Post Syndicated from Grab Tech original https://engineering.grab.com/graph-anomaly-model
Earlier in this series, we covered the importance of graph networks, graph concepts, graph visualisation, and graph-based fraud detection methods. In this article, we will discuss how to automatically detect new types of fraudulent behaviour and swiftly take action on them.
One of the challenges in fraud detection is that fraudsters are incentivised to always adversarially innovate their way of conducting frauds, i.e., their modus operandi (MO in short). Machine learning models trained using historical data may not be able to pick up new MOs, as they are new patterns that are not available in existing training data. To enhance Grab’s existing security defences and protect our users from these new MOs, we needed a machine learning model that is able to detect them quickly without the need for any label supervision, i.e., an unsupervised learning model rather than the regular supervised learning model.
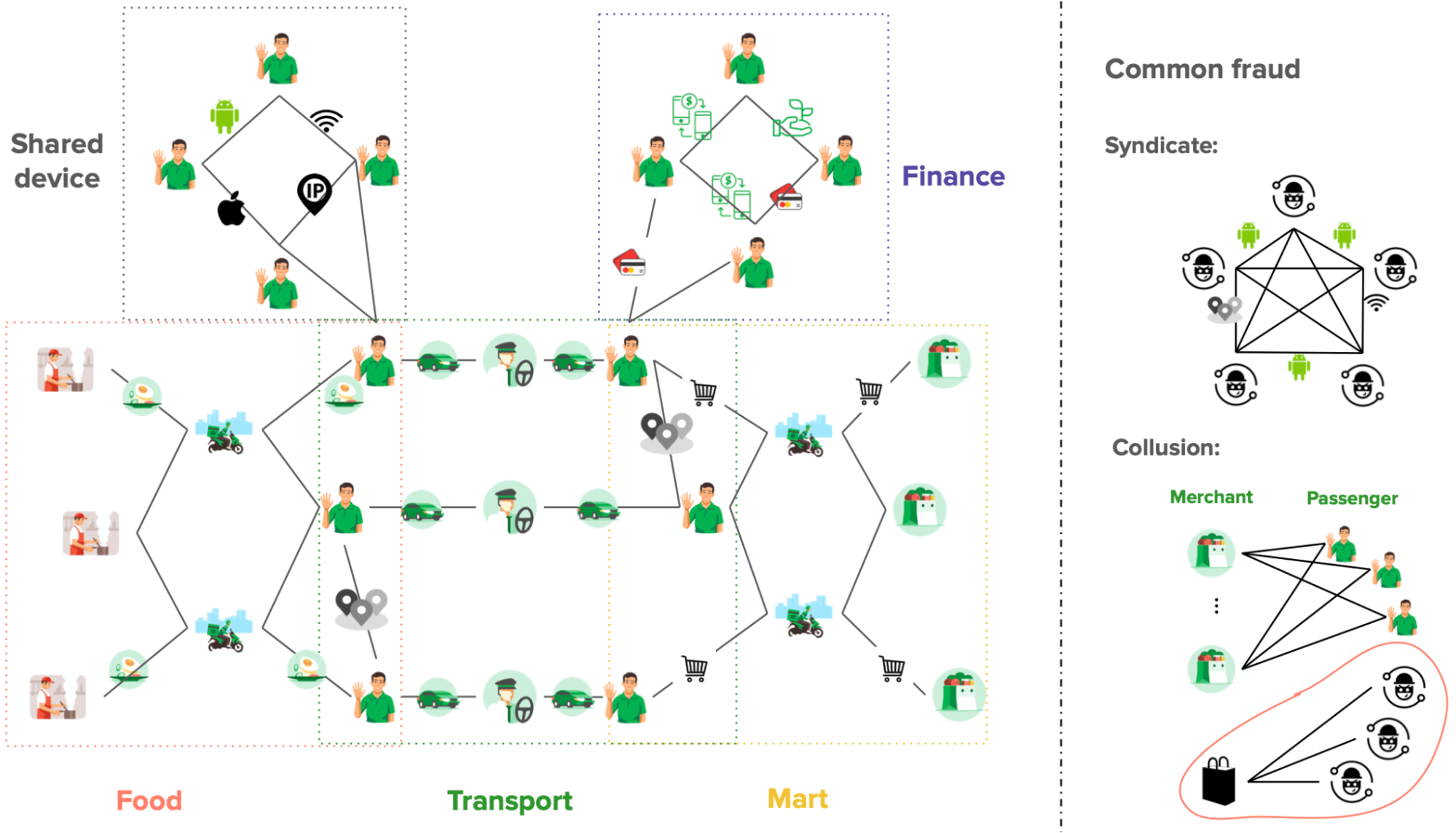
To address this, we developed an in-house machine learning model for detecting anomalous patterns in graphs, which has led to the discovery of new fraud MOs. Our focus was initially on GrabFood and GrabMart verticals, where we monitored the interactions between consumers and merchants. We modelled these interactions as a bipartite graph (a type of graph for modelling interactions between two groups) and then performed anomaly detection on the graph. Our in-house anomaly detection model was also presented at the International Joint Conference on Neural Networks (IJCNN) 2023, a premier academic conference in the area of neural networks, machine learning, and artificial intelligence.
