Post Syndicated from Michelle Chen original https://blog.cloudflare.com/workers-ai-bigger-better-faster
Birthday Week 2024 marks our first anniversary of Cloudflare’s AI developer products — Workers AI, AI Gateway, and Vectorize. For our first birthday this year, we’re excited to announce powerful new features to elevate the way you build with AI on Cloudflare.
Workers AI is getting a big upgrade, with more powerful GPUs that enable faster inference and bigger models. We’re also expanding our model catalog to be able to dynamically support models that you want to run on us. Finally, we’re saying goodbye to neurons and revamping our pricing model to be simpler and cheaper. On AI Gateway, we’re moving forward on our vision of becoming an ML Ops platform by introducing more powerful logs and human evaluations. Lastly, Vectorize is going GA, with expanded index sizes and faster queries.
Whether you want the fastest inference at the edge, optimized AI workflows, or vector database-powered RAG, we’re excited to help you harness the full potential of AI and get started on building with Cloudflare.
The fast, global AI platform
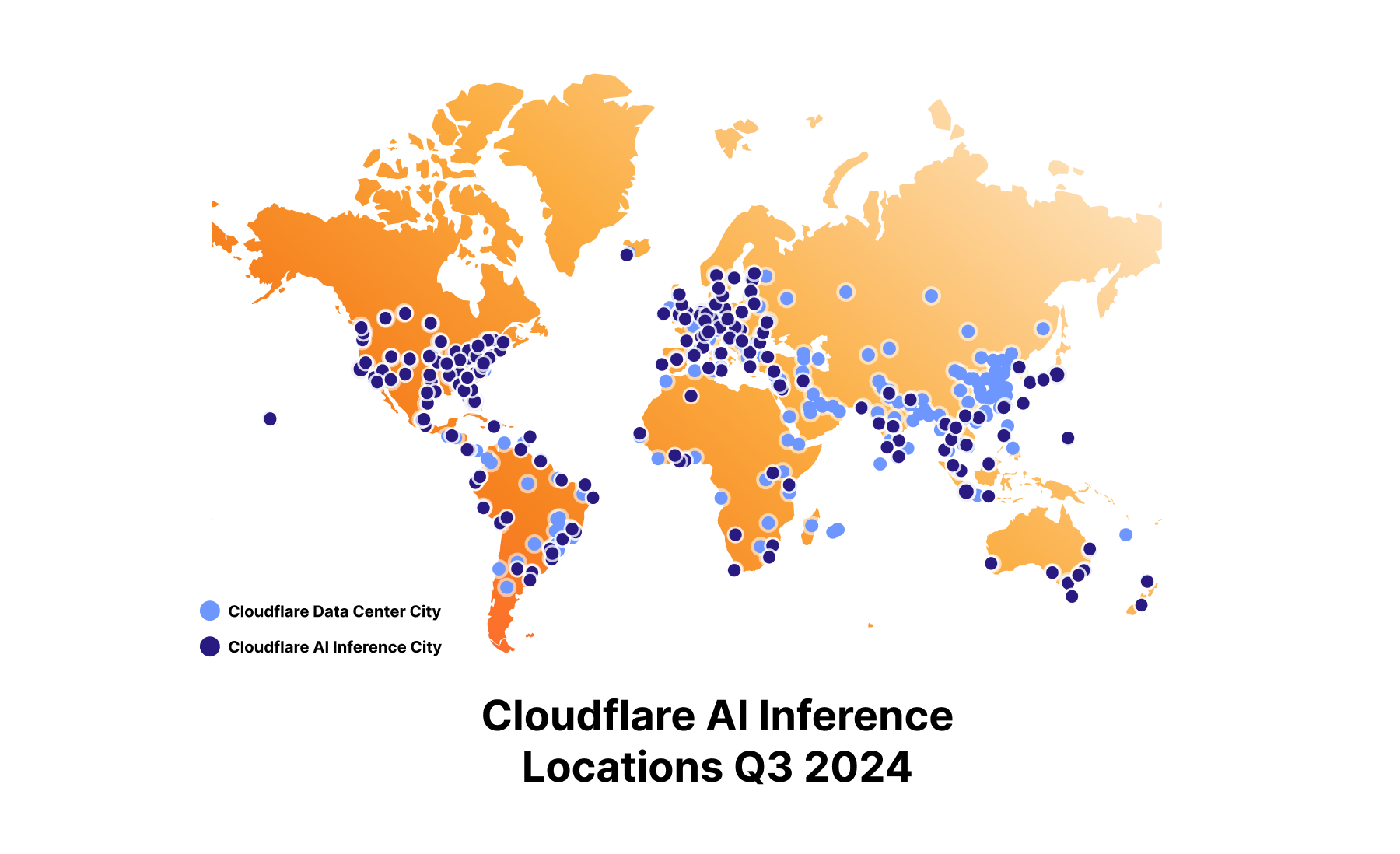
The first thing that you notice about an application is how fast, or in many cases, how slow it is. This is especially true of AI applications, where the standard today is to wait for a response to be generated.
At Cloudflare, we’re obsessed with improving the performance of applications, and have been doubling down on our commitment to make AI fast. To live up to that commitment, we’re excited to announce that we’ve added even more powerful GPUs across our network to accelerate LLM performance.
