Rapid7 is thrilled to announce that the 2nd annual VeloCON: Digging Deeper Together virtual summit will be held this September 13th at 9 am ET. Once again, the conference will be online and completely free!
VeloCON is a one-day event focused on the Velociraptor community. It’s a place to share experiences in using and developing Velociraptor to address the needs of the wider DFIR community and an opportunity to take a look ahead at the future of our platform.
This year’s event calls for even more of the stimulating and informative content that made last year’s VeloCON so much fun. Don’t miss your chance at being a part of the marquee event of the open-source DFIR calendar.
Registration is now OPEN! Click here to register and get event updates and start time reminders.
Last year’s event was a tremendous success, with over 500 unique participants enjoying fascinating discussions, tech talks and the opportunity to get to know real members of our own community.
Leading Edge Panel
Rapid7 and the Velociraptor team have invited industry leading DFIR professionals, community advocates and thought leaders to host an exciting presentation panel. Proposals underwent a thorough review process to select presentations of maximum interest to VeloCON attendees and the wider Velociraptor community.
VeloCON focuses on work that pushes the envelope of what is currently possible using Velociraptor. Potential topics to be addressed by the panel include, but are not limited to:
Use cases of Velociraptor in real investigations
Novel deployment modes to cater for specific requirements
Contributions to Velociraptor to address new capabilities
Potential future ideas and features that Velociraptor
Integration of Velociraptor with other tools/frameworks
Analysis and acquisition on novel Forensic Artifacts
Register Today
Please register for VeloCON 2023 by following this link. You’ll be able to preview panelist bios as well as receive email confirmations and reminders as we get closer to the event.
Learn more about Velociraptor by visiting any of our web and social media channels below:
Rapid7 is thrilled to announce that the 2nd annual VeloCON virtual summit will be held this September (date TBD), with times oriented to the continental USA time zones. Once again, the conference will be online and completely free!
VeloCON is a one-day event focused on the Velociraptor community. It’s a place to share experiences in using and developing Velociraptor to address the needs of the wider DFIR community and an opportunity to take a look ahead at the future of our platform.
This year’s event calls for even more of the stimulating and informative content that made last year’s VeloCON so much fun. Don’t miss your chance at being a part of this year’s marquee event of the open-source DFIR calendar.
The call for presentations closes Monday, July 17, 2023 (see details below).
Last year’s event was a tremendous success, with over 500 unique participants enjoying our lineup of fascinating discussions, tech talks and the opportunity to get to know real members of our own community.
Call for presentations (CFP)
VeloCON invites contributions in the form of a 30-45 minute presentation. We require a brief proposal (~500 words; not a paper). These proposals undergo a review process to select presentations of maximum interest to VeloCON attendees and the wider Velociraptor community and to filter out sales pitches.
VeloCON focuses on work that pushes the envelope of what is currently possible using Velociraptor. Potential topics to be addressed by submissions include, but are not limited to:
Use cases of Velociraptor in real investigations
Novel deployment modes to cater for specific requirements
Contributions to Velociraptor to address new capabilities
Potential future ideas and features that Velociraptor
Integration of Velociraptor with other tools/frameworks
Analysis and acquisition on novel Forensic Artifacts
Submission process
Please email your submission to [email protected] and include the following details:
Your name and email address (if different from the sending email)
Company/affiliation and title to be included on the agenda
Presentation title
A short abstract (~500 words) to be included in the agenda
Deadline
Submissions are due Monday, July 17, 2023 and a decision will be announced shortly afterwards.
A New Client-Server Communication Protocol, VFS GUI, and More Performance Upgrades Make This The Fastest and Most Scalable Velociraptor Yet
Rapid7 is excited to announce the release of version 0.6.8 of Velociraptor—an advanced, open-source digital forensics and incident response (DFIR) tool that enhances visibility into your organization’s endpoints. This release has been in development and testing for several months and features significant contributions and testing from our community. We are thrilled to share its powerful new features and improvements here today.
Performance Improvements
A big theme in the 0.6.8 release was about performance improvement, making Velociraptor faster, more efficient and more scalable (even more so than it currently is!).
New Client-Server Communication Protocol
When collecting artifacts from endpoints Velociraptor maintains a collection state (e.g. how many bytes were transferred?, how many rows? was the collection successful? etc). Previously tracking the collection was the task of the server, but this extra processing limited the total number of collections it could process.
In the 0.6.8 release, a new communication protocol was added to offload a lot of the collection tracking to the client itself. This reduces the amount of work on the server and allows more collections to be processed at the same time.
To maintain support with older clients, the server continues to use the older communication protocol with them—but will achieve the most improvement in performance once the newer clients are deployed.
New Virtual File System GUI
The VFS feature in Velociraptor allows users to interactively inspect directories and files on the endpoint, in a familiar tree-style user interface. The previous VFS view would store the entire directory listing in a single table for each directory. For very large directories like C:\Windows or C:\Windows\System32 (which typically have thousands of files) this would strain the browser leading to unusable UI.
In the latest release, the VFS GUI uses the familiar paged table and syncs this directory listing in a more efficient way. This improves performance significantly: for example, it is now possible and reasonable to perform a recursive directory sync on C:\Windows, on my system syncs over 250k files in less than 90 seconds.
Inspecting a large directory is faster with paging tables.
Since the VFS is now using the familiar paging table UI, it is also possible to filter, sort on any column using that same UI.
Faster Export Functionality
Velociraptor hunts and collections can be exported to a ZIP file for easy consumption in other tools. The 0.6.8 release improved the export code to make it much faster. Additionally, the GUI was improved to show how many files were exported into the zip, and other statistics.
Exporting collections is much faster!
Tracing Capability On Client Collections
We often get questions about what happened to a collection that seems to be hung? It is difficult to know why a collection seems to be unresponsive or stopped – it could mean the client was killed for some reason, (e.g. due to excessive memory use or a timeout).
Previously the only way to gather client side information was to collect a Generic.Client.Profile collection. This required running it at just the right time and did not guarantee that we would get helpful insight of what the query and the client binary were doing during the operation in question.
In the latest release it is now possible to specify a trace on any collection to automatically collect client side state as the collection is progressing.
Enabling trace on every collection increases visibility
Trace files contain debugging information
VQL Improvement – Disk Based Materialize Operator
The VQL LET ... <= operator is called the materializing LET operator because it expands the following query into a memory array which can be accessed cheaply multiple times.
While this is useful for small queries, it has proved dangerous in some cases, because users inadvertently attempted to materialize a very large query (e.g. a large glob() operation) dramatically increasing memory use. For example, the following query could cause problems in earlier versions.
LET X <= SELECT * FROM glob(globs=specs.Glob, accessor=Accessor)
In the latest release the VQL engine was improved to support a temp file based materialized operator. If the materialized query exceeds a reasonable level (by default 1000 rows), the engine will automatically switch away from memory based storage into file backed storage. Although file based storage is slower, memory usage is more controlled.
Ideally the VQL is rewritten to avoid this type of operation, but sometimes it is unavoidable, and in this case, file based materialize operations are essential to maintain stability and acceptable memory consumption.
New MSI Deployment Option
On Windows the recommended way to install Velociraptor is via an MSI package. The MSI package allows the software to be properly installed and uninstalled and it is also compatible with standard Windows software management procedures.
Previously however, building the MSI required using the WIX toolkit – a Windows only MSI builder which is difficult to run on other platforms. Operationally building with WIX complicates deployment procedures and requires using a complex release platform.
In the 0.6.8 release, a new method for repacking the official MSI package is now recommended. This can be done on any operating system and does not require WIX to be installed. Simply embed the client configuration file in the officially distributed MSI packages using the following command:
If you’re interested in any of these new features, we welcome you to take Velociraptor for a spin by downloading it from our release page. It’s available for free on GitHub under an open-source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing [email protected]. You can also chat with us directly on our Discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:
Rapid7 is excited to announce the release of version 0.6.6 of Velociraptor – an advanced, open-source digital forensics and incident response (DFIR) tool that enhances visibility into your organization’s endpoints. After several months of development and testing, we are excited to share its powerful new features and improvements.
Multi-tenant mode
The largest improvement in the 0.6.6 release by far is the introduction of organizational division within Velociraptor. Velociraptor is now a fully multi-tenanted application. Each organization is like a completely different Velociraptor installation, with unique hunts, notebooks, and clients. That means:
Organizations can be created and deleted easily with no overheads.
Users can seamlessly switch between organizations using the graphic user interface (GUI).
Operations like hunting and post processing can occur across organizations.
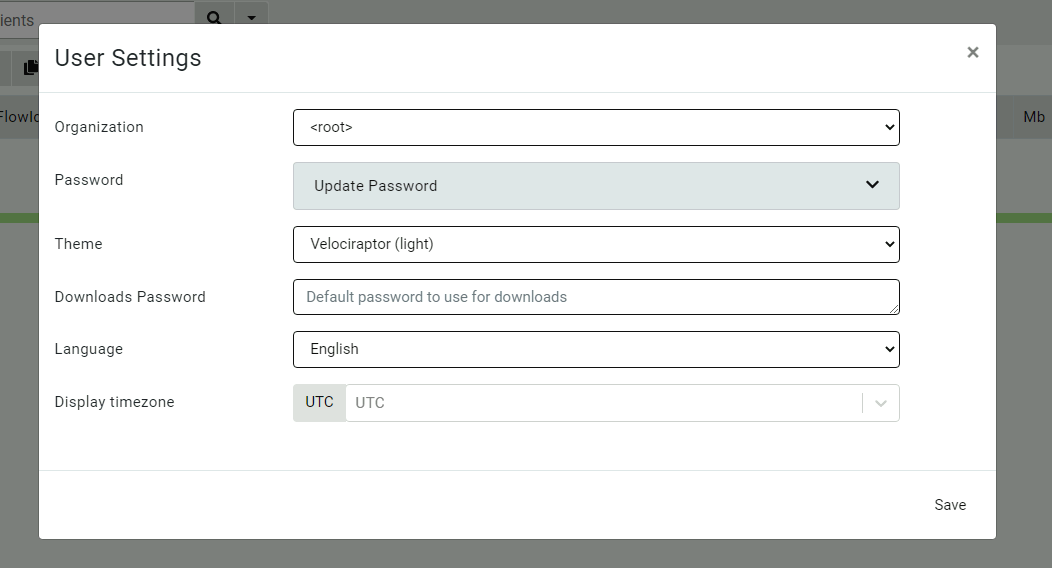
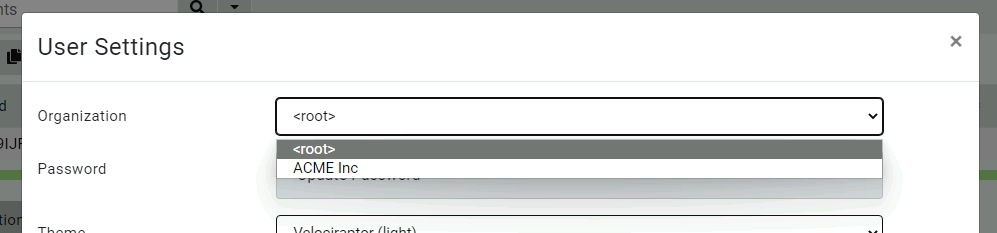
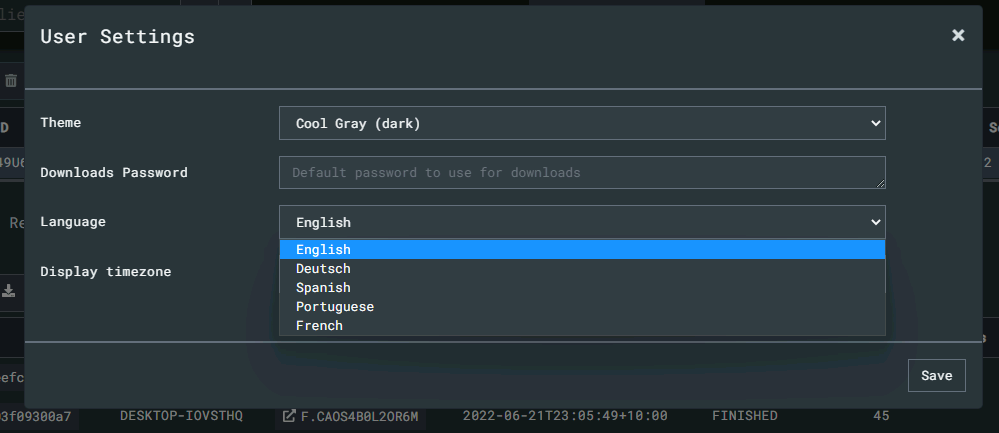
When looking at the latest Velociraptor GUI you might notice the organizations selector in the User Setting page.
