Post Syndicated from Sekar Srinivasan original https://aws.amazon.com/blogs/big-data/how-zoom-implemented-streaming-log-ingestion-and-efficient-gdpr-deletes-using-apache-hudi-on-amazon-emr/
In today’s digital age, logging is a critical aspect of application development and management, but efficiently managing logs while complying with data protection regulations can be a significant challenge. Zoom, in collaboration with the AWS Data Lab team, developed an innovative architecture to overcome these challenges and streamline their logging and record deletion processes. In this post, we explore the architecture and the benefits it provides for Zoom and its users.
Application log challenges: Data management and compliance
Application logs are an essential component of any application; they provide valuable information about the usage and performance of the system. These logs are used for a variety of purposes, such as debugging, auditing, performance monitoring, business intelligence, system maintenance, and security. However, although these application logs are necessary for maintaining and improving the application, they also pose an interesting challenge. These application logs may contain personally identifiable data, such as user names, email addresses, IP addresses, and browsing history, which creates a data privacy concern.
Laws such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) require organizations to retain application logs for a specific period of time. The exact length of time required for data storage varies depending on the specific regulation and the type of data being stored. The reason for these data retention periods is to ensure that companies aren’t keeping personal data longer than necessary, which could increase the risk of data breaches and other security incidents. This also helps ensure that companies aren’t using personal data for purposes other than those for which it was collected, which could be a violation of privacy laws. These laws also give individuals the right to request the deletion of their personal data, also known as the “right to be forgotten.” Individuals have the right to have their personal data erased, without undue delay.
So, on one hand, organizations need to collect application log data to ensure the proper functioning of their services, and keep the data for a specific period of time. But on the other hand, they may receive requests from individuals to delete their personal data from the logs. This creates a balancing act for organizations because they must comply with both data retention and data deletion requirements.
This issue becomes increasingly challenging for larger organizations that operate in multiple countries and states, because each country and state may have their own rules and regulations regarding data retention and deletion. For example, the Personal Information Protection and Electronic Documents Act (PIPEDA) in Canada and the Australian Privacy Act in Australia are similar laws to GDPR, but they may have different retention periods or different exceptions. Therefore, organizations big or small must navigate this complex landscape of data retention and deletion requirements, while also ensuring that they are in compliance with all applicable laws and regulations.
Zoom’s initial architecture
During the COVID-19 pandemic, the use of Zoom skyrocketed as more and more people were asked to work and attend classes from home. The company had to rapidly scale its services to accommodate the surge and worked with AWS to deploy capacity across most Regions globally. With a sudden increase in the large number of application endpoints, they had to rapidly evolve their log analytics architecture and worked with the AWS Data Lab team to quickly prototype and deploy an architecture for their compliance use case.
At Zoom, the data ingestion throughput and performance needs are very stringent. Data had to be ingested from several thousand application endpoints that produced over 30 million messages every minute, resulting in over 100 TB of log data per day. The existing ingestion pipeline consisted of writing the data to Apache Hadoop HDFS storage through Apache Kafka first and then running daily jobs to move the data to persistent storage. This took several hours while also slowing the ingestion and creating the potential for data loss. Scaling the architecture was also an issue because HDFS data would have to be moved around whenever nodes were added or removed. Furthermore, transactional semantics on billions of records were necessary to help meet compliance-related data delete requests, and the existing architecture of daily batch jobs was operationally inefficient.
It was at this time, through conversations with the AWS account team, that the AWS Data Lab team got involved to assist in building a solution for Zoom’s hyper-scale.
Solution overview
The AWS Data Lab offers accelerated, joint engineering engagements between customers and AWS technical resources to create tangible deliverables that accelerate data, analytics, artificial intelligence (AI), machine learning (ML), serverless, and container modernization initiatives. The Data Lab has three offerings: the Build Lab, the Design Lab, and Resident Architect. During the Build and Design Labs, AWS Data Lab Solutions Architects and AWS experts supported Zoom specifically by providing prescriptive architectural guidance, sharing best practices, building a working prototype, and removing technical roadblocks to help meet their production needs.
Zoom and the AWS team (collectively referred to as “the team” going forward) identified two major workflows for data ingestion and deletion.