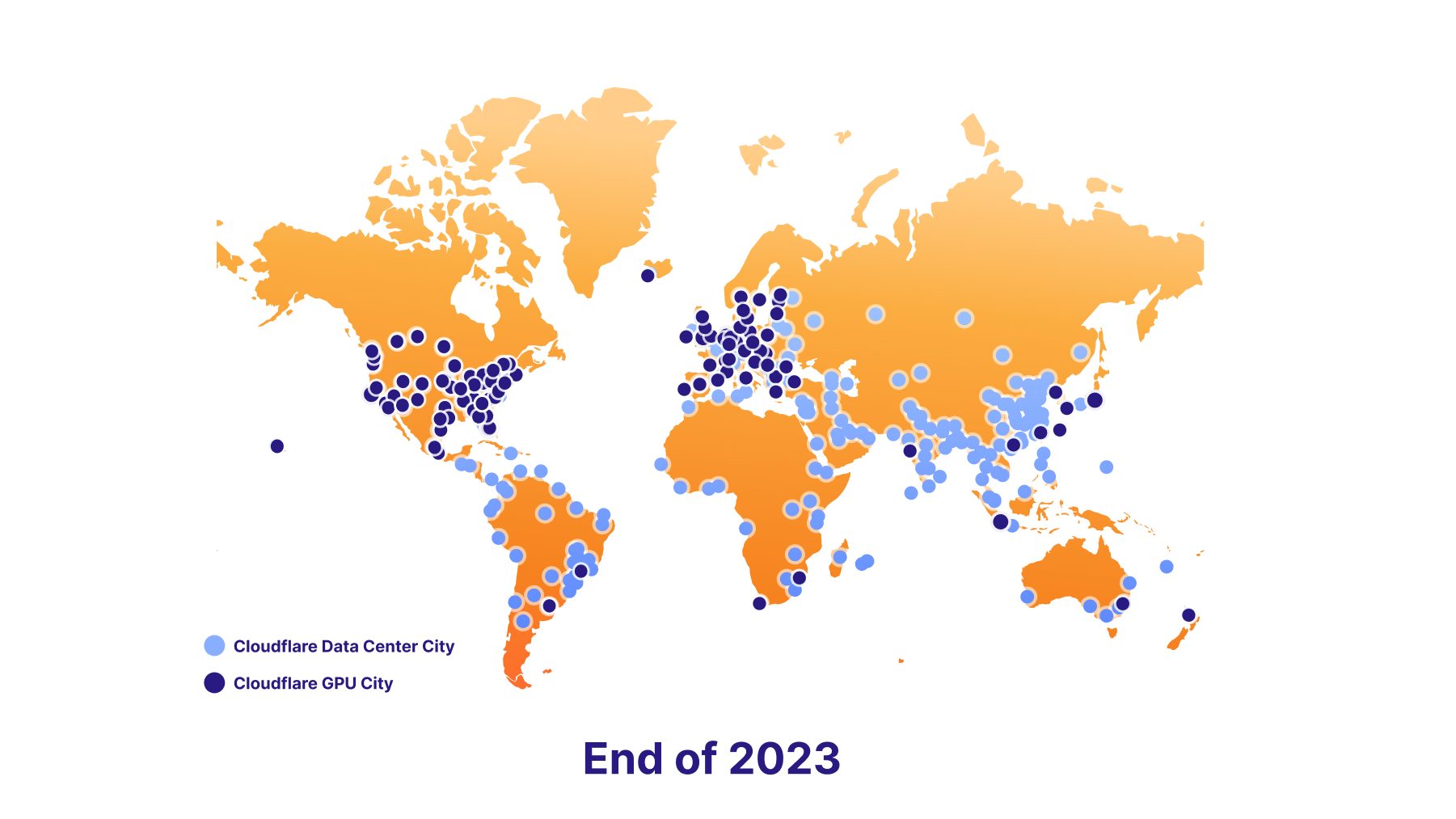
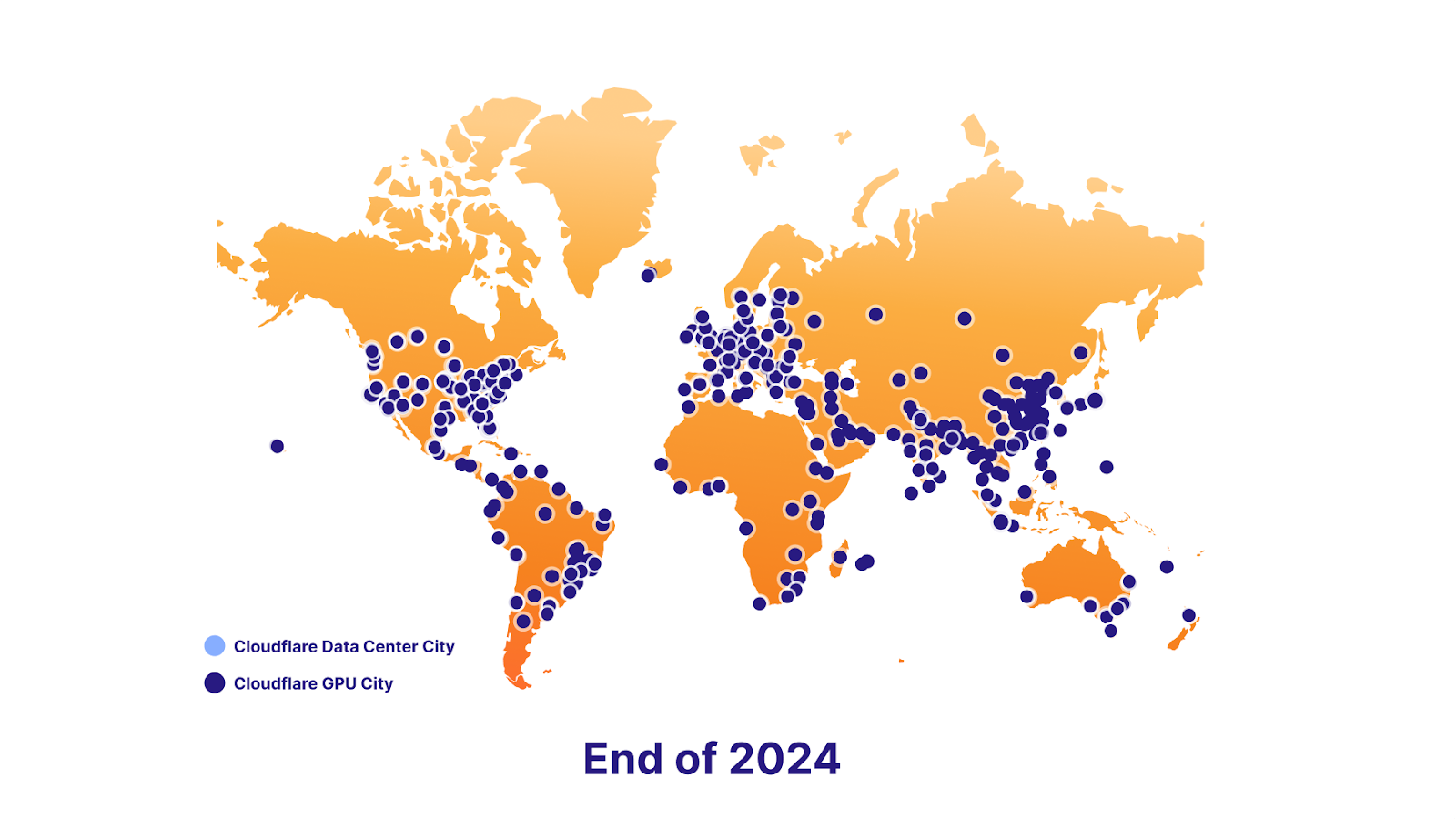
In addition to more powerful GPUs, we’ve continued to expand our GPU footprint to get as close to the user as possible, reducing latency even further. Today, we have GPUs in over 180 cities, having doubled our capacity in a year.
