Post Syndicated from Alexei Vladishev original https://blog.zabbix.com/zabbix-6-0-lts-the-next-great-leap-in-monitoring-by-alexei-vladishev-zabbix-summit-online-2021/17683/
The Zabbix Summit Online 2021 keynote speech by Zabbix founder and CEO Alexei Vladishev focuses on the role of Zabbix in modern, dynamic IT infrastructures. The keynote speech also highlights the major milestones leading up to Zabbix 6.0 LTS and together we take a look at the future of Zabbix.
The full recording of the speech is available on the official Zabbix Youtube channel.
Digital transformation journey
Infrastructure monitoring challenges
Zabbix – Universal Open Source enterprise-level monitoring solution
Cost-Effectiveness
Deploy Anywhere
Monitor Anything
Monitoring of Kubernetes and Hybrid Clouds
Data collection and Aggregation
Security on all levels
Powerful Solution for MSPs
Scalability and High Availability
Machine learning and Statistical analysis
More value to users
New visualization capabilities
IoT monitoring
Infrastructure as a code
Tags for classification
What’s next?
Advanced event correlation engine
Multi DC Monitoring
Zabbix Release Schedule
Zabbix Roadmap
Questions
First, let’s talk about how Zabbix plays a role as a part of the Digital Transformation journey for many companies.
As IT infrastructures evolve, there are many ongoing challenges. Most larger companies for example have a set of legacy systems that require to be integrated with more modern systems. This results in a mix of legacy and new technologies and protocols. This means that most management and monitoring tools need to support all of these technologies – Zabbix is no exception here.
Hybrid clouds, containers, and container orchestration systems such as K8S and OpenShift have also played an immense part in the digital transformation of enterprises. It has been a very major paradigm shift – from physical machines to virtual machines, to containers and hybrid parts. We certainly must provide the required set of technologies to monitor such environments and the monitoring endpoints unique to them.
The rapid increase in the complexity of IT infrastructures caused by the two previous points requires our tools to be a lot more scalable than before. We have many more moving parts, likely located in different locations that we need to stay aware of. This also means that any downtime is not acceptable – this is why the high availability of our tools is also vital to us.
Let’s not forget that with increased complexity, many new potential security attack vectors arise and our tools need to support features that can help us with minimizing the security risks.
But making our infrastructures more agile usually comes at a very real financial cost. We must not forget that most of the time we are working with a dedicated budget for our tools and procedures.
Infrastructure monitoring challenges
The increase in the complexity of IT infrastructures also poses multiple monitoring challenges that we have to strive to overcome:
- Requirements for scalability and high availability for our tools
- The growing number of devices and networks as well as the increased complexity of IT infrastructures
- Increasingly complex infrastructures often force us to utilize multiple tools to obtain the required metrics
- This leads to a requirement for a single pane of glass to enable centralized monitoring
- Collecting values is often not enough – we need to be able to leverage the collected data to gain the most value out of it
- We need a solution that can deliver centralized visualization and reporting based on the obtained data
- Our tools need to be hand-picked so that they can deliver the best ROI in an already complex infrastructure
Zabbix – Universal Open Source enterprise-level monitoring solution
Zabbix is a Universal free and Open Source enterprise-level monitoring solution. The tool comes at absolutely no cost and is available for everyone to try out and use. Zabbix provides the monitoring of modern IT infrastructures on multiple levels.
Universal is the term that we are focusing on. Given the open-source nature of the product, Zabbix can be used in infrastructures of different sizes – from small and medium organizations to large, globe-spanning enterprises. Zabbix is also capable of delivering monitoring of the whole IT stack – from hardware and network monitoring to high-level monitoring such as Business Service monitoring and more.
Cost-Effectiveness
Zabbix delivers a large set of enterprise-grade features at no cost! Features such as 2FA, Single sign-on solutions, no restrictions when it comes to data collection methods, number of monitored devices and services, or database size.
- Exceptionally low total cost of ownership
- Free and Open Source solution with quality and security in mind
- Backed by reliable vendors, a global partner network, and commercial services, such as the 24/7 support
- No limitations regarding how you use the software
- Free and readily available documentation, HOWTOs, community resources, videos, and more.
- Zabbix engineers are easy to find and hire for your organization
- Cost is fully under your control – Zabbix Commercial services are under fixed-price agreements
Deploy Anywhere
Our users always have the choice of where and how they wish to deploy Zabbix. With official packages for the most popular operating systems such as RHEL, Oracle Linux, Ubuntu, Raspberry Pi OS, and more. With official Helm charts, you can quickly also deploy Zabbix in a Kubernetes cluster or in your OpenShift instance. We also provide official Docker container images with pre-installed Zabbix components that you can deploy in your environment.

We also provide one-click deployment options for multiple cloud service providers, such as Amazon AWS, Microsoft Azure, Google Cloud, Openstack, and many other cloud service providers.
Monitor Anything
With Zabbix, you can monitor anything – from legacy solutions to modern systems. With a large selection of official solutions and substantial community backing our users can be sure that they can find a suitable approach to monitor their IT infrastructure components. There are hundreds of ready-to-use monitoring solutions by Zabbix.

Whenever you deploy a new IT solution in your enterprise, you will want to tie it together with the existing toolset. Zabbix provides many out of the box integrations for the most popular ticketing and alerting systems

Recently we have introduced advanced search capabilities for the Zabbix integrations page, which allows you to quickly lookup the integrations that currently exist on the market. If you visit the Zabbix integrations page and look up a specific vendor or tool, you will see a list of both the official solutions supported by Zabbix and also a long list of community solutions backed by our users, partners, and customers.

