Post Syndicated from Alex Robinson original https://blog.cloudflare.com/rearchitecting-workers-kv-for-redundancy/
On June 12, 2025, Cloudflare suffered a significant service outage that affected a large set of our critical services. As explained in our blog post about the incident, the cause was a failure in the underlying storage infrastructure used by our Workers KV service. Workers KV is not only relied upon by many customers, but serves as critical infrastructure for many other Cloudflare products, handling configuration, authentication and asset delivery across the affected services. Part of this infrastructure was backed by a third-party cloud provider, which experienced an outage on June 12 and directly impacted availability of our KV service.
Today we’re providing an update on the improvements that have been made to Workers KV to ensure that a similar outage cannot happen again. We are now storing all data on our own infrastructure. We are also serving all requests from our own infrastructure in addition to any third-party cloud providers used for redundancy, ensuring high availability and eliminating single points of failure. Finally, the work has meaningfully improved performance and set a clear path for the removal of any reliance on third-party providers as redundant back-ups.
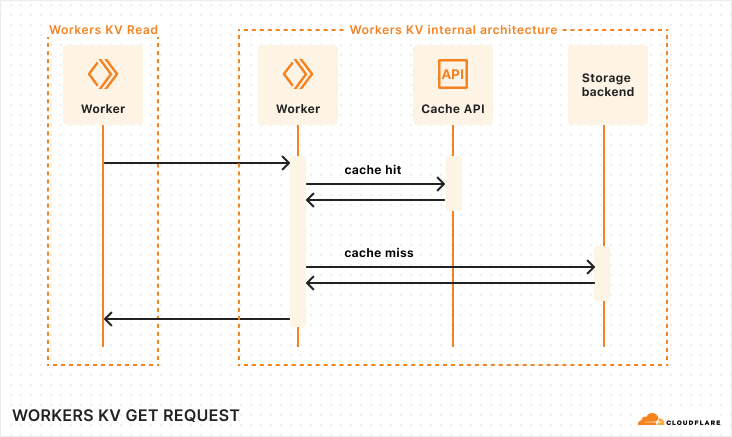
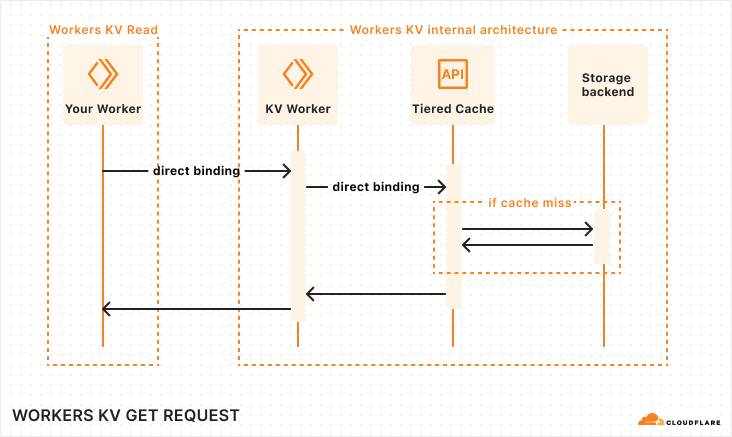
Workers KV is a global key-value store that supports high read volumes with low latency. Behind the scenes, the service stores data in regional storage and caches data across Cloudflare’s network to deliver exceptional read performance, making it ideal for configuration data, static assets, and user preferences that need to be available instantly around the globe.
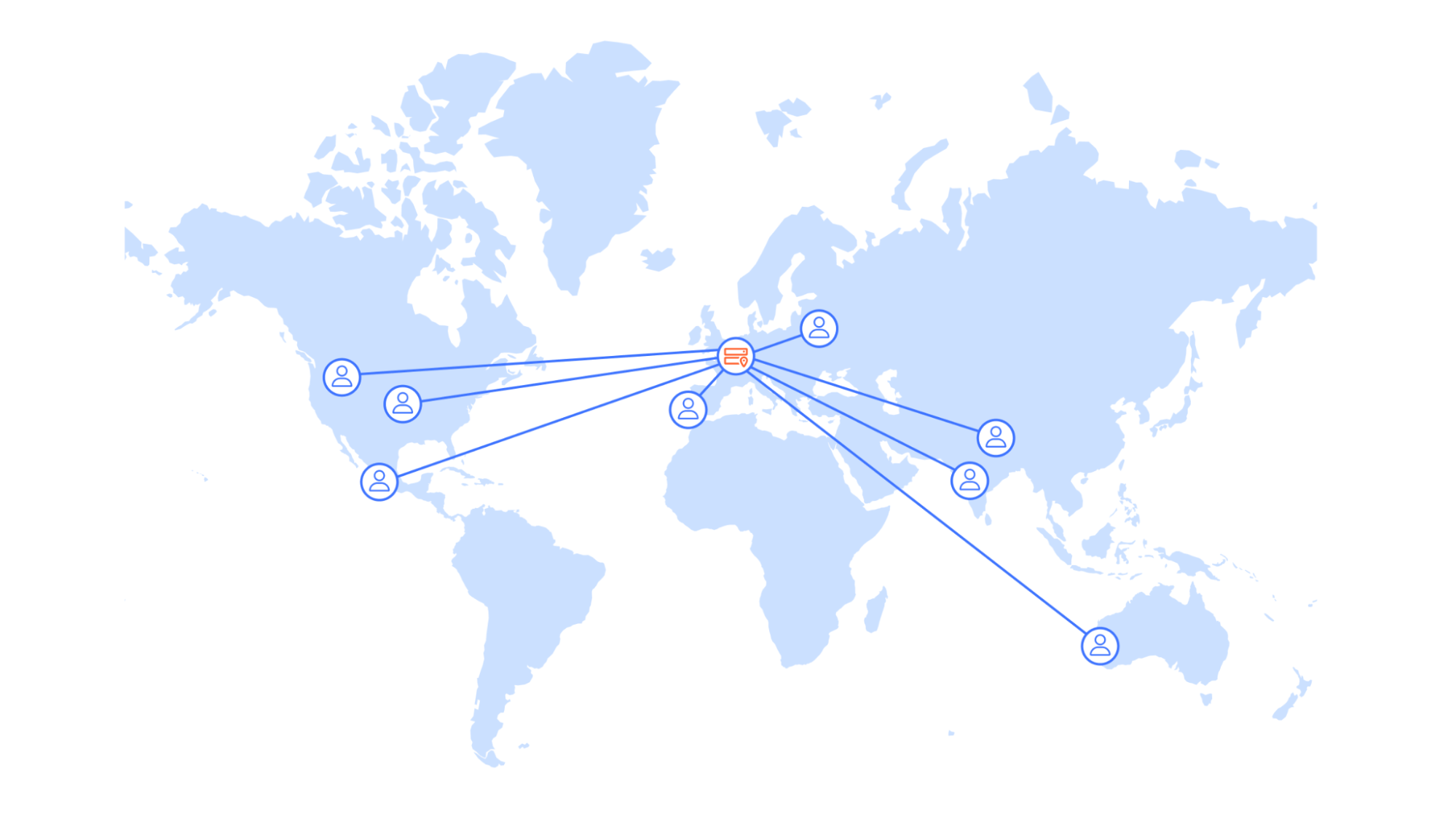
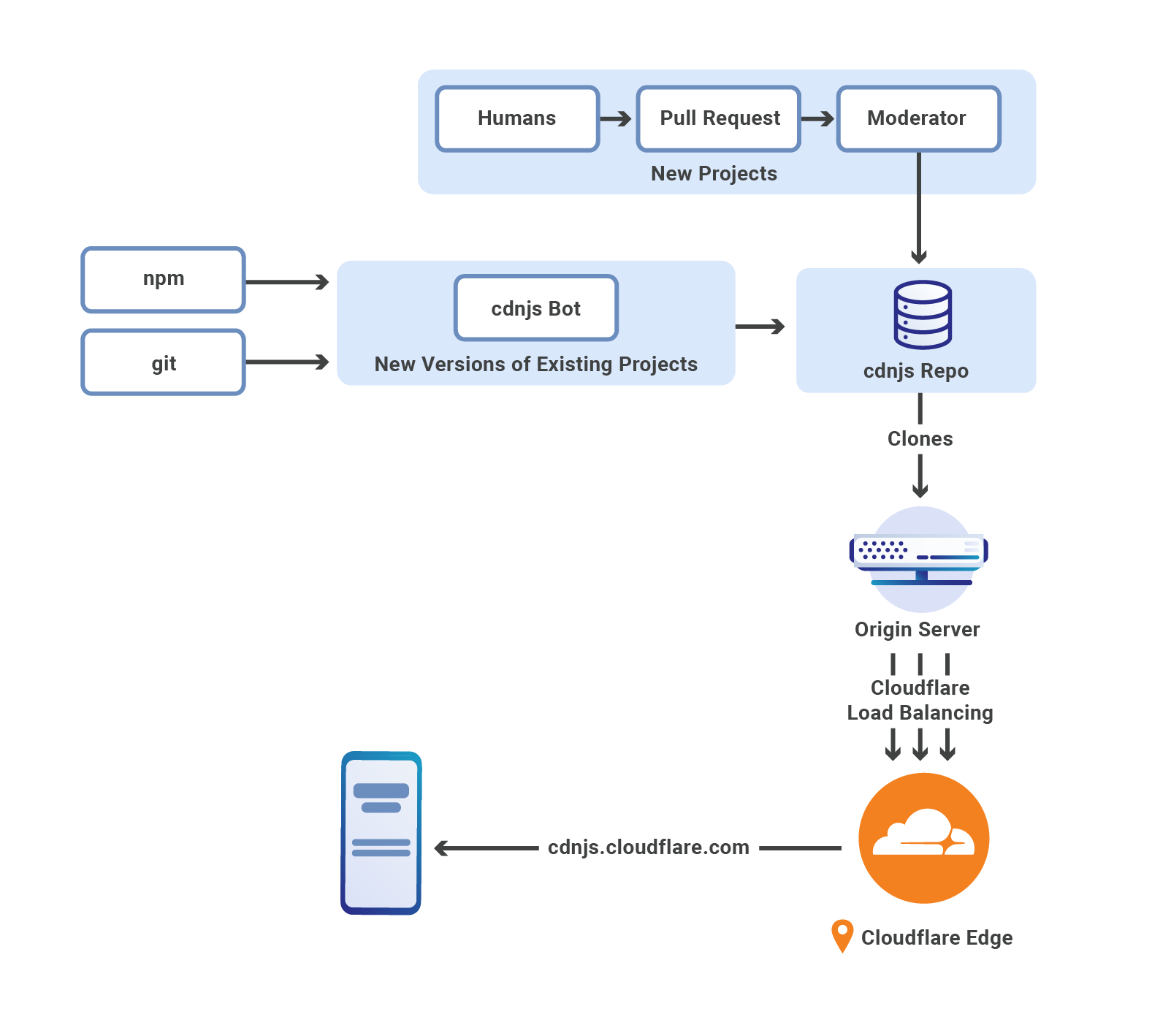
Workers KV was initially launched in September 2018, predating Cloudflare-native storage services like Durable Objects and R2. As a result, Workers KV’s original design leveraged object storage offerings from multiple third-party cloud service providers, maximizing availability via provider redundancy. The system operated in an active-active configuration, successfully serving requests even when one of the providers was unavailable, experiencing errors, or performing slowly.