Bigger, better, faster
With the introduction of our new, more powerful GPUs, you can now run inference on significantly larger models, including Meta Llama 3.1 70B. Previously, our model catalog was limited to 8B parameter LLMs, but we can now support larger models, faster response times, and larger context windows. This means your applications can handle more complex tasks with greater efficiency.
|
Model |
|
@cf/meta/Llama-3.2-11B-Vision-Instruct |
|
@cf/meta/Llama-3.2-1B-Instruct |
|
@cf/meta/Llama-3.2-3B-Instruct |
|
@cf/meta/Llama-3.1-8B-Instruct |
|
@cf/meta/Llama-3.1-70B-Instruct |
|
@cf/black-forest-labs/flux-1-schnell |
The set of models above are available on our new GPUs at faster speeds. If you’re using Llama 3.1, we’ve already upgraded you to the faster inference – so your applications are automatically sped up! In general, you can expect throughput of 80+ Tokens per Second (TPS) for 8b models and a Time To First Token of 300 ms (depending on where you are in the world).
Our model instances now support larger context windows, like the full 128K context window for Llama 3.1 and 3.2. To give you full visibility into performance, we’ll also be publishing metrics like TTFT, TPS, Context Window, and pricing on models in our catalog, so you know exactly what to expect.
We’re committed to bringing the best of open-source models to our platform, and that includes Meta’s release of the new Llama 3.2 collection of models. As a Meta launch partner, we were excited to have Day 0 support for the 11B vision model, as well as the 1B and 3B text-only model on Workers AI.
For more details on how we made Workers AI fast, take a look at our technical blog post, where we share a novel method for KV cache compression (it’s open-source!), as well as details on speculative decoding, our new hardware design, and more.
Greater model flexibility
With our commitment to helping you run more powerful models faster, we are also expanding the breadth of models you can run on Workers AI with our Run Any* Model feature. Until now, we have manually curated and added only the most popular open source models to Workers AI. Now, we are opening up our catalog to the public, giving you the flexibility to choose from a broader selection of models. We will support models that are compatible with our GPUs and inference stack at the start (hence the asterisk on Run Any* Model). We’re launching this feature in closed beta and if you’d like to try it out, please fill out the form, so we can grant you access to this new feature.
The Workers AI model catalog will now be split into two parts: a static catalog and a dynamic catalog. Models in the static catalog will remain curated by Cloudflare and will include the most popular open source models with guarantees on availability and speed (the models listed above). These models will always be kept warm in our network, ensuring you don’t experience cold starts. The usage and pricing model remains serverless, where you will only be charged for the requests to the model and not the cold start times.
Models that are launched via Run Any* Model will make up the dynamic catalog. If the model is public, users can share an instance of that model. In the future, we will allow users to launch private instances of models as well.
This is just the first step towards running your own custom or private models on Workers AI. While we have already been supporting private models for select customers, we are working on making this capacity available to everyone in the near future.
New Workers AI pricing
We launched Workers AI during Birthday Week 2023 with the concept of “neurons” for pricing. Neurons were intended to simplify the unit of measure across various models on our platform, including text, image, audio, and more. However, over the past year, we have listened to your feedback and heard that neurons were difficult to grasp and challenging to compare with other providers. Additionally, the industry has matured, and new pricing standards have materialized. As such, we’re excited to announce that we will be moving towards unit-based pricing and saying goodbye to neurons.
Moving forward, Workers AI will be priced based on model task, size, and units. LLMs will be priced based on the model size (parameters) and input/output tokens. Image generation models will be priced based on the output image resolution and the number of steps. Embeddings models will be priced based on input tokens. Speech-to-text models will be priced on seconds of audio input.
|
Model Task |
Units |
Model Size |
Pricing |
|
LLMs (incl. Vision models) |
Tokens in/out (blended) |
<= 3B parameters |
$0.10 per Million Tokens |
|
3.1B – 8B |
$0.15 per Million Tokens |
||
|
8.1B – 20B |
$0.20 per Million Tokens |
||
|
20.1B – 40B |
$0.50 per Million Tokens |
||
|
40.1B+ |
$0.75 per Million Tokens |
||
|
Embeddings |
Tokens in |
<= 150M parameters |
$0.008 per Million Tokens |
|
151M+ parameters |
$0.015 per Million Tokens |
||
|
Speech-to-text |
Audio seconds in |
N/A |
$0.0039 per minute of audio input |
|
Image Size |
Model Type |
Steps |
Price |
|
<=256×256 |
Standard |
25 |
$0.00125 per 25 steps |
|
Fast |
5 |
$0.00025 per 5 steps |
|
|
<=512×512 |
Standard |
25 |
$0.0025 per 25 steps |
|
Fast |
5 |
$0.0005 per 5 steps |
|
|
<=1024×1024 |
Standard |
25 |
$0.005 per 25 steps |
|
Fast |
5 |
$0.001 per 5 steps |
|
|
<=2048×2048 |
Standard |
25 |
$0.01 per 25 steps |
|
Fast |
5 |
$0.002 per 5 steps |
We paused graduating models and announcing pricing for beta models over the past few months as we prepared for this new pricing change. We’ll be graduating all models to this new pricing, and billing will take effect on October 1, 2024.
