Post Syndicated from Tanya Verma original https://blog.cloudflare.com/inside-geo-key-manager-v2/


In December 2022 we announced the closed beta of the new version of Geo Key Manager. Geo Key Manager v2 (GeoV2) is the next step in our journey to provide customers with a secure and flexible way to control the distribution of their private keys by geographic location. Our original system, Geo Key Manager v1, was launched as a research project in 2017, but as customer needs evolved and our scale increased, we realized that we needed to make significant improvements to provide a better user experience.
One of the principal challenges we faced with Geo Key Manager v1 (GeoV1) was the inflexibility of our access control policies. Customers required richer data localization, often spurred by regulatory concerns. Internally, events such as the conflict in Ukraine reinforced the need to be able to quickly restrict access to sensitive key material. Geo Key Manager v1’s underlying cryptography was a combination of identity-based broadcast encryption and identity-based revocation that simulated a subset of the functionality offered by Attribute-Based Encryption (ABE). Replacing this with an established ABE scheme addressed the inflexibility of our access control policies and provided a more secure foundation for our system.
Unlike our previous scheme, which limited future flexibility by freezing the set of participating data centers and policies at the outset, using ABE made the system easily adaptable for future needs. It allowed us to take advantage of performance gains from additional data centers added after instantiation and drastically simplified the process for handling changes to attributes and policies. Furthermore, GeoV1 struggled with some perplexing performance issues that contributed to high tail latency and a painfully manual key rotation process. GeoV2 is our answer to these challenges and limitations of GeoV1.
While this blog focuses on our solution for geographical key management, the lessons here can also be applied to other access control needs. Access control solutions are traditionally implemented using a highly-available central authority to police access to resources. As we will see, ABE allows us to avoid this single point of failure. As there are no large scale ABE-based access control systems we are aware of, we hope our discussion can help engineers consider using ABE as an alternative to access control with minimal reliance on a centralized authority. To facilitate this, we’ve included our implementation of ABE in CIRCL, our open source cryptographic library.
Unsatisfactory attempts at a solution
Before coming back to GeoV2, let’s take a little detour and examine the problem we’re trying to solve.
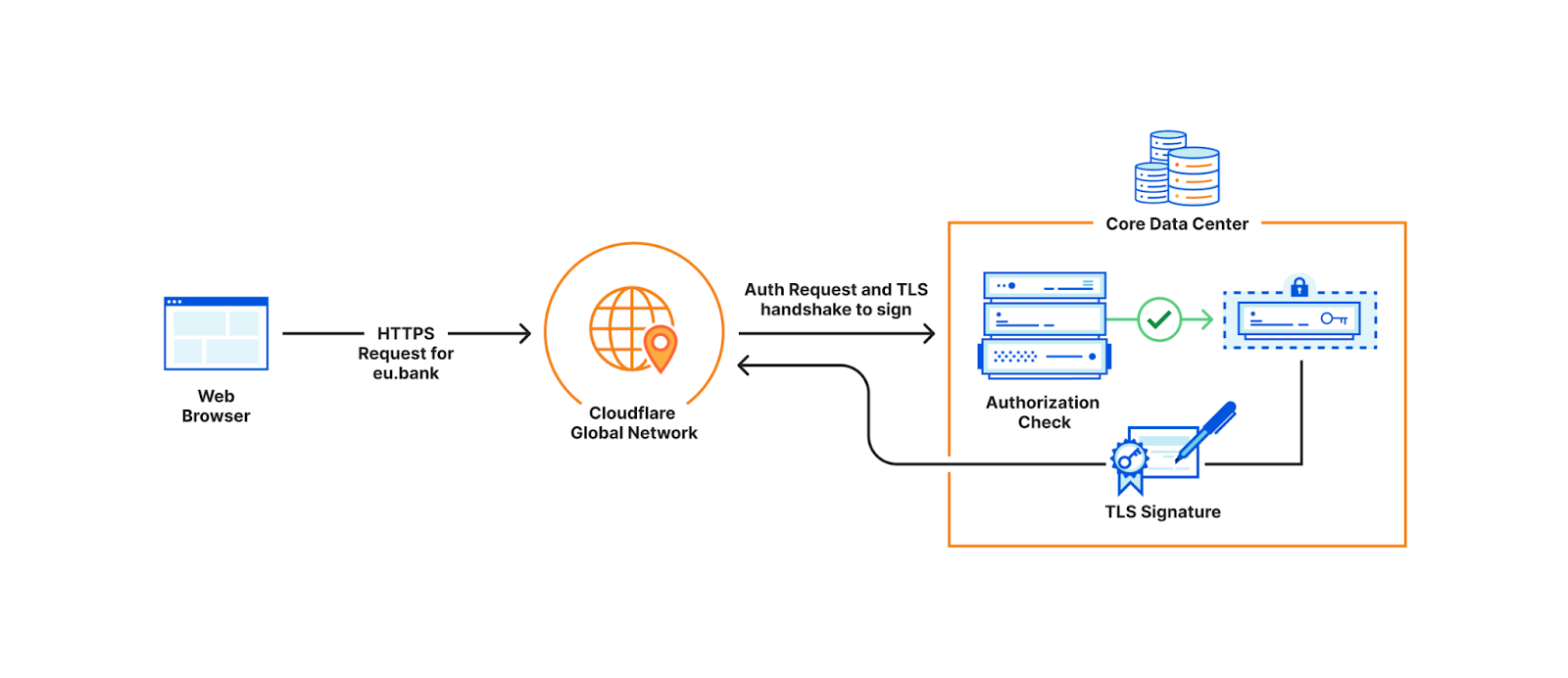
Consider this example: a large European bank wants to store their TLS private keys only within the EU. This bank is a customer of Cloudflare, which means we perform TLS handshakes on their behalf. The reason we need to terminate TLS for them is so that we can provide the best protection against DDoS attacks, improve performance by caching, support web application firewalls, etc.
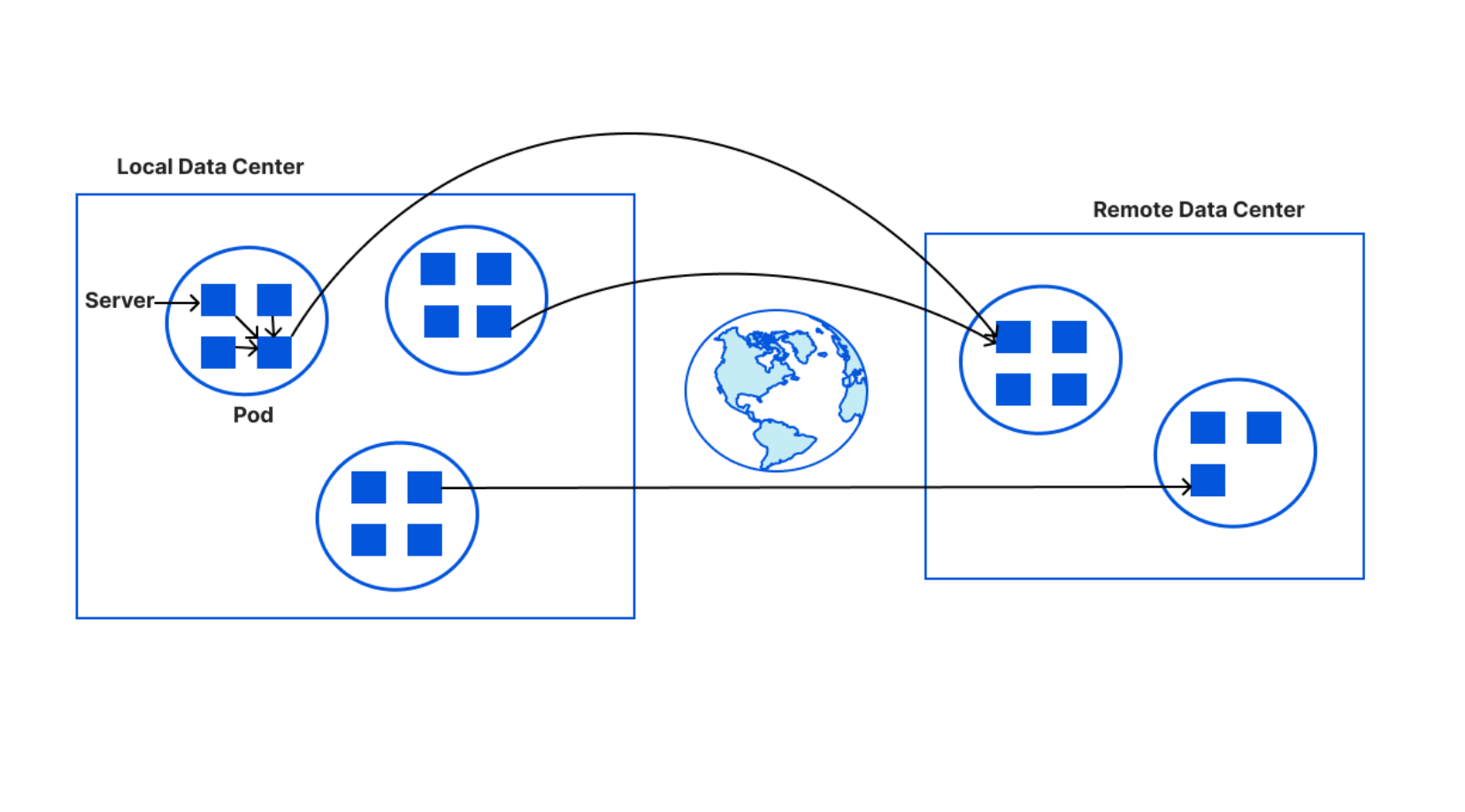
In order to terminate TLS, we need to have access to their TLS private keys1. The control plane, which handles API traffic, encrypts the customer’s uploaded private key with a master public key shared amongst all machines globally. It then puts the key into a globally distributed KV store, Quicksilver. This means every machine in every data center around the world has a local copy of this customer’s TLS private key. Consequently, every machine in each data center has a copy of every customer’s private key.
