Monitoring data storage systems is the key to keeping modern IT systems running smoothly. With the rapid growth of data and the need for instant access, using high-performance solutions like Pure Storage FlashArray is not just an advantage – it’s a necessity. However, even the most advanced systems require careful oversight regarding their performance and health. Good monitoring helps find problems early and makes it possible to use resources more efficiently. In this article, we will explore how to set up monitoring for the Pure Storage FlashArray storage system with Zabbix using our new templates.
Pure Storage FlashArray offers two API versions: REST API 1.X and REST API 2.X. To ensure compatibility and comprehensive coverage for the maximum number of devices, two templates have been developed for these API versions. This allows users to effectively monitor their Pure Storage FlashArray storage systems regardless of which API version they are utilizing, making sure that they can take full advantage of the monitoring capabilities and performance metrics provided by each version. By accommodating both API versions, organizations can achieve a more flexible and comprehensive monitoring setup tailored to meet their specific infrastructure needs.
Table of Contents
Preparing Pure Storage FlashArray for monitoring with Zabbix
In all of these examples, the Purity for FlashArray (Purity//FA) graphical user interface (GUI) will be used, so keep in mind that some of the UI elements or navigation menus can potentially change in the future.
User creation
First of all, you need to set up a user in GUI that Zabbix will use to access the REST API and gather data. To do so, navigate to 'Settings' -> 'Users and Policies' -> 'Users' from the left-side menu. On this page, pay attention to the ‘Users’ block. In the upper right corner of this block, you will see three dots. Click on them to open a context menu. In this menu, select the 'Create User...' option. Here, create a new user by filling in the fields.
API Key creation
Unlike Pure Storage FlashArray v2 by HTTP, Pure Storage FlashArray v1 by HTTP supports authentication using a username and password instead of a token. This feature is left for backward compatibility with older versions of devices and firmware. However, it is strongly recommended to use token authentication if there are no technical limitations.
If you do plan to use username and password authentication in the Pure Storage FlashArray v1 by HTTP template, you can skip this step and move on to the next one.
Once you have created the user, the next step is to generate an API token. To do this, find the newly created user in the 'Users' block on the 'Settings' -> 'Users and Policies' page. On the right side of the user’s entry, locate the three dots and click on them to open the menu. From this menu, select 'Create API Token...'. Follow the prompts to generate the API token, which Zabbix will use to authenticate requests. The 'Expires In' field can be left empty.
After clicking the Create button, the GUI will show you details about the API key. Save this information somewhere safe for now, as we will need to use this data later in Zabbix. After saving, you can close this pop-up.
Preparing Zabbix
Create a host
Open your Zabbix web interface, then navigate to the ‘Configuration' -> 'Hosts‘ page and create a new host. In this step, you need to specify a host name of your choice, so choose one of the Pure Storage FlashArray v1 by HTTP or Pure Storage FlashArray v2 by HTTP templates and assign the host to a group. The choice of template depends on the version of the Pure Storage FlashArray RESTful API that is supported by your devices.
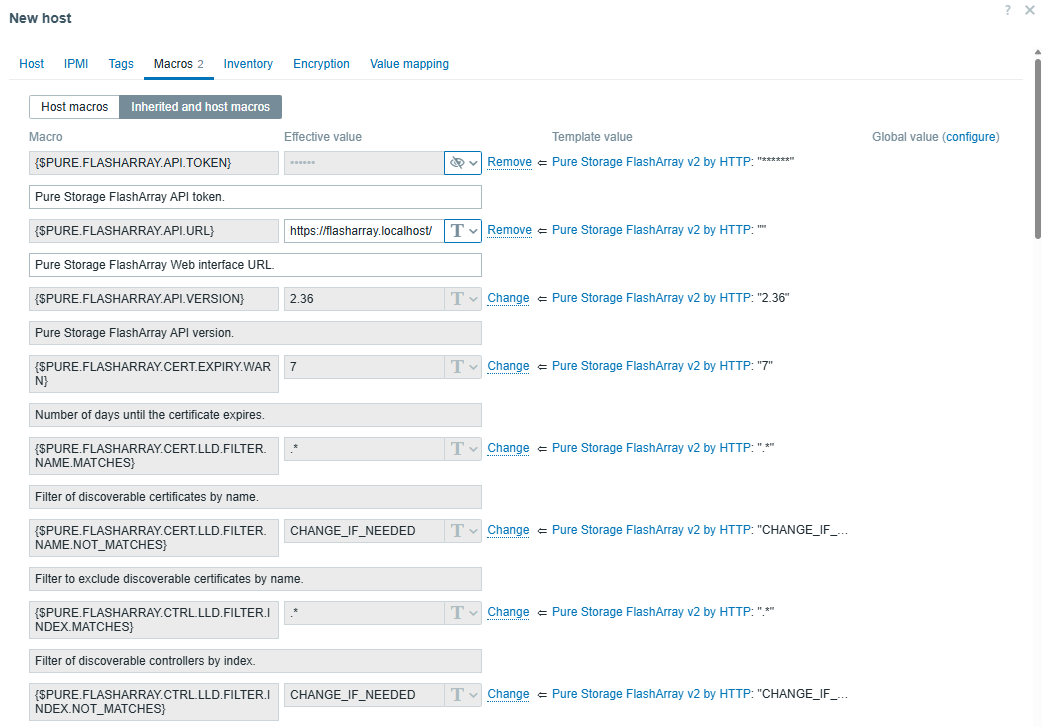
Before clicking the Add button, you need to configure macros. Open the Macros tab and choose both Inherited and host macros. You’ll find a lot of macros there, but only a few of them need to be changed to start using the template. Let’s take a look at these macros.
Macro list in the Pure Storage FlashArray v1 by HTTP template:
Macro
Default value
Description
{$PURE.FLASHARRAY.API.URL}
–
Web interface URL.
{$PURE.FLASHARRAY.API.TOKEN}
–
API token.
{$PURE.FLASHARRAY.API.USERNAME}
–
Web interface username.
{$PURE.FLASHARRAY.API.PASSWORD}
–
Web interface password.
{$PURE.FLASHARRAY.API.VERSION}
1.19
API version.
For the Pure Storage FlashArray v1 by HTTP template, it is mandatory to specify the {$PURE.FLASHARRAY.API.URL} macro, as well as either the {$PURE.FLASHARRAY.API.TOKEN} or {$PURE.FLASHARRAY.API.USERNAME} and {$PURE.FLASHARRAY.API.PASSWORD}. It is highly recommended to use a token for authentication.
Macro list in the Pure Storage FlashArray v2 by HTTP template:
Macro
Default value
Description
{$PURE.FLASHARRAY.API.URL}
–
Web interface URL.
{$PURE.FLASHARRAY.API.TOKEN}
–
API token.
{$PURE.FLASHARRAY.API.VERSION}
2.36
API version.
For the Pure Storage FlashArray v2 by HTTP template, it is mandatory to specify just the {$PURE.FLASHARRAY.API.URL} and {$PURE.FLASHARRAY.API.TOKEN} macros to start using the template.
You can change the value for the {$PURE.FLASHARRAY.API.VERSION} macro if your device does not support this version of the API.
After specifying at least the mandatory macro values, your Macros tab should look something like this:
After clicking the Add button, this host will be added to Zabbix.
