Post Syndicated from Luke Valenta original https://blog.cloudflare.com/bootstrap-mtc/
The world is in a race to build its first quantum computer capable of solving practical problems not feasible on even the largest conventional supercomputers. While the quantum computing paradigm promises many benefits, it also threatens the security of the Internet by breaking much of the cryptography we have come to rely on.
To mitigate this threat, Cloudflare is helping to migrate the Internet to Post-Quantum (PQ) cryptography. Today, about 50% of traffic to Cloudflare’s edge network is protected against the most urgent threat: an attacker who can intercept and store encrypted traffic today and then decrypt it in the future with the help of a quantum computer. This is referred to as the harvest now, decrypt later threat.
However, this is just one of the threats we need to address. A quantum computer can also be used to crack a server’s TLS certificate, allowing an attacker to impersonate the server to unsuspecting clients. The good news is that we already have PQ algorithms we can use for quantum-safe authentication. The bad news is that adoption of these algorithms in TLS will require significant changes to one of the most complex and security-critical systems on the Internet: the Web Public-Key Infrastructure (WebPKI).
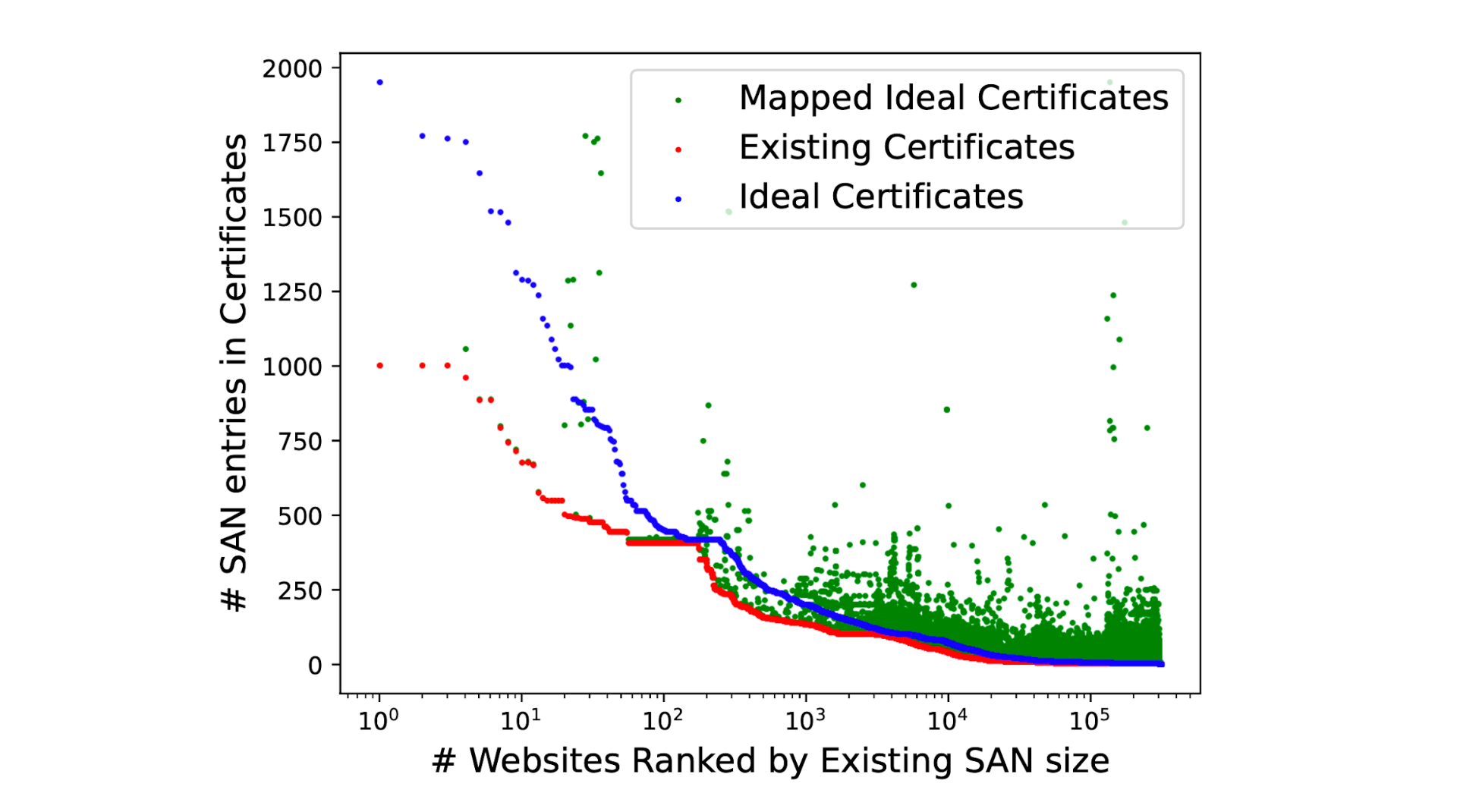
The central problem is the sheer size of these new algorithms: signatures for ML-DSA-44, one of the most performant PQ algorithms standardized by NIST, are 2,420 bytes long, compared to just 64 bytes for ECDSA-P256, the most popular non-PQ signature in use today; and its public keys are 1,312 bytes long, compared to just 64 bytes for ECDSA. That’s a roughly 20-fold increase in size. Worse yet, the average TLS handshake includes a number of public keys and signatures, adding up to 10s of kilobytes of overhead per handshake. This is enough to have a noticeable impact on the performance of TLS.