Our free tier has been redone to fit these new metrics, and will include a monthly allotment of usage across all the task types.
|
Model |
Free tier size |
|
Text Generation – LLM |
10,000 tokens a day across any model size |
|
Embeddings |
10,000 tokens a day across any model size |
|
Images |
Sum of 250 steps, up to 1024×1024 resolution |
|
Whisper |
10 minutes of audio a day |
Optimizing AI workflows with AI Gateway
AI Gateway is designed to help developers and organizations building AI applications better monitor, control, and optimize their AI usage, and thanks to our users, AI Gateway has reached an incredible milestone — over 2 billion requests proxied by September 2024, less than a year after its inception. But we are not stopping there.
Persistent logs (open beta)
Persistent logs allow developers to store and analyze user prompts and model responses for extended periods, up to 10 million logs per gateway. Each request made through AI Gateway will create a log. With a log, you can see details of a request, including timestamp, request status, model, and provider.
We have revamped our logging interface to offer more detailed insights, including cost and duration. Users can now annotate logs with human feedback using thumbs up and thumbs down. Lastly, you can now filter, search, and tag logs with custom metadata to further streamline analysis directly within AI Gateway.
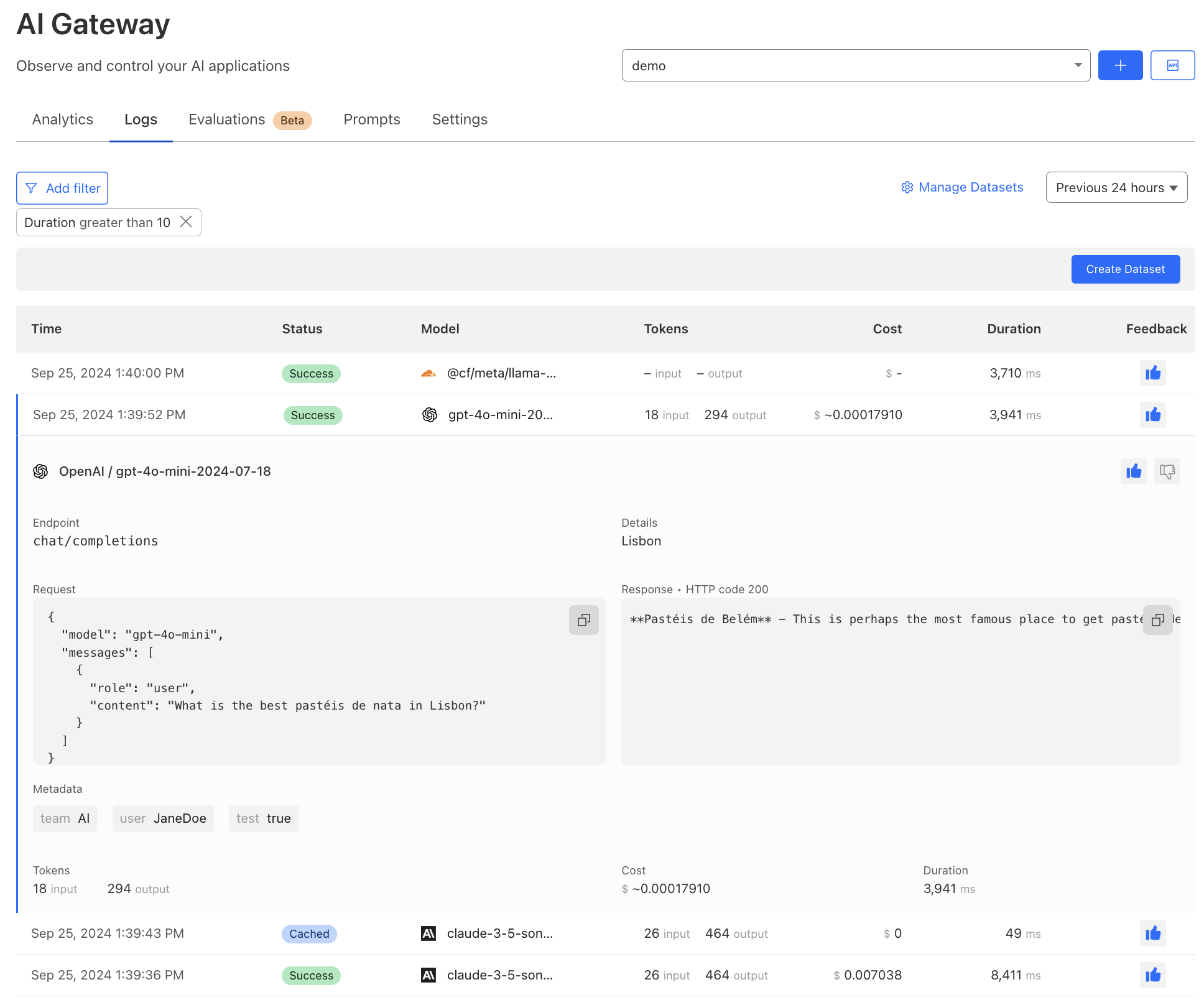
Persistent logs are available to use on all plans, with a free allocation for both free and paid plans. On the Workers Free plan, users can store up to 100,000 logs total across all gateways at no charge. For those needing more storage, upgrading to the Workers Paid plan will give you a higher free allocation — 200,000 logs stored total. Any additional logs beyond those limits will be available at $8 per 100,000 logs stored per month, giving you the flexibility to store logs for your preferred duration and do more with valuable data. Billing for this feature will be implemented when the feature reaches General Availability, and we’ll provide plenty of advance notice.
|
Workers Free |
Workers Paid |
Enterprise |
|
|
Included Volume |
100,000 logs stored (total) |
200,000 logs stored (total) |
|
|
Additional Logs |
N/A |
$8 per 100,000 logs stored per month |
Export logs with Logpush
For users looking to export their logs, AI Gateway now supports log export via Logpush. With Logpush, you can automatically push logs out of AI Gateway into your preferred storage provider, including Cloudflare R2, Amazon S3, Google Cloud Storage, and more. This can be especially useful for compliance or advanced analysis outside the platform. Logpush follows its existing pricing model and will be available to all users on a paid plan.