The latest User Settings page
This allows the user to switch between the different organizations they belong in.
Multi-tenanted example
Let’s go through a quick example of how to create a new organization and use this feature in practice.
Multi-tenancy is simply a layer of abstraction in the GUI separating Velociraptor objects (such as clients, hunts, notebooks, etc.) into different organizational units.
You do not need to do anything specific to prepare for a multi-tenant deployment. Every Velociraptor deployment can create a new organization at any time without affecting the current install base at all.
By default all Velociraptor installs (including upgraded ones) have a root organization which contains their current clients, hunts, notebooks, etc. (You can see this in the screenshot above.) If you choose to not use the multi-tenant feature, your Velociraptor install will continue working with the root organization without change.
Suppose a new customer is onboarded, but they do not have a large enough install base to warrant a new cloud deployment (with the associated infrastructure costs). We want to create a new organization for this customer in the current Velociraptor deployment.
Creating a new organization
To create a new organization, we simply run the Server.Orgs.NewOrg server artifact from the Server Artifacts screen.
Creating a new organization
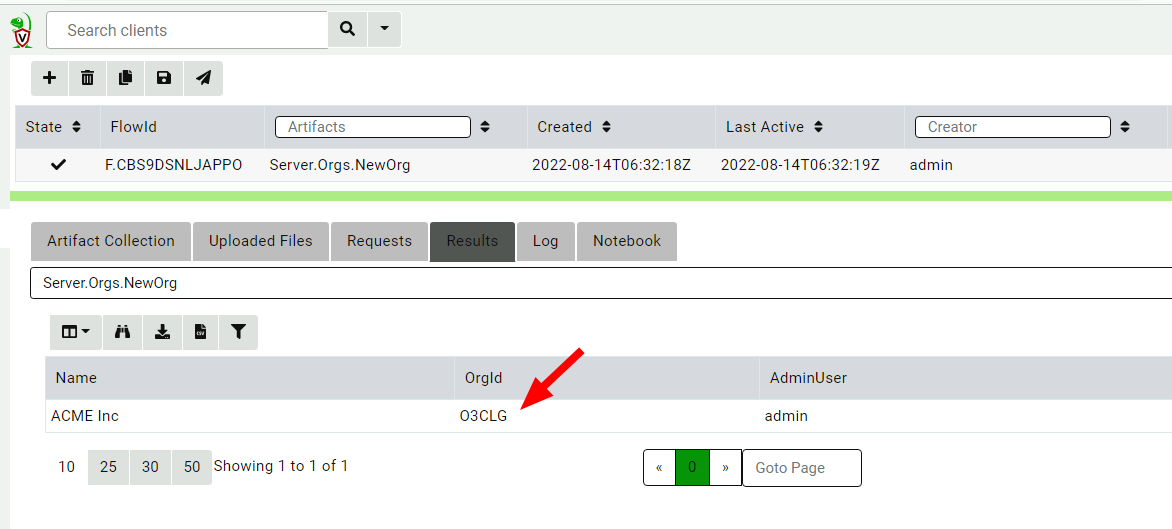
All we need to do is give the organization a name.
New organization is created with a new OrgId and an Admin User
Velociraptor uses the OrgId internally to refer to the organization, but the organization name is used in the GUI to select the different organizations. The new organization is created with the current user being the new administrator of this org.
Deploying clients to the new organization
Since all Velociraptor agents connect to the same server, there has to be a way for the server to identify which organization each client belongs in. This is determined by the unique nonce inside the client’s configuration file. Therefore, each organization has a unique client configuration that should be deployed to that organization.
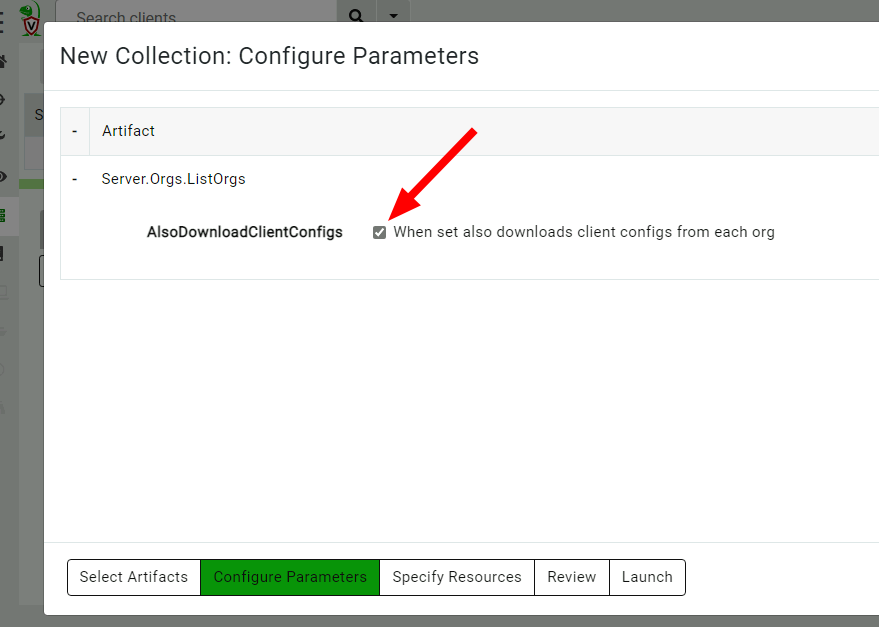
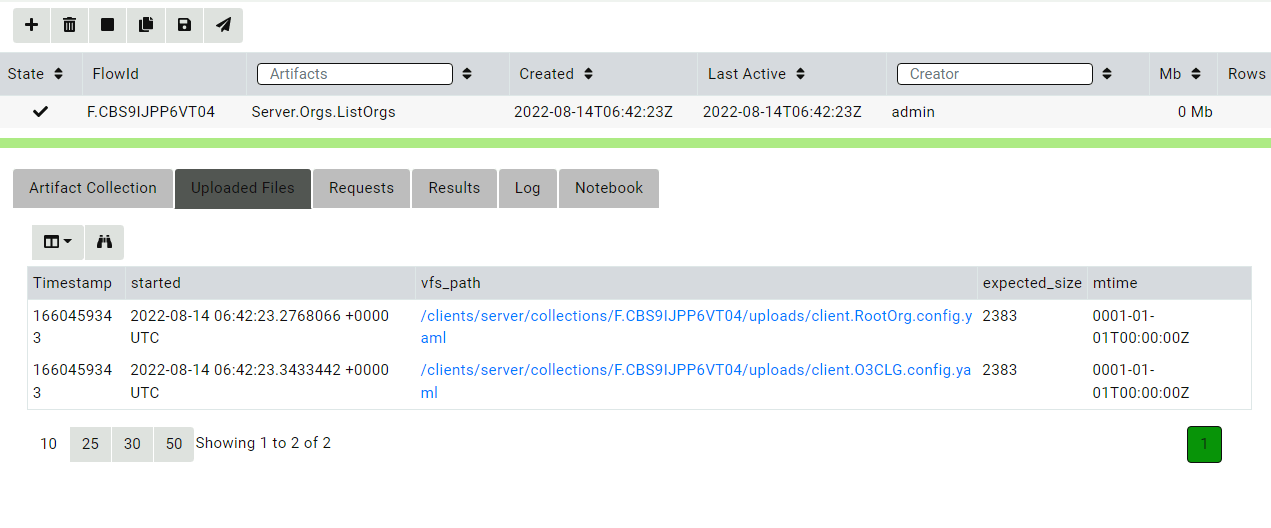
We will list all the organizations on the server using the Server.Orgs.ListOrgs artifact. Note that we are checking the AlsoDownloadConfigFiles parameter to receive the relevant configuration files.
Listing all the organizations on the server
The artifact also uploads the configuration files.
Viewing the organization’s configuration files
Now, we go through the usual deployment process with these configuration files and prepare MSI, RPM, or Deb packages as normal.
Switching between organizations
We can now switch between organizations using the organization selector.
Switching between orgs
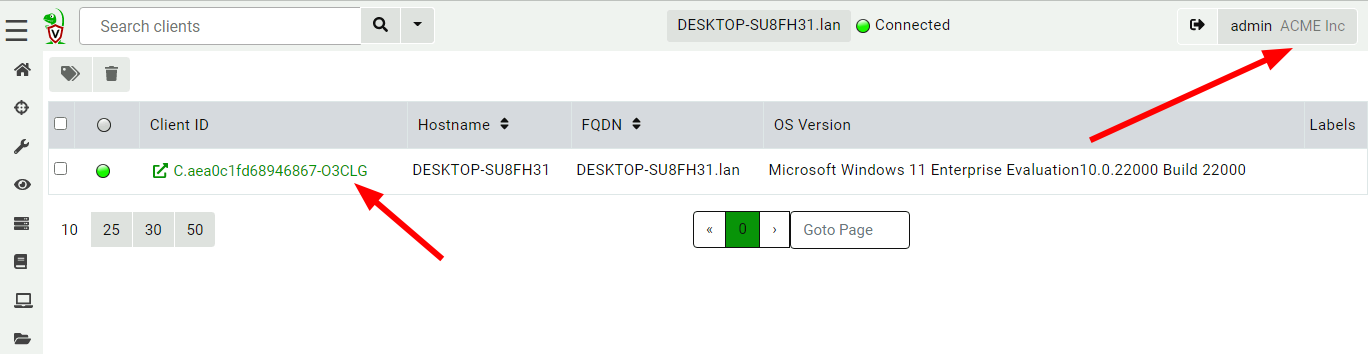
Now the interface is inside the new organization.
