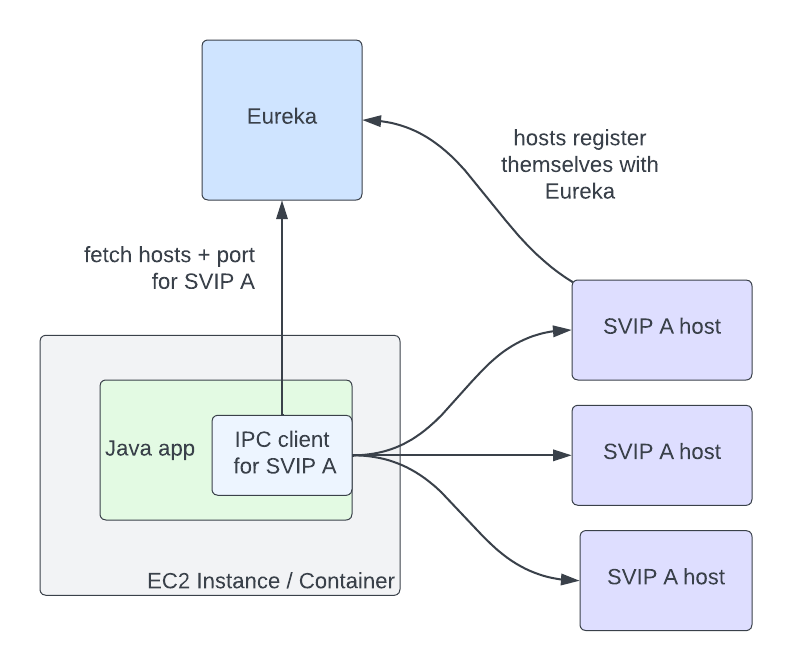
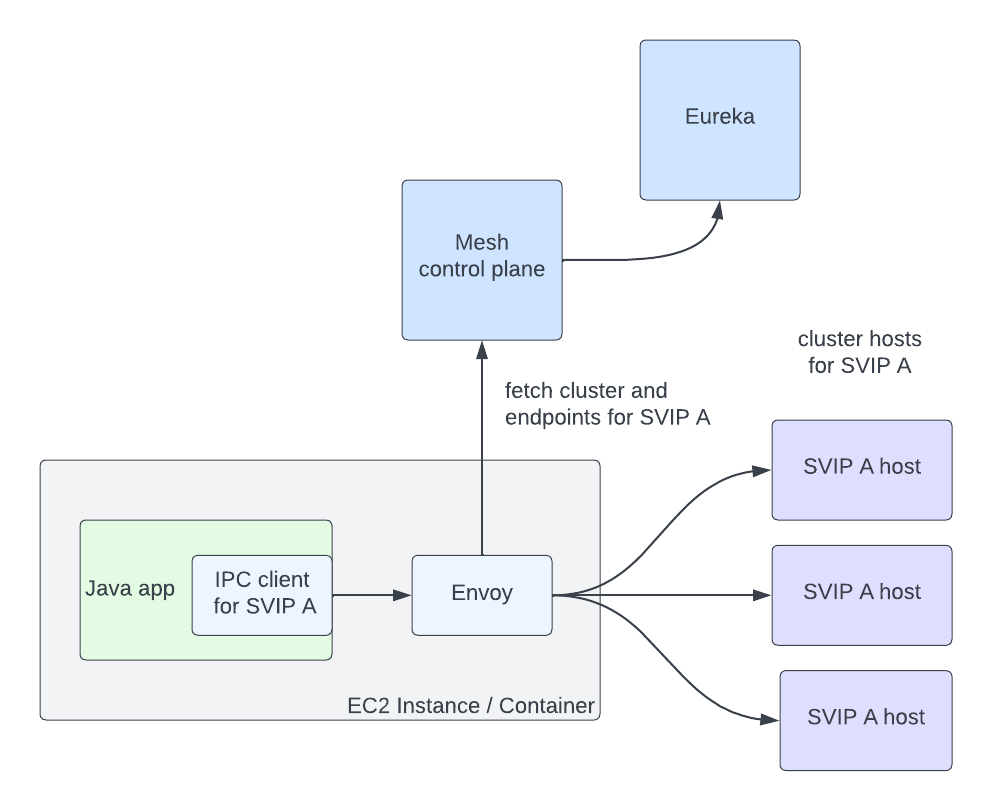
Post Syndicated from Grab Tech original https://engineering.grab.com/service-mesh-evolution
The challenge: When good enough isn’t good enough
Picture this: It’s 2024, and Grab’s microservices ecosystem is thriving with over 1000 services running in different infrastructure. But behind the scenes, our service mesh setup is showing its age. We’re running Consul with a fallback mechanism called Catcher – a setup that has served us well but is starting to feel like wearing a winter coat in Singapore’s heat.
