Post Syndicated from Aleksandr Iantsen original https://blog.zabbix.com/python-zabbix-utils-alert-tracker-tool/29010/
In this article, we will explore a practical example of using the zabbix_utils library to solve a non-trivial task – obtaining a list of alert recipients for triggers associated with a specific Zabbix host. You will learn how to easily automate the process of collecting this information, and see examples of real code that can be adapted to your needs.
Table of Contents
Over the last year, the zabbix_utils library has become one of the most popular tools for working with the Zabbix API. It is a convenient tool that simplifies interacting with the Zabbix server, proxy, or agent, especially for those who automate monitoring and management tasks.
Due to its ease of use and extensive functionality, zabbix_utils has found a following among system administrators, monitoring, and DevOps engineers. According to data from PyPI, the library has already been downloaded over 140,000 times since its release, confirming its demand within the community. It’s all thanks to you and your attention to zabbix_utils!
Task Description
Administrators often need to check which Zabbix users receive alerts for specific triggers in the Zabbix monitoring system. This can be useful for auditing, configuring new notifications, or simply for a quick diagnosis of issues. The task becomes especially relevant when you have plenty of hosts containing numerous triggers, and manually checking the recipients for each trigger through the Zabbix interface becomes very time-consuming.
In such cases, it is advisable to use a custom solution based on the Zabbix API. You can directly access all the required data using the API, and then use additional logic to determine the final alert recipients. The zabbix_utils library makes working with the Zabbix API more convenient and allows you to automate this process. In this project, we use the zabbix_utils library to write a Python script that collects a list of alert recipients for the triggers of the selected Zabbix host. This will allow you to obtain the necessary information faster and with minimal effort.
Environment Setup and Installation
To get started with zabbix_utils, you need to install the library and configure the connection to the Zabbix API. This article provides more details and examples on getting started with the library. However, it would be better if I describe the basic steps to prepare the environment here.
The library supports several installation methods described in the official README, making it convenient for use in different environments.
1. Installation via pip
The simplest and most common installation method is using the pip package manager. To do this, execute the command:
~$ pip install zabbix_utils
To install all necessary dependencies for asynchronous work, you can use the command:
~$ pip install zabbix_utils[async]
This method is suitable for most users, as pip automatically installs all required dependencies.
2. Installation from Zabbix Repository
Since writing the previous articles, we have added one more installation method – from the official Zabbix repository. First and foremost, you need to add the repository to your system if it has not been installed yet. Official Zabbix packages for Red Hat Enterprise Linux and Debian-based distributions are available on the Zabbix website.
For Red Hat Enterprise Linux and derivatives:
~# dnf install python3-zabbix-utils
For Debian / Ubuntu and derivatives:
~# apt install python3-zabbix-utils
3. Installation from Source Code
If you require the latest version of the library that has not yet been published on PyPI, or you want to customize the code, you can install the library directly from GitHub:
1. Clone the repository from GitHub:
~$ git clone https://github.com/zabbix/python-zabbix-utils
2. Navigate to the project folder:
~$ cd python-zabbix-utils/
3. Install the library by executing the command:
~$ python3 setup.py install
4. Testing the Connection to Zabbix API
After installing zabbix_utils, it is a good idea to check the connection to your Zabbix server via the API. To do this, use the URL to the Zabbix server, the token, or the username and password of the user who has permission to access the Zabbix API.
Example code for checking the connection:
from zabbix_utils import ZabbixAPI ZABBIX_AUTH = { "url": "your_zabbix_server", "user": "your_username", "password": "your_password" } api = ZabbixAPI(**ZABBIX_AUTH) hosts = api.host.get( output=['hostid', 'name'] ) print(hosts) api.logout()
Main Steps of the Task Solution
Now that the environment is set up, let’s look at the main steps for solving the task of retrieving the list of alert recipients for triggers associated with a specific Zabbix host in Zabbix.
In zabbix_utils, asynchronous API interaction support is built in through the AsyncZabbixAPI class. This allows multiple requests to be sent simultaneously and their results to be handled as they become ready, significantly reducing latencies when making multiple API calls. Therefore, we will use the AsyncZabbixAPI class and the asynchronous approach in this project.