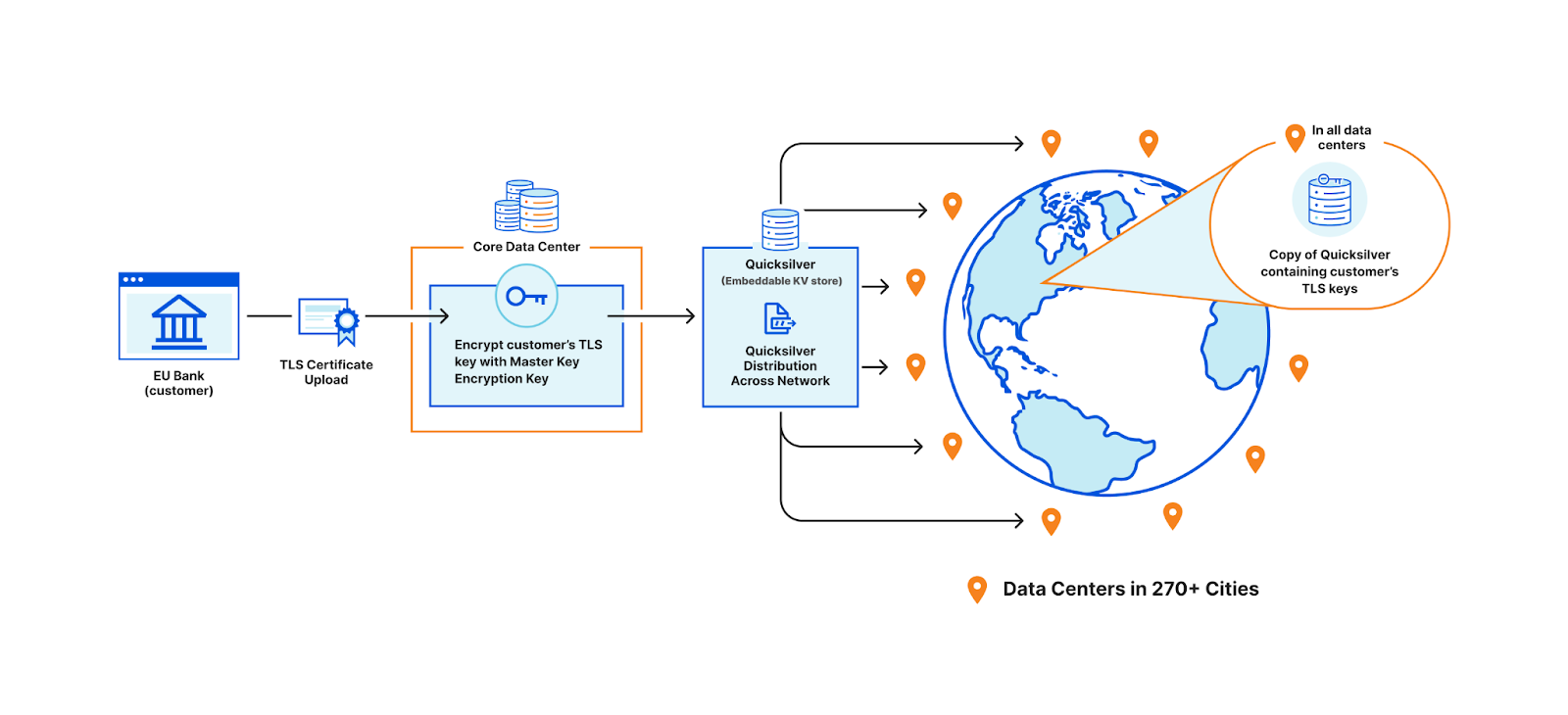
This bank however, wants its key to be stored only in EU data centers. In order to allow this to happen, we have three options.
The first option is to ensure that only EU data centers can receive this key and terminate the handshake. All other machines proxy TLS requests to an EU server for processing. This would require giving each machine only a subset of the entire keyset stored in Quicksilver, which challenges core design decisions Cloudflare has made over the years that assume the entire dataset is replicated on every machine.
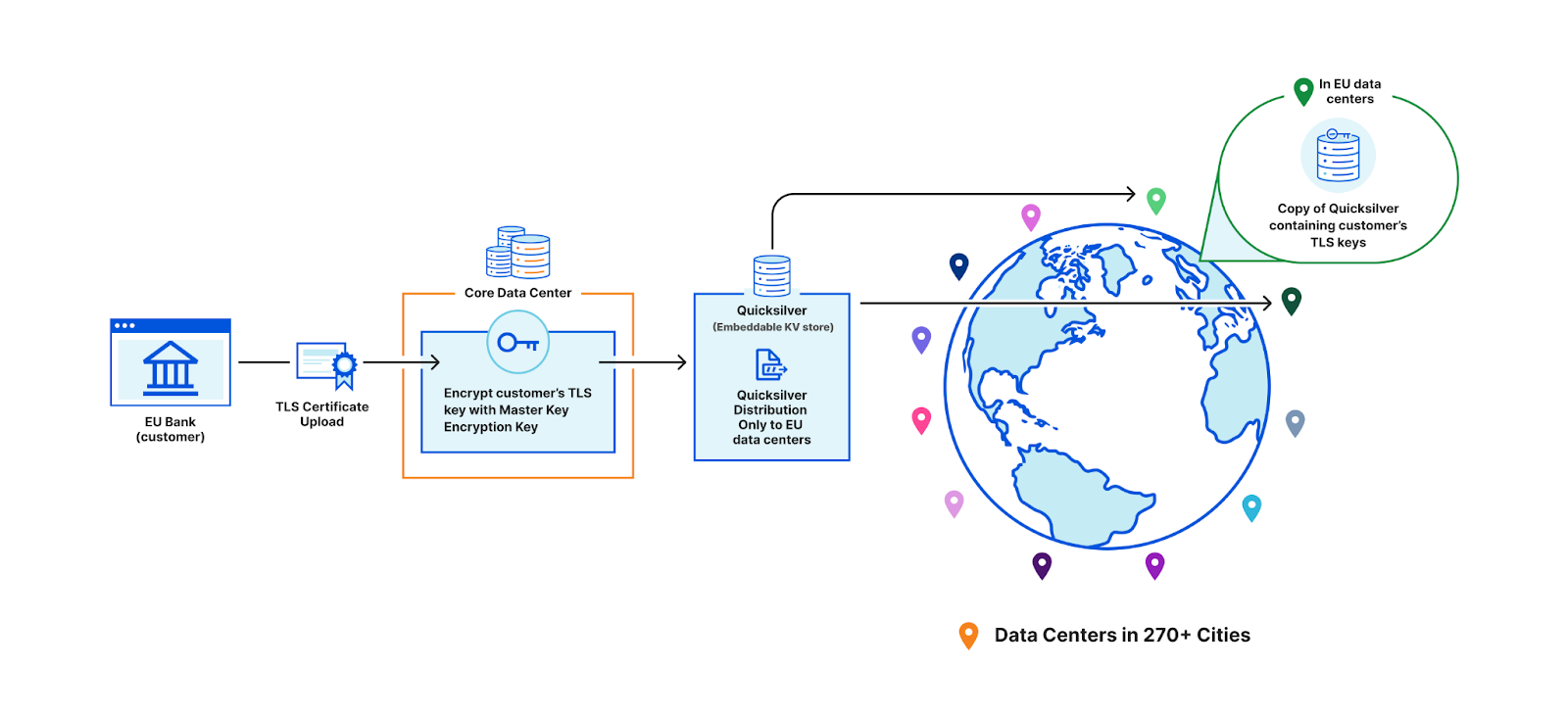
Another option is to store the keys in the core data center instead of Quicksilver. This would allow us to enforce the proper access control policy every time, ensuring that only certain machines can access certain keys. However, this would defeat the purpose of having a global network in the first place: to reduce latency and avoid a single point of failure at the core.
A third option is to use public key cryptography. Instead of having a master key pair, every data center is issued its own key pair. The core encrypts the customer’s private key with the keys of every data center allowed to use it. Only machines in the EU will be able to access the key in this example. Let’s assume there are 500 data centers, with 50 machines each. Of these 500 data centers, let’s say 200 are in the EU. Where 100 keys of 1kB consumed a total of 100 x 500 x 50 x 1 kB (globally), now they will consume 200 times that, and in the worst case, up to 500 times. This increases the space it takes to store the keys on each machine by a whole new factor – before, the storage space was purely a function of how many customer keys are registered; now, the storage space is still a function of the number of customer keys, but also multiplied by the number of data centers.
