Post Syndicated from Jaskaran Singh original https://www.raspberrypi.org/blog/adapting-our-computing-curriculum-resources-for-telangana-the-journey-so-far/
This blog is the third and final in our mini-series about the things we’ve learnt from adapting The Computing Curriculum resources, and from training teachers to use them in schools. In the first two blogs, we wrote about our experiences in Kenya and Odisha, India. Here, we focus on our work in Telangana, India.
This blog was written by Jaskaran Singh, Impact Manager, and Mamta Manaktala, Senior Learning Manager.
Adapting for unique needs
Every country and region has unique opportunities, challenges, and needs. In a vast country like India, every state is different — what works in Odisha may not work in other locations. Thus, to meet the needs of students in the state of Telangana, we’ve been working on adapting The Computing Curriculum specifically for them.
Our work in Telangana began in 2023, when we kickstarted a five-year partnership with the Telangana Social Welfare Residential Educational Institutions Society (TGSWREIS), a society under the Government of Telangana. Through the partnership, we’ve developed an adapted curriculum, along with training for educators working in educational institutions with limited resources. The adapted curriculum includes localised examples and activities, and teaching approaches to make the learning experience feel relevant and meaningful for students in Telangana, while keeping the core learning outcomes aligned with global standards.
Testing and iterating
Since the start of the partnership, we’ve been testing the curriculum at the Coding Academy School, a co-educational school at Moinabad, and the Coding Academy College, a degree college for women in Shamirpet.
Our work delivering the curriculum in Telangana was our first time using a direct-to-learners model. The Coding Academy School and College gave us unique opportunities to work with students directly and observe first-hand the difference the programme made in their learning journeys.
During the first year of implementation, we gathered useful feedback from students and teachers. Check out one of our earlier blogs where we share some of the findings. We used these inputs to further develop the curriculum.
This updated version of the curriculum was implemented in the 2024/25 academic year. At the school, our educators worked with 210 students in grades 7–9, while at the college, our educators worked with 382 undergraduate students. As in the first year, we used data from assessments, lesson observations, educator interviews, student surveys, and student focus groups to understand what’s working well and what could be improved. So what did we learn?
What we learnt over the past year
Our evaluation findings show that the updated curriculum worked well and positive outcomes are being achieved for most students. Educators felt prepared to teach the curriculum in this second year and found the ongoing support and spaces for discussion really useful. Moreover, we found that there are potential positive ripple effects beyond the school as well.
Learning outcomes are being achieved to a high degree
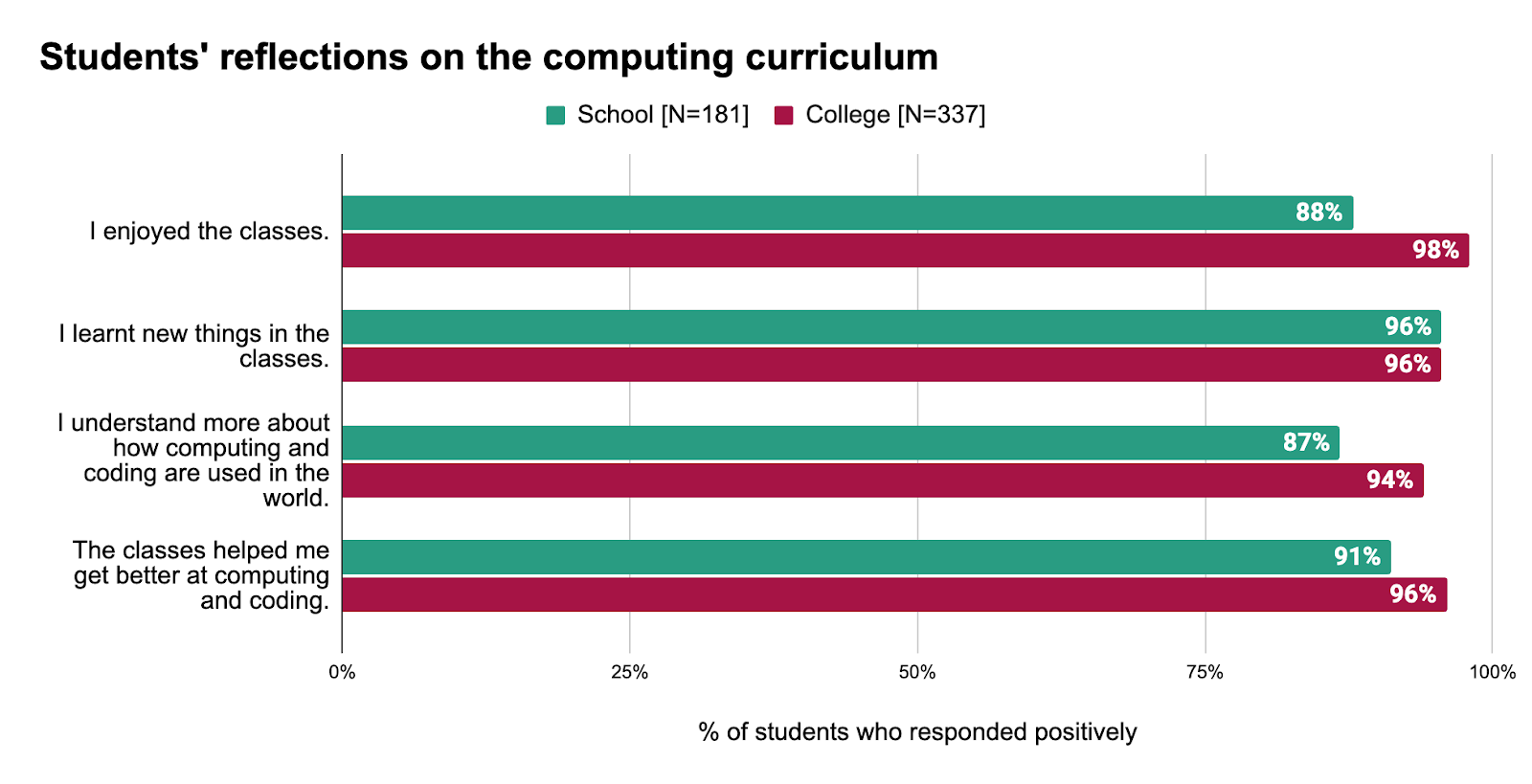