Requests to Workers KV were handled by Storage Gateway Worker (SGW), a service running on Cloudflare Workers. When it received a write request, SGW would simultaneously write the key-value pair to two different third-party object storage providers, ensuring that data was always available from multiple independent sources. Deletes were handled similarly, by writing a special tombstone value in place of the object to mark the key as deleted, with these tombstones garbage collected later.
Reads from Workers KV could usually be served from Cloudflare’s cache, providing reliably low latency. For reads of data not in cache, the system would race requests against both providers and return whichever response arrived first, typically from the geographically closer provider. This racing approach optimized read latency by always taking the fastest response while providing resilience against provider issues.

Given the inherent difficulty of keeping two independent storage providers synchronized, the architecture included sophisticated machinery to handle data consistency issues between backends. Despite this machinery, consistency edge cases remained more frequent than consumers required due to the inherently imperfect availability of upstream object storage systems and the challenges of maintaining perfect synchronization across independent providers.
Over the years, the system’s implementation evolved significantly, including a variety of performance improvements we discussed last year, but the fundamental dual-provider architecture remained unchanged. This provided a reliable foundation for the massive growth in Workers KV usage while maintaining the performance characteristics that made it valuable for global applications.
As Workers KV usage scaled dramatically and access patterns became more diverse, the dual-provider architecture faced mounting operational challenges. The providers had fundamentally different limits, failure modes, APIs, and operational procedures that required constant adaptation.
The scaling issues extended beyond provider reliability. As KV traffic increased, the total number of IOPS exceeded what we could write to local cache infrastructure, forcing us to rely on traditional caching approaches when data was fetched from origin storage. This shift exposed additional consistency edge cases that hadn’t been apparent at smaller scales, as the caching behavior became less predictable and more dependent on upstream provider performance characteristics.