Data collection
After following the above steps, you should notice the newly created triggers and items after a short time if the macro values are correct.
In case there are any problems with the template’s data collection, you will find errors in the last history data of items with a name ending with item errors. Also, the corresponding triggers should be fired if there are any problems with the collection of any data.
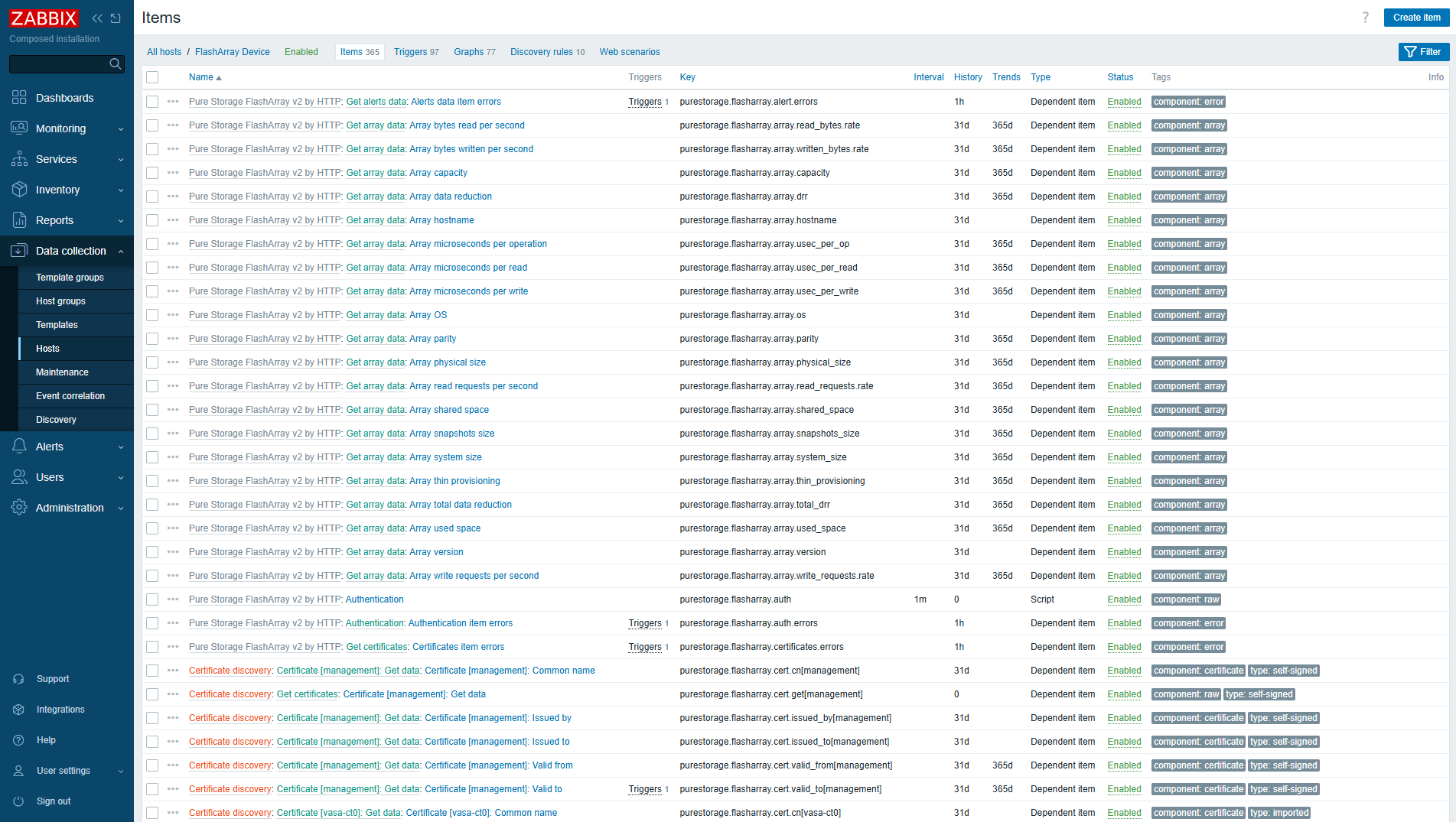
After that, you should see newly discovered items in the Items view (for example).
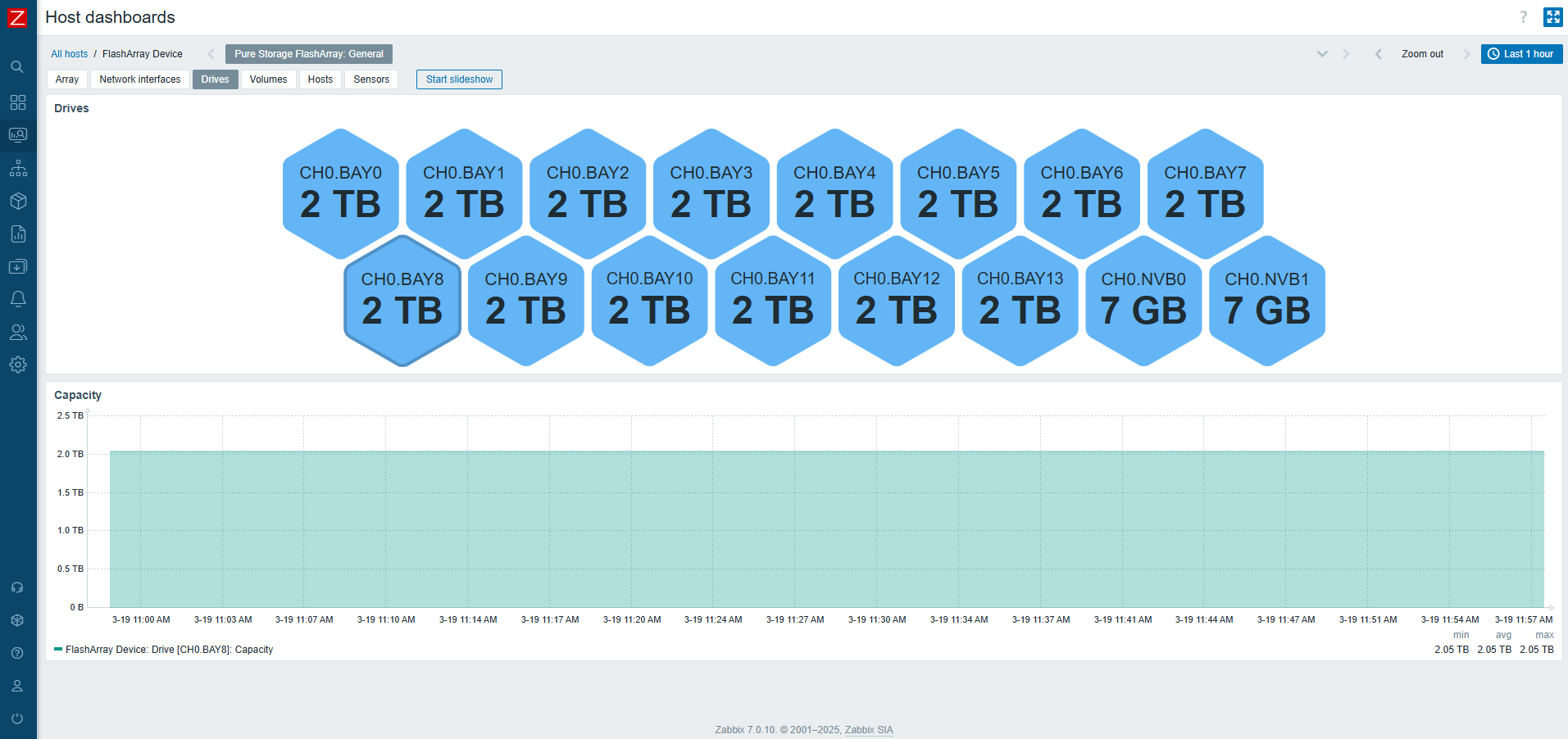
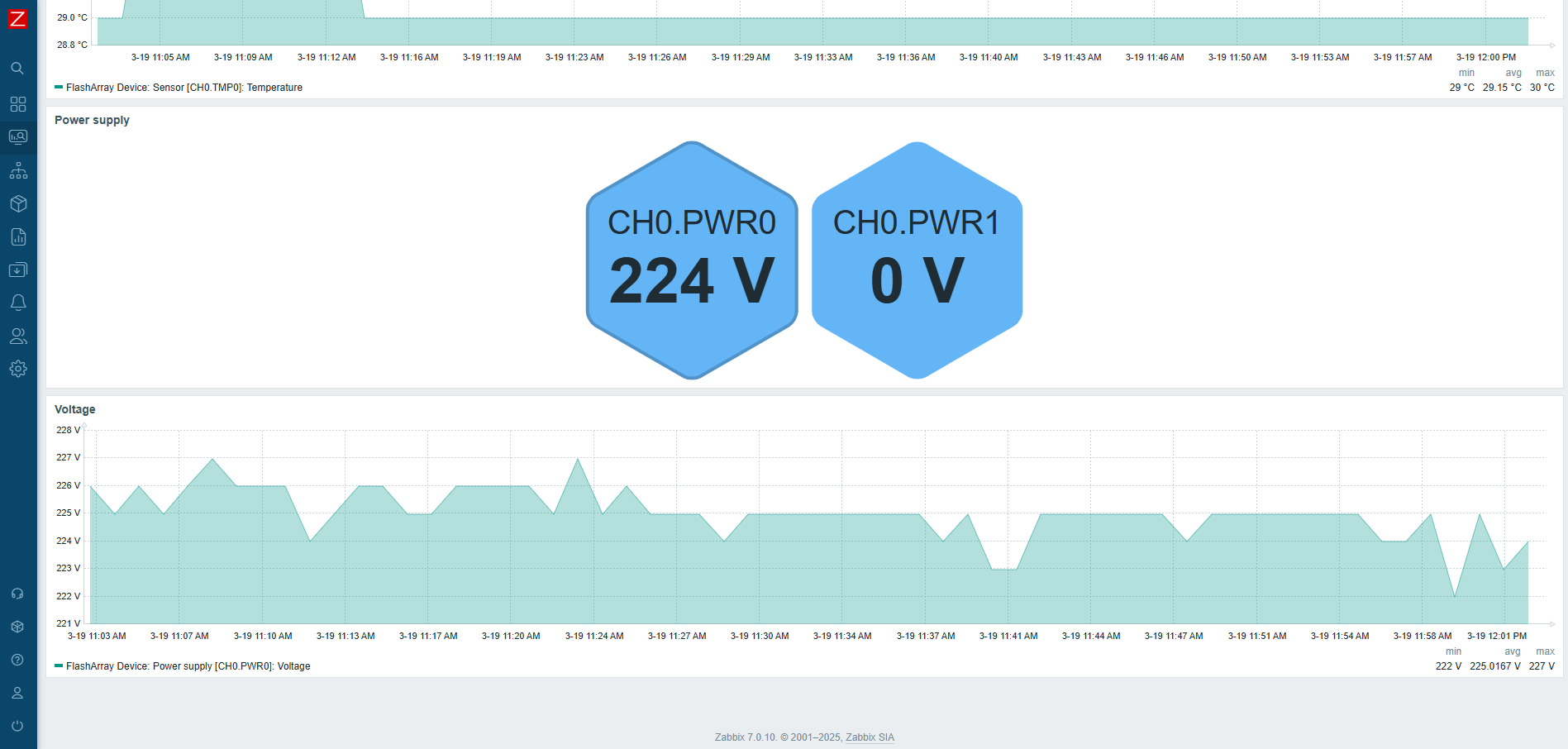
On top of that, each host will have its own dashboard created automatically that will provide you with a good overview of resource utilization.
Use macros for low-level discovery filtering
In official Zabbix templates, you might find macros that end with MATCHES and NOT_MATCHES. These are used for low-level discovery rules (LLDs), to help you filter resources that should or should not be discovered. These values use regular expressions. Therefore, you can use wildcard symbols for pattern matching.
Usage of these macros can be found in the Filters tab, under discovery rules.
The typical default value for MATCHES is .* and for NOT_MATCHES – CHANGE_IF_NEEDED. This means that any kind of value will be discovered if it is not equal to CHANGE_IF_NEEDED. For example, in Network interface discovery, filters are used to check the interface name:
Macro {$PURE.FLASHARRAY.NETIF.LLD.FILTER.NAME.MATCHES} has a value of .*;
Macro {$PURE.FLASHARRAY.NETIF.LLD.FILTER.NAME.NOT_MATCHES} has a value of CHANGE_IF_NEEDED.
You can set the value of macro {$PURE.FLASHARRAY.NETIF.LLD.FILTER.NAME.NOT_MATCHES} to filevip, which will cause an interface named filevip to not be discovered.
Now that you have an idea how these filters work, you can adjust them based on your requirements.
HTTP proxy usage
If needed, you can specify an HTTP proxy for the template to use by changing the value of the{$PURE.FLASHARRAY.HTTP_PROXY} user macro. Every request will use this proxy.
Afterword
To wrap things up, setting up monitoring for Pure Storage FlashArray devices in Zabbix is an important step that guarantees the smooth operation of your infrastructure. I hope that our new templates will help you manage and monitor your devices more effectively.
This short article has been created to provide you with the necessary knowledge and tools to set up a monitoring system that meets your specific needs. By enabling efficient monitoring, you will be better equipped to respond to changes in system performance and maintain optimal operation. I believe this material will be valuable in helping you achieve these goals!
