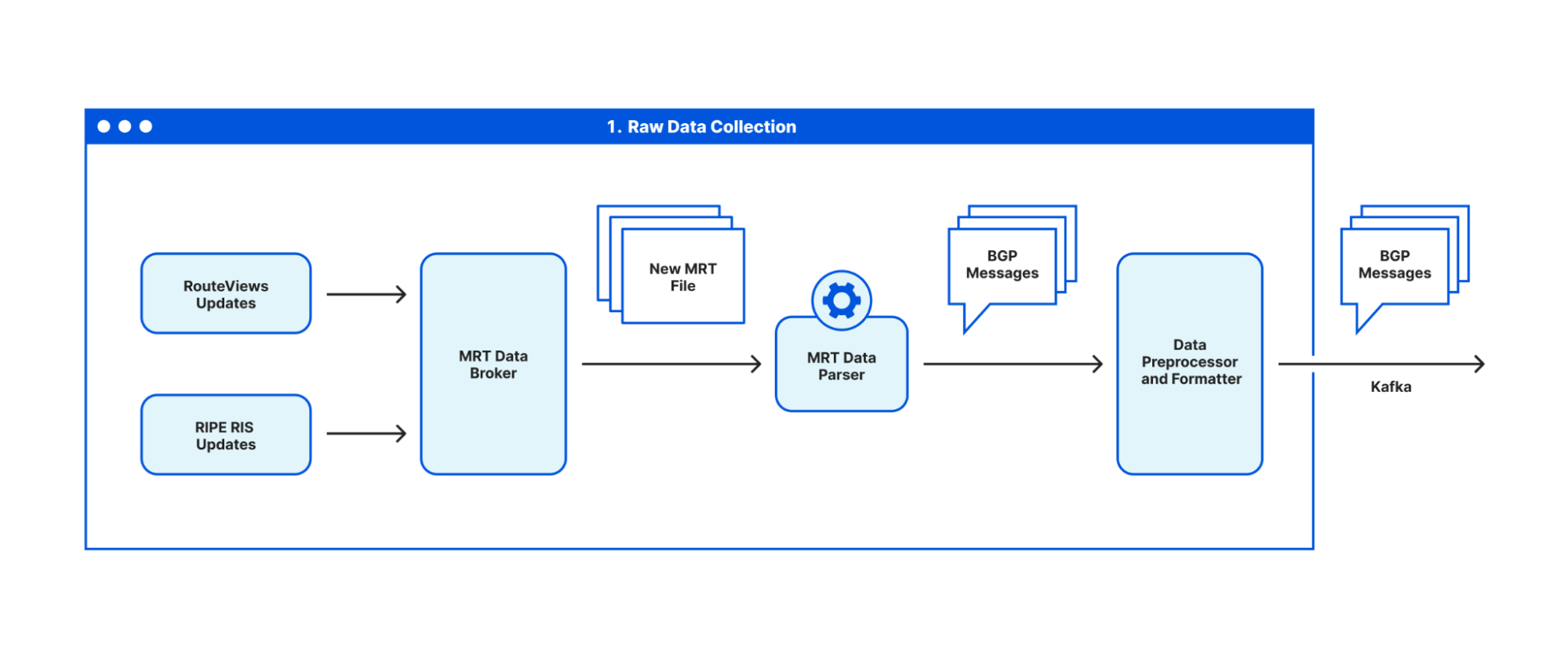
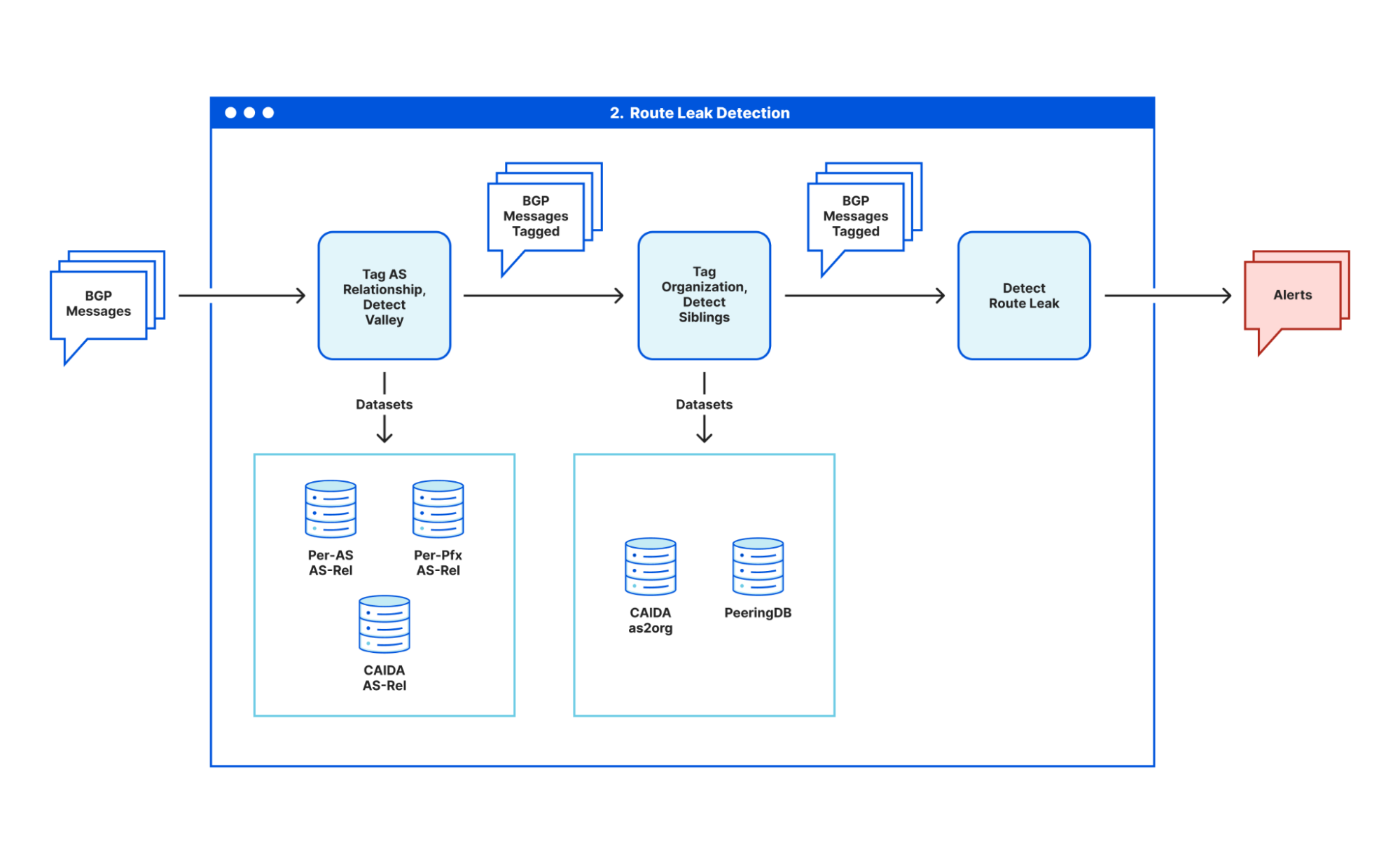
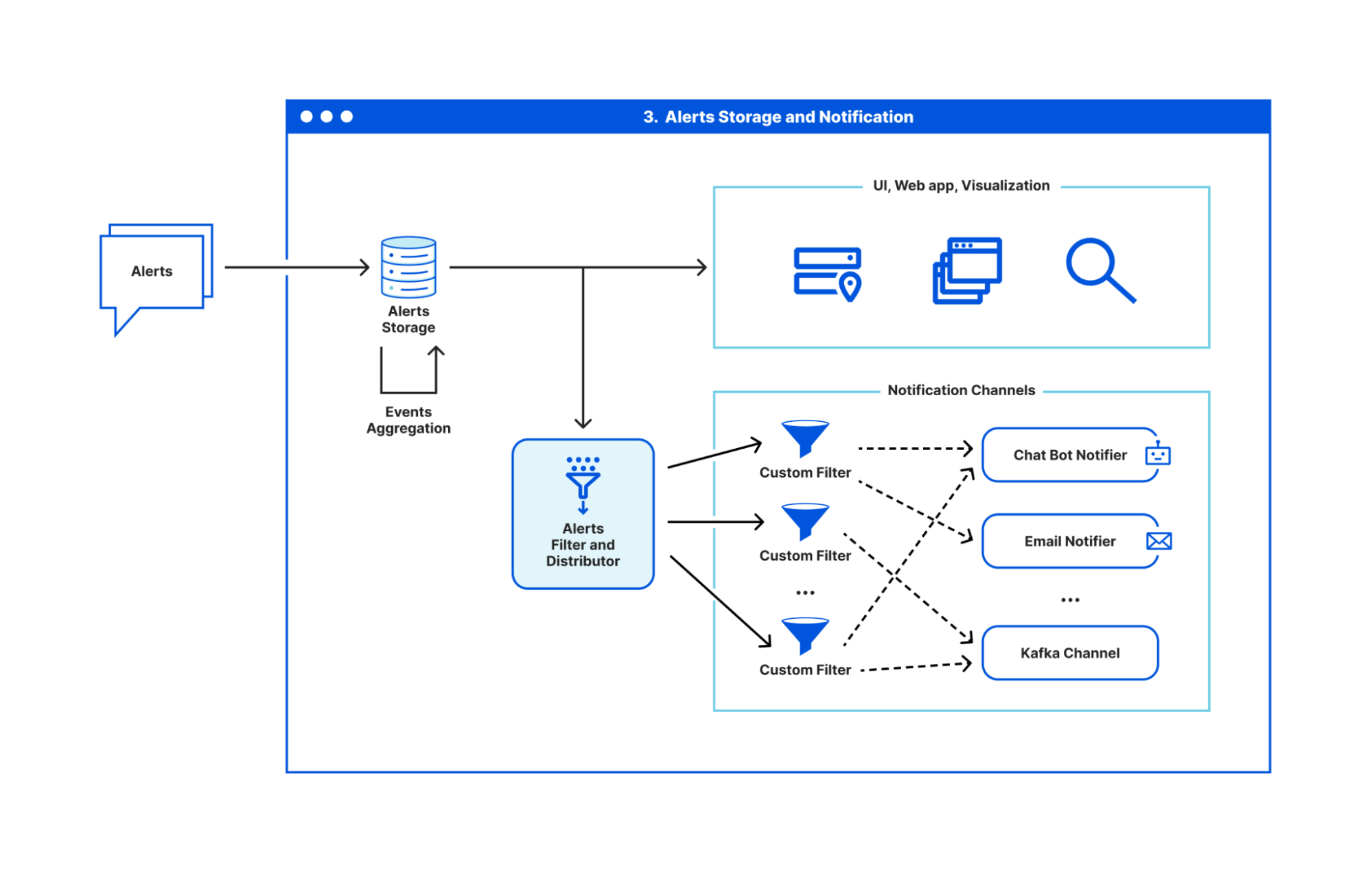
Post Syndicated from Vasilis Giotsas original https://blog.cloudflare.com/a-framework-for-measuring-internet-resilience/
On July 8, 2022, a massive outage at Rogers, one of Canada’s largest telecom providers, knocked out Internet and mobile services for over 12 million users. Why did this single event have such a catastrophic impact? And more importantly, why do some networks crumble in the face of disruption while others barely stumble?
The answer lies in a concept we call Internet resilience: a network’s ability not just to stay online, but to withstand, adapt to, and rapidly recover from failures.