In this blog, we discuss the model and its application within Grab. For avid audiences that want to read the details of our model, you can access it here. Note that even though we implemented our model for anomaly detection in GrabFood and GrabMart, the model is designed for general purposes and is applicable to interaction graphs between any two groups.
 |
Interaction-Focused Anomaly Detection on Bipartite Node-and-Edge-Attributed Graphs By Rizal Fathony, Jenn Ng, Jia Chen Presented at International Joint Conference on Neural Networks (IJCNN) 2023 |
Before we dive into how our model works, it is important to understand the process of graph construction in our application as the model assumes the availability of the graphs in a standardised format.
Graph construction
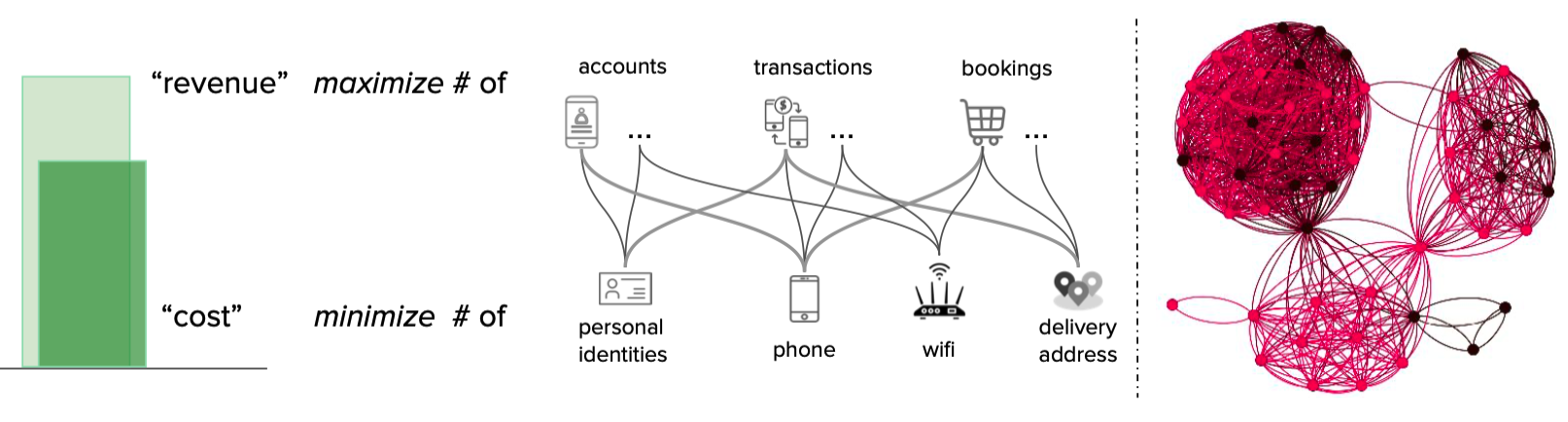
We modelled the interactions between consumers and merchants in GrabFood and GrabMart platforms as bipartite graphs (G), where the first group of nodes (U) represents the consumers, the second group of nodes (V) represents the merchants, and the edges (E) connecting them means that the consumers have placed some food/mart orders to the merchants. The graph is also supplied with rich transactional information about the consumers and the merchants in the form of node features (Xu and Xv), as well as order information in the form of edge features (Xe).
