Post Syndicated from Caio Montovani original https://aws.amazon.com/blogs/big-data/unlock-scalable-analytics-with-a-secure-connectivity-pattern-in-aws-glue-to-read-from-or-write-to-snowflake/
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. As organizations increasingly rely on data stored across various platforms, such as Snowflake, Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
AWS Glue is a robust data integration service that facilitates the consolidation of data from different origins, empowering businesses to use the full potential of their data assets. By using AWS Glue to integrate data from Snowflake, Amazon S3, and SaaS applications, organizations can unlock new opportunities in generative artificial intelligence (AI), machine learning (ML), business intelligence (BI), and self-service analytics or feed data to underlying applications.
In this post, we explore how AWS Glue can serve as the data integration service to bring the data from Snowflake for your data integration strategy, enabling you to harness the power of your data ecosystem and drive meaningful outcomes across various use cases.
Use case
Consider a large ecommerce company that relies heavily on data-driven insights to optimize its operations, marketing strategies, and customer experiences. The company stores vast amounts of transactional data, customer information, and product catalogs in Snowflake. However, they also generate and collect data from various other sources, such as web logs stored in Amazon S3, social media platforms, and third-party data providers. To gain a comprehensive understanding of their business and make informed decisions, the company needs to integrate and analyze data from all these sources seamlessly.
One crucial business requirement for the ecommerce company is to generate a Pricing Summary Report that provides a detailed analysis of pricing and discounting strategies. This report is essential for understanding revenue streams, identifying opportunities for optimization, and making data-driven decisions regarding pricing and promotions. After the Pricing Summary Report is generated and stored in Amazon S3, the company can use AWS analytics services to generate interactive BI dashboards and run one-time queries on the report. This allows business analysts and decision-makers to gain valuable insights, visualize key metrics, and explore the data in depth, enabling informed decision-making and strategic planning for pricing and promotional strategies.
Solution overview
The following architecture diagram illustrates a secure and efficient solution of integrating Snowflake data with Amazon S3, using the native Snowflake connector in AWS Glue. This setup uses AWS PrivateLink to provide secure connectivity between AWS services across different virtual private clouds (VPCs), eliminating the need to expose data to the public internet, which is a critical need for organizations.

