Post Syndicated from Chaitanya Shah original https://aws.amazon.com/blogs/big-data/stream-vpc-flow-logs-to-datadog-via-amazon-kinesis-data-firehose/
It’s common to store the logs generated by customer’s applications and services in various tools. These logs are important for compliance, audits, troubleshooting, security incident responses, meeting security policies, and many other purposes. You can perform log analysis on these logs to understand users’ application behavior and patterns to make informed decisions.
When running workloads on Amazon Web Services (AWS), you need to analyze Amazon Virtual Private Cloud (Amazon VPC) Flow Logs to track the IP traffic going to and from the network interfaces for the workloads in their VPC. Analyzing VPC flow logs helps you understand how your applications are communicating over the VPC network and acts as a main source of information to the network in your VPC.
You can easily deliver data to supported destinations using the Amazon Kinesis Data Firehose integration with VPC flow logs. Kinesis Data Firehose is a fully managed service for delivering near-real-time streaming data to various destinations for storage and performing near-real-time analytics. With its extensible data transformation capabilities, you can also streamline log processing and log delivery pipelines into a single Kinesis Data Firehose delivery stream. You can perform analytics on VPC flow logs delivered from your VPC using the Kinesis Data Firehose integration with Datadog as a destination.
Datadog is a monitoring and security platform and AWS Partner Network (APN) Advanced Technology Partner with AWS Competencies in AWS Cloud Operations, DevOps, Migration, Security, Networking, Containers, and Microsoft Workloads, along with many others.
Datadog enables you to easily explore and analyze logs to gain deeper insights into the state of your applications and AWS infrastructure. You can analyze all your AWS service logs while storing only the ones you need, generate metrics from aggregated logs to uncover, and send alerts about trends in your AWS services.
In this post, you learn how to integrate VPC flow logs with Kinesis Data Firehose and deliver it to Datadog.
Solution overview
This solution uses native integration of VPC flow logs streaming to Kinesis Data Firehose. We use a Kinesis Data Firehose delivery stream to buffer the streamed VPC flow logs to a Datadog destination endpoint in your Datadog account. You can use these logs with Datadog Log Management and Datadog Cloud SIEM to analyze the health, performance, and security of your cloud resources.
The following diagram illustrates the solution architecture.

We walk you through the following high-level steps:
- Link your AWS account with your Datadog account.
- Create the Kinesis Data Firehose stream where VPC service streams the flow logs.
- Create the VPC flow log subscription to Kinesis Data Firehose.
- Visualize VPC flow logs in the Datadog dashboard.
The account ID 123456781234 used in this post is a dummy account. It is used only for demonstration purposes.
Prerequisites
You should have the following prerequisites:
- An Amazon Simple Storage Service (Amazon S3) bucket to store the Firehose delivery stream backups and failed logs.
- A Datadog account is needed. If you don’t already have an account, visit the Datadog website to sign up for a free 14-day trial.
- A Datadog API key needed for submitting logs to Datadog.
- AWS Identity and Access Management (IAM) permission to create and modify IAM roles and policies.
Link your AWS account with your Datadog account for AWS integration
Follow the instructions provided on the Datadog website for AWS Integration. To configure log archiving and enrich the log data sent from your AWS account with useful context, link the accounts. When you complete the linking setup, proceed to the following step.
Create a Kinesis Data Firehose stream
Now that your Datadog integration with AWS is complete, you can create a Kinesis Data Firehose delivery stream where VPC Flow Logs are streamed by following these steps:
- On the Amazon Kinesis console, choose Kinesis Data Firehose in the navigation pane.
- Choose Create delivery stream.
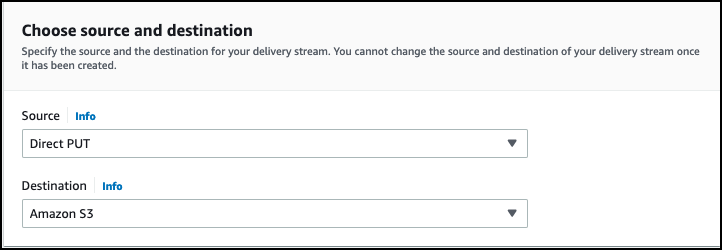
- Choose Direct PUT as the source.
- Set Destination as Datadog.