Data ingestion workflow
The following diagram illustrates the data ingestion workflow.

The team needed to quickly populate millions of Kafka messages in the dev/test environment to achieve this. To expedite the process, we (the team) opted to use Amazon Managed Streaming for Apache Kafka (Amazon MSK), which makes it simple to ingest and process streaming data in real time, and we were up and running in under a day.
To generate test data that resembled production data, the AWS Data Lab team created a custom Python script that evenly populated over 1.2 billion messages across several Kafka partitions. To match the production setup in the development account, we had to increase the cloud quota limit via a support ticket.
We used Amazon MSK and the Spark Structured Streaming capability in Amazon EMR to ingest and process the incoming Kafka messages with high throughput and low latency. Specifically, we inserted the data from the source into EMR clusters at a maximum incoming rate of 150 million Kafka messages every 5 minutes, with each Kafka message holding 7–25 log data records.
To store the data, we chose to use Apache Hudi as the table format. We opted for Hudi because it’s an open-source data management framework that provides record-level insert, update, and delete capabilities on top of an immutable storage layer like Amazon Simple Storage Service (Amazon S3). Additionally, Hudi is optimized for handling large datasets and works well with Spark Structured Streaming, which was already being used at Zoom.
After 150 million messages were buffered, we processed the messages using Spark Structured Streaming on Amazon EMR and wrote the data into Amazon S3 in Apache Hudi-compatible format every 5 minutes. We first flattened the message array, creating a single record from the nested array of messages. Then we added a unique key, known as the Hudi record key, to each message. This key allows Hudi to perform record-level insert, update, and delete operations on the data. We also extracted the field values, including the Hudi partition keys, from incoming messages.
This architecture allowed end-users to query the data stored in Amazon S3 using Amazon Athena with the AWS Glue Data Catalog or using Apache Hive and Presto.
Data deletion workflow
The following diagram illustrates the data deletion workflow.
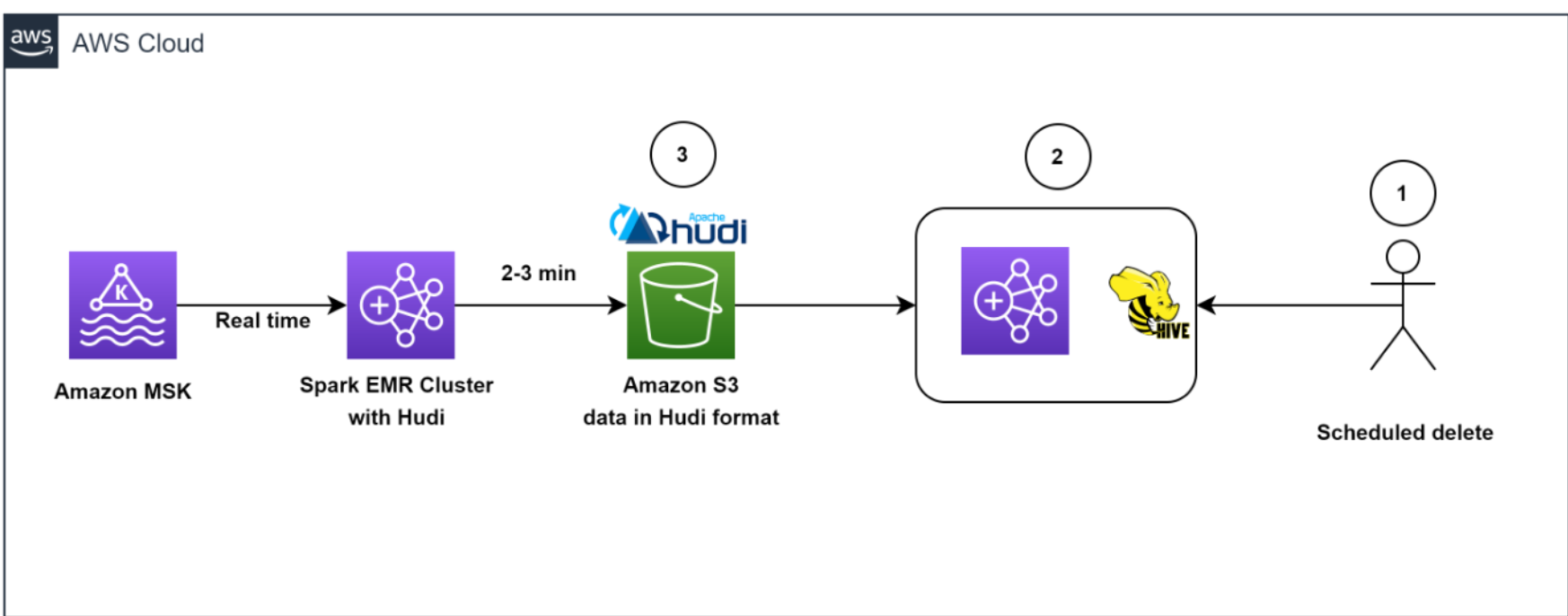
Our architecture allowed for efficient data deletions. To help comply with the customer-initiated data retention policy for GDPR deletes, scheduled jobs ran daily to identify the data to be deleted in batch mode.