Below are the main steps for solving the task, and code examples for each step. Please note that the code in this project is for demonstration purposes, may not be optimal, or could contain errors. Use it as an example or a base for your project, but not as a complete tool.
Step 1. Obtain Host ID
The first step is to identify the host for which we will retrieve information about triggers and alerts. We need to find the hostid using its name/host to do this. The Zabbix API provides a method to obtain this information, and using zabbix_utils makes this process much simpler.
Example of obtaining the host ID by its name:
host = api.host.get( output=["hostid"], filter={"name": "your_host_name"} )
This method returns a unique identifier for the host, which can be used further. However, for our test project, we will use a manually specified host identifier.
Step 2. Retrieve Host Triggers
With the hostid in hand, the next step is to retrieve all triggers associated with this host. Triggers contain the conditions that trigger the alerts. We need to collect information about all triggers so that we can then use it to select actions that match all the conditions.
Example of retrieving node triggers:
triggers = api.trigger.get( hostids=[hostid], selectTags="extend", selectHosts=["hostid"], selectHostGroups=["groupid"], selectDiscoveryRule=["templateid"], output="extend", )
This request returns complete information about the triggers for the host. We get not only the triggers but also their tags, associated host and host groups, and discovery rule information. All this information will be necessary to check the conditions of the actions.
Step 3. Initialize Trigger Metadata
At this stage, objects for each trigger are created to store their metadata. This is done using the Trigger class, which includes information about the trigger such as its name, ID, associated host groups, hosts, tags, templates, and operations.
Here’s the code defining the Trigger class:
class Trigger: def __init__(self, trigger): self.name = trigger["description"] self.triggerid = trigger["triggerid"] self.hostgroups = [g["groupid"] for g in trigger["hostgroups"]] self.hosts = [h["hostid"] for h in trigger["hosts"]] self.tags = {t["tag"]: t["value"] for t in trigger["tags"]} self.tmpl_triggerid = self.triggerid self.lld_rule = trigger["discoveryRule"] or {} if trigger["templateid"] != "0": self.tmpl_triggerid = trigger["templateid"] self.templates = [] self.messages = [] self._conditions = { "0": self.hostgroups, "1": self.hosts, "2": [self.triggerid], "3": trigger["event_name"] or trigger["description"], "4": trigger["priority"], "13": self.templates, "25": self.tags.keys(), "26": self.tags, } def eval_condition(self, operator, value, trigger_data): # equals or does not equal if operator in ["0", "1"]: equals = operator == "0" if isinstance(value, dict) and isinstance( trigger_data, dict): if value["tag"] in trigger_data: if value["value"] == trigger_data[ value["tag"]]: return equals elif value in trigger_data and isinstance( trigger_data, list): return equals elif value == trigger_data: return equals return not equals # contains or does not contain if operator in ["2", "3"]: contains = operator == "2" if isinstance(value, dict) and isinstance( trigger_data, dict): if value["tag"] in trigger_data: if value["value"] in trigger_data[ value["tag"]]: return contains elif value in trigger_data: return contains return not contains # is greater/less than or equals if operator in ["5", "6"]: greater = operator != "5" try: if int(value) < int(trigger_data): return not greater if int(value) == int(trigger_data): return True if int(value) > int(trigger_data): return greater except: raise ValueError( "Values must be numbers to compare them" ) def select_templates(self, templates): for template in templates: if self.tmpl_triggerid in [ t["triggerid"] for t in template["triggers"]]: self.templates.append(template["templateid"]) if self.lld_rule.get("templateid") in [ d["itemid"] for d in template["discoveries"] ]: self.templates.append(template["templateid"]) def select_actions(self, actions): selected_actions = [] for action in actions: conditions = [] if "filter" in action: conditions = action["filter"]["conditions"] eval_formula = action["filter"]["eval_formula"] # Add actions without conditions directly if not conditions: selected_actions.append(action) continue condition_check = {} for condition in conditions: if ( condition["conditiontype"] != "6" and