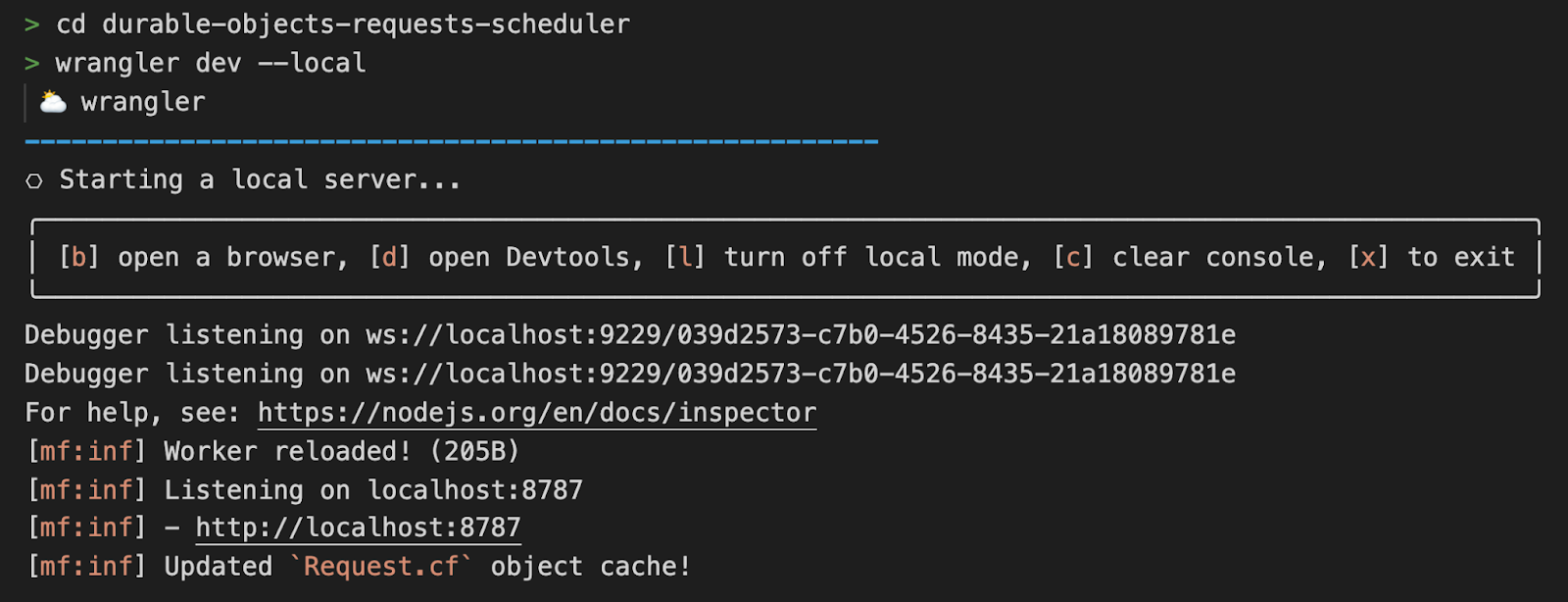
Social media users are tired of losing their identity and data every time a platform shuts down or pivots. In the ATProto ecosystem — short for Authenticated Transfer Protocol — users own their data and identities. Everything they publish becomes part of a global, cryptographically signed shared social web. Bluesky is the first big example, but a new wave of decentralized social networks is just beginning. In this post I’ll show you how to get started, by building and deploying a fully serverless ATProto application on Cloudflare’s Developer Platform.
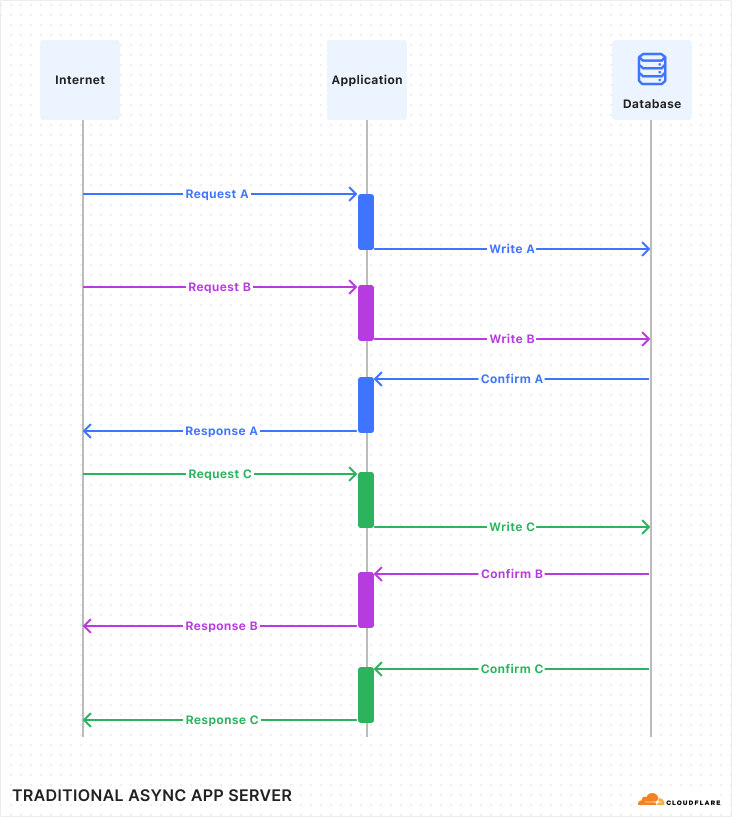
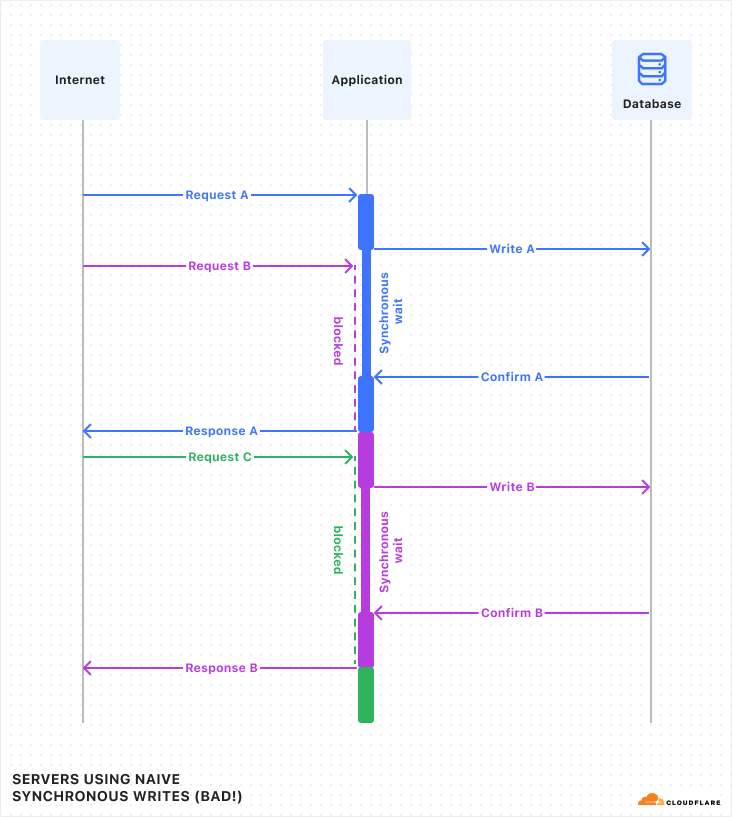
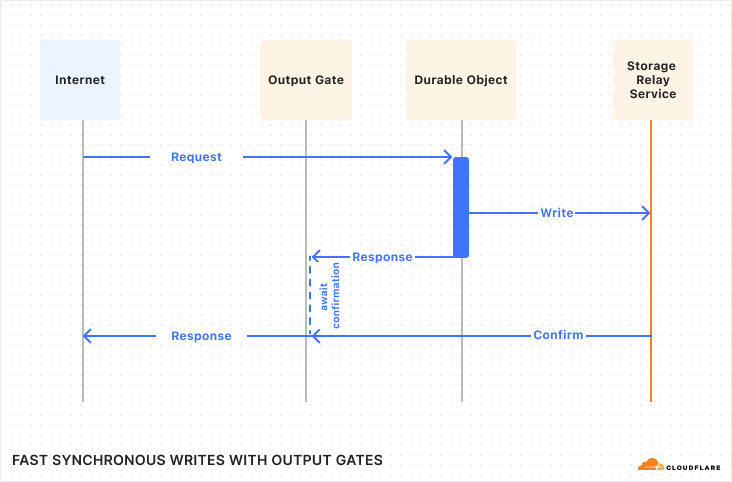
Why serverless? The overhead of managing VMs, scaling databases, maintaining CI pipelines, distributing data across availability zones, and securing APIs against DDoS attacks pulls focus away from actually building.
That’s where Cloudflare comes in. You can take advantage of our Developer Platform to build applications that run on our global network: Workers deploy code globally in milliseconds, KV provides fast, globally distributed caching, D1 offers a distributed relational database, and Durable Objects manage WebSockets and handle real-time coordination. Best of all, everything you need to build your serverless ATProto application is available on our free tier, so you can get started without spending a cent.
The ATProto ecosystem: a quick introduction
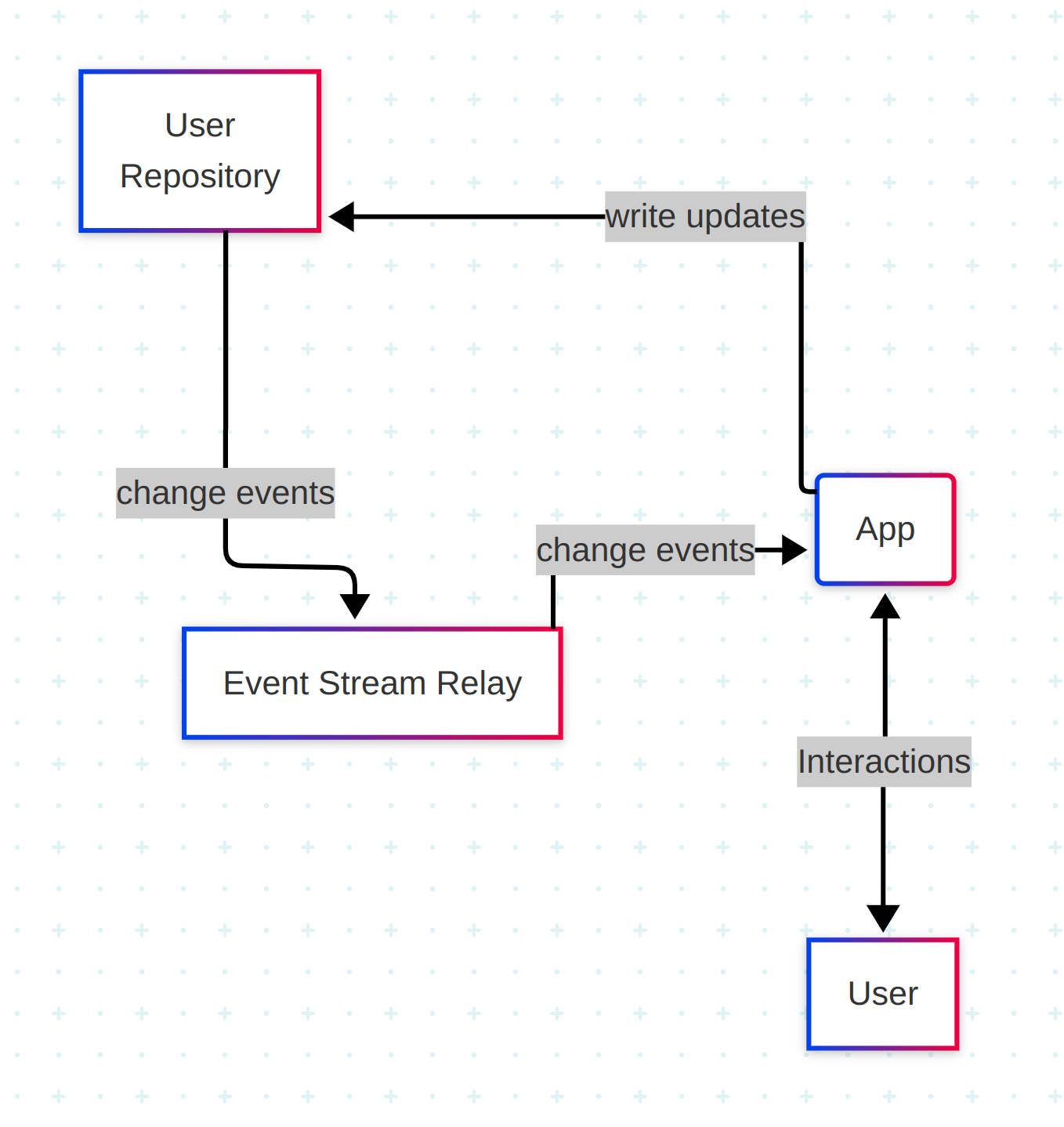
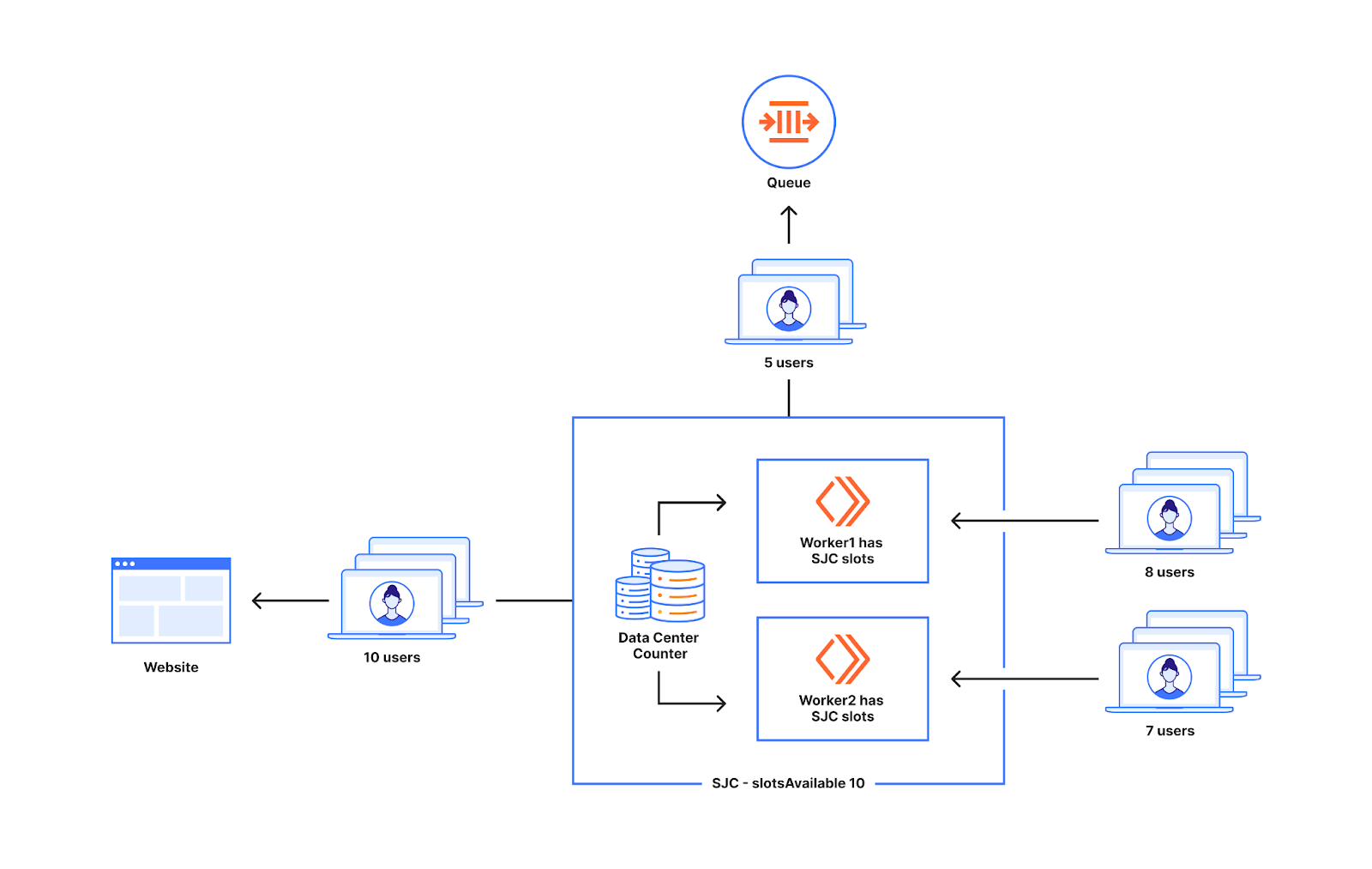
Let’s start with a conceptual overview of how data flows in the ATProto ecosystem:
Users interact with apps, which write updates to their personal repositories. Those updates trigger change events, which are published to a relay and broadcast through the global event stream. Any app can subscribe to these events — even if it didn’t publish the original update — because in ATProto, repos, relays, and apps are all independent components, which can be (and are) run by different operators.
Identity
User identity starts with handles — human-readable names like alice.example.com. Each handle must be a valid domain name, allowing the protocol to leverage DNS to provide a global view of who owns what account. Handles map to a user’s Decentralized Identifier (DID), which contains the location of the user’s Personal Data Server (PDS).
Authentication
A user’s PDS manages their keys and repos. It handles authentication and provides an authoritative view of their data via their repo.
What’s different here — and easy to miss — is how little any part of this stack relies on trust in a single service. DID resolution is verifiable. The PDS is user-selected. The client app is just an interface.
When we publish or fetch data, it’s signed and self-validating. That means any other app can consume or build on top of it without asking permission, and without trusting our backend.
Our application
We’ll be working with Statusphere, a tiny but complete demo app built by the ATProto team. It’s the simplest possible social media app: users post single-emoji status updates. Because it’s so minimal, Statusphere is a perfect starting point for learning how decentralized ATProto apps work, and how to adapt them to run on Cloudflare’s serverless stack.
Statusphere schema
In ATProto, all repository data is typed using Lexicons — a shared schema language similar to JSON-Schema. For Statusphere, we use the xyz.statusphere.status record, originally defined by the ATProto team:
Lexicons are strongly typed, which allows for easy interoperability between apps.
How it’s built
In this section, we’ll follow the flow of data inside Statusphere: from authentication, to repo reads and writes, to real-time updates, and look at how we handle live event streams on serverless infrastructure.
1. Language choice
ATProto’s core libraries are written in TypeScript, and Cloudflare Workers provide first-class TypeScript support. It’s the natural starting point for building ATProto services on Cloudflare Workers.
Cloudflare also supports Rust in Workers via WASM cross-compilation, so I tried that next. The ATProto Rust crates and codegen tooling make strong use of Rust’s type system and build tooling, but they’re still in active development. Rust’s WASM ecosystem is solid, though, so I was able to get a working prototype running quickly by adapting an existing Rust implementation of Statusphere — originally written by Bailey Townsend. You can find the code in this GitHub repo.
If you’re building ATProto apps on Cloudflare Workers, I’d suggest contributing to the TypeScript libraries to better support serverless runtimes. A TypeScript version of this app would be a great next step — if you’re interested in building it, please get in touch via the Cloudflare Developer Discord server.
2. Follow along
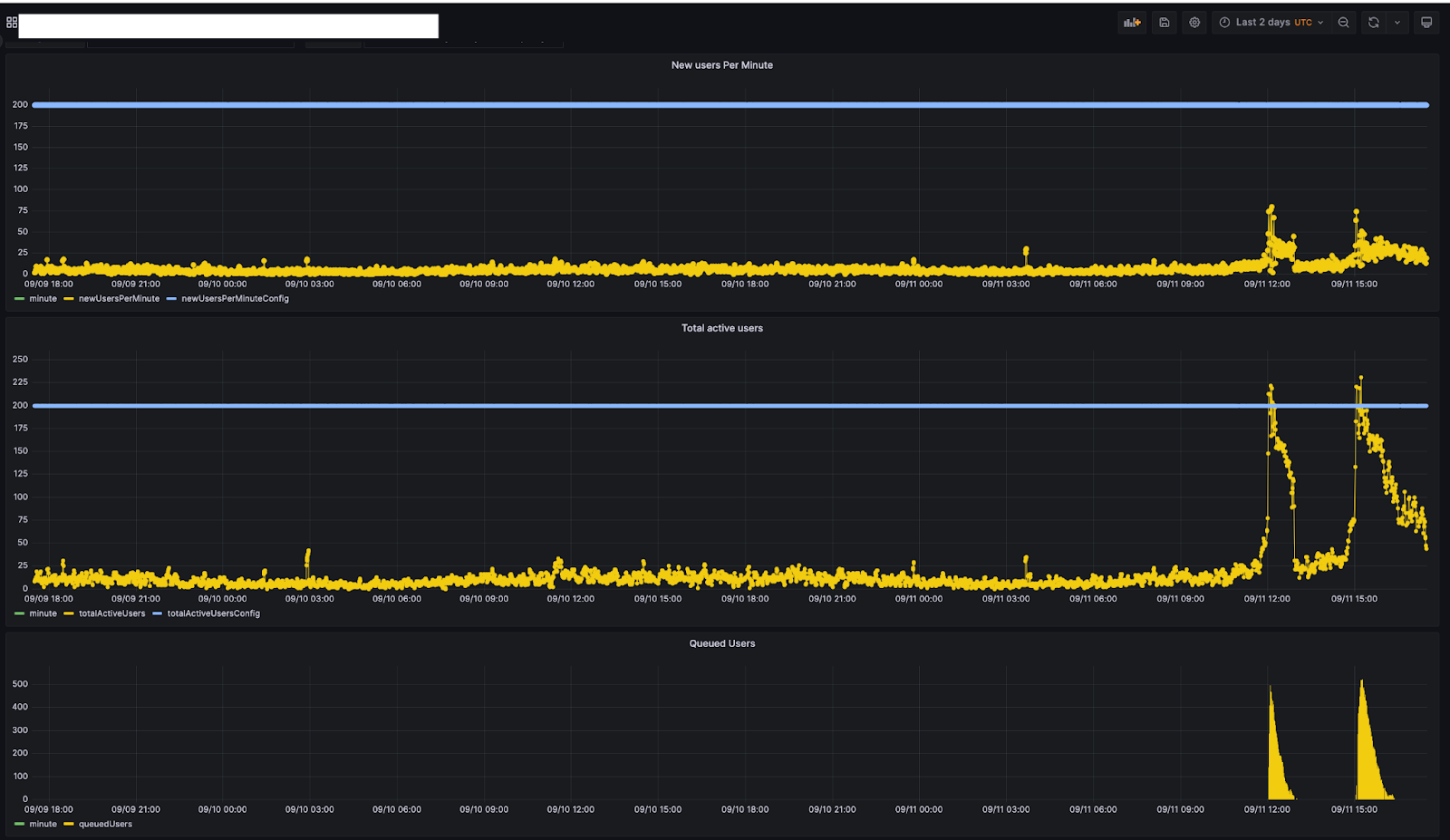
Use this Deploy to Cloudflare button to clone the repo and set up your own KV and D1 instances and a CI pipeline.
Follow the steps at this link, use the default values or choose custom names, and it’ll build and deploy your own Statusphere Worker.
Note: this project includes a scheduled component that reads from the public event stream. You may wish to delete it when you finish experimenting to save resources.
3. Resolving the user’s handle
To interact with a user’s data, we start by resolving their handle to a DID using the record registered at the _atproto subdomain. For example, my handle is inanna.recursion.wtf, so my DID record is stored at _atproto.inanna.recursion.wtf. The value of that record is did:plc:p2sm7vlwgcbbdjpfy6qajd4g.
We then resolve the DID to its corresponding DID Document, which contains identity metadata including the location of the user’s Personal Data Server. Depending on the DID method, this resolution is handled directly via DNS (for did:web identifiers) or, more frequently, via the Public Ledger of Credentials for did:plc identifiers.
Since these values don’t change frequently, we cache them using Cloudflare KV — it’s perfect for cases like this, where we have some infrequently updated but frequently read key-value mapping that needs to be globally available with low latency.
From the DID document, we extract the location of the user’s Personal Data Server. In my case, it’s bsky.social, but other users may self-host their own PDS or use an alternative provider.
The details of the OAuth flow aren’t important here — you can read the code I used to implement it or dig into the OAuth spec if you’re curious — but the short version is: the user signs in via their PDS, and it grants our app permission to act on their behalf, using the signing keys it manages.
We persist session data in a secure session cookie using tower-sessions. This means that only an opaque session ID is stored client-side, and all session/oauth state data is stored in Cloudflare KV. Again, it’s a natural fit for this use case.
When a user posts a new emoji status, we create a new record in their personal repo — using the same authenticated agent we used to fetch their data. This time, instead of reading, we perform a create record operation:
let uri = agent.create_status(form.status.clone()).await?.uri;
The operation returns a URI — the canonical identifier for the new record.
We then write the status update into D1, so it can immediately be reflected in the UI.
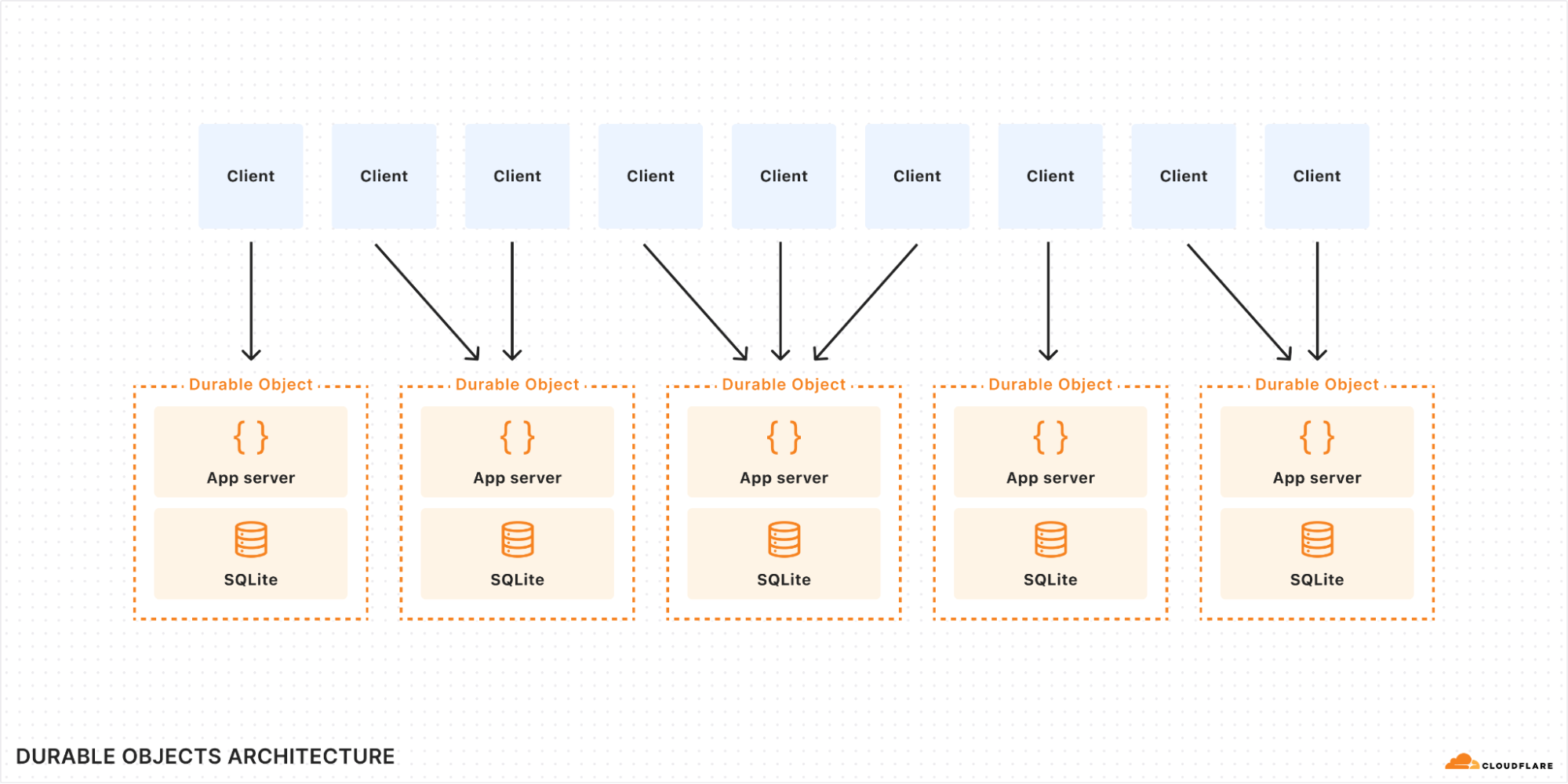
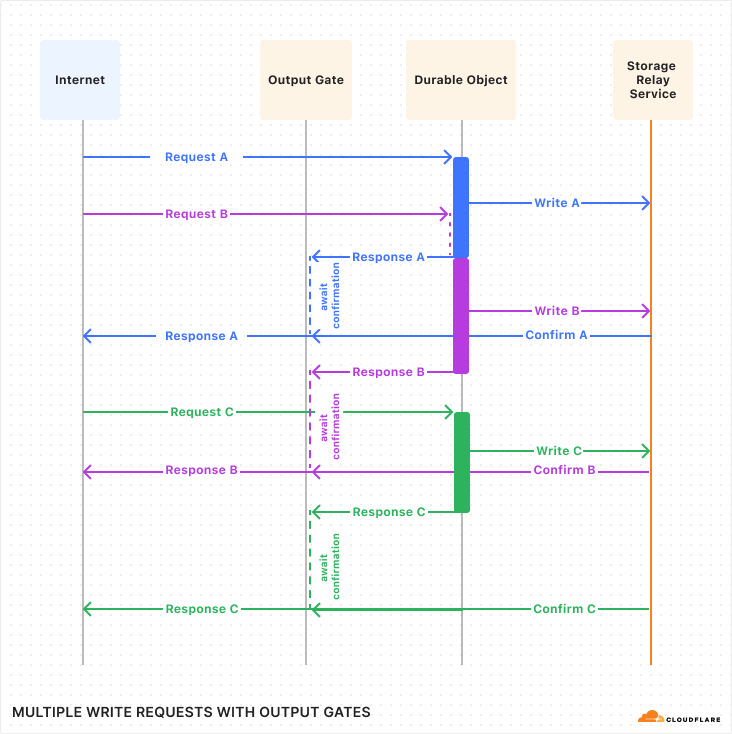
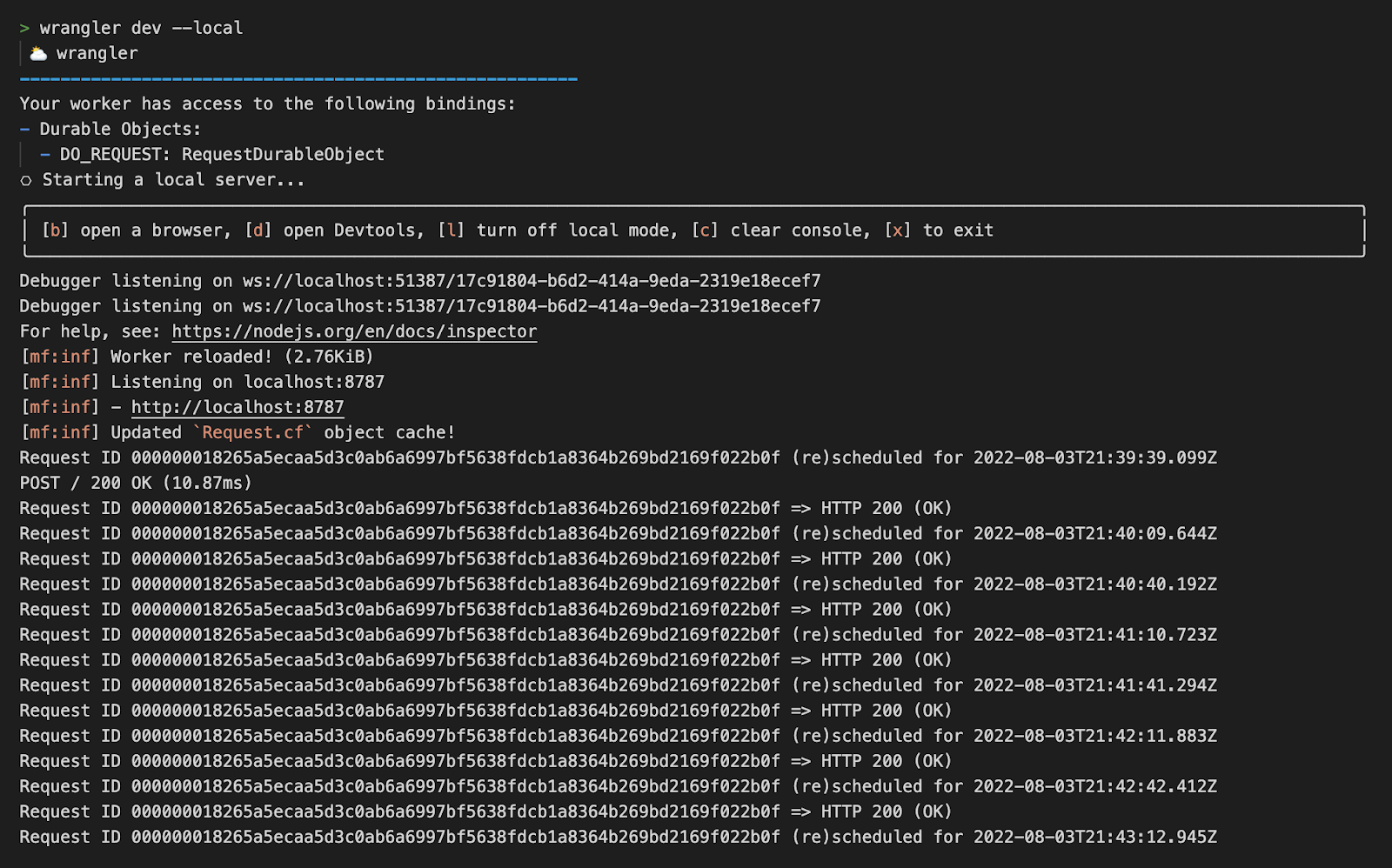
6. Using Durable Objects to broadcast updates
Every active homepage maintains a WebSocket connection to a Durable Object, which acts as a lightweight real-time message broker. When idle, the Durable Object hibernates, saving resources while keeping the WebSocket connections alive. We send a message to the Durable Object to wake it up and broadcast the new update:
for ws in self.state.get_websockets() {
ws.send(&status);
}
It then iterates over every live WebSocket and sends the update.
