Post Syndicated from Laquie TN Campbell original https://www.backblaze.com/blog/workflow-playbook-migrating-your-media-assets-to-a-mam/

Media asset management systems (MAM) have become a standard tool in the tech stack of many media organizations. MAM systems have evolved from basic file storage to sophisticated platforms with advanced organization features, increasing efficiency, collaboration, and distribution speeds.
In this post, I’ll explain some media asset management basics and introduce five key plays you can put into practice to get the most out of your assets, including how to move them into a MAM system or migrate from an older system to a new one.
Why do you need a MAM system?
As a media professional, I’ve come across some, let’s say, creative file naming conventions in my day. While it’s hilarious, “Episode6-Final-final-v2.3_OH_YEAH_THIS_IS_DEFINITELY_THE_FINAL_ONE_2_LOL.mp4” isn’t going to be the easiest thing to find years later when you’re searching through hundreds of files for the (for real) final one.
Whether you make videos, images, or music, the more you produce, the more difficult those assets become to manage, organize, find, and protect. Managing files by carefully placing them in specific folders and implementing more logical naming conventions can only get you so far. At some point, as the scale of your business grows, you’ll find your current way of organizing and searching for assets can’t keep up. That’s where media asset management systems come in.
MAM systems explained: Key concepts
Before you start building a playbook to get the most from your creative assets, let’s review a few key concepts.
Assets and metadata
Asset: A rich media file with intrinsic metadata.
An asset is simply a file that is the result of your creative operation. Most often, it is a rich media file like an image or a video. Typically, these files are captured or created in a raw state, then your creative team adds value to that raw asset by editing it and creating a finished story that in turn, becomes another asset to manage.
Metadata: Information about a file, either embedded within the file itself or associated with the file by another system, typically a MAM application.
Any given file carries information about itself that can be understood by your laptop or workstation’s operating system. Some of these seem obvious, like the name of the file, how much storage space it occupies, when it was first created, and when it was last modified. These would all be helpful ways to try to find one particular file you are looking for among thousands just using the tools available in your OS’s file manager.
File metadata: Information about a file specifically pertaining to the technical attributes of the file.
There’s usually another level of metadata embedded in media files that is not so obvious but potentially enormously useful: Metadata embedded in the file when it’s created by a camera, film scanner, or output by a program.
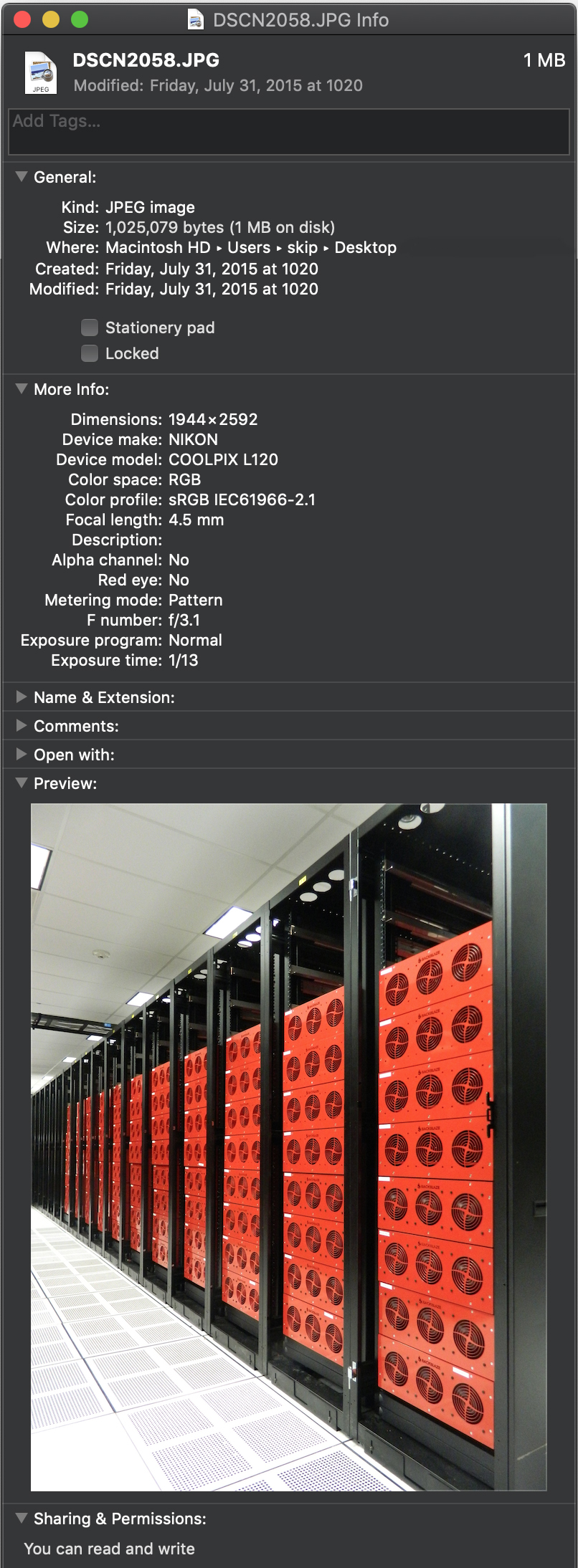
For example, this image taken in Backblaze’s data center carries all kinds of interesting information. When I inspect the file, I can see a wealth of information. I now know the image’s dimensions and when the image was taken, as well as exactly what kind of camera took this picture and the lens settings that were used.