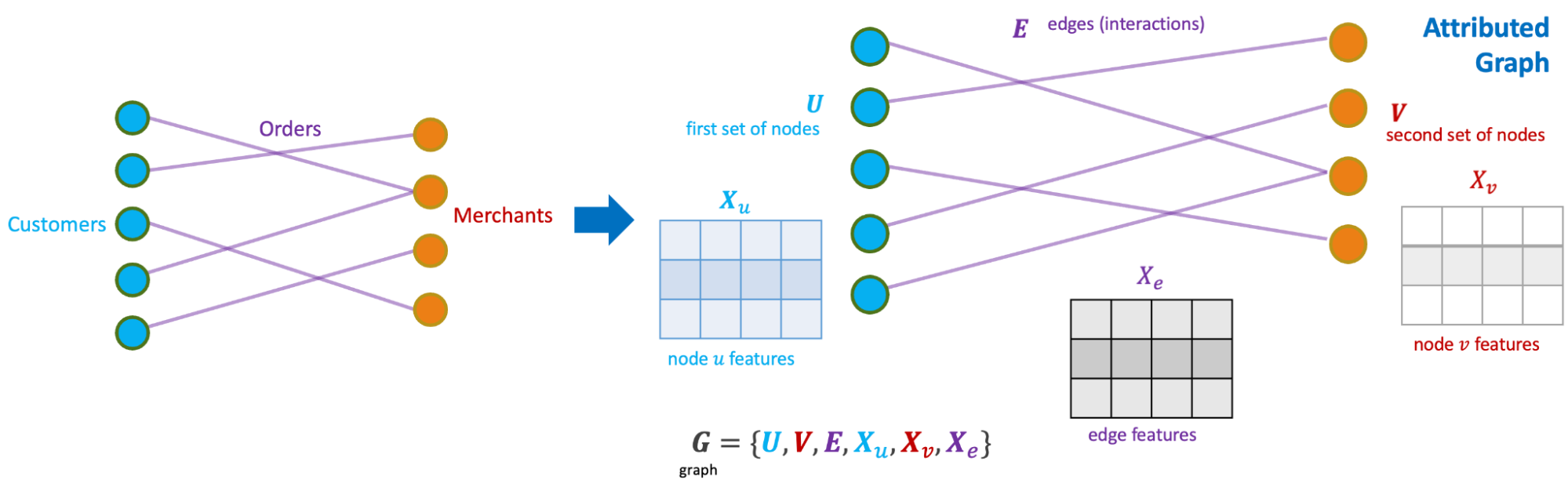
The goal of our anomaly model is to detect anomalous and suspicious behaviours from the consumers or merchants (node-level anomaly detection), as well as anomalous order interactions (edge-level anomaly detection). As mentioned, this detection needs to be done without any label supervision.
Model architecture
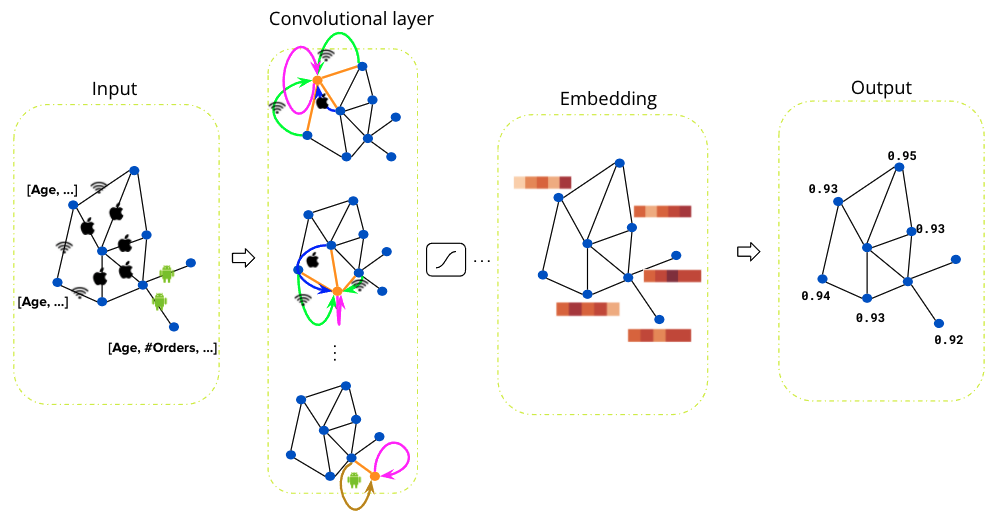
We designed our graph anomaly model as a type of autoencoder, with an encoder and two decoders – a feature decoder and a structure decoder. The key feature of our model is that it accepts a bipartite graph with both node and edge attributes as the input. This is important as both node and edge attributes encode essential information for determining if certain behaviours are suspicious. Many previous works on graph anomaly detection only support node attributes. In addition, our model can produce both node and edge level anomaly scores, unlike most of the previous works that produce node-level scores only. We named our model GraphBEAN, which is short for Bipartite Node-and-Edge-Attributed Networks.
