Post Syndicated from Benjamin Smith original https://aws.amazon.com/blogs/compute/the-serverless-lamp-stack-part-6-from-mvc-to-serverless-microservices/
In this post, you learn how to build serverless PHP applications using microservices.
I show how to move from using a single Lambda function as scalable web host with an MVC framework, to a decoupled microservice model. The accompanying code examples for this blog post can be found in this GitHub repository.
The MVC architectural pattern
A traditional LAMP stack often implements the Model-View-Controller (MVC) architecture. This is a well-established way of separating application logic into three parts: the model, the view, and the controller.
- Model: This part is responsible for managing the data of the application. Its role is to retrieve raw information from the database or receive user input from the controller.
- View: This component focuses on the display. Data received from the model is presented to the user. Any response from the user is also recognized and sent to the controller component.
- Controller: This part is responsible for the application logic. It responds to the user input and performs interactions on the data model objects.
The MVC principal of decoupling data, logic, and presentation layers means that changes in one layer have minimal impact on the others. This speeds the development process and makes it easier to update layouts, change business rules, and add new features. Components are more adaptable for reuse and refactoring, and allow for a degree of simultaneous development.

The serverless LAMP stack
The preceding serverless LAMP stack architecture is first discussed in this post. A web application is split in to two components. A single AWS Lambda function contains the application’s MVC framework. Each response is synchronously returned via Amazon API Gateway. This architecture addresses the scalability challenge that is often seen in traditional LAMP stack applications. It scales automatically with a managed infrastructure and a pay-per-use billing model. However, the serverless paradigm makes it possible to apply the MVC principles of decoupling and reusability to an even greater degree.
The “Lambda-lith”
The preceding architecture represents a serverless monolith or “Lambda-lith”. A single Lambda function contains the entire business logic within an MVC framework. This implementation can be used to “lift and shift” from a legacy MVC to a serverless application. Simple applications often start this way too, but as the application grows more complex over time new challenges can occur.

Lambda Day 1 to day 100
A Lambda-lith is often maintained in a single repository that contains the entire application logic. This is sometimes referred to as a mono-repo.

Lamba-lith monorepo
A mono-repo makes it harder to separate responsibility of ownership between development teams. Consequently, projects in a mono-repo are prone to depend on each other, creating tight coupling. The tightly coupled code base with all of its interconnected modules be challenging to maintain a regular release cadence. Any small fix can require updates to other parts of the code base, making maintenance challenging without fracturing the whole application. Onboarding can be slow as new developers take time to learn and understand the code base and all of the interdependencies.
By applying the following principles, Lambda-lith MVC applications can be refactored into decoupled serverless microservices.
Divide into independent Lambda functions with finite business logic
The following example illustrates a Lambda-lith with all business and routing logic stored in a single Lambda function. Every request is routed to this function from API Gateway. The function code base contains a `router.php` file to direct requests to the correct model, view, or controller.
This is similar to a traditional LAMP stack implementation in which a web server such as Apache or NGINX routes all requests to a single index.php function. However, it’s often more practical to split applications into multiple functions or services.

Lambda as a web server
In the following example, this Lambda function is split into multiple functions based on each CRUD operation. The internal routing logic is now decoupled from the business logic. The API Gateway service uses rules to route requests to the correct Lambda function. This allows each function to scale independently and updates can be made to one function without impacting another.
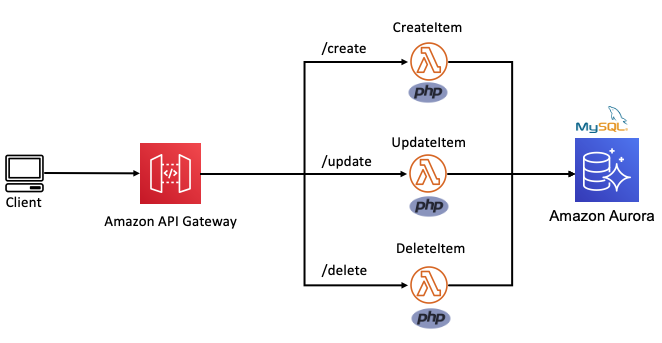
Routing decoupled from business logic
Build micro-perimeters to enforce strict verification of every person or service.
Traditional MVC applications often use a castle-and-moat security model. This provides security by placing a perimeter around the entire application to protect it from malicious actors. This perimeter guards the application or network by verifying requests and user identities at the point of entry or exit.
This is typically achieved with firewalls, proxy servers, honeypots, and other intrusion prevention tools. It assumes that activity inside the perimeter is safe. However, a network vulnerability may provide access to everything inside.
Microservice-based applications allow developers to apply a “zero trust” security model. This enables developers to build micro-perimeters around each resource. This is sometimes referred to as the principle of least privilege. It ensures that each request, service, or user can access only the data or resource that is necessary for its legitimate purpose. Even with a vulnerability, the blast radius is limited only to the service within that micro-perimeter.