We then spun up a transient EMR cluster to run the GDPR upsert job to delete the records. The data was stored in Amazon S3 in Hudi format, and Hudi’s built-in index allowed us to efficiently delete records using bloom filters and file ranges. Because only those files that contained the record keys needed to be read and rewritten, it only took about 1–2 minutes to delete 1,000 records out of the 1 billion records, which had previously taken hours to complete as entire partitions were read.
Overall, our solution enabled efficient deletion of data, which provided an additional layer of data security that was critical for Zoom, in light of its GDPR requirements.
Architecting to optimize scale, performance, and cost
In this section, we share the following strategies Zoom took to optimize scale, performance, and cost:
- Optimizing ingestion
- Optimizing throughput and Amazon EMR utilization
- Decoupling ingestion and GDPR deletion using EMRFS
- Efficient deletes with Apache Hudi
- Optimizing for low-latency reads with Apache Hudi
- Monitoring
Optimizing ingestion
To keep the storage in Kafka lean and optimal, as well as to get a real-time view of data, we created a Spark job to read incoming Kafka messages in batches of 150 million messages and wrote to Amazon S3 in Hudi-compatible format every 5 minutes. Even during the initial stages of the iteration, when we hadn’t started scaling and tuning yet, we were able to successfully load all Kafka messages consistently under 2.5 minutes using the Amazon EMR runtime for Apache Spark.
Optimizing throughput and Amazon EMR utilization
We launched a cost-optimized EMR cluster and switched from uniform instance groups to using EMR instance fleets. We chose instance fleets because we needed the flexibility to use Spot Instances for task nodes and wanted to diversify the risk of running out of capacity for a specific instance type in our Availability Zone.
We started experimenting with test runs by first changing the number of Kafka partitions from 400 to 1,000, and then changing the number of task nodes and instance types. Based on the results of the run, the AWS team came up with the recommendation to use Amazon EMR with three core nodes (r5.16xlarge (64 vCPUs each)) and 18 task nodes using Spot fleet instances (a combination of r5.16xlarge (64 vCPUs), r5.12xlarge (48 vCPUs), r5.8xlarge (32 vCPUs)). These recommendations helped Zoom to reduce their Amazon EMR costs by more than 80% while meeting their desired performance goals of ingesting 150 million Kafka messages under 5 minutes.
Decoupling ingestion and GDPR deletion using EMRFS
A well-known benefit of separation of storage and compute is that you can scale the two independently. But a not-so-obvious advantage is that you can decouple continuous workloads from sporadic workloads. Previously data was stored in HDFS. Resource-intensive GDPR delete jobs and data movement jobs would compete for resources with the stream ingestion, causing a backlog of more than 5 hours in upstream Kafka clusters, which was close to filling up the Kafka storage (which only had 6 hours of data retention) and potentially causing data loss. Offloading data from HDFS to Amazon S3 allowed us the freedom to launch independent transient EMR clusters on demand to perform data deletion, helping to ensure that the ongoing data ingestion from Kafka into Amazon EMR is not starved for resources. This enabled the system to ingest data every 5 minutes and complete each Spark Streaming read in 2–3 minutes. Another side effect of using EMRFS is a cost-optimized cluster, because we removed reliance on Amazon Elastic Block Store (Amazon EBS) volumes for over 300 TB storage that was used for three copies (including two replicas) of HDFS data. We now pay for only one copy of the data in Amazon S3, which provides 11 9s of durability and is relatively inexpensive storage.