That makes drop-in PQ certificates a tough sell to enable today: they don’t bring any security benefit before Q-day — the day a cryptographically relevant quantum computer arrives — but they do degrade performance. We could sit and wait until Q-day is a year away, but that’s playing with fire. Migrations always take longer than expected, and by waiting we risk the security and privacy of the Internet, which is dear to us.
It’s clear that we must find a way to make post-quantum certificates cheap enough to deploy today by default for everyone — not just those that can afford it. In this post, we’ll introduce you to the plan we’ve brought together with industry partners to the IETF to redesign the WebPKI in order to allow a smooth transition to PQ authentication with no performance impact (and perhaps a performance improvement!). We’ll provide an overview of one concrete proposal, called Merkle Tree Certificates (MTCs), whose goal is to whittle down the number of public keys and signatures in the TLS handshake to the bare minimum required.
But talk is cheap. We know from experience that, as with any change to the Internet, it’s crucial to test early and often. Today we’re announcing our intent to deploy MTCs on an experimental basis in collaboration with Chrome Security. In this post, we’ll describe the scope of this experiment, what we hope to learn from it, and how we’ll make sure it’s done safely.
Why does the TLS handshake have so many public keys and signatures?
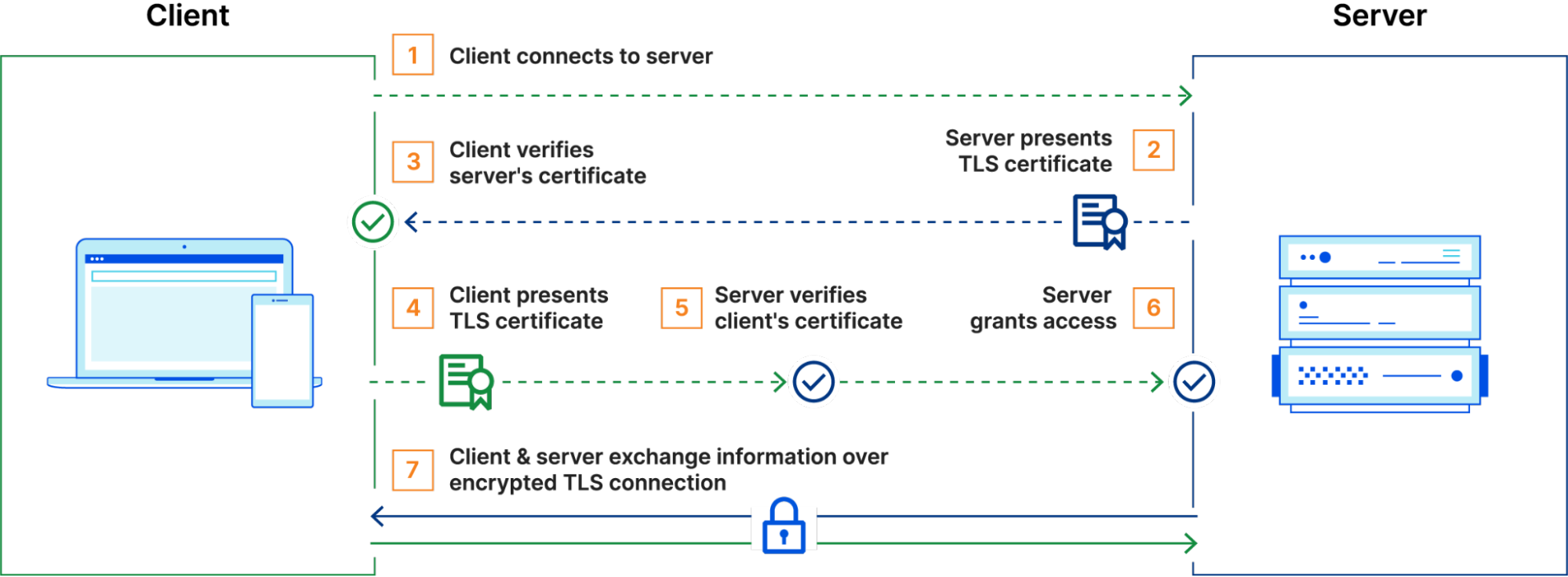
