Post Syndicated from Deanna Lam original https://blog.cloudflare.com/ai-face-cropping-for-images/
During Developer Week 2024, we introduced AI face cropping in private beta. This feature automatically crops images around detected faces, and marks the first release in our upcoming suite of AI image manipulation capabilities.
AI face cropping is now available in Images for everyone. To bring this feature to general availability, we moved our CPU-based prototype to a GPU-based implementation in Workers AI, enabling us to address a number of technical challenges, including memory leaks that could hamper large-scale use.

Photograph by Suad Kamardeen (@suadkamardeen) on Unsplash
We developed face cropping with two particular use cases in mind:
Social media platforms and AI chatbots. We observed a lot of traffic from customers who use Images to turn unedited images of people into smaller profile pictures in neat, fixed shapes.
E-commerce platforms. The same product photo might appear in a grid of thumbnails on a gallery page, then again on an individual product page with a larger view. The following example illustrates how cropping can change the emphasis from the model’s shirt to their sunglasses.

Photograph by Media Modifier (@mediamodifier) on Unsplash
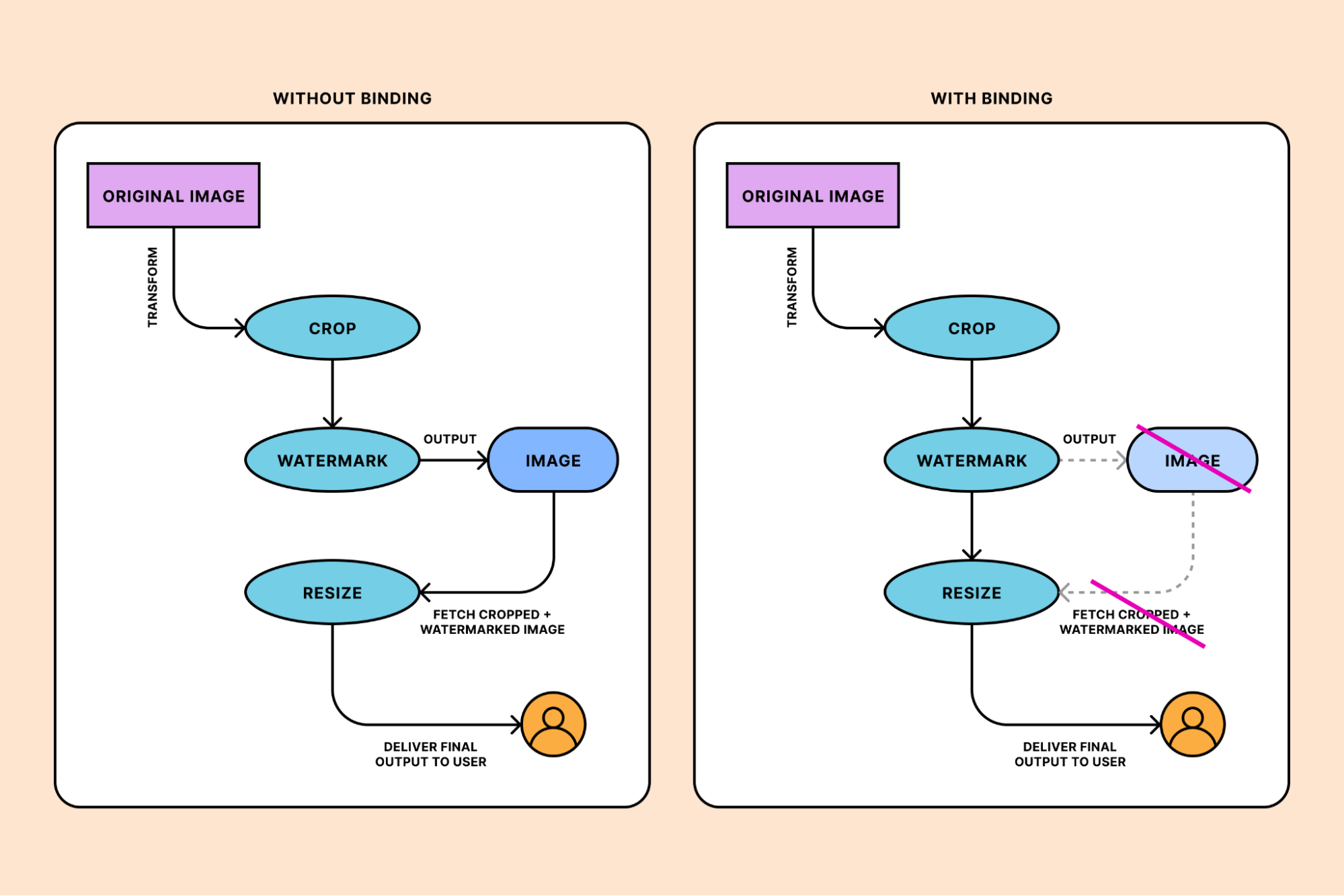
When handling high volumes of media content, preparing images for production can be tedious. With Images, you don’t need to manually generate and store multiple versions of the same image. Instead, we serve copies of each image, each optimized to your specifications, while you continue to store only the original image.