One practical note: Durable Objects perform better when sharded across instances. For simplicity, I’ve described the case where everything runs everything through one single Durable Object.
To scale beyond that, the next step would be using multiple Durable Object instances per supported location using location hints, to minimize latency for users around the globe and avoid bottlenecks if we encounter high numbers of concurrent users in a single location. I initially considered implementing this pattern, but it conflicted with my goal of creating a concise ‘hello world’ style example that ATProto devs could clone and use as a template for their app.
7. Listening for live changes
The challenge: realtime feeds vs serverless
Publishing updates inside our own app is easy, but in the ATProto ecosystem, other applications can publish status updates for users. If we want Statusphere to be fully integrated, we need to pick up those events too.
Listening for live event updates requires a persistent WebSocket connection to the ATProto Jetstream service. Traditional server-based apps can keep WebSocket client sockets open indefinitely, but serverless platformscan’t — workers aren’t allowed to run forever.
We need a way to “listen” without running a live server.
The solution: Cloudflare worker Cron Triggers
To solve this, we moved the listening logic into a Cron Trigger — instead of keeping a live socket open, we used this feature to read updates in small batches using a recurring scheduled job.
When the scheduled worker invocation fires, it loads the last seen cursor from its persistent storage. Then it connects to Jetstream — a streaming service for ATProto repo events — filtered by the xyz.statusphere.status collection and starting at the last seen cursor.
let ws = WebSocket::connect("wss://jetstream1.us-east.bsky.network/subscribe?wantedCollections=xyz.statusphere.status&cursor={cursor}").await?;
We store a cursor — a microsecond timestamp marking the last message we received — in the Durable Object’s persistent storage, so even if the object restarts, it knows exactly where to resume. As soon as we process an event newer than our start time, we close the WebSocket connection and let the Durable Object go back to sleep.
The tradeoff: updates can lag by up to a minute, but the system stays fully serverless. This is a great fit for early-stage apps and prototypes, where minimizing infrastructure complexity matters more than achieving perfect real-time delivery.
Optional upgrade: real-time event listener
If you want real time updates, and you’re willing to bend the serverless model slightly, you can deploy a lightweight listener process that maintains a live WebSocket connection to Jetstream.
Instead of polling once a minute, this process listens for new events for the xyz.statusphere.status collection and pushes updates to our Cloudflare Worker as soon as they arrive. When this mode is active, we disable the Cron Trigger step with an environment variable. You can find a sketch of this listener process here and the endpoint that handles updates from it here.
The result still isn’t a traditional server:
No public exposure to the web
No open HTTP ports
No persistent database
It’s just a single-purpose, stateless listener — something simple enough to run on a home server until your app grows large enough to need more serious infrastructure.
Later on, you could swap this design for something more scalable using tools like Cloudflare Queues to provide batching and retries — but for small-to-medium apps, this lightweight listener is an easy and effective upgrade.
Looking ahead
Today, Durable Objects can hibernate while holding long-lived WebSocket server connections but don’t support hibernation when holding long-lived WebSocket client connections (like a Jetstream listener). That’s why Statusphere uses workarounds — scheduled Worker invocations via Cron Trigger and lightweight external listeners — to stay synced with the network.
Future improvements to Durable Objects — like adding support for hibernating active WebSocket clients — could remove the need for these workarounds entirely.
Build your own ATProto app
This is a full-featured atproto app running entirely on Cloudflare with zero servers and minimal ops overhead. Workers run your code within 50 ms of most users, KV and D1 keep your data available, and Durable Objects handle WebSocket fan-out and live coordination.
Use the Deploy to Cloudflare Button to clone the repo and set up your serverless environment. Then show us what you build. Drop a link in our Discord, or tag @cloudflare.social on Bluesky or @CloudflareDev on X — we’d love to see it.
There’s a lot of talk right now about building AI agents, but not a lot out there about what it takes to make those agents truly useful.
An Agent is an autonomous system designed to make decisions and perform actions to achieve a specific goal or set of goals, without human input.
No matter how good your agent is at making decisions, you will need a person to provide guidance or input on the agent’s path towards its goal. After all, an agent that cannot interact or respond to the outside world and the systems that govern it will be limited in the problems it can solve.
That’s where the “human-in-the-loop” interaction pattern comes in. You’re bringing a human into the agent’s loop and requiring an input from that human before the agent can continue on its task.
In this blog post, we’ll useKnock and the CloudflareAgents SDK to build an AI Agent for a virtual card issuing workflow that requires human approval when a new card is requested.
Knock is messaging infrastructure you can use to send multi-channel messages across in-app, email, SMS, push, and Slack, without writing any integration code.
With Knock, you gain complete visibility into the messages being sent to your users while also handling reliable delivery, user notification preferences, and more.
You can use Knock to power human-in-the-loop flows for your agents using Knock’sAgent Toolkit, which is a set of tools that expose Knock’s APIs and messaging capabilities to your AI agents.
Using the Agent SDK as the foundation of our AI Agent
The Agents SDK provides an abstraction for building stateful, real-time agents on top of Durable Objects that are globally addressable and persist state using an embedded, zero-latency SQLite database.
Building an AI agent outside of using the Agents SDK and the Cloudflare platform means we need to consider WebSocket servers, state persistence, and how to scale our service horizontally. Because a Durable Object backs the Agents SDK, we receive these benefits for free, while having a globally addressable piece of compute with built-in storage, that’s completely serverless and scales to zero.
In the example, we’ll use these features to build an agent that users interact with in real-time via chat, and that can be paused and resumed as needed. The Agents SDK is the ideal platform for powering asynchronous agentic workflows, such as those required in human-in-the-loop interactions.
Setting up our Knock messaging workflow
Within Knock, we design our approval workflow using the visual workflow builder to create the cross-channel messaging logic. We then make the notification templates associated with each channel to which we want to send messages.
Knock will automatically apply theuser’s preferences as part of the workflow execution, ensuring that your user’s notification settings are respected.
You can find an example workflow that we’ve already created for this demo in the repository. You can use this workflow template via theKnock CLI to import it into your account.
Building our chat UI
We’ve built the AI Agent as a chat interface on top of the AIChatAgent abstraction from Cloudflare’s Agents SDK (docs). The Agents SDK here takes care of the bulk of the complexity, and we’re left to implement our LLM calling code with our system prompt.
// src/index.ts
import { AIChatAgent } from "agents/ai-chat-agent";
import { openai } from "@ai-sdk/openai";
import { createDataStreamResponse, streamText } from "ai";
export class AIAgent extends AIChatAgent {
async onChatMessage(onFinish) {
return createDataStreamResponse({
execute: async (dataStream) => {
try {
const stream = streamText({
model: openai("gpt-4o-mini"),
system: `You are a helpful assistant for a financial services company. You help customers with credit card issuing.`,
messages: this.messages,
onFinish,
maxSteps: 5,
});
stream.mergeIntoDataStream(dataStream);
} catch (error) {
console.error(error);
}
},
});
}
}
On the client side, we’re using the useAgentChat hook from the agents/ai-react package to power the real-time user-to-agent chat.
We’ve modeled our agent as a chat per user, which we set up using the useAgent hook by specifying the name of the process as the userId.
This means we have an agent process, and therefore a durable object, per-user. For our human-in-the-loop use case, this becomes important later on as we talk about resuming our deferred tool call.
Deferring the tool call to Knock
We give the agent our card issuing capability through exposing an issueCard tool. However, instead of writing the approval flow and cross-channel logic ourselves, we delegate it entirely to Knock by wrapping the issue card tool in our requireHumanInput method.
Now when the user asks to request a new card, we make a call out to Knock to initiate our card request, which will notify the appropriate admins in the organization to request an approval.
To set this up, we need to use Knock’s Agent Toolkit, which exposes methods to work with Knock in our AI agent and power cross-channel messaging.
import { createKnockToolkit } from "@knocklabs/agent-toolkit/ai-sdk";
import { tool } from "ai";
import { z } from "zod";
import { AIAgent } from "./index";
import { issueCard } from "./api";
import { BASE_URL } from "./constants";
async function initializeToolkit(agent: AIAgent) {
const toolkit = await createKnockToolkit({ serviceToken: agent.env.KNOCK_SERVICE_TOKEN });
const issueCardTool = tool({
description: "Issue a new credit card to a customer.",
parameters: z.object({
customerId: z.string(),
}),
execute: async ({ customerId }) => {
return await issueCard(customerId);
},
});
const { issueCard } = toolkit.requireHumanInput(
{ issueCard: issueCardTool },
{
workflow: "approve-issued-card",
actor: agent.name,
recipients: ["admin_user_1"],
metadata: {
approve_url: `${BASE_URL}/card-issued/approve`,
reject_url: `${BASE_URL}/card-issued/reject`,
},
}
);
return { toolkit, tools: { issueCard } };
}
There’s a lot going on here, so let’s walk through the key parts:
We wrap our issueCard tool in the requireHumanInput method, exposed from the Knock Agent Toolkit
We want the messaging workflow to be invoked to be our approve-issued-card workflow
We pass the agent.name as the actor of the request, which translates to the user ID
We set the recipient of this workflow to be the user admin_user_1
We pass the approve and reject URLs so that they can be used in our message templates
The wrapped tool is then returned as issueCard
Under the hood, these options are passed to theKnock workflow trigger API to invoke a workflow per-recipient. The set of the recipients listed here could be dynamic, or go to a group of users throughKnock’s subscriptions API.
We can then pass the wrapped issue card tool to our LLM call in the onChatMessage method on the agent so that the tool call can be called as part of the interaction with the agent.
export class AIAgent extends AIChatAgent {
// ... other methods
async onChatMessage(onFinish) {
const { tools } = await initializeToolkit(this);
return createDataStreamResponse({
execute: async (dataStream) => {
const stream = streamText({
model: openai("gpt-4o-mini"),
system: "You are a helpful assistant for a financial services company. You help customers with credit card issuing.",
messages: this.messages,
onFinish,
tools,
maxSteps: 5,
});
stream.mergeIntoDataStream(dataStream);
},
});
}
}
Now when the agent calls the issueCardTool, we invoke Knock to send our approval notifications, deferring the tool call to issue the card until we receive an approval. Knock’s workflows take care of sending out the message to the set of recipient’s specified, generating and delivering messages according to each user’s preferences.
Using Knockworkflows for our approval message makes it easy to build cross-channel messaging to reach the user according to their communicationpreferences. We can also leveragedelays,throttles,batching, andconditions to orchestrate more complex messaging.
Handling the approval
Once the message has been sent to our approvers, the next step is to handle the approval coming back, bringing the human into the agent’s loop.
The approval request is asynchronous, meaning that the response can come at any point in the future. Fortunately, Knock takes care of the heavy lifting here for you, routing the event to the agent worker via awebhook that tracks the interaction with the underlying message. In our case, that’s a click to the “approve” or “reject” button.
First, we set up a message.interacted webhook handler within the Knock dashboard to forward the interactions to our worker, and ultimately to our agent process.
In our example here, we route the approval click back to the worker to handle, appending a Knock message ID to the end of the approve_url and reject_url to track engagement against the specific message sent. We do this via liquid inside of our message templates in Knock: {{ data.approve_url }}?messageId={{ current_message.id }} . One caveat here is that if this were a production application, we’re likely going to handle our approval click in a different application than this agent is running. We co-located it here for the purposes of this demo only.
Once the link is clicked, we have a handler in our worker to mark the message as interacted using Knock’smessage interaction API, passing through the status as metadata so that it can be used later.
import Knock from '@knocklabs/node';
import { Hono } from "hono";
const app = new Hono();
const client = new Knock();
app.get("/card-issued/approve", async (c) => {
const { messageId } = c.req.query();
if (!messageId) return c.text("No message ID found", { status: 400 });
await client.messages.markAsInteracted(messageId, {
status: "approved",
});
return c.text("Approved");
});
The message interaction will flow from Knock to our worker via the webhook we set up, ensuring that the process is fully asynchronous. The payload of the webhook includes the full message, including metadata about the user that generated the original request, and keeps details about the request itself, which in our case contains the tool call.
import { getAgentByName, routeAgentRequest } from "agents";
import { Hono } from "hono";
const app = new Hono();
app.post("/incoming/knock/webhook", async (c) => {
const body = await c.req.json();
const env = c.env as Env;
// Find the user ID from the tool call for the calling user
const userId = body?.data?.actors[0];
if (!userId) {
return c.text("No user ID found", { status: 400 });
}
// Find the agent DO for the user
const existingAgent = await getAgentByName(env.AIAgent, userId);
if (existingAgent) {
// Route the request to the agent DO to process
const result = await existingAgent.handleIncomingWebhook(body);
return c.json(result);
} else {
return c.text("Not found", { status: 404 });
}
});
We leverage the agent’s ability to be addressed by a named identifier to route the request from the worker to the agent. In our case, that’s the userId. Because the agent is backed by a durable object, this process of going from incoming worker request to finding and resuming the agent is trivial.
Resuming the deferred tool call
We then use the context about the original tool call, passed through to Knock and round tripped back to the agent, to resume the tool execution and issue the card.
export class AIAgent extends AIChatAgent {
// ... other methods
async handleIncomingWebhook(body: any) {
const { toolkit } = await initializeToolkit(this);
const deferredToolCall = toolkit.handleMessageInteraction(body);
if (!deferredToolCall) {
return { error: "No deferred tool call given" };
}
// If we received an "approved" status then we know the call was approved
// so we can resume the deferred tool call execution
if (result.interaction.status === "approved") {
const toolCallResult =
await toolkit.resumeToolExecution(result.toolCall);
const { response } = await generateText({
model: openai("gpt-4o-mini"),
prompt: `You were asked to issue a card for a customer. The card is now approved. The result was: ${JSON.stringify(toolCallResult)}.`,
});
const message = responseToAssistantMessage(
response.messages[0],
result.toolCall,
toolCallResult
);
// Save the message so that it's displayed to the user
this.persistMessages([...this.messages, message]);
}
return { status: "success" };
}
}
Again, there’s a lot going on here, so let’s step through the important parts:
We attempt to transform the body, which is the webhook payload from Knock, into a deferred tool call via the handleMessageInteraction method
If the metadata status we passed through to the interaction call earlier has an “approved” status then we resume the tool call via the resumeToolExecution method
Finally, we generate a message from the LLM and persist it, ensuring that the user is informed of the approved card
With this last piece in place, we can now request a new card be issued, have an approval request be dispatched from the agent, send the approval messages, and route those approvals back to our agent to be processed. The agent will asynchronously process our card issue request and the deferred tool call will be resumed for us, with very little code.
Protecting against duplicate approvals
One issue with the above implementation is that we’re prone to issuing multiple cards if someone clicks on the approve button more than once. To rectify this, we want to keep track of the tool calls being issued, and ensure that the call is processed at most once.
To power this we leverage theagent’s built-in state, which can be used to persist information without reaching for another persistence store like a database or Redis, although we could absolutely do so if we wished. We can track the tool calls by their ID and capture their current status, right inside the agent process.
Here, we create the initial state for the tool calls as an empty object. We also add a quick setter helper method to make interactions easier.
Next up, we need to record the tool call being made. To do so, we can use the onAfterCallKnock option in the requireHumanInput helper to capture that the tool call has been requested for the user.
const { issueCard } = toolkit.requireHumanInput(
{ issueCard: issueCardTool },
{
// Keep track of the tool call state once it's been sent to Knock
onAfterCallKnock: async (toolCall) =>
agent.setToolCallStatus(toolCall.id, "requested"),
// ... as before
}
);
Finally, we then need to check the state when we’re processing the incoming webhook, and mark the tool call as approved (some code omitted for brevity).
export class AIAgent extends AIChatAgent {
async handleIncomingWebhook(body: any) {
const { toolkit } = await initializeToolkit(this);
const deferredToolCall = toolkit.handleMessageInteraction(body);
const toolCallId = result.toolCall.id;
// Make sure this is a tool call that can be processed
if (this.state.toolCalls[toolCallId] !== "requested") {
return { error: "Tool call is not requested" };
}
if (result.interaction.status === "approved") {
const toolCallResult = await toolkit.resumeToolExecution(result.toolCall);
this.setToolCallStatus(toolCallId, "approved");
// ... rest as before
}
}
}
Conclusion
Using the Agents SDK and Knock, it’s easy to build advanced human-in-the-loop experiences that defer tool calls.
Knock’s workflow builder and notification engine gives you building blocks to create sophisticated cross-channel messaging for your agents. You can easily create escalation flows that send messages through SMS, push, email, or Slack that respect the notification preferences of your users. Knock also gives you complete visibility into the messages your users are receiving.
The Durable Object abstraction underneath the Agents SDK means that we get a globally addressable agent process that’s easy to yield and resume back to. The persistent storage in the Durable Object means we can retain the complete chat history per-user, and any other state that’s required in the agent process to resume the agent with (like our tool calls). Finally, the serverless nature of the underlying Durable Object means we’re able to horizontally scale to support a large number of users with no effort.
If you’re looking to build your own AI Agent chat experience with a multiplayer human-in-the-loop experience, you’ll find the complete code from this guideavailable in GitHub.
Cloudflare Workers Builds is our CI/CD product that makes it easy to build and deploy Workers applications every time code is pushed to GitHub or GitLab. What makes Workers Builds special is that projects can be built and deployed with minimal configuration.Just hook up your project and let us take care of the rest!
But what happens when things go wrong, such as failing to install tools or dependencies? What usually happens is that we don’t fix the problem until a customer contacts us about it, at which point many other customers have likely faced the same issue. This can be a frustrating experience for both us and our customers because of the lag time between issues occurring and us fixing them.
We want Workers Builds to be reliable, fast, and easy to use so that developers can focus on building, not dealing with our bugs. That’s why we recently started building an error detection system that can detect, categorize, and surface all build issues occurring on Workers Builds, enabling us to proactively fix issues and add missing features.
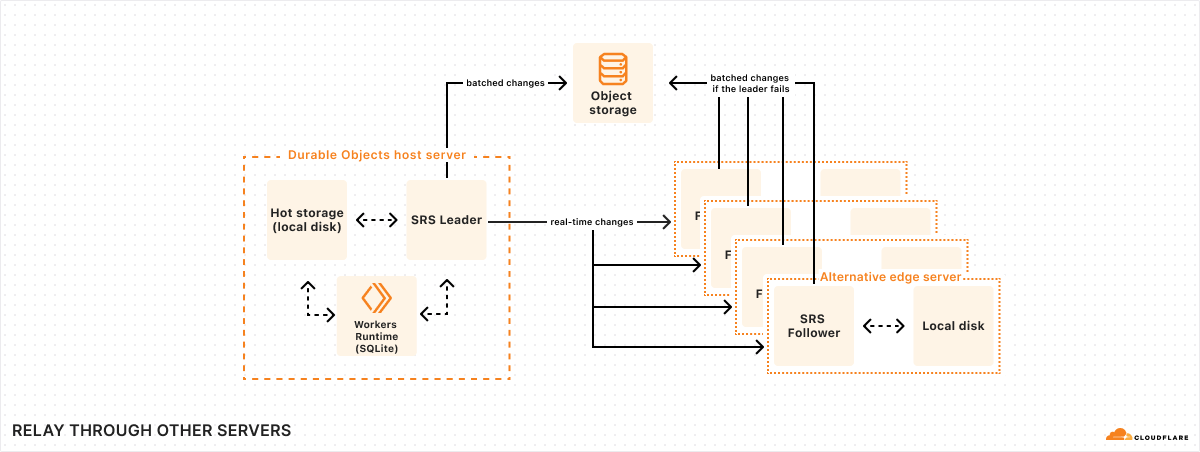
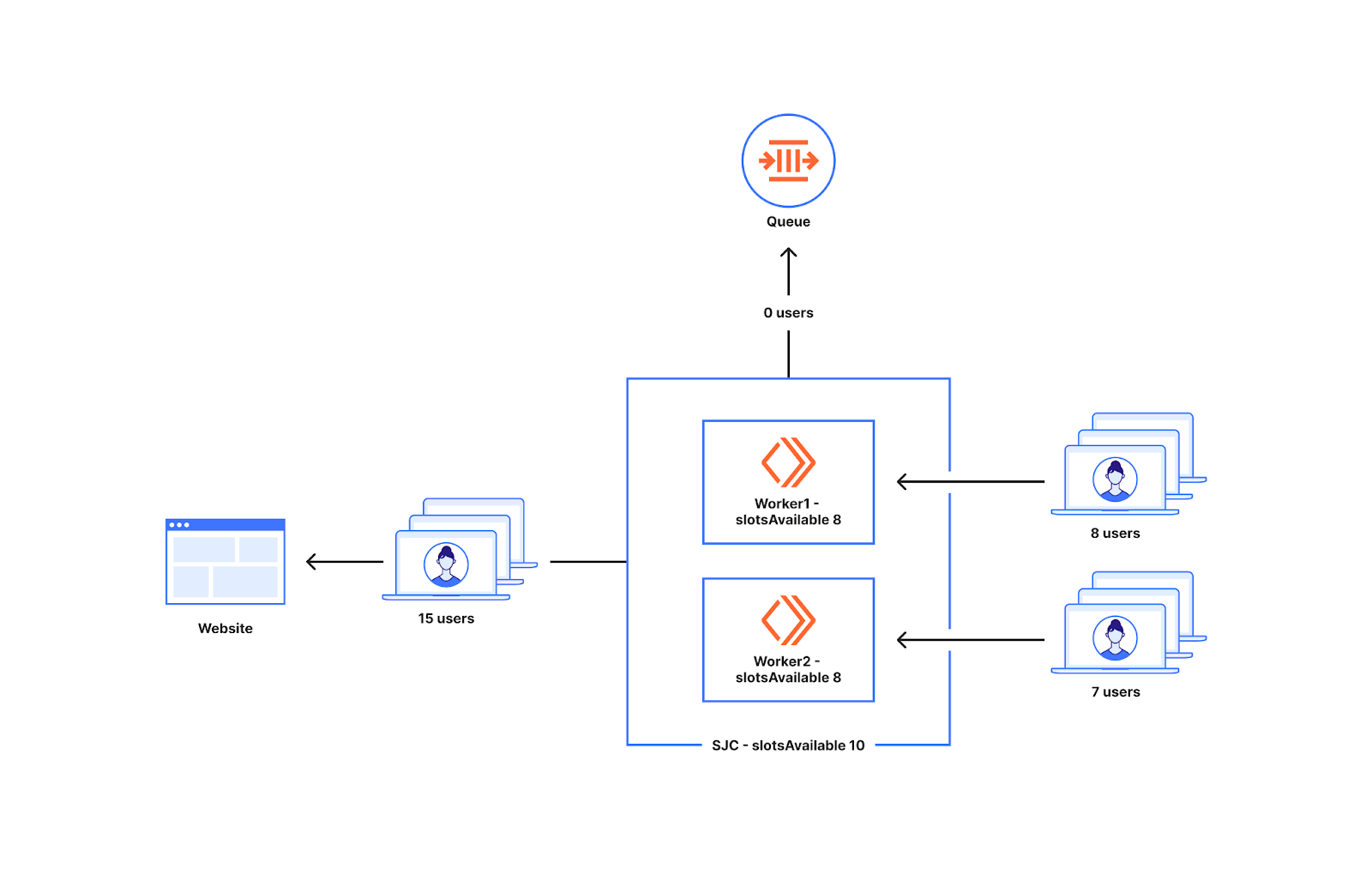
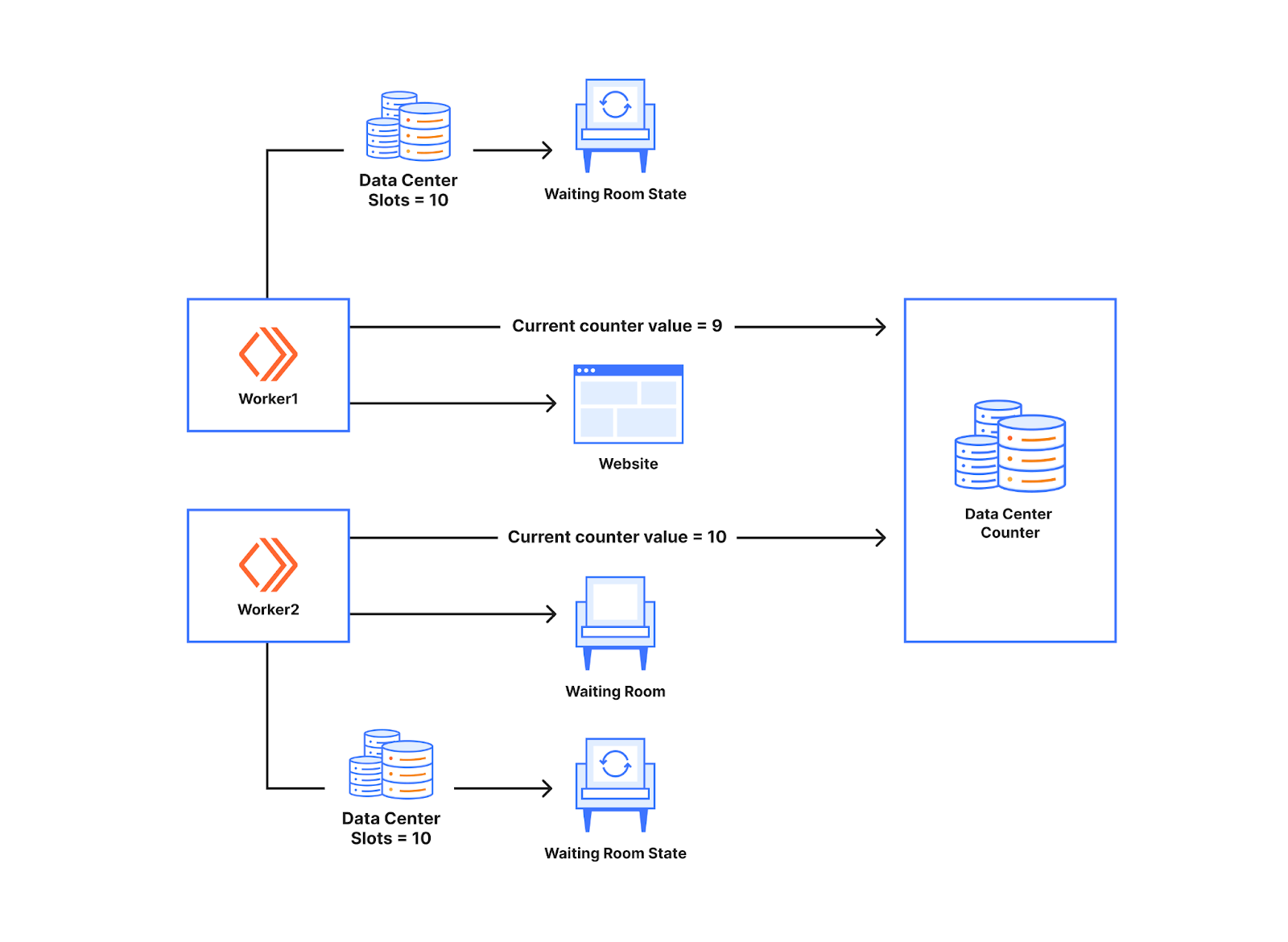
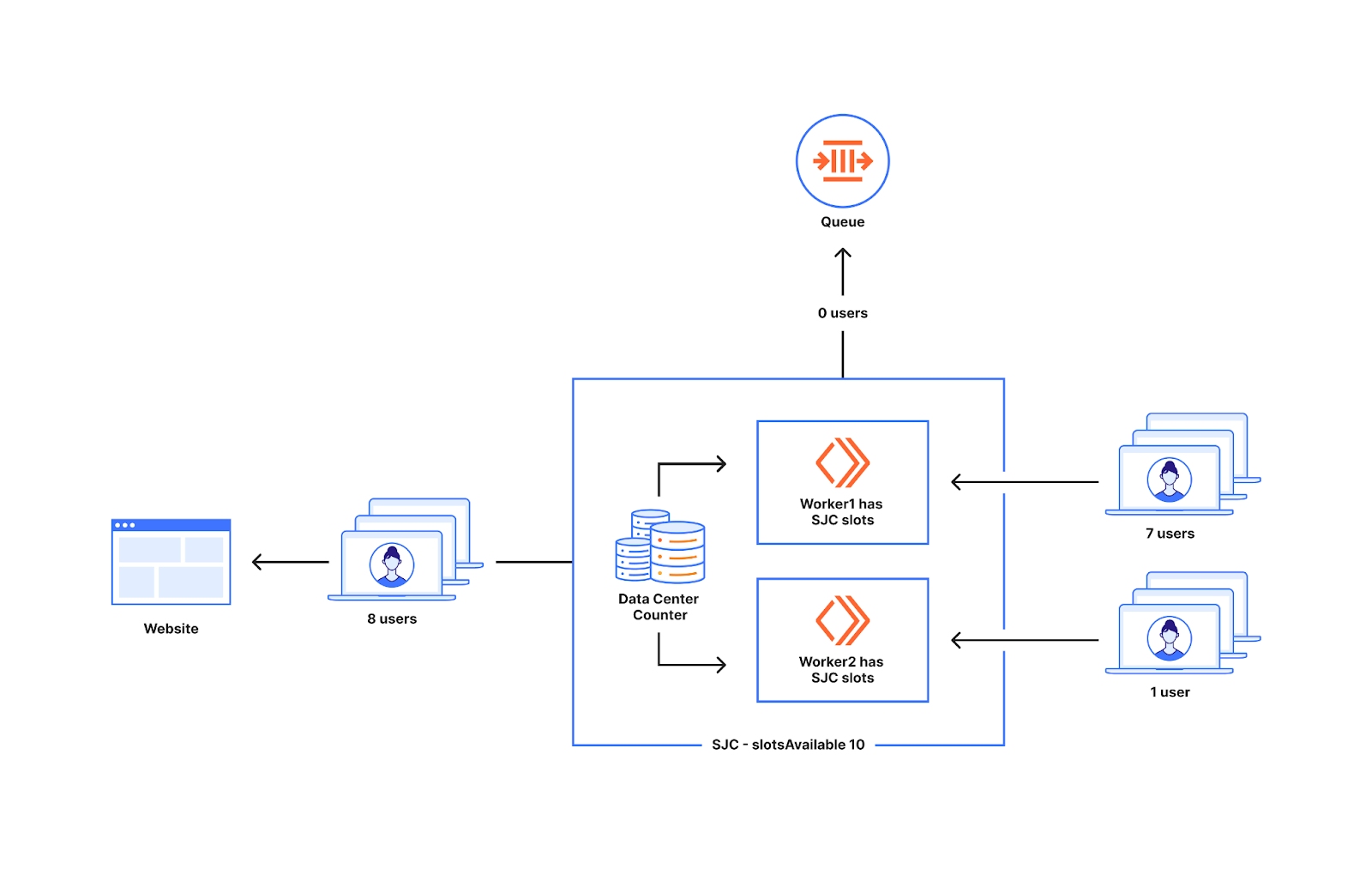
In this post, we will dive into how we used the Cloudflare Developer Platform to check for issues across more than 1 million Durable Objects.
Background: Workers Builds architecture
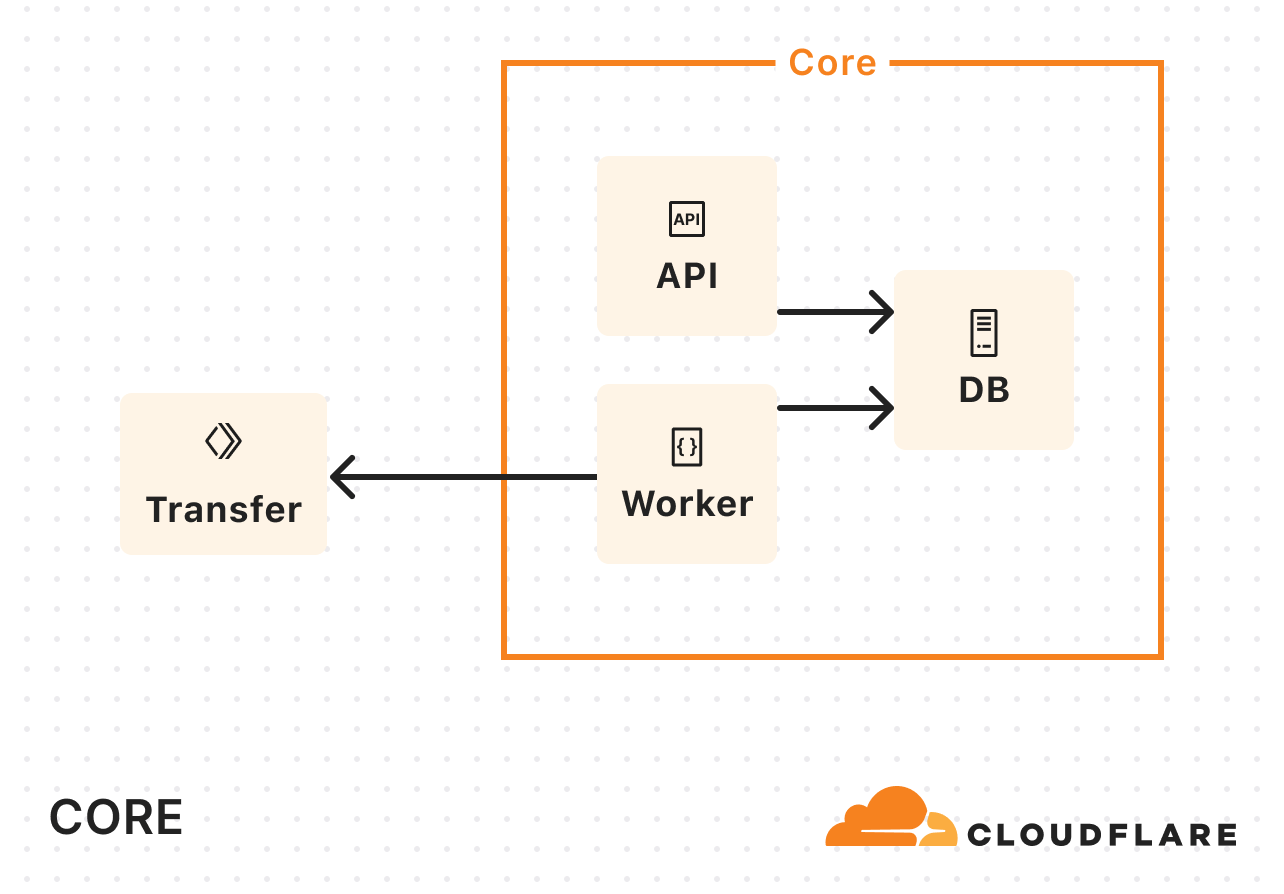
Back in October 2024, we wrote abouthow we built Workers Builds entirely on the Workers platform. To recap, Builds is built using Workers, Durable Objects, Workers KV, R2, Queues, Hyperdrive, and a Postgres database. Some of these things were not present when launched back in October (for example, Queues and KV). But the core of the architecture is the same.
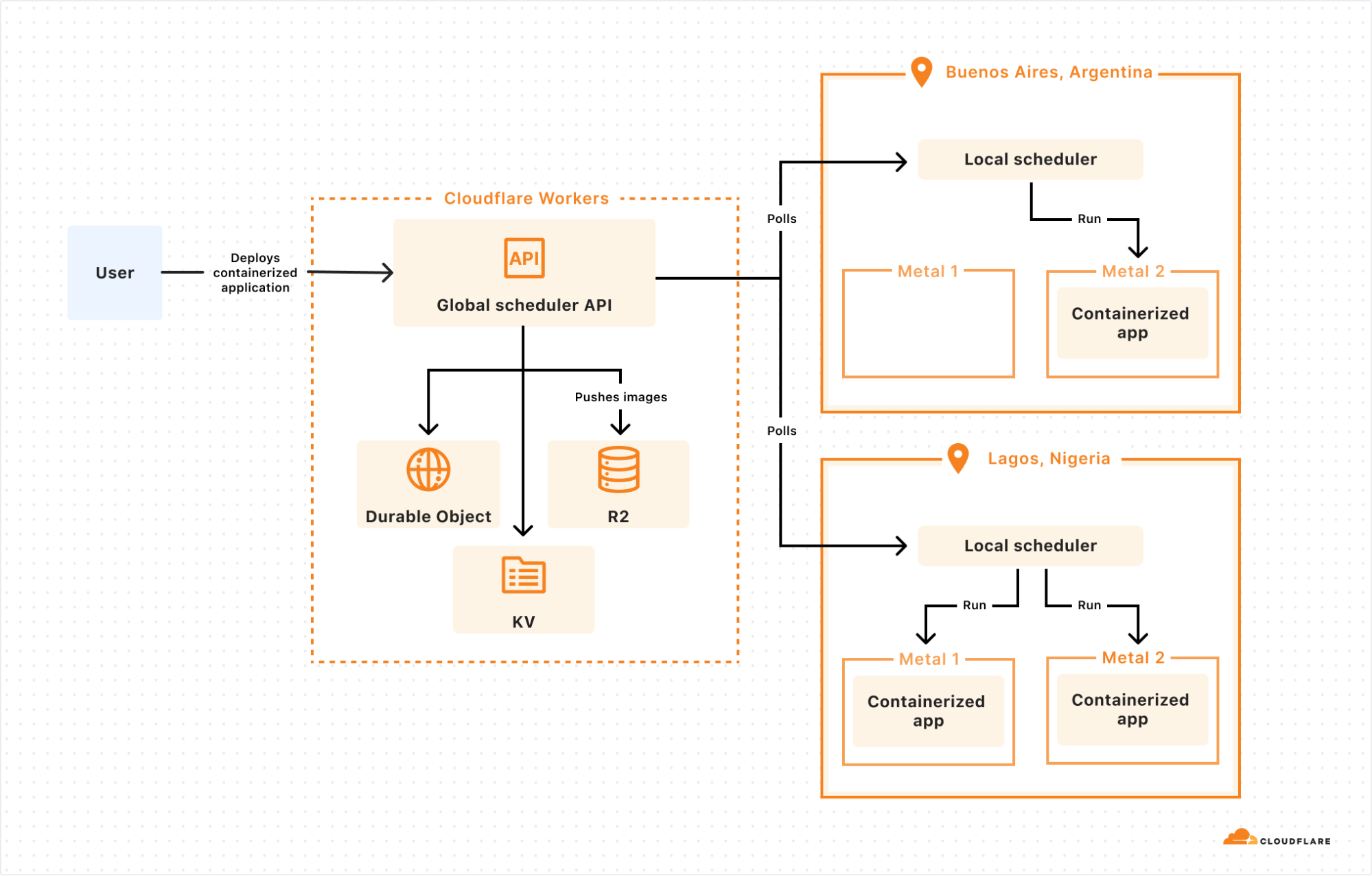
A client Worker receives GitHub/GitLab webhooks and stores build metadata in Postgres (via Hyperdrive). A build management Worker uses two Durable Object classes: a Scheduler class to find builds in Postgres that need scheduling, and a class called BuildBuddy to manage the lifecycle of a build. When a build needs to be started, Scheduler creates a new BuildBuddy instance which is responsible for creating a container for the build (usingCloudflare Containers), monitoring the container with health checks, and receiving build logs so that they can be viewed in the Cloudflare Dashboard.
In addition to this core scheduling logic, we have several Workers Queues for background work such as sending PR comments to GitHub/GitLab.
The problem: builds are failing
While this architecture has worked well for us so far, we found ourselves with a problem: compared toCloudflare Pages, a concerning percentage of builds were failing. We needed to dig deeper and figure out what was wrong, and understand how we could improve Workers Builds so that developers can focus more on shipping instead of build failures.
Types of build failures
Not all build failures are the same. We have several categories of failures that we monitor:
Initialization failures: when the container fails to start.
Clone failures: failing to clone the repository from GitHub/GitLab.
Build timeouts: builds that ran past the limit and were terminated by BuildBuddy.
Builds failing health checks: the container stopped responding to health checks, e.g. the container crashed for an unknown reason.
Failure to install tools or dependencies.
Failed user build/deploy commands.
The first few failure types were straightforward, and we’ve been able to track down and fix issues in our build system and control plane to improve what we call “build completion rate”. We define build completion as the following:
We successfully started the build.
We attempted to install tools/dependencies (considering failures as “user error”).
We attempted to run the user-defined build/deploy commands (again, considering failures as “user error”).
We successfully marked the build as stopped in our database.
For example, we had a bug where builds for a deleted Worker would attempt to run and continuously fail, which affected our build completion rate metric.
User error
We’ve made a lot of progress improving the reliability of build and container orchestration, but we had a significant percentage of build failures in the “user error” metric. We started asking ourselves “is this actually user error? Or is there a problem with the product itself?”
This presented a challenge because questions like “did the build command fail due to a bug in the build system, or user error?” are a lot harder to answer than pass/fail issues like failing to create a container for the build. To answer these questions, we had to build something new, something smarter.
Build logs
The most obvious way to determine why a build failed is to look at its logs. When spot-checking build failures, we can typically identify what went wrong. For example, some builds fail to install dependencies because of an out of date lockfile (e.g. package-lock.json out of date with package.json). But looking through build failures one by one doesn’t scale. We didn’t want engineers looking through customer build logs without at least suspecting that there was an issue with our build system that we could fix.
Automating error detection
At this point, next steps were clear: we needed an automated way to identify why a build failed based on build logs, and provide a way for engineers to see what the top issues were while ensuring privacy (e.g. removing account-specific identifiers and file paths from the aggregate data).
Detecting errors in build logs using Workers Queues
The first thing we needed was a way to categorize build errors after a build fails. To do this, we created a queue named BuildErrorsQueue to process builds and look for errors. After a build fails, BuildBuddy will send the build ID to BuildErrorsQueue which fetches the logs, checks for issues, and saves results to Postgres.
We started out with a few static patterns to match things like Wrangler errors in log lines:
It wouldn’t be useful if all Wrangler errors were grouped under a single generic “wrangler_error” code, so we further grouped them by normalizing the log lines into groups:
function getWranglerLogGroupFromLogLine(
logLine: LogLine,
regexMatchers: RegexMatcher[]
): string {
const original = logLine[2].trim().replaceAll(/[\t\n\r]+/g, ' ')
let message = original
let group = original
for (const { mustMatch, patterns, stopOnMatch, name, useNameAsGroup } of regexMatchers) {
if (mustMatch !== undefined) {
const matched = matchLineToRegexes(message, mustMatch)
if (!matched) continue
}
if (patterns) {
for (const [pattern, mask] of patterns) {
message = message.replaceAll(pattern, mask)
}
}
if (useNameAsGroup === true) {
group = name
} else {
group = message
}
if (Boolean(stopOnMatch) && message !== original) break
}
return group
}
const wranglerRegexMatchers: RegexMatcher[] = [
{
name: 'could_not_resolve',
// ✘ [ERROR] Could not resolve "./balance"
// ✘ [ERROR] Could not resolve "node:string_decoder" (originally "string_decoder/")
mustMatch: [/^✘ \[ERROR\] Could not resolve "[@\w :/\\.-]*"/i],
stopOnMatch: true,
patterns: [
[/(?<=^✘ \[ERROR\] Could not resolve ")[@\w :/\\.-]*(?=")/gi, '<MODULE>'],
[/(?<=\(originally ")[@\w :/\\.-]*(?=")/gi, '<MODULE>'],
],
},
{
name: 'no_matching_export_for_import',
// ✘ [ERROR] No matching export in "src/db/schemas/index.ts" for import "someCoolTable"
mustMatch: [/^✘ \[ERROR\] No matching export in "/i],
stopOnMatch: true,
patterns: [
[/(?<=^✘ \[ERROR\] No matching export in ")[@~\w:/\\.-]*(?=")/gi, '<MODULE>'],
[/(?<=" for import ")[\w-]*(?=")/gi, '<IMPORT>'],
],
},
// ...many more added over time
]
Once we had our error detection matchers and normalizing logic in place, implementing the BuildErrorsQueue consumer was easy:
Here, we’re fetching logs from each build’s BuildBuddy Durable Object, detecting why it failed using the matchers we wrote, and saving errors to the Postgres DB. We also delete any existing errors for when we improve our error detection patterns to prevent subsequent runs from adding duplicate data to our database.
What about historical builds?
The BuildErrorsQueue was great for new builds, but this meant we still didn’t know why all the previous build failures happened other than “user error”. We considered only tracking errors in new builds, but this was unacceptable because it would significantly slow down our ability to improve our error detection system because each iteration would require us to wait days to identify issues we need to prioritize.
Problem: logs are stored across one million+ Durable Objects
Remember how every build has an associated BuildBuddy DO to store logs? This is a great design for ensuring our logging pipeline scales with our customers, but it presented a challenge when trying to aggregate issues based on logs because something would need to go through all historical builds (>1 million at the time) to fetch logs and detect why they failed.
If we were using Go and Kubernetes, we might solve this using a long-running container that goes through all builds and runs our error detection. But how do we solve this in Workers?
How do we backfill errors for historical builds?
At this point, we already had the Queue to process new builds. If we could somehow send all of the old build IDs to the queue, it could scan them all quickly usingQueues concurrent consumers to quickly work through all builds. We thought about hacking together a local script to fetch all of the log IDs and sending them to an API to put them on a queue. But we wanted something more secure and easier to use so that running a new backfill was as simple as an API call.
That’s when an idea hit us: what if we used a Durable Object with alarms to fetch a range of builds and send them to BuildErrorsQueue? At first, it seemed far-fetched, given that Durable Object alarms have a limited amount of work they can do per invocation. But wait, ifAI Agents built on Durable Objects can manage background tasks, why can’t we fetch millions of build IDs and forward them to queues?
Building a Build Errors Agent with Durable Objects
The idea was simple: create a Durable Object class named BuildErrorsAgent and run a single instance that loops through the specified range of builds in the database and sends them to BuildErrorsQueue.
The first thing we did was set up an RPC method to start a backfill and save the parameters inDurable Object KV storage so that it can be read each time the alarm executes:
async start({
min_build_id,
max_build_id,
}: {
min_build_id: BuildRecord['build_id']
max_build_id: BuildRecord['build_id']
}): Promise<void> {
logger.setTags({ handler: 'start', environment: this.env.ENVIRONMENT })
try {
if (min_build_id < 0) throw new Error('min_build_id cannot be negative')
if (max_build_id < min_build_id) {
throw new Error('max_build_id cannot be less than min_build_id')
}
const [started_on, stopped_on] = await Promise.all([
this.kv.get('started_on'),
this.kv.get('stopped_on'),
])
await match({ started_on, stopped_on })
.with({ started_on: P.not(null), stopped_on: P.nullish }, () => {
throw new Error('BuildErrorsAgent is already running')
})
.otherwise(async () => {
// delete all existing data and start queueing failed builds
await this.state.storage.deleteAlarm()
await this.state.storage.deleteAll()
this.kv.put('started_on', new Date())
this.kv.put('config', { min_build_id, max_build_id })
void this.state.storage.setAlarm(this.getNextAlarmDate())
})
} catch (e) {
this.sentry.captureException(e)
throw e
}
}
The most important part of the implementation is the alarm that runs every second until the job is complete. Each alarm invocation has the following steps:
Set a new alarm (always first to ensure an error doesn’t cause it to stop).
Retrieve state from KV.
Validate that the agent is supposed to be running:
Ensure the agent is supposed to be running.
Ensure we haven’t reached the max build ID set in the config.
Finally, queue up another batch of builds by querying Postgres and sending to the BuildErrorsQueue.
async alarm(): Promise<void> {
logger.setTags({ handler: 'alarm', environment: this.env.ENVIRONMENT })
try {
void this.state.storage.setAlarm(Date.now() + 1000)
const kvState = await this.getKVState()
this.sentry.setContext('BuildErrorsAgent', kvState)
const ctxLogger = logger.withFields({ state: JSON.stringify(kvState) })
await match(kvState)
.with({ started_on: P.nullish }, async () => {
ctxLogger.info('BuildErrorsAgent is not started, cancelling alarm')
await this.state.storage.deleteAlarm()
})
.with({ stopped_on: P.not(null) }, async () => {
ctxLogger.info('BuildErrorsAgent is stopped, cancelling alarm')
await this.state.storage.deleteAlarm()
})
.with(
// we should never have started_on set without config set, but just in case
{ started_on: P.not(null), config: P.nullish },
async () => {
const msg =
'BuildErrorsAgent started but config is empty, stopping and cancelling alarm'
ctxLogger.error(msg)
this.sentry.captureException(new Error(msg))
this.kv.put('stopped_on', new Date())
await this.state.storage.deleteAlarm()
}
)
.when(
// make sure there are still builds to enqueue
(s) =>
s.latest_build_id !== null &&
s.config !== null &&
s.latest_build_id >= s.config.max_build_id,
async () => {
ctxLogger.info('BuildErrorsAgent job complete, cancelling alarm')
this.kv.put('stopped_on', new Date())
await this.state.storage.deleteAlarm()
}
)
.with(
{
started_on: P.not(null),
stopped_on: P.nullish,
config: P.not(null),
latest_build_id: P.any,
},
async ({ config, latest_build_id }) => {
// 1. select batch of ~1000 builds
// 2. send them to Queues 100 at a time, updating
// latest_build_id after each batch is sent
const failedBuilds = await this.store.builds.selectFailedBuilds({
min_build_id: latest_build_id !== null ? latest_build_id + 1 : config.min_build_id,
max_build_id: config.max_build_id,
limit: 1000,
})
if (failedBuilds.length === 0) {
ctxLogger.info(`BuildErrorsAgent: ran out of builds, stopping and cancelling alarm`)
this.kv.put('stopped_on', new Date())
await this.state.storage.deleteAlarm()
}
for (
let i = 0;
i < BUILDS_PER_ALARM_RUN && i < failedBuilds.length;
i += QUEUES_BATCH_SIZE
) {
const batch = failedBuilds
.slice(i, QUEUES_BATCH_SIZE)
.map((build) => ({ body: build }))
if (batch.length === 0) {
ctxLogger.info(`BuildErrorsAgent: ran out of builds in current batch`)
break
}
ctxLogger.info(
`BuildErrorsAgent: sending ${batch.length} builds to build errors queue`
)
await this.env.BUILD_ERRORS_QUEUE.sendBatch(batch)
this.kv.put(
'latest_build_id',
Math.max(...batch.map((m) => m.body.build_id).concat(latest_build_id ?? 0))
)
this.kv.put(
'total_builds_processed',
((await this.kv.get('total_builds_processed')) ?? 0) + batch.length
)
}
}
)
.otherwise(() => {
const msg = 'BuildErrorsAgent has nothing to do - this should never happen'
this.sentry.captureException(msg)
ctxLogger.info(msg)
})
} catch (e) {
this.sentry.captureException(e)
throw e
}
}
Using pattern matching with ts-pattern made it much easier to understand what states we were expecting and what will happen compared to procedural code. We considered using a more powerful library like XState, but decided on ts-pattern due to its simplicity.
Running the backfill
Once everything rolled out, we were able to trigger an errors backfill for over a million failed builds in a couple of hours with a single API call, categorizing 80% of failed builds on the first run. With a fast backfill process, we were able to iterate on our regex matchers to further refine our error detection and improve error grouping. Here’s what the error list looks like in our staging environment:
Fixes and improvements
Having a better understanding of what’s going wrong has already enabled us to make several improvements:
Fixed multiple edge-cases where the wrong package manager was used in TypeScript/JavaScript projects.
Added support for bun.lock (previously only checked for bun.lockb).
Fixed several edge cases where build caching did not work in monorepos.
Projects that use a runtime.txt file to specify a Python version no longer fail.
….and more!
We’re still working on fixing other bugs we’ve found, but we’re making steady progress. Reliability is a feature we’re striving for in Workers Builds, and this project has helped us make meaningful progress towards that goal. Instead of waiting for people to contact support for issues, we’re able to proactively identify and fix issues (and catch regressions more easily).
One of the great things about building on the Developer Platform is how easy it is to ship things. The core of this error detection pipeline (the Queue and Durable Object) only took two days to build, which meant we could spend more time working on improving Workers Builds instead of spending weeks on the error detection pipeline itself.
What’s next?
In addition to continuing to improve build reliability and speed, we’ve also started thinking about other ways to help developers build their applications on Workers. For example, we built aBuilds MCP server that allows users to debug builds directly in Cursor/Claude/etc. We’re also thinking about ways we can expose these detected issues in the Cloudflare Dashboard so that users can identify issues more easily without scrolling through hundreds of logs.
Ready to get started?
Building applications on Workers has never been easier! Try deploying a Durable Object-backed chat application with Workers Builds:
Streamable HTTP Transport: The Agents SDK now supports the new Streamable HTTP transport, allowing you to future-proof your MCP server. Our implementation allows your MCP server to simultaneously handle both the new Streamable HTTP transport and the existing SSE transport, maintaining backward compatibility with all remote MCP clients.
Deploy MCP servers written in Python: In 2024, we introduced first-class Python language support in Cloudflare Workers, and now you can build MCP servers on Cloudflare that are entirely written in Python.
Click “Deploy to Cloudflare” to get started with a remote MCP server that supports the new Streamable HTTP transport method, with backwards compatibility with the SSE transport.
Streamable HTTP: A simpler way for AI agents to communicate with services via MCP
The MCP spec was updated on March 26 to introduce a new transport mechanism for remote MCP, called Streamable HTTP. The new transport simplifies how AI agents can interact with services by using a single HTTP endpoint for sending and receiving responses between the client and the server, replacing the need to implement separate endpoints for initializing the connection and for sending messages.
Upgrading your MCP server to use the new transport method
If you’ve already built a remote MCP server on Cloudflare using the Cloudflare Agents SDK, then adding support for Streamable HTTP is straightforward. The SDK has been updated to support both the existing Server-Sent Events (SSE) transport and the new Streamable HTTP transport concurrently.
Here’s how you can configure your server to handle both transports:
Use MyMcpAgent.serveSSE('/sse') for the existing SSE transport. Previously, this would have been MyMcpAgent.mount('/sse'), which has been kept as an alias.
Add a new path with MyMcpAgent.serve('/mcp') to support the new Streamable HTTP transport
That’s it! With these few lines of code, your MCP server will support both transport methods, making it compatible with both existing and new clients.
Using Streamable HTTP from an MCP client
While most MCP clients haven’t yet adopted the new Streamable HTTP transport, you can start testing it today using mcp-remote, an adapter that lets MCP clients like Claude Desktop that otherwise only support local connections work with remote MCP servers. This tool allows any MCP client to connect to remote MCP servers via either SSE or Streamable HTTP, even if the client doesn’t natively support remote connections or the new transport method.
So, what’s new with Streamable HTTP?
Initially, remote MCP communication between AI agents and services used a single connection but required interactions with two different endpoints: one endpoint (/sse) to establish a persistent Server-Sent Events (SSE) connection that the client keeps open for receiving responses and updates from the server, and another endpoint (/sse/messages) where the client sends requests for tool calls.
While this works, it’s like having a conversation with two phones, one for listening and one for speaking. This adds complexity to the setup, makes it harder to scale, and requires connections to be kept open for long periods of time. This is because SSE operates as a persistent one-way channel where servers push updates to clients. If this connection closes prematurely, clients will miss responses or updates sent from the MCP server during long-running operations.
The new Streamable HTTP transport addresses these challenges by enabling:
Communication through a single endpoint: All MCP interactions now flow through one endpoint, eliminating the need to manage separate endpoints for requests and responses, reducing complexity.
Bi-directional communication: Servers can send notifications and requests back to clients on the same connection, enabling the server to prompt for additional information or provide real-time updates.
Automatic connection upgrades: Connections start as standard HTTP requests, but can dynamically upgrade to SSE (Server-Sent Events) to stream responses during long-running tasks.
Now, when an AI agent wants to call a tool on a remote MCP server, it can do so with a single POST request to one endpoint (/mcp). Depending on the tool call, the server will either respond immediately or decide to upgrade the connection to use SSE to stream responses or notifications as they become available — all over the same request.
Our current implementation of Streamable HTTP provides feature parity with the previous SSE transport. We’re actively working to implement the full capabilities defined in the specification, including resumability, cancellability, and session management to enable more complex, reliable, and scalable agent-to-agent interactions.
What’s coming next?
The MCP specification is rapidly evolving, and we’re committed to bringing these changes to the Agents SDK to keep your MCP server compatible with all clients. We’re actively tracking developments across both transport and authorization, adding support as they land, and maintaining backward compatibility to prevent breaking changes as adoption grows. Our goal is to handle the complexity behind the scenes, so you can stay focused on building great agent experiences.
On the transport side, here are some of the improvements coming soon to the Agents SDK:
Resumability: If a connection drops during a long-running operation, clients will be able to resume exactly where they left off without missing any responses. This eliminates the need to keep connections open continuously, making it ideal for AI agents that run for hours.
Cancellability: Clients will have explicit mechanisms to cancel operations, enabling cleaner termination of long-running processes.
Session management: We’re implementing secure session handling with unique session IDs that maintain state across multiple connections, helping build more sophisticated agent-to-agent communication patterns.
Deploying Python MCP Servers on Cloudflare
In 2024, we introduced Python Workers, which lets you write Cloudflare Workers entirely in Python. Now, you can use them to build and deploy remote MCP servers powered by the Python MCP SDK — a library for defining tools and resources using regular Python functions.
You can deploy a Python MCP server to your Cloudflare account with the button below, or read the code here.
Here’s how you can define tools and resources in the MCP server:
class FastMCPServer(DurableObject):
def __init__(self, ctx, env):
self.ctx = ctx
self.env = env
from mcp.server.fastmcp import FastMCP
self.mcp = FastMCP("Demo")
@mcp.tool()
def calculate_bmi(weight_kg: float, height_m: float) -> float:
"""Calculate BMI given weight in kg and height in meters"""
return weight_kg / (height_m**2)
@mcp.resource("greeting://{name}")
def get_greeting(name: str) -> str:
"""Get a personalized greeting"""
return f"Hello, {name}!"
self.app = mcp.sse_app()
async def call(self, request):
import asgi
return await asgi.fetch(self.app, request, self.env, self.ctx)
async def on_fetch(request, env):
id = env.ns.idFromName("example")
obj = env.ns.get(id)
return await obj.call(request)
If you’re already building APIs withFastAPI, a popular Python package for quickly building high performance API servers, you can use FastAPI-MCP to expose your existing endpoints as MCP tools. It handles the protocol boilerplate for you, making it easy to bring FastAPI-based services into the agent ecosystem.
On Cloudflare, you can start building today. We’re ready for you, and ready to help build with you. Email us at [email protected], and we’ll help get you going. There’s lots more to come with MCP, and we’re excited to see what you build.
Super Slurper is Cloudflare’s data migration tool that is designed to make large-scale data transfers between cloud object storage providers and Cloudflare R2 easy. Since its launch, thousands of developers have used Super Slurper to move petabytes of data from AWS S3, Google Cloud Storage, and other S3-compatible services to R2.
But we saw an opportunity to make it even faster. We rearchitected Super Slurper from the ground up using our Developer Platform — building on Cloudflare Workers, Durable Objects, and Queues — and improved transfer speeds by up to 5x. In this post, we’ll dive into the original architecture, the performance bottlenecks we identified, how we solved them, and the real-world impact of these improvements.
Initial architecture and performance bottlenecks
Super Slurper originally shared its architecture with SourcingKit, a tool built to bulk import images from AWS S3 into Cloudflare Images. SourcingKit was deployed on Kubernetes and ran alongside the Images service. When we started building Super Slurper, we split it into its own Kubernetes namespace and introduced a few new APIs to make it easier to use for the object storage use case. This setup worked well and helped thousands of developers move data to R2.
However, it wasn’t without its challenges. SourcingKit wasn’t designed to handle the scale required for large, petabytes-scale transfers. SourcingKit, and by extension Super Slurper, operated on Kubernetes clusters located in one of our core data centers, meaning it had to share compute resources and bandwidth with Cloudflare’s control plane, analytics, and other services. As the number of migrations grew, these resource constraints became a clear bottleneck.
For a service transferring data between object storage providers, the job is simple: list objects from the source, copy them to the destination, and repeat. This is exactly how the original Super Slurper worked. We listed objects from the source bucket, pushed that list to a Postgres-based queue (pg_queue), and then pulled from this queue at a steady pace to copy objects over. Given the scale of object storage migrations, bandwidth usage was inevitably going to be high. This made it challenging to scale.
To address the bandwidth constraints operating solely in our core data center, we introduced Cloudflare Workers into the mix. Instead of handling the copying of data in our core data center, we started calling out to a Worker to do the actual copying:
As Super Slurper’s usage grew, so did our Kubernetes resource consumption. A significant amount of time during data transfers was spent waiting on network I/O or storage, and not actually doing compute-intensive tasks. So we didn’t need more memory or more CPU, we needed more concurrency.
To keep up with demand, we kept increasing the replica count. But eventually, we hit a wall. We were dealing with scalability challenges when running on the order of tens of pods when we wanted multiple orders of magnitude more.
We decided to rethink the entire approach from first principles, instead of leaning on the architecture we had inherited. In about a week, we built a rough proof of concept using Cloudflare Workers, Durable Objects, and Queues. We listed objects from the source bucket, pushed them into a queue, and then consumed messages from the queue to initiate transfers. Although this sounds very similar to what we did in the original implementation, building on our Developer Platform allowed us to automatically scale an order of magnitude higher than before.
Cloudflare Queues: Enables asynchronous object transfers and auto-scales to meet the number of objects being migrated.
Cloudflare Workers: Runs lightweight compute tasks without the overhead of Kubernetes and optimizes where in the world each part of the process runsfor lower latency and better performance.
SQLite-backed Durable Objects (DOs): Acts as a fully distributed database, eliminating the limitations of a single PostgreSQL instance.
Hyperdrive: Provides fast access to historical job data from the original PostgreSQL database, keeping it as an archive store.
We ran a few tests and found that our proof of concept was slower than the original implementation for small transfers (a few hundred objects), but it matched and eventually exceeded the performance of the original as transfers scaled into the millions of objects. That was the signal we needed to invest the time to take our proof of concept to production.
We removed our proof of concept hacks, worked on stability, and found new ways to make transfers scale to even higher concurrency. After a few iterations, we landed on something we were happy with.
