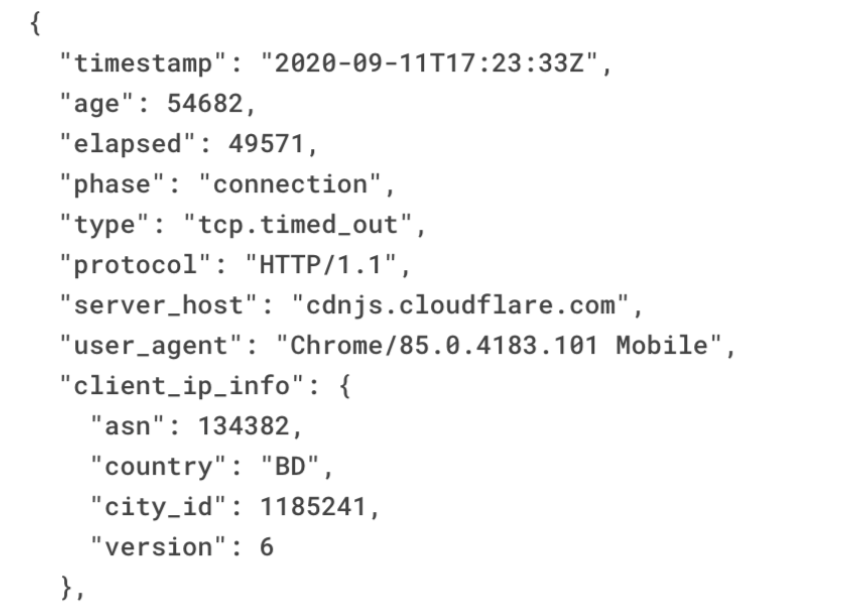
Post Syndicated from David Tuber original https://blog.cloudflare.com/more-offices-faster/
Building a corporate network is hard. We want to enable IT teams to focus on exploring and deploying cutting edge technologies to make employees happier and more productive — not figuring out how to add 100 Mbps of capacity on the third floor of a branch office building.
And yet, as we speak to CIOs and IT teams, we consistently hear of the challenge required to manage organization connectivity. Today, we’re sharing more about how we’re solving connectivity challenges for CIOs and IT teams. There are three parts to our approach: we’re making our network more valuable in terms of the benefit you get from connecting to us; we’re expanding our reach, so we can offer connectivity in more places; and we’re further reducing our provisioning times, so there’s no more need to plan six months in advance.
Making Interconnection Valuable
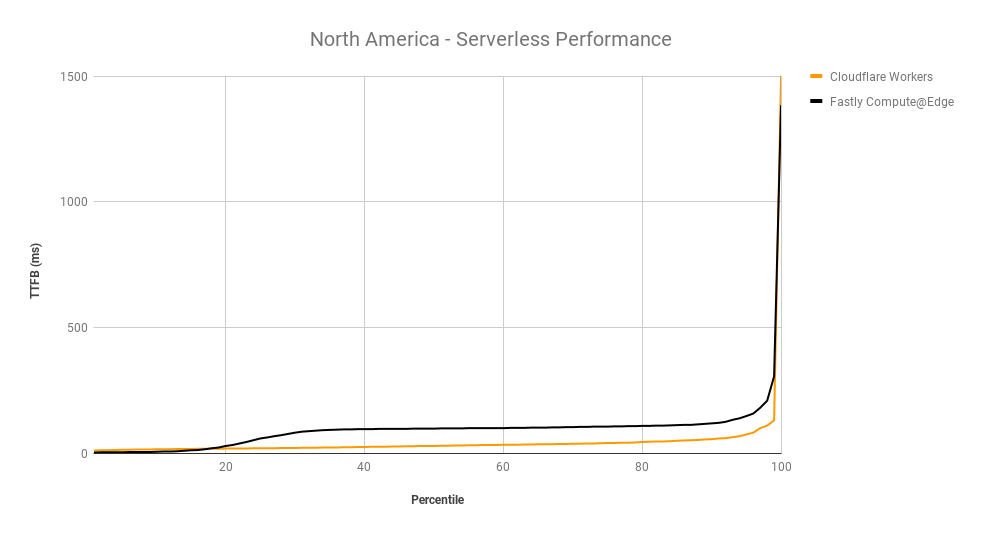
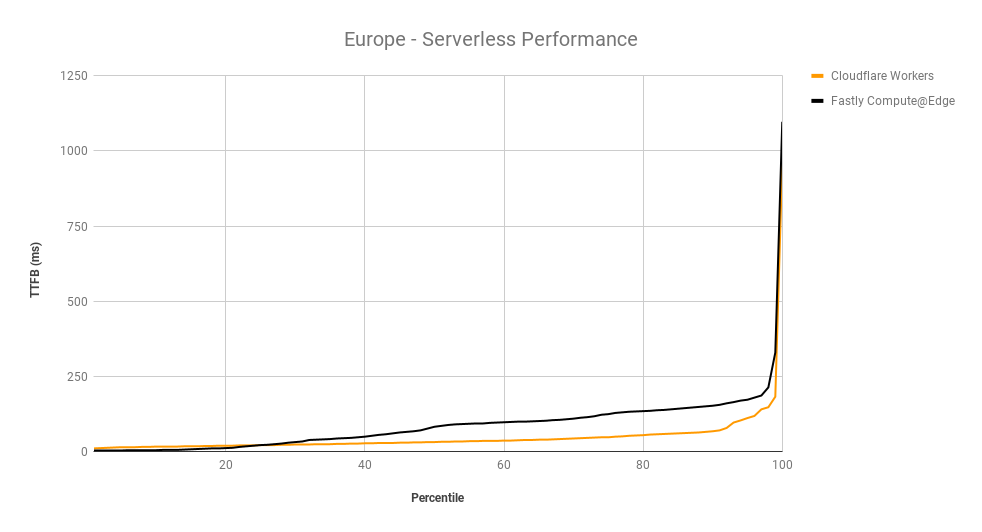
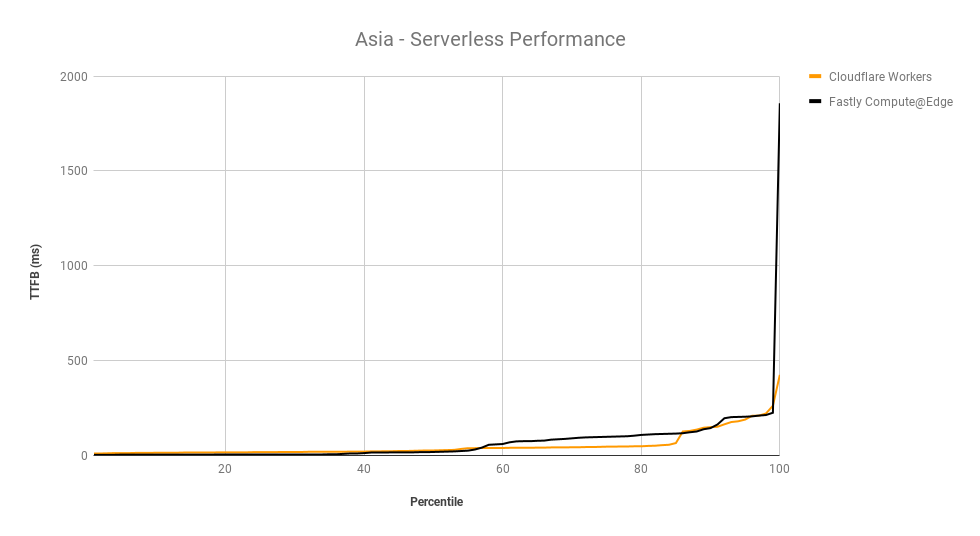
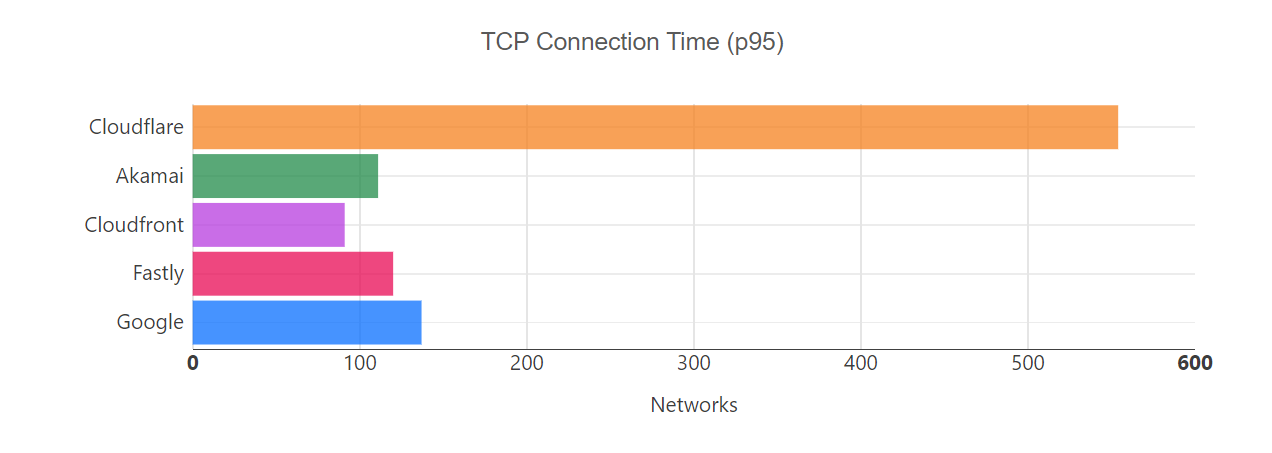
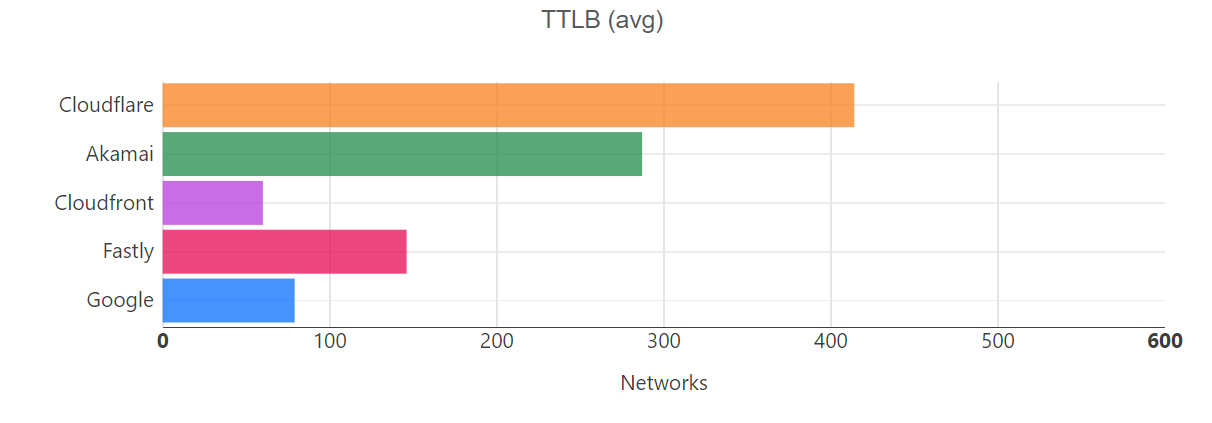
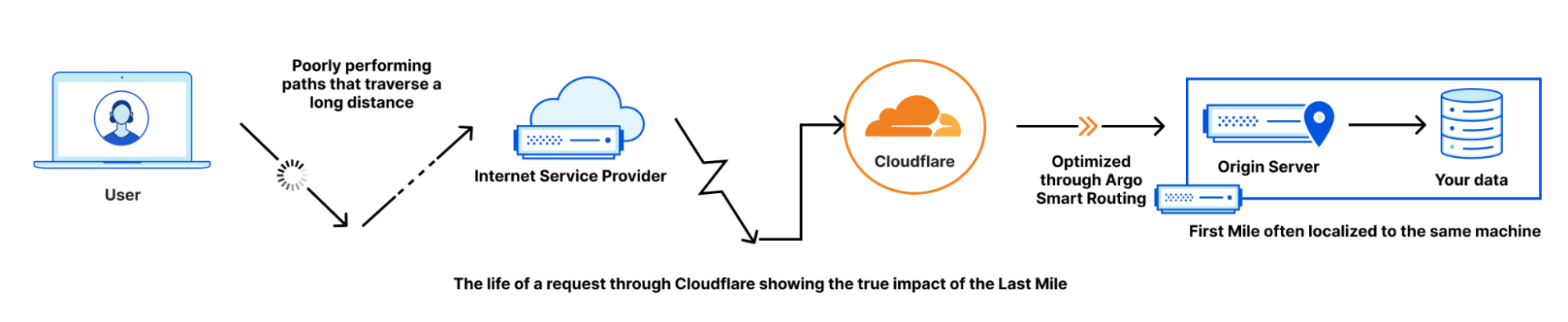
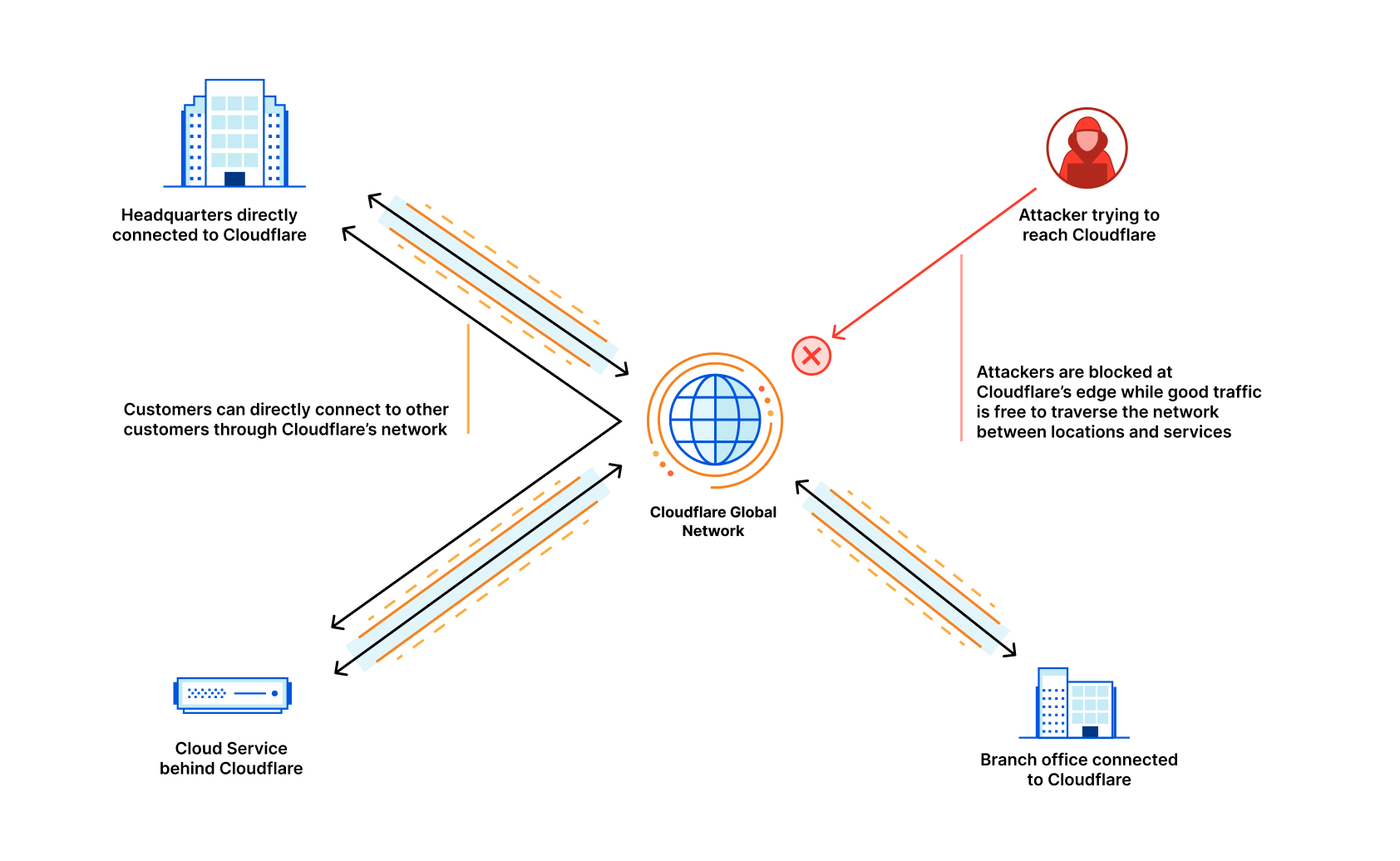
Cloudflare delivers security, reliability, and performance products as a service, all from our global network. We’ve spent the past week talking about new releases and enhanced functionality — if you haven’t yet, please check out some exciting posts on how to replace your hardware firewall, managing third party tools in the cloud, and protecting your web pages from malicious