Post Syndicated from Vasilis Giotsas original https://blog.cloudflare.com/detecting-cgn-to-reduce-collateral-damage/
IP addresses have historically been treated as stable identifiers for non-routing purposes such as for geolocation and security operations. Many operational and security mechanisms, such as blocklists, rate-limiting, and anomaly detection, rely on the assumption that a single IP address represents a cohesive, accountable entity or even, possibly, a specific user or device.
But the structure of the Internet has changed, and those assumptions can no longer be made. Today, a single IPv4 address may represent hundreds or even thousands of users due to widespread use of Carrier-Grade Network Address Translation (CGNAT), VPNs, and proxy middleboxes. This concentration of traffic can result in significant collateral damage – especially to users in developing regions of the world – when security mechanisms are applied without taking into account the multi-user nature of IPs.
This blog post presents our approach to detecting large-scale IP sharing globally. We describe how we build reliable training data, and how detection can help avoid unintentional bias affecting users in regions where IP sharing is most prevalent. Arguably it’s those regional variations that motivate our efforts more than any other.
Our work was initially motivated by a simple observation: CGNAT is a likely unseen source of bias on the Internet. Those biases would be more pronounced wherever there are more users and few addresses, such as in developing regions. And these biases can have profound implications for user experience, network operations, and digital equity.
The reasons are understandable for many reasons, not least because of necessity. Countries in the developing world often have significantly fewer available IPs, and more users. The disparity is a historical artifact of how the Internet grew: the largest blocks of IPv4 addresses were allocated decades ago, primarily to organizations in North America and Europe, leaving a much smaller pool for regions where Internet adoption expanded later.
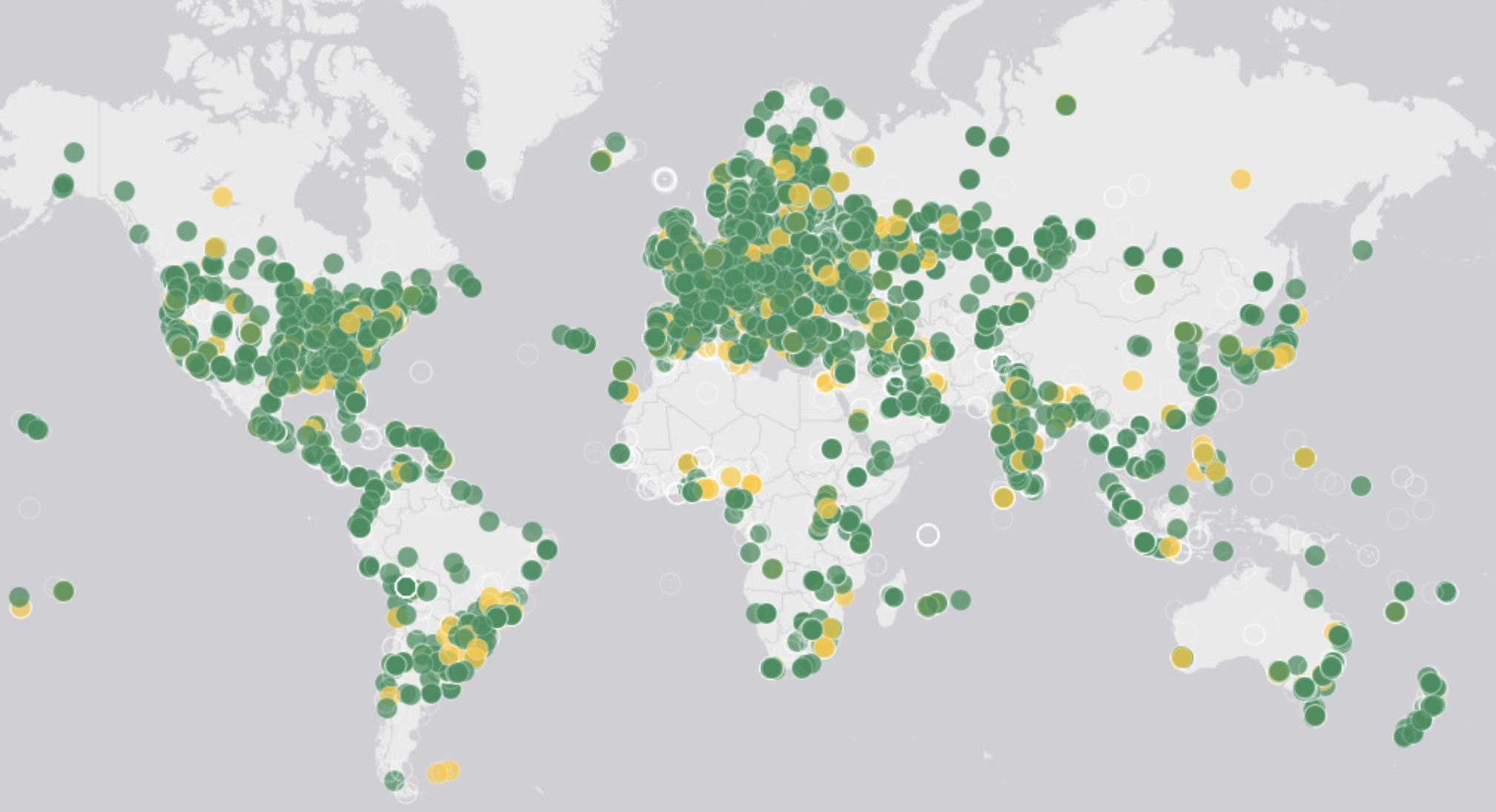
To visualize the IPv4 allocation gap, we plot country-level ratios of users to IP addresses in the figure below. We take online user estimates from the World Bank Group and the number of IP addresses in a country from Regional Internet Registry (RIR) records. The colour-coded map that emerges shows that the usage of each IP address is more concentrated in regions that generally have poor Internet penetration. For example, large portions of Africa and South Asia appear with the highest user-to-IP ratios. Conversely, the lowest user-to-IP ratios appear in Australia, Canada, Europe, and the USA — the very countries that otherwise have the highest Internet user penetration numbers.