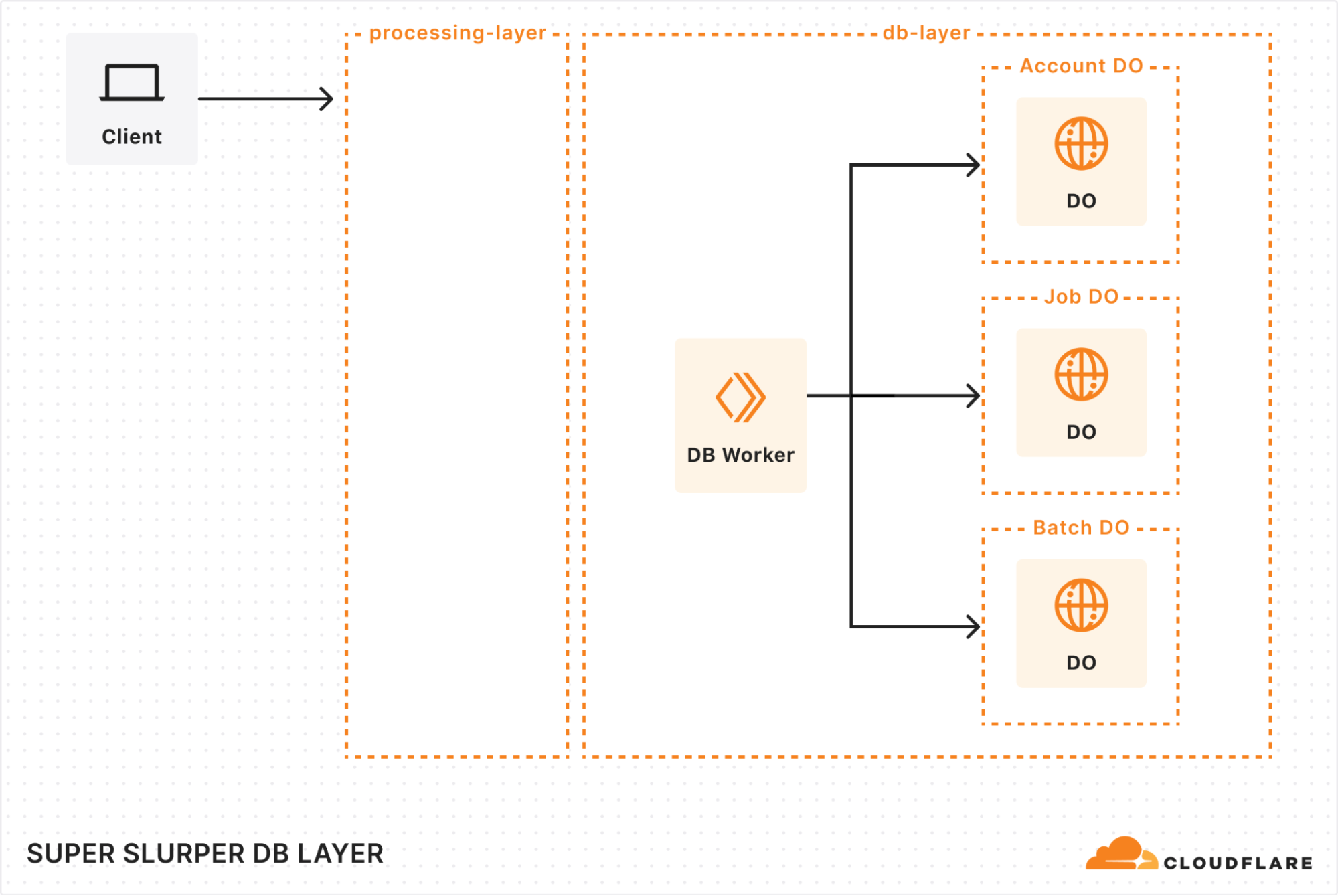
New architecture: Workers, Queues, and Durable Objects
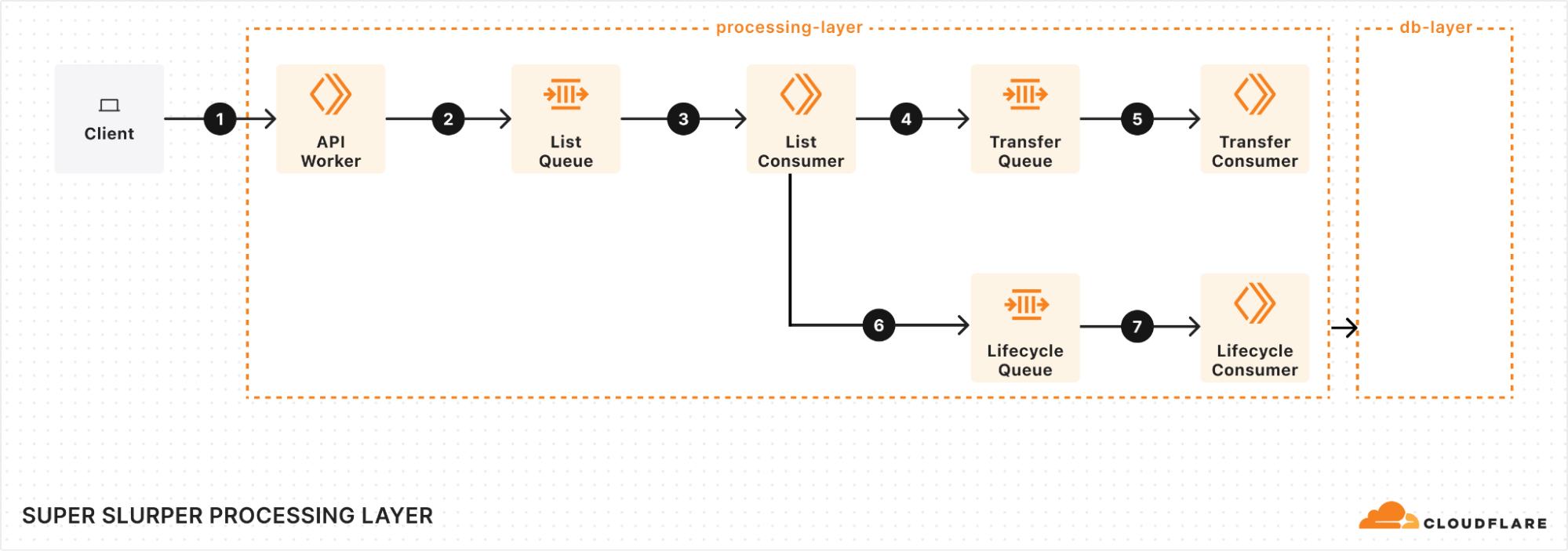
Processing layer: managing the flow of migration
At the heart of our processing layer are queues, consumers, and workers. Here’s what the process looks like:
Kicking off a migration
When a client triggers a migration, it starts with a request sent to our API Worker. This worker takes the details of the migration, stores them in the database, and adds a message to the List Queue to start the process.
Listing source bucket objects
The List Queue Consumer is where things start to pick up. It pulls messages from the queue, retrieves object listings from the source bucket, applies any necessary filters, and stores important metadata in the database. Then, it creates new tasks by enqueuing object transfer messages into the Transfer Queue.
We immediately queue new batches of work, maximizing concurrency. A built-in throttling mechanism prevents us from adding more messages to our queues when unexpected failures occur, such as dependent systems going down. This helps maintain stability and prevents overload during disruptions.
Efficient object transfers
The Transfer Queue Consumer Workers pull object transfer messages from the queue, ensuring that each object is processed only once by locking the object key in the database. When the transfer finishes, the object is unlocked. For larger objects, we break them into manageable chunks and transfer them as multipart uploads.
Handling failures gracefully
Failures are inevitable in any distributed system, and we had to make sure we accounted for that. We implemented automatic retries for transient failures, so issues don’t interrupt the flow of the migration. But if something can’t be resolved with retries, the message goes into the Dead Letter Queue (DLQ), where it is logged for later review and resolution.
Job completion & lifecycle management
Once all the objects are listed and the transfers are in progress, the Lifecycle Queue Consumer keeps an eye on everything. It monitors the ongoing transfers, ensuring that no object is left behind. When all the transfers are complete, the job is marked as finished and the migration process wraps up.
Database layer: durable storage & legacy data retrieval
When building our new architecture, we knew we needed a robust solution to handle massive datasets while ensuring retrieval of historical job data. That’s where our combination of Durable Objects (DOs) and Hyperdrive came in.
Durable Objects
We gave each account a dedicated Durable Object to track migration jobs. Each job’s DO stores vital details, such as bucket names, user options, and job state. This ensured everything stayed organized and easy to manage. To support large migrations, we also added a Batch DO that manages all the objects queued for transfer, storing their transfer state, object keys, and any extra metadata.
As migrations scaled up to billions of objects, we had to get creative with storage. We implemented a sharding strategy to distribute request loads, preventing bottlenecks and working around SQLite DO’s 10 GB storage limit. As objects are transferred, we clean up their details, optimizing storage space along the way. It’s surprising how much storage a billion object keys can require!
Hyperdrive
Since we were rebuilding a system with years of migration history, we needed a way to preserve and access every past migration detail. Hyperdrive serves as a bridge to our legacy systems, enabling seamless retrieval of historical job data from our core PostgreSQL database. It’s not just a data retrieval mechanism, but an archive for complex migration scenarios.
Results: Super Slurper now transfers data to R2 up to 5x faster
So, after all of that, did we actually achieve our goal of making transfers faster?
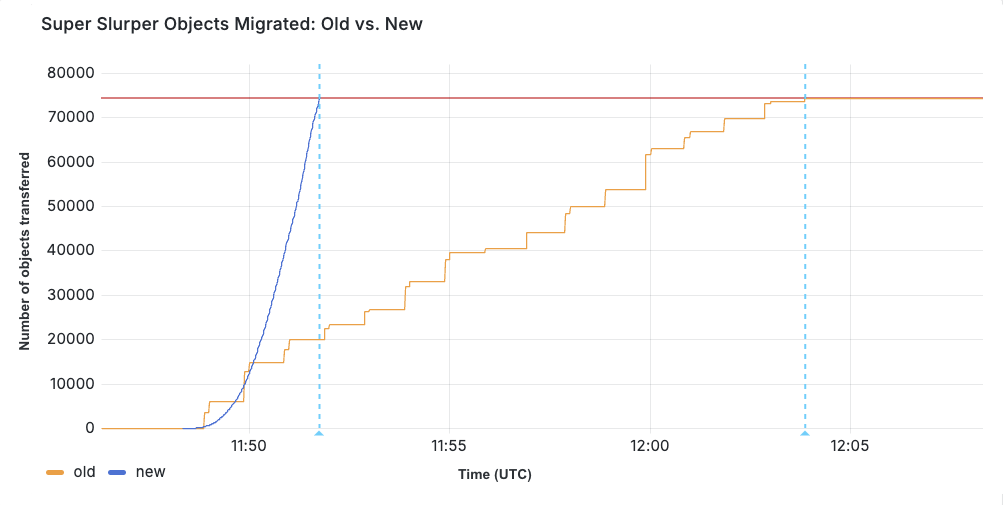
We ran a test migration of 75,000 objects from AWS S3 to R2. With the original implementation, the transfer took 15 minutes and 30 seconds. After our performance improvements, the same migration completed in just 3 minutes and 25 seconds.
When production migrations started using the new service in February, we saw even greater improvements in some cases, especially depending on the distribution of object sizes. Super Slurper has been around for about two years. But the improved performance has led to it being able to move much more data — 35% of all objects copied by Super Slurper happened just in the last two months.
Challenges
One of the biggest challenges we faced with the new architecture was handling duplicate messages. There were a couple of ways duplicates could occur:
Queues provides at-least-once delivery, which means consumers may receive the same message more than once to guarantee delivery.
Failures and retries could also create apparent duplicates. For example, if a request to a Durable Object fails after the object has already been transferred, the retry could reprocess the same object.
If not handled correctly, this could result in the same object being transferred multiple times. To solve this, we implemented several strategies to ensure each object was accurately accounted for and only transferred once:
Since listing is sequential (e.g., to get object 2, you need the continuation token from listing object 1), we assign a sequence ID to each listing operation. This allows us to detect duplicate listings and prevent multiple processes from starting simultaneously. This is particularly useful because we don’t wait for database and queue operations to complete before listing the next batch. If listing 2 fails, we can retry it, and if listing 3 has already started, we can short-circuit unnecessary retries.
Each object is locked when its transfer begins, preventing parallel transfers of the same object. Once successfully transferred, the object is unlocked by deleting its key from the database. If a message for that object reappears later, we can safely assume it has already been transferred if the key no longer exists.
We rely on database transactions to keep our counts accurate. If an object fails to unlock, its count remains unchanged. Similarly, if an object key fails to be added to the database, the count isn’t updated, and the operation will be retried later.
As a last failsafe, we check whether the object already exists in the target bucket and was published after the start of our migration. If so, we assume it was transferred by our process (or another) and safely skip it.
What’s next for Super Slurper?
We’re always exploring ways to make Super Slurper faster, more scalable, and even easier to use — this is just the beginning.
Data migrations are still currently limited to 3 concurrent migrations per account, but we want to increase that limit. This will allow object prefixes to be split up into separate migrations and run in parallel, drastically increasing the speed at which a bucket can be migrated. For more information on Super Slurper and how to migrate data from existing object storage to R2, refer to our documentation.
P.S. As part of this update, we made the API much simpler to interact with, so migrations can now be managed programmatically!
I’m thrilled to share that Cloudflare has acquired Outerbase. This is such an amazing opportunity for us, and I want to explain how we got here, what we’ve built so far, and why we are so excited about becoming part of the Cloudflare team.
Databases are key to building almost any production application: you need to persist state for your users (or agents), be able to query it from a number of different clients, and you want it to be fast. But databases aren’t always easy to use: designing a good schema, writing performant queries, creating indexes, and optimizing your access patterns tends to require a lot of experience. Add that to exposing your data through easy-to-grok APIs that make the ‘right’ way to do things obvious, a great developer experience (from dashboard to CLI), and well… there’s a lot of work involved.
The Outerbase team is already getting to work on some big changes to how databases (and your data) are viewed, edited, and visualized from within Workers, and we’re excited to give you a few sneak peeks into what we’ll be landing as we get to work.
Database DX
When we first started Outerbase, we saw how complicated databases could be. Even experienced developers struggled with writing queries, indexing data, and locking down their data. Meanwhile, non-developers often felt locked out and that they couldn’t access the data they needed. We believed there had to be a better way. From day one, our goal was to make data accessible to everyone, no matter their skill level. While it started out by simply building a better database interface, it quickly evolved into something much more special.
Outerbase became a platform that helps you manage data in a way that feels natural. You can browse tables, edit rows, and run queries without having to deal with memorizing SQL structure. Even if you do know SQL, you can use Outerbase to dive in deeper and share your knowledge with your team. We also added visualization features so entire teams, both technical and not, could see what’s happening with their data at a glance. Then, with the growth of AI, we realized we could use it to handle many of the more complicated tasks.
One of our more exciting offerings is Starbase, a SQLite-compatible database built on top of Cloudflare’s Durable Objects. Our goal was never to simply wrap a legacy system in a shiny interface; we wanted to make it so easy to get started from day one with nothing, and Cloudflare’s Durable Objects gave us a way to easily manage and spin up databases for anyone who needed one. On top of them, we provided automatic REST APIs, row-level security, WebSocket support for streaming queries, and much more.
1 + 1 = 3
Our collaboration with Cloudflare first started last year, when we introduced a way for developers to import and manage their D1 databases inside Outerbase. We were impressed with how powerful Cloudflare’s tools are for deploying and scaling applications. As we worked together, we quickly saw how well our missions aligned. Cloudflare was building the infrastructure we wished we’d had when we first started, and we were building the data experience that many Cloudflare developers were asking for. This eventually led to the seemingly obvious decision of Outerbase joining Cloudflare — it just made so much sense.
Going forward, we’ll integrate Outerbase’s core features into Cloudflare’s platform. If you’re a developer using D1 or Durable Objects, you’ll start seeing features from Outerbase show up in the Cloudflare dashboard. Expect to see our data explorer for browsing and editing tables, new REST APIs, query editor with type-ahead functionality, real-time data capture, and more of the other tooling we’ve been refining over the last couple of years show up inside the Cloudflare dashboard.
As part of this transition, the hosted Outerbase cloud will shut down on October 15, 2025, which is about six months from now. We know some of you rely on Outerbase as it stands today, so we’re leaving the open-source repositories as they are.
You will still be able to self-host Outerbase if you prefer, and we’ll provide guidance on how to do that within your own Cloudflare account. Our main goal will be to ensure that the best parts of Outerbase become part of the Cloudflare developer experience, so you no longer have to make a choice (it’ll be obvious!).
Sneak peek
We’ve already done a lot of thinking about how we’re going to bring the best parts of Outerbase into D1, Durable Objects, Workflows, and Agents, and we’re going to a share a little about what will be landing over the course of Q2 2025 as the Outerbase team gets to work.
Specifically, we’ll be heads-down focusing on:
Adapting the powerful table viewer and query runner experiences to D1 and Durable Objects (amongst many other things!)
Making it easier to get started with Durable Objects: improving the experience in Wrangler (our CLI tooling), the Cloudflare dashboard, and how you plug into them from your client applications
Improvements to how you visualize the state of a Workflow and the (thousands to millions!) of Workflow instances you might have at any point in time
Pre- and post-query hooks for D1 that allow you to automatically register handlers that can act on your data
Bringing the Starbase API to D1, expanding D1’s existing REST API, and adding WebSockets support — making it easier to use D1, even for applications hosted outside of Workers.
We have already started laying the groundwork for these changes. In the coming weeks, we’ll release a unified data explorer for D1 and Durable Objects that borrows heavily from the Outerbase interface you know.
Bringing Outerbase’s Data Explorer into the Cloudflare Dashboard
We’ll also tie some of Starbase’s features directly into Cloudflare’s platform, so you can tap into its unique offerings like pre- and post-query hooks or row-level security right from your existing D1 databases and Durable Objects:
const beforeQuery = ({ sql, params }) => {
// Prevent unauthorized queries
if (!isAllowedQuery(sql)) throw new Error('Query not allowed');
};
const afterQuery = ({ sql, result }) => {
// Basic PII masking example
for (const row of result) {
if ('email' in row) row.email = '[redacted]';
}
};
// Execute the query with pre- and post- query hooks
const { results } = await env.DB.prepare("SELECT * FROM users;", beforeQuery, afterQuery);
Define hooks on your D1 queries that can be re-used, shared and automatically executed before or after your queries run.
This should give you more clarity and control over your data, as well as new ways to secure and optimize it.
Rethinking the Durable Objects getting started experience
We have even begun optimizing the Cloudflare dashboard experience around Durable Objects and D1 to improve the empty state, provide more Getting Started resources, and overall, make managing and tracking your database resources even easier.
For those of you who’ve supported us, given us feedback, and stuck with us as we grew: thank you. You have helped shape Outerbase into what it is today. This acquisition means we can pour even more resources and attention into building the data experience we’ve always wanted to deliver. Our hope is that, by working as part of Cloudflare, we can help reach even more developers by building intuitive experiences, accelerating the speed of innovation, and creating tools that naturally fit into your workflows.
This is a big step for Outerbase, and we couldn’t be more excited. Thank you for being part of our journey so far. We can’t wait to show you what we’ve got in store as we continue to make data more accessible, intuitive, and powerful — together with Cloudflare.
What’s next?
We’re planning to get to work on some of the big changes to how you interact with your data on Cloudflare, starting with D1 and Durable Objects.
We’ll also be ensuring we bring a great developer experience to the broader database & storage platform on Cloudflare, including how you access data in Workers KV, R2, Workflows and even your AI Agents (just to name a few).
As engineers, we’re obsessed with efficiency and automating anything we find ourselves doing more than twice. If you’ve ever done this, you know that the happy path is always easy, but the second the inputs get complex, automation becomes really hard. This is because computers have traditionally required extremely specific instructions in order to execute.
The state of AI models available to us today has changed that. We now have access to computers that can reason, and make judgement calls in lieu of specifying every edge case under the sun.
That’s what AI agents are all about.
Today we’re excited to share a few announcements on how we’re making it eveneasier to build AI agents on Cloudflare, including:
agents-sdk — a new JavaScript framework for building AI agents
Updates to Workers AI: structured outputs, tool calling, and longer context windows for Workers AI, Cloudflare’s serverless inference engine
We truly believe that Cloudflare is the ideal platform for building Agents and AI applications (more on why below), and we’re constantly working to make it better — you can expect to see more announcements from us in this space in the future.
Before we dive deep into the announcements, we wanted to give you a quick primer on agents. If you are familiar with agents, feel free to skip ahead.
What are agents?
Agents are AI systems that can autonomously execute tasks by making decisions about tool usage and process flow. Unlike traditional automation that follows predefined paths, agents can dynamically adapt their approach based on context and intermediate results. Agents are also distinct from co-pilots (e.g. traditional chat applications) in that they can fully automate a task, as opposed to simply augmenting and extending human input.
Agents → non-linear, non-deterministic (can change from run to run)
Workflows → linear, deterministic execution paths
Co-pilots → augmentative AI assistance requiring human intervention
Example: booking vacations
If this is your first time working with, or interacting with agents, this example will illustrate how an agent works within a context like booking a vacation.
Imagine you’re trying to book a vacation. You need to research flights, find hotels, check restaurant reviews, and keep track of your budget.
Traditional workflow automation
A traditional automation system follows a predetermined sequence: it can take inputs such as dates, location, and budget, and make calls to predefined APIs in a fixed order. However, if any unexpected situations arise, such as flights being sold out, or the specified hotels being unavailable, it cannot adapt.
AI co-pilot
A co-pilot acts as an intelligent assistant that can provide hotel and itinerary recommendations based on your preferences. If you have questions, it can understand and respond to natural language queries and offer guidance and suggestions. However, it is unable to take the next steps to execute the end-to-end action on its own.
Agent
An agent combines AI’s ability to make judgements and call the relevant tools to execute the task. An agent’s output will be nondeterministic given: real-time availability and pricing changes, dynamic prioritization of constraints, ability to recover from failures, and adaptive decision-making based on intermediate results. In other words, if flights or hotels are unavailable, an agent can reassess and suggest a new itinerary with altered dates or locations, and continue executing your travel booking.
agents-sdk — the framework for building agents
You can now add agent powers to any existing Workers project with just one command:
$ npm i agents-sdk
… or if you want to build something from scratch, you can bootstrap your project with the agents-starter template:
$ npm create cloudflare@latest agents-starter --template=cloudflare/agents-starter
// ... and then deploy it
$ npm run deploy
agents-sdk is a framework that allows you to build agents — software that can autonomously execute tasks — and deploy them directly into production on Cloudflare Workers.
Your agent can start with the basics and act on HTTP requests…
import { Agent } from "agents-sdk";
export class IntelligentAgent extends Agent {
async onRequest(request) {
// Transform intention into response
return new Response("Ready to assist.");
}
}
Although this is just the initial release of agents-sdk, we wanted to ship more than just a thin wrapper over an existing library. Agents can communicate with clients in real time, persist state, execute long-running tasks on a schedule, send emails, run asynchronous workflows, browse the web, query data from your Postgres database, call AI models, and support human-in-the-loop use-cases. All of this works today, out of the box.
For example, you can build a powerful chat agent with the AIChatAgent class:
// src/index.ts
export class Chat extends AIChatAgent<Env> {
/**
* Handles incoming chat messages and manages the response stream
* @param onFinish - Callback function executed when streaming completes
*/
async onChatMessage(onFinish: StreamTextOnFinishCallback<any>) {
// Create a streaming response that handles both text and tool outputs
return agentContext.run(this, async () => {
const dataStreamResponse = createDataStreamResponse({
execute: async (dataStream) => {
// Process any pending tool calls from previous messages
// This handles human-in-the-loop confirmations for tools
const processedMessages = await processToolCalls({
messages: this.messages,
dataStream,
tools,
executions,
});
// Initialize OpenAI client with API key from environment
const openai = createOpenAI({
apiKey: this.env.OPENAI_API_KEY,
});
// Cloudflare AI Gateway
// const openai = createOpenAI({
// apiKey: this.env.OPENAI_API_KEY,
// baseURL: this.env.GATEWAY_BASE_URL,
// });
// Stream the AI response using GPT-4
const result = streamText({
model: openai("gpt-4o-2024-11-20"),
system: `
You are a helpful assistant that can do various tasks. If the user asks, then you can also schedule tasks to be executed later. The input may have a date/time/cron pattern to be input as an object into a scheduler The time is now: ${new Date().toISOString()}.
`,
messages: processedMessages,
tools,
onFinish,
maxSteps: 10,
});
// Merge the AI response stream with tool execution outputs
result.mergeIntoDataStream(dataStream);
},
});
return dataStreamResponse;
});
}
async executeTask(description: string, task: Schedule<string>) {
await this.saveMessages([
...this.messages,
{
id: generateId(),
role: "user",
content: `scheduled message: ${description}`,
},
]);
}
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
if (!env.OPENAI_API_KEY) {
console.error(
"OPENAI_API_KEY is not set, don't forget to set it locally in .dev.vars, and use `wrangler secret bulk .dev.vars` to upload it to production"
);
return new Response("OPENAI_API_KEY is not set", { status: 500 });
}
return (
// Route the request to our agent or return 404 if not found
(await routeAgentRequest(request, env)) ||
new Response("Not found", { status: 404 })
);
},
} satisfies ExportedHandler<Env>;
… and connect to your Agent with any React-based front-end with the useAgent hook that can automatically establish a bidirectional WebSocket, sync client state, and allow you to build Agent-based applications without a mountain of bespoke code:
We spent some time thinking about the production story here too: an agent framework that absolves itself of the hard parts — durably persisting state, handling long-running tasks & loops, and horizontal scale — is only going to get you so far. Agents built with agents-sdk can be deployed directly to Cloudflare and run on top of Durable Objects — which you can think of as stateful micro-servers that can scale to tens of millions — and are able to run wherever they need to. Close to a user for low-latency, close to your data, and/or anywhere in between.
agents-sdk also exposes:
Integration with React applications via a useAgent hook that can automatically set up a WebSocket connection between your app and an agent
An AIChatAgent extension that makes it easier to build intelligent chat agents
State management APIs via this.setState as well as a native sql API for writing and querying data within each Agent
State synchronization between frontend applications and the agent state
Agent routing, enabling agent-per-user or agent-per-workflow use-cases. Spawn millions (or tens of millions) of agents without having to think about how to make the infrastructure work, provision CPU, or scale out storage.
Over the coming weeks, expect to see even more here: tighter integration with email APIs to enable more human-in-the-loop use-cases, hooks into WebRTC for voice & video interactivity, a built-in evaluation (evals) framework, and the ability to self-host agents on your own infrastructure.
We’re aiming high here: we think this is just the beginning of what agents are capable of, and we think we can make Workers the best place (but not the only place) to build & run them.
JSON mode, longer context windows, and improved tool calling in Workers AI
When users express needs conversationally, tool calling converts these requests into structured formats like JSON that APIs can understand and process, allowing the AI to interact with databases, services, and external systems. This is essential for building agents, as it allows users to express complex intentions in natural language, and AI to decompose these requests, call appropriate tools, evaluate responses and deliver meaningful outcomes.
When using tool calling or building AI agents, the text generation model must respond with valid JSON objects rather than natural language. Today, we’re adding JSON mode support to Workers AI, enabling applications to request a structured output response when interacting with AI models. Here’s a request to @cf/meta/llama-3.1-8b-instruct-fp8-fast using JSON mode:
As you can see, the model is complying with the JSON schema definition in the request and responding with a validated JSON object. JSON mode is compatible with OpenAI’s response_format implementation:
We will continue extending this list to keep up with new, and requested models.
Lastly, we are changing how we restrict the size of AI requests to text generation models, moving from byte-counts to token-counts, introducing the concept of context window and raising the limits of the models in our catalog.
In generative AI, the context window is the sum of the number of input, reasoning, and completion or response tokens a model supports. You can now find the context window limit on each model page in our developer documentation and decide which suits your requirements and use case.
JSON mode is also the perfect companion when using function calling. You can use structured JSON outputs with traditional function calling or the Vercel AI SDK via the workers-ai-provider.
workers-ai-provider 0.1.1
One of the most common ways to build with AI tooling today is by using the popular AI SDK. Cloudflare’s provider for the AI SDK makes it easy to use Workers AI the same way you would call any other LLM, directly from your code.
A key part of building agents is using LLMs for routing, and making decisions on which tools to call next, and summarizing structured and unstructured data. All of these things need to happen quickly, as they are on the critical path of the user-facing experience.
Workers AI, with its globally distributed fleet of GPUs, is a perfect fit for smaller, low-latency LLMs, so we’re excited to make it easy to use with tools developers are already familiar with.
Why build agents on Cloudflare?
Since launching Workers in 2017, we’ve been building a platform to allow developers to build applications that are fast, scalable, and cost-efficient from day one. We took a fundamentally different approach from the way code was previously run on servers, making a bet about what the future of applications was going to look like — isolates running on a global network, in a way that was truly serverless. No regions, no concurrency management, no managing or scaling infrastructure.
The release of Workers was just the beginning, and we continued shipping primitives to extend what developers could build. Some more familiar, like a key-value store (Workers KV), and some that we thought would play a role in enabling net new use cases like Durable Objects. While we didn’t quite predict AI agents (though “Agents” was one of the proposed names for Durable Objects), we inadvertently created the perfect platform for building them.
What do we mean by that?
A platform that only charges you for what you use (regardless of how long it takes)
To be able to run agents efficiently, you need a system that can seamlessly scale up and down to support the constant stop, go, wait patterns. Agents are basically long-running tasks, sometimes waiting on slow reasoning LLMs and external tools to execute. With Cloudflare, you don’t have to pay for long-running processes when your code is not executing. Cloudflare Workers is designed to scale down and only charge you for CPU time, as opposed to wall-clock time.
In many cases, especially when calling LLMs, the difference can be in orders of magnitude — e.g. 2–3 milliseconds of CPU vs. 10 seconds of wall-clock time. When building on Workers, we pass that difference on to you as cost savings.
Serverless AI Inference
We took a similar serverless approach when it comes to inference itself. When you need to call an AI model, you need it to be instantaneously available. While the foundation model providers offer APIs that make it possible to just call the LLM, if you’re running open-source models, LoRAs, or self-trained models, most cloud providers today require you to pre-provision resources for what your peak traffic will look like. This means that the rest of the time, you’re still paying for GPUs to sit there idle. With Workers AI, you can pay only when you’re calling our inference APIs, as opposed to unused infrastructure. In fact, you don’t have to think about infrastructure at all, which is the principle at the core of everything we do.
A platform designed for durable execution
Durable Objects and Workflows provide a robust programming model that ensures guaranteed execution for asynchronous tasks that require persistence and reliability. This makes them ideal for handling complex operations like long-running deep thinking LLM calls, human-in-the-loop approval processes, or interactions with unreliable third-party APIs. By maintaining state across requests and automatically handling retries, these tools create a resilient foundation for building sophisticated AI agents that can perform complex, multistep tasks without losing context or progress, even when operations take significant time to complete.
Lastly, new and updated agents documentation
Did you catch all of that?
No worries if not: we’ve updated our agents documentation to include everything we talked about above, from breaking down the basics of agents, to showing you how to tackle foundational examples of building with agents.
We’ve also updated our Workers prompt with knowledge of the agents-sdk library, so you can use Cursor, Windsurf, Zed, ChatGPT or Claude to help you build AI Agents and deploy them to Cloudflare.
Can’t wait to see what you build!
We’re just getting started, and we love to see all that you build. Please join our Discord, ask questions, and tell us what you’re building.
Cloudflare Queues let a developer decouple their Workers into event-driven services. Producer Workers write events to a Queue, and consumer Workers are invoked to take actions on the events. For example, you can use a Queue to decouple an e-commerce website from a service which sends purchase confirmation emails to users. During 2024’s Birthday Week, we announced that Cloudflare Queues is now Generally Available, with significant performance improvements that enable larger workloads. To accomplish this, we switched to a new architecture for Queues that enabled the following improvements:
Median latency for sending messages has dropped from ~200ms to ~60ms
Maximum throughput for each Queue has increased over 10x, from 400 to 5000 messages per second
Maximum Consumer concurrency for each Queue has increased from 20 to 250 concurrent invocations
Median latency drops from ~200ms to ~60ms as Queues are migrated to the new architecture
In this blog post, we’ll share details about how we built Queues using Durable Objects and the Cloudflare Developer Platform, and how we migrated from an initial Beta architecture to a geographically-distributed, horizontally-scalable architecture for General Availability.
v1 Beta architecture
When initially designing Cloudflare Queues, we decided to build something simple that we could get into users’ hands quickly. First, we considered leveraging an off-the-shelf messaging system such as Kafka or Pulsar. However, we decided that it would be too challenging to operate these systems at scale with the large number of isolated tenants that we wanted to support.
Instead of investing in new infrastructure, we decided to build on top of one of Cloudflare’s existing developer platform building blocks: Durable Objects.Durable Objects are a simple, yet powerful building block for coordination and storage in a distributed system. In our initial v1 architecture, each Queue was implemented using a single Durable Object. As shown below, clients would send messages to a Worker running in their region, which would be forwarded to the single Durable Object hosted in the WNAM (Western North America) region. We used a single Durable Object for simplicity, and hosted it in WNAM for proximity to our centralized configuration API service.
One of a Queue’s main responsibilities is to accept and store incoming messages. Sending a message to a v1 Queue used the following flow:
A client sends a POST request containing the message body to the Queues API at /accounts/:accountID/queues/:queueID/messages
The request is handled by an instance of the Queue Broker Worker in a Cloudflare data center running near the client.
The Worker performs authentication, and then uses Durable Objects idFromName API to route the request to the Queue Durable Object for the given queueID
The Queue Durable Object persists the message to storage before returning a success back to the client.
Durable Objects handled most of the heavy-lifting here: we did not need to set up any new servers, storage, or service discovery infrastructure. To route requests, we simply provided a queueID and the platform handled the rest. To store messages, we used the Durable Object storage API to put each message, and the platform handled reliably storing the data redundantly.
Consuming messages
The other main responsibility of a Queue is to deliver messages to a Consumer. Delivering messages in a v1 Queue used the following process:
Each Queue Durable Object maintained an alarm that was always set when there were undelivered messages in storage. The alarm guaranteed that the Durable Object would reliably wake up to deliver any messages in storage, even in the presence of failures. The alarm time was configured to fire after the user’s selected max wait time, if only a partial batch of messages was available. Whenever one or more full batches were available in storage, the alarm was scheduled to fire immediately.
The alarm would wake the Durable Object, which continually looked for batches of messages in storage to deliver.
Each batch of messages was sent to a “Dispatcher Worker” that used Workers for Platformsdynamic dispatch to pass the messages to the queue() function defined in a user’s Consumer Worker
This v1 architecture let us flesh out the initial version of the Queues Beta product and onboard users quickly. Using Durable Objects allowed us to focus on building application logic, instead of complex low-level systems challenges such as global routing and guaranteed durability for storage. Using a separate Durable Object for each Queue allowed us to host an essentially unlimited number of Queues, and provided isolation between them.
However, using only one Durable Object per queue had some significant limitations:
Latency: we created all of our v1 Queue Durable Objects in Western North America. Messages sent from distant regions incurred significant latency when traversing the globe.
Throughput: A single Durable Object is not scalable: it is single-threaded and has a fixed capacity for how many requests per second it can process. This is where the previous 400 messages per second limit came from.
Consumer Concurrency: Due to concurrent subrequest limits, a single Durable Object was limited in how many concurrent subrequests it could make to our Dispatcher Worker. This limited the number of queue() handler invocations that it could run simultaneously.
To solve these issues, we created a new v2 architecture that horizontally scales across multiple Durable Objects to implement each single high-performance Queue.
v2 Architecture
In the new v2 architecture for Queues, each Queue is implemented using multiple Durable Objects, instead of just one. Instead of a single region, we place Storage Shard Durable Objects in all available regions to enable lower latency. Within each region, we create multiple Storage Shards and load balance incoming requests amongst them. Just like that, we’ve multiplied message throughput.
Sending a message to a v2 Queue uses the following flow:
A client sends a POST request containing the message body to the Queues API at /accounts/:accountID/queues/:queueID/messages
The request is handled by an instance of the Queue Broker Worker running in a Cloudflare data center near the client.
The Worker:
Performs authentication
Reads from Workers KV to obtain a Shard Map that lists available storage shards for the given region and queueID
Picks one of the region’s Storage Shards at random, and uses Durable Objects idFromName API to route the request to the chosen shard
The Storage Shard persists the message to storage before returning a success back to the client.
In this v2 architecture, messages are stored in the closest available Durable Object storage cluster near the user, greatly reducing latency since messages don’t need to be shipped all the way to WNAM. Using multiple shards within each region removes the bottleneck of a single Durable Object, and allows us to scale each Queue horizontally to accept even more messages per second. Workers KV acts as a fast metadata store: our Worker can quickly look up the shard map to perform load balancing across shards.
To improve the Consumer side of v2 Queues, we used a similar “scale out” approach. A single Durable Object can only perform a limited number of concurrent subrequests. In v1 Queues, this limited the number of concurrent subrequests we could make to our Dispatcher Worker. To work around this, we created a new Consumer Shard Durable Object class that we can scale horizontally, enabling us to execute many more concurrent instances of our users’ queue() handlers.
Consumer Durable Objects in v2 Queues use the following approach:
Each Consumer maintains an alarm that guarantees it will wake up to process any pending messages. v2 Consumers are notified by the Queue’s Coordinator (introduced below) when there are messages ready for consumption. Upon notification, the Consumer sets an alarm to go off immediately.
The Consumer looks at the shard map, which contains information about the storage shards that exist for the Queue, including the number of available messages on each shard.
The Consumer picks a random storage shard with available messages, and asks for a batch.
The Consumer sends the batch to the Dispatcher Worker, just like for v1 Queues.
After processing the messages, the Consumer sends another request to the Storage Shard to either “acknowledge” or “retry” the messages.
This scale-out approach enabled us to work around the subrequest limits of a single Durable Object, and increase the maximum supported concurrency level of a Queue from 20 to 250.
The Coordinator and “Control Plane”
So far, we have primarily discussed the “Data Plane” of a v2 Queue: how messages are load balanced amongst Storage Shards, and how Consumer Shards read and deliver messages. The other main piece of a v2 Queue is the “Control Plane”, which handles creating and managing all the individual Durable Objects in the system. In our v2 architecture, each Queue has a single Coordinator Durable Object that acts as the brain of the Queue. Requests to create a Queue, or change its settings, are sent to the Queue’s Coordinator.
The Coordinator maintains a Shard Map for the Queue, which includes metadata about all the Durable Objects in the Queue (including their region, number of available messages, current estimated load, etc.). The Coordinator periodically writes a fresh copy of the Shard Map into Workers KV, as pictured in step 1 of the diagram. Placing the shard map into Workers KV ensures that it is globally cached and available for our Worker to read quickly, so that it can pick a shard to accept the message.
Every shard in the system periodically sends a heartbeat to the Coordinator as shown in steps 2 and 3 of the diagram. Both Storage Shards and Consumer Shards send heartbeats, including information like the number of messages stored locally, and the current load (requests per second) that the shard is handling. The Coordinator uses this information to perform autoscaling. When it detects that the shards in a particular region are overloaded, it creates additional shards in the region, and adds them to the shard map in Workers KV. Our Worker sees the updated shard map and naturally load balances messages across the freshly added shards. Similarly, the Coordinator looks at the backlog of available messages in the Queue, and decides to add more Consumer shards to increase Consumer throughput when the backlog is growing. Consumer Shards pull messages from Storage Shards for processing as shown in step 4 of the diagram.
Switching to a new scalable architecture allowed us to meet our performance goals and take Queues to GA. As a recap, this new architecture delivered these significant improvements:
P50 latency for writing to a Queue has dropped from ~200ms to ~60ms.
Maximum throughput for a Queue has increased from 400 to 5000 messages per second.
Maximum consumer concurrency has increased from 20 to 250 invocations.
What’s next for Queues
We plan on leveraging the performance improvements in the new beta version of Durable Objects which use SQLite to continue to improve throughput/latency in Queues.
We will soon be adding message management features to Queues so that you can take actions to purge messages in a queue, pause consumption of messages, or “redrive”/move messages from one queue to another (for example messages that have been sent to a Dead Letter Queue could be “redriven” or moved back to the original queue).
Work to make Queues the “event hub” for the Cloudflare Developer Platform:
Create a low-friction way for events emitted from other Cloudflare services with event schemas to be sent to Queues.
Build multi-Consumer support for Queues so that Queues are no longer limited to one Consumer per queue.
To start using Queues, head over to our Getting Started guide.
Do distributed systems like Cloudflare Queues and Durable Objects interest you? Would you like to help build them at Cloudflare? We’re Hiring!
With the rapid advancements occurring in the AI space, developers face significant challenges in keeping up with the ever-changing landscape. New models and providers are continuously emerging, and understandably, developers want to experiment and test these options to find the best fit for their use cases. This creates the need for a streamlined approach to managing multiple models and providers, as well as a centralized platform to efficiently monitor usage, implement controls, and gather data for optimization.
AI Gateway is specifically designed to address these pain points. Since its launch in September 2023, AI Gateway has empowered developers and organizations by successfully proxying over 2 billion requests in just one year, as we highlighted during September’s Birthday Week. With AI Gateway, developers can easily store, analyze, and optimize their AI inference requests and responses in real time.
With our initial architecture, AI Gateway faced a significant challenge: the logs, those critical trails of data interactions between applications and AI models, could only be retained for 30 minutes. This limitation was not just a minor inconvenience; it posed a substantial barrier for developers and businesses needing to analyze long-term patterns, ensure compliance, or simply debug over more extended periods.
In this post, we’ll explore the technical challenges and strategic decisions behind extending our log storage capabilities from 30 minutes to being able to store billions of logs indefinitely. We’ll discuss the challenges of scale, the intricacies of data management, and how we’ve engineered a system that not only meets the demands of today, but is also scalable for the future of AI development.
Background
AI Gateway is built on Cloudflare Workers, a serverless platform that runs on the Cloudflare network, allowing developers to write small JavaScript functions that can execute at the point of need, near the user, on Cloudflare’s vast network of data centers, without worrying about platform scalability.
Our customers use multiple providers and models and are always looking to optimize the way they do inference. And, of course, in order to evaluate their prompts, performance, cost, and to troubleshoot what’s going on, AI Gateway’s customers need to store requests and responses. New requests show up within 15 seconds and customers can check a request’s cost, duration, number of tokens, and provide their feedback (thumbs up or down).
This scales in a way where an account can have multiple gateways and each gateway has its own settings. In our first implementation, a backend worker was responsible for storing Real Time Logs and other background tasks. However, in the rapidly evolving domain of artificial intelligence, where real-time data is as precious as the insights it provides, managing log data efficiently becomes paramount. We recognized that to truly empower our users, we needed to offer a solution where logs weren’t just transient records but could be stored permanently. Permanent log storage means developers can now track the performance, security, and operational insights of their AI applications over time, enabling not only immediate troubleshooting but also longitudinal studies of AI behavior, usage trends, and system health.
The diagram above describes our old architecture, which could only store 30 minutes of data.
Tracing the path of a request through the AI Gateway, as depicted in the sequence above:
A developer sends a new inference request, which is first received by our Gateway Worker.
The Gateway Worker then performs several checks: it looks for cached results, enforces rate limits, and verifies any other configurations set by the user for their gateway. Provided all conditions are met, it forwards the request to the selected inference provider (in this diagram, OpenAI).
The inference provider processes the request and sends back the response.
Simultaneously, as the response is relayed back to the developer, the request and response details are also dispatched to our Backend Worker. This worker’s role is to manage and store the log of this transaction.
The challenge: Store two billion logs
First step: real-time logs
Initially, the AI Gateway project stored both request metadata and the actual request bodies in a D1 database. This approach facilitated rapid development in the project’s infancy. However, as customer engagement grew, the D1 database began to fill at an accelerating rate, eventually retaining logs for only 30 minutes at a time.
To mitigate this, we first optimized the database schema, which extended the log retention to one hour. However, we soon encountered diminishing returns due to the sheer volume of byte data from the request bodies. Post-launch, it became clear that a more scalable solution was necessary. We decided to migrate the request bodies to R2 storage, significantly alleviating the data load on D1. This adjustment allowed us to incrementally extend log retention to 24 hours.
Consequently, D1 functioned primarily as a log index, enabling users to search and filter logs efficiently. When users needed to view details or download a log, these actions were seamlessly proxied through to R2.
This dual-system approach provided us with the breathing room to contemplate and develop more sophisticated storage solutions for the future.
Second step: persistent logs and Durable Object transactional storage
As our traffic surged, we encountered a growing number of requests from customers wanting to access and compare older logs.
Upon learning that the Durable Objects team was seeking beta testers for their new Durable Objects with SQLite, we eagerly signed up.
Originally, we considered Durable Objects as the ideal solution for expanding our log storage capacity, which required us to shard the logs by a unique string. Initially, this string was the account ID, but during a mid-development load test, we hit a cap at 10 million logs per Durable Object. This limitation meant that each account could only support up to this number of logs.
Given our commitment to the DO migration, we saw an opportunity rather than a constraint. To overcome the 10 million log limit per account, we refined our approach to shard by both account ID and gateway name. This adjustment effectively raised the storage ceiling from 10 million logs per account to 10 million per gateway. With the default setting allowing each account up to 10 gateways, the potential storage for each account skyrocketed to 100 million logs.
This strategic pivot not only enabled us to store a significantly larger number of logs. But also enhanced our flexibility in gateway management. Now, when a gateway is deleted, we can simply remove the corresponding Durable Object.
Additionally, this sharding method isolates high-volume request scenarios. If one customer’s heavy usage slows down log insertion, it only impacts their specific Durable Object, thereby preserving performance for other customers.
Taking a glance at the revised architecture diagram, we replaced the Backend Worker with our newly integrated Durable Object. The rest of the request flow remains unchanged, including the concurrent response to the user and the interaction with the Durable Object, which occurs in the fourth step.
Leveraging Cloudflare’s network, our Gateway Worker operates near the user’s location, which in turn positions the user’s Durable Object close by. This proximity significantly enhances the speed of log insertion and query operations.
Third step: managing thousands of Durable Objects
As the number of users and requests on AI Gateway grows, managing each unique Durable Object (DO) becomes increasingly complex. New customers join continuously, and we needed an efficient method to track each DO, ensure users stay within their 10 gateway limit, and manage the storage capacity for free users.
To address these challenges, we introduced another layer of control with a new Durable Object we’ve named the Account Manager. The primary function of the Account Manager is straightforward yet crucial: it keeps user activities in check.
Here’s how it works: before any Gateway commits a new log to permanent storage, it consults the Account Manager. This check determines whether the gateway is allowed to insert the log based on the user’s current usage and entitlements. The Account Manager uses its own SQLite database to verify the total number of rows a user has and their service level. If all checks pass, it signals the Gateway that the log can be inserted. It was paramount to guarantee that this entire validation process occurred in the background, ensuring that the user experience remains seamless and uninterrupted.
The Account Manager stays updated by periodically receiving data from each Gateway’s Durable Object. Specifically, after every 1000 inference requests, the Gateway sends an update on its total rows to the Account Manager, which then updates its local records. This system ensures that the Account Manager has the most current data when making its decisions.
Additionally, the Account Manager is responsible for monitoring customer entitlements. It tracks whether an account is on a free or paid plan, how many gateways a user is permitted to create, and the log storage capacity allocated to each gateway.
Through these mechanisms, the Account Manager not only helps in maintaining system integrity but also ensures fair usage across all users of AI Gateway.
AI evaluations and Durable Objects sharding
As we continue to develop evaluations to fully automatic and, in the future, use Large Language Models (LLMs), we are now taking the first step towards this goal and launching the open beta phase of comprehensive AI evaluations, centered on Human-in-the-Loop feedback.
This feature empowers users to create bespoke datasets from their application logs, thereby enabling them to score and evaluate the performance, speed, and cost-effectiveness of their models, with a primary focus on LLMs and automated scoring, analyzing the performance of LLMs, providing developers with objective, data-driven insights to refine their models.
To do this, developers require a reliable logging mechanism that persists logs from multiple gateways, storing up to 100 million logs in total (10 million logs per gateway, across 10 gateways). This represents a significant volume of data, as each request made through the AI Gateway generates a log entry, with some log entries potentially exceeding 50 MB in size.
This necessity leads us to work on the expansion of log storage capabilities. Since log storage is limited to 10 million logs per gateway, in future iterations, we aim to scale this capacity by implementing sharded Durable Objects (DO), allowing multiple Durable Objects per gateway to handle and store logs. This scaling strategy will enable us to store significantly larger volumes of logs, providing richer data for evaluations (using LLMs as a judge or from user input), all through AI Gateway.
Coming Soon
We are working on improving our existing Universal Endpoint, the next step on an enhanced solution that builds on existing fallback mechanisms to offer greater resilience, flexibility, and intelligence in request management.
Currently, when a provider encounters an error or is unavailable, our system falls back to an alternative provider to ensure continuity. The improved Universal Endpoint takes this a step further by introducing automatic retry capabilities, allowing failed requests to be reattempted before fallback is triggered. This significantly improves reliability by handling transient errors and increasing the likelihood of successful request fulfillment. It will look something like this:
The request to the improved Universal Endpoint system demonstrates how it handles multiple providers with integrated retry mechanisms and fallback logic. In this example, the first request is sent to a provider like OpenAI, asking it to generate a text-to-image prompt. The “retry” option ensures that transient issues don’t result in immediate failure.
The system’s ability to seamlessly switch between providers while applying retry strategies ensures higher reliability and robustness in managing requests. By leveraging fallback logic, the Improved Universal Endpoint can dynamically adapt to provider failures, ensuring that tasks are completed successfully even in complex, multi-step workflows.
In addition to retry logic, we will have the ability to inspect requests and responses and make dynamic decisions based on the content of the result. This enables developers to create conditional workflows where the system can adapt its behavior depending on the nature of the response, creating a highly flexible and intelligent decision-making process.
If you haven’t yet used AI Gateway, check out our developer documentation on how to get started. If you have any questions, reach out on our Discord channel.
Workflows, Cloudflare’s durable execution engine that allows you to build reliable, repeatable multi-step applications that scale for you, is now in open beta. Any developer with a free or paid Workers plan can build and deploy a Workflow right now: no waitlist, no sign-up form, no fake line around-the-block.
Open the src/index.ts file, poke around, start extending it, and deploy it with a quick wrangler deploy.
If you want to learn more about how Workflows works, how you can use it to build applications, and how we built it, read on.
Workflows? Durable Execution?
Workflows—which we announced back during Developer Week earlier this year—is our take on the concept of “Durable Execution”: the ability to build and execute applications that are durable in the face of errors, network issues, upstream API outages, rate limits, and (most importantly) infrastructure failure.
As over 2.4 million developers continue to build applications on top of Cloudflare Workers, R2, and Workers AI, we’ve noticed more developers building multi-step applications and workflows that process user data, transform unstructured data into structured, export metrics, persist state as they progress, and automatically retry & restart. But writing any non-trivial application and making it durable in the face of failure is hard: this is where Workflows comes in. Workflows manages the retries, emitting the metrics, and durably storing the state (without you having to stand up your own database) as the Workflow progresses.
What makes Workflows different from other takes on “Durable Execution” is that we manage the underlying compute and storage infrastructure for you. You’re not left managing a compute cluster and hoping it scales both up (on a Monday morning) and down (during quieter periods) to manage costs, or ensuring that you have compute running in the right locations. Workflows is built on Cloudflare Workers — our job is to run your code and operate the infrastructure for you.
As an example of how Workflows can help you build durable applications, assume you want to post-process file uploads from your users that were uploaded to an R2 bucket directly via a pre-signed URL. That post-processing could involve multiple actions: text extraction via a Workers AI model, calls to a third-party API to validate data, updating or querying rows in a database once the file has been processed… the list goes on.
But what each of these actions has in common is that it could fail. Maybe that upstream API is unavailable, maybe you get rate-limited, maybe your database is down. Having to write extensive retry logic around each action, manage backoffs, and (importantly) ensure your application doesn’t have to start from scratch when a later step fails is more boilerplate to write and more code to test and debug.
What’s a step, you ask? The core building block of every Workflow is the step: an individually retriable component of your application that can optionally emit state. That state is then persisted, even if subsequent steps were to fail. This means that your application doesn’t have to restart, allowing it to not only recover more quickly from failure scenarios, but it can also avoid doing redundant work. You don’t want your application hammering an expensive third-party API (or getting you rate limited) because it’s naively retrying an API call that you don’t have to.
Notably, a Workflow can have hundreds of steps: one of the Rules of Workflows is to encapsulate every API call or stateful action within your application into its own step. Each step can also define its own retry strategy, automatically backing off, adding a delay and/or (eventually) giving up after a set number of attempts.
await step.do(
'make a call to write that could maybe, just might, fail',
// Define a retry strategy
{
retries: {
limit: 5,
delay: '5 seconds',
backoff: 'exponential',
},
timeout: '15 minutes',
},
async () => {
// Do stuff here, with access to the state from our previous steps
if (Math.random() > 0.5) {
throw new Error('API call to $STORAGE_SYSTEM failed');
}
},
);
To illustrate this further, imagine you have an application that reads text files from an R2 storage bucket, pre-processes the text into chunks, generates text embeddings using Workers AI, and then inserts those into a vector database (like Vectorize) for semantic search.
In the Workflows programming model, each of those is a discrete step, and each can emit state. For example, each of the four actions below can be a discrete step.do call in a Workflow:
Reading the files from storage and emitting the list of filenames
Chunking the text and emitting the results
Generating text embeddings
Upserting them into Vectorize and capturing the result of a test query
You can also start to imagine that some steps, such as chunking text or generating text embeddings, can be broken down into even more steps — a step per file that we chunk, or a step per API call to our text embedding model, so that our application is even more resilient to failure.
Steps can be created programmatically or conditionally based on input, allowing you to dynamically create steps based on the number of inputs your application needs to process. You do not need to define all steps ahead of time, and each instance of a Workflow may choose to conditionally create steps on the fly.
Building Cloudflare on Cloudflare
As the Cloudflare Developer platform continues to grow, almost all of our own products are built on top of it. Workflows is yet another example of how we built a new product from scratch using nothing but Workers and its vast catalog of features and APIs. This section of the blog has two goals: to explain how we built it, and to demonstrate that anyone can create a complex application or platform with demanding requirements and multiple architectural layers on our stack, too.
To understand how Workflows uses Workers & Durable Objects, here’s the high-level overview of our architecture:
There are three main blocks in this diagram:
The user-facing APIs are where the user interacts with the platform, creating and deploying new workflows or instances, controlling them, and accessing their state and activity logs. These operations can be executed through our public API gateway using REST calls, a Worker script using bindings, Wrangler (Cloudflare’s developer platform command line tool), or via the Dashboard user interface.
The managed platform holds the internal configuration APIs running on a Worker implementing a catalog of REST endpoints, the binding shim, which is supported by another dedicated Worker, every account controller, and their correspondent workflow engines, all powered by SQLite-backed Durable Objects. This is where all the magic happens and what we are sharing more details about in this technical blog.
Finally, there are the workflow instances, essentially independent clones of the workflow application. Instances are user account-owned and have a one-to-one relationship with a managed engine that powers them. You can run as many instances and engines as you want concurrently.
Let’s get into more detail…
Configuration API and Binding Shim
The Configuration API and the Binding Shim are two stateless Workers; one receives REST API calls from clients calling our API Gateway directly, using Wrangler, or navigating the Dashboard UI, and the other is the endpoint for the Workflows binding, an efficient and authenticated interface to interact with the Cloudflare Developer Platform resources from a Workers script.
The configuration API worker uses HonoJS and Zod to implement the REST endpoints, which are declared in an OpenAPI schema and exported to our API Gateway, thus adding our methods to the Cloudflare API catalog.
import { swaggerUI } from '@hono/swagger-ui';
import { createRoute, OpenAPIHono, z } from '@hono/zod-openapi';
import { Hono } from 'hono';
...
api.openapi(
createRoute({
method: 'get',
path: '/',
request: {
query: PaginationParams,
},
responses: {
200: {
content: {
'application/json': {
schema: APISchemaSuccess(z.array(WorkflowWithInstancesCountSchema)),
},
},
description: 'List of all Workflows belonging to a account.',
},
},
}),
async (ctx) => {
...
},
);
...
api.route('/:workflow_name', routes.workflows);
api.route('/:workflow_name/instances', routes.instances);
api.route('/:workflow_name/versions', routes.versions);
These Workers perform two different functions, but they share a large portion of their code and implement similar logic; once the request is authenticated and ready to travel to the next stage, they use the account ID to delegate the operation to a Durable Object called Account Controller.
// env.ACCOUNTS is the Account Controllers Durable Objects namespace
const accountStubId = c.env.ACCOUNTS.idFromName(accountId.toString());
const accountStub = c.env.ACCOUNTS.get(accountStubId);
As you can see, every account has its own Account Controller Durable Object.
Account Controllers
The Account Controller is a dedicated persisted database that stores the list of all the account’s workflows, versions, and instances. We scale to millions of account controllers, one per every Cloudflare account using Workflows, by leveraging the power of Durable Objects with SQLite backend.
Durable Objects (DOs) are single-threaded singletons that run in our data centers and are bound to a stateful storage API, in this case, SQLite. They are also Workers, just a special kind, and have access to all of our other APIs. This makes it easy to build consistent, highly available distributed applications with them.
Here’s what we get for free by using one Durable Object per Workflows account:
Sharding based on account boundaries aligns perfectly with the way we manage resources at Cloudflare internally. Also, due to the nature of DOs, there are other things that this model gets us for free: Not that we expect them, but eventual bugs or state inconsistencies during beta are confined to the affected account, and don’t impact everyone.
DO instances run close to the end user; Alice is in London and will call the config API through our LHR data center, while Bob is in Lisbon and will connect to LIS.
Because every account is a Worker, we can gradually upgrade them to new versions, starting with the internal users, thus derisking real customers.
Before SQLite, our only option was to use the Durable Object’s key-value storage API, but having a relational database at our fingertips and being able to create tables and do complex queries is a significant enabler. For example, take a look at how we implement the internal method getWorkflow():
async function getWorkflow(accountId: number, workflowName: string) {
try {
const res = this.ctx.storage.transactionSync(() => {
const cursor = Array.from(
this.ctx.storage.sql.exec(
`
SELECT *,
(SELECT class_name
FROM versions
WHERE workflow_id = w.id
ORDER BY created_on DESC
LIMIT 1) AS class_name
FROM workflows w
WHERE w.name = ?
`,
workflowName
)
)[0] as Workflow;
return cursor;
});
this.sendAnalytics(accountId, begin, "getWorkflow");
return res as Workflow | undefined;
} catch (err) {
this.sendErrorAnalytics(accountId, begin, "getWorkflow");
throw err;
}
}
The other thing we take advantage of in Workflows is using the recently announced JavaScript-native RPC feature when communicating between components.
Before RPC, we had to fetch() between components, make HTTP requests, and serialize and deserialize the parameters and the payload. Now, we can async call the remote object’s method as if it was local. Not only does this feel more natural and simplify our logic, but it’s also more efficient, and we can take advantage of TypeScript type-checking when writing code.
This is how the Configuration API would call the Account Controller’s countWorkflows() method before:
The other powerful feature of our RPC system is that it supports passing not only Structured Cloneable objects back and forth but also entire classes. More on this later.
Let’s move on to Engine.
Engine and instance
Every instance of a workflow runs alongside an Engine instance. The Engine is responsible for starting up the user’s workflow entry point, executing the steps on behalf of the user, handling their results, and tracking the workflow state until completion.
When we started thinking about the Engine, we thought about modeling it after a state machine, and that was what our initial prototypes looked like. However, state machines require an ahead-of-time understanding of the userland code, which implies having a build step before running them. This is costly at scale and introduces additional complexity.
A few iterations later, we had another idea. What if we could model the engine as a game loop?
Unlike other computer programs, games operate regardless of a user’s input. The game loop is essentially a sequence of tasks that implement the game’s logic and update the display, typically one loop per video frame. Here’s an example of a game loop in pseudo-code:
while (game in running)
check for user input
move graphics
play sounds
end while
Well, an oversimplified version of our Workflow engine would look like this:
while (last step not completed)
iterate every step
use memoized cache as response if the step has run already
continue running step or timer if it hasn't finished yet
end while
A workflow is indeed a loop that keeps on going, performing the same sequence of logical tasks until the last step completes.
The Engine and the instance run hand-in-hand in a one-to-one relationship. The first is managed, and part of the platform. It uses SQLite and other platform APIs internally, and we can constantly add new features, fix bugs, and deploy new versions, while keeping everything transparent to the end user. The second is the actual account-owned Worker script that declares the Workflow steps.
For example, when someone passes a callback into step.do():
We switch execution over to the Engine. Again, this is possible because of the power of JS RPC. Besides passing Structured Cloneable objects back and forth, JS RPC allows us to create and pass entire application-defined classes that extend the built-in RpcTarget. So this is what happens behind the scenes when your Instance calls step.do() (simplified):
export class Context extends RpcTarget {
async do<T>(name: string, callback: () => Promise<T>): Promise<T> {
// First we check we have a cache of this step.do() already
const maybeResult = await this.#state.storage.get(name);
// We return the cache if it exists
if (maybeValue) { return maybeValue; }
// Else we run the user callback
return doWrapper(callback);
}
}
Here’s a more complete diagram of the Engine’s step.do() lifecycle:
Again, this diagram only partially represents everything we do in the Engine; things like logging for observability or handling exceptions are missing, and we don’t get into the details of how queuing is implemented. However, it gives you a good idea of how the Engine abstracts and handles all the complexities of completing a step under the hood, allowing us to expose a simple-to-use API to end users.
Also, it’s worth reiterating that every workflow instance is an Engine behind the scenes, and every Engine is an SQLite-backed Durable Object. This ensures that every instance runtime and state are isolated and independent of each other and that we can effortlessly scale to run billions of workflow instances, a solved problem for Durable Objects.
Durability
Durable Execution is all the rage now when we talk about workflow engines, and ours is no exception. Workflows are typically long-lived processes that run multiple functions in sequence where anything can happen. Those functions can time out or fail because of a remote server error or a network issue and need to be retried. A workflow engine ensures that your application runs smoothly and completes regardless of the problems it encounters.
Durability means that if and when a workflow fails, the Engine can re-run it, resume from the last recorded step, and deterministically re-calculate the state from all the successful steps’ cached responses. This is possible because steps are stateful and idempotent; they produce the same result no matter how many times we run them, thus not causing unintended duplicate effects like sending the same invoice to a customer multiple times.
We ensure durability and handle failures and retries by sharing the same technique we use for a step.sleep() that requires sleeping for days or months: a combination of using scheduler.wait(), a method of the upcoming WICG Scheduling API that we already support, and Durable Objects alarms, which allow you to schedule the Durable Object to be woken up at a time in the future.
These two APIs allow us to overcome the lack of guarantees that a Durable Object runs forever, giving us complete control of its lifecycle. Since every state transition through userland code persists in the Engine’s strongly consistent SQLite, we track timestamps when a step begins execution, its attempts (if it needs retries), and its completion.
This means that steps pending if a Durable Object is evicted — perhaps due to a two-month-long timer — get rerun on the next lifetime of the Engine (with its cache from the previous lifetime hydrated) that is triggered by an alarm set with the timestamp of the next expected state transition.
Real-life workflow, step by step
Let’s walk through an example of a real-life application. You run an e-commerce website and would like to send email reminders to your customers for forgotten carts that haven’t been checked out in a few days.
What would typically have to be a combination of a queue, a cron job, and querying a database table periodically can now simply be a Workflow that we start on every new cart:
import {
WorkflowEntrypoint,
WorkflowEvent,
WorkflowStep,
} from "cloudflare:workers";
import { sendEmail } from "./legacy-email-provider";
type Params = {
cartId: string;
};
type Env = {
DB: D1Database;
};
export class Purchase extends WorkflowEntrypoint<Env, Params> {
async run(
event: WorkflowEvent<Params>,
step: WorkflowStep
): Promise<unknown> {
await step.sleep("wait for three days", "3 days");
// Retrieve cart from D1
const cart = await step.do("retrieve cart from database", async () => {
const { results } = await this.env.DB.prepare(`SELECT * FROM cart WHERE id = ?`)
.bind(event.payload.cartId)
.all();
return results[0];
});
if (!cart.checkedOut) {
await step.do("send an email", async () => {
await sendEmail("reminder", cart);
});
}
}
}
This works great. However, sometimes the sendEmail function fails due to an upstream provider erroring out. While step.do automatically retries with a reasonable default configuration, we can define our settings:
The HTTP API makes it easy to trigger new instances of workflows from any system, even if it isn’t on Cloudflare, or from the command line. For example:
Wrangler goes one step further and gives us a friendlier set of commands to interact with workflows with fancy formatted outputs without needing to authenticate with tokens. Type npx wrangler workflows for help, or:
Furthermore, Workflows has first-party support in wrangler, and you can test your instances locally. A Workflow is similar to a regular WorkerEntrypoint in your Worker, which means that wrangler dev just naturally works.
❯ npx wrangler dev
⛅️ wrangler 3.82.0
----------------------------
Your worker has access to the following bindings:
- Workflows:
- CART_WORKFLOW: EcommerceCartWorkflow
⎔ Starting local server...
[wrangler:inf] Ready on http://localhost:8787
╭───────────────────────────────────────────────╮
│ [b] open a browser, [d] open devtools │
╰───────────────────────────────────────────────╯
Workflow APIs are also available as a Worker binding. You can interact with the platform programmatically from another Worker script in the same account without worrying about permissions or authentication. You can even have workflows that call and interact with other workflows.
import { WorkerEntrypoint } from "cloudflare:workers";
type Env = { DEMO_WORKFLOW: Workflow };
export default class extends WorkerEntrypoint<Env> {
async fetch() {
// Pass in a user defined name for this instance
// In this case, we use the same as the cartId
const instance = await this.env.DEMO_WORKFLOW.create({
id: "f3bcc11b-2833-41fb-847f-1b19469139d1",
params: {
cartId: "f3bcc11b-2833-41fb-847f-1b19469139d1",
}
});
}
async scheduled() {
// Restart errored out instances in a cron
const instance = await this.env.DEMO_WORKFLOW.get(
"f3bcc11b-2833-41fb-847f-1b19469139d1"
);
const status = await instance.status();
if (status.error) {
await instance.restart();
}
}
}
Observability
Having good observability and data on often long-lived asynchronous tasks is crucial to understanding how we’re doing under normal operation and, more importantly, when things go south, and we need to troubleshoot problems or when we are iterating on code changes.
We designed Workflows around the philosophy that there is no such thing as too much logging. You can get all the SQLite data for your workflow and its instances by calling the REST APIs. Here is the output of an instance:
As you can see, this is essentially a dump of the instance engine SQLite in JSON. You have the errors, messages, current status, and what happened with every step, all time stamped to the millisecond.
It’s one thing to get data about a specific workflow instance, but it’s another to zoom out and look at aggregated statistics of all your workflows and instances over time. Workflows data is available through our GraphQL Analytics API, so you can query it in aggregate and generate valuable insights and reports. In this example we ask for aggregated analytics about the wall time of all the instances of the “e-commerce-carts” workflow:
For convenience, you can evidently also use Wrangler to describe a workflow or an instance and get an instant and beautifully formatted response:
sid ~ npx wrangler workflows instances describe purchase-workflow latest
⛅️ wrangler 3.80.4
Workflow Name: purchase-workflow
Instance Id: d4280218-7756-41d2-bccd-8d647b82d7ce
Version Id: 0c07dbc4-aaf3-44a9-9fd0-29437ed11ff6
Status: ✅ Completed
Trigger: 🌎 API
Queued: 14/10/2024, 16:25:17
Success: ✅ Yes
Start: 14/10/2024, 16:25:17
End: 14/10/2024, 16:26:17
Duration: 1 minute
Last Successful Step: wait for three days
Output: false
Steps:
Name: wait for three days
Type: 💤 Sleeping
Start: 14/10/2024, 16:25:17
End: 17/10/2024, 16:25:17
Duration: 3 day
And finally, we worked really hard to get you the best dashboard UI experience when navigating Workflows data.
So, how much does it cost?
It’d be painful if we introduced a powerful new way to build Workers applications but made it cost prohibitive.
Workflows is priced just like Cloudflare Workers, where we introduced CPU-based pricing: only on active CPU time and requests, not duration (aka: wall time).
Workers Standard pricing model
This is especially advantageous when building the long-running, multi-step applications that Workflows enables: if you had to pay while your Workflow was sleeping, waiting on an event, or making a network call to an API, writing the “right” code would be at odds with writing affordable code.
There’s also no need to keep a Kubernetes cluster or a group of virtual machines running (and burning a hole in your wallet): we manage the infrastructure, and you only pay for the compute your Workflows consume.
What’s next?
Today, after months of developing the platform, we are announcing the open beta program, and we couldn’t be more excited to see how you will be using Workflows. Looking forward, we want to do things like triggering instances from queue messages and have other ideas, but at the same time, we are certain that your feedback will help us shape the roadmap ahead.
We hope that this blog post gets you thinking about how to use Workflows for your next application, but also that it inspires you on what you can build on top of Workers. Workflows as a platform is entirely built on top of Workers, its resources, and APIs. Anyone can do it, too.
We’ve been working on something new — a platform for running containers across Cloudflare’s network. We already use it in production for Workers AI, Workers Builds, Remote Browsing Isolation, and the Browser Rendering API. Today, we want to share an early look at how it’s built, why we built it, and how we use it ourselves.
