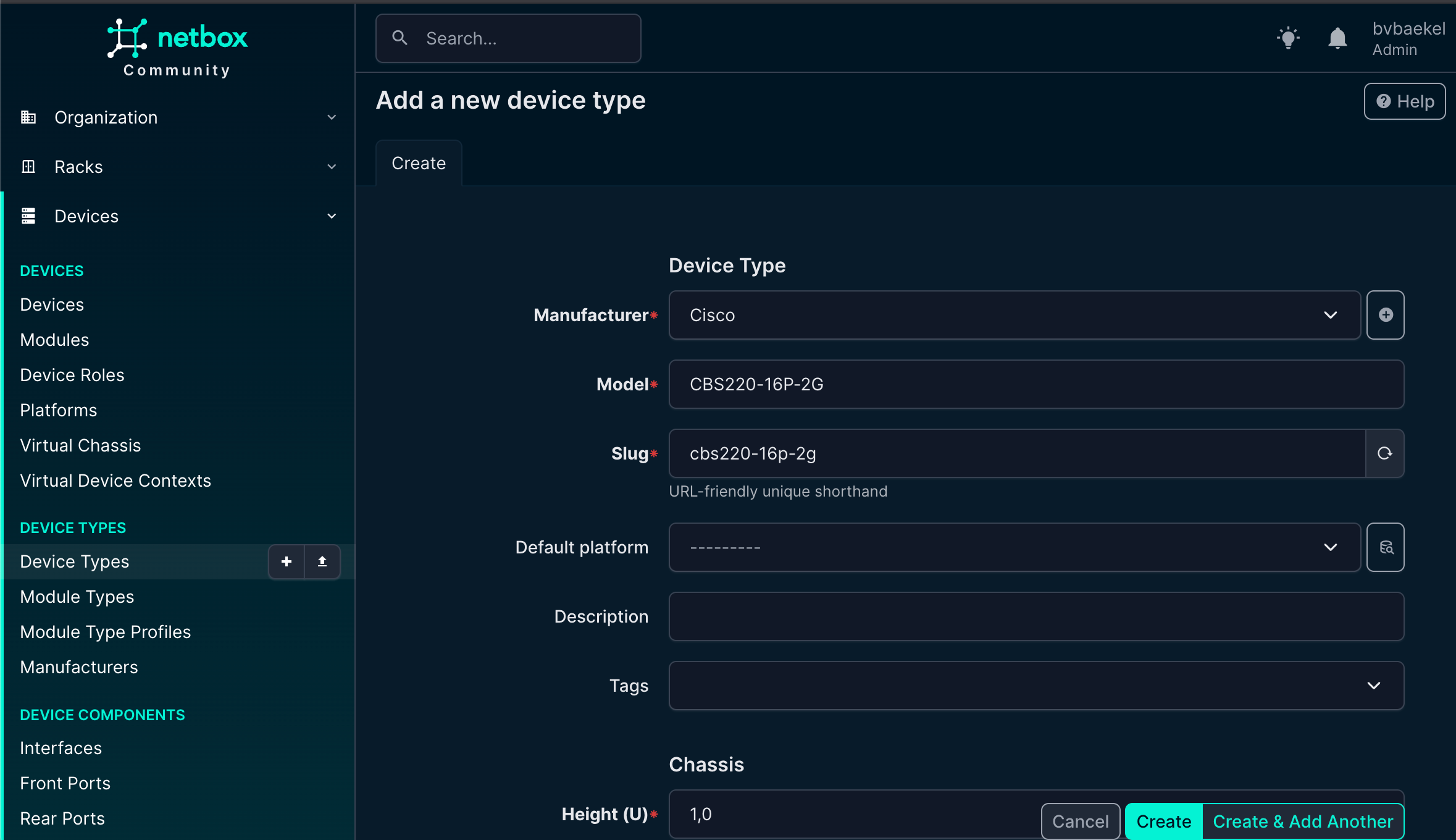
The next step is device type. In the end, we need to know the vendor, but it is equally important to know what type of device we are monitoring. As such, the next step is to add a device type, again under the main menu “Devices.” As we add in the example, we are going to add a CBS220 switch:
NetBox device type configuration
Once again, click on “create” when you are done.
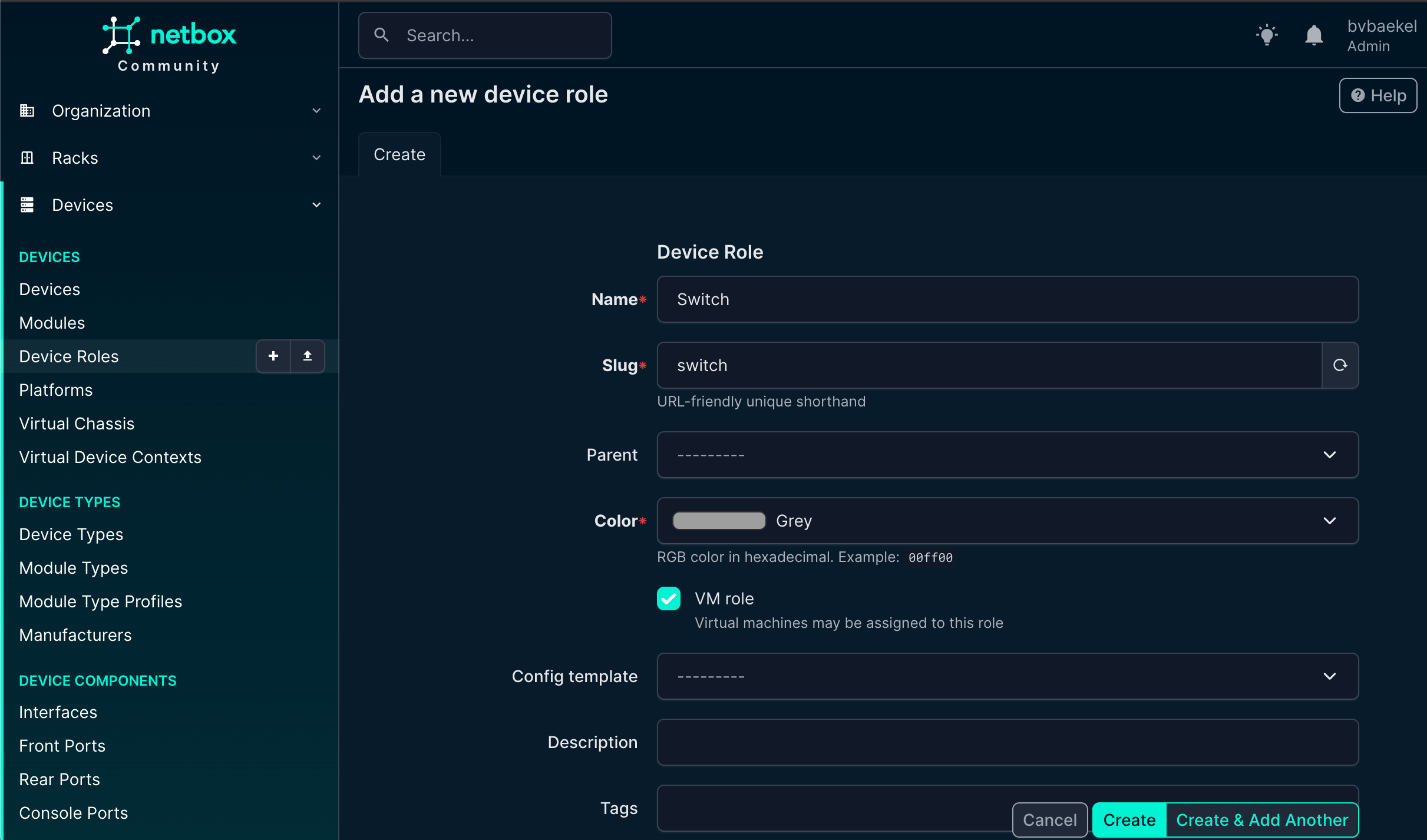
Last but not least, we need to add a device role. The device role is an important attribute because it helps us clearly define the function of the device within the network. By categorizing devices based on their role (such as router, switch, firewall, server, or access point) we create a structured overview that makes it much easier to manage, monitor, and troubleshoot the environment. Assigning roles also ensures consistency, improves documentation quality, and allows us to quickly identify the purpose of each device in larger infrastructures.
We go to “Devices” → Device roles and from there:
NetBox Device Role
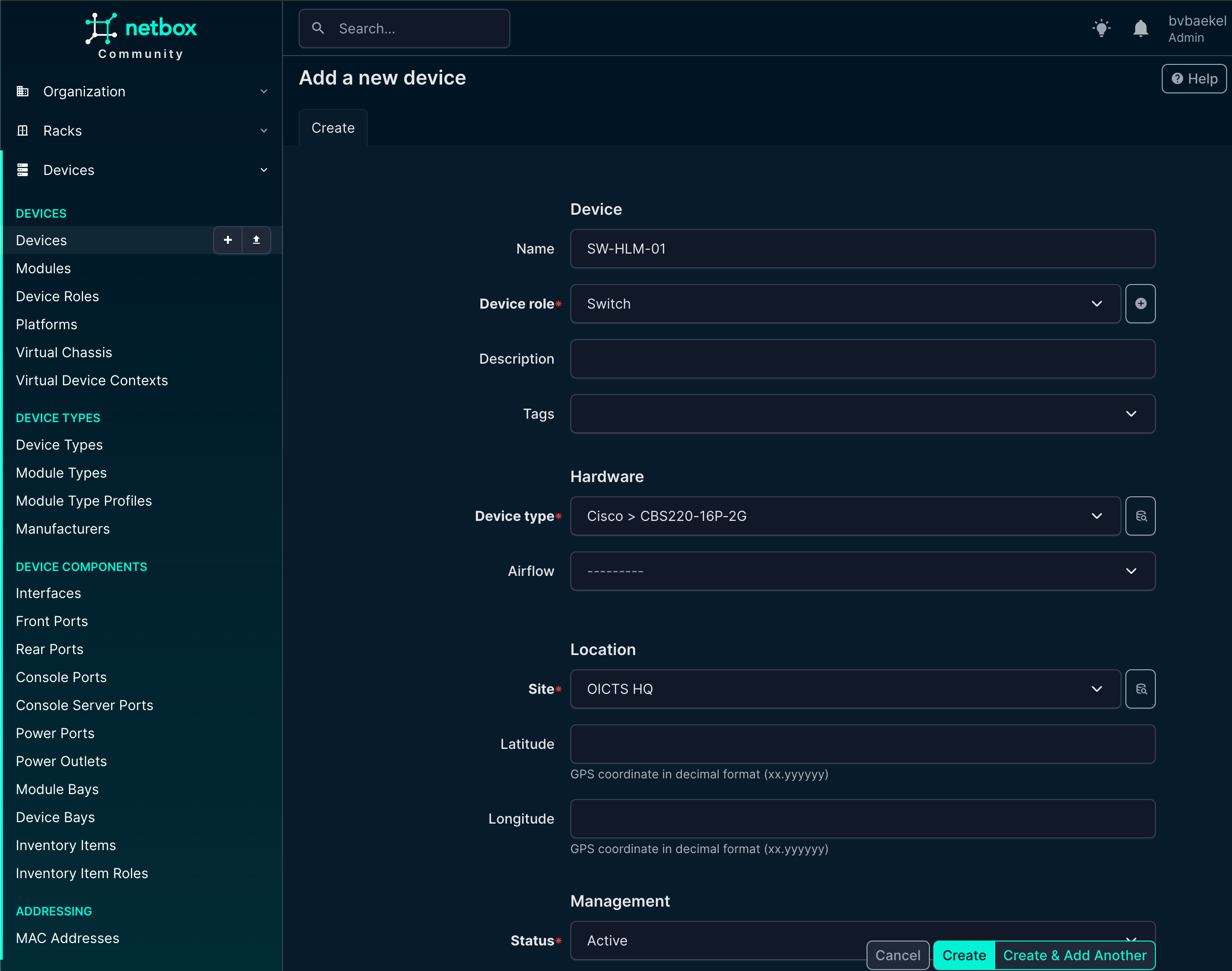
Now we can finally add the device itself! This is what it all is about – the work we’ve done before is really just laying the foundation for this moment. We add a device which will eventually become a Host in Zabbix, with all related properties pushed from NetBox its configuration.
So we navigate to Devices → Devices and from there add it:
NetBox Device configuration (truncated some fields)
After we save the device by clicking “Create,” NetBox immediately takes us to the newly created device’s detail page. Here we can see an overview of all the information we have just entered, such as the device name, role, site, rack position, and other attributes. This page acts as the central point for managing and extending the device configuration.
From here, we can add interfaces, assign IP addresses, connect cables, or link the device to virtual resources. In other words, once created the device record becomes the foundation for documenting its place and function in the network.
NetBox device overview with Zabbix options
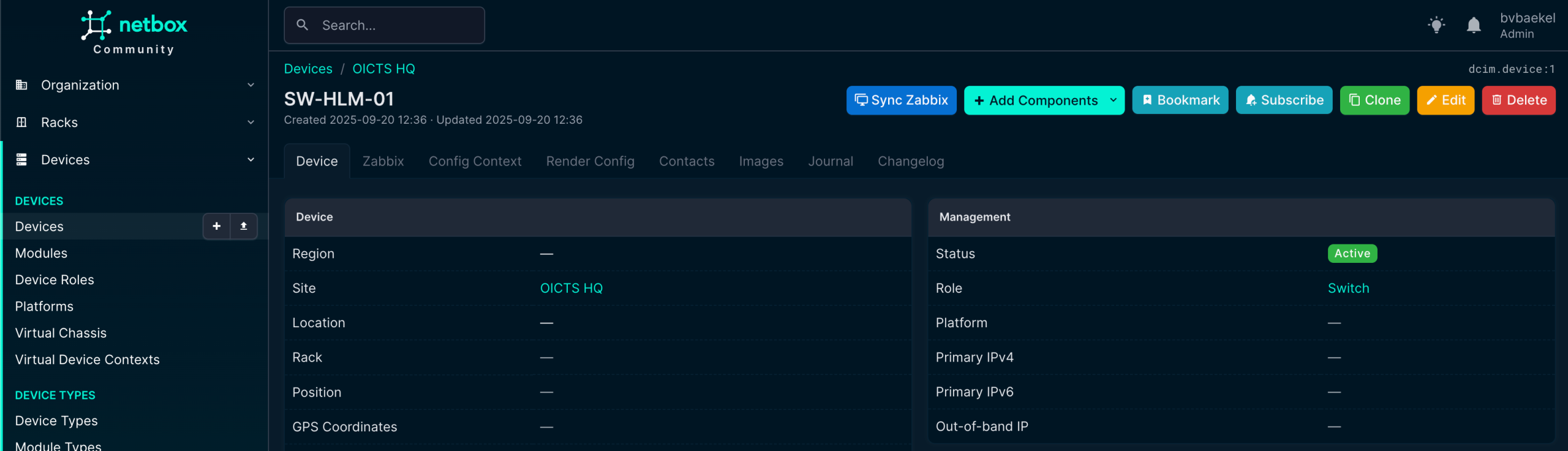
In this screenshot, we can see already that there is a new tab “Zabbix” (just under the device name) and we’ve also got a new button “Sync Zabbix.”
In the tab “Zabbix” we should assign this device to a Zabbix server, as by default it will not get assigned to any. You might think this is a bit strange, especially if you’ve got one Zabbix server. However, the mindset during development is that NetBox typically is used by MSPs, which have multiple Zabbix servers and even might have the need to assign multiple Zabbix servers to this device for operational reasons.