The following are the key components and steps in the integration process:
- Establish a secure, private connection between your AWS account and your Snowflake account using PrivateLink. This involves creating VPC endpoints in both the AWS and Snowflake VPCs, making sure data transfer remains within the AWS network.
- Use Amazon Route 53 to create a private hosted zone that resolves the Snowflake endpoint within your VPC. This allows AWS Glue jobs to connect to Snowflake using a private DNS name, maintaining the security and integrity of the data transfer.
- Create an AWS Glue job to handle the extract, transform, and load (ETL) process on data from Snowflake to Amazon S3. The AWS Glue job uses the secure connection established by the VPC endpoints to access Snowflake data. Snowflake credentials are securely stored in AWS Secrets Manager. The AWS Glue job retrieves these credentials at runtime to authenticate and connect to Snowflake, providing secure access management. A VPC endpoint enables you to securely communicate with this service without traversing the public internet, enhancing security and performance.
- Store the extracted and transformed data in Amazon S3. Organize the data into appropriate structures, such as partitioned folders, to optimize query performance and data management. We use a VPC endpoint enabled to securely communicate with this service without traversing the public internet, enhancing security and performance. We also use Amazon S3 to store AWS Glue scripts, logs, and temporary data generated during the ETL process.
This approach offers the following benefits:
- Enhanced security – By using PrivateLink and VPC endpoints, data transfer between Snowflake and Amazon S3 is secured within the AWS network, reducing exposure to potential security threats.
- Efficient data integration – AWS Glue simplifies the ETL process, providing a scalable and flexible solution for data integration between Snowflake and Amazon S3.
- Cost-effectiveness – Using Amazon S3 for data storage, combined with the AWS Glue pay-as-you-go pricing model, helps optimize costs associated with data management and integration.
- Scalability and flexibility – The architecture supports scalable data transfers and can be extended to integrate additional data sources and destinations as needed.
By following this architecture and taking advantage of the capabilities of AWS Glue, PrivateLink, and associated AWS services, organizations can achieve a robust, secure, and efficient data integration solution, enabling them to harness the full potential of their Snowflake and Amazon S3 data for advanced analytics and BI.
Prerequisites
Complete the following prerequisites before setting up the solution:
- Verify that you have access to AWS account with the necessary permissions to provision resources in services such as Route 53, Amazon S3, AWS Glue, Secrets Manager, and Amazon Virtual Private Cloud (Amazon VPC) using AWS CloudFormation, which lets you model, provision, and manage AWS and third-party resources by treating infrastructure as code.
- Confirm that you have access to Snowflake hosted in AWS with required permissions to run the steps to configure PrivateLink. Refer to Enabling AWS PrivateLink in the Snowflake documentation to verify the steps, required access level, and service level to set the configurations. After you enable PrivateLink, save the value of the following parameters provided by Snowflake to use in the next step in this post:
privatelink-vpce-idprivatelink-account-urlprivatelink_ocsp-urlregionless-snowsight-privatelink-url
- Make sure you have a Snowflake user
snowflakeUserand passwordsnowflakePasswordwith required permissions to read from and write to Snowflake. The user and password are used in the AWS Glue connection to authenticate within Snowflake. - If your Snowflake user doesn’t have a default warehouse set, you will need a warehouse name. We use
snowflakeWarehouseas a placeholder for the warehouse name; replace it with your actual warehouse name. - If you’re new to Snowflake, consider completing the Snowflake in 20 Minutes By the end of the tutorial, you should know how to create required Snowflake objects, including warehouses, databases, and tables for storing and querying data.
Create resources with AWS CloudFormation
This post includes a CloudFormation template for a quick setup of the base resources. You can review and customize it to suit your needs if needed. The CloudFormation template generates the following resources:
- VPC (
vpc-blog-glue-snowflake) - Subnets (one public subnet and three private subnets)
- Route tables that are explicitly associated with the subnets
- Security groups that are used to provision the endpoints for Secrets Manager, Amazon S3, and Snowflake, as well as used to provision the AWS Glue connection
- Endpoints for Secrets Manager, Amazon S3, and Snowflake
- Route 53 hosted zone, which is a container for DNS records
- Route 53 record set to route traffic to the Snowflake endpoint
- S3 bucket (
blog-glue-snowflake-*) - AWS Identity and Access Management (IAM) role for AWS Glue (
blog-glue-snowflake-GlueServiceRole-*) - AWS Glue database (
db_blog_glue_snowflake) - Amazon Athena workgroup (
blog-workgroup)
To create your resources, complete the following steps:
- Sign in to the AWS CloudFormation console.
- Choose Launch Stack to launch the CloudFormation stack.
- Provide the CloudFormation stack parameters:
- For PrivateLinkAccountURL, enter the value of the parameter
privatelink-account-urlobtained in the prerequisites. - For PrivateLinkOcspURL, enter the value of the parameter
privatelink_ocsp-urlobtained in the prerequisites. - For PrivateLinkVpceId, enter the value of the parameter
privatelink-vpce-idobtained in the prerequisites. - For PrivateSubnet1CIDR, enter the IP addresses for your private subnet 1.
- For PrivateSubnet2CIDR, enter the IP addresses for your private subnet 2.
- For PrivateSubnet3CIDR, enter the IP addresses for your private subnet 3.
- For PublicSubnet1CIDR, enter the IP addresses for your public subnet 1.
- For RegionlessSnowsightPrivateLinkURL, enter the value of the parameter
regionless-snowsight-privatelink-urlobtained in the prerequisites. - For VpcCIDR, enter the IP addresses for your VPC.
- For PrivateLinkAccountURL, enter the value of the parameter
- Choose Next.
- Select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Submit and wait for the stack creation step to complete.
After the CloudFormation stack is successfully created, you can see all the resources created on the Resources tab.
Navigate to the Outputs tab to see the outputs provided by CloudFormation stack. Save the value of the outputs GlueSecurityGroupId, VpcId, and PrivateSubnet1Id to use in the next step in this post.

Update the Secrets Manager secret with Snowflake credentials for the AWS Glue connection
To update the Secrets Manager secret with user snowflakeUser, password snowflakePassword, and warehouse snowflakeWarehouse that you will use in the AWS Glue connection to establish a connection to Snowflake, complete the following steps:
- On the Secrets Manager console, choose Secrets in the navigation pane.
- Open the secret
blog-glue-snowflake-credentials. - Under Secret value, choose Retrieve secret value.

- Choose Edit.
- Enter the user snowflakeUser, password
snowflakePassword, and warehousesnowflakeWarehousefor the keyssfUser,sfPassword, andsfWarehouse, respectively. - Choose Save.
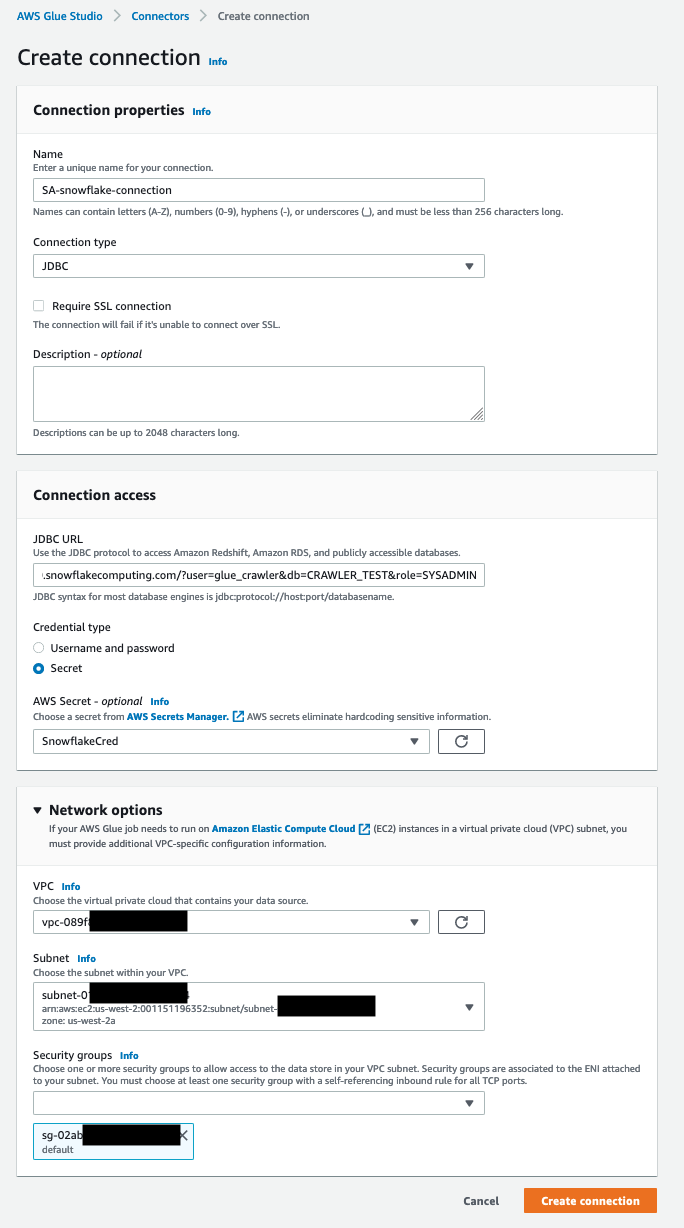
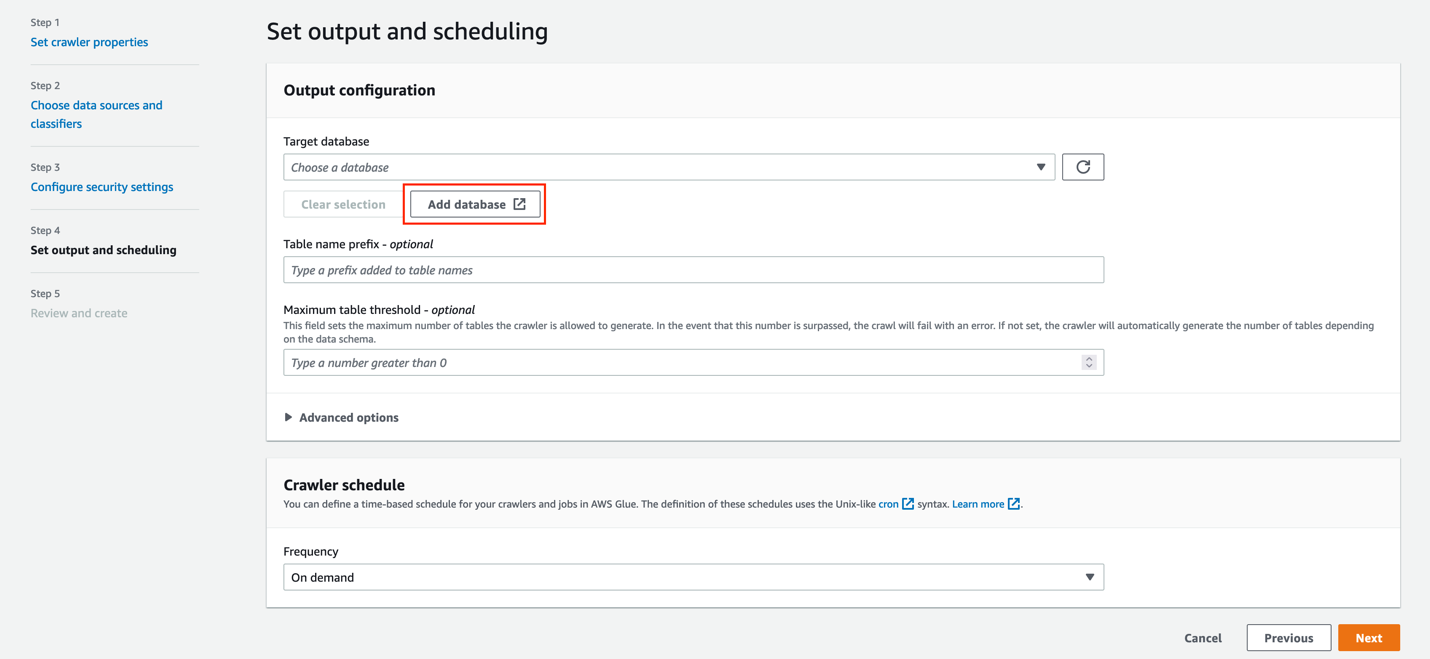
Create the AWS Glue connection for Snowflake
An AWS Glue connection is an AWS Glue Data Catalog object that stores login credentials, URI strings, VPC information, and more for a particular data store. AWS Glue crawlers, jobs, and development endpoints use connections in order to access certain types of data stores. To create an AWS Glue connection to Snowflake, complete the following steps:
- On the AWS Glue console, in the navigation pane, under Data catalog, choose Connections.
- Choose Create connection.
- For Data sources, search for and select Snowflake.
- Choose Next.