From the input, the encoder then processes the attributed bipartite graph into a series of graph convolution layers to produce latent representations for both node groups. Our graph convolution layers produce new representations for each node in both node groups (U and V), as well as for each edge in the graph. Note that the last convolution layer in the encoder only produces the latent representations for nodes, without producing edge representations. The reason for this design is that we only put the latent representations for the active actors, the nodes representing consumers and merchants, but not their interactions.
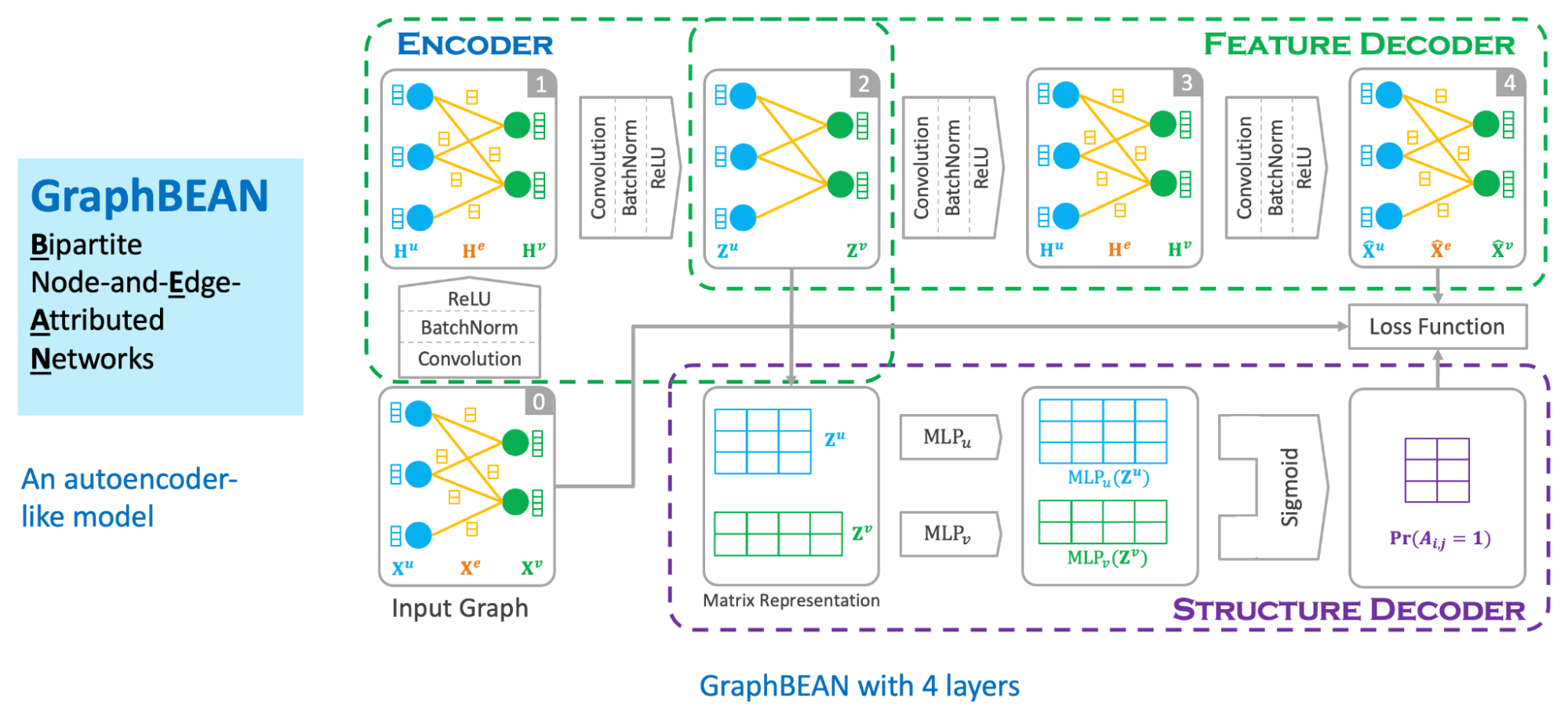
From the nodes’ latent representations, the feature decoder is tasked to reconstruct the original graph with both node and edge attributes via a series of graph convolution layers. As the graph structure is provided by the feature decoder, we task the structure decoder to learn the graph structure by predicting if there exists an edge connecting two nodes. This edge prediction, as well as the graph reconstructed by the feature decoder, are then compared to the original input graph via a reconstruction loss function.