condition["conditiontype"] != "16" ): if ( condition["conditiontype"] == "26" and isinstance(condition["value"], str) ): condition["value"] = { "tag": condition["value2"], "value": condition["value"], } if condition["conditiontype"] in self._conditions: condition_check[ condition["formulaid"] ] = self.eval_condition( condition["operator"], condition["value"], self._conditions[ condition["conditiontype"] ], ) else: condition_check[ condition["formulaid"] ] = True for formulaid, bool_result in condition_check.items(): eval_formula = eval_formula.replace( formulaid, str(bool_result))# Evaluate the final condition formula if eval(eval_formula): selected_actions.append(action) return selected_actions def select_operations(self, actions, mediatypes): messages_metadata = [] for action in self.select_actions(actions): messages_metadata += self.check_operations( "operations", action, mediatypes ) messages_metadata += self.check_operations( "update_operations", action, mediatypes ) messages_metadata += self.check_operations( "recovery_operations", action, mediatypes ) return messages_metadatadef check_operations(self, optype, action, mediatypes): messages_metadata = [] optype_mapping = { "operations": "0", # Problem event "recovery_operations": "1", # Recovery event "update_operations": "2", # Update event } operations = copy.deepcopy(action[optype]) # Processing "notify all involved" scenarios for idx, _ in enumerate(operations): if operations[idx]["operationtype"] not in ["11", "12"]: continue # Copy operation as a template for reuse op_template = copy.deepcopy(operations[idx]) del operations[idx] # Checking for message sending operations for key in [ k for k in ["operations", "update_operations"] if k != optype ]: if not action[key]: continue # Checking for message sending type operations for op in [ o for o in action[key] if o["operationtype"] == "0" ]: # Copy template for the current operation operation = copy.deepcopy(op_template) operation.update( { "operationtype": "0", "opmessage_usr": op["opmessage_usr"], "opmessage_grp": op["opmessage_grp"], } ) operation["opmessage"]["mediatypeid"] = op[ "opmessage" ]["mediatypeid"] operations.append(operation) for operation in operations: if operation["operationtype"] != "0": continue # Processing "all mediatypes" scenario if operation["opmessage"]["mediatypeid"] == "0": for mediatype in mediatypes: operation["opmessage"]["mediatypeid"] = mediatype[ "mediatypeid" ] messages_metadata.append( self.create_messages( optype_mapping[optype], action, operation, [ mediatype ] ) ) else: messages_metadata.append( self.create_messages( optype_mapping[optype], action, operation, mediatypes ) ) return messages_metadata def create_messages(self, optype, action, operation, mediatypes): message = Message(optype, action, operation) message.select_mediatypes(mediatypes) self.messages.append(message) return message
The code for creating Trigger class objects for each of the retrieved triggers:
for trigger in triggers: triggers_metadata[trigger["triggerid"]] = Trigger(trigger)
This loop iterates through all triggers and saves them in a dictionary called triggers_metadata, where the key is the triggerid and the value is the trigger object.
Step 4. Retrieve Template Information
The next step is to obtain data about the templates associated with all the triggers:
templates = api.template.get( triggerids=list(set([t.tmpl_triggerid for t in triggers_metadata.values()])), selectTriggers=["triggerid"], selectDiscoveries=["itemid"], output=["templateid"], )
This request returns information about all templates linked to the host’s triggers being examined. Executing a single query for all triggers is a more optimal solution than making individual requests for each trigger. This information will be needed for evaluating the “Template” condition in actions.
Step 5. Get Actions and Media Types
Next, we obtain the list of actions and media types configured in the system:
actions = api.action.get( selectFilter="extend", selectOperations="extend", selectRecoveryOperations="extend", selectUpdateOperations="extend", filter={"eventsource": 0, "status": 0}, output=["actionid", "esc_period", "eval_formula", "name"], )mediatypes = api.mediatype.get( selectUsers="extend", selectActions="extend", selectMessageTemplates="extend", filter={"status": 0}, output=["mediatypeid", "name"], )
Here we retrieve actions that define how and to whom alerts are sent, and mediatypes through which users can receive notifications (for example, email or SMS).