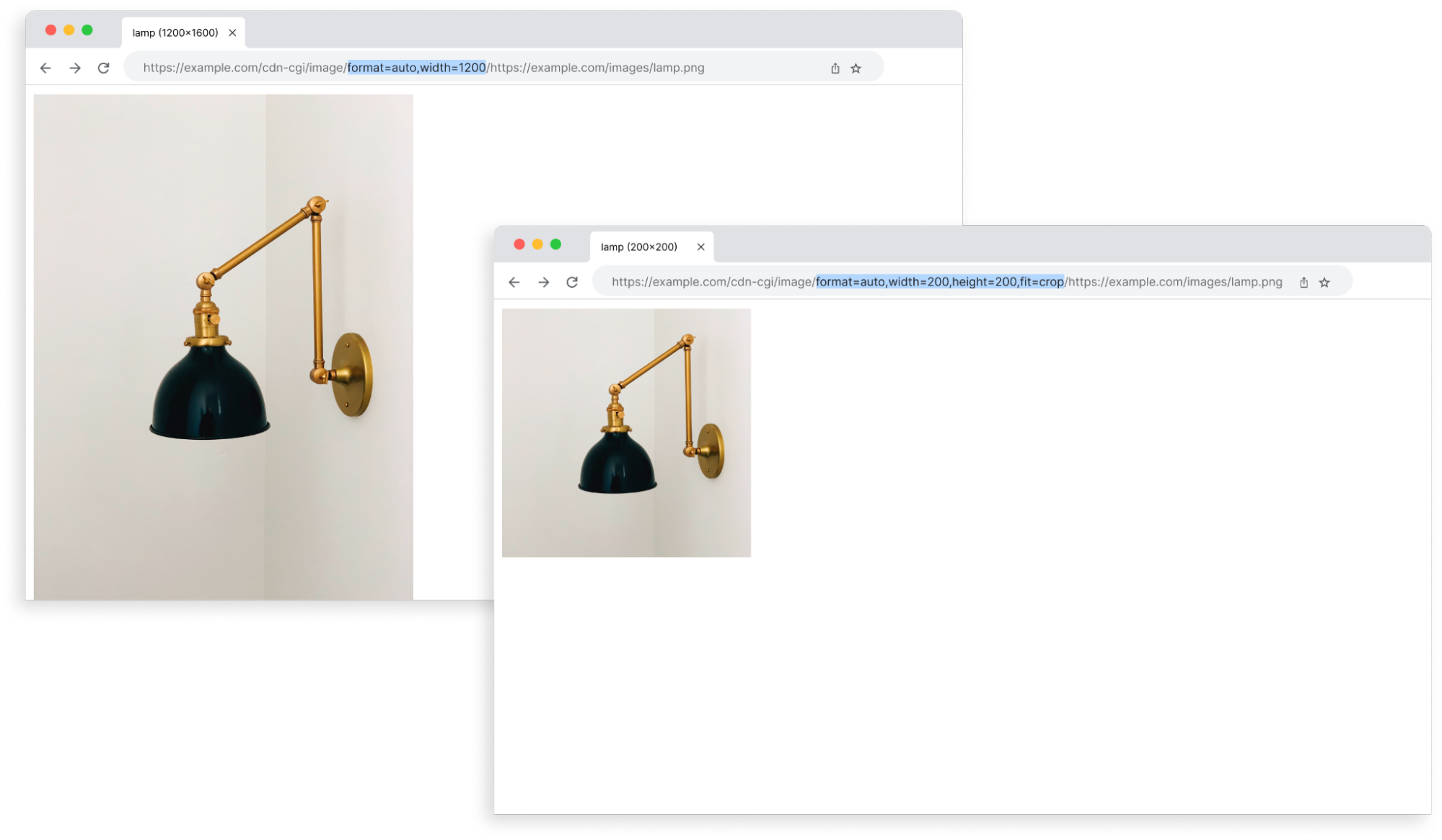
Cloudflare provides a library of parameters to manipulate how an image is served to the end user. For example, you can crop an image to a square by setting its width and height dimensions to 100×100.