Let’s start with Cryptography 101. When your browser connects to a website, it asks the server to authenticate itself to make sure it’s talking to the real server and not an impersonator. This is usually achieved with a cryptographic primitive known as a digital signature scheme (e.g., ECDSA or ML-DSA). In TLS, the server signs the messages exchanged between the client and server using its secret key, and the client verifies the signature using the server’s public key. In this way, the server confirms to the client that they’ve had the same conversation, since only the server could have produced a valid signature.
If the client already knows the server’s public key, then only 1 signature is required to authenticate the server. In practice, however, this is not really an option. The web today is made up of around a billion TLS servers, so it would be unrealistic to provision every client with the public key of every server. What’s more, the set of public keys will change over time as new servers come online and existing ones rotate their keys, so we would need some way of pushing these changes to clients.
This scaling problem is at the heart of the design of all PKIs.
Instead of expecting the client to know the server’s public key in advance, the server might just send its public key during the TLS handshake. But how does the client know that the public key actually belongs to the server? This is the job of a certificate.
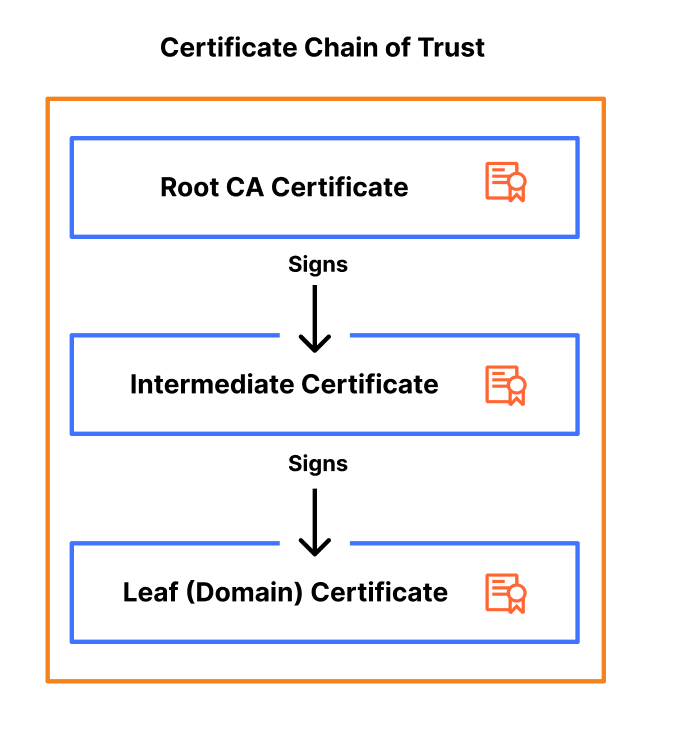
A certificate binds a public key to the identity of the server — usually its DNS name, e.g., cloudflareresearch.com. The certificate is signed by a Certification Authority (CA) whose public key is known to the client. In addition to verifying the server’s handshake signature, the client verifies the signature of this certificate. This establishes a chain of trust: by accepting the certificate, the client is trusting that the CA verified that the public key actually belongs to the server with that identity.