In 2024, Cloudflare Workers celebrates its 7th birthday. When we first announced Workers, it was a completely new model for running compute in a multi-tenant way — on isolates, as opposed to containers. While, at the time, Workers was a pretty bare-bones functions-as-a-service product, we took a big bet that this was going to become the way software was going to be written going forward. Since introducing Workers, in addition to expanding our developer products in general to include storage and AI, we have been steadily adding more compute capabilities to Workers:
With each of these, we’ve faced a question — can we build this natively into the platform, in a way that removes, rather than adds complexity? Can we build it in a way that lets developers focus on building and shipping, rather than managing infrastructure, so that they don’t have to be a distributed systems engineer to build distributed systems?
In each instance, the answer has been YES. We try to solve problems in a way that simplifies things for developers in the long run, even if that is the harder path for us to take ourselves. If we didn’t, you’d be right to ask — why not self-host and manage all of this myself? What’s the point of the cloud if I’m still provisioning and managing infrastructure? These are the questions many are asking today about the earlier generation of cloud providers.
Pushing ourselves to build platform-native products and features helped us answer this question. Particularly because some of these actually use containers behind the scenes, even though as a developer you never interact with or think about containers yourself.
If you’ve used AI inference on GPUs with Workers AI, spun up headless browsers with Browser Rendering, or enqueued build jobs with the new Workers Builds, you’ve run containers on our network, without even knowing it. But to do so, we needed to be able to run untrusted code across Cloudflare’s network, outside a v8 isolate, in a way that fits what we promise:
You shouldn’t have to think about regions or data centers. Routing, scaling, load balancing, scheduling, and capacity are our problem to solve, not yours, with tools like Smart Placement.
You should be able to build distributed systems without being a distributed systems engineer.
Every millisecond matters — Cloudflare has to be fast.
There wasn’t an off-the-shelf container platform that solved for what we needed, so we built it ourselves — from scheduling to IP address management, pulling and caching images, to improving startup times and more. Our container platform powers many of our newest products, so we wanted to share how we built it, optimized it, and well, you can probably guess what’s next.
Global scheduling — “The Network is the Computer”
Cloudflare serves the entire world — region: earth. Rather than asking developers to provision resources in specific regions, data centers and availability zones, we think “The Network is the Computer”. When you build on Cloudflare, you build software that runs on the Internet, not just in a data center.
When we started working on this, Cloudflare’s architecture was to just run every service via systemd on every server (we call them “metals” — we run our own hardware), allowing all services to take advantage of new capacity we add to our network. That fits running NGINX and a few dozen other services, but cannot fit a world where we need to run many thousands of different compute heavy, resource hungry workloads. We’d run out of space just trying to load all of them! Consider a canonical AI workload — deploying Llama 3.1 8B to an inference server. If we simply ran a Llama 3.1 8B service on every Cloudflare metal, we’d have no flexibility to use GPUs for the many other models that Workers AI supports.
We needed something that would allow us to still take advantage of the full capacity of Cloudflare’s entire network, not just the capacity of individual machines. And ideally not put that burden on the developer.
The answer: we built a control plane on our own Developer Platform that lets us schedule a container anywhere on Cloudflare’s Network:
The global scheduler is built on Cloudflare Workers, Durable Objects, and KV, and decides which Cloudflare location to schedule the container to run in. Each location then runs its own scheduler, which decides which metals within that location to schedule the container to run on. Location schedulers monitor compute capacity, and expose this to the global scheduler. This allows Cloudflare to dynamically place workloads based on capacity and hardware availability (e.g. multiple types of GPUs) across our network.
Why does global scheduling matter?
When you run compute on a first generation cloud, the “contract” between the developer and the platform is that the developer must specify what runs where. This is regional scheduling, the status quo.
Let’s imagine for a second if we applied regional scheduling to running compute on Cloudflare’s network, with locations in 330+ cities, across 120+ countries. One of the obvious reasons people tell us they want to run on Cloudflare is because we have compute in places where others don’t, within 50ms of 95% of the world’s Internet-connected population. In South America, other clouds have one region in one city. Cloudflare has 19:
Running anywhere means you can be faster, highly available, and have more control over data location. But with regional scheduling, the more locations you run in, the more work you have to do. You configure and manage load balancing, routing, auto-scaling policies and more. Balancing performance and cost in a multi-region setup is literally a full-time job (or more) at most companies who have reached meaningful scale on traditional clouds.
But most importantly, no matter what tools you bring, you were the one who told the cloud provider, “run this container over here”. The cloud platform can’t move it for you, even if moving it would make your workload faster. This prevents the platform from adding locations, because for each location, it has to convince developers to take action themselves to move their compute workloads to the new location. Each new location carries a risk that developers won’t migrate workloads to it, or migrate too slowly, delaying the return on investment.
Global scheduling means Cloudflare can add capacity and use it immediately, letting you benefit from it. The “contract” between us and our customers isn’t tied to a specific datacenter or region, so we have permission to move workloads around to benefit customers. This flexibility plays an essential role in all of our own uses of our container platform, starting with GPUs and AI.
GPUs everywhere: Scheduling large images with Workers AI
In late 2023, we launched Workers AI, which provides fast, easy to use, and affordable GPU-backed AI inference.
The more efficiently we can use our capacity, the better pricing we can offer. And the faster we can make changes to which models run in which Cloudflare locations, the closer we can move AI inference to the application, lowering Time to First Token (TTFT). This also allows us to be more resilient to spikes in inference requests.
AI models that rely on GPUs present three challenges though:
Models have different GPU memory needs. GPU memory is the most scarce resource, and different GPUs have different amounts of memory.
Not all container runtimes, such as Firecracker, support GPU drivers and other dependencies.
AI models, particularly LLMs, are very large. Even a smaller parameter model, like @cf/meta/llama-3.1-8b-instruct, is at least 5 GB. The larger the model, the more bytes we need to pull across the network when scheduling a model to run in a new location.
Let’s dive into how we solved each of these…
First, GPU memory needs. The global scheduler knows which Cloudflare locations have blocks of GPU memory available, and then delegates scheduling the workload on a specific metal to the local scheduler. This allows us to prioritize placement of AI models that use a large amount of GPU memory, and then move smaller models to other machines in the same location. By doing this, we maximize the overall number of locations that we run AI models in, and maximize our efficiency.
Second, container runtimes and GPU support. Thankfully, from day one we built our container platform to be runtime agnostic. Using a runtime agnostic scheduler, we’re able to support gVisor, Firecracker microVMs, and traditional VMs with QEMU. We are also evaluating adding support for another one: cloud-hypervisor which is based on rust-vmm and has a few compelling advantages for our use case:
vhost-user-net support, enabling high throughput between the host network interface and the VM
vhost-user-blk support, adding flexibility to introduce novel network-based storage backed by other Cloudflare Workers products
all the while being a smaller codebase than QEMU and written in a memory-safe language
Our goal isn’t to build a platform that makes you as the developer choose between runtimes, and ask, “should I use Firecracker or gVisor”. We needed this flexibility in order to be able to run workloads with different needs efficiently, including workloads that depend on GPUs. gVisor has GPU support, while Firecracker microVMs currently does not.
gVisor’s main component is an application kernel (called Sentry) that implements a Linux-like interface but is written in a memory-safe language (Go) and runs in userspace. It works by intercepting application system calls and acting as the guest kernel, without the need for translation through virtualized hardware.
The resource footprint of a containerized application running on gVisor is lower than a VM because it does not require managing virtualized hardware and booting up a kernel instance. However, this comes at the price of reduced application compatibility and higher per-system call overhead.
To add GPU support, the Google team introduced nvproxy which works using the same principles as described above for syscalls: it intercepts ioctls destined to the GPU and proxies a subset to the GPU kernel module.
To solve the third challenge, and make scheduling fast with large models, we weren’t satisfied with the status quo. So we did something about it.
Docker pull was too slow, so we fixed it (and cut the time in half)
Many of the images we need to run for AI inference are over 15 GB. Specialized inference libraries and GPU drivers add up fast. For example, when we make a scheduling decision to run a fresh container in Tokyo, naively running docker pull to fetch the image from a storage bucket in Los Angeles would be unacceptably slow. And scheduling speed is critical to being able to scale up and down in new locations in response to changes in traffic.
We had 3 essential requirements:
Pulling and pushing very large images should be fast
We should not rely on a single point of failure
Our teams shouldn’t waste time managing image registries
We needed globally distributed storage, so we used R2. We needed the highest cache hit rate possible, so we used Cloudflare’s Cache, and will soon use Tiered Cache. And we needed a fast container image registry that we could run everywhere, in every Cloudflare location, so we built and open-sourced serverless-registry, which is built on Workers. You can deploy serverless-registry to your own Cloudflare account in about 5 minutes. We rely on it in production.
This is fast, but we can be faster. Our performance bottleneck was, somewhat surprisingly, docker push. Docker uses gzip to compress and decompress layers of images while pushing and pulling. So we started using Zstandard (zstd) instead, which compresses and decompresses faster, and results in smaller compressed files.
In order to build, chunk, and push these images to the R2 registry, we built a custom CLI tool that we use internally in lieu of running docker build and docker push. This makes it easy to use zstd and split layers into 500 MB chunks, which allows uploads to be processed by Workers while staying under body size limits.
Using our custom build and push tool doubled the speed of image pulls. Our 30 GB GPU images now pull in 4 minutes instead of 8. We plan on open sourcing this tool in the near future.
Anycast is the gift that keeps on simplifying — Virtual IPs and the Global State Router
We still had another challenge to solve. And yes, we solved it with anycast. We’re Cloudflare, did you expect anything else?
First, a refresher — Cloudflare operates Unimog, a Layer 4 load balancer that handles all incoming Cloudflare traffic. Cloudflare’s network uses anycast, which allows a single IP address to route requests to a variety of different locations. For most Cloudflare services with anycast, the given IP address will route to the nearest Cloudflare data center, reducing latency. Since Cloudflare runs almost every service in every data center, Unimog can simply route traffic to any Cloudflare metal that is online and has capacity, without needing to map traffic to a specific service that runs on specific metals, only in some locations.
The new compute-heavy, GPU-backed workloads we were taking on forced us to confront this fundamental “everything runs everywhere” assumption. If we run a containerized workflow in 20 Cloudflare locations, how does Unimog know which locations, and which metals, it runs in? You might say “just bring your own load balancer” — but then what happens when you make scheduling decisions to migrate a workload between locations, scale up, or scale down?
Anycast is foundational to how we build fast and simple products on our network, and we needed a way to keep building new types of products this way — where a team can deploy an application, get back a single IP address, and rely on the platform to balance traffic, taking load, container health, and latency into account, without extra configuration. We started letting teams use the container platform without solving this, and it was painfully clear that we needed to do something about it.
So we started integrating directly into our networking stack, building a sidecar service to Unimog. We’ll call this the Global State Router. Here’s how it works:
An eyeball makes a request to a virtual IP address issued by Cloudflare
Request sent to the best location as determined by BGP routing. This is anycast routing.
A small eBPF program sits on the main networking interface and ensures packets bound to a virtual IP address are handled by the Global State Router.
The main Global State Router program contains a mapping of all anycast IPs addresses to potential end destination container IP addresses. It updates this mapping based on container health, readiness, distance, and latency. Using this information, it picks a best-fit container.
Packets are forwarded at the L4 layer.
When a target container’s server receives a packet, its own Global State Router program intercepts the packet and routes it to the local container.
This might sound like just a lower level networking detail, disconnected from developer experience. But by integrating directly with Unimog, we can let developers:
Push a containerized application to Cloudflare.
Provide constraints, health checks, and load metrics that describe what the application needs.
Delegate scheduling and scaling many containers across Cloudflare’s network.
Get back a single IP address that can be used everywhere.
We’re actively working on this, and are excited to continue building on Cloudflare’s anycast capabilities, and pushing to keep the simplicity of running “everywhere” with new categories of workloads.
Our container platform actually started because of a very specific challenge, running Remote Browser Isolation across our network. Remote Browser Isolation provides Chromium browsers that run on Cloudflare, in containers, rather than on the end user’s own computer. Only the rendered output is sent to the end user. This provides a layer of protection against zero-day browser vulnerabilities, phishing attacks, and ransomware.
Location is critical — people expect their interactions with a remote browser to feel just as fast as if it ran locally. If the server is thousands of miles away, the remote browser will feel slow. Running across Cloudflare’s network of over 330 locations means the browser is nearly always as close to you as possible.
Imagine a user in Santiago, Chile, if they were to access a browser running in the same city, each interaction would incur negligible additional latency. Whereas a browser in Buenos Aires might add 21 ms, São Paulo might add 48 ms, Bogota might add 67 ms, and Raleigh, NC might add 128 ms. Where the container runs significantly impacts the latency of every user interaction with the browser, and therefore the experience as a whole.
It’s not just browser isolation that benefits from running near the user: WebRTC servers stream video better, multiplayer games have less lag, online advertisements can be served faster, financial transactions can be processed faster. Our container platform lets us run anything we need to near the user, no matter where they are in the world.
Using spare compute — “off-peak” jobs for Workers CI/CD builds
At any hour of the day, Cloudflare has many CPU cores that sit idle. This is compute power that could be used for something else.
Via anycast, most of Cloudflare’s traffic is handled as close as possible to the eyeball (person) that requested it. Most of our traffic originates from eyeballs. And the eyeballs of (most) people are closed and asleep between midnight and 5:00 AM local time. While we use our compute capacity very efficiently during the daytime in any part of the world, overnight we have spare cycles. Consider what a map of the world looks like at night-time in Europe and Africa:
As shown above, we can run containers during “off-peak” in Cloudflare locations receiving low traffic at night. During this time, the CPU utilization of a typical Cloudflare metal looks something like this:
We have many “background” compute workloads at Cloudflare. These are workloads that don’t actually need to run close to the eyeball because there is no eyeball waiting on the request. The challenge is that many of these workloads require running untrusted code — either a dependency on open-source code that we don’t trust enough to run outside of a sandboxed environment, or untrusted code that customers deploy themselves. And unlike Cron Triggers, which already make a best-effort attempt to use off-peak compute, these other workloads can’t run in v8 isolates.
On Builder Day 2024, we announced Workers Builds in open beta. You connect your Worker to a git repository, and Cloudflare builds and deploys your Worker each time you merge a pull request. Workers Builds run on our containers platform, using otherwise idle “off-peak” compute, allowing us to offer lower pricing, and hold more capacity for unexpected spikes in traffic in Cloudflare locations during daytime hours when load is highest. We preserve our ability to serve requests as close to the eyeball as possible where it matters, while using the full compute capacity of our network.
We developed a purpose-built API for these types of jobs. The Workers Builds service has zero knowledge of where Cloudflare has spare compute capacity on its network — it simply schedules an “off-peak” job to run on the containers platform, by defining a scheduling policy:
scheduling_policy: "off-peak"
Making off-peak jobs faster with prewarmed images
Just because a workload isn’t “eyeball-facing” doesn’t mean speed isn’t relevant. When a build job starts, you still want it to start as soon as possible.
Each new build requires a fresh container though, and we must avoid reusing containers to provide strong isolation between customers. How can we keep build job start times low, while using a new container for each job without over-provisioning?
We prewarm servers with the proper image.
Before a server becomes eligible to receive an “off peak” job, the container platform instructs it to download the correct image. Once the image is downloaded and cached locally, new containers can start quickly in a Firecracker VM after receiving a request for a new build. When a build completes, we throw away the container, and start the next build using a fresh container based on the prewarmed image.
Without prewarming, pulling and unpacking our Workers Build images would take roughly 75 seconds. With prewarming, we’re able to spin up a new container in under 10 seconds. We expect this to get even faster as we introduce optimizations like pre-booting images before new runs, or Firecracker snapshotting, which can restore a VM in under 200ms.
Workers and containers, better together
As more of our own engineering teams rely on our containers platform in production, we’ve noticed a pattern: they want a deeper integration with Workers.
We plan to give it to them.
Let’s take a look at a project deployed on our container platform already, Key Transparency. If the container platform were highly integrated with Workers, what would this team’s experience look like?
Cloudflare regularly audits changes to public keys used by WhatsApp for encrypting messages between users. Much of the architecture is built on Workers, but there are long-running compute-intensive tasks that are better suited for containers.
We don’t want our teams to have to jump through hoops to deploy a container and integrate with Workers. They shouldn’t have to pick specific regions to run in, figure out scaling, expose IPs and handle IP updates, or set up Worker-to-container auth.
We’re still exploring many different ideas and API designs, and we want your feedback. But let’s imagine what it might look like to use Workers, Durable Objects and Containers together.
In this case, an outer layer of Workers handles most business logic and ingress, a specialized Durable Object is configured to run alongside our new container, and the platform ensures the image is loaded on the right metals and can scale to meet demand.
I didn’t have to worry about placement, scaling, service discovery authorization, and I was able to leverage integrations into other services like KV and R2 with just a few lines of code. The container platform took care of routing, placement, and auth. If I needed more instances, I could call the binding with a new ID, and the platform would scale up containers for me.
We are still in the early stages of building these integrations, but we’re excited about everything that containers will bring to Workers and vice versa.
So, what do you want to build?
If you’ve read this far, there’s a non-zero chance you were hoping to get to run a container yourself on our network. While we’re not ready (quite yet) to open up the platform to everyone, now that we’ve built a few GA products on our container platform, we’re looking for a handful of engineering teams to start building, in advance of wider availability in 2025. And we’re continuing to hire engineers to work on this.
We’ve told you about our use cases for containers, and now it’s your turn. If you’re interested, tell us here what you want to build, and why it goes beyond what’s possible today in Workers and on our Developer Platform. What do you wish you could build on Cloudflare, but can’t yet today?
Traditional cloud storage is inherently slow, because it is normally accessed over a network and must carefully synchronize across many clients that could be accessing the same data. But what if we could instead put your application code deep into the storage layer, such that your code runs directly on the machine where the data is stored, and the database itself executes as a local library embedded inside your application?
Durable Objects (DO) are a novel approach to cloud computing which accomplishes just that: Your application code runs exactly where the data is stored. Not just on the same machine: your storage lives in the same thread as the application, requiring not even a context switch to access. With proper use of caching, storage latency is essentially zero, while nevertheless being durable and consistent.
Until today, DOs only offered key/value oriented storage. But now, they support a full SQL query interface with tables and indexes, through the power of SQLite.
SQLite is the most-used SQL database implementation in the world, with billions of installations. It’s on practically every phone and desktop computer, and many embedded devices use it as well. It’s known to be blazingly fast and rock solid. But it’s been less common on the server. This is because traditional cloud architecture favors large distributed databases that live separately from application servers, while SQLite is designed to run as an embedded library. In this post, we’ll show you how Durable Objects turn this architecture on its head and unlock the full power of SQLite in the cloud.
Refresher: what are Durable Objects?
Durable Objects (DOs) are a part of the Cloudflare Workers serverless platform. A DO is essentially a small server that can be addressed by a unique name and can keep state both in-memory and on-disk. Workers running anywhere on Cloudflare’s network can send messages to a DO by its name, and all messages addressed to the same name — from anywhere in the world — will find their way to the same DO instance.
DOs are intended to be small and numerous. A single application can create billions of DOs distributed across our global network. Cloudflare automatically decides where a DO should live based on where it is accessed, automatically starts it up as needed when requests arrive, and shuts it down when idle. A DO has in-memory state while running and can also optionally store long-lived durable state. Since there is exactly one DO for each name, a DO can be used to coordinate between operations on the same logical object.
For example, imagine a real-time collaborative document editor application. Many users may be editing the same document at the same time. Each user’s changes must be broadcast to other users in real time, and conflicts must be resolved. An application built on DOs would typically create one DO for each document. The DO would receive edits from users, resolve conflicts, broadcast the changes back out to other users, and keep the document content updated in its local storage.
DOs are especially good at real-time collaboration, but are by no means limited to this use case. They are general-purpose servers that can implement any logic you desire to serve requests. Even more generally, DOs are a basic building block for distributed systems.
When using Durable Objects, it’s important to remember that they are intended to scale out, not up. A single object is inherently limited in throughput since it runs on a single thread of a single machine. To handle more traffic, you create more objects. This is easiest when different objects can handle different logical units of state (like different documents, different users, or different “shards” of a database), where each unit of state has low enough traffic to be handled by a single object. But sometimes, a lot of traffic needs to modify the same state: consider a vote counter with a million users all trying to cast votes at once. To handle such cases with Durable Objects, you would need to create a set of objects that each handle a subset of traffic and then replicate state to each other. Perhaps they use CRDTs in a gossip network, or perhaps they implement a fan-in/fan-out approach to a single primary object. Whatever approach you take, Durable Objects make it fast and easy to create more stateful nodes as needed.
Why is SQLite-in-DO so fast?
In traditional cloud architecture, stateless application servers run business logic and communicate over the network to a database. Even if the network is local, database requests still incur latency, typically measured in milliseconds.
When a Durable Object uses SQLite, SQLite is invoked as a library. This means the database code runs not just on the same machine as the DO, not just in the same process, but in the very same thread. Latency is effectively zero, because there is no communication barrier between the application and SQLite. A query can complete in microseconds.
Reads and writes are synchronous
The SQL query API in DOs does not require you to await results — they are returned synchronously:
// No awaits!
let cursor = sql.exec("SELECT name, email FROM users");
for (let user of cursor) {
console.log(user.name, user.email);
}
This may come as a surprise to some. Querying a database is I/O, right? I/O should always be asynchronous, right? Isn’t this a violation of the natural order of JavaScript?
It’s OK! The database content is probably cached in memory already, and SQLite is being called as a library in the same thread as the application, so the query often actually won’t spend any time at all waiting for I/O. Even if it does have to go to disk, it’s a local SSD. You might as well consider the local disk as just another layer in the memory cache hierarchy: L5 cache, if you will. In any case, it will respond quickly.
Meanwhile, synchronous queries provide some big benefits. First, the logistics of asynchronous event loops have a cost, so in the common case where the data is already in memory, a synchronous query will actually complete faster than an async one.
More importantly, though, synchronous queries help you avoid subtle bugs. Any time your application awaits a promise, it’s possible that some other code executes while you wait. The state of the world may have changed by the time your await completes. Maybe even other SQL queries were executed. This can lead to subtle bugs that are hard to reproduce because they require events to happen at just the wrong time. With a synchronous API, though, none of that can happen. Your code always executes in the order you wrote it, uninterrupted.
Fast writes with Output Gates
Database experts might have a deeper objection to synchronous queries: Yes, caching may mean we can perform reads and writes very fast. However, in the case of a write, just writing to cache isn’t good enough. Before we return success to our client, we must confirm that the write is actually durable, that is, it has actually made it onto disk or network storage such that it cannot be lost if the power suddenly goes out.
Normally, a database would confirm all writes before returning to the application. So if the query is successful, it is confirmed. But confirming writes can be slow, because it requires waiting for the underlying storage medium to respond. Normally, this is OK because the write is performed asynchronously, so the program can go on and work on other things while it waits for the write to finish. It looks kind of like this:
But I just told you that in Durable Objects, writes are synchronous. While a synchronous call is running, no other code in the program can run (because JavaScript does not have threads). This is convenient, as mentioned above, because it means you don’t need to worry that the state of the world may have changed while you were waiting. However, if write queries have to wait a while, and the whole program must pause and wait for them, then throughput will suffer.
Luckily, in Durable Objects, writes do not have to wait, due to a little trick we call “Output Gates”.
In DOs, when the application issues a write, it continues executing without waiting for confirmation. However, when the DO then responds to the client, the response is blocked by the “Output Gate”. This system holds the response until all storage writes relevant to the response have been confirmed, then sends the response on its way. In the rare case that the write fails, the response will be replaced with an error and the Durable Object itself will restart. So, even though the application constructed a “success” response, nobody can ever see that this happened, and thus nobody can be misled into believing that the data was stored.
Let’s see what this looks like with multiple requests:
If you compare this against the first diagram above, you should notice a few things:
The timing of requests and confirmations are the same.
But, all responses were sent to the client sooner than in the first diagram. Latency was reduced! This is because the application is able to work on constructing the response in parallel with the storage layer confirming the write.
Request handling is no longer interleaved between the three requests. Instead, each request runs to completion before the next begins. The application does not need to worry, during the handling of one request, that its state might change unexpectedly due to a concurrent request.
With Output Gates, we get the ease-of-use of synchronous writes, while also getting lower latency and no loss of throughput.
N+1 selects? No problem.
Zero-latency queries aren’t just faster, they allow you to structure your code differently, often making it simpler. A classic example is the “N+1 selects” or “N+1 queries” problem. Let’s illustrate this problem with an example:
// N+1 SELECTs example
// Get the 100 most-recently-modified docs.
let docs = sql.exec(`
SELECT title, authorId FROM documents
ORDER BY lastModified DESC
LIMIT 100
`).toArray();
// For each returned document, get the author name from the users table.
for (let doc of docs) {
doc.authorName = sql.exec(
"SELECT name FROM users WHERE id = ?", doc.authorId).one().name;
}
If you are an experienced SQL user, you are probably cringing at this code, and for good reason: this code does 101 queries! If the application is talking to the database across a network with 5ms latency, this will take 505ms to run, which is slow enough for humans to notice.
// Do it all in one query with a join?
let docs = sql.exec(`
SELECT documents.title, users.name
FROM documents JOIN users ON documents.authorId = users.id
ORDER BY documents.lastModified DESC
LIMIT 100
`).toArray();
Here we’ve used SQL features to turn our 101 queries into one query. Great! Except, what does it mean? We used an inner join, which is not to be confused with a left, right, or cross join. What’s the difference? Honestly, I have no idea! I had to look up joins just to write this example and I’m already confused.
Well, good news: You don’t need to figure it out. Because when using SQLite as a library, the first example above works just fine. It’ll perform about the same as the second fancy version.
More generally, when using SQLite as a library, you don’t have to learn how to do fancy things in SQL syntax. Your logic can be in regular old application code in your programming language of choice, orchestrating the most basic SQL queries that are easy to learn. It’s fine. The creators of SQLite have made this point themselves.
Point-in-Time Recovery
While not necessarily related to speed, SQLite-backed Durable Objects offer another feature: any object can be reverted to the state it had at any point in time in the last 30 days. So if you accidentally execute a buggy query that corrupts all your data, don’t worry: you can recover. There’s no need to opt into this feature in advance; it’s on by default for all SQLite-backed DOs. See the docs for details.
How do I use it?
Let’s say we’re an airline, and we are implementing a way for users to choose their seats on a flight. We will create a new Durable Object for each flight. Within that DO, we will use a SQL table to track the assignments of seats to passengers. The code might look something like this:
import {DurableObject} from "cloudflare:workers";
// Manages seat assignment for a flight.
//
// This is an RPC interface. The methods can be called remotely by other Workers
// running anywhere in the world. All Workers that specify same object ID
// (probably based on the flight number and date) will reach the same instance of
// FlightSeating.
export class FlightSeating extends DurableObject {
sql = this.ctx.storage.sql;
// Application calls this when the flight is first created to set up the seat map.
initializeFlight(seatList) {
this.sql.exec(`
CREATE TABLE seats (
seatId TEXT PRIMARY KEY, -- e.g. "3B"
occupant TEXT -- null if available
)
`);
for (let seat of seatList) {
this.sql.exec(`INSERT INTO seats VALUES (?, null)`, seat);
}
}
// Get a list of available seats.
getAvailable() {
let results = [];
// Query returns a cursor.
let cursor = this.sql.exec(`SELECT seatId FROM seats WHERE occupant IS NULL`);
// Cursors are iterable.
for (let row of cursor) {
// Each row is an object with a property for each column.
results.push(row.seatId);
}
return results;
}
// Assign passenger to a seat.
assignSeat(seatId, occupant) {
// Check that seat isn't occupied.
let cursor = this.sql.exec(`SELECT occupant FROM seats WHERE seatId = ?`, seatId);
let result = [...cursor][0]; // Get the first result from the cursor.
if (!result) {
throw new Error("No such seat: " + seatId);
}
if (result.occupant !== null) {
throw new Error("Seat is occupied: " + seatId);
}
// If the occupant is already in a different seat, remove them.
this.sql.exec(`UPDATE seats SET occupant = null WHERE occupant = ?`, occupant);
// Assign the seat. Note: We don't have to worry that a concurrent request may
// have grabbed the seat between the two queries, because the code is synchronous
// (no `await`s) and the database is private to this Durable Object. Nothing else
// could have changed since we checked that the seat was available earlier!
this.sql.exec(`UPDATE seats SET occupant = ? WHERE seatId = ?`, occupant, seatId);
}
}
(With just a little more code, we could extend this example to allow clients to subscribe to seat changes with WebSockets, so that if multiple people are choosing their seats at the same time, they can see in real time as seats become unavailable. But, that’s outside the scope of this blog post, which is just about SQL storage.)
Then in wrangler.toml, define a migration setting up your DO class like usual, but instead of using new_classes, use new_sqlite_classes:
[[migrations]]
tag = "v1"
new_sqlite_classes = ["FlightSeating"]
SQLite-backed objects also support the existing key/value-based storage API: KV data is stored into a hidden table in the SQLite database. So, existing applications built on DOs will work when deployed using SQLite-backed objects.
However, because SQLite-backed objects are based on an all-new storage backend, it is currently not possible to switch an existing deployed DO class to use SQLite. You must ask for SQLite when initially deploying the new DO class; you cannot change it later. We plan to begin migrating existing DOs to the new storage backend in 2025.
Pricing
We’ve kept pricing for SQLite-in-DO similar to D1, Cloudflare’s serverless SQL database, by billing for SQL queries (based on rows) and SQL storage. SQL storage per object is limited to 1 GB during the beta period, and will be increased to 10 GB on general availability. DO requests and duration billing are unchanged and apply to all DOs regardless of storage backend.
During the initial beta, billing is not enabled for SQL queries (rows read and rows written) and SQL storage. SQLite-backed objects will incur charges for requests and duration. We plan to enable SQL billing in the first half of 2025 with advance notice.
Workers Paid
Rows read
First 25 billion / month included + $0.001 / million rows
Rows written
First 50 million / month included + $1.00 / million rows
SQL storage
5 GB-month + $0.20/ GB-month
For more on how to use SQLite-in-Durable Objects, check out the documentation.
What about D1?
Cloudflare Workers already offers another SQLite-backed database product: D1. In fact, D1 is itself built on SQLite-in-DO. So, what’s the difference? Why use one or the other?
In short, you should think of D1 as a more “managed” database product, while SQLite-in-DO is more of a lower-level “compute with storage” building block.
D1 fits into a more traditional cloud architecture, where stateless application servers talk to a separate database over the network. Those application servers are typically Workers, but could also be clients running outside of Cloudflare. D1 also comes with a pre-built HTTP API and managed observability features like query insights. With D1, where your application code and SQL database queries are not colocated like in SQLite-in-DO, Workers has Smart Placement to dynamically run your Worker in the best location to reduce total request latency, considering everything your Worker talks to, including D1. By the end of 2024, D1 will support automatic read replication for scalability and low-latency access around the world. If this managed model appeals to you, use D1.
Durable Objects require a bit more effort, but in return, give you more power. With DO, you have two pieces of code that run in different places: a front-end Worker which routes incoming requests from the Internet to the correct DO, and the DO itself, which runs on the same machine as the SQLite database. You may need to think carefully about which code to run where, and you may need to build some of your own tooling that exists out-of-the-box with D1. But because you are in full control, you can tailor the solution to your application’s needs and potentially achieve more.
Under the hood: Storage Relay Service
When Durable Objects first launched in 2020, it offered only a simple key/value-based interface for durable storage. Under the hood, these keys and values were stored in a well-known off-the-shelf database, with regional instances of this database deployed to locations in our data centers around the world. Durable Objects in each region would store their data to the regional database.
For SQLite-backed Durable Objects, we have completely replaced the persistence layer with a new system built from scratch, called Storage Relay Service, or SRS. SRS has already been powering D1 for over a year, and can now be used more directly by applications through Durable Objects.
SRS is based on a simple idea:
Local disk is fast and randomly-accessible, but expensive and prone to disk failures. Object storage (like R2) is cheap and durable, but much slower than local disk and not designed for database-like access patterns. Can we get the best of both worlds by using a local disk as a cache on top of object storage?
So, how does it work?
The mismatch in functionality between local disk and object storage
A SQLite database on disk tends to undergo many small changes in rapid succession. Any row of the database might be updated by any particular query, but the database is designed to avoid rewriting parts that didn’t change. Read queries may randomly access any part of the database. Assuming the right indexes exist to support the query, they should not require reading parts of the database that aren’t relevant to the results, and should complete in microseconds.
Object storage, on the other hand, is designed for an entirely different usage model: you upload an entire “object” (blob of bytes) at a time, and download an entire blob at a time. Each blob has a different name. For maximum efficiency, blobs should be fairly large, from hundreds of kilobytes to gigabytes in size. Latency is relatively high, measured in tens or hundreds of milliseconds.
So how do we back up our SQLite database to object storage? An obviously naive strategy would be to simply make a copy of the database files from time to time and upload it as a new “object”. But, uploading the database on every change — and making the application wait for the upload to complete — would obviously be way too slow. We could choose to upload the database only occasionally — say, every 10 minutes — but this means in the case of a disk failure, we could lose up to 10 minutes of changes. Data loss is, uh, bad! And even then, for most databases, it’s likely that most of the data doesn’t change every 10 minutes, so we’d be uploading the same data over and over again.
Trick one: Upload a log of changes
Instead of uploading the entire database, SRS records a log of changes, and uploads those.