Efficient deletes with Apache Hudi
What about the conflict between ingest writes and GDPR deletes when running concurrently? This is where the power of Apache Hudi stands out.
Apache Hudi provides a table format for data lakes with transactional semantics that enables the separation of ingestion workloads and updates when run concurrently. The system was able to consistently delete 1,000 records in less than a minute. There were some limitations in concurrent writes in Apache Hudi 0.7.0, but the Amazon EMR team quickly addressed this by back-porting Apache Hudi 0.8.0, which supports optimistic concurrency control, to the current (at the time of the AWS Data Lab collaboration) Amazon EMR 6.4 release. This saved time in testing and allowed for a quick transition to the new version with minimal testing. This enabled us to query the data directly using Athena quickly without having to spin up a cluster to run ad hoc queries, as well as to query the data using Presto, Trino, and Hive. The decoupling of the storage and compute layers provided the flexibility to not only query data across different EMR clusters, but also delete data using a completely independent transient cluster.
Optimizing for low-latency reads with Apache Hudi
To optimize for low-latency reads with Apache Hudi, we needed to address the issue of too many small files being created within Amazon S3 due to the continuous streaming of data into the data lake.
We utilized Apache Hudi’s features to tune file sizes for optimal querying. Specifically, we reduced the degree of parallelism in Hudi from the default value of 1,500 to a lower number. Parallelism refers to the number of threads used to write data to Hudi; by reducing it, we were able to create larger files that were more optimal for querying.
Because we needed to optimize for high-volume streaming ingestion, we chose to implement the merge on read table type (instead of copy on write) for our workload. This table type allowed us to quickly ingest the incoming data into delta files in row format (Avro) and asynchronously compact the delta files into columnar Parquet files for fast reads. To do this, we ran the Hudi compaction job in the background. Compaction is the process of merging row-based delta files to produce new versions of columnar files. Because the compaction job would use additional compute resources, we adjusted the degree of parallelism for insertion to a lower value of 1,000 to account for the additional resource usage. This adjustment allowed us to create larger files without sacrificing performance throughput.
Overall, our approach to optimizing for low-latency reads with Apache Hudi allowed us to better manage file sizes and improve the overall performance of our data lake.
Monitoring
The team monitored MSK clusters with Prometheus (an open-source monitoring tool). Additionally, we showcased how to monitor Spark streaming jobs using Amazon CloudWatch metrics. For more information, refer to Monitor Spark streaming applications on Amazon EMR.
Outcomes
The collaboration between Zoom and the AWS Data Lab demonstrated significant improvements in data ingestion, processing, storage, and deletion using an architecture with Amazon EMR and Apache Hudi. One key benefit of the architecture was a reduction in infrastructure costs, which was achieved through the use of cloud-native technologies and the efficient management of data storage. Another benefit was an improvement in data management capabilities.
We showed that the costs of EMR clusters can be reduced by about 82% while bringing the storage costs down by about 90% compared to the prior HDFS-based architecture. All of this while making the data available in the data lake within 5 minutes of ingestion from the source. We also demonstrated that data deletions from a data lake containing multiple petabytes of data can be performed much more efficiently. With our optimized approach, we were able to delete approximately 1,000 records in just 1–2 minutes, as compared to the previously required 3 hours or more.
Conclusion
In conclusion, the log analytics process, which involves collecting, processing, storing, analyzing, and deleting log data from various sources such as servers, applications, and devices, is critical to aid organizations in working to meet their service resiliency, security, performance monitoring, troubleshooting, and compliance needs, such as GDPR.
This post shared what Zoom and the AWS Data Lab team have accomplished together to solve critical data pipeline challenges, and Zoom has extended the solution further to optimize extract, transform, and load (ETL) jobs and resource efficiency. However, you can also use the architecture patterns presented here to quickly build cost-effective and scalable solutions for other use cases. Please reach out to your AWS team for more information or contact Sales.
About the Authors
 Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education.
Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education.
 Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment.
Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment.
 Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family.
Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family.
 Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.
Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.