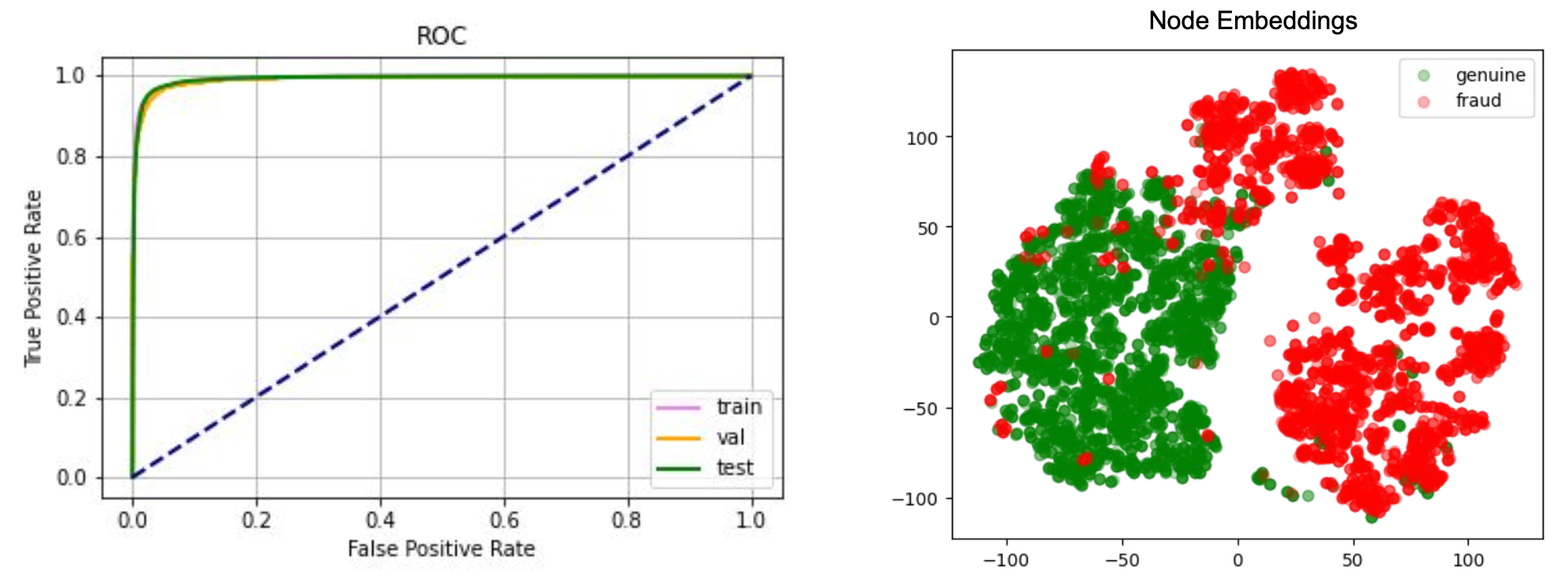
The model is then trained using the bipartite graph constructed from GrabFood and GrabMart transactions. We use a reconstruction-based loss function as the training objective of the model. After the training is completed, we compute the anomaly score of each node and edge in the graph using the trained model.
