Not only is the universe stranger than we think, but it is stranger than we can think of — Werner Heisenberg
Even for a physicist as renowned as Heisenberg, the universe was strange. And it was strange because several phenomena could only be explained through the lens of quantum mechanics. This field changed the way we understood the world, challenged our imagination, and, since the Fifth Solvay Conference in 1927, has been integrated into every explanation of the physical world (it is, to this day, our best description of the inner workings of nature). Quantum mechanics created a rift: every physical phenomena (even the most micro and macro ones) stopped being explained only by classical physics and started to be explained by quantum mechanics. There is another world in which quantum mechanics has not yet created this rift: the realm of computers (note, though, that manufacturers have been affected by quantum effects for a long time). That is about to change.
In the 80s, several physicists (including, for example, Richard Feynman and Yuri Manin) asked themselves these questions: are there computers that can, with high accuracy and in a reasonable amount of time, simulate physics? And, specifically, can they simulate quantum mechanics? These two questions started a long field of work that we now call “quantum computing”. Note that you can simulate quantum phenomena with classical computers. But we can simulate in a much faster manner with a quantum computer.
Any computer is already a quantum system, but a quantum computer uses the true computational power that quantum mechanics offers. It solves some problems much faster than a classical computer. Any computational problem solvable by a classical computer is also solvable by a quantum computer, as any physical phenomena (such as operations performed in classical computers) can be described using quantum mechanics. Contrariwise, any problem solvable by a quantum computer is also solvable by a classical computer: quantum computers provide no additional power over classical computers in terms of what they could theoretically compute. Quantum computers cannot solve undecidable problems, and they do not disprove the Church–Turing thesis. But, they are faster for specific problems! Let’s explore now why this is the case.
In a classical computer, data is stored in bits: 0 or 1, current on or current off, true or false. Nature is not that binary: any physical bit (current or not; particle or not; magnetized or not) is in fact a qubit and exists on a spectrum (or rather a sphere) of superpositions between 0 and 1. We have mentioned two terms that might be new to the reader: qubit and superposition. Let’s first define the second term.
A superposition is a normalized linear combination of all the possible configurations of something. What is this something? If we take the Schrödinger equation to explain, “for any isolated region of the universe that you want to consider, that equation describes the evolution in time of the state of that region, which we represent as a normalized linear combination — a superposition — of all the possible configurations of elementary particles in that region”, as Aaronson put it. Something, then, refers to all elementary particles. Does it mean, then, that we all are in a superposition? The answer to that question is open to many interpretations (for a nice introduction on the topic, one can read “Quantum Computing Since Democritus” by Scott Aaronson).
As you see, we are concerned then no longer on matter or energy or waves (as in classical physics), but rather on information and probabilities. In a quantum system, we first initialize information (like a bit) to some “easy” states, like 0 and 1. This information will be in a superposition of both states at the same time rather than just one or the other. If we examine a classical bit, we will either get the states of 1 or 0. Instead, with a qubit (quantum information) we can only get results with some probability. A qubit can exist in a continuum of states between ⟨0 and ⟨1 (using Dirac’s notation) all waiting to happen with some probability until it is observed.
A qubit stores a combination of two or more states.
In day-to-day life, we don’t see this quantum weirdness because we’re looking at huge jittery ensembles of qubits where this weirdness gets lost in noise. However, if we turn the temperature way down and isolate some qubits from noise, we can do some proper quantum computation. For instance, to find a 256-bit decryption key, we can set 256 qubits to a superposition of all possible keys. Then, we can run the decryption algorithm, trying the key in the qubits. We end up with a superposition of many failures and one success. We did 2256 computations in a single go! Unfortunately, we can’t read out this superposition. In fact, if we open up the quantum computer to inspect the qubits inside, the outside noise will collapse the superposition into one outcome, which will most certainly be a failure. The real art of quantum computing is interfering this superposition with itself in a clever way to amplify out the answer we want. For the case we are talking about, Lov Grover figured out how to do it. Unfortunately, it requires about 2128 steps: we have a nice, but not exponential speed-up.
Quantum computers do not provide any additional power over classical computers in terms of computability: they don’t solve unsolvable problems. But they provide efficiency: they find solutions in faster time, even for algorithms that are too “expensive” for a non-quantum (classical) computer. A classical computer can solve any known computational problem if it is given enough time and resources. But, on some occasions, they will need so much time and so many resources that it will be deemed inefficient to try to solve this problem: waiting millions of years with millions of computers working at the same time trying to solve a problem is not something that we consider feasible to do. This idea of efficient and inefficient algorithms was made mathematically precise by the field of computational complexity. Roughly speaking, an efficient algorithm is one which runs in time polynomial in the size of the problem solved.
We can look at this differently. The many quantum states can be potentially observed (even in a classical computer), but states interfere with each other, which prevents the usage of statistical sampling to obtain the state. We, then, have to track every possible configuration that a quantum system can be in. Tracking every possible configuration is theoretically possible by a classical computer, but would exceed the memory capacity of even the most powerful classical computers. So, we need quantum computers to efficiently solve these problems.
Quantum computers are powerful. They can efficiently simulate quantum mechanics experiments, and are able to perform a number of mathematical, optimization, and search problems in a faster manner than classical computers. A sufficiently scaled quantum computer can, for example, factor large integers efficiently, as was shown by Shor. They also have significant advantages when it comes to searching on unstructured databases or solving the discrete logarithm problem. These advances are the solace: they efficiently advance computational problems that seem stalled. But, they are also a spectre, a threat: the problems that they efficiently solve are what is used as the core of much of cryptography as it exists today. They, hence, can break most of the secure connections we use nowadays. For a longer explanation of the matter, see our past blog post.