scripting. By interconnecting with us, you get access to all these new products and features with zero additional latency and super easy configuration. This includes, for example, leveraging private paths from Cloudflare’s Magic Transit to your datacenters, completely bypassing the public Internet. It also includes the ability to leverage our private backbone and global network, to gain dramatic performance improvements throughout your network. You can read more examples about how interconnection gives you faster, more secure access to our products which improve your Internet experience in our Cloudflare Network Interconnect blog.
But it’s not just all the products and features you gain access to. Cloudflare has over 28 million Internet properties that rely on it to protect and accelerate their Internet presence. Every time a new property connects to our network, our network becomes more useful. Our free customers or consumers who use 1.1.1.1 provide us unparalleled vision into the Internet to improve our network performance. Similarly, as we expand our surface area on the Internet, it helps us improve our threat detection; it’s like an immune system that learns as it gets exposed to more pathogens. Each customer we make faster and more secure helps others in turn. We have a vast network of customers, including the titans of ecommerce, banking, ERP and CRM systems, and other cloud services. It’s only continuing to grow — and that will be to your advantage.
Making Interconnection Available Everywhere
Building corporate networks requires diverse types of locations to connect to each other: data centers, remote workers, branches in various locations, factories, and more. To accommodate the diversity and geographic spread of modern networks, Cloudflare offers many interconnection options, from our 250 locations around the world to 1000 new interconnection locations that will be enabled over the next year as a part of Cloudflare for Offices.
Connecting data centers to Cloudflare
You can interconnect with Cloudflare in over 250 locations around the world. Check out our peeringDB page to learn more about where you can connect with us.
We also have several Interconnect Partners who provide even more locations for interconnection. If you already have datacenter presence in these locations, interconnection with Cloudflare becomes even easier. Go to our partnership page to learn more about how to get connected through one of our partners.
Connecting your branch offices
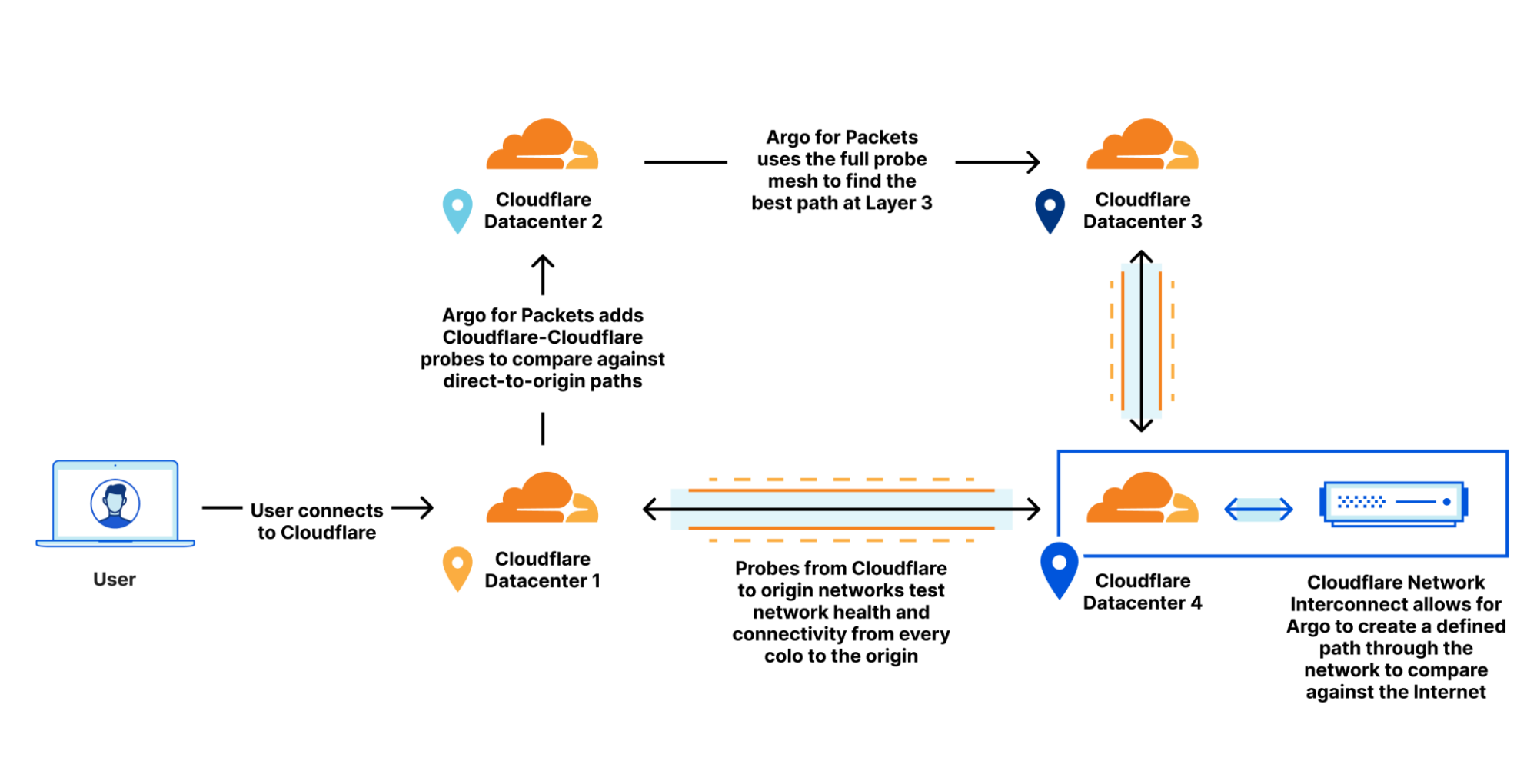
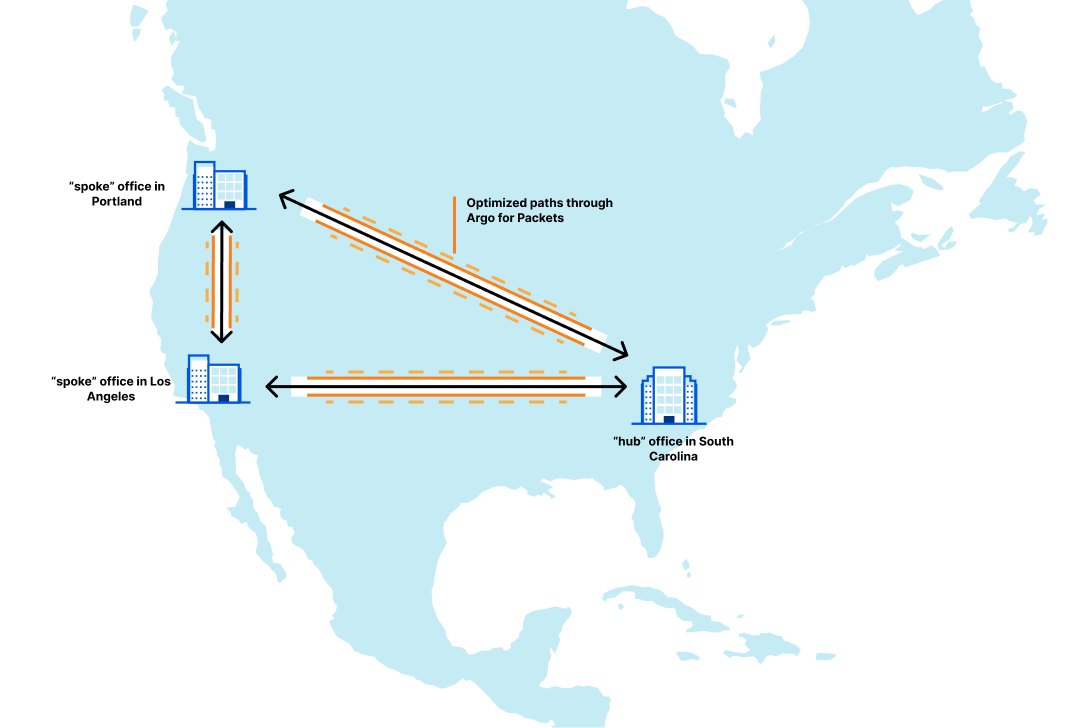
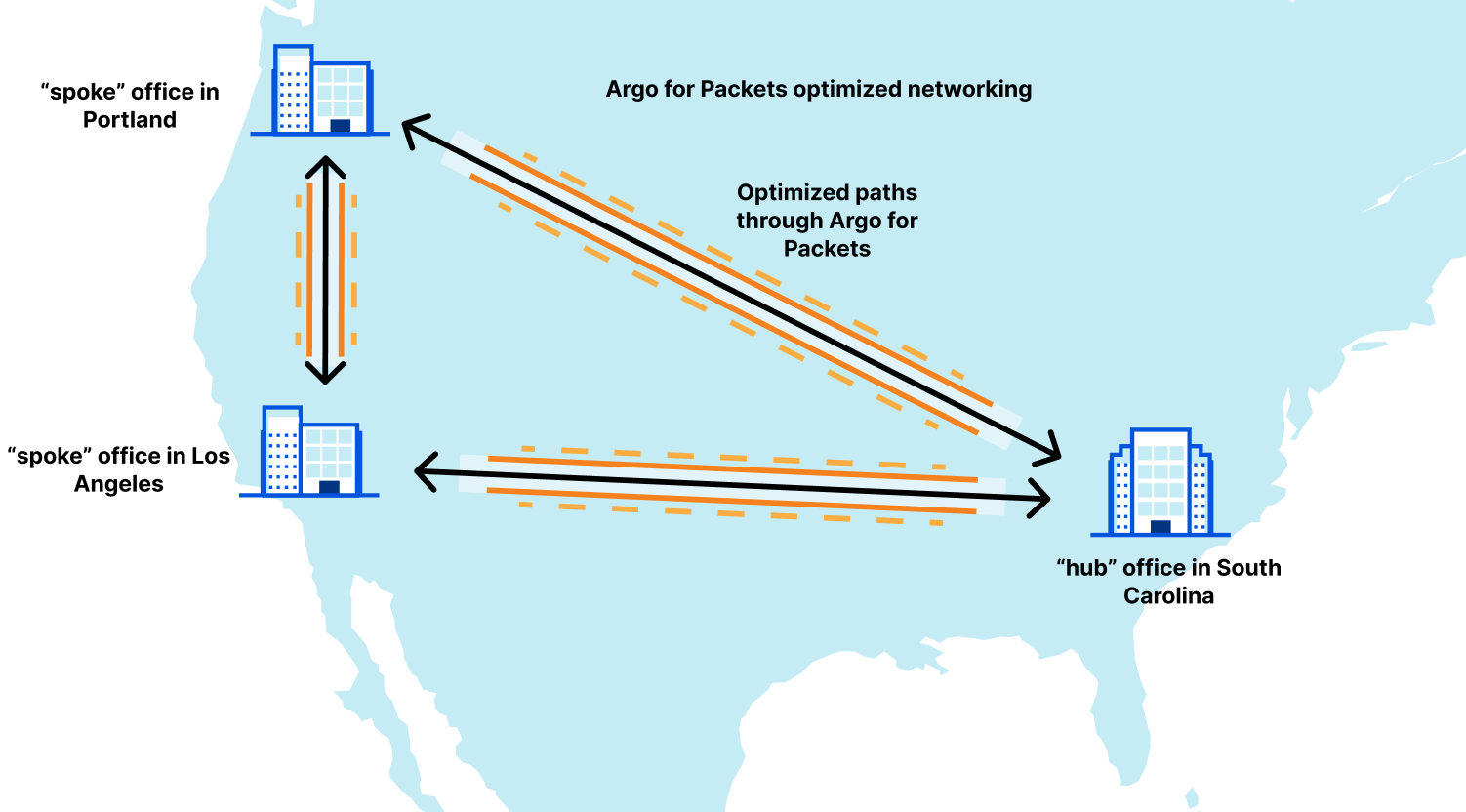
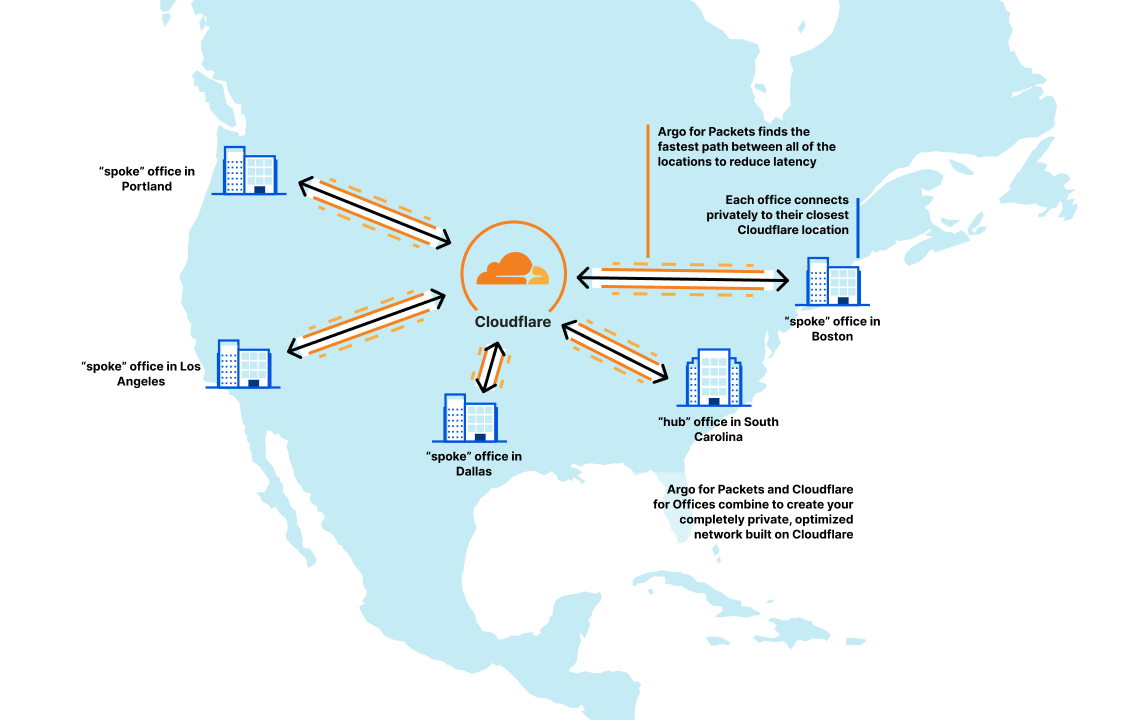
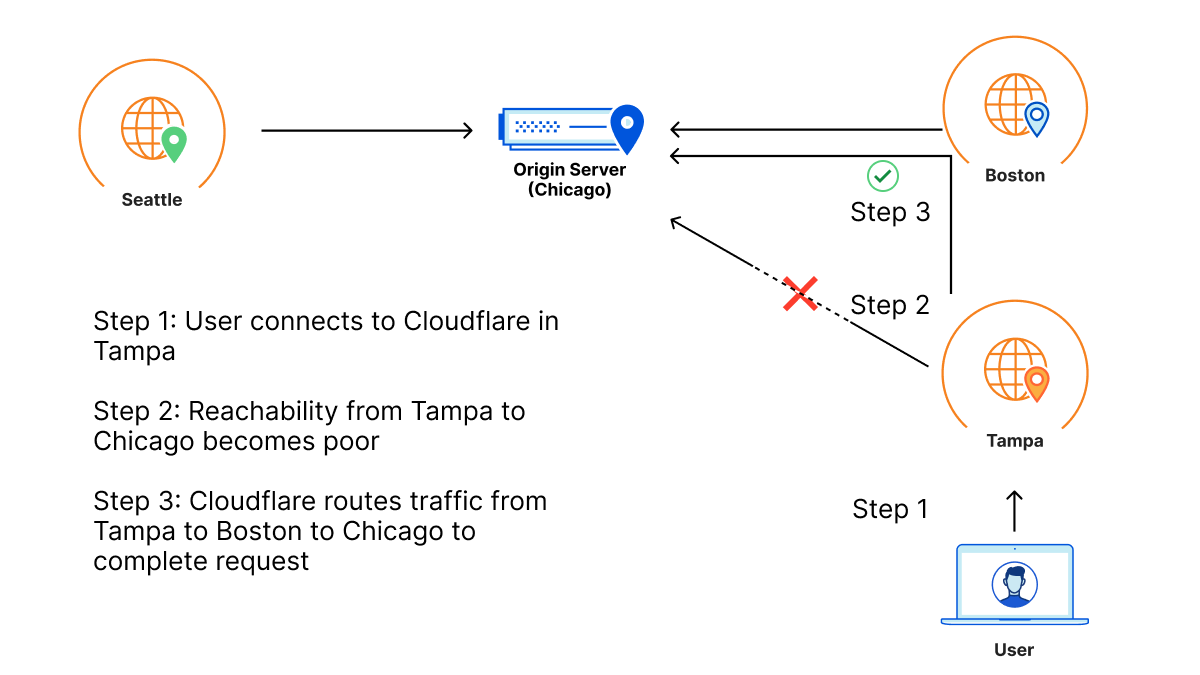
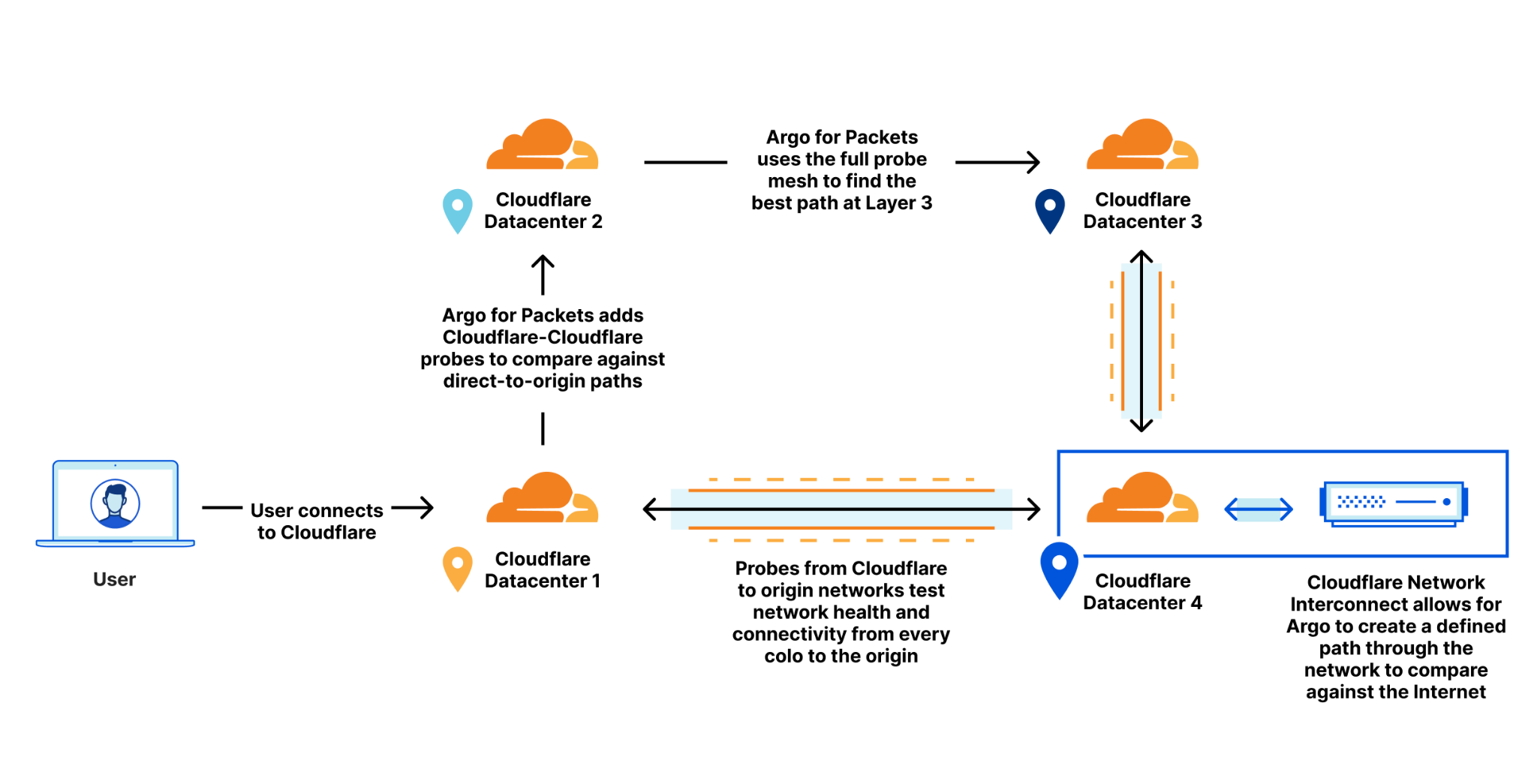
A refresher on our Birthday Week post: Cloudflare for Offices is our initiative to bring Cloudflare’s presence to office buildings and multi-homed dwellings. Simply put, Cloudflare is coming to an office near you. That means that by plugging into Cloudflare you get direct, private, performant access to all Cloudflare services, particularly Cloudflare One. With Cloudflare for Offices, your Gateway queries never traverse the public Internet before Cloudflare, your private network built on Magic WAN is even more private, and Argo for Packets makes your offices faster than before. Cloudflare for Offices is the ultimate on-ramp for all on-premise traffic.