Viewing an organization
Note the organization name is shown in the user tile, and client IDs have the org ID appended to them to remind us that the client exists within the org.
The new organization is functionally equivalent to a brand-new deployed server! It has a clean data store with new hunts, clients, notebooks, etc. Any server artifacts will run on this organization only, and server monitoring queries will also only apply to this organization.
Adding other users to the new organization
By default, the user which created the organization is given the administrator role within that organization. Users can be assigned arbitrary roles within the organization – so, for example, a user may be an administrator in one organization but a reader in another organization.
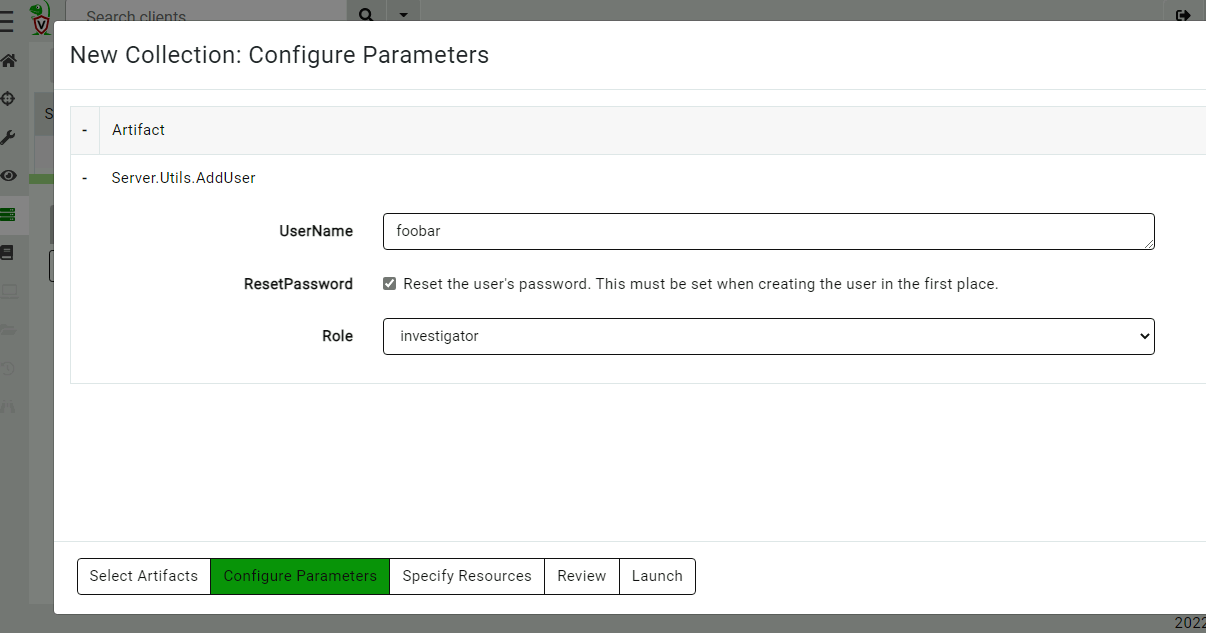
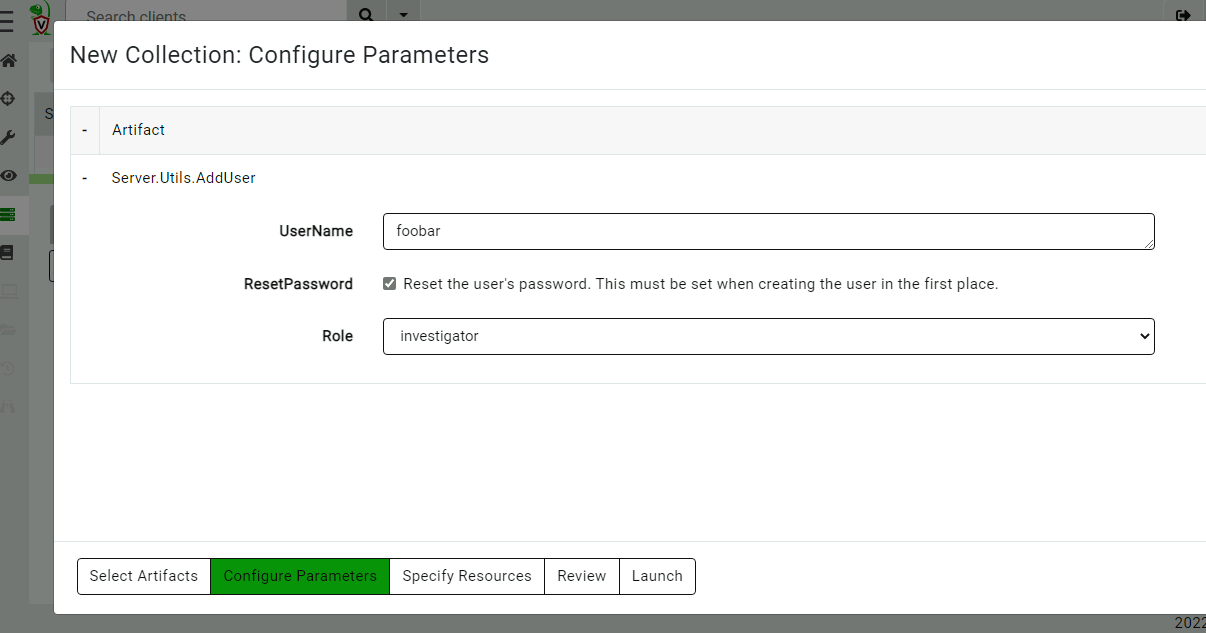
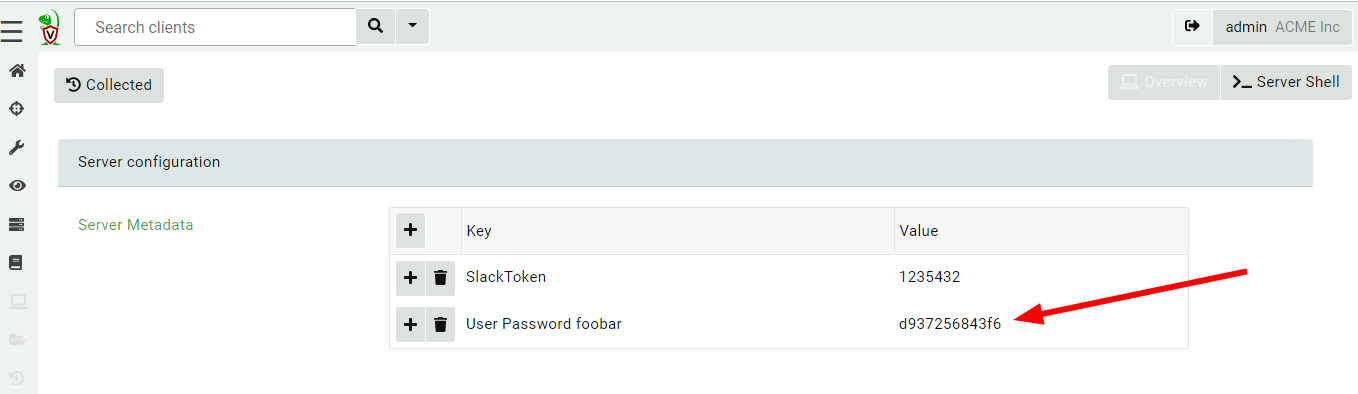
You can add new users or change the user’s roles using the Server.Utils.AddUser artifact. When using basic authentication, this artifact will create a user with a random password. The password will then be stored in the server’s metadata, where it can be shared with the user. We normally recommend Velociraptor to be used with single sign-on (SSO), such as OAuth2 or SAML, and not to use passwords to manage access.
Adding a new user into the org
View the user’s password in the server metadata screen. (You can remove this entry when done with it or ask the user to change their password.)
View the new user password in the server metadata screen
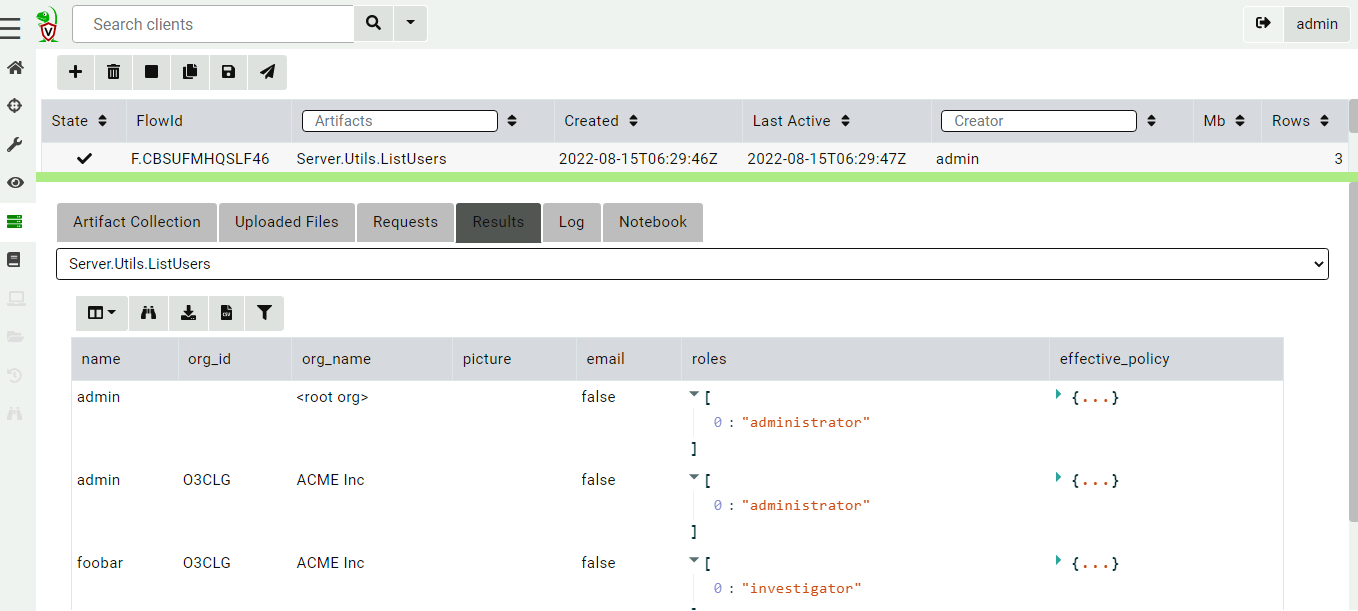
You can view all users in all orgs by collecting the Server.Utils.ListUsers artifact within the root org context.