The realization of large-scale quantum computers will pose a threat to our connections and infrastructure. This threat is urgent and acts as a spectre of the future: an attacker can record and store secured traffic now and decrypt it later when a quantum computer exists. The spectre is ever more present if one recalls that migrating applications, architectures and protocols is a long procedure. Migrating these services to quantum-secure cryptography will take a lot of time.
In our other blog posts, we talk at length about what quantum computers are and what threats they pose. In this one, we want to give an overview of the advances in quantum computing and their threats to cryptography, as well as an update to what is considered quantum-secure cryptography.
Why will it take them (and, generally, anyone) so long to create this quantum computer? Classical mechanisms, like Newtonian physics or classical computers, provide great detail and prediction of events and phenomena at a macroscopic level, which makes them perfect for our everyday computational needs. Quantum mechanics, on the other hand, are better manifested and understood at the microscopic level. Quantum phenomena are, furthermore, very fragile: uncontrolled interaction of quantum phenomena with the environment can make quantum features disappear, a process which is referred to as decoherence. Due to this, measurement of quantum states has to be controlled, properly prepared and isolated from its environment. Furthermore, measuring a quantum phenomenon disturbs its state, so reliable methods of computing information have to be developed.
Creating a computer that achieves computational tasks with these challenges is a daunting one. In fact, it may ultimately be impossible to completely eliminate errors in the computational tasks. It can even be an impossible task at a perfect level, as a certain amount of errors will persist. Reliable computation seems to be only achievable in a quantum computational model by employing error correction.
So, when will we know that a created quantum device is ready for the “quantum” use cases? One can use the idea of “quantum supremacy”, which is defined as the ability for a quantum device to perform a computational task that would be practically impossible (in terms of efficiency and usage of computational power) for classical computers. Nevertheless, this idea can be criticized as classical algorithms improve over time, and there is no clear definition on how to compare quantum computations with their classical counterparts (one must prove that no classical means would allow us to perform the same computational task in a faster time) in order to say that indeed quantum computations of the task are faster.
A molecule can indeed be claimed to be “quantum supreme” if researchers find it computationally prohibitive (unrealistically expensive) to solve the Schrödinger equation and calculate its ground state. That molecule constitutes a “useful quantum computer, for the task of simulating itself.” But, for computer science, this individual instance is not enough: “for any one molecule, the difficulty in simulating it classically might reflect genuine asymptotic hardness, but it might also reflect other issues (e.g., a failure to exploit special structure in the molecule, or the same issues of modeling error, constant-factor overheads, and so forth that arise even in simulations of classical physics)”, as stated by Aaronson and Chen.
By the end of 2019, Google argued they had reached quantum supremacy (with the quantum processor named “Sycamore”) but their claim was debated mainly due to the perceived lack of criteria to properly define when “quantum supremacy” is reached1. Google claimed that “a state-of-the-art supercomputer would require approximately 10,000 years to perform the equivalent task” and it was refuted by IBM by saying that “an ideal simulation of the same task can be performed on a classical system in 2.5 days and with far greater fidelity”. Regardless of this lack of criteria, this result in itself is a remarkable achievement and shows great interest of parties into creating a quantum computer. Last November, it was claimed that the most challenging sampling task performed on Sycamore can be accomplished within one week on the Sunway supercomputer. A crucial point has to be understood on the matter, though: “more like a week still seems to be needed on the supercomputer”, as noted by Aaronson. Quantum supremacy then is still not an irrevocable agreement.
Google’s quantum computer has already been applied to simulating real physical phenomena. Early in 2021, it was used to demonstrate a “time crystal” (a quantum system of particles which move in a regular, repeating motion without burning any energy to the environment). On the other hand, by late 2021, IBM unveiled its 127-qubit chip Eagle, but we don’t yet know how much gate fidelity (how close two operations are to each other) it really attains, as outlined by Aaronson in his blog post.
What do all of these advances mean for cryptography? Does it mean that soon all secure connections will be broken? If not “soon”, when will it be? The answers to all of these questions are complex and unclear. The Quantum Threat Timeline Report of 2020 suggests that the majority of researchers on the subject think that 15 to 40 years2 will be the time frame for when a “cryptography-breaking” quantum computer arrives. It is worth noting that these predictions are more optimistic than compared to the same report of 2019, which suggests that, due to the advances of the quantum computing field, researchers feel more assured of their imminent arrival.
The upcoming decades of breaking cryptography
Quantum computing will shine a light into new areas of development and advances, but it will also expose secret areas: faster mechanisms to solve mathematical problems and break cryptography. The metaphor of the dawn can be used to show how close we are to quantum computers breaking some types of cryptography (how far are we to twilight), which will be catastrophic to the needs of privacy, communication and security we have.
It is worth noting again, though, that the advent of quantum computing is not a bad scenario in itself. Quantum computing will bring much progress in the form of advances to the understanding and mimicking of the fundamental way in which nature interacts. Their inconvenience is that they break most of the cryptography algorithms we use nowadays. They also have their limits: they cannot solve every problem, and in cryptography there are algorithms that will not be broken by them.
Let’s start by defining first what dawn is. Dawn is the arrival of stable quantum computers that break cryptography in a reasonable amount of time and space (explicitly: breaking the mathematical foundation of the p256 algorithm; although some research defines this as breaking RSA2048). It is also the time by which a new day arrives: a day that starts with new advances in medicine, for example, by better mimicking molecules’ nature with a computer.
How close to dawn are we? To answer this question, we have to look at the recent advances in the aim of breaking cryptography with a quantum computer. One of the most interesting advances is that the number 15 was factored in 2001 (it is 20 years already) and number 21 was factored in 2012 by a quantum computer. While this does not seem so exciting for us (as we can factor it in our minds), it is astonishing to see that a quantum computer was stable enough to do so.