It’s a quality that goes far beyond simple “uptime.” True resilience is a multi-layered capability, built on everything from the diversity of physical subsea cables to the security of BGP routing and the health of a competitive market. It’s an emergent property much like psychological resilience: while each individual network must be robust, true resilience only arises from the collective, interoperable actions of the entire ecosystem. In this post, we’ll introduce a data-driven framework to move beyond abstract definitions and start quantifying what makes a network resilient. All of our work is based on public data sources, and we’re sharing our metrics to help the entire community build a more reliable and secure Internet for everyone.
In networking, we often talk about “reliability” (does it work under normal conditions?) and “robustness” (can it handle a sudden traffic surge?). But resilience is more dynamic. It’s the ability to gracefully degrade, adapt, and most importantly, recover. For our work, we’ve adopted a pragmatic definition:
Internet resilience is the measurable capability of a national or regional network ecosystem to maintain diverse and secure routing paths in the face of challenges, and to rapidly restore connectivity following a disruption.
This definition links the abstract goal of resilience to the concrete, measurable metrics that form the basis of our analysis.
The Internet is a global system but is built out of thousands of local pieces. Every country depends on the global Internet for economic activity, communication, and critical services, yet most of the decisions that shape how traffic flows are made locally by individual networks.
In most national infrastructures like water or power grids, a central authority can plan, monitor, and coordinate how the system behaves. The Internet works very differently. Its core building blocks are Autonomous Systems (ASes), which are networks like ISPs, universities, cloud providers or enterprises. Each AS controls autonomously how it connects to the rest of the Internet, which routes it accepts or rejects, how it prefers to forward traffic, and with whom it interconnects. That’s why they’re called Autonomous Systems in the first place! There’s no global controller. Instead, the Internet’s routing fabric emerges from the collective interaction of thousands of independent networks, each optimizing for its own goals.
This decentralized structure is one of the Internet’s greatest strengths: no single failure can bring the whole system down. But it also makes measuring resilience at a country level tricky. National statistics can hide local structures that are crucial to global connectivity. For example, a country might appear to have many international connections overall, but those connections could be concentrated in just a handful of networks. If one of those fails, the whole country could be affected.
For resilience, the goal isn’t to isolate national infrastructure from the global Internet. In fact, the opposite is true: healthy integration with diverse partners is what makes both local and global connectivity stronger. When local networks invest in secure, redundant, and diverse interconnections, they improve their own resilience and contribute to the stability of the Internet as a whole.
This perspective shapes how we design and interpret resilience metrics. Rather than treating countries as isolated units, we look at how well their networks are woven into the global fabric: the number and diversity of upstream providers, the extent of international peering, and the richness of local interconnections. These are the building blocks of a resilient Internet.
The Internet is constructed according to a layered model, by design, so that different Internet components and features can evolve independent of the others. The Physical layer stores, carries, and forwards, all the bits and bytes transmitted in packets between devices. It consists of cables, routers and switches, but also buildings that house interconnection facilities. The Application layer sits above all others and has virtually no information about the network so that applications can communicate without having to worry about the underlying details, for example, if a network is ethernet or Wi-Fi. The application layer includes web browsers, web servers, as well as caching, security, and other features provided by Content Distribution Networks (CDNs). Between the physical and application layers is the Network layer responsible for Internet routing. It is ‘logical’, consisting of software that learns about interconnection and routes, and makes (local) forwarding decisions that deliver packets to their destinations.
Good route hygiene works like personal hygiene: it prevents problems before they spread. The Internet relies on the Border Gateway Protocol (BGP) to exchange routes between networks, but BGP wasn’t built with security in mind. A single bad route announcement, whether by mistake or attack, can send traffic the wrong way or cause widespread outages.
Two practices help stop this: The RPKI (Resource Public Key Infrastructure) lets networks publish cryptographic proof that they’re allowed to announce specific IP prefixes. ROV (Route Origin Validation) checks those proofs before accepting routes.
Together, they act like passports and border checks for Internet routes, helping filter out hijacks and leaks early.
Hygiene doesn’t just happen in the routing table – it spans multiple layers of the Internet’s architecture, and weaknesses in one layer can ripple through the rest. At the physical layer, having multiple, geographically diverse cable routes ensures that a single cut or disaster doesn’t isolate an entire region. For example, distributing submarine landing stations along different coastlines can protect international connectivity when one corridor fails. At the network layer, practices like multi-homing and participation in Internet Exchange Points (IXPs) give operators more options to reroute traffic during incidents, reducing reliance on any single upstream provider. At the application layer, Content Delivery Networks (CDNs) and caching keep popular content close to users, so even if upstream routes are disrupted, many services remain accessible. Finally, policy and market structure also play a role: open peering policies and competitive markets foster diversity, while dependence on a single ISP or cable system creates fragility.
Resilience emerges when these layers work together. If one layer is weak, the whole system becomes more vulnerable to disruption.
The more networks adopt these practices, the stronger and more resilient the Internet becomes. We actively support the deployment of RPKI, ROV, and diverse routing to keep the global Internet healthy.
The biggest hurdle in measuring resilience is data access. The most valuable information, like internal network topologies, the physical paths of fiber cables, or specific peering agreements, is held by private network operators. This is the ground truth of the network.
However, operators view this information as a highly sensitive competitive asset. Revealing detailed network maps could expose strategic vulnerabilities or undermine business negotiations. Without access to this ground truth data, we’re forced to rely on inference, approximation, and the clever use of publicly available data sources. Our framework is built entirely on these public sources to ensure anyone can reproduce and build upon our findings.
Projects like RouteViews and RIPE RIS collect BGP routing data that shows how networks connect. Traceroute measurements reveal paths at the router level. IXP and submarine cable maps give partial views of the physical layer. But each of these sources has blind spots: peering links often don’t appear in BGP data, backup paths may remain hidden, and physical routes are hard to map precisely. This lack of a single, complete dataset means that resilience measurement relies on combining many partial perspectives, a bit like reconstructing a city map from scattered satellite images, traffic reports, and public utility filings. It’s challenging, but it’s also what makes this field so interesting.
Once we understand why resilience matters and what makes it hard to measure, the next step is to translate these ideas into concrete metrics. These metrics give us a way to evaluate how well different parts of the Internet can withstand disruptions and to identify where the weak points are. No single metric can capture Internet resilience on its own. Instead, we look at it from multiple angles: physical infrastructure, network topology, interconnection patterns, and routing behavior. Below are some of the key dimensions we use. Some of these metrics are inspired from existing research, like the ISOC Pulse framework. All described methods rely on public data sources and are fully reproducible. As a result, in our visualizations we intentionally omit country and region names to maintain focus on the methodology and interpretation of the results.
Networks primarily interconnect in two types of physical facilities: colocation facilities (colos), and Internet Exchange Points (IXPs) often housed within the colos. Although symbiotically linked, they serve distinct functions in a nation’s digital ecosystem. A colocation facility provides the foundational infrastructure —- secure space, power, and cooling – for network operators to place their equipment. The IXP builds upon this physical base to provide the logical interconnection fabric, a role that is transformative for a region’s Internet development and resilience. The networks that connect at these facilities are its members.
Metrics that reflect resilience include:
-
Number and distribution of IXPs, normalized by population or geography. A higher IXP count, weighted by population or geographic coverage, is associated with improved local connectivity.
-
Peering participation rates — the percentage of local networks connected to domestic IXPs. This metric reflects the extent to which local networks rely on regional interconnection rather than routing traffic through distant upstream providers.
-
Diversity of IXP membership, including ISPs, CDNs, and cloud providers, which indicates how much critical content is available locally, making it accessible to domestic users even if international connectivity is severely degraded.
Resilience also depends on how well local networks connect globally:
-
How many local networks peer at international IXPs, increasing their routing options
-
How many international networks peer at local IXPs, bringing content closer to users
A balanced flow in both directions strengthens resilience by ensuring multiple independent paths in and out of a region.
The geographic distribution of IXPs further enhances resilience. A resilient IXP ecosystem should be geographically dispersed to serve different regions within a country effectively, reducing the risk of a localized infrastructure failure from affecting the connectivity of an entire country. Spatial distribution metrics help evaluate how infrastructure is spread across a country’s geography or its population. Key spatial metrics include:
-
Infrastructure per Capita: This metric – inspired by teledensity – measures infrastructure relative to population size of a sub-region, providing a per-person availability indicator. A low IXP-per-population ratio in a region suggests that users there rely on distant exchanges, increasing the bit-risk miles.
-
Infrastructure per Area (Density): This metric evaluates how infrastructure is distributed per unit of geographic area, highlighting spatial coverage. Such area-based metrics are crucial for critical infrastructures to ensure remote areas are not left inaccessible.
These metrics can be summarized using the Location Quotient (LQ). The location quotient is a widely used geographic index that measures a region’s share of infrastructure relative to its share of a baseline (such as population or area).

For example, the figure above represents US states where a region hosts more or less infrastructure that is expected for its population, based on its LQ score. This statistic illustrates how even for the states with the highest number of facilities this number is still lower than would be expected given the population size of those states.
While spatial metrics capture the physical distribution of infrastructure, economic and usage-weighted metrics reveal how infrastructure is actually used. These account for traffic, capacity, or economic activity, exposing imbalances that spatial counts miss. Infrastructure Utilization Concentration measures how usage is distributed across facilities, using indices like the Herfindahl–Hirschman Index (HHI). HHI sums the squared market shares of entities, ranging from 0 (competitive) to 10,000 (highly concentrated). For IXPs, market share is defined through operational metrics such as:
-
Peak/Average Traffic Volume (Gbps/Tbps): indicates operational significance
-
Number of Connected ASNs: reflects network reach
-
Total Port Capacity: shows physical scale
The chosen metric affects results. For example, using connected ASNs yields an HHI of 1,316 (unconcentrated) for a Central European country, whereas using port capacity gives 1,809 (moderately concentrated).
The Gini coefficient measures inequality in resource or traffic distribution (0 = equal, 1 = fully concentrated). The Lorenz curve visualizes this: a straight 45° line indicates perfect equality, while deviations show concentration.

The chart on the left suggests substantial geographical inequality in colocation facility distribution across the US states. However, the population-weighted analysis in the chart on the right demonstrates that much of that geographic concentration can be explained by population distribution.
Internet resilience, in the context of undersea cables, is defined by the global network’s capacity to withstand physical infrastructure damage and to recover swiftly from faults, thereby ensuring the continuity of intercontinental data flow. The metrics for quantifying this resilience are multifaceted, encompassing the frequency and nature of faults, the efficiency of repair operations, and the inherent robustness of both the network’s topology and its dedicated maintenance resources. Such metrics include:
-
Number of landing stations, cable corridors, and operators. The goal is to ensure that national connectivity should withstand single failure events, be they natural disaster, targeted attack, or major power outage. A lack of diversity creates single points of failure, as highlighted by incidents in Tonga where damage to the only available cable led to a total outage.
-
Fault rates and mean time to repair (MTTR), which indicate how quickly service can be restored. These metrics measure a country’s ability to prevent, detect, and recover from cable incidents, focusing on downtime reduction and protection of critical assets. Repair times hinge on vessel mobilization and government permits, the latter often the main bottleneck.
-
Availability of satellite backup capacity as an emergency fallback. While cable diversity is essential, resilience planning must also cover worst-case outages. The Non-Terrestrial Backup System Readiness metric measures a nation’s ability to sustain essential connectivity during major cable disruptions. LEO and MEO satellites, though costlier and lower capacity than cables, offer proven emergency backup during conflicts or disasters. Projects like HEIST explore hybrid space-submarine architectures to boost resilience. Key indicators include available satellite bandwidth, the number of NGSO providers under contract (for diversity), and the deployment of satellite terminals for public and critical infrastructure. Tracking these shows how well a nation can maintain command, relief operations, and basic connectivity if cables fail.