Viewing all the users on the system
Although Velociraptor respects the assigned roles of users within an organization, at this stage this should not be considered an adequate security control. This is because there are obvious escalation paths between roles on the same server. For example, currently an administrator role by design has the ability to write arbitrary files on the server and run arbitrary commands (primarily this functionality allows for post processing flows with external tools).
This is currently also the case in different organizations, so an organization administrator can easily add themselves to another organization (or indeed to the root organization) or change their own role.
Velociraptor is not designed to contain untrusted users to their own organization unit at this stage – instead, it gives administrators flexibility and power.
GUI improvements
The 0.6.6 release introduces a number of other GUI improvements.
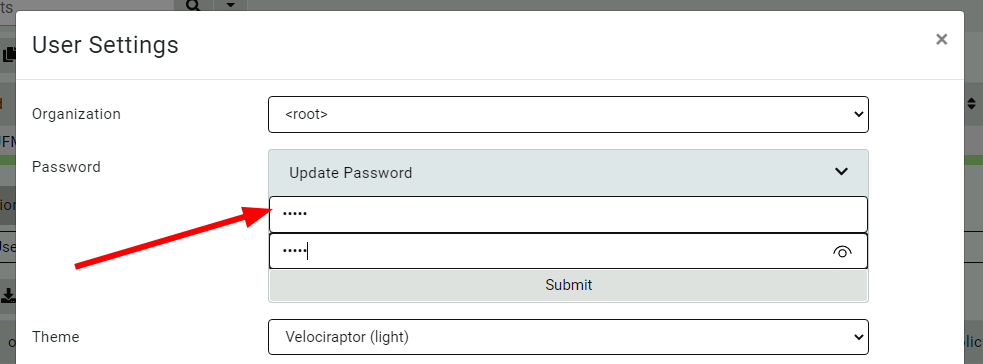
Updating user’s passwords
Usually Velociraptor is deployed in production using SSO such as Google’s OAuth2, and in this case, users manage their passwords using the provider’s own infrastructure.
However, it is sometimes convenient to deploy Velociraptor in Basic authentication mode (for example, for on-premises or air-gapped deployment). Velociraptor now lets users change their own passwords within the GUI.
Users may update their passwords in the GUI
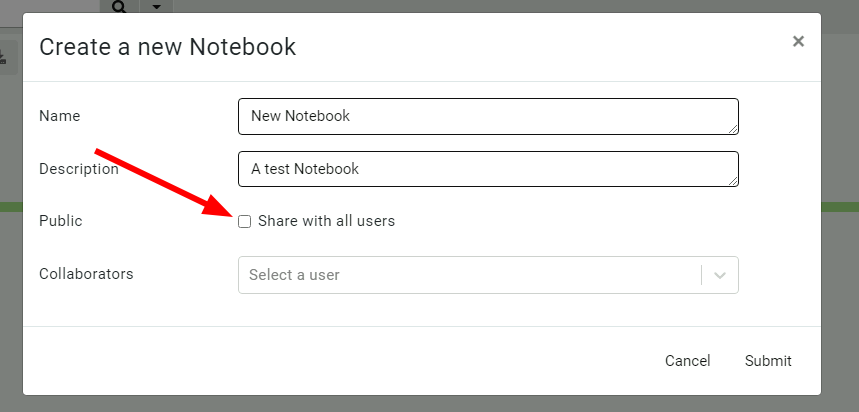
Allow notebook GUI to set notebooks to public
Previously, notebooks could be shared with specific other users, but this proved unwieldy for larger installs with many users. In this release, Velociraptor offers a notebook to be public – this means the notebook will be shared with all users within the org.
Sharing a notebook with all users
More improvements to the process tracker
The experimental process tracker is described in more details here, but you can already begin using it by enabling the Windows.Events.TrackProcessesBasic client event artifact and using artifacts just as Generic.System.Pstree, Windows.System.Pslist, and many others.
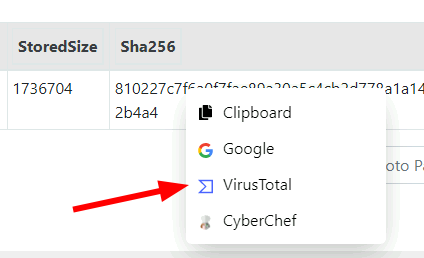
Context menu
A new context menu is now available to allow sending any table cell data to an external service.
Sending a cell content to an external service
This allows for quick lookups using VirusTotal or a quick CyberChef analysis. You can also add your own send to items in the configuration files.
Conclusion
If you’re interested in the new features, take Velociraptor for a spin by downloading it from our release page. It’s available for free on GitHub under an open-source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing [email protected]. You can also chat with us directly on our Discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:
September 15, 2022 | Live at 9 am EDT | Virtual and Free
Join the open-source digital forensics and incident response (DFIR) community for a day-long, virtual summit as we DIG DEEPER TOGETHER!
Have you ever wanted to share your passion and interest in Velociraptor with the rest of the community? VeloCON is your chance! Come together with other DFIR experts and enthusiasts from around the world on September 15th as we delve into new ideas, workflows, and features that will take Velociraptor to the next level of endpoint management, detection, and response.
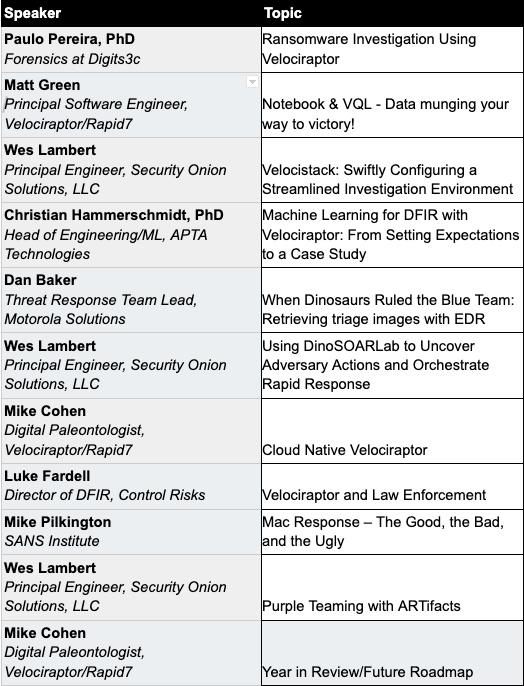
The first annual VeloCON summit will be held Thursday Sept 15th, 2022 at 9 am EDT. It is a 1-day event focused on the Velociraptor community – a forum to share experiences in using and developing Velociraptor to address the needs of the wider DFIR community. This year, the conference will be online and completely free! User-created presentations will be streamed live via Zoom webinar and on the Velociraptor YouTube channel, and will be archived on our Velociraptor website.
Registration is completely free. Here is the speaker list and agenda at a glance:
We look forward to seeing you at VeloCON. If you can’t make the event live, be sure to catch a replay of the event, which we’ll have posted to our website and YouTube channel.
Register for VeloCON today! Learn more about Velociraptor by visiting any of our web and social media channels below:
Rapid7 is pleased to announce the release of Velociraptor version 0.6.5 – an advanced, open-source digital forensics and incident response (DFIR) tool that enhances visibility into your organization’s endpoints. This release has been in development and testing for several months now, and we are excited to share its new features and improvements.
Table transformations
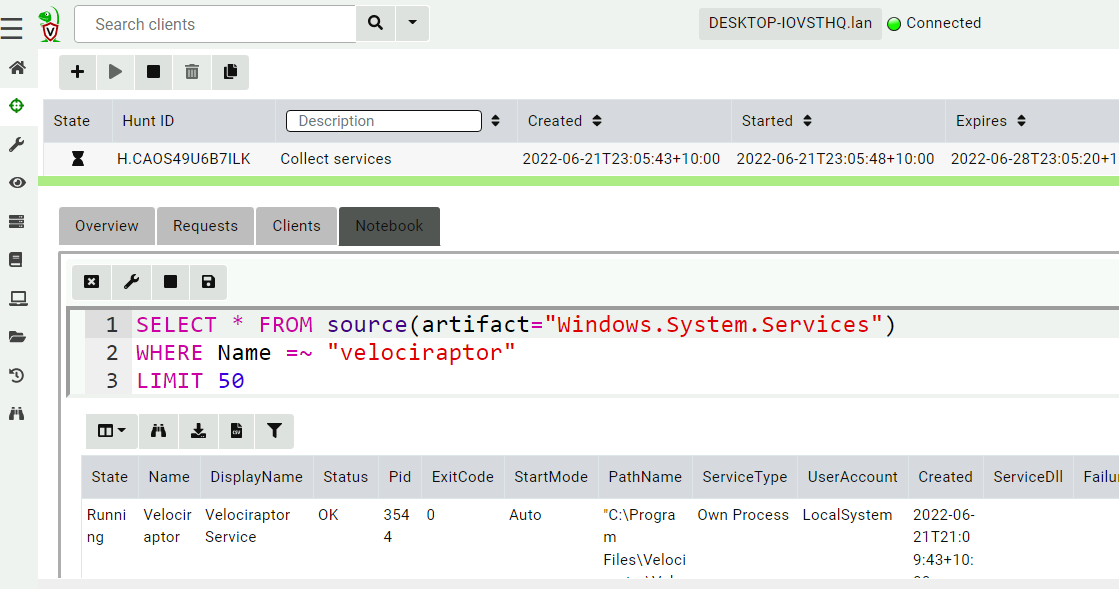
Velociraptor collections or hunts are usually post-processed or filtered in Notebooks. This allows users to refine and post-process the data in complex ways. For example, to view only the Velociraptor service from a hunt collecting all services (Windows.System.Services), one would click on the Notebook tab and modify the query by adding a WHERE statement.
Filtering rows with VQL
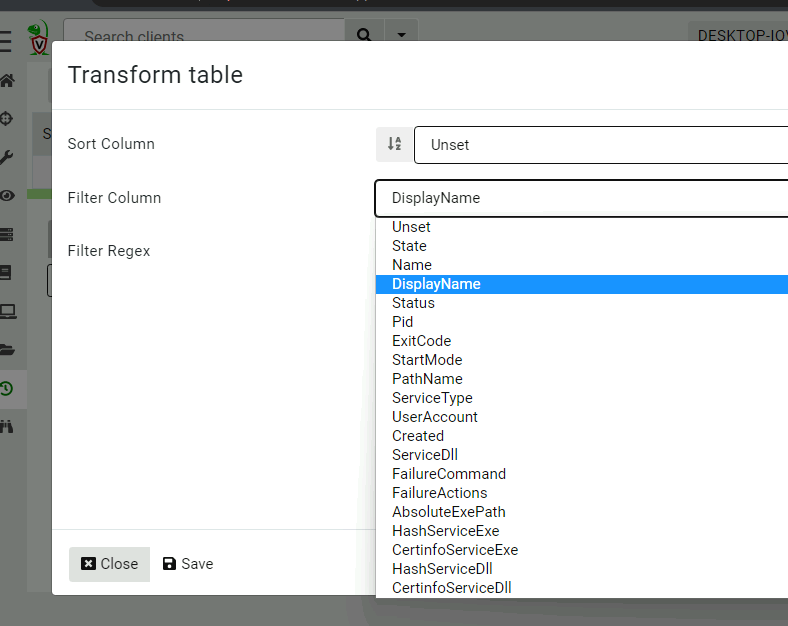
In our experience, this ability to quickly filter or sort a table is very common, and sometimes we don’t really need the full power of VQL. In 0.6.5, we introduced table transformations — simple filtering/sorting operations on every table in the GUI.