Conveniently, SQLite itself already has a concept of a change log: the Write-Ahead Log, or WAL. SRS always configures SQLite to use WAL mode. In this mode, any changes made to the database are first written to a separate log file. From time to time, the database is “checkpointed”, merging the changes back into the main database file. The WAL format is well-documented and easy to understand: it’s just a sequence of “frames”, where each frame is an instruction to write some bytes to a particular offset in the database file.
SRS monitors changes to the WAL file (by hooking SQLite’s VFS to intercept file writes) to discover the changes being made to the database, and uploads those to object storage.
Unfortunately, SRS cannot simply upload every single change as a separate “object”, as this would result in too many objects, each of which would be inefficiently small. Instead, SRS batches changes over a period of up to 10 seconds, or up to 16 MB worth, whichever happens first, then uploads the whole batch as a single object.
When reconstructing a database from object storage, we must download the series of change batches and replay them in order. Of course, if the database has undergone many changes over a long period of time, this can get expensive. In order to limit how far back it needs to look, SRS also occasionally uploads a snapshot of the entire content of the database. SRS will decide to upload a snapshot any time that the total size of logs since the last snapshot exceeds the size of the database itself. This heuristic implies that the total amount of data that SRS must download to reconstruct a database is limited to no more than twice the size of the database. Since we can delete data from object storage that is older than the latest snapshot, this also means that our total stored data is capped to 2x the database size.
Credit where credit is due: This idea — uploading WAL batches and snapshots to object storage — was inspired by Litestream, although our implementation is different.
Trick two: Relay through other servers in our global network
Batches are only uploaded to object storage every 10 seconds. But obviously, we cannot make the application wait for 10 whole seconds just to confirm a write. So what happens if the application writes some data, returns a success message to the user, and then the machine fails 9 seconds later, losing the data?
To solve this problem, we take advantage of our global network. Every time SQLite commits a transaction, SRS will immediately forward the change log to five “follower” machines across our network. Once at least three of these followers respond that they have received the change, SRS informs the application that the write is confirmed. (As discussed earlier, the write confirmation opens the Durable Object’s “output gate”, unblocking network communications to the rest of the world.)
When a follower receives a change, it temporarily stores it in a buffer on local disk, and then awaits further instructions. Later on, once SRS has successfully uploaded the change to object storage as part of a batch, it informs each follower that the change has been persisted. At that point, the follower can simply delete the change from its buffer.
However, if the follower never receives the persisted notification, then, after some timeout, the follower itself will upload the change to object storage. Thus, if the machine running the database suddenly fails, as long as at least one follower is still running, it will ensure that all confirmed writes are safely persisted.
Each of a database’s five followers is located in a different physical data center. Cloudflare’s network consists of hundreds of data centers around the world, which means it is always easy for us to find four other data centers nearby any Durable Object (in addition to the one it is running in). In order for a confirmed write to be lost, then, at least four different machines in at least three different physical buildings would have to fail simultaneously (three of the five followers, plus the Durable Object’s host machine). Of course, anything can happen, but this is exceedingly unlikely.
Followers also come in handy when a Durable Object’s host machine is unresponsive. We may not know for sure if the machine has died completely, or if it is still running and responding to some clients but not others. We cannot start up a new instance of the DO until we know for sure that the previous instance is dead – or, at least, that it can no longer confirm writes, since the old and new instances could then confirm contradictory writes. To deal with this situation, if we can’t reach the DO’s host, we can instead try to contact its followers. If we can contact at least three of the five followers, and tell them to stop confirming writes for the unreachable DO instance, then we know that instance is unable to confirm any more writes going forward. We can then safely start up a new instance to replace the unreachable one.
Bonus feature: Point-in-Time Recovery
I mentioned earlier that SQLite-backed Durable Objects can be asked to revert their state to any time in the last 30 days. How does this work?
This was actually an accidental feature that fell out of SRS’s design. Since SRS stores a complete log of changes made to the database, we can restore to any point in time by replaying the change log from the last snapshot. The only thing we have to do is make sure we don’t delete those logs too soon.
Normally, whenever a snapshot is uploaded, all previous logs and snapshots can then be deleted. But instead of deleting them immediately, SRS merely marks them for deletion 30 days later. In the meantime, if a point-in-time recovery is requested, the data is still there to work from.
For a database with a high volume of writes, this may mean we store a lot of data for a lot longer than needed. As it turns out, though, once data has been written at all, keeping it around for an extra month is pretty cheap — typically cheaper, even, than writing it in the first place. It’s a small price to pay for always-on disaster recovery.
Get started with SQLite-in-DO
SQLite-backed DOs are available in beta starting today. You can start building with SQLite-in-DO by visiting developer documentation and provide beta feedback via the #durable-objects channel on our Developer Discord.
Do distributed systems like SRS excite you? Would you like to be part of building them at Cloudflare? We’re hiring!
We’re thrilled to announce that PartyKit, an open source platform for deploying real-time, collaborative, multiplayer applications, is now a part of Cloudflare. This acquisition marks a significant milestone in our journey to redefine the boundaries of serverless computing, making it more dynamic, interactive, and, importantly, stateful.
Defining the future of serverless compute around state
Building real-time applications on the web have always been difficult. Not only is it a distributed systems problem, but you need to provision and manage infrastructure, databases, and other services to maintain state across multiple clients. This complexity has traditionally been a barrier to entry for many developers, especially those who are just starting out.
We announced Durable Objects in 2020 as a way of building synchronized real time experiences for the web. Unlike regular serverless functions that are ephemeral and stateless, Durable Objects are stateful, allowing developers to build applications that maintain state across requests. They also act as an ideal synchronization point for building real-time applications that need to maintain state across multiple clients. Combined with WebSockets, Durable Objects can be used to build a wide range of applications, from multiplayer games to collaborative drawing tools.
In 2022, PartyKit began as a project to further explore the capabilities of Durable Objects and make them more accessible to developers by exposing them through familiar components. In seconds, you could create a project that configured behavior for these objects, and deploy it to Cloudflare. By integrating with popular libraries such as Yjs (the gold standard in collaborative editing) and React, PartyKit made it possible for developers to build a wide range of use cases, from multiplayer games to collaborative drawing tools, into their applications.
Building experiences with real-time components was previously only accessible to multi-billion dollar companies, but new computing primitives like Durable Objects on the edge make this accessible to regular developers and teams. With PartyKit now under our roof, we’re doubling down on our commitment to this future — a future where serverless is stateful.
We’re excited to give you a preview into our shared vision for applications, and the use cases we’re excited to simplify together.
Making state for serverless easy
Unlike conventional approaches that rely on external databases to maintain state, thereby complicating scalability and increasing costs, PartyKit leverages Cloudflare’s Durable Objects to offer a seamless model where stateful serverless functions can operate as if they were running on a single machine, maintaining state across requests. This innovation not only simplifies development but also opens up a broader range of use cases, including real-time computing, collaborative editing, and multiplayer gaming, by allowing thousands of these “machines” to be spun up globally, each maintaining its own state. PartyKit aims to be a complement to traditional serverless computing, providing a more intuitive and efficient method for developing applications that require stateful behavior, thereby marking the “next evolution” of serverless computing.
Simplifying WebSockets for Real-Time Interaction
WebSockets have revolutionized how we think about bidirectional communication on the web. Yet, the challenge has always been about scaling these interactions to millions without a hitch. Cloudflare Workers step in as the hero, providing a serverless framework that makes real-time applications like chat services, multiplayer games, and collaborative tools not just possible but scalable and efficient.
Powering Games and Multiplayer Applications Without Limits
Imagine building multiplayer platforms where the game never lags, the collaboration is seamless, and video conferences are crystal clear. Cloudflare’s Durable Objects morph the stateless serverless landscape into a realm where persistent connections thrive. PartyKit’s integration into this ecosystem means developers now have a powerhouse toolkit to bring ambitious multiplayer visions to life, without the traditional overheads.
This is especially critical in gaming — there are few areas where low-latency and real-time interaction matter more. Every millisecond, every lag, every delay defines the entire experience. With PartyKit’s capabilities integrated into Cloudflare, developers will be able to leverage our combined technologies to create gaming experiences that are not just about playing but living the game, thanks to scalable, immersive, and interactive platforms.
The toolkit for building Local-First applications
The Internet is great, and increasingly always available, but there are still a few situations where we are forced to disconnect — whether on a plane, a train, or a beach.
The premise of local-first applications is that work doesn’t stop when the Internet does. Wherever you left off in your doc, you can keep working on it, assuming the state will be restored when you come back online. By storing data on the client and syncing when back online, these applications offer resilience and responsiveness that’s unmatched. Cloudflare’s vision, enhanced by PartyKit’s technology, aims to make local-first not just an option but the standard for application development.
What’s next for PartyKit users?
Users can expect their existing projects to continue working as expected. We will be adding more features to the platform, including the ability to create and use PartyKit projects inside existing Workers and Pages projects. There will be no extra charges to use PartyKit for commercial purposes, other than the standard usage charges for Cloudflare Workers and other services. Further, we’re going to expand the roadmap to begin working on integrations with popular frameworks and libraries, such as React, Vue, and Angular. We’re deeply committed to executing on the PartyKit vision and roadmap, and we’re excited to see what you build with it.
The Beginning of a New Chapter
The acquisition of PartyKit by Cloudflare isn’t just a milestone for our two teams; it’s a leap forward for developers everywhere. Together, we’re not just building tools; we’re crafting the foundation for the next generation of Internet applications. The future of serverless is stateful, and with PartyKit’s expertise now part of our arsenal, we’re more ready than ever to make that future a reality.
Welcome to the Cloudflare team, PartyKit. Look forward to building something remarkable together.
Last year, we announced the Browser Rendering API – letting users running Puppeteer, a browser automation library, directly in Workers. Puppeteer is one of the most popular libraries used to interact with a headless browser instance to accomplish tasks like taking screenshots, generating PDFs, crawling web pages, and testing web applications. We’ve heard from developers that configuring and maintaining their own serverless browser automation systems can be quite painful.
The Workers Browser Rendering API solves this. It makes the Puppeteer library available directly in your Worker, connected to a real web browser, without the need to configure and manage infrastructure or keep browser sessions warm yourself. You can use @cloudflare/puppeteer to run the full Puppeteer API directly on Workers!
We’ve seen so much interest from the developer community since launching last year. While the Browser Rendering API is still in beta (sign up to our waitlist to get access), we wanted to share a way to get more out of our current limits by using the Browser Rendering API with Durable Objects. We’ll also be sharing pricing for the Rendering API, so you can build knowing exactly what you’ll pay for.
Building a responsive web design testing tool with the Browser Rendering API
As a designer or frontend developer, you want to make sure that content is well-designed for visitors browsing on different screen sizes. With the number of possible devices that users are browsing on are growing, it becomes difficult to test all the possibilities manually. While there are many testing tools on the market, we want to show how easy it is to create your own Chromium based tool with the Workers Browser Rendering API and Durable Objects.
We’ll be using the Worker to handle any incoming requests, pass them to the Durable Object to take screenshots and store them in an R2 bucket. The Durable Object is used to create a browser session that’s persistent. By using Durable Object Alarms we can keep browsers open for longer and reuse browser sessions across requests.
Let’s dive into how we can build this application:
Create a Worker with a Durable Object, Browser Rendering API binding and R2 bucket. This is the resulting wrangler.toml:
name = "rendering-api-demo"
main = "src/index.js"
compatibility_date = "2023-09-04"
compatibility_flags = [ "nodejs_compat"]
account_id = "c05e6a39aa4ccdd53ad17032f8a4dc10"
# Browser Rendering API binding
browser = { binding = "MYBROWSER" }
# Bind an R2 Bucket
[[r2_buckets]]
binding = "BUCKET"
bucket_name = "screenshots"
# Binding to a Durable Object
[[durable_objects.bindings]]
name = "BROWSER"
class_name = "Browser"
[[migrations]]
tag = "v1" # Should be unique for each entry
new_classes = ["Browser"] # Array of new classes
2. Define the Worker
This Worker simply passes the request onto the Durable Object.
export default {
async fetch(request, env) {
let id = env.BROWSER.idFromName("browser");
let obj = env.BROWSER.get(id);
// Send a request to the Durable Object, then await its response.
let resp = await obj.fetch(request.url);
let count = await resp.text();
return new Response("success");
}
};
3. Define the Durable Object class
const KEEP_BROWSER_ALIVE_IN_SECONDS = 60;
export class Browser {
constructor(state, env) {
this.state = state;
this.env = env;
this.keptAliveInSeconds = 0;
this.storage = this.state.storage;
}
async fetch(request) {
// screen resolutions to test out
const width = [1920, 1366, 1536, 360, 414]
const height = [1080, 768, 864, 640, 896]
// use the current date and time to create a folder structure for R2
const nowDate = new Date()
var coeff = 1000 * 60 * 5
var roundedDate = (new Date(Math.round(nowDate.getTime() / coeff) * coeff)).toString();
var folder = roundedDate.split(" GMT")[0]
//if there's a browser session open, re-use it
if (!this.browser) {
console.log(`Browser DO: Starting new instance`);
try {
this.browser = await puppeteer.launch(this.env.MYBROWSER);
} catch (e) {
console.log(`Browser DO: Could not start browser instance. Error: ${e}`);
}
}
// Reset keptAlive after each call to the DO
this.keptAliveInSeconds = 0;
const page = await this.browser.newPage();
// take screenshots of each screen size
for (let i = 0; i < width.length; i++) {
await page.setViewport({ width: width[i], height: height[i] });
await page.goto("https://workers.cloudflare.com/");
const fileName = "screenshot_" + width[i] + "x" + height[i]
const sc = await page.screenshot({
path: fileName + ".jpg"
}
);
this.env.BUCKET.put(folder + "/"+ fileName + ".jpg", sc);
}
// Reset keptAlive after performing tasks to the DO.
this.keptAliveInSeconds = 0;
// set the first alarm to keep DO alive
let currentAlarm = await this.storage.getAlarm();
if (currentAlarm == null) {
console.log(`Browser DO: setting alarm`);
const TEN_SECONDS = 10 * 1000;
this.storage.setAlarm(Date.now() + TEN_SECONDS);
}
await this.browser.close();
return new Response("success");
}
async alarm() {
this.keptAliveInSeconds += 10;
// Extend browser DO life
if (this.keptAliveInSeconds < KEEP_BROWSER_ALIVE_IN_SECONDS) {
console.log(`Browser DO: has been kept alive for ${this.keptAliveInSeconds} seconds. Extending lifespan.`);
this.storage.setAlarm(Date.now() + 10 * 1000);
} else console.log(`Browser DO: cxceeded life of ${KEEP_BROWSER_ALIVE_IN_SECONDS}. Browser DO will be shut down in 10 seconds.`);
}
}
That’s it! With less than a hundred lines of code, you can fully customize a powerful tool to automate responsive web design testing. You can even incorporate it into your CI pipeline to automatically test different window sizes with each build and verify the result is as expected by using an automated library like pixelmatch.
How much will this cost?
We’ve spoken to many customers deploying a Puppeteer service on their own infrastructure, on public cloud containers or functions or using managed services. The common theme that we’ve heard is that these services are costly – costly to maintain and expensive to run.
While you won’t be billed for the Browser Rendering API yet, we want to be transparent with you about costs you start building. We know it’s important to understand the pricing structure so that you don’t get a surprise bill and so that you can design your application efficiently.
You pay based on two usage metrics:
Number of sessions: A Browser Session is a new instance of a browser being launched
Number of concurrent sessions: Concurrent Sessions is the number of browser instances open at once
Using Durable Objects to persist browser sessions improves performance by eliminating the time that it takes to spin up a new browser session. Since it re-uses sessions, it cuts down on the number of concurrent sessions needed. We highly encourage this model of session re-use if you expect to see consistent traffic for applications that you build on the Browser Rendering API.
If you have feedback about this pricing, we’re all ears. Feel free to reach out through Discord (channel name: browser-rendering-api-beta) and share your thoughts.
Get Started
Sign up to our waitlist to get access to the Workers Browser Rendering API. We’re so excited to see what you build! Share your creations with us on Twitter/X @CloudflareDev or on our Discord community.
Almost three years ago, we launched Cloudflare Waiting Room to protect our customers’ sites from overwhelming spikes in legitimate traffic that could bring down their sites. Waiting Room gives customers control over user experience even in times of high traffic by placing excess traffic in a customizable, on-brand waiting room, dynamically admitting users as spots become available on their sites. Since the launch of Waiting Room, we’ve continued to expand its functionality based on customer feedback with features like mobile app support, analytics, Waiting Room bypass rules, and more.
We love announcing new features and solving problems for our customers by expanding the capabilities of Waiting Room. But, today, we want to give you a behind the scenes look at how we have evolved the core mechanism of our product–namely, exactly how it kicks in to queue traffic in response to spikes.
How was the Waiting Room built, and what are the challenges?
The diagram below shows a quick overview of where the Waiting room sits when a customer enables it for their website.
Waiting Room is built on Workers that runs across a global network of Cloudflare data centers. The requests to a customer’s website can go to many different Cloudflare data centers. To optimize for minimal latency and enhanced performance, these requests are routed to the data center with the most geographical proximity. When a new user makes a request to the host/path covered by the Waiting room, the waiting room worker decides whether to send the user to the origin or the waiting room. This decision is made by making use of the waiting room state which gives an idea of how many users are on the origin.
The waiting room state changes continuously based on the traffic around the world. This information can be stored in a central location or changes can get propagated around the world eventually. Storing this information in a central location can add significant latency to each request as the central location can be really far from where the request is originating from. So every data center works with its own waiting room state which is a snapshot of the traffic pattern for the website around the world available at that point in time. Before letting a user into the website, we do not want to wait for information from everywhere else in the world as that adds significant latency to the request. This is the reason why we chose not to have a central location but have a pipeline where changes in traffic get propagated eventually around the world.
This pipeline which aggregates the waiting room state in the background is built on Cloudflare Durable Objects. In 2021, we wrote a blog talking about how the aggregation pipeline works and the different design decisions we took there if you are interested. This pipeline ensures that every data center gets updated information about changes in traffic within a few seconds.
The Waiting room has to make a decision whether to send users to the website or queue them based on the state that it currently sees. This has to be done while making sure we queue at the right time so that the customer's website does not get overloaded. We also have to make sure we do not queue too early as we might be queueing for a falsely suspected spike in traffic. Being in a queue could cause some users to abandon going to the website. Waiting Room runs on every server in Cloudflare’s network, which spans over 300 cities in more than 100 countries. We want to make sure, for every new user, the decision whether to go to the website or the queue is made with minimal latency.This is what makes the decision of when to queue a hard question for the waiting room. In this blog, we will cover how we approached that tradeoff. Our algorithm has evolved to decrease the false positives while continuing to respect the customer’s set limits.
How a waiting room decides when to queue users
The most important factor that determines when your waiting room will start queuing is how you configured the traffic settings. There are two traffic limits that you will set when configuring a waiting room–total active users and new users per minute.The total active users is a target threshold for how many simultaneous users you want to allow on the pages covered by your waiting room. New users per minute defines the target threshold for the maximum rate of user influx to your website per minute. A sharp spike in either of these values might result in queuing. Another configuration that affects how we calculate the total active users is session duration. A user is considered active for session duration minutes since the request is made to any page covered by a waiting room.
The graph below is from one of our internal monitoring tools for a customer and shows a customer's traffic pattern for 2 days. This customer has set their limits, new users per minute and total active users to 200 and 200 respectively.
If you look at their traffic you can see that users were queued on September 11th around 11:45. At that point in time, the total active users was around 200. As the total active users ramped down (around 12:30), the queued users progressed to 0. The queueing started again on September 11th around 15:00 when total active users got to 200. The users that were queued around this time ensured that the traffic going to the website is around the limits set by the customer.
Once a user gets access to the website, we give them an encrypted cookie which indicates they have already gained access. The contents of the cookie can look like this.
The cookie is like a ticket which indicates entry to the waiting room.The bucketId indicates which cluster of users this user is part of. The acceptedAt time and lastCheckInTime indicate when the last interaction with the workers was. This information can ensure if the ticket is valid for entry or not when we compare it with the session duration value that the customer sets while configuring the waiting room. If the cookie is valid, we let the user through which ensures users who are on the website continue to be able to browse the website. If the cookie is invalid, we create a new cookie treating the user as a new user and if there is queueing happening on the website they get to the back of the queue. In the next section let us see how we decide when to queue those users.
To understand this further, let's see what the contents of the waiting room state are. For the customer we discussed above, at the time "Mon, 11 Sep 2023 11:45:54 GMT", the state could look like this.
{
"activeUsers": 50,
}
As mentioned above the customer’s configuration has new users per minute and total active users equal to 200 and 200 respectively.
So the state indicates that there is space for the new users as there are only 50 active users when it's possible to have 200. So there is space for another 150 users to go in. Let's assume those 50 users could have come from two data centers San Jose (20 users) and London (30 users). We also keep track of the number of workers that are active across the globe as well as the number of workers active at the data center in which the state is calculated. The state key below could be the one calculated at San Jose.
Imagine at the time "Mon, 11 Sep 2023 11:45:54 GMT", we get a request to that waiting room at a datacenter in San Jose.
To see if the user that reached San Jose can go to the origin we first check the traffic history in the past minute to see the distribution of traffic at that time. This is because a lot of websites are popular in certain parts of the world. For a lot of these websites the traffic tends to come from the same data centers.
Looking at the traffic history for the minute "Mon, 11 Sep 2023 11:44:00 GMT" we see San Jose has 20 users out of 200 users going there (10%) at that time. For the current time "Mon, 11 Sep 2023 11:45:54 GMT" we divide the slots available at the website at the same ratio as the traffic history in the past minute. So we can send 10% of 150 slots available from San Jose which is 15 users. We also know that there are three active workers as "dataCenterWorkersActive" is 3.
The number of slots available for the data center is divided evenly among the workers in the data center. So every worker in San Jose can send 15/3 users to the website. If the worker that received the traffic has not sent any users to the origin for the current minute they can send up to five users (15/3).
At the same time ("Mon, 11 Sep 2023 11:45:54 GMT"), imagine a request goes to a data center in Delhi. The worker at the data center in Delhi checks the trafficHistory and sees that there are no slots allotted for it. For traffic like this we have reserved the Anywhere slots as we are really far away from the limit.
The Anywhere slots are divided among all the active workers in the globe as any worker around the world can take a part of this pie. 75% of the remaining 150 slots which is 113.
The state key also keeps track of the number of workers (globalWorkersActive) that have spawned around the world. The Anywhere slots allotted are divided among all the active workers in the world if available. globalWorkersActive is 10 when we look at the waiting room state. So every active worker can send as many as 113/10 which is approximately 11 users. So the first 11 users that come to a worker in the minute Mon, 11 Sep 2023 11:45:00 GMT gets admitted to the origin. The extra users get queued. The extra reserved slots (5) in San Jose for minute Mon, 11 Sep 2023 11:45:00 GMT discussed before ensures that we can admit up to 16(5 + 11) users from a worker from San Jose to the website.
Queuing at the worker level can cause users to get queued before the slots available for the data center
As we can see from the example above, we decide whether to queue or not at the worker level. The number of new users that go to workers around the world can be non-uniform. To understand what can happen when there is non-uniform distribution of traffic to two workers, let us look at the diagram below.
Imagine the slots available for a data center in San Jose are ten. There are two workers running in San Jose. Seven users go to worker1 and one user goes to worker2. In this situation worker1 will let in five out of the seven workers to the website and two of them get queued as worker1 only has five slots available. The one user that shows up at worker2 also gets to go to the origin. So we queue two users, when in reality ten users can get sent from the datacenter San Jose when only eight users show up.
This issue while dividing slots evenly among workers results in queueing before a waiting room’s configured traffic limits, typically within 20-30% of the limits set. This approach has advantages which we will discuss next. We have made changes to the approach to decrease the frequency with which queuing occurs outside that 20-30% range, queuing as close to limits as possible, while still ensuring Waiting Room is prepared to catch spikes. Later in this blog, we will cover how we achieved this by updating how we allocate and count slots.
What is the advantage of workers making these decisions?
The example above talked about how a worker in San Jose and Delhi makes decisions to let users through to the origin. The advantage of making decisions at the worker level is that we can make decisions without any significant latency added to the request. This is because to make the decision, there is no need to leave the data center to get information about the waiting room as we are always working with the state that is currently available in the data center. The queueing starts when the slots run out within the worker. The lack of additional latency added enables the customers to turn on the waiting room all the time without worrying about extra latency to their users.
Waiting Room’s number one priority is to ensure that customer’s sites remain up and running at all times, even in the face of unexpected and overwhelming traffic surges. To that end, it is critical that a waiting room prioritizes staying near or below traffic limits set by the customer for that room. When a spike happens at one data center around the world, say at San Jose, the local state at the data center will take a few seconds to get to Delhi.
Splitting the slots among workers ensures that working with slightly outdated data does not cause the overall limit to be exceeded by an impactful amount. For example, the activeUsers value can be 26 in the San Jose data center and 100 in the other data center where the spike is happening. At that point in time, sending extra users from Delhi may not overshoot the overall limit by much as they only have a part of the pie to start with in Delhi. Therefore, queueing before overall limits are reached is part of the design to make sure your overall limits are respected. In the next section we will cover the approaches we implemented to queue as close to limits as possible without increasing the risk of exceeding traffic limits.
Allocating more slots when traffic is low relative to waiting room limits
The first case we wanted to address was queuing that occurs when traffic is far from limits. While rare and typically lasting for one refresh interval (20s) for the end users who are queued, this was our first priority when updating our queuing algorithm. To solve this, while allocating slots we looked at the utilization (how far you are from traffic limits) and allotted more slots when traffic is really far away from the limits. The idea behind this was to prevent the queueing that happens at lower limits while still being able to readjust slots available per worker when there are more users on the origin.
To understand this let's revisit the example where there is non-uniform distribution of traffic to two workers. So two workers similar to the one we discussed before are shown below. In this case the utilization is low (10%). This means we are far from the limits. So the slots allocated(8) are closer to the slotsAvailable for the datacenter San Jose which is 10. As you can see in the diagram below, all the eight users that go to either worker get to reach the website with this modified slot allocation as we are providing more slots per worker at lower utilization levels.
The diagram below shows how the slots allocated per worker changes with utilization (how far you are away from limits). As you can see here, we are allocating more slots per worker at lower utilization. As the utilization increases, the slots allocated per worker decrease as it’s getting closer to the limits, and we are better prepared for spikes in traffic. At 10% utilization every worker gets close to the slots available for the data center. As the utilization is close to 100% it becomes close to the slots available divided by worker count in the data center.
How do we achieve more slots at lower utilization?
This section delves into the mathematics which helps us get there. If you are not interested in these details, meet us at the “Risk of over provisioning” section.
To understand this further, let's revisit the previous example where requests come to the Delhi data center. The activeUsers value is 50, so utilization is 50/200 which is around 25%.
The idea is to allocate more slots at lower utilization levels. This ensures that customers do not see unexpected queueing behaviors when traffic is far away from limits. At time Mon, 11 Sep 2023 11:45:54 GMT requests to Delhi are at 25% utilization based on the local state key.
To allocate more slots to be available at lower utilization we added a workerMultiplier which moves proportionally to the utilization. At lower utilization the multiplier is lower and at higher utilization it is close to one.
utilization – how far away from the limits you are.
curveFactor – is the exponent which can be adjusted which decides how aggressive we are with the distribution of extra budgets at lower worker counts. To understand this let's look at the graph of how y = x and y = x^2 looks between values 0 and 1.
The graph for y=x is a straight line passing through (0, 0) and (1, 1).
The graph for y=x^2 is a curved line where y increases slower than x when x < 1 and passes through (0, 0) and (1, 1)
Using the concept of how the curves work, we derived the formula for workerCountMultiplier where y=workerCountMultiplier,x=utilization and curveFactor is the power which can be adjusted which decides how aggressive we are with the distribution of extra budgets at lower worker counts. When curveFactor is 1, the workerMultiplier is equal to the utilization.
Let's come back to the example we discussed before and see what the value of the curve factor will be. At time Mon, 11 Sep 2023 11:45:54 GMT requests to Delhi are at 25% utilization based on the local state key. The Anywhere slots are divided among all the active workers in the globe as any worker around the world can take a part of this pie. i.e. 75% of the remaining 150 slots (113).
globalWorkersActive is 10 when we look at the waiting room state. In this case we do not divide the 113 slots by 10 but instead divide by the adapted worker count which is globalWorkersActive * workerMultiplier. If curveFactor is 1, the workerMultiplier is equal to the utilization which is at 25% or 0.25.
So effective workerCount = 10 * 0.25 = 2.5
So, every active worker can send as many as 113/2.5 which is approximately 45 users. The first 45 users that come to a worker in the minute Mon, 11 Sep 2023 11:45:00 GMT gets admitted to the origin. The extra users get queued.
Therefore, at lower utilization (when traffic is farther from the limits) each worker gets more slots. But, if the sum of slots are added up, there is a higher chance of exceeding the overall limit.
Risk of over provisioning
The method of giving more slots at lower limits decreases the chances of queuing when traffic is low relative to traffic limits. However, at lower utilization levels a uniform spike happening around the world could cause more users to go into the origin than expected. The diagram below shows the case where this can be an issue. As you can see the slots available are ten for the data center. At 10% utilization we discussed before, each worker can have eight slots each. If eight users show up at one worker and seven show up at another, we will be sending fifteen users to the website when only ten are the maximum available slots for the data center.
With the range of customers and types of traffic we have, we were able to see cases where this became a problem. A traffic spike from low utilization levels could cause overshooting of the global limits. This is because we are over provisioned at lower limits and this increases the risk of significantly exceeding traffic limits. We needed to implement a safer approach which would not cause limits to be exceeded while also decreasing the chance of queueing when traffic is low relative to traffic limits.
Taking a step back and thinking about our approach, one of the assumptions we had was that the traffic in a data center directly correlates to the worker count that is found in a data center. In practice what we found is that this was not true for all customers. Even if the traffic correlates to the worker count, the new users going to the workers in the data centers may not correlate. This is because the slots we allocate are for new users but the traffic that a data center sees consists of both users who are already on the website and new users trying to go to the website.
In the next section we are talking about an approach where worker counts do not get used and instead workers communicate with other workers in the data center. For that we introduced a new service which is a durable object counter.
Decrease the number of times we divide the slots by introducing Data Center Counters
From the example above, we can see that overprovisioning at the worker level has the risk of using up more slots than what is allotted for a data center. If we do not over provision at low levels we have the risk of queuing users way before their configured limits are reached which we discussed first. So there has to be a solution which can achieve both these things.
The overprovisioning was done so that the workers do not run out of slots quickly when an uneven number of new users reach a bunch of workers. If there is a way to communicate between two workers in a data center, we do not need to divide slots among workers in the data center based on worker count. For that communication to take place, we introduced counters. Counters are a bunch of small durable object instances that do counting for a set of workers in the data center.
To understand how it helps with avoiding usage of worker counts, let's check the diagram below. There are two workers talking to a Data Center Counter below. Just as we discussed before, the workers let users through to the website based on the waiting room state. The count of the number of users let through was stored in the memory of the worker before. By introducing counters, it is done in the Data Center Counter. Whenever a new user makes a request to the worker, the worker talks to the counter to know the current value of the counter. In the example below for the first new request to the worker the counter value received is 9. When a data center has 10 slots available, that will mean the user can go to the website. If the next worker receives a new user and makes a request just after that, it will get a value 10 and based on the slots available for the worker, the user will get queued.
The Data Center Counter acts as a point of synchronization for the workers in the waiting room. Essentially, this enables the workers to talk to each other without really talking to each other directly. This is similar to how a ticketing counter works. Whenever one worker lets someone in, they request tickets from the counter, so another worker requesting the tickets from the counter will not get the same ticket number. If the ticket value is valid, the new user gets to go to the website. So when different numbers of new users show up at workers, we will not over allocate or under allocate slots for the worker as the number of slots used is calculated by the counter which is for the data center.
The diagram below shows the behavior when an uneven number of new users reach the workers, one gets seven new users and the other worker gets one new user. All eight users that show up at the workers in the diagram below get to the website as the slots available for the data center is ten which is below ten.
This also does not cause excess users to get sent to the website as we do not send extra users when the counter value equals the slotsAvailable for the data center. Out of the fifteen users that show up at the workers in the diagram below ten will get to the website and five will get queued which is what we would expect.
Risk of over provisioning at lower utilization also does not exist as counters help workers to communicate with each other.
To understand this further, let's look at the previous example we talked about and see how it works with the actual waiting room state.
The waiting room state for the customer is as follows.
The objective is to not divide the slots among workers so that we don’t need to use that information from the state. At time Mon, 11 Sep 2023 11:45:54 GMT requests come to San Jose. So, we can send 10% of 150 slots available from San Jose which is 15.
The durable object counter at San Jose keeps returning the counter value it is at right now for every new user that reaches the data center. It will increment the value by 1 after it returns to a worker. So the first 15 new users that come to the worker get a unique counter value. If the value received for a user is less than 15 they get to use the slots at the data center.
Once the slots available for the data center runs out, the users can make use of the slots allocated for Anywhere data-centers as these are not reserved for any particular data center. Once a worker in San Jose gets a ticket value that says 15, it realizes that it's not possible to go to the website using the slots from San Jose.
The Anywhere slots are available for all the active workers in the globe i.e. 75% of the remaining 150 slots (113). The Anywhere slots are handled by a durable object that workers from different data centers can talk to when they want to use Anywhere slots. Even if 128 (113 + 15) users end up going to the same worker for this customer we will not queue them. This increases the ability of Waiting Room to handle an uneven number of new users going to workers around the world which in turn helps the customers to queue close to the configured limits.