The challenges we faced were becoming increasingly apparent. A single Consul server issue could trigger a fleet-wide impact, affecting critical services like food delivery and ride-hailing. Our fallback solution, while necessary, added complexity and limited our ability to implement advanced features like circuit breaking and retry policies. As we expanded our presence across Southeast Asia, the need for robust multi-cluster support became more critical than ever. The existing setup struggled with modern requirements like advanced traffic management and fine-grained security controls, while the growing complexity of our microservices architecture demanded better traffic management capabilities.
The complexity of Grab’s infrastructure
Our infrastructure landscape is as diverse as the Southeast Asian markets we serve. We operate a complex hybrid environment encompassing services on traditional VMs and EKS clusters with diverse infrastructure provisioning and deployment approaches. This diversity isn’t merely about deployment models—it’s about meeting the unique needs of different business units and regulatory requirements across the region.
The complexity doesn’t stop there. We handle dual traffic protocols (HTTP and gRPC) across our entire service ecosystem. Our services communicate across cloud providers between AWS and GCP. Within AWS alone, we maintain multiple organizations to segregate different Grab entities, each operating in its own isolated network. This multi-cloud, multi-protocol, multi-organization setup presented unique challenges for our service mesh implementation.
The quest for a better solution
Like any good tech team, we didn’t just jump to conclusions. We embarked on a thorough evaluation of service mesh solutions, considering various options including Application Load Balancer (ALB), Istio, AWS Lattice, and Linkerd. Our evaluation process was comprehensive and focused on real-world needs, examining everything from stability under high load to the performance impact on service-to-service communication.
We needed a solution that could handle our distributed architecture while maintaining operational simplicity. The ideal service mesh would need to integrate seamlessly with our existing infrastructure landscape while offering the flexibility to scale with our growing needs. After careful consideration, Istio emerged as the clear winner, offering robust multi-cluster support with flexible deployment models and a comprehensive set of features for traffic management, security, and observability.
What really sealed the deal was Istio’s strong Kubernetes integration and native support, combined with active community backing. The rich ecosystem of tools and integrations meant we wouldn’t be building everything from scratch, while the flexible deployment options could accommodate our unique requirements.
Designing our Istio architecture
When it came to designing our Istio implementation, we took a slightly unconventional approach. Instead of following the traditional “one control plane per cluster” pattern, we designed a more resilient architecture that would better suit our needs. We implemented multiple control planes running on dedicated Kubernetes clusters for better isolation and scalability, with active-active pairs ensuring high availability.