Setting simple table transformations
Multi-lingual support
Velociraptor’s community of DFIR professionals is global! We have users from all over the world, and although most users are fluent in English, we wanted to acknowledge our truly international user base by adding internationalization into the GUI. You can now select from a number of popular languages. (Don’t see your language here? We would love additional contributions!)
Select from a number of popular languages
Here is a screenshot showing our German translations:
The Velociraptor interface in German
New interface themes
The 0.6.5 release expanded our previous offering of 3 themes into 7, with a selection of light and dark themes. We even have a retro feel ncurses theme that looks like a familiar terminal…
A stunning retro ‘ncurses’ theme
Error-handling in VQL
Velociraptor is simply a VQL engine – users write VQL artifacts and run these queries on the endpoint.
Previously, it was difficult to tell when VQL encountered an error. Sometimes a missing file is expected, and other times it means something went wrong. From Velociraptor’s point of view, as long as the VQL query ran successfully on the endpoint, the collection was a success. The VQL query can generate logs to provide more information, but the user had to actually look at the logs to determine if there was a problem.
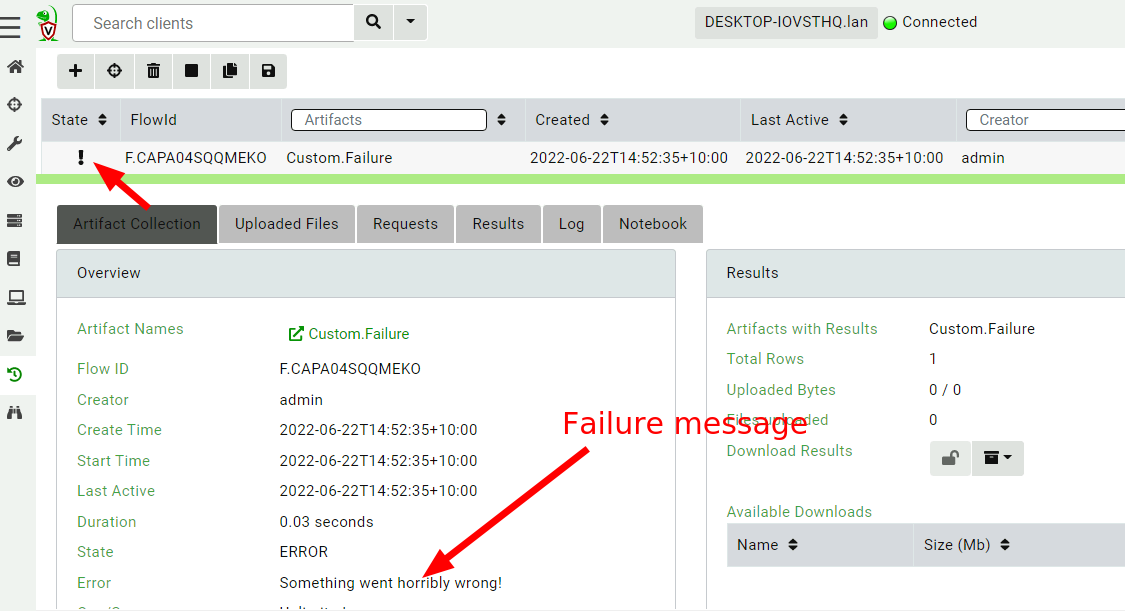
For example, in a hunt parsing a file on the endpoints, it was difficult to tell which of the thousands of machines failed to parse a file. Previously, Velociraptor marked the collection as successful if the VQL query ran – even if it returned no rows because the file failed to parse.
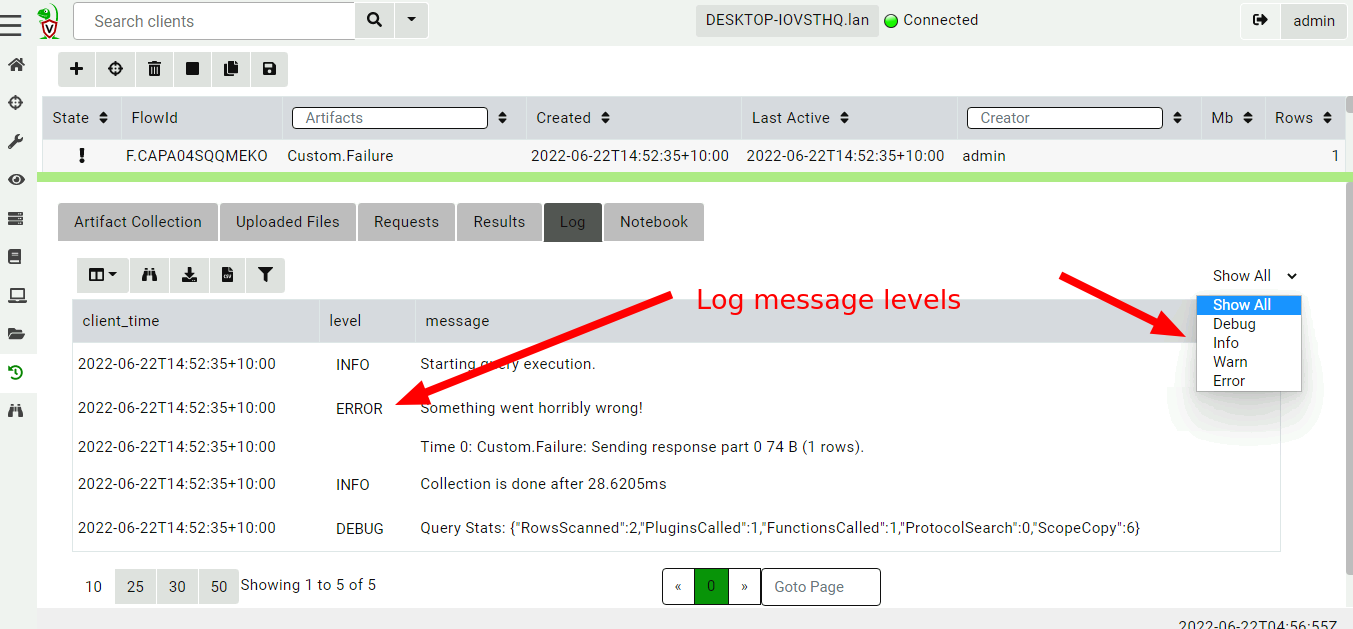
In 0.6.5, there is a mechanism for VQL authors to convey more nuanced information to the user by way of error levels. The VQL log() function was expanded to take a level parameter. When the level is ERROR the collection will be marked as failed in the GUI.
A failed VQL queryQuery Log messages have their own log level
Custom time zone support
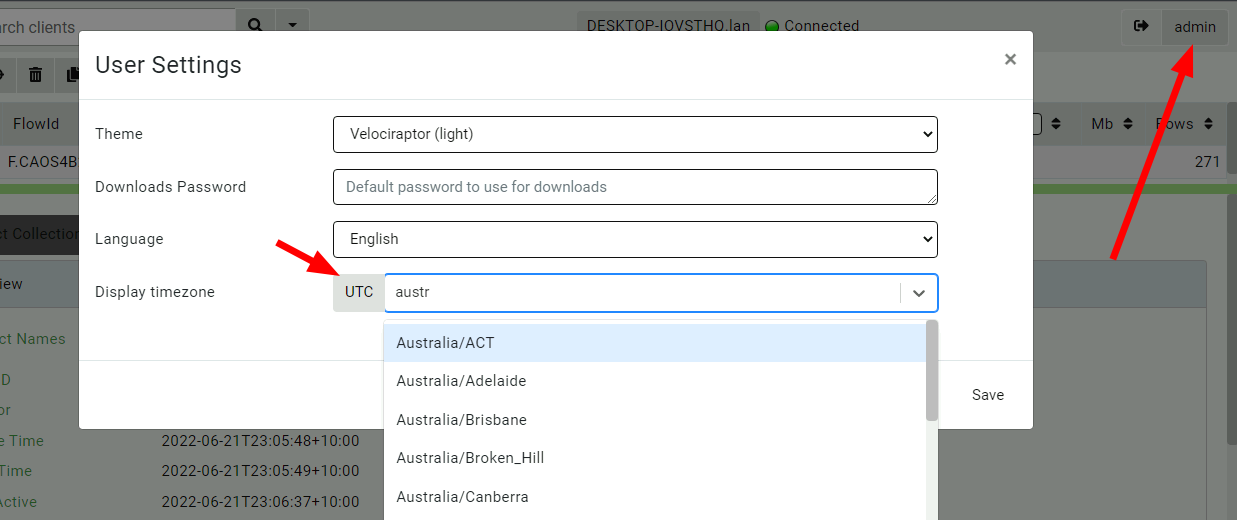
Timestamps are a central part of most DFIR work. Although it is best practice to always work in UTC times, it can be a real pain to have to convert from UTC to local time in your head! Since Velociraptor always uses RFC3389 to represent times unambiguously but for human consumption, it is convenient to represent these times in different local times.
You can now select a more convenient time zone in the GUI by clicking your user preferences and setting the relevant timezone.
Selecting a custom timezone
The preferred time will be shown in most instances in the UI:
Time zone selection influences how times are shown
A new MUSL build target
On Linux Go binaries are mostly static but always link to Glibc, which is shipped with the Linux distribution. This means that traditionally Velociraptor had problems running on very old Linux machines (previous to Ubuntu 18.04). We used to build a more compatible version on an old Centos VM, but this was manual and did not support the latest Go compiler.
In 0.6.5, we added a new build target using MUSL – a lightweight Glibc replacement. The produced binary is completely static and should run on a much wider range of Linux versions. This is still considered experimental but should improve the experience on older Linux machines.
Try it out!
If you’re interested in the new features, take Velociraptor for a spin by downloading it from our release page. It’s available for free on GitHub under an open source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing [email protected]. You can also chat with us directly on our Discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:
Rapid7 is pleased to announce the release of Velociraptor version 0.6.4 – an advanced, open-source digital forensics and incident response (DFIR) tool that enhances visibility into your organization’s endpoints. This release has been in development and testing for several months now and has a lot of new features and improvements.