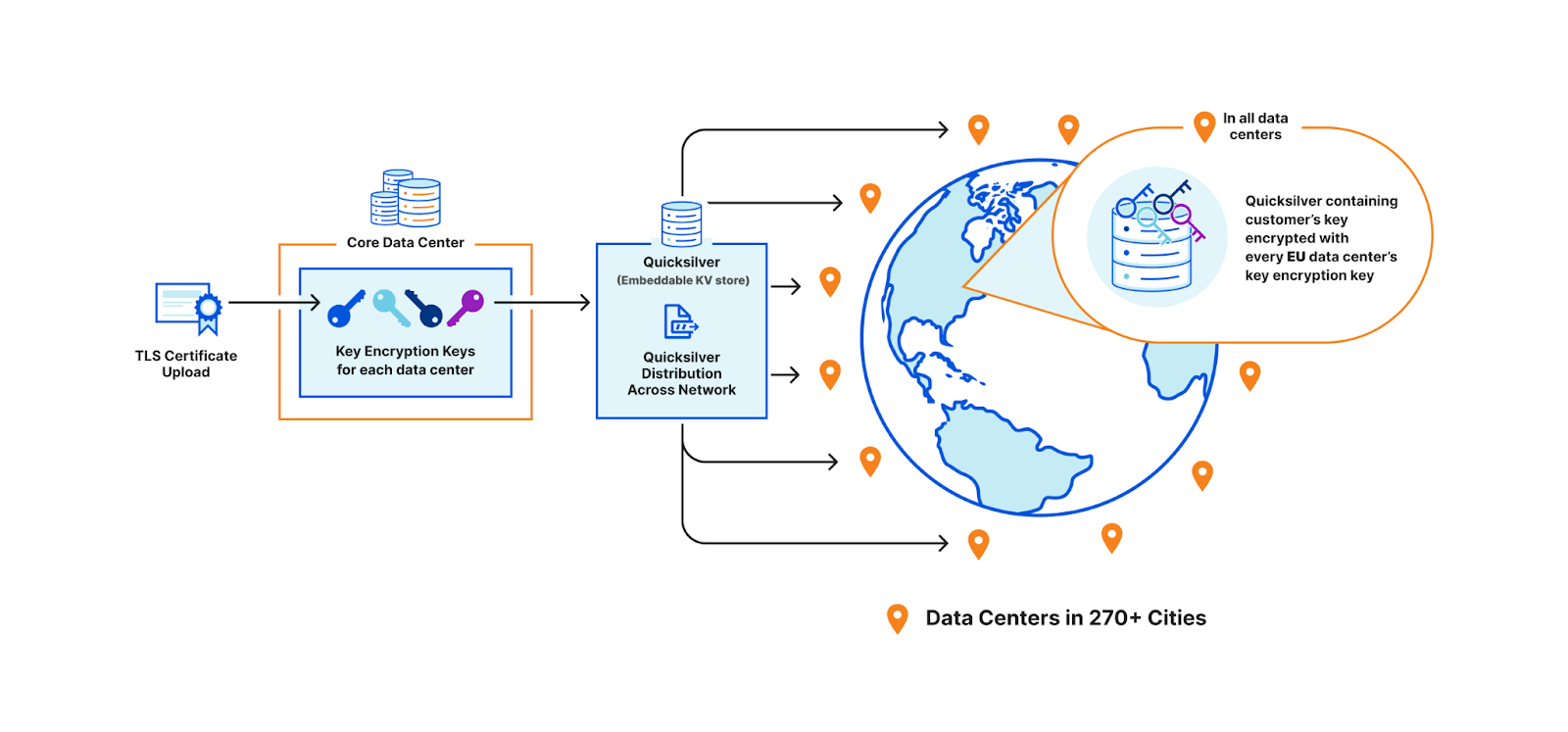
Unfortunately, all three of these options are undesirable in their own ways. They would either require changing fundamental assumptions we made about the architecture of Cloudflare, abandoning the advantages of using a highly distributed network, or quadratically increasing the storage this feature uses.
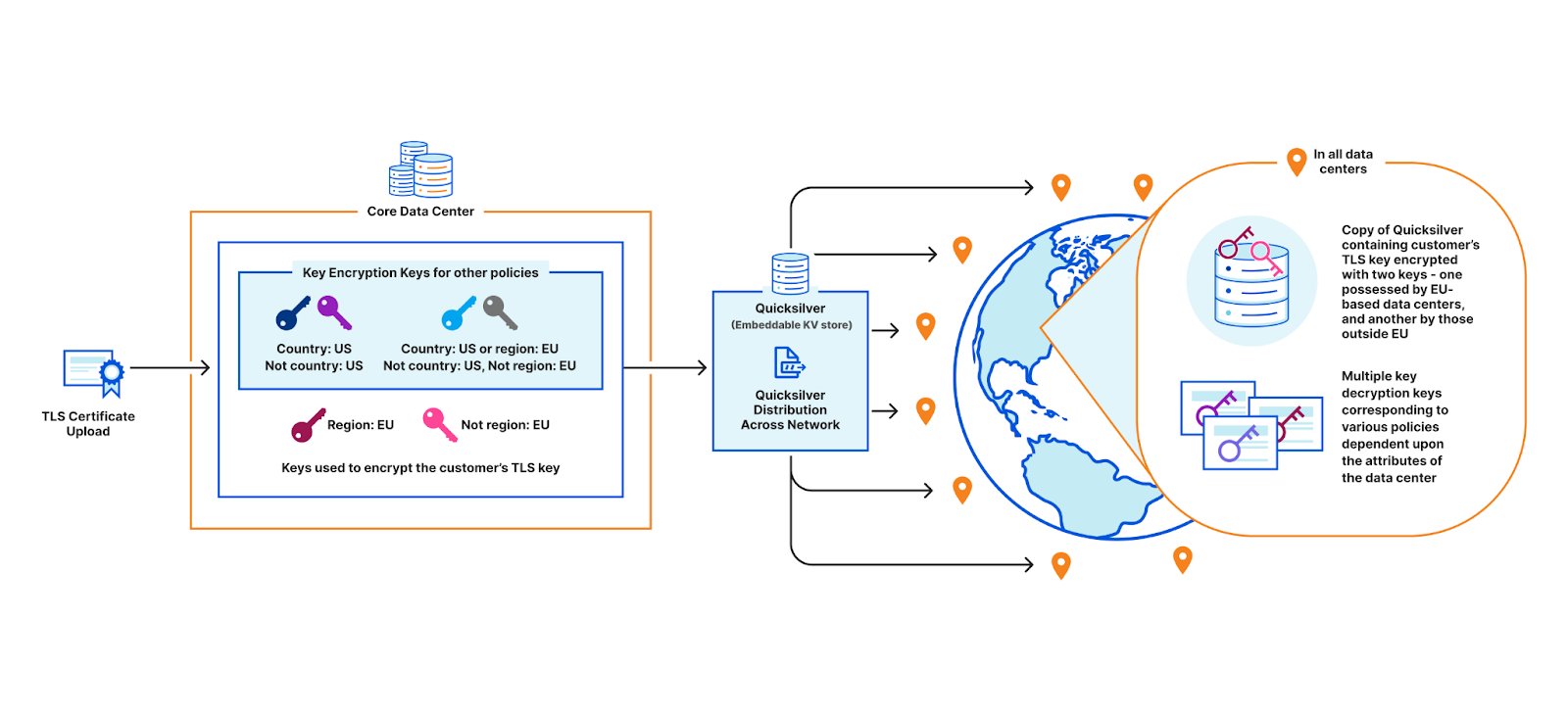
A deeper look at the third option reveals – why not create two key pairs instead of a unique one for each data center? One pair would be common among all EU data centers, and one for all non-EU data centers. This way, the core only needs to encrypt the customer’s key twice instead of for each EU data center. This is a good solution for the EU bank, but it doesn’t scale once we start adding additional policies. Consider the example: a data center in New York City could have a key for the policy “country: US”, another one for “country: US or region: EU”, another one for “not country: RU”, and so on… You can already see this getting rather unwieldy. And every time a new data center is provisioned, all policies must be re-evaluated and the appropriate keys assigned.
Geo Key Manager v1: identity-based encryption and broadcast encryption
The invention of RSA in 1978 kicked off the era of modern public key cryptography, but anyone who has used GPG or is involved with certificate authorities can attest to the difficulty of managing public key infrastructure that connects keys to user identities. In 1984, Shamir asked if it was possible to create a public-key encryption system where the public key could be any string. His motivation for this question was to simplify email management. Instead of encrypting an email to Bob using Bob’s public key, Alice could encrypt it to Bob’s identity [email protected]. Finally, in 2001, Boneh and Franklin figured out how to make it work.
Broadcast encryption was first proposed in 1993 by Fiat and Naor. It lets you send the same encrypted message to everyone, but only people with the right key can decrypt it. Looking back to our third option, instead of wrapping the customer’s key with the key of every EU data center, we could use broadcast encryption to create a singular encryption of the customer’s key that only EU-based data centers could decrypt. This would solve the storage problem.
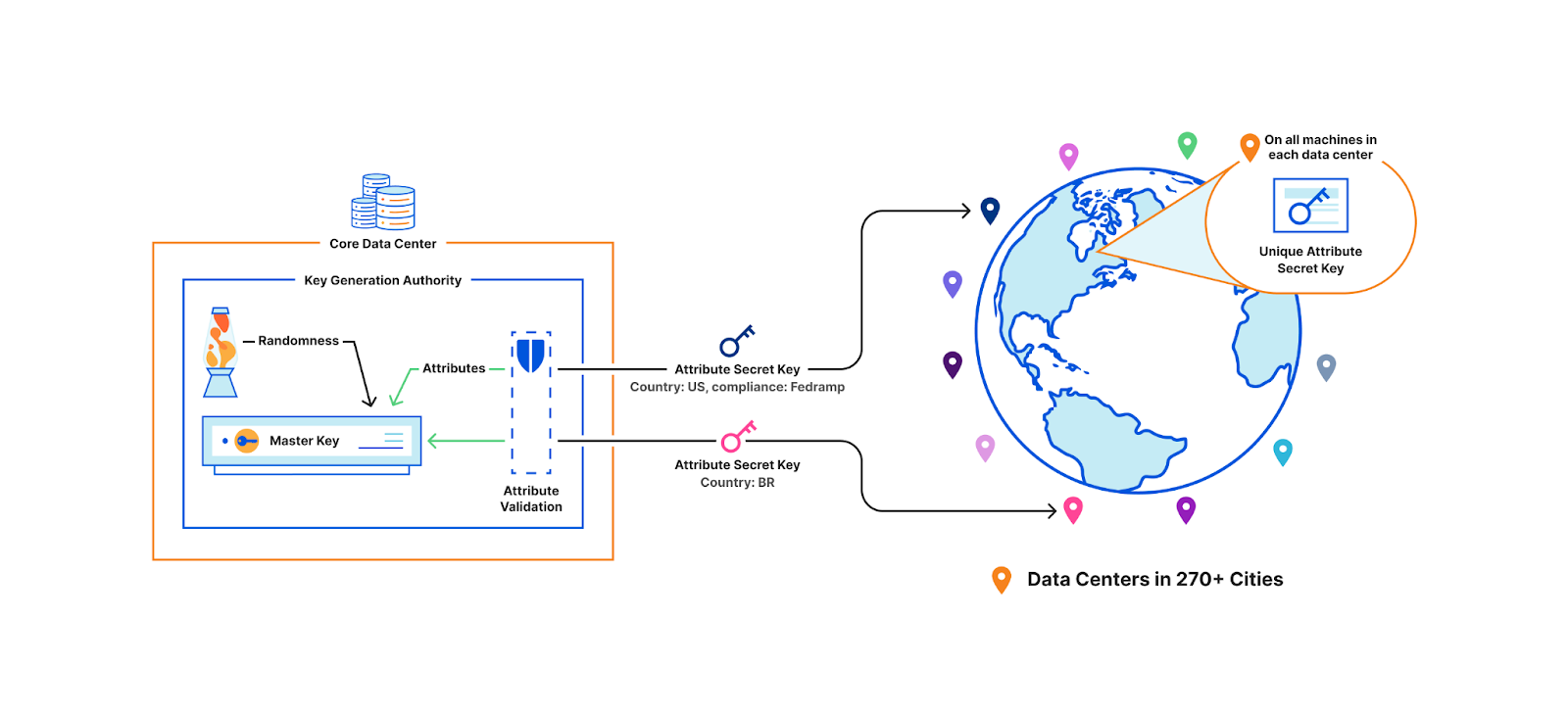
Geo Key Manager v1 used a combination of identity-based broadcast encryption and identity-based revocation to implement access control. Briefly, a set of identities is designated for each region and each data center location. Then, each machine is issued an identity-based private key for its region and location. With this in place, access to the customer’s key can be controlled using three sets: the set of regions to encrypt to, the set of locations inside the region to exclude, and the set of locations outside the region to include. For example, the customer’s key could be encrypted so that it is available in all regions except for a few specific locations, and also available in a few locations outside those regions. This blog post has all the nitty-gritty details of this approach.