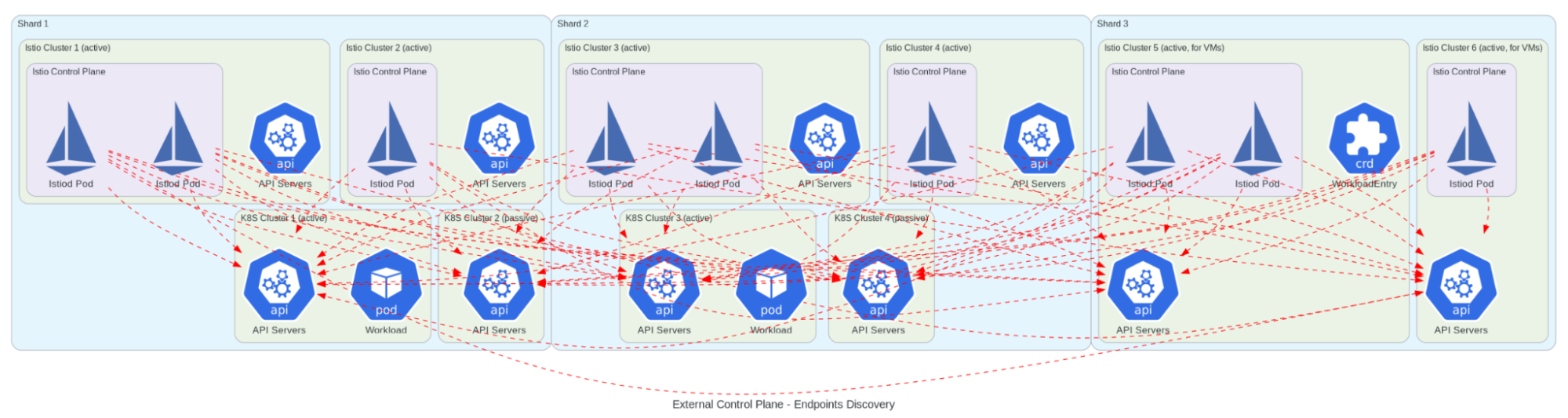
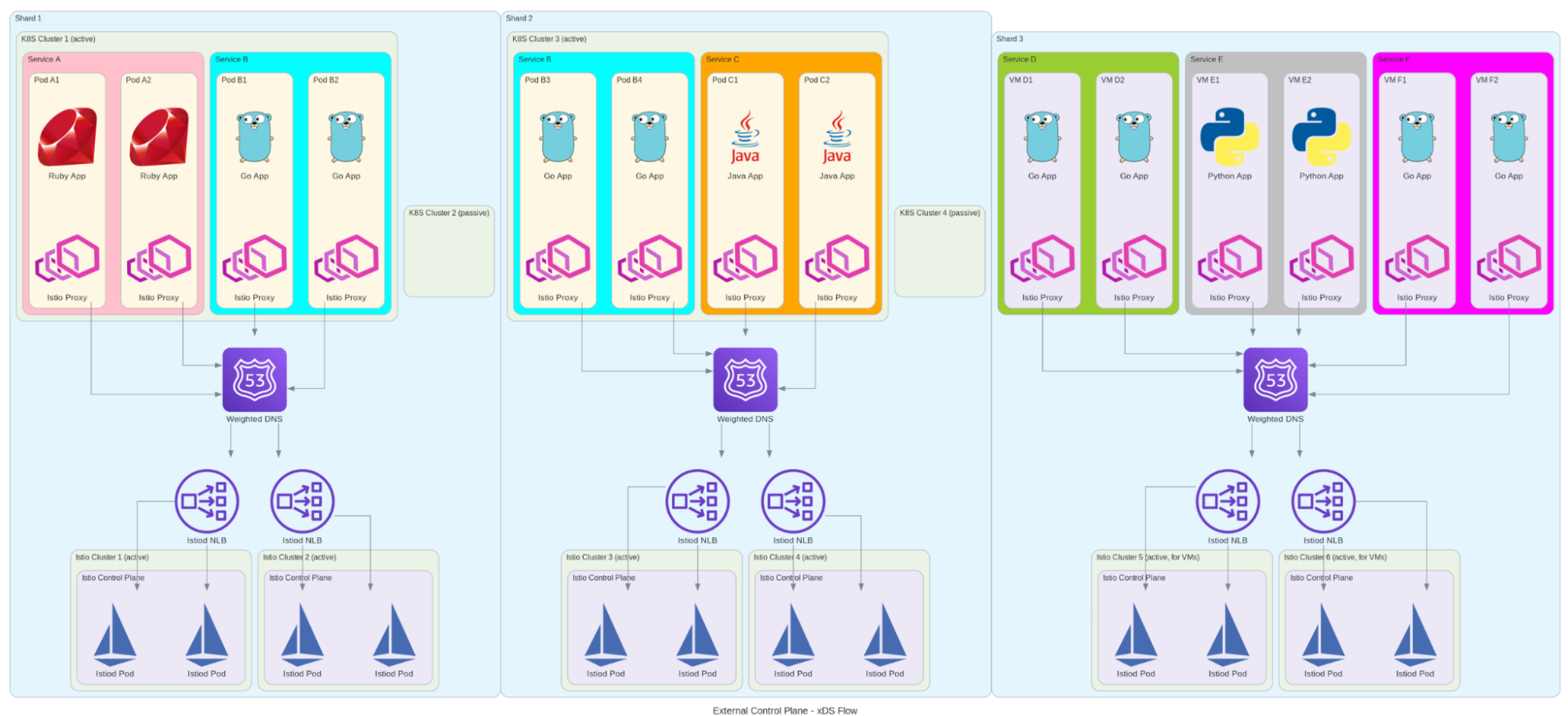
Our architecture needed to support high-throughput service-to-service communication while enabling complex routing rules for A/B testing and canary deployments. We implemented custom resource definitions for service mesh configuration and integrated with our existing monitoring and alerting systems. The organization-based mesh boundaries we designed would support our multi-tenant architecture, while our solution for cross-cluster endpoint discovery would ensure reliable service communication across our distributed system.