The scarcity of IPv4 address space means that regional differences can only worsen as Internet penetration rates increase. A natural consequence of increased demand in developing regions is that ISPs would rely even more heavily on CGNAT, and is compounded by the fact that CGNAT is common in mobile networks that users in developing regions so heavily depend on. All of this means that actions known to be based on IP reputation or behaviour would disproportionately affect developing economies.
Cloudflare is a global network in a global Internet. We are sharing our methodology so that others might benefit from our experience and help to mitigate unintended effects. First, let’s better understand CGNAT.
Large-scale IP address sharing is primarily achieved through two distinct methods. The first, and more familiar, involves services like VPNs and proxies. These tools emerge from a need to secure corporate networks or improve users’ privacy, but can be used to circumvent censorship or even improve performance. Their deployment also tends to concentrate traffic from many users onto a small set of exit IPs. Typically, individuals are aware they are using such a service, whether for personal use or as part of a corporate network.
Separately, another form of large-scale IP sharing often goes unnoticed by users: Carrier-Grade NAT (CGNAT). One way to explain CGNAT is to start with a much smaller version of network address translation (NAT) that very likely exists in your home broadband router, formally called a Customer Premises Equipment (or CPE), which translates unseen private addresses in the home to visible and routable addresses in the ISP. Once traffic leaves the home, an ISP may add an additional enterprise-level address translation that causes many households or unrelated devices to appear behind a single IP address.
The crucial difference between large-scale IP sharing is user choice: carrier-grade address sharing is not a user choice, but is configured directly by Internet Service Providers (ISPs) within their access networks. Users are not aware that CGNATs are in use.
The primary driver for this technology, understandably, is the exhaustion of the IPv4 address space. IPv4’s 32-bit architecture supports only 4.3 billion unique addresses — a capacity that, while once seemingly vast, has been completely outpaced by the Internet’s explosive growth. By the early 2010s, Regional Internet Registries (RIRs) had depleted their pools of unallocated IPv4 addresses. This left ISPs unable to easily acquire new address blocks, forcing them to maximize the use of their existing allocations.
While the long-term solution is the transition to IPv6, CGNAT emerged as the immediate, practical workaround. Instead of assigning a unique public IP address to each customer, ISPs use CGNAT to place multiple subscribers behind a single, shared IP address. This practice solves the problem of IP address scarcity. Since translated addresses are not publicly routable, CGNATs have also had the positive side effect of protecting many home devices that might be vulnerable to compromise.