As you can see, this metadata could be very useful if you want to find all images taken on that day, or even images taken with that same camera, focal length, F-stop, or exposure.
Going through files one at a time to find the one you need is incredibly inefficient. Yet that’s how things still work in many creative environments—an ad hoc system of folders plus the memory of whoever’s been with the team longest. Files are often kept on the same storage used for production or even on an external hard drive.
Teams quickly outgrow that system when they find themselves juggling multiple hard drives or they run out of space on production storage. Worst of all, assets kept on a single hard drive are vulnerable to disk damage or to being accidentally copied or overwritten. Even if standard protocol is a redundant backup process, natural disasters can become a serious threat depending on the location of the physical tapes or drives.
Why your assets need to be managed
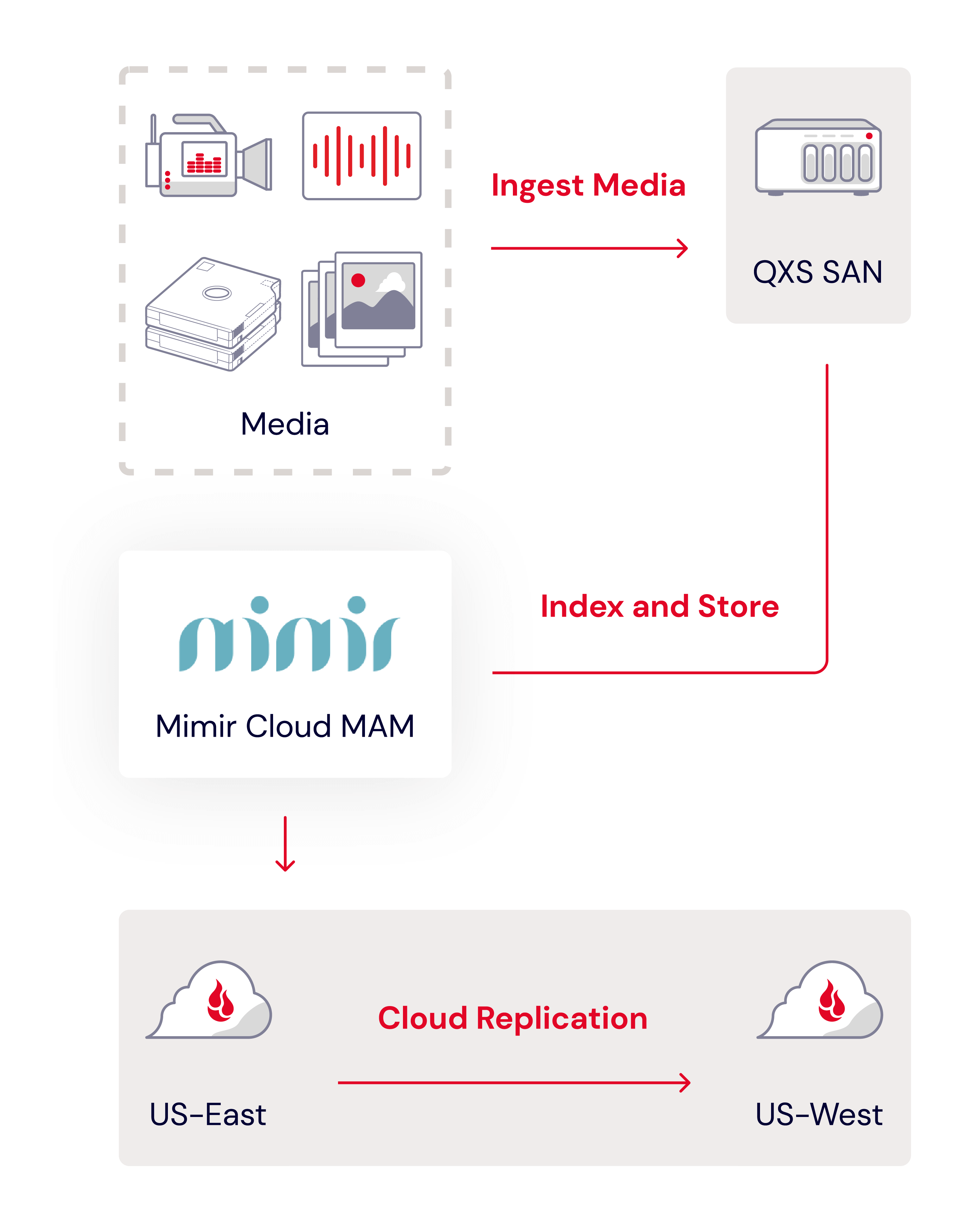
To meet this challenge, creative teams have often turned to MAMs. A MAM automatically extracts all of the assets’ inherent metadata, helps move files to protected storage, and makes them instantly available to MAM users. As time has gone on, we’ve seen MAM systems be powerfully enhanced by AI. In a way, these MAMs become a private media search engine where any file attribute can be a search query to instantly uncover the needed files in even the largest media asset libraries.