If we’re going to 1000 new locations, there has to be a method to the madness! The process for selecting new locations includes a number of factors. Our goal for each location is to allow the most customers to interconnect with us, while also leveraging our network partners to get connected as fast as possible.
What does a building need to have?
We want to offer reliable, turnkey connectivity to our zero trust security and other services customers connect to our network to consume.
When we evaluate any building, it has to meet the following criteria:
- It must be connected to the Internet with one or more telecom partners. Working with existing providers reduces overhead and time to provision. Plugging into our network to get protected doesn’t work if we have to lay fiber for three months.
- It must be multi-tenant and in a large metro area. Eventually we want to go everywhere, even to buildings with only one tenant. But as we’re starting from zero, we want to go to the places where we can have the most impact immediately. That means looking at buildings that are large, have a large number of potential or active customers, and have large population counts.
However, once we’ve chosen the building, the journey is far from over. Getting connected in a building has a host of challenges beyond just choosing a connectivity partner to the building. After the building is selected, Cloudflare works with building operators and network providers to provide connectivity to tenants in the building. Regardless of how we get to your office, we want to make it as easy as possible to get connected. And our expansion into 1000 more buildings means we’re on the path to being everywhere.
Once a building is provisioned for connectivity, you have to get connected. We’ve been working to provide a one-stop solution for all your office and datacenter connectivity that will look the same, regardless of location.
Getting Interconnection Done Quickly
Interconnection should be easy, and should just involve plugging in and getting connected. Cloudflare has been hard at work since the release of Cloudflare Network Interconnect thinking through the best ways to streamline connectivity to make provisioning an interconnection as seamless as plugging in a cable. With Cloudflare for Offices expanding its reach as we detailed above, this will be easy: users who are connecting via offices are using pre-established connectivity through partners.
But for customers who aren’t in a building covered by Cloudflare for Offices, or who use Cloudflare Network Interconnect, it’s not that simple. Provisioning network connectivity has traditionally been a time-consuming process for everyone involved. Customers need to deal with datacenter providers, receive letters of authorization (or LOAs for short), contract remote hands to plug in cables, read light levels, and that’s before software gets involved. This process has typically taken weeks in the industry, and Cloudflare has spent a lot of time shrinking that down. We don’t want weeks, we want minutes, and we’re excited that we are finally getting there.
There are three main initiatives we are pursuing to get this done: automating BGP configurations, streamlining cross-connect provisioning, and improving uptime. Let’s dive into each of those.
Instant BGP session turnup
When you provision a CNI, you’re essentially creating a brand new road between your neighborhood and the Cloudflare neighborhood. If the cross-connected cable is the paving of the actual street, BGP sessions are the street signs and map applications that tell everyone the new road is up. Establishing a BGP session is critical to using a CNI because it lets traffic going through Cloudflare and through your network know that a new private path exists between the two networks.
But when you pave a new road, you update the street signs in parallel to building the road. So why shouldn’t you do the same with interconnection? Cloudflare is now provisioning BGP sessions once the cross-connects are ordered so that the session is up and ready for you to configure. This cuts down on lots of back-and-forth and also parallelizes critical work to reduce overall provisioning time.
Cross-connect provisioning and Interconnect partners
Building the road itself takes a lot of time, and provisioning cross-connects can run into similar issues if we’re following the metaphor. Although we all wish robots could manage cross-connects in every data center, we still rely on booking time with humans and filling out purchase orders, completing methods of procedure (or MOP) to tell them what to do, and hoping that nobody bumps any cables or is accidentally clumsy during the maintenance. Imagine trying to plug your cables into one of these.