CGNATs also create significant operational fallout stemming from the fact that hundreds or even thousands of clients can appear to originate from a single IP address. This means an IP-based security system may inadvertently block or throttle large groups of users as a result of a single user behind the CGNAT engaging in malicious activity.
This isn’t a new or niche issue. It has been recognized for years by the Internet Engineering Task Force (IETF), the organization that develops the core technical standards for the Internet. These standards, known as Requests for Comments (RFCs), act as the official blueprints for how the Internet should operate. RFC 6269, for example, discusses the challenges of IP address sharing, while RFC 7021 examines the impact of CGNAT on network applications. Both explain that traditional abuse-mitigation techniques, such as blocklisting or rate-limiting, assume a one-to-one relationship between IP addresses and users: when malicious activity is detected, the offending IP address can be blocked to prevent further abuse.
In shared IPv4 environments, such as those using CGNAT or other address-sharing techniques, this assumption breaks down because multiple subscribers can appear under the same public IP. Blocking the shared IP therefore penalizes many innocent users along with the abuser. In 2015 Ofcom, the UK’s telecommunications regulator, reiterated these concerns in a report on the implications of CGNAT where they noted that, “In the event that an IPv4 address is blocked or blacklisted as a source of spam, the impact on a CGNAT would be greater, potentially affecting an entire subscriber base.”
While the hope was that CGNAT was only a temporary solution until the eventual switch to IPv6, as the old proverb says, nothing is more permanent than a temporary solution. While IPv6 deployment continues to lag, CGNAT deployments have become increasingly common, and so do the related problems.
To enable a fairer treatment of users behind CGNAT IPs by security techniques that rely on IP reputation, our goal is to identify large-scale IP sharing. This allows traffic filtering to be better calibrated and collateral damage minimized. Additionally, we want to distinguish CGNAT IPs from other large-scale sharing (LSS) IP technologies, such as VPNs and proxies, because we may need to take different approaches to different kinds of IP-sharing technologies.
To do this, we decided to take advantage of Cloudflare’s extensive view of the active IP clients, and build a supervised learning classifier that would distinguish CGNAT and VPN/proxy IPs from IPs that are allocated to a single subscriber (non-LSS IPs), based on behavioural characteristics. The figure below shows an overview of our supervised classifier:

While our classification approach is straightforward, a significant challenge is the lack of a reliable, comprehensive, and labeled dataset of CGNAT IPs for our training dataset.
Detection begins by building an initial dataset of IPs believed to be associated with CGNAT. Cloudflare has vast HTTP and traffic logs. Unfortunately there is no signal or label in any request to indicate what is or is not a CGNAT.
To build an extensive labelled dataset to train our ML classifier, we employ a combination of network measurement techniques, as described below. We rely on public data sources to help disambiguate an initial set of large-scale shared IP addresses from others in Cloudflare’s logs.
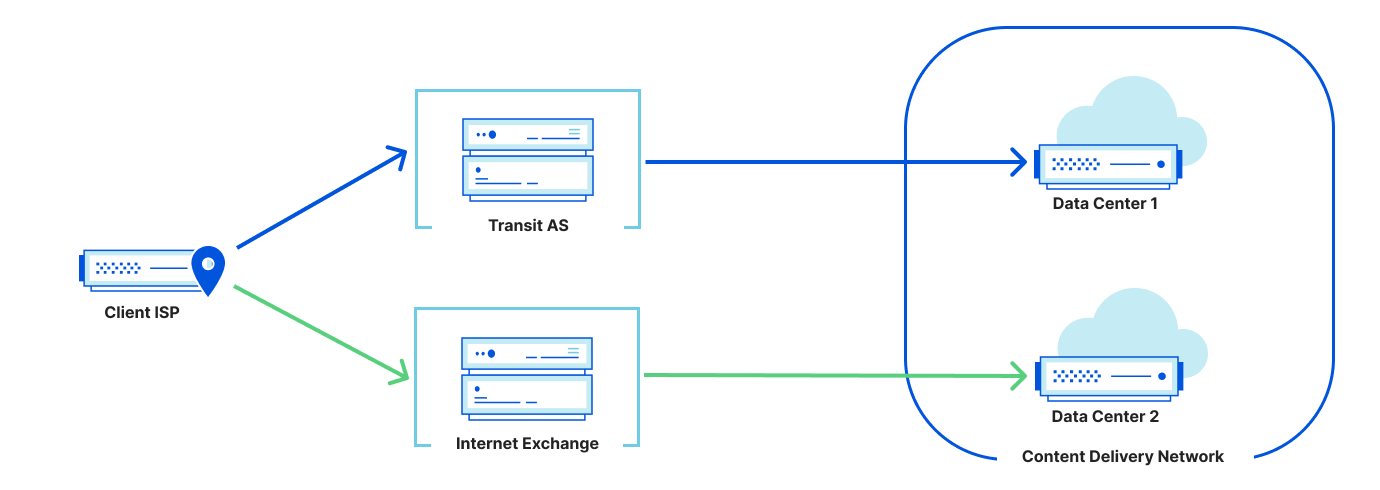
The presence of a client behind CGNAT can often be inferred through traceroute analysis. CGNAT requires ISPs to insert a NAT step that typically uses the Shared Address Space (RFC 6598) after the customer premises equipment (CPE). By running a traceroute from the client to its own public IP and examining the hop sequence, the appearance of an address within 100.64.0.0/10 between the first private hop (e.g., 192.168.1.1) and the public IP is a strong indicator of CGNAT.