Unfortunately this scheme was insufficiently responsive to customer needs; the parameters used during initial cryptographic setup, such as the list of regions, data centers, and their attributes, were baked into the system and could not be easily changed. Tough luck excluding the UK from the EU region post Brexit, or supporting a new region based on a recent compliance standard that customers need. Using a predetermined static list of locations also made it difficult to quickly revoke machine access. Additionally, decryption keys could not be assigned to new data centers provisioned after setup, preventing them from speeding up requests. These limitations provided the impetus for integrating Attribute-Based Encryption (ABE) into Geo Key Manager.
Attribute-Based Encryption
In 2004, Amit Sahai and Brent Waters proposed a new cryptosystem based on access policies, known as attribute-based encryption (ABE). Essentially, a message is encrypted under an access policy rather than an identity. Users are issued a private key based on their attributes, and they can only decrypt the message if their attributes satisfy the policy. This allows for more flexible and fine-grained access control than traditional methods of encryption.
The policy can be attached either to the key or to the ciphertext, leading to two variants of ABE: key-policy attribute-based encryption (KP-ABE) and ciphertext-policy attribute-based encryption (CP-ABE). There exist trade-offs between them, but they are functionally equivalent as they are duals of each other. Let’s focus on CP-ABE it aligns more closely with real-world access control. Imagine a hospital where a doctor has the attributes “role: doctor” and “region: US”, while a nurse has the attributes “role: nurse” and “region: EU”. A document encrypted under the policy “role: doctor or region: EU” can be decrypted by both the doctor and nurse. In other words, ABE is like a magical lock that only opens for people who have the right attributes.
| Policy | Semantics |
|---|---|
| country: US or region: EU | Decryption is possible either in the US or in the European Union |
| not (country: RU or country: US) | Decryption is not possible in Russia and US |
| country: US and security: high | Decryption is possible only in data centers within the US that have a high level of security (for some security definition established previously) |
There are many different ABE schemes out there, with varying properties. The scheme we choose must satisfy a few requirements:
- Negation We want to be able to support boolean formulas consisting of AND, OR and NOT, aka non-monotonic boolean formulas. While practically every scheme handles AND and OR, NOT is rarer to find. Negation makes blocklisting certain countries or machines easier.
- Repeated Attributes Consider the policy “
organization: executive or (organization: weapons and clearance: top-secret)”. The attribute “organization” has been repeated twice in the policy. Schemes with support for repetition add significant expressibility and flexibility when composing policies. - Security against Chosen Ciphertext Attacks Most schemes are presented in a form that is only secure if the attacker doesn’t choose the messages to decrypt (CPA). There are standard ways to convert such a scheme into one that is secure even if the attacker manipulates ciphertexts (CCA), but it isn’t automatic. We apply the well-known Boneh-Katz transform to our chosen scheme to make it secure against this class of attacks. We will present a proof of security for the end to end scheme in our forthcoming paper.
Negation in particular deserves further comment. For an attribute to be satisfied when negated, the name must stay the same, but the value must differ. It’s like the data center is saying, “I have a country, but it’s definitely not Japan”, instead of “I don’t have a country”. This might seem counterintuitive, but it enables decryption without needing to examine every attribute value. It also makes it safe to roll out attributes incrementally. Based on these criteria, we ended up choosing the scheme by Tomida et al (2021).
Implementing a complex cryptographic scheme such as this can be quite challenging. The discrete log assumption that underlies traditional public key cryptography is not sufficient to meet the security requirements of ABE. ABE schemes must secure both ciphertexts and the attribute-based secret keys, whereas traditional public key cryptography only imposes security constraints on the ciphertexts, while the secret key is merely an integer. To achieve this, most ABE schemes are constructed using a mathematical operation known as bilinear pairings.
The speed at which we can perform pairing operations determines the baseline performance of our implementation. Their efficiency is particularly desirable during decryption, where they are used to combine the attribute-based secret key with the ciphertext in order to recover the plaintext. To this end, we rely on our highly optimized pairing implementations in our open source library of cryptographic suites, CIRCL, which we discuss at length in a previous blog. Additionally, the various keys, attributes and the ciphertext that embeds the access structure are expressed as matrices and vectors. We wrote linear algebra routines to handle matrix operations such as multiplication, transpose, inverse that are necessary to manipulate the structures as needed. We also added serialization, extensive testing and benchmarking. Finally, we implemented our conversion to a CCA2 secure scheme.
In addition to the core cryptography, we had to decide how to express and represent policies. Ultimately we decided on using strings for our API. While perhaps less convenient for programs than structures would be, users of our scheme would have to implement a parser anyway. Having us do it for them seemed like a way to have a more stable interface. This means the frontend of our policy language was composed of boolean expressions as strings, such as “country: JP or (not region: EU)”, while the backend is a monotonic boolean circuit consisting of wires and gates. Monotonic boolean circuits only include AND and OR gates. In order to handle NOT gates, we assigned positive or negative values to the wires. Every NOT gate can be placed directly on a wire because of De Morgan’s Law, which allows the conversion of a formula like “not (X and Y)” into “not X or not Y”, and similarly for disjunction.
The following is a demonstration of the API. The central authority runs Setup to generate the master public key and master secret key. The master public key can be used by anyone to encrypt a message over an access policy. The master secret key, held by the central authority, is used to generate secret keys for users based on their attributes. Attributes themselves can be supplied out-of-band. In our case, we rely on the machine provisioning database to provide and validate attributes. These attribute-based secret keys are securely distributed to users, such as over TLS, and are used to decrypt ciphertexts. The API also includes helper functions to check decryption capabilities and extract policies from ciphertexts for improved usability.
publicKey, masterSecretKey := cpabe.Setup()
policy := cpabe.Policy{}
policy.FromString("country: US or region: EU")
ciphertext := publicKey.Encrypt(policy, []byte("secret message"))
attrsParisDC := cpabe.Attributes{}
attrsParisDC.FromMap(map[string]string{"country": "FR", "region": "EU"}
secretKeyParisDC := masterSecretKey.KeyGen(attrsParisDC)
plaintext := secretKeyParisDC.Decrypt(ciphertext)
assertEquals(plaintext, "secret message")
We now come back to our original example. This time, the central authority holds the master secret key. Each machine in every data center presents its set of attributes to the central authority, which, after some validation, generates a unique attribute-based secret key for that particular machine. Key issuance happens when a machine is first brought up, if keys must be rotated, or if an attribute has changed, but never in the critical path of a TLS handshake. This solution is also collusion resistant, which means two machines without the appropriate attributes cannot combine their keys to decrypt a secret that they individually could not decrypt. For example, a machine with the attribute “country: US” and another with “security: high”. These machines cannot collude together to decrypt a resource with the policy “country: US and security: high”.
Crucially, this solution can seamlessly scale and respond to changes to machines. If a new machine is added, the central authority can simply issue it a secret key since the participants of the scheme don’t have to be predetermined at setup, unlike our previous identity-broadcast scheme.
