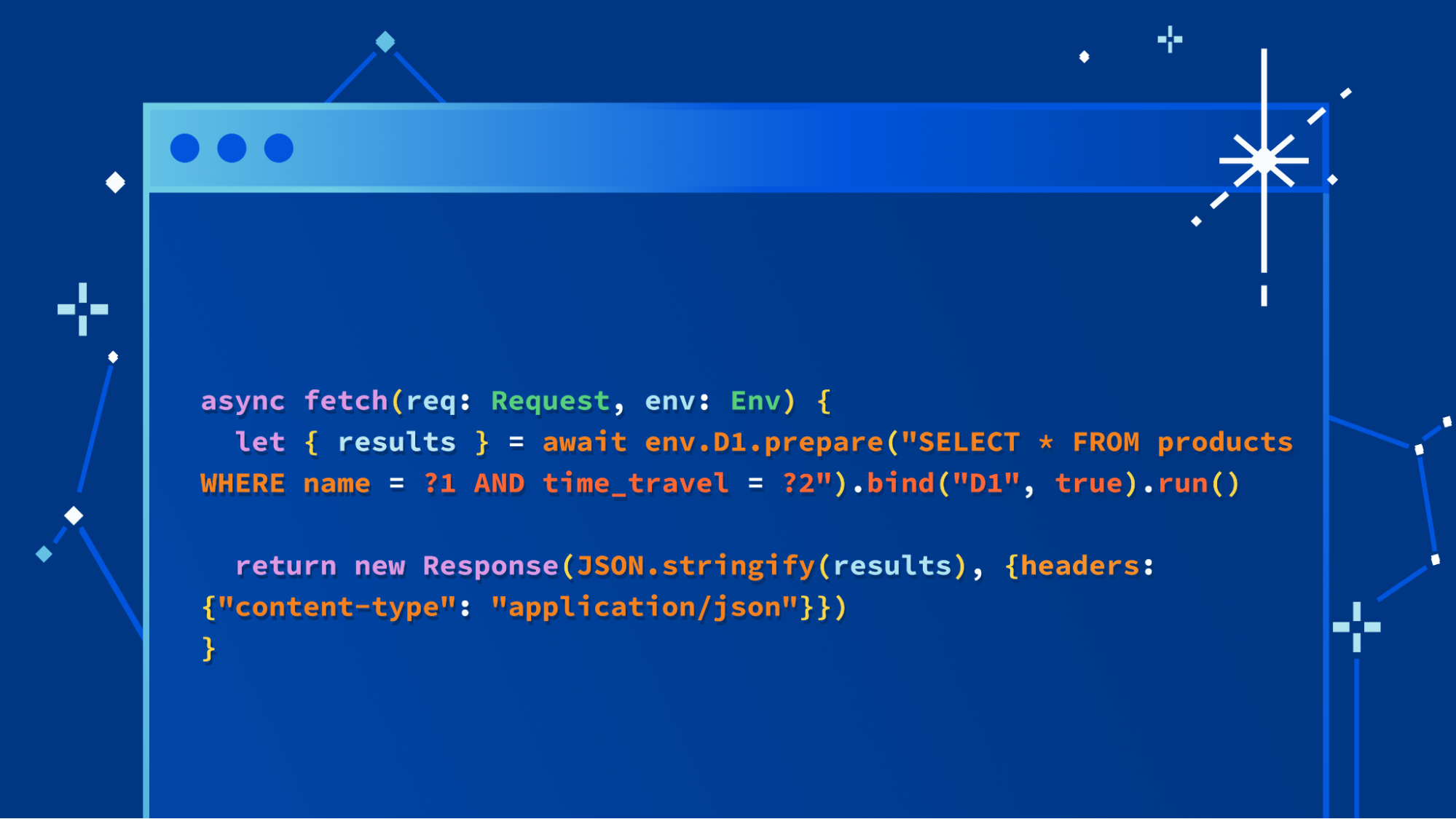
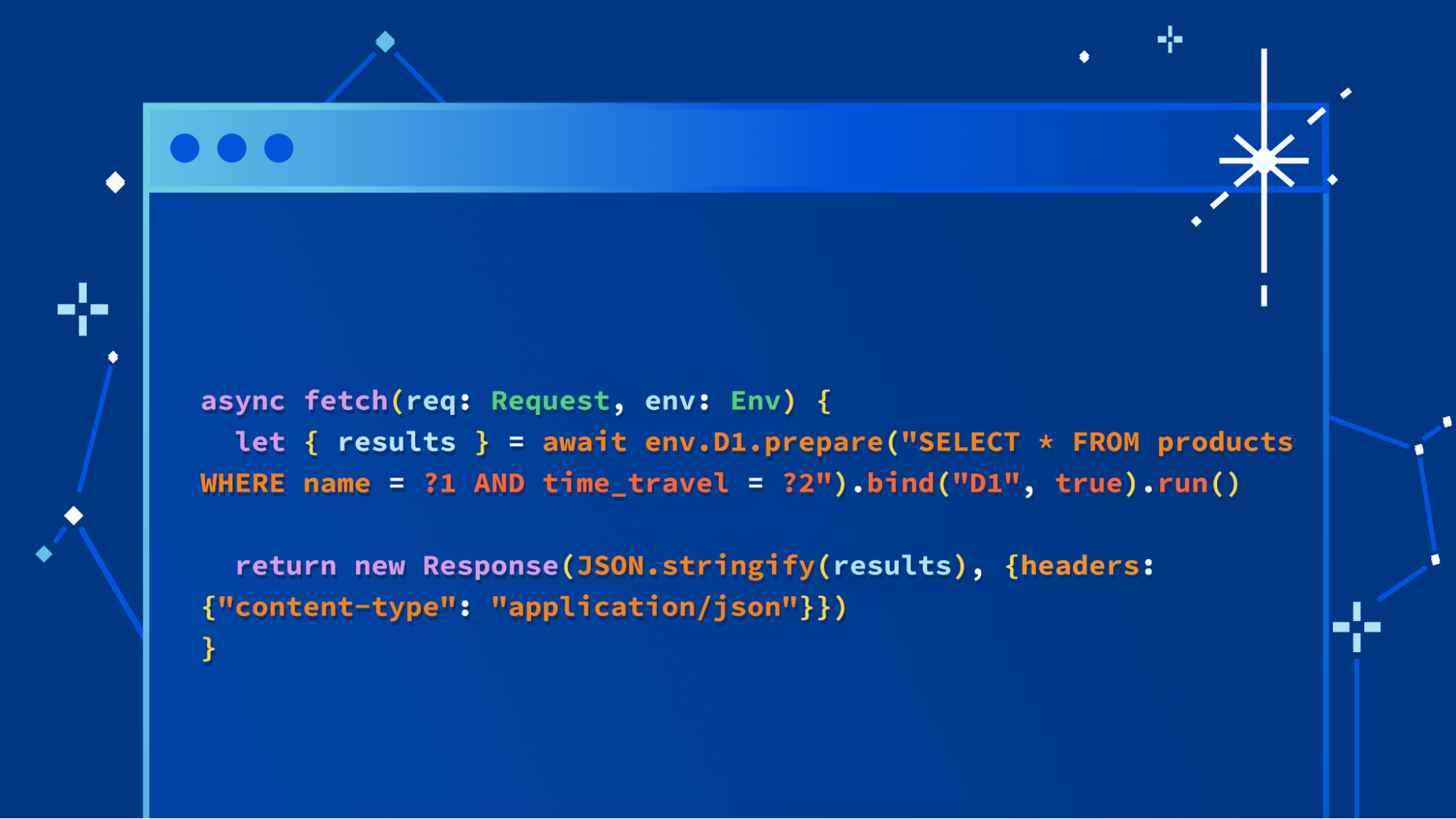
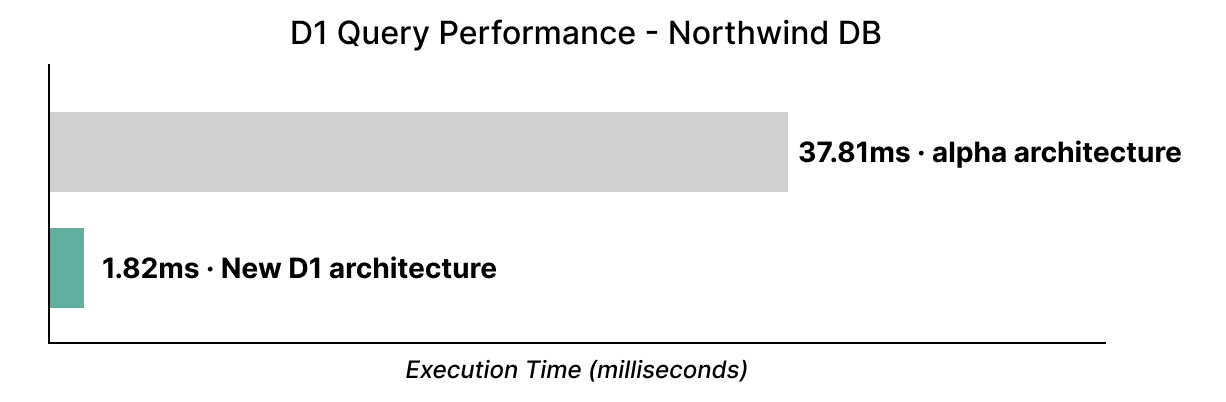
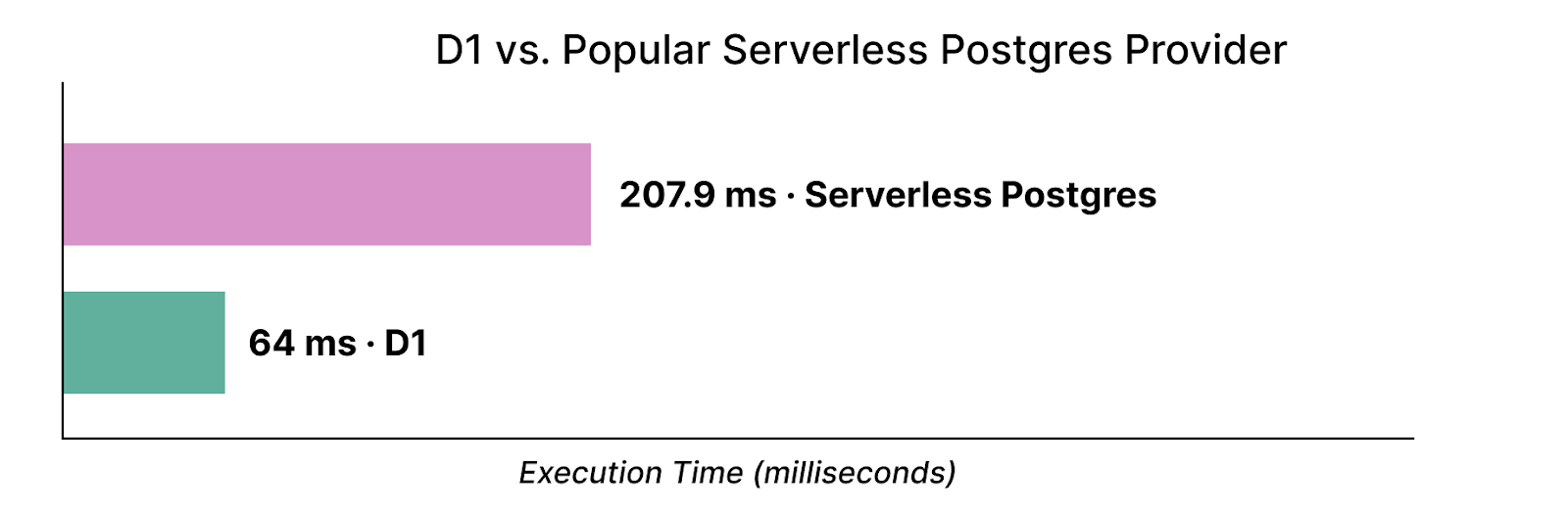
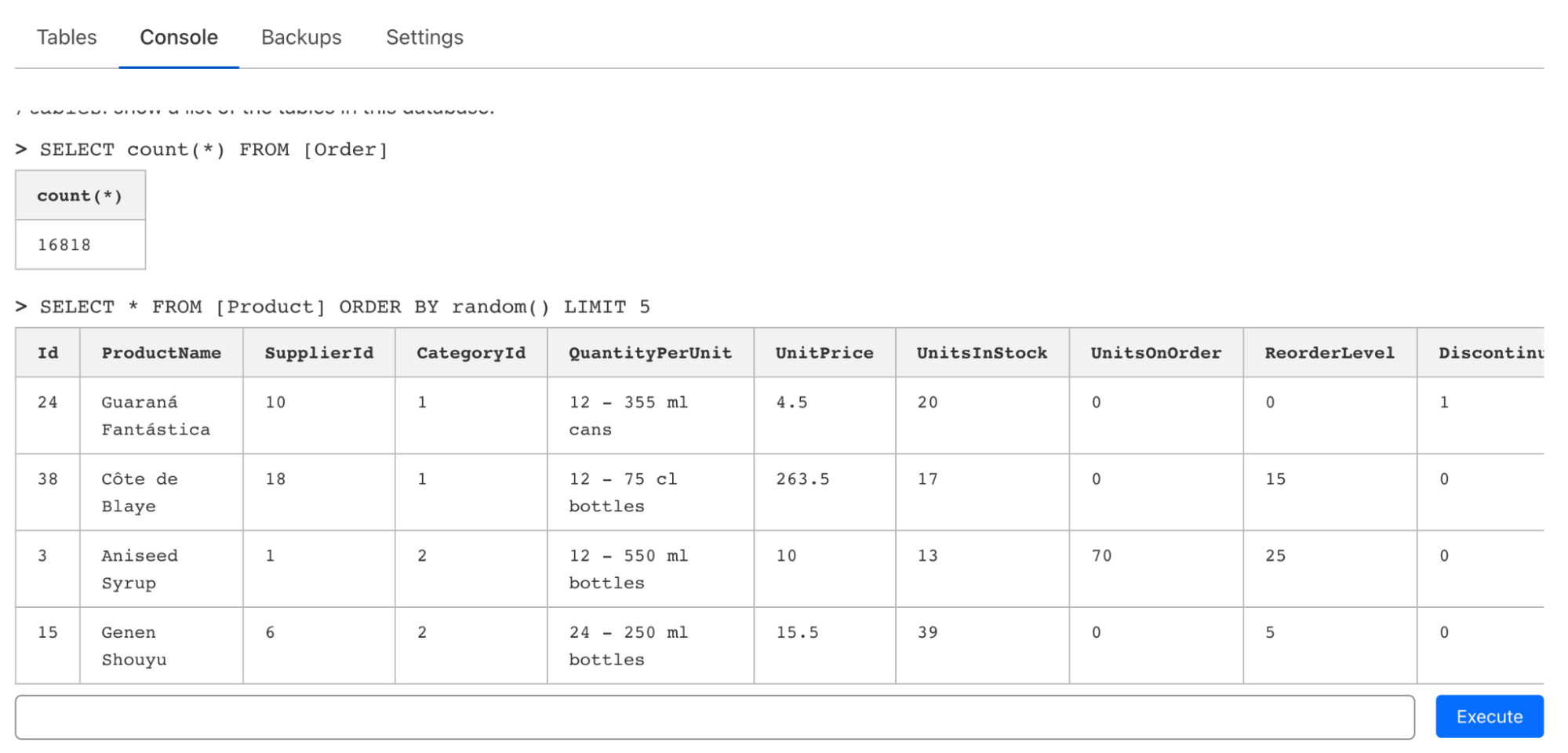
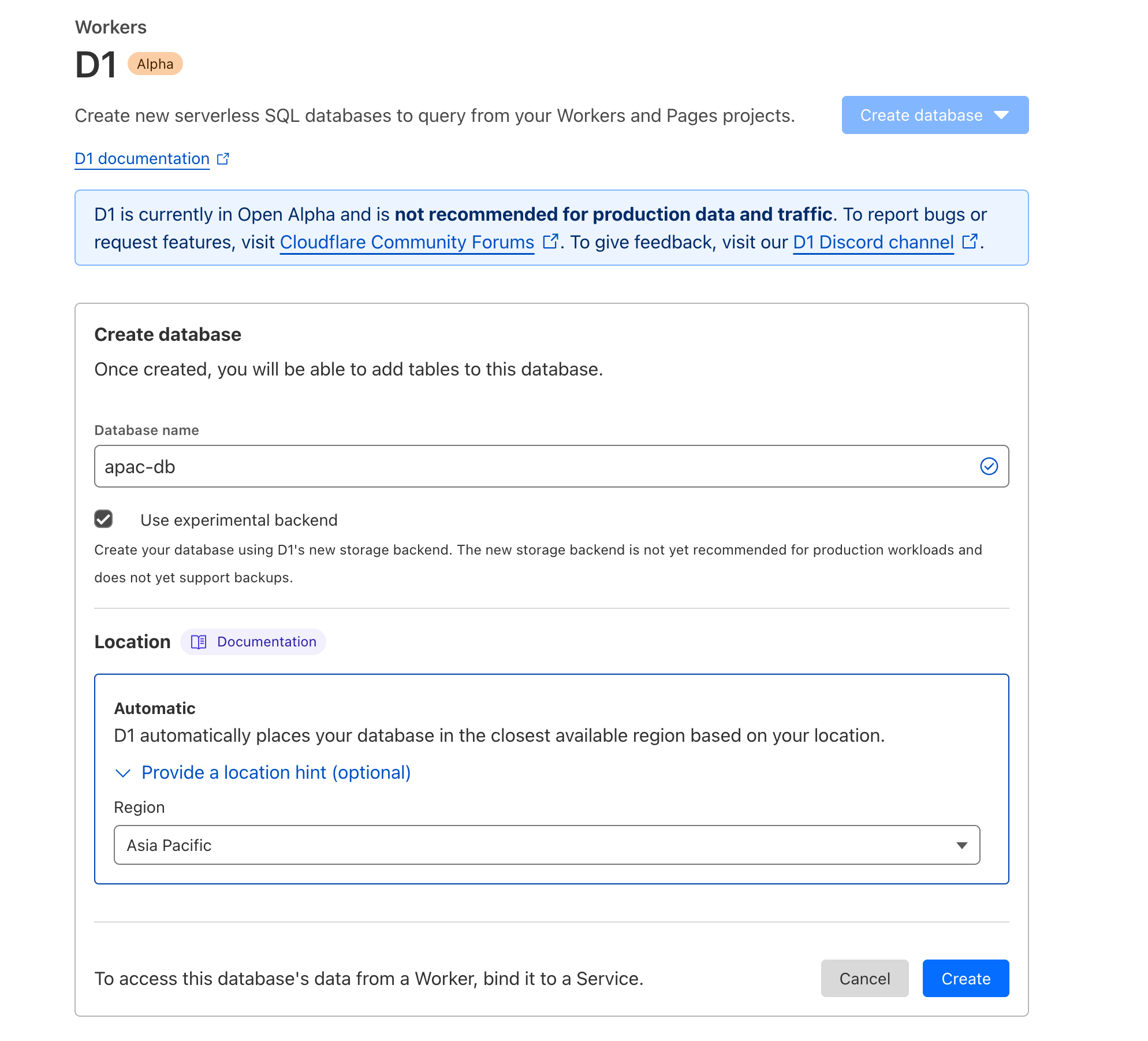
We’re not burying the lede on this one: you can now connect Cloudflare Workers to your PlanetScale databases directly and ship full-stack applications backed by Postgres or MySQL.
We’ve teamed up with PlanetScale because we wanted to partner with a database provider that we could confidently recommend to our users: one that shares our obsession with performance, reliability and developer experience. These are all critical factors for any development team building a serious application.
Now, when connecting to PlanetScale databases, your connections are automatically configured for optimal performance with Hyperdrive, ensuring that you have the fastest access from your Workers to your databases, regardless of where your Workers are running.
Building full-stack
As Workers has matured into a full-stack platform, we’ve introduced more options to facilitate your connectivity to data. With Workers KV, we made it easy to store configuration and cache unstructured data on the edge. With D1 and Durable Objects, we made it possible to build multi-tenant apps with simple, isolated SQL databases. And with Hyperdrive, we made connecting to external databases fast and scalable from Workers.
Today, we’re introducing a new choice for building on Cloudflare: Postgres and MySQL PlanetScale databases, directly accessible from within the Cloudflare dashboard. Link your Cloudflare and PlanetScale accounts, stop manually copying API keys back-and-forth, and connect Workers to any of your PlanetScale databases (production or otherwise!).
Connect to a PlanetScale database — no figuring things out on your own
Postgres and MySQL are the most popular options for building applications, and with good reason. Many large companies have built and scaled on these databases, providing for a robust ecosystem (like Cloudflare!). And you may want to have access to the power, familiarity, and functionality that these databases provide.
Importantly, all of this builds on Hyperdrive, our distributed connection pooler and query caching infrastructure. Hyperdrive keeps connections to your databases warm to avoid incurring latency penalties for every new request, reduces the CPU load on your database by managing a connection pool, and can cache the results of your most frequent queries, removing load from your database altogether. Given that about 80% of queries for a typical transactional database are read-only, this can be substantial — we’ve observed this in reality!
No more copying credentials around
Starting today, you can connect to your PlanetScale databases from the Cloudflare dashboard in just a few clicks. Connecting is now secure by default with a one-click password rotation option, without needing to copy and manage credentials back and forth. A Hyperdrive configuration will be created for your PlanetScale database, providing you with the optimal setup to start building on Workers.
And the experience spans both Cloudflare and PlanetScale dashboards: you can also create and view attached Hyperdrive configurations for your databases from the PlanetScale dashboard.
By automatically integrating with Hyperdrive, your PlanetScale databases are optimally configured for access from Workers. When you connect your database via Hyperdrive, Hyperdrive’s Placement system automatically determines the location of the database and places its pool of database connections in Cloudflare data centers with the lowest possible latency.
When one of your Workers connects to your Hyperdrive configuration for your PlanetScale database, Hyperdrive will ensure the fastest access to your database by eliminating the unnecessary roundtrips included in a typical database connection setup. Hyperdrive will resolve connection setup within the Hyperdrive client and use existing connections from the pool to quickly serve your queries. Better yet, Hyperdrive allows you to cache your query results in case you need to scale for high-read workloads.
This is a peek under the hood of how Hyperdrive makes access to PlanetScale as fast as possible. We’ve previously blogged about Hyperdrive’s technical underpinnings — it’s worth a read. And with this integration with Hyperdrive, you can easily connect to your databases across different Workers applications or environments, without having to reconfigure your credentials. All in all, a perfect match.
Get started with PlanetScale and Workers
With this partnership, we’re making it trivially easy to build on Workers with PlanetScale. Want to build a new application on Workers that connects to your existing PlanetScale cluster? With just a few clicks, you can create a globally deployed app that can query your database, cache your hottest queries, and keep your database connections warmed for fast access from Workers.
Connect directly to your PlanetScale MySQL or Postgres databases from the Cloudflare dashboard, for optimal configuration with Hyperdrive.
Multiple Cloudflare services, including our R2 object storage, were unavailable for 59 minutes on Thursday, February 6th. This caused all operations against R2 to fail for the duration of the incident, and caused a number of other Cloudflare services that depend on R2 — including Stream, Images, Cache Reserve, Vectorize and Log Delivery — to suffer significant failures.
The incident occurred due to human error and insufficient validation safeguards during a routine abuse remediation for a report about a phishing site hosted on R2. The action taken on the complaint resulted in an advanced product disablement action on the site that led to disabling the production R2 Gateway service responsible for the R2 API.
Critically, this incident did not result in the loss or corruption of any data stored on R2.
We’re deeply sorry for this incident: this was a failure of a number of controls and we are prioritizing work to implement additional system-level controls related not only to our abuse processing systems, but so that we continue to reduce the blast radius of any system- or human- action that could result in disabling any production service at Cloudflare.
What was impacted?
All customers using Cloudflare R2 would have observed a 100% failure rate against their R2 buckets and objects during the primary incident window. Services that depend on R2 (detailed in the table below) observed heightened error rates and failure modes depending on their usage of R2.
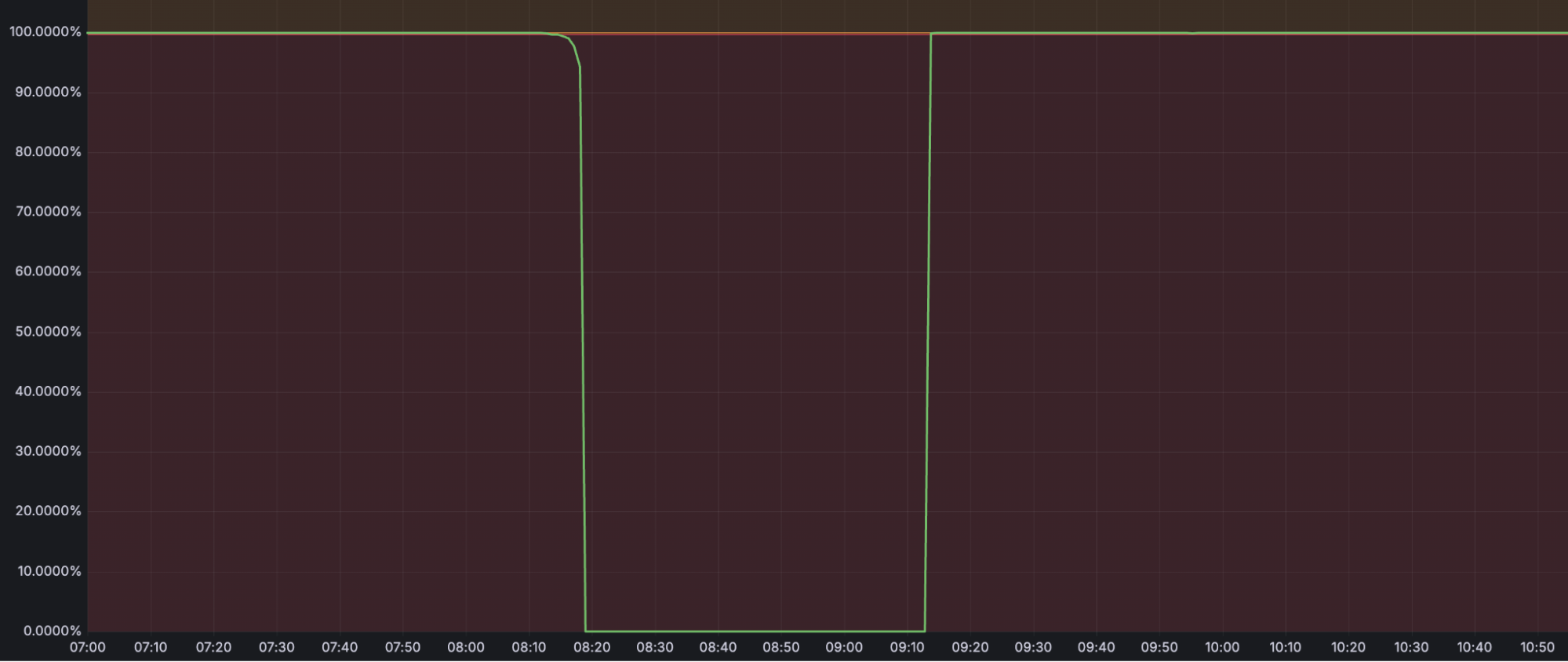
The primary incident window occurred between 08:14 UTC to 09:13 UTC, when operations against R2 had a 100% error rate. Dependent services (detailed below) observed increased failure rates for operations that relied on R2.
From 09:13 UTC to 09:36 UTC, as R2 recovered and clients reconnected, the backlog and resulting spike in client operations caused load issues with R2’s metadata layer (built on Durable Objects). This impact was significantly more isolated: we observed a 0.09% increase in error rates in calls to Durable Objects running in North America during this window.
The following table details the impacted services, including the user-facing impact, operation failures, and increases in error rates observed:
Product/Service
Impact
R2
100% of operations against R2 buckets and objects, including uploads, downloads, and associated metadata operations were impacted during the primary incident window. During the secondary incident window, we observed a <1% increase in errors as clients reconnected and increased pressure on R2’s metadata layer.
There was no data loss within the R2 storage subsystem: this incident impacted the HTTP frontend of R2. Separation of concerns and blast radius management meant that the underlying R2 infrastructure was unaffected by this.
Stream
100% of operations (upload & streaming delivery) against assets managed by Stream were impacted during the primary incident window.
Images
100% of operations (uploads & downloads) against assets managed by Images were impacted during the primary incident window.
Impact to Image Delivery was minor: success rate dropped to 97% as these assets are fetched from existing customer backends and do not rely on intermediate storage.
Cache Reserve
Cache Reserve customers observed an increase in requests to their origin during the incident window as 100% of operations failed. This resulted in an increase in requests to origins to fetch assets unavailable in Cache Reserve during this period. This impacted less than 0.049% of all cacheable requests served during the incident window.