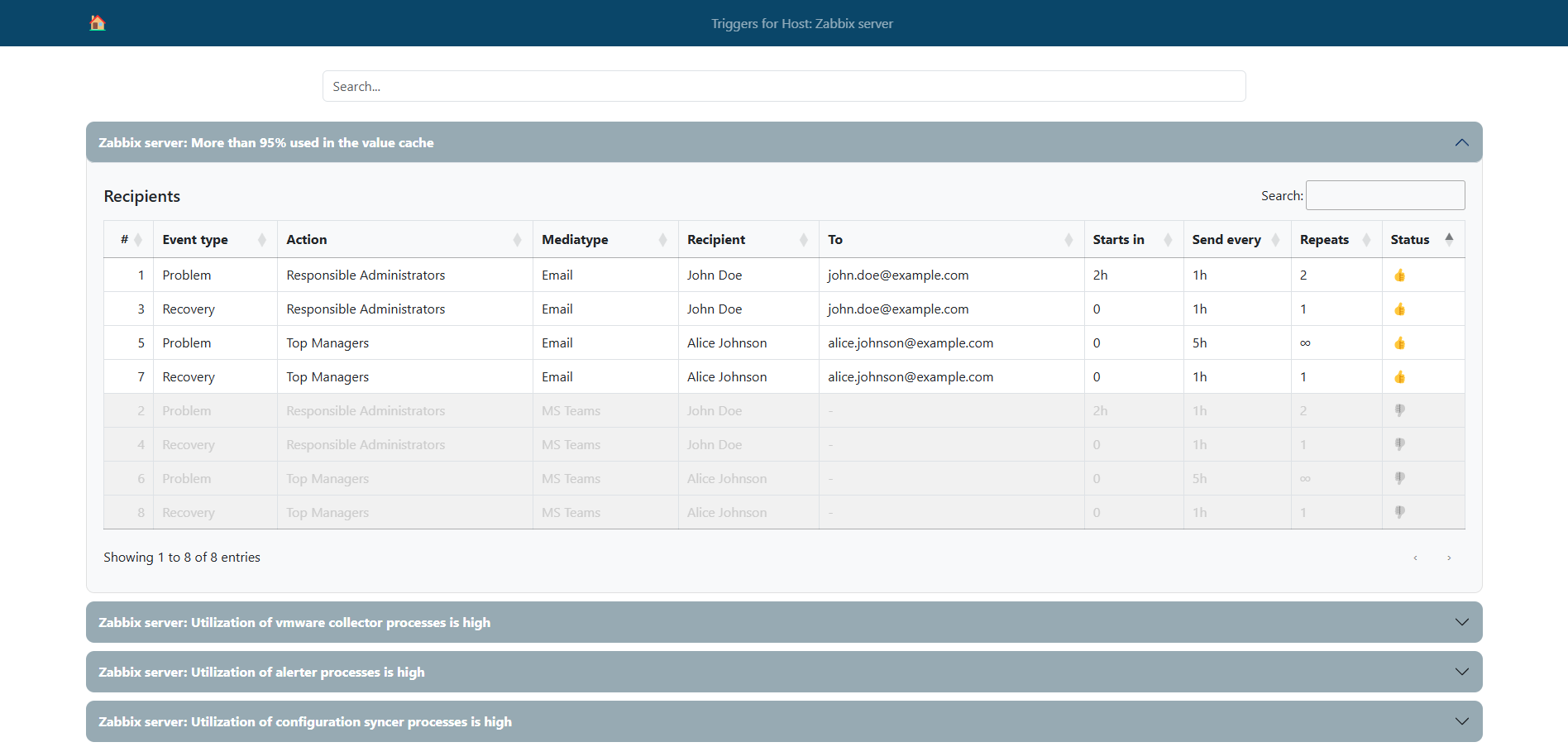
In this article, we will explore a practical example of using the zabbix_utils library to solve a non-trivial task – obtaining a list of alert recipients for triggers associated with a specific Zabbix host. You will learn how to easily automate the process of collecting this information, and see examples of real code that can be adapted to your needs.
Table of Contents
Over the last year, the zabbix_utils library has become one of the most popular tools for working with the Zabbix API. It is a convenient tool that simplifies interacting with the Zabbix server, proxy, or agent, especially for those who automate monitoring and management tasks.
Due to its ease of use and extensive functionality, zabbix_utils has found a following among system administrators, monitoring, and DevOps engineers. According to data from PyPI, the library has already been downloaded over 140,000 times since its release, confirming its demand within the community. It’s all thanks to you and your attention to zabbix_utils!
Task Description
Administrators often need to check which Zabbix users receive alerts for specific triggers in the Zabbix monitoring system. This can be useful for auditing, configuring new notifications, or simply for a quick diagnosis of issues. The task becomes especially relevant when you have plenty of hosts containing numerous triggers, and manually checking the recipients for each trigger through the Zabbix interface becomes very time-consuming.
In such cases, it is advisable to use a custom solution based on the Zabbix API. You can directly access all the required data using the API, and then use additional logic to determine the final alert recipients. The zabbix_utils library makes working with the Zabbix API more convenient and allows you to automate this process. In this project, we use the zabbix_utils library to write a Python script that collects a list of alert recipients for the triggers of the selected Zabbix host. This will allow you to obtain the necessary information faster and with minimal effort.
Environment Setup and Installation
To get started with zabbix_utils, you need to install the library and configure the connection to the Zabbix API. This article provides more details and examples on getting started with the library. However, it would be better if I describe the basic steps to prepare the environment here.
The library supports several installation methods described in the official README, making it convenient for use in different environments.
1. Installation via pip
The simplest and most common installation method is using the pip package manager. To do this, execute the command:
~$ pip install zabbix_utils
To install all necessary dependencies for asynchronous work, you can use the command:
~$ pip install zabbix_utils[async]
This method is suitable for most users, as pip automatically installs all required dependencies.
2. Installation from Zabbix Repository
Since writing the previous articles, we have added one more installation method – from the official Zabbix repository. First and foremost, you need to add the repository to your system if it has not been installed yet. Official Zabbix packages for Red Hat Enterprise Linux and Debian-based distributions are available on the Zabbix website.
For Red Hat Enterprise Linux and derivatives:
~# dnf install python3-zabbix-utils
For Debian / Ubuntu and derivatives:
~# apt install python3-zabbix-utils
3. Installation from Source Code
If you require the latest version of the library that has not yet been published on PyPI, or you want to customize the code, you can install the library directly from GitHub:
After installing zabbix_utils, it is a good idea to check the connection to your Zabbix server via the API. To do this, use the URL to the Zabbix server, the token, or the username and password of the user who has permission to access the Zabbix API.
Now that the environment is set up, let’s look at the main steps for solving the task of retrieving the list of alert recipients for triggers associated with a specific Zabbix host in Zabbix.
In zabbix_utils, asynchronous API interaction support is built in through the AsyncZabbixAPI class. This allows multiple requests to be sent simultaneously and their results to be handled as they become ready, significantly reducing latencies when making multiple API calls. Therefore, we will use the AsyncZabbixAPI class and the asynchronous approach in this project.
Below are the main steps for solving the task, and code examples for each step. Please note that the code in this project is for demonstration purposes, may not be optimal, or could contain errors. Use it as an example or a base for your project, but not as a complete tool.
Step 1. Obtain Host ID
The first step is to identify the host for which we will retrieve information about triggers and alerts. We need to find the hostid using its name/host to do this. The Zabbix API provides a method to obtain this information, and using zabbix_utils makes this process much simpler.
This method returns a unique identifier for the host, which can be used further. However, for our test project, we will use a manually specified host identifier.
Step 2. Retrieve Host Triggers
With the hostid in hand, the next step is to retrieve all triggers associated with this host. Triggers contain the conditions that trigger the alerts. We need to collect information about all triggers so that we can then use it to select actions that match all the conditions.
This request returns complete information about the triggers for the host. We get not only the triggers but also their tags, associated host and host groups, and discovery rule information. All this information will be necessary to check the conditions of the actions.
Step 3. Initialize Trigger Metadata
At this stage, objects for each trigger are created to store their metadata. This is done using the Trigger class, which includes information about the trigger such as its name, ID, associated host groups, hosts, tags, templates, and operations.