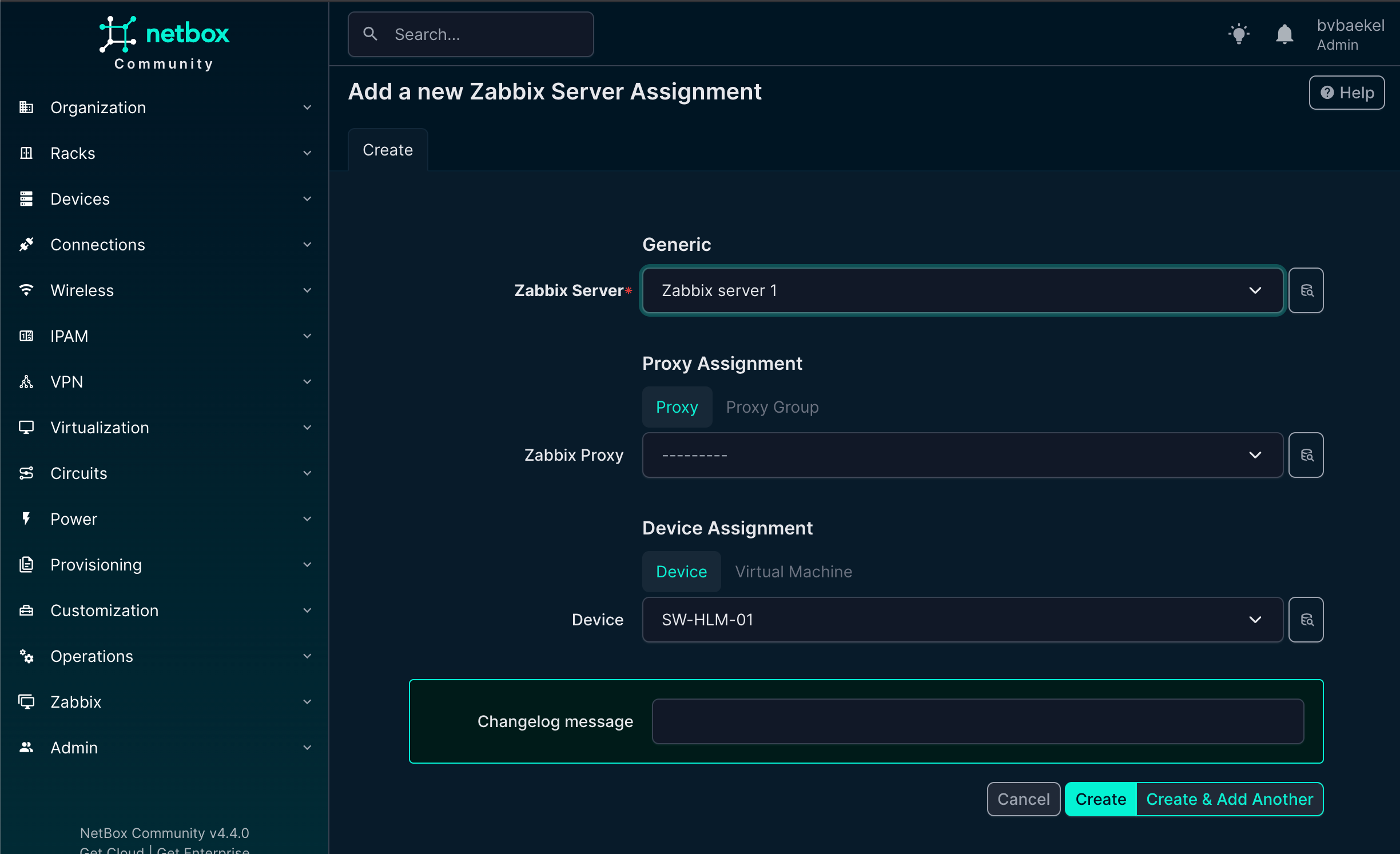
We open the tab “Zabbix” and click on “Add” next to the Zabbix Servers. A new configuration page opens and we select the server we just added:
NetBox Zabbix server assignment
When you click on “create” the server is assigned. We can of course add an template to it, but as we know the vendor and type already, there should be some inheritance!
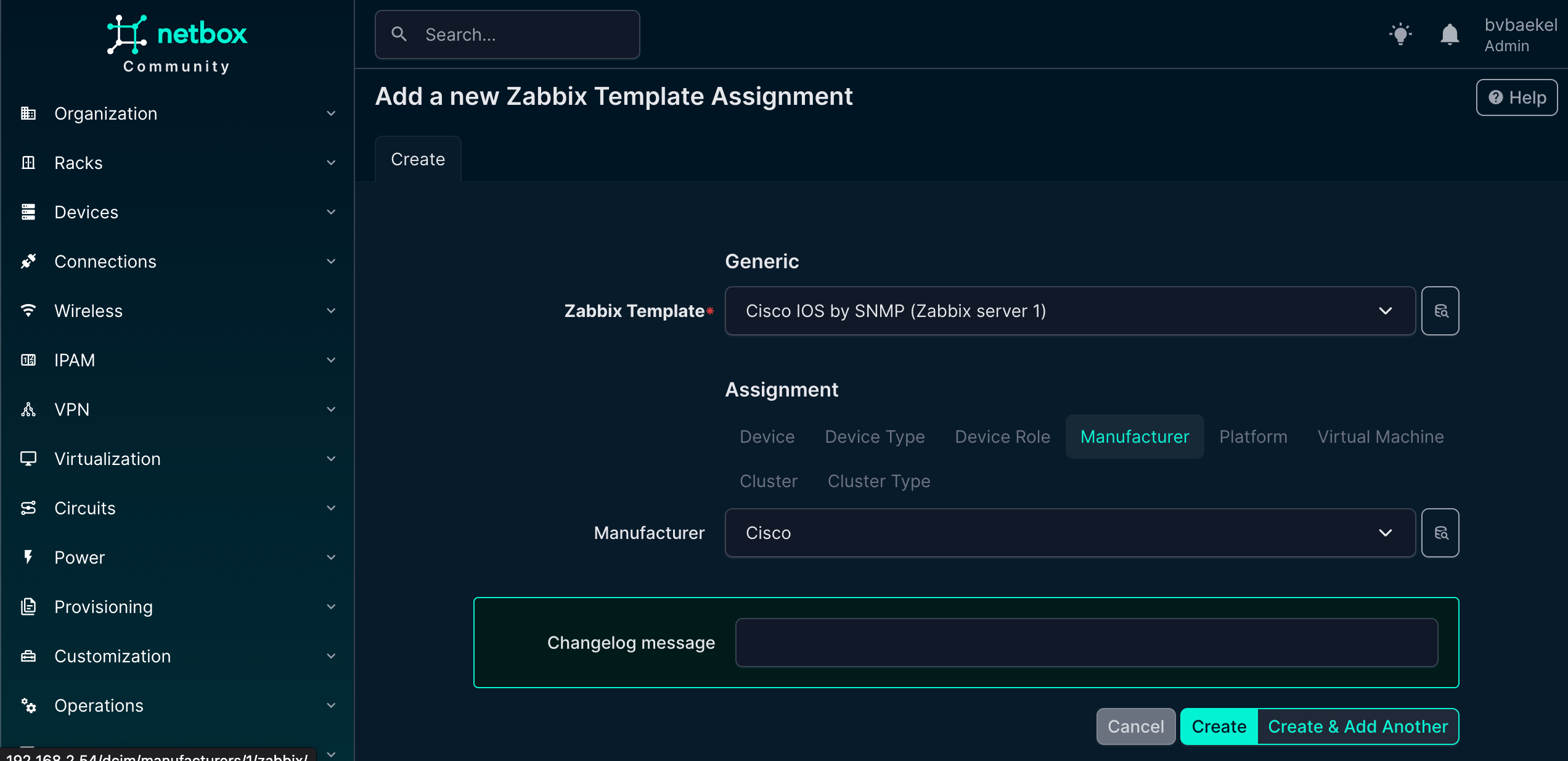
Let’s go back to Device → Manufacturers and click on the vendor(Cisco) we just added. Click on the name and you will see that this object also got a new “Zabbix” tab. In this tab you can configure that for this vendor, always these templates, hostgroups, tags and macros should be used. Here we will just add the template to this vendor, to show inheritance:
Netbox template inheritance
Once you’ve clicked on Create, navigate back to the device we made and observe how the template is inherited. As Zabbix also requires a host group and an interface, we are going to configure that now.
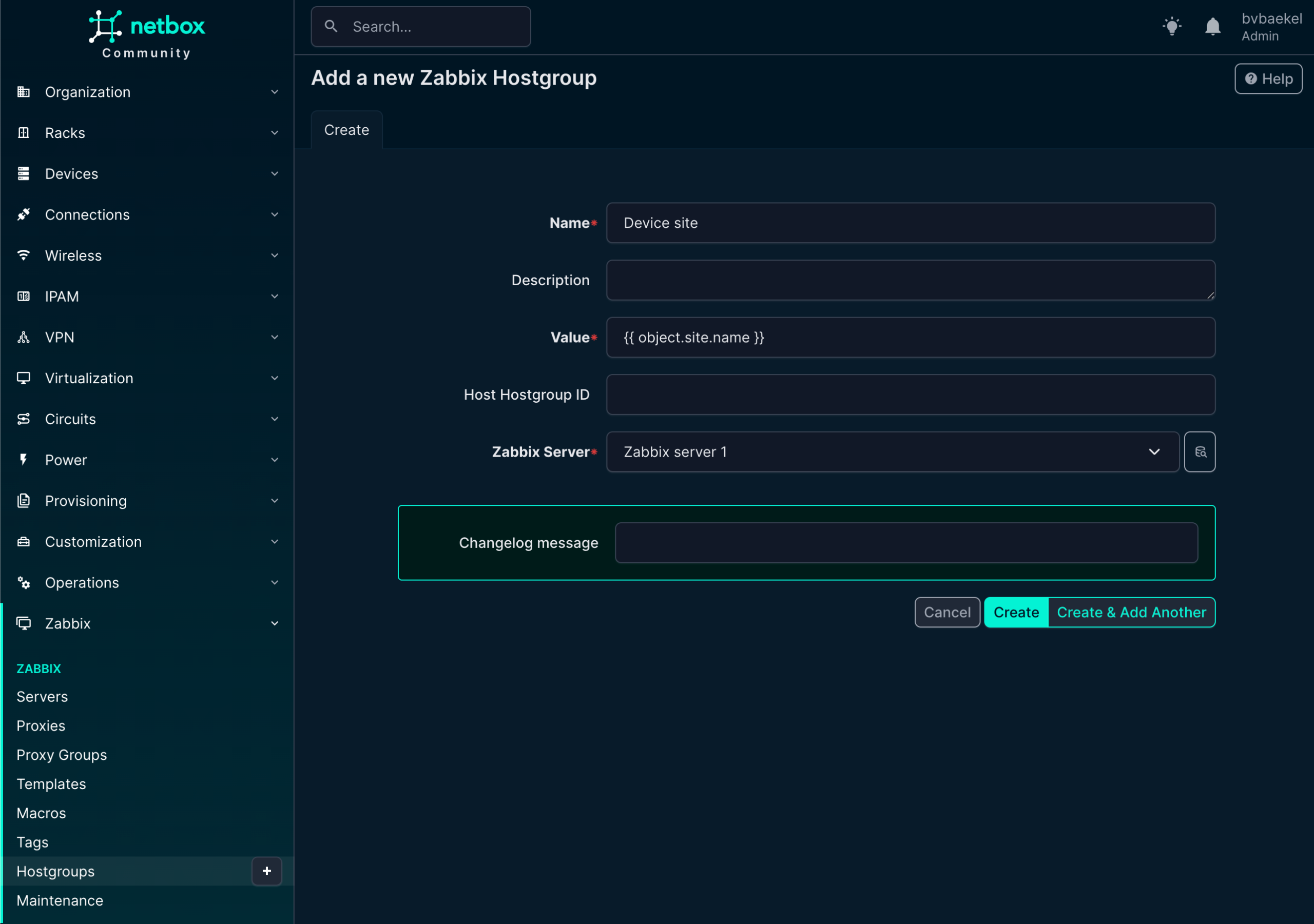
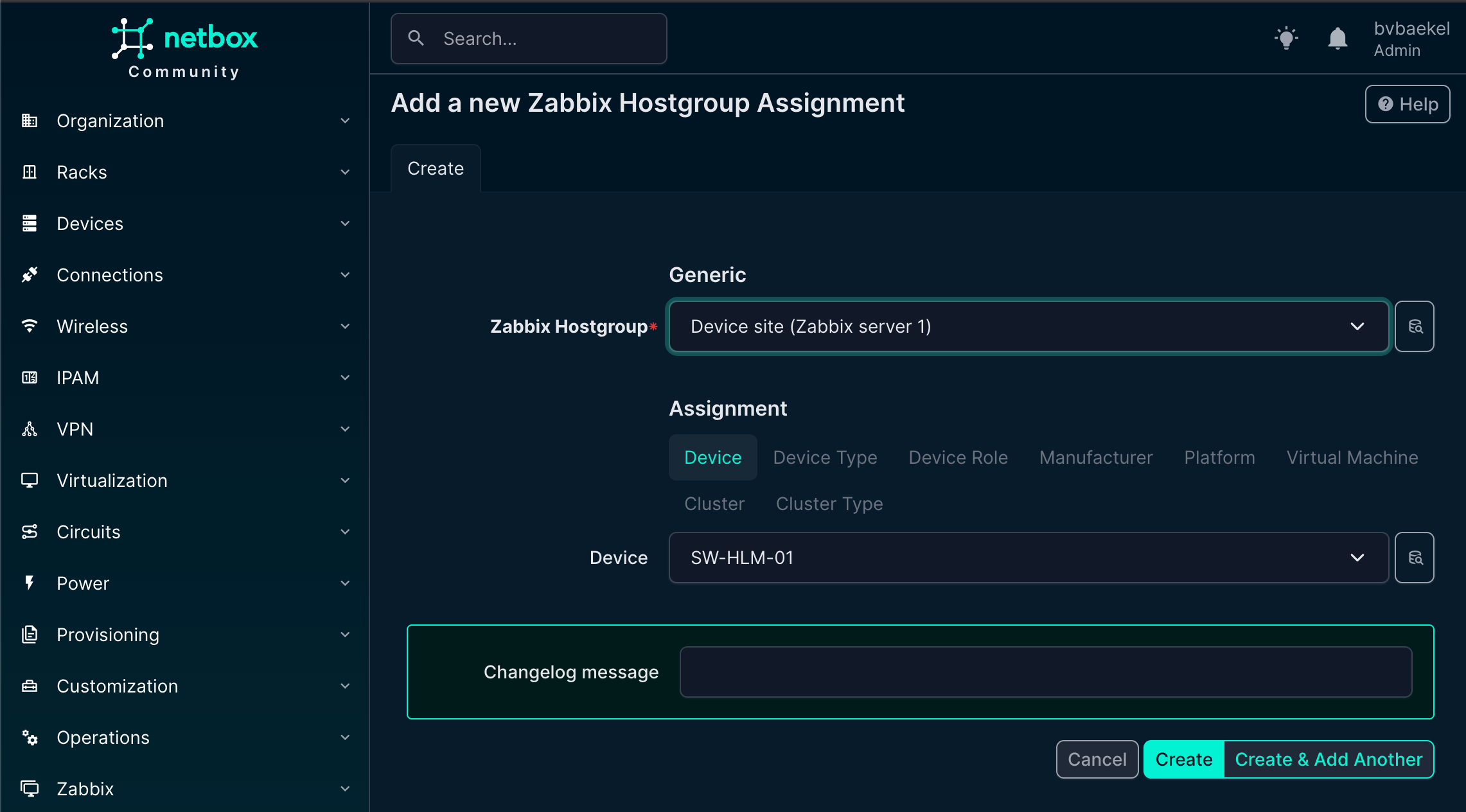
We will start with the host group, so click on Zabbix -> Hostgroups. There we create a new one as per the screenshot below. There is something strange with our configuration, as we use Jinja2 templates instead of static names.
The object name is “Device site” but the actual value will resolve to the site name we created (OICTS HQ) earlier. The power here lies in the variables – if we create a new device for another site and link this hostgroup, it will automatically resolve to the correct site name with no need for static configurations anymore!
Of course, the host group should be assigned to a Zabbix server again:
NetBox Zabbix hostgroups
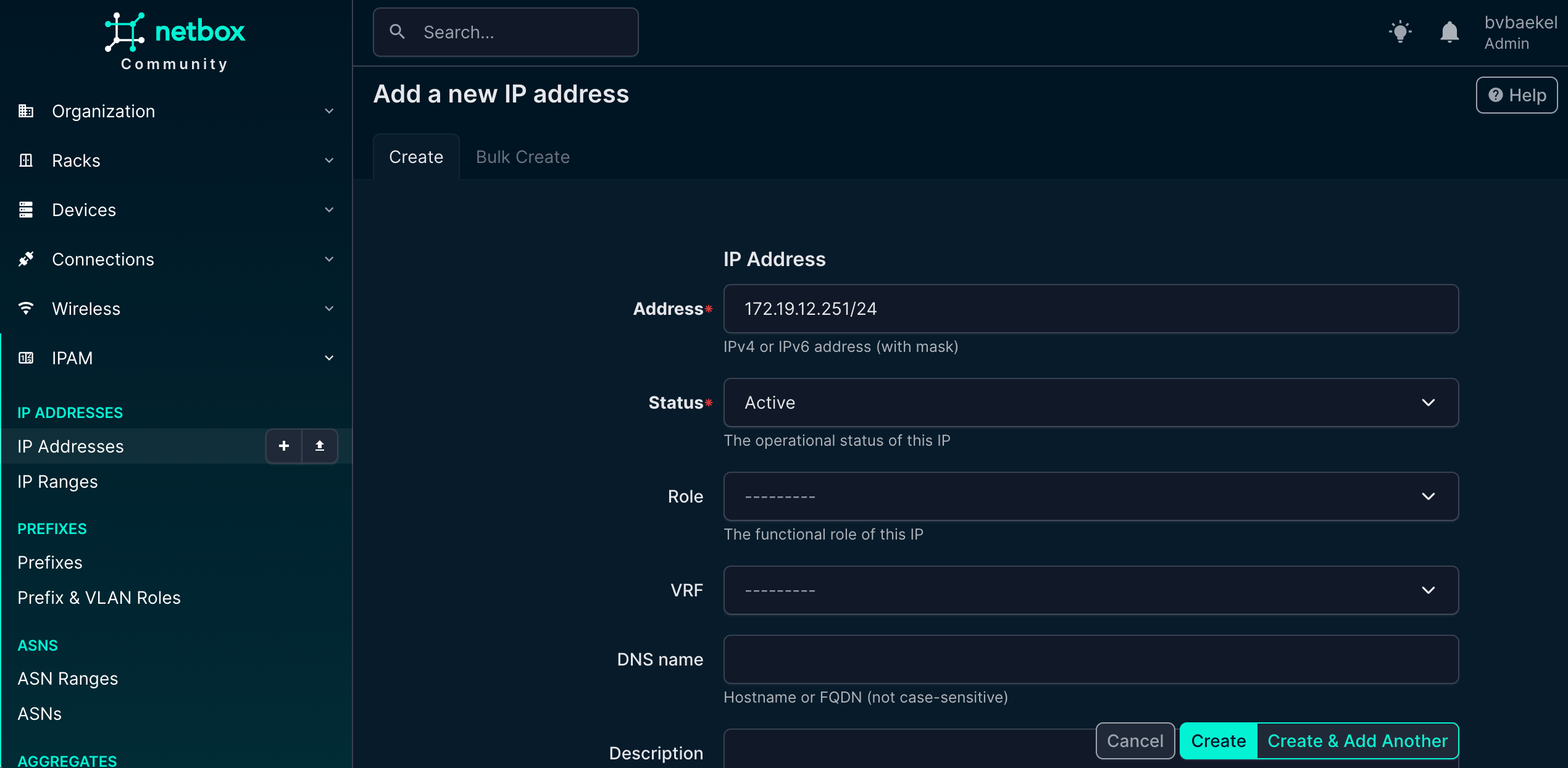
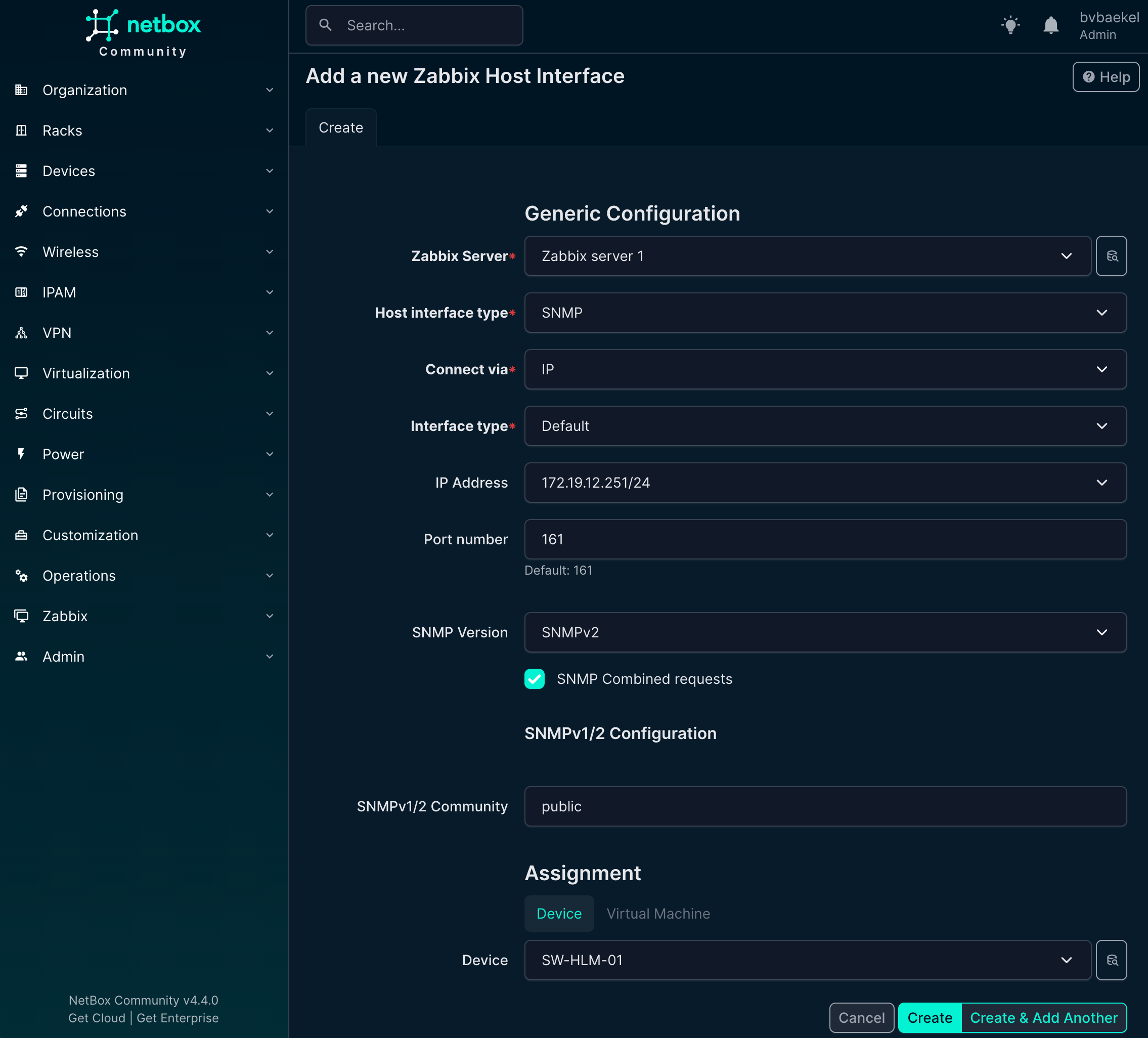
The next step is to create a Zabbix host interface, which is essential for monitoring and communication between Zabbix and the device. To do this, we leverage the IPAM (IP Address Management) functionality within NetBox.
IPAM provides a structured way to manage and allocate addresses across the network, ensuring consistency and avoiding conflicts. In this case, we navigate to IPAM → IP Addresses and add a new IP address that will serve as the management interface for the device. This IP address will later be linked to the Zabbix host configuration, allowing monitoring data to flow seamlessly.
NetBox IPAM config – IP address
If we now go back to Devices -> the device we want to configure → tab “Zabbix” we should add an Host interface and Host group. Click on Add for the respective config and populate the minimum fields. For the Host interfaces that looks like this:
NetBox Zabbix host Interface
For the host group, there are fewer fields to fill in compared to other objects. All you need to do is select the appropriate group from the available options. This keeps the process straightforward and avoids unnecessary configuration.
Once saved, the host group will be correctly linked and ready for use in Zabbix:
NetBox Zabbix hostgroups
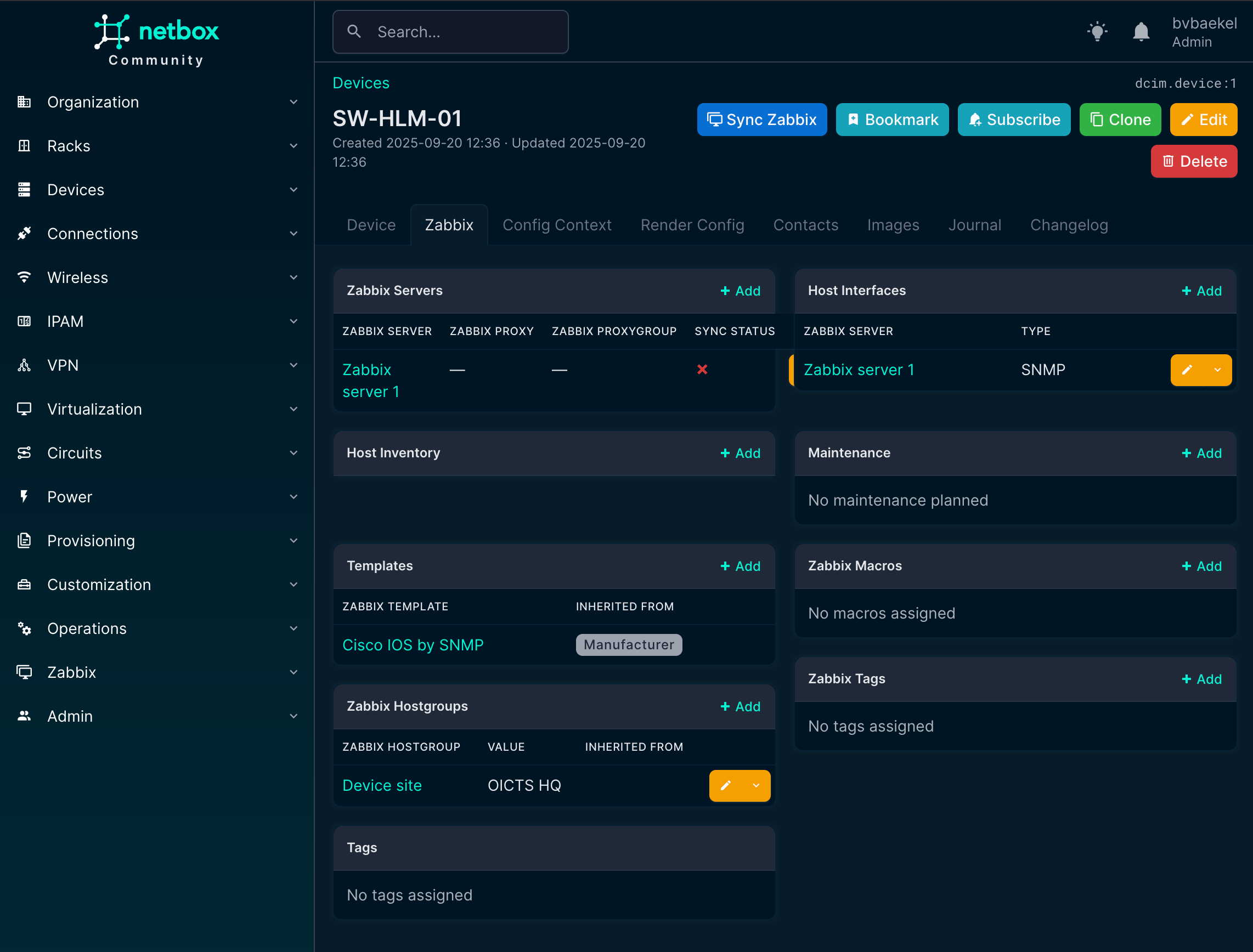
So the final result looks like this. At this point, all of the required elements have been configured in NetBox and properly linked to the Zabbix environment. The device now has its host group, host interface, and templates assigned, giving us a complete picture of how it will appear in monitoring.
What we see here is essentially the end-to-end outcome of the earlier configuration steps, where NetBox acts as the single source of truth and Zabbix automatically inherits the correct setup.
NetBox Zabbix device overview
Now it’s time to actually synchronize the device with Zabbix. At the top of the device detail page, right next to the device name, there is a button labeled “Sync Zabbix.” By clicking this button, NetBox will push all the information we’ve configured—such as interfaces, templates, and host groups—directly into Zabbix.
Within a few seconds, the host is created and fully ready for monitoring, without any manual setup inside Zabbix. With the heavy lifting automated, you can sit back and relax knowing that the device has been synchronized correctly.
Actually, let’s head over to Zabbix and confirm the synchronization:
Zabbix host overview from NetBox
Brilliant! The host is there, the template is linked, the host group automatically was set to “OICTS HQ” and the interface also looks correct. Monitoring will start and we did not touch Zabbix itself!
Want to see it in action?
Can do! We’ve created a YouTube video for you to actually see how it works. On top of that, we plan to host webinars regarding this plugin as well. You can register for all our webinars for free via the Zabbix website.
Is this it?
No! Actually there is a lot more we can do with this NetBox plugin, but it’s just that this blog post is not the correct place to show it all. Just to give you an idea, we can set maintenance from NetBox, which automatically will sync it to Zabbix. This way we again have a single source of truth and make sure we can see from a helicopter view where the impact is.
Furthermore, automatic synchronization can be set up so that any changes in Zabbix are overridden by the NetBox configuration. This way, we make sure there is no drift between NetBox and Zabbix. It also guarantees that if engineers forget to manually synchronize, no harm is done. However, the manual sync button will always be there, as nobody wants to wait to fix the monitoring when changes are made!
In addition, the plugin fully supports proxies and proxy groups – just as you know them from Zabbix. We’ve just haven’t shown it here to keep it somewhat short.
Roadmap
Although this project is just a side gig (we still dedicate our resources to Zabbix) we of course have a vision and roadmap that we would like to chase.
One major feature that’s on the roadmap is to show host problems in NetBox. By retrieving the current problems for a given host and showing them in NetBox, we should be able to limit the time spent in Zabbix even further. Our goal is to realize a “Single Pane of Glass” (just as NetBox is the “Single Source of Truth.”
High availability on a platform like Zabbix is a hard requirement for many users. With native high availability on the Zabbix servers, proxies, and at the frontend through various solutions for web servers, all that’s left is at the database layer. Any downtime in your MariaDB database would disrupt your monitoring availability, at the least on the frontend side of things in case of proxy buffering. Let’s have a look at the easiest way to create a high availability (HA) architecture for Zabbix using MariaDB with built-in Galera clustering – by removing single points of failure from your database and finalizing the HA puzzle for Zabbix.