In surveys, 91% of students in the school and 96% of students in the college responded that the lessons helped them get better at computing and coding. Students feel they are not just learning new skills but also finding the content enjoyable: 88% of students in the school and 98% of students in the college responded that they are enjoying their classes. Educators and observers also reported that students were engaged during lessons, and often completed activities without needing any support.
Students’ assessment scores further confirmed positive learning outcomes. 4 out of every 5 scores in the school and 9 out of every 10 scores in the college were 60% or above, which was higher than in the first year of the adapted curriculum’s implementation.
The updated curriculum is more aligned to student needs
The changes we made to the curriculum included:
- Adding more localised examples
- Simplifying the language
- Restructuring the flow of the content
Educators were highly positive about the updates to the curriculum.
“The students are able to [better] understand the examples because we updated [to] the India context examples.” — Educator, Coding Academy School
“Students are receiving it very well because we have modified the content this year, and [that includes] the placements of the unit and the connectivity of the lessons and units.” — Educator, Coding Academy School
Additionally, for the college curriculum, we aligned the content more closely with the learning objectives set by Osmania University — with which the college is affiliated. We also included more advanced topics for students specialising in data science. During interviews, educators reported that the content was now much better aligned to student expectations.
“[The curriculum] we have designed is based as per [the] Osmania University curriculum. [The lessons] are definitely meeting the students’ needs because whatever discussions we are taking in classes, they are [successfully] participating in those discussions and they are doing whatever activities we give them.” — Educator, Coding Academy College
Outside of knowledge and skills in computing, the curriculum is also helping students develop wider life skills. In our survey, college students shared that working on projects gives them a sense of accomplishment and the confidence to solve real-world problems. Many students also reported that through the curriculum they are developing higher-order thinking skills, which will support their future careers.
“The thrill lies the creativity and problem-solving aspects. I get to turn ideas into reality pieces, and there is something incredible satisfying about debugging code and watching it run flawlessly. It’s like slow, challenging puzzles, frustrating at times but rewarding when everything clicks.” — Student, Coding Academy College
“My favourite thing [about] the computing and coding classes [is the] Scratch programme. I have learnt it [for the] first time. By learning I have enjoyed a lot. During the coding process, it trains our brain to think deeply, identify trouble, and break things up and put pieces together [as] a solution.” — Student, Coding Academy College
Students are inspired to continue engaging
Students are showing high interest in applying their skills outside of their classes. Almost all students — 100% in the school and 99% in the college — reported that they would like to participate in coding-related competitions.