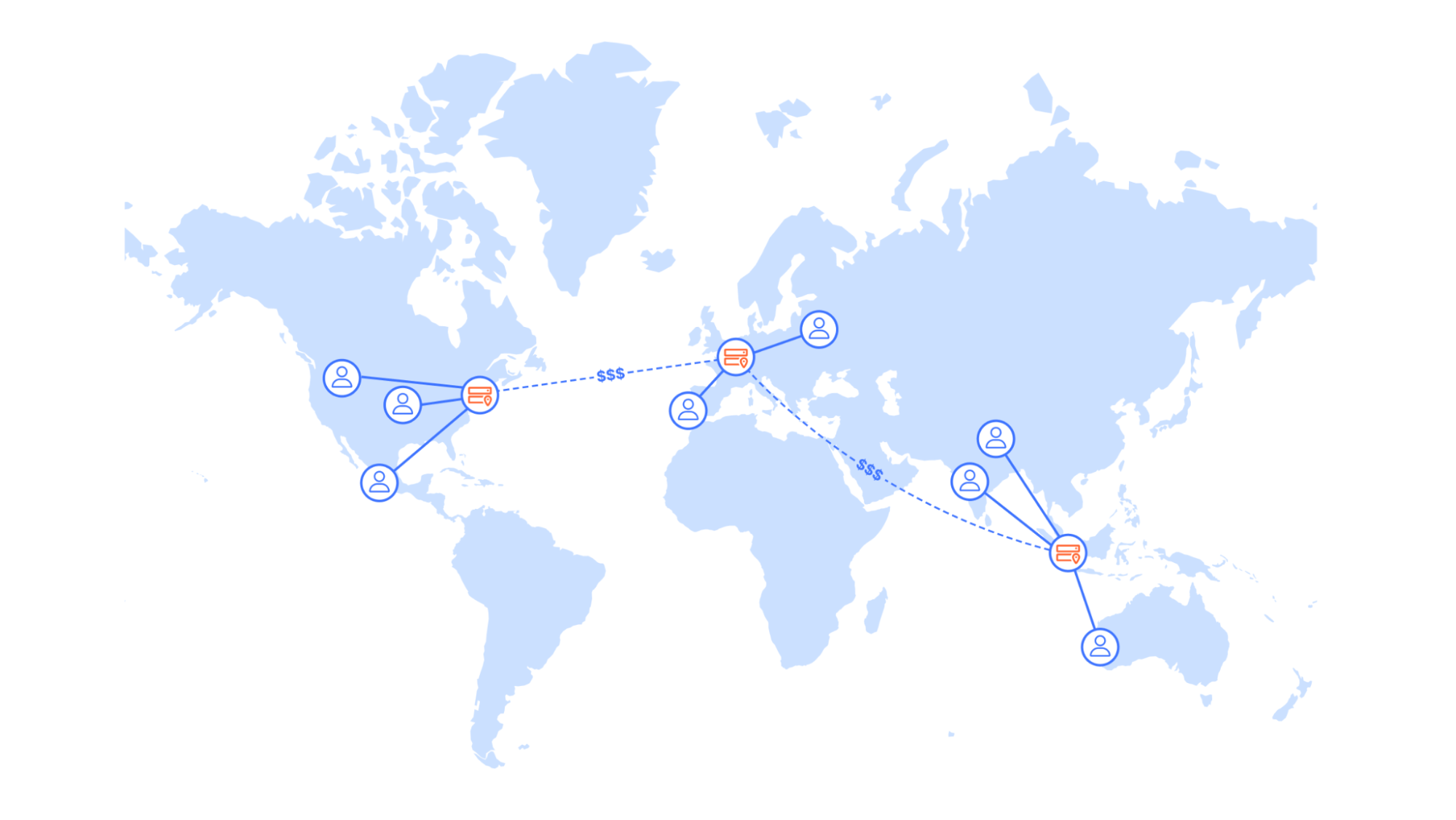
Eventually, the combination of consistency issues, provider reliability disparities, and operational overhead led to a strategic decision to reduce complexity by moving to a single object storage provider earlier this year. This decision was made with awareness of the increased risk profile, but we believed the operational benefits outweighed the risks and viewed this as a temporary intermediate state while we developed our own storage infrastructure.

Unfortunately, on June 12, 2025, that risk materialized when our remaining third-party cloud provider experienced a global outage, causing a high percentage of Workers KV requests to fail for a period that lasted over two hours. The cascading impact to customers and to other Cloudflare services was severe: Access failed all identity-based logins, Gateway proxy became unavailable, WARP clients couldn’t connect, and dozens of other services experienced significant disruptions.
The immediate goal after the incident was clear: bring at least one other fully redundant provider online such that another single-provider outage would not bring KV down. The new provider needed to handle massive scale along several dimensions: hundreds of billions of key-value pairs, petabytes of data stored, millions of GET requests per second, tens of thousands of steady-state PUT/DELETE requests per second, and tens of gigabits per second of throughput—all with high availability and low single-digit millisecond internal latency.
One obvious option was to bring back the provider that we had disabled earlier in the year. However, we could not just flip the switch back. The infrastructure to run in the dual backend configuration on the prior third-party storage provider was gone and the code had experienced some bit rot, making it infeasible to quickly revert to the previous dual-provider setup.
Additionally, the other provider had frequently been a source of their own operational problems, with relatively high error rates and concerningly low request throughput limits, that made us hesitant to rely on it again. Ultimately, we decided that our second provider should be entirely owned and operated by Cloudflare.
The next option was to build directly on top of Cloudflare R2. We already had a private beta version of Workers KV running on R2, but this experience helped us better understand Workers KV’s unique storage requirements. Workers KV’s traffic patterns are characterized by hundreds of billions of small objects with a median size of just 288 bytes—very different from typical object storage workloads that assume larger file sizes.

For workloads dominated by sub-1KB objects at this scale, database storage becomes significantly more efficient and cost-effective than traditional object storage. When you need to store billions of very small values with minimal per-value overhead, a database is a natural architectural fit. We’re working on optimizations for R2 such as inlining small objects with metadata to eliminate additional retrieval hops that will improve performance for small objects, but for our immediate needs, a database-backed solution offered the most promising path forward.
After thorough evaluation of possible options, we decided to use a distributed database already in production at Cloudflare. This same database is used behind the scenes by both R2 and Durable Objects, giving us several key advantages: we have deep in-house expertise and existing automation for deployment and operations, and we knew we could depend on its reliability and performance characteristics at scale.
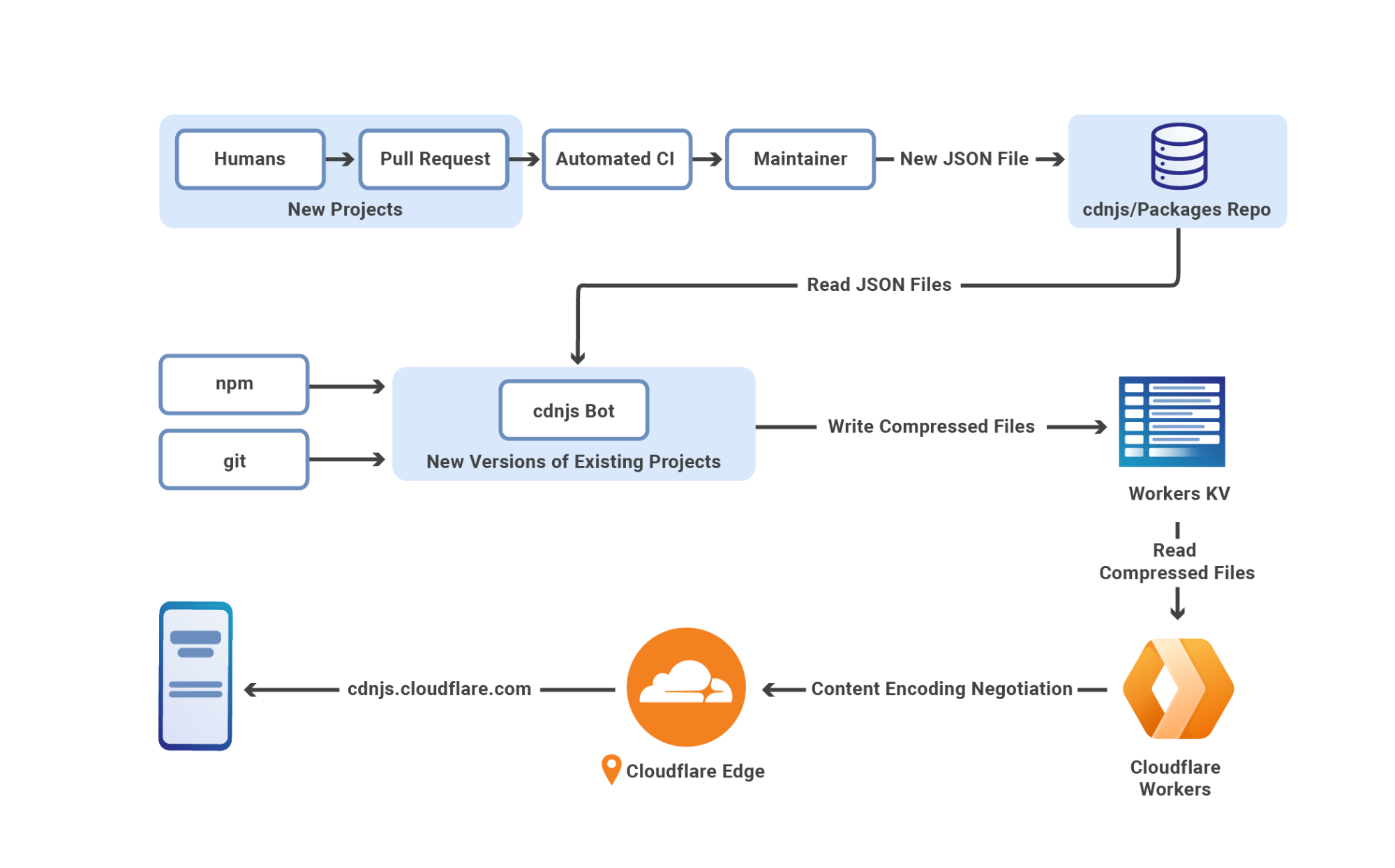
We sharded data across multiple database clusters, each with three-way replication for durability and availability. This approach allows us to scale capacity horizontally while maintaining strong consistency guarantees within each shard. We chose to run multiple clusters rather than one massive system to ensure a smaller blast radius if any cluster becomes unhealthy and to avoid pushing the practical limits of single-cluster scalability as Workers KV continues to grow.
One immediate challenge that we ran into when implementing the system was connectivity. The SGW needed to communicate with database clusters running in our core datacenters, but databases typically use binary protocols over persistent TCP connections—not the HTTP-based communication patterns that work efficiently across our global network.
We built KV Storage Proxy (KVSP) to bridge this gap. KVSP is a service that provides an HTTP interface that our SGW can use while managing the complex database connectivity, authentication, and shard routing behind the scenes. KVSP stripes namespaces across multiple clusters using consistent hashing, preventing hotspotting where popular namespaces could overwhelm single clusters, eliminating noisy neighbor issues, and ensuring capacity limitations are distributed rather than concentrated.
The biggest downside of using a distributed database for Workers KV’s storage is that, while it excels at handling the small objects that dominate KV traffic, it is not optimal for the occasional large values of up to 25 MiB that some users store. Rather than compromise on either use case, we extended KVSP to automatically route larger objects to Cloudflare R2, creating a hybrid storage architecture that optimizes the backend choice based on object characteristics. From the perspective of SGW, this complexity is completely transparent—the same HTTP API works for all objects regardless of size.
We also restored our dual-provider capabilities between storage providers from KV’s prior architecture and adapted them to work well in tandem with the changes that had been made to KV’s implementation since it dropped down to a single provider. The modified system now operates by racing writes to both backends simultaneously, but returns success to the client as soon as the first backend confirms the write.
This improvement minimizes latency while ensuring durability across both systems. When one backend succeeds but the other fails—due to temporary network issues, rate limiting, or service degradation—the failed write is queued for background reconciliation, which serves as part of our synchronization machinery that is described in more detail below.

With the hybrid architecture implemented, we began a careful rollout process designed to validate the new system while maintaining service availability.
The first step was introducing background writes from SGW to the new Cloudflare backend. This allowed us to validate write performance and error rates under real production load without affecting read traffic or user experience. It also was a necessary step in copying all data over to the new backend.
Next, we copied existing data from the third-party provider to our new backend running on Cloudflare infrastructure, routing the data through KVSP. This brought us to a critical milestone: we were now in a state where we could manually failover all operations to the new backend within minutes in the event of another provider outage. The single point of failure that caused the June incident had been eliminated.
With confidence in the failover capability, we began enabling our first namespaces in active-active mode, starting with internal Cloudflare services where we had sophisticated monitoring and deep understanding of the workloads. We dialed up traffic very slowly, carefully comparing results between backends. The fact that SGW could see responses from both backends asynchronously—after already returning a response to the user—allowed us to perform detailed comparisons and catch any discrepancies without impacting user-facing latency.
During testing, we discovered an important consistency regression compared to our single provider setup, which caused us to briefly roll back the change to put namespaces in active-active mode. While Workers KV is eventually consistent by design, with changes taking up to 60 seconds to propagate globally as cached versions time out, we had inadvertently regressed read-your-own-write (RYOW) consistency for requests routed through the same Cloudflare point of presence.
In the previous dual provider active-active setup, RYOW was provided within each PoP because we wrote PUT operations directly to a local cache instead of relying on the traditional caching system in front of upstream storage. However, KV throughput had outscaled the number of IOPS that the caching infrastructure could support, so we could no longer rely on that approach. This wasn’t a documented property of Workers KV, but it is behavior that some customers have come to rely on in their applications.
To understand the scope of this issue, we created an adversarial test framework designed to maximize the likelihood of hitting consistency edge cases by rapidly interspersing reads and writes to a small set of keys from a handful of locations around the world. This framework allowed us to measure the percentage of reads where we observed a violation of RYOW consistency—scenarios where a read immediately following a write from the same point of presence would return stale data instead of the value that was just written. This allowed us to design and verify a new approach to how KV populates and invalidates data in cache, which restored the RYOW behavior that customers expect while maintaining the performance characteristics that make Workers KV effective for high-read workloads.
With writes racing to both backends and reads potentially returning different results, maintaining data consistency across independent storage providers requires a sophisticated multi-layered approach. While the details have evolved over time, KV has always taken the same basic approach, consisting of three complementary mechanisms that work together to reduce the likelihood of inconsistencies and minimize the window for data divergence.
The first line of defense happens during write operations. When SGW sends writes to both backends simultaneously, we treat the write as successful as soon as either provider confirms persistence. However, if a write succeeds on one provider but fails on the other—due to network issues, rate limiting, or temporary service degradation—the failed write is captured and sent to a background reconciliation system. This system deduplicates failed keys and initiates a synchronization process to resolve the inconsistency.
The second mechanism activates during read operations. When SGW races reads against both providers and notices different results, it triggers the same background synchronization process. This helps ensure that keys that become inconsistent are brought back into alignment when first accessed rather than remaining divergent indefinitely.
The third layer consists of background crawlers that continuously scan data across both providers, identifying and fixing any inconsistencies missed by the previous mechanisms. These crawlers also provide valuable data on consistency drift rates, helping us understand how frequently keys slip through the reactive mechanisms and address any underlying issues.