This design wasn’t just about following best practices – it was about learning from our past experiences with etcd and Consul. We wanted a setup that could handle Grab’s scale while maintaining simplicity and reliability. The architecture needed to support everything from high-throughput service-to-service communication to complex routing rules for A/B testing and canary deployments, all while maintaining fine-grained security policies and comprehensive observability.
The migration journey begins
In Q4 2024, we kicked off our migration journey with a clear plan. While our initial strategy focused on gRPC traffic migration, real-world priorities led us down a different path. Our first major milestone was the GCP to AWS migration, a cross-cloud initiative that would test our service mesh capabilities in a complex, multi-cloud environment.
This cross-cloud migration was a significant undertaking, requiring careful coordination between teams and careful consideration of network policies, security requirements, and service dependencies. We had to ensure seamless communication between services running in different cloud providers while maintaining security and performance standards.
Alongside our ongoing cloud migration efforts, we launched parallel initiatives focused on gRPC and HTTP traffic migration with cross-mesh connectivity requirements. This phase introduced distinct challenges, as it involved migrating business-critical services while implementing gradual traffic shifting capabilities and quick rollback mechanisms to ensure zero-downtime migrations. We also maintained close monitoring of performance metrics throughout the process.
Additionally, we needed to ensure seamless compatibility between different service mesh implementations and navigate the complexities of cross-mesh communication. The insights and experience gained from our cloud migration phase have proven invaluable in informing our approach and execution strategy for this critical migration effort.
The journey hasn’t been without its challenges. We’ve had to balance migration speed with stability while coordinating across multiple teams and organizations. Handling both gRPC and HTTP traffic patterns required careful planning and execution. We’ve had to deal with legacy systems and technical debt while training and supporting teams through the transition. Maintaining service continuity during these transitions has been our top priority.
Lessons learned
This journey has taught us several valuable lessons. We’ve learned that sometimes the standard approach isn’t the best fit, and innovation often comes from questioning assumptions. We’ve discovered the importance of balancing innovation with stability, taking calculated risks while building capability for a quick mitigation.
Keeping the bigger picture in mind has been crucial, considering long-term implications and planning for scale and growth. We’ve learned to document challenges and solutions, sharing knowledge across teams to avoid repeating mistakes. Most importantly, we’ve learned to stay flexible and adapt to changing needs, being ready to pivot when necessary while keeping an eye on emerging technologies.
What’s next?
The service mesh landscape is constantly evolving, and we’re excited to be part of this journey. Our next steps include continuing our migration efforts with a focus on stability while exploring mesh features like advanced traffic management, and enhanced security policies.
We’re also working on enhancing our operational capabilities through automated testing and validation, improved monitoring and alerting, and better debugging tools. As we progress, we’re committed to sharing our experiences with the community through open source contributions, conference participation, and technical blogs.
Shape the future with us
We’re not just implementing a service mesh—we’re architecting the backbone of Grab’s microservices future. Every decision prioritizes reliability, scalability, and maintainability, ensuring we build something that will stand the test of time.
The journey continues, and we’re excited about what lies ahead. Follow our progress for real-world insights that might shape your own service mesh evolution.
Want to help us build the future? We have exciting opportunities waiting for you.
Credits to the Service Mesh team: Aashif Bari, Hilman Kurniawan, Hofid Mashudi, Jingshan Pang, Kaitong Guo, Mikko Turpeinen, Sok Ann Yap, Jesse Nguyen, and Xing Yii.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!