By default, images are cropped toward the center coordinates of the original image. The gravity parameter can affect how an image gets cropped by changing its focal point. You can specify coordinates to use as the focal point of an image or allow Cloudflare to automatically determine a new focal point.

The gravity parameter is useful when cropping images with off-centered subjects. Photograph by Andrew Small (@andsmall) on Unsplash
The gravity=auto option uses a saliency algorithm to pick the most optimal focal point of an image. Saliency detection identifies the parts of an image that are most visually important; the cropping operation is then applied toward this region of interest. Our algorithm analyzes images using visual cues such as color, luminance, and texture, but doesn’t consider context within an image. While this setting works well on images with inanimate objects like plants and skyscrapers, it doesn’t reliably account for subjects as contextually meaningful as people’s faces.
And yet, images of people comprise the majority of bandwidth usage for many applications, such as an AI chatbot platform that uses Images to serve over 45 million unique transformations each month. This presented an opportunity for us to improve how developers can optimize images of people.
AI face cropping can be performed by using the gravity=face option, which automatically detects which pixels represent the face (or faces) and uses this information to crop the image. You can also affect how closely the image is cropped toward the face; the zoom parameter controls the threshold for how much of the surrounding area around the face will be included in the image.
We carefully designed our model pipeline with privacy and confidentiality top of mind. This feature doesn’t support facial identification or recognition. In other words, when you optimize with Cloudflare, we’ll never know that two different images depict the same person, or identify the specific people in a given image. Instead, AI face cropping with Images is intentionally limited to face detection, or identifying the pixels that represent a human face.
Our first step was to select an open-source model that met our requirements. Behind the scenes, our AI face cropping uses RetinaFace, a convolutional neural network model that classifies images with human faces.
A neural network is a type of machine learning process that loosely resembles how the human brain works. A basic neural network has three parts: an input layer, one or more hidden layers, and an output layer. Nodes in each layer form an interconnected network to transmit and process data, where each input node is connected to nodes in the next layer.

A fully connected layer passes data from one layer to the next.
Data enters through the input layer, where it is analyzed before being passed to the first hidden layer. All of the computation is done in the hidden layers, where a result is eventually delivered through the output layer.
A convolutional neural network (CNN) mirrors how humans look at things. When we look at other people, we start with abstract features, like the outline of their body, before we process specific features, like the color of their eyes or the shape of their lips.
Similarly, a CNN processes an image piece-by-piece before delivering the final result. Earlier layers look for abstract features like edges and colors and lines; subsequent layers become more complex and are each responsible for identifying the various features that comprise a human face. The last fully connected layer combines all categorized features to produce one final classification of the entire image. In other words, if an image contains all of the individual features that define a human face (e.g. eyes, nose), then the CNN concludes that the image contains a human face.