User-facing requests for assets to sites with Cache Reserve did not observe failures as cache misses failed over to the origin.
Log Delivery
Log delivery was delayed during the primary incident window, resulting in significant delays (up to an hour) in log processing, as well as some dropped logs.
Specifically:
Non-R2 delivery jobs would have experienced up to 4.5% data loss during the incident. This level of data loss could have been different between jobs depending on log volume and buffer capacity in a given location.
R2 delivery jobs would have experienced up to 13.6% data loss during the incident.
R2 is a major destination for Cloudflare Logs. During the primary incident window, all available resources became saturated attempting to buffer and deliver data to R2. This prevented other jobs from acquiring resources to process their queues. Data loss (dropped logs) occurred when the job queues expired their data (to allow for new, incoming data). The system recovered when we enabled a kill switch to stop processing jobs sending data to R2.
Durable Objects
Durable Objects, and services that rely on it for coordination & storage, were impacted as the stampeding horde of clients re-connecting to R2 drove an increase in load.
We observed a 0.09% actual) increase in error rates in calls to Durable Objects running in North America, starting at 09:13 UTC and recovering by 09:36 UTC.
Cache Purge
Requests to the Cache Purge API saw a 1.8% error rate (HTTP 5xx) increase and a 10x increase in p90 latency for purge operations during the primary incident window. Error rates returned to normal immediately after this.
Vectorize
Queries and operations against Vectorize indexes were impacted during the primary incident window. 75% of queries to indexes failed (the remainder were served out of cache) and 100% of insert, upsert, and delete operations failed during the incident window as Vectorize depends on R2 for persistent storage. Once R2 recovered, Vectorize systems recovered in full.
We observed no continued impact during the secondary incident window, and we have not observed any index corruption as the Vectorize system has protections in place for this.
Key Transparency Auditor
100% of signature publish & read operations to the KT auditor service failed during the primary incident window. No third party reads occurred during this window and thus were not impacted by the incident.
Workers & Pages
A small volume (0.002%) of deployments to Workers and Pages projects failed during the primary incident window. These failures were limited to services with bindings to R2, as our control plane was unable to communicate with the R2 service during this period.
Incident timeline and impact
The incident timeline, including the initial impact, investigation, root cause, and remediation, are detailed below.
All timestamps referenced are in Coordinated Universal Time (UTC).
Time
Event
2025-02-06 08:12
The R2 Gateway service is inadvertently disabled while responding to an abuse report.
2025-02-06 08:14
— IMPACT BEGINS —
2025-02-06 08:15
R2 service metrics begin to show signs of service degradation.
2025-02-06 08:17
Critical R2 alerts begin to fire due to our service no longer responding to our health checks.
2025-02-06 08:18
R2 on-call engaged and began looking at our operational dashboards and service logs to understand impact to availability.
2025-02-06 08:23
Sales engineering escalated to the R2 engineering team that customers are experiencing a rapid increase in HTTP 500’s from all R2 APIs.
2025-02-06 08:25
Internal incident declared.
2025-02-06 08:33
R2 on-call was unable to identify the root cause and escalated to the lead on-call for assistance.
2025-02-06 08:42
Root cause identified as R2 team reviews service deployment history and configuration, which surfaces the action and the validation gap that allowed this to impact a production service.
2025-02-06 08:46
On-call attempts to re-enable the R2 Gateway service using our internal admin tooling, however this tooling was unavailable because it relies on R2.
2025-02-06 08:49
On-call escalates to an operations team who has lower level system access and can re-enable the R2 Gateway service.
2025-02-06 08:57
The operations team engaged and began to re-enable the R2 Gateway service.
2025-02-06 09:09
R2 team triggers a redeployment of the R2 Gateway service.
2025-02-06 09:10
R2 began to recover as the forced re-deployment rolled out as clients were able to reconnect to R2.
2025-02-06 09:13
— IMPACT ENDS — R2 availability recovers to within its service-level objective (SLO). Durable Objects begins to observe a slight increase in error rate (0.09%) for Durable Objects running in North America due to the spike in R2 clients reconnecting.
2025-02-06 09:36
The Durable Objects error rate recovers.
2025-02-06 10:29
The incident is closed after monitoring error rates.
At the R2 service level, our internal Prometheus metrics showed R2’s SLO near-immediately drop to 0% as R2’s Gateway service stopped serving all requests and terminated in-flight requests.
The slight delay in failure was due to the product disablement action taking 1-2 minutes to take effect as well as our configured metrics aggregation intervals:
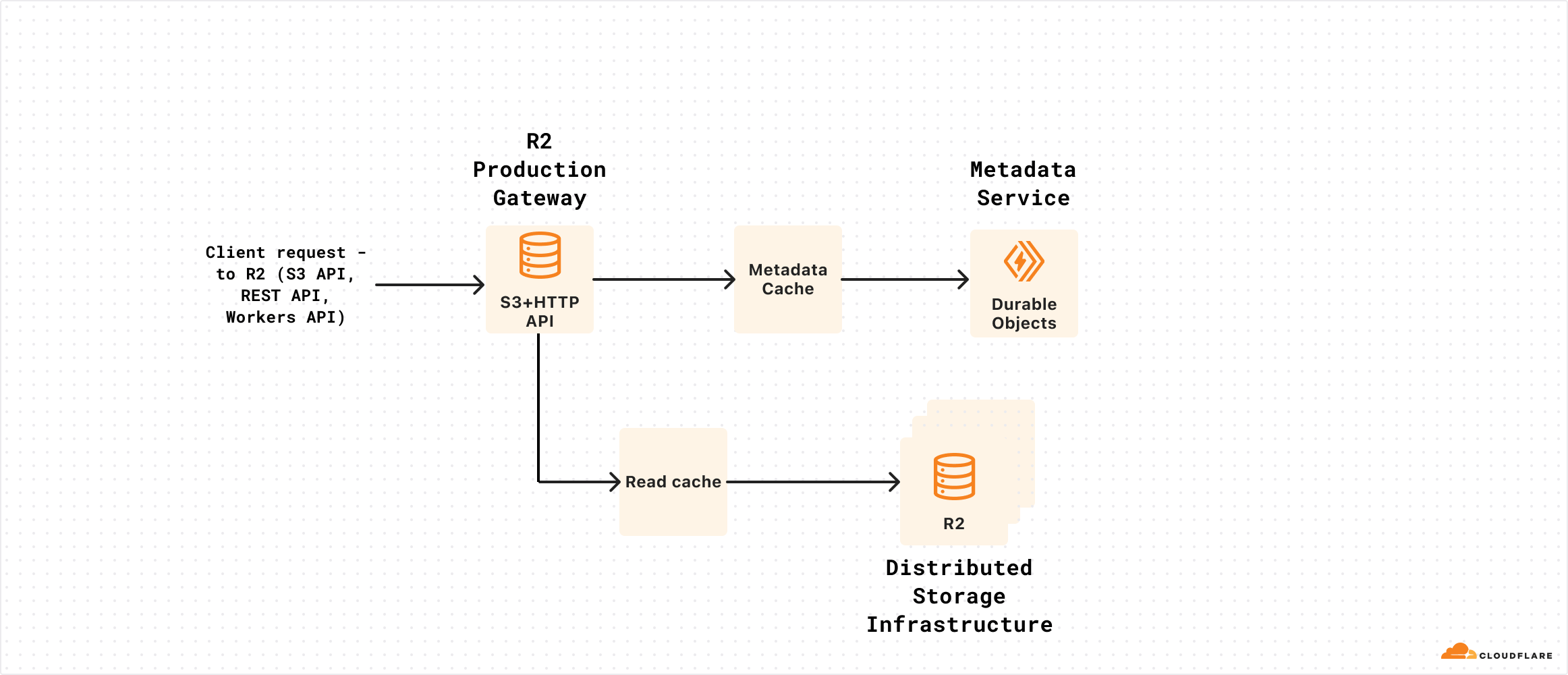
For context, R2’s architecture separates the Gateway service, which is responsible for authenticating and serving requests to R2’s S3 & REST APIs and is the “front door” for R2 — its metadata store (built on Durable Objects), our intermediate caches, and the underlying, distributed storage subsystem responsible for durably storing objects.
During the incident, all other components of R2 remained up: this is what allowed the service to recover so quickly once the R2 Gateway service was restored and re-deployed. The R2 Gateway acts as the coordinator for all work when operations are made against R2. During the request lifecycle, we validate authentication and authorization, write any new data to a new immutable key in our object store, then update our metadata layer to point to the new object. When the service was disabled, all running processes stopped.
While this means that all in-flight and subsequent requests fail, anything that had received a HTTP 200 response had already succeeded with no risk of reverting to a prior version when the service recovered. This is critical to R2’s consistency guarantees and mitigates the chance of a client receiving a successful API response without the underlying metadata and storage infrastructure having persisted the change.
Deep dive
Due to human error and insufficient validation safeguards in our admin tooling, the R2 Gateway service was taken down as part of a routine remediation for a phishing URL.
During a routine abuse remediation, action was taken on a complaint that inadvertently disabled the R2 Gateway service instead of the specific endpoint/bucket associated with the report. This was a failure of multiple system level controls (first and foremost) and operator training.
A key system-level control that led to this incident was in how we identify (or “tag”) internal accounts used by our teams. Teams typically have multiple accounts (dev, staging, prod) to reduce the blast radius of any configuration changes or deployments, but our abuse processing systems were not explicitly configured to identify these accounts and block disablement actions against them. Instead of disabling the specific endpoint associated with the abuse report, the system allowed the operator to (incorrectly) disable the R2 Gateway service.
Once we identified this as the cause of the outage, remediation and recovery was inhibited by the lack of direct controls to revert the product disablement action and the need to engage an operations team with lower level access than is routine. The R2 Gateway service then required a re-deployment in order to rebuild its routing pipeline across our edge network.
Once re-deployed, clients were able to re-connect to R2, and error rates for dependent services (including Stream, Images, Cache Reserve and Vectorize) returned to normal levels.
Remediation and follow-up steps
We have taken immediate steps to resolve the validation gaps in our tooling to prevent this specific failure from occurring in the future.
We are prioritizing several work-streams to implement stronger, system-wide controls (defense-in-depth) to prevent this, including how we provision internal accounts so that we are not relying on our teams to correctly and reliably tag accounts. A key theme to our remediation efforts here is around removing the need to rely on training or process, and instead ensuring that our systems have the right guardrails and controls built-in to prevent operator errors.
These work-streams include (but are not limited to) the following:
Actioned: deployed additional guardrails implemented in the Admin API to prevent product disablement of services running in internal accounts.
Actioned: Product disablement actions in the abuse review UI have been disabled while we add more robust safeguards. This will prevent us from inadvertently repeating similar high-risk manual actions.
In-flight: Changing how we create all internal accounts (staging, dev, production) to ensure that all accounts are correctly provisioned into the correct organization. This must include protections against creating standalone accounts to avoid re-occurrence of this incident (or similar) in the future.
In-flight: Further restricting access to product disablement actions beyond the remediations recommended by the system to a smaller group of senior operators.
In-flight: Two-party approval required for ad-hoc product disablement actions. Going forward, if an investigator requires additional remediations, they must be submitted to a manager or a person on our approved remediation acceptance list to approve their additional actions on an abuse report.
In-flight: Expand existing abuse checks that prevent accidental blocking of internal hostnames to also prevent any product disablement action of products associated with an internal Cloudflare account.
In-flight: Internal accounts are being moved to our new Organizations model ahead of public release of this feature. The R2 production account was a member of this organization but our abuse remediation engine did not have the necessary protections to prevent acting against accounts within this organization.
We’re continuing to discuss & review additional steps and effort that can continue to reduce the blast radius of any system- or human- action that could result in disabling any production service at Cloudflare.
Conclusion
We understand this was a serious incident and we are painfully aware of — and extremely sorry for — the impact it caused to customers and teams building and running their businesses on Cloudflare.
This is the first (and ideally, the last) incident of this kind and duration for R2, and we’re committed to improving controls across our systems and workflows to prevent this in the future.
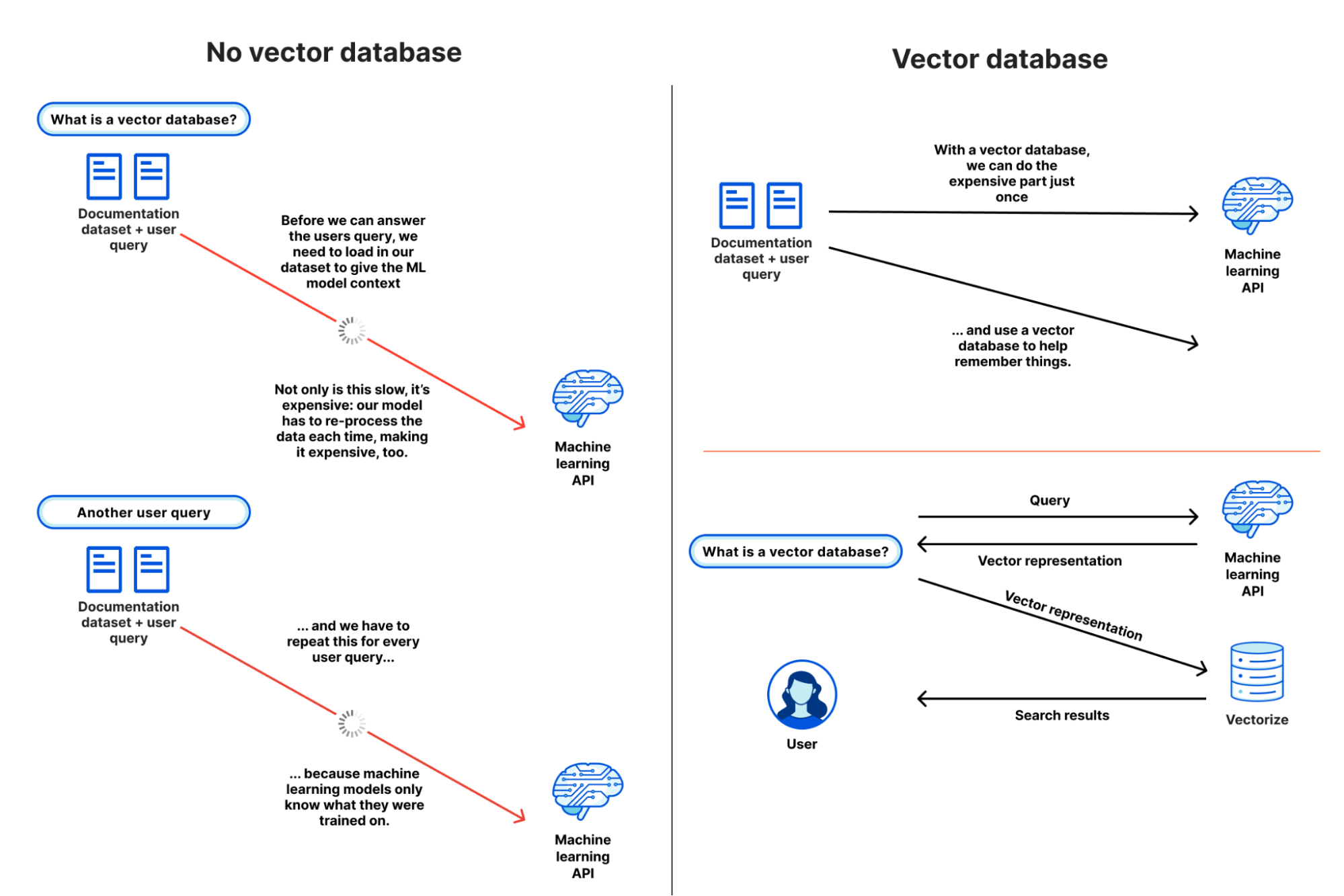
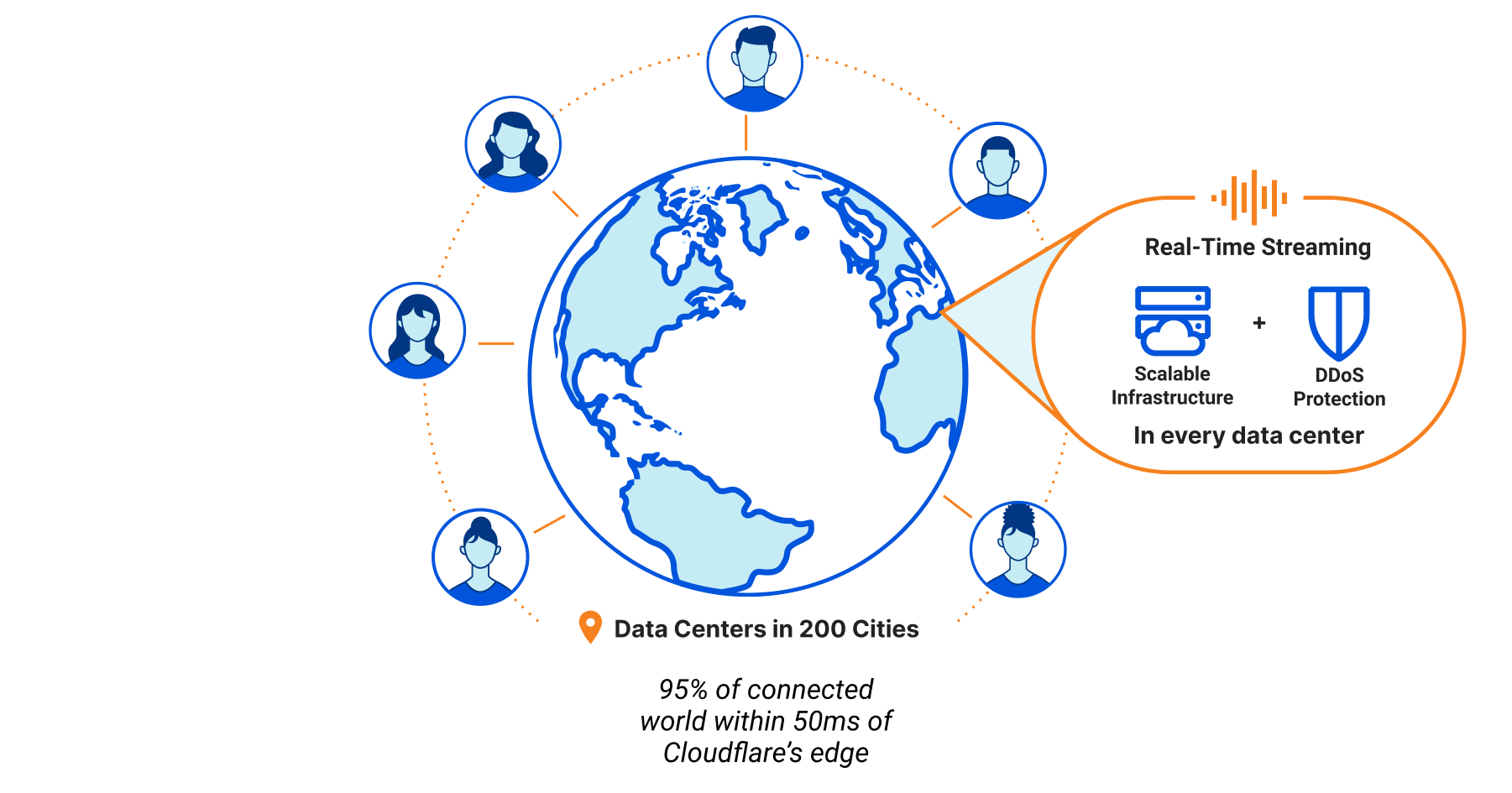
Data is fundamental to any real-world application: the database storing your user data and inventory, the analytics tracking sales events and/or error rates, the object storage with your web assets and/or the Parquet files driving your data science team, and the vector database enabling semantic search or AI-powered recommendations for your users.
When we first announced Workers back in 2017, and then Workers KV, Cloudflare R2, and D1, it was obvious that the next big challenge to solve for developers would be in making it easier to ingest, store, and query the data needed to build scalable, full-stack applications.
To that end, as part of our quest to make building stateful, distributed-by-default applications even easier, we’re launching our new Event Notifications service; a preview of our upcoming streaming ingestion product, Pipelines; and a sneak peek into our take on durable execution, Workflows.
Event-based architectures
When you’re writing data — whether that’s new data, changing existing data, or deleting old data — you often want to trigger other, asynchronous work to run in response. That could be processing user-driven uploads, updating search indexes as the underlying data changes, or removing associated rows in your SQL database when content is removed.
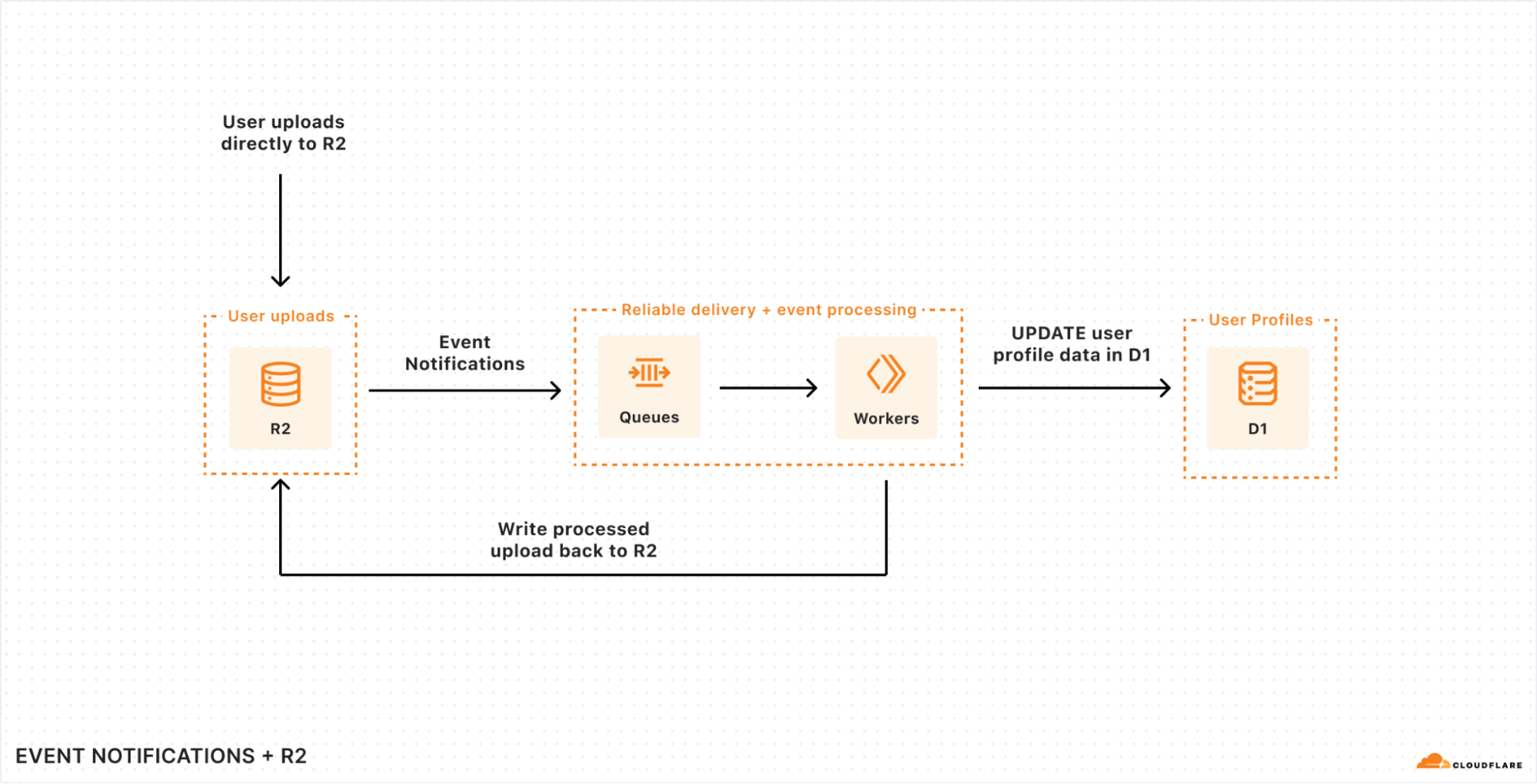
In order to make these event-driven workflows far easier to build across Cloudflare, we’re launching the first step towards a wider Event Notifications platform across Cloudflare, starting with notifications support in R2.
You can read more in the deep-dive on Event Notifications for R2, but in a nutshell: you can configure changes to content in any R2 bucket to write directly to a Queue, allowing you to reliably consume those events in a Worker or to pull from compute in a legacy cloud.
Event Notifications for R2 are just the beginning, though. There are many kinds of events you might want to trigger as a developer — these are just some of the event types we’re planning to support:
Changes (writes) to key-value pairs in your Workers KV namespaces.
Updates to your D1 databases, including changed rows or triggers.
Consuming event notifications from a single Worker is just one approach, though. As you start to consume events, you may want to trigger multi-step workflows that execute reliably, resume from errors or exceptions, and ensure that previous steps aren’t duplicated or repeated unnecessarily. An event notification framework turns out to be just the thing needed to drive a workflow engine that executes durably…
Making it even easier to ingest data
When we launched Cloudflare R2, our object storage service, we knew that supporting the de facto-standard S3 API was critical in order to allow developers to bring the tooling and services they already had over to R2. But the S3 API is designed to be simple: at its core, it provides APIs for upload, download, multipart and metadata operations, and many tools don’t support the S3 API.
What if you want to batch clickstream data from your web services so that it’s efficient (and cost-effective) to query by your analytics team? Or partition data by customer ID, merchant ID, or locale within a structured data format like JSON?
Well, we want to help solve this problem too, and so we’re announcing Pipelines, an upcoming streaming ingestion service designed to ingest data at scale, aggregate it, and write it directly to R2, without you having to manage infrastructure, partitions, runners, or worry about durability.
With Pipelines, creating a globally scalable ingestion endpoint that can ingest tens-of-thousands of events per second doesn’t require any code:
$ wrangler pipelines create clickstream-ingest-prod --batch-size="1MB" --batch-timeout-secs=120 --batch-on-json-key=".merchantId" --destination-bucket="prod-cs-data"
✅ Successfully created new pipeline "clickstream-ingest-prod"
📥 Created endpoints:
➡ HTTPS: https://d458dbe698b8eef41837f941d73bc5b3.pipelines.cloudflarestorage.com/clickstream-ingest-prod
➡ WebSocket: wss://d458dbe698b8eef41837f941d73bc5b3.pipelines.cloudflarestorage.com:8443/clickstream-ingest-prod
➡ Kafka: d458dbe698b8eef41837f941d73bc5b3.pipelines.cloudflarestorage.com:9092 (topic: clickstream-ingest-prod)
As you can see here, we’re already thinking about how to make Pipelines protocol-agnostic: write from a HTTP client, stream events over a WebSocket, and/or redirect your existing Kafka producer (and stop having to manage and scale Kafka) directly to Pipelines.
But that’s just the beginning of our vision here. Scalable ingestion and simple batching is one thing, but what about if you have more complex needs? Well, we have a massively scalable compute platform (Cloudflare Workers) that can help address this too.
The code below is just an initial exploration for how we’re thinking about an API for running transforms over streaming data. If you’re aware of projects like Apache Beam or Flink, this programming model might even look familiar:
export default {
// Pipeline handler is invoked when batch criteria are met
async pipeline(stream: StreamPipeline, env: Env, ctx: ExecutionContext): Promise<StreamingPipeline> {
// ...
return stream
// Type: transform(label: string, transformFunc: TransformFunction): Promise<StreamPipeline>
// Each transform has a label that is used in metrics to provide
// per-transform observability and debugging
.transform("human readable label", (events: Array<StreamEvent>) => {
return events.map((e) => ...)
})
.transform("another transform", (events: Array<StreamEvent>) => {
return events.map((e) => ...)
})
.writeToR2({
format: "json",
bucket: "MY_BUCKET_NAME",
prefix: somePrefix,
batchSize: "10MB"
})
}
}
Specifically:
The Worker describes a pipeline of transformations (mapping, reducing, filtering) that operates over each subset of events (records)
You can call out to other services — including D1 or KV — in order to synchronously or asynchronously hydrate data or lookup values during your stream processing
We take care of scaling horizontally based on records-per-second and/or any concurrency settings you configure based on processing latency requirements.
We’ll be bringing Pipelines into open beta later in 2024, and it will initially launch with support for HTTP ingestion and R2 as a destination (sink), but we’re already thinking bigger.
We’ll be sharing more as Pipelines gets closer to release. In the meantime, you can register your interest and share your use-case, and we’ll reach out when Pipelines reaches open beta.
Durable Execution
If the term “Durable Execution” is new to you, don’t worry: the term comes from the desire to run applications that can resume execution from where they left off, even if the underlying host or compute fails (where the “durable” part comes from).