The main focus of this release is in improving path handling in VQL to allow for more efficient path manipulation. This leads to the ability to analyze dead disk images, which depends on accurate path handling.
Path handling
A path is a simple concept – it’s a string similar to /bin/ls that can be used to pass to an OS API and have it operate on the file in the filesystem (e.g. read/write it).
However, it turns out that paths are much more complex than they first seem. For one thing, paths have an OS-dependent separator (usually / or \). Some filesystems support path separators inside a filename too! To read about the details, check out Paths and Filesystem Accessors, but one of the most interesting things with the new handling is that stacking filesystem accessors is now possible. For example, it’s possible to open a docx file inside a zip file inside an ntfs drive inside a partition.
Dead disk analysis
Velociraptor offers top-notch forensic analysis capability, but it’s been primarily used as a live response agent. Many users have asked if Velociraptor can be used on dead disk images. Although dead disk images are rarely used in practice, sometimes we do encounter these in the field (e.g. in cloud investigations).
Previously, Velociraptor couldn’t be used easily on dead disk images without having to carefully tailor and modify each artifact. In the 0.6.4 release, we now have the ability to emulate a live client from dead disk images. We can use this feature to run the exact same VQL artifacts that we normally do on live systems, but against a dead disk image. If you’d like to read more about this new feature, check out Dead Disk Forensics.
Resource control
When collecting artifacts from endpoints, we need to be mindful of the overall load that collection will cost on endpoints. For performance-sensitive servers, our collection can cause operational disruption. For example, running a yara scan over the entire disk would utilize a lot of IO operations and may use a lot of CPU resources. Velociraptor will then compete for these resources with the legitimate server functionality and may cause degraded performance.
Previously, Velociraptor had a setting called Ops Per Second, which could be used to run the collection “low and slow” by limiting the rate at which notional “ops” were utilized. In reality, this setting was only ever used for Yara scans because it was hard to calculate an appropriate setting: Notional ops didn’t correspond to anything measurable like CPU utilization.
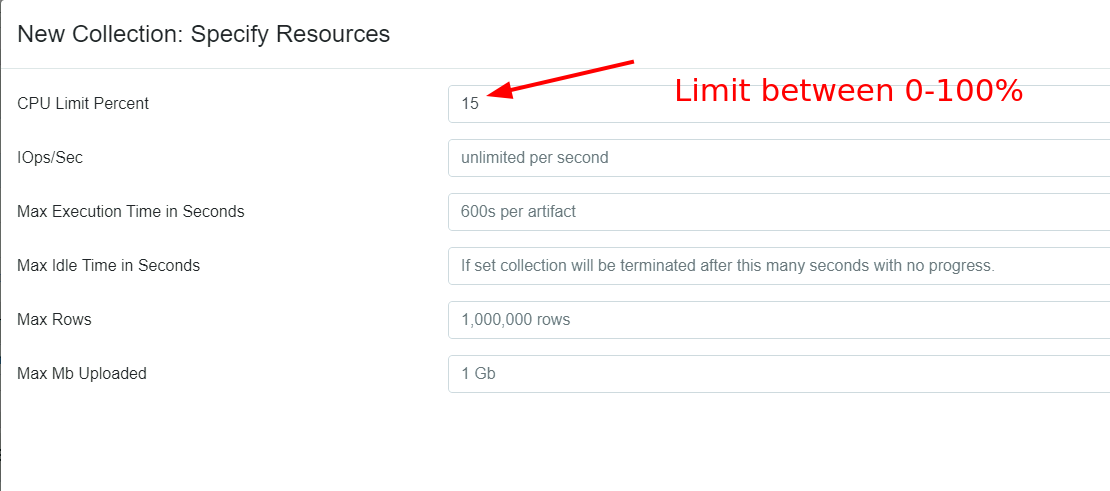
In 0.6.4, we’ve implemented a feedback-based throttler that can control VQL queries to a target average CPU utilization. Since CPU utilization is easy to measure, it’s a more meaningful control. The throttler actively measures the Velociraptor process’s CPU utilization, and when the simple moving average (SMA) rises above the limit, the query is paused until the SMA drops below the limit.
Selecting resource controls for collections
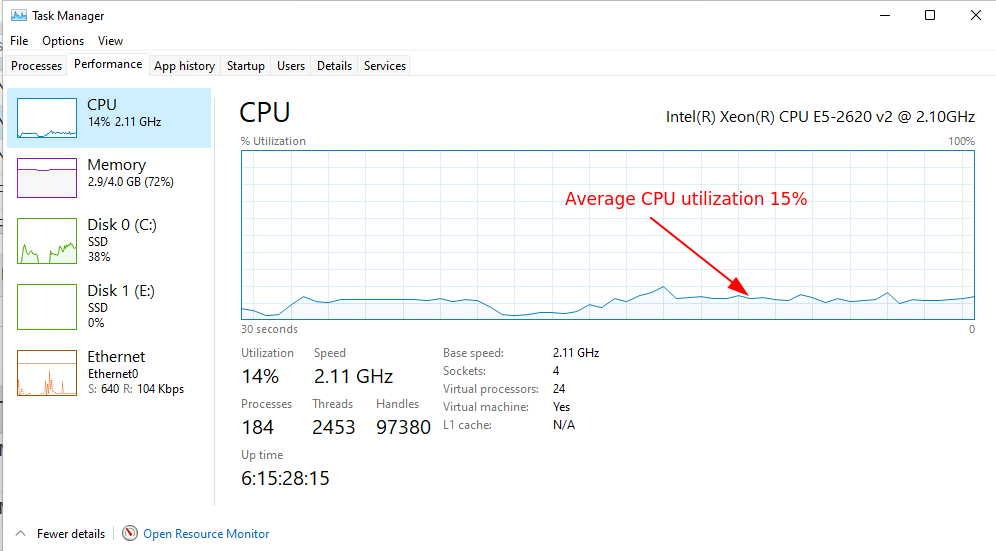
The above screenshot shows the latest resource controls dialog. You can now set a target CPU utilization between 0 and 100%. The image below shows how that looks in the Windows task manager.
CPU control keeps Velociraptor at 15%
By reducing the allowed CPU utilization, Velociraptor will be slowed down, so collections will take longer. You may need to increase the collection timeout to correspond with the extra time it takes.
Note that the CPU limit refers to a percentage of the total CPU resources available on the endpoint. So for example, if the endpoint is a 2 core cloud instance a 50% utilization refers to 1 full core. But on a 32 core server, a 50% utilization is allowed to use 16 cores!
IOPS limits
On some cloud resources, IO operations per second (IOPS) are more important than CPU loading since cloud platforms tend to rate limit IOPS. So if Velociraptor uses many IOPS (e.g. in Yara scanning), it may affect the legitimate workload.
Velociraptor now offers limits on IOPS which may be useful for some scenarios. See for example here and here for a discussion of these limits.
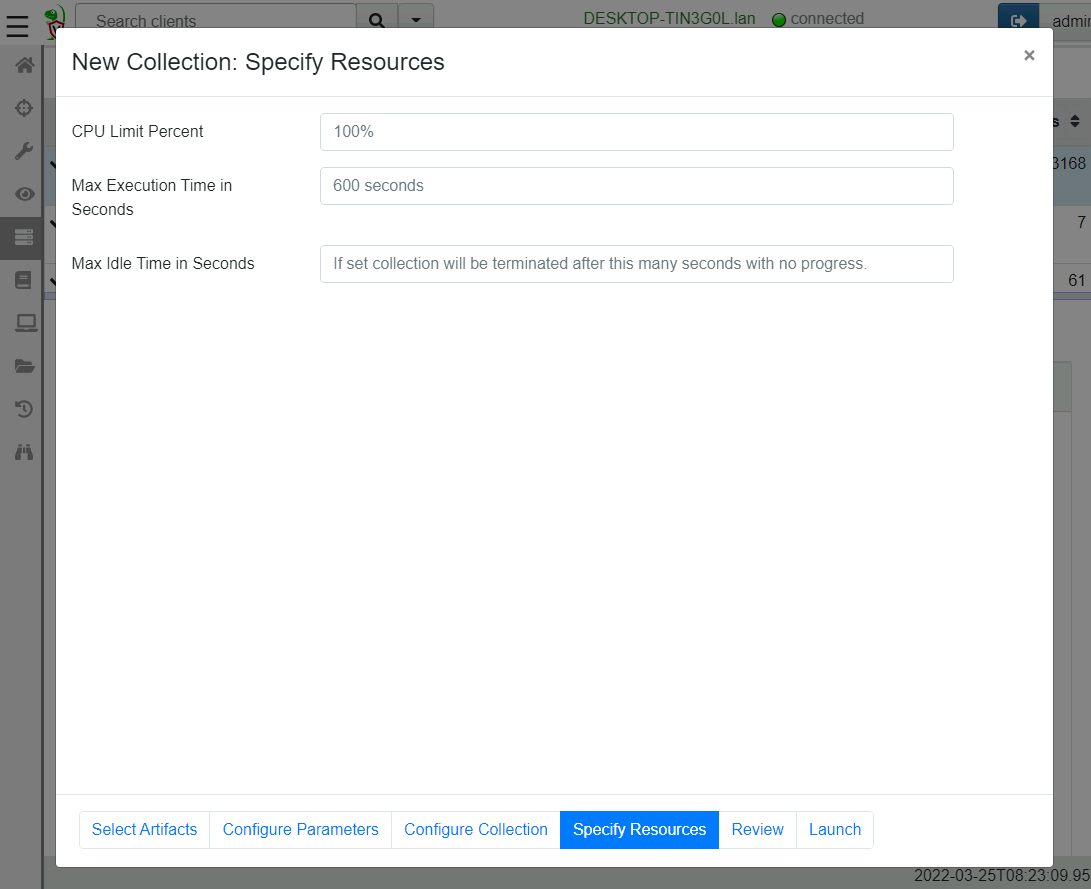
The offline collector resource controls
Many people use the Velociraptor offline collector to collect artifacts from endpoints that they’re unable to install a proper client/server architecture on. In previous versions, there was no resource control or time limit imposed on the offline collector, because it was assumed that it would be used interactively by a user.
However, experience shows that many users use automated tools to push the offline collector to the endpoint (e.g. an EDR or another endpoint agent), and therefore it would be useful to provide resource controls and timeouts to control Velociraptor acquisitions. The below screenshot shows the new resource control page in the offline collector wizard.
Configuring offline collector resource controls
GUI changes
Version 0.6.4 brings a lot of useful GUI improvements.