Architecture overview
Let’s start of with the MariaDB + Galera number one design requirement. For a proper quorum to be made, 3 nodes should be used in the cluster. With only two nodes in a Galera cluster, quorum rules become a bit of a headache, as Galera uses a majority vote (more than half the nodes) to decide if the cluster can still accept writes. In a two-node setup, all is good when the database is online. But when we lose one node, quorum is lost and that node needs to rejoin.
This makes a two-node setup fragile but not impossible, and it does work with Zabbix since we do only have one Zabbix server active at the time. In a split-brain scenario where both nodes either think they are the last to leave, you might have to decide which node you think has your up-to-date data. We will detail both scenario’s, but the principle remains the same. We will use MariaDB as our database and Galera will be used to create a primary/primary cluster. In such a cluster, all nodes in the cluster are writeable, which is great for the Zabbix native HA.
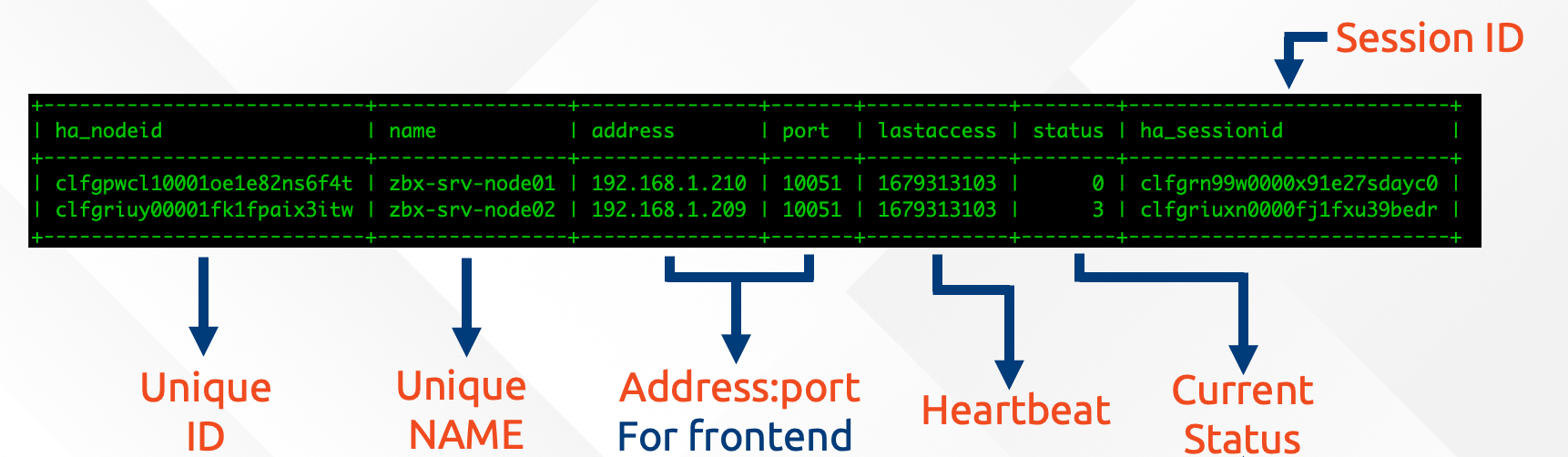
When we look in the Zabbix database, we can see that Zabbix keeps all of it’s Zabbix server HA information and states in the database.
This means that whatever one Zabbix server node writes into the database will also be replicated to all other nodes in the MariaDBGalera cluster.
The design
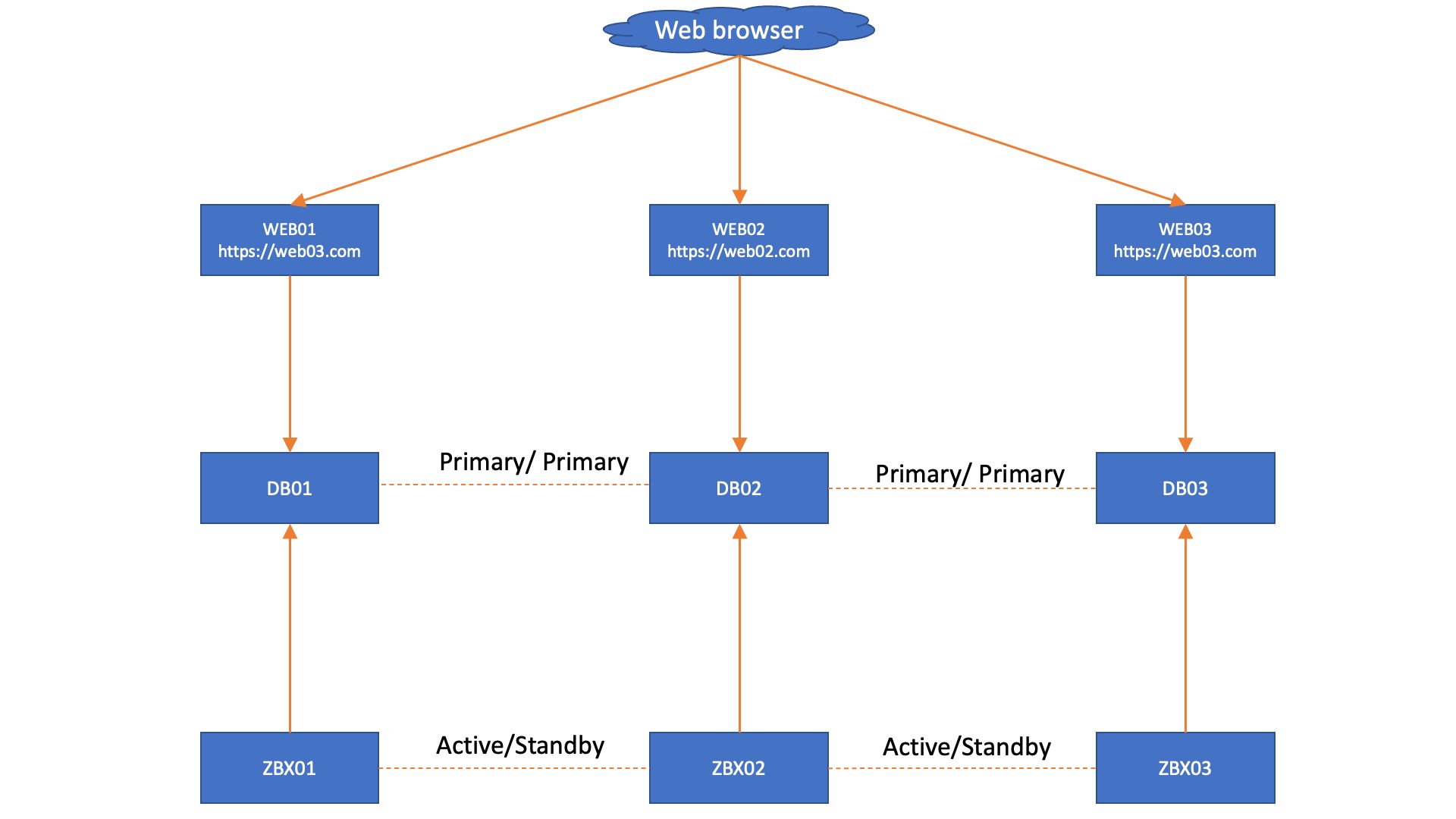
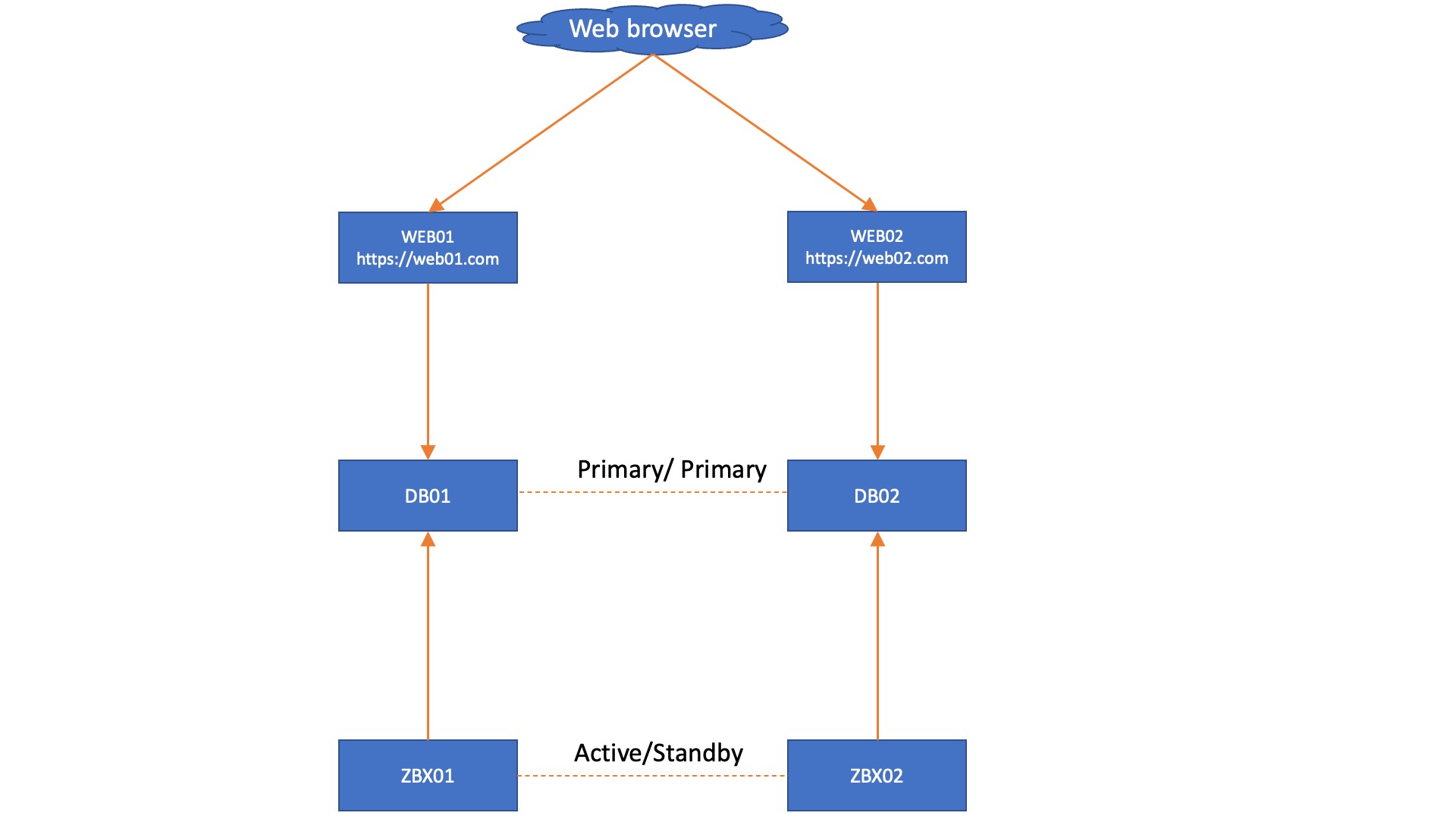
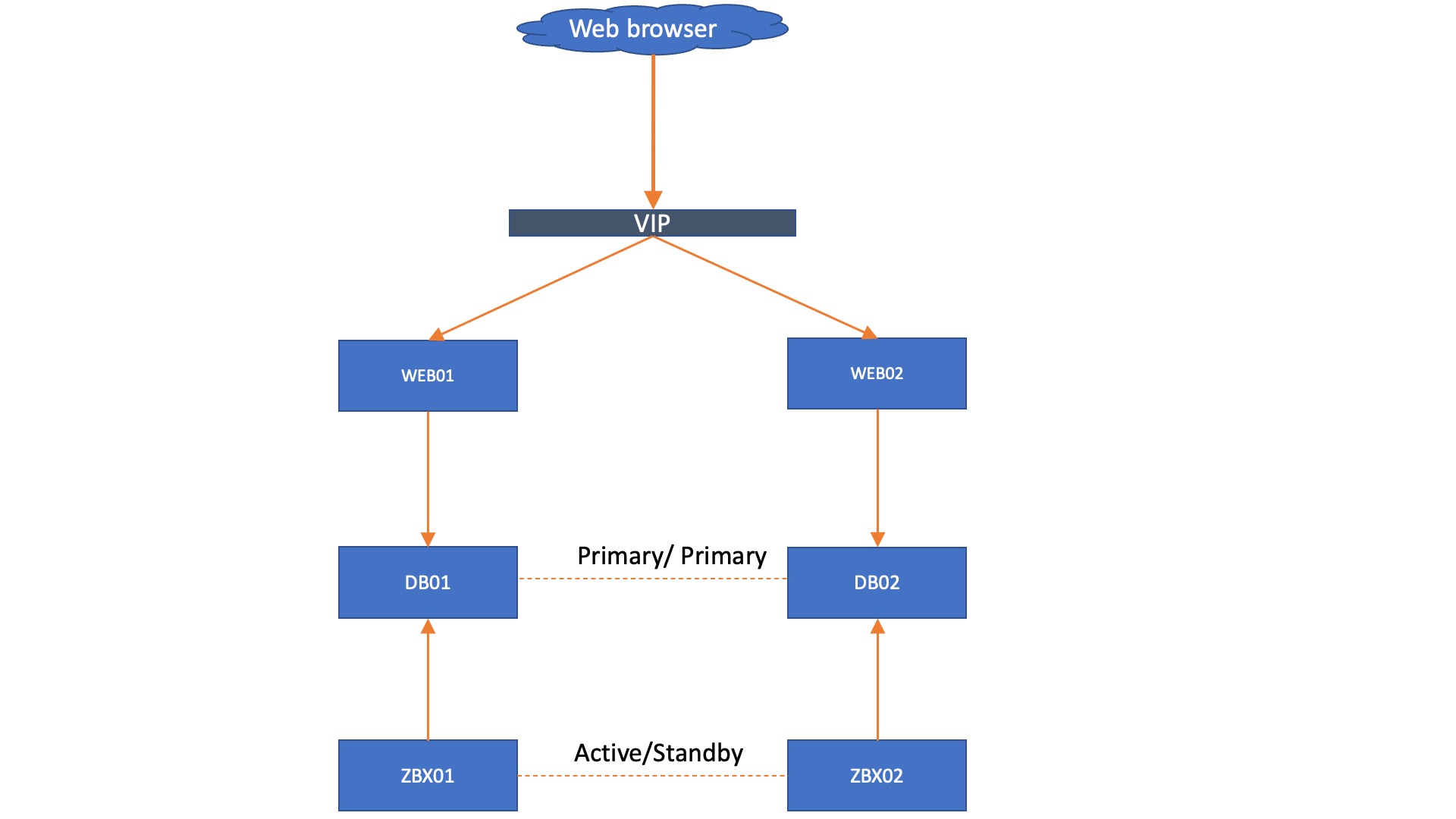
Knowing what we know now, we can create a very simple design for a solid Zabbix HA setup with Mariadb + Galera. When we have a single Zabbix frontend and we keep to the MariaDB + Galera requirement of having 3 database nodes, we get a fairly simple setup, as seen below.