The synchronization process itself relies on version metadata that we attach to every key-value pair. Each write automatically generates a new version consisting of a high-precision timestamp plus a random nonce, stored alongside the actual data. When comparing values between providers, we can determine which version is newer based on these timestamps. The newer value is then copied to the provider with the older version.
In rare cases where timestamps are within milliseconds of each other, clock skew could theoretically cause incorrect ordering, though given the tight bounds we maintain on our clocks through Cloudflare Time Services and typical write latencies, such conflicts would only occur with nearly simultaneous overlapping writes.
To prevent data loss during synchronization, we use conditional writes that verify that the last timestamp is older before writing instead of blindly overwriting values. This allows us to avoid introducing new inconsistency issues in cases where requests in close proximity succeed to different backends and the synchronization process copies older values over newer values.
Similarly, we can’t just delete data when the user requests it because if the delete only succeeded to one backend, the synchronization process would see this as missing data and copy it from the other backend. Instead, we overwrite the value with a tombstone that has a newer timestamp and no actual data. Only after both providers have the tombstone do we proceed with actually removing the keys from storage.
This layered consistency architecture doesn’t guarantee strong consistency, but in practice it does eliminate most mismatches between backends while maintaining a performance profile that makes Workers KV attractive for latency-sensitive, high-read workloads while also providing high availability in the case of any backend errors. In distributed systems terms, KV chooses availability (AP) over consistency (CP) in the CAP theorem, and more interestingly also chooses latency over consistency in the absence of a partition, meaning it’s PA/EL under the PACELC theorem. Most inconsistencies are resolved within seconds through the reactive mechanisms, while the background crawlers ensure that even edge cases are typically corrected over time.
The above description applies to both our historical dual-provider setup and today’s implementation, but two key improvements in the current architecture lead to significantly better consistency outcomes. First, KVSP maintains a much lower steady-state error rate compared to our previous third-party providers, reducing the frequency of write failures that create inconsistencies in the first place. Second, we now race all reads against both backends, whereas the previous system optimized for cost and latency by preferentially routing reads to a single provider after an initial learning period.
In the original dual-provider architecture, each SGW instance would initially race reads against both providers to establish baseline performance characteristics. Once an instance determined that one provider consistently outperformed the other for its geographic region, it would route subsequent reads exclusively to the faster provider, only falling back to the slower provider when the primary experienced failures or abnormal latency. While this approach effectively controlled third-party provider costs and optimized read performance, it created a significant blind spot in our consistency detection mechanisms—inconsistencies between providers could persist indefinitely if reads were consistently served from only one backend.
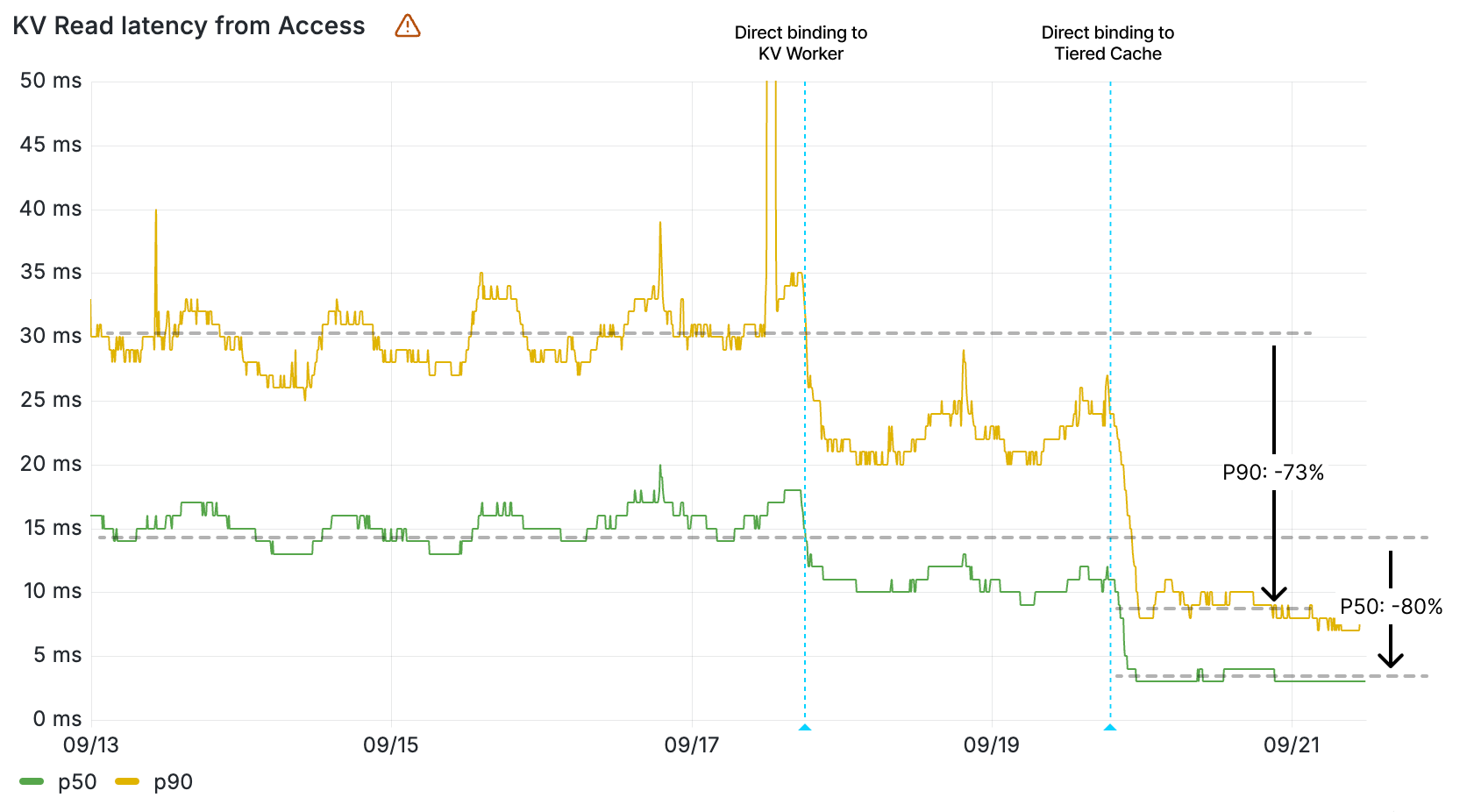
With these consistency mechanisms in place and our careful rollout strategy validated through internal services, we continued expanding active-active operation to additional namespaces across both internal and external workloads, and we were thrilled with what we saw. Not only did the new architecture provide the increased availability we needed for Workers KV, it also delivered significant performance improvements.