Why do counters work well for us?
When we built the Waiting Room, we wanted the decisions for entry into the website to be made at the worker level itself without talking to other services when the request is in flight to the website. We made that choice to avoid adding latency to user requests. By introducing a synchronization point at a durable object counter, we are deviating from that by introducing a call to a durable object counter.
However, the durable object for the data center stays within the same data center. This leads to minimal additional latency which is usually less than 10 ms. For the calls to the durable object that handles Anywhere data centers, the worker may have to cross oceans and long distances. This could cause the latency to be around 60 or 70 ms in those cases. The 95th percentile values shown below are higher because of calls that go to farther data centers.
The design decision to add counters adds a slight extra latency for new users going to the website. We deemed the trade-off acceptable because this reduces the number of users that get queued before limits are reached. In addition, the counters are only required when new users try to go into the website. Once new users get to the origin, they get entry directly from workers as the proof of entry is available in the cookies that the customers come with, and we can let them in based on that.
Counters are really simple services which do simple counting and do nothing else. This keeps the memory and CPU footprint of the counters minimal. Moreover, we have a lot of counters around the world handling the coordination between a subset of workers.This helps counters to successfully handle the load for the synchronization requirements from the workers. These factors add up to make counters a viable solution for our use case.
Summary
Waiting Room was designed with our number one priority in mind–to ensure that our customers’ sites remain up and running, no matter the volume or ramp up of legitimate traffic. Waiting Room runs on every server in Cloudflare’s network, which spans over 300 cities in more than 100 countries. We want to make sure, for every new user, the decision whether to go to the website or the queue is made with minimal latency and is done at the right time. This decision is a hard one as queuing too early at a data center can cause us to queue earlier than the customer set limits. Queuing too late can cause us to overshoot the customer set limits.
With our initial approach where we divide slots among our workers evenly we were sometimes queuing too early but were pretty good at respecting customer set limits. Our next approach of giving more slots at low utilization (low traffic levels compared to customer limits) ensured that we did better at the cases where we queued earlier than the customer set limits as every worker has more slots to work with at each worker. But as we have seen, this made us more likely to overshoot when a sudden spike in traffic occurred after a period of low utilization.
With counters we are able to get the best of both worlds as we avoid the division of slots by worker counts. Using counters we are able to ensure that we do not queue too early or too late based on the customer set limits. This comes at the cost of a little bit of latency to every request from a new user which we have found to be negligible and creates a better user experience than getting queued early.
We keep iterating on our approach to make sure we are always queuing people at the right time and above all protecting your website. As more and more customers are using the waiting room, we are learning more about different types of traffic and that is helping the product be better for everyone.
We rely on technology to help us on a daily basis – if you are not good at keeping track of time, your calendar can remind you when it’s time to prepare for your next meeting. If you made a reservation at a really nice restaurant, you don’t want to miss it! You appreciate the app to remind you a day before your plans the next evening.
However, who tells the application when it’s the right time to send you a notification? For this, we generally rely on scheduled events. And when you are relying on them, you really want to make sure that they occur. Turns out, this can get difficult. The scheduler and storage backend need to be designed with scale in mind – otherwise you may hit limitations quickly.
Workers, Durable Objects, and Alarms are actually a perfect match for this type of workload. Thanks to the distributed architecture of Durable Objects and their storage, they are a reliable and scalable option. Each Durable Object has access to its own isolated storage and alarm scheduler, both being automatically replicated and failover in case of failures.
There are many use cases where having a reliable scheduler can come in handy: running a webhook service, sending emails to your customers a week after they sign up to keep them engaged, sending invoices reminders, and more!
Today, we’re going to show you how to build a scalable service that will schedule HTTP requests on a specific schedule or as one-off at a specific time as a way to guide you through any use case that requires scheduled events.
Quick intro into the application stack
Before we dive in, here are some of the tools we’re going to be using today:
Wrangler – CLI tool to develop and publish Workers
The application is going to have following components:
Scheduling system API to accept scheduled requests and manage Durable Objects
Unique Durable Object per scheduled request, each with
Storage – keeping the request metadata, such as URL, body, or headers.
Alarm – a timer (trigger) to wake Durable Object up.
While we will focus on building the application, the Cloudflare global network will take care of the rest – storing and replicating our data, and making sure to wake our Durable Objects up when the time’s right. Let’s build it!
Initialize new Workers project
Get started by generating a completely new Workers project using the wrangler init command, which makes creating new projects quick & easy.
From my personal experience, at least a draft of TypeScript types significantly helps to be more productive down the road, so let’s prepare and describe our scheduled request in advance. Create a file types.ts in src directory and paste the following TypeScript definitions.
src/types.ts
export interface Env {
DO_REQUEST: DurableObjectNamespace
}
export interface ScheduledRequest {
url: string // URL of the request
triggerAt?: number // optional, unix timestamp in milliseconds, defaults to `new Date()`
requestInit?: RequestInit // optional, includes method, headers, body
}
A scheduled request Durable Object class & alarm
Based on our architecture design, each scheduled request will be saved into its own Durable Object, effectively separating storage and alarms from each other and allowing our scheduling system to scale horizontally – there is no limit to the number of Durable Objects we create.
In the end, the Durable Object class is a matter of a couple of lines. The code snippet below accepts and saves the request body to a persistent storage and sets the alarm timer. Workers runtime will wake up the Durable Object and call the alarm() method to process the request.
The alarm method reads the scheduled request data from the storage, then processes the request, and in the end reschedules itself in case it’s configured to be executed on a recurring schedule.
src/request-durable-object.ts
import { ScheduledRequest } from "./types";
export class RequestDurableObject {
id: string|DurableObjectId
storage: DurableObjectStorage
constructor(state:DurableObjectState) {
this.storage = state.storage
this.id = state.id
}
async fetch(request:Request) {
// read scheduled request from request body
const scheduledRequest:ScheduledRequest = await request.json()
// save scheduled request data to Durable Object storage, set the alarm, and return Durable Object id
this.storage.put("request", scheduledRequest)
this.storage.setAlarm(scheduledRequest.triggerAt || new Date())
return new Response(JSON.stringify({
id: this.id.toString()
}), {
headers: {
"content-type": "application/json"
}
})
}
async alarm() {
// read the scheduled request from Durable Object storage
const scheduledRequest:ScheduledRequest|undefined = await this.storage.get("request")
// call fetch on scheduled request URL with optional requestInit
if (scheduledRequest) {
await fetch(scheduledRequest.url, scheduledRequest.requestInit ? webhook.requestInit : undefined)
// cleanup scheduled request once done
this.storage.deleteAll()
}
}
}
Wrangler configuration
Once we have the Durable Object class, we need to create a Durable Object binding by instructing Wrangler where to find it and what the exported class name is.
wrangler.toml
name = "durable-objects-request-scheduler"
main = "src/index.ts"
compatibility_date = "2022-08-02"
# added Durable Objects configuration
[durable_objects]
bindings = [
{ name = "DO_REQUEST", class_name = "RequestDurableObject" },
]
[[migrations]]
tag = "v1"
new_classes = ["RequestDurableObject"]
Scheduling system API
The API Worker will accept POST HTTP methods only, and is expecting a JSON body with scheduled request data – what URL to call, optionally what method, headers, or body to send. Any other method than POST will return 405 – Method Not Allowed HTTP error.
HTTP POST /:scheduledRequestId? will create or override a scheduled request, where :scheduledRequestId is optional Durable Object ID returned from a scheduling system API before.
src/index.ts
import { Env } from "./types"
export { RequestDurableObject } from "./request-durable-object"
export default {
async fetch(
request: Request,
env: Env
): Promise<Response> {
if (request.method !== "POST") {
return new Response("Method Not Allowed", {status: 405})
}
// parse the URL and get Durable Object ID from the URL
const url = new URL(request.url)
const idFromUrl = url.pathname.slice(1)
// construct the Durable Object ID, use the ID from pathname or create a new unique id
const doId = idFromUrl ? env.DO_REQUEST.idFromString(idFromUrl) : env.DO_REQUEST.newUniqueId()
// get the Durable Object stub for our Durable Object instance
const stub = env.DO_REQUEST.get(doId)
// pass the request to Durable Object instance
return stub.fetch(request)
},
}
It’s good to mention that the script above does not implement any listing of scheduled or processed webhooks. Depending on how the scheduling system would be integrated, you can save each created Durable Object ID to your existing backend, or write your own registry – using one of the Workers storage options.
Starting a local development server and testing our application
We are almost done! Before we publish our scheduler system to the Cloudflare edge, let’s start Wrangler in a completely local mode to run a couple of tests against it and to see it in action – which will work even without an Internet connection!
wrangler dev --local
The development server is listening on localhost:8787, which we will use for scheduling our first request. The JSON request payload should match the TypeScript schema we defined in the beginning – required URL, and optional triggerEverySeconds number or triggerAt unix timestamp. When only the required URL is passed, the request will be dispatched right away.
An example of request payload that will send a GET request to https://example.com every 30 seconds.
From the wrangler logs we can see the scheduled request ID 000000018265a5ecaa5d3c0ab6a6997bf5638fdcb1a8364b269bd2169f022b0f is being triggered in 30s intervals.
Need to double the interval? No problem, just send a new POST request and pass the request ID as a pathname.
Every scheduled request gets a unique Durable Object ID with its own storage and alarm. As we demonstrated, the ID becomes handy when you need to change the settings of the scheduled request, or to deschedule them completely.
Publishing to the network
Following command will bundle our Workers application, export and bind Durable Objects, and deploy it to our workers.dev subdomain.
wrangler publish
That’s it, we are live! 🎉 The URL of your deployment is shown in the Workers logs. In a reasonably short period of time we managed to write our own scheduling system that is ready to handle requests at scale.
After many announcements from Platform Week, we’re thrilled to make one more: our Spring Developer Challenge!
The theme for this challenge is building real-time, collaborative applications — one of the most exciting use-cases emerging in the Cloudflare ecosystem. This is an opportunity for developers to merge their ideas with our newly released features, earn recognition on our blog, and take home our best swag yet.
Here’s a list of our tools that will get you started:
Workers can either be powerful middleware connecting your app to different APIs and an origin — or it can be the entire application itself. We recommend using Worktop, a popular framework for Workers, if you need TypeScript support, routing, and well-organized submodules. Worktop can also complement your existing app even if it already uses a framework, such as Svelte.
Cloudflare Pages makes it incredibly easy to deploy sites, which you can make into truly dynamic apps by putting a Worker in front or using the Pages Functions (beta).
Durable Objects are great for collaborative apps because you can use websockets while coordinating state at the edge, seen in this chat demo. To help scale any load, we also recommend Durable Object Groups.
Workers KV provides a global key-value data store that securely stores and quickly serves data across Cloudflare’s network. R2 allows you to store enormous amounts of data without trapping you with costly egress services.
Last year, our Developer Spotlight series highlighted how developers around the world built entire applications on Cloudflare. Our Discord server maintained that momentum with users demonstrating that any type of application can be built. Need a way to organize thousands of lines of JSON? JSON Hero, built with Remix and deployed with Workers, provides an incredibly readable UI for your JSON files. Trying to deploy a GraphQL server for your app that scales? helix-flare deploys a GraphQL server easily through Workers and uses Durable Objects to coordinate data.
We hope developers continue to explore the boundaries of what they can build on Cloudflare as our platform evolves. During our Summer Developer Challenge in 2021, we received over 1,200 submissions that revealed you can build almost any app imaginable with Workers, Pages, and the rest of the developer ecosystem. We sent out hundreds of swag boxes to participants, to show our appreciation. The ensuing unboxing videos on Twitter and YouTube thrilled our team.
This year’s Spring Developer Challenge is all about making real-time, collaborative apps such as chat rooms, games, web-based editing tools, or anything else in your imagination! Here are the rules:
You must be at least 18 years old to participate
You can work in teams of up to 10 people per submission
As you build your app, join our Discord if you or your team need any help. We will be enthusiastically reviewing submissions, promoting them on Twitter, and sending out swag boxes.
If you’re new to Cloudflare or have an exciting idea as a developer, this is your opportunity to see how far our platform has evolved and get rewarded for it!
Since we launched Durable Objects, developers have leveraged them as a novel building block for distributed applications.
Durable Objects provide globally unique instances of a JavaScript class a developer writes, accessed via a unique ID. The Durable Object associated with each ID implements some fundamental component of an application — a banking application might have a Durable Object representing each bank account, for example. The bank account object would then expose methods for incrementing a balance, transferring money or any other actions that the application needs to do on the bank account.
Durable Objects work well as a stateful backend for applications — while Workers can instantiate a new instance of your code in any of Cloudflare’s data centers in response to a request, Durable Objects guarantee that all requests for a given Durable Object will reach the same instance on Cloudflare’s network.
Each Durable Object is single-threaded and has access to a stateful storage API, making it easy to build consistent and highly-available distributed applications on top of them.
This system makes distributed systems’ development easier — we’ve seen some impressive applications launched atop Durable Objects, from collaborative whiteboarding tools to conflict-free replicated data type (CRDT) systems for coordinating distributed state launch.
However, up until now, there’s been a piece missing — how do you invoke a Durable Object when a client Worker is not making requests to it?
As with any distributed system, Durable Objects can become unavailable and stop running. Perhaps the machine you were running on was unplugged, or the datacenter burned down and is never coming back, or an individual object exceeded its memory limit and was reset. Before today, a subsequent request would reinitialize the Durable Object on another machine, but there was no way to programmatically wake up an Object.
Durable Objects Alarms are here to change that, unlocking new use cases for Durable Objects like queues and deferred processing.
What is a Durable Object Alarm?
Durable Object Alarms allow you, from within your Durable Object, to schedule the object to be woken up at a time in the future. When the alarm’s scheduled time comes, the Durable Object’s alarm() handler will be called. If this handler throws an exception, the alarm will be automatically retried using exponential backoff until it succeeds — alarms have guaranteed at-least-once execution.
How are Alarms different from Workers Cron Triggers?
Alarms are more fine-grained than Cron Triggers. While a Workers service can have up to three Cron Triggers configured at once, it can have an unlimited amount of Durable Objects, each of which can have a single alarm active at a time.
Alarms are directly scheduled from and invoke a function within your Durable Object. Cron Triggers, on the other hand, are not programmatic — they execute based on their schedules, which have to be configured via the Cloudflare Dashboard or centralized configuration APIs.
How do I use Alarms?
First, you’ll need to add the durable_object_alarms compatibility flag to your wrangler.toml.
compatibility_flags = ["durable_object_alarms"]
Next, implement an alarm() handler in your Durable Object that will be called when the alarm executes. From anywhere else in your Durable Object, call state.storage.setAlarm() and pass in a time for the alarm to run at. You can use state.storage.getAlarm() to retrieve the currently set alarm time.
In this example, we implemented an alarm handler that wakes the Durable Object up once every 10 seconds to batch requests to a single Durable Object, deferring processing until there is enough work in the queue for it to be worthwhile to process them.
export default {
async fetch(request, env) {
let id = env.BATCHER.idFromName("foo");
return await env.BATCHER.get(id).fetch(request);
},
};
const SECONDS = 1000;
export class Batcher {
constructor(state, env) {
this.state = state;
this.storage = state.storage;
this.state.blockConcurrencyWhile(async () => {
let vals = await this.storage.list({ reverse: true, limit: 1 });
this.count = vals.size == 0 ? 0 : parseInt(vals.keys().next().value);
});
}
async fetch(request) {
this.count++;
// If there is no alarm currently set, set one for 10 seconds from now
// Any further POSTs in the next 10 seconds will be part of this kh.
let currentAlarm = await this.storage.getAlarm();
if (currentAlarm == null) {
this.storage.setAlarm(Date.now() + 10 * SECONDS);
}
// Add the request to the batch.
await this.storage.put(this.count, await request.text());
return new Response(JSON.stringify({ queued: this.count }), {
headers: {
"content-type": "application/json;charset=UTF-8",
},
});
}
async alarm() {
let vals = await this.storage.list();
await fetch("http://example.com/some-upstream-service", {
method: "POST",
body: Array.from(vals.values()),
});
await this.storage.deleteAll();
this.count = 0;
}
}
Once every 10 seconds, the alarm() handler will be called. In the event an unexpected error terminates the Durable Object, it will be re-instantiated on another machine, following a short delay, after which it can continue processing.
Under the hood, Alarms are implemented by making reads and writes to the storage layer. This means Alarm get and set operations follow the same rules as any other storage operation – writes are coalesced with other writes, and reads have a defined ordering. See our blog post on the caching layer we implemented for Durable Objects for more information.
Durable Objects Alarms guarantee fault-tolerance
Alarms are designed to have no single point of failure and to run entirely on our edge – every Cloudflare data center running Durable Objects is capable of running alarms, including migrating Durable Objects from unhealthy data centers to healthy ones as necessary to ensure that their Alarm executes. Single failures should resolve in under 30 seconds, while multiple failures may take slightly longer.
We achieve this by storing alarms in the same distributed datastore that backs the Durable Object storage API. This allows alarm reads and writes to behave identically to storage reads and writes and to be performed atomically with them, and ensures that alarms are replicated across multiple datacenters.
Within each data center capable of running Durable Objects, there are multiple processes responsible for tracking upcoming alarms and triggering them, providing fault tolerance and scalability within the data center. A single elected leader in each data center is responsible for detecting failure of other data centers and assigning responsibility of those alarms to healthy local processes in its own data center. In the event of leader failure, another leader will be elected and become responsible for executing Alarms in the data center. This allows us to guarantee at-least-once execution for all Alarms.
How do I get started?
Alarms are a great way to build new distributed primitives, like queues, atop Durable Objects. They also provide a method for guaranteeing work within a Durable Object will complete, without relying on a client request to “kick” the Object.
You can get started with Alarms now by enabling Durable Objects in the Cloudflare dashboard. For more info, check the developer docs or jump in our Discord.
Welcome to a new blog post series called Developer Spotlight. In this series we will be showcasing interesting applications built on top of the Cloudflare Workers Ecosystem.
And to celebrate Durable Objects going GA, what better to kick off the series than with a really cool tech demo of Durable Objects called Full Tilt?
Full Tilt by Guido Zuidhof is a game jam entry for Ludum Dare, one of the biggest and oldest game jams around, where he won first place in the innovation category. A game jam is like a hackathon for games, where you have a very short amount of time (usually 48-72 hours) to create a game from scratch.
We love Full Tilt, not just because Guido used Workers and Durable Objects to build a cool game where you control a game on your computer via your phone, but especially because it shows how powerful Durable Objects are. In less than 48 hours Guido was able to write all the logic to instantly spin up a personal gaming server anywhere in the world, as close to that player as possible. And it is so fast that you feel like you are controlling the computer directly.
But here is Guido, to tell you about his experience developing Full Tilt.
Last October I participated in the Ludum Dare 49 game jam. The thing I love about game jams is that the time constraint forces you to work quickly, iterate often, and most importantly cut scope.
In this game jam I created Full Tilt, a game in which you seamlessly use your phone as a Wiimote-like motion controller for a game that is run on your laptop in a web browser. The secret sauce to making it so smooth was in combining a game jam with Jamstack and mixing in some Durable Objects.
Full Tilt is a browser game in which you move the player character by moving your hand around. There are a few different ways we can do that. One idea would be to use your computer’s webcam to track a marker object through 3D space. While that is possible, it is tricky to get it working in any situation (a dark room can be problematic!) and also some players may feel uncomfortable turning on their webcam for a simple web game.
A smartphone has a bunch of sensors built in, including a magnetometer and gyroscope — those sensors are exactly what we need, and we can assume that the majority of our potential players have a smartphone within arm’s reach. When a native mobile application uses these sensors, it adds a lot of friction (users now have to install an app), as well as a bunch of implementation work. Fortunately modern web browsers allow you to read from these sensors through the DeviceMotion API: a small web app will do the job perfectly!
The next challenge is communicating the sensor readings from the phone to the game running on the main computer. For that we will use a combination of Cloudflare Workers and Durable Objects. There needs to be some shared contact (i.e., a game server) that both the main computer and the smartphone talk to. Using a serverless solution makes a lot of sense for a web game. And as we only have 48 hours here, less stuff to worry about is a big selling point too. Workers and Durable Objects also make it easy to keep the game running after the game jam, without having to pay for — and more importantly worry about — keeping servers running.
Setting up a line of communication
There are roughly two ways for browsers to communicate: through a shared connection (a game server somewhere) or a peer to peer connection, so browsers can talk directly to each other without a middleman by leveraging WebRTC DataChannels.
WebRTC can be very challenging to make reliable and may still need a proxy server for some especially problematic network setups behind multiple NATs. Setting up a WebRTC connection may have been the perfect solution for the lowest possible latency, but it was out of scope for such a short game jam.
The game we are creating has low latency requirements, when I tilt my phone the game should respond quickly. We can probably get away with anything under 100ms, although low double digits or less is definitely preferred! If I’m geographically located in one place and the game server is geographically close enough, then this game server will be able to pass messages from my smartphone to my laptop without too much delay. Edge computing is hot nowadays, and for this gaming use case it is not just a nice-to-have but also a necessity.
Enough background, let’s architect the system.
On-demand game rooms
The first thing I needed to set up was game rooms. Something that both the phone and the computer browsers could connect to, so they can pass messages between them.
Durable Objects allow us to create a large amount of small stateful “mini servers” or “rooms” that multiple clients can connect to simultaneously over WebSockets, providing perfect small on-demand game servers. Think of Durable Objects as a single thread of Javascript that runs in a data center close to where the user first asked for it to be created.
After the browser on the computer starts the game, it asks our Cloudflare Worker API to create a room for the current game session. This API request is a simple POST request, the server responds with a four character room code that uniquely identifies the room that was created. The reason we want the room code to be short is because the user may need to copy this code and type it into their smartphone if they are unable to scan a QR code.
Humans are notoriously bad at copying random character strings as different characters look alike, so we use a limited character set that excludes the most commonly confused characters:
const DICTIONARY = "2345679ADEFGHJKLMNPQRSTUVWXYZ"; // 29 chars (no 0, O, I, 1, B, 8)
A four character code will allow us to uniquely point to ~700,000 different rooms, that seems like it would be enough even if our game got quite popular! What’s more: these game sessions don’t last forever. After some period of time (say 24 hours) we can be certain enough that the game session has ended, and we can re-use that room code.
Room code coordination
In your Cloudflare Worker script, there are two ways to create a Durable Object: either we ask for one to be created with an ID generated from a name, or we ask for one to be created with a random unique ID. The naive solution would be to create a Durable Object with an ID generated from the room code. However, that is not a good idea here because a Durable Object gets created in a data center that is geographically close to the end user.
A problematic situation would be if a user in Mumbai requests a room and gets room code ABCD. Initially, they play the game for a bit, and it works great.
The issue comes a week later when that room code is reused for another player based in Los Angeles, The game room Durable Object will be revived in Mumbai and latency will be awful for our Los Angeles player. In the future, Durable Objects may get migrated between data centers, but that’s not yet guaranteed.
Instead, what we can do is create a new Durable Object with a random ID for every new game session and keep a mapping from the four character room code to this random ID. We are introducing some state in our system: we will need a central source of truth which is where Durable Objects can come to the rescue again.
We will solve this by creating a single “Room Hub” Durable Object that keeps track of this mapping from room code to Durable Object ID. This Durable Object will have two endpoints, one to request a new room and another to look up a room’s information.
Here’s our request handler for the Room Request endpoint (the argument is a Sunder Context, Sunder is the web framework I used for this project):
export async function handleRoomRequest(ctx: Context<Env>) {
const now = Date.now();
const reqBody = await ctx.request.json();
// We make some attempts to find a room that is available..
const attempts = 5
let roomCode: string;
let roomStorageKey: string;
for (let i = 0; i < attempts; i++) {
roomCode = generateRoomCode();
roomStorageKey = ROOM_STATE_PREFIX + roomCode;
const room = await ctx.state.storage.get<RoomData>(roomStorageKey);
if (room === undefined) {
break;
} else if (now - room.createdAt > MAX_ROOM_AGE) {
await ctx.state.storage.delete(roomStorageKey);
break;
}
if (i === attempts-1) {
return ctx.throw("Couldn't find available room code :(");
}
}
const roomData: RoomData = {
roomCode: roomCode,
durableObjectId: reqBody.durableObjectId,
createdAt: now,
}
await ctx.state.storage.put<RoomData>(roomStorageKey, roomData);
ctx.response.body = {
room: roomData
};
ctx.response.status = HttpStatus.Created;
}
In a nutshell, we generate a few room codes until we find one that has never been used or hasn’t been used in a long enough time.
There is a subtle but important nuance in this code: the Durable Object gets created in the Cloudflare Worker that talks to our Room Hub, not in the Room Hub itself. Our Room Hub will run in a single data center somewhere on Cloudflare’s network. If we create the game room from there it may still be far away from our end user!
Looking up a room’s information is simpler, we return either the room data or status 404.
export async function handleRoomLookup(ctx: Context<Env, {roomCode: string}>) {
const now = Date.now();
let roomStorageKey = ROOM_STATE_PREFIX + ctx.params.roomCode;
const roomData = await ctx.state.storage.get<RoomData>(roomStorageKey);
if (roomData === undefined) {
ctx.throw(404, "Room not found");
return;
}
if (now - roomData.createdAt > MAX_ROOM_AGE) {
// About time we cleaned it up.
await ctx.state.storage.delete(roomStorageKey);
ctx.response.status = HttpStatus.NotFound;
return;
}
ctx.response.body = {
room: roomData
};
}
The smartphone browser needs to connect to that same room. To make things easy for the user we generate a four character room code which points at that specific “Game Room” Durable Object. This way the user can take their smartphone, navigate to the website address https://ld49.pages.dev, and enter the code “ABCD” (or more commonly, they scan a QR code with the link https://ld49.pages.dev?room=ABCD).
Game Room Durable Object
Our game room Durable Object can be pretty simple since it is only responsible for passing along messages from the smartphone to the laptop with the latest sensor readings. I was able to modify the Durable Objects chat room example to do exactly this — a good time saver for a game jam!
When a browser connects, they either connect as a “peer” or as a “host” role. Any messages sent by peers are forwarded to the host, and all messages from the host get forwarded to all peers. In this case, our host is the laptop browser running the game and the peer is the smartphone controller. Implementation-wise this means that we keep two lists of users: the peers and the hosts. Whenever a message comes in, we loop over the list to broadcast it to all connections of the other role. In practice, the code is a bit more involved to deal with users disconnecting.
Full Tilt is a singleplayer game, but adapting it to be a multiplayer game would be easy with this setup. Imagine a Mario Kart-like game that runs in your browser in which multiple friends can join using their smartphones as their steering wheel controller! Unfortunately there was not enough time in this game jam to make a polished game.
Front end
With the backend ready, we still need to create the actual game and the controller web app.
My initial plan was to create a game in which you fly a 3D plane by tilting your phone, collecting stars and completing aerobatic tricks. It would fit the theme “Unstable” as I expected this control method to be pretty flimsy! Since there was no time left to create anything close to that, it was time to cut scope.
I ended up using the Phaser game engine and put the entire system together in a Svelte app. This was certainly a challenge, as I had only used Phaser once before many years ago and had never used Svelte. Luckily, I was able to put together something simple quickly enough: a snake-like game in which you move a thingy to collect blips that appear randomly on the screen.
In order for a game to be a game there needs to be some goal for the user, usually some game over condition. I changed the game to go faster and faster over time, added a score counter, and added a game over condition where you lose the game if you touch the edge of the screen. I made my “art” in MS Paint, generated some sound effects using the online tool sfxr, and “composed” the music soundtrack in Chrome’s Music Lab Song Maker.
Simultaneously I wrote a small client for my game server and duct-taped together the smartphone controller app which is powered by the browser’s DeviceMotion APIs. To distribute my game I used Cloudflare Pages, which worked like a charm the first time.
All done
And then the deadline was there — I barely made it, but I submitted something I was proud of. A not-so-great game, but with an interesting backend system and a novel input method. Do try the game yourself here, and the source code is available here (warning: it’s pretty hacky code of course!).
The reception of my co-jammers was great. While everybody agreed the game itself and its graphics were awful, it was novel. The game ended up rated first in the *Innovation* category for this game jam, out of hundreds of other games!
Finally, is this the future of game servers? For indie developers and smaller studios, setting up and maintaining a globally distributed fleet of game servers is both a huge distraction and cost. Serverless and in particular Durable Objects can provide an amazing solution.
But not every game is well-suited for a WebSocket-based backend. In some real-time games you are not interested in what happened a second ago and only the latest information matters. This is where the reliable and ordered nature of WebSockets can get in the way.
All in all my first impressions of Durable Objects are very positive, it is a great tool to have in your toolbelt for all kinds of web projects. You can now tackle problems that would otherwise take days in mere minutes. I am very excited to see what other problems will be made easy by Durable Objects, even those I haven’t even thought of yet.
Full Stack Week is all about how developers are embracing the power of Cloudflare’s network to build entire applications that are global by default. The promise of Workers isn’t just improved latency — it’s fundamentally different programming paradigms that make developer’s lives easier and applications more resilient.
Last year, we announced Durable Objects — Cloudflare’s approach to coordinating state across Workers running at Cloudflare’s edge. Durable Objects let developers implement previously complex applications, like collaborative whiteboarding, game servers, or global queues, in just a few lines of code.
Today, we’re announcing that Durable Objects are generally available and production-ready for you to use!
What makes Durable Objects so cool?
For many traditional applications, state coordination happens through a database. Applications built on Workers present some unique challenges for a database — namely needing to handle global scale out-of-the-box and heavy concurrency that could lead to frequent transaction rollbacks when coordinating on shared keys. Databases themselves are hard to configure and scale, especially at global scale, so developers would need to tweak their database specifically for Workers’ access patterns.
Durable Objects present a simpler paradigm: write a JavaScript class, and your application can create named instances of that class — which are guaranteed to be unique across Cloudflare’s entire network. That instance is a Durable Object — Workers (and other Durable Objects!) can send messages to it via its ID. The Durable Object processes messages in-order and on a single-thread, allowing for coordination across messages. We also provide a strongly consistent storage API, which can store key-value pairs the object needs to make durable.
Take, for example, an online document editor. A typical architecture would save the state of the document in a database and have users persist changes there. This makes collaboration difficult, though — how can multiple users ensure that they all see the latest copy of changes to the document?
With Durable Objects, this is a much simpler problem. By writing a Document class, you store the state of each document in-memory in a Durable Object. As users connect, they’ll see the latest copy of the document — and can make their changes in-sync with other users. When users leave the document, the Durable Object will leave memory and stop incurring charges, while its state is persisted durably. There’s no networking to configure, database to manage, or autoscaling policy to implement — it all just works.
While individual objects are single-threaded, Durable Objects’ design means a collection of objects can scale effectively infinitely. An object’s lifecycle is managed for you, meaning there’s no clean-up tasks to run or systems to scale down — Durable Objects can instantly scale to hundreds of thousands of requests per second, then scale back down with no developer interaction.
What have we been building since announcing Early Access?
First, we’ve kept busy improving reliability and performance. Durable Objects are behind a number of new products being developed at Cloudflare, including powering R2 storage and Cloudflare Waiting Room.
Specifically, Waiting Room uses Durable Objects to provide a strongly consistent view of the current number of users attempting to access a given site globally. Storing this frequently updated state in a traditional database would be difficult to scale and be significantly harder to run globally.
Our customers have also embraced Durable Objects. We’ve seen a major gaming company build their new backend architecture on Durable Objects — coordinating both individual game state and multiplayer game lobbies. The ability to dynamically scale without managing servers or databases made Durable Objects an easy choice for them, letting them grow their game with a relatively small team.
Customers have built more applications — from status page monitors to collaborative whiteboard applications. We’ve seen particular interest in using Durable Objects with WebSockets to create entirely responsive applications and have published a reference architecture to help customers build this out further.
We’ve also gotten better at operating the system, particularly in response to large volumes of requests. Durable Objects can now serve hundreds of thousands of requests per second across objects, and hundreds of requests on a single object, making them production-ready for even the most demanding customers.
We’ve shipped Jurisdictional Restrictions, which bring the simplicity of scaling Durable Objects to compliance by letting developers tag a Durable Object with a region, ensuring it processes and stores data in that region.
We added a cache in front of Durable Object storage requests, making read and write operations blazing fast while also making it easier to write correct concurrent code.
Beyond that, we’ve made a number of smaller improvements that included simplified uploads of new Durable Objects classes, a UI in the dashboard and support for `wrangler dev` and `wrangler tail` for live debugging.
What’s next for Durable Objects?
We’re continuing to work on making Durable Objects the easiest platform for building infinitely-scalable applications.
Today, Durable Objects scale well when objects can be partitioned, but individual objects are limited to a single execution thread. Many workloads could be scaled across multiple threads, providing read-only access to an object’s state and choosing to only synchronize when mutating state. We’re calling this replication for Durable Objects, and we’re working on it now.
We’re also working on adding an API for a guaranteed callback to a Durable Object, letting developers wake a Durable Object at a specified time in the future to run a function. This simplifies lifecycle management, making it easy to build primitives like reliable queues on top of Durable Objects.
We’re also looking into how to better geo-distribute objects, including the vision for automatic migration of objects we talked about in our initial announcement.
Have something you’d like to see us add? Shoot us an email or a tweet!
How do I use Durable Objects?
Head over to the Cloudflare Dashboard to enable Durable Objects and opt in to pricing, then check out our sample chat application and reference architecture here!
Happy building!
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.