Clients are typically configured to trust many CAs and must be provisioned with a public key for each. Things are much easier however, since there are only 100s of CAs instead of billions. In addition, new certificates can be created without having to update clients.
These efficiencies come at a relatively low cost: for those counting at home, that’s +1 signature and +1 public key, for a total of 2 signatures and 1 public key per TLS handshake.
That’s not the end of the story, however. As the WebPKI has evolved, so have these chains of trust grown a bit longer. These days it’s common for a chain to consist of two or more certificates rather than just one. This is because CAs sometimes need to rotate their keys, just as servers do. But before they can start using the new key, they must distribute the corresponding public key to clients. This takes time, since it requires billions of clients to update their trust stores. To bridge the gap, the CA will sometimes use the old key to issue a certificate for the new one and append this certificate to the end of the chain.
That’s +1 signature and +1 public key, which brings us to 3 signatures and 2 public keys. And we still have a little ways to go.
The main job of a CA is to verify that a server has control over the domain for which it’s requesting a certificate. This process has evolved over the years from a high-touch, CA-specific process to a standardized, mostly automated process used for issuing most certificates on the web. (Not all CAs fully support automation, however.) This evolution is marked by a number of security incidents in which a certificate was mis-issued to a party other than the server, allowing that party to impersonate the server to any client that trusts the CA.
Automation helps, but attacks are still possible, and mistakes are almost inevitable. Earlier this year, several certificates for Cloudflare’s encrypted 1.1.1.1 resolver were issued without our involvement or authorization. This apparently occurred by accident, but it nonetheless put users of 1.1.1.1 at risk. (The mis-issued certificates have since been revoked.)
Ensuring mis-issuance is detectable is the job of the Certificate Transparency (CT) ecosystem. The basic idea is that each certificate issued by a CA gets added to a public log. Servers can audit these logs for certificates issued in their name. If ever a certificate is issued that they didn’t request itself, the server operator can prove the issuance happened, and the PKI ecosystem can take action to prevent the certificate from being trusted by clients.
Major browsers, including Firefox and Chrome and its derivatives, require certificates to be logged before they can be trusted. For example, Chrome, Safari, and Firefox will only accept the server’s certificate if it appears in at least two logs the browser is configured to trust. This policy is easy to state, but tricky to implement in practice:
-
Operating a CT log has historically been fairly expensive. Logs ingest billions of certificates over their lifetimes: when an incident happens, or even just under high load, it can take some time for a log to make a new entry available for auditors.
-
Clients can’t really audit logs themselves, since this would expose their browsing history (i.e., the servers they wanted to connect to) to the log operators.
The solution to both problems is to include a signature from the CT log along with the certificate. The signature is produced immediately in response to a request to log a certificate, and attests to the log’s intent to include the certificate in the log within 24 hours.
Per browser policy, certificate transparency adds +2 signatures to the TLS handshake, one for each log. This brings us to a total of 5 signatures and 2 public keys in a typical handshake on the public web.
The WebPKI is a living, breathing, and highly distributed system. We’ve had to patch it a number of times over the years to keep it going, but on balance it has served our needs quite well — until now.
Previously, whenever we needed to update something in the WebPKI, we would tack on another signature. This strategy has worked because conventional cryptography is so cheap. But 5 signatures and 2 public keys on average for each TLS handshake is simply too much to cope with for the larger PQ signatures that are coming.
The good news is that by moving what we already have around in clever ways, we can drastically reduce the number of signatures we need.