Step 6. Match Triggers with Templates and Actions
At this stage, each trigger is associated with the corresponding templates and actions:
for trigger in triggers_metadata.values(): trigger.select_templates(templates) messages += trigger.select_operations(actions, mediatypes)
Here, for each trigger, we update information about its templates and configured actions for sending notifications. The list of associated actions is determined by checking the conditions specified in them against the accumulated data for each trigger.
For each operation of the corresponding trigger action, a Message class object is created:
class Message: def __init__(self, optype, action, operation): self.optype = optype self.mediatypename = "" self.actionid = action["actionid"] self.actionname = action["name"] self.operationid = operation["operationid"] self.mediatypeid = operation["opmessage"]["mediatypeid"] self.subject = operation["opmessage"]["subject"] self.message = operation["opmessage"]["message"] self.default_msg = operation["opmessage"]["default_msg"] self.users = [u["userid"] for u in operation["opmessage_usr"]] self.groups = [g["usrgrpid"] for g in operation["opmessage_grp"]] self.recipients = [] # Escalation period set to action's period if not specified self.esc_period = operation.get("esc_period", "0") if self.esc_period == "0": self.esc_period = action["esc_period"] # Use action's escalation period if unset self.esc_step_from = self.multiply_time( self.esc_period, int(operation.get("esc_step_from", "1")) - 1 ) if operation.get("esc_step_to", "0") != "0": self.repeat_count = str( int(operation["esc_step_to"]) - int(operation["esc_step_from"]) + 1 ) # If not a problem event, set repeat count to 1 elif self.optype != "0": self.repeat_count = "1" # Infinite repeat count if esc_step_to is 0 else: self.repeat_count = “∞” def multiply_time(self, time_str, multiplier): # Multiply numbers within the time string result = re.sub( r"(\d+)", lambda m: str(int(m.group(1)) * multiplier), time_str ) if result[0] == "0": return "0" return result def select_mediatypes(self, mediatypes): for mediatype in mediatypes: if mediatype["mediatypeid"] == self.mediatypeid: self.mediatypename = mediatype["name"] # Select message templates related to operation type msg_template = [ m for m in mediatype["message_templates"] if ( m["recovery"] == self.optype and m["eventsource"] == "0" ) ] # Use default message if applicable if msg_template and self.default_msg == "1": self.subject = msg_template[0]["subject"] self.message = msg_template[0]["message"] def select_recipients(self, user_groups, recipients): for groupid in self.groups: if groupid in user_groups: self.users += user_groups[groupid] for userid in self.users: if userid in recipients: recipient = copy.deepcopy(recipients[userid]) if self.mediatypeid in recipient.sendto: recipient.mediatype = True self.recipients.append(recipient)
Each such object represents a separate message sent to users (recipients) and will contain all message information – its subject, text, recipients, and escalation parameters.
Step 7. Collect User and Group Identifiers
After matching the triggers with actions, the process of collecting unique identifiers for users and groups starts:
userids = set() groupids = set() for message in messages: userids.update(message.users) groupids.update(message.groups)
This code snippet collects the IDs of all users and groups involved in the operations for each trigger. This is necessary to perform only one request to the Zabbix API for all involved users and their groups, rather than making separate requests for each trigger.
Step 8. Obtain User and Group Information
The next step is to collect detailed information about users and user groups:
usergroups = { group["usrgrpid"]: group for group in api.usergroup.get( selectUsers=["userid"], selectHostGroupRights="extend", output=["usrgrpid", "role"], ) } users = { user["userid"]: user for user in api.user.get( selectUsrgrps=["usrgrpid"], selectMedias=["mediatypeid", "active", "sendto"], selectRole=["roleid", "type"], filter={"status": 0}, output=["userid", "username", "name", "surname"], ) }
Here we gather data about users, including their role and media types through which they receive notifications, as well as data about user groups, including access rights to host groups and the list of users in each group. All this information will be needed to check access to the host with the triggers we are working with.