To fix this and reduce complexity, Cloudflare is standardizing connectivity in our datacenters to make it easy for humans to know where things get plugged in. We’re also better utilizing things like patch panels, which allow operators to interconnect with us without having to go in cages. This reduces time and complexity because operators are less likely to bump into things in cages, causing outages.
In addition, we also have our Interconnect Partners, which leverage existing connectivity with Cloudflare to provide virtual interconnection. Our list of partners is ever growing, and they’re super excited to work with us and you to give you the best, fastest, most secure connectivity experience possible.
“Megaport’s participation in Cloudflare Network Interconnect as an Interconnection Platform Partner helps make connectivity easier for our mutual customers. Reducing the time it takes for customers to go live with new Virtual Cross Connects and Megaport Cloud Routers helps them realize the promise of software-defined networking.”
– Peter Gallagher, Head of Channel, Megaport
“Console Connect and Cloudflare are continuing our partnership as part of Cloudflare’s Network Interconnect program, helping our mutual customers enhance the performance and control of their network through Software-Defined Interconnection®. As more and more customers move from physical to virtual connectivity, our partnership will help shorten onboarding times and make interconnecting easier than ever before.”
– Michael Glynn, VP of Digital Automated Innovation, Console Connect.
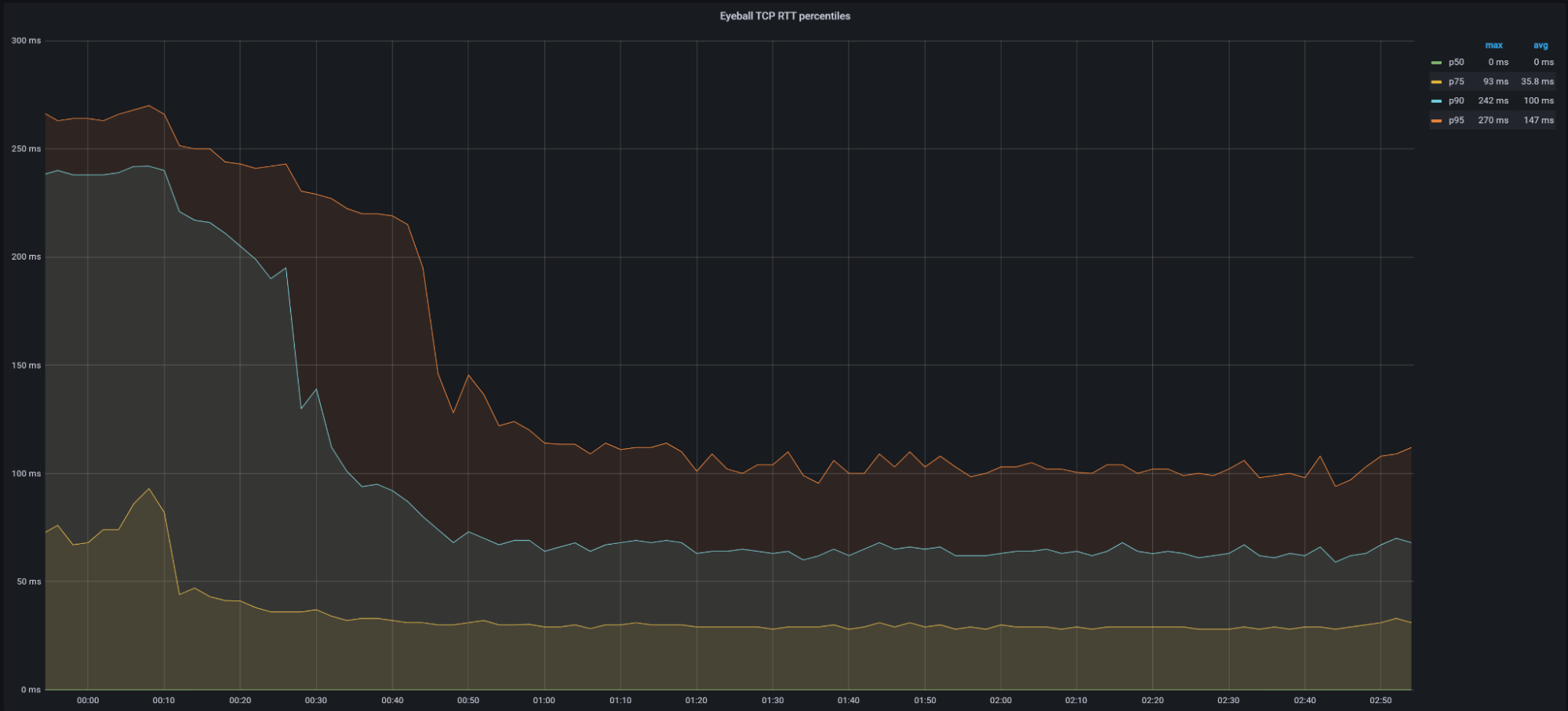
Improving connection resilience uptime
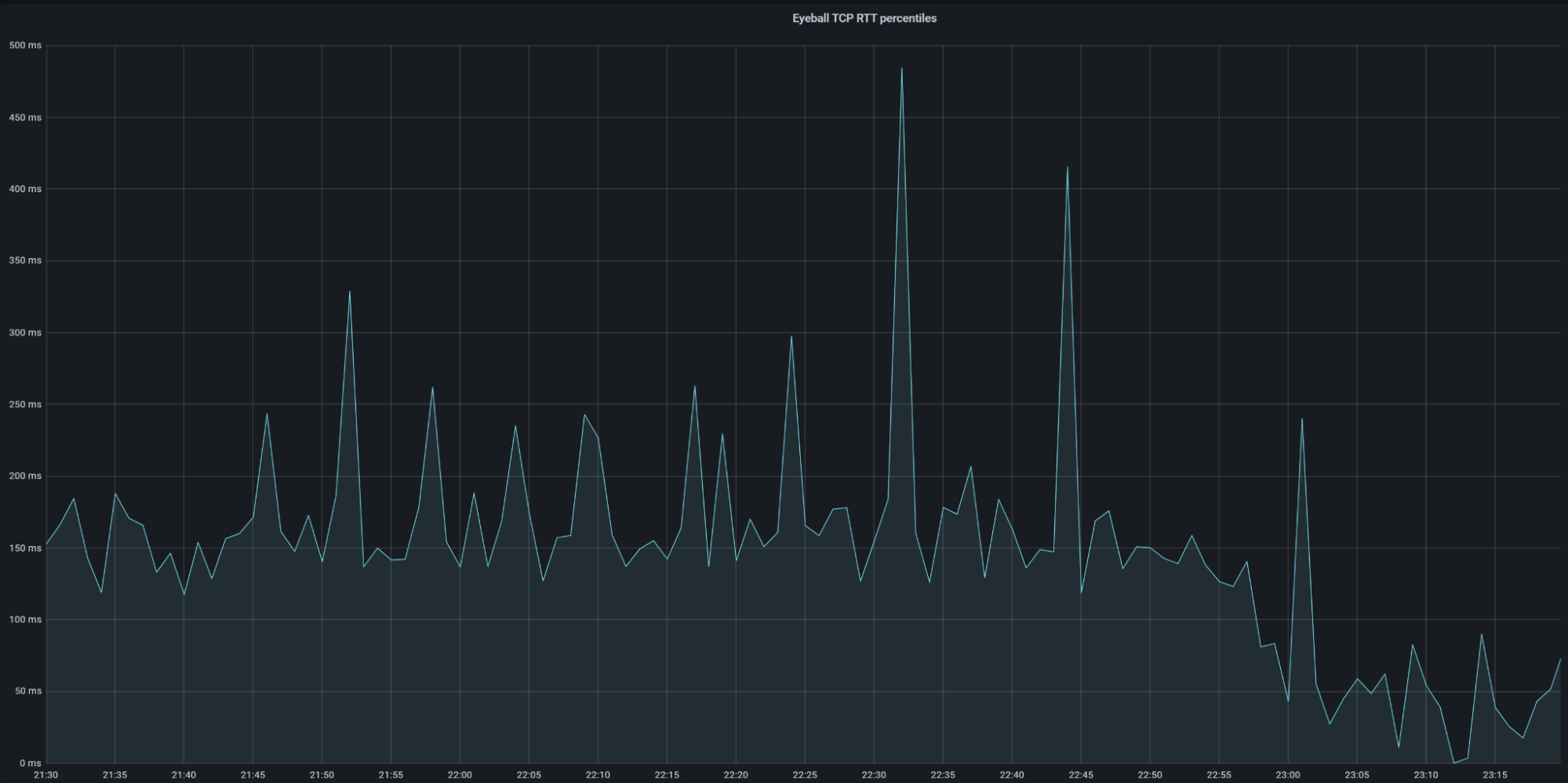
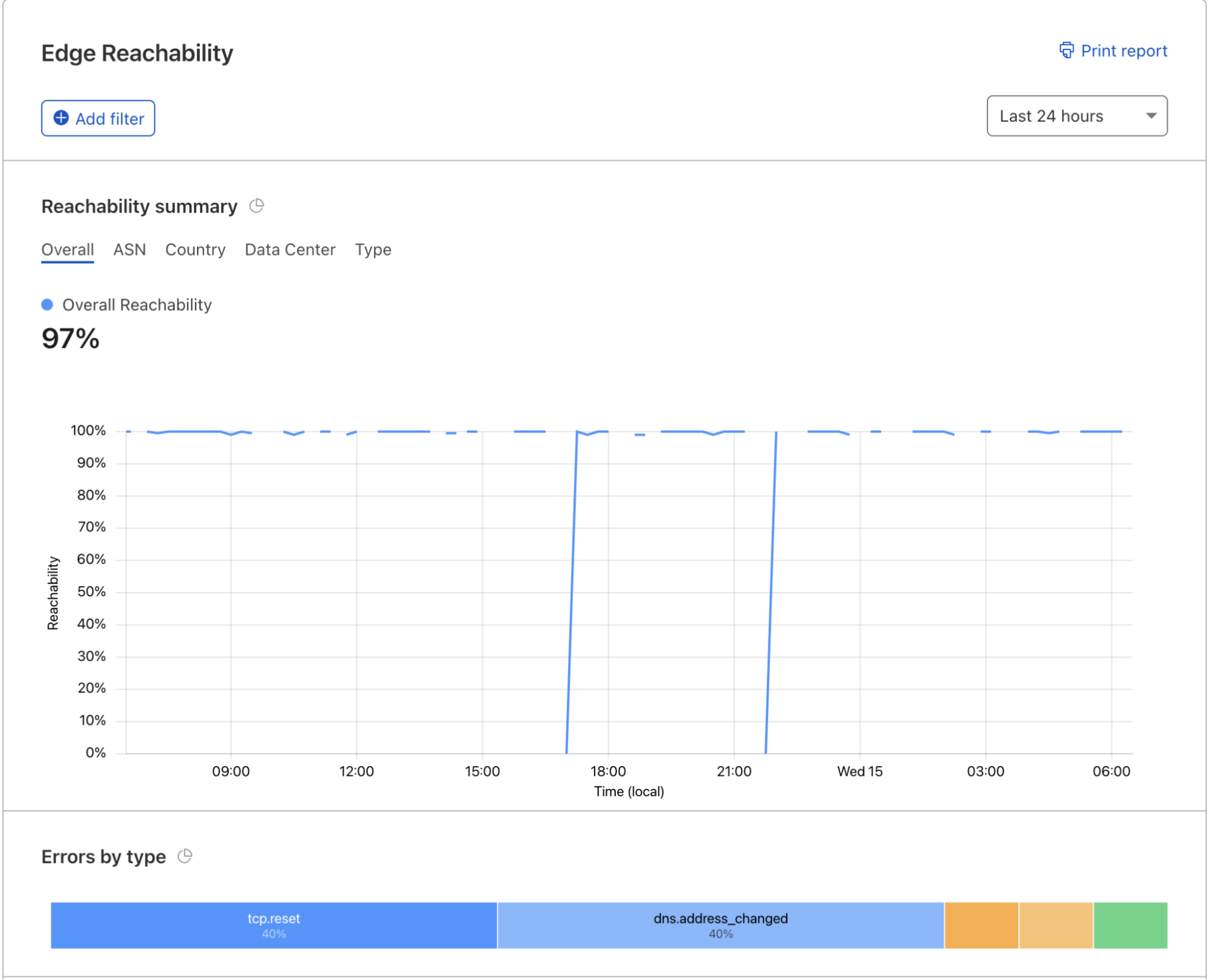