Here’s the code defining the Trigger class:
classTrigger:def__init__(self, trigger):self.name=trigger["description"]self.triggerid=trigger["triggerid"]self.hostgroups= [g["groupid"] forgintrigger["hostgroups"]]self.hosts= [h["hostid"] forhintrigger["hosts"]]self.tags= {t["tag"]: t["value"] fortintrigger["tags"]}self.tmpl_triggerid=self.triggeridself.lld_rule=trigger["discoveryRule"] or {}iftrigger["templateid"] !="0":self.tmpl_triggerid=trigger["templateid"]self.templates= []self.messages= []self._conditions= {"0": self.hostgroups,"1": self.hosts,"2": [self.triggerid],"3": trigger["event_name"] ortrigger["description"],"4": trigger["priority"],"13": self.templates,"25": self.tags.keys(),"26": self.tags, }defeval_condition(self, operator, value, trigger_data):# equals or does not equalifoperatorin ["0", "1"]:equals=operator=="0"ifisinstance(value, dict) andisinstance(trigger_data, dict):ifvalue["tag"] intrigger_data:ifvalue["value"] ==trigger_data[value["tag"]]:returnequalselifvalueintrigger_dataandisinstance(trigger_data, list):returnequalselifvalue==trigger_data:returnequalsreturnnotequals# contains or does not containifoperatorin ["2", "3"]:contains=operator=="2"ifisinstance(value, dict) andisinstance(trigger_data, dict):ifvalue["tag"] intrigger_data:ifvalue["value"] intrigger_data[value["tag"]]:returncontainselifvalueintrigger_data:returncontainsreturnnotcontains# is greater/less than or equalsifoperatorin ["5", "6"]:greater=operator!="5"try:ifint(value) <int(trigger_data):returnnotgreaterifint(value) ==int(trigger_data):returnTrueifint(value) >int(trigger_data):returngreaterexcept:raiseValueError("Values must be numbers to compare them" )defselect_templates(self, templates):fortemplateintemplates:ifself.tmpl_triggeridin [t["triggerid"] fortintemplate["triggers"]]:self.templates.append(template["templateid"])ifself.lld_rule.get("templateid") in [d["itemid"] fordintemplate["discoveries"] ]:self.templates.append(template["templateid"])defselect_actions(self, actions):selected_actions= []foractioninactions:conditions= []if"filter"inaction:conditions=action["filter"]["conditions"]eval_formula=action["filter"]["eval_formula"]# Add actions without conditions directlyifnotconditions:selected_actions.append(action)continuecondition_check= {}forconditioninconditions:if (condition["conditiontype"] !="6"andcondition["conditiontype"] !="16" ):if (condition["conditiontype"] =="26"andisinstance(condition["value"], str) ):condition["value"] = {"tag": condition["value2"],"value": condition["value"], }ifcondition["conditiontype"] inself._conditions:condition_check[condition["formulaid"] ] =self.eval_condition(condition["operator"],condition["value"],self._conditions[condition["conditiontype"] ], )else:condition_check[condition["formulaid"] ] =Trueforformulaid, bool_resultincondition_check.items():eval_formula=eval_formula.replace(formulaid, str(bool_result))
# Evaluate the final condition formulaifeval(eval_formula):selected_actions.append(action)returnselected_actionsdefselect_operations(self, actions, mediatypes):messages_metadata= []foractioninself.select_actions(actions):messages_metadata+=self.check_operations("operations", action, mediatypes )messages_metadata+=self.check_operations("update_operations", action, mediatypes )messages_metadata+=self.check_operations("recovery_operations", action, mediatypes )returnmessages_metadata
defcheck_operations(self, optype, action, mediatypes):messages_metadata= []optype_mapping= {"operations": "0", # Problem event"recovery_operations": "1", # Recovery event"update_operations": "2", # Update event }operations=copy.deepcopy(action[optype])# Processing "notify all involved" scenariosforidx, _inenumerate(operations):ifoperations[idx]["operationtype"] notin ["11", "12"]:continue# Copy operation as a template for reuseop_template=copy.deepcopy(operations[idx])deloperations[idx]# Checking for message sending operationsforkeyin [kforkin ["operations", "update_operations"] ifk!=optype ]:ifnotaction[key]:continue# Checking for message sending type operationsforopin [oforoinaction[key] ifo["operationtype"] =="0" ]:# Copy template for the current operationoperation=copy.deepcopy(op_template)operation.update( {"operationtype": "0","opmessage_usr": op["opmessage_usr"],"opmessage_grp": op["opmessage_grp"], } )operation["opmessage"]["mediatypeid"] =op["opmessage" ]["mediatypeid"]operations.append(operation)foroperationinoperations:ifoperation["operationtype"] !="0":continue# Processing "all mediatypes" scenarioifoperation["opmessage"]["mediatypeid"] =="0":formediatypeinmediatypes:operation["opmessage"]["mediatypeid"] =mediatype["mediatypeid" ]messages_metadata.append(self.create_messages(optype_mapping[optype], action, operation, [mediatype ] ) )else:messages_metadata.append(self.create_messages(optype_mapping[optype],action,operation,mediatypes ) )returnmessages_metadatadefcreate_messages(self, optype, action, operation, mediatypes):message=Message(optype, action, operation)message.select_mediatypes(mediatypes)self.messages.append(message)returnmessage
The code for creating Trigger class objects for each of the retrieved triggers:
This loop iterates through all triggers and saves them in a dictionary called triggers_metadata, where the key is the triggerid and the value is the trigger object.
Step 4. Retrieve Template Information
The next step is to obtain data about the templates associated with all the triggers:
This request returns information about all templates linked to the host’s triggers being examined. Executing a single query for all triggers is a more optimal solution than making individual requests for each trigger. This information will be needed for evaluating the “Template” condition in actions.
Step 5. Get Actions and Media Types
Next, we obtain the list of actions and media types configured in the system:
Here we retrieve actions that define how and to whom alerts are sent, and mediatypes through which users can receive notifications (for example, email or SMS).
Step 6. Match Triggers with Templates and Actions
At this stage, each trigger is associated with the corresponding templates and actions:
Here, for each trigger, we update information about its templates and configured actions for sending notifications. The list of associated actions is determined by checking the conditions specified in them against the accumulated data for each trigger.
For each operation of the corresponding trigger action, a Message class object is created:
classMessage:def__init__(self, optype, action, operation):self.optype=optypeself.mediatypename=""self.actionid=action["actionid"]self.actionname=action["name"]self.operationid=operation["operationid"]self.mediatypeid=operation["opmessage"]["mediatypeid"]self.subject=operation["opmessage"]["subject"]self.message=operation["opmessage"]["message"]self.default_msg=operation["opmessage"]["default_msg"]self.users= [u["userid"] foruinoperation["opmessage_usr"]]self.groups= [g["usrgrpid"] forginoperation["opmessage_grp"]]self.recipients= []# Escalation period set to action's period if not specifiedself.esc_period=operation.get("esc_period", "0")ifself.esc_period=="0":self.esc_period=action["esc_period"]# Use action's escalation period if unsetself.esc_step_from=self.multiply_time(self.esc_period, int(operation.get("esc_step_from", "1")) -1 )ifoperation.get("esc_step_to", "0") !="0":self.repeat_count=str(int(operation["esc_step_to"]) -int(operation["esc_step_from"]) +1 )# If not a problem event, set repeat count to 1elifself.optype!="0":self.repeat_count="1"# Infinite repeat count if esc_step_to is 0else:self.repeat_count=“∞”defmultiply_time(self, time_str, multiplier):# Multiply numbers within the time stringresult=re.sub(r"(\d+)",lambdam: str(int(m.group(1)) *multiplier),time_str )ifresult[0] =="0":return"0"returnresultdefselect_mediatypes(self, mediatypes):formediatypeinmediatypes:ifmediatype["mediatypeid"] ==self.mediatypeid:self.mediatypename=mediatype["name"]# Select message templates related to operation typemsg_template= [mforminmediatype["message_templates"]if (m["recovery"] ==self.optypeandm["eventsource"] =="0" ) ]# Use default message if applicableifmsg_templateandself.default_msg=="1":self.subject=msg_template[0]["subject"]self.message=msg_template[0]["message"]defselect_recipients(self, user_groups, recipients):forgroupidinself.groups:ifgroupidinuser_groups:self.users+=user_groups[groupid]foruseridinself.users:ifuseridinrecipients:recipient=copy.deepcopy(recipients[userid])ifself.mediatypeidinrecipient.sendto:recipient.mediatype =Trueself.recipients.append(recipient)
Each such object represents a separate message sent to users (recipients) and will contain all message information – its subject, text, recipients, and escalation parameters.
Step 7. Collect User and Group Identifiers
After matching the triggers with actions, the process of collecting unique identifiers for users and groups starts:
This code snippet collects the IDs of all users and groups involved in the operations for each trigger. This is necessary to perform only one request to the Zabbix API for all involved users and their groups, rather than making separate requests for each trigger.
Step 8. Obtain User and Group Information
The next step is to collect detailed information about users and user groups:
Here we gather data about users, including their role and media types through which they receive notifications, as well as data about user groups, including access rights to host groups and the list of users in each group. All this information will be needed to check access to the host with the triggers we are working with.
Step 9. Match Users and Groups with Triggers
After obtaining user information, we match users and groups with their respective rights to receive notifications. Here we also link users with groups, updating the information regarding rights and groups for each user.
foruseridin userids:ifuseridin users:user= users[userid] recipients[userid] =Recipient(user)forgroupinuser["usrgrps"]:ifgroup["usrgrpid"] in usergroups: recipients[userid].permissions.update([h["id"]forhin usergroups[group["usrgrpid"]]["hostgroup_rights"]ifint(h["permission"]) >1 ])forgroupidin groupids:ifgroupidin usergroups:group= usergroups[groupid] user_groups[group["usrgrpid"]] = []foruseringroup["users"]: user_groups[group["usrgrpid"]].append(user["userid"])ifuser["userid"] in recipients: recipients[user["userid"]].groups.update(group["usrgrpid"])elifuser["userid"] in users: recipients[user["userid"]] =Recipient(users[user["userid"]]) recipients[user["userid"]].permissions.update([h["id"]forhingroup["hostgroup_rights"]ifint(h["permission"]) >1 ])
This code fragment connects each user with their groups and vice versa, creating a complete list of users with their access rights to the host, and thus their eligibility to receive notifications about events for this host.
For each recipient, a Recipient class object is created containing data about the recipient, such as the notification address, access rights to hosts, configured mediatypes, etc.
Here’s the code that describes the Recipient class:
classRecipient:def__init__(self, user):self.userid=user["userid"]self.username=user["username"]self.fullname="{name}{surname}".format(**user).strip()self.type=user["role"]["type"]self.groups=set([g["usrgrpid"] forginuser["usrgrps"]])self.has_right=Falseself.permissions=set()self.sendto= {m["mediatypeid"]: m["sendto"] forminuser["medias"] ifm["active"] =="0" }# Check if the user is a super admin (type 3)ifself.type=="3":self.has_right=True
Step 10. Match Messages with Recipients
Finally, we match recipients with specific messages from Step 6:
This step completes the main process – each message is assigned to the relevant recipients.
Step 11. Check Recipient Access Rights and Output the Result
Before the actual output of the result with the list of recipients, we can perform a check of the recipients’ message rights and filter only those who have the corresponding rights to receive notifications for the events related to the trigger, or those who have all configured media types specified and active. After these actions, the information can be output in any convenient way – whether it be exporting to a file or displaying it on the screen:
All the examples and code snippets described above have been compiled to create a solution demonstrating the algorithm for obtaining notification recipients for triggers associated with the selected host. We have implemented this algorithm as a simple web interface to make the result more illustrative and convenient for familiarization.
This interface allows users to enter the host’s ID. The script then processes the data and provides a list of notification recipients associated with the triggers on that host. The web interface uses asynchronous requests to the Zabbix API and the zabbix_utils library to ensure fast data processing and ease of use with many triggers and users.
This lets you familiarize yourself with the theoretical steps and code examples and also try to put this solution into action.
Please note once again that the code in this project is for demonstration purposes, may not be optimal, or could contain errors. Use it as an example or a base for your project, but not as a complete tool.
The web interface’s complete source code and installation instructions can be found on GitHub.
Conclusion
In this article, we explored a practical example of using the zabbix_utils library to solve the task of obtaining alert recipients for triggers associated with a selected Zabbix host using the Zabbix API. We detailed the key steps, from setting up the environment and initializing trigger metadata to working with notification recipients and optimizing performance with asynchronous requests.
Using zabbix_utils allowed us to optimize and accelerate interaction with the Zabbix API, expanding the capabilities of the Zabbix web interface and increasing efficiency when working with large volumes of data. Thanks to support for asynchronous processing and selective API requests, it is possible to significantly reduce the load on the server and improve system performance when working with Zabbix, which is especially important in large infrastructures.
We hope this example will assist you in implementing your own solutions based on the Zabbix API and zabbix_utils, and demonstrate the possibilities for optimizing your interaction with the Zabbix API.
In this article, we will explore the capabilities of the new asynchronous modules of the zabbix_utils library. Thanks to asynchronous execution, users can expect improved efficiency, reduced latency, and increased flexibility in interacting with Zabbix components, ultimately enabling them to create efficient and reliable monitoring solutions that meet their specific requirements.
There is a high demand for the Python library zabbix_utils. Since its release and up to the moment of writing this article, zabbix_utils has been downloaded from PyPI more than 15,000 times. Over the past week, the library has been downloaded more than 2,700 times. The first article about the zabbix_utils library has already gathered around 3,000 views. Among the array of tools available, the library has emerged as a popular choice, offering developers and administrators a comprehensive set of functions for interacting with Zabbix components such as Zabbix server, proxy, and agents.
Considering the demand from users, as well as the potential of asynchronous programming to optimize interaction with Zabbix, we are pleased to present a new version of the library with new asynchronous modules in addition to the existing synchronous ones. The new zabbix_utils modules are designed to provide a significant performance boost by taking advantage of the inherent benefits of asynchronous programming to speed up communication between Zabbix and your service or script.
From expedited data retrieval and real-time event monitoring to enhanced scalability, asynchronous programming empowers you to build highly efficient, flexible, and reliable monitoring solutions adapted to meet your specific needs and challenges.
The new version of zabbix_utils and its asynchronous components may be useful in the following scenarios:
Mass data gathering from multiple hosts: When it’s necessary to retrieve data from a large number of hosts simultaneously, asynchronous programming allows requests to be executed in parallel, significantly speeding up the data collection process;
Mass resource exporting: When templates, hosts or problems need to be exported in parallel. This parallel execution reduces the overall export time, especially when dealing with a large number of resources;
Sending alerts from or to your system: When certain actions need to be performed based on monitoring conditions, such as sending alerts or running scripts, asynchronous programming provides rapid condition processing and execution of corresponding actions;
Scaling the monitoring system: With an increase in the number of monitored resources or the volume of collected data, asynchronous programming provides better scalability and efficiency for the monitoring system.
Installation and Configuration
If you already use the zabbix_utils library, simply updating the library to the latest version and installing all necessary dependencies for asynchronous operation is sufficient. Otherwise, you can install the library with asynchronous support using the following methods:
By using pip:
~$ pip install zabbix_utils[async]
Using [async] allows you to install additional dependencies (extras) needed for the operation of asynchronous modules.
The process of working with the asynchronous version of the zabbix_utils library is similar to the synchronous one, except for some syntactic differences of asynchronous code in Python.
Working with Zabbix API
To work with the Zabbix API in asynchronous mode, you need to import the AsyncZabbixAPI class from the zabbix_utils library:
from zabbix_utils import AsyncZabbixAPI
Similar to the synchronous ZabbixAPI, the new AsyncZabbixAPI can use the following environment variables: ZABBIX_URL, ZABBIX_TOKEN, ZABBIX_USER, ZABBIX_PASSWORD. However, when creating an instance of the AsyncZabbixAPI class you cannot specify a token or a username and password, unlike the synchronous version. They can only be passed when calling the login() method. The following usage scenarios are available here:
Use preset values of environment variables, i.e., not pass any parameters to AsyncZabbixAPI:
Pass only the Zabbix API address as input, which can be specified as either the server IP/FQDN address or DNS name (in this case, the HTTP protocol will be used) or as an URL of Zabbix API:
api = AsyncZabbixAPI(url="127.0.0.1")
After declaring an instance of the AsyncZabbixAPI class, you need to call the login() method to authenticate with the Zabbix API. There are two ways to do this:
After completing all needed API requests, it is necessary to call logout() to close the API session if authentication was done using username and password, and also close the asynchronous sessions:
The asynchronous class AsyncSender has been added, which also helps to send values to the Zabbix server or proxy for items of the Zabbix Trapper data type.
AsyncSender can be imported as follows:
from zabbix_utils import AsyncSender
Values can be sent in a group, for this it is necessary to import ItemValue:
In the example, the chunk size is set to 2. So, 5 values passed in the code above will be sent in three requests of two, two, and one value, respectively.
If your server has multiple network interfaces, and values need to be sent from a specific one, the AsyncSender provides the option to specify a source_ip for sent values:
AsyncSender also supports reading connection parameters from the Zabbix agent/agent2 configuration file. To do this, you need to set the use_config flag and specify the path to the configuration file if it differs from the default /etc/zabbix/zabbix_agentd.conf:
Getting values from Zabbix Agent/Agent2 by item key.
In cases where you need the functionality of our standart zabbix_get utility but native to your Python project and working asynchronously, consider using the AsyncGetter class. A simple example of its usage looks like this:
The new version of the zabbix_utils library provides users with the ability to implement efficient and scalable monitoring solutions, ensuring fast and reliable communication with the Zabbix components. Asynchronous way of interaction gives a lot of room for performance improvement and flexible task management when handling a large volume of requests to Zabbix components such as Zabbix API and others.
We have no doubt that the new version of zabbix_utils will become an indispensable tool for developers and administrators, helping them create more efficient, flexible, and reliable monitoring solutions that best meet their requirements and expectations.
Zabbix is a flexible and universal monitoring solution that integrates with a wide variety of different systems right out of the box. Despite actively expanding the list of natively supported systems for integration (via templates or webhook integrations), there may still be a need to integrate with custom systems and services that are not yet supported. In such cases, a library taking care of implementing interaction protocols with the Zabbix API, Zabbix server/proxy, or Agent/Agent2 becomes extremely useful. Given that Python is widely adopted among DevOps and SRE engineers as well as server administrators, we decided to release a library for this programming language first.
We are pleased to introduce zabbix_utils – a Python library for seamless interaction with Zabbix API, Zabbix server/proxy, and Zabbix Agent/Agent2. Of course, there are popular community solutions for working with these Zabbix components in Python. Keeping this fact in mind, we have tried to consolidate popular issues and cases along with our experience to develop as convenient a tool as possible. Furthermore, we made sure that transitioning to the tool is as straightforward and clear as possible. Thanks to official support, you can be confident that the current version of the library is compatible with the latest Zabbix release.
In this article, we will introduce you to the main capabilities of the library and provide examples of how to use it with Zabbix components.
Usage Scenarios
The zabbix_utils library can be used in the following scenarios, but is not limited to them:
Zabbix automation
Integration with third-party systems
Custom monitoring solutions
Data export (hosts, templates, problems, etc.)
Integration into your Python application for Zabbix monitoring support
Anything else that comes to mind
You can use zabbix_utils for automating Zabbix tasks, such as scripting the automatic monitoring setup of your IT infrastructure objects. This can involve using ZabbixAPI for the direct management of Zabbix objects, Sender for sending values to hosts, and Getter for gathering data from Agents. We will discuss Sender and Getter in more detail later in this article.
For example, let’s imagine you have an infrastructure consisting of different branches. Each server or workstation is deployed from an image with an automatically configured Zabbix Agent and each branch is monitored by a Zabbix proxy since it has an isolated network. Your custom service or script can fetch a list of this equipment from your CMDB system, along with any additional information. It can then use this data to create hosts in Zabbix and link the necessary templates using ZabbixAPI based on the received information. If the information from CMDB is insufficient, you can request data directly from the configured Zabbix Agent using Getter and then use this information for further configuration and decision-making during setup. Another part of your script can access AD to get a list of branch users to update the list of users in Zabbix through the API and assign them the appropriate permissions and roles based on information from AD or CMDB (e.g., editing rights for server owners).
Another use case of the library may be when you regularly export templates from Zabbix for subsequent import into a version control system. You can also establish a mechanism for loading changes and rolling back to previous versions of templates. Here a variety of other use cases can also be implemented – it’s all up to your requirements and the creative usage of the library.
Of course, if you are a developer and there is a requirement to implement Zabbix monitoring support for your custom system or tool, you can implement sending data describing any events generated by your custom system/tool to Zabbix using Sender.
Installation and Configuration
To begin with, you need to install the zabbix_utils library. You can do this in two main ways:
No additional configuration is required. But you can specify values for the following environment variables: ZABBIX_URL, ZABBIX_TOKEN, ZABBIX_USER, ZABBIX_PASSWORD if you need. These use cases are described in more detail below.
Working with Zabbix API
To work with Zabbix API, it is necessary to import the ZabbixAPI class from the zabbix_utils library:
from zabbix_utils import ZabbixAPI
If you are using one of the existing popular community libraries, in most cases, it will be sufficient to simply replace the ZabbixAPI import statement with an import from our library.
At that point you need to create an instance of the ZabbixAPI class. T4here are several usage scenarios:
Use preset values of environment variables, i.e., not pass any parameters to ZabbixAPI:
from zabbix_utils import ZabbixAPI
api = ZabbixAPI()
Pass only the Zabbix API address as input, which can be specified as either the server IP/FQDN address or DNS name (in this case, the HTTP protocol will be used) or as an URL, and the authentication data should still be specified as values for environment variables:
from zabbix_utils import ZabbixAPI
api = ZabbixAPI(url="127.0.0.1")
Pass only the Zabbix API address to ZabbixAPI, as in the example above, and pass the authentication data later using the login() method:
from zabbix_utils import ZabbixAPI
api = ZabbixAPI(url="127.0.0.1")
api.login(user="Admin", password="zabbix")
Pass all parameters at once when creating an instance of ZabbixAPI; in this case, there is no need to subsequently call login():
from zabbix_utils import ZabbixAPI
api = ZabbixAPI(
url="127.0.0.1",
user="Admin",
password="zabbix"
)
The ZabbixAPI class supports working with various Zabbix versions, automatically checking the API version during initialization. You can also work with the Zabbix API version as an object as follows:
from zabbix_utils import ZabbixAPI
api = ZabbixAPI()
# ZabbixAPI version field
ver = api.version
print(type(ver).__name__, ver) # APIVersion 6.0.24
# Method to get ZabbixAPI version
ver = api.api_version()
print(type(ver).__name__, ver) # APIVersion 6.0.24
# Additional methods
print(ver.major) # 6.0
print(ver.minor) # 24
print(ver.is_lts()) # True
As a result, you will get an APIVersion object that has major and minor fields returning the respective minor and major parts of the current version, as well as the is_lts() method, returning true if the current version is LTS (Long Term Support), and false otherwise. The APIVersion object can also be compared to a version represented as a string or a float number:
If the account and password (or starting from Zabbix 5.4 – token instead of login/password) are not set as environment variable values or during the initialization of ZabbixAPI, then it is necessary to call the login() method for authentication:
from zabbix_utils import ZabbixAPI
api = ZabbixAPI(url="127.0.0.1")
api.login(token="xxxxxxxx")
After authentication, you can make any API requests described for all supported versions in the Zabbix documentation.
The format for calling API methods looks like this:
api_instance.zabbix_object.method(parameters)
For example:
api.host.get()
After completing all the necessary API requests, it’s necessary to execute logout() if authentication was done using login and password:
There is often a need to send values to Zabbix Trapper. For this purpose, the zabbix_sender utility is provided. However, if your service or script sending this data is written in Python, calling an external utility may not be very convenient. Therefore, we have developed the Sender, which will help you send values to Zabbix server or proxy one by one or in groups. To work with Sender, you need to import it as follows:
For cases when there is a necessity to send more values than Zabbix Trapper can accept at one time, there is an option for fragmented sending, i.e. sequential sending in separate fragments (chunks). By default, the chunk size is set to 250 values. In other words, when sending values in bulk, the 400 values passed to the send() method for sending will be sent in two stages. 250 values will be sent first, and the remaining 150 values will be sent after receiving a response. The chunk size can be changed, to do this, you simply need to specify your value for the chunk_size parameter when initializing Sender:
In the example above, the chunk size is set to 2. So, 5 values passed will be sent in three requests of two, two, and one value, respectively.
If your server has multiple network interfaces, and values need to be sent from a specific one, the Sender provides the option to specify a source_ip for the sent values:
It also supports reading connection parameters from the Zabbix Agent/Agent2 configuration file. To do this, set the use_config flag, after which it is not necessary to pass connection parameters when creating an instance of Sender:
Since the Zabbix Agent/Agent2 configuration file can specify one or even several Zabbix clusters consisting of multiple Zabbix server instances, Sender will send data to the first available server of each cluster specified in the ServerActive parameter in the configuration file. In case the ServerActive parameter is not specified in the Zabbix Agent/Agent2 configuration file, the server address from the Server parameter with the standard Zabbix Trapper port – 10051 will be taken.
By default, Sender returns the aggregated result of sending across all clusters. But it is possible to get more detailed information about the results of sending for each chunk and each cluster:
print(response)
# {"processed": 2, "failed": 0, "total": 2, "time": "0.000108", "chunk": 2}
if response.failed == 0:
print(f"Value sent successfully in {response.time}")
else:
print(response.details)
# {
# 127.0.0.1:10051: [
# {
# "processed": 1,
# "failed": 0,
# "total": 1,
# "time": "0.000051",
# "chunk": 1
# }
# ],
# zabbix.example.local:10051: [
# {
# "processed": 1,
# "failed": 0,
# "total": 1,
# "time": "0.000057",
# "chunk": 1
# }
# ]
# }
for node, chunks in response.details.items():
for resp in chunks:
print(f"processed {resp.processed} of {resp.total} at {node.address}:{node.port}")
# processed 1 of 1 at 127.0.0.1:10051
# processed 1 of 1 at zabbix.example.local:10051
Getting values from Zabbix Agent/Agent2 by item key.
Sometimes it can also be useful to directly retrieve values from the Zabbix Agent. To assist with this task, zabbix_utils provides the Getter. It performs the same function as the zabbix_get utility, allowing you to work natively within Python code. Getter is straightforward to use; just import it, create an instance by passing the Zabbix Agent’s address and port, and then call the get() method, providing the data item key for the value you want to retrieve:
In cases where your server has multiple network interfaces, and requests need to be sent from a specific one, you can specify the source_ip for the Agent connection:
The zabbix_utils library for Python allows you to take full advantage of monitoring using Zabbix, without limiting yourself to the integrations available out of the box. It can be valuable for both DevOps and SRE engineers, as well as Python developers looking to implement monitoring support for their system using Zabbix.
In the next article, we will thoroughly explore integration with an external service using this library to demonstrate the capabilities of zabbix_utils more comprehensively.
Questions
Q: Which Agent versions are supported for Getter?
A: Supported versions of Zabbix Agents are the same as Zabbix API versions, as specified in the readme file. Our goal is to create a library with full support for all Zabbix components of the same version.
Q: Does Getter support Agent encryption?
A: Encryption support is not yet built into Sender and Getter, but you can create your wrapper using third-party libraries for both.
from zabbix_utils import Sender
def psk_wrapper(sock, tls):
# ...
# Implementation of TLS PSK wrapper for the socket
# ...
sender = Sender(
server='zabbix.example.local',
port=10051,
socket_wrapper=psk_wrapper
)
Q: Is it possible to set a timeout value for Getter?
A: The response timeout value can be set for the Getter, as well as for ZabbixAPI and Sender. In all cases, the timeout is set for waiting for any responses to requests.
# Example of setting a timeout for Sender
sender = Sender(server='127.0.0.1', port=10051, timeout=30)
# Example of setting a timeout for Getter
agent = Getter(host='127.0.0.1', port=10050, timeout=30)
Q: Is parallel (asynchronous) mode supported?
A: Currently, the library does not include asynchronous classes and methods, but we plan to develop asynchronous versions of ZabbixAPI and Sender.
Q: Is it possible to specify multiple servers when sending through Sender without specifying a configuration file (for working with an HA cluster)?
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.