The network layer above the physical interconnection infrastructure governs how traffic is routed across the Autonomous Systems (ASes). Failures or instability at this layer – such as misconfigurations, attacks, or control-plane outages – can disrupt connectivity even when the underlying physical infrastructure remains intact. In this layer, we look at resilience metrics that characterize the robustness and fault tolerance of AS-level routing and BGP behavior.
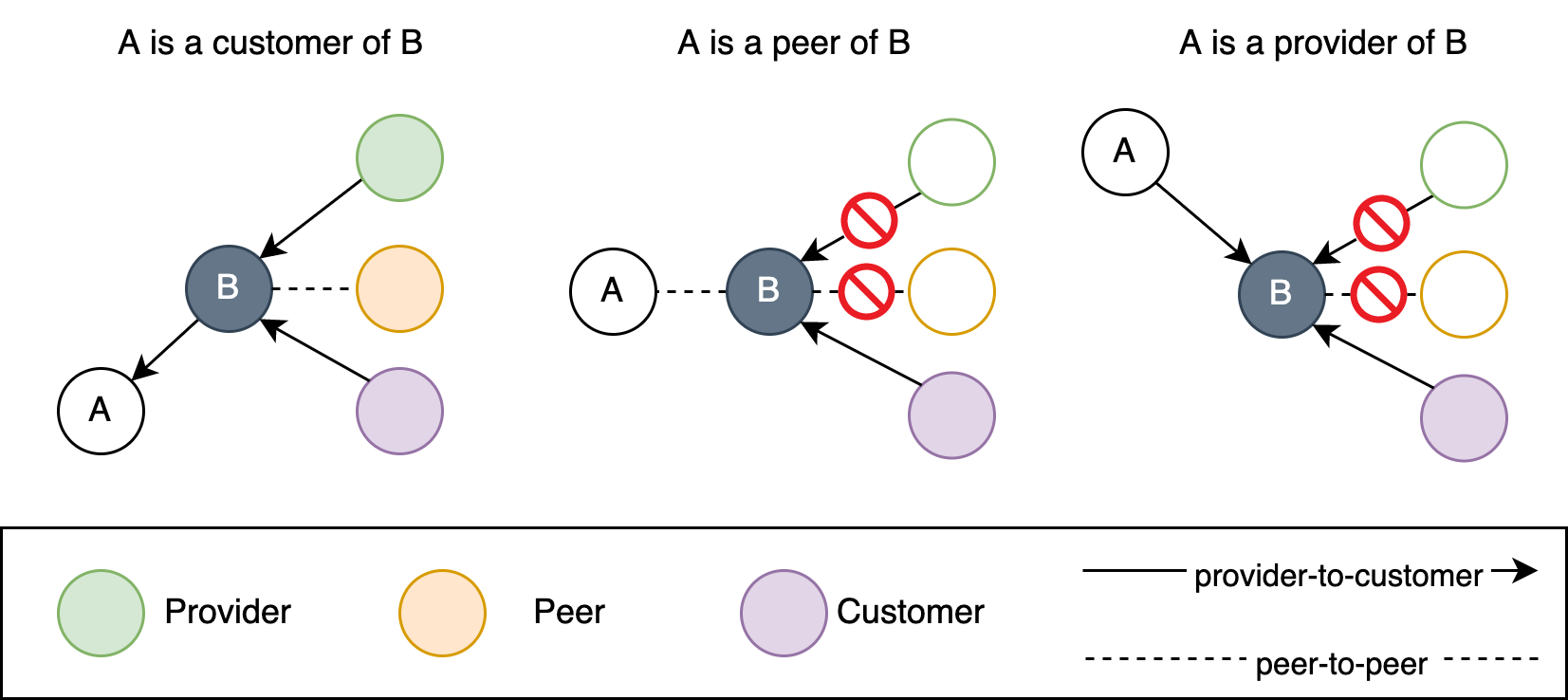
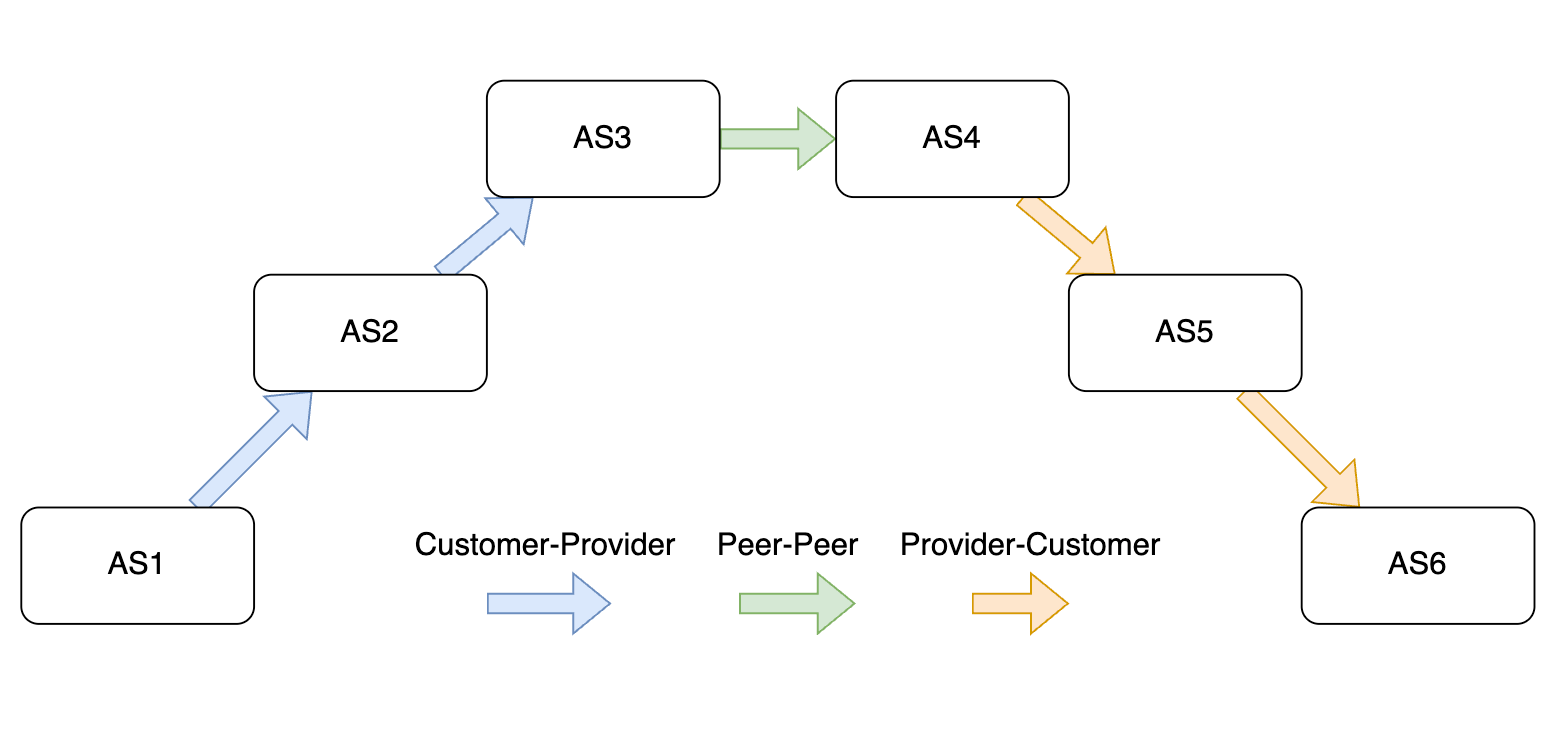
AS Path Diversity measures the number and independence of AS-level routes between two points. High diversity provides alternative paths during failures, enabling BGP rerouting and maintaining connectivity. Low diversity leaves networks vulnerable to outages if a critical AS or link fails. Resilience depends on upstream topology.
-
Single-homed ASes rely on one provider, which is cheaper and simpler but more fragile.
-
Multi-homed ASes use multiple upstreams, requiring BGP but offering far greater redundancy and performance at higher cost.
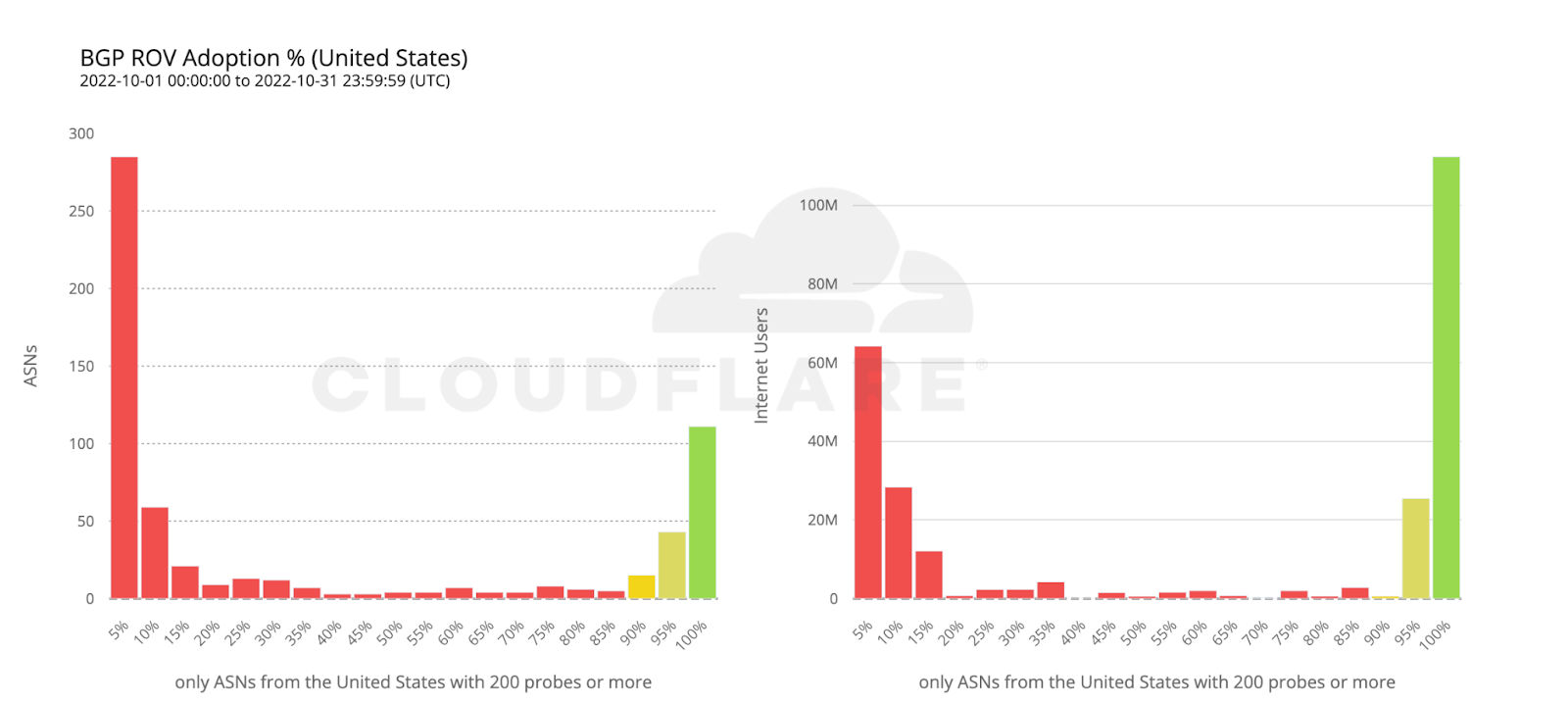
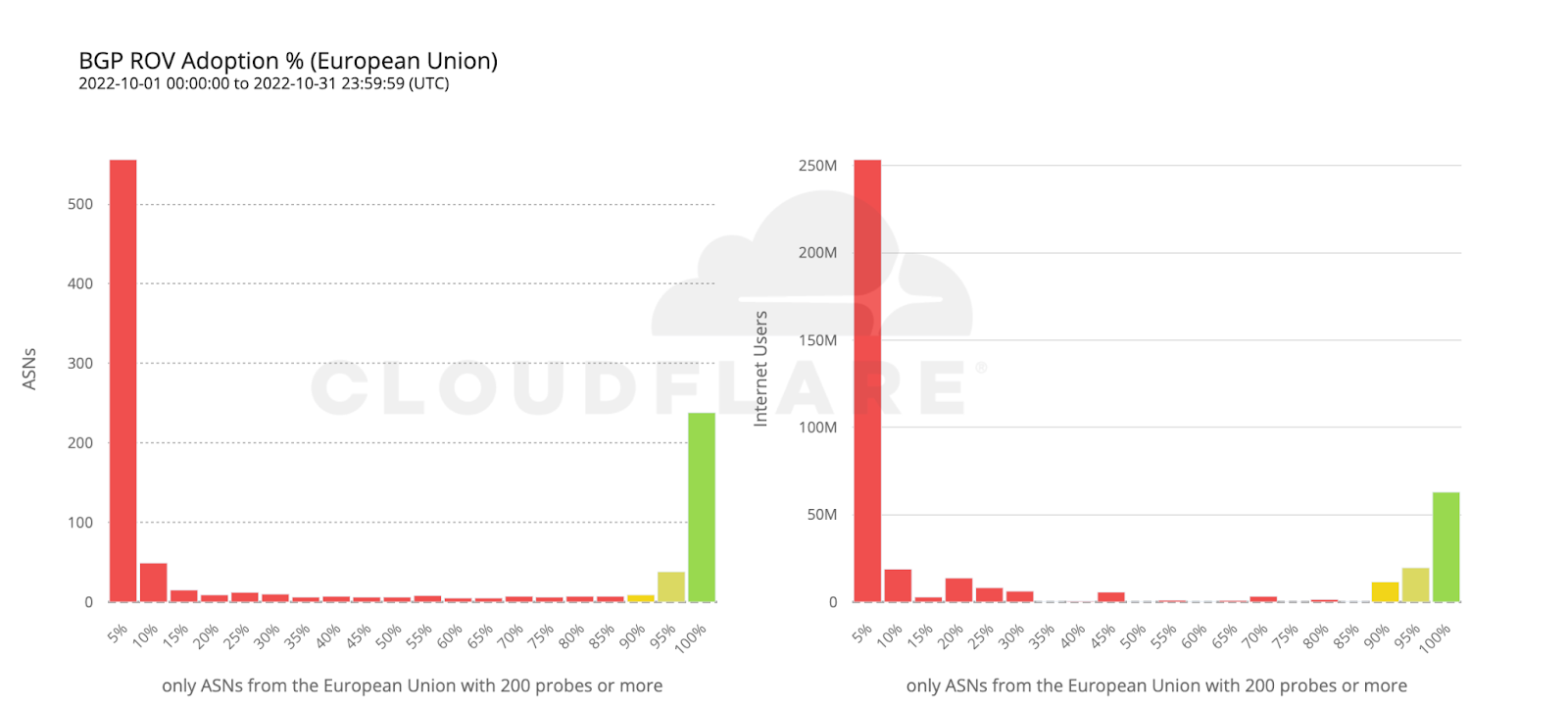
The share of multi-homed ASes reflects an ecosystem’s overall resilience: higher rates signal greater protection from single-provider failures. This metric is easy to measure using public BGP data (e.g., RouteViews, RIPE RIS, CAIDA). Longitudinal BGP monitoring helps reveal hidden backup links that snapshots might miss.
Beyond multi-homing rates, the distribution of single-homed ASes per transit provider highlights systemic weak points. For each provider, counting customer ASes that rely exclusively on it reveals how many networks would be cut off if that provider fails.

The figure above shows Canadian transit providers for July 2025: the x-axis is total customer ASes, the y-axis is single-homed customers. Canada’s overall single-homing rate is 30%, with some providers serving many single-homed ASes, mirroring vulnerabilities seen during the 2022 Rogers outage, which disrupted over 12 million users.
While multi-homing metrics provide a valuable, static view of an ecosystem’s upstream topology, a more dynamic and nuanced understanding of resilience can be achieved by analyzing the characteristics of the actual BGP paths observed from global vantage points. These path-centric metrics move beyond simply counting connections to assess the diversity and independence of the routes to and from a country’s networks. These metrics include:
-