Why do we care about computers factoring or not factoring integers? The reason is that they are the mathematical base of certain public key cryptography algorithms (like, RSA) and, if they are factored, the algorithm is broken.
Taking a step further, quantum computers are also able to break encryption algorithms themselves, such as AES, as we can use quantum efficient searching algorithms for the task. This kind of searching algorithm, Grover’s algorithm, solves the task of function inversion, which speeds up collision and preimage attacks (attacks that you don’t want to be sped up in your encryption algorithms). These attacks are related to hash functions: a collision attack is one that tries to find two messages that produce the same hash; a preimage attack is one that tries to find a message given its hash value. A smart evolution of this algorithm, using Hidden Variables as part of a computational model, will theoretically make searching much more efficient.
So what are the tasks needed for a quantum computer to break cryptography? It should:
Be able to factor big integers, or,
Be able to efficiently search for collisions or pre-images, or,
Why do we care about these quantum computers breaking cryptographic algorithms that we rarely hear of? What has it to do with the connections we make? Cryptographic algorithms are the base of the secure protocols that we use today. Every time we visit a website, we are using a broad suite of cryptographic algorithms that preserve the security, privacy and integrity of connections. Without them, we don’t have the properties we are used to when connecting over digital means.
What can we do? Do we now stop using digital means altogether? There are solutions. Of course, the easy answer will be, for example, to increase the size of integers to make them impossible to be factored by a quantum computer. But, is it really a usable algorithm? How slow will our connections be if we have to increase these algorithms exponentially?
As we get closer to twilight, we also get closer to the dawn of new beginnings, the rise of post-quantum cryptography.
The rise and state of post-quantum cryptography
As dawn approaches, researchers everywhere have been busy looking for solutions. If the mathematical underpinnings of an algorithm are what is broken by a quantum computer, can we just change them? Are there mathematical problems that are hard even for quantum computers? The answer is yes and, even more interestingly, we already know how to create algorithms out of them.
The mathematical problems that we use in this new upcoming era, called post-quantum, are of many kinds:
Lattices by using learning with errors (LWE) or ring learning with errors problems (rLWE).
Isogenies, which rely on properties of supersingular elliptic curves and supersingular isogeny graphs.
Multivariate cryptography, which relies on the difficulty of solving systems of multivariate equations.
Code-based cryptography, which relies on the theory of error-correcting codes.
With these mathematical constructions, we can build algorithms that can be used to protect our connections and data. How do we know, nevertheless, that the algorithms are safe? Even if a mathematical construction that an algorithm uses is safe from the quantum spectre, is the interaction with other parts of the system or in regard to adversaries safe? Who decides on this?
Because it is difficult to determine answers to these questions on an isolated level, the National Institute of Standards and Technology of the United States has been running, since 2016, a post-quantum process that will define how these algorithms work, their design, what properties they provide and how they will be used. We now have a set of finalists that are close to being standardized. The competition standardizes on two tracks: algorithms for key encapsulation mechanisms and public-key encryption (or KEMs) and algorithms for the authentication (mainly, digital signatures). The current finalists are:
For the public-key encryption and key-establishment algorithms:
Classic McEliece, a code-based cryptography scheme.
CRYSTALS-KYBER, a lattice based scheme.
NTRU, a lattice based scheme.
SABER, a lattice based scheme.
For the digital signature algorithms:
CRYSTALS-DILITHIUM, a lattice based scheme.
FALCON, a lattice based scheme.
Rainbow, a multivariate cryptography scheme.
What do these finalists show us? It seems that we can rely on the security given by lattice-based schemes (which is no slight to the security of any of the other schemes). It also shows us that in the majority of the cases, we prioritize schemes that can be used in the same way cryptography is used nowadays: with fast operations’ computation time, and with small parameters’ sizes. In the migration to post-quantum cryptography, it is not only about using safe mathematical constructions and secure algorithms but also about how they integrate into the systems, architectures, protocols, and expected speed and space efficiencies we currently depend on. More research seems to be needed in the signatures/authentication front and the inclusion of new innovative signature schemes (like SQISign or MAYO), and that is why NIST will be calling for a fourth round of its competition.
It is worth noting that there exists another flavor of upcoming cryptography called “quantum cryptography”, but its efficient dawn seems to be far away (though, some Quantum Key Distribution — QKD — protocols are being deployed now). Quantum cryptography is one that uses quantum mechanical properties to perform cryptographic tasks. It has mainly focused on QKD), but it seems to be too inefficient to be used in practice outside very limited settings. And even though, in theory, these schemes should be perfectly secure against any eavesdropper; in practice, the physical machines may still fall victim to side-channel attacks.
Is dawn, then, the collapse of cryptography? It can be, on one hand, as it is the collapse of most classical cryptography. But, on the other hand, it is also the dawn of new, post-quantum cryptography and the start of quantum computing for the benefit of the world. Will the process of reaching dawn be simple? Certainly, not. Migrating systems, architectures and protocols to new algorithms is an intimidating task. But we at Cloudflare and as a community are taking the steps, as you will read in other blog posts throughout this week.
……. 1In the original paper, they estimate of 10,000 years is based on the observation that there is not enough Random Access Memory (RAM) to store the full state vector in a Schrödinger-type simulation and, then, it is needed to use a hybrid Schrödinger–Feynman algorithm, which is memory-efficient but exponentially more computationally expensive. In contrast, IBM used a Schrödinger-style classical simulation approach that uses both RAM and hard drive space. 2There is a 50% or more likelihood of “cryptography-breaking” quantum computers arriving. Slightly more than half of the researchers answered that, in the next 15 years, they will arrive. About 86% of the researchers answered that, in the next 20 years, they will arrive. All but one among the researchers answered that, in the next 30 years, they will arrive. 3Although, in practice, this seems difficult to attain.