Merkle Tree Certificates (MTCs) is a proposal for the next generation of the WebPKI that we are implementing and plan to deploy on an experimental basis. Its key features are as follows:
-
All the information a client needs to validate a Merkle Tree Certificate can be disseminated out-of-band. If the client is sufficiently up-to-date, then the TLS handshake needs just 1 signature, 1 public key, and 1 Merkle tree inclusion proof. This is quite small, even if we use post-quantum algorithms.
-
The MTC specification makes certificate transparency a first class feature of the PKI by having each CA run its own log of exactly the certificates they issue.
Let’s poke our head under the hood a little. Below we have an MTC generated by one of our internal tests. This would be transmitted from the server to the client in the TLS handshake:
-----BEGIN CERTIFICATE-----
MIICSzCCAUGgAwIBAgICAhMwDAYKKwYBBAGC2ksvADAcMRowGAYKKwYBBAGC2ksv
AQwKNDQzNjMuNDguMzAeFw0yNTEwMjExNTMzMjZaFw0yNTEwMjgxNTMzMjZaMCEx
HzAdBgNVBAMTFmNsb3VkZmxhcmVyZXNlYXJjaC5jb20wWTATBgcqhkjOPQIBBggq
hkjOPQMBBwNCAARw7eGWh7Qi7/vcqc2cXO8enqsbbdcRdHt2yDyhX5Q3RZnYgONc
JE8oRrW/hGDY/OuCWsROM5DHszZRDJJtv4gno2wwajAOBgNVHQ8BAf8EBAMCB4Aw
EwYDVR0lBAwwCgYIKwYBBQUHAwEwQwYDVR0RBDwwOoIWY2xvdWRmbGFyZXJlc2Vh
cmNoLmNvbYIgc3RhdGljLWN0LmNsb3VkZmxhcmVyZXNlYXJjaC5jb20wDAYKKwYB
BAGC2ksvAAOB9QAAAAAAAAACAAAAAAAAAAJYAOBEvgOlvWq38p45d0wWTPgG5eFV
wJMhxnmDPN1b5leJwHWzTOx1igtToMocBwwakt3HfKIjXYMO5CNDOK9DIKhmRDSV
h+or8A8WUrvqZ2ceiTZPkNQFVYlG8be2aITTVzGuK8N5MYaFnSTtzyWkXP2P9nYU
Vd1nLt/WjCUNUkjI4/75fOalMFKltcc6iaXB9ktble9wuJH8YQ9tFt456aBZSSs0
cXwqFtrHr973AZQQxGLR9QCHveii9N87NXknDvzMQ+dgWt/fBujTfuuzv3slQw80
mibA021dDCi8h1hYFQAA
-----END CERTIFICATE-----Looks like your average PEM encoded certificate. Let’s decode it and look at the parameters:
$ openssl x509 -in merkle-tree-cert.pem -noout -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 531 (0x213)
Signature Algorithm: 1.3.6.1.4.1.44363.47.0
Issuer: 1.3.6.1.4.1.44363.47.1=44363.48.3
Validity
Not Before: Oct 21 15:33:26 2025 GMT
Not After : Oct 28 15:33:26 2025 GMT
Subject: CN=cloudflareresearch.com
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
pub:
04:70:ed:e1:96:87:b4:22:ef:fb:dc:a9:cd:9c:5c:
ef:1e:9e:ab:1b:6d:d7:11:74:7b:76:c8:3c:a1:5f:
94:37:45:99:d8:80:e3:5c:24:4f:28:46:b5:bf:84:
60:d8:fc:eb:82:5a:c4:4e:33:90:c7:b3:36:51:0c:
92:6d:bf:88:27
ASN1 OID: prime256v1
NIST CURVE: P-256
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature
X509v3 Extended Key Usage:
TLS Web Server Authentication
X509v3 Subject Alternative Name:
DNS:cloudflareresearch.com, DNS:static-ct.cloudflareresearch.com
Signature Algorithm: 1.3.6.1.4.1.44363.47.0
Signature Value:
00:00:00:00:00:00:02:00:00:00:00:00:00:00:02:58:00:e0:
44:be:03:a5:bd:6a:b7:f2:9e:39:77:4c:16:4c:f8:06:e5:e1:
55:c0:93:21:c6:79:83:3c:dd:5b:e6:57:89:c0:75:b3:4c:ec:
75:8a:0b:53:a0:ca:1c:07:0c:1a:92:dd:c7:7c:a2:23:5d:83:
0e:e4:23:43:38:af:43:20:a8:66:44:34:95:87:ea:2b:f0:0f:
16:52:bb:ea:67:67:1e:89:36:4f:90:d4:05:55:89:46:f1:b7:
b6:68:84:d3:57:31:ae:2b:c3:79:31:86:85:9d:24:ed:cf:25:
a4:5c:fd:8f:f6:76:14:55:dd:67:2e:df:d6:8c:25:0d:52:48:
c8:e3:fe:f9:7c:e6:a5:30:52:a5:b5:c7:3a:89:a5:c1:f6:4b:
5b:95:ef:70:b8:91:fc:61:0f:6d:16:de:39:e9:a0:59:49:2b:
34:71:7c:2a:16:da:c7:af:de:f7:01:94:10:c4:62:d1:f5:00:
87:bd:e8:a2:f4:df:3b:35:79:27:0e:fc:cc:43:e7:60:5a:df:
df:06:e8:d3:7e:eb:b3:bf:7b:25:43:0f:34:9a:26:c0:d3:6d:
5d:0c:28:bc:87:58:58:15:00:00While some of the parameters probably look familiar, others will look unusual. On the familiar side, the subject and public key are exactly what we might expect: the DNS name is cloudflareresearch.com and the public key is for a familiar signature algorithm, ECDSA-P256. This algorithm is not PQ, of course — in the future we would put ML-DSA-44 there instead.
On the unusual side, OpenSSL appears to not recognize the signature algorithm of the issuer and just prints the raw OID and bytes of the signature. There’s a good reason for this: the MTC does not have a signature in it at all! So what exactly are we looking at?
The trick to leave out signatures is that a Merkle Tree Certification Authority (MTCA) produces its signatureless certificates in batches rather than individually. In place of a signature, the certificate has an inclusion proof of the certificate in a batch of certificates signed by the MTCA.
To understand how inclusion proofs work, let’s think about a slightly simplified version of the MTC specification. To issue a batch, the MTCA arranges the unsigned certificates into a data structure called a Merkle tree that looks like this:

Each leaf of the tree corresponds to a certificate, and each inner node is equal to the hash of its children. To sign the batch, the MTCA uses its secret key to sign the head of the tree. The structure of the tree guarantees that each certificate in the batch was signed by the MTCA: if we tried to tweak the bits of any one of the certificates, the treehead would end up having a different value, which would cause the signature to fail.
An inclusion proof for a certificate consists of the hash of each sibling node along the path from the certificate to the treehead:

Given a validated treehead, this sequence of hashes is sufficient to prove inclusion of the certificate in the tree. This means that, in order to validate an MTC, the client also needs to obtain the signed treehead from the MTCA.
This is the key to MTC’s efficiency:
-
Signed treeheads can be disseminated to clients out-of-band and validated offline. Each validated treehead can then be used to validate any certificate in the corresponding batch, eliminating the need to obtain a signature for each server certificate.
-
During the TLS handshake, the client tells the server which treeheads it has. If the server has a signatureless certificate covered by one of those treeheads, then it can use that certificate to authenticate itself. That’s 1 signature,1 public key and 1 inclusion proof per handshake, both for the server being authenticated.
Now, that’s the simplified version. MTC proper has some more bells and whistles. To start, it doesn’t create a separate Merkle tree for each batch, but it grows a single large tree, which is used for better transparency. As this tree grows, periodically (sub)tree heads are selected to be shipped to browsers, which we call landmarks. In the common case browsers will be able to fetch the most recent landmarks, and servers can wait for batch issuance, but we need a fallback: MTC also supports certificates that can be issued immediately and don’t require landmarks to be validated, but these are not as small. A server would provision both types of Merkle tree certificates, so that the common case is fast, and the exceptional case is slow, but at least it’ll work.