As we’ve continued to build out our data and AI platforms, we’ve been acutely aware that developers need ways to create reliable, repeatable workflows that operate over that data, turn unstructured data into structured data, trigger on fresh data (or periodically), and automatically retry, restart, and export metrics for each step along the way. The industry calls this Durable Execution: we’re just calling it Workflows.
What makes Workflows different from other takes on Durable Execution is that we provide the underlying compute as part of the platform. You don’t have to bring-your-own compute, or worry about scaling it or provisioning it in the right locations. Workflows runs on top of Cloudflare Workers – you write the workflow, and we take care of the rest.
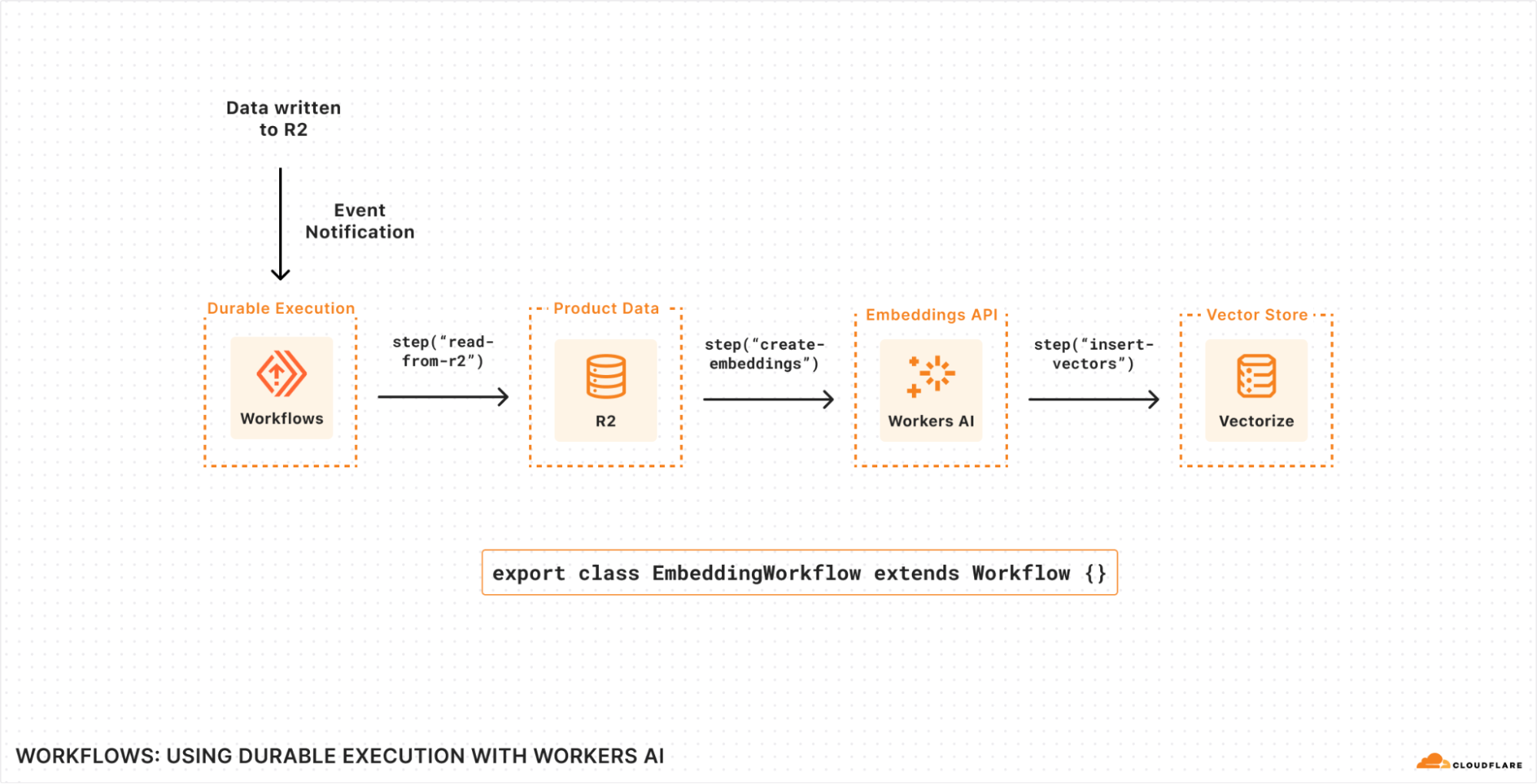
Here’s an early example of writing a Workflow that generates text embeddings using Workers AI and stores them (ready to query) in Vectorize as new content is written to (or updated within) R2.
Each Workflow run is triggered by an Event Notification consumed from a Queue, but could also be triggered by a HTTP request, another Worker, or even scheduled on a timer.
Individual steps within the Workflow allow us to define individually retriable units of work: in this case, we’re reading the new objects from R2, creating text embeddings using Workers AI, and then inserting.
State is durably persisted between steps: each step can emit state, and Workflows will automatically persist that so that any underlying failures, uncaught exceptions or network retries can resume execution from the last successful step.
Every call to step() automatically emits metrics associated with the unique Workflow run, making it easier to debug within each step and/or break down your application into its smallest units of execution, without having to worry about observability.
Step-by-step, it looks like this:
Transforming this series of steps into real code, here’s what this would look like with Workflows:
import { Ai } from "@cloudflare/ai";
import { Workflow } from "cloudflare:workers";
export interface Env {
R2: R2Bucket;
AI: any;
VECTOR_INDEX: VectorizeIndex;
}
export default class extends Workflow {
async run(event: Event) {
const ai = new Ai(this.env.AI);
// List of keys to fetch from our incoming event notification
const keysToFetch = event.messages.map((val) => {
return val.object.key;
});
// The return value of each step is stored (the "durable" part
// of "durable execution")
// This ensures that state can be persisted between steps, reducing
// the need to recompute results ($$, time) should subsequent
// steps fail.
const inputs = await this.ctx.run(
// Each step has a user-defined label
// Metrics are emitted as each step runs (to success or failure)
// with this label attached and available within per-Workflow
// analytics in near-real-time.
"read objects from R2", async () => {
const objects = [];
for (const key of keysToFetch) {
const object = await this.env.R2.get(key);
objects.push(await object.text());
}
return objects;
});
// Persist the output of this step.
const embeddings = await this.ctx.run(
"generate embeddings",
async () => {
const { data } = await ai.run("@cf/baai/bge-small-en-v1.5", {
text: inputs,
});
if (data.length) {
return data;
} else {
// Uncaught exceptions trigger an automatic retry of the step
// Retries and timeouts have sane defaults and can be overridden
// per step
throw new Error("Failed to generate embeddings");
}
},
{
retries: {
limit: 5,
delayMs: 1000,
backoff: "exponential",
},
}
);
await this.ctx.run("insert vectors", async () => {
const vectors = [];
keysToFetch.forEach((key, index) => {
vectors.push({
id: crypto.randomUUID(),
// Our embeddings from the previous step
values: embeddings[index].values,
// The path to each R2 object to map back to during
// vector search
metadata: { r2Path: key },
});
});
return this.env.VECTOR_INDEX.upsert();
});
}
}
This is just one example of what a Workflow can do. The ability to durably execute an application, modeled as a series of steps, applies to a wide number of domains. You can apply this model of execution to a number of use-cases, including:
Deploying software: each step can define a build step and subsequent health check, gating further progress until your deployment meets your criteria for “healthy”.
Post-processing user data: triggering a workflow based on user uploads (e.g. to Cloudflare R2) that then subsequently parses that data asynchronously, redacts PII or sensitive data, writes the sanitized output, and triggers a notification via email, webhook, or mobile push.
Payment and batch workflows: aggregating raw customer usage data on a periodic schedule by querying your data warehouse (or Workers Analytics Engine), triggering usage or spend alerts, and/or generating PDF invoices.
Each of these use cases model tasks that you want to run to completion, minimize redundant retries by persisting intermediate state, and (importantly) easily observe success and failure.
We’ll be sharing more about Workflows during the second quarter of 2024 as we work towards an open (public!) beta. This includes how we’re thinking about idempotency and interactions with our storage, per-instance observability and metrics, local development, and templates to bootstrap common workflows.
Putting it together
We’ve often thought of Cloudflare’s own network as one massively scalable parallel data processing cluster: data centers in 310+ cities, with the ability to run compute close to users and/or close to data, keep it within the bounds of regulatory or compliance requirements, and most importantly, use our massive scale to enable our customers to scale as well.
Recapping, a fully-fledged data platform needs to enable three things:
Ingesting data: getting data into the platform (in the right format, from the right sources)
Storing data: securely, reliably, and durably.
Querying data: understanding and extracting insights from the data, and/or transforming it for use by other tools.
When we launched R2 we tackled the second part, but knew that we’d need to follow up with the first and third parts in order to make it easier for developers to get data in and make use of it.
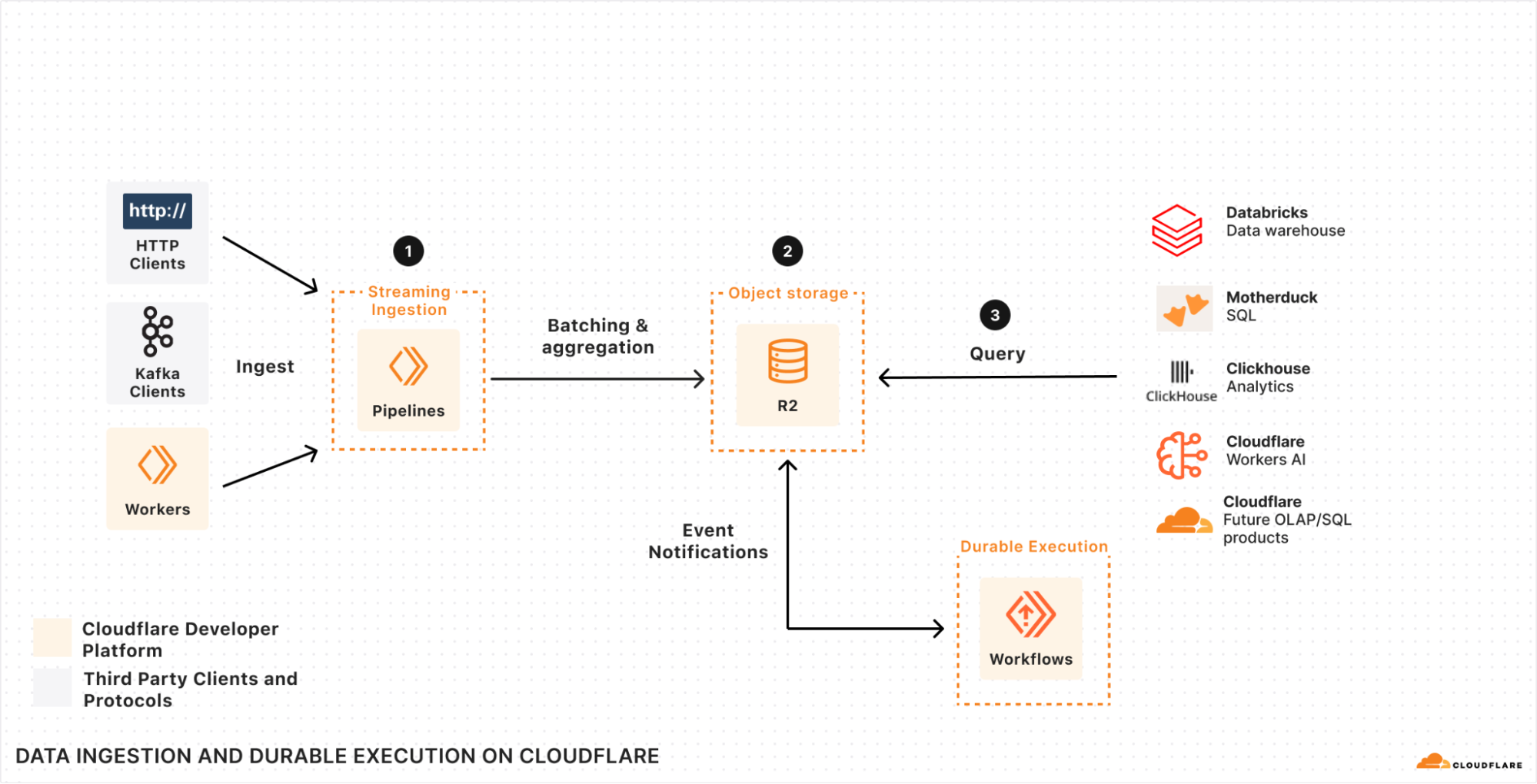
If we look at how we can build a system that helps us solve each of these three parts together with Pipelines, Event Notifications, R2, and Workflows, we end up with an architecture that resembles this:
Specifically, we have Pipelines (1) scaling out to ingest data, batch it, filter it, and then durably store it in R2 (2) in a format that’s ready and optimized for querying. Workflows, ClickHouse, Databricks, or the query engine of your choice can then query (3) that data as soon as it’s ready — with “ready” being automatically triggered by an Event Notification as soon as the data is ingested and written to R2.
There’s no need to poll, no need to batch after the fact, no need to have your query engine slow down on data that wasn’t pre-aggregated or filtered, and no need to manage and scale infrastructure in order to keep up with load or data jurisdiction requirements. Create a Pipeline, write your data directly to R2, and query directly from it.
If you’re also looking at this and wondering about the costs of moving this data around, then we’re holding to one important principle: zero egress fees across all of our data products. Just as we set the stage for this with our R2 object storage, we intend to apply this to every data product we’re building, Pipelines included.
Start Building
We’ve shared a lot of what we’re building so that developers have an opportunity to provide feedback (including via our Developer Discord), share use-cases, and think about how to build their next application on Cloudflare.
Multiple Cloudflare services were unavailable for 37 minutes on October 30, 2023. This was due to the misconfiguration of a deployment tool used by Workers KV. This was a frustrating incident, made more difficult by Cloudflare’s reliance on our own suite of products. We are deeply sorry for the impact it had on customers. What follows is a discussion of what went wrong, how the incident was resolved, and the work we are undertaking to ensure it does not happen again.
Workers KV is our globally distributed key-value store. It is used by both customers and Cloudflare teams alike to manage configuration data, routing lookups, static asset bundles, authentication tokens, and other data that needs low-latency access.
During this incident, KV returned what it believed was a valid HTTP 401 (Unauthorized) status code instead of the requested key-value pair(s) due to a bug in a new deployment tool used by KV.
These errors manifested differently for each product depending on how KV is used by each service, with their impact detailed below.
What was impacted
A number of Cloudflare services depend on Workers KV for distributing configuration, routing information, static asset serving, and authentication state globally. These services instead received an HTTP 401 (Unauthorized) error when performing any get, put, delete, or list operation against a KV namespace.
Customers using the following Cloudflare products would have observed heightened error rates and/or would have been unable to access some or all features for the duration of the incident:
Product
Impact
Workers KV
Customers with applications leveraging KV saw those applications fail during the duration of this incident, including both the KV API within Workers, and the REST API. Workers applications not using KV were not impacted.
Pages
Applications hosted on Pages were unreachable for the duration of the incident and returned HTTP 500 errors to users. New Pages deployments also returned HTTP 500 errors to users for the duration.
Access
Users who were unauthenticated could not log in; any origin attempting to validate the JWT using the /certs endpoint would fail; any application with a device posture policy failed for all users. Existing logged-in sessions that did not use the /certs endpoint or posture checks were unaffected. Overall, a large percentage of existing sessions were still affected.
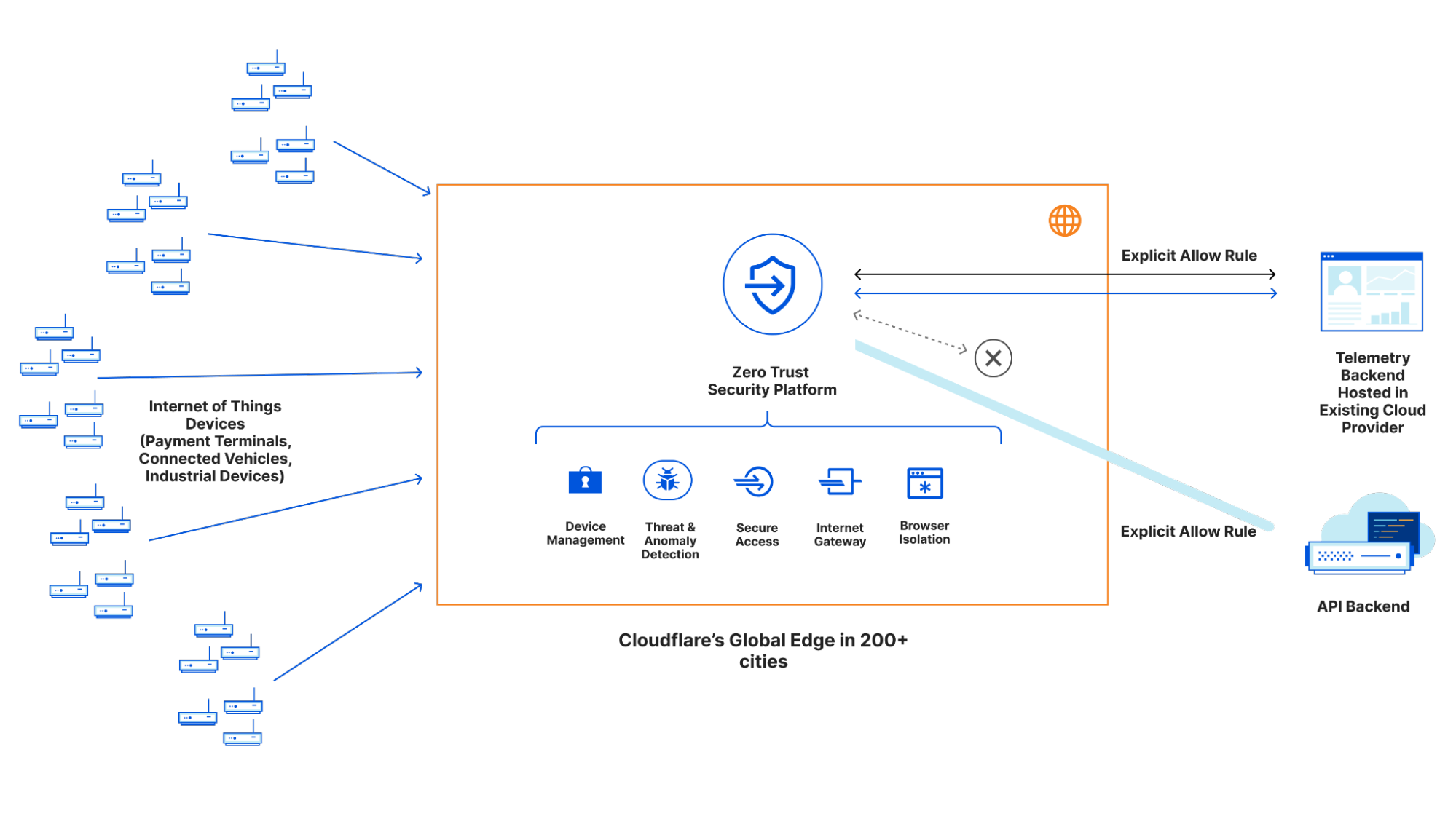
WARP / Zero Trust
Users were unable to register new devices or connect to resources subject to policies that enforce Device Posture checks or WARP Session timeouts. Devices already enrolled, resources not relying on device posture, or that had re-authorized outside of this window were unaffected.
Images
The Images API returned errors during the incident. Existing image delivery was not impacted.
Cache Purge (single file)
Single file purge was partially unavailable for the duration of the incident as some data centers could not access configuration data in KV. Data centers that had existing configuration data locally cached were unaffected. Other cache purge mechanisms, including purge by tag, were unaffected.
Workers
Uploading or editing Workers through the dashboard, wrangler or API returned errors during the incident. Deployed Workers were not impacted, unless they used KV.
AI Gateway
AI Gateway was not able to proxy requests for the duration of the incident.
Waiting Room
Waiting Room configuration is stored at the edge in Workers KV. Waiting Room configurations, and configuration changes, were unavailable and the service failed open. When access to KV was restored, some Waiting Room users would have experienced queuing as the service came back up.
Turnstile and Challenge Pages
Turnstile’s JavaScript assets are stored in KV, and the entry point for Turnstile (api.js) was not able to be served. Clients accessing pages using Turnstile could not initialize the Turnstile widget and would have failed closed during the incident window. Challenge Pages (which products like Custom, Managed and Rate Limiting rules use) also use Turnstile infrastructure for presenting challenge pages to users under specific conditions, and would have blocked users who were presented with a challenge during that period.
Cloudflare Dashboard
Parts of the Cloudflare dashboard that rely on Turnstile and/or our internal feature flag tooling (which uses KV for configuration) returned errors to users for the duration.
Timeline
All timestamps referenced are in Coordinated Universal Time (UTC).
Time
Description
2023-10-30 18:58 UTC
The Workers KV team began a progressive deployment of a new KV build to production.
2023-10-30 19:29 UTC
The internal progressive deployment API returns staging build GUID to a call to list production builds.
2023-10-30 19:40 UTC
The progressive deployment API was used to continue rolling out the release. This routed a percentage of traffic to the wrong destination, triggering alerting and leading to the decision to roll back.
2023-10-30 19:54 UTC
Rollback via progressive deployment API attempted, traffic starts to fail at scale. — IMPACT START —
2023-10-30 20:15 UTC
Cloudflare engineers manually edit (via break glass mechanisms) deployment routes to revert to last known good build for the majority of traffic.
2023-10-30 20:29 UTC
Workers KV error rates return to normal pre-incident levels, and impacted services recover within the following minute.
2023-10-30 20:31 UTC
Impact resolved — IMPACT END —
As shown in the above timeline, there was a delay between the time we realized we were having an issue at 19:54 UTC and the time we were actually able to perform the rollback at 20:15 UTC.
This was caused by the fact that multiple tools within Cloudflare rely on Workers KV including Cloudflare Access. Access leverages Workers KV as part of its request verification process. Due to this, we were unable to leverage our internal tooling and had to use break-glass mechanisms to bypass the normal tooling. As described below, we had not spent sufficient time testing the rollback mechanisms. We plan to harden this moving forward.
Resolution
Cloudflare engineers manually switched (via break glass mechanism) the production route to the previous working version of Workers KV, which immediately eliminated the failing request path and subsequently resolved the issue with the Workers KV deployment.
Analysis
Workers KV is a low-latency key-value store that allows users to store persistent data on Cloudflare’s network, as close to the users as possible. This distributed key-value store is used in many applications, some of which are first-party Cloudflare products like Pages, Access, and Zero Trust.
The Workers KV team was progressively deploying a new release using a specialized deployment tool. The deployment mechanism contains a staging and a production environment, and utilizes a process where the production environment is upgraded to the new version at progressive percentages until all production environments are upgraded to the most recent production build. The deployment tool had a latent bug with how it returns releases and their respective versions. Instead of returning releases from a single environment, the tool returned a broader list of releases than intended, resulting in production and staging releases being returned together.
In this incident, the service was deployed and tested in staging. But because of the deployment automation bug, when promoting to production, a script that had been deployed to the staging account was incorrectly referenced instead of the pre-production version on the production account. As a result, the deployment mechanism pointed the production environment to a version that was not running anywhere in the production environment, effectively black-holing traffic.
When this happened, Workers KV became unreachable in production, as calls to the product were directed to a version that was not authorized for production access, returning a HTTP 401 error code. This caused dependent products which stored key-value pairs in KV to fail, regardless of whether the key-value pair was cached locally or not.
Although automated alerting detected the issue immediately, there was a delay between the time we realized we were having an issue and the time we were actually able to perform the roll back. This was caused by the fact that multiple tools within Cloudflare rely on Workers KV including Cloudflare Access. Access uses Workers KV as part of the verification process for user JWTs (JSON Web Tokens).
These tools include the dashboard which was used to revert the change, and the authentication mechanism to access our continuous integration (CI) system. As Workers KV was down, so too were these services. Automatic rollbacks via our CI system had been successfully tested previously, but the authentication issues (Access relies on KV) due to the incident made accessing the necessary secrets to roll back the deploy impossible.
The fix ultimately was a manual change of the production build path to a previous and known good state. This path was known to have been deployed and was the previous production build before the attempted deployment.
Next steps
As more teams at Cloudflare have built on Workers, we have “organically” ended up in a place where Workers KV now underpins a tremendous amount of our products and services. This incident has continued to reinforce the need for us to revisit how we can reduce the blast radius of critical dependencies, which includes improving the sophistication of our deployment tooling, its ease-of-use for our internal teams, and product-level controls for these dependencies. We’re prioritizing these efforts to ensure that there is not a repeat of this incident.
This also reinforces the need for Cloudflare to improve the tooling, and the safety of said tooling, around progressive deployments of Workers applications internally and for customers.
This includes (but is not limited) to the below list of key follow-up actions (in no specific order) this quarter:
Onboard KV deployments to standardized Workers deployment models which use automated systems for impact detection and recovery.
Ensure that the rollback process has access to a known good deployment identifier and that it works when Cloudflare Access is down.
Add pre-checks to deployments which will validate input parameters to ensure version mismatches don’t propagate to production environments.
Harden the progressive deployment tooling to operate in a way that is designed for multi-tenancy. The current design assumes a single-tenant model.
Add additional validation to progressive deployment scripts to verify that the deployment matches the app environment (production, staging, etc.).
Again, we’re extremely sorry this incident occurred, and take the impact of this incident on our customers extremely seriously.
Hyperdrive는 어디에서 실행되는 Cloudflare Workers에서 기존 데이터베이스에 액세스하는 것을 매우 빠르게 만듭니다. Hyperdrive를 데이터베이스와 연결하고 Hyperdrive로 연결하기 위해 단 한 줄의 코드를 바꾸면 연결과 쿼리가 마법처럼 빨라집니다(오늘 바로 사용할 수 있습니다).
요약하자면, Hyperdrive는 Cloudflare의 전역 네트워크를 사용하므로 기존 데이터베이스에 대한 쿼리 속도가 단축됩니다. 데이터베이스가 레거시 클라우드 공급자에 있든, 여러분이 좋아하는 서버리스 데이터베이스 공급자에 있든 구애받지 않습니다. Hyperdrive를 사용하면 반복적으로 새로운 데이터베이스 연결을 설정할 때 발생하는 대기 시간이 대폭 단축되고, 데이터베이스에 대한 가장 인기 있는 읽기 쿼리가 캐시되어 데이터베이스에 돌아갈 필요가 없어지는 경우가 많습니다.
Hyperdrive가 없으면 기존 클라우드 공급자의 미국 동부1 지역에 있는 핵심 데이터베이스(사용자 프로필, 제품 인벤토리, 중요한 웹 앱을 실행하는 데이터베이스)는 파리, 싱가포르, 두바이에 있는 사용자가 액세스하는 속도가 매우 느려질 수 있습니다. 로스앤젤레스나 밴쿠버에 있는 사용자에게도 예상보다 느려질 것입니다. 각 왕복 시간이 최대 200ms이므로 연결을 설정하는 데 필요한 몇 번의 왕복 자체만으로도 최대 1초(또는 그 이상!)가 걸리기 쉽습니다. 데이터를 위해 쿼리를 작성하기도 전에도 말입니다. Hyperdrive는 이러한 현상을 해결하기 위해 설계되었습니다.
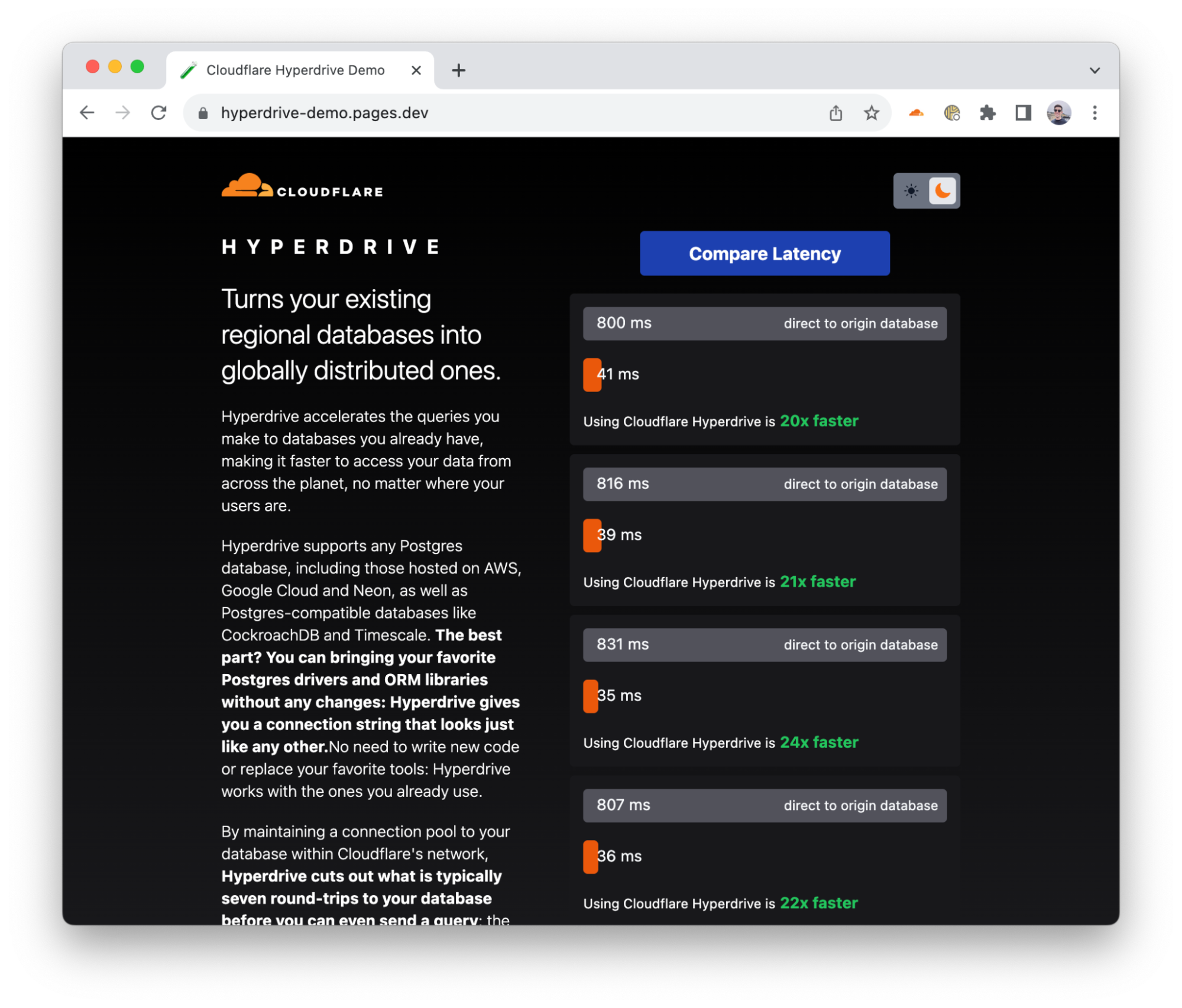
Hyperdrive의 성능을 선보이기 위해 Cloudflare에서는 데모 애플리케이션을 구축했습니다. 이는 Hyperdrive를 사용한 채로 그리고 사용하지 않은 채로 (바로) 동일한 데이터베이스에 대해 연속되는 쿼리를 작성합니다. 이 앱은 주변 대륙에 있는 데이터베이스를 선택합니다. 여러분이 유럽에 있다면 이는 미국에 있는 데이터베이스를 선택합니다. 많은 유럽 인터넷 사용자가 흔히 겪는 상황입니다. 여러분이 아프리카에 있다면 이는 유럽에 있는 데이터베이스를 선택합니다(다른 경우에도 비슷합니다). 이는 원시 결과를 간단한 `SELECT` 쿼리에서 반환합니다. 세심하게 선정한 평균이나 고르고 고른 메트릭은 없습니다.
Cloudflare에서는 Hyperdrive를 사용한 채로 그리고 사용하지 않은 채로 PostgreSQL 데이터베이스에 대한 진짜 쿼리를 작성하는 데모 앱을 구축했습니다.
내부 테스트, 초기 사용자 보고서, 벤치마크에서 수행한 여러 번의 실행에 따르면 Hyperdrive는 캐시된 쿼리를 위해 데이터베이스에 직접 접근하는 것에 비해 17~25배 개선된 성능을 제공합니다. 또한, 캐시되지 않은 쿼리 및 쓰기는 6~8배 개선됩니다. 여러분에게 캐시된 대기 시간이 놀랍지 않을 수 있지만, 6~8배 더 빨라진 캐시되지 않은 쿼리가 “Cloudflare Workers에서는 중앙 집중식 데이터베이스를 쿼리할 수 없어”라는 생각을 “이걸 이제야 사용하다니?!”로 바꿀 수 있을 것으로 생각합니다. Cloudflare에서는 성능을 개선하려고 지속해서 노력하고 있습니다. 이미 대기 시간이 추가적으로 단축되었으며 몇 주 후에 이를 선보일 예정입니다.
Cloudflare는 한동안 비밀리에 Hyperdrive를 구축했습니다. 하지만 우리는 한동안 개발자가 이미 보유하고 있는 기존 데이터, 쿼리, 툴링과 데이터베이스를 연결할 수 있도록 하는 것에 초점을 두었습니다.
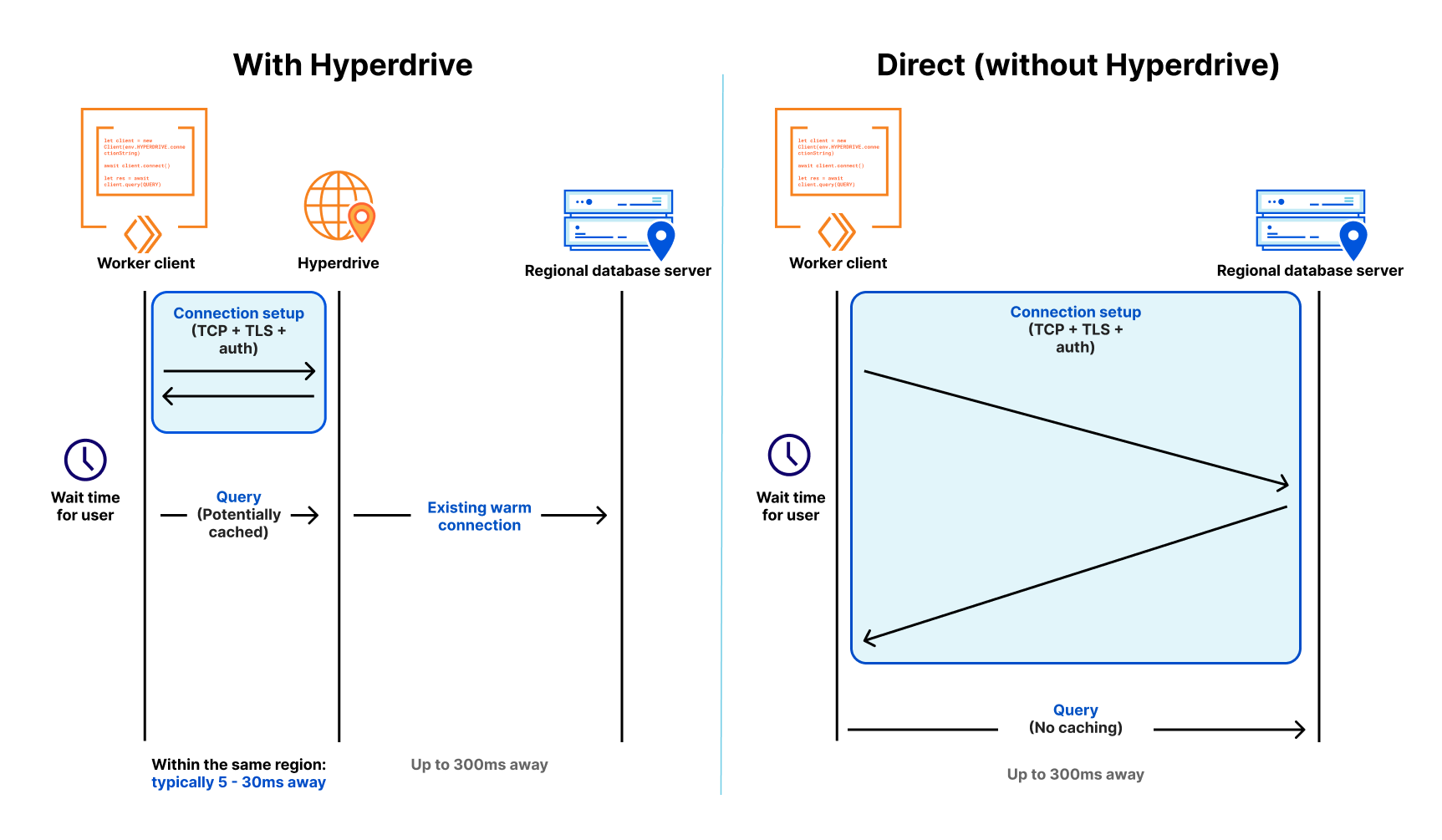
컴퓨팅이 (사용자에 가깝도록) 전 세계에 걸쳐 분산되어 있고 기능의 수명이 짧은 (따라서 더 이상 한 필요하지 않은 기능에 요금을 지불해야 하게 되는) Workers와 같은 최신 분산 클라우드 환경에서는 기존 데이터베이스와의 연결이 느리고 확장할 수 없는 작업이었습니다. 느린 이유는 연결을 설정하려면 7번 이상의 왕복(TCP 핸드셰이크, TLS 협상, 인증)이 필요하기 때문입니다. 확장할 수 없는 이유는 PostgreSQL 등의 데이터베이스에 연결당 높은 리소스 비용이 들기 때문입니다. 쿼리에 필요한 메모리는 제외하더라도, 데이터베이스와 수백 번 연결하는 것만 해도 무시할 수 없는 양의 메모리가 사용될 수 있습니다.
Neon(인기 있는 서버리스 Postgres 공급자)에서 근무하고 있는 지인이 이에 대한 글을 작성하고 WebSocket 프록시 및 드라이버를 출시하여 연결 오버헤드를 줄이고자 했지만, 여전히 힘든 노력을 하고 있습니다. 사용자 지정 드라이버를 사용하면 왕복 횟수가 4번으로 줄지만, 왕복할 때마다 잠재적으로 여전히 50~200ms 이상이 소요됩니다. 이러한 연결이 오래 유지된다면 괜찮습니다. 최대 몇 시간에 한 번씩 연결되곤 하니까요. 하지만 개별 기능 호출 측면에서 살펴보면 최대 몇 밀리초~몇 분 동안만 유용합니다. 코드는 대기하는 데 더 많은 시간을 씁니다. 사실상 이는 다른 유형의 콜드 스타트입니다. 쿼리를 작성하기 전에 데이터베이스를 대상으로 새로운 연결을 시작해야 한다는 것은 분산 또는 서버리스 환경에서 기존 데이터베이스를 사용하는 것이 (가볍게 표현한다고 해도) 정말 느려진다는 것을 의미합니다.
이 현상을 해결하기 위해 Hyperdrive는 2가지 조치를 취합니다.
첫째, Hyperdrive는 Cloudflare 네트워크에 걸쳐 지역 데이터베이스 연결 풀 세트를 유지하여 Cloudflare Worker가 모든 요청을 대상으로 데이터베이스에 새롭게 연결하지 않도록 합니다. 대신, Worker는 빠르게 Hyperdrive와의 연결을 설정할 수 있습니다. Hyperdrive가 바로 사용할 수 있는 데이터베이스와의 연결 풀을 유지하고 있기 때문입니다. 데이터베이스가 한 번 왕복(새로운 연결의 경우, 7번 이상일 수 있음)하는 데 걸리는 시간은 30~300ms(보통 300ms)이므로, 사용할 수 있는 연결 풀을 확보하고 있으면 단기간 유지되는 연결로 인한 대기 시간 문제가 대폭 줄어듭니다.
둘째, Hyperdrive는 읽기(미변형)와 쓰기(변형) 쿼리 및 트랜잭션의 차이를 이해합니다. 또한, 가장 인기 있는 읽기 쿼리를 자동으로 캐시할 수 있습니다. 읽기 쿼리는 일반적인 웹 애플리케이션에서 데이터베이스가 작성하는 대부분의 쿼리에서 80% 이상을 차지합니다. 매시간 수만 명의 사용자가 방문하는 제품 목록 페이지, 대규모 채용 사이트의 일자리, 가끔 바뀌는 구성 데이터에 대한 쿼리 등 많은 쿼리 대상은 자주 바뀌지 않습니다. 그러므로 사용자가 쿼리하는 위치에 더 가깝게 이를 캐시하면 수만 명의 향후 사용자가 이러한 데이터에 액세스하는 데 걸리는 시간을 크게 단축할 수 있습니다. 안전하게 캐시할 수 없는 쓰기 쿼리도 Hyperdrive의 연결 풀링 및 Cloudflare 전역 네트워크의 이점을 누릴 수 있습니다. 또한, Cloudflare 백본을 지나 인터넷을 거치는 가장 빠른 경로를 사용하면 대기 시간을 단축할 수 있습니다.
데이터베이스가 해당 국가의 반대편에 있더라도 70ms의 속도로 6번 왕복하는 데 걸리는 시간은 사용자가 쿼리 응답을 기다리기에는 너무 깁니다.
Hyperdrive는 Neon, Google Cloud SQL, AWS RDS, Timescale 등 PostgreSQL 데이터베이스와 작동하지만, Materialize(강력한 스트리밍 처리 데이터베이스), CockroachDB(주요 분산 데이터베이스), Google Cloud의 AlloyDB, AWS Aurora Postgres 등의 PostgreSQL 호환 가능 데이터베이스와도 작동합니다.
Cloudflare에서는 올해 말까지 PlanetScale 같은 공급자를 포함한 MySQL을 지원하기 위해 노력하고 있습니다. 앞으로 더 많은 데이터베이스 엔진을 지원할 예정입니다.
마법 같은 연결 문자열
Hyperdrive의 주요 설계 목적 중 하나는 기존 드라이버, 쿼리 빌더, ORM(객체-관계 매퍼) 라이브러리를 계속해서 사용하고자 하는 개발자의 필요를 충족하는 것이었습니다. Hyperdrive의 성능이 선사하는 이점을 누리기 위해 여러분이 좋아하는 ORM에서 마이그레이션하거나 수백 줄의 코드를 다시 작성하고 테스트해야 한다면 Hyperdrive가 얼마나 빠르든 사용하기 어려울 것입니다.
Hyperdrive에 숨겨진 마법은 기존 Workers 애플리케이션에서 기존 쿼리로 사용을 시작할 수 있다는 것입니다. 기존 연결 문자열을 Hyperdrive에서 생성하는 문자열로 바꾸기만 하면 됩니다.
Hyperdrive 생성
이 예시에서는 기존 데이터베이스가 준비되어 있으니 Neon의 Postgres 데이터베이스를 사용하겠습니다. Hyperdrive를 실행하는 데 1분도 걸리지 않습니다(예, 시간을 직접 측정해 봤습니다).
기존 Cloudflare Workers 프로젝트가 없더라도, 빠르게 프로젝트를 생성할 수 있습니다.
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
이 단계에서는 데이터베이스를 위한 데이터베이스 연결 문자열과 Hyperdrive와 연결하기 위한 빠른 wrangler command-line 호출이 필요합니다.
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
[[hyperdrive]]
name = "HYPERDRIVE"
id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
이제 Worker를 작성하거나 기존 Worker 스크립트를 사용할 수 있습니다. 그리고 Hyperdrive를 사용하여 기존 데이터베이스에 대한 연결과 쿼리 속도를 단축할 수 있습니다. 여기에서는 node-postgres를 사용하지만, Drizzle ORM을 사용하여 똑같이 쉽게 속도를 단축할 수 있습니다.
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
위에 있는 코드는 의도적으로 단순하게 작성되었지만, 이를 통해 Hyperdrive에 숨겨진 마법을 확인할 수 있으셨기를 바랍니다. Cloudflare 데이터베이스 드라이버는 Hyperdrive에서 연결 문자열을 가져오며 이를 이해하지 못합니다. 데이터베이스 드라이버는 Hyperdrive에 대한 모든 것을 알 필요가 없고, 사용자는 좋아하는 쿼리 빌더 라이브러리의 사용을 중단할 필요가 없습니다. 그리고 쿼리를 작성할 때 속도가 선사하는 이점을 즉각적으로 느낄 수 있습니다.
연결은 자동으로 풀링되고 언제든지 사용할 수 있도록 유지됩니다. 이렇게 하면 가장 인기 있는 쿼리가 캐시되고 전체 애플리케이션이 빨라집니다.
Cloudflare에서는 모든 대규모 데이터베이스 공급자에 대한 가이드를 작성하여 이러한 데이터베이스에 필요한 것(연결 문자열)을 쉽게 Hyperdrive로 가져올 수 있게 했습니다.
저비용으로 속도를 빠르게 할 수는 없죠?
Cloudflare에서는 Cloudflare Workers에서 구축할 때 Hyperdrive가 기존 데이터베이스에 액세스하는 데 중요하다고 생각합니다. 기존 데이터베이스는 클라이언트가 전 세계적으로 분산된 환경을 위해 설계되지는 않았습니다.
Hyperdrive의 연결 풀링은 항상 무료일 것입니다. 현재 지원하는 데이터베이스 프로토콜과 앞으로 Cloudflare에서 추가할 새로운 데이터베이스 프로토콜 모두를 대상으로 말입니다. Cloudflare에서는 DDoS 방어 및 글로벌 CDN과 마찬가지로 Hyperdrive의 핵심 기능에 대한 액세스가 너무 유용하므로 제한해서는 안 된다고 생각합니다.
오픈 베타 기간에는 Hyperdrive를 어떻게 사용하든 요금이 부과되지 않습니다. 충분한 여유 기간을 두고 GA(2024년 초) 시점이 가까워지면 Hyperdrive 이용 가격에 대한 자세한 내용을 발표할 예정입니다.
쿼리할 시간
Hyperdrive의 향후 계획은 어떨까요?
2024년 초에 Hyperdrive를 대중적으로 제공할 예정입니다. Cloudflare는 쓰기, 상세한 쿼리 및 성능 분석(곧 제공!), 더 많은 데이터베이스 엔진(MySQL 포함) 지원, 추가적인 시간 단축 등을 위한 지속적인 노력을 기반으로 캐시하고 자동으로 무효화하는 방식에 대한 더 많은 제어 기능을 제공하는 데 집중하고 있습니다.
Cloudflare에서는 Magic WAN 및 Cloudflare Tunnel을 통해 비공개 네트워크 연결을 가능하게 만들기 위해 노력하고 있습니다. 이를 통해 공개 인터넷에 노출되지 않거나 노출할 수 없는 데이터베이스에 연결할 수 있습니다.
기존 데이터베이스에 Hyperdrive를 연결하려면 Cloudflare 개발자 문서를 읽어보세요. Hyperdrive를 생성하고 이를 사용하기 위해 기존 코드를 업데이트하는 데는 1분도 걸리지 않습니다. Cloudflare Developer Discord에서 #hyperdrive-beta 채널에 참여하여 질문하고, 버그를 신고하며, Cloudflare 제품 및 엔지니어링 팀과 직접 대화를 나눠보세요.
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
Hyperdrive te permite un acceso ultrarrápido a tus bases de datos existentes desde Cloudflare Workers, dondequiera que se ejecuten. Conectas Hyperdrive a tu base de datos, modificas una línea de código para conectarte a través de Hyperdrive, y listo: las conexiones y las consultas son más rápidas (spoiler: puedes utilizarlo hoy mismo).
En pocas palabras, Hyperdrive utiliza nuestra red global para acelerar las consultas a tus bases de datos existentes, tanto si se encuentran en un proveedor de nube heredado como en tu proveedor favorito de bases de datos sin servidor; reduce drásticamente la latencia que implica configurar repetidamente nuevas conexiones a la base de datos; y almacena en caché las consultas de lectura a tu base de datos más populares, lo que a menudo evita incluso la necesidad de volver a tu base de datos.
Sin Hyperdrive, esa base de datos principal (la que contiene tus perfiles de usuario, tu inventario de productos o que ejecuta tus aplicaciones web críticas), ubicada en la región us-east1 de tu proveedor de nube heredado, ofrecerá un acceso muy lento a los usuarios en París, Singapur y Dubái, y más lento de lo que debería ser para los usuarios en Los Ángeles o Vancouver. Cada viaje de ida y vuelta puede representar hasta 200 ms, por lo que es fácil perder hasta un segundo (¡o más!) en varios viajes de día y vuelta necesarios solo para establecer una conexión, antes incluso de que hayas realizado la consulta de tus datos. Hyperdrive se ha diseñado para resolver esta situación.
Para demostrar el rendimiento de Hyperdrive, hemos creado una aplicación de demostración que realiza consultas consecutivas a la misma base de datos: con Hyperdrive y sin Hyperdrive (directamente). La aplicación selecciona una base de datos ubicada en un continente vecino: si estás en Europa, selecciona una base de datos de EE. UU. (una experiencia con la que están demasiado familiarizados muchos usuarios de Internet en Europa) y, si estás en África, selecciona una base de datos en Europa (y así sucesivamente). Devuelve los resultados sin procesar de una consulta `SELECT` sencilla, sin promedios seleccionados o métricas elegidas cuidadosamente.
Las pruebas internas, los primeros informes de los usuarios y las múltiples ejecuciones en nuestro banco de pruebas muestran que Hyperdrive mejora el rendimiento entre 17 y 25 veces en comparación con el acceso directo a la base de datos para las solicitudes almacenadas en cache, y entre 6 y 8 veces para las solicitudes y las escrituras no almacenadas en caché. La latencia del almacenamiento en caché podría no extrañarte, pero creemos que el hecho de ser entre 6 y 8 veces más rápido para las consultas no almacenadas en caché hace que cambie la cuestión de “No puedo consultar una base de datos centralizada desde Cloudflare Workers” a “¿por qué no estaba esto disponible antes?”. Asimismo, continuamos trabajando para mejorar aún más el rendimiento: ya hemos identificado nuevos métodos de reducir la latencia, y los aplicaremos en las próximas semanas.
Hace relativamente poco que empezamos a trabajar en secreto con Hyperdrive: pero permitir a los desarrolladores conectarse a las bases de datos que ya tienen (con sus datos, sus consultas y sus herramientas existentes) es algo a lo que llevamos bastante tiempo dándole vueltas.
En un entorno moderno de nube distribuida, como Workers, donde los recursos informáticos están distribuidos a nivel global (por lo tanto, cerca de los usuarios) y donde las funciones son de corta duración (para que no pagues más de lo necesario), la conexión a las bases de datos tradicionales ha sido lenta y sin escalabilidad. Lenta porque requiere como mínimo siete viajes de ida y vuelta (protocolo de enlace TCP, negociación TLS y autenticación) para establecer la conexión. Sin escalabilidad porque las bases de datos como PostgreSQL tienen un coste elevado de recursos por conexión. Incluso unos centenares de conexiones a una base de datos pueden consumir una cantidad importante de memoria, aparte de la memoria necesaria para las consultas.
Nuestros amigos de Neon (un conocido proveedor de Postgres sin servidor) han escrito sobre este tema, e incluso han lanzado un proxy y un controlador WebSocket para reducir la carga de conexión, pero aún tienen dificultades a resolver: incluso con un controlador personalizado, nos quedan 4 viajes de ida y vuelta, y cada uno de ellos puede representar entre 50 y 200 milisegundos o más. Cuando estas conexiones son de larga duración, no hay problema (en el mejor de los casos, podría suceder una vez cada cierto número de horas). Sin embargo, cuando se limitan a una invocación de función individual y solo son útiles durante unos milisegundos o minutos en el mejor de los casos, tu código pasa más tiempo a la espera. De hecho, se trata de otro tipo de arranque en frío: el hecho de tener que iniciar una conexión nueva a tu base de datos antes de realizar una consulta significa que la utilización de una base de datos tradicional en un entorno distribuido o sin servidor es (por decirlo suavemente) realmente lenta.
Para hacer frente a este problema, Hyperdrive hace dos cosas.
En primer lugar, mantiene una serie de agrupaciones de conexiones de bases de datos regionales en la red de Cloudflare, por lo que Cloudflare Worker evita crear una nueva conexión a una base de datos con cada solicitud. En su lugar, Worker puede establecer una conexión a Hyperdrive (¡rápidamente!), e Hyperdrive mantiene una agrupación de conexiones listas para usar a la base de datos. Puesto que una base de datos puede estar a entre 30 ms y (a menudo) 300 ms en un único viaje de ida y vuelta (sin contar los siete o más que necesitas para una nueva conexión), el hecho de tener una agrupación de conexiones disponibles reduce considerablemente el problema de latencia que en caso contrario sufrirían las conexiones de corta duración.
En segundo lugar, comprende la diferencia entre las consultas de lectura (no mutantes) y las consultas de escritura (mutantes), y puede almacenar automáticamente en caché tus consultas de lectura más habituales, lo que representa más del 80 % de la mayoría de las consultas realizadas a bases de datos en aplicaciones web típicas. Esa página de listado de productos que visitan a diario decenas de miles de usuarios; las ofertas de empleo en un popular sitio de búsqueda de empleo; o incluso las consultas de datos de configuración que cambian ocasionalmente; una gran parte de lo que consultamos no cambia con frecuencia, y el hecho de almacenarlo en caché más cerca de la ubicación donde el usuario realiza la consulta puede acelerar considerablemente el acceso a esos datos para los siguientes diez mil usuarios. Las consultas de escritura, que no se pueden almacenar de forma segura en la caché, se siguen beneficiando tanto de la agrupación de conexiones de Hyperdrive como de lared global de Cloudflare: el hecho de poder tomar las rutas más rápidas de Internet a través de nuestra red troncal reduce la latencia también en ese caso.
Incluso si tu base de datos se encuentra en el otro extremo del país, 70 ms x 6 viajes de ida y vuelta es mucho tiempo para un usuario que está a la espera de una respuesta a su consulta.
Hyperdrive funciona no solo con las bases de datos PostgreSQL Neon, Google Cloud SQL, AWS RDS y Timescale, sino también con bases de datos compatibles con PostgreSQL como Materialize (una potente base de datos de proceso en streaming), CockroachDB (una de las principales bases de datos distribuidas), AlloyDB de Google Cloud y AWS Aurora Postgres.
Estamos trabajando para añadir compatibilidad con MySQL, incluidos proveedores como PlanetScale, antes de finales de año, así como otros motores de bases de datos más adelante.
La cadena de conexión mágica
Uno de los principales objetivos del diseño de Hyperdrive era permitir a los desarrolladores mantener sus controladores, su creador de consultas y sus bibliotecas ORM (Object-Relational Mapper) existentes. Poca importancia hubiera tenido la velocidad que pudiera ofrecer Hyperdrive si hubieras tenido que abandonar tu ORM favorito o reescribir centenares (o más) de líneas de código y pruebas para beneficiarte de su rendimiento.
Con este fin, hemos trabajado con aquellos que mantienen conocidos controladores de código abierto, como node-postgres y Postgres.js, para ayudar a que sus bibliotecas admitan la nueva API de socket TCP de Worker, que está en curso de normalización y que esperamos que llegue también a Node.js, Deno y Bun.
La cadena de conexión a la base de datos es el lenguaje compartido de los controladores de bases de datos, y suele tener este formato:
La magia que hace posible Hyperdrive es que puedes empezar a utilizarlo en tus aplicaciones Workers existentes, con tus consultas existentes, simplemente reemplazando tu cadena de conexión por la que genera Hyperdrive.
Creación de un Hyperdrive
Con una base de datos existente lista para su uso (en este ejemplo, utilizaremos una base de datos Postgres de Neon) en menos de un minuto Hyperdrive ya está en funcionamiento (sí, lo hemos cronometrado).
Si no tienes un proyecto Cloudflare Workers existente, puedes crear uno rápidamente:
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
A partir de aquí, solo necesitamos la cadena de conexión a nuestra base de datos y una invocación rápida en la línea de comandos wrangler para que Hyperdrive se conecte a ella.
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
[[hyperdrive]]
name = "HYPERDRIVE"
id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
Ahora podemos escribir un Worker (o utilizar un script de Worker existente) y utilizar Hyperdrive para acelerar las conexiones y consultas a nuestra base de datos existente. Aquí utilizamos node-postgres, pero sería igual de fácil utilizar Drizzle ORM.
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
El código anterior es intencionadamente sencillo, pero esperamos que puedas ver la magia: nuestro controlador de base de datos obtiene una cadena de conexión de Hyperdrive, sin ninguna dificultad. No es necesario conocer Hyperdrive, no tenemos que deshacernos de nuestra biblioteca favorita de creación de consultas, y podemos beneficiarnos inmediatamente de las ventajas de velocidad al hacer consultas.
Las conexiones se agrupan automáticamente y se mantienen listas para usar, nuestras consultas más habituales se almacenan en caché, y toda nuestra aplicación es más rápida.
Creemos que Hyperdrive es esencial para acceder a tus bases de datos existentes cuando desarrolles en Cloudflare Workers: las bases de datos tradicionales simplemente nunca estuvieron adecuadamente diseñadas para un mundo donde los clientes están distribuidos a nivel global.