Path independence measures whether those alternative routes truly avoid shared bottlenecks. Multi-homing only helps if upstream paths are truly distinct. If two providers share upstream transit ASes, redundancy is weak. Independence can be measured with the Jaccard distance between AS paths. A stricter path disjointness score calculates the share of path pairs with no common ASes, directly quantifying true redundancy.
-
Transit entropy measures how evenly traffic is distributed across transit providers. High Shannon entropy signals a decentralized, resilient ecosystem; low entropy shows dependence on few providers, even if nominal path diversity is high.
-
International connectivity ratios evaluate the share of domestic ASes with direct international links. High percentages reflect a mature, distributed ecosystem; low values indicate reliance on a few gateways.
The figure below encapsulates the aforementioned AS-level resilience metrics into single polar pie charts. For the purpose of exposition we plot the metrics for infrastructure from two different nations with very different resilience profiles.

To pinpoint critical ASes and potential single points of failure, graph centrality metrics can provide useful insights. Betweenness Centrality (BC) identifies nodes lying on many shortest paths, but applying it to BGP data suffers from vantage point bias. ASes that provide BGP data to the RouteViews and RIS collectors appear falsely central. AS Hegemony, developed by Fontugne et al., corrects this by filtering biased viewpoints, producing a 0–1 score that reflects the true fraction of paths crossing an AS. It can be applied globally or locally to reveal Internet-wide or AS-specific dependencies.
Customer cone size developed by CAIDA offers another perspective, capturing an AS’s economic and routing influence via the set of networks it serves through customer links. Large cones indicate major transit hubs whose failure affects many downstream networks. However, global cone rankings can obscure regional importance, so country-level adaptations give more accurate resilience assessments.
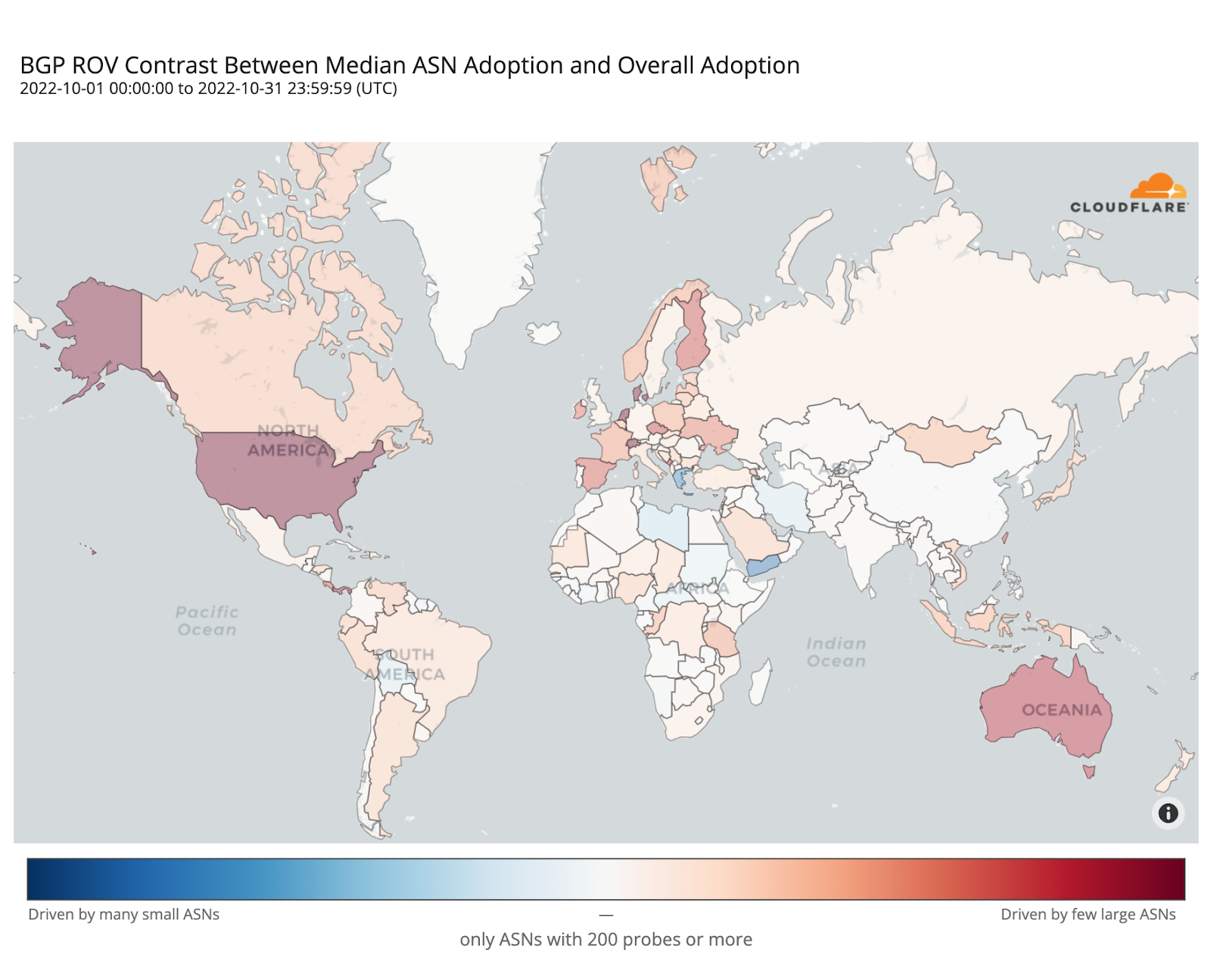
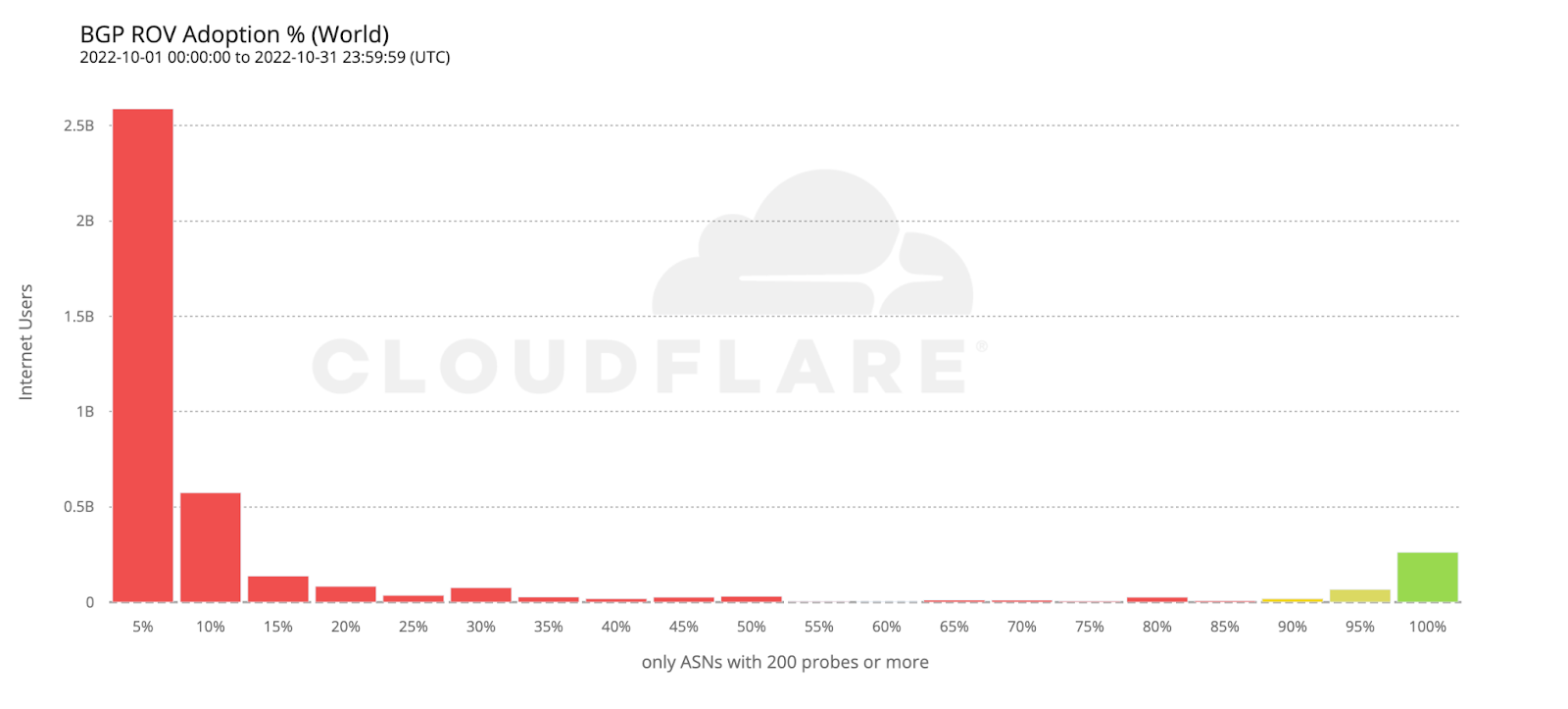
Not all networks have the same impact when they fail. A small hosting provider going offline affects far fewer people than if a national ISP does. Traditional resilience metrics treat all networks equally, which can mask where the real risks are. To address this, we use impact-weighted metrics that factor in a network’s user base or infrastructure footprint. For example, by weighting multi-homing rates or path diversity by user population, we can see how many people actually benefit from redundancy — not just how many networks have it. Similarly, weighting by the number of announced prefixes highlights networks that carry more traffic or control more address space.