Ever since early designs for MTCs emerged, we’ve been eager to experiment with the idea. In line with the IETF principle of “running code”, it often takes implementing a protocol to work out kinks in the design. At the same time, we cannot risk the security of users. In this section, we describe our approach to experimenting with aspects of the Merkle Tree Certificates design without changing any trust relationships.
Let’s start with what we hope to learn. We have lots of questions whose answers can help to either validate the approach, or uncover pitfalls that require reshaping the protocol — in fact, an implementation of an early MTC draft by Maximilian Pohl and Mia Celeste did exactly this. We’d like to know:
What breaks? Protocol ossification (the tendency of implementation bugs to make it harder to change a protocol) is an ever-present issue with deploying protocol changes. For TLS in particular, despite having built-in flexibility, time after time we’ve found that if that flexibility is not regularly used, there will be buggy implementations and middleboxes that break when they see things they don’t recognize. TLS 1.3 deployment took years longer than we hoped for this very reason. And more recently, the rollout of PQ key exchange in TLS caused the Client Hello to be split over multiple TCP packets, something that many middleboxes weren’t ready for.
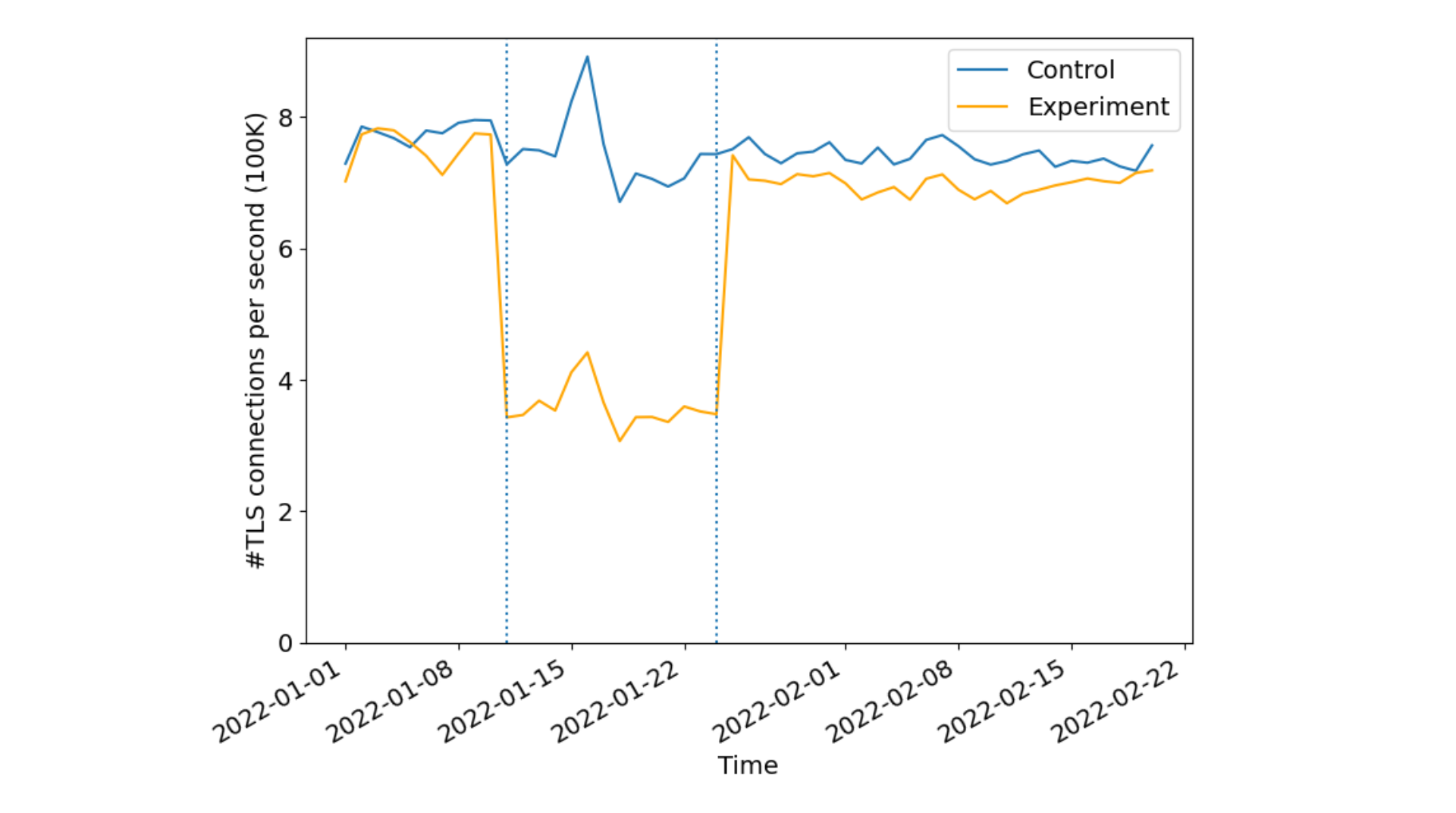
What is the performance impact? In fact, we expect MTCs to reduce the size of the handshake, even compared to today’s non-PQ certificates. They will also reduce CPU cost: ML-DSA signature verification is about as fast as ECDSA, and there will be far fewer signatures to verify. We therefore expect to see a reduction in latency. We would like to see if there is a measurable performance improvement.
What fraction of clients will stay up to date? Getting the performance benefit of MTCs requires the clients and servers to be roughly in sync with one another. We expect MTCs to have fairly short lifetimes, a week or so. This means that if the client’s latest landmark is older than a week, the server would have to fallback to a larger certificate. Knowing how often this fallback happens will help us tune the parameters of the protocol to make fallbacks less likely.
In order to answer these questions, we are implementing MTC support in our TLS stack and in our certificate issuance infrastructure. For their part, Chrome is implementing MTC support in their own TLS stack and will stand up infrastructure to disseminate landmarks to their users.