We needed a model that could determine whether an image depicts a person (image classification), as well as exactly where they are in the image (object detection). When selecting a model, some factors we considered were:
-
Performance on the WIDERFACE dataset. This is the state-of-the-art face detection benchmark dataset, which contains 32,203 images of 393,703 labeled faces with a high degree of variability in scale, pose, and occlusion.
-
Speed (in frames per second). Most of our image optimization requests occur on delivery (rather than before an image gets uploaded to storage), so we prioritized performance for end-user delivery.
-
Model size. Smaller model sizes run more efficiently.
-
Quality. The performance boost from smaller models often gets traded for the quality—the key is balancing speed with results.
Our initial test sample contained 500 images with varying factors like the number of faces in the image, face size, lighting, sharpness, and angle. We tested various models, including BlazeFast, R-CNN (and its successors Fast R-CNN and Faster R-CNN), RetinaFace, and YOLO (You Only Look Once).
Two-stage detectors like BlazeFast and R-CNN propose potential object locations in an image, then identify objects in those regions of interest. One-stage detectors like RetinaFace and YOLO predict object locations and classes in a single pass. In our research, we observed that two-stage detector methods provided higher accuracy, but performed too slowly to be practical for real traffic. On the other hand, one-stage detector methods were efficient and performant while still highly accurate.
Ultimately, we selected RetinaFace, which showed the highest precision of 99.4% and performed faster than other models with comparable values. We found that RetinaFace delivered strong results even with images containing multiple blurry faces:

Photograph by Anne Nygård (@polarmermaid) on Unsplash
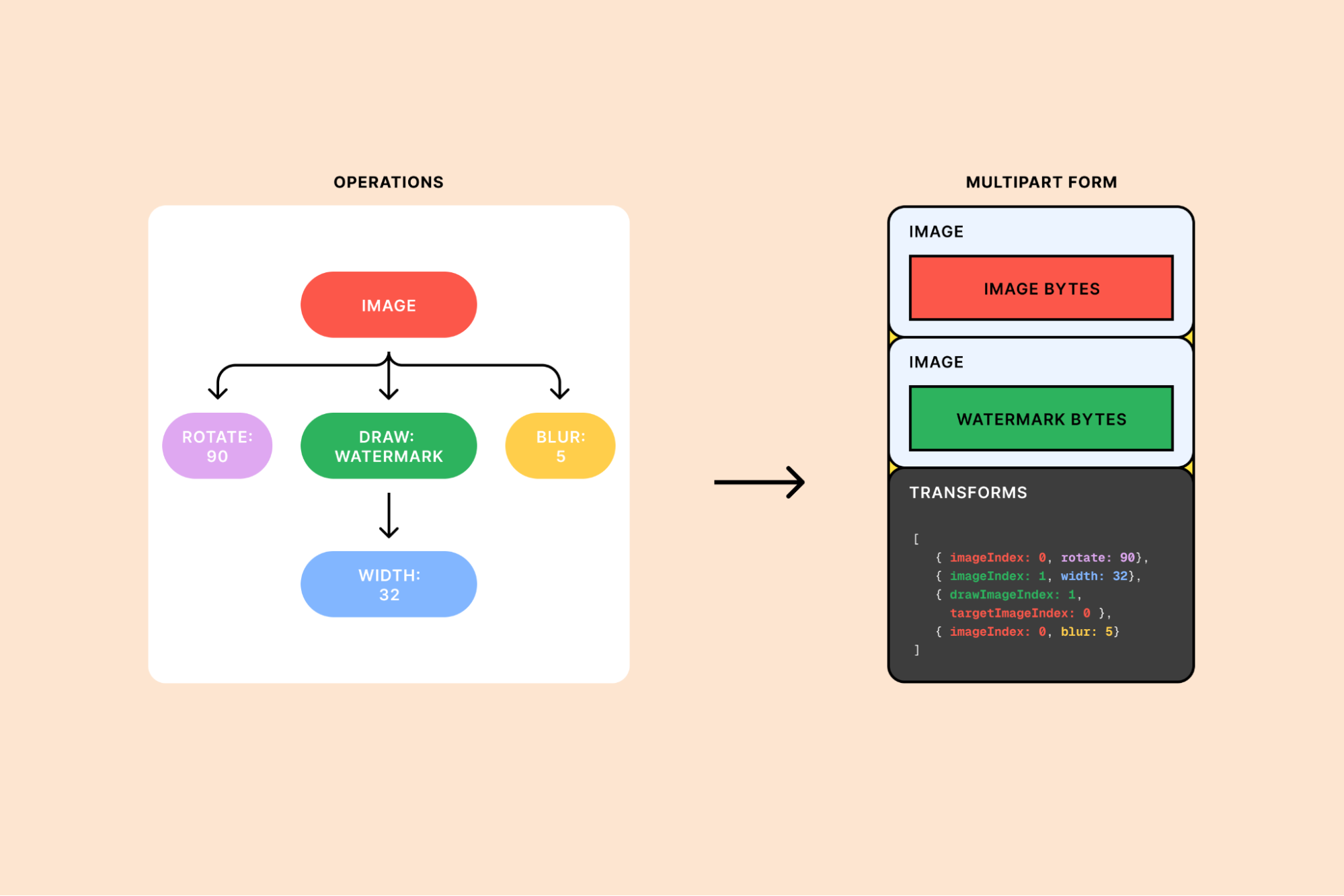
Inference—the process of using training models to make decisions—can be computationally demanding, especially with very large images. To maintain efficiency, we set a maximum size limit of 1024×1024 pixels when sending images to the model.
We pass images within these dimensions directly to the model for analysis. But if either width or height dimension exceeds 1024 pixels, then we instead create an inference image to send to the model; this is a smaller copy that retains the same aspect ratio as the original image and does not exceed 1024 pixels in either dimension. For example, a 125×2000 image will be downscaled to 64×1024. Creating this resized, temporary version reduces the amount of data that the model needs to analyze, enabling faster processing.