In this setup, each Zabbix server connects to its own Database node and we don’t need added complexity by using load balancers. However, we do get an automatic failover from the Zabbix servers, as they know exactly which node is active through the database. However, in this situation we are still left with 3 frontends that do not have automatic failover, simply because we do not have database aware Apache or NGINX. This also works in a two database setup, with the side note that you might have quorum issues to manually resolve after an outage:
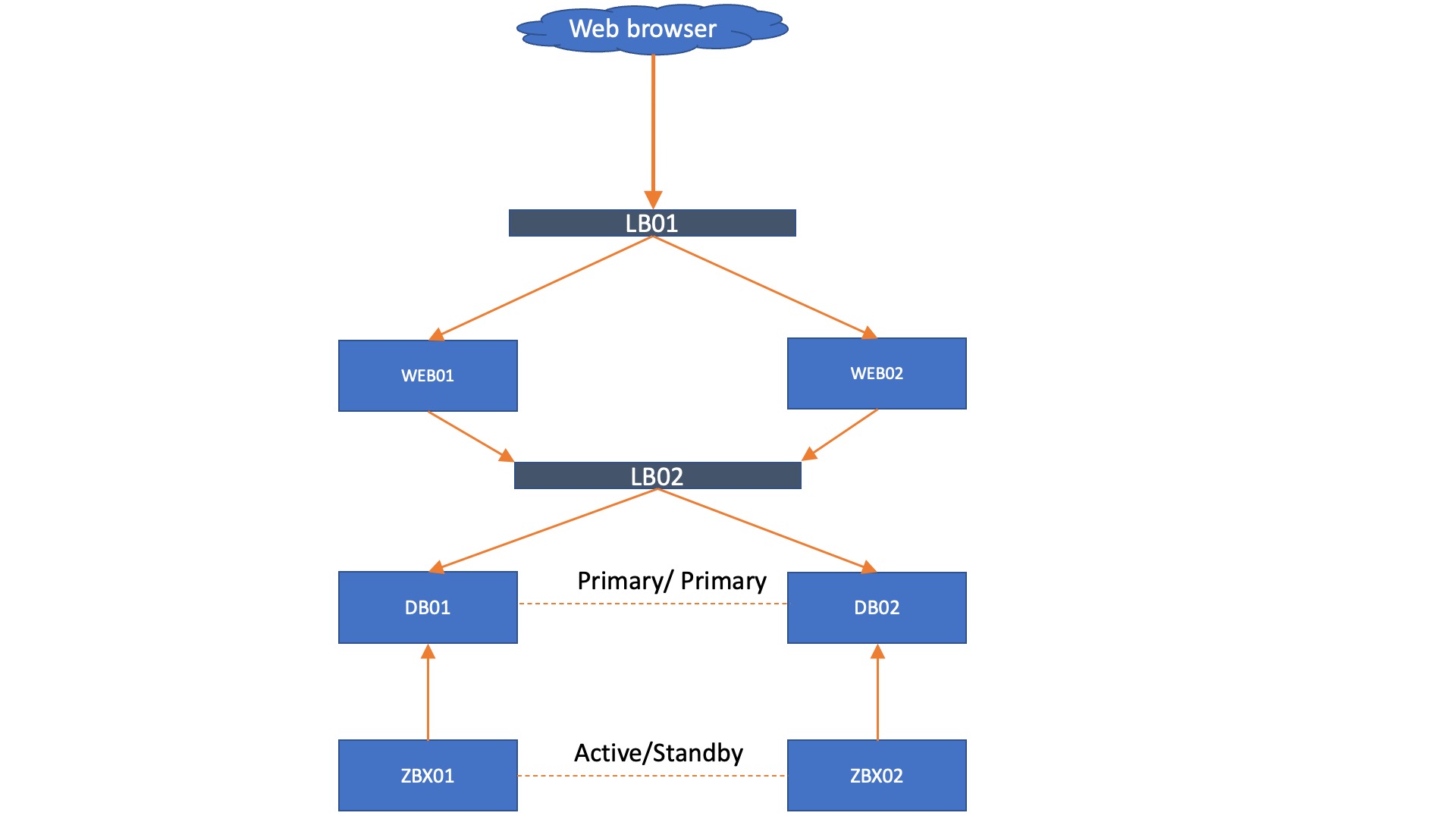
Adding onto this setup, we could install a VIP, load balancer, or something like HA proxy in front of the frontend to make a failover happen there as well. Keep in mind though, the failover needs to happen based on whether or not the webfrontend can reach a writeable database.
Optional Arbitrator
If you are set on running only 2 database nodes (your wallet is thankful), but still worried about quorums, we can bring in the ARBITRATOR.
If there are only 2 Database nodes in your Galera cluster, not to worry! It’s definitely possible even while maintaining a good quorum resolution in case of outages.
What about load balancing?
Lastly, it is also possible to add load balancing to the mix. Let’s say, for example, you cannot add a VIP to your environment but still need your WEB servers to failover. A load balancer can provide the solution here.
We still prefer to run the Zabbix servers with a direct database connection, but even there a load balancer could be added if you wish. However, please keep in mind that the more load balancers you add, the more complex troubleshooting might become. The whole idea about the setup without load balancers is to have a solid Zabbix setup that is easy to maintain, while providing high availability.
Conclusion
In the end, even with a minimal setup of 2 DB nodes, 2 Zabbix servers, and 2 WEB frontends, we can make a high availability setup. As we’ve shown with Galera, this setup becomes highly flexible, allowing us to run without automatic WEB failover all the way up to including complicated load balancers.
High availability doesn’t have to be overly complicated in a setup like this – it really is all about how far you want to push things. Besides that, in this setup everything is horizontally scalable on the database side. Do keep in mind, however, that Zabbix does still run in an Active/Passive setup.
I hope you enjoyed reading this blog post. If you have any questions or need help configuring anything in your Zabbix setup feel free to contact me and the team at Opensource ICT Solutions. We build a ton of cool stuff like this and more!
We love hearing from members of the community and sharing the stories of amazing young people, volunteers, and educators who are using their passion for technology to create positive change in the world around them.
Marie is a force of nature. As the founder of Breadline London, a grassroots community project in Haringey, she has spent years supporting families with essential services — she’s run a food bank, offered budgeting advice, and hosted well-being workshops. But when she heard about Code Club, she saw another way to help local children: by giving them the skills to shape their futures.
From community support to coding
Marie had no background in tech, but that didn’t stop her. She knew that many families in Tottenham couldn’t afford extracurricular activities like coding classes, and she was determined to change that.
“I’ve wanted a coding club for children, children in Tottenham, because that’s not something that is actually here,” she explains. “Unfortunately for us, we are on the very high end of poverty… and some of our children in this area don’t get the opportunity to attend things like coding club.”
With the support of Haringey Giving and the Raspberry Pi Foundation, Marie launched her Code Club at Tottenham Community Sports Centre. She started from scratch, learning alongside the kids, attending free training at the Raspberry Pi Foundation’s headquarters in Cambridge, and soaking up everything she could about coding.
“I don’t know anything about coding. Nothing. But going to the training days, it was so inspiring. I got so excited thinking, these are the things I can hopefully share with the children.”
Creating a space to experiment
Marie’s club is more than just learning how to code — it’s about teamwork, creativity, and confidence.
“They need to learn these skills outside of a school environment, outside of a place where it’s really structured. I want them to come in, experiment, make things up as they go along. Sometimes they follow instructions, but mostly, they just try things out.”
She also sees her role as a mentor, even if the kids sometimes know more than she does!
“Most of the children know more about coding than I do. So for me, it’s just about encouraging them: ‘What’s next? What else can you add to your project?’ And helping parents understand that they need to let the children create what they want to create, not just steer them.”
Discovering Coolest Projects
Marie’s journey didn’t stop with Code Club. When she learnt about Coolest Projects, a global showcase where kids celebrate what they’ve built with code, she knew she had to take her club to one of the in-person events.
“I was in Cambridge when I first heard about it, and this fabulous young woman spoke about Coolest Projects. I just felt so excited to take the children somewhere that’s just kids, just kids learning about coding and developing these amazing things. I even said, ‘Even if no one from my club comes, I’m going by myself!’”
Taking the kids to Coolest Projects was a game-changer. They saw what was possible, talked to other young coders, and left inspired.
“Next year, when we go again, everybody’s going to have a project. Seeing the kids’ faces when adults wanted to try their projects, it was so exciting for them!”
Making a change
Marie is proof that you don’t need to be a tech expert to start a Code Club — you just need passion and a willingness to learn.
Marie’s message to others who are thinking about setting up a coding club but worry about their lack of experience is simple:
“Start a [Code Club] because the children will help you to run [it]. They will help you. They will help each other. Don’t get put off running a coding club because you don’t know how to code. Because I don’t[…]and I love it.”
Marie’s story is a testament to what’s possible when someone believes in their community and takes action. She is creating opportunities for young people in Tottenham, giving them a space to learn, collaborate, and dream big regardless of their background. We can’t wait to see what her club achieves next!
For more information to help you set up a Code Club in your community, visit codeclub.org.
Help us celebrate Marie and her dedication to opening doors for young creators by sharing her story on X (formerly Twitter), LinkedIn, and Facebook.
Banco do Estado do Pará (Banpará) is the main public financial institution in the Brazilian state of Pará. It is a mixed-capital company, organized as a multiple bank with the mission of generating value for the state of Pará. It currently has approximately 198 physical customer service units and is present in all 144 municipalities in the state.
The challenge
Until 2016, Banpará used a monitoring environment installed on a single physical server. This environment was centralized, not very scalable, and vulnerable due to the lack of updates to recent versions of the software used. Centralization created a critical dependency – if there was a server failure, the entire monitoring system would be compromised.
There was no integration with the tool that orchestrates the company’s routine activities (which also generated an alert and a need for proper support of the bank’s infrastructure) and there was also the issue of including the routines of the internal demand generation tool in the monitoring panel, which was done manually.
With each new routine created, it was necessary to open calls with the technical teams for inclusion in the monitoring plan, which were then entered into a list of tasks. This process, in addition to being time-consuming, was subject to human error and delays, which compromised real-time visibility of critical operations.
The lack of proactive and integrated monitoring in Banpará’s structure resulted in operational gaps that created real risks to the continuous functioning of banking operations.
The solution
Given the challenges posed, the project developed with Zabbix had as its main objective to recreate the monitoring environment in a virtualized, scalable and resilient way, without dependence on a physical server. From rebuilding the infrastructure to integrating it with critical banking systems, the primary requirements included the following:
Integration with existing systems
Intelligent data processing and analysis
Reduction of manual processes and operational dependency
Development of customized solutions
Reorganization of the technological infrastructure
After implementing and structuring Zabbix at the bank (with the help of Master Support, an official Zabbix Certified Partner in Brazil), the structure became modular, scalable, and resilient, aligned with best practices, and able to expand monitoring without compromising system performance as the bank integrated new routines and services.
The results
The modernization of monitoring environment with Zabbix brought immediate benefits for Banpará’s IT monitoring scenario, especially with regard to operational efficiency, reliability and process automation:
More than 2,000 monitored devices
Around 100,000 metrics collected
More than 26,000 active alerts in Zabbix
Automated coverage of around 2,300 routines
An estimated gain of 2,300 operational hours
The adoption of Zabbix as a monitoring tool at Banpará was a practical response to the need to modernize the bank’s IT infrastructure. The project contributed to the elimination of manual processes, reduction of operational time, and increased visibility over critical routines. It also enabled the monitoring of a greater number of services, with greater agility in identifying failures and supporting decision-making.
In conclusion
With the current structure, Banpará now has a more integrated monitoring system, adjusted to operational demands and with the capacity to monitor the evolution of the bank’s activities in an organized and secure manner.
To learn more about what Zabbix can do for customers in banking and finance, visit our website.
Running a monitoring platform like Zabbix in a production environment demands reliability and resilience. When your monitoring solution is down, you’re flying blind – and for many organizations, that simply isn’t acceptable. This post introduces a robust high-availability (HA) architecture for Zabbix, using PostgreSQL, Patroni, etcd, HAProxy, keepalived and PgBackRest. Built on RHEL 9 or derrivates, this solution combines modern open-source tools to provide automatic failover, load balancing, and seamless monitoring, all while maintaining consistency and performance.
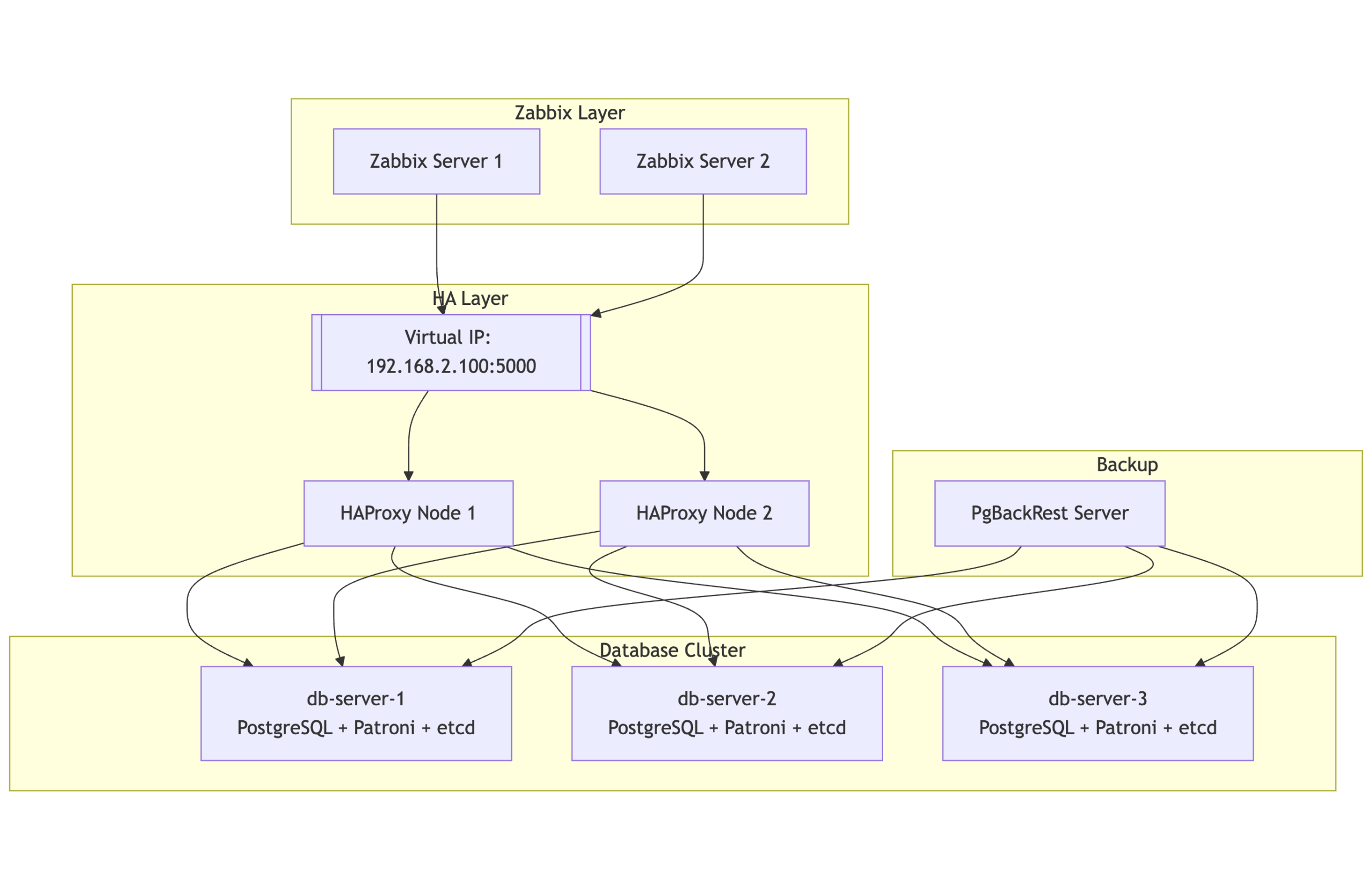
Architecture overview
The HA design consists of multiple layers working in tandem to maintain continuity even during node or service failures:
Database Cluster Layer
2 or more nodes form the PostgreSQL cluster, managed by Patroni and coordinated using etcd. At any given time, one node is the primary (read/write), and the others are hot standbys ready to take over automatically.