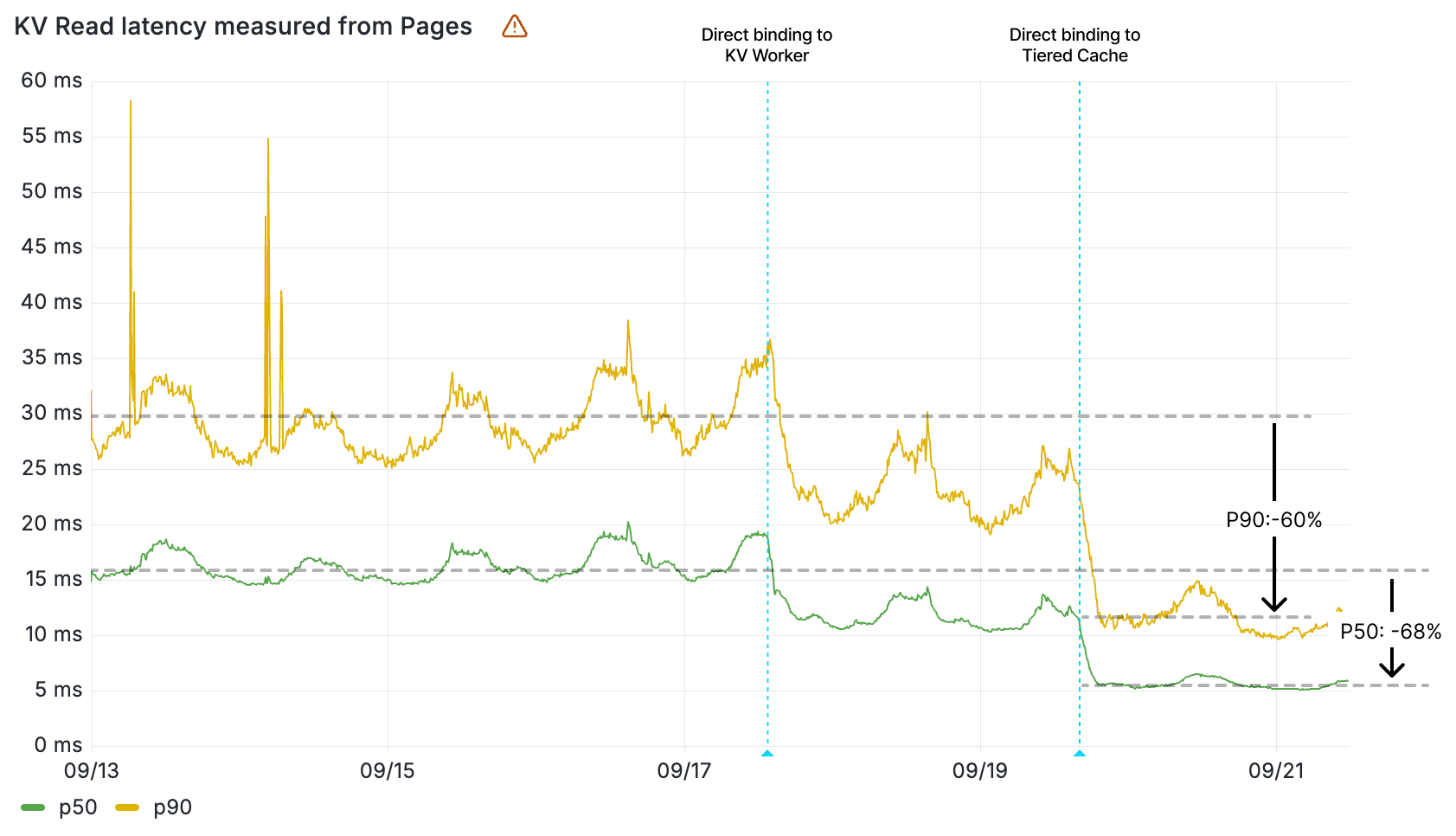
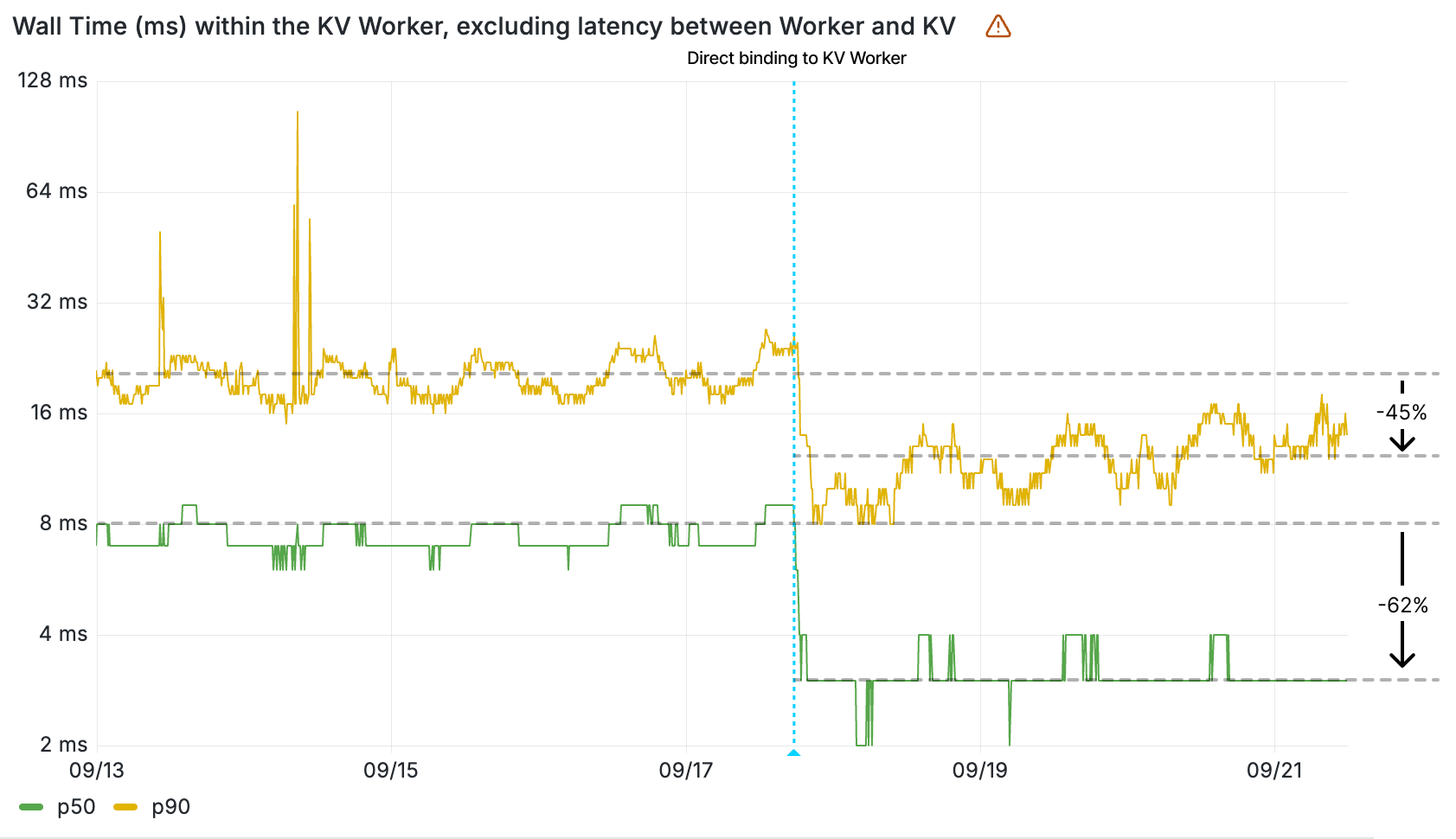
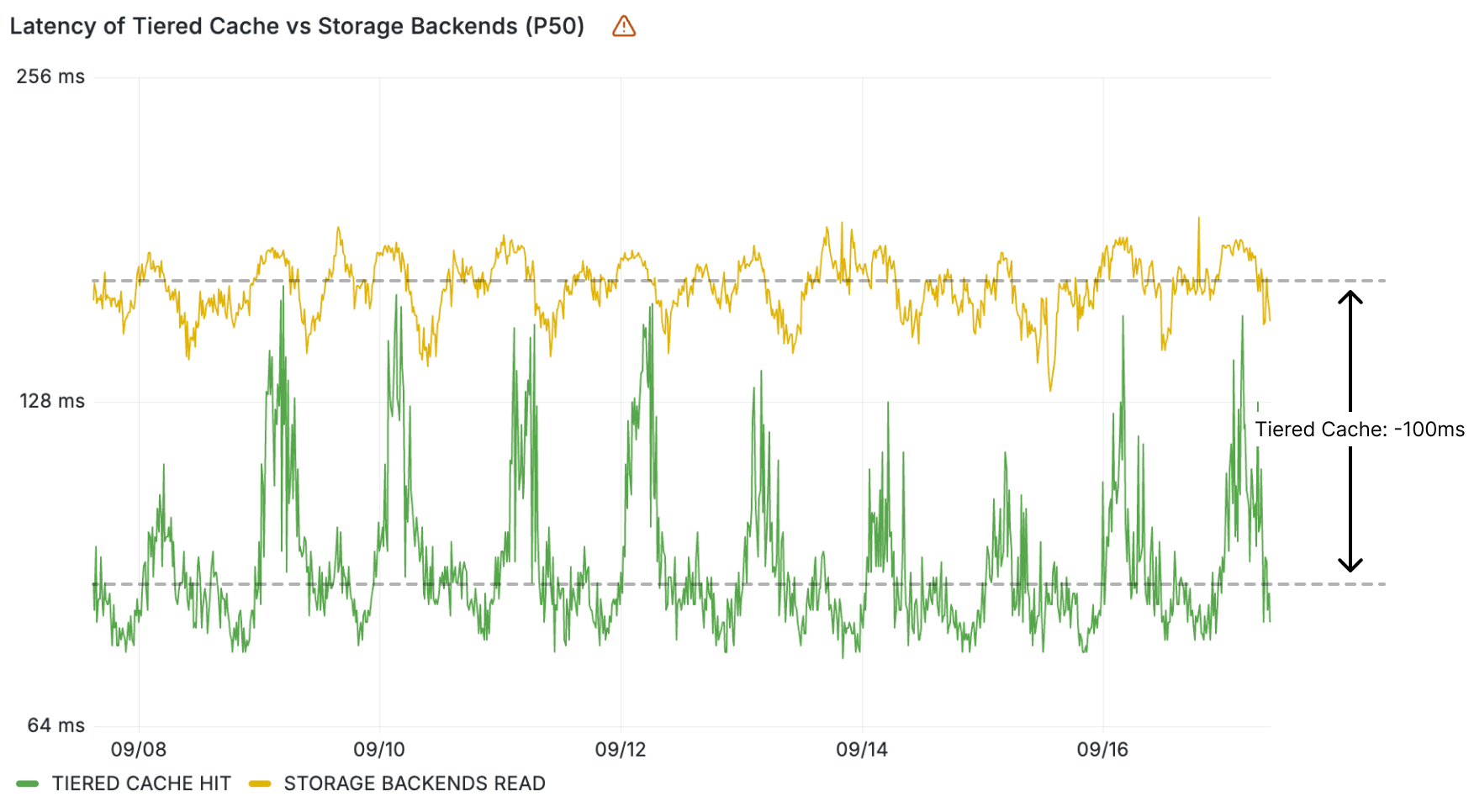
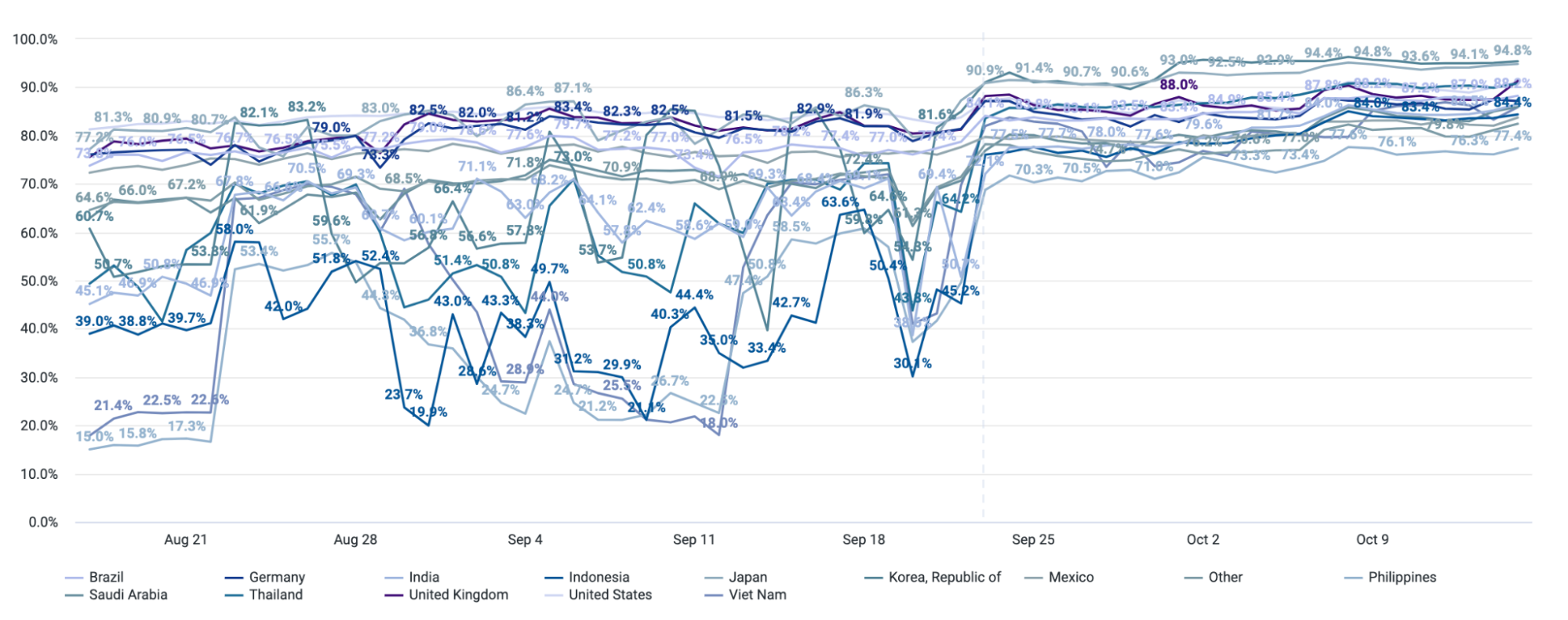
These performance gains were particularly pronounced in Europe, where our new storage backend is located, but the benefits extended far beyond what geographic locality alone could explain. The internal latency improvements compared to the third-party object store we were writing to in parallel were remarkable.