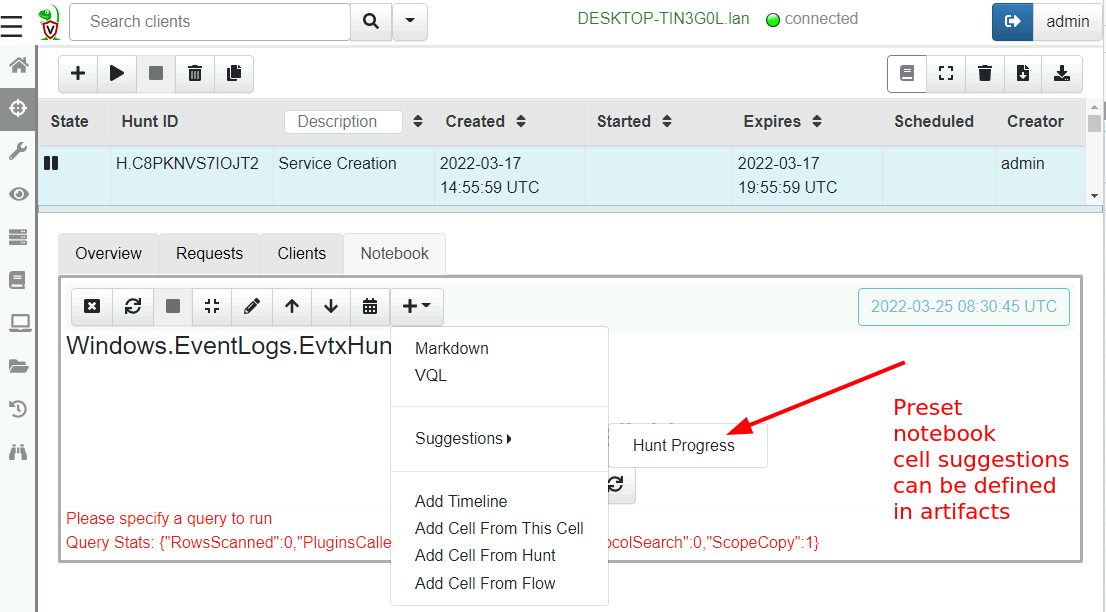
Notebook suggestions
Notebooks are an excellent tool for post processing and analyzing the collected results from various artifacts. Most of the time, similar post processing queries are used for the same artifacts, so it makes sense to allow notebook templates to be defined in the artifact definition. In this release, you can define an optional suggestion in the artifact yaml to allow a user to include certain cells when needed.
The following screenshot shows the default suggestion for all hunt notebooks: Hunt Progress. This cell queries all clients in a hunt and shows the ones with errors, running and completed.
Hunt notebooks offer a hunt status cellHunt notebooks offer a hunt status cell
Multiple OAuth2 authenticators
Velociraptor has always had SSO support to allow strong two-factor authentication for access to the GUI. Previously, however, Velociraptor only supported one OAuth2 provider at a time. Users had to choose between Google, Github, Azure, or OIDC (e.g. Okta) for the authentication provider.
This limitation is problematic for some organizations that need to share access to the Velociraptor console with third parties (e.g. consultants need to provide read-only access to customers).
In 0.6.4, Velociraptor can be configured to support multiple SSO providers at the same time. So an organization can provide access through Okta for their own team members at the same time as Azure or Google for their customers.
The Velociraptor login screen supports multiple providers
The Velociraptor knowledge base
Velociraptor is a very powerful tool. Its flexibility means that it can do things that you might have never realized it can! For a while now, we’ve been thinking about ways to make this knowledge more discoverable and easily available.
Many people ask questions on the Discord channel and learn new capabilities in Velociraptor. We want to try a similar format to help people discover what Velociraptor can do.
The Velociraptor Knowledge Base is a new area on the documentation site that allows anyone to submit small (1-2 paragraphs) tips about how to do a particular task. Knowledge base tips are phrased as questions to help people search for them. Provided tips and solutions are short, but they may refer users to more detailed information.
If you learned something about Velociraptor that you didn’t know before and would like to share your experience to make the next user’s journey a little bit easier, please feel free to contribute a small note to the knowledge base.
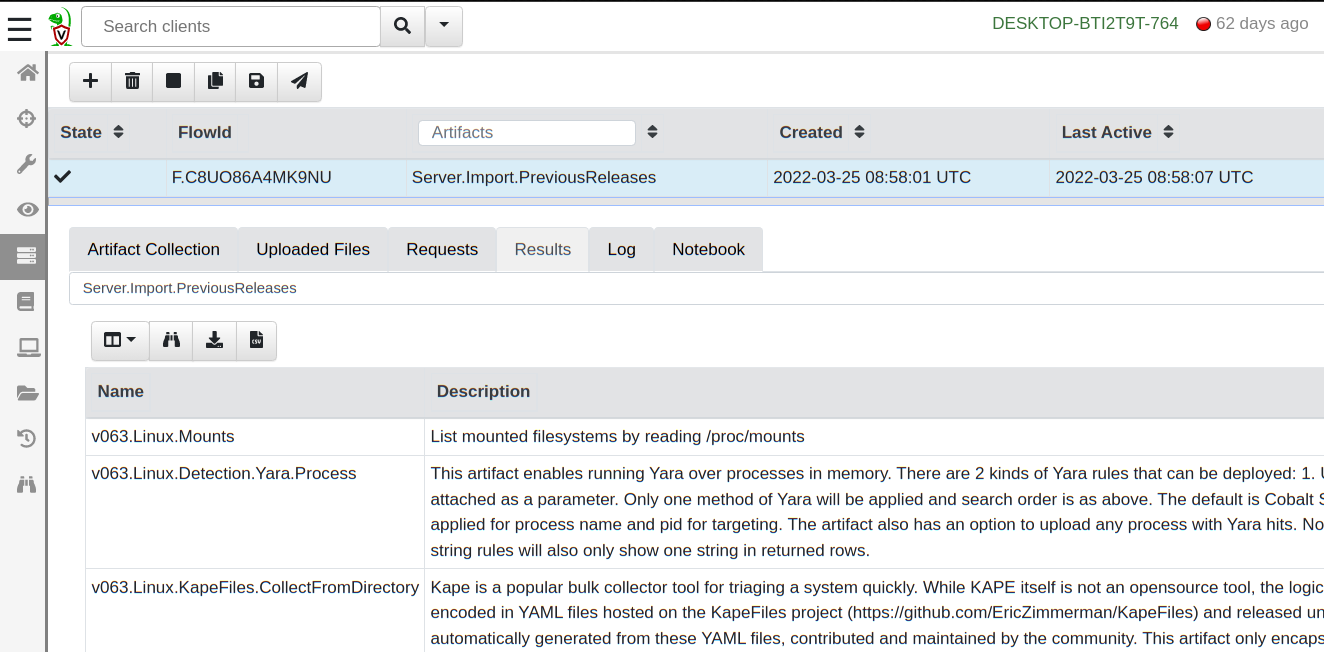
Importing previous artifacts
Updating the VQL path handling in 0.6.4 introduces a new column called OSPath (replacing the old FullPath column), which wasn’t present in previous versions. While we attempt to ensure that older artifacts should continue to work on 0.6.4 clients, it’s possible that the new VQL artifacts built into 0.6.4 won’t work correctly on older versions.
To make migration easier, 0.6.4 comes built in with the Server.Import.PreviousReleases artifact. This server artifact will load all the artifacts from a previous release into the server, allowing you to use those older versions with older clients.
Importing previous versions of core artifacts
Try it out!
If you’re interested in the new features, take Velociraptor for a spin by downloading it from our release page. It’s available for free on GitHub under an open source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing [email protected]. You can also chat with us directly on our discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:
Rapid7 is very excited to announce the latest Velociraptor release 0.6.3. This release has been in the making for a few months now and has several exciting new features.
Scalability and speed have been the main focus of development since our previous release. Working with some of our larger partners on scaling Velociraptor to a large number of endpoints, we’ve addressed a number of challenges that we believe have improved Velociraptor for everyone at any level of scale.
Performance running on EFS
Running on a distributed filesystem such as EFS presents many advantages, not the least of which is removing the risk that disk space will run out. Many users previously faced disk full errors when running large hunts and accidentally collecting too much data from endpoints. Since Velociraptor is so fast, it’s quite easy to do a hunt collecting a large number of files, but before you know it, the disk may be full.
Using EFS removed this risk, since storage is essentially infinite (but not free). So there is a definite advantage to running the data store on EFS even when not running multiple frontends. When scaling to multiple frontends, EFS use is essential to facilitate a shared distributed filesystem among all the servers.
However, EFS presents some challenges. Although conceptually EFS behaves as a transparent filesystem, in reality the added network latency of EFS IO has caused unacceptable performance issues.
In this release, we employed a number of strategies to improve performance on EFS — and potentially other distributed filesystems, such as NFS. You can read all about the new changes here, but the gist is that added caching and delayed writing strategies help isolate the GUI performance from the underlying EFS latency, making the GUI snappy and quick even with slow filesystems.
We encourage everyone to test the new release on an EFS backend, to assess the performance on this setup — there are many advantages to this configuration. While this configuration is still considered experimental, it’s running successfully in a number of environments.
Searching and indexing
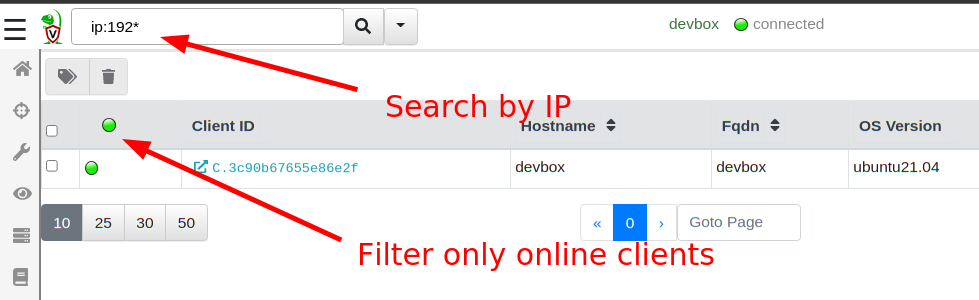
More as a side effect of the EFS work, Velociraptor 0.6.3 moves the client index into memory. This means that searching for clients by DNS name or labels is almost instant, significantly improving the performance of these operations over previous versions.
VQL queries that walk over all clients are now very fast as well. For example, the following query iterates over all clients (maybe thousands!) and checks if their last IP came from a particular subnet:
SELECT * , split(sep=":", string=last_ip)[0] AS LastIp
FROM clients()
WHERE cidr_contains(ip=LastIp, ranges="192.168.1.0/16")
This query will complete in a few seconds even with a large number of clients.
The GUI search bar can now search for IP addresses (e.g. ip:192.168*), and the online only filter is much faster as a result.