La agrupación de conexiones de Hyperdrive siempre será gratuita, para los dos protocolos de base de datos que admitimos actualmente y para los nuevos protocolos de base de datos que admitiremos más adelante. Al igual que con la protección contra DDoS y nuestra CDN global, creemos que el acceso a la función principal de Hyperdrive es demasiado útil para que esté limitado.
Durante la versión beta abierta, la utilización de Hyperdrive será gratuita, independientemente de cómo lo utilices. Proporcionaremos más detalles acerca de las tarifas de Hyperdrive cuando la fecha de disponibilidad general esté próxima (a principios de 2024), y lo haremos con la antelación suficiente.
Es la hora de las consultas
¿Qué será lo siguiente con Hyperdrive?
Tenemos previsto lanzar la disponibilidad general de Hyperdrive a principios de 2024. Estamos centramos en la implementación de controles adicionales sobre el almacenamiento en caché y la invalidación automática en función de las escrituras, las consultas detalladas y los análisis del rendimiento (¡en breve!) y en la compatibilidad con más motores de bases de datos (incluido MySQL), así como en seguir trabajando para que sea aún más rápido.
También estamos trabajando para ofrecer conectividad de red privada mediante Magic WAN y Cloudflare Tunnel, para que puedas conectarte a las bases de datos que no están (o no pueden estar) expuestas a la red pública.
Para conectar Hyperdrive a tu base de datos existente, visita nuestra documentación para desarrolladores (en menos de un minuto puedes crear un Hyperdrive y actualizar el código existente para utilizarlo). Únete al canal #hyperdrive-beta en Developer Discord para plantear preguntas, indicar errores y hablar directamente con nuestros equipos de productos e ingeniería.
Hyperdrive macht den Zugriff auf Ihre bestehenden Datenbanken von Cloudflare Workers aus hyperschnell, egal wo sie laufen. Sie verbinden Hyperdrive mit Ihrer Datenbank, ändern eine Codezeile, um eine Verbindung über Hyperdrive herzustellen, und voilà: Verbindungen und Abfragen werden schneller (und Spoiler: Sie können es schon heute nutzen).
Kurz gesagt: Hyperdrive nutzt unser globales Netzwerk, um Abfragen an Ihre bestehenden Datenbanken zu beschleunigen, unabhängig davon, ob sich diese bei einem alten Cloud-Provider oder bei Ihrem bevorzugten Provider für Serverless-Datenbanken befinden. Die Latenz, die durch das wiederholte Einrichten neuer Datenbankverbindungen entsteht, wird drastisch reduziert, und die beliebtesten Leseabfragen an Ihre Datenbank werden zwischengespeichert, sodass Sie oft gar nicht mehr zu Ihrer Datenbank zurückkehren müssen.
Wenn Ihre Kerndatenbank – mit Ihren Nutzerprofilen, Ihrem Produktbestand oder Ihrer wichtigen Web-App – in der us-east1-Region eines veralteten Cloud-Anbieters angesiedelt ist, wird der Zugriff für Nutzende in Paris, Singapur und Dubai ohne Hyperdrive sehr langsam sein und selbst für Nutzende in Los Angeles oder Vancouver langsamer, als er sein sollte. Da jeder Roundtrip bis zu 200 ms dauert, können die mehrfachen Roundtrips, die allein für den Verbindungsaufbau erforderlich sind, leicht bis zu einer Sekunde (oder mehr!) in Anspruch nehmen; und das, bevor Sie überhaupt eine Abfrage für Ihre Daten gemacht haben. Hyperdrive soll dieses Problem lösen.
Um die Performance von Hyperdrive zu demonstrieren, haben wir eine Demo-Anwendung erstellt, die Abfragen gegen dieselbe Datenbank durchführt: sowohl mit Hyperdrive als auch ohne Hyperdrive (direkt). Die App wählt eine Datenbank in einem Nachbarkontinent aus: Wenn Sie sich in Europa befinden, wählt sie eine Datenbank in den USA – etwas, das europäische Nutzende allzu häufig erleben – und wenn Sie sich in Afrika befinden, wählt sie eine Datenbank in Europa (und so weiter). Sie erhalten die Rohdaten einer einfachen SELECT-Abfrage, ohne sorgfältig ausgewählte Durchschnittswerte oder herausgepickte Metriken.
Wir haben eine Demo-App entwickelt, die echte Abfragen an eine PostgreSQL-Datenbank stellt, mit und ohne Hyperdrive.
Bei internen Tests, ersten Berichten von Nutzenden und mehreren Durchläufen in unserem Benchmark erzielte Hyperdrive bei gecachten Abfragen eine 17- bis 25-fache Performance-Verbesserung im Vergleich zur direkten Abfrage der Datenbank und eine sechs- bis achtfache Verbesserung bei ungecachten Abfragen und Schreibvorgängen. Die gecachte Latenz wird Sie vielleicht nicht überraschen, aber wir sind der Meinung, dass die sechs- bis achtfache Verbesserung bei nicht gecachten Abfragen aus „Ich kann keine zentralisierte Datenbank von Cloudflare Workers aus abfragen“ in „Wie bin ich nur solange ohne diese Möglichkeit ausgekommen?!“ verwandelt. Wir arbeiten auch weiterhin an der Verbesserung der Performance: Wir haben bereits weitere Einsparungen bei der Latenz festgestellt und werden diese in den kommenden Wochen veröffentlichen.
Wir arbeiten seit einiger Zeit im Verborgenen an Hyperdrive. Aber die Möglichkeit für Entwicklungsteams, sich mit bereits vorhandenen Datenbanken zu verbinden – mit ihren bestehenden Daten, Abfragen und Werkzeugen – beschäftigt uns schon seit geraumer Zeit.
In einer modernen verteilten Cloud-Umgebung wie der von Workers, in der die Rechenleistung global verteilt ist (also in der Nähe der Nutzenden) und die Funktionen kurzlebig sind (sodass nicht mehr als nötig in Rechnung gestellt wird), war die Verbindung zu herkömmlichen Datenbanken sowohl langsam als auch nicht skalierbar. Langsam, weil es für den Verbindungsaufbau mehr als sieben Runden braucht (TCP-Handshake, TLS-Verhandlung und Autorisierung). Und nicht skalierbar, weil Datenbanken wie PostgreSQL hohe Ressourcenkosten pro Verbindung verursachen. Schon einige hundert Verbindungen zu einer Datenbank können einen nicht zu unterschätzenden Arbeitsspeicher verbrauchen – den für die Abfragen benötigten Arbeitsspeicher nicht mitgerechnet.
Unsere Freunde bei Neon (einem beliebten Serverless Postgres-Provider) haben darüber geschrieben und sogar einen WebSocket-Proxy und -Treiber veröffentlicht, um den Verbindungsaufwand zu reduzieren. Aber sie haben trotzdem zu kämpfen: Selbst mit einem benutzerdefinierten Treiber sind wir bei vier Roundtrips, die jeweils 50–200 Millisekunden oder mehr dauern können. Wenn diese Verbindungen langlebig sind, ist das in Ordnung – es kann bestenfalls einmal alle paar Stunden passieren. Aber wenn sie auf einen einzelnen Funktionsaufruf beschränkt sind und nur wenige Millisekunden bis bestenfalls Minuten von Nutzen sind, verbringt Ihr Code mehr Zeit mit Warten. Das ist praktisch eine andere Art von Kaltstart: Da Sie vor einer Abfrage eine neue Verbindung zu Ihrer Datenbank herstellen müssen, ist die Verwendung einer herkömmlichen Datenbank in einer verteilten oder serverlosen Umgebung (vorsichtig ausgedrückt) sehr langsam.
Um dies zu verhindern, macht Hyperdrive zweierlei.
Erstens unterhält es eine Reihe regionaler Datenbankverbindungspools im gesamten Cloudflare-Netzwerk, sodass ein Cloudflare Worker nicht bei jeder Anfrage eine neue Verbindung zu einer Datenbank herstellen muss. Stattdessen kann der Worker eine Verbindung zu Hyperdrive herstellen (schnell!), wobei Hyperdrive einen Pool von einsatzbereiten Verbindungen zurück zur Datenbank unterhält. Da eine Datenbank bei einem einzigen Roundtrip zwischen 30 ms und (oft) 300 ms entfernt sein kann (ganz zu schweigen von den sieben Roundtrips oder mehr, die Sie für eine neue Verbindung benötigen), reduziert ein Pool verfügbarer Verbindungen das Latenzproblem, das bei kurzlebigen Verbindungen sonst auftreten würde, drastisch.
Zweitens versteht es den Unterschied zwischen lesenden (nicht verändernden) und schreibenden (verändernden) Abfragen und Transaktionen und kann Ihre beliebtesten lesenden Abfragen automatisch zwischenspeichern: Diese machen über 80 % der meisten Abfragen aus, die in typischen Webanwendungen an Datenbanken gestellt werden. Die Seite mit den Produktangeboten, die stündlich von Zehntausenden besucht wird, offene Stellen auf einer renommierten Karriereseite oder auch Abfragen von Konfigurationsdaten, die sich gelegentlich ändern. Ein Großteil der abgefragten Daten ändert sich nicht oft, und das Cachen dieser Daten in der Nähe des Ortes, von dem ein Nutzender sie abfragt, kann den Zugriff auf diese Daten für die nächsten zehntausend Nutzenden dramatisch beschleunigen. Schreibabfragen, die nicht sicher zwischengespeichert werden können, profitieren dennoch sowohl vom Verbindungspooling von Hyperdrive als auch vom globalen Netzwerk von Cloudflare: Da wir über unser Backbone die schnellsten Routen durch das Internet nehmen können, wird auch hier die Latenz reduziert.
Selbst wenn sich Ihre Datenbank auf der anderen Seite des Landes befindet, sind 70 ms x 6 Roundtrips eine Menge Zeit für Nutzende, die auf eine Antwort auf ihre Abfrage warten.
Hyperdrive funktioniert nicht nur mit PostgreSQL-Datenbanken – einschließlich Neon, Google Cloud SQL, AWS RDS und Timescale – sondern auch mit PostgreSQL-kompatiblen Datenbanken wie Materialize (einer leistungsstarken Stream-Processing-Datenbank), CockroachDB (einer großen verteilten Datenbank), AlloyDB von Google Cloud und AWS Aurora Postgres.
Wir arbeiten außerdem daran, bis zum Ende des Jahres Unterstützung für MySQL, einschließlich Providern wie PlanetScale, zu bieten, und planen für die Zukunft die Unterstützung weiterer Datenbank-Engines.
Der magische Verbindungsstring
Eines der wichtigsten Ziele bei der Entwicklung von Hyperdrive war, dass die Entwicklungsteams ihre bestehenden Treiber, Abfrage-Builder und ORM-Bibliotheken (Object-Relational Mapper) weiter verwenden können. Es wäre egal gewesen, wie schnell Hyperdrive ist, wenn wir von Ihnen verlangt hätten, von Ihrem bevorzugten ORM zu migrieren und/oder Hunderte (oder mehr) von Codezeilen und Tests neu zu schreiben, um von der Performance von Hyperdrive zu profitieren.
Um dies zu erreichen, haben wir mit den Betreuenden beliebter Open-Source-Treiber – einschließlich node-postgres und Postgres.js – zusammengearbeitet, damit ihre Bibliotheken die neue TCP-Socket-API von Workers unterstützen, die derzeit den Standardisierungsprozess durchläuft, und wir erwarten, dass sie auch in Node.js, Deno und Bun Einzug halten wird.
Der einfache Datenbankverbindungsstring ist die gemeinsame Sprache der Datenbanktreiber und hat normalerweise dieses Format:
Der Zauber von Hyperdrive besteht darin, dass Sie es in Ihren bestehenden Workers-Anwendungen mit Ihren bestehenden Abfragen einsetzen können, indem Sie einfach Ihren Verbindungsstring gegen den von Hyperdrive generierten austauschen.
Hyperdrive erstellen
Mit einer vorhandenen Datenbank – in diesem Beispiel verwenden wir eine Postgres-Datenbank von Neon – dauert es weniger als eine Minute, um Hyperdrive zum Laufen zu bringen (ja, wir haben die Zeit gemessen).
Wenn Sie kein bestehendes Cloudflare Workers-Projekt haben, können Sie schnell eines erstellen:
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
Von hier aus brauchen wir nur noch den Datenbankverbindungsstring für unsere Datenbank und einen kurzen Wrangler-Befehlszeilenaufruf, damit Hyperdrive sich mit ihr verbindet.
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
[[hyperdrive]]
name = "HYPERDRIVE"
id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
Wir können nun einen Worker schreiben – oder ein bestehendes Worker-Skript nehmen – und Hyperdrive verwenden, um Verbindungen und Abfragen zu unserer bestehenden Datenbank zu beschleunigen. Wir verwenden hier node-postgres, aber wir könnten genauso gut Drizzle ORM nutzen.
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
Der obige Code ist absichtlich einfach gehalten, aber die Magie ist hoffentlich nachvollziehbar: Unser Datenbanktreiber erhält einen Verbindungsstring von Hyperdrive und ist dabei völlig ahnungslos. Er muss nichts über Hyperdrive wissen, wir müssen unsere Lieblingsbibliothek für Abfrageerstellung nicht über Bord werfen und wir profitieren sofort von den Geschwindigkeitsvorteilen bei Abfragen.
Verbindungen werden automatisch gepoolt und warmgehalten, unsere beliebtesten Abfragen werden gecacht, und unsere gesamte Anwendung wird schneller.
Wir haben auch Leitfäden für alle wichtigen Datenbank-Provider erstellt, damit Sie das, was Sie von diesen Providern benötigen (einen Verbindungsstring), ganz einfach in Hyperdrive übertragen können.
Schnelles Tempo kann nicht günstig sein, oder?
Wir sind der Meinung, dass Hyperdrive für den Zugriff auf Ihre bestehenden Datenbanken entscheidend ist, wenn Sie auf Cloudflare Workers entwickeln: Herkömmliche Datenbanken wurden einfach nie für eine Welt entwickelt, in der Clients global verteilt sind.
Das Verbindungspooling von Hyperdrive wird immer kostenlos sein, sowohl für Datenbankprotokolle, die wir heute unterstützen, als auch für neue Datenbankprotokolle, die wir in Zukunft hinzufügen werden. Genau wie der DDoS-Schutz und unser globales CDN sind wir der Meinung, dass der Zugang zum Kernfeature von Hyperdrive zu nützlich ist, um ihn zurückzuhalten.
Während der offenen Beta-Phase wird Hyperdrive selbst keine Gebühren für die Nutzung erheben, unabhängig davon, wie Sie es verwenden. Weitere Details zur Preisgestaltung von Hyperdrive werden wir rechtzeitig vor der allgemeinen Freigabe (Anfang 2024) bekannt geben.
Zeit für eine Abfrage
Wie geht es nun mit Hyperdrive weiter?
Wir planen, Hyperdrive Anfang 2024 auf den Markt zu bringen – und arbeiten an mehr Kontrolle über das Caching und die automatische Invalidierung auf der Grundlage von Schreibvorgängen, detaillierten Abfrage- und Performance-Analytics (bald!), Unterstützung für weitere Datenbank-Engines (einschließlich MySQL) und möchten die Geschwindigkeit weiter ankurbeln.
Wir arbeiten auch daran, die Verbindung zu privaten Netzwerken über Magic WAN und Cloudflare Tunneling zu ermöglichen, sodass Sie auf Datenbanken zugreifen können, die nicht im öffentlichen Internet zugänglich sind (oder sein können).
Um Hyperdrive mit Ihrer bestehenden Datenbank zu verbinden, besuchen Sie unsere Dokumentation für die Entwicklung. Es dauert weniger als eine Minute, um einen Hyperdrive zu erstellen und bestehenden Code zu aktualisieren, um ihn zu verwenden. Treten Sie dem Kanal #hyperdrive-beta in unserem Entwicklungs-Discord bei, um Fragen zu stellen, Fehler zu melden und direkt mit unseren Produkt- und Entwicklungsteams zu sprechen.
Hyperdrive vous permet d’accéder très rapidement à vos bases de données existantes à partir de Cloudflare Workers, quel que soit leur lieu d’exécution. Il vous suffit de connecter Hyperdrive à votre base de données, de modifier une ligne de code pour vous connecter via Hyperdrive, et voilà : les connexions et les requêtes sont accélérées (et spoiler : vous pouvez l’utiliser dès aujourd’hui).
En un mot, Hyperdrive s’appuie sur notre réseau mondial pour accélérer les requêtes vers vos bases de données existantes, qu’elles se situent chez un fournisseur de cloud traditionnel ou chez votre fournisseur de base de données serverless préféré. La solution réduit considérablement la latence induite par l’établissement répété de nouvelles connexions avec la base de données. En outre, elle met en cache les requêtes de lecture les plus populaires adressées à votre base de données, une opération qui évite souvent d’avoir à s’adresser à nouveau à votre base de données.
Sans Hyperdrive, l’accès à votre base de données principale (celle qui contient les profils de vos utilisateurs, votre stock de produits ou qui exécute votre application web essentielle) hébergée dans la région us-east1 d’un fournisseur de cloud traditionnel se révèlera très lent pour les utilisateurs situés à Paris, Singapour et Dubaï, et plus lent qu’il ne devrait l’être pour les utilisateurs de Los Angeles ou de Vancouver. Chaque aller-retour pouvant prendre jusqu’à 200 ms, il est facile de perdre jusqu’à une seconde (ou plus !) lors des nombreux allers-retours nécessaires à l’établissement d’une connexion, avant même d’avoir envoyé la requête visant à récupérer vos données. Le service Hyperdrive est conçu pour remédier à cette situation.
Pour démontrer les performances d’Hyperdrive, nous avons développé une application de démonstration qui envoie des requêtes consécutives à la même base de données : à la fois avec Hyperdrive et sans Hyperdrive (directement donc). L’application commence par sélectionner une base de données située dans un continent voisin : elle sélectionne ainsi une base de données hébergée aux États-Unis si vous vous trouvez en Europe, par exemple (une expérience bien trop courante pour de nombreux internautes européens). De même, si vous vous trouvez en Afrique, elle sélectionnera une base de données située en Europe (et ainsi de suite). Elle renvoie ensuite les résultats bruts d’une requête « SELECT » simple, sans moyennes ni indicateurs choisis avec soin.
Tout au long de la phase de tests internes, les premiers rapports d’utilisateurs et les multiples tests d’évaluation réalisés révèlent qu’Hyperdrive améliore les performances de 17 à 25 fois par rapport à l’accès direct à la base de données pour les requêtes en cache, et de 6 à 8 fois pour les requêtes et les opérations d’écriture non mises en cache. La latence de la mise en cache ne vous surprendra peut-être pas, mais nous pensons que le fait d’accélérer 6 à 8 fois les requêtes non mises en cache vous fera changer d’idée, en passant de « Je ne peux pas interroger une base de données centralisée à partir de Cloudflare Workers » à « Mais où te cachais-tu, fonctionnalité de mes rêves ?! ». Nous continuons également à travailler sur l’amélioration des performances. Nous avons déjà identifié des économies supplémentaires en termes de latence et les mettrons en œuvre dans les semaines à venir.
Le plus beau dans tout ça ? Les développeurs titulaires d’une offre Workers payante peuvent commencer à utiliser immédiatement la bêta ouverte d’Hyperdrive : pas besoin de s’inscrire sur une liste d’attente ni de parcourir de formulaires d’inscription spéciaux.
Hyperdrive ? Vous n’en avez jamais entendu parler ?
Nous travaillons sur Hyperdrive en secret depuis quelque temps, mais le fait de permettre aux développeurs de se connecter aux bases de données dont ils disposent déjà (avec leurs données, leurs requêtes et leurs outils existants) nous trotte dans la tête depuis un bon moment.
Dans un environnement cloud distribué moderne comme Workers, au sein duquel les calculs sont distribués à l’échelle mondiale (ils sont donc effectués à proximité des utilisateurs) et les fonctions de courte durée (afin de ne pas être facturé plus que nécessaire), la connexion aux bases de données traditionnelles se montre à la fois lente et non évolutive. Lente, parce qu’il faut plus de sept allers-retours (négociation TCP, négociation TLS, authentification) pour établir la connexion et non évolutive, car les bases de données telles que PostgreSQL présentent un coût en ressources par connexion plutôt élevé. Même quelques centaines de connexions à une base de données peuvent consommer une quantité importante de mémoire, indépendamment de la mémoire nécessaire pour les requêtes.
Nos amis chez Neon (un fournisseur populaire de bases de données Postgres serverless) ont d’ailleurs écrit à ce sujet. Ils ont même lancé un proxy et un pilote WebSocket permettant de réduire la surcharge de connexion, mais ils ont toujours du mal à se sortir de l’ornière. Même avec un pilote personnalisé, nous en sommes à 4 allers-retours, chacun demandant potentiellement 50 à 200 millisecondes, voire plus. Ce délai ne pose aucun problème lorsque les connexions sont de longue durée (il surviendra une fois toutes les quelques heures au mieux), mais lorsque ces connexions se limitent à une invocation de fonction individuelle et qu’elles ne restent donc utiles que pendant quelques millisecondes ou quelques minutes, votre code passe plus de temps à attendre. Il s’agit en fait d’une autre sorte de démarrage à froid. Le fait d’avoir à établir une nouvelle connexion avec votre base de données avant d’envoyer une requête implique que l’utilisation d’une base de données traditionnelle au sein d’un environnement distribué ou serverless sera vraiment lente (pour le dire gentiment).
Pour remédier à ce problème, la solution Hyperdrive accomplit deux tâches.
Tout d’abord, elle entretient un ensemble de pools de connexions avec des bases de données régionales via le réseau Cloudflare, de sorte qu’un Worker Cloudflare puisse éviter d’établir une nouvelle connexion à une base de données pour chaque requête. À la place, le Worker peut établir une connexion à Hyperdrive (une opération des plus rapides !), car Hyperdrive dispose d’un pool de connexions prêtes à l’emploi vers la base de données. Comme une base de données peut être distante de 30 ms à (bien souvent) 300 ms lors d’un unique aller-retour (sans parler des sept ou plus dont vous avez besoin pour établir une nouvelle connexion), le fait de disposer d’un pool de connexions disponibles réduit considérablement le problème de latence dont souffriraient autrement les connexions de courte durée.
Ensuite, la solution comprend la différence entre les requêtes et les transactions de lecture (non mutantes) et d’écriture (mutantes). Elle peut ainsi mettre automatiquement en cache vos requêtes de lecture les plus populaires, qui représentent plus de 80 % de l’ensemble des requêtes adressées aux bases de données au sein des applications web typiques. Il peut, par exemple, s’agir de cette liste de produits que des dizaines de milliers d’utilisateurs visitent chaque heure, des annonces publiées sur un grand site d’offres d’emploi, voire de requêtes visant des données de configuration qui changent de temps en temps. Une grande partie des ressources visées par les requêtes des utilisateurs ne changent pas souvent et le fait de les mettre en cache à proximité de l’endroit d’où l’utilisateur envoie sa requête peut accélérer considérablement l’accès à ces données pour les dix mille utilisateurs suivants. Les requêtes d’écriture, qui ne peuvent pas être réellement mises en cache de manière sûre, bénéficient toujours des pools de connexions entretenus par Hyperdrive et du réseau mondial de Cloudflare. La possibilité d’emprunter les itinéraires les plus rapides sur Internet via notre infrastructure permet là aussi de réduire la latence.
Même si votre base de données se situe à l’autre bout du pays, 70 ms × 6 allers-retours, c’est beaucoup de temps pour un utilisateur qui attend une réponse à une requête.
Hyperdrive fonctionne non seulement avec les bases de données PostgreSQL (dont celles de Neon, de Google Cloud SQL, d’AWS RDS, et de Timescale), mais aussi avec les bases de données compatibles PostgreSQL, comme Materialize (une puissante base de données de traitement de flux), CockroachDB (une des principales bases de données distribuées), AlloyDB de Google Cloud, et Aurora Postgres d’AWS.
Nous travaillons également à la prise en charge de MySQL, notamment avec des fournisseurs comme PlanetScale, d’ici la fin de l’année. D’autres moteurs de base de données sont prévus par la suite.
La chaîne de connexion magique
L’un des principaux objectifs à l’origine de la conception d’Hyperdrive était de permettre aux développeurs de continuer à utiliser leurs outils existants, comme leurs pilotes, leurs générateurs de requêtes et leurs bibliothèques ORM (Object-Relational Mapper, mappeur objet-relationnel). La rapidité d’Hyperdrive n’aurait pas d’importance si nous vous avions demandé d’abandonner votre bibliothèque ORM préférée et/ou de réécrire des centaines (ou plus) de lignes de code et de tests pour bénéficier des performances de notre solution.
Pour ce faire, nous avons travaillé avec des éditeurs de pilotes open-source bien connus (notamment node-postgres et Postgres.js) afin d’aider leurs bibliothèques à prendre en charge la nouvelle API Socket TCP de Workers, qui est en cours de normalisation, et que nous espérons voir arriver dans Node.js, Deno et Bun également.
Langage partagé par les pilotes de base de données, la simple chaîne de connexion à la base de données se présente généralement ainsi :
La magie d’Hyperdrive réside dans le fait que vous pouvez commencer à l’utiliser dans vos applications Workers existantes, avec vos requêtes existantes, en remplaçant simplement votre chaîne de connexion par celle générée par Hyperdrive.
Création d’un Hyperdrive
Avec une base de données existante prête à l’emploi (dans cet exemple, nous utiliserons une base de données Postgres de Neon), il suffit de moins d’une minute pour faire fonctionner Hyperdrive (oui, nous avons chronométré le temps nécessaire).
Si vous ne disposez pas d’un projet Cloudflare Workers existant, vous pouvez rapidement en créer un :
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
À partir de là, nous avons juste besoin de la chaîne de connexion à notre base de données et d’une invocation rapide de la ligne de commande wrangler pour qu’Hyperdrive s’y connecte.
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
[[hyperdrive]]
name = "HYPERDRIVE"
id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
Nous pouvons maintenant écrire un Worker (ou employer un script Worker existant) et utiliser Hyperdrive pour accélérer les connexions et les requêtes à notre base de données existante. Nous utilisons ici node-postgres, mais nous pourrions tout aussi bien utiliser Drizzle ORM.
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
Le code ci-dessus est intentionnellement simple, mais j’espère que vous pouvez en voir la magie : notre pilote de base de données reçoit ainsi une chaîne de connexion d’Hyperdrive et reste indifférent. Il n’a pas besoin de connaître Hyperdrive, nous n’avons pas besoin de nous débarrasser de notre bibliothèque de génération de requêtes préférée et nous pouvons immédiatement réaliser les avantages en termes de rapidité lorsque nous envoyons des requêtes.
Les connexions sont automatiquement mises en commun et conservées, nos requêtes les plus populaires sont mises en cache et l’ensemble de notre application s’en trouve accélérée.
Nous considérons Hyperdrive comme un outil essentiel pour accéder à vos bases de données existantes lorsque vous développez sur Cloudflare Workers. Les bases de données traditionnelles n’ont tout simplement pas été conçues pour un monde dans lequel les clients sont distribués à l’échelle mondiale.
La mise en commun des connexions par Hyperdrive sous forme de pools sera toujours gratuite, à la fois pour les protocoles de base de données que nous prenons en charge aujourd’hui et pour les nouveaux protocoles que nous ajouterons à l’avenir. Tout comme pour notre service de protection contre les attaques DDoS et notre réseau CDN mondial, nous pensons que l’accès aux fonctionnalités principales d’Hyperdrive est trop utile pour être limité.
L’utilisation d’Hyperdrive ne sera pas facturée pendant la bêta ouverte, quelle que soit la manière dont vous vous en servez. Nous vous donnerons plus de détails sur la tarification d’Hyperdrive à l’approche de son lancement (début 2024), et ce bien à l’avance.
Le moment des questions
Quel est l’avenir pour Hyperdrive ?
Nous prévoyons de mettre Hyperdrive en disponibilité générale au début de l’année 2024 et nous concentrons actuellement sur la mise en place de davantage de mesures de contrôle sur la manière dont nous mettons en cache et invalidons automatiquement les ressources en nous appuyant sur les analyses des opérations d’écriture, des requêtes détaillées et des performances (bientôt !). Nous prévoyons aussi de prendre en charge davantage de moteurs de base de données (dont MySQL), tout en poursuivant nos travaux visant à rendre la solution encore plus rapide.
Nous travaillons également à la mise en place d’une connectivité réseau privée via Magic WAN et Cloudflare Tunnel, afin de vous permettre de vous connecter à des bases de données non exposées à l’Internet public (ou qui ne peuvent pas l’être). Pour connecter Hyperdrive à votre base de données existante, rendez-vous dans nos documents pour les développeurs. Il suffit de moins d’une minute pour créer un Hyperdrive et mettre à jour le code existant afin de pouvoir utiliser la solution. Rejoignez le canal #hyperdrive-beta de notre Discord pour développeurs si vous souhaitez poser des questions, signaler des bugs et discuter directement avec notre équipe produits et notre équipe technique.
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
Hyperdrive makes accessing your existing databases from Cloudflare Workers, wherever they are running, hyper fast. You connect Hyperdrive to your database, change one line of code to connect through Hyperdrive, and voilà: connections and queries get faster (and spoiler: you can use it today).
In a nutshell, Hyperdrive uses our global network to speed up queries to your existing databases, whether they’re in a legacy cloud provider or with your favorite serverless database provider; dramatically reduces the latency incurred from repeatedly setting up new database connections; and caches the most popular read queries against your database, often avoiding the need to go back to your database at all.
Without Hyperdrive, that core database — the one with your user profiles, product inventory, or running your critical web app — sitting in the us-east1 region of a legacy cloud provider is going to be really slow to access for users in Paris, Singapore and Dubai and slower than it should be for users in Los Angeles or Vancouver. With each round trip taking up to 200ms, it’s easy to burn up to a second (or more!) on the multiple round-trips needed just to set up a connection, before you’ve even made the query for your data. Hyperdrive is designed to fix this.
To demonstrate Hyperdrive’s performance, we built a demo application that makes back-to-back queries against the same database: both with Hyperdrive and without Hyperdrive (directly). The app selects a database in a neighboring continent: if you’re in Europe, it selects a database in the US — an all-too-common experience for many European Internet users — and if you’re in Africa, it selects a database in Europe (and so on). It returns raw results from a straightforward SELECT query, with no carefully selected averages or cherry-picked metrics.
We built a demo app that makes real queries to a PostgreSQL database, with and without Hyperdrive
Throughout internal testing, initial user reports and the multiple runs in our benchmark, Hyperdrive delivers a 17 – 25x performance improvement vs. going direct to the database for cached queries, and a 6 – 8x improvement for uncached queries and writes. The cached latency might not surprise you, but we think that being 6 – 8x faster on uncached queries changes “I can’t query a centralized database from Cloudflare Workers” to “where has this been all my life?!”. We’re also continuing to work on performance improvements: we’ve already identified additional latency savings, and we’ll be pushing those out in the coming weeks.
We’ve been working on Hyperdrive in secret for a short while: but allowing developers to connect to databases they already have — with their existing data, queries and tooling — has been something on our minds for quite some time.
In a modern distributed cloud environment like Workers, where compute is globally distributed (so it’s close to users) and functions are short-lived (so you’re billed no more than is needed), connecting to traditional databases has been both slow and unscalable. Slow because it takes upwards of seven round-trips (TCP handshake; TLS negotiation; then auth) to establish the connection, and unscalable because databases like PostgreSQL have a high resource cost per connection. Even just a couple of hundred connections to a database can consume non-negligible memory, separate from any memory needed for queries.
Our friends over at Neon (a popular serverless Postgres provider) wrote about this, and even released a WebSocket proxy and driver to reduce the connection overhead, but are still fighting uphill in the snow: even with a custom driver, we’re down to 4 round-trips, each still potentially taking 50-200 milliseconds or more. When those connections are long-lived, that’s OK — it might happen once every few hours at best. But when they’re scoped to an individual function invocation, and are only useful for a few milliseconds to minutes at best — your code spends more time waiting. It’s effectively another kind of cold start: having to initiate a fresh connection to your database before making a query means that using a traditional database in a distributed or serverless environment is (to put it lightly) really slow.
To combat this, Hyperdrive does two things.
First, it maintains a set of regional database connection pools across Cloudflare’s network, so a Cloudflare Worker avoids making a fresh connection to a database on every request. Instead, the Worker can establish a connection to Hyperdrive (fast!), with Hyperdrive maintaining a pool of ready-to-go connections back to the database. Since a database can be anywhere from 30ms to (often) 300ms away over a single round-trip (let alone the seven or more you need for a new connection), having a pool of available connections dramatically reduces the latency issue that short-lived connections would otherwise suffer.
Second, it understands the difference between read (non-mutating) and write (mutating) queries and transactions, and can automatically cache your most popular read queries: which represent over 80% of most queries made to databases in typical web applications. That product listing page that tens of thousands of users visit every hour; open jobs on a major careers site; or even queries for config data that changes occasionally; a tremendous amount of what is queried does not change often, and caching it closer to where the user is querying it from can dramatically speed up access to that data for the next ten thousand users. Write queries, which can’t be safely cached, still get to benefit from both Hyperdrive’s connection pooling and Cloudflare’s global network: being able to take the fastest routes across the Internet across our backbone cuts down latency there, too.
Even if your database is on the other side of the country, 70ms x 6 round-trips is a lot of time for a user to be waiting for a query response.
Hyperdrive works not only with PostgreSQL databases — including Neon, Google Cloud SQL, AWS RDS, and Timescale, but also PostgreSQL-compatible databases like Materialize (a powerful stream-processing database), CockroachDB (a major distributed database), Google Cloud’s AlloyDB, and AWS Aurora Postgres.
We’re also working on bringing support for MySQL, including providers like PlanetScale, by the end of the year, with more database engines planned in the future.
The magic connection string
One of the major design goals for Hyperdrive was the need for developers to keep using their existing drivers, query builder and ORM (Object-Relational Mapper) libraries. It wouldn’t have mattered how fast Hyperdrive was if we required you to migrate away from your favorite ORM and/or rewrite hundreds (or more) lines of code & tests to benefit from Hyperdrive’s performance.
The magic behind Hyperdrive is that you can start using it in your existing Workers applications, with your existing queries, just by swapping out your connection string for the one Hyperdrive generates instead.
Creating a Hyperdrive
With an existing database ready to go — in this example, we’ll use a Postgres database from Neon — it takes less than a minute to get Hyperdrive running (yes, we timed it).
If you don’t have an existing Cloudflare Workers project, you can quickly create one:
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
From here, we just need the database connection string for our database and a quick wrangler command-line invocation to have Hyperdrive connect to it.
# Using wrangler v3.8.0 or above
wrangler hyperdrive databases create a-faster-database --connection-string="postgres://user:[email protected]/neondb"
# This will return an ID: we'll use this in the next step
[[hyperdrive]]
name = "HYPERDRIVE"
database_id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
We can now write a Worker — or take an existing Worker script — and use Hyperdrive to speed up connections and queries to our existing database. We use node-postgres here, but we could just as easily use Drizzle ORM.
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
The code above is intentionally simple, but hopefully you can see the magic: our database driver gets a connection string from Hyperdrive, and is none-the-wiser. It doesn’t need to know anything about Hyperdrive, we don’t have to toss out our favorite query builder library, and we can immediately realize the speed benefits when making queries.
Connections are automatically pooled and kept warm, our most popular queries are cached, and our entire application gets faster.
We think Hyperdrive is critical to accessing your existing databases when building on Cloudflare Workers: traditional databases were just never designed for a world where clients are globally distributed.
Hyperdrive’s connection pooling will always be free, for both database protocols we support today and new database protocols we add in the future. Just like DDoS protection and our global CDN, we think access to Hyperdrive’s core feature is too useful to hold back.
During the open beta, Hyperdrive itself will not incur any charges for usage, regardless of how you use it. We’ll be announcing more details on how Hyperdrive will be priced closer to GA (early in 2024), with plenty of notice.
Time to query
So where to from here for Hyperdrive?
We’re planning on bringing Hyperdrive to GA in early 2024 — and we’re focused on landing more controls over how we cache & automatically invalidate based on writes, detailed query and performance analytics (soon!), support for more database engines (including MySQL) as well as continuing to work on making it even faster.
We’re also working to enable private network connectivity via Magic WAN and Cloudflare Tunnel, so that you can connect to databases that aren’t (or can’t be) exposed to the public Internet.
To connect Hyperdrive to your existing database, visit our developer docs — it takes less than a minute to create a Hyperdrive and update existing code to use it. Join the #hyperdrive-beta channel in our Developer Discord to ask questions, surface bugs, and talk to our Product & Engineering teams directly.
D1 is now in open beta, and the theme is “scale”: with higher per-database storage limits and the ability to create more databases, we’re unlocking the ability for developers to build production-scale applications on D1. Any developers with an existing paid Workers plan don’t need to lift a finger to benefit: we’ve retroactively applied this to all existing D1 databases.
D1 our native serverless database, which we launched into alpha in November last year: the queryable database complement to Workers KV, Durable Objects and R2.
When we set out to build D1, we knew a few things for certain: it needed to be fast, it needed to be incredibly easy to create a database, and it needed to be SQL-based.
That last one was critical: so that developers could a) avoid learning another custom query language and b) make it easier for existing query buildings, ORM (object relational mapper) libraries and other tools to connect to D1 with minimal effort. From this, we’ve seen a huge number of projects build support in for D1: from support for D1 in the Drizzle ORM and Kysely, to the T4 App, a full-stack toolkit that uses D1 as its database.
We also knew that D1 couldn’t be the only way to query a database from Workers: for teams with existing databases and thousands of lines of SQL or existing ORM code, migrating across to D1 isn’t going to be an afternoon’s work. For those teams, we built Hyperdrive, allowing you to connect to your existing databases and make them feel global. We think this gives teams flexibility: combine D1 and Workers for globally distributed apps, and use Hyperdrive for querying the databases you have in legacy clouds and just can’t get rid of overnight.
Larger databases, and more of them
This has been the biggest ask from the thousands of D1 users throughout the alpha: not just more databases, but also bigger databases.
Developers on the Workers paid plan will now be able to grow each database up to 2GB and create 25 databases (up from 500MB and 10).
We’ll be continuing to work on unlocking even larger databases over the coming weeks and months: developers using the D1 beta will see automatic increases to these limits published on D1’s public changelog.
One of the biggest impediments to double-digit-gigabyte databases is performance: we want to ensure that a database can load in and be ready really quickly — cold starts of seconds (or more) just aren’t acceptable. A 10GB or 20GB database that takes 15 seconds before it can answer a query ends up being pretty frustrating to use.
Users on the Workers free plan will keep the ten 500MB databases (changelog) forever: we want to give more developers the room to experiment with D1 and Workers before jumping in.
Time Travel is here
Time Travel allows you to roll your database back to a specific point in time: specifically, any minute in the last 30 days. And it’s enabled by default for every D1 database, doesn’t cost any more, and doesn’t count against your storage limit.
For those who have been keeping tabs: we originally announced Time Travel earlier this year, and made it available to all D1 users in July. At its core, it’s deceptively simple: Time Travel introduces the concept of a “bookmark” to D1. A bookmark represents the state of a database at a specific point in time, and is effectively an append-only log. Time Travel can take a timestamp and turn it into a bookmark, or a bookmark directly: allowing you to restore back to that point. Even better: restoring doesn’t prevent you from going back further.
We think Time Travel works best with an example, so let’s make a change to a database: one with an Order table that stores every order made against our e-commerce store:
# To illustrate: we have 89,185 unique addresses in our order database.
# To illustrate: we have 89,185 unique addresses in our order database.
➜ wrangler d1 execute northwind --command "SELECT count(distinct ShipAddress) FROM [Order]"
┌──────────┐
│ count(*) │
├──────────┤
│ 89185 │
└──────────┘
OK, great. Now what if we wanted to make a change to a specific set of orders: an address change or freight company change?
# I think we might be forgetting something here...
➜ wrangler d1 execute northwind --command "UPDATE [Order] SET ShipAddress = 'Av. Veracruz 38, Roma Nte., Cuauhtémoc, 06700 Ciudad de México, CDMX, Mexico'
Wait: we’ve made a mistake that many, many folks have before: we forgot the WHERE clause on our UPDATE query. Instead of updating a specific order Id, we’ve instead updated the ShipAddress for every order in our table.
# Every order is now going to a wine bar in Mexico City.
➜ wrangler d1 execute northwind --command "SELECT count(distinct ShipAddress) FROM [Order]"
┌──────────┐
│ count(*) │
├──────────┤
│ 1 │
└──────────┘
Panic sets in. Did we remember to make a backup before we did this? How long ago was it? Did we turn on point-in-time recovery? It seemed potentially expensive at the time…
It’s OK. We’re using D1. We can Time Travel. It’s on by default: let’s fix this and travel back a few minutes.
# Let's go back in time.
➜ wrangler d1 time-travel restore northwind --timestamp="2023-09-23T14:20:00Z"
🚧 Restoring database northwind from bookmark 0000000b-00000002-00004ca7-9f3dba64bda132e1c1706a4b9d44c3c9
✔ OK to proceed (y/N) … yes
⚡️ Time travel in progress...
✅ Database dash-db restored back to bookmark 00000000-00000004-00004ca7-97a8857d35583887de16219c766c0785
↩️ To undo this operation, you can restore to the previous bookmark: 00000013-ffffffff-00004ca7-90b029f26ab5bd88843c55c87b26f497
We think that Time Travel becomes even more powerful when you have many smaller databases, too: the downsides of any restore operation is reduced further and scoped to a single user or tenant.
This is also just the beginning for Time Travel: we’re working to support not just only restoring a database, but also the ability to fork from and overwrite existing databases. If you can fork a database with a single command and/or test migrations and schema changes against real data, you can de-risk a lot of the traditional challenges that working with databases has historically implied.
Row-based pricing
Back in May we announced pricing for D1, to a lot of positive feedback around how much we’d included in our Free and Paid plans. In August, we published a new row-based model, replacing the prior byte-units, that makes it easier to predict and quantify your usage. Specifically, we moved to rows as it’s easier to reason about: if you’re writing a row, it doesn’t matter if it’s 1KB or 1MB. If your read query uses an indexed column to filter on, you’ll see not only performance benefits, but cost savings too.
Here’s D1’s pricing — almost everything has stayed the same, with the added benefit of charging based on rows:
As before, D1 does not charge you for “database hours”, the number of databases, or point-in-time recovery (Time Travel) — just query D1 and pay for your reads, writes, and storage — that’s it.
We believe this makes D1 not only far more cost-efficient, but also makes it easier to manage multiple databases to isolate customer data or prod vs. staging: we don’t care which database you query. Manage your data how you like, separate your customer data, and avoid having to fall for the trap of “Billing Based Architecture”, where you build solely around how you’re charged, even if it’s not intuitive or what makes sense for your team.
To make it easier to both see how much a given query charges and when to optimize your queries with indexes, D1 also returns the number of rows a query read or wrote (or both) so that you can understand how it’s costing you in both cents and speed.
For example, the following query filters over orders based on date:
The unindexed query above scans 16,800 rows. Even if we don’t optimize it, D1 includes 25 billion queries per month for free, meaning we could make this query 1.4 million times for a whole month before having to worry about extra costs.
But we can do better with an index:
CREATE INDEX IF NOT EXISTS idx_orders_date ON [Order](ShippedDate)
With the index created, let’s see how many rows our query needs to read now:
The same query with an index on the ShippedDate column reads just 417 rows: not only it is faster (duration is in milliseconds!), but it costs us less: we could run this query 59 million times per month before we’d have to pay any more than what the $5 Workers plan gives us.
D1 also exposes row counts via both the Cloudflare dashboard and our GraphQL analytics API: so not only can you look at this per-query when you’re tuning performance, but also break down query patterns across all of your databases.
D1 for Platforms
Throughout D1’s alpha period, we’ve both heard from and worked with teams who are excited about D1’s ability to scale out horizontally: the ability to deploy a database-per-customer (or user!) in order to keep data closer to where teams access it and more strongly isolate that data from their other users.
Teams building the next big thing on Workers for Platforms — think of it as “Functions as a Service, as a Service” — can use D1 to deploy a database per user — keeping customer data strongly separated from each other.
For example, and as one of the early adopters of D1, RONIN is building an edge-first content & data platform backed by a dedicated D1 database per customer, which allows customers to place data closer to users and provides each customer isolation from the queries of others.
Instead of spinning up and managing countless traditional database instances, RONIN uses D1 for Platforms to offer automatic infinite scalability at the edge. This allows RONIN to focus on providing a sleek, intuitive editing experience for your content & data.
When it comes to enabling “D1 for Platforms”, we’ve thought about this in a few ways from the very beginning:
Support for more than 100,000+ databases for Workers for Platforms users (there’s no limit, but if we said “unlimited” you might not believe us).
D1’s pricing – you don’t pay per-database or for “idle databases”. If you have a range of users, from thousands of QPS down to 1-2 every 10 minutes — you aren’t paying more for “database hours” on the less trafficked databases, or having to plan around spiky workloads across your user-base.
The ability to programmatically configure more databases via D1’s HTTP APIand attach them to your Worker without re-deploying. There’s no “provisioning” delay, either: you create the database, and it’s immediately ready to query by you or your users.
Detailed per-database analytics, so you can understand which databases are being used and how they’re being queried via D1’s GraphQL analytics API.
If you’re building the next big platform on top of Workers & want to use D1 at scale — whether you’re part of the Workers Launchpad program or not — reach out.
What’s next for D1?
We’re setting a clear goal: we want to make D1 “generally available” (GA) for production use-cases by early next year(Q1 2024). Although you can already use D1 without a waitlist or approval process, we understand that the GA label is an important one for many when it comes to a database (and as do we).
Between now and GA, we’re working on some really key parts of the D1 vision, with a continued focus on reliability and performance.
One of the biggest remaining pieces of that vision is global read replication, which we wrote about earlier this year. Importantly, replication will be free, won’t multiply your storage consumption, and will still enable session consistency (read-your-writes). Part of D1’s mission is about getting data closer to where users are, and we’re excited to land it.
We’re also working to expand Time Travel, D1’s built-in point-in-time recovery capabilities, so that you can branch and/or clone a database from a specific point-in-time on the fly.
We’ll also be progressively opening up our limits around per-database storage, unlocking more storage per account, and the number of databases you can create over the rest of this year, so keep an eye on the D1 changelog (or your inbox).
In the meantime, if you haven’t yet used D1, you can get started right now, visit D1’s developer documentation to spark some ideas, or join the #d1-beta channel on our Developer Discord to talk to other D1 developers and our product-engineering team.
Vectorize is our brand-new vector database offering, designed to let you build full-stack, AI-powered applications entirely on Cloudflare’s global network: and you can start building with it right away. Vectorize is in open beta, and is available to any developer using Cloudflare Workers.
You can use Vectorize with Workers AI to power semantic search, classification, recommendation and anomaly detection use-cases directly with Workers, improve the accuracy and context of answers from LLMs (Large Language Models), and/or bring-your-own embeddings from popular platforms, including OpenAI and Cohere.
Visit Vectorize’s developer documentation to get started, or read on if you want to better understand what vector databases do and how Vectorize is different.
Why do I need a vector database?
Machine learning models can’t remember anything: only what they were trained on.
Vector databases are designed to solve this, by capturing how an ML model represents data — including structured and unstructured text, images and audio — and storing it in a way that allows you to compare against future inputs. This allows us to leverage the power of existing machine-learning models and LLMs (Large Language Models) for content they haven’t been trained on: which, given the tremendous cost of training models, turns out to be extremely powerful.
To better illustrate why a vector database like Vectorize is useful, let’s pretend they don’t exist, and see how painful it is to give context to an ML model or LLM for a semantic search or recommendation task. Our goal is to understand what content is similar to our query and return it: based on our own dataset.
Our user query comes in: they’re searching for “how to write to R2 from Cloudflare Workers”
We load up our entire documentation dataset — a thankfully “small” dataset at about 65,000 sentences, or 2.1 GB — and provide it alongside the query from our user. This allows the model to have the context it needs, based on our data.
We wait.
(A long time)
We get our similarity scores back, with the sentences most similar to the user’s query, and then work to map those back to URLs before we return our search results.
… and then another query comes in, and we have to start this all over again.
In practice, this isn’t really possible: we can’t pass that much context in an API call (prompt) to most machine learning models, and even if we could, it’d take tremendous amounts of memory and time to process our dataset over-and-over again.
With a vector database, we don’t have to repeat step 2: we perform it once, or as our dataset updates, and use our vector database to provide a form of long-term memory for our machine learning model. Our workflow looks a little more like this:
We load up our entire documentation dataset, run it through our model, and store the resulting vector embeddings in our vector database (just once).
For each user query (and only the query) we ask the same model and retrieve a vector representation.
We query our vector database with that query vector, which returns the vectors closest to our query vector.
If we looked at these two flows side by side, we can quickly see how inefficient and impractical it is to use our own dataset with an existing model without a vector database:
Using a vector database to help machine learning models remember.
From this simple example, it’s probably starting to make some sense: but you might also be wondering why you need a vector database instead of just a regular database.
Vectors are the model’s representation of an input: how it maps that input to its internal structure, or “features”. Broadly, the more similar vectors are, the more similar the model believes those inputs to be based on how it extracts features from an input.
This is seemingly easy when we look at example vectors of only a handful of dimensions. But with real-world outputs, searching across 10,000 to 250,000 vectors, each potentially 1,536 dimensions wide, is non-trivial. This is where vector databases come in: to make search work at scale, vector databases use a specific class of algorithm, such as k-nearest neighbors (kNN) or other approximate nearest neighbor (ANN) algorithms to determine vector similarity.
And although vector databases are extremely useful when building AI and machine learning powered applications, they’re not only useful in those use-cases: they can be used for a multitude of classification and anomaly detection tasks. Knowing whether a query input is similar — or potentially dissimilar — from other inputs can power content moderation (does this match known-bad content?) and security alerting (have I seen this before?) tasks as well.
Building a recommendation engine with vector search
We built Vectorize to be a powerful partner to Workers AI: enabling you to run vector search tasks as close to users as possible, and without having to think about how to scale it for production.
We’re going to take a real world example — building a (product) recommendation engine for an e-commerce store — and simplify a few things.
Our goal is to show a list of “relevant products” on each product listing page: a perfect use-case for vector search. Our input vectors in the example are placeholders, but in a real world application we would generate them based on product descriptions and/or cart data by passing them through a sentence similarity model (such as Worker’s AI’s text embedding model)
Each vector represents a product across our store, and we associate the URL of the product with it. We could also set the ID of each vector to the product ID: both approaches are valid. Our query — vector search — represents the product description and content for the product user is currently viewing.
Let’s step through what this looks like in code: this example is pulled straight from our developer documentation:
export interface Env {
// This makes our vector index methods available on env.MY_VECTOR_INDEX.*
// e.g. env.MY_VECTOR_INDEX.insert() or .query()
TUTORIAL_INDEX: VectorizeIndex;
}
// Sample vectors: 3 dimensions wide.
//
// Vectors from a machine-learning model are typically ~100 to 1536 dimensions
// wide (or wider still).
const sampleVectors: Array<VectorizeVector> = [
{ id: '1', values: [32.4, 74.1, 3.2], metadata: { url: '/products/sku/13913913' } },
{ id: '2', values: [15.1, 19.2, 15.8], metadata: { url: '/products/sku/10148191' } },
{ id: '3', values: [0.16, 1.2, 3.8], metadata: { url: '/products/sku/97913813' } },
{ id: '4', values: [75.1, 67.1, 29.9], metadata: { url: '/products/sku/418313' } },
{ id: '5', values: [58.8, 6.7, 3.4], metadata: { url: '/products/sku/55519183' } },
];
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
if (new URL(request.url).pathname !== '/') {
return new Response('', { status: 404 });
}
// Insert some sample vectors into our index
// In a real application, these vectors would be the output of a machine learning (ML) model,
// such as Workers AI, OpenAI, or Cohere.
let inserted = await env.TUTORIAL_INDEX.insert(sampleVectors);
// Log the number of IDs we successfully inserted
console.info(`inserted ${inserted.count} vectors into the index`);
// In a real application, we would take a user query - e.g. "durable
// objects" - and transform it into a vector emebedding first.
//
// In our example, we're going to construct a simple vector that should
// match vector id #5
let queryVector: Array<number> = [54.8, 5.5, 3.1];
// Query our index and return the three (topK = 3) most similar vector
// IDs with their similarity score.
//
// By default, vector values are not returned, as in many cases the
// vectorId and scores are sufficient to map the vector back to the
// original content it represents.
let matches = await env.TUTORIAL_INDEX.query(queryVector, { topK: 3, returnVectors: true });
// We map over our results to find the most similar vector result.
//
// Since our index uses the 'cosine' distance metric, scores will range
// from 1 to -1. A value of '1' means the vector is the same; the
// closer to 1, the more similar. Values of -1 (least similar) and 0 (no
// match).
// let closestScore = 0;
// let mostSimilarId = '';
// matches.matches.map((match) => {
// if (match.score > closestScore) {
// closestScore = match.score;
// mostSimilarId = match.vectorId;
// }
// });
return Response.json({
// This will return the closest vectors: we'll see that the vector
// with id = 5 has the highest score (closest to 1.0) as the
// distance between it and our query vector is the smallest.
// Return the full set of matches so we can see the possible scores.
matches: matches,
});
},
};
The code above is intentionally simple, but illustrates vector search at its core: we insert vectors into our database, and query it for vectors with the smallest distance to our query vector.
Here are the results, with the values included, so we visually observe that our query vector [54.8, 5.5, 3.1] is similar to our highest scoring match: [58.799, 6.699, 3.400] returned from our search. This index uses cosine similarity to calculate the distance between vectors, which means that the closer the score to 1, the more similar a match is to our query vector.
In a real application, we could now quickly return product recommendation URLs based on the most similar products, sorting them by their score (highest to lowest), and increasing the topK value if we want to show more. The metadata stored alongside each vector could also embed a path to an R2 object, a UUID for a row in a D1 database, or a key-value pair from Workers KV.
Workers AI + Vectorize: full stack vector search on Cloudflare
In a real application, we need a machine learning model that can both generate vector embeddings from our original dataset (to seed our database) and quickly turn user queries into vector embeddings too. These need to be from the same model, as each model represents features differently.
Here’s a compact example building an entire end-to-end vector search pipeline on Cloudflare:
import { Ai } from '@cloudflare/ai';
export interface Env {
TEXT_EMBEDDINGS: VectorizeIndex;
AI: any;
}
interface EmbeddingResponse {
shape: number[];
data: number[][];
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const ai = new Ai(env.AI);
let path = new URL(request.url).pathname;
if (path.startsWith('/favicon')) {
return new Response('', { status: 404 });
}
// We only need to generate vector embeddings just the once (or as our
// data changes), not on every request
if (path === '/insert') {
// In a real-world application, we could read in content from R2 or
// a SQL database (like D1) and pass it to Workers AI
const stories = ['This is a story about an orange cloud', 'This is a story about a llama', 'This is a story about a hugging emoji'];
const modelResp: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: stories,
});
// We need to convert the vector embeddings into a format Vectorize can accept.
// Each vector needs an id, a value (the vector) and optional metadata.
// In a real app, our ID would typicaly be bound to the ID of the source
// document.
let vectors: VectorizeVector[] = [];
let id = 1;
modelResp.data.forEach((vector) => {
vectors.push({ id: `${id}`, values: vector });
id++;
});
await env.TEXT_EMBEDDINGS.upsert(vectors);
}
// Our query: we expect this to match vector id: 1 in this simple example
let userQuery = 'orange cloud';
const queryVector: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: [userQuery],
});
let matches = await env.TEXT_EMBEDDINGS.query(queryVector.data[0], { topK: 1 });
return Response.json({
// We expect vector id: 1 to be our top match with a score of
// ~0.896888444
// We are using a cosine distance metric, where the closer to one,
// the more similar.
matches: matches,
});
},
};
The code above does four things:
It passes the three sentences to Workers AI’s text embedding model (@cf/baai/bge-base-en-v1.5) and retrieves their vector embeddings.
It inserts those vectors into our Vectorize index.
Takes the user query and transforms it into a vector embedding via the same Workers AI model.
Queries our Vectorize index for matches.
This example might look “too” simple, but in a production application, we’d only have to change two things: just insert our vectors once (or periodically via Cron Triggers), and replace our three example sentences with real data stored in R2, a D1 database, or another storage provider.
In fact, this is incredibly similar to how we run Cursor, the AI assistant that can answer questions about Cloudflare Worker: we migrated Cursor to run on Workers AI and Vectorize. We generate text embeddings from our developer documentation using its built-in text embedding model, insert them into a Vectorize index, and transform user queries on the fly via that same model.
BYO embeddings from your favorite AI API
Vectorize isn’t just limited to Workers AI, though: it’s a fully-fledged, standalone vector database.
If you’re already using OpenAI’s Embedding API, Cohere’s multilingual model, or any other embedding API, then you can easily bring-your-own (BYO) vectors to Vectorize.
It works just the same: generate your embeddings, insert them into Vectorize, and pass your queries through the model before you query your index. Vectorize includes a few shortcuts for some of the most popular embedding models.
# Vectorize has ready-to-go presets that set the dimensions and distance metric for popular embeddings models
$ wrangler vectorize create openai-index-example --preset=openai-text-embedding-ada-002
This can be particularly useful if you already have an existing workflow around an existing embeddings API, and/or have validated a specific multimodal or multilingual embeddings model for your use-case.
Making the cost of AI predictable
There’s a tremendous amount of excitement around AI and ML, but there’s also one big concern: that it’s too expensive to experiment with, and hard to predict at scale.
With Vectorize, we wanted to bring a simpler pricing model to vector databases. Have an idea for a proof-of-concept at work? That should fit into our free-tier limits. Scaling up and optimizing your embedding dimensions for performance vs. accuracy? It shouldn’t break the bank.
Importantly, Vectorize aims to be predictable: you don’t need to estimate CPU and memory consumption, which can be hard when you’re just starting out, and made even harder when trying to plan for your peak vs. off-peak hours in production for a brand new use-case. Instead, you’re charged based on the total number of vector dimensions you store, and the number of queries against them each month. It’s our job to take care of scaling up to meet your query patterns.
Here’s the pricing for Vectorize — and if you have a Workers paid plan now, Vectorize is entirely free to use until 2024:
Workers Free (coming soon)
Workers Paid ($5/month)
Queried vector dimensions included
30M total queried dimensions / month
50M total queried dimensions / month
Stored vector dimensions included
5M stored dimensions / month
10M stored dimensions / month
Additional cost
$0.04 / 1M vector dimensions queried or stored
$0.04 / 1M vector dimensions queried or stored
Pricing is based entirely on what you store and query: (total vector dimensions queried + stored) * dimensions_per_vector * price. Query more? Easy to predict. Optimizing for smaller dimensions per vector to improve speed and reduce overall latency? Cost goes down. Have a few indexes for prototyping or experimenting with new use-cases? We don’t charge per-index.
Create as many as you need indexes to prototype new ideas and/or separate production from dev.
As an example: if you load 10,000 Workers AI vectors (384 dimensions each) and make 5,000 queries against your index each day, it’d result in 49 million total vector dimensions queried and still fit into what we include in the Workers Paid plan ($5/month). Better still: we don’t delete your indexes due to inactivity.
Note that while this pricing isn’t final, we expect few changes going forward. We want to avoid the element of surprise: there’s nothing worse than starting to build on a platform and realizing the pricing is untenable after you’ve invested the time writing code, tests and learning the nuances of a technology.
This is also just the beginning of the vector database story for us at Cloudflare. Over the next few weeks and months, we intend to land a new query engine that should further improve query performance, support even larger indexes, introduce sub-index filtering capabilities, increased metadata limits, and per-index analytics.
If you’re looking for inspiration on what to build, see the semantic search tutorial that combines Workers AI and Vectorize for document search, running entirely on Cloudflare. Or an example of how to combine OpenAI and Vectorize to give an LLM more context and dramatically improve the accuracy of its answers.
And if you have questions about how to use Vectorize for our product & engineering teams, or just want to bounce an idea off of other developers building on Workers AI, join the #vectorize and #workers-ai channels on our Developer Discord.
Over the last couple of months, Workers KV has suffered from a series of incidents, culminating in three back-to-back incidents during the week of July 17th, 2023. These incidents have directly impacted customers that rely on KV — and this isn’t good enough.
We’re going to share the work we have done to understand why KV has had such a spate of incidents and, more importantly, share in depth what we’re doing to dramatically improve how we deploy changes to KV going forward.
Workers KV?
Workers KV — or just “KV” — is a key-value service for storing data: specifically, data with high read throughput requirements. It’s especially useful for user configuration, service routing, small assets and/or authentication data.
We use KV extensively inside Cloudflare too, with Cloudflare Access (part of our Zero Trust suite) and Cloudflare Pages being some of our highest profile internal customers. Both teams benefit from KV’s ability to keep regularly accessed key-value pairs close to where they’re accessed, as well its ability to scale out horizontally without any need to become an expert in operating KV.
Given Cloudflare’s extensive use of KV, it wasn’t just external customers impacted. Our own internal teams felt the pain of these incidents, too.
The summary of the post-mortem
Back in June 2023, we announced the move to a new architecture for KV, which is designed to address two major points of customer feedback we’ve had around KV: high latency for infrequently accessed keys (or a key accessed in different regions), and working to ensure the upper bound on KV’s eventual consistency model for writes is 60 seconds — not “mostly 60 seconds”.
At the time of the blog, we’d already been testing this internally, including early access with our community champions and running a small % of production traffic to validate stability and performance expectations beyond what we could emulate within a staging environment.
However, in the weeks between mid-June and culminating in the series of incidents during the week of July 17th, we would continue to increase the volume of new traffic onto the new architecture. When we did this, we would encounter previously unseen problems (many of these customer-impacting) — then immediately roll back, fix bugs, and repeat. Internally, we’d begun to identify that this pattern was becoming unsustainable — each attempt to cut traffic onto the new architecture would surface errors or behaviors we hadn’t seen before and couldn’t immediately explain, and thus we would roll back and assess.
The issues at the root of this series of incidents proved to be significantly challenging to track and observe. Once identified, the two causes themselves proved to be quick to fix, but an (1) observability gap in our error reporting and (2) a mutation to local state that resulted in an unexpected mutation of global state were both hard to observe and reproduce over the days following the customer-facing impact ending.
The detail
One important piece of context to understand before we go into detail on the post-mortem: Workers KV is composed of two separate Workers scripts – internally referred to as the Storage Gateway Worker and SuperCache. SuperCache is an optional path in the Storage Gateway Worker workflow, and is the basis for KV's new (faster) backend (refer to the blog).
Here is a timeline of events:
Time
Description
2023-07-17 21:52 UTC
Cloudflare observes alerts showing 500 HTTP status codes in the MEL01 data-center (Melbourne, AU) and begins investigating. We also begin to see a small set of customers reporting HTTP 500s being returned via multiple channels. It is not immediately clear if this is a data-center-wide issue or KV specific, as there had not been a recent KV deployment, and the issue directly correlated with three data-centers being brought back online.
2023-07-18 00:09 UTC
We disable the new backend for KV in MEL01 in an attempt to mitigate the issue (noting that there had not been a recent deployment or change to the % of users on the new backend).
2023-07-18 05:42 UTC
Investigating alerts showing 500 HTTP status codes in VIE02 (Vienna, AT) and JNB01 (Johannesburg, SA).
2023-07-18 13:51 UTC
The new backend is disabled globally after seeing issues in VIE02 (Vienna, AT) and JNB01 (Johannesburg, SA) data-centers, similar to MEL01. In both cases, they had also recently come back online after maintenance, but it remained unclear as to why KV was failing.
2023-07-20 19:12 UTC
The new backend is inadvertently re-enabled while deploying the update due to a misconfiguration in a deployment script.
2023-07-20 19:33 UTC
The new backend is (re-) disabled globally as HTTP 500 errors return.
2023-07-20 23:46 UTC
Broken Workers script pipeline deployed as part of gradual rollout due to incorrectly defined pipeline configuration in the deployment script. Metrics begin to report that a subset of traffic is being black-holed.
All timestamps referenced are in Coordinated Universal Time (UTC).
We initially observed alerts showing 500 HTTP status codes in the MEL01 data-center (Melbourne, AU) at 21:52 UTC on July 17th, and began investigating. We also received reports from a small set of customers reporting HTTP 500s being returned via multiple channels. This correlated with three data centers being brought back online, and it was not immediately clear if it related to the data centers or was KV-specific — especially given there had not been a recent KV deployment. On 05:42, we began investigating alerts showing 500 HTTP status codes in VIE02 (Vienna) and JNB02 (Johannesburg) data-centers; while both had recently come back online after maintenance, it was still unclear why KV was failing. At 13:51 UTC, we made the decision to disable the new backend globally.
Following the incident on July 18th, we attempted to deploy an allow-list configuration to reduce the scope of impacted accounts. However, while attempting to roll out a change for the Storage Gateway Worker at 19:12 UTC on July 20th, an older configuration was progressed causing the new backend to be enabled again, leading to the third event. As the team worked to fix this and deploy this configuration, they attempted to manually progress the deployment at 23:46 UTC, which resulted in the passing of a malformed configuration value that caused traffic to be sent to an invalid Workers script configuration.
After all deployments and the broken Workers configuration (pipeline) had been rolled back at 23:56 on the 20th July, we spent the following three days working to identify the root cause of the issue. We lacked observability as KV's Worker script (responsible for much of KV's logic) was throwing an unhandled exception very early on in the request handling process. This was further exacerbated by prior work to disable error reporting in a disabled data-center due to the noise generated, which had previously resulted in logs being rate-limited upstream from our service.
This previous mitigation prevented us from capturing meaningful logs from the Worker, including identifying the exception itself, as an uncaught exception terminates request processing. This has raised the priority of improving how unhandled exceptions are reported and surfaced in a Worker (see Recommendations, below, for further details). This issue was exacerbated by the fact that KV's Worker script would fail to re-enter its "healthy" state when a Cloudflare data center was brought back online, as the Worker was mutating an environment variable perceived to be in request scope, but that was in global scope and persisted across requests. This effectively left the Worker “frozen” with the previous, invalid configuration for the affected locations.
Further, the introduction of a new progressive release process for Workers KV, designed to de-risk rollouts (as an action from a prior incident), prolonged the incident. We found a bug in the deployment logic that led to a broader outage due to an incorrectly defined configuration.
This configuration effectively caused us to drop a single-digit % of traffic until it was rolled back 10 minutes later. This code is untested at scale, and we need to spend more time hardening it before using it as the default path in production.
Additionally: although the root cause of the incidents was limited to three Cloudflare data-centers (Melbourne, Vienna, and Johannesburg), traffic across these regions still uses these data centers to route reads and writes to our system of record. Because these three data centers participate in KV’s new backend as regional tiers, a portion of traffic across the Oceania, Europe, and African regions was affected. Only a portion of keys from enrolled namespaces use any given data center as a regional tier in order to limit a single (regional) point of failure, so while traffic across all data centers in the region was impacted, nowhere was all traffic in a given data center affected.
We estimated the affected traffic to be 0.2-0.5% of KV's global traffic (based on our error reporting), however we observed some customers with error rates approaching 20% of their total KV operations. The impact was spread across KV namespaces and keys for customers within the scope of this incident.
Both KV’s high total traffic volume and its role as a critical dependency for many customers amplify the impact of even small error rates. In all cases, once the changes were rolled back, errors returned to normal levels and did not persist.
Thinking about risks in building software
Before we dive into what we’re doing to significantly improve how we build, test, deploy and observe Workers KV going forward, we think there are lessons from the real world that can equally apply to how we improve the safety factor of the software we ship.
In traditional engineering and construction, there is an extremely common procedure known as a “JSEA”, or Job Safety and Environmental Analysis (sometimes just “JSA”). A JSEA is designed to help you iterate through a list of tasks, the potential hazards, and most importantly, the controls that will be applied to prevent those hazards from damaging equipment, injuring people, or worse.
One of the most critical concepts is the “hierarchy of controls” — that is, what controls should be applied to mitigate these hazards. In most practices, these are elimination, substitution, engineering, administration and personal protective equipment. Elimination and substitution are fairly self-explanatory: is there a different way to achieve this goal? Can we eliminate that task completely? Engineering and administration ask us whether there is additional engineering work, such as changing the placement of a panel, or using a horizontal boring machine to lay an underground pipe vs. opening up a trench that people can fall into.
The last and lowest on the hierarchy, is personal protective equipment (PPE). A hard hat can protect you from severe injury from something falling from above, but it’s a last resort, and it certainly isn’t guaranteed. In engineering practice, any hazard that only lists PPE as a mitigating factor is unsatisfactory: there must be additional controls in place. For example, instead of only wearing a hard hat, we should engineer the floor of scaffolding so that large objects (such as a wrench) cannot fall through in the first place. Further, if we require that all tools are attached to the wearer, then it significantly reduces the chance the tool can be dropped in the first place. These controls ensure that there are multiple degrees of mitigation — defense in depth — before your hard hat has to come into play.
Coming back to software, we can draw parallels between these controls: engineering can be likened to improving automation, gradual rollouts, and detailed metrics. Similarly, personal protective equipment can be likened to code review: useful, but code review cannot be the only thing protecting you from shipping bugs or untested code. Automation with linters, more robust testing, and new metrics are all vastly safer ways of shipping software.
As we spent time assessing where to improve our existing controls and how to put new controls in place to mitigate risks and improve the reliability (safety) of Workers KV, we took a similar approach: eliminating unnecessary changes, engineering more resilience into our codebase, automation, deployment tooling, and only then looking at human processes.
How we plan to get better
Cloudflare is undertaking a larger, more structured review of KV's observability tooling, release infrastructure and processes to mitigate not only the contributing factors to the incidents within this report, but recent incidents related to KV. Critically, we see tooling and automation as the most powerful mechanisms for preventing incidents, with process improvements designed to provide an additional layer of protection. Process improvements alone cannot be the only mitigation.
Specifically, we have identified and prioritized the below efforts as the most important next steps towards meeting our own availability SLOs, and (above all) make KV a service that customers building on Workers can rely on for storing configuration and service data in the hot path of their traffic:
Substantially improve the existing observability tooling for unhandled exceptions, both for internal teams and customers building on Workers. This is especially critical for high-volume services, where traditional logging alone can be too noisy (and not specific enough) to aid in tracking down these cases. The existing ongoing work to land this will be prioritized further. In the meantime, we have directly addressed the specific uncaught exception with KV's primary Worker script.
Improve the safety around the mutation of environmental variables in a Worker, which currently operate at "global" (per-isolate) scope, but can appear to be per-request. Mutating an environmental variable in request scope mutates the value for all requests transiting that same isolate (in a given location), which can be unexpected. Changes here will need to take backwards compatibility in mind.
Continue to expand KV’s test coverage to better address the above issues, in parallel with the aforementioned observability and tooling improvements, as an additional layer of defense. This includes allowing our test infrastructure to simulate traffic from any source data-center, which would have allowed us to more quickly reproduce the issue and identify a root cause.
Improvements to our release process, including how KV changes and releases are reviewed and approved, going forward. We will enforce a higher level of scrutiny for future changes, and where possible, reduce the number of changes deployed at once. This includes taking on new infrastructure dependencies, which will have a higher bar for both design and testing.
Additional logging improvements, including sampling, throughout our request handling process to improve troubleshooting & debugging. A significant amount of the challenge related to these incidents was due to the lack of logging around specific requests (especially non-2xx requests)
Review and, where applicable, improve alerting thresholds surrounding error rates. As mentioned previously in this report, sub-% error rates at a global scale can have severe negative impact on specific users and/or locations: ensuring that errors are caught and not lost in the noise is an ongoing effort.
Address maturity issues with our progressive deployment tooling for Workers, which is net-new (and will eventually be exposed to customers directly).
This is not an exhaustive list: we're continuing to expand on preventative measures associated with these and other incidents. These changes will not only improve KVs reliability, but other services across Cloudflare that KV relies on, or that rely on KV.
We recognize that KV hasn’t lived up to our customers’ expectations recently. Because we rely on KV so heavily internally, we’ve felt that pain first hand as well. The work to fix the issues that led to this cycle of incidents is already underway. That work will not only improve KV’s reliability but also improve the reliability of any software written on the Cloudflare Workers developer platform, whether by our customers or by ourselves.
We’re not going to bury the lede: we’re excited to launch a major update to our D1 database, with dramatic improvements to performance and scalability. Alpha users (which includes any Workers user) can create new databases using the new storage backend right now with the following command:
In the coming weeks, it’ll be the default experience for everyone, but we want to invite developers to start experimenting with the new version of D1 immediately. We’ll also be sharing more about how we built D1’s new storage subsystem, and how it benefits from Cloudflare’s distributed network, very soon.
Remind me: What’s D1?
D1 is Cloudflare’s native serverless database, which we launched into alpha in November last year. Developers have been building complex applications with Workers, KV, Durable Objects, and more recently, Queues & R2, but they’ve also been consistently asking us for one thing: a database they can query.
We also heard consistent feedback that it should be SQL-based, scale-to-zero, and (just like Workers itself), take a Region: Earth approach to replication. And so we took that feedback and set out to build D1, with SQLite giving us a familiar SQL dialect, robust query engine and one of the most battle tested code-bases to build on.
We shipped the first version of D1 as a “real” alpha: a way for us to develop in the open, gather feedback directly from developers, and better prioritize what matters. And living up to the alpha moniker, there were bugs, performance issues and a fairly narrow “happy path”.
Despite that, we’ve seen developers spin up thousands of databases, make billions of queries, popular ORMs like Drizzle and Kysely add support for D1 (already!), and Remix and Nuxt templates build directly around it, as well.
Turning it up to 11
If you’ve used D1 in its alpha state to date: forget everything you know. D1 is now substantially faster: up to 20x faster on the well-known Northwind Traders Demo, which we’ve just migrated to use our new storage backend:
Our new architecture also increases write performance: a simple benchmark inserting 1,000 rows (each row about 200 bytes wide) is approximately 6.8x faster than the previous version of D1.
Larger batches (10,000 rows at ~200 bytes wide) see an even larger improvement: between 10-11x, with the new storage backend’s latency also being significantly more consistent. We’ve also not yet started to optimize our overall write throughput, and so expect D1 to only get faster here.
With our new storage backend, we also want to make clear that D1 is not a toy, and we’re constantly benchmarking our performance against other serverless databases. A query against a 500,000 row key-value table (recognizing that benchmarks are inherently synthetic) sees D1 perform about 3.2x faster than a popular serverless Postgres provider:
We ran the Postgres queries several times to prime the page cache and then took the median query time, as measured by the server. We’ll continue to sharpen our performance edge as we go forward.
Developers with existing databases can import data into a new database backed by the storage engine by following the steps to export their database and then import it in our docs.
What did I miss?
We’ve also been working on a number of improvements to D1’s developer experience:
A new console interface that allows you to issue queries directly from the dashboard, making it easier to get started and/or issue one-shot queries.
Location Hints, allowing you to influence where your leader (which is responsible for writes) is located globally.
Although D1 is designed to work natively within Cloudflare Workers, we realize that there’s often a need to quickly issue one-shot queries via CLI or a web editor when prototyping or just exploring a database. On top of the support in wrangler for executing queries (and files), we’ve also introduced a console editor that allows you to issue queries, inspect tables, and even edit data on the fly:
JSON functions allow you to query JSON stored in TEXT columns in D1: allowing you to be flexible about what data is associated strictly with your relational database schema and what isn’t, whilst still being able to query all of it via SQL (before it reaches your app).
For example, suppose you store the last login timestamps as a JSON array in a login_history TEXT column: I can query (and extract) sub-objects or array items directly by providing a path to their key:
SELECT user_id, json_extract(login_history, '$.[0]') as latest_login FROM users
D1’s support for JSON functions is extremely flexible, and leverages the SQLite core that D1 builds on.
When you create a database for the first time with D1, we automatically infer the location based on where you’re currently connecting from. There are some cases, however, where you might want to influence that — maybe you’re traveling, or you have a distributed team that’s distinct from the region you expect the majority of your writes to come from.
D1’s support for Location Hints makes that easy:
# Automatically inferred based your location
$ wrangler d1 create user-prod-db --experimental-backend
# Indicate a preferred location to create your database
$ wrangler d1 create eu-users-db --location=weur --experimental-backend
Location Hints are also now available in the Cloudflare dashboard:
We’ve also published more documentation to help developers not only get started, but make use of D1’s advanced features. Expect D1’s documentation to continue to grow substantially over the coming months.
Not going to burn a hole in your wallet
We’ve had many, many developers ask us about how we’ll be pricing D1 since we announced the alpha, and we’re ready to share what it’s going to look like. We know it’s important to understand what something might cost before you start building on it, so you’re not surprised six months later.
In a nutshell:
We’re announcing pricing so that you can start to model how much D1 will cost for your use-case ahead of time. Final pricing may be subject to change, although we expect changes to be relatively minor.
We won’t be enabling billing until later this year, and we’ll notify existing D1 users via email ahead of that change. Until then, D1 will remain free to use.
D1 will include an always-free tier, included usage as part of our $5/mo Workers subscription, and charge based on reads, writes and storage.
If you’re already subscribed to Workers, then you don’t have to lift a finger: your existing subscription will have D1 usage included when we enable billing in the future.
Here’s a summary (we’re keeping it intentionally simple):
Importantly, when we enable global read replication, you won’t have to pay extra for it, nor will replication multiply your storage consumption. We think built-in, automatic replication is important, and we don’t think developers should have to pay multiplicative costs (replicas x storage fees) in order to make their database fast everywhere.
Beyond that, we wanted to ensure D1 took the best parts of serverless pricing — scale-to-zero and pay-for-what-you-use — so that you’re not trying to figure out how many CPUs and/or how much memory you need for your workload or writing scripts to scale down your infrastructure during quieter hours.
D1’s read pricing is based on the familiar concept of a read unit (per 4KB read), and a write unit (per 1KB written). A query that reads (scans) ~10,000 rows of 64 bytes each would consume 160 read units. Write a big 3KB row in a “blog_posts” table that has a lot of Markdown, and that’s three write units. And if you create indexes for your most popular queries to improve performance and reduce how much data those queries need to scan, you’ll also reduce how much we bill you. We think making the fast path more cost-efficient by default is the right approach.
Importantly: we’ll continue to take feedback on our pricing before we flip the switch.
Time Travel
We’re also introducing new backup functionality: point-in-time-recovery, and we’re calling this Time Travel, because it feels just like it. Time Travel allows you to restore your D1 database to any minute within the last 30 days, and will be built into D1 databasesusing our new storage system. We expect to turn on Time Travel for new D1 databases in the very near future.
What makes Time Travel really powerful is that you no longer need to panic and wonder “oh wait, did I take a backup before I made this major change?!” — because we do it for you. We retain a stream of all changes to your database (the Write-Ahead Log), allowing us to restore your database to a point in time by replaying those changes in sequence up until that point.
Here’s an example (subject to some minor API changes):
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
And although the idea of point-in-time recovery is not new, it’s often a paid add-on, if it is even available at all. Realizing you should have had it turned on after you’ve deleted or otherwise made a mistake means it’s often too late.
For example, imagine if I made the classic mistake of forgetting a WHERE on an UPDATE statement:
-- Don't do this at home
UPDATE users SET email = '[email protected]' -- missing: WHERE id = "abc123"
Without Time Travel, I’d have to hope that either a scheduled backup ran recently, or that I remembered to make a manual backup just prior. With Time Travel, I can restore to a point a minute or so before that mistake (and hopefully learn a lesson for next time).
We’re also exploring features that can surface larger changes to your database state, including making it easier to identify schema changes, the number of tables, large deltas in data stored and even specific queries (via transaction IDs) — to help you better understand exactly what point in time to restore your database to.
On the roadmap
So what’s next for D1?
Open beta: we’re ensuring we’ve observed our new storage subsystem under load (and real-world usage) prior to making it the default for all `d1 create` commands. We hold a high bar for durability and availability, even for a “beta”, and we also recognize that access to backups (Time Travel) is important for folks to trust a new database. Keep an eye on the Cloudflare blog in the coming weeks for more news here!
Bigger databases: we know this is a big ask from many, and we’re extremely close. Developers on the Workers Paid plan will get access to 1GB databases in the very near future, and we’ll be continuing to ramp up the maximum per-database size over time.
Metrics & observability: you’ll be able to inspect overall query volume by database, failing queries, storage consumed and read/write units via both the D1 dashboard and our GraphQL API, so that it’s easier to debug issues and track spend.
Automatic read replication: our new storage subsystem is built with replication in mind, and we’re working on ensuring our replication layer is both fast & reliable before we roll it out to developers. Read replication is not only designed to improve query latency by storing copies — replicas — of your data in multiple locations, close to your users, but will also allow us to scale out D1 databases horizontally for those with larger workloads.
It’s hard to imagine life without our smartphones. Whereas computers were mostly fixed and often shared, smartphones meant that every individual on the planet became a permanent, mobile node on the Internet — with some 6.5B smartphones on the planet today.
While that represents an explosion of devices on the Internet, it will be dwarfed by the next stage of the Internet’s evolution: connecting devices to give them intelligence. Already, Internet of Things (IoT) devices represent somewhere in the order of double the number of smartphones connected to the Internet today — and unlike smartphones, this number is expected to continue to grow tremendously, since they aren’t bound to the number of humans that can carry them.
But the exponential growth in devices has brought with it an explosion in risk. We’ve been defending against DDoS attacks from Internet of Things (IoT) driven botnets like Mirai and Meris for years now. They keep growing, because securing IoT devices still remains challenging, and manufacturers are often not incentivized to secure them. This has driven NIST (the U.S. National Institute of Standards and Technology) to actively define requirements to address the (lack of) IoT device security, and the EU isn’t far behind.
It’s also the type of problem that Cloudflare solves best.
Today, we’re excited to announce our Internet of Things platform: with the goal to provide a single pane-of-glass view over your IoT devices, provision connectivity for new devices, and critically, secure every device from the moment it powers on.
Not just lightbulbs
It’s common to immediately think of lightbulbs or simple motion sensors when you read “IoT”, but that’s because we often don’t consider many of the devices we interact with on a daily basis as an IoT device.
Think about:
Almost every payment terminal
Any modern car with an infotainment or GPS system
Millions of industrial devices that power — and are critical to — logistics services, industrial processes, and manufacturing businesses
You especially may not realize that nearly every one of these devices has a SIM card, and connects over a cellular network.
Cellular connectivity has become increasingly ubiquitous, and if the device can connect independently of Wi-Fi network configuration (and work out of the box), you’ve immediately avoided a whole class of operational support challenges. If you’ve just read our earlier announcement about the Zero Trust SIM, you’re probably already seeing where we’re headed.
Hundreds of thousands of IoT devices already securely connect to our network today using mutual TLS and our API Shield product. Major device manufacturers use Workers and our Developer Platform to offload authentication, compute and most importantly, reduce the compute needed on the device itself. Cloudflare Pub/Sub, our programmable, MQTT-based messaging service, is yet another building block.
But we realized there were still a few missing pieces: device management, analytics and anomaly detection. There are a lot of “IoT SIM” providers out there, but the clear majority are focused on shipping SIM cards at scale (great!) and less so on the security side (not so great) or the developer side (also not great). Customers have been telling us that they wanted a way to easily secure their IoT devices, just as they secure their employees with our Zero Trust platform.
Cloudflare’s IoT Platform will build in support for provisioning cellular connectivity at scale: we’ll support ordering, provisioning and managing cellular connectivity for your devices. Every packet that leaves each IoT device can be inspected, approved or rejected by policies you create before it reaches the Internet, your cloud infrastructure, or your other devices.
Emerging standards like IoT SAFE will also allow us to use the SIM card as a root-of-trust, storing device secrets (and API keys) securely on the device, whilst raising the bar to compromise.
This also doesn’t mean we’re leaving the world of mutual TLS behind: we understand that not every device makes sense to connect over solely over a cellular network, be it due to per-device costs, lack of coverage, or the need to support an existing deployment that can’t just be re-deployed.
Bringing Zero Trust security to IoT
Unlike humans, who need to be able to access a potentially unbounded number of destinations (websites), the endpoints that an IoT device needs to speak to are typically far more bounded. But in practice, there are often few controls in place (or available) to ensure that a device only speaks to your API backend, your storage bucket, and/or your telemetry endpoint.
Our Zero Trust platform, however, has a solution for this: Cloudflare Gateway. You can create DNS, network or HTTP policies, and allow or deny traffic based not only on the source or destination, but on richer identity- and location- based controls. It seemed obvious that we could bring these same capabilities to IoT devices, and allow developers to better restrict and control what endpoints their devices talk to (so they don’t become part of a botnet).
At the same time, we also identified ways to extend Gateway to be aware of IoT device specifics. For example, imagine you’ve provisioned 5,000 IoT devices, all connected over cellular directly into Cloudflare’s network. You can then choose to lock these devices to a specific geography if there’s no need for them to “travel”; ensure they can only speak to your API backend and/or metrics provider; and even ensure that if the SIM is lifted from the device it no longer functions by locking it to the IMEI (the serial of the modem).
Building these controls at the network layer raises the bar on IoT device security and reduces the risk that your fleet of devices becomes the tool of a bad actor.
Get the compute off the device
We’ve talked a lot about security, but what about compute and storage? A device can be extremely secure if it doesn’t have to do anything or communicate anywhere, but clearly that’s not practical.
Simultaneously, doing non-trivial amounts of compute “on-device” has a number of major challenges:
It requires a more powerful (and thus, more expensive) device. Moderately powerful (e.g. ARMv8-based) devices with a few gigabytes of RAM might be getting cheaper, but they’re always going to be more expensive than a lower-powered device, and that adds up quickly at IoT-scale.
You can’t guarantee (or expect) that your device fleet is homogenous: the devices you deployed three years ago can easily be several times slower than what you’re deploying today. Do you leave those devices behind?
The more business logic you have on the device, the greater the operational and deployment risk. Change management becomes critical, and the risk of “bricking” — rendering a device non-functional in a way that you can’t fix it remotely — is never zero. It becomes harder to iterate and add new features when you’re deploying to a device on the other side of the world.
Security continues to be a concern: if your device needs to talk to external APIs, you have to ensure you have explicitly scoped the credentials they use to avoid them being pulled from the device and used in a way you don’t expect.
We’ve heard other platforms talk about “edge compute”, but in practice they either mean “run the compute on the device” or “in a small handful of cloud regions” (introducing latency) — neither of which fully addresses the problems highlighted above.
Instead, by enabling secure access to Cloudflare Workers for compute, Analytics Engine for device telemetry, D1 as a SQL database, and Pub/Sub for massively scalable messaging — IoT developers can both keep the compute off the device, but still keep it close to the device thanks to our global network (275+ cities and counting).
On top of that, developers can use modern tooling like Wrangler to both iterate more rapidly and deploy software more safely, avoiding the risk of bricking or otherwise breaking part of your IoT fleet.
Where do I sign up?
You can register your interest in our IoT Platform today: we’ll be reaching out over the coming weeks to better understand the problems teams are facing and working to get our closed beta into the hands of customers in the coming months. We’re especially interested in teams who are in the throes of figuring out how to deploy a new set of IoT devices and/or expand an existing fleet, no matter the use-case.
In the meantime, you can start building on API Shield and Pub/Sub (MQTT) if you need to start securing IoT devices today.
The humble cell phone is now a critical tool in the modern workplace; even more so as the modern workplace has shifted out of the office. Given the billions of mobile devices on the planet — they now outnumber PCs by an order of magnitude — it should come as no surprise that they have become the threat vector of choice for those attempting to break through corporate defenses.
The problem you face in defending against such attacks is that for most Zero Trust solutions, mobile is often a second-class citizen. Those solutions are typically hard to install and manage. And they only work at the software layer, such as with WARP, the mobile (and desktop) apps that connect devices directly into our Zero Trust network. And all this is before you add in the further complication of Bring Your Own Device (BYOD) that more employees are using — you’re trying to deploy Zero Trust on a device that doesn’t belong to the company.
It’s a tricky — and increasingly critical — problem to solve. But it’s also a problem which we think we can help with.
What if employers could offer their employees a deal: we’ll cover your monthly data costs if you agree to let us direct your work-related traffic through a network that has Zero Trust protections built right in? And what’s more, we’ll make it super easy to install — in fact, to take advantage of it, all you need to do is scan a QR code — which can be embedded in an employee’s onboarding material — from your phone’s camera.
Well, we’d like to introduce you to the Cloudflare SIM: the world’s first Zero Trust SIM.
In true Cloudflare fashion, we think that combining the software layer and the network layer enables better security, performance, and reliability. By targeting a foundational piece of technology that underpins every mobile device — the (not so) humble SIM card — we’re aiming to bring an unprecedented level of security (and performance) to the mobile world.
The threat is increasingly mobile
When we say that mobile is the new threat vector, we’re not talking in the abstract. Last month, Cloudflare was one of 130 companies that were targeted by a sophisticated phishing attack. Mobile was the cornerstone of the attack — employees were initially reached by SMS, and the attack relied heavily on compromising 2FA codes.
So far as we’re aware, we were the only company to not be compromised.
A big part of that was because we’re continuously pushing multi-layered Zero Trust defenses. Given how foundational mobile is to how companies operate today, we’ve been working hard to further shore up Zero Trust defenses in this sphere. And this is how we think about Zero Trust SIM: another layer of defense at a different level of the stack, making life even harder for those who are trying to penetrate your organization. With the Zero Trust SIM, you get the benefits of:
Preventing employees from visiting phishing and malware sites: DNS requests leaving the device can automatically and implicitly use Cloudflare Gateway for DNS filtering.
Mitigating common SIM attacks: an eSIM-first approach allows us to prevent SIM-swapping or cloning attacks, and by locking SIMs to individual employee devices, bring the same protections to physical SIMs.
Enabling secure, identity-based private connectivity to cloud services, on-premise infrastructure and even other devices (think: fleets of IoT devices) via Magic WAN. Each SIM can be strongly tied to a specific employee, and treated as an identity signal in conjunction with other device posture signals already supported by WARP.
By integrating Cloudflare’s security capabilities at the SIM-level, teams can better secure their fleets of mobile devices, especially in a world where BYOD is the norm and no longer the exception.
Zero Trust works better when it’s software + On-ramps
Beyond all the security benefits that we get for mobile devices, the Zero Trust SIM transforms mobile into another on-ramp pillar into the Cloudflare One platform.
Cloudflare One presents a single, unified control plane: allowing organizations to apply security controls across all the traffic coming to, and leaving from, their networks, devices and infrastructure. It’s the same with logging: you want one place to get your logs, and one location for all of your security analysis. With the Cloudflare SIM, mobile is now treated as just one more way that traffic gets passed around your corporate network.
Working at the on-ramp rather than the software level has another big benefit — it grants the flexibility to allow devices to reach services not on the Internet, including cloud infrastructure, data centers and branch offices connected into Magic WAN, our Network-as-a-Service platform. In fact, under the covers, we’re using the same software networking foundations that our customers use to build out the connectivity layer behind the Zero Trust SIM. This will also allow us to support new capabilities like Geneve, a new network tunneling protocol, further expanding how customers can connect their infrastructure into Cloudflare One.
We’re following efforts like IoT SAFE (and parallel, non-IoT standards) that enable SIM cards to be used as a root-of-trust, which will enable a stronger association between the Zero Trust SIM, employee identity, and the potential to act as a trusted hardware token.
Get Zero Trust up and running on mobile immediately (and easily)
Of course, every Zero Trust solutions provider promises protection for mobile. But especially in the case of BYOD, getting employees up and running can be tough. To get a device onboarded, there is a deep tour of the Settings app of your phone: accepting profiles, trusting certificates, and (in most cases) a requirement for a mature mobile device management (MDM) solution.
It’s a pain to install.
Now, we’re not advocating the elimination of the client software on the phone any more than we would be on the PC. More layers of defense is always better than fewer. And it remains necessary to secure Wi-Fi connections that are established on the phone. But a big advantage is that the Cloudflare SIM gets employees protected behind Cloudflare’s Zero Trust platform immediately for all mobile traffic.
It’s not just the on-device installation we wanted to simplify, however. It’s companies’ IT supply chains, as well.
One of the traditional challenges with SIM cards is that they have been, until recently, a physical card. A card that you have to mail to employees (a supply chain risk in modern times), that can be lost, stolen, and that can still fail. With a distributed workforce, all of this is made even harder. We know that whilst security is critical, security that is hard to deploy tends to be deployed haphazardly, ad-hoc, and often, not at all.
But in recent years, nearly every modern phone shipped today has an eSIM — or more precisely, an eUICC (Embedded Universal Integrated Circuit Card) — that can be re-programmed dynamically. This is a huge advancement, for two major reasons:
You avoid all the logistical issues of a physical SIM (mailing them; supply chain risk; getting users to install them!)
You can deploy them automatically, either via QR codes, Mobile Device Management (MDM) features built into mobile devices today, or via an app (for example, our WARP mobile app).
We’re also exploring introducing physical SIMs (just like the ones above): although we believe eSIMs are the future, especially given their deployment & security advantages, we understand that the future is not always evenly distributed. We’ll be working to make sure that the physical SIMs we ship are as secure as possible, and we’ll be sharing more of how this works in the coming months.
Privacy and transparency for employees
Of course, more and more of the devices that employees use for work are their own. And while employers want to make sure their corporate resources are secure, employees also have privacy concerns when work and private life are blended on the same device. You don’t want your boss knowing that you’re swiping on Tinder.
We want to be thoughtful about how we approach this, from the perspective of both sides. We have sophisticated logging set up as part of Cloudflare One, and this will extend to Cloudflare SIM. Today, Cloudflare One can be explicitly configured to log only the resources it blocks — the threats it’s protecting employees from — without logging every domain visited beyond that. We’re working to make this as obvious and transparent as possible to both employers and employees so that, in true Cloudflare fashion, security does not have to compromise privacy.
What’s next?
Like any product at Cloudflare, we’re testing this on ourselves first (or “dogfooding”, to those in the know). Given the services we provide for over 30% of the Fortune 1000, we continue to observe, and be the target of, increasingly sophisticated cybersecurity attacks. We believe that running the service first is an important step in ensuring we make the Zero Trust SIM both secure and as easy to deploy and manage across thousands of employees as possible.
We’re also bringing the Zero Trust SIM to the Internet of Things: almost every vehicle shipped today has an expectation of cellular connectivity; an increasing number of payment terminals have a SIM card; and a growing number of industrial devices across manufacturing and logistics. IoT device security is under increasing levels of scrutiny, and ensuring that the only way a device can connect is a secure one — protected by Cloudflare’s Zero Trust capabilities — can directly prevent devices from becoming part of the next big DDoS botnet.
We’ll be rolling the Zero Trust SIM out to customers on a regional basis as we build our regional connectivity across the globe (if you’re an operator: reach out). We’d especially love to talk to organizations who don’t have an existing mobile device solution in place at all, or who are struggling to make things work today. If you’re interested, then sign up here.
One of the underlying questions that drives Platform Week is “how do we enable developers to build full stack applications on Cloudflare?”. With Workers as a serverless environment for easily deploying distributed-by-default applications, KV and Durable Objects for caching and coordination, and R2 as our zero-egress cost object store, we’ve continued to discuss what else we need to build to help developers both build new apps and/or bring existing ones over to Cloudflare’s Developer Platform.
With that in mind, we’re excited to announce the private beta of Cloudflare Pub/Sub, a programmable message bus built on the ubiquitous and industry-standard MQTT protocol supported by tens of millions of existing devices today.
In a nutshell, Pub/Sub allows you to:
Publish event, telemetry or sensor data from any MQTT capable client (and in the future, other client-facing protocols)
Write code that can filter, aggregate and/or modify messages as they’re published to the broker using Cloudflare Workers, and before they’re distributed to subscribers, without the need to ferry messages to a single “cloud region”
Push events from applications in other clouds, or from on-prem, with Pub/Sub acting as a programmable event router or a hook into persistent data storage (such as R2 or KV)
Move logic out of the client, where it can be hard (or risky!) to push updates, or where running code on devices raises the materials cost (CPU, memory), while still keeping latency as low as possible (your code runs in every location).
And there’s likely a long list of things we haven’t even predicted yet. We’ve seen developers build incredible things on top of Cloudflare Workers, and we’re excited to see what they build with the power of a programmable message bus like Pub/Sub, too.
Why, and what is, MQTT?
If you haven’t heard of MQTT before, you might be surprised to know that it’s one of the most pervasive “messaging protocols” deployed today. There are tens of millions (at least!) of devices that speak MQTT today, from connected payment terminals through to autonomous vehicles, cell phones, and even video games. Sensor readings, telemetry, financial transactions and/or mobile notifications & messages are all common use-cases for MQTT, and the flexibility of the protocol allows developers to make trade-offs around reliability, topic hierarchy and persistence specific to their use-case.
We chose MQTT as the foundation for Cloudflare Pub/Sub as we believe in building on top of open, accessible standards, as we did when we chose the Service Worker API as the foundation for Workers, and with our recently announced participation in the Winter Community Group around server-side runtime APIs. We also wanted to enable existing clients an easy path to benefit from Cloudflare’s scale and programmability, and ensure that developers have a rich ecosystem of client libraries in languages they’re familiar with today.
Beyond that, however, we also think MQTT meets the needs of a modern “publish-subscribe” messaging service. It has flexible delivery guarantees, TLS for transport encryption (no bespoke crypto!), a scalable topic creation and subscription model, extensible per-message metadata, and importantly, it provides a well-defined specification with clear error messages.
With that in mind, we expect to support many more “on-ramps” to Pub/Sub: a lot of the best parts of MQTT can be abstracted away from clients who might want to talk to us over HTTP or WebSockets.
Building Blocks
Given the ability to write code that acts on every message published to a Pub/Sub Broker, what does it look like in practice?
Here’s a simple-but-illustrative example of handling Pub/Sub messages directly in a Worker. We have clients (in this case, payment terminals) reporting back transaction data, and we want to capture the number of transactions processed in each region, so we can track transaction volumes over time.
Specifically, we:
Filter on a specific topic prefix for messages we care about
Parse the message for a specific key:value pair as a metric
Write that metric directly into Workers Analytics Engine, our new serverless time-series analytics service, so we can directly query it with GraphQL.
This saves us having to stand up and maintain an external metrics service, configure another cloud service, or think about how it will scale: we can do it all directly on Cloudflare.
# language: TypeScript
async function pubsub(
messages: Array<PubSubMessage>,
env: any,
ctx: ExecutionContext
): Promise<Array<PubSubMessage>> {
for (let msg of messages) {
// Extract a value from the payload and write it to Analytics Engine
// In this example, a transactionsProcessed counter that our clients are sending
// back to us.
if (msg.topic.startsWith(“/transactions/”)) {
// This is non-blocking, and doesn’t hold up our message
// processing.
env.TELEMETRY.writeDataPoint({
// We label this metric so that we can query against these labels
labels: [`${msg.broker}.${msg.namespace}`, msg.payload.region, msg.payload.merchantId],
metrics: [msg.payload.transactionsProcessed ?? 0]
});
}
}
// Return our messages back to the Broker
return messages;
}
const worker = {
async fetch(req: Request, env: any, ctx: ExecutionContext) {
// Critical: you must validate the incoming request is from your Broker
// In the future, Workers will be able to do this on your behalf for Workers
// in the same account as your Pub/Sub Broker.
if (await isValidBrokerRequest(req)) {
// Parse the incoming PubSub messages
let incomingMessages: Array<PubSubMessage> = await req.json();
// Pass the message to our pubsub handler, and capture the returned
// messages
let outgoingMessages = await pubsub(incomingMessages, env, ctx);
// Re-serialize the messages and return a HTTP 200 so our Broker
// knows we’ve successfully handled them
return new Response(JSON.stringify(outgoingMessages), { status: 200 });
}
return new Response("not a valid Broker request", { status: 403 });
},
};
export default worker;
We can then query these metrics directly using a familiar language: SQL. Our query takes the metrics we’ve written and gives us a breakdown of transactions processed by our payment devices, grouped by merchant (and again, all on Cloudflare):
SELECT
label_2 as region,
label_3 as merchantId,
sum(metric_1) as total_transactions
FROM TELEMETRY
WHERE
metric_1 > 0
AND timestamp >= now() - 604800
GROUP BY
region,
merchantId
ORDER BY
total_transactions DESC
LIMIT 10
You could replace or augment the calls to Analytics Engine with any number of examples:
Asynchronously writing messages (using ctx.waitUntil) on specific topics to our R2 object storage without blocking message delivery
Rewriting messages on-the-fly with data populated from KV, before the message is pushed to subscribers
Aggregate messages based on their payload and HTTP POST them to legacy infrastructure hosted outside of Cloudflare
Pub/Sub gives you a way to get data into Cloudflare’s network, filter, aggregate and/or mutate it, and push it back out to subscribers — whether there’s 10, 1,000 or 10,000 of them listening on that topic.
Where are we headed?
As we often like to say: we’re just getting started. The private beta for Pub/Sub is just the beginning of our journey, and we have a long list of capabilities we’re already working on.
Critically, one of our priorities is to cover as much of the MQTT v5.0 specification as we can, so that customers can migrate existing deployments and have it “just work”. Useful capabilities like shared subscriptions that allow you to load-balance messages across many subscribers; wildcard subscriptions (both single- and multi-tier) for aggregation use cases, stronger delivery guarantees (QoS), and support for additional authentication modes (specifically, Mutual TLS) are just a few of the things we’re working on.
Beyond that, we’re focused on making sure Pub/Sub’s developer experience is the best it can be, and during the beta we’ll be:
Supporting a new set of “pubsub” sub-commands in Wrangler, our developer CLI, so that getting started is as low-friction as possible
Building ‘native’ bindings (similar to how Workers KV operates) that allow you to publish messages and subscribe to topics directly from Worker code, regardless of whether the message originates from (or is destined for) a client beyond Cloudflare
Exploring more ways to publish & subscribe from non-MQTT based clients, including HTTP requests and WebSockets, so that integrating existing code is even easier.
We’re also aware that pricing is a huge part of developer experience, and are committed to ensuring that there is an accessible and flexible free tier. We want to enable developers to experiment, prototype and solve problems we haven’t thought of yet. We’ll be sharing more on pricing during the course of the beta.
Getting Started
If you want to start using Pub/Sub, sign up for the private beta: we plan to start enabling access within the next month. We’re looking forward to collecting feedback from developers and seeing what folks start to build.
In the meantime, review the brand-new Pub/Sub developer documentation to understand how Pub/Sub works under the hood, the MQTT protocol, and how it integrates with Cloudflare Workers.
How do you know the code your web browser downloads when visiting a website is the code the website intended you to run? In contrast to a mobile app downloaded from a trusted app store, the web doesn’t provide the same degree of assurance that the code hasn’t been tampered with. Today, we’re excited to be partnering with WhatsApp to provide a system that assures users that the code run when they visit WhatsApp on the web is the code that WhatsApp intended.
With WhatsApp usage in the browser growing, and the increasing number of at-risk users — including journalists, activists, and human rights defenders — WhatsApp wanted to take steps to provide assurances to browser-based users. They approached us to help dramatically raise the bar for third-parties looking to compromise or otherwise tamper with the code responsible for end-to-end encryption of messages between WhatsApp users.
So how will this work? Cloudflare holds a hash of the code that WhatsApp users should be running. When users run WhatsApp in their browser, the WhatsApp Code Verify extension compares a hash of that code that is executing in their browser with the hash that Cloudflare has — enabling them to easily see whether the code that is executing is the code that should be.
The idea itself — comparing hashes to detect tampering or even corrupted files — isn’t new, but automating it, deploying it at scale, and making sure it “just works” for WhatsApp users is. Given the reach of WhatsApp and the implicit trust put into Cloudflare, we want to provide more detail on how this system actually works from a technical perspective.
Before we dive in, there’s one important thing to explicitly note: Cloudflare is providing a trusted audit endpoint to support Code Verify. Messages, chats or other traffic between WhatsApp users are never sent to Cloudflare; those stay private and end-to-end encrypted. Messages or media do not traverse Cloudflare’s network as part of this system, an important property from Cloudflare’s perspective in our role as a trusted third party.
Making verification easier
Hark back to 2003: Fedora, a popular Linux distribution based on Red Hat, has just been launched. You’re keen to download it, but want to make sure you have the “real” Fedora, and that the download isn’t a “fake” version that siphons off your passwords or logs your keystrokes. You head to the download page, kick off the download, and see an MD5 hash (considered secure at the time) next to the download. After the download is complete, you run md5 fedora-download.iso and compare the hash output to the hash on the page. They match, life is good, and you proceed to installing Fedora onto your machine.
But hold on a second: if the same website providing the download is also providing the hash, couldn’t a malicious actor replace both the download and the hash with their own values? The md5 check we ran above would still pass, but there’s no guarantee that we have the “real” (untampered) version of the software we intended to download.
Hosting the hash on the same server as the software is still common in 2022.
There are other approaches that attempt to improve upon this — providing signed signatures that users can verify were signed with “well known” public keys hosted elsewhere. Hosting those signatures (or “hashes”) with a trusted third party dramatically raises the bar when it comes to tampering, but now we require the user to know who to trust, and require them to learn tools like GnuPG. That doesn’t help us trust and verify software at the scale of the modern Internet.
This is where the Code Verify extension and Cloudflare come in. The Code Verify extension, published by Meta Open Source, automates this: locally computing the cryptographic hash of the libraries used by WhatsApp Web and comparing that hash to one from a trusted third-party source (Cloudflare, in this case).
We’ve illustrated this to make how it works a little clearer, showing how each of the three parties — the user, WhatsApp and Cloudflare — interact with each other.
Broken down, there are four major steps to verifying the code hasn’t been tampered with:
WhatsApp publishes the latest version of their JavaScript libraries to their servers, and the corresponding hash for that version to Cloudflare’s audit endpoint.
A WhatsApp web client fetches the latest libraries from WhatsApp.
The Code Verify browser extension subsequently fetches the hash for that version from Cloudflare over a separate, secure connection.
Code Verify compares the “known good” hash from Cloudflare with the hash of the libraries it locally computed.
If the hashes match, as they should under almost any circumstance, the code is “verified” from the perspective of the extension. If the hashes don’t match, it indicates that the code running on the user’s browser is different from the code WhatsApp intended to run on all its user’s browsers.
Security needs to be convenient
It’s this process — and the fact that is automated on behalf of the user — that helps provide transparency in a scalable way. If users had to manually fetch, compute and compare the hashes themselves, detecting tampering would only be for the small fraction of technical users. For a service as large as WhatsApp, that wouldn’t have been a particularly accessible or user-friendly approach.
This approach also has parallels to a number of technologies in use today. One of them is Subresource Integrity in web browsers: when you fetch a third-party asset (such as a script or stylesheet), the browser validates that the returned asset matches the hash described. If it doesn’t, it refuses to load that asset, preventing potentially compromised scripts from siphoning off user data. Another is Certificate Transparency and the related Binary Transparency projects. Both of these provide publicly auditable transparency for critical assets, including WebPKI certificates and other binary blobs. The system described in this post doesn’t scale to arbitrary assets – yet – but we are exploring ways in which we could extend this offering for something more general and usable like Binary Transparency.
Our collaboration with the team at WhatsApp is just the beginning of the work we’re doing to help improve privacy and security on the web. We’re aiming to help other organizations verify the code delivered to users is the code they’re meant to be running. Protecting Internet users at scale and enabling privacy are core tenets of what we do at Cloudflare, and we look forward to continuing this work throughout 2022.
For every successful technology, there is a moment where its time comes. Something happens, usually external, to catalyze it — shifting it from being a good idea with promise, to a reality that we can’t imagine living without. Perhaps the best recent example was what happened to the cloud as a result of the introduction of the iPhone in 2007. Smartphones created a huge addressable market for small developers; and even big developers found their customer base could explode in a way that they couldn’t handle without access to public cloud infrastructure. Both wanted to be able to focus on building amazing applications, without having to worry about what lay underneath.
Last year, during the outbreak of COVID-19, a similar moment happened to real time communication. Being able to communicate is the lifeblood of any organization. Before 2020, much of it happened in meeting rooms in offices all around the world. But in March last year — that changed dramatically. Those meeting rooms suddenly were emptied. Fast-forward 18 months, and that massive shift in how we work has persisted.
While, undoubtedly, many organizations would not have been able to get by without the likes of Slack, Zoom and Teams as real time collaboration tools, we think today’s iteration of communication tools is just the tip of the iceberg. Looking around, it’s hard to escape the feeling there is going to be an explosion in innovation that is about to take place to enable organizations to communicate in a remote, or at least hybrid, world.
With this in mind, today we’re excited to be introducing Cloudflare’s Real Time Communications platform. This is a new suite of products designed to help you build the next generation of real-time, interactive applications. Whether it’s one-to-one video calling, group audio or video-conferencing, the demand for real-time communications only continues to grow.
Running a reliable and scalable real-time communications platform requires building out a large-scale network. You need to get your network edge within milliseconds of your users in multiple geographies to make sure everyone can always connect with low latency, low packet loss and low jitter. A backbone to route around Internet traffic jams. Infrastructure that can efficiently scale to serve thousands of participants at once. And then you need to deploy media servers, write business logic, manage multiple client platforms, and keep it all running smoothly. We think we can help with this.
Launching today, you will be able to leverage Cloudflare’s global edge network to improve connectivity for any existing WebRTC-based video and audio application, with what we’re calling “WebRTC Components”. This includes scaling to (tens of) thousands of participants, leveraging our DDoS mitigation to protect your services from attacks, and enforce IP and ASN-based access policies in just a few clicks.
How Real Time is “Real Time”?
Real-time typically refers to communication that happens in under 500ms: that is, as fast as packets can traverse the fibre optic networks that connect the world together. In 2021, most real-time audio and video applications use WebRTC, a set of open standards and browser APIs that define how to connect, secure, and transfer both media and data over UDP. It was designed to bring better, more flexible bi-directional communication when compared to the primary browser-based communication protocol we rely on today, HTTP. And because WebRTC is supported in the browser, it means that users don’t need custom clients, nor do developers need to build them: all they need is a browser.
Importantly, we’ve seen the need for reliable, real-time communication across time-zones and geographies increase dramatically, as organizations change the way they work (yes, including us).
So where is real-time important in practice?
One-to-one calls (think FaceTime). We’re used to almost instantaneous communication over traditional telephone lines, and there’s no reason for us to head backwards.
Group calling and conferencing (Zoom or Google Meet), where even just a few seconds of delay results in everyone talking over each other.
Social video, gaming and sports. You don’t want to be 10 seconds behind the action or miss that key moment in a game because the stream dropped a few frames or decided to buffer.
Interactive applications: from 3D modeling in the browser, Augmented Reality on your phone, and even game streaming need to be in real-time.
We believe that we’ve only collectively scratched the surface when it comes to real-time applications — and part of that is because scaling real-time applications to even thousands of users requires new infrastructure paradigms and demands more from the network than traditional HTTP-based communication.
Enter: WebRTC Components
Today, we’re launching our closed beta WebRTC Components, allowing teams running centralized WebRTC TURN servers to offload it to Cloudflare’s distributed, global network and improve reliability, scale to more users, and spend less time managing infrastructure.
TURN, or Traversal Using Relays Around NAT (Network Address Translation), was designed to navigate the practical shortcomings of WebRTC’s peer-to-peer origins. WebRTC was (and is!) a peer-to-peer technology, but in practice, establishing reliable peer-to-peer connections remains hard due to Carrier-Grade NAT, corporate NATs and firewalls. Further, each peer is limited by its own network connectivity — in a traditional peer-to-peer mesh, participants can quickly find their network connections saturated because they have to receive data from every other peer. In a mixed environment with different devices (mobile, desktops), networks (high-latency 3G through to fast fiber), scaling to more than a handful of peers becomes extremely challenging.
Running a TURN service at the edge instead of your own infrastructure gets you a better connection. Cloudflare operates an anycast network spanning 250+ cities, meaning we’re very close to wherever your users are. This means that when users connect to Cloudflare’s TURN service, they get a really good connection to the Cloudflare network. Once it’s on there, we leverage our network and private backbone to get you superior connectivity, all the way back to the other user on the call.
But even better: stop worrying about scale. WebRTC infrastructure is notoriously difficult to scale: you need to make sure you have the right capacity in the right location. Cloudflare’s TURN service scales automatically and if you want more endpoints they’re just an API call away.
Of course WebRTC Components is built on the Cloudflare network, benefiting from the DDoS protection that it’s 100 Tbps network offers. From now on deploying scalable, secure, production-grade WebRTC relays globally is only a couple of API calls away.
A Developer First Real-Time Platform
But, as we like to say at Cloudflare: we’re just getting started. Managed, scalable TURN infrastructure is a critical building block to building real-time services for one-to-one and small group calling, especially for teams who have been managing their own infrastructure, but things become rapidly more complex when you start adding more participants.
Whether that’s managing the quality of the streams (“tracks”, in WebRTC parlance) each client is sending and receiving to keep call quality up, permissions systems to determine who can speak or broadcast in large-scale events, and/or building signalling infrastructure with support chat and interactivity on top of the media experience, one thing is clear: it there’s a lot to bite off.
With that in mind, here’s a sneak peek at where we’re headed:
Developer-first APIs that abstract the need to manage and configure low-level infrastructure, authentication, authorization and participant permissions. Think in terms of your participants, rooms and channels, without having to learn the intricacies of ICE, peer connections and media tracks.
Integration with Cloudflare for Teams to support organizational access policies: great for when your company town hall meetings are now conducted remotely.
Making it easy to connect any input and output source, including broadcasting to traditional HTTP streaming clients and recording for on-demand playback with Stream Live, and ingesting from RTMP sources with Stream Connect, or future protocols such as WHIP.
Embedded serverless capabilities via Cloudflare Workers, from triggering Workers on participant events (e.g. join, leave) through to building stateful chat and collaboration tools with Durable Objects and WebSockets.
… and this is just the beginning.
We’re also looking for ambitious engineers who want to play a role in building our RTC platform. If you’re an engineer interested in building the next generation of real-time, interactive applications, joinus!
If you’re interested in working with us to help connect more of the world together, and are struggling with scaling your existing 1-to-1 real-time video & audio platform beyond a few hundred or thousand concurrent users, sign up for the closed beta of WebRTC Components. We’re especially interested in partnering with teams at the beginning of their real-time journeys and who are keen to iterate closely with us.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.