Post Syndicated from Greg McKeon original https://blog.cloudflare.com/r2-open-beta/
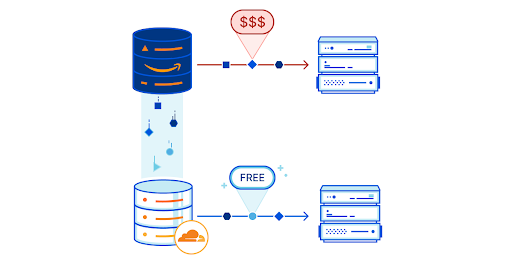
In September, we announced that we were building our own object storage solution: Cloudflare R2. R2 is our answer to egregious egress charges from incumbent cloud providers, letting developers store as much data as they want without worrying about the cost of accessing that data.
The response has been overwhelming.
- Independent developers had bills too small for cloud providers to negotiate fair egress rates with them. Egress charges were the largest line-item on their cloud bills, strangling side projects and the new businesses they were building.
- Large corporations had written off multi-cloud storage – and thus multi-cloud itself – as a pipe dream. They came to us with excitement, pitching new products that integrated data with partner companies.
- Non-profit research organizations were paying massive egress fees just to share experiment data with one another. Egress fees were having a real impact on their ability to collaborate, driving silos between organizations and restricting the experiments and analyses they could run.
Cloudflare exists to help build a better Internet. Today, the Internet gets what it deserves: R2 is now in open beta.
Self-serve customers can enable R2 in the Cloudflare dashboard. Enterprise accounts can reach out to their CSM for onboarding.
Internal and external APIs
R2 has two APIs: an API accessible only from within Workers, which we call the In-Worker API, and an S3-compatible API, which exposes your bucket on a URL of the form bucket.account.r2storage.com. Before you can make requests to R2, you’ll need to be authenticated — R2 buckets are private by default.
In-Worker API
With the in-Worker API, a bucket is “bound” to a specific Worker, which can then perform PUT, GET, DELETE and LIST operations against the bucket.
S3-compatible API
For the S3-compatible API, authentication is done the same way as on S3: SigV4 against an R2 URL. SigV4 signs requests using a secret key to authenticate them to R2. This means public access to R2 over the Internet is only possible today by hosting a Worker, connecting it to R2, and routing requests through it.
The easiest way to test the S3-compatible API is to use an S3 client. One of the most popular S3 clients is the boto3 SDK.
In Python, copy the following script and fill in the account_id, access_key, and secret_access_key fields with your R2 account credentials.
#!/usr/bin/env python
import boto3
import pprint
from botocore.client import Config
account_id = ''
access_key_id = ''
secret_access_key = ''
endpoint = f'https://{account_id}.r2.cloudflarestorage.com'
cl = boto3.client(
's3',
aws_access_key_id=access_key_id,
aws_secret_access_key=secret_access_key,
endpoint_url=endpoint,
config=Config(
region_name = endpoints[endpoint_name].get('region', 'auto'),
s3={'addressing_style': 'path'},
retries=dict( max_attempts=0 ),
),
)
printer = pprint.PrettyPrinter().pprint
printer(cl.head_bucket(Bucket='some bucket'))
printer(cl.create_bucket(Bucket='some other bucket'))
printer(cl.put_object(Bucket='some bucket', Key='my object', Body='some payload'))
Features
R2 comes with support for all basic create/read/update/delete S3 features through both of its APIs.
During the open beta period, we’re targeting R2 to sustain 1,000 GET operations per second and 100 PUT operations per second, per bucket. R2 supports objects up to approximately 5 TB in size, with individual parts limited to 5 GB of data.
R2 provides strongly consistent access to data. Once a PUT is confirmed by R2, future GET operations will always reflect the new key/value pair. The only exception to this is when deleting a bucket. For a short period of time following deletion, the bucket may still exist and continue to allow reads/writes.
Pricing
When we initially announced R2, we included preliminary pricing numbers. One of our main goals with R2 has been to serve the developers who can’t negotiate large discounts with cloud vendors. To that end, we’re also announcing a forever-free tier that lets developers start building on R2 with no charges at all.
R2 charges depend on the total volume of data stored and the type of operation performed on the data:
- Storage is priced at \$0.015 / GB, per month.
- Class A operations (including writes and lists) cost \$4.50 / million.
- Class B operations cost \$0.36 / million.
Class A operations tend to mutate state, such as creating a bucket, listing objects in a bucket, or writing an object. Class B operations tend to read existing state, for example reading an object from a bucket. You can find more information on pricing and a full list of operation types in the docs.
Of course, there is no charge for egress bandwidth from R2. You can access your bucket to your heart’s content.
R2’s forever-free tier includes:
- 10 GB-months of stored data
- 1,000,000 Class A operations, per month
- 10,000,000 Class B operations, per month
Free usage resets each month. While in the open beta phase, R2 usage over the free tier will be billed.
Future plans
We’ve spent the past six months in closed beta with a number of design partners, building out our storage solution. Backed by Durable Objects, R2’s novel architecture delivers both high availability and consistent performance.
While we’ve made great progress on R2, we still have plenty left to build in the coming months.
Improving performance
Our first priority is to improve performance and reliability. While we’ve thrown internal usage and our design partner’s demands at R2, there’s no substitute for live production traffic.
During the open beta period, R2 can sustain a maximum of 1,000 GET operations per second and 100 PUT operations per second, per bucket. We’ll look to raise these limits as we get comfortable operating the system. If you have higher needs, reach out to us!
When you create a bucket, you won’t see a region selector. Our vision for R2 includes automatically globally distributed storage, where R2 seamlessly places each object into the storage region closest to where the request comes from. Today, R2 primarily stores data in North America, which can lead to higher latencies when accessing content from other regions. We’ll first look to address this by adding additional regions where objects can be created, before adding automatic migration of existing objects across regions. Similar to what we’ve built with jurisdictional restrictions for Durable Objects, we’ll also enable restricting where an R2 bucket places data to comply with privacy regulations.
Expanding R2’s feature set
We’ll then focus on expanding R2 capabilities beyond the basic S3 API. In the near term, we’re focused on delivering:
- Support for TTLs, so data can automatically be deleted from buckets over time.
- Public buckets, so a bucket can be exposed to the internet without writing a Worker
- Pre-signed URL support, which delegates read and write access for a specific key to a token.
- Integration with Cloudflare’s cache, to scale read requests and provide global distribution of data.
If you have additional feature requests that aren’t listed above, we want to hear from you! Reach out and let us know what you need to make R2 your new, zero-cost egress object store.