Traceroute can also reveal multi-level NAT, which CGNAT requires, as shown in the diagram below. If the ISP assigns the CPE a private RFC 1918 address that appears right after the local hop, this indicates at least two NAT layers. While ISPs sometimes use private addresses internally without CGNAT, observing private or shared ranges immediately downstream combined with multiple hops before the public IP strongly suggests CGNAT or equivalent multi-layer NAT.

Although traceroute accuracy depends on router configurations, detecting private and shared IP ranges is a reliable way to identify large-scale IP sharing. We apply this method to distributed traceroutes from over 9,000 RIPE Atlas probes to classify hosts as behind CGNAT, single-layer NAT, or no NAT.
Many operators encode metadata about their IPs in the corresponding reverse DNS pointer (PTR) record that can signal administrative attributes and geographic information. We first query the DNS for PTR records for the full IPv4 space and then filter for a set of known keywords from the responses that indicate a CGNAT deployment. For example, each of the following three records matches a keyword (cgnat, cgn or lsn) used to detect CGNAT address space:
node-lsn.pool-1-0.dynamic.totinternet.net
103-246-52-9.gw1-cgnat.mobile.ufone.nz
cgn.gsw2.as64098.net
WHOIS and Internet Routing Registry (IRR) records may also contain organizational names, remarks, or allocation details that reveal whether a block is used for CGNAT pools or residential assignments.
Given that both PTR and WHOIS records may be manually maintained and therefore may be stale, we try to sanitize the extracted data by validating the fact that the corresponding ISPs indeed use CGNAT based on customer and market reports.
Compiling a list of VPN and proxy IPs is more straightforward, as we can directly find such IPs in public service directories for anonymizers. We also subscribe to multiple VPN providers, and we collect the IPs allocated to our clients by connecting to a unique HTTP endpoint under our control.
By combining the above techniques, we accumulated a dataset of labeled IPs for more than 200K CGNAT IPs, 180K VPNs & proxies and close to 900K IPs allocated that are not LSS IPs. These were the entry points to modeling with machine learning.
Our hypothesis was that aggregated activity from CGNAT IPs is distinguishable from activity generated from other non-CGNAT IP addresses. Our feature extraction is an evaluation of that hypothesis — since networks do not disclose CGNAT and other uses of IPs, the quality of our inference is strictly dependent on our confidence in the training data. We claim the key discriminator is diversity, not just volume. For example, VM-hosted scanners may generate high numbers of requests, but with low information diversity. Similarly, globally routable CPEs may have individually unique characteristics, but with volumes that are less likely to be caught at lower sampling rates.
In our feature extraction, we parse a 1% sampled HTTP requests log for distinguishing features of IPs compiled in our reference set, and the same features for the corresponding /24 prefix (namely IPs with the same first 24 bits in common). We analyse the features for each of the VPNs, proxies, CGNAT, or non LSS IP. We find that features from the following broad categories are key discriminators for the different types of IPs in our training dataset:
-
Client-side signals: We analyze the aggregate properties of clients connecting from an IP. A large, diverse user base (like on a CGNAT) naturally presents a much wider statistical variety of client behaviors and connection parameters than a single-tenant server or a small business proxy.