- For Snowflake URL, enter
https://<privatelink-account-url>.
To obtain the Snowflake PrivateLink account URL, refer to parameters obtained in the prerequisites.
- For AWS Secret, choose the secret
blog-glue-snowflake-credentials. - For VPC, choose the
VpcIdvalue obtained from the CloudFormation stack output. - For Subnet, choose the
PrivateSubnet1Idvalue obtained from the CloudFormation stack output. - For Security groups, choose the
GlueSecurityGroupIdvalue obtained from the CloudFormation stack output. - Choose Next.

- In the Connection Properties section, for Name, enter
glue-snowflake-connection. - Choose Next.

- Choose Create connection.
Create an AWS Glue job
You’re now ready to define the AWS Glue job using the Snowflake connection. To create an AWS Glue job to read from Snowflake, complete the following steps:
- On the AWS Glue console, under ETL jobs in the navigation pane, choose Visual ETL.

- Choose the Job details tab.
- For Name, enter a name, for example,
Pricing Summary Report Job. - For Description, enter a meaningful description for the job.
- For IAM Role, choose the role that has access to the target S3 location where the job is writing to and the source location from where it’s loading the Snowflake data and also to run the AWS Glue job. You can find this role in your CloudFormation stack output, named
blog-glue-snowflake-GlueServiceRole-*. - Use the default options for Type, Glue version, Language, Worker type, Number of workers, Number of retries, and Job timeout.
- For Job bookmark, choose Disable.
- Choose Save to save the job.

- On the Visual tab, choose Add nodes.

- For Sources, choose Snowflake.