Educators also told us that many students are exploring future job opportunities in the computing and digital technology fields, and are curious about topics outside the curriculum. Interestingly, 93% of the college students who were studying courses not traditionally associated with jobs in computing and digital technology reported that they would like to pursue a job in computing.
The positive benefits go beyond the school
We have also learnt that a high-quality computing education for young people has potentially wider benefits for the community. One educator described how students are helping their families, many of whom have limited experiences, engage more confidently with digital technologies.
“Families don’t know how to use smartphones and laptop computers, but our students know very well so I can say they do teach to their elders how to use these platforms.” — Educator, Coding Academy School
Ongoing support for educators was important
To help educators feel confident and prepared, individualised learning resources were provided throughout the year. These were well received by educators. Educators also found the weekly meetings with our India-based team members useful to discuss ongoing challenges regarding delivery and assessments.
What could still be improved
There were improvements this year in the availability of equipment, and the use of Wi-Fi dongles addressed internet connectivity issues to some degree. However, educators still faced some challenges. For example, educators in the school faced issues accessing printed worksheets and educators in the college faced issues accessing projectors during their lessons. We are working closely with our delivery partner to address these issues for the new academic year.
With regard to the content, educators felt the curriculum could benefit from some further amendments. For the school curriculum, these include easing the transition from block-based to text-based coding. For the college curriculum, there were suggestions for more focus on real-world applications of coding and including advanced topics, like machine learning, for undergraduates specialising in computing-related subjects. We have considered all these suggestions and made necessary revisions to the curriculum.
Next steps in Telangana: Scaling up impact
With the success of the pilot, we’re excited to announce that the adapted curriculum will now be implemented at over 350 schools and junior colleges in the state of Telangana. A majority of schools will be with the same partner, TGSWREIS, while some schools and junior colleges will be with other partners. The Coding Academy School will become our hub for trialling new curriculum content and strategies, and conducting research studies and teacher training and support. Additionally, the school will also host inter-school events.
The progress we’ve seen so far in Telangana is very encouraging. We look forward to continuing these partnerships and helping more young people realise their potential through the power of computing and digital technologies.
What we learnt about adapting curriculum resources for different regions
From our work in Telangana, Odisha, and Kenya, we’ve learnt that a curriculum isn’t a one-size-fits-all product. The local context, culture, and educational provisions are important considerations when adapting learning resources for different regions. We’ve also learnt that building long-term partnerships with organisations who have local expertise is key to understanding these considerations and effectively reaching communities where we can make the biggest difference. Finally, we’ve learnt that adaptation isn’t a one-time activity. It’s a cycle of continuous refinement; listening closely to feedback from the ground is important to ensure that our support for educators and learning experiences for young people have the best possible impact.
Want to learn more about our curriculum resources?
You can access our free Computing Curriculum resources on our website — we are currently working to make the materials for India and Kenya downloadable there.
The post Adapting our computing curriculum resources for Telangana — the journey so far appeared first on Raspberry Pi Foundation.

































































 Michael Davies is a Data Engineer at OUA. He has extensive experience within the education industry, with a particular focus on building robust and efficient data architecture and pipelines.
Michael Davies is a Data Engineer at OUA. He has extensive experience within the education industry, with a particular focus on building robust and efficient data architecture and pipelines. Emma Arrigo is a Solutions Architect at AWS, focusing on education customers across Australia. She specializes in leveraging cloud technology and machine learning to address complex business challenges in the education sector. Emma’s passion for data extends beyond her professional life, as evidenced by her dog named Data.
Emma Arrigo is a Solutions Architect at AWS, focusing on education customers across Australia. She specializes in leveraging cloud technology and machine learning to address complex business challenges in the education sector. Emma’s passion for data extends beyond her professional life, as evidenced by her dog named Data.