Post Syndicated from Benjamin Smith original https://aws.amazon.com/blogs/compute/introducing-aws-step-functions-redrive-a-new-way-to-restart-workflows/
Developers use AWS Step Functions, a visual workflow service to build distributed applications, automate IT and business processes, and orchestrate AWS services with minimal code.
Step Functions redrive for Standard Workflows allows you to redrive a failed workflow execution from its point of failure, rather than having to restart the entire workflow. This blog post explains how to use the new redrive feature to skip unnecessary workflow steps and reduce the cost of redriving failed workflows.
Handling workflow errors
Any workflow state can encounter runtime errors. Errors happen for various reasons, including state machine definition issues, task failures, incorrect permissions, and exceptions from downstream services. By default, when a state reports an error, Step Functions causes the workflow execution to fail. Step Functions allows you to handle errors by retrying, catching, and falling back to a defined state.
Now, you can also redrive the workflow from the failed state, skipping the successful prior workflow steps. This results in faster workflow completion and lower costs. You can only redrive a failed workflow execution from the step where it failed using the same input as the last non-successful state. You cannot redrive a failed workflow execution using a state machine definition that is different from the initial workflow execution.
Choosing between retry and redrive
Use the retry mechanism for transient issues such as network connectivity problems or momentary service unavailability You can configure the number of retries, along with intervals and back-off rates, providing the workflow with multiple attempts to complete a task successfully.
In scenarios where the underlying cause of an error requires longer investigation or resolution time, redrive becomes a valuable tool. Consider a situation where a downstream service experiences extended downtime or manual intervention is needed, such as updating a database or making code changes to a Lambda function. In these cases, being able to redrive the workflow can give you time to address the root cause before resuming the workflow execution.
Combining retry and redrive
Adopt a hybrid strategy that combines retry and redrive mechanisms:
- Retry mechanism: Configure an initial set of retries for automatically resolvable errors. This ensures that transient issues are promptly addressed, and the workflow proceeds without unnecessary delays.
- Error catching and redrive: If the retry mechanism exhausts without success, allow the state to fail and use the redrive feature to restart the workflow from the last non-successful state. This approach allows for intervention where errors persist or require external actions.
Reducing costs
AWS charges for Standard Workflows based on the number of state transitions required to run a workload. Step Functions counts a state transition each time a step of your workflow runs. Step Functions charges for the total number of state transitions across state machines, including retries. The cost is $0.025 per 1,000 state transitions. This means that reducing the number of state transitions reduces the cost of running your Standard Workflows.
If a workflow has many steps, includes parallel or map states, or is prone to errors that require frequent re-runs, this new feature reduces the costs incurred. You pay only for each state transition after the failed state and those costs for every downstream service invoked as part of the re-run.
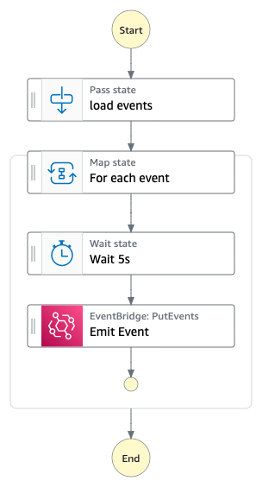
The following example explains the cost implications of retrying a workflow that has failed, with and without redrive. In this example, a Step Functions workflow orchestrates Amazon Transcribe to generate a text transcription from an .mp4 file.

Since the failed state occurs towards the end of this workflow, the redrive execution does not run the successful states, reducing the overall successful completion time. If this workflow were to fail regularly, the reduction in transitions and execution duration becomes increasingly valuable.
The first time this workflow runs, the final state, which uses an AWS Lambda function to make an HTTP request fails with an IAM error. This is because the workflow does not have the required permissions to invoke the Lambda function. After granting the required permissions to the workflow’s execution role, redrive to continue the workflow from the failed state.

After the redrive, Step Functions workflow reports a different failure. This time it is related to the configuration of the Lambda function. This is an example of a downstream failure that does not require an update to my workflow definition.