This approach helps separate theoretical resilience from practical resilience. A country might have many multi-homed networks, but if most users rely on just one single-homed ISP, its resilience is weaker than it looks. Impact weighting helps surface these kinds of structural risks so that operators and policymakers can prioritize improvements where they matter most.
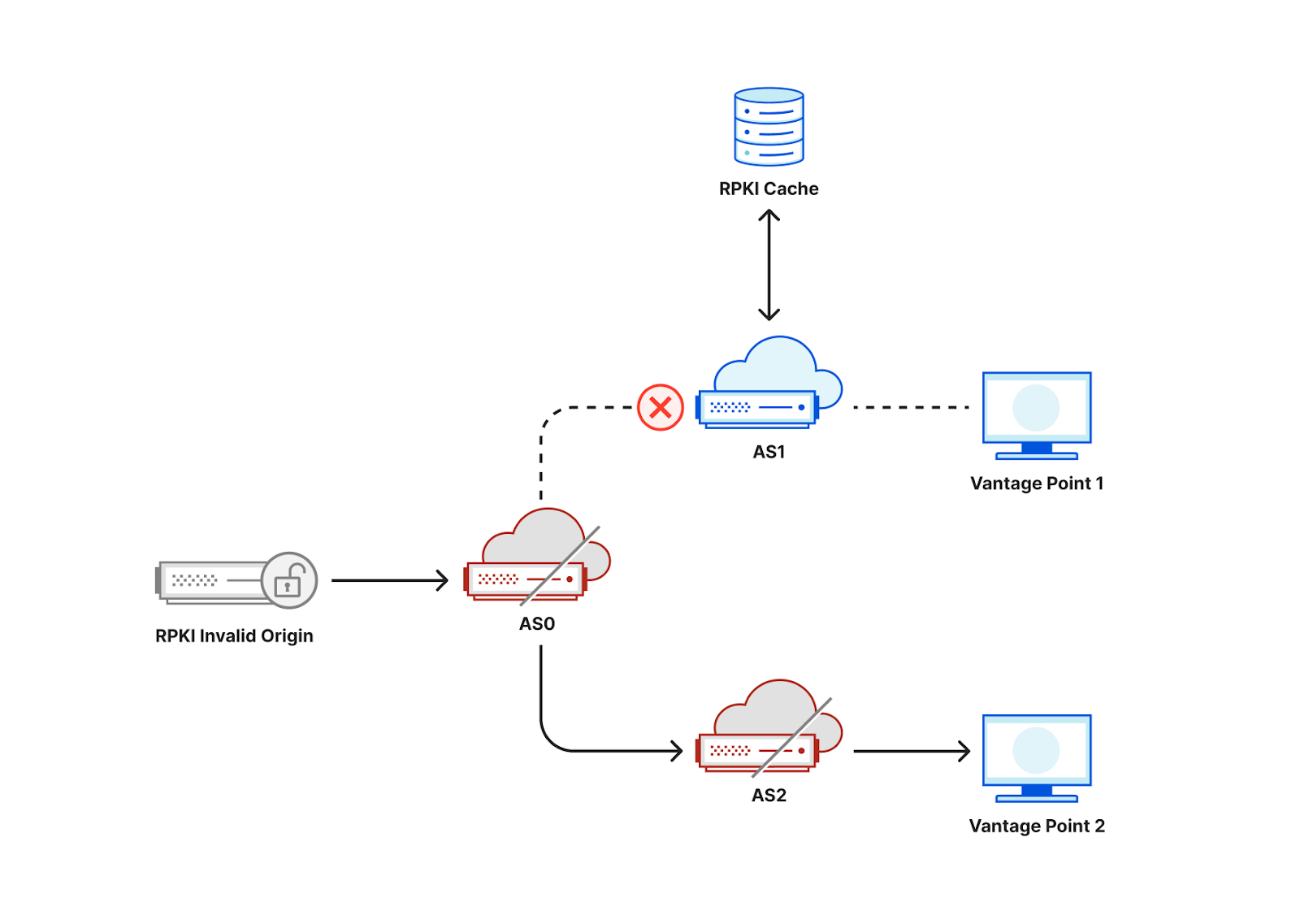
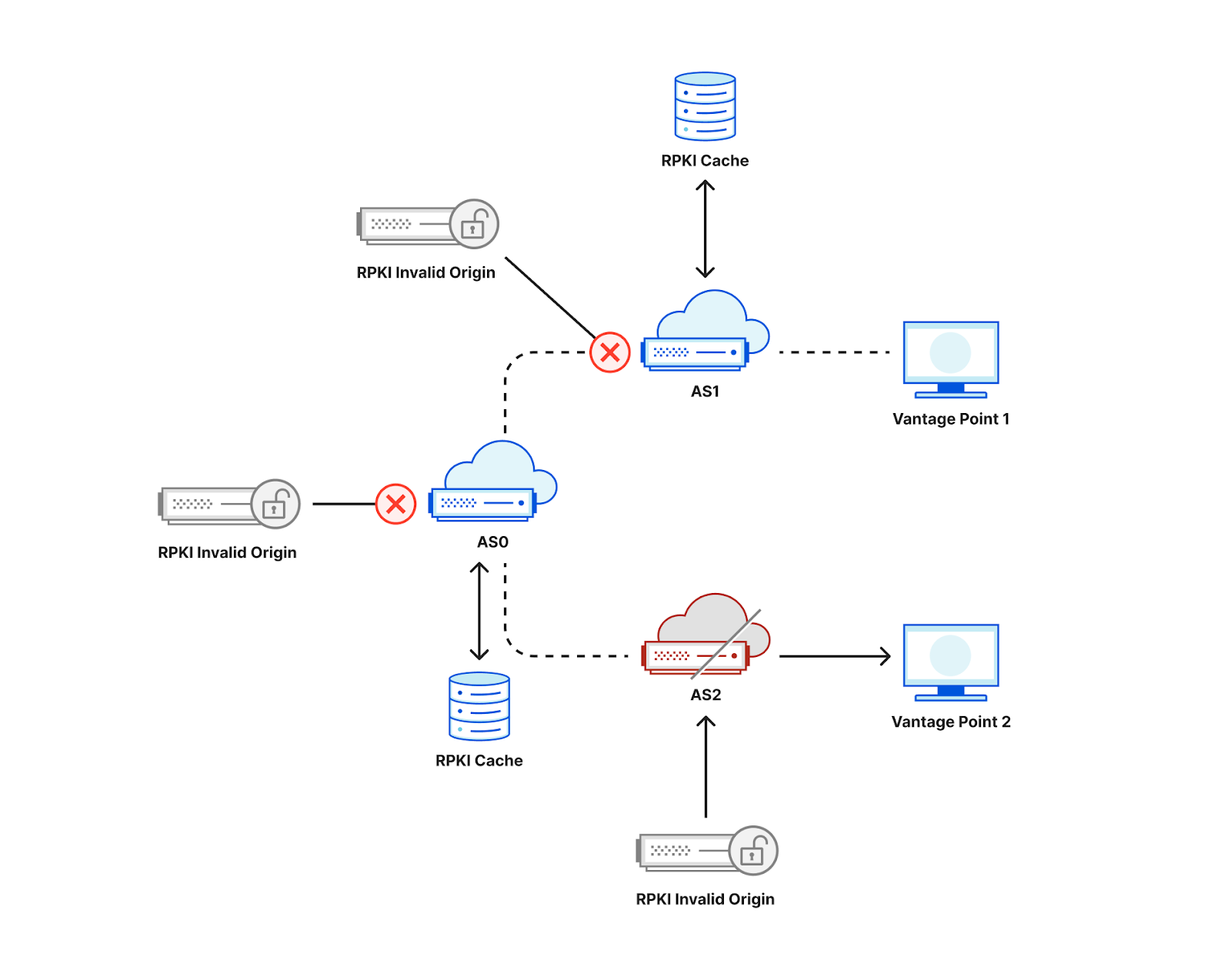
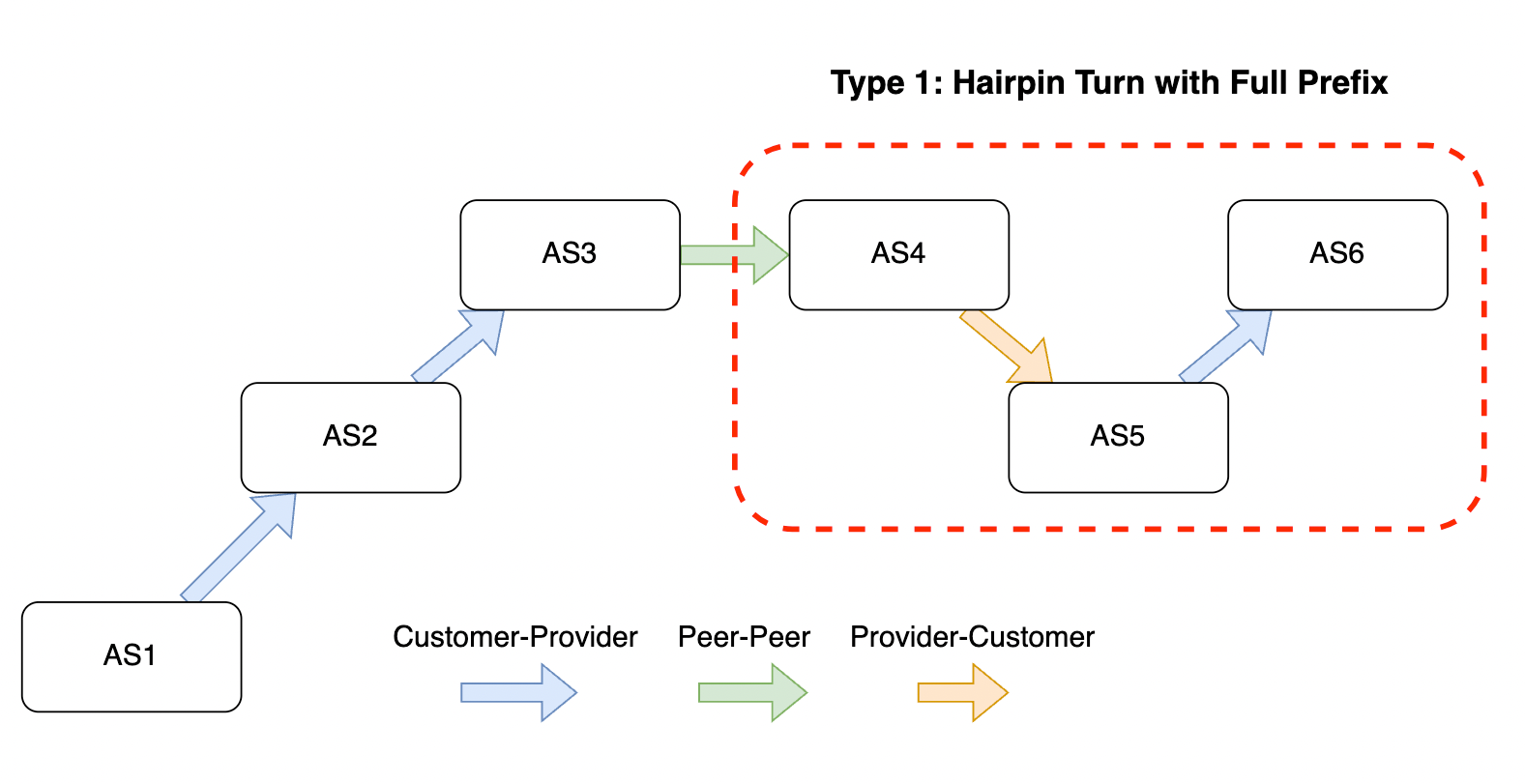