Step 9. Match Users and Groups with Triggers
After obtaining user information, we match users and groups with their respective rights to receive notifications. Here we also link users with groups, updating the information regarding rights and groups for each user.
for userid in userids: if userid in users: user = users[userid] recipients[userid] = Recipient(user) for group in user["usrgrps"]: if group["usrgrpid"] in usergroups: recipients[userid].permissions.update([ h["id"] for h in usergroups[group["usrgrpid"]]["hostgroup_rights"] if int(h["permission"]) > 1 ]) for groupid in groupids: if groupid in usergroups: group = usergroups[groupid] user_groups[group["usrgrpid"]] = [] for user in group["users"]: user_groups[group["usrgrpid"]].append(user["userid"]) if user["userid"] in recipients: recipients[user["userid"]].groups.update(group["usrgrpid"]) elif user["userid"] in users: recipients[user["userid"]] = Recipient(users[user["userid"]]) recipients[user["userid"]].permissions.update([ h["id"] for h in group["hostgroup_rights"] if int(h["permission"]) > 1 ])
This code fragment connects each user with their groups and vice versa, creating a complete list of users with their access rights to the host, and thus their eligibility to receive notifications about events for this host.
For each recipient, a Recipient class object is created containing data about the recipient, such as the notification address, access rights to hosts, configured mediatypes, etc.
Here’s the code that describes the Recipient class:
class Recipient: def __init__(self, user): self.userid = user["userid"] self.username = user["username"] self.fullname = "{name} {surname}".format(**user).strip() self.type = user["role"]["type"] self.groups = set([g["usrgrpid"] for g in user["usrgrps"]]) self.has_right = False self.permissions = set() self.sendto = { m["mediatypeid"]: m["sendto"] for m in user["medias"] if m["active"] == "0" } # Check if the user is a super admin (type 3) if self.type == "3": self.has_right = True
Step 10. Match Messages with Recipients
Finally, we match recipients with specific messages from Step 6:
for message in messages: message.select_recipients(user_groups, recipients)
This step completes the main process – each message is assigned to the relevant recipients.
Step 11. Check Recipient Access Rights and Output the Result
Before the actual output of the result with the list of recipients, we can perform a check of the recipients’ message rights and filter only those who have the corresponding rights to receive notifications for the events related to the trigger, or those who have all configured media types specified and active. After these actions, the information can be output in any convenient way – whether it be exporting to a file or displaying it on the screen:
for trigger in triggers_metadata.values(): for message in trigger.messages: for recipient in message.recipients: recipient.show = True if not recipient.has_right: recipient.has_right = (len([gid for gid in trigger.hostgroups if gid in recipient.permissions ]) > 0) if not recipient.has_right and not show_unavail: recipient.show = False
Example Implementation
All the examples and code snippets described above have been compiled to create a solution demonstrating the algorithm for obtaining notification recipients for triggers associated with the selected host. We have implemented this algorithm as a simple web interface to make the result more illustrative and convenient for familiarization.
This interface allows users to enter the host’s ID. The script then processes the data and provides a list of notification recipients associated with the triggers on that host. The web interface uses asynchronous requests to the Zabbix API and the zabbix_utils library to ensure fast data processing and ease of use with many triggers and users.