Consensus layer
etcd runs on the same nodes and acts as the distributed configuration store and coordination layer for Patroni. It ensures a consistent cluster state and enables safe failover decisions.
Load balancing layer
Two HAProxy nodes provide a single point of entry for all clients (including Zabbix), routing requests to the current PostgreSQL primary. These nodes are monitored and coordinated via Keepalived to maintain a floating Virtual IP (VIP), ensuring seamless failover at the connection layer.
Backup layer
A separate backup server is responsible for running PgBackRest, which handles full and incremental backups, WAL archiving, and Point-In-Time Recovery (PITR). This server communicates securely with all database nodes over SSH.
Monitoring layer
Two Zabbix servers, running in active-passive mode, continuously monitor all layers of this stack including the HAProxy health, Patroni cluster role, and etcd status by accessing the PostgreSQL VIP for backend connectivity.
This multi-tiered setup ensures that no single failure be it a database, load balancer, or monitoring server brings down the monitoring platform.
Why HA matters for Zabbix
Zabbix depends heavily on its PostgreSQL database backend. Every metric, trigger, event, and alert is stored there. If PostgreSQL becomes unavailable, even briefly, data loss or monitoring blind spots can occur. That’s why introducing HA at the database layer is a crucial step when scaling Zabbix for enterprise environments.
While Zabbix itself supports HA at the application level, this architecture ensures that the database backend is also fully fault-tolerant, using modern consensus-based clustering with automatic failover.
Component overview
To achieve HA, we bring together several specialized components, each fulfilling a critical role in the system:
PostgreSQL
The relational database engine used by Zabbix. In this example setup, it runs on three nodes, forming a cluster managed by Patroni.
Patroni
Patroni is the orchestrator for the PostgreSQL cluster. It monitors node health, manages replication, promotes standbys when needed, and ensures only one writable leader exists at any time. Patroni leverages a distributed consensus store in this case, etcd but other DCS’s are possible to coordinate decisions across the cluster.
etcd
etcd is a lightweight and highly available key-value store used by Patroni to maintain the cluster’s state. It stores leader election data, health statuses, and locks. We deploy it as a three-node cluster, co-located with the PostgreSQL nodes for convenience, though this setup can be scaled independently if needed as etcd is very latency prone.
HAProxy
To simplify application connectivity, HAProxy acts as a load balancer in front of the database cluster. It monitors the role of each node using Patroni’s REST API and routes connections to the active primary server. If the leader fails, HAProxy automatically reroutes traffic to the new primary.
Keepalived
Keepalived provides a floating virtual IP address (VIP) across the HAProxy nodes. This VIP allows client systems, such as the Zabbix frontend, to connect to a single stable IP even if one HAProxy node fails.
PgBackRest
To protect the data itself, we use PgBackRest for full and incremental backups, as well as Point-In-Time Recovery (PITR). A dedicated backup server is included to pull and store archive logs and backups securely via SSH.
Zabbix server
Finally, we run two Zabbix servers in active-passive mode. Both are configured to connect to the PostgreSQL cluster through the VIP exposed by HAProxy. The Zabbix frontend is deployed on both nodes as well, ensuring continued accessibility through the load-balanced setup.
Topology at a glance
Here’s a simplified view of the architecture:
2 or more database nodes (PostgreSQL + Patroni + etcd)
Two HAProxy nodes, each configured with Keepalived to manage a floating virtual IP
One backup node for PgBackRest
Two Zabbix servers pointing to the PostgreSQL VIP
All systems are tied together with consistent hostname mappings, time synchronization (Chrony), and service monitoring.
Notes:
PgBackRest is directly connected to all three PostgreSQL nodes, allowing it to archive WAL segments and pull backups regardless of which node is primary.
This design enables full standby backups and supports Point-In-Time Recovery (PITR).
HAProxy ensures Zabbix always talks to the current primary node, while Patroni and etcd handle automatic failover and cluster state management.
Design rationale
This setup prioritizes resilience and self-healing. If any single component fails a database node, a load balancer, or even a monitoring server the system continues to function.
Using Patroni with etcd ensures that failovers are handled automatically, without human intervention. HAProxy ensures client traffic is always routed to the current primary, while Keepalived ensures that this routing layer itself is highly available.
We opted for PgBackRest over simple scripts or base backups because it provides not just efficient incremental backups, but also full WAL archiving and point-in-time recovery, which are invaluable for both disaster recovery and debugging.
Lastly, we chose to integrate Zabbix itself into this HA design, treating it not just as a application but as a fully resilient service able to monitor itself, so to speak.
Real-world considerations
Resource planning: While our nodes run comfortably, scaling this setup to heavy workloads requires careful tuning of memory, I/O, and PostgreSQL parameters.
etcd placement: Although we run etcd co-located with the database nodes in this example, separating etcd onto dedicated infrastructure is ideal for large-scale environments. This avoids resource contention and preserves quorum in extreme failure scenarios.
Monitoring the monitors: Zabbix itself must be monitored. In our setup, each component including etcd, Patroni, and PostgreSQL exposes health endpoints that can be used by Zabbix agents or scripts to generate alerts on replication lag, cluster health, and failover events.
Conclusion
This architecture provides a solid foundation for running Zabbix in a fault-tolerant, production-ready environment. It not only ensures high availability for the database layer but also offers flexibility, observability, and operational safety.
Whether you’re running internal infrastructure monitoring or offering Zabbix as a managed service, adopting this type of HA setup removes single points of failure and gives you peace of mind — all using open-source technologies that are battle-tested and widely supported.
If you need assistance with the migration or want to ensure best practices for scaling and optimizing Zabbix, don’t hesitate to reach out to OICTS. We are a Zabbix Premium Partner operating globally, with offices in the USA, UK, Netherlands, and Belgium, and we’re ready to help you every step of the way.
There are plenty of good reasons to attend Zabbix Summit 2025, but one of the most important is the fact that this year’s Summit will feature Dylan Beattie as a special guest speaker. A Software Development Consultant and Founder of Ursatile, Dylan is an international keynote speaker, and a long-time contributor to the open-source community. He’s also a Microsoft MVP and has created Rockstar, an esoteric programming language that started as an inside joke and ended up being featured in Classic Rock magazine.
At the Summit, Dylan will give a talk titled “Open Source, Open Minds. The Cost of Free Software.” We asked him about his beginnings in the tech industry, what drove the creation of Rockstar, and why communication is the key to successful software development.
Can you tell us a bit about your journey into software development? How did you get started, and was there any particular moment when you realized that you were on the right path?
Like a lot of folks in tech, I got started on the 8-bit home computers of the 1980s – mine was an Amstrad 6128, which came with a couple of fairly mediocre games, but it also had a BASIC and a LOGO interpreter, and I pretty quickly found out that writing little programs and trying to create my own games was way more fun than playing the games which were included with it. I graduated from that to a 286 PC with MS—DOS 5, Windows 3.1 – but I really wasn’t thinking about it as a career.
The turning point was when I was sixteen years old, and I was supposed to be going to university to study mathematics. Dad brought home a new 486 PC a couple of weeks before my final exams, I spent my study leave messing around on the computer instead of studying, and when I didn’t get the grades I needed for my university course I figured maybe that was a sign I should be studying computer science instead. I went to Southampton and got a bachelor’s degree in computer science, learned C, C++, Lisp, SQL, and HTML. I graduated right as the dot-com bubble was bursting but still managed to get a job building data-driven web applications, and I’ve never really looked back.
You talk a lot about the human side of software. Why do you think communication is such a critical skill in development?
One of the perennial challenges facing the craft of programming is that it can be a profoundly solitary activity. One person working on their own can create an app or a game, put it online, and share their creation with literally millions of people – no meetings, no emails, just one person cranking out code. But then you try to translate those coding skills into domains like banking, healthcare, aviation, domains where software quality can have a real, material effect on people’s lives, and you realize that the code is actually the easy part.
The ability to talk to people, figure out what they need, help them understand your own ideas; to create consensus and avoid misunderstanding? It’s way more important than being able to crank out code. The most expensive problems I’ve had to deal with in my career haven’t been bugs in the code, they’ve been misunderstandings about what the team is doing and why it matters.
How did you end up creating a programming language (Rockstar) that can do double-duty as rock lyrics?
Good question! So, there’s always been this trope of the “rockstar programmer” – these mythical, high-powered, hyper-productive developers who can crank out millions of lines of fast, flawless code – and about a decade ago there was a massive spike in recruiters putting out adverts for “rockstar programmers.” When somebody suggested on Twitter that somebody should create a programming language called Rockstar to really confuse recruiters, that gave me an idea.
Initially it was just a piece of comedy writing – a parody of a programming language specification. I wanted to see if it was possible to extract enough clichés from rock music to create a formal grammar for a Turing-complete programming language that read exactly like song lyrics. It turns out that the answer is yes! I published the parody spec on GitHub, it got shared on Reddit and Hacker News, and the whole thing snowballed from there. Eventually I had no choice but to actually build a Rockstar interpreter, which turned out to be way more difficult than I thought, but also a lot of fun. The latest version is online here – it’s built in C#, compiles to native binaries for WIndows, Linux, and macOS, plus there’s a web assembly version on the website so curious folks can run Rockstar right in their browser without having to download anything!
Before taking on a speaking slot at this year’s Summit, how familiar were you with Zabbix? What has your experience of using it been like?
I’ve got to be honest – I’m not sure I’d ever heard of Zabbix before I was invited to speak at Zabbix Summit 2025, but that’s not unusual. I get invited to a lot of events that are focused around a particular technology or platform, and it’s a constant reminder of just how vast our industry is that somebody will organize a conference around a product I’ve never even heard of and attract literally hundreds of smart, curious people who want to share their own experiences and learn from each other. One thing about Zabbix which was particularly interesting to me when I started researching it was the licensing model. I think it’s a relatively unusual example of a commercially sustainable product or software that’s published under the Affero GPL license, so I’m really looking forward to chatting with other attendees about that and how that’s influenced their decision to use it.
You’re famous for your detailed and theatrical presentations – what makes a technical talk memorable to you?
A great talk is one that really connects with an audience, and the best way I’ve found to do that is to look for the little things that we all do every day that we’ve all learned just accept at face value, even when we have no idea why they work that way. Why is a capital “A” ASCII code 65 but a lowercase “a” is code 97? Why is validating email addresses difficult? Why is vertically aligning something in CSS such a big deal? There’s a good chance that a lot of folks in the audience have asked themselves that same question at some point, so the curiosity is already there. Tapping into that curiosity gets their attention, and then you can tell them the good stuff: the history, the stories, the personalities, the decisions.
There’s a lot of stuff in tech which feels kinda stupid, but none of it was designed to be stupid (well, except Rockstar!) Once you understand the context and the history, everything makes a lot more sense – and then at some point, maybe months later, you’ll hit a weird text encoding bug, or a problem with a system that won’t accept certain kinds of email addresses, and you’ll remember the talk. I get email from folks sometimes talking about how something from one of my presentations has helped them fix a weird bug years after they saw the presentation. That’s a great feeling.
Can you drop any hints about your presentation at this year’s Summit? What should audience members expect?
Sure! We’re going to talk about MIT, laser printers, software, Commander Keen, Doom, Quake, Netscape, the origins of the term “open source”, Linksys routers, WordPress, how the xz-utils backdoor nearly ended up compromising about half the computers on the internet – and a really cute story about a squirrel. It’s going to be awesome. I can’t wait!
For companies looking to migrate from PRTG Network Monitor to Zabbix, one of the most critical aspects is making sure a smooth migration of monitored devices and configurations. While there is no official tool to directly migrate between the two platforms, creating a bridge using custom export/import scripts allows for an effective and large migation. This blog post outlines a practical approach to achieving that migration based on the export/import methodology we at Opensource ICT Solutions previously implemented for one of our clients.
Why migrate?
While PRTG offers an intuitive interface and is popular for its ease of use, Zabbix provides:
Greater flexibility and scalability
Full open-source licensing
More powerful automation and templating
A robust API for integrations
Lower costs, especially since Paessler was sold to an investor
These features make Zabbix an attractive choice for teams looking to scale or standardize on open-source infrastructure.
Migration overview
The migration involves two key steps:
Exporting PRTG device information
Importing data into Zabbix
Because the two systems are conceptually and structurally different, we focused our scripts on migrating what is most transferable: device names, IP addresses, and interface types. SNMP versions or PRTG-specific sensor details were excluded or simplified where not applicable to Zabbix. PRTG, for example, will only export probes that have an OID that was not built-in in PRTG but added later, making our export incomplete. This does not mean we did a partial migration, it just means we have not included it in the automated approach.
Step 1: Exporting from PRTG
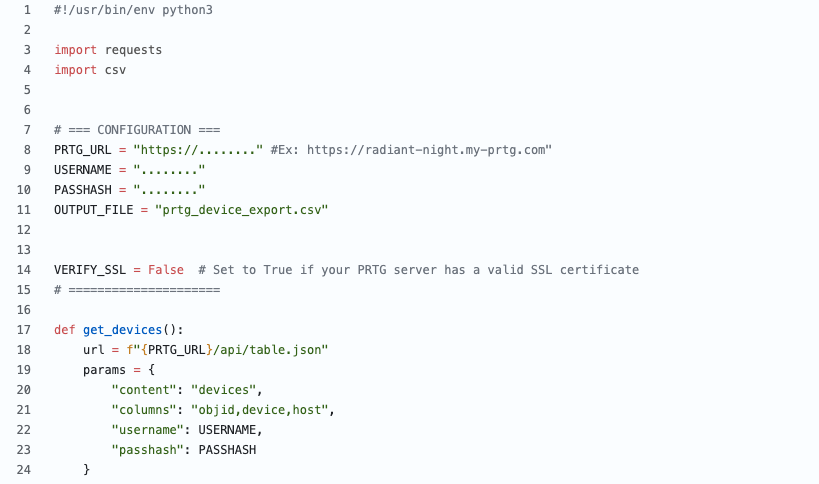
We developed a Python-based script that interacts with the PRTG API to extract monitored device data and export it to a CSV file. The script filters out irrelevant objects and organizes the output for easy Zabbix processing.
This creates a clean CSV, like this:
Device Name, IP Address, Interface Type
zabbix-server,10.0.0.10,agent
ServerA,192.168.0.2,SNMP
ServerA,192.168.0.2,agent
core-switch,192.168.0.1,SNMP
This file serves as a clean, structured inventory of monitored devices.
Note: SNMP version fields were excluded in the final export, as Zabbix does not currently display or rely on an SNMP version in the same way PRTG does.
Step 2: Importing into Zabbix
Using Zabbix’s API, we created an import script that reads the CSV and:
Creates host entries
Assigns them to the appropriate host group
Adds relevant interfaces (e.g., Agent,ILO,SNMP or a combination of …)
Each host is configured based on its detected interface type in PRTG.
On the Zabbix side, we used the Zabbix API to automate the creation of hosts, interfaces, and template assignment. The import script reads the CSV line-by-line and takes action based on the interface type.
Considerations and “gotchas”
Templates: We didn’t add templates, as there is no 1:1 solution – PRTG has a different concept and adding a standard template would be possible but probably not the best solution.
Host Groups: For ease of use and the limited time we had, we added all hosts in a temporary host group made for the migration. Although we do have scripts that take it out from PRTG and create it in Zabbix, in this particular migration it was not needed.
Permissions: The API token used in the import script must have sufficient privileges to create hosts.
What is NOTmigrated
Because of fundamental differences between the platforms, the following are not directly migrated:
Historical data or sensor readings: Mainly because the customer had no hard requirement for it.
Custom PRTG notifications or dependencies: It was easier to manually re-create them.
Maps or dashboards: The Zabbix approach is so different that it was easier to recreate it manually (and improve).
Sensors: Zabbix is working with a different concept.
Post-migration tips
Validation: After the import, verify that each host is reachable and monitored correctly in Zabbix.
Discovery: Consider using Zabbix’s LLD (Low-Level Discovery) to dynamically find interfaces, disks, or other entities.
Housekeeping: Disable PRTG monitoring only after confirming Zabbix is fully operational.
Conclusion
Migrating from PRTG to Zabbix is not a one click operation, but with some scripting, planning, and experience from a partner like us, it can be done efficiently and with minimal disruption. The custom export/import scripts act as a reliable bridge between the two systems, allowing for a clean transfer of your monitoring inventory. From there, Zabbix’s automation and scalability features can help take your monitoring to the next level.
If you need assistance with the migration or want to ensure best practices for scaling and optimizing Zabbix, don’t hesitate to reach out to OICTS. We are a Zabbix Premium Partner operating globally, with offices in the USA, UK, Netherlands, and Belgium ready to help you every step of the way.
October is just around the corner, and that annual shift into Q4 can mean only one thing – it’s almost Summit time! Zabbix Summit 2025 will take place on October 8-10 in Riga, Latvia at the Radisson Blu Hotel Latvija, and it’s shaping up to be the perfect blend of established traditions and fresh approaches – we’ve been at this for a (very lucky) 13 years now, and we’d like to think we’ve kept the aspects of the Summit experience that everyone knows and loves while adding a few twists! Here’s what you can expect for the price of admission:
Table of Contents
Top-tier presentations from Zabbix leaders and experts
The learning begins with Zabbix Founder and CEO Alexei Vladishev’s keynote speech, which promises to be an “info drop” full of details about upcoming releases, new features, and what Alexei sees on the horizon for Zabbix. From there, it will be time for over 30 main stage speakers spread across two days of conference action. Some of the highlights include:
Presentations from Zabbix experts on topics like:
Turning playbooks into automated action plans
Streaming metrics for multiple tenants without chaos
Syncing systems painlessly
Maintaining control over massive amounts of Zabbix data
Detecting and responding to security threats before they escalate
Deep dives that will show you how to:
Spot the blind spots in large-scale networks (and fix them)
Keep tabs on Zabbix itself (after all, even monitoring needs monitoring)
Take full control of tag management
Use Zabbix Proxy to scale without breaking a sweat
Practical case studies, including:
Turning sensor data into insights with AI
Keeping SAP environments and multisite clusters in check
Transforming enterprise-level monitoring
Supercharging operations via migration projects
Making discovery, correlation, and AI work together for smart monitoring in action
Expect all this, plus inside information from the Zabbix team on the path to becoming a Zabbix partner and how Zabbix services can help you scale efficiently. As if that weren’t enough, this year’s Summit will also feature special guest Dylan Beattie! A Software Development Consultant and Founder of Ursatile, Dylan is an international keynote speaker, and a long-time contributor to the open-source community.
At the Summit, Dylan will give a talk titled “Open Source, Open Minds. The Cost of Free Software.” Expect stories about why developers choose to give their code away, what happens when they change their minds, the quirks of licenses and legalities, and the big question of whether open source can ever be truly sustainable.
Dedicated Dev and Community tracks
Created by developers and for developers, the Dev Track makes its debut this year and brings together some of the top minds on the Zabbix development team to cover topics as diverse as extending Zabbix Agent 2 with custom plugins, enhanced widget development, and template design best practices.
For attendees of a slightly less technical persuasion, the Community Track is there to facilitate author led discussions about community-driven content and resources, like the Zabbix Book. Assembled by longtime Zabbix enthusiasts Patrik Uytterhoeven, Brian van Baekel, and Nathan Liefting, the Zabbix Book will get its own breakout room, where Summit attendees can brainstorm in small groups about how to improve the book via new ideas and topics.
Hands-on workshops
The Summit experience has always been about finding opportunities to put theory into practice, and this year’s workshops showcase the latest features and use cases in action. Attendees will be able to dive into workshops on AI powered monitoring with Zabbix and ESP32, nested LLDs (low-level discovery), reducing alert noise, diagnosing performance issues with Diaginfo, and using Netflow integration via H5 Network. It’s a rare opportunity to confirm your knowledge retention by performing real-world tasks under the guidance of workshop hosts and their assistants.
Training and certification (yes, with discounts!)
A Zabbix Summit is the perfect place to get recognized as a Zabbix specialist or professional by taking part in Zabbix Certified Training sessions and exams at bargain prices. These one-day courses will be held from October 6 through October 13:
Automation and Integration with Zabbix API
Advanced Zabbix Database Monitoring
Advanced Zabbix SNMP Monitoring
Zabbix Certified Specialist Upgrade
Zabbix Certified Professional Upgrade
If you find yourself in Riga after the Summit, it’s worth your time to take part in the full Zabbix Certified Specialist course scheduled for October 13-17. Please remember that you can choose more than one training course and also keep in mind that you can attend the courses (without the 50% Summit discount) even if you’re not joining us at the Summit. You can register for all training sessions and exams here.
Networking and community building
A big part of what makes a Zabbix Summit a Zabbix Summit is the vibe – a big, global community coming together to catch up with old friends, welcome new members, and celebrate a certain open-source monitoring solution that brings us all together. That atmosphere of conviviality is exactly what makes a Summit such a one-of-a-kind networking opportunity. We’ve put together an open house visit and three evening events that are the ideal places to connect with like-minded monitoring enthusiasts, show off your skills, or get your company’s name in front of industry decision-makers.
This year’s Zabbix Open House on October 8 is your chance to see where the magic happens – drop by our offices and chat with our team members, grab yourself a coffee in our kitchen, and take part in a quiz that will teach even the most seasoned Zabbix fans a few new fun facts.
No summit would be complete without its events, and the opening event of Zabbix Summit 2025 on October 8 will take place at Riga’s renowned Monkey Club, with delicious fusion cuisine, a broad selection of cocktails and beverages, and a chance to unwind in style with your fellow Summit attendees.
The main event on October 9 is hosted by the Tallinn Quarter Hangar, which boasts a concert hall as well as a modern, open-plan street food kitchen and bar that are guaranteed to offer something for everyone.
On October 10, Zabbix Summit 2025 will wrap up at downtown Riga’s Burzma food hall, which offers 10 restaurants and a bar serving up a broad range of flavors from every corner of the globe. It’s the perfect location to relive Summit highlights in the company of your fellow Zabbix enthusiasts, and we’re looking forward to seeing you there!
Can’t make it? There’s always YouTube
A Zabbix Summit is one of those “you had to be there” events, but if you can’t make it to Riga, no worries – as in previous years, we’re going to be livestreaming all the speeches on our YouTube channel! Find out more and subscribe to the livestream here.
We love hearing from members of the community and sharing stories of amazing young people, volunteers, and educators who are using their passion for technology to create positive change in the world around them.
Today, we introduce Shajan, a digital storyteller and senior business advisor at the BBC, whose extraordinary personal and professional journey has led him to champion digital literacy for young people in Bangladesh.
Family roots in Bangladesh
Shajan is British-born, but his roots deeply connect him to Bangladesh. This connection was instilled by childhood holidays to Bangladesh, as well as his late father, who emigrated to the UK in the 1960s but always encouraged Shajan to maintain ties with the community he left behind. Shajan’s pull towards Bangladesh intensified after his father’s passing fifteen years ago.
“I always thought I’d like to do something, carry on the work he left behind with efforts in building schools and supporting his local community.”
The memory of his sister Khela, who passed away at just 12 years old while in Bangladesh, also motivates Shajan. He says, “She was a really creative person, really into her arts and crafts and learning.”
Khela’s loss fuels Shajan’s desire to do something specifically for the young people of Bangladesh, connecting with their potential for creativity and learning.
Setting off on a new path
Shajan’s 15 years of working for the BBC led him to discover the power of digital education. In 2015, he project-managed the BBC’s “Make It Digital” campaign, a UK-wide initiative addressing the National Digital Skills Gap.
As part of this, he led partnerships with organisations like Code Club.
“That experience showed me how digital tools could unlock creativity in young people and build their confidence.”
During his visits to Bangladesh, Shajan observed a widening digital divide. Young people, especially in rural areas, lacked access to basic internet and computers. Teachers faced heavy workloads, and many students needed to pause their education to support their families. Seeing no equivalent to Code Club in Bangladesh to inspire young people, Shajan felt he had to act. Before he knew it, he was requesting a six-month career break.
“I said, ‘This is what I always wanted to do. If I don’t do it now, I will miss the opportunity.’”
With the support of both the BBC and Code Club, Shajan packed his bags and moved to Dhaka, the capital city of Bangladesh.
Creating a movement
Shajan’s initial goal was to raise awareness and build a sustainable model for Code Club in Bangladesh. Recognising that teachers needed support to run clubs, Shajan’s strategy was to engage university students as volunteers. He organised a national coding festival, leveraging these student volunteers to connect with schools and prepare young participants for a Scratch-based project challenge. The event received lots of media attention, encouraging interest and inspiring a new generation of coders.
However, there were some hurdles that had to be worked around, including unreliable internet connections, limited access to computers, and unstable electricity supply. Beyond practical challenges, Shajan faced a crucial mindset shift.
“Not everybody’s convinced yet that their children should be doing coding. For many families, generating immediate income takes precedence over digital education. Balancing the need to put food on the table with the long-term benefits of coding remains a constant battle.”
Despite these obstacles, Shajan’s efforts proved successful. Some of the creators from the 2016–2017 classes, now in their twenties, have pursued computer science and now share how Code Club helped them on their paths. He also organised an incredible exchange program, bringing creators and mentors from Code Club South Korea to Bangladesh for a seven-day visit. Despite not sharing a language, creators connected through the language of code, an experience Shajan describes as inspiring for the young people and adults alike.
A new chapter
Shajan’s focus now is to launch a Coolest Projects event in Sylhet, the place his father was born and a region he wants to focus on before taking Coolest Projects national as well.
He is actively engaging with teachers and student volunteers across the city, with strong support from Nooraiya Khan, an ICT Lecturer with a background in computer science. Nooraiya is working hard with Shajan to co-lead all Code Club activities in Bangladesh, bringing valuable expertise and shared passion to the movement.
Shajan believes the current digital landscape offers new opportunities. He is a strong advocate for the role of artificial intelligence (AI) in education, viewing it as a way to help bring opportunities to all young people. He plans to introduce AI-focused Code Club projects to Bangladesh, ensuring the next generation is prepared for a future driven by technology.
For Shajan, Code Club Bangladesh is “for everybody”. He wants to ensure that no child, especially girls and those from underserved communities, is left behind. He would welcome anyone interested in helping the young people of Bangladesh, including teachers, educators, tech professionals, and government bodies, to join Code Club Bangladesh’s journey.
If you’d like to support young people in your community to explore coding, why not start a Code Club? The team will support you every step of the way with resources, training, and a collaborative community.
Recently, a new customer of ours at Opensource ICT Solutions asked whether we could migrate their Nagios instance to Zabbix. Because Nagios and Zabbix are very different in their storage methods, we told them that we would have to investigate and see if we could come up with a viable solution. It wasn’t long until we found a way to do it and started building some script to get it done.
Table of Contents
The customer’s wishes
No loss of any Nagios configuration data
Historic performance data migrated to Zabbix
Existing problems migrated from Nagios
Nagios XI to be disabled entirely, as the license is expiring
The customer was clear in their wishes – we needed to turn off Nagios, but without losing historic data. As such, they wanted all their old data visible in Zabbix instead of having Nagios running somewhere as a backup. This meant that a script had to be built to get that Nagios data out and into Zabbix.
The configuration data
The good part here is that it starts simple. When we dive into the Nagios configuration data, we clearly see that Nagios has hosts just like Zabbix. They just have a slightly different build than our usual Zabbix hosts. For example, we can see three different names for a host in Nagios:
Host Name
Alias = Host name
Display Name = Visible name
That immediately gives us a good way to hook up Nagios names to Zabbix host and visible names.
When we then take a look at the checks and how they are executed in Nagios, we also see similarities with Zabbix. In the end, both of them are monitoring solutions, of course. However, Nagios works more in a command execution kind of way, which is good for our migration. We can take this command and find an equivalent item in Zabbix. For example the check_icmp command can easily be translated into a simple check in Zabbix icmpping, icmppingloss, and icmppingsec.
For the check_tcp command we can do a similar translation. Making sure we use the simple check net.tcp.service whenever this command is executed on a Nagios host.
Because of the big differences between Nagios and Zabbix, this does mean we need to make some manual translations between the Nagios commands and Zabbix items. Depending on your Nagios instance, this could be a big task. Luckily for us, this was a smaller instance with only ICMP and TCP port checks.
The history (i.e. performance) data
Now that we know how to start creating our hosts and items, we need to understand how Nagios is storing its data. Zabbix has a big centralized MariaDB or PostgreSQL database, which makes it easy to parse through and work with our data. Unfortunately, Nagios instances use a different technique. Nagios stores data in .rrd (Round Robin Database) files and with it a .xml file to interpret the RRD file. The RRD files are not centralized like a Zabbix database, but they are more manageable in terms of storage size. We can see an RRD file per type of check in Nagios, which means we will have to grab the data from that file while understanding what it is going to belong to in Zabbix.
To see the data in the RRD file, we can use a special command line tool.
rrdtool /usr/local/nagios/share/perfdata/BeNeLux-Host-Name/Availability.rrd LAST --start -30d --end now | grep -v "nan"
Now we can clearly see that this specific RRD file above contains 8 columns, 7 with a performance value. The first column contains the timestamp in Unixtime, which is great because it will be perfect for storing in the Zabbix database. The other 7 columns in this file are different though, because we do not know what the value in the column belongs to. This is where the .xml file comes into play. The XML file belongs with the RRD file and contains details on what is included in the RRD file.
In this XML file we will find all of the required host information, which is great for creating the host in Zabbix. It also contains the check information, so we can also use this file to create the items in Zabbix. The biggest thing we will have to keep in mind is to make sure that the XML and RRD file match up in terms of number of RRD entries and columns. Column 1 in the RRD file will match with the first entry in our XML.
Let’s create a script
With the host, item and history data identified, we can start to create a script. In our case we decided to create a Python import tool. As Zabbix comes with some limitations in terms of which hostnames we can use (which are different from the limitations in Nagios), we need to sanitize our hostnames slightly.
Then all we need to do is parse through all the XML files and create new hosts in Zabbix through the Zabbix API.
It will be a very similar process for our items, as we parse through our XML file and create all of the required items in Zabbix through the API.
We can even create the triggers straight from the XML file by parsing through the different severities already set up in Nagios.
Once everything is created in Zabbix, the Python script can now start using RRDTool to parse through the RRD file, making sure to keep the XML file structure in mind when parsing through the columns.
This script can now create the hosts, the items, the triggers, and then import all of the data. We can see the hosts being created and data being imported.
The beauty of importing history data into Zabbix while the triggers are already created is then also seen below.
All of the triggers will trigger and be resolved based on the data imported, meaning that we can create problems with historic data. This means that not only do we have our historic data, but also all the problems with the correct duration as they are now discovered from the actual imported data.
To make this possible we can use the Zabbixsender tool. It has an option to include the timestamp upon every historic value imported.
Our Python script grabs the values from the RRD file and then converts them into a new _HOST_.sender file. This file will be sent to the Zabbix server using the Zabbix sender tool.
Looking at the file, we can see it contains only the name of the host, the unixtime stamp, and the actual value to send.
All we need to do is make our script send this file to the correct item in Zabbix.
Manual template and item creation
The last step will be our cleanup. We decided that we would start dirty with a one-on-one data import from Nagios. This means hostnames, item names, and trigger names are imported straight from Nagios. No templates will be created in Zabbix by the tool either, skipping the Zabbix best practice to use templates for all hosts.