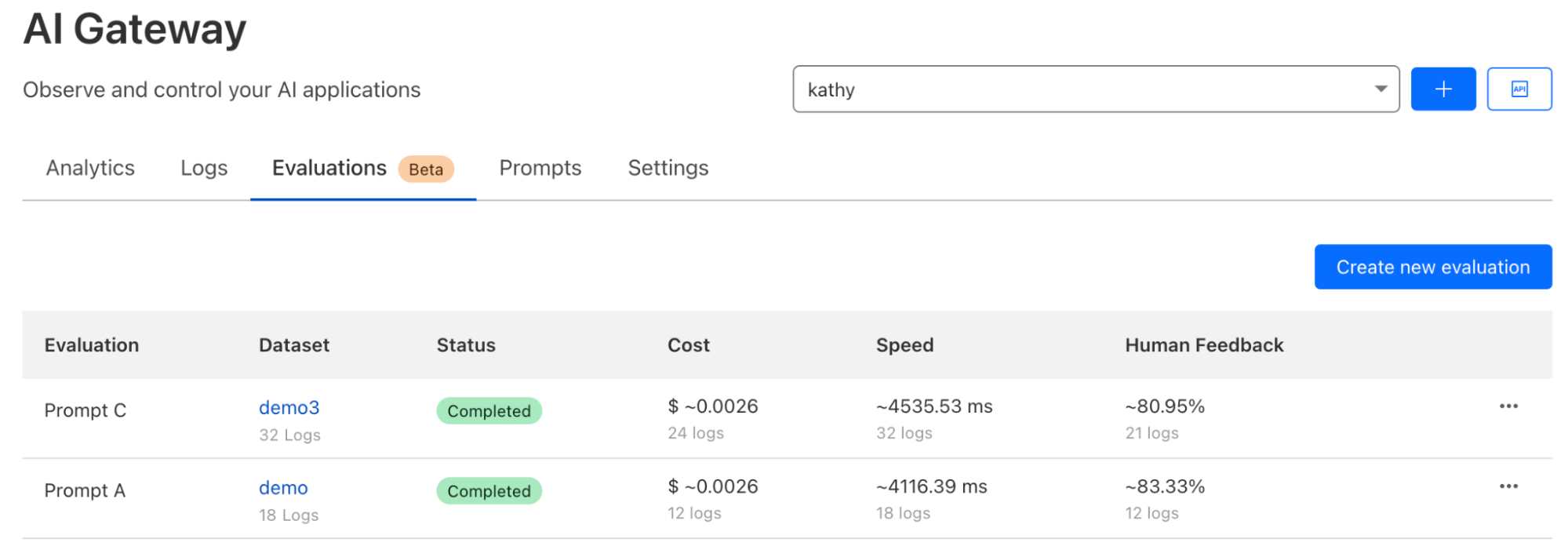
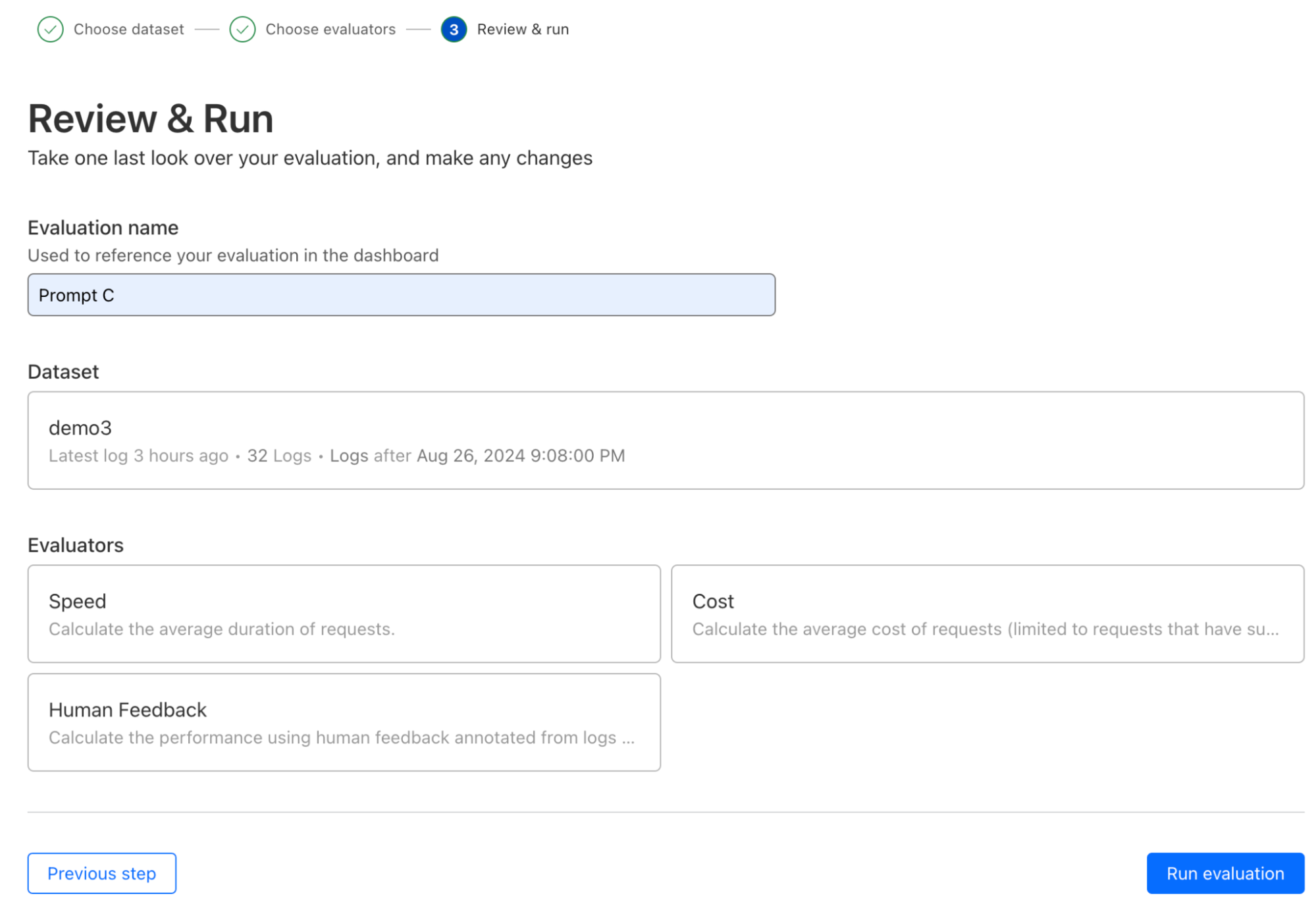
AI evaluations
We are also taking our first step towards comprehensive AI evaluations, starting with evaluation using human in the loop feedback (this is now in open beta). Users can create datasets from logs to score and evaluate model performance, speed, and cost, initially focused on LLMs. Evaluations will allow developers to gain a better understanding of how their application is performing, ensuring better accuracy, reliability, and customer satisfaction. We’ve added support for cost analysis across many new models and providers to enable developers to make informed decisions, including the ability to add custom costs. Future