As we’ve done in past experiments, we plan to enable MTCs for a subset of our free customers with enough traffic that we will be able to get useful measurements. Chrome will control the experimental rollout: they can ramp up slowly, measuring as they go and rolling back if and when bugs are found.
Which leaves us with one last question: who will run the Merkle Tree CA?
Standing up a proper CA is no small task: it takes years to be trusted by major browsers. That’s why Cloudflare isn’t going to become a “real” CA for this experiment, and Chrome isn’t going to trust us directly.
Instead, to make progress on a reasonable timeframe, without sacrificing due diligence, we plan to “mock” the role of the MTCA. We will run an MTCA (on Workers based on our StaticCT logs), but for each MTC we issue, we also publish an existing certificate from a trusted CA that agrees with it. We call this the bootstrap certificate. When Chrome’s infrastructure pulls updates from our MTCA log, they will also pull these bootstrap certificates, and check whether they agree. Only if they do, they’ll proceed to push the corresponding landmarks to Chrome clients. In other words, Cloudflare is effectively just “re-encoding” an existing certificate (with domain validation performed by a trusted CA) as an MTC, and Chrome is using certificate transparency to keep us honest.
With almost 50% of our traffic already protected by post-quantum encryption, we’re halfway to a fully post-quantum secure Internet. The second part of our journey, post-quantum certificates, is the hardest yet though. A simple drop-in upgrade has a noticeable performance impact and no security benefit before Q-day. This means it’s a hard sell to enable today by default. But here we are playing with fire: migrations always take longer than expected. If we want to keep an ubiquitously private and secure Internet, we need a post-quantum solution that’s performant enough to be enabled by default today.
Merkle Tree Certificates (MTCs) solves this problem by reducing the number of signatures and public keys to the bare minimum while maintaining the WebPKI’s essential properties. We plan to roll out MTCs to a fraction of free accounts by early next year. This does not affect any visitors that are not part of the Chrome experiment. For those that are, thanks to the bootstrap certificates, there is no impact on security.
We’re excited to keep the Internet fast and secure, and will report back soon on the results of this experiment: watch this space! MTC is evolving as we speak, if you want to get involved, please join the IETF PLANTS mailing list.