We did this to make the initial import easier and not go overboard with scripting. It’s easier to have a messy Zabbix to clean up than to script everything perfectly in Python. Time is valuable.
What we did afterwards is create all the templates manually to take over the items as is from the hosts. For example, we can translate the ICMP ping and TCP stuff easily into a template.
After doing so, we do end up with some bad looking templates, but we can now start cleaning up.
We can also start creating normal trigger names and clean up…
…while changing our dynamic port names for something more expected as well.
Headquartered in Shanghai, the China Pacific Insurance (Group) Co., Ltd. (CPI) is a Chinese insurance company that was established on the basis of the former China Pacific Insurance Corporation. CPI Group is the second largest property insurance company and the third largest life insurance company in Mainland China. It provides integrated insurance services (including life insurance, property insurance, and reinsurance) through its subsidiaries.
The challenge:
The overall data center operation structure of the company works along financial industry lines, with a two-site, three-center operation model. The total scale of China Pacific Insurance’s on-premises hosts is over 6,000, and the three centers add up to nearly 40,000 host devices in the production environment.
It’s an enormous amount of information to monitor, so any monitoring solution needs to significantly reduce the difficulty of overall alert analysis. The alert information provided by the mixture of cloud product components that CPI were using caused a serious case of alert fatigue for their operations and maintenance personnel, with some alerts taking as long as 4 months to process.
The solution:
The bank’s cloud platforms all had their own monitoring and alerting functions, but the configuration of value threshold and notification policies was not flexible enough. Zabbix’s ability to uniformly collect data while configuring triggers and alerting proved to be a game-changer.
In addition, when compared to cloud vendors whose solutions require adjustments to thresholds in each product component, Zabbix proved to be a much simpler and more cost-effective way to notify operators of only the most essential alerts.
The results:
In practice, CPI found that the Zabbix multi-index combined alert function eliminates 30% of invalid alerts. Thanks to this success, CPI now plans to transfer the Zabbix Data Transmission Service to their digital twin data center, so that the inspection of physical facilities and the impact analysis of the application system can be quickly displayed to their operations and maintenance personnel.
Conclusion
The team at China Pacific Insurance successfully built an intelligent operation and maintenance system covering a number of key modules such as automated operation and maintenance, intelligent monitoring, logging platforms, and container platforms – all with Zabbix at the core. They are currently exploring the cutting-edge integration of monitoring systems with LLMs, further advancing intelligent monitoring and observability solutions in the process.
To learn more about what Zabbix can do for customers in banking and finance, visit our website.
We love hearing from members of the community and sharing stories of amazing young people, volunteers, and educators who are using their passion for technology to create positive change in the world around them.
Meet Isabelle, a youth mentor at a library Code Club, whose inspiring story tells how a passion for helping others and a love for reading led back to a childhood interest, shaping an unexpected and rewarding journey.
Saturdays spent at the library
Isabelle’s coding journey began around the age of nine. An avid reader, she regularly attended her local library in Stourbridge with her gran. When they saw there was a Code Club held on a Saturday morning, they both decided it might be a good skill for Isabelle to learn.
“I used to have like an entire folder of all the projects I’d completed. I’ve still got it somewhere in my room!”
She quickly progressed through Scratch, Python, and HTML, even finding herself teaching the adults at the club at some points! But, as secondary school approached, her involvement naturally tapered off as she began to focus on her studies.
A return through volunteering
In secondary school, Isabelle was looking for volunteering opportunities as part of her Duke of Edinburgh (DofE) award. Remembering her positive experiences at the library, and continued love of books, she initially considered volunteering there. Then, she had an idea.
“I suddenly thought ‘What if they still do Code Club?’ I really enjoyed it when I did it and I still remembered enough about it to help others. So, I felt like I could actually be useful instead.”
Isabelle reached out, and thanks to her gran’s long-standing connection with the library, she was remembered and welcomed back. What started as a three-month commitment for her DofE award soon extended to six.
“I really looked forward to each session at the library and decided to stick with it for the whole time.”
Embracing the chaos and connection
Isabelle’s return coincided with the Code Club restarting. Stepping into a mentoring role, she quickly found herself in the thick of it. With five computers and a group of new young people, most of whom had no prior coding experience, the first sessions were a whirlwind.
“It’s like the best kind of chaos. It doesn’t get easier as such. But it’s so fun meeting these new kids, they’re all different and they bounce off each other.”
She works closely with Lucy, the club leader, helping manage the flow of projects and supporting the children as they navigate everything from creating Scratch accounts to tackling challenging projects.
Isabelle with Lucy, Stourbridge Library Assistant, and Rujeko, Code Club Community Coordinator
More than just code
While the technical skills are central, Isabelle emphasises that Code Club offers so much more. She’s seen shy children blossom, making new friends and becoming more involved.
“I think there’s the whole element of socialising as well. And beyond coding, kids develop essential IT skills, like learning how to use a mouse and keyboard. Something many who just use tablets and phones don’t know!”
Four years and counting
Isabelle, now preparing to go on to further education, could not have predicted how her mentoring journey would turn out. What began as a three-month DofE requirement has turned into a four-year commitment.
“It has just never been something that I thought ‘oh, I don’t want to do this anymore’. It’s just part of the weekly routine now. It’s been four years and it’s shocking how quickly it’s gone.”
Isabelle’s dedication hasn’t gone unnoticed. She’s built strong bonds with the staff and gained invaluable experience. She’s learned to organise, work in a team, and even run sessions independently, developing skills that will be invaluable for her future.
“I like the bond that I have with the staff and with Lucy. It feels great to be trusted that much and it has just been such a nice experience.”
Lucy, Stourbridge Code Club leader and Library Assistant, shared her experience with the club and collaborating.
“Since Code Club offers so much more than just coding — confidence building, creativity, friendship, etc. — it plays an important role for children and young people in the community. The library is much more than just a place for books, and hosting Code Club here creates a welcoming space where young people can explore technology away from the classroom.”
“Isabelle has been absolutely fantastic both in supporting us with club admin as well as supporting the children with their coding! She understands the projects inside and out and is brilliant at not only solving problems, but also, importantly, encouraging the club to find ways of solving problems themselves. Our Code Club couldn’t have become what it is today without her input!”
Isabelle’s advice for future mentors
As Isabelle prepares to head off to the Bath Spa University to study media communications and publishing, she offers this advice for other young people considering becoming a Code Club mentor…”just go for it!”
Isabelle admits to being anxious at times, but the experience has significantly boosted her confidence.
“It built my confidence a bit more. You make friends along the way and you learn a lot of new things. And don’t worry if you don’t have a lot of coding experience. I don’t think you need it. I had a little bit but I was still basing it mainly off of reading the project instructions. And in all fairness, the instructions are really helpful!”
Mentoring at Code Club isn’t just about teaching, it’s about learning, growing, and connecting. It’s an opportunity to give back, build confidence, and discover the joy in supporting the next generation of digital creators. As Isabelle’s journey shows, sometimes the most rewarding paths are the ones you never planned to take.
Lucy shared why she thinks having youth mentors involved with Code Club is such an important dynamic.
“Youth mentors are great as role models and inspiration for children, and as a young person themselves they build such a great rapport with the club members. A mentor who’s closer to their age often feels more approachable, which helps create a comfortable and encouraging environment for them.”
If Isabelle’s story has inspired you, why not explore the world of coding? You can get started at home with over 250 free projects on the Code Club Projects website.
Looking for a little extra support in your own coding journey or open to mentoring others? Join a Code Club near you to meet a like-minded and supportive community.
We love hearing from members of the community and sharing the stories of amazing young people, volunteers, and educators who are using their passion for technology to create positive change in the world around them.
Seung Woo, also known as Tony, is a 17-year-old student from Canada and the co-founder of his school’s Code Club, alongside his teacher, Kay. A curious and driven teen with big ambitions in computer science, Tony is not only passionate about technology, but also dedicated to building a safe, welcoming space where others can learn, explore, and grow alongside him.
A spark of inspiration
Tony’s fascination with computers started early, driven by his love of video games, coding, and, perhaps most memorably, his admiration for Tony Stark, the comic-book and film character who becomes the superhero Iron Man! The idea of building something powerful from scratch stuck with him.
“My whole life, I have been curious about the inner workings of a computer and my inspiration for coding is Tony Stark or Iron Man from the Marvel Cinematic Universe!”
Tony’s early coding journey wasn’t without its challenges. Finding the right resources was difficult, and staying motivated during tough moments was often hard without a support system.
“Like many others, I was independently taught, and during this time of independent learning I’d find many different roadblocks and challenges that I had to overcome alone. A big setback for me was finding the right resources in order to learn how to code. Another big obstacle for me was motivation. I would find myself losing interest in a project. I didn’t have the exterior motivation to help me push through the inevitable hardships that come with coding.”
That’s where the idea for a coding club began to take shape.
Creating a community of coders
Tony co-founded the Code Club at Collège Jeanne-Sauvé in December 2024 with that exact vision in mind — he wanted to provide a fun, collaborative, and welcoming environment where students of all skill levels could explore their love of technology together.
“I created the coding club to help everyone on their journey of computer science, no matter their skill level, and that is exactly what it is turning out to be. Finding resources is easier than ever with a teacher and all of the amazing members.”
Tony’s teacher and co-founder, Kay, shared why Code Club was the right fit for the school.
“I thought Code Club was the best way to start our club for a few reasons. The amount of coding language options was varied and appealed to the different learners in our club. It was also important for us to promote our club and let our community know about the presence of a coding club in our school, and Code Club helped us do so via their online presence.”
What makes Code Club special
For Tony, the secret ingredient behind his club’s success is simple: teamwork.
“Without teamwork, our club wouldn’t really be a club, it would simply be an ensemble of people coding in their own little cubicles, much like a stereotypical office job, and to me, that does not sound too enjoyable. Teamwork is our little secret ingredient in problem-solving and building motivation, we embrace it by creating a safe space where everyone can speak their minds without judgement!”
Members are free to choose their own learning paths. No matter the project, the atmosphere is always filled with laughter, energy, and curiosity.
“Coding should be something that is fun — not stressful like others may make it seem. Celebrating achievements, making short term goals, and problem solving with friends are all great ways that we make coding fun in our club. A second word would be teamwork. Without teamwork, our club wouldn’t really be a club.”
Teamwork, he adds, transforms what could be a solitary activity into something social and deeply motivating.
Looking to the future
Tony hopes the club will continue to grow, bringing more students into the world of coding and helping them feel at home in it. His story is a great reminder that learning to code isn’t just about computers — it’s about building community, confidence, and creativity.
“I wanted to create a space where everyone would be accepted and encouraged to learn more about coding and not be ashamed to ‘nerd out’ about this subject like I do very frequently. I’ve dreamed of creating a space that embraces this beautiful passion.”
If you’d like to explore coding, you can get started at home with over 250 free projects.
For a little more support, or if you’re open to mentoring others, you can also join a Code Club. Check our website to find a club near you and become part of a like-minded and welcoming community.
LMT is a mobile GSM/UMTS/LTE operator in Latvia. Founded on January 2, 1992, it was the first mobile network operator in the country. In addition to providing mobile network and ISP services, LMT uses innovative technologies and solutions to develop and maintain a variety of IT solutions for public and private organizations. Currently, LMT is the largest telecommunications service provider in the country, with over 1,660 base stations and over 1.5 million users as of 2024.
The challenge
LMT utilizes a variety of monitoring solutions for a variety of purposes – from tools performing and monitoring ping responses to vendor-specific solutions and all-in-one tools such as Zabbix. LMT has 2 data centers, and since the vast majority of services delivered by LMT can be considered critical, most of the relevant infrastructure is duplicated across them.
Multiple Zabbix instances are used in the environment, including Zabbix 5.0 with MySQL database backend, Zabbix 7.0 with PostgreSQL, and TimescaleDB. Over 3,000 hosts with approximately 500,000 items are monitored by Zabbix.
The solution
Here is one example of how Zabbix is used to monitor switch cabinets in LMT data centers. Switch cabinets contain devices to measure the electric current, which support Modbus protocol and which can in turn be used to collect data.
Modbus monitoring was achieved by using Zabbix agent2 with the official Modbus plugin. This was combined with NetBox and GraphQL. NetBox was used as the source of truth, providing information about power feed and various electrical characteristics, such as voltage, amperage, utilization, phase, and more. The data was collected from NetBox via HTTP agent checks and GraphQL, and a JSON result was created by utilizing Zabbix preprocessing features.
The information collected from NetBox is combined with Modbus data collection utilizing Zabbix agent2. The data collected by Zabbix agent2 is preprocessed after the collection. The collected data is normalized and used by Zabbix low-level discovery features to automatically create Zabbix items and triggers for the available resources. Finally, the resulting data is visualized on Zabbix dashboards.
The results
Monitoring with Zabbix has made reacting to changes in the monitored power feed (detecting spikes, observing gradual power feed changes, etc.) a much simpler proposition for LMT, which in turn improves service for its millions of users.
In conclusion
Zabbix has proven itself to be an ideal solution for telecommunications clients, making it easier than ever to keep track of network health and performance, driving a more positive customer experience and greater revenue growth in the process.
To learn more about what Zabbix can do for customers in telecommunications, get in touch with us.
Established in 2020 to consolidate Doğan Group’s automotive and mobility companies and brands under a single entity, Doğan Trend Automotive is a prominent player in their industry. Representing a diverse portfolio ranging from automobiles, motorcycles, and marine engines to electric commercial vehicles, Doğan Trend also delivers innovative solutions to customers through its e-commerce platforms, such as suvmarket.com and vespastoreturkey.com.
The challenge
Doğan Trend’s IT ecosystem spans data centers, remote locations, and multiple units, necessitating seamless operations as well as an efficient monitoring and alert system. The existing infrastructure posed challenges in monitoring, making it difficult to detect potential issues in a timely manner, thus increasing operational risks.
The solution
To address Doğan Trend’s needs, our associates at ASNSKY implemented a Zabbix-based monitoring system. Key highlights of the project included:
Centralized dashboards: Custom dashboards were designed for data centers and remote locations, enabling the unified monitoring of IT locations and components from a single interface.
A dynamic alert system: Alerts prioritized based on predefined conditions allowed for the swift and effective resolution of critical issues.
Seamless operations: Early detection of potential issues prevented operational disruptions and ensured continuity.
Throughout the integration process, ASNSKY’s team collaborated closely with Doğan Trend’s IT department, addressing the specific requirements of different units and providing training for effective system use.
The results
Implementing the new monitoring system rapidly delivered the following results:
Enhanced visibility: Real-time monitoring of all IT locations and components made potential issues easy to spot.
Proactive issue management: Early detection of critical issues reduced operational downtime.
Increased efficiency: The centralized monitoring system drastically improved the responsiveness and effectiveness of Doğan Trend’s IT team.
“This project with the ASNSKY team made our IT infrastructure more transparent and manageable. With Zabbix’s flexible and effective monitoring capabilities, we gained active control over our critical operations. We thank the ASNSKY team for this successful collaboration.” – Burak Altunalan, IT System Management Specialist at Doğan Trend Automotive
In conclusion
Doğan Trend plans to further take advantage of Zabbix’s flexibility to strengthen their resilience and operational efficiency. Their association with ASNSKY marks a significant step toward achieving these objectives.
To learn more about what Zabbix can do for retail customers in every sector, get in touch with us.
About ASNSKY
ASNSKY enhances its customers’ competitiveness by integrating the power of enterprise-grade open-source-solutions in security and infrastructure with a professional service approach and high quality standards.
Backed by deep industry expertise and a team of seasoned professionals, ASNSKY stands as a trusted partner in your digital transformation journey.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.