Anomaly score computation
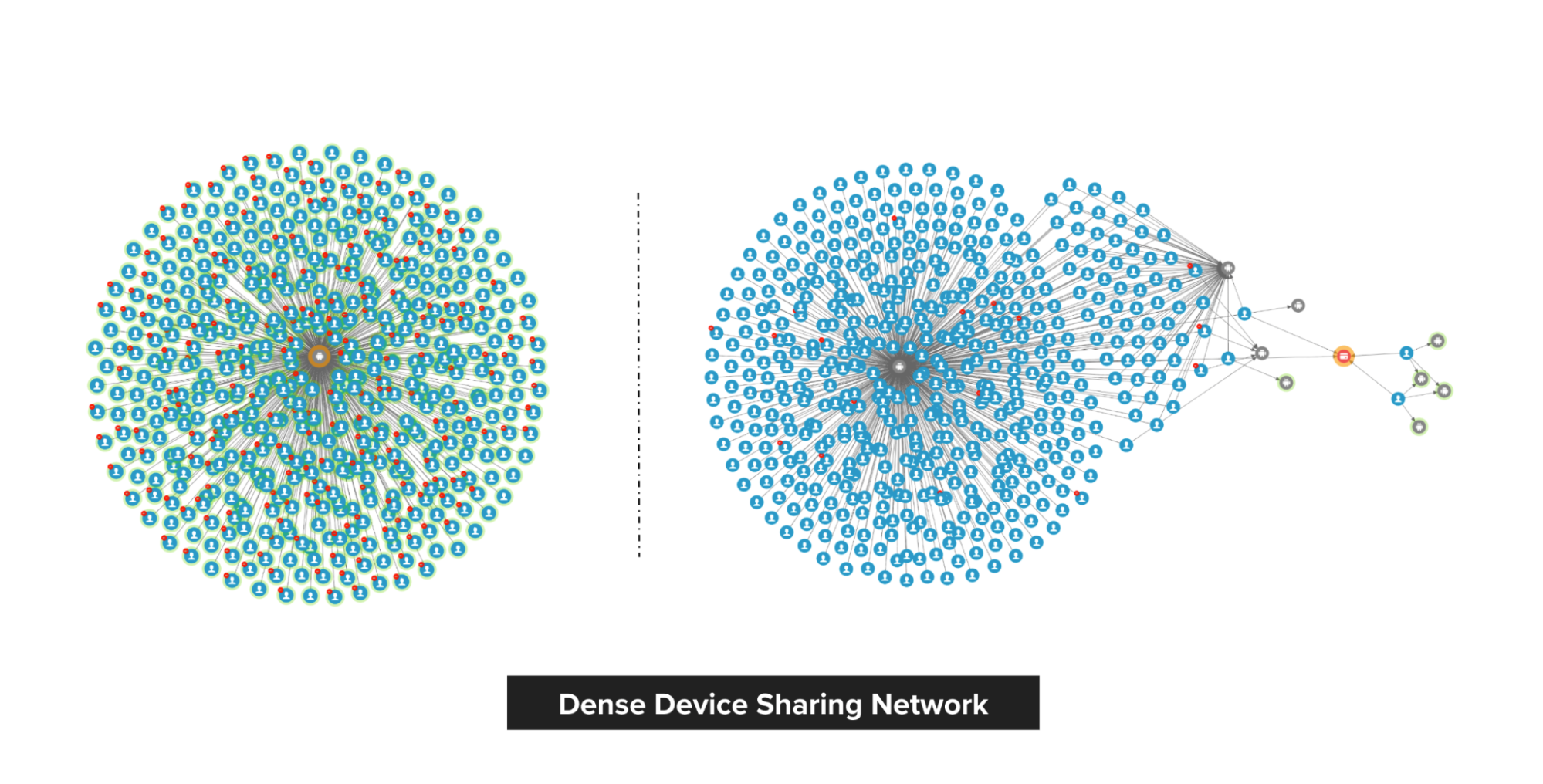
Our anomaly scores are reconstruction-based. The score design assumes that normal behaviours are common in the dataset and thus, can be easily reconstructed by the model. On the other hand, anomalous behaviours are rare. Therefore the model will have a hard time reconstructing them, hence producing high errors.