- Choose Data source – Snowflake in the AWS Glue Studio canvas.
- For Name, enter
Snowflake_Pricing_Summary. - For Snowflake connection, choose
glue-snowflake-connection. - For Snowflake source, select Enter a custom query.
- For Database, enter
snowflake_sample_data. - For Snowflake query, add the following Snowflake query:
The Pricing Summary Report provides a summary pricing report for all line items shipped as of a given date. The date is within 60–120 days of the greatest ship date contained in the database. The query lists totals for extended price, discounted extended price, discounted extended price plus tax, average quantity, average extended price, and average discount. These aggregates are grouped by RETURNFLAG and LINESTATUS, and listed in ascending order of RETURNFLAG and LINESTATUS. A count of the number of line items in each group is included.
- For Custom Snowflake properties, specify Key as
sfSchemaand Value astpch_sf1. - Choose Save.

Next, you add the destination as an S3 bucket.
- On the Visual tab, choose Add nodes.
- For Targets, choose Amazon S3.

- Choose Data target – S3 bucket in the AWS Glue Studio canvas.
- For Name, enter
S3_Pricing_Summary. - For Node parents, select
Snowflake_Pricing_Summary. - For Format, select Parquet.
- For S3 Target Location, enter
s3://<YourBucketName>/pricing_summary_report/(use the name of your bucket). - For Data Catalog update options, select Create a table in the Data Catalog and on subsequent runs, update the schema and add new partitions.
- For Database, choose
db_blog_glue_snowflake. - For Table name, enter
tb_pricing_summary. - Choose Save.
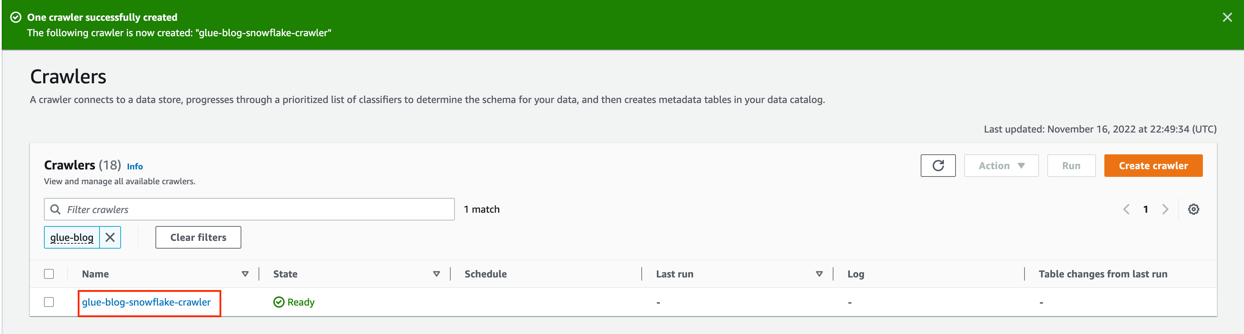
- Choose Run to run the job, and monitor its status on the Runs tab.
You successfully completed the steps to create an AWS Glue job that reads data from Snowflake and loads the results into an S3 bucket using a secure connectivity pattern. Eventually, if you want to transform the data before loading it into Amazon S3, you can use AWS Glue transformations available in AWS Glue Studio. Using AWS Glue transformations is crucial when creating an AWS Glue job because they enable efficient data cleansing, enrichment, and restructuring, making sure the data is in the desired format and quality for downstream processes. Refer to Editing AWS Glue managed data transform nodes for more information.
Validate the results
After the job is complete, you can validate the output of the ETL job run in Athena, a serverless interactive analytics service. To validate the output, complete the following steps:
- On the Athena console, choose Launch Query Editor.
- For Workgroup, choose
blog-workgroup. - If the message “All queries run in the Workgroup, blog-workgroup, will use the following settings:” is displayed, choose Acknowledge.
- For Database, choose
db_blog_glue_snowflake. - For Query, enter the following statement:
- Choose Run.
You have successfully validated your data for the AWS Glue job Pricing Summary Report Job.
Clean up
To clean up your resources, complete the following tasks:
- Delete the AWS Glue job
Pricing Summary Report Job. - Delete the AWS Glue connection
glue-snowflake-connection. - Stop any AWS Glue interactive sessions.
- Delete content from the S3 bucket
blog-glue-snowflake-*. - Delete the CloudFormation stack
blog-glue-snowflake.
Conclusion
Using the native Snowflake connector in AWS Glue provides an efficient and secure way to integrate data from Snowflake into your data pipelines on AWS. By following the steps outlined in this post, you can establish a private connectivity channel between AWS Glue and your Snowflake using PrivateLink, Amazon VPC, security groups, and Secrets Manager.
This architecture allows you to read data from and write data to Snowflake tables directly from AWS Glue jobs running on Spark. The secure connectivity pattern prevents data transfers over the public internet, enhancing data privacy and security.
Combining AWS data integration services like AWS Glue with data platforms like Snowflake allows you to build scalable, secure data lakes and pipelines to power analytics, BI, data science, and ML use cases.
In summary, the native Snowflake connector and private connectivity model outlined here provide a performant, secure way to include Snowflake data in AWS big data workflows. This unlocks scalable analytics while maintaining data governance, compliance, and access control. For more information on AWS Glue, visit AWS Glue.
About the Authors
 Caio Sgaraboto Montovani is a Sr. Specialist Solutions Architect, Data Lake and AI/ML within AWS Professional Services, developing scalable solutions according customer needs. His vast experience has helped customers in different industries such as life sciences and healthcare, retail, banking, and aviation build solutions in data analytics, machine learning, and generative AI. He is passionate about rock and roll and cooking, and loves to spend time with his family.
Caio Sgaraboto Montovani is a Sr. Specialist Solutions Architect, Data Lake and AI/ML within AWS Professional Services, developing scalable solutions according customer needs. His vast experience has helped customers in different industries such as life sciences and healthcare, retail, banking, and aviation build solutions in data analytics, machine learning, and generative AI. He is passionate about rock and roll and cooking, and loves to spend time with his family.
 Kartikay Khator is a Solutions Architect within Global Life Sciences at AWS, where he dedicates his efforts to developing innovative and scalable solutions that cater to the evolving needs of customers. His expertise lies in harnessing the capabilities of AWS analytics services. Extending beyond his professional pursuits, he finds joy and fulfillment in the world of running and hiking. Having already completed two marathons, he is currently preparing for his next marathon challenge.
Kartikay Khator is a Solutions Architect within Global Life Sciences at AWS, where he dedicates his efforts to developing innovative and scalable solutions that cater to the evolving needs of customers. His expertise lies in harnessing the capabilities of AWS analytics services. Extending beyond his professional pursuits, he finds joy and fulfillment in the world of running and hiking. Having already completed two marathons, he is currently preparing for his next marathon challenge.
 Navnit Shukla, an AWS Specialist Solution Architect specializing in Analytics, is passionate about helping clients uncover valuable insights from their data. Leveraging his expertise, he develops inventive solutions that empower businesses to make informed, data-driven decisions. Notably, Navnit is the accomplished author of the book “Data Wrangling on AWS,” showcasing his expertise in the field.
Navnit Shukla, an AWS Specialist Solution Architect specializing in Analytics, is passionate about helping clients uncover valuable insights from their data. Leveraging his expertise, he develops inventive solutions that empower businesses to make informed, data-driven decisions. Notably, Navnit is the accomplished author of the book “Data Wrangling on AWS,” showcasing his expertise in the field.
 Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
 Bosco Albuquerque is a Sr. Partner Solutions Architect at AWS and has over 20 years of experience working with database and analytics products from enterprise database vendors and cloud providers. He has helped technology companies design and implement data analytics solutions and products.
Bosco Albuquerque is a Sr. Partner Solutions Architect at AWS and has over 20 years of experience working with database and analytics products from enterprise database vendors and cloud providers. He has helped technology companies design and implement data analytics solutions and products.















 Ramesh Ranganathan is a Senior Partner Solution Architect at AWS. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, application modernization and cloud native development. He is passionate about technology and enjoys experimenting with AWS Serverless services.
Ramesh Ranganathan is a Senior Partner Solution Architect at AWS. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, application modernization and cloud native development. He is passionate about technology and enjoys experimenting with AWS Serverless services. Kamen Sharlandjiev is an Analytics Specialist Solutions Architect and Amazon AppFlow expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding.
Kamen Sharlandjiev is an Analytics Specialist Solutions Architect and Amazon AppFlow expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding. Amit Shah is a cloud based modern data architecture expert and currently leading AWS Data Analytics practice in Atos. Based in Pune in India, he has 20+ years of experience in data strategy, architecture, design and development. He is on a mission to help organization become data-driven.
Amit Shah is a cloud based modern data architecture expert and currently leading AWS Data Analytics practice in Atos. Based in Pune in India, he has 20+ years of experience in data strategy, architecture, design and development. He is on a mission to help organization become data-driven.