- For Delivery stream name, enter
PUT-DATADOG-DEMO. - Keep Data transformation set to Disabled under Transform records.
- In Destination settings, for HTTP endpoint URL, choose the desired log’s HTTP endpoint based on your Region and Datadog account configuration.

- For API key, enter your Datadog API key.

This allows your delivery stream to publish VPC Flow logs to the Datadog endpoint. API keys are unique to your organization. An API key is required by the Datadog Agent to submit metrics and events to Datadog.
- Set Content encoding to GZIP to reduce the size of data transferred.
- Set the Retry duration to 60.You can change the Retry duration value if you need to. This depends on the request handling capacity of the Datadog endpoint.

Under Buffer hints, Buffer size and Buffer interval are set with default values for Datadog integration.



- Under Backup settings, as mentioned in the prerequisites, choose the S3 bucket that you created to store failed logs and backup with specific prefix.
- Under S3 buffer hints section, set Buffer size to 5 and Buffer interval to 300.
You can change the S3 buffer size and interval based on your requirements.
- Under S3 compression and encryption, select GZIP for Compression for data records or another compression method of your choice.
Compressing data reduces the required storage space.
- Select Disabled for Encryption of the data records. You can enable encryption of the data records to secure access to your logs.


- Optionally, in Advanced settings, select Enable server-side encryption for source records in delivery stream.
You can use AWS managed keys or a CMK managed by you for the encryption type.
- Enable CloudWatch error logging.
- Choose Create or update IAM role, which is created by Kinesis Data Firehose as part of this stream.


- Choose Next.
- Review your settings.
- Choose Create delivery stream.
Create a VPC flow logs subscription
Create a VPC flow logs subscription for the Kinesis Data Firehose delivery stream you created in the previous step:
- On the Amazon VPC console, choose Your VPCs.
- Select the VPC that you to create the flow log for.
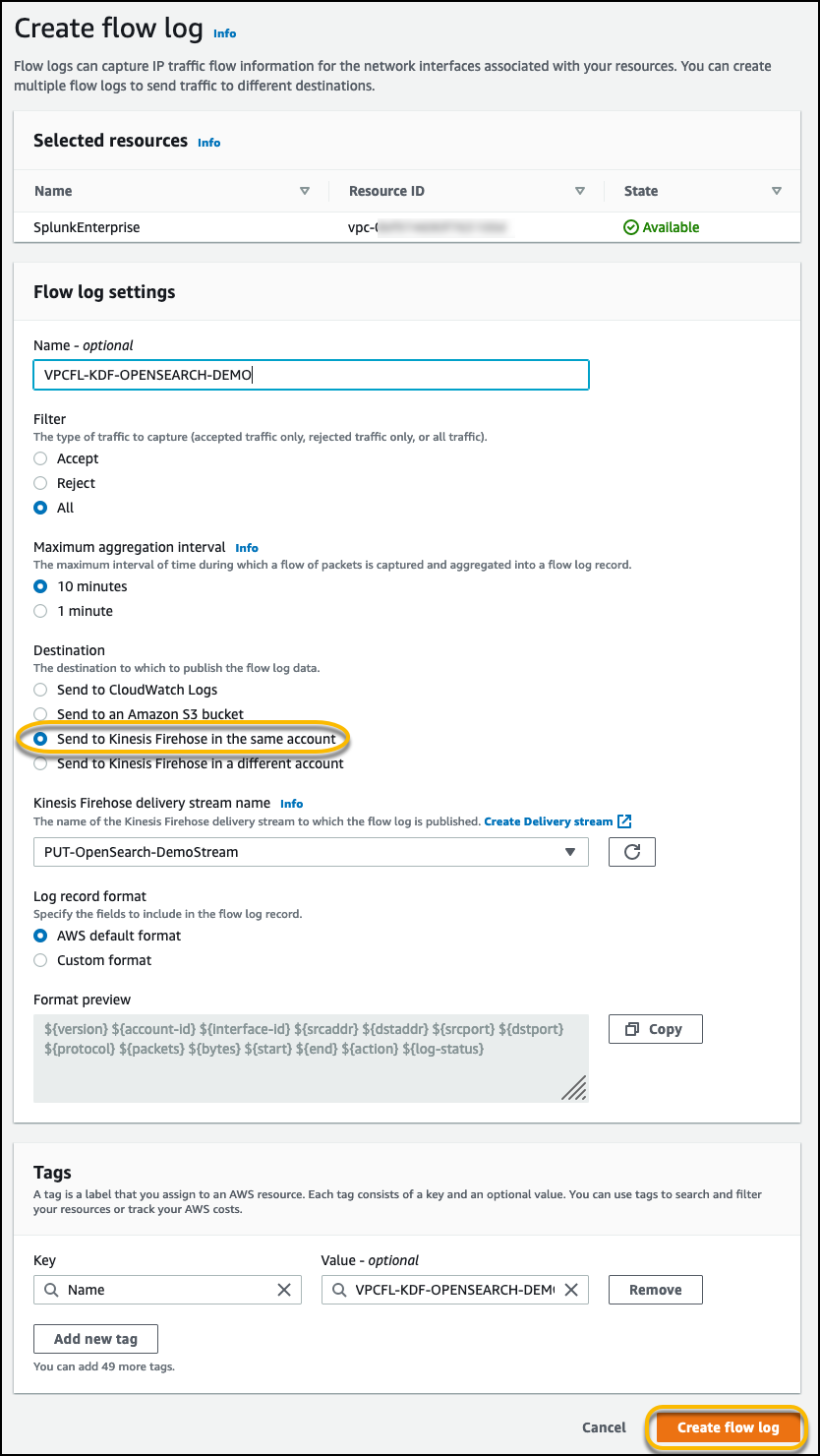
- On the Actions menu, choose Create flow log.