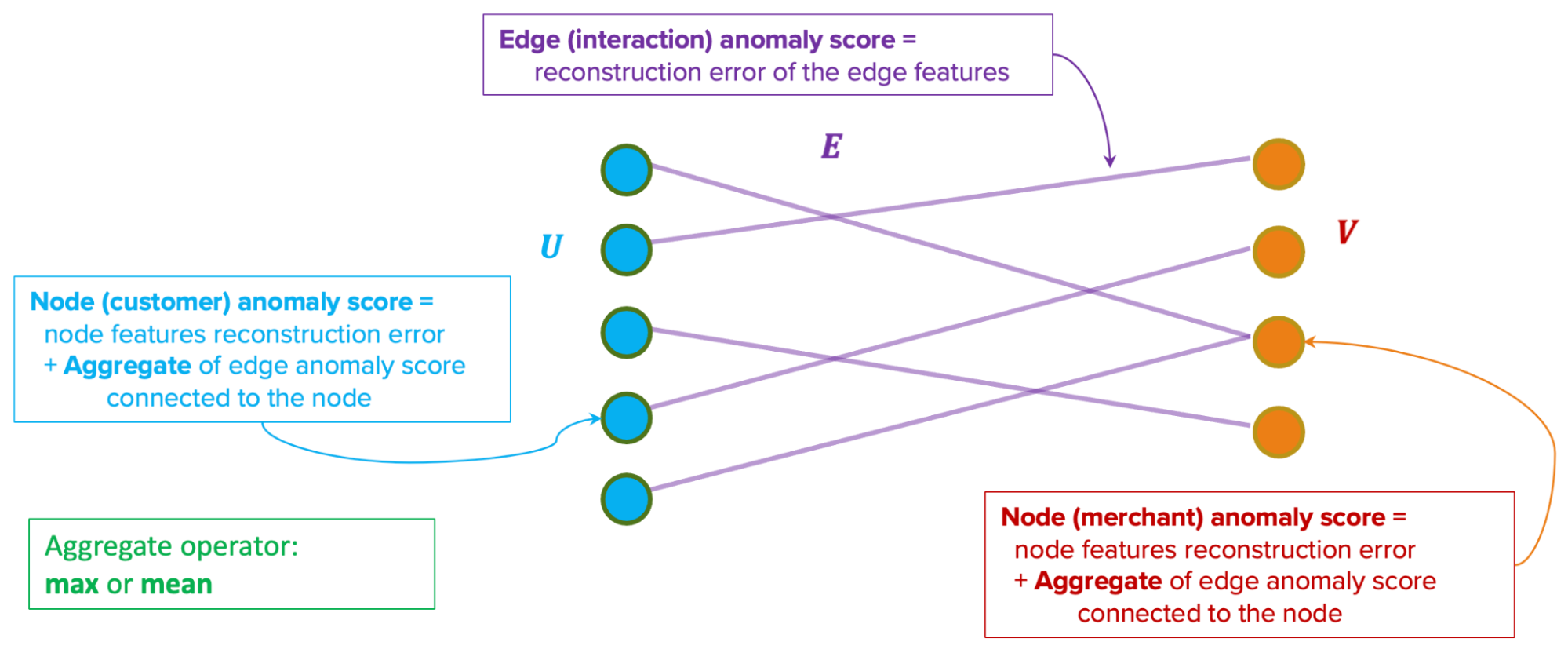
The model produces two types of anomaly scores. First, the edge-level anomaly scores, which are calculated from the edge reconstruction error. Second, the node-level anomaly scores, which are calculated from node reconstruction error plus an aggregate over the edge scores from the edges connected to the node. This aggregate could be a mean or max aggregate.
Actioning system
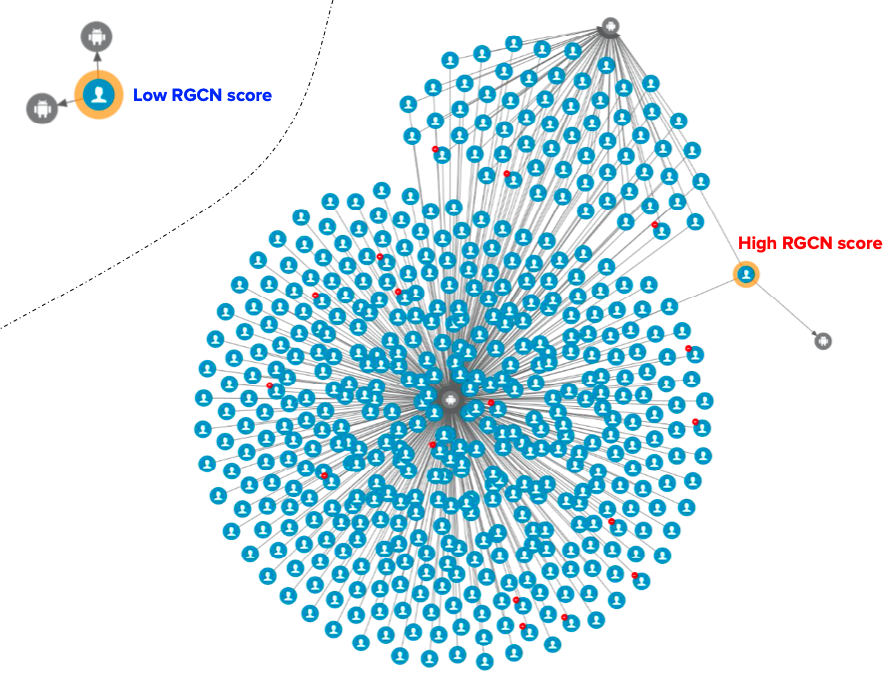
In our implementation of GraphBEAN within Grab, we designed a full pipeline of anomaly detection and actioning systems. It is a fully-automated system for constructing a bipartite graph from GrabFood and GrabMart transactions, training a GraphBEAN model using the graph, and computing anomaly scores. After computing anomaly scores for all consumers and merchants (node-level), as well as all of their interactions (edge-level), it automatically passes the scores to our actioning system. But before that, it also passes them through a system we call fraud type tagger. This is also a fully-automated heuristic-based system that tags some of the detected anomalies with some fraud tags. The purpose of this tagging is to provide some context in general, like the types of detected anomalies. Some examples of these tags are promo abuse or possible collusion.
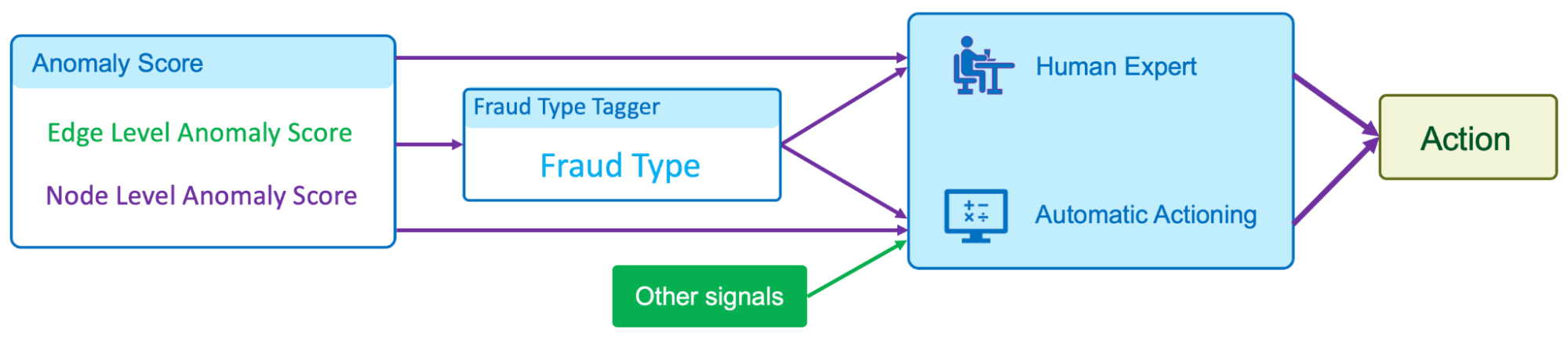
Both the anomaly scores and the fraud type tags are then forwarded to our actioning system. The system consists of two subsystems:
- Human expert actioning system: Our fraud experts analyse the detected anomalies and perform certain actioning on them, like suspending certain transaction features from suspicious merchants.
- Automatic actioning system: Combines the anomaly scores and fraud type tags with other external signals to automatically do actioning on the detected anomalies, like preventing promos from being used by fraudsters or preventing fraudulent transactions from occurring. These actions vary depending on the type of fraud and the scores.
What’s next?
The GraphBEAN model enables the detection of suspicious behaviour on graph data without the need for label supervision. By implementing the model on GrabFood and GrabMart platforms, we learnt that having such a system enables us to quickly identify new types of fraudulent behaviours and then swiftly perform action on them. This also allows us to enhance Grab’s defence against fraudulent activity and actively protect our users.
We are currently working on extending the model into more generic heterogeneous (multi-entity) graphs. In addition, we are also working on implementing it to more use cases within Grab.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!