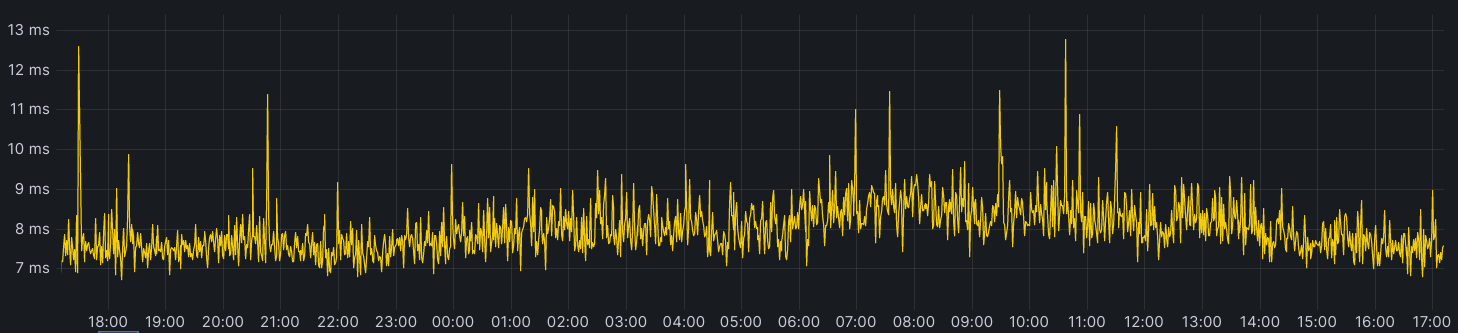
For example, p99 internal latency for reads to KVSP were below 5 milliseconds. For comparison, non-cached reads to the third-party object store from our closest location—after normalizing for transit time to create an apples-to-apples comparison—were typically around 80ms at p50 and 200ms at p99.
The graphs below show the closest thing that we can get to an apples-to-apples comparison: our observed internal latency for requests to KVSP compared with observed latency for requests that are cache misses and end up being forwarded to the external service provider from the closest point of presence, which includes an additional 5-10 milliseconds of request transit time.


These performance improvements translated directly into faster response times for the many internal Cloudflare services that depend on Workers KV, creating cascading benefits across our platform. The database-optimized storage proved particularly effective for the small object access patterns that dominate Workers KV traffic.
After seeing these positive results, we continued expanding the rollout, copying data and enabling groups of namespaces for both internal and external customers. The combination of improved availability and better performance validated our architectural approach and demonstrated the value of building critical infrastructure on our own platform.
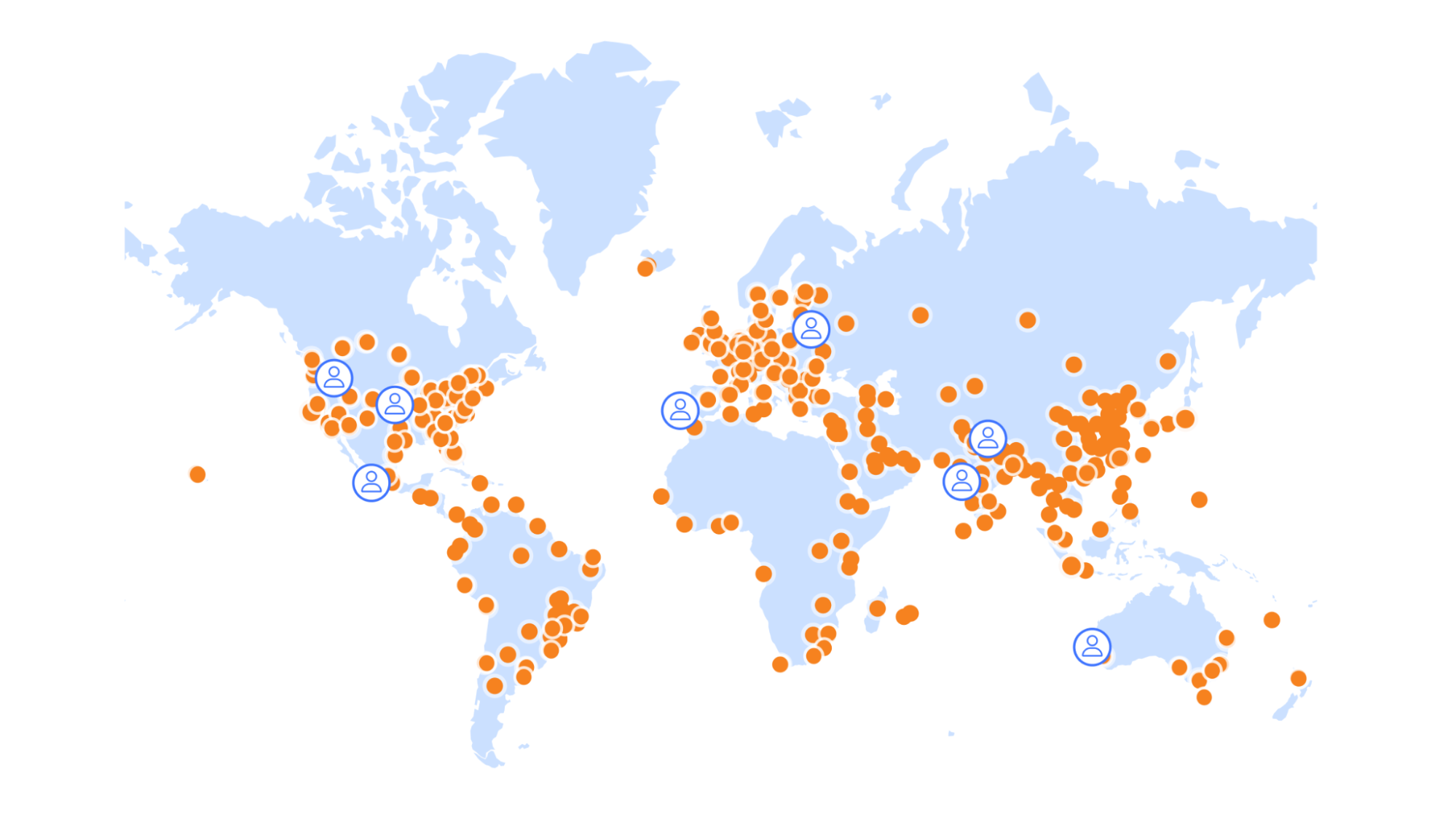
Our immediate plans focus on expanding this hybrid architecture to provide even greater resilience and performance for Workers KV. We’re rolling out the KVSP solution to additional locations, creating a truly global distributed backend that can serve traffic entirely from our own infrastructure while also working to further improve how quickly we reach consistency between providers and in cache after writes.
Our ultimate goal is to eliminate our remaining third-party storage dependency entirely, achieving full infrastructure independence for Workers KV. This will remove the external single points of failure that led to the June incident while giving us complete control over the performance and reliability characteristics of our storage layer.
Beyond Workers KV, this project has demonstrated the power of hybrid architectures that combine the best aspects of different storage technologies. The patterns we’ve developed—using KVSP as a translation layer, automatically routing objects based on size characteristics, and leveraging our existing database expertise—can be leveraged by other services that need to balance global scale with strong consistency requirements. The journey from a single-provider setup to a resilient hybrid architecture running on Cloudflare infrastructure demonstrates how thoughtful engineering can turn operational challenges into competitive advantages. With dramatically improved performance and active-active redundancy, Workers KV is well positioned to serve as an even more reliable foundation for the growing set of customers that depend on it.