Castle-and-moat vs zero trust security model
Use AWS Identity and Access Management (IAM) resource policies and execution roles to decouple business logic from security posture. Lambda resource policies define the events and services that are authorized to invoke the function. Lambda execution roles place constraints the resource or service the Lambda function has access to. When defining resource policies and execution roles, start with a minimum set of permissions and grant additional permissions as necessary.
Create building blocks based on common functionality
Each component is a single building block that makes up an application together with other blocks. These blocks form microservices that deliver a set of capabilities on a specific domain. This makes is easy to change, upgrade, and replace with no impact on the remaining microservice components. This creates natural ownership boundaries to help organize repositories.
Development teams can then easily be assigned ownership to individual microservice repositories. Use the AWS Serverless Application Model (AWS SAM) to organize microservices into multiple code repositories, as explained in this blog post.

Use messages to connect and communicate between microservices.
In traditional MVC applications, one part of the application uses method calls to communicate with the other parts. With serverless microservices, the code base is spread across short-lived stateless functions and services. Communication between these services is achieved using asynchronous messages or synchronous HTTP requests.
Synchronous communication
In this method, a service calls an API and waits for a response from the receiving service before proceeding. Use API Gateway to create a front door to your backend microservices. API Gateway is a fully managed service for creating and managing RESTful and WebSocket APIs.
Using API Gateway to transport data addresses common concerns such as authorization, API tokens, access control and rate limiting from your code, and helps to reduce code complexity. API Gateway can also be used for synchronous internal microservice communications where the services have clear separation, strict authentication requirements, or have been deployed across accounts.
The following architecture demonstrates an application that is deployed across two accounts. The Booking microservice, invokes a loyalty booking function via API Gateway that exists in the Loyalty points account.

Synchronous internal microservice communications
Asynchronous communication
In this pattern, a service sends a message without waiting for a response, and one or more services process the message asynchronously. Here, the services involved do not directly communicate with each other. Instead, services publish messages to a broker such as Amazon Simple Queue Service (SQS) or Amazon EventBridge. Other services can choose to subscribe to the topic in the broker that they care about. This enables further decoupling of business logic from data transportation and reduces your code complexity.
Use services instead of code, where possible
A service-first mindset is an important part of serverless application development. Each line of code you write may limit your project’s responsiveness to change and adds cognitive overhead for new developers. Using an appropriate AWS service for each domain (messaging, storage, orchestration) helps to build faster. Embracing this mind-set allows developers to focus on solving those unique challenges that add the most value to their customers.
By applying these principles to refactor an MVC Lambda-lith, I build the following CRUD API microservice. This application can be deployed from this GitHub repository. It uses an AWS Serverless Application Model (AWS SAM) template to define an HTTP API, 5 Lambda functions, an Amazon DynamoDB table and all the IAM roles required.
All routing logic and authentication is managed by Amazon API Gateway. Each Lambda function has limited scope and minimal business logic. It uses a lightweight custom-built PHP runtime, explained in this post. Each Lambda function uses the AWS PHP SDK to interact with the DynamoDB table. This architecture is suitable as a serverless microservice for a website backend.

A serverless API microservice with PHP
Conclusion
In this post, I show how to move from using a single Lambda function as a scalable web host with an MVC framework, to a decoupled microservice model. I explain the principles that can be applied to help transition an MCV application into a collection of microservices and show the benefits of doing so. I provide code examples for a serverless PHP CRUD microservice with a deployable AWS SAM template.
PHP development teams can transition from Lambda-lith MVC applications to a decoupled microservice model. This allows them to focus on shipping code to delight their customers without managing infrastructure.
Find more resources for building serverless PHP applications at ServerlessLand.com.