- Select All to send all flow log records to the Firehose destination.
If you want to filter the flow logs, you could alternatively select Accept or Reject.
- For Maximum aggregation interval, select 10 minutes or the minimum setting of 1 minute if you need the flow log data to be available for near-real-time analysis in Datadog.
- For Destination, select Send to Kinesis Data Firehose in the same account if the delivery stream is set up on the same account where you create the VPC flow logs.
If you want to send the data to a different account, refer to Publish flow logs to Kinesis Data Firehose.
- Choose an option for Log record format:
- If you leave Log record format as the AWS default format, the flow logs are sent as version 2 format.
- Alternatively, you can specify the custom fields for flow logs to capture and send it to Datadog.
For more information on log format and available fields, refer to Flow log records.
- Choose Create flow log.


Now let’s explore the VPC flow logs in Datadog.
Visualize VPC flow logs in the Datadog dashboard
In the Logs Search option in the navigation pane, filter to source:vpc. The VPC flow logs from your VPC are in the Datadog Log Explorer and are automatically parsed so you can analyze your logs by source, destination, action, or other attributes.

Clean up
After you test this solution, delete all the resources you created to avoid incurring future charges. Refer to the following links for instructions for deleting the resources:
- IAM role
- IAM policy
- VPC flow logs subscription
- Kinesis Data Firehose delivery stream and associated IAM role and policies
- S3 bucket for VPC Flow Logs backup and failed logs
- The resources and VPC (if you have created a new VPC and new resources in the VPC)
Conclusion
In this post, we walked through a solution of how to integrate VPC flow logs with a Kinesis Data Firehose delivery stream, deliver it to a Datadog destination with no code, and visualize it in a Datadog dashboard. With Datadog, you can easily explore and analyze logs to gain deeper insights into the state of your applications and AWS infrastructure.
Try this new, quick, and hassle-free way of sending your VPC flow logs to a Datadog destination using Kinesis Data Firehose.
About the Author
 Chaitanya Shah is a Sr. Technical Account Manager(TAM) with AWS, based out of New York. He has over 22 years of experience working with enterprise customers. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their AWS Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain.
Chaitanya Shah is a Sr. Technical Account Manager(TAM) with AWS, based out of New York. He has over 22 years of experience working with enterprise customers. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their AWS Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain.