Post Syndicated from Alex Krivit original https://blog.cloudflare.com/early-hints/


Want to know a secret about Internet performance? Browsers spend an inordinate amount of time twiddling their thumbs waiting to be told what to do. This waiting impacts page load performance. Today, we’re excited to announce support for Early Hints, which dramatically improves browser page load performance and reduces thumb-twiddling time.
In initial tests using Early Hints, we have observed more than 30% improvement to page load time for browsers visiting a website for the first time.
Early Hints is available in beta today — Cloudflare customers can request access to Early Hints in the dashboard’s Speed tab. It’s free for all customers because we think the web should be fast!
Early Hints in a nutshell
Browsers need instructions for what to render and what resources need to be fetched to complete “painting” a given web page. These instructions come from a server response. But the servers sending these responses often need time to compile these resources — this is known as “server think time.” While the servers are busy during this time… browsers sit idle and wait.
Early Hints takes advantage of “server think time” to asynchronously send instructions to the browser to begin loading resources while the origin server is compiling the full response. By sending these hints to a browser before the full response is prepared, the browser can figure out what it needs to do to load the webpage faster for the end user. Faster page loads and lower user-perceived latency means happier users!
More formally, Early Hints is a web standard that defines a new HTTP status code (103 Early Hints) that defines new interactions between a client and server. 103s are served to clients while a 200 OK (or error) response is being prepared (the so-called “server think time”), and contain hints on which assets will likely be needed to fully render the web page. This hinting speeds up page loads and generally reduces user-perceived latency.
Sending hints on which assets to expect before the entire response is compiled allows the browser to use think time (when it would otherwise have been waiting) to fetch needed assets, prepare parts of the displayed page, and otherwise get ready for the full response to be returned.

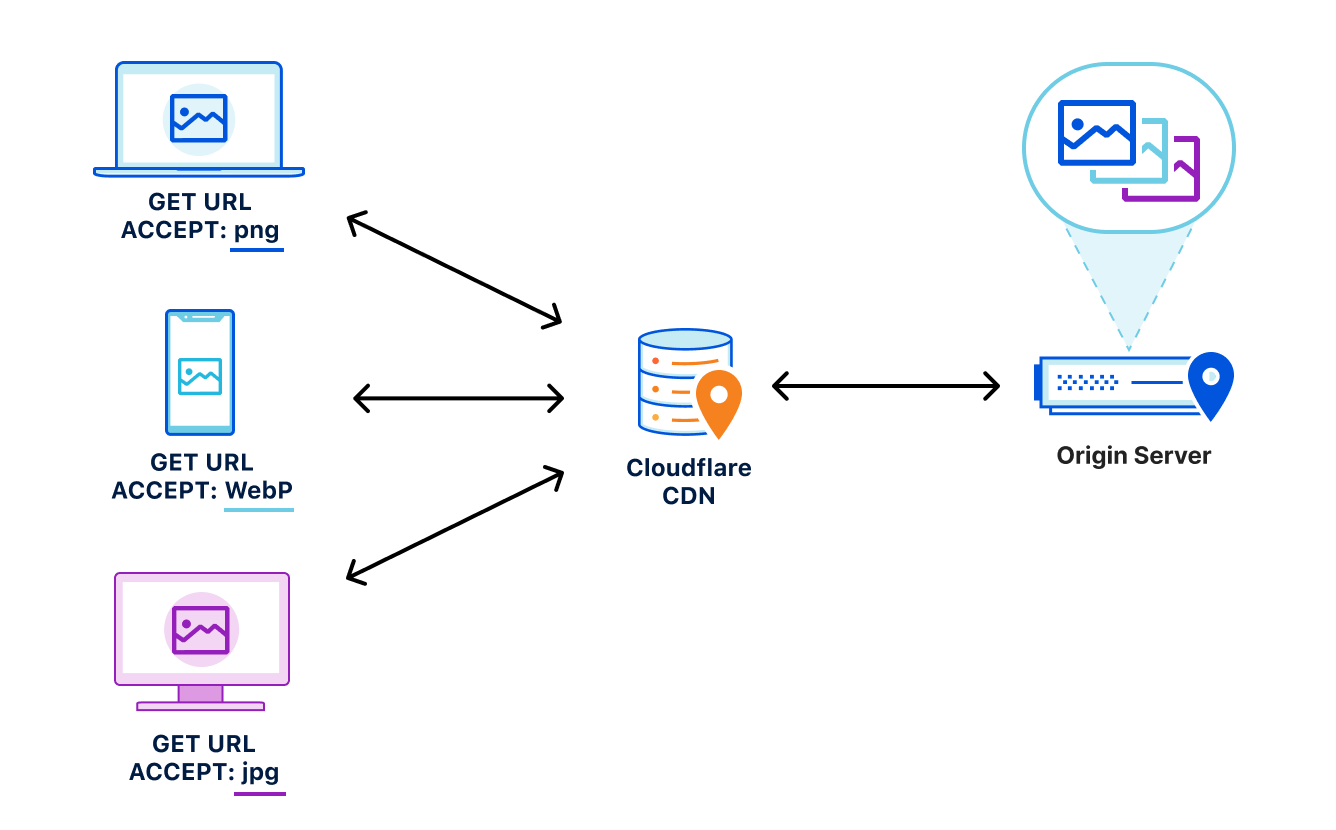
Cloudflare, as an edge network that sits in between client and server, is well positioned to issue these hints to clients on servers’ behalf. This is true for a few reasons:
- 103 is an experimental status code that origins may not be able to emit on their own, mostly for legacy reasons. Much of the machinery that powers the web incorrectly assumes that HTTP requests always correspond 1:1 with HTTP responses. This mistaken premise is baked into most HTTP server software, making it difficult for origin servers to emit Early Hints 103 responses prior to a “final” 200 OK response.
Cloudflare edge servers handling this complexity on behalf of our customers neatly sidesteps these technical challenges and gets the adoption flywheel spinning faster on this exciting new technology (more on this flywheel later).
- Cloudflare’s edge is very close to end users. This means we can serve hints very quickly, filling even the smallest of server think blocks with useful information the client can use to get a jump start on loading assets.
- Cloudflare already sees request and response flow from our customers. We use this data to generate hints automatically, without a customer needing to make any origin changes at all.
How can we speed up “slow” dynamic page loads?
The typical request/response cycle between browsers and servers leaves a lot of room for optimization. When you type an address into the search bar of your browser and press Enter, a series of things happen to get you the content you need, as quickly as possible. Your browser first converts the hostname in the URL into an IP address, then establishes an initial connection to the server where the content is stored.
After the connection is established, the actual request is sent. This is often a GET request with a bunch of information about what the browser can and cannot display to the end user. Following the request, the browser must wait for the origin server to send the first bytes of the response before it begins to render the page. In this time, the server is busy executing all sorts of business logic (looking things up in databases, personalizing the page, detecting fraud, etc.) before spitting a response out to the browser.
Once the response for the original HTML page is received, the browser then needs to parse the page, generate a Document Object Model (DOM), and begin loading subresources specified on the page, like images, scripts, and additional stylesheets.
Let’s take a look at this in action. Below is the performance waterfall for a checkout page on pinecoffeesupply.com, a coffee shop with a storefront on Shopify:
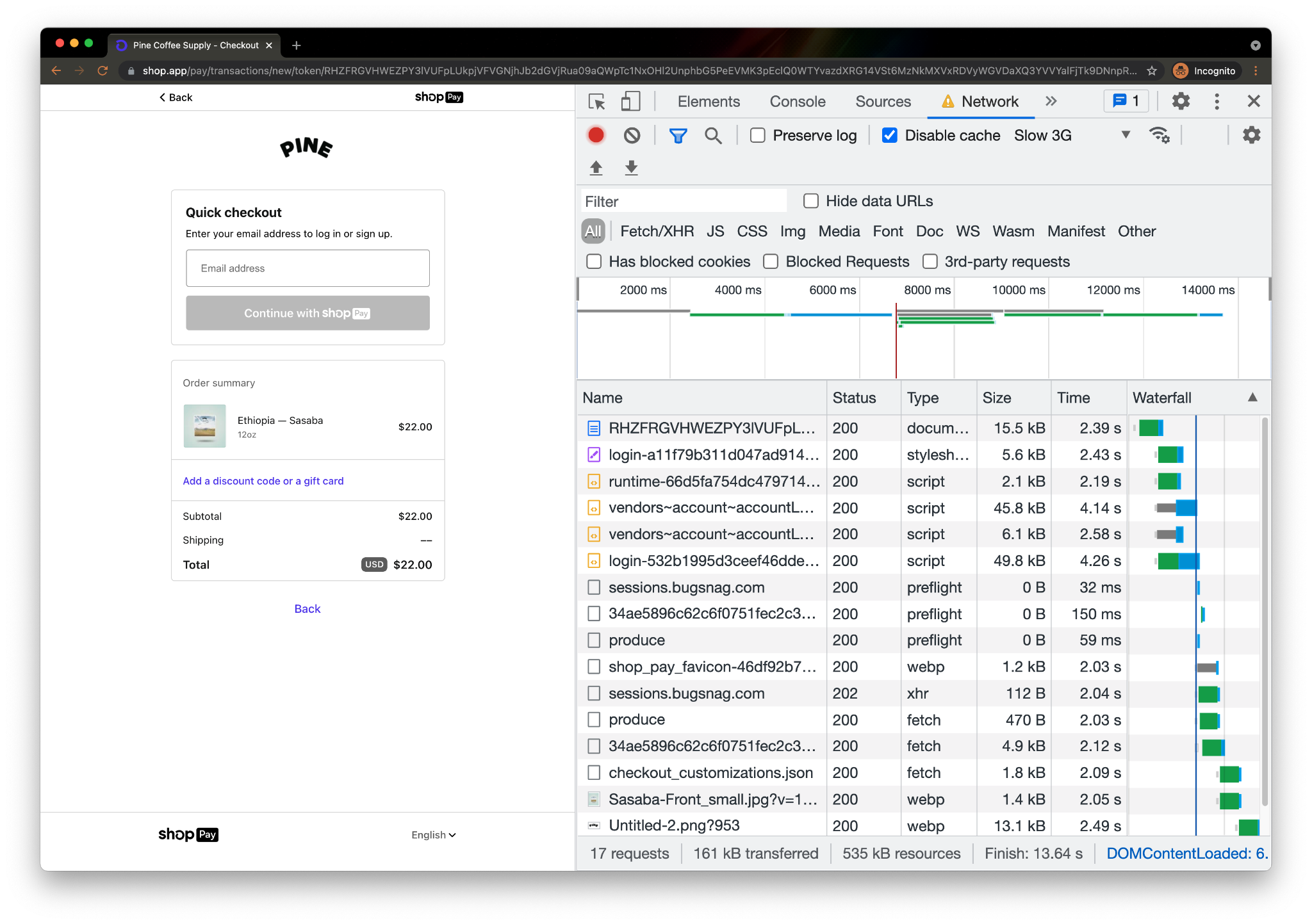