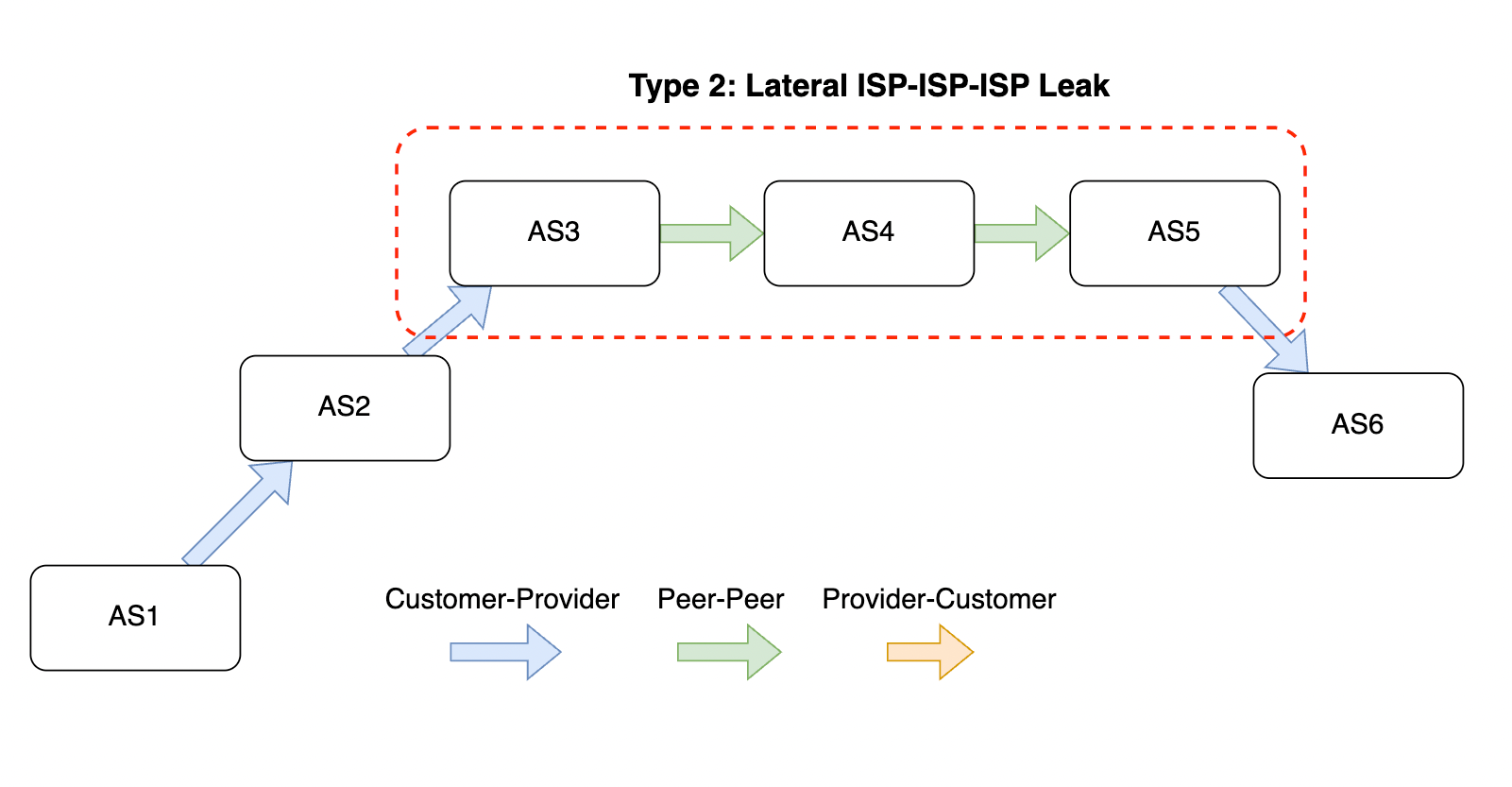
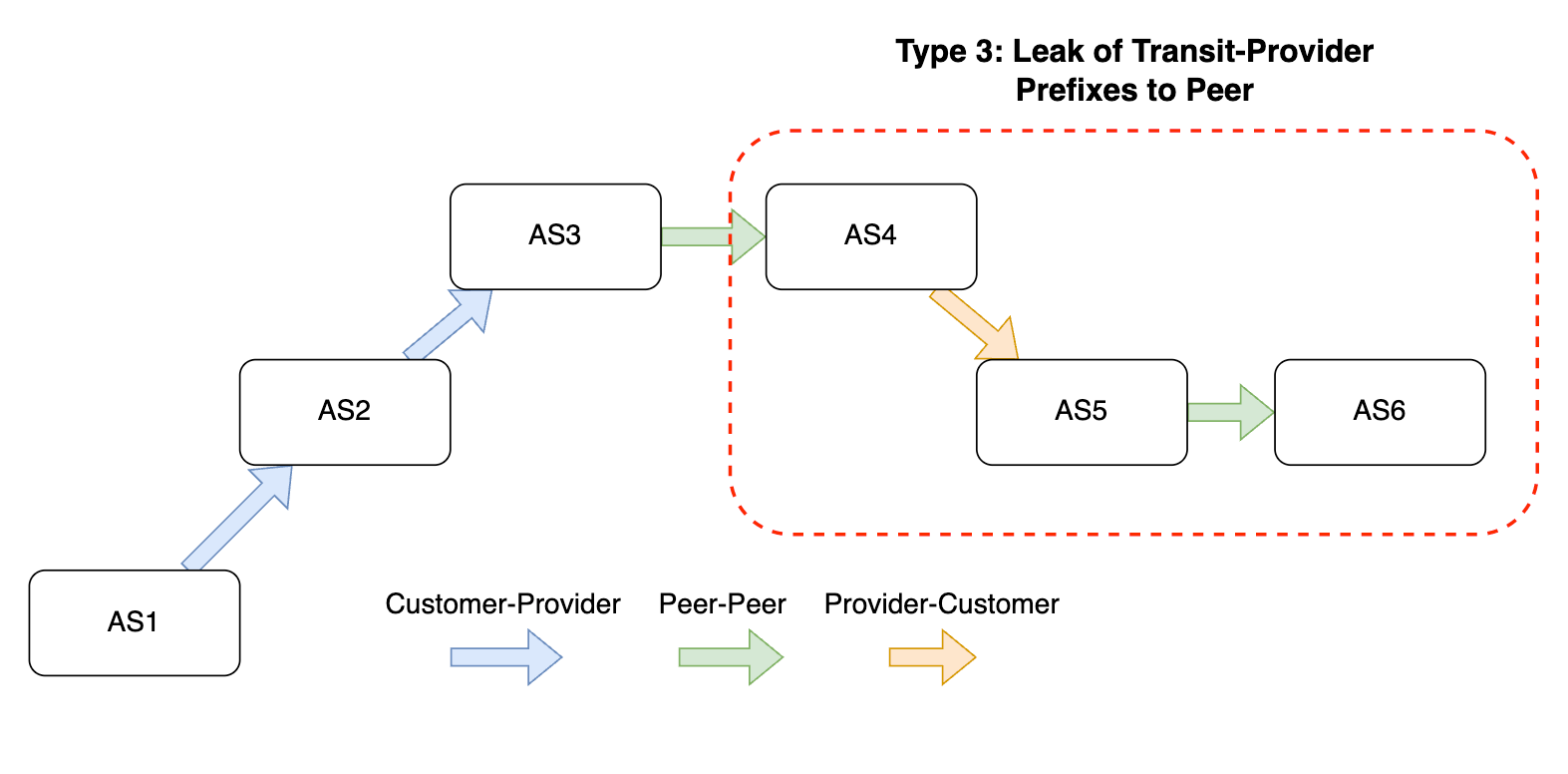
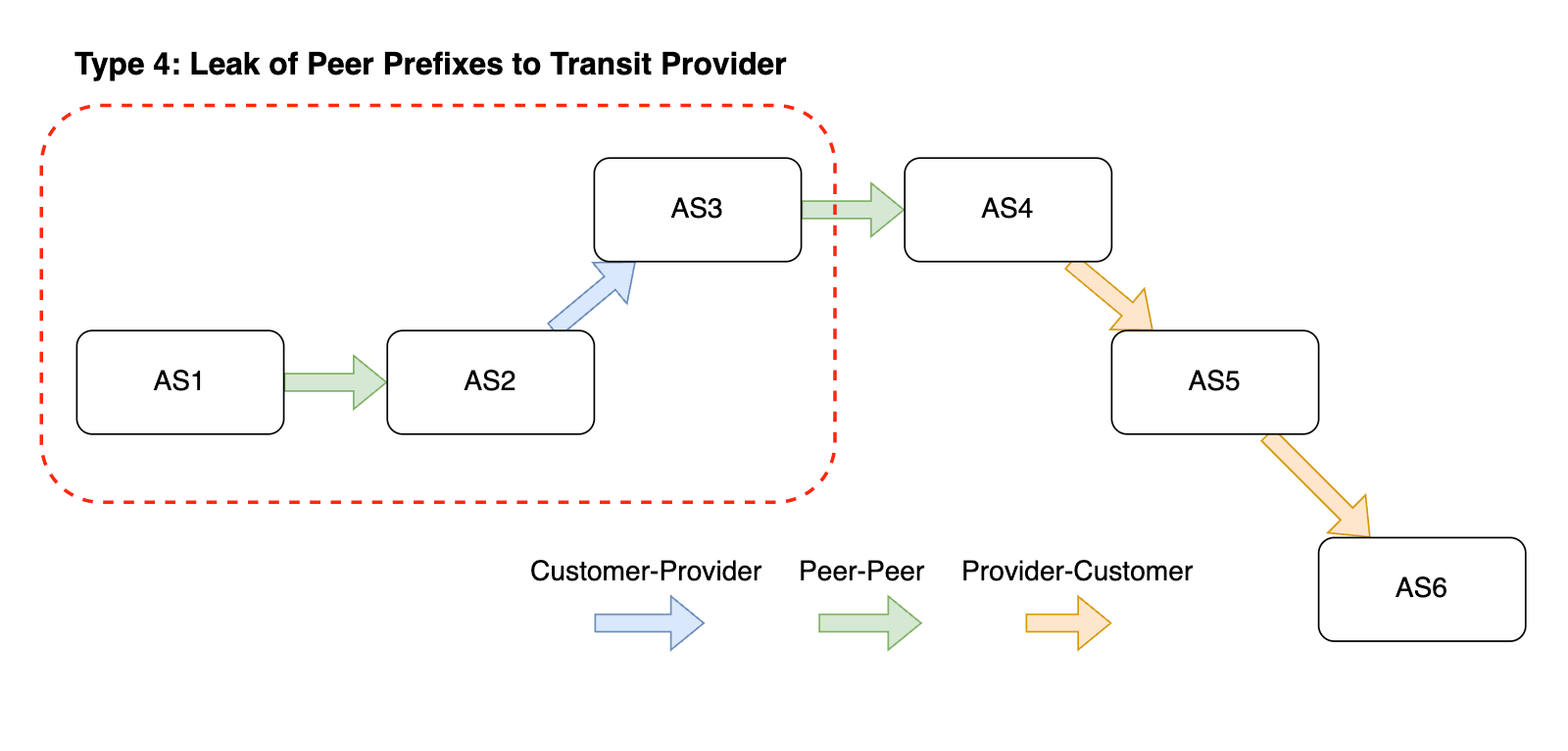
Large Internet outages aren’t always caused by cable cuts or natural disasters — sometimes, they stem from routing mistakes or security gaps. Route hijacks, leaks, and spoofed announcements can disrupt traffic on a national scale. How well networks protect themselves against these incidents is a key part of resilience, and that’s where network hygiene comes in.
Network hygiene refers to the security and operational practices that make the global routing system more trustworthy. This includes:
-
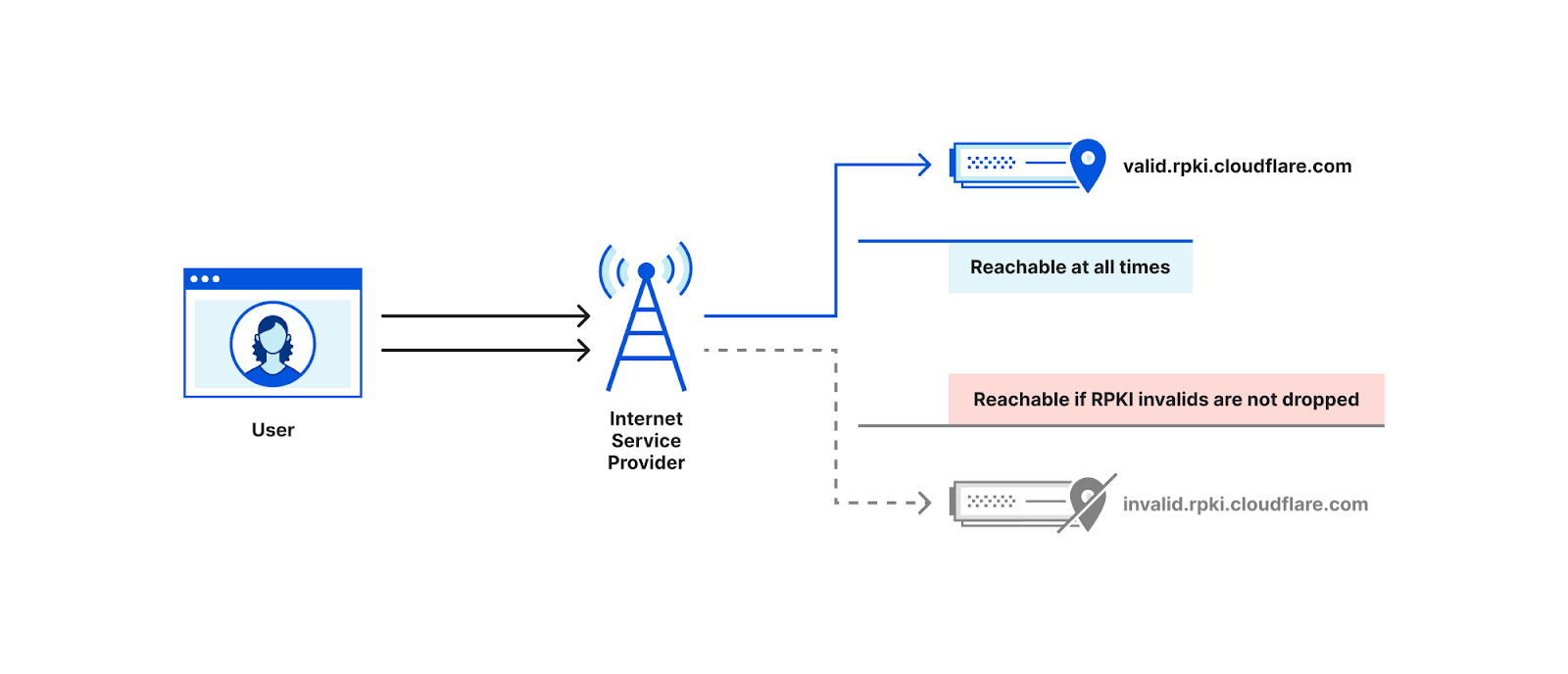
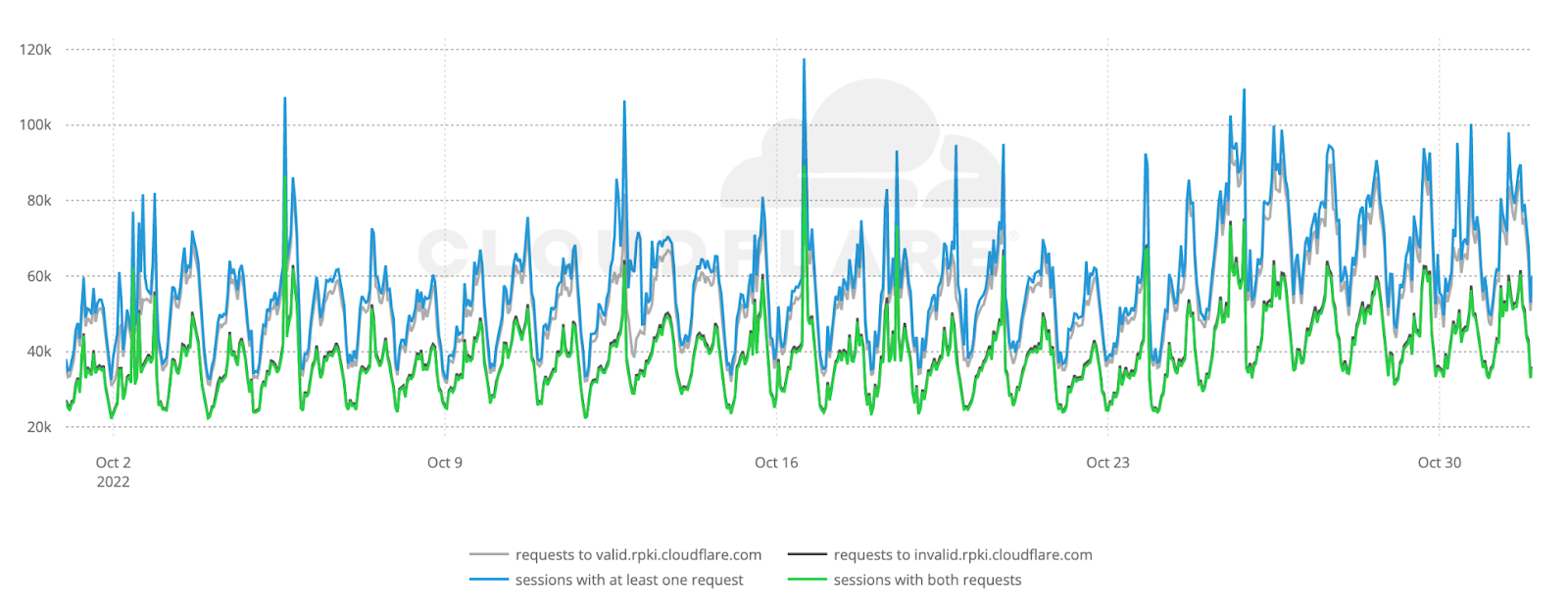
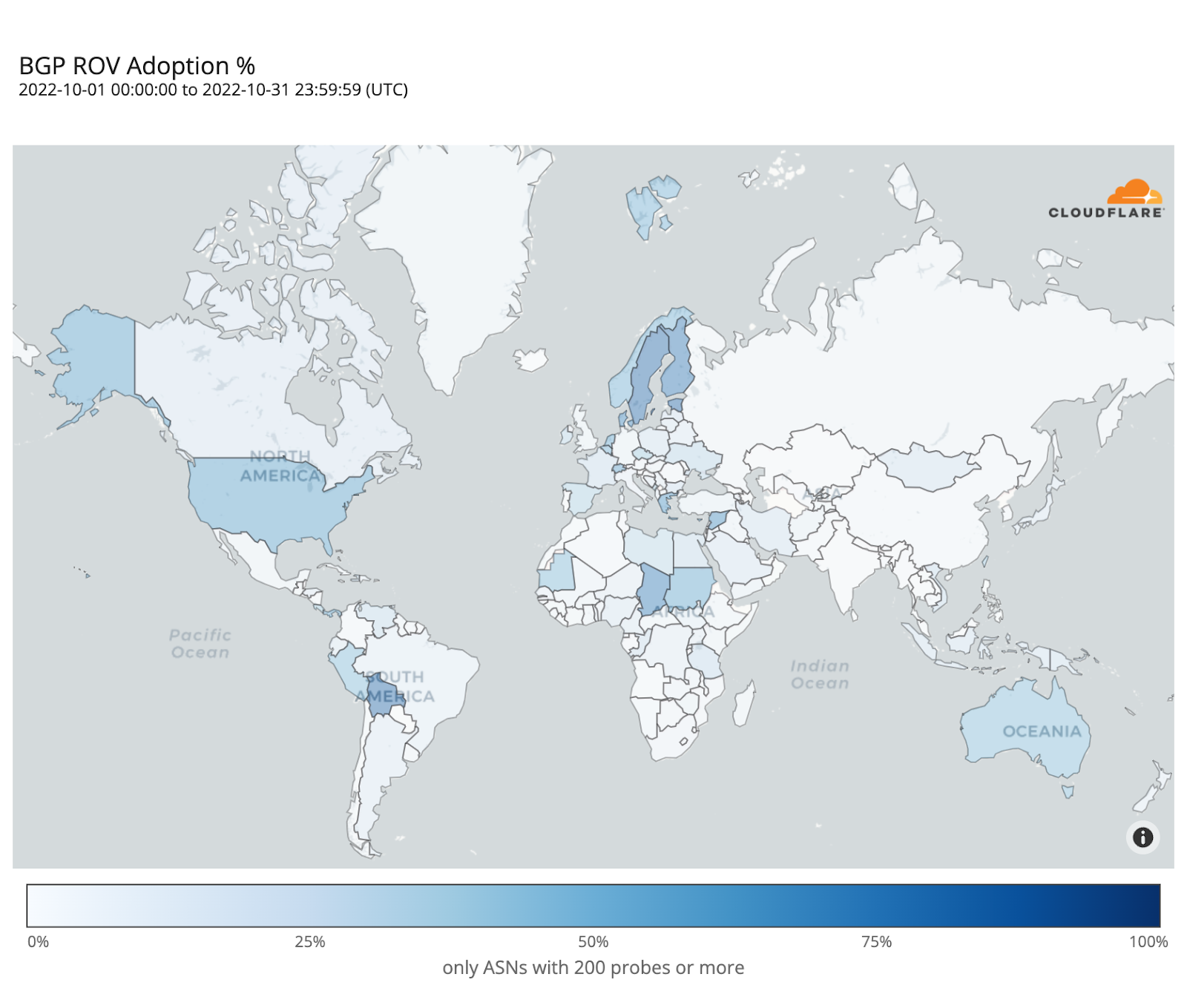
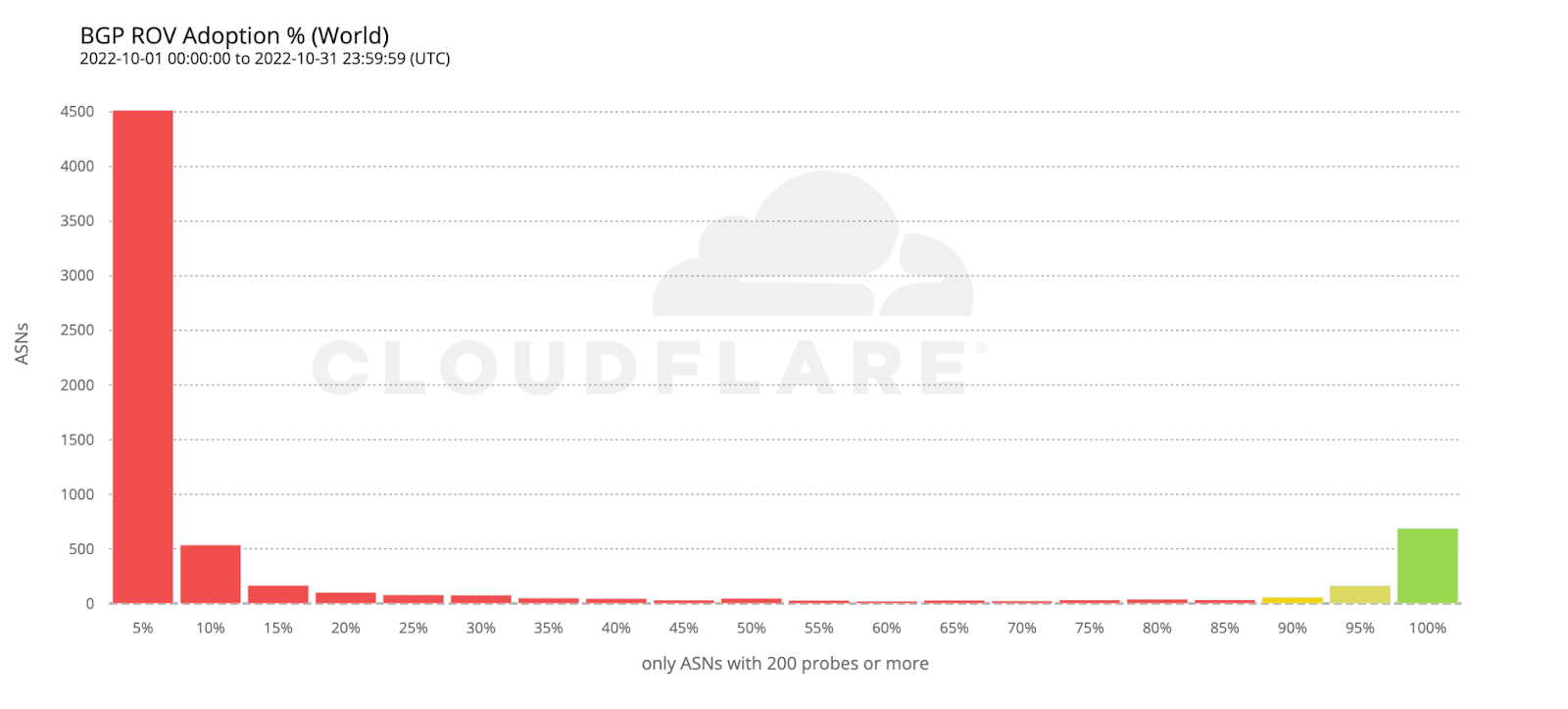
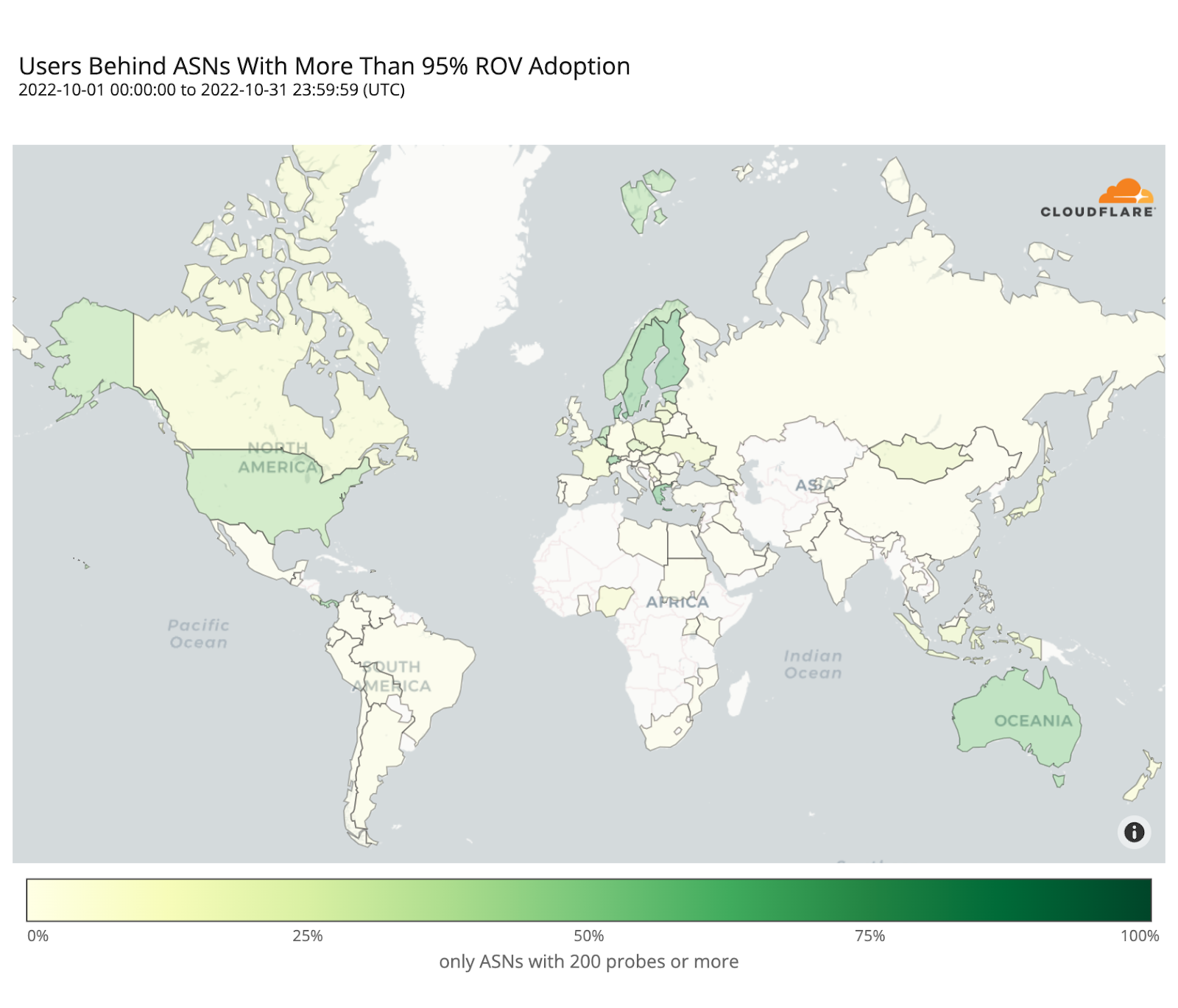
Cryptographic validation, like RPKI, to prevent unauthorized route announcements. ROA Coverage measures the share of announced IPv4/IPv6 space with valid Route Origin Authorizations (ROAs), indicating participation in the RPKI ecosystem. ROV Deployment gauges how many networks drop invalid routes, but detecting active filtering is difficult. Policymakers can improve visibility by supporting independent measurements, data transparency, and standardized reporting.
-
Filtering and cooperative norms, where networks block bogus routes and follow best practices when sharing routing information.
-
Consistent deployment across both domestic networks and their international upstreams, since traffic often crosses multiple jurisdictions.
Strong hygiene practices reduce the likelihood of systemic routing failures and limit their impact when they occur. We actively support and monitor the adoption of these mechanisms, for instance through crowd-sourced measurements and public advocacy, because every additional network that validates routes and filters traffic contributes to a safer and more resilient Internet for everyone.
Another critical aspect of Internet hygiene is mitigating DDoS attacks, which often rely on IP address spoofing to amplify traffic and obscure the attacker’s origin. BCP-38, the IETF’s network ingress filtering recommendation, addresses this by requiring operators to block packets with spoofed source addresses, reducing a region’s role as a launchpad for global attacks. While BCP-38 does not prevent a network from being targeted, its deployment is a key indicator of collective security responsibility. Measuring compliance requires active testing from inside networks, which is carried out by the CAIDA Spoofer Project. Although the global sample remains limited, these metrics offer valuable insight into both the technical effectiveness and the security engagement of a nation’s network community, complementing RPKI in strengthening the overall routing security posture.
Beyond securing individual networks through mechanisms like RPKI and BCP-38, strengthening the Internet’s resilience also depends on collective action and visibility. While origin validation and anti-spoofing reduce specific classes of threats, broader frameworks and shared measurement infrastructures are essential to address systemic risks and enable coordinated responses.
The Mutually Agreed Norms for Routing Security (MANRS) initiative promotes Internet resilience by defining a clear baseline of best practices. It is not a new technology but a framework fostering collective responsibility for global routing security. MANRS focuses on four key actions: filtering incorrect routes, anti-spoofing, coordination through accurate contact information, and global validation using RPKI and IRRs. While many networks implement these independently, MANRS participation signals a public commitment to these norms and to strengthening the shared security ecosystem.
Additionally, a region’s participation in public measurement platforms reflects its Internet observability, which is essential for fault detection, impact assessment, and incident response. RIPE Atlas and CAIDA Ark provide dense data-plane measurements; RouteViews and RIPE RIS collect BGP routing data to detect anomalies; and PeeringDB documents interconnection details, reflecting operational maturity and integration into the global peering fabric. Together, these platforms underpin observatories like IODA and GRIP, which combine BGP and active data to detect outages and routing incidents in near real time, offering critical visibility into Internet health and security.
Measuring Internet resilience is complex, but it’s not impossible. By using publicly available data, we can create a transparent and reproducible framework to identify strengths, weaknesses, and single points of failure in any network ecosystem.
This isn’t just a theoretical exercise. For policymakers, this data can inform infrastructure investment and pro-competitive policies that encourage diversity. For network operators, it provides a benchmark to assess their own resilience and that of their partners. And for everyone who relies on the Internet, it’s a critical step toward building a more stable, secure, and reliable global network.
For more details of the framework, including a full table of the metrics and links to source code, please refer to the full paper: Regional Perspectives for Route Resilience in a Global Internet: Metrics, Methodology, and Pathways for Transparency published at TPRC23.