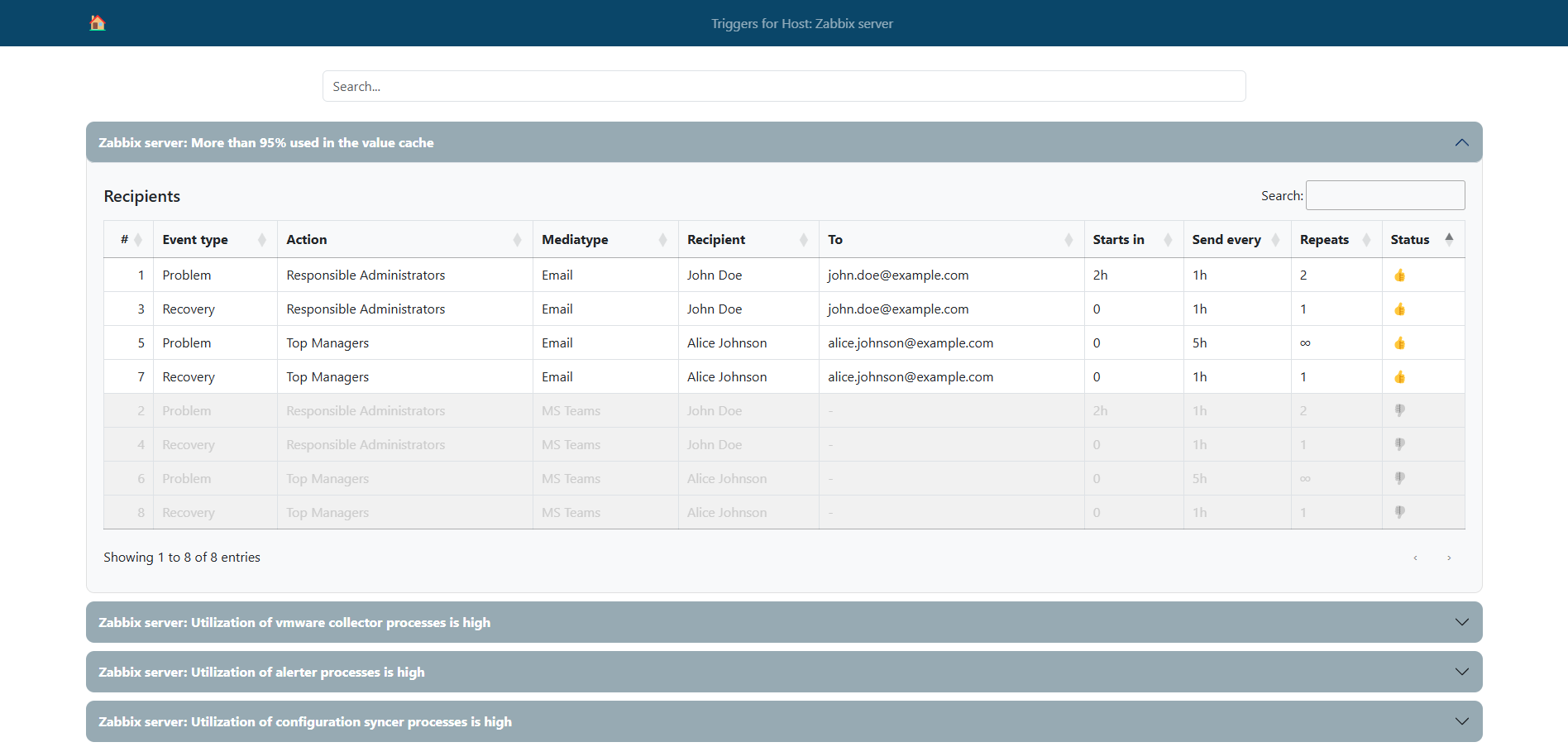
This lets you familiarize yourself with the theoretical steps and code examples and also try to put this solution into action.
Please note once again that the code in this project is for demonstration purposes, may not be optimal, or could contain errors. Use it as an example or a base for your project, but not as a complete tool.
The web interface’s complete source code and installation instructions can be found on GitHub.
Conclusion
In this article, we explored a practical example of using the zabbix_utils library to solve the task of obtaining alert recipients for triggers associated with a selected Zabbix host using the Zabbix API. We detailed the key steps, from setting up the environment and initializing trigger metadata to working with notification recipients and optimizing performance with asynchronous requests.
Using zabbix_utils allowed us to optimize and accelerate interaction with the Zabbix API, expanding the capabilities of the Zabbix web interface and increasing efficiency when working with large volumes of data. Thanks to support for asynchronous processing and selective API requests, it is possible to significantly reduce the load on the server and improve system performance when working with Zabbix, which is especially important in large infrastructures.
We hope this example will assist you in implementing your own solutions based on the Zabbix API and zabbix_utils, and demonstrate the possibilities for optimizing your interaction with the Zabbix API.
The post Using the zabbix_utils Library for Tool Development appeared first on Zabbix Blog.