The model draws all of the bounding boxes, or the regions within an image that define the detected faces. From there, we construct a new, outer bounding box that encompasses all of the individual boxes, calculating its top-left and bottom-right points based on the boxes that are closest to the top, left, bottom, and right edges of the image.
The top-left point uses the x coordinate from the left-most box and the y coordinate from the top-most box. Similarly, the bottom-right point uses the x coordinate from the right-most box and the y coordinate from the bottom-most box. These coordinates can be taken from the same bounding boxes; if a single box is closest to both the top and left edges, then we would use its top-left corner as the top-left point of the outer bounding box.

AI face cropping identifies regions that represent faces, then determines an outer bounding box and focal point based on the top-most, left-most, right-most, and bottom-most bounding boxes.
Once we define the outer bounding box, we use its center coordinates as the focal point when cropping the image. From our experiments, we found that this produced better and more balanced results for images with multiple faces compared to other methods, like establishing the new focal point around the largest detected face.
The cropped image area is calculated based on the dimensions of the outer bounding box (“d”) and a specified zoom level (“z”) in the formula (1 ÷ z) × d. The zoom parameter accepts floating points between 0 and 1, where we crop the image to the bounding box when zoom=1 and include more of the area around the box as zoom trends toward 0.
Consider an original image that is 2048×2048. First, we create an inference image that is 1024×1024 to meet our size limits for face detection. Second, we define the outer bounding box using the model’s predictions—we’ll use 100×500 for this example. At zoom=0.5, our formula generates a crop area that is twice as large as the bounding box, with new width (“w”) and height (“h”) dimensions of 200×1000:

We also apply a min function that chooses the smaller number between the input dimensions and the calculated dimensions, ensuring that the new width and height never exceed the dimensions of the image itself. In other words, if you try to zoom out too much, then we use the full width or height of the image instead of defining a crop area that will extend beyond the edge of the image. For example, at zoom=0.25, our formula yields an initial crop area of 400×2000. Here, since the calculated height (2000) is larger than the input height (1024), we use the input height to set the crop area to 400×1024.