Monitoring of Kubernetes and Hybrid Clouds
Nowadays many existing companies are considering migrating their existing infrastructure to either solutions such as Kubernetes or OpenShift, or utilizing cloud service providers such as Amazon AWS or Microsoft Azure.
I am proud to announce, that with the release of Zabbix 6.0 LTS, Zabbix will officially support out-of-the-box monitoring of OpenShfit and Kubernetes clusters.
Data collection and Aggregation
Let’s cover a few recent features that improve the out-of-the-box flexibility of Zabbix by a large margin.
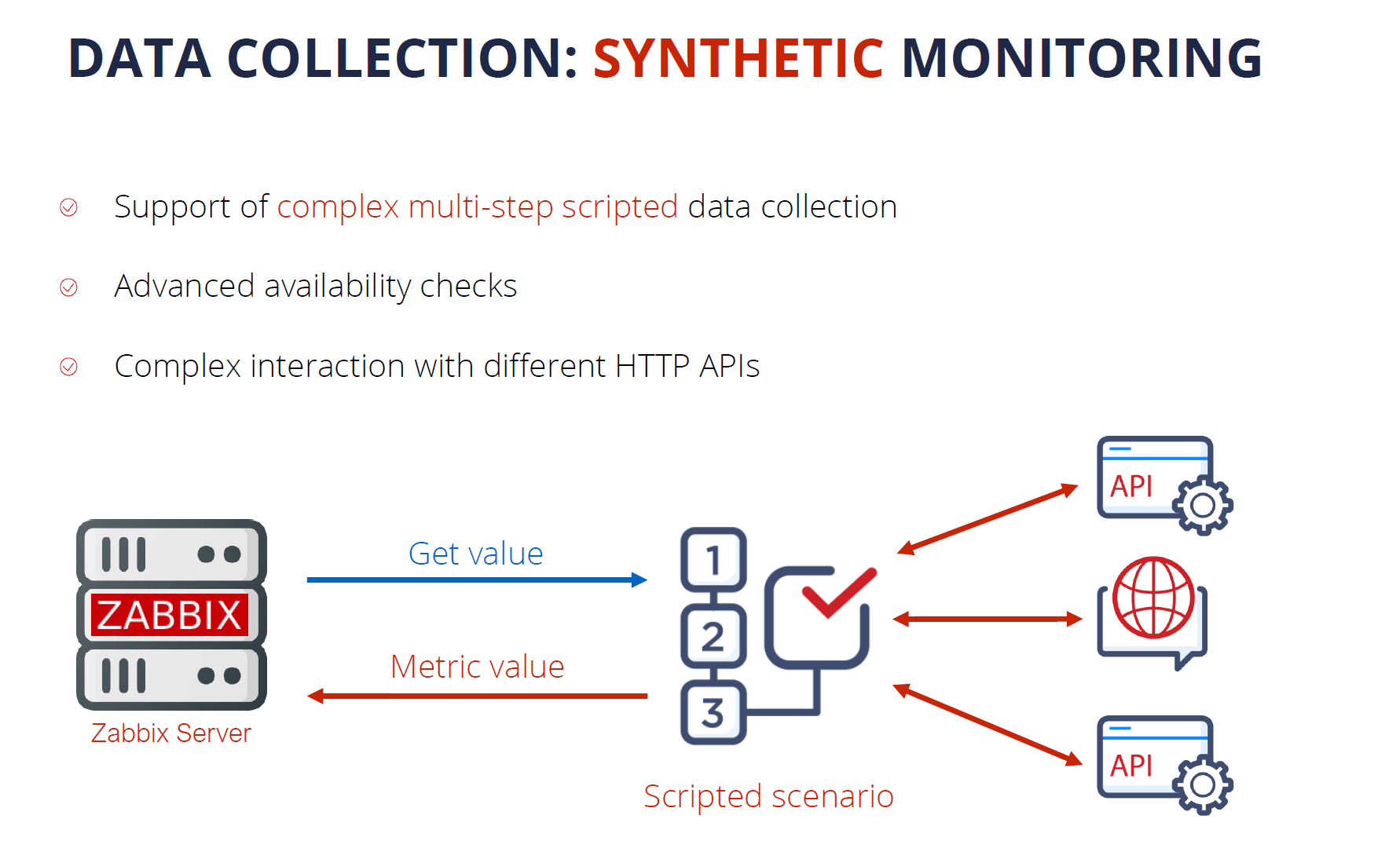
Synthetic monitoring is a feature that was introduced a year ago in Zabbix version 5.2 and it has already become quite popular with our user base. The feature enables monitoring of different devices and solutions over the HTTP protocol. By using synthetic monitoring Zabbix can connect to your HTTP endpoints, such as cloud APIs, Kubernetes, and OpenShift APIs, and other HTTP endpoints, collect the metrics and then process them to extract the required information. Synthetic monitoring is extremely transparent and flexible – it can be fine-tuned to communicate with any HTTP endpoints.

Another major feature introduced in Zabbix 5.4 is the new trigger syntax. This enables our users to define much more flexible trigger expressions, supporting many new problem detection use cases. In addition, we can use this syntax to perform flexible data aggregation operations. For example, now we can aggregate data filtered by wildcards, tags, and host groups, instead of specifying individual items. This is extremely valuable for monitoring complex infrastructures, such as Kubernetes or cloud environments. At the same time, the new syntax is a lot more simple to learn and understand when compared to the old trigger syntax.

Security on all levels
Many companies are concerned about security and data protection when it comes to the tools that they are using in their day-to-day tasks. I’m happy to tell you that Zabbix follows the highest security standards when it comes to the development and usage of the product.
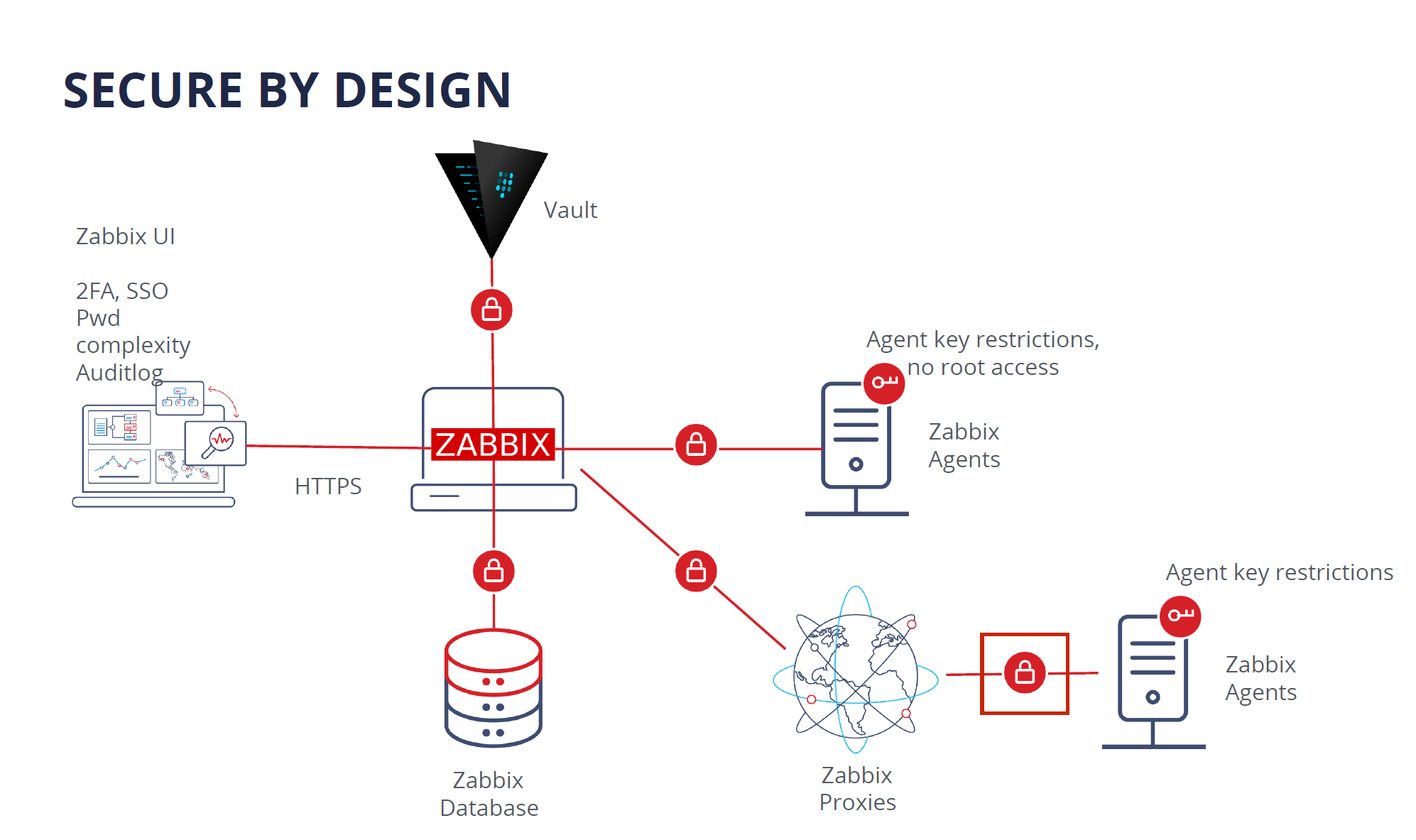
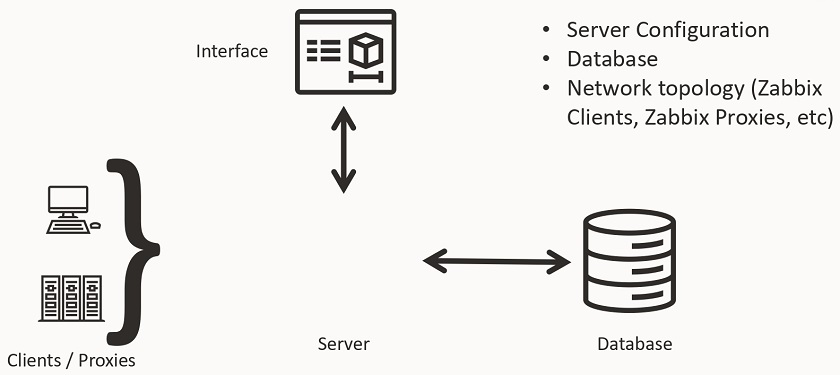
Zabbix is secure by design. In the diagram below you can see all of the Zabbix components, all of which are interconnected, like Zabbix Agent, Server, Proxy, Database, and Frontend. All of the communication between different Zabbix components can be encrypted by using strong encryption protocols like TLS.
If you’re using Zabbix Agent, the agent does not require root privileges. You can run Zabbix Agent under a normal user with all of the necessary user level restrictions in place. Zabbix agent can also be restricted with metric allow and deny lists, so it has access only to the metrics which are permitted for collection by your company policies.
The connections between the Zabbix database backend and the Zabbix Frontend and Zabbix Server also support encryption as of version 5.0 LTS.
As for the frontend component – users can add an additional security layer for their Zabbix frontends by configuring 2FA and SSO logins. Zabbix 6.0 LTS also introduces flexible login password complexity requirements, which can reduce the security breach risk if your frontend is exposed to the internet. To ensure that Zabbix meets the highest standards of the company security compliance, the new Audit log, introduced in Zabbix 6.0 LTS, is capable of logging all of the Zabbix Frontend and Zabbix Server operations.
For an additional security layer – sensitive information like Usernames, Passwords, API keys can be stored in an external vault. Currently, Zabbix supports secret storage in the HashiCorp Vault. Support for the CyberArk vault will be added in the Zabbix 6.2 release.

Another Zabbix feature – the Zabbix API, is often used for the automation of day-to-day configuration workflows, as well as custom integrations and data migration tasks. Zabbix 5.4 added the ability to create API tokens for particular frontend users with pre-defined token expiration dates.
In Zabbix 5.2 we added another layer for the Zabbix Frontend user permissions – User Roles. Now it is possible to define granular user roles with different types of rights and privileges, assigned to specific types of users in your organization. With User Roles, we can define which parts of the Zabbix UI the specific user role has access to and which UI actions the members of this role can perform. This can be combined with API method restrictions which can also be defined for a particular role.

Powerful Solution for MSPs
When we combine all of these features, we can see how Zabbix becomes a powerful solution for MSP customers. MSPs can use Zabbix as an added value service. This way they can provide a monitoring service for their customers and get additional revenue out of it. It is possible to build a customer portal which is a combination of User Roles for read-only access to dashboards and customized UI, rebranding option – which was just introduced in Zabbix 6.0 LTS, and a combination of SLA reporting together with scheduled PDF reports, so the customers can receive reports on a weekly, daily or monthly basis.
Scalability and High Availability
With a growing number of devices and ever-increasing network complexity, Scalability and High availability are extremely important requirements.
Zabbix provides Load balancing options for Zabbix UI and Zabbix API. In order to scale the Zabbix Frontend and Zabbix API, we can simply deploy additional Zabbix Frontend nodes, thus introducing redundancy and high availability.

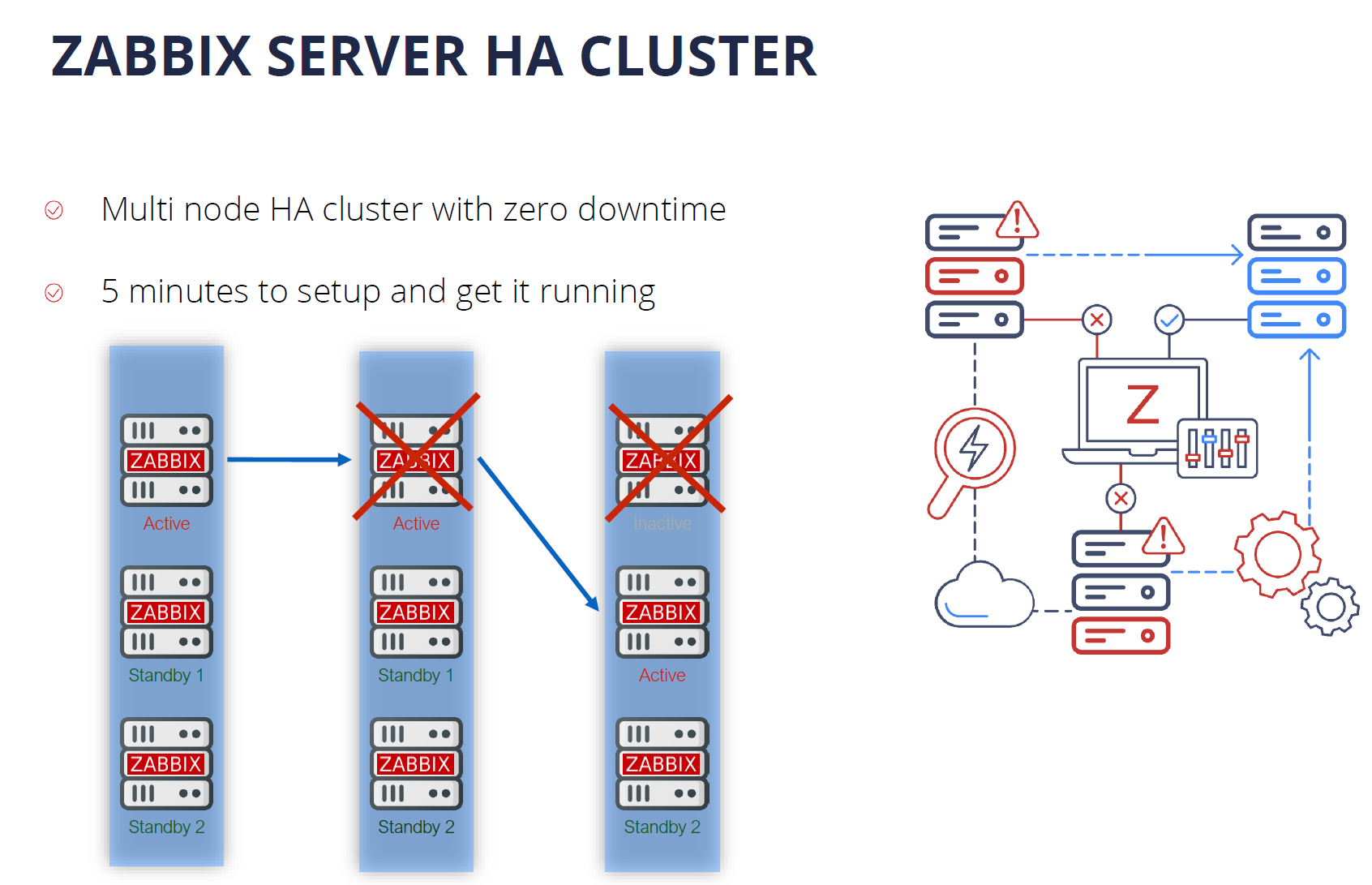
Zabbix 6.0 LTS comes with out-of-the-box support for the Zabbix Server High Availability cluster. If one of the Zabbix Server nodes goes down, Zabbix will automatically switch to one of the standby nodes. And the best thing about the Zabbix Server High Availability cluster – it takes only 5 minutes to get it up and running. the HA cluster is very easy to configure and use.

One of the features in our future roadmap is introducing support for the History API to work with different time-series DB backends for extra efficiency and scalability. Another feature that we would like to implement in the future is load balancing for Zabbix Servers and Zabbix Proxies. Combining all of these features would truly make Zabbix a cloud-native application with unlimited horizontal scalability.
Machine learning and Statistical analysis
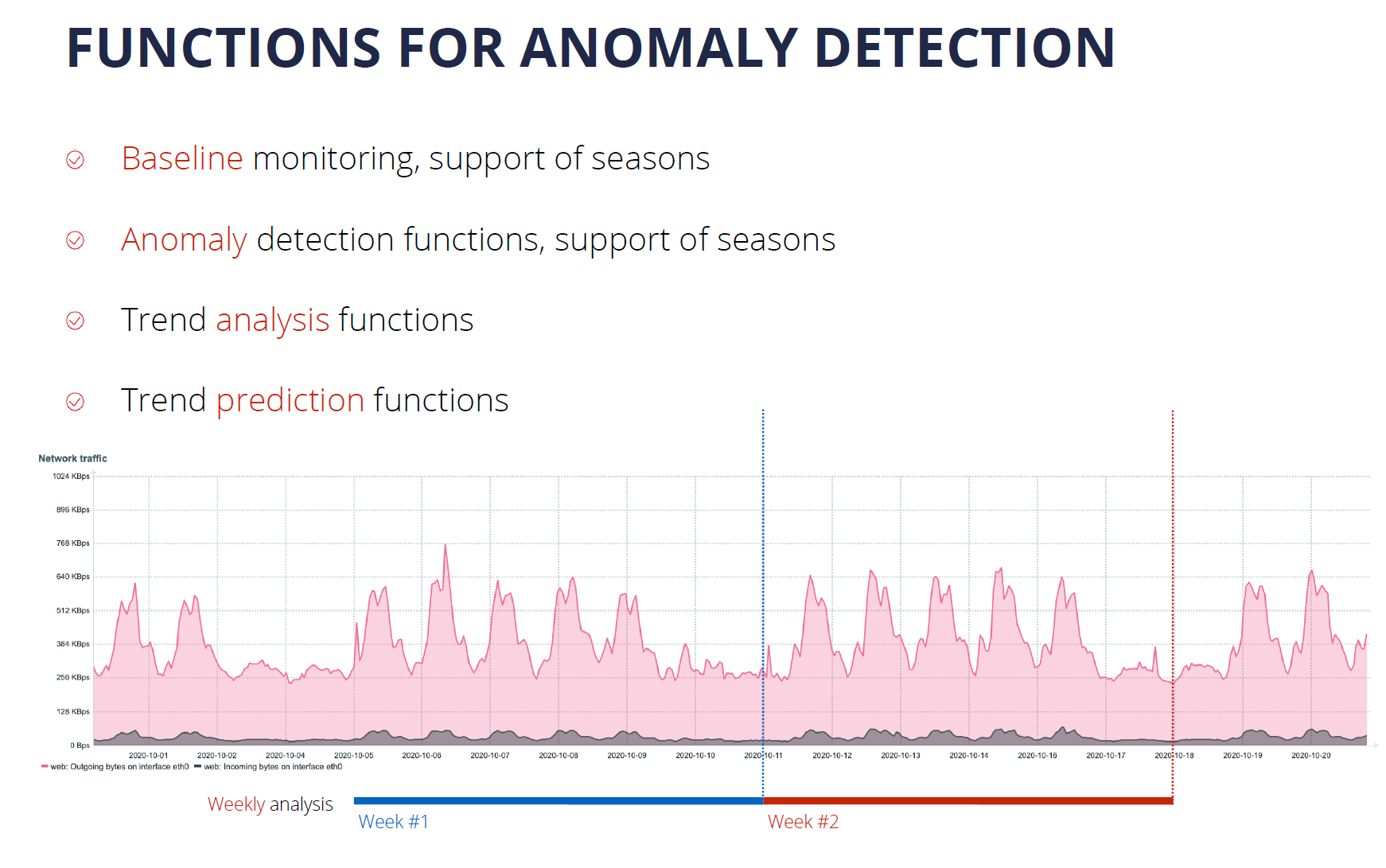
Defining static trigger thresholds is a relatively simple task, but it doesn’t scale too well in dynamic environments. With Machine Learning and Statistical Analysis, we can analyze our data trends and perform anomaly detection. This has been greatly extended in Zabbix 6.0 LTS with Anomaly Detection and Baseline Monitoring functionality.

Zabbix 6.0 Adds an extended set of functions for trend analysis and trend prediction. These support multiple flexible parameters, such as the ability to define seasonality for your data analysis. This is another way how to get additional insights out of the data collected by Zabbix

More value to users
When I think about the direction that Zabbix is headed in, and look at the Zabbix roadmap, one of the main questions I ask is “How can we deliver more value to our enterprise users?”
In Zabbix 6.0 LTS we made some major steps to make Zabbix fit not only for infrastructure monitoring but also fit for Business Service monitoring – the monitoring of services that we provide for our end-users or internal company users. Zabbix 6.0 LTS comes with complex service level object definitions, real-time SLA reporting, multi-tenancy options, Business Service alerting options, and root cause and Impact analysis.
New visualization capabilities
It is important to present the collected data in a human-readable way. That’s why we invest a lot of time and effort in order to improve the native visualization capabilities. In Zabbix 6.0 LTS we have introduced Geographical Maps together with additional widgets for TOP N reporting and templated and multi-page dashboards.

The introduction of reports in Zabbix 5.2 allowed our users to leverage their Zabbix Dashboards to generate scheduled PDF reports with respect to user permissions. Our users can generate daily, weekly, monthly or yearly reports and send them to their infrastructure administrators or customers.
IoT monitoring
With the introduction of support for Modbus and MQTT protocols, Zabbix can be used to monitor IoT devices and obtain environmental information from different sensors such as temperature, humidity, and more. In addition, Zabbix can now be used to monitor factory equipment, building management systems, IoT gateways, and more.

Infrastructure as a code
With IT infrastructures growing in scale, automation is more important than ever. For this reason, many companies prefer preserving and deploying their infrastructure as code. With the support of YAML format for our templates, you can now keep them in a git repository and by utilizing CI/CD tools you can now deploy your templates automatically.
This enables our users to manage their templates in a central location – the git repository, which helps users to perform change management and versioning and then deploy the template to Zabbix by using CI/CD tools.

Over the past few versions, we have made a major push to support tags for most Zabbix entities. The switch from applications to tags in Zabbix 5.4 made the tool much more flexible. Tags can now be used for the classification of items, triggers, hosts, business services. The tags that the users define can also be used in alerting, filtering, and reporting.

What’s next?
You’re probably wondering – what’s coming next? What are the main vectors for the future development of Zabbix?
First off – we will continue to invest in usability. While the tool is made by professionals for professionals, it is important for us to make using the tool as easy as possible. Improvements to the Zabbix Frontend, general usability, and UX can be expected very soon.
We plan to continue to invest in the visualization and reporting capabilities of Zabbix. We want all data collected by our monitoring tool to provide information in a single pane of glass. This way our users can see the full picture of their environment while also seeing the root cause analysis for the ongoing problems that we face. This way we can get most of the data that Zabbix collects.
Extending the scope of monitoring is an ongoing process for us. We would like to implement additional features for compliance monitoring. I think that we will be able to introduce a solution for application performance monitoring very soon. We’d like to make log monitoring more powerful and comprehensive. monitoring of public and private clouds is also very important for us, given the current IT paradigms.
We’d like to make sure that Zabbix is absolutely extendable on all levels. While we can already extend Zabbix with different types of plugins, webhooks, and UI modules there’s more to come in the near future.
The topic of high availability, scalability, and load balancing is extremely important to us. We will continue building on the existing foundations to make Zabbix a truly cloud-native solution.
Advanced event correlation engine
Advanced event processing is a really important topic. When we talk about a monitoring solution, we pay very much attention to the number of metrics that we are collecting. We mustn’t forget, that for large-scale environments the number of events that we generate based on those metrics is also extremely important. We need to keep control and manage the ever-growing number of different events coming from different sources. This is why we would like to focus on noise reduction, specifically – root cause analysis.
For this reason, we can expect Zabbix to introduce an advanced event correlation model in the future. This model should have the ability to filter and deduplicate the events as well as perform event enrichment, thus leading to a much better root cause analysis.

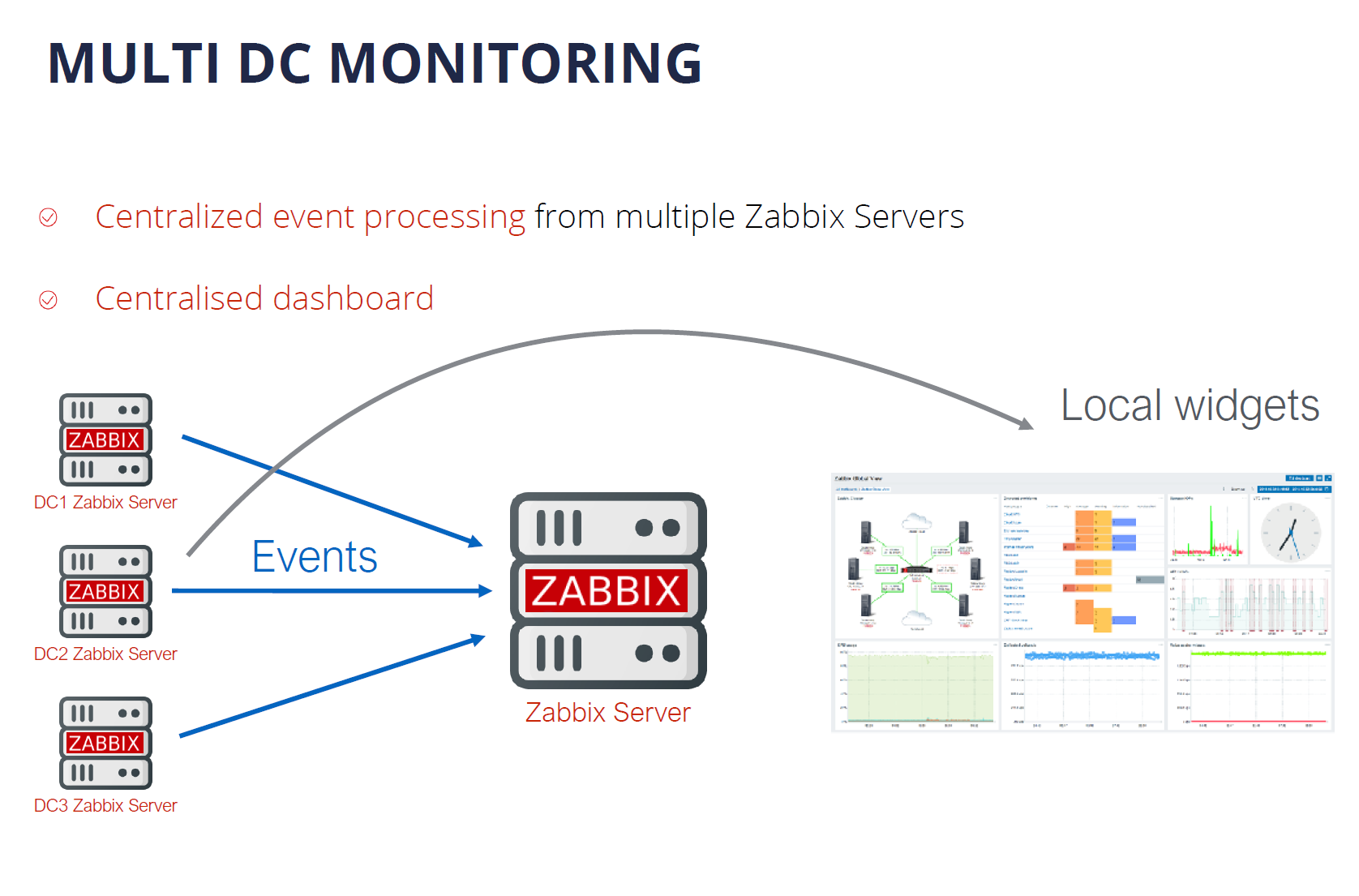
Multi DC Monitoring
Currently, Multi DC monitoring can be done with Zabbix by deploying a distributed Zabbix instance that utilizes Zabbix proxies. But there are use cases, where it would be more beneficial to have multiple Zabbix servers deployed across different datacenters – all reporting to a single location for centralized event processing, centralized visualization, and reporting as well as centralized dashboards. This is something that is coming soon to Zabbix.

Zabbix Release Schedule
Of course, the burning question is – when is Zabbix 6.0 LTS going to be released? And we are very close to finalizing the next LTS release. I would expect Zabbix 6.0 LTS to be officially released in January 2022.
As for Zabbix 6.2 and 6.4 – these releases are still planned for Q2 and Q4, 2022. The next LTS release – Zabbix 7.0 LTS is planned to be released in Q2, 2023.
Zabbix Roadmap
If you want to follow the development of Zabbix – we have a special page just for that – the Zabbix Roadmap. Here you can find up-to-date information about the development plans for Zabbix 6.2, 6.4, and 7.0 LTS. The Roadmap also represents the current development status of Zabbix 6.0 LTS.

Questions
Q: What would you say is the main benefit of why users should migrate from Zabbix 5.0/4.0 or older versions to 6.0 LTS?
A: I think that Zabbix 6.0 LTS is a very different product – even when you compare it with the relatively recent Zabbix 5.0 LTS. It comes with many improvements, some of which I mentioned here in my keynote. For example, Business Service monitoring provides huge added value to enterprise customers.
With the new trigger syntax and the new functions related to anomaly detection and baseline monitoring our users can get much more out of the data that they already have in their monitoring tool.
The new visualization options – multiple new widgets, geographical maps, scheduled PDF reporting provide a lot of added value to our end-users and to their customers as well.
Q: Any plans to make changes on the Zabbix DB backend level – make it more scaleable or completely redesign it?
A: Right now we keep all of our information in a relational database such as MySQL or PostgreSQL. We have added the support for TimescaleDB which brings some huge advantages to our users, thanks to improved data storage and performance efficiency.
But we still have users that wish to connect different storage engines to Zabbix – maybe specifically optimized to keep time-series data. Actually, this is already on our roadmap. Our plan is to introduce a unified API for historical data so that if you wish to attach your own storage, we just have to deploy a plugin that will communicate both with our historical API and also talk to the storage engine of your choosing. This feature is coming and is already on our Roadmap.
Q: What is your personal favorite feature? Something that you 100% wanted to see implemented in Zabbix 6.0 LTS?
A: I see Zabbix 6.0 LTS as a combination of Zabbix 5.2, 5.4, and finally the features introduced directly in Zabbix 6.0 LTS. Personally, I think that my favorite features in Zabbix 6.0 LTS are features that make up the latest implementation of Anomaly detection.
We could be at the very beginning of exploring more advanced machine learning and statistical analysis capabilities, but I’m pretty sure that with every new release of Zabbix there will be new features related to machine learning, anomaly detection, and trend prediction.
This could provide a way for Zabbix to generate and share insights with our users. Analysis of what’s happening with your system, with your metrics – how the metrics in your system behave.












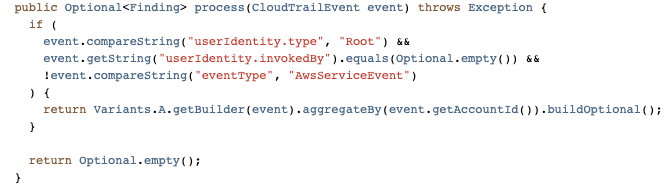
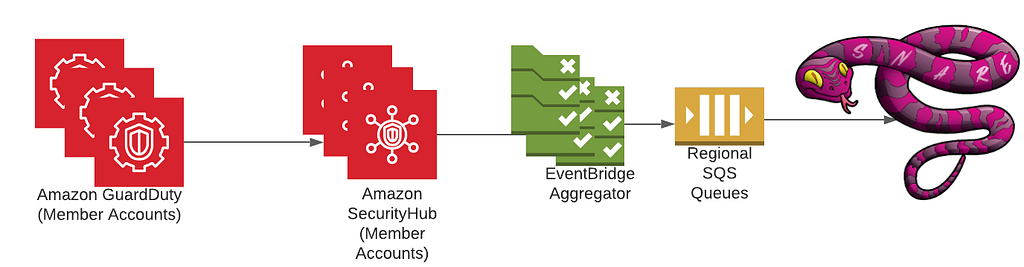
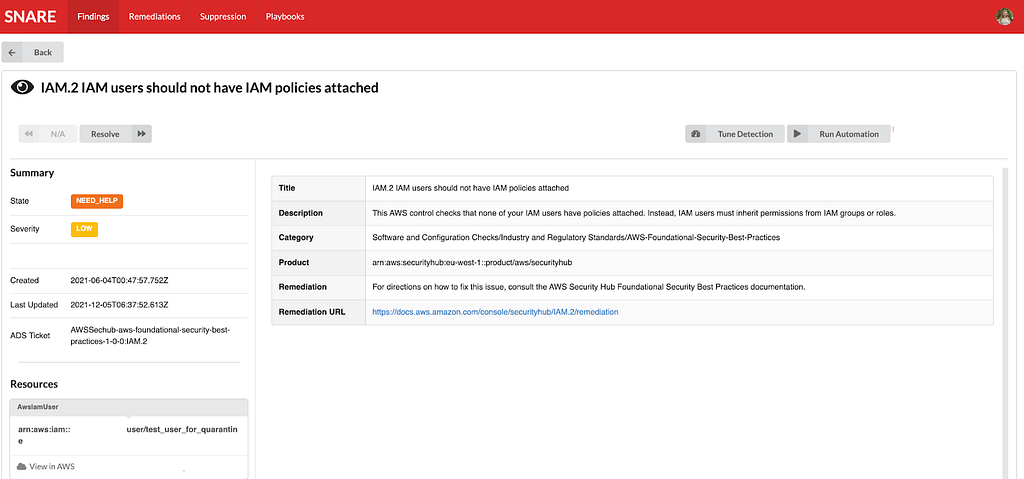
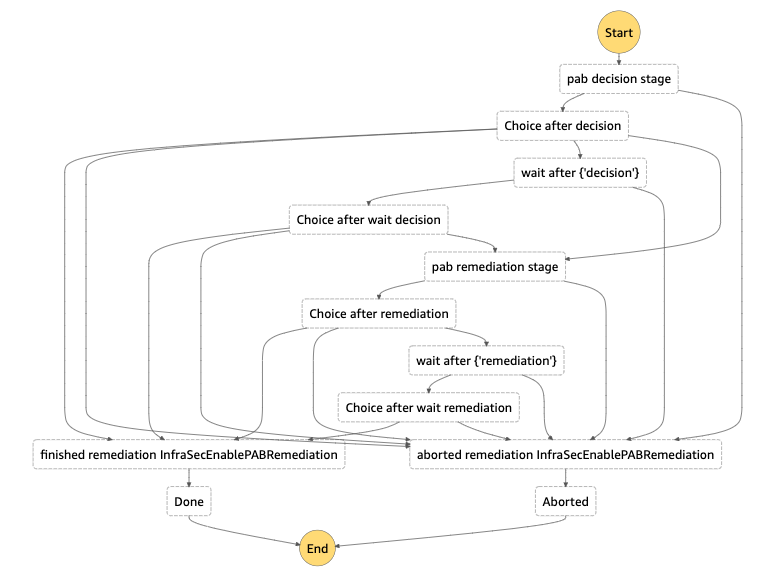
































 Mike is a Principal Solutions Architect with the Startup Team at Amazon Web Services. He is a former founder, current mentor, and enjoys helping startups live their best cloud life.
Mike is a Principal Solutions Architect with the Startup Team at Amazon Web Services. He is a former founder, current mentor, and enjoys helping startups live their best cloud life. Sean is a Senior Startup Solutions Architect at AWS. Before AWS, he was Director of Scientific Computing at the Howard Hughes Medical Institute.
Sean is a Senior Startup Solutions Architect at AWS. Before AWS, he was Director of Scientific Computing at the Howard Hughes Medical Institute.







{kind=link}