Beyond that, asset management systems are rapidly becoming highly effective collaboration and workflow tools. For example, tagging a series of files as Field Interviews — April 2019, or flagging an edited piece of content as HOLD — do not show customer can be very useful indeed.
Inner workings of a media asset manager
When you add files into an asset management system, the application inspects each file, extracting every available bit of information about the file, noting the file’s location on storage, and often creating a proxy version of the file that is easier to present to users.
To keep track of this information, asset manager applications employ a database and keep information about your files in it. This way, when you’re searching for a particular set of files among your entire asset library, you can simply make a query of your asset manager’s database in an instant rather than rifling through your entire asset library storage system. The application takes the results of that database query and retrieves the files you need.
A MAM Case Study: Complex Networks
Complex Networks was running out of space. Whenever local shared storage filled up, they had to pull assets off to give everybody enough room to continue working. They moved all of their assets to iconik media asset management software and backed them all up to the Backblaze B2 Cloud Storage. They’re now free to focus on what they do best—making culture-defining content—rather than spending time searching for assets.

Asset migration playbook
Whether you need to move from a file and folder based system to a new asset manager, or have been using an older system and want to move to a new one without losing all of the metadata that you have painstakingly developed, a sound playbook for migrating your assets can help guide you. Below we’ll explain five plays you can use to approach your asset management journey:
Play 1: Protecting assets saved in a folder hierarchy without an asset management system
In this scenario, your assets are in a set of files and folders, and you aren’t ready to implement your asset management system yet.
The first consideration is for the safety of the assets—backup and archive. Files on a single hard drive are vulnerable, so if you are not ready to choose an asset manager your first priority should be to get those files into a secure cloud storage service like Backblaze B2.
Then, when you have chosen an asset management system, you can simply point the system at your cloud-based asset storage to extract the metadata out of the files and populate the asset information in your asset manager.
How to run it:
- Get assets archived or moved to cloud storage.
- Choose your asset management system.
- Ingest assets directly from your cloud storage.
Play 2: Moving assets saved in a folder hierarchy into your asset management system and archiving in cloud storage
In this scenario, you’ve chosen your asset management system, and need to get your local assets in files and folders ingested and protected in the most efficient way possible.
You’ll ingest all of your files into your asset manager from local storage, then back them up to cloud storage. Once your asset manager has been configured with your cloud storage credentials, it can automatically move a copy of local files to the cloud for you. Later, when you have confirmed that the file has been copied to the cloud, you can safely delete the local copy.
How to run it:
- Ingest assets from local storage directly into your asset manager system.
- From within your asset manager system archive a copy of files to your cloud storage.
- Once safely archived, the local copy can be deleted.
Play 3: Getting a lot of assets on local storage into your asset management system and backing up to cloud storage
If you have a lot of content, more than say, 20TB, you will want to use a rapid ingest service similar to the Backblaze Fireball system. You copy the files to the Backblaze Fireball, Backblaze puts them directly into your asset management bucket, and the asset manager is then updated with the file’s new location in your Backblaze B2 account.
This can be a manual process, or can be done with scripting to make the process faster.
How to run it:
- Ingest assets from local storage directly into your asset manager system.
- Archive your local assets to Fireball (up to 90TB at a time).
- Once the files have been uploaded by Backblaze, relink the new location of the cloud copy in your asset management system.
Play 4: Moving from one asset manager system to another without losing metadata
In this scenario you have an existing asset management system and need to move to a new one as efficiently as possible. You want to take advantage of your new system’s features and safeguard in cloud storage in a way that does not impact your existing production.
Some asset management systems will allow you to export the database contents in a format that can be imported by a new system. Some older systems may not have that feature and will require the expertise of a database expert to manually extract the metadata. Either way, you can expect to need to map the fields from the old system to the fields in the new system.
Making a copy of your old database is a must. Don’t work on the primary copy, and be sure to conduct tests on small groups of files as you’re migrating from the older system to the new. You need to ensure that the metadata is correct in the new system, with special attention that the actual file location is mapped properly. It’s wise to keep the old system up and running for a while before completely phasing it out.
How to run it:
- Export the database from the old system.
- Import the records into the new system.
- Ensure that the metadata is correct in the new system and file locations are working properly.
- Make archive copies of your files to cloud storage.
- Once the new system has been running through a few production cycles, it’s safe to power down the old system.
Play 5: Moving quickly from a MAM on local storage to a cloud-based system
In this variation of Play 4, you can move content to object storage with a rapid ingest service like Backblaze Fireball at the same time that you migrate to a cloud-based system. This step will benefit from scripting to create records in your new system with all of your metadata, then relink with the actual file location in your cloud storage all in one pass.
You should test that your asset management system can recognize a file already in the system without creating a duplicate copy of the file. This is done differently by each asset management system.
How to run it:
- Export the database from the old system.
- Import the records into the new system while creating placeholder records with the metadata only.
- Archive your local assets to the Backblaze Fireball (up to 90TB at a time).
- Once the files have been uploaded by Backblaze, relink the cloud based location to the asset record.
Bonus play: Using cloud storage to scale a media heavy workload
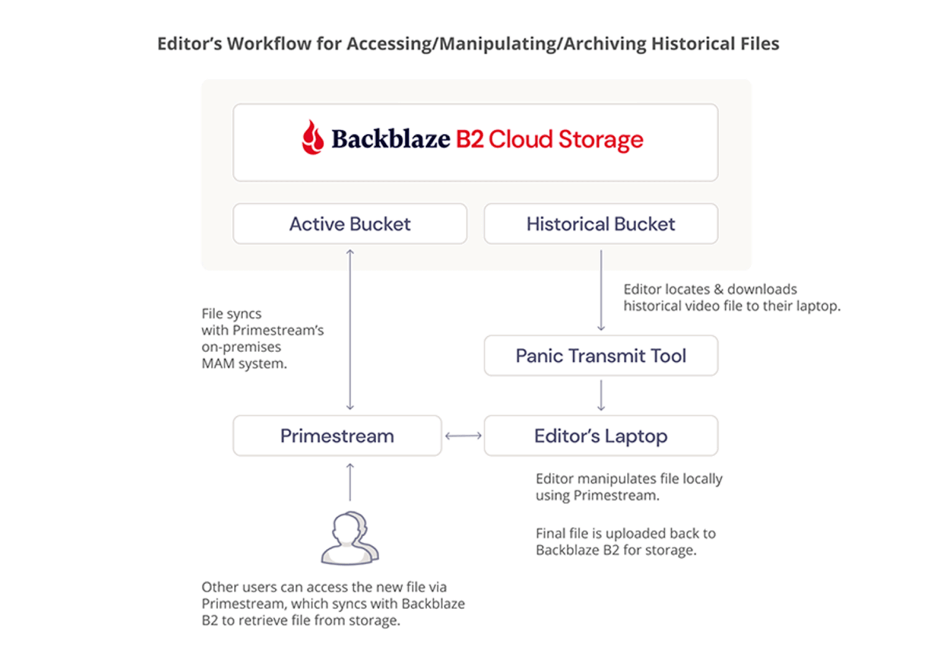
Fortune Media’s tech stack was expensive, difficult to use, and not 100% reliable. They migrated over 300TB of data, mainly video files, to Backblaze B2 Cloud Storage, which integrated with their preferred MAM system, Primestream Xchange, removing the need for archiving middleware and simplifying the tech stack.
Wrapping up
Every creative environment is different, but all need the same thing: to be able to find assets fast and organize content to enhance productivity and rest easy knowing that content is safe.
With these plays, you can take that step and be ready for any future production challenges and opportunities.
The post A Playbook for Migrating Your Media to a MAM System appeared first on Backblaze Blog | Cloud Storage & Cloud Backup