-
Network and transport-level behaviors: We examine traffic at the network and transport layers. The way a large-scale network appliance (like a CGNAT) manages and routes connections often leaves subtle, measurable artifacts in its traffic patterns, such as in port allocation and observed network timing.
-
Traffic volume and destination diversity: We also model the volume and “shape” of the traffic. An IP representing thousands of independent users will, on average, generate a higher volume of requests and target a much wider, less correlated set of destinations than an IP representing a single user.
Crucially, to distinguish CGNAT from VPNs and proxies (which is absolutely necessary for calibrated security filtering), we had to aggregate these features at two different scopes: per-IP and per /24 prefixes. CGNAT IPs are typically allocated large blocks of IPs, whereas VPNs IPs are more scattered across different IP prefixes.
We compute the above features from HTTP logs over 24-hour intervals to increase data volume and reduce noise due to DHCP IP reallocation. The dataset is split into 70% training and 30% testing sets with disjoint /24 prefixes, and VPN and proxy labels are merged due to their similarity and lower operational importance compared to CGNAT detection.
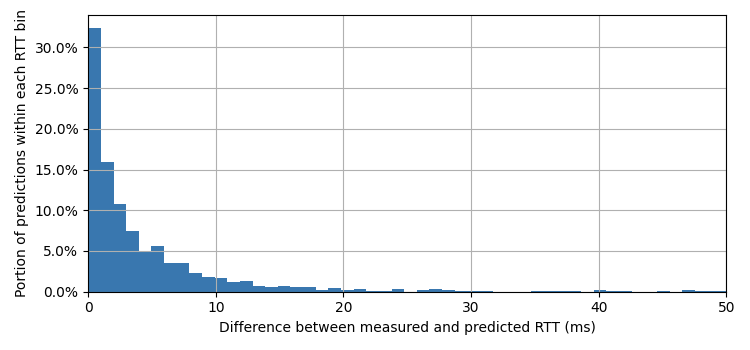
Then we train a multi-class XGBoost model with class weighting to address imbalance, assigning each IP to the class with the highest predicted probability. XGBoost is well-suited for this task because it efficiently handles large feature sets, offers strong regularization to prevent overfitting, and delivers high accuracy with limited parameter tuning. The classifier achieves 0.98 accuracy, 0.97 weighted F1, and 0.04 log loss. The figure below shows the confusion matrix of the classification.

Our model is accurate for all three labels. The errors observed are mainly misclassifications of VPN/proxy IPs as CGNATs, mostly for VPN/proxy IPs that are within a /24 prefix that is also shared by broadband users outside of the proxy service. We also evaluate the prediction accuracy using k-fold cross validation, which provides a more reliable estimate of performance by training and validating on multiple data splits, reducing variance and overfitting compared to a single train–test split. We select 10 folds and we evaluate the Area Under the ROC Curve (AUC) and the multi-class logloss. We achieve a macro-average AUC of 0.9946 (σ=0.0069) and log loss of 0.0429 (σ=0.0115). Prefix-level features are the most important contributors to classification performance.
The figure below shows the daily number of CGNAT IP inferences generated by our CDN-deployed detection service between December 17, 2024 and January 9, 2025. The number of inferences remains largely stable, with noticeable dips during weekends and holidays such as Christmas and New Year’s Day. This pattern reflects expected seasonal variations, as lower traffic volumes during these periods lead to fewer active IP ranges and reduced request activity.

Next, recall that actions that rely on IP reputation or behaviour may be unduly influenced by CGNATs. One such example is bot detection. In an evaluation of our systems, we find that bot detection is resilient to those biases. However, we also learned that customers are more likely to rate limit IPs that we find are CGNATs.
We analyze bot labels by analyzing how often requests from CGNAT and non-CGNAT IPs are labeled as bots. Cloudflare assigns a bot score to each HTTP request using CatBoost models trained on various request features, and these scores are then exposed through the Web Application Firewall (WAF), allowing customers to apply filtering rules. The median bot rate is nearly identical for CGNAT (4.8%) and non-CGNAT (4.7%) IPs. However, the mean bot rate is notably lower for CGNATs (7%) than for non-CGNATs (13.1%), indicating different underlying distributions. Non-CGNAT IPs show a much wider spread, with some reaching 100% bot rates, while CGNAT IPs cluster mostly below 15%. This suggests that non-CGNAT IPs tend to be dominated by either human or bot activity, whereas CGNAT IPs reflect mixed behavior from many end users, with human traffic prevailing.
Interestingly, despite bot scores that indicate traffic is more likely to be from human users, CGNAT IPs are subject to rate limiting three times more often than non-CGNAT IPs. This is likely because multiple users share the same public IP, increasing the chances that legitimate traffic gets caught by customers’ bot mitigation and firewall rules.
This tells us that users behind CGNAT IPs are indeed susceptible to collateral effects, and identifying those IPs allows us to tune mitigation strategies to disrupt malicious traffic quickly while reducing collateral impact on benign users behind the same address.
One of the early motivations of this work was to understand if our knowledge about IP addresses might hide a bias along socio-economic boundaries—and in particular if an action on an IP address may disproportionately affect populations in developing nations, often referred to as the Global South. Identifying where different IPs exist is a necessary first step.
The map below shows the fraction of a country’s inferred CGNAT IPs over all IPs observed in the country. Regions with a greater reliance on CGNAT appear darker on the map. This view highlights the geodiversity of CGNATs in terms of importance; for example, much of Africa and Central and Southeast Asia rely on CGNATs.

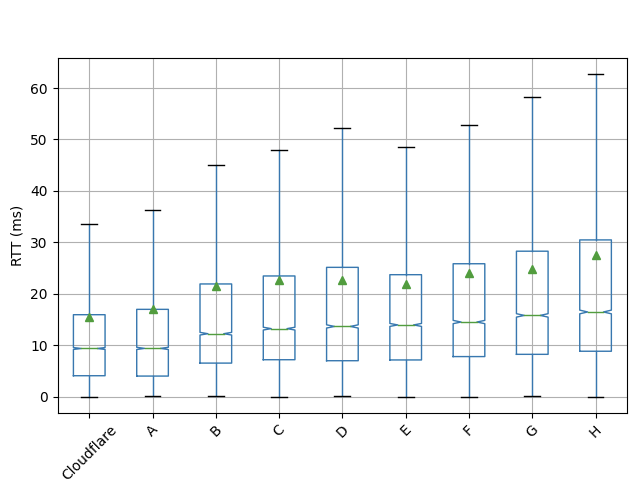
As further evidence of continental differences, the boxplot below shows the distribution of distinct user agents per IP across /24 prefixes inferred to be part of a CGNAT deployment in each continent.

Notably, Africa has a much higher ratio of user agents to IP addresses than other regions, suggesting more clients share the same IP in African ASNs. So, not only do African ISPs rely more extensively on CGNAT, but the number of clients behind each CGNAT IP is higher.
While the deployment rate of CGNAT per country is consistent with the users-per-IP ratio per country, it is not sufficient by itself to confirm deployment. The scatterplot below shows the number of users (according to APNIC user estimates) and the number of IPs per ASN for ASNs where we detect CGNAT. ASNs that have fewer available IP addresses than their user base appear below the diagonal. Interestingly the scatterplot indicates that many ASNs with more addresses than users still choose to deploy CGNAT. Presumably, these ASNs provide additional services beyond broadband, preventing them from dedicating their entire address pool to subscribers.

Accurate detection of CGNAT IPs is crucial for minimizing collateral effects in network operations and for ensuring fair and effective application of security measures. Our findings underscore the potential socio-economic and geographical variations in the use of CGNATs, revealing significant disparities in how IP addresses are shared across different regions.
At Cloudflare we are going beyond just using these insights to evaluate policies and practices. We are using the detection systems to improve our systems across our application security suite of features, and working with customers to understand how they might use these insights to improve the protections they configure.
Our work is ongoing and we’ll share details as we go. In the meantime, if you’re an ISP or network operator that operates CGNAT and want to help, get in touch at [email protected]. Sharing knowledge and working together helps make better and equitable user experience for subscribers, while preserving web service safety and security.