Searching is much faster
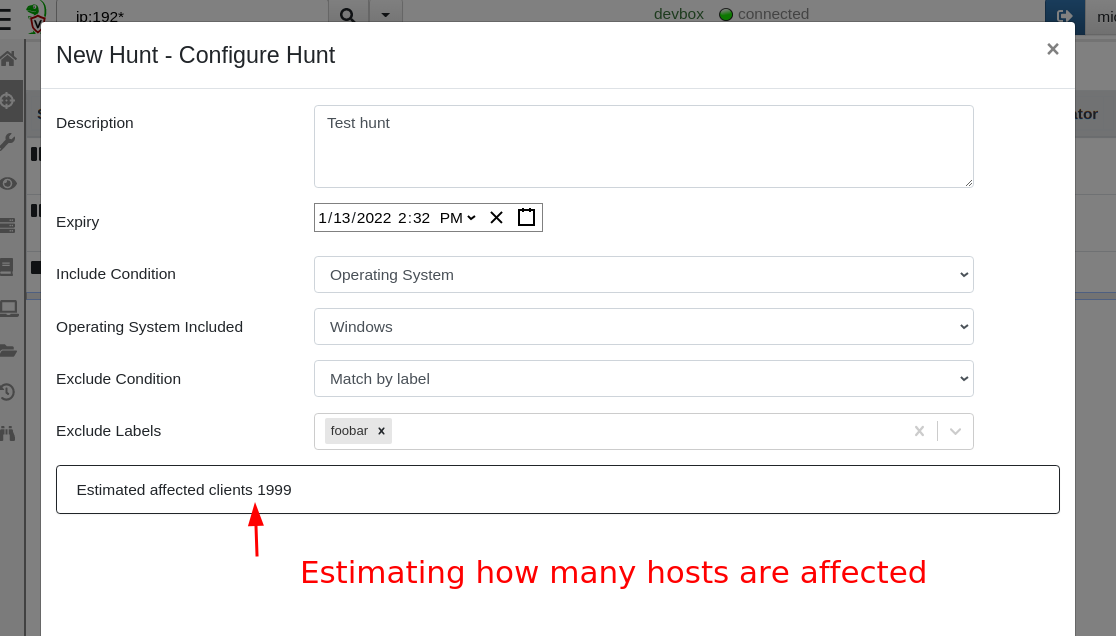
Another benefit of rapid index searching is that we can now quickly estimate how many hosts will be affected by a hunt (calculated based on how many hosts are included and how many are excluded from the hunt). When users have multiple label groups, this helps to quickly understand how targeted a specific hunt is.
Estimating hunt scope
Regular expressions and Yara rules
Velociraptor artifacts are just a way of wrapping a VQL query inside a YAML file for ease of use. Artifacts accept parameters that are passed to the VQL itself, controlling how it runs.
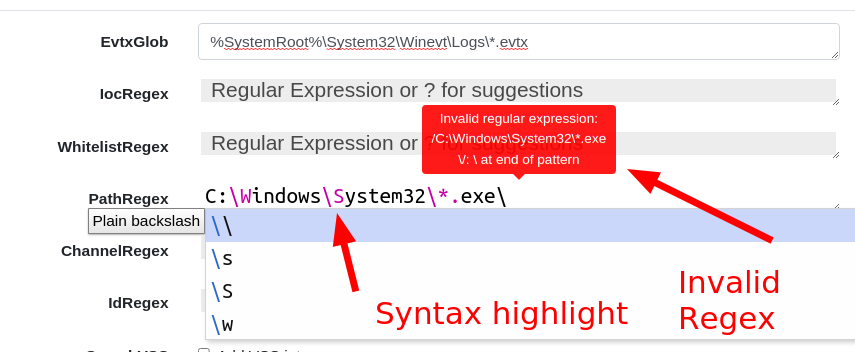
Velociraptor artifacts accept a number of parameters of different types. Sometimes, they accept a windows path — for example, the Windows.EventLogs.EvtxHunter artifact accepts a Windows glob path like %SystemRoot%\System32\Winevt\Logs\*.evtx. In the same artifact, we also can provide a PathRegex, which is a regular expression.
A regular expression is not the same thing as a path at all. In fact, when users get mixed up providing something like C:\Windows\System32 to a regular expression field, this is an invalid expression — backslashes have a specific meaning in a regular expression.
In 0.6.3, there are now dedicated GUI elements for Regular Expression inputs. Special regex patterns, such as backslash sequences, are visually distinct. Additionally, the GUI verifies that the regex is syntactically correct and offers suggestions. Users can type ? to receive further regular expression suggestions and help them build their regex.
Entering regex in the GUI
To receive a RegEx GUI selector in your custom artifacts, simply denote the parameter’s type as regex.
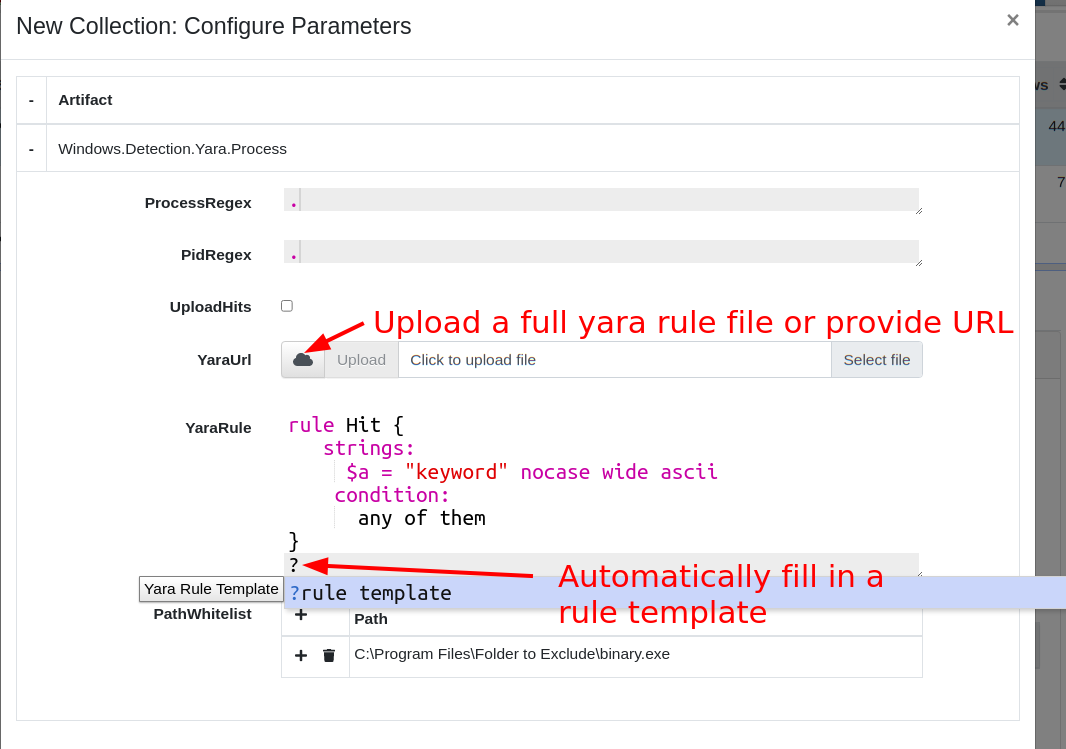
Similarly, other artifacts require the user to enter a Yara rule to use the yara() VQL plugin. The Yara domain specific language (DSL) is rather verbose, so even for very simple search terms (e.g. a simple keyword search) a full rule needs to be constructed.
To help with this task, the GUI now presents a specific Yara GUI element. Users can press ? to automatically fill in a skeleton Yara rule suitable for a simple keyword match. Additionally, syntax highlighting gives visual feedback to the validity of the yara syntax.
Entering Yara Rules in the GUI
Some artifacts allow file upload as a parameter to the artifact. This allows users to upload larger inputs, for example a large Yara rule-set. The content of the file will be made available to the VQL running on the client transparently.
To receive a RegEx GUI selector in your custom artifacts, simply denote the parameter’s type as yara. To allow uploads in your artifact parameters simply denote the parameter as an upload type. Within the VQL, the content of the uploaded file will be available as that parameter.
Overriding Generic.Client.Info
When a new client connects to the Velociraptor server, the server performs an Interrogation flow by scheduling the Generic.Client.Info artifact on it. This artifact collects basic metadata about the client, such as the type of OS it is, the hostname, and the version of Velociraptor. This information is used to feed the search index and is also displayed in the “VQL drilldown” page of the Host Information screen.
In the latest release, it’s possible to customize the Generic.Client.Info artifact, and Velociraptor will use the customized version instead to interrogate new clients. This allows users to add more deployment specific collections to the interrogate flow and customize the “VQL drilldown” page. Simply search for Generic.Client.Info in the View Artifact screen, and customize as needed.
Root certificates are now embedded
By default, Golang searches for root certificates from the running system so it can verify TLS connections. This behavior caused problems when running Velociraptor on very old unpatched systems that did not receive the latest Let’s Encrypt Root Certificate update. We decided it was safer to just include the root certs in the binary so we don’t need to rely on the OS itself.
Additionally, Velociraptor will now accept additional root certs embedded in its config file — just add all the certs in PEM format under the Client.Crypto.root_certs key in the config file. This helps deployments that must use a MITM proxy or traffic inspection proxies.
When adding a Root Certificate to the configuration file, Velociraptor will treat that certificate as part of the public PKI roots — therefore, you’ll need to have Client.use_self_signed_ssl as false.
This allows Velociraptor to trust the TLS connection — however, bear in mind that Velociraptor’s internal encryption channel is still present. The MITM proxy won’t be able to actually decode the data or interfere with the communications by injecting or modifying data. Only the outer layer of TLS encryption can be stripped by the MITM proxy.
VQL changes
Glob plugin improvements
The glob plugin now has a new option: recursion_callback. This allows much finer control over which directories to visit making file searches much more efficient and targeted. To learn more about it, read our previous Velociraptor blog post “Searching for Files.”
Notable new artifacts
Many people use Velociraptor to collect and hunt for data from endpoints. Once the data is inspected and analyzed, often the data is no longer needed.
To help with the task of expiring old data, the latest release incorporates the Server.Utils.DeleteManyFlows and Server.Utils.DeleteMonitoringData artifacts that allow users to remove older collections. This helps manage disk usage and reduce ongoing costs.
Try it out!
If you’re interested in the new features, take Velociraptor for a spin by downloading it from our release page. It’s available for free on GitHub under an open source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing [email protected]. You can also chat with us directly on our discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:
Velociraptor and Rapid7 are excited to announce the winners of our 2021 Velociraptor Contributor Competition on Friday, October 8. This competition encourages development of useful content and extensions to the Velociraptor platform. Submissions include new functionality in the form of VQL artifacts, Velociraptor plugins, or new Velociraptor code and integrations. Judging will be done by a panel of various digital forensics and incident response (DFIR) industry leaders and security experts.
You can watch the announcement of the winners LIVE at the SANS Threat Hunting Summit on Friday, October 8th at 1 pm ET. To register for the summit, head to this page and click on the “Register for Summit” link. Registration is completely free.
The competition carries 3 prize levels: First prize is $5,000 USD, second prize is $3,000 USD, and third prize is $2,000 USD. The winning submissions will also be published on the Velociraptor website.
Velociraptor is an advanced DFIR tool that enhances visibility into all of your endpoints. To learn more about Velociraptor, visit our website or follow us on Twitter @velocidex.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.