enhancements will include automated scoring using LLMs, comparing performance of multiple models, and prompt evaluations, helping developers make decisions on what is best for their use case and ensuring their applications are both efficient and cost-effective.
Vectorize GA
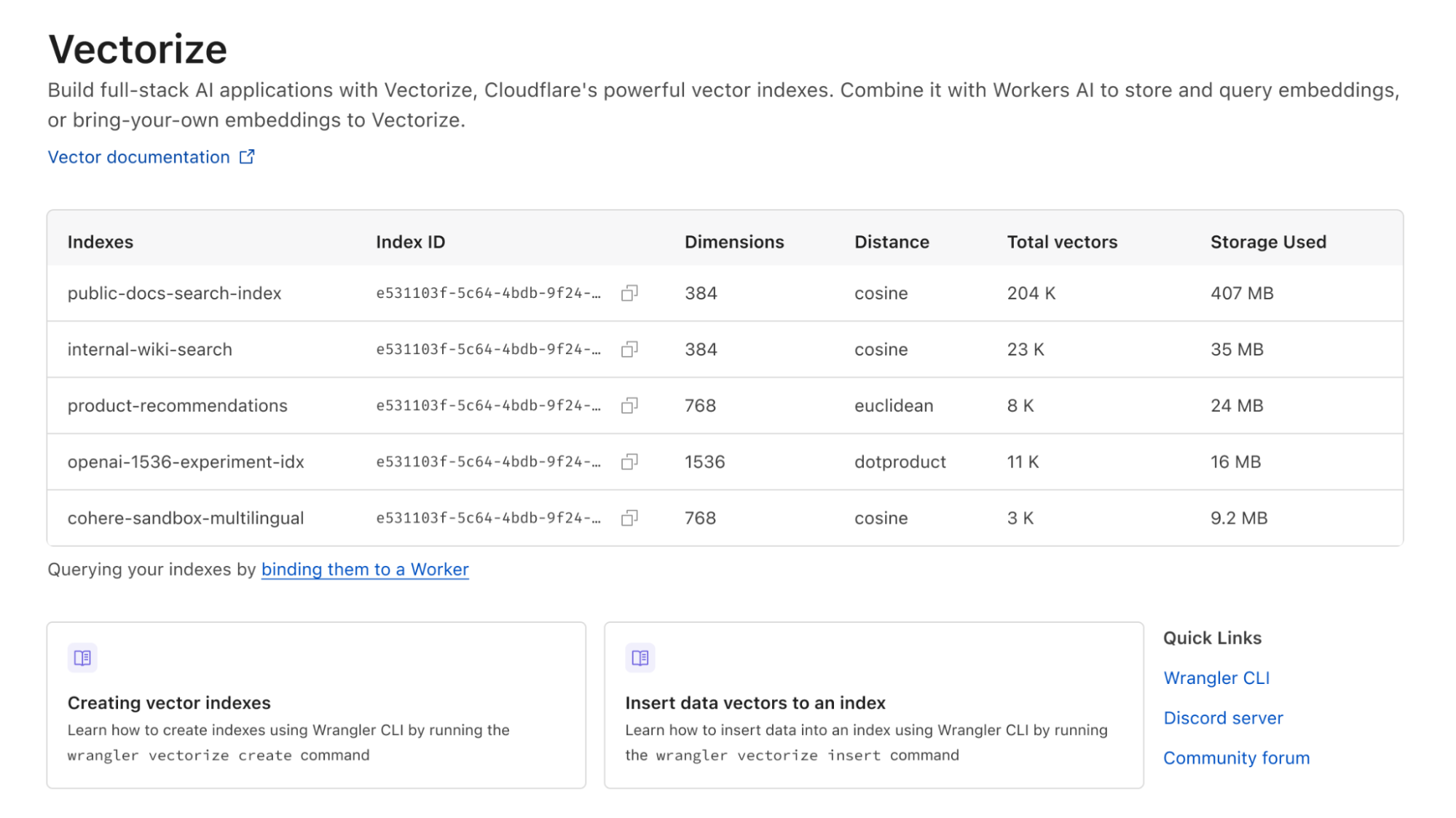
We’ve completely redesigned Vectorize since our initial announcement in 2023 to better serve customer needs. Vectorize (v2) now supports indexes of up to 5 million vectors (up from 200,000), delivers faster queries (median latency is down 95% from 500 ms to 30 ms), and returns up to 100 results per query (increased from 20). These improvements significantly enhance Vectorize’s capacity, speed, and depth of results.