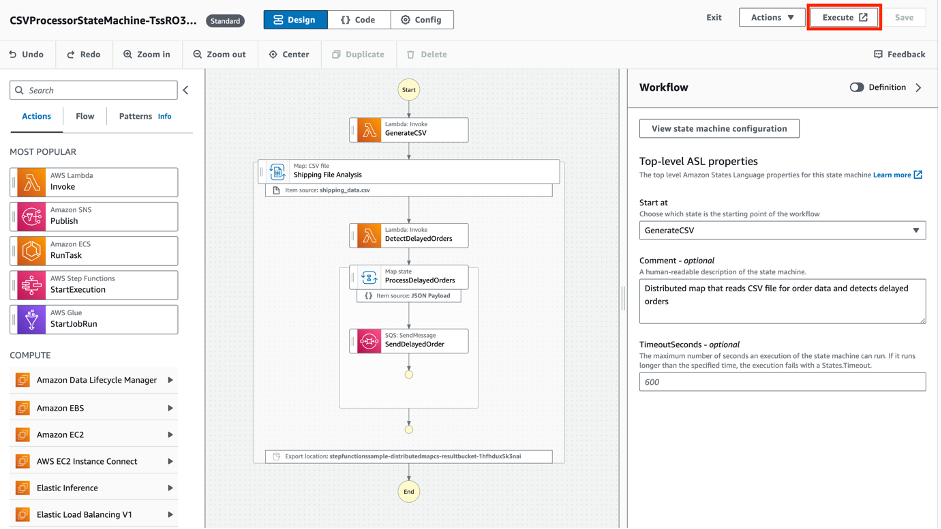
After resolving the Lambda configuration issue and redriving the workflow, the execution completes successfully. The following image shows the execution details, including the number of redrives, the total state transitions, and the last redrive time:

Getting started with redrive
Redrive works for Standard Workflows only. You can redrive a workflow from its failed step programmatically, via the AWS CLI or AWS SDK, or using the Step Functions console, which provides a visual operator experience:
- From the Step Functions console, select the failed workflow you want to redrive, and choose Redrive.

- A modal appears with the execution details. Choose Redrive execution.



The state to redrive from, the workflow definition, and the previous input are immutable.
To redrive a workflow execution programmatically from its point of failure, call the new Redrive Execution API action. The same workflow execution starts from the last non-successful state and uses the same input as the last non-successful state from the initial failed workflow execution.
Programmatically catching failed workflow executions to redrive
Step Functions can process workloads autonomously, without the need for human interaction, or can include intervention from a user by implementing the .waitForTastToken pattern.
Redrive is for unhandled and unexpected errors only. Handling errors within a workflow using the built-in mechanisms for catch, retry, and routing to a Fail state, does not permit the workflow to redrive. However, it is possible to detect in near real-time when a workflow has failed, and programmatically redrive. When a workflow fails, it emits an event onto the Amazon EventBridge default event bus. The event looks like the following JSON object:

There are four new key/values pairs in this event:
"redriveCount": 0,
"redriveDate": null,
"redriveStatus": "REDRIVABLE",
"redriveStatusReason": null,
The redrive count shows how many times the workflow has previously been redriven. The redrive status shows if the failed workflow is eligible for redrive execution.
To programmatically redrive the workflow from the failed state. Create a rule that pattern matches this event, and route the event onto a target service to handle the error. The target service uses the new States.RedriveExecution API to redrive the workflow.
Download and deploy the previous pattern from this example on serverlessland.com.
In the following example, the first state sends a post request to an API endpoint. If the request fails due to network connectivity or latency issues, the state retries. If the retry fails, then Step Functions emits a ` Step Functions Execution Status Change event onto the EventBridge default event bus. An EventBridge rule routes this event to a service where you can rectify this error and then redrive the task using the Step Functions API.

The new redrive feature also supports the distributed map state.
Redrive for express child workflow executions
For failed child workflow executions that are Express Workflows within a Distributed Map, the redrive capability ensures a seamless restart from the beginning of the child workflow. This allows you to resolve issues that are specific to individual iterations without restarting the entire map.
Redrive for standard child workflow executions
For failed child workflow executions within a Distributed Map that are Standard Workflows, the redrive feature functions in the same way in standalone Standard Workflows. You can restart the failed iteration from its point of failure, skipping unnecessary steps that have already successfully executed.
Conclusion
Step Functions redrive for Standard Workflows allows you to redrive a failed workflow execution from its point of failure rather than having to restart the entire workflow. This results in faster workflow completion and lower costs for processing failed executions. This is because it minimizes the number of state transitions and downstream service invocations.
Visit the Serverless Workflows Collection to browse the many deployable workflows to help build your serverless applications.



















































































 The workflows collection currently supports deployable workflow templates defined with
The workflows collection currently supports deployable workflow templates defined with  ASL is a JSON-based, structured language for authoring Step Functions workflows. It enables developers to filter and manipulate data at various stages of a workflow state’s execution using
ASL is a JSON-based, structured language for authoring Step Functions workflows. It enables developers to filter and manipulate data at various stages of a workflow state’s execution using 
















{kind=link}
{kind=link}