One customer quote that always resonates is, “I love using your services and products, but if you’re not up, then that doesn’t matter.” In the arena of interconnectivity, that is never more true. To that end, Cloudflare is excited to announce Bidirectional Forwarding Detection (or BFD) support on physical CNI links. BFD is a networking protocol that constantly monitors links and BGP sessions down to the second by sending a constant stream of traffic across the session. If a small number of those packets does not make it to the other side of the session, that session is considered down. This solution is useful for CNI customers who cannot tolerate any amount of packet loss during the session. If you’re a CNI customer, or even just a Cloudflare customer who has a low-loss requirement, CNI with BFD is a great solution to ensure that quick decisions are made with regard to your CNI to ensure your traffic always gets through.
Get connected today
Cloudflare is always trying to push the boundaries of what’s possible. We built a better path through the Internet with Argo, took on edge computing with Workers, and showed that zero trust networking could be done in the cloud with Cloudflare One. Pushing the boundaries of improving connectivity is the next step in Cloudflare’s journey to help build a better Internet. There are hard problems for people to solve on the Internet, like how to best protect what belongs to you. Figuring out how to get connected and protected should be fast and easy. With Cloudflare for Offices and CNI, we want to make it that easy.
If you are interested in CNI or Cloudflare for Offices, visit our landing page or reach out to your account team to get plugged in today!