Quantum computers are a boon and a bane. Originally conceived by Manin and Feyman to simulate nature efficiently, large-scale quantum computers will speed-up innovation in material sciences by orders of magnitude. Consider the technical advances enabled by the discovery of new materials (with bronze, iron, steel and silicon each ascribed their own age!); quantum computers could help to unlock the next age of innovation. Unfortunately, they will also break the majority of the cryptography that’s currently used in TLS to protect our web browsing. They fall in two categories:
Digital signatures, such as RSA, which ensure you’re talking to the right server.
Key exchanges, such as Diffie–Hellman, which are used to agree on encryption keys.
A moderately-sized stable quantum computer will easily break the signatures and key exchanges currently used in TLS using Shor’s algorithm. Luckily this can be fixed: over the last two decades, there has been great progress in so-called post-quantum cryptography. “Post quantum”, abbreviated PQ, means secure against quantum computers. Five years ago, the standards institute NIST started a public process to standardise post-quantum signature schemes and key exchanges. The outcome is expected to be announced early 2022.
At Cloudflare, we’re not just following this process closely, but are also testing the real-world performance of PQ cryptography. In our 2019 experiment with Google, we saw that we can switch to a PQ key exchange with little performance impact. Among the NIST finalists, there are many with even better performance. This is good news, as we would like to switch to PQ key exchanges as soon as possible — indeed, an attacker could intercept sensitive data today, then keep and decrypt it years into the future using a quantum computer.
Why worry about PQ signatures today
One would think we can take it easy with signatures for TLS: we only need to have them replaced before a large quantum computer is built. The situation, however, is more complicated.
The lead time to change signatures is higher. Not only do we need to change the browsers and servers, we also need to change certificate authorities (CAs) and everyone’s certificate management.
TLS is addicted to small and fast signatures. For this page that you’re viewing we sent six signatures: two in the certificate chain; one handshake signature; one OCSP staple and finally two SCTs used for certificate transparency.
PQ signature schemes have wildly varying performance trade-offs and quirks (as we’ll see below) which stack up quickly with six signatures, which all have slightly different requirements.
One might ask: can’t we be clever and get rid of some of these signatures? We think so! For instance, we can replace the handshake signature with a smaller key exchange or suppress intermediate certificates. Such fundamental changes take years to be adopted. That is why we are also investigating the performance of plain TLS with drop-inPQ signatures.
So, what are our options?
The zoo of PQ signatures
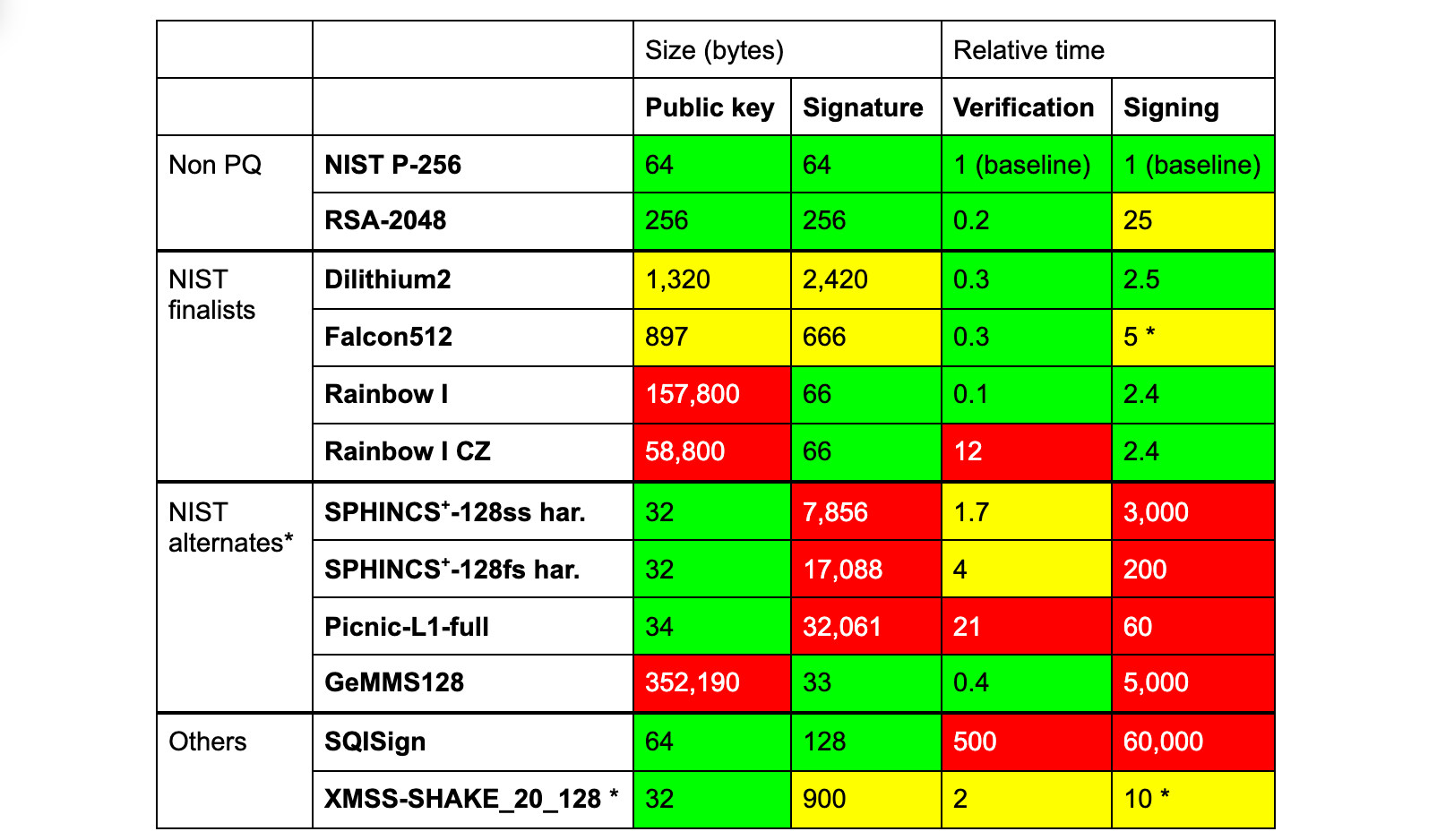
The three finalists of the NIST competition are Dilithium, Falcon and Rainbow. In the table below we compare them against RSA and ECDSA, both of which are in common use today, and a selection of other PQ schemes that might see standardisation in the future.
(* There are many caveats to this table. We compare instances of PQC security level 1. Signing and verification times vary considerably by hardware platform and implementation constraints. They should be taken as a rough indication only. The signing time of Falcon512 is discussed later on. We do not list all relevant variants of the NIST alternates or promising schemes. This instance of XMSS can only sign a million messages, is stateful, requires quite a bit of storage for quick signing, is not standardised and thus far from a drop-in replacement. Rainbow has one other variant, which has smaller private keys.)
None of these PQ signatures are a clear-cut drop-in replacement. To start, all have (much) larger signatures, except for Rainbow, GeMMS and SQISign. Rainbow and GeMMS have huge public keys and SQISign is very slow.
TLS signatures
To confuse matters even more, the signatures within TLS are not all the same:
Online. Only the handshake signature is created with every incoming TLS connection, and so signing needs to be fast. Dilithium fits this role well.
Offline. All other signatures are made months/years in advance, and so signing time is not that important. This group splits in two:
With a public key. The certificate chain includes signatures and their public keys. Here Falcon seems most suited.
Without a public key. The remaining three (SCTs and OCSP staple) are just signatures. For these, Rainbow seems optimal, as its large public keys are not transmitted.
Using Dilithium, Falcon, and Rainbow, together, allows optimization for both speed and size simultaneously, which seems like a great idea. However, combining different signatures at the same time has disadvantages:
A security issue in the design or implementation of one of the signatures compromises the whole.
Clients need to implement multiple cryptographic algorithms, in this case three of them, which is troublesome for smaller devices — especially if separate hardware support is needed for each of them.
So do we really need to eke out every byte and every cycle of performance? Or can we stick to a single signature scheme for simplicity and security?
Can we pick just one?
If we stick to one signature scheme, looking just at the numbers, Falcon512 seems like a reasonable option. It needs 5KB of extra space (compared to a classical handshake), about the same as the Dilithium–Falcon–Rainbow chimera of before. Unfortunately Falcon comes with a caveat: creating signatures efficiently requires constant-time 64-bit floating point arithmetic. Without it, signing is 20x slower. But speed alone is not enough; it has to run inconstant time. Without that, one can slowly learn the secret key by measuring the time it takes to create a signature.
Although PCs typically have a sufficiently constant-time floating-point unit, many smaller devices do not. Thus, Falcon seems ill-suited for general purpose online signatures.
What about Dilithium2? It needs 17KB extra — let’s find out if that makes a big difference.
Evidence by Experiment
All the different variables and constraints clearly complicate an already challenging puzzle. The best thing is to just try the options. Over the last few years several interesting papers have appeared studying the various options, such as SKD20, PST20, SKD21 and PKNLN22. These are great starts, but don’t provide a complete picture:
SCTs and OCSP staples have yet to be considered. Leaving half (three) of the signatures out changes the results significantly.
The networks tested or emulated offer insights, but are far from representative of real-world conditions. All tests were conducted between two datacenters (which does not include real-world last-mile conditions such as Wi-Fi or spotty mobile connections); or a network was simulated with unrealistic packet loss rates.
Here, Cloudflare can contribute. One of the things we like to do is to put new ideas in the community to the test on a global scale.
In this case we’re just taking a first step. Setting up a real-world experiment with a modified browser is quite involved, especially when we consider the many possible variations. Instead, as a first step, we decided first to investigate the most striking variable, the size, and try to answer the question:
How do larger signatures affect the TLS handshake?
There are two parts to this: how fast are they, and, more importantly, do they work at all?
Experimental setup
We need some way to emulate bigger signatures without having to modify the clients. We considered several options. The first idea we had was to pad a valid certificate with a dummy extension. That would require a custom certificate for each size to test, which is cumbersome. Then we considered responding with a dummy ServerHello extension. This is, however, not allowed by TLS 1.2 without a corresponding ClientHello extension. In the end, we went for adding dummy certificates.
Dummy certificates
These dummy certificates are 1kB self-signed invalid certificates that have nothing to do with the certificate chain. To vary the size to test, we simply add more copies. Adding unrelated certificates to the certificate chain is a common misconfiguration and clients have learnt to ignore them. In fact, TLS 1.3 stipulates that these (in rfc-speak) SHOULD be ignored by the client. Testing out hundreds of browsers, we saw no issues.
Standards and reality don’t always agree: when inserting dummy certificates on actual traffic, we saw issues with a small, but not insignificant number of clients. We don’t want to ruin anyone’s connection, and so we decided to use separate connections for this purpose.
Using challenge pages to launch probes
So what did we actually do? On a small percentage of the challenge pages (those with the CAPTCHA), we pick a number n and a random key and send this key in two separate background requests to:
0.tls-size-experiment-c.cloudflareresearch.com
[n].tls-size-experiment-1.cloudflareresearch.com
The first, the control, is a normal webpage that stores the TLS handshake time under the key that’s been sent. The real action happens at the second, the live, which adds the n dummy certificates to its chain. The live also stores handshake time under the given key. We could call it “experimental” instead of “live”, but the benign control connection is also an important part of the experiment. Indeed, it allows us to see if live connections are missing. These endpoints were a breeze to write using Cloudflare Workers and KV.
How much dummy data to test?
Before launching the experiment, we tested several libraries and browsers on the live endpoint to see whether they would error due to the dummy certificates. None rejected a single certificate, but how far can we go? TLS 1.3 theoretically allows a certificate chain of 16MB, but in practice many clients reject a much shorter chain. OpenSSL, for instance, rejects one of 102kB. The most stingy we found is Go’s TLS client, which rejects a handshake larger than 64kB. Because of this, we tested with between 1 and 59 dummy certificates.
Intermezzo: TCP’s congestion window
So, what did we find? The graphs are in the next section, have a peek! Before diving right in, we would like to explain a crucial concept, the TCP congestion window, that helps us read the results.
Data sent over the Internet is broken down in packets of around 1.4kB that traverse many routers to reach their destination. Sometimes a router has more incoming packets than it can handle and it has to drop them — this is called congestion. To avoid causing congestion, TCP initially sends just a few packets (typically ten, so ~14kB). Then, with every acknowledgement received in return, the TCP sender will very quickly ramp up the number of packets that it keeps in flight. This number is called the congestion window (cwnd). When it gets too high, congestion occurs, packets are dropped and in response the sender backs off by dialing down the congestion window. Any dropped packet is seen as a sign of congestion by TCP. For this reason, Wi-Fi has its own retransmission mechanism transparent to TCP.
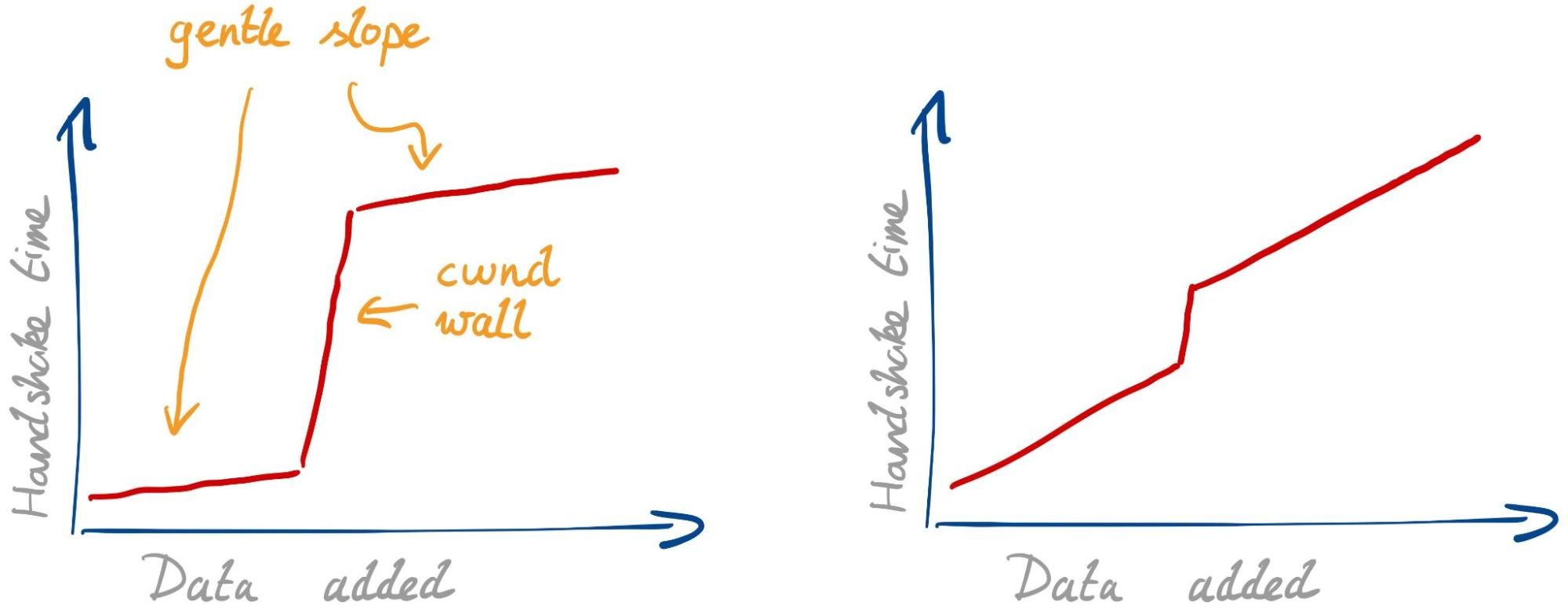
Considering all this, we would expect to see two effects with larger signatures:
Gentle slope. Every single packet needs some extra time to transmit, due to limited bandwidth and possible physical-layer retransmissions. This slope isn’t so gentle if your internet connection is slow or spotty.
cwnd wall. Once we fill the congestion window, we have to wait for a whole roundtrip before we can continue. This effect is stronger if the roundtrip time (RTT) is higher.
The strength of the two effects can differ. With a fast connection and high RTT we expect to see the graph below on the left. With a slow connection and low RTT, we expect the one on the right.
There might be other unknown effects. The best thing is to have a look.
In PQ research, the second effect has gained the most attention. The larger signatures simply do not fit in the initial congestion windows used today. A common suggestion in response has been to simply increase the initial congestion window to accommodate the larger signatures. This is far from a simplechange to make globally, and we have to understand if this solves the problem to begin with.