Page rendering cannot complete (and the shopper can’t get their coffee fix, and the coffee shop can’t get paid!) until key assets are loaded. Information on subresources needed for the browser to load the page aren’t available until the server has thought about and returned the initial response (the first document in the above table). In the above example, the page load could have been accelerated had the browser known, prior to receiving the full response, that the stylesheet and the four subsequent scripts will be needed to render the page.
Attempting to parallelize this dependency is what Early Hints is all about — productively using that “server think time” to help get the browser going on critical steps to render the page before the full server response arrives. The green “thinking” bar overlaps with the blue “content download” bar, allowing both the browser and server to be preparing the page at the same time. No more waiting. This is what Early Hints is all about!
“Entrepreneurs know that first impressions matter. Shopify’s own data shows that on average, when a store improves the speed of the first page in the buyer journey by 10%, there is a 7% increase in conversion. We see great promise in Early Hints being another tool to help improve the performance and experience for all merchants and customers.”
— Colin Bendell, Director Performance Engineering at Shopify
How does Early Hints speed things up?
Early Hints is a status code used in non-final HTTP responses. It is designed to speed up overall page load times by giving the browser an early signal about what certain linked assets might appear in the final response. The browser takes those hints and begins preparing the page for when the final 200 OK response from the server arrives.
The RFC provides this example of how the request/response cycle will look with Early Hints:
Client request:
GET / HTTP/1.1
Host: example.comServer responses:
Early Hint Response
HTTP/1.1 103 Early Hints
Link: </style.css>; rel=preload; as=style
Link: </script.js>; rel=preload; as=script⏱…Server Think Time… ⏱
Full Response
HTTP/1.1 200 OK
Date: Thurs, 16 Sept 2021 11:30:00 GMT
Content-Length: 1234
Content-Type: text/html; charset=utf-8
Link: </style.css>; rel=preload; as=style
Link: </script.js>; rel=preload; as=script
[Rest of Response]Seems simple enough. We’ve neatly communicated information to the browser on what resources it should consider preloading while the server is computing a full response.
This isn’t a new idea though!
Didn’t server push try to solve this problem?
There have been previous attempts at solving this problem, notably HTTP/2 “server push”. However, server push suffered from two major problems:
Server push sent the wrong bytes at the wrong time
The server pushed assets to the client, without great awareness of what was already present in browser caches, without knowing how much “server think time” would elapse and how best to spend it. Web performance guru Pat Meenan summarized server push’s gotchas in a mail thread discussing Chrome’s intent to deprecate and remove server push support:
Push sounds like a great solution, particularly when it can be done intelligently to not push resources already in cache and if it can exactly only fill the wait time while a CDN edge goes back to an origin for the HTML but getting those conditions right in practice is extremely rare. In virtually every case I have seen, the pushed resources end up delaying the HTML itself, the CSS and other render-blocking resources. Delaying the HTML is particularly bad because it delays the browser’s discovery of all of the other resources on the page. Preload works with the normal document parsing and resource discovery, letting preloaded resources intermix with other important resources and giving the dev, browsers and origins more control over prioritization.
Early Hints avoids these issues by “hinting” (vs. push being dictatorial) to clients which assets they should load, allowing them to prioritize resource loads with more complete information about what they will likely need to render a page, what they have cached, and other heuristics.
Using Early Hints with “rel=preload” solves the unsolicited bytes problem, but can still suffer from the ordering issue (forcing clients to load the wrong bytes at the wrong time). Early Hints’ superpower may actually be its use in conjunction with “rel=preconnect”. Many pages load hundreds of third party resources, and setting up connections and TLS sessions with each outside origin is time (but not bandwidth) intensive. Setting up these third party origin connections early, during think time, has practical advantages for page loading experience without the potential collateral damage of using “rel=preload”.
Server push wasn’t broadly implemented
The other notable issue with Server Push was that browsers supported it, and some origin servers implemented the feature, but no major CDN products (Cloudflare’s included) deemed the feature promising enough to implement and support at scale. Support for standards like server push or Early Hints in each key piece of the web content supply chain is critical for mass adoption.
Cracking the chicken and egg problem

Standards like Early Hints often don’t get off the ground because of this chicken and egg problem: clients have no reason to support new standards without server support and servers have no reason to implement support without clients speaking their language. As previously discussed, Early Hints is particularly complicated for origins to directly support, because 103 is an unfamiliar status code and multiple responses to a single request may not be a well-supported pattern in common HTTP server and application stacks.
We’ve tackled this in a few ways:
- Close partnership with Google Chrome and other browser teams to build support for the same standard at the same time, ensuring a critical mass of adoption for Early Hints from day one.
- Developing ways for hints to be emitted by our edge to clients with support for the standard without requiring support for the standard from the origin. We’ve been fortunate to have a ready, willing, and able design partner in Shopify, whose performance engineering team has been instrumental in shaping our implementation and testing our production deployment.
We plan to support Early Hints in two ways: one enabled now, and the other coming soon.
Now: Turning 200 OK Link: headers into 103 Early Hints
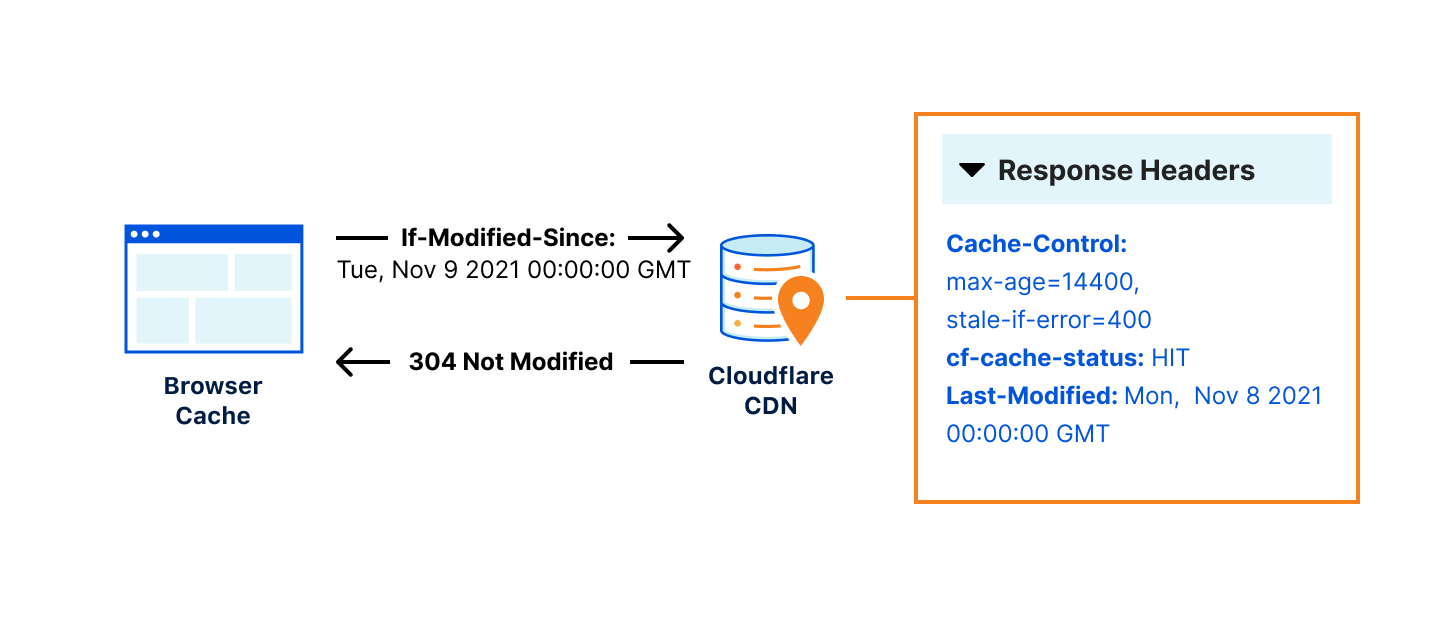
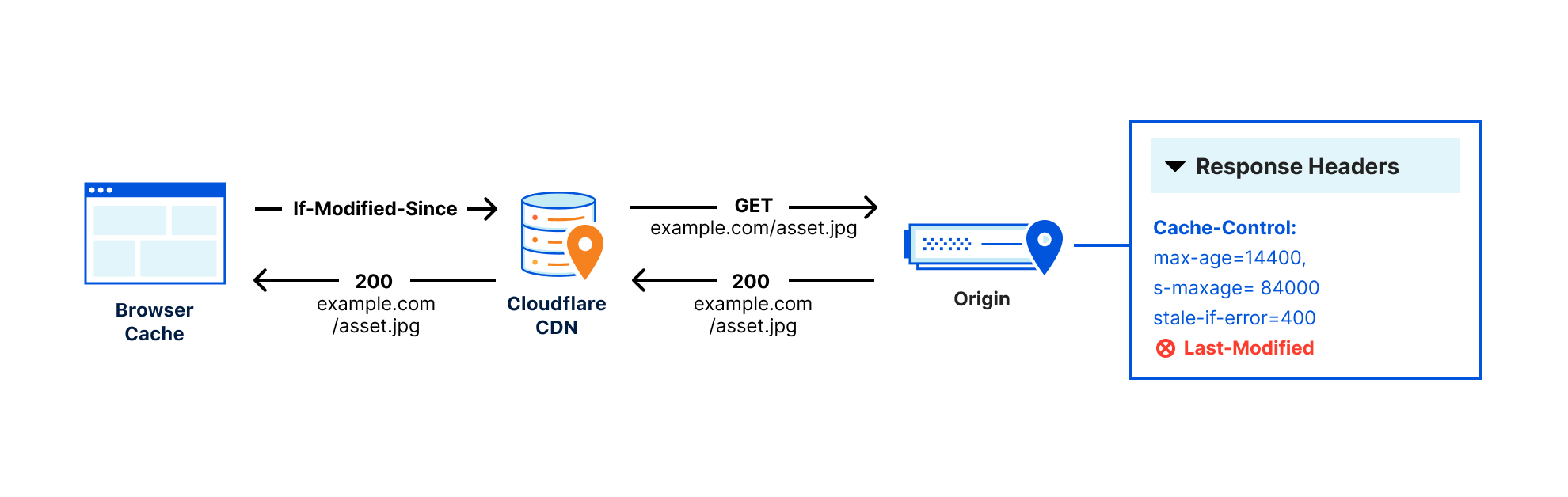
To avoid requiring origins to emit 103 responses from their origins directly, we settled on an approach that takes advantage of something many customers already used to indicate which assets an HTML page depends on, the Link: response header.
- When Cloudflare gets a response from the origin, we will parse it for Link headers with preload or preconnect rel types. These rel types indicate to the browser that the asset should be loaded as soon as possible (preload), or that a connection should be established to the specified origin but no bytes should be transferred (preconnect).
- Cloudflare takes these headers and caches them at our edge, ready to be served as a 103 Early Hints payload.
- When subsequent requests come for that asset, we immediately send the browser the cached Early Hints response while proxying the request to the origin server to generate the full response.
- Cloudflare then proxies the full response from origin to the browser when it’s available.
- When the full response is available, it will contain Link headers (that’s how we started this whole story). We will compare the Link headers in the 200 response with the cached version to make sure that they are the most up to date. If they have changed since they’ve been cached, we will automatically purge the out-of-date Early Hints and re-cache the new ones.
Coming soon: Smart Early Hints generation at the edge
We’re working hard on the next version of Early Hints. Smart Early Hints will use machine learning to generate Early Hints even when there isn’t a Link header present in the response from which we can harvest a 103. By analyzing historical request/response cycles for our customers, we can infer what assets being preloaded would help browsers load a webpage more quickly.
Look for Smart Early Hints in the next few months.
Browser support
As previously mentioned, we’ve partnered closely with Google Chrome and other browser vendors to ensure that their implementations of Early Hints interoperate well with Cloudflare’s. Google Chrome, Microsoft Edge, and Mozilla Firefox have announced their intention to support Early Hints. Progress for this support can be tracked here and here. We expect more browsers to announce support soon.
Benchmarking the impact of Early Hints
Once you get accepted into the beta and enable the feature, you can see Early Hints in action using Google Chrome, version 94 or higher. As of Sept 16th 2021, the Chrome Dev channel is at version 94.
Testing Early Hints with Chrome version 94 or higher
Early Hints support is available in Chrome by running (assuming a Mac, but the same flag works on Windows or Linux):
open /Applications/Google\ Chrome\ Dev.app --args --enable-features=EarlyHintsPreloadForNavigation
Testing Early Hints with Web Page Test
- Open webpagetest.org (a free performance testing tool).
- Specify the desired test URL. It should have the necessary preload/preconnect rel types in the Link header of the response.
- Choose Chrome Canary (or any Chrome version higher than 94) for the browser
- Under advanced settings, select Chromium.
- At the bottom of the Chromium section there’s a command-line section where you should paste Chrome’s Early Hints flag:
--enable-features=EarlyHintsPreloadForNavigation.
- To see the page load comparison, you can remove this flag and Early Hints won’t be enabled.
You can also test via Chrome’s Origin Trials.
Using Web Page Test, we’ve been able to observe greater than 30% improvement to a page’s content loading in the browser as measured by Largest Contentful Paint (LCP). An example test filmstrip:

A few other considerations when testing…
- Chrome will not support Early Hints on HTTP/1.1 (or earlier protocols).
- Chrome will not support Early Hints on subresource requests.
- We encourage testers to see how different rel types improve performance along with other Cloudflare performance enhancements like Argo.
- It can be hard to see which resources are actually being loaded early as a result of Early Hints. Interrogating the ResourceTiming API will return initiator=EarlyHints for those assets.
Signing up for the Early Hints beta
Early Hints promises to revolutionize web performance. Support for the standard is live at our edge globally and is being tested by customers hungry for speed.
How to sign up for Cloudflare’s Early Hints beta:
- Sign in to your Cloudflare Account
- In the dashboard, navigate to Speed tab
- Click on the Optimization section
- Locate the Early Hints beta sign up card and request access. We’re enabling access for users on the beta list in batches.
Early Hints holds tremendous promise to speed up everyone’s experience on the web. It’s exactly the kind of product we like working on at Cloudflare and exactly the kind of feature we think should be free, for everyone. Be sure to check out the beta and let us know what you think.
You can explore our beta implementation in the Speed tab. And if you’re an engineer interested in improving the performance of the web for all, come join us!