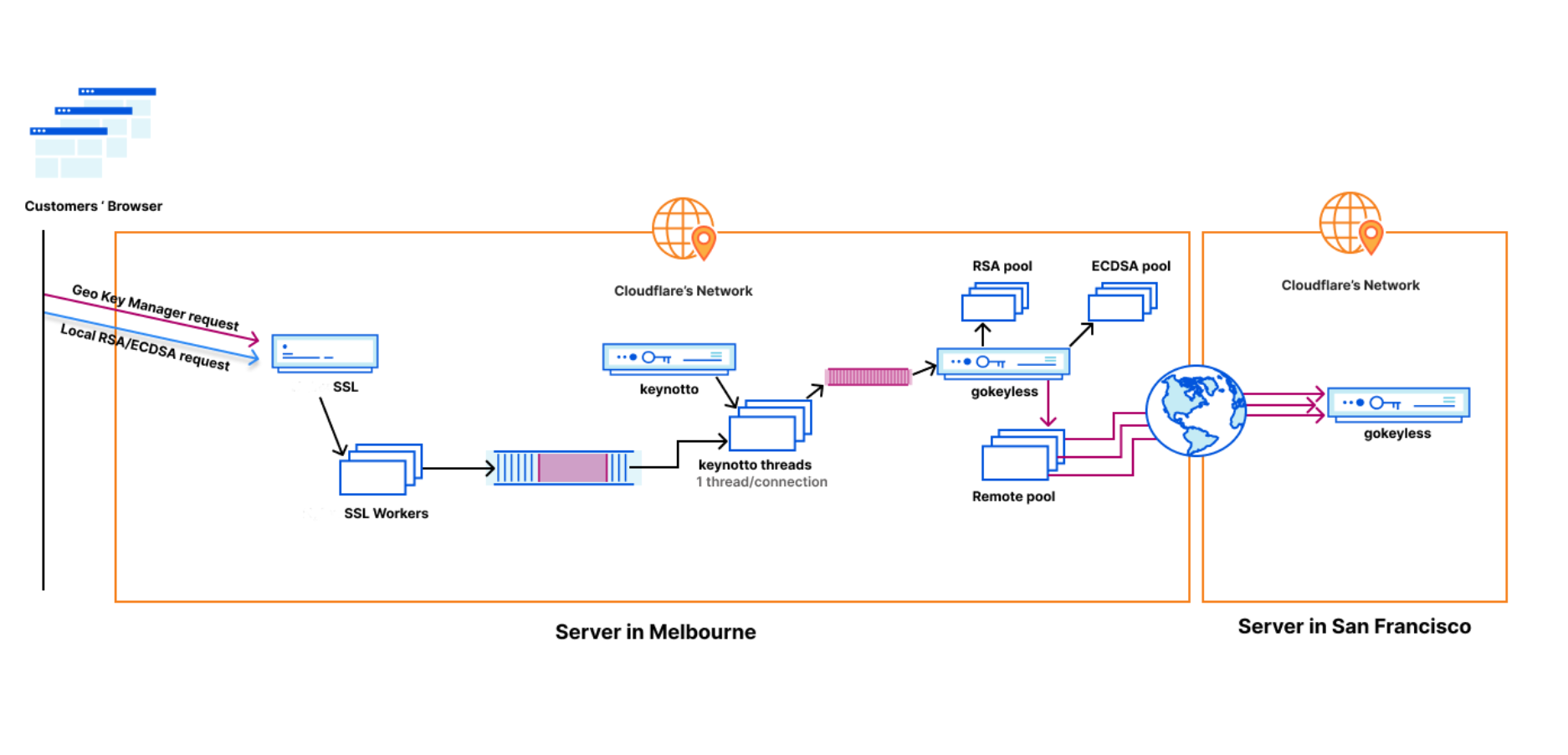
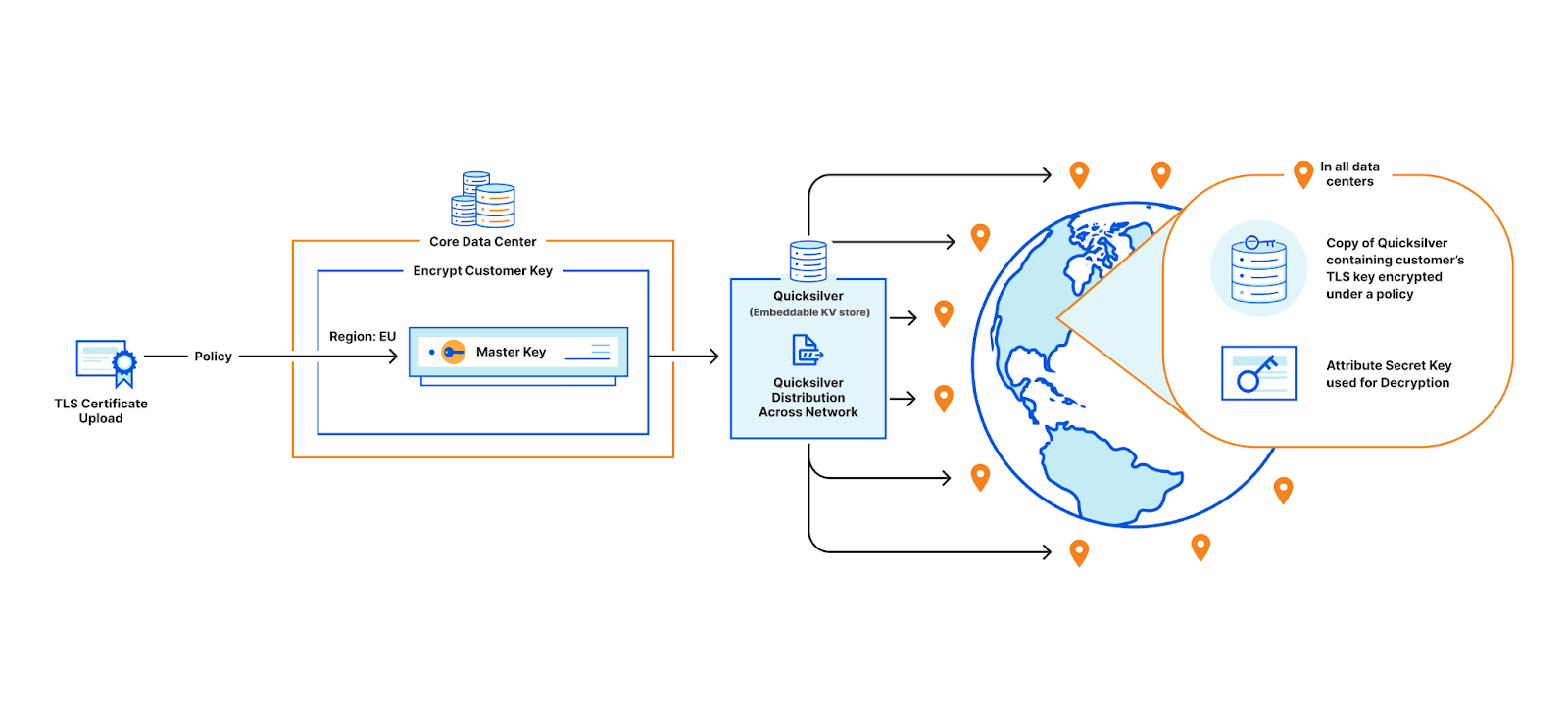
When a customer uploads their TLS certificate, they can specify a policy, and the central authority will encrypt their private key with the master public key under the specified policy. The encrypted customer key then gets written to Quicksilver, to be distributed to all data centers. In practice, there is a layer of indirection here that we will discuss in a later section.
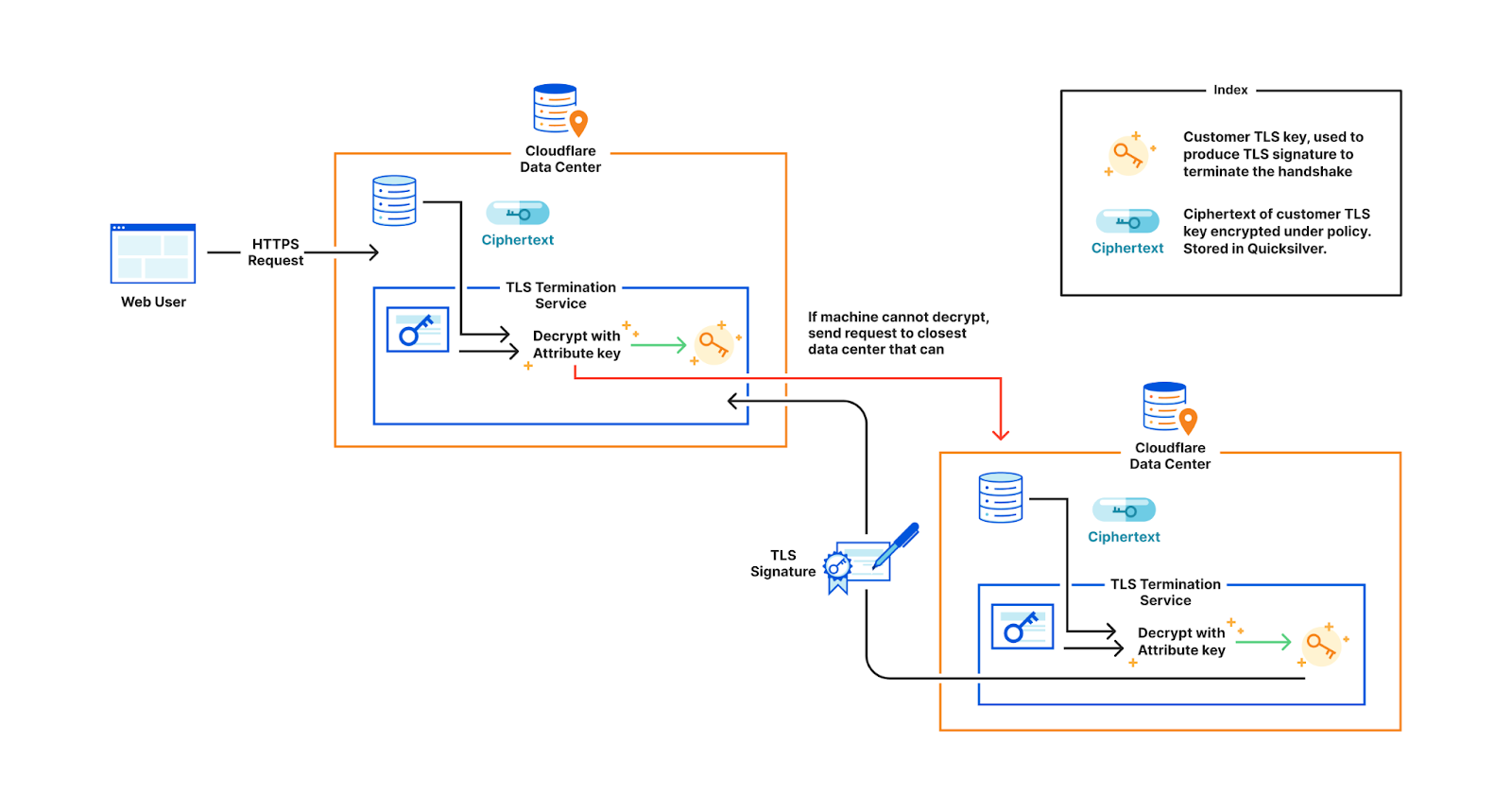
When a user visits the customer’s website, the TLS termination service at the data center that first receives the request, fetches the customer’s encrypted private key from Quicksilver. If the service’s attributes do not satisfy the policy, decryption fails and the request is proxied to the closest data center that satisfies the policy. Whichever data center can successfully decrypt the key performs the signature to complete the TLS handshake.
The following table summarizes the pros and cons of the various solutions we discussed:
| Solution | Flexible policies | Fault Tolerant | Efficient Space | Low Latency | Collusion-resistant | Changes to machines |
|---|---|---|---|---|---|---|
| Different copies of Quicksilver in data centers | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Complicated Business Logic in Core | ✅ | ✅ | ✅ | ✅ | ||
| Encrypt customer keys with each data center’s unique keypair | ✅ | ✅ | ✅ | ✅ | ||
| Encrypt customer keys with a policy-based keypair, where each data center has multiple policy-based keypairs | ✅ | ✅ | ✅ | |||
| Identity-Based Broadcast Encryption + Identity-Based Negative Broadcast Encryption(Geo Key Manager v1) | ✅ | ✅ | ✅ | |||
| Attribute-Based Encryption(Geo Key Manager v2) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Performance characteristics
We characterize our scheme’s performance on measures inspired by ECRYPT. We set the attribute size to 50, which is significantly higher than necessary for most applications, but serves as a worst case scenario for benchmarking purposes. We conduct our measurements on a laptop with Intel Core i7-10610U CPU @ 1.80GHz and compare the results against RSA with 2048-bit security, X25519 and our previous scheme.
| Scheme | Secret key(bytes) | Public key(bytes) | Overhead of encrypting 23 bytes (ciphertext length – message length) |
Overhead of encrypting 10k bytes (ciphertext length – message length) |
|---|---|---|---|---|
| RSA-2048 | 1190 (PKCS#1) | 256 | 233 | 3568 |
| X25519 | 32 | 32 | 48 | 48 |
| GeoV1 scheme | 4838 | 4742 | 169 | 169 |
| GeoV2 ABE scheme | 33416 | 3282 | 19419 | 19419 |
Different attribute based encryption schemes optimize for different performance profiles. Some may have fast key generation, while others may prioritize fast decryption. In our case, we only care about fast decryption because it is the only part of the process that lies in the critical path of a request. Everything else happens out-of-band where the extra overhead is acceptable.
| Scheme | Generating keypair | Encrypting 23 bytes | Decrypting 23 bytes |
|---|---|---|---|
| RSA-2048 | 117 ms | 0.043 ms | 1.26 ms |
| X25519 | 0.045 ms | 0.093 ms | 0.046 ms |
| GeoV1 scheme | 75 ms | 10.7 ms | 13.9 ms |
| GeoV2 ABE scheme | 1796 ms | 704 ms | 62.4 ms |
A Brief Note on Attribute-Based Access Control (ABAC)
We have used Attribute-Based Encryption to implement what is commonly known as Attribute-Based Access Control (ABAC).
ABAC is an extension of the more familiar Role-Based Access Control (RBAC). To understand why ABAC is relevant, let’s briefly discuss its origins. In 1970, the United States Department of Defense introduced Discretionary Access Control (DAC). DAC is how Unix file systems are implemented. But DAC isn’t enough if you want to restrict resharing, because the owner of the resource can grant other users permission to access it in ways that the central administrator does not agree with. To address this, the Department of Defense introduced Mandatory Access Control (MAC). DRM is a good example of MAC. Even though you have the file, you don’t have a right to share it to others.
RBAC is an implementation of certain aspects of MAC. ABAC is an extension of RBAC that was defined by NIST in 2017 to address the increasing characteristics of users that are not restricted to their roles, such as time of day, user agent, and so on.
However, RBAC/ABAC is simply a specification. While they are traditionally implemented using a central authority to police access to some resource, it doesn’t have to be so. Attribute-based encryption is an excellent mechanism to implement ABAC in distributed systems.
Key rotation
While it may be tempting to attribute all failures to DNS, changing keys is another strong contender in this race. Suffering through the rather manual and error-prone key rotation process of Geo Key Manager v1 taught us to make robust and simple key rotation without impact on availability, an explicit design goal for Geo Key Manager v2.
To facilitate key rotation and improve performance, we introduce a layer of indirection to the customer key wrapping (encryption) process. When a customer uploads their TLS private key, instead of encrypting with the Master Public Key, we generate a X25519 keypair, called the policy key. The central authority then adds the public part of this newly minted policy keypair and its associated policy label to a database. It then encrypts the private half of the policy keypair with the Master Public Key, over the associated access policy. The customer’s private key is encrypted with the public policy key, and saved into Quicksilver.
When a user accesses the customer’s website, the TLS termination service at the data center that receives the request fetches the encrypted policy key associated with the customer’s access policy. If the machine’s attributes don’t satisfy the policy, decryption fails and the request is forwarded to the closest satisfying data center. If decryption succeeds, the policy key is used to decrypt the customer’s private key and complete the handshake.
| Key | Purpose | CA in core | Core | Network |
|---|---|---|---|---|
| Master Public Key | Encrypts private policy keys over an access policy | Generate | Read | |
| Master Secret Key | Generates secret keys for machines based on their attributes | Generate,Read | ||
| Machine Secret Key / Attribute-Based Secret Key | Decrypts private policy keys stored in global KV store, Quicksilver | Generate | Read | |
| Customer TLS Private Key | Performs digital signature necessary to complete TLS handshake to the customer’s website | Read (transiently on upload) | Read | |
| Public Policy Key | Encrypts customers’ TLS private keys | Generate, Read |
||
| Private Policy Key | Decrypts customer’s TLS private keys | Read (transiently during key rotation) | Generate | Read |
However, policy keys are not generated for every customer’s certificate upload. As shown in the figure below, if a customer requests a policy that already exists in the system and thus has an associated policy key, the policy key will get re-used. Since most customers use the same few policies, such as restricting to one country, or restricting to the EU, the number of policy keys is orders of magnitude smaller compared to the number of customer keys.
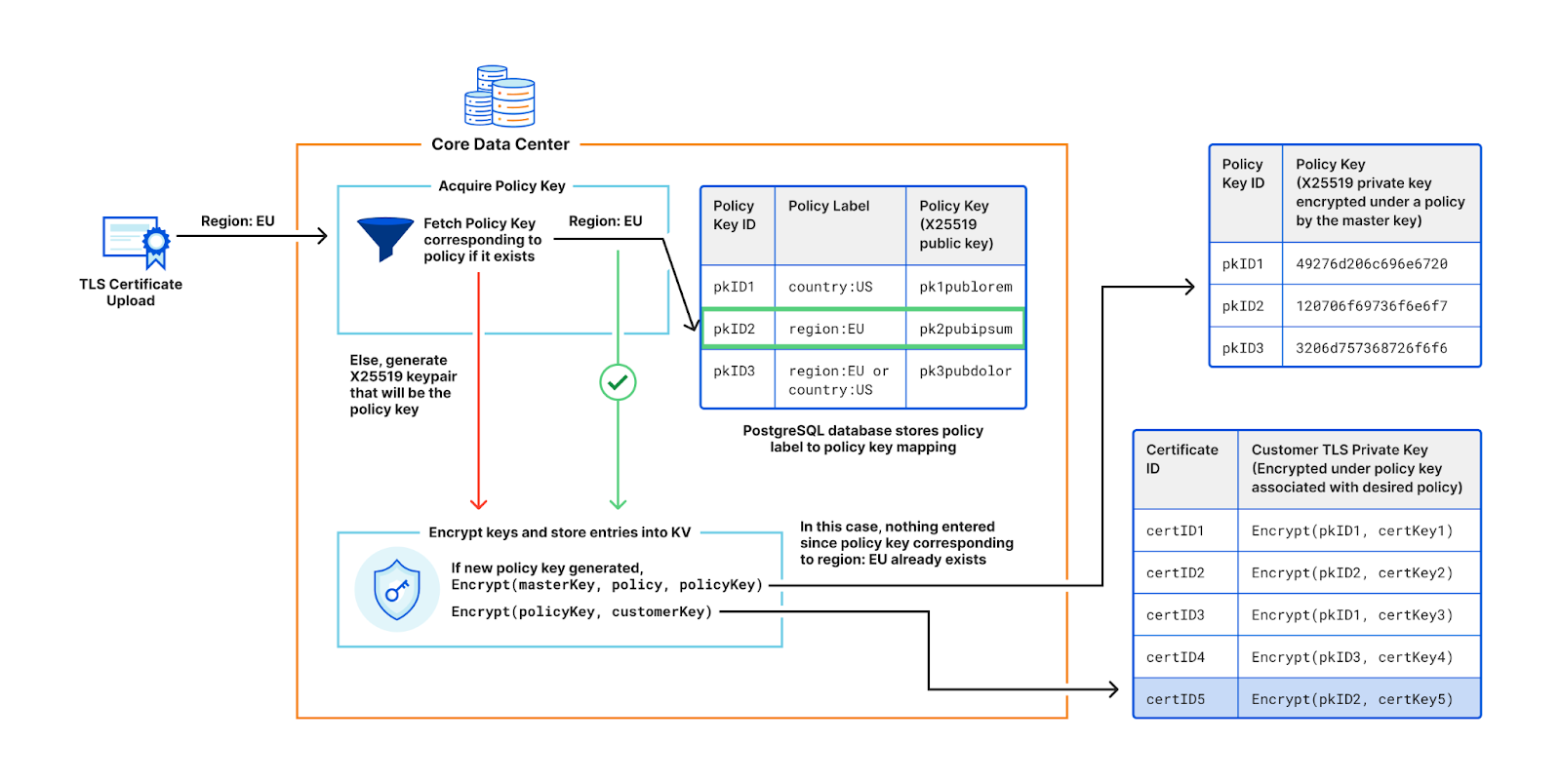
This sharing of policy keys is tremendously useful for key rotation. When master keys are rotated (and consequently the machine secret keys), only the handful of policy keys used to control access to the customers’ keys need to be re-encrypted, rather than every customer’s key encryption. This reduces compute and bandwidth requirements. Additionally, caching policy keys at the TLS termination service improves performance by reducing the need for frequent decryptions in the critical path.
This is similar to hybrid encryption, where public key cryptography is used to establish a shared symmetric key, which then gets used to encrypt data. The difference here is that the policy keys are not symmetric, but rather X25519 keypairs, which is an asymmetric scheme based on elliptic curves. While not as fast as symmetric schemes like AES, traditional elliptic curve cryptography is significantly faster than attribute-based encryption. The advantage here is that the central service doesn’t need access to secret key material to encrypt customer keys.
The other component of robust key rotation involves maintaining multiple key versions.The latest key generation is used for encryption, but the latest and previous versions can be used for decryption. We use a system of states to manage key transitions and safe deletion of older keys. We also have extensive monitoring in place to alert us if any machines are not using the appropriate key generations.
The Tail At Scale
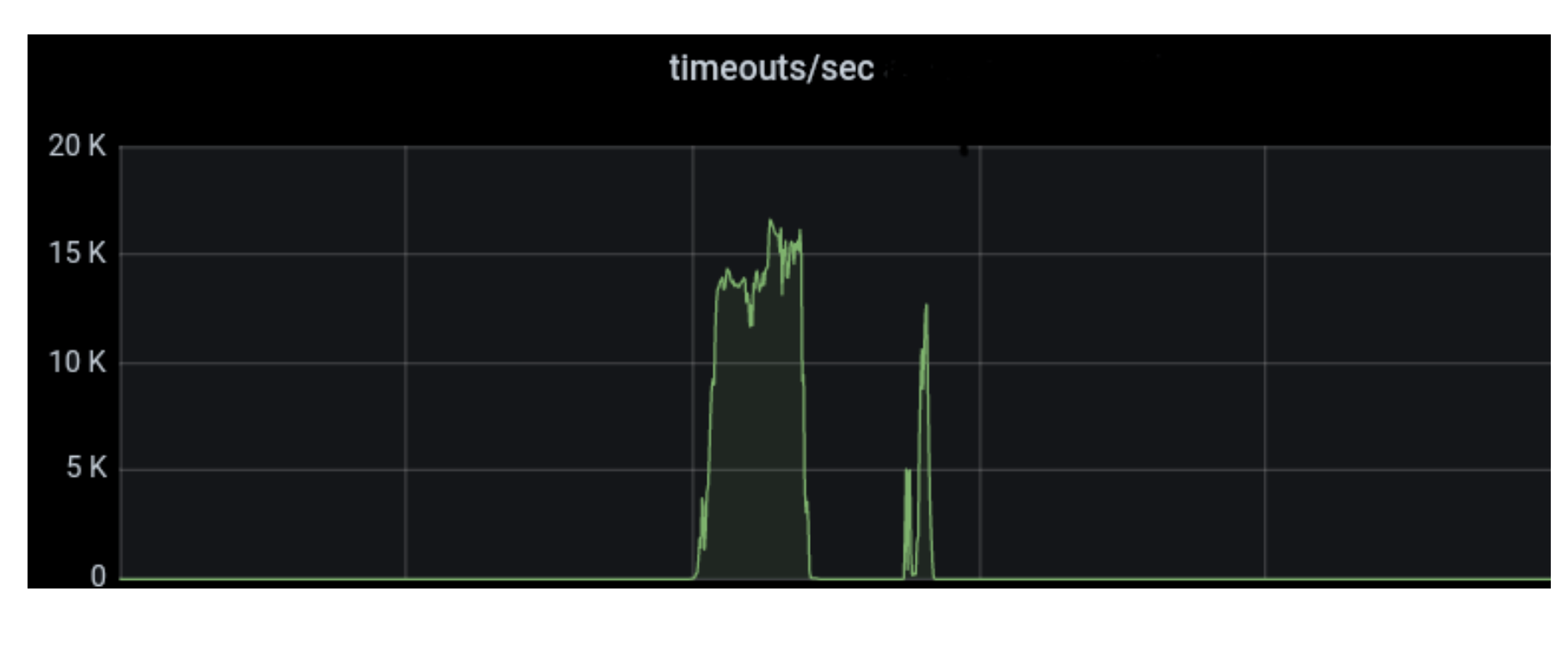
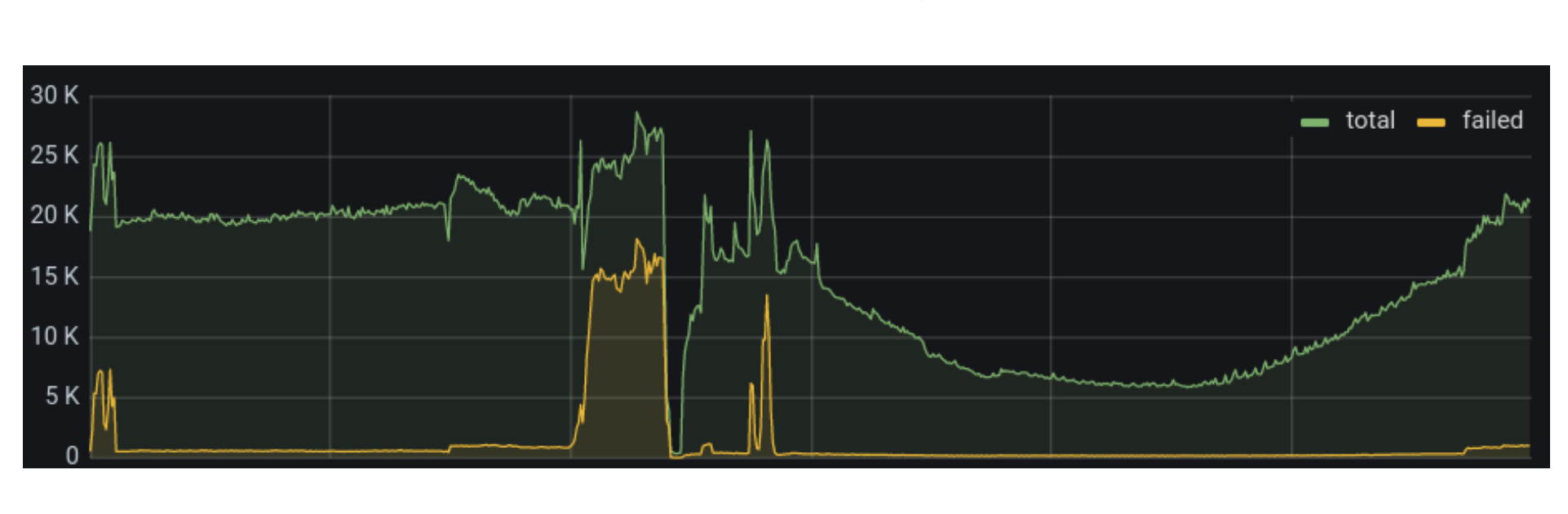
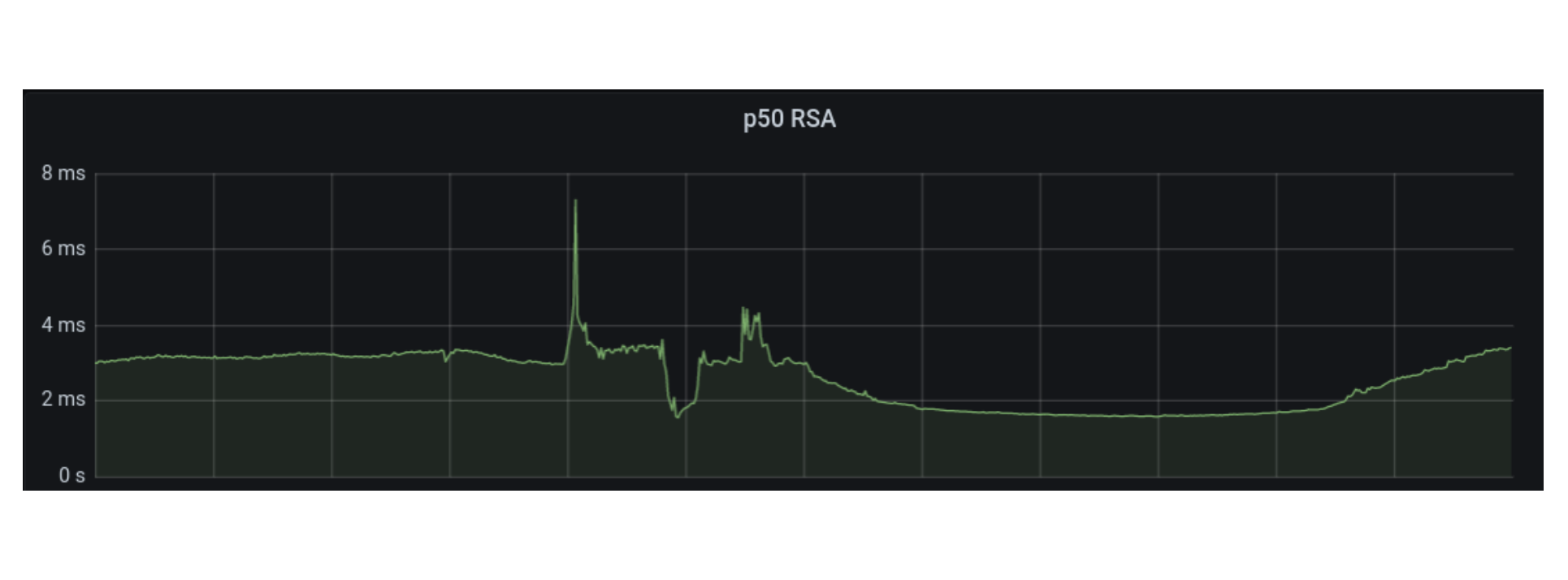
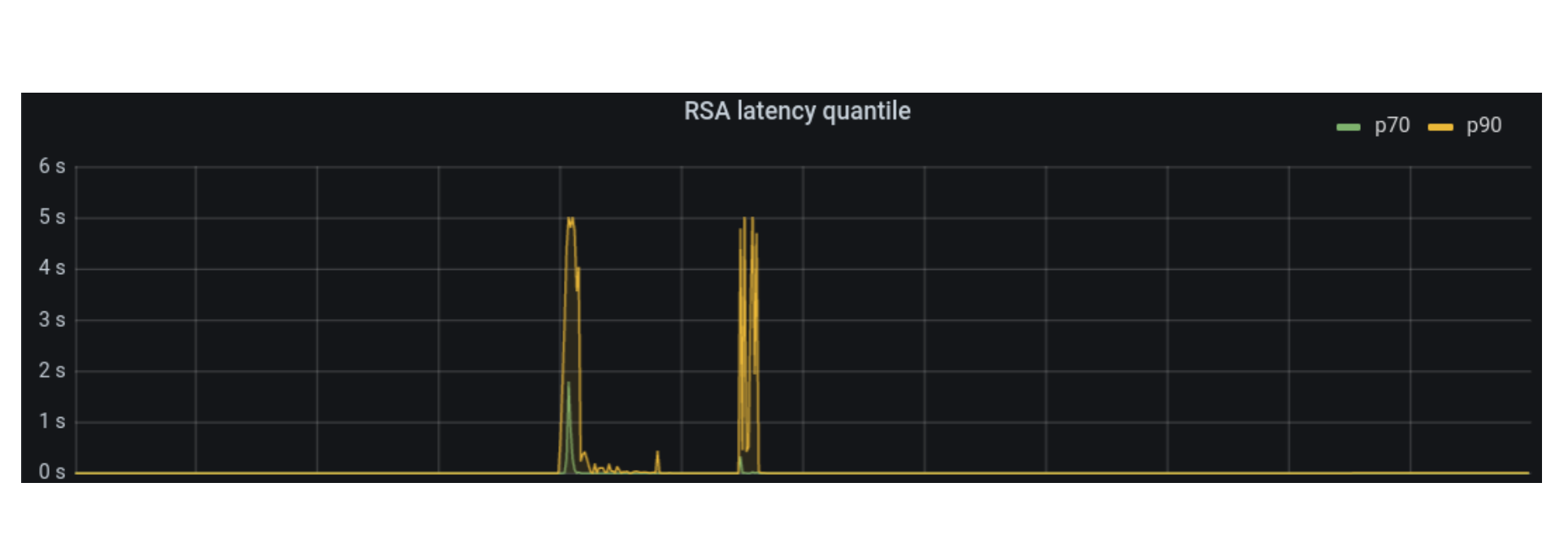
Geo Key Manager suffered from high tail latency, which occasionally impacted availability. Jeff Dean’s paper, The Tail at Scale, is an enlightening read on how even elevated p99 latency at Cloudflare scale can be damaging. Despite revamping the server and client components of our service, the p99 latency didn’t budge. These revamps, such as switching from worker pools to one goroutine per request, did simplify the service, as they removed thousands of lines of code. Distributed tracing was able to pin down the delays: they took place between the client sending a request and the server receiving it. But we could not dig in further. We even wrote a blog last year describing our debugging endeavors, but without a concrete solution.
Finally, we realized that there is a level of indirection between the client and the server. Our data centers around the world are very different sizes. To avoid swamping smaller data centers with connections, larger data centers would task individual, intermediary machines with proxying requests to other data centers using the Go net/rpc library.
Once we included the forwarding function on the intermediary server in the trace, the problem became clear. There was a long delay between issuing the request and processing it. Yet the code was merely a call to a built-in library function. Why was it delaying the request?
Ultimately we found that there was a lock held while the request was serialized. The net/rpc package does not support streams, but our packet-oriented custom application protocol, which we wrote before the advent of gRPC, does support streaming. To bridge this gap, we executed a request and waited for the response in the serialization function. While an expedient way to get the code written, it created a performance bottleneck as only one request could be forwarded at a time.
Our solution was to use channels for coordination, letting multiple requests execute while we waited for the responses to arrive. When we rolled it out we saw dramatic decreases in tail latency.
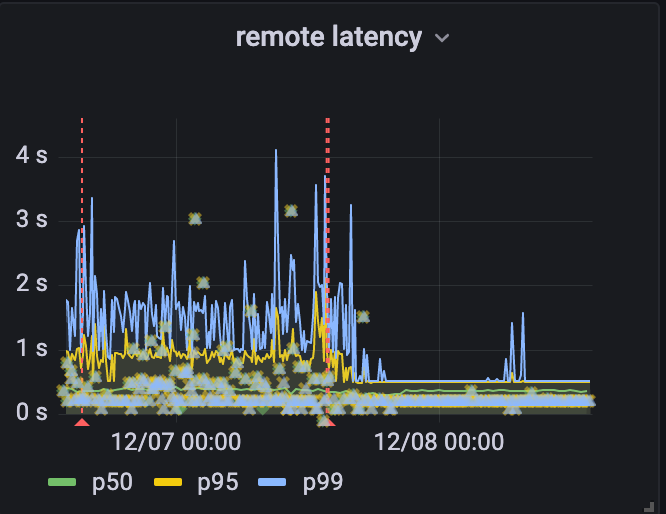
Unfortunately we cannot make the speed of light any faster (yet). Customers who want their keys kept only in the US while their website users are in the land down under will have to endure some delays as we make the trans-pacific voyage. But thanks to session tickets, those delays only affect new connections.
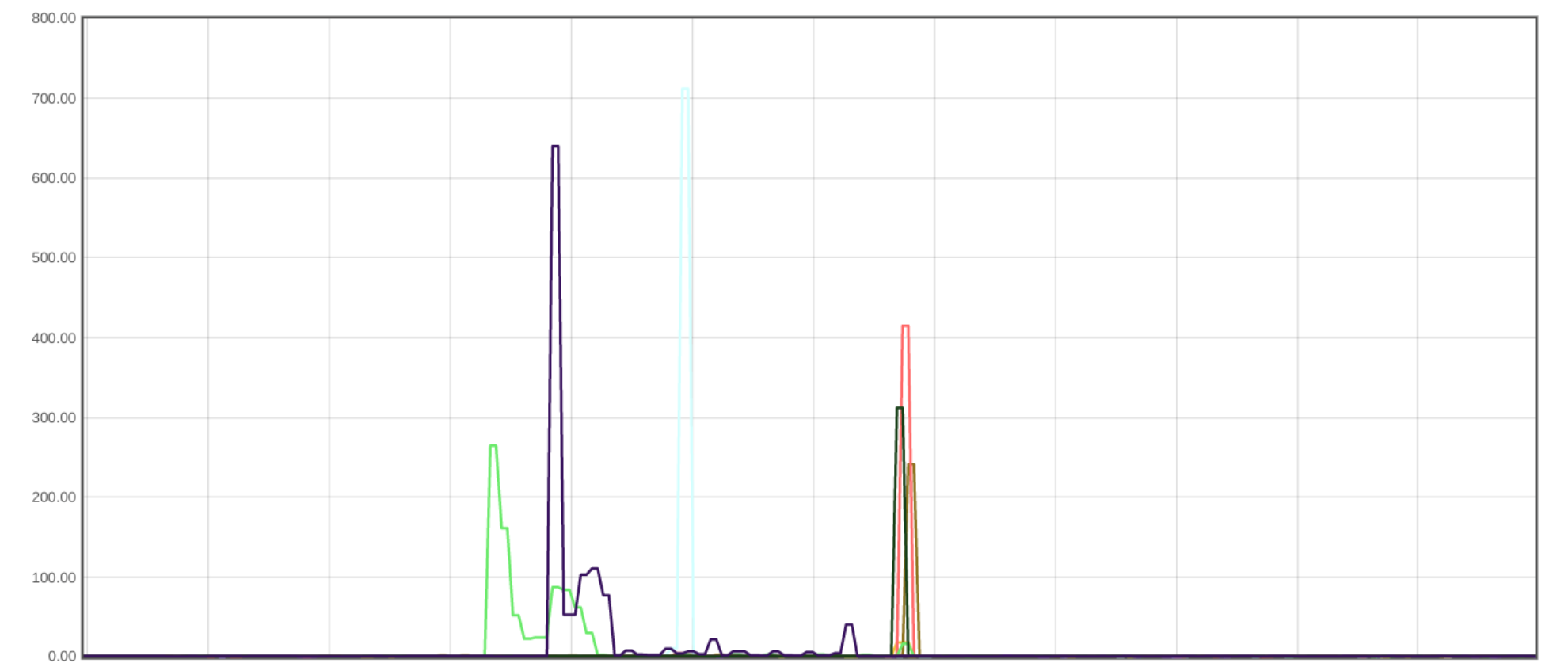
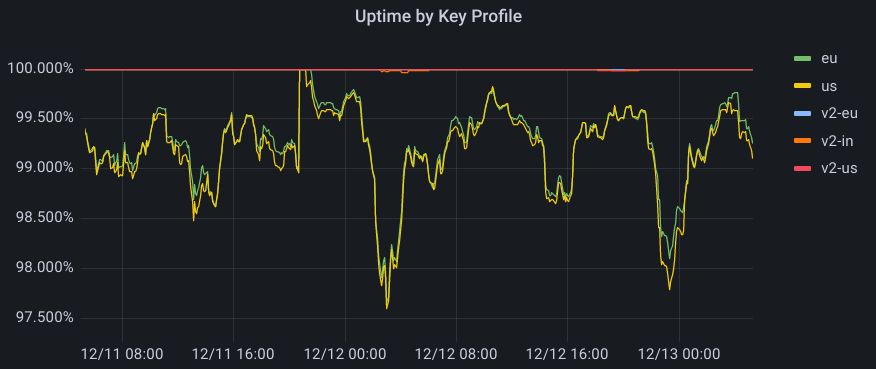
Uptime was also significantly improved. Data centers provisioned after cryptographic initiation could now participate in the system, which also implies that data centers that did not satisfy a certain policy had a broader range of satisfying neighbors to which they could forward the signing request to. This increased redundancy in the system, and particularly benefited data centers in regions without the best internet connectivity. The graph below represents successful probes spanning every machine globally over a two-day period. For GeoV1, we see websites with policies for US and EU regions falling to under 98% at one point, while for GeoV2, uptime rarely drops below 4 9s of availability.
Conclusion
Congratulations dear reader for making it this far. Just like you, applied cryptography has come a long way, but only limited slivers manage to penetrate the barrier between research and real-world adoption. Bridging this gap can help enable novel capabilities for protecting sensitive data. Attribute-based encryption itself has become much more efficient and featureful over the past few years. We hope that this post encourages you to consider ABE for your own access control needs, particularly if you deal with distributed systems and don’t want to depend on a highly available central authority. We have open-sourced our implementation of CP-ABE in CIRCL, and plan on publishing a paper with additional details.
We look forward to the numerous product improvements to Geo Key Manager made possible by this new cryptographic foundation. We plan to use this ABE-based mechanism for storing not just private keys, but also other types of data. We are working on making it more user-friendly and generalizable for internal services to use.
Acknowledgements
We’d like to thank Watson Ladd for his contributions to this project during his tenure at Cloudflare.
……
1While true for most customers, we do offer Keyless SSL that allows customers who can run their own keyservers, the ability to store their private keys on-prem