Finally, we need to scale the crop area back to the size of the original image. This applies only when a smaller inference image is created.
We initially downscaled the original 2048×2048 image by a factor of 2 to create the 1024×1024 inference image. This means that we need to multiply the dimensions of the crop area—400×1024 in our latest example—by 2 to produce our final result: a cropped image that is 800×2048.
In the beta version, we rewrote the model using TensorFlow Rust to make it compatible with our existing Rust-based stack. All of the computations for inference—where the model classifies and locates human faces—were executed on CPUs within our network.
Initially, this worked well and we saw near-realtime results.
However, the underlying limitations of our implementation became apparent when we started receiving consistent alerts that our underlying Images service was nearing its limits for memory usage. The increased memory usage didn’t line up with any recent deployments around this time, but a hunch led us to discover that the face cropping compute time graph had an uptick that matched the uptick in memory usage. Further tracing confirmed that AI face cropping was at the root of the problem.
When a service runs out of memory, it terminates its processes to free up memory and prevent the system from crashing. Since CPU-based implementations share RAM with other processes, this can potentially cause errors for other image optimization operations. In response, we switched our memory allocator from glibc malloc to jemalloc. This allowed us to use less memory at runtime, saving about 20 TiB of RAM globally. We also started culling the number of face cropping requests to limit CPU usage.
At this point, AI face cropping was already limited to our own internal uses and a small number of beta customers. These steps only temporarily reduced our memory consumption. They weren’t sufficient for handling global traffic, so we looked toward a more scalable design for long-term use.
With memory usage alerts looming in the distance, it became clear that we needed to move to a GPU-based approach.
Unlike with CPUs, a GPU-based implementation avoids contention with other processes because memory access is typically dedicated and managed more tightly. We partnered with the Workers AI team, who created a framework for internal teams to integrate payloads into their model catalog for GPU access.
Some Workers AI models have their own standalone containers; this isn’t practical for every model, as routing traffic to multiple containers can be expensive. When using a GPU through Workers AI, the data needs to travel over the network, which can introduce latency. This is where model size is especially relevant, as network transport overhead becomes more noticeable with larger models.
To address this, Workers AI wraps smaller models in a single container and utilizes a latency-sensitive routing algorithm to identify the best instance to serve each payload. This means that models can be offloaded when there is no traffic.

A scheduler is used to optimize how—and when—models in the same container interact with GPUs.
RetinaFace runs on 1 GB of VRAM on the smallest GPU; it’s small enough that it can be hot swapped at runtime alongside similarly sized models. If there is a call for the RetinaFace model, then the Python code will be loaded into the environment and executed.
As expected, we saw a significant drop in memory usage after we moved the feature to Workers AI. Now, each instance of our Images service consumes about 150 MiB of memory.

With this new approach, memory leaks pose less concern to the overall availability of our service. Workers AI executes models within containers, so they can be terminated and restarted as needed without impacting other processes. Since face cropping runs separately from our Images service, restarting it won’t halt our other image optimization operations.
As part of our beta launch, we updated the Cloudflare blog to apply AI face cropping on author images.
Authors can submit their own images, which appear as circular profile pictures in both the main blog feed and individual blog posts. By default, CSS centers images within their containers, making off-centered head positions more obvious. When two profile pictures include different amounts of negative space, this can also lead to a visual imbalance where authors’ faces appear at different scales:

AI face cropping makes posts with multiple authors appear more balanced.
In the example above, Austin’s original image is cropped tightly around his face. On the other hand, Taylor’s original image includes his torso and a larger margin of the background. As a result, Austin’s face appears larger and closer to the center than Taylor’s does. After we applied AI face cropping to profile pictures on the blog, their faces appear more similar in size, creating more balance and cohesion on their co-authored post.
Many developers already use Images to build scalable media pipelines. Our goal is to accelerate image workflows by automating rote, manual tasks.
For the Images team, this is only the beginning. We plan to release new AI capabilities, including features like background removal and generative upscale. You can try AI face cropping for free by enabling transformations in the Images dashboard.