Note: if you got started on Vectorize before GA, to ease the move from v1 to v2, a migration solution will be available in early Q4 — stay tuned!
New Vectorize pricing
Not only have we improved performance and scalability, but we’ve also made Vectorize one of the most cost-effective options on the market. We’ve reduced query prices by 75% and storage costs by 98%.
|
New Vectorize pricing |
Old Vectorize pricing |
Price reduction |
|
|
Writes |
Free |
Free |
n/a |
|
Query |
$.01 per 1 million vector dimensions |
$0.04 per 1 million vector dimensions |
75% |
|
Storage |
$0.05 per 100 million vector dimensions |
$4.00 per 100 million vector dimensions |
98% |
You can learn more about our pricing in the Vectorize docs.
Vectorize free tier
There’s more good news: we’re introducing a free tier to Vectorize to make it easy to experiment with our full AI stack.
The free tier includes:
-
30 million queried vector dimensions / month
-
5 million stored vector dimensions / month
How fast is Vectorize?
To measure performance, we conducted benchmarking tests by executing a large number of vector similarity queries as quickly as possible. We measured both request latency and result precision. In this context, precision refers to the proportion of query results that match the known true-closest results for all benchmarked queries. This approach allows us to assess both the speed and accuracy of our vector similarity search capabilities. Here are the following datasets we benchmarked on:
-
dbpedia-openai-1M-1536-angular: 1 million vectors, 1536 dimensions, queried with cosine similarity at a top K of 10
-
Laion-768-5m-ip: 5 million vectors, 768 dimensions, queried with cosine similarity at a top K of 10
-
We ran this again skipping the result-refinement pass to return approximate results faster
-
|
Benchmark dataset |
P50 (ms) |
P75 (ms) |
P90 (ms) |
P95 (ms) |
Throughput (RPS) |
Precision |
|
dbpedia-openai-1M-1536-angular |
31 |
56 |
159 |
380 |
343 |
95.4% |
|
Laion-768-5m-ip |
81.5 |
91.7 |
105 |
123 |
623 |
95.5% |
|
Laion-768-5m-ip w/o refinement |
14.7 |
19.3 |
24.3 |
27.3 |
698 |
78.9% |
These benchmarks were conducted using a standard Vectorize v2 index, queried with a concurrency of 300 via a Cloudflare Worker binding. The reported latencies reflect those observed by the Worker binding querying the Vectorize index on warm caches, simulating the performance of an existing application with sustained usage.
Beyond Vectorize’s fast query speeds, we believe the combination of Vectorize and Workers AI offers an unbeatable solution for delivering optimal AI application experiences. By running Vectorize close to the source of inference and user interaction, rather than combining AI and vector database solutions across providers, we can significantly minimize end-to-end latency.
With these improvements, we’re excited to announce the general availability of the new Vectorize, which is more powerful, faster, and more cost-effective than ever before.
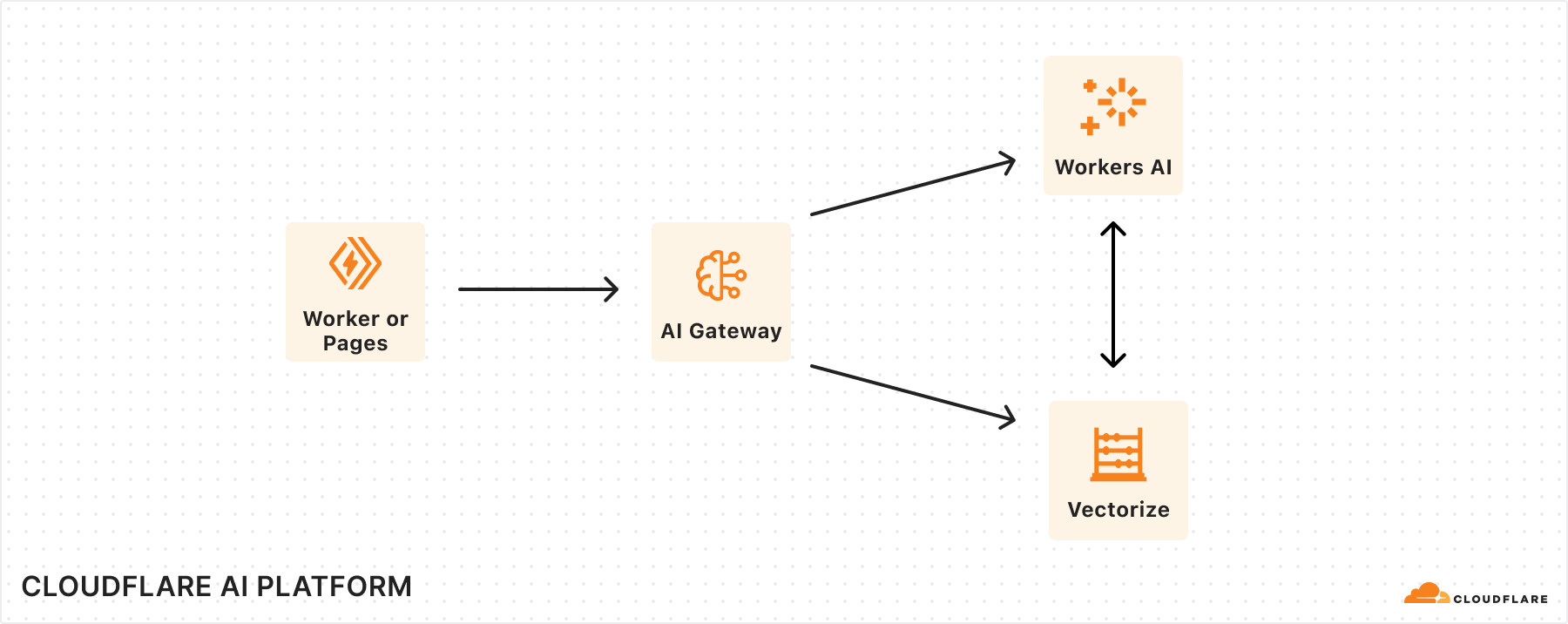
Tying it all together: the AI platform for all your inference needs
Over the past year, we’ve been committed to building powerful AI products that enable users to build on us. While we are making advancements on each of these individual products, our larger vision is to provide a seamless, integrated experience across our portfolio.
With Workers AI and AI Gateway, users can easily enable analytics, logging, caching, and rate limiting to their AI application by connecting to AI Gateway directly through a binding in the Workers AI request. We imagine a future where AI Gateway can not only help you create and save datasets to use for fine-tuning your own models with Workers AI, but also seamlessly redeploy them on the same platform. A great AI experience is not just about speed, but also accuracy. While Workers AI ensures fast performance, using it in combination with AI Gateway allows you to evaluate and optimize that performance by monitoring model accuracy and catching issues, like hallucinations or incorrect formats. With AI Gateway, users can test out whether switching to new models in the Workers AI model catalog will deliver more accurate performance and a better user experience.
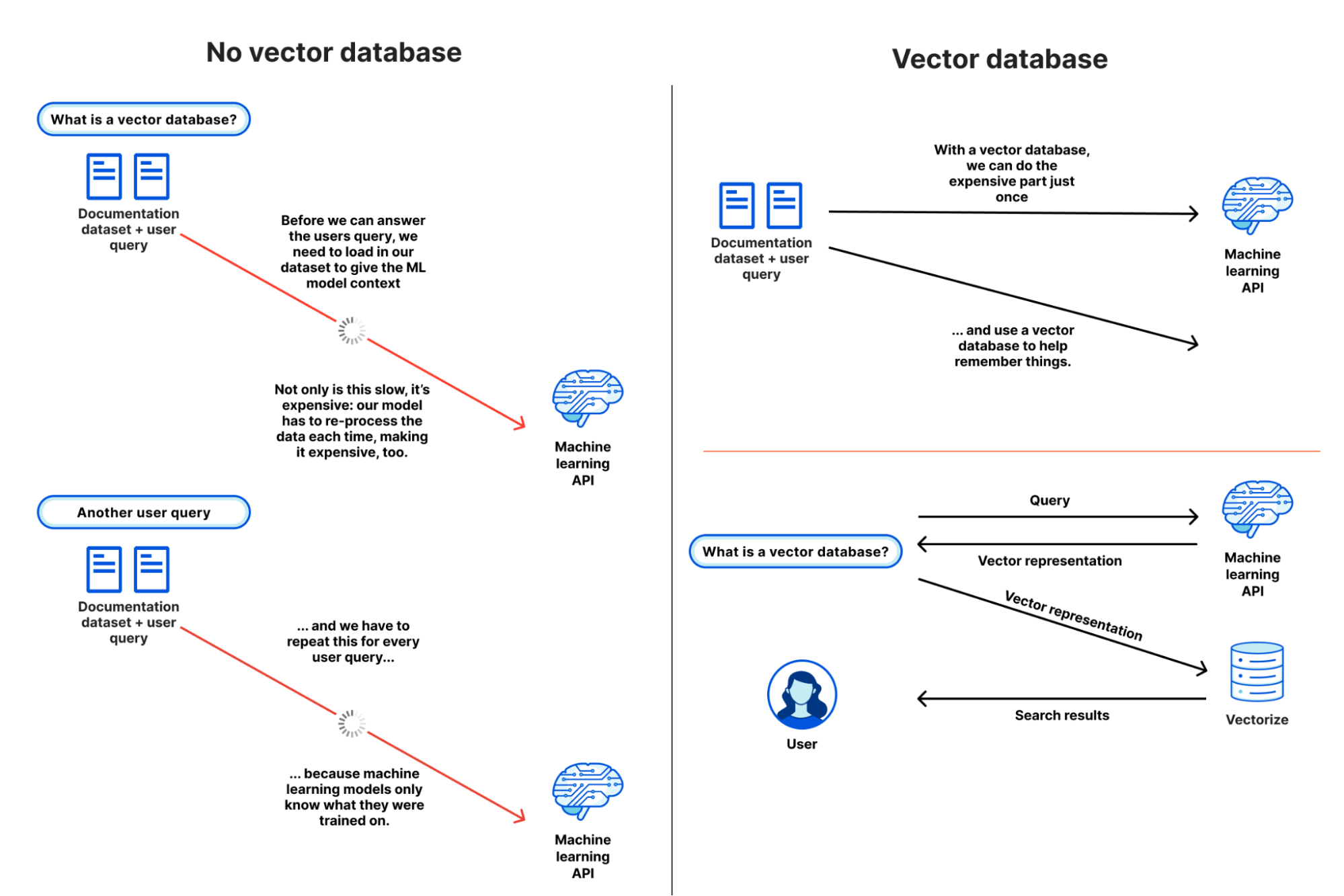
In the future, we’ll also be working on tighter integrations between Vectorize and Workers AI, where you can automatically supply context or remember past conversations in an inference call. This cuts down on the orchestration needed to run a RAG application, where we can automatically help you make queries to vector databases.
If we put the three products together, we imagine a world where you can build AI apps with full observability (traces with AI Gateway) and see how the retrieval (Vectorize) and generation (Workers AI) components are working together, enabling you to diagnose issues and improve performance.
This Birthday Week, we’ve been focused on making sure our individual products are best-in-class, but we’re continuing to invest in building a holistic AI platform within our AI portfolio, but also with the larger Developer Platform Products. Our goal is to make sure that Cloudflare is the simplest, fastest, more powerful place for you to build full-stack AI experiences with all the batteries included.
We’re excited for you to try out all these new features! Take a look at our updated developer docs on how to get started and the Cloudflare dashboard to interact with your account.