Results
Over 24 days we’ve received 964,499 live connections from 454,218 different truncated IPs (to 24 bits, “/24”, for IPv4 and 48 bits for IPv6) and 11,239 different ASNs. First, let’s check how many clients had trouble with the bigger handshakes.
Can clients handle the larger handshakes?
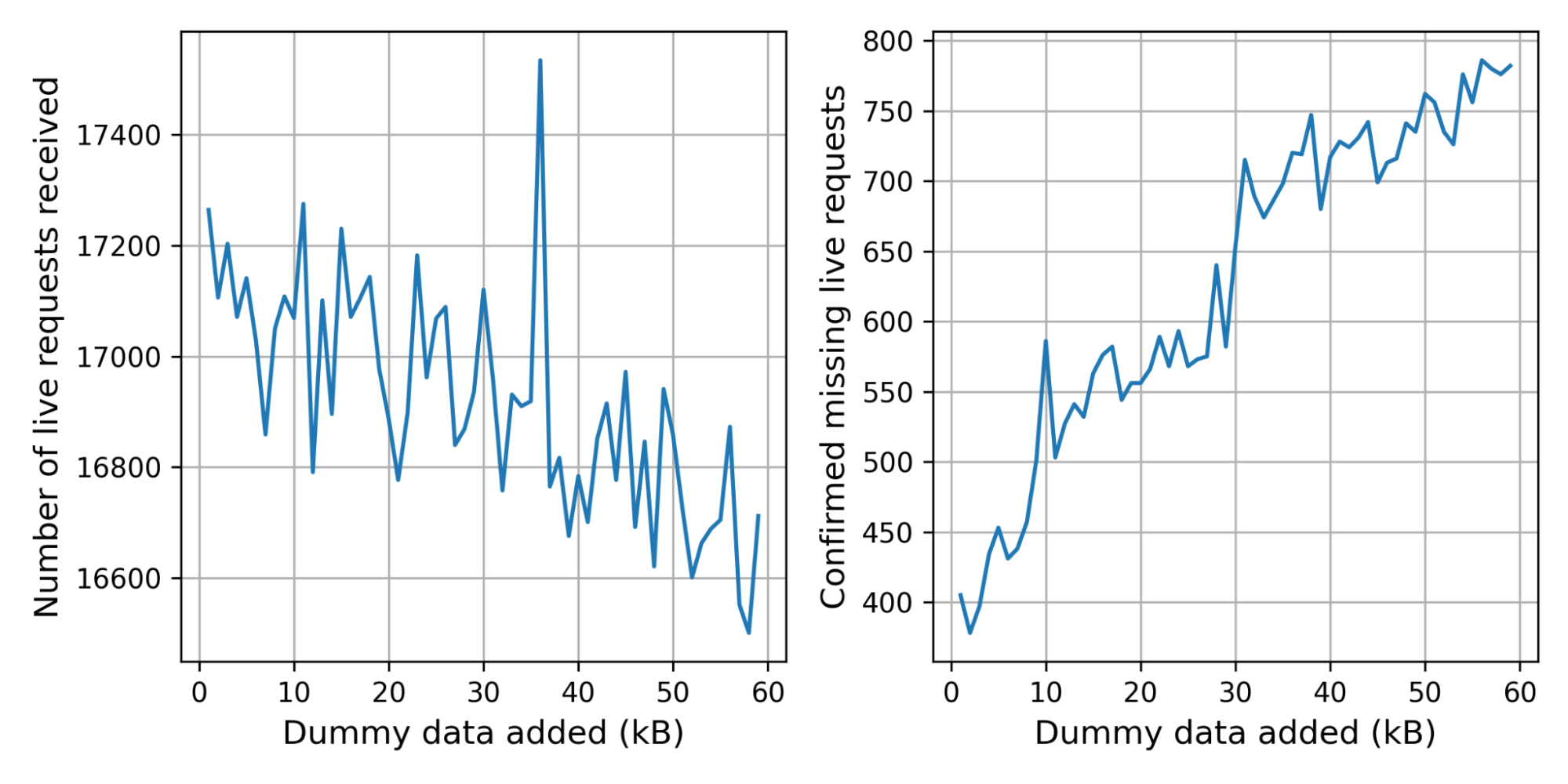
The control connection was missing for 2.4% of the live connections. This is not alarming: we expect some connections to be missing for harmless reasons, such as the user browsing away from the challenge page. There are, however, significantly more live connections without control connection at 3.6%.
In the graph below on the left we break the number of received live connections down by the number of dummy certificates added. Because we pick the number of certificates randomly, the graph is noisy. To get a clearer picture, we started storing the number of certificates added in the corresponding control request, which gives us the graph on the right. The bumps at 10kB and 30kB suggest that there are clients or middleboxes that cannot handle these handshake sizes.
Handshake times with larger signatures
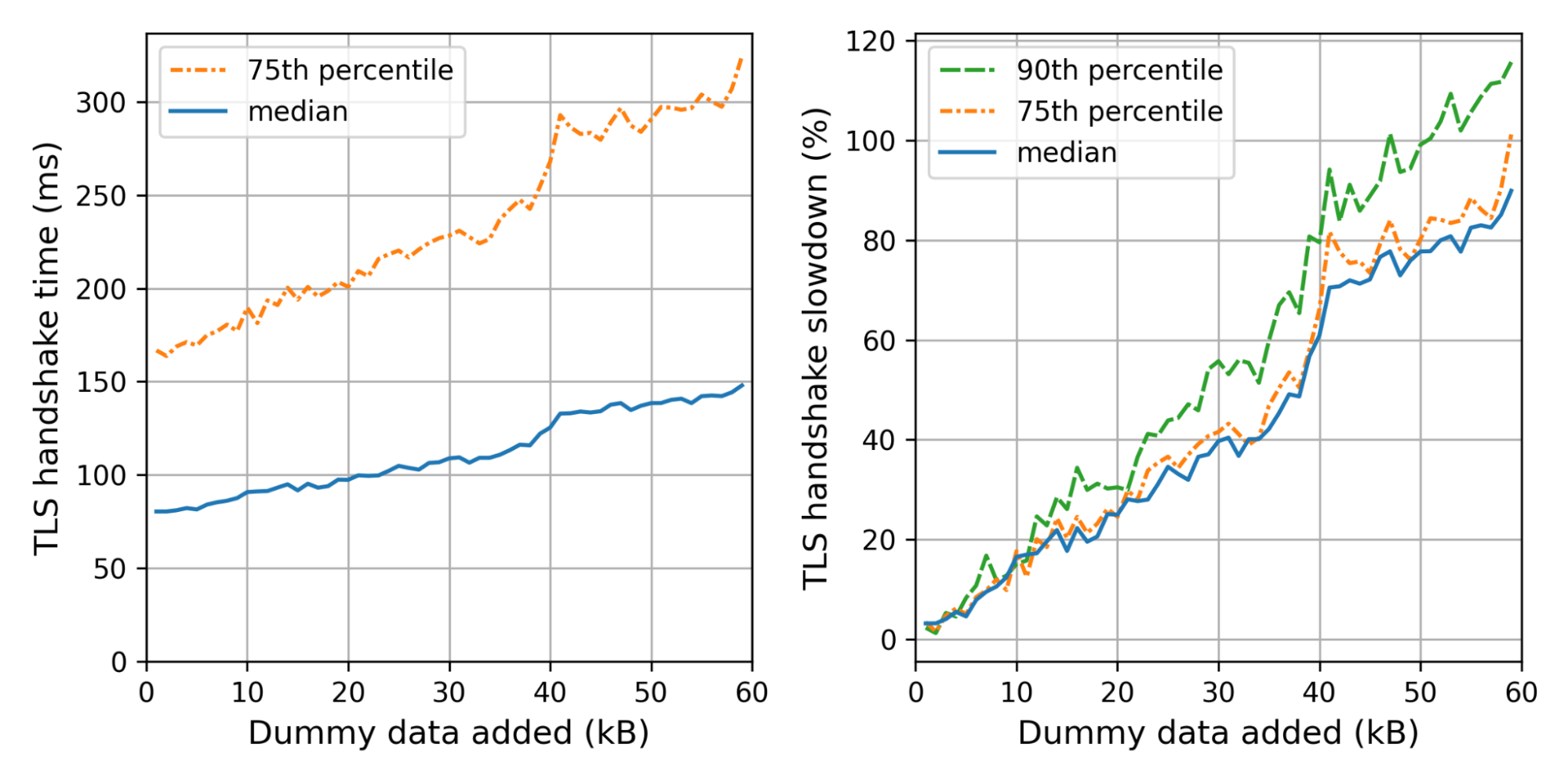
What is the effect on the handshake time? The graph on the left shows the weighted median and 75th percentile TLS handshake times for different amounts of dummy data added. We use the weight so that every truncated IP contributes equally. On the right we show the slowdowns for each size, relative to the handshake time of the control connection.
We can see the not-so-gentle slope until 40kB, where we hit a littlewall that corresponds to Cloudflare’s default initial congestion window of 30 packets.
Adding 35kB fits within our initial congestion window. Nonetheless, the median handshake with 35kB extra is 40% slower. The slowest 10% are even worse off, taking 60% as much time. Thus even though we stay within the congestion window, the added data is not for free at all.
We can now translate these insights back to concrete PQ signatures. For example, using Dilithium2 as a drop-in replacement, we need around 17kB extra. That also fits within our initial congestion window with a median slowdown of 20%, which gets worse for the tail-end of users. For the normal initial congestion window of ten, we expect the slowdown to be much worse — around 60–80%.
There are several caveats to point out:
These experiments used an initial congestion window of 30 packets instead of ten. With a smaller initial congestion window of ten, which is the default for most systems, we would expect the wall to move from 40kB to around 10kB.
Because of our presence all across the world, our RTTs are fairly low. Thus the effect of the cwnd wall is smaller for us.
Challenge pages are served, by design, to those clients that we expect to be bots. This adds a significant bias because bots are generally hosted at well-connected providers, and so are closer than users.
HTTP/3 was not supported by the server we used for the endpoint. Support for IPv6 was only added ten days into the experiment and accounts for 10.9% of the measurements.
Actual TLS handshakes differ in size much more than tested in this setup due to differences in certificate sizes and extensions and other factors.
What have we learned?
The TLS handshake is just one step (~5–20%) in a long chain required to show you a webpage. Casually browsing, it would be hard to notice a TLS handshake that’s 60% slower. But such differences add up. To make a website really fast, you need many seemingly insignificant speedups. Browser developers take this seriously: only in exceptional cases does Chrome allow a change that slows down any microbenchmark by even a percent.
Because of the many parties and complexities involved, we should avoid waiting too long to adopt post-quantum signatures in TLS. That’s a hard sell if it comes at the price of a double-digit slowdown, not least to content servers but also to browser vendors and clients.
A timely adoption of PQ signatures on the web would be great. Our evidence so far suggests that this will be easiest, if six signatures and two public keys would fit in 9kB.
We will continue our efforts to help build a post-quantum secure Internet. To follow along, keep an eye on this blog or have a look at research.cloudflare.com.
Bas Westerbaan